深度网络学习笔记(二)——Transformer架构详解(包括多头自注意力机制)
Transformer架构详解
- 前言
- Transformer的整体架构
- 多头注意力机制(Multi-Head Attention)
- 具体步骤
- 1. 步骤1
- 2. 步骤2
- 3. 步骤3
- 4. 步骤4
- Self-Attention应用与比较
- Self-Attention用于图像处理
- Self-Attention vs. CNN
- Self-Attention vs. RNN
- Transformer架构详解
- Encoder
- 位置编码(Positional Encoding)
- Decoder
- Decoder vs Encoder
- Cross Attention
- Train
- 结论
前言
在现代深度学习模型的发展中,自注意力机制(Self-Attention)和Transformer架构成为了诸多领域中的重要组成部分。自注意力机制通过捕捉序列数据中不同位置之间的关系,显著提升了模型的表示能力。而Transformer架构则利用多层自注意力机制和前馈神经网络(Feed-Forward Network, FFN),构建了强大且高效的序列到序列模型。本文着重介绍多头注意力机制(Multi-Head Attention)和Transformer架构,深入剖析其核心组件和工作原理,并探讨其在自然语言处理和图像处理等领域中的应用。
Transformer的整体架构
Transformer架构由多层自注意力和前馈神经网络(Feed-Forward Network, FFN)组成,每层都有残差连接和层归一化。典型的Transformer编码器层结构包括:
- 多头自注意力机制(Multi-Head Self-Attention)
- 残差连接和层归一化
- 前馈神经网络(FFN)
- 残差连接和层归一化
接下来我们首先介绍其中的重点部分多头自注意力机制,再详解Transformer的结构。
多头注意力机制(Multi-Head Attention)
在Transformer中,自注意力机制通常采用多头注意力机制,即**将Query、Key和Value分成多个头,每个头分别进行自注意力操作,然后将结果拼接起来。**这种方式可以捕捉不同子空间的特征,提高模型的表示能力。以下是具体步骤。
具体步骤
1. 步骤1
针对输入 a i a^i ai分别有对应的 q i , k i , v i q^i, k^i, v^i qi,ki,vi(计算公式位于上一篇文章:self-attention机制介绍和计算步骤),当采用多头注意力机制且设定有两个头时, q i , k i , v i q^i, k^i, v^i qi,ki,vi会被分为 q i , 1 , q i , 2 , k i , 1 , k i , 2 q^{i,1}, q^{i,2}, k^{i,1}, k^{i,2} qi,1,qi,2,ki,1,ki,2和 v i , 1 , v i , 2 v^{i,1}, v^{i,2} vi,1,vi,2。同理,另一个位置的输入 a j a^j aj也分别有对应的 q j , 1 , q j , 2 , k j , 1 , k j , 2 q^{j,1}, q^{j,2}, k^{j,1}, k^{j,2} qj,1,qj,2,kj,1,kj,2和 v j , 1 , v j , 2 v^{j,1}, v^{j,2} vj,1,vj,2。
2. 步骤2
对每个头分别进行自注意力操作。计算输入 a i a^i ai 第一个头的输出值,公式为:
b i , 1 = ( q i , 1 ⋅ k i , 1 ) ⋅ v i , 1 + ( q i , 1 ⋅ k j , 1 ) ⋅ v j , 1 b^{i,1} = (q^{i,1} \cdot k^{i,1}) \cdot v^{i,1} + (q^{i,1} \cdot k^{j,1}) \cdot v^{j,1} bi,1=(qi,1⋅ki,1)⋅vi,1+(qi,1⋅kj,1)⋅vj,1

3. 步骤3
同理,继续计算输入 a i a^{i} ai的第二个头的输出值 b i , 2 b^{i,2} bi,2,公式为:
b i , 2 = ( q i , 2 ⋅ k i , 2 ) ⋅ v i , 2 + ( q i , 2 ⋅ k j , 2 ) ⋅ v j , 2 b^{i,2} = (q^{i,2} \cdot k^{i,2}) \cdot v^{i,2} + (q^{i,2} \cdot k^{j,2}) \cdot v^{j,2} bi,2=(qi,2⋅ki,2)⋅vi,2+(qi,2⋅kj,2)⋅vj,2

4. 步骤4
我们已经计算出了了输入 a i a^i ai两个头的输出值,接下来只需将它们进行拼接即可,拼接方法是将 b i , 1 b^{i,1} bi,1和 b i , 2 b^{i,2} bi,2合并为一个向量,并与一个系数 W o W^o Wo相乘,得到 b i b^{i} bi:
b i = W o ⋅ [ b i , 1 b i , 2 ] T b^{i} = W^o \cdot [ b^{i,1}\ b^{i,2}]^T bi=Wo⋅[bi,1 bi,2]T
此时,完成了输入 a i a^i ai最后的输出值 b i b^{i} bi。同理,我们也可计算输入 a j a^j aj最后的输出值 b j b^{j} bj。具体步骤大家可自行根据上述公式进行推算。
Self-Attention应用与比较
Self-Attention用于图像处理
将图片中的一个像素视为具有三个通道的向量输入,整个图片则可以看作是一个向量组输入到Self-Attention中进行处理。这种方法可以在图像处理中应用Self-Attention机制,以捕捉图片中的重要特征。
Self-Attention vs. CNN
- CNN也可以被看作是一种Self-Attention机制,但它仅考虑感受野区域的内容。这里补充一下感受野的概念和计算公式:深度学习常见概念解释(二)—— 感受野:定义与计算公式。
- Self-Attention可以看作是具有可学习感受野的复杂CNN(因为其感受野是通过self-attention机制学出来的,即找到所有和当前所处理的像素有关的像素)。在数据量较少时,CNN模型比较适合,因为模型简单轻便;在数据量较大时,Self-Attention更合适,效率更高。当输入图片数量大于100M时,Self-Attention的效率明显高于CNN。

Self-Attention vs. RNN
首先我们分别列出两个网络的结构图:

通过上图可知,RNN和Self-Attention在功能上非常类似,输入都是向量序列(vector sequence),且输出都考虑了上下文内容。但它们最大的不同是,RNN难以考虑较久之前的内容,因为其逐层处理数据,信息会逐渐丢失。而Self-Attention没有这个问题,且可以并行处理(每一个输出都是同时产生的)。所以从运行效率的角度看,Self-Attention比RNN更有效率。

Transformer架构详解
Transformer是一个序列到序列(Seq2Seq)的模型(也就是输入是sequence,输出也是由model决定长度的sequence),可以应用于多个方面,如语音识别、机器翻译、语音合成,语言模型创作等。
其架构主要由两个组件构成,它们分别是Encoder和Decoder,如下图所示(左边为示意图,右边为详细结构):

Encoder
首先我们来分析Encoder,Encoder部分接受输入向量 [ x 1 x 2 x 3 x 4 ] [x^1\ x^2\ x^3\ x^4] [x1 x2 x3 x4],并通过多个block进行处理,得到要传递给Decoder的中间值 [ h 1 h 2 h 3 h 4 ] [h^1\ h^2\ h^3\ h^4] [h1 h2 h3 h4],block主要包含Self-Attention和前馈神经网络(FFN)层对输入进行处理。下图仅为简单示意图,具体操作在下下张图中。

这里注意:block中每层都有残差连接和层归一化,以防止信息丢失。
首先是Self-Attention层,输入通过该层得到输出a,同时加上原始输入b得到残差值a+b以免忽略细节特征,再对获取的残差值进行层级归一化(Layer Normalization),该归一化步骤为计算整层的平均值m和方差 σ \sigma σ,再通过图中所示公式计算即可。

同样,在前馈神经网络(即全连接层FC)处也要做同样的事情,获取残差值并进行层归一化。

最后补充一点,输入在进入Encoder之前需要增加Positional Encoding步骤。其定义如下:
位置编码(Positional Encoding)
由于自注意力机制本身不包含位置信息,Transformer通过添加位置编码(Positional Encoding)来引入位置信息,使模型能够利用输入序列中元素的顺序关系。位置编码是一种给每个位置添加独特位置向量 e i e^i ei的方式,并将这个位置向量加到输入 a i a^i ai中。

Decoder
该文件介绍的Decoder部分是为自回归解码器(Autoregressive Decoder,缩写为AT)。还有一种Decoder是Non-autoregressive Decoder,因为篇幅原因暂不介绍。为了能清楚解释Decoder的作用,我们用语音识别的例子来解释。

在语音识别中,Decoder接受一个特殊的输入标志(如BEGIN)让其开始运行,并生成概率分布(对语音识别来说是一个词汇列表的概率分布,所有列都可以用one-hot vector来表示),从中取出概率最大的输出。

然后将Decoder每次生出的输出作为下一次的输入,每次生成输出都同上一步取概率最大的内容。
但同时我们也要考虑何时让Decoder停下来输入。

同样的,我们增加一个END输入,标注结束。

之后让Decoder判断什么时候输出END,代表结束。
Decoder vs Encoder
但当我们回到Transformer架构(见架构详解第一张图)的时候,我们会发现Decoder和Encoder的架构几乎一模一样,只是Decoder比Encoder多了一个最底下的块,和输出端的线性处理及softmax分类。这个多出来的块包括Masked Multi-Head Attention和其归一化处理。其中Masked Multi-Head Attention是一种特殊的Self-Attention,只是它仅仅考虑当前输入及其左边的上下文。这里图解同样以上面四个输入来举例。

当我们考虑 a 1 a^1 a1的输出时,输入仅考虑 a 1 a^1 a1,不考虑其他。当考虑 a 2 a^2 a2的输出的时候,输入仅考虑 a 1 a^1 a1和 a 2 a^2 a2。同理,到a^3的时候考虑 a 1 , a 2 , a 3 a^1,a^2,a^3 a1,a2,a3,到a4的时候考虑 a 1 , a 2 , a 3 , a 4 a^1,a^2,a^3,a^4 a1,a2,a3,a4。下图为处理到 a 2 a^2 a2的输出 b 2 b^2 b2时,我们仅计算 a 1 a^1 a1和 a 2 a^2 a2的q,k,v组成的 b 2 b^2 b2。

采用该块的理由:贴合Decoder的执行步骤,因为Decoder的输出是一个一个产生的。
Cross Attention
介绍完Encoder和Decoder后之后,我们来介绍这两个模块之间的联系——Cross Attention。

Cross Attention机制其实和Self Attention一样,只不过q来自Decoder中的Self-Attention(Mask)的输出。让q和来自Encoder输出内容的k和v进行计算获得结果v,再将v通过全连接层。这就是整个Cross Attention的运作过程。
下图中的q是来自Decoder中的Self-Attention(Mask)针对BEGIN的输出。

同理,对于其他的输出也会从Encoder得到q,再从Encoder中得到输出后计算出的k和v进行运算。

Train
计算Decoder输出与真实值(Ground Truth)之间的差异,使用交叉熵(cross entropy)作为损失函数,训练网络的目标是最小化交叉熵。

这里需要注意,Decoder中的输入不仅有来自Encoder的输出,还有Ground Truth,这种输入真实值来推测输出的方法叫做Teacher Forcing。
结论
Transformer架构通过引入多头自注意力机制、前馈神经网络和位置编码,实现了高效的序列到序列转换。这种架构摆脱了传统循环神经网络(RNN)对序列处理的限制,可以并行处理序列中的每一个元素,从而大大提高了计算效率。多头自注意力机制使得模型能够捕捉不同子空间的特征,增强了模型的表示能力。位置编码则引入了位置信息,使得模型能够理解输入序列的顺序。前馈神经网络在每个编码器和解码器层中对自注意力机制的输出进行了进一步的非线性变换,增强了模型的复杂特征学习能力。综上所述,Transformer架构凭借其高效的并行处理能力和强大的表示能力,已经在自然语言处理、图像处理等多个领域中取得了显著的成果,展示了其广泛的应用前景和发展潜力。
相关文章:
深度网络学习笔记(二)——Transformer架构详解(包括多头自注意力机制)
Transformer架构详解 前言Transformer的整体架构多头注意力机制(Multi-Head Attention)具体步骤1. 步骤12. 步骤23. 步骤34. 步骤4 Self-Attention应用与比较Self-Attention用于图像处理Self-Attention vs. CNNSelf-Attention vs. RNN Transformer架构详…...
Python 快速查找并替换Excel中的数据
Excel中的查找替换是一个非常实用的功能,能够帮助用户快速完成大量数据的整理和处理工作,避免手动逐一修改数据的麻烦,提高工作效率。要使用Python实现这一功能, 我们可以借助Spire.XLS for Python 库,具体操作如下&am…...

KafkaStream Local Store和Global Store区别和用法
前言 使用kafkaStream进行流式计算时,如果需要对数据进行状态处理,那么常用的会遇到kafkaStream的store,而store也有Local Store以及Global Store,当然也可以使用其他方案的来进行状态保存,文本主要理清楚kafkaStream…...
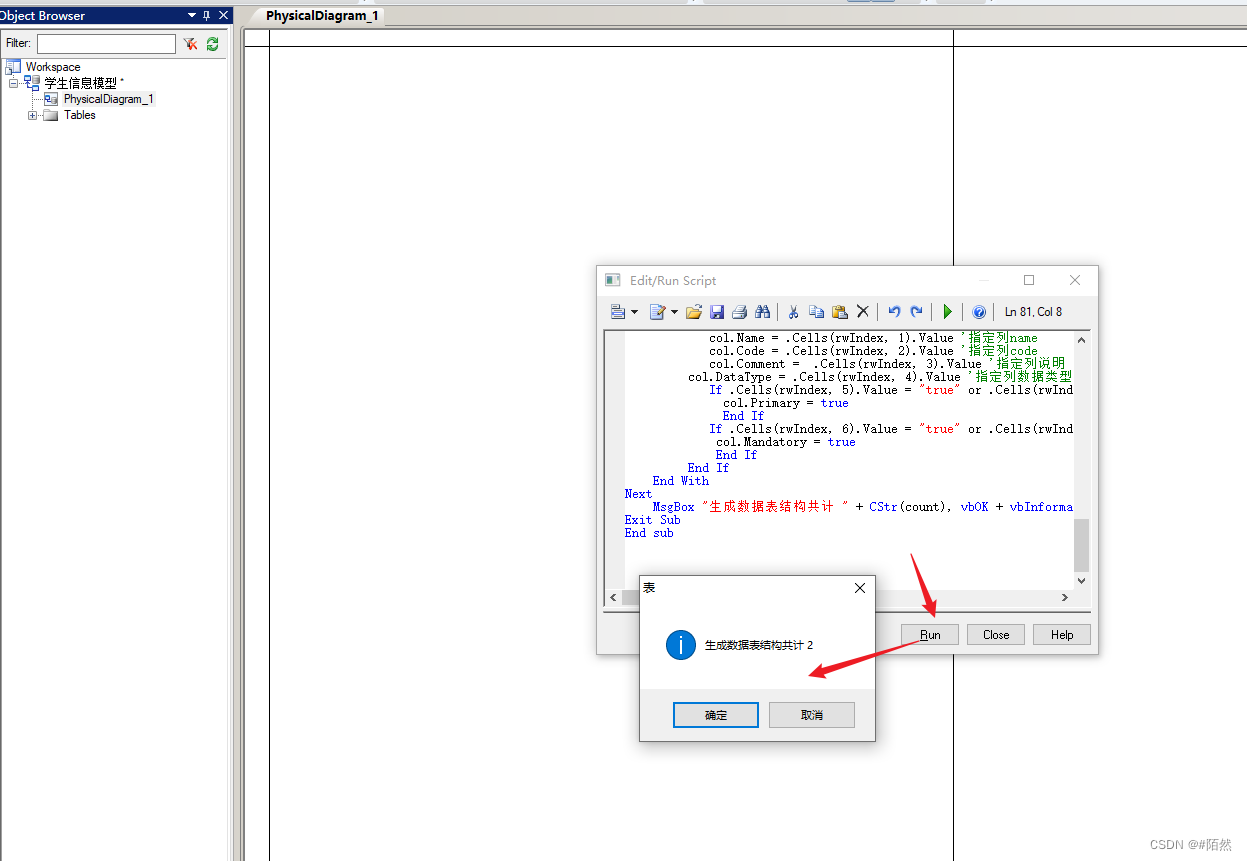
PowerDesigner导入Excel模板生成数据表
PowerDesigner导入Excel模板生成数据表 1.准备好需要导入的Excel表结构数据,模板内容如下图所示 2.打开PowerDesigner,新建一个physical data model文件,填入文件名称,选择数据库类型 3.点击Tools|Execute Commands|Edit/Run Script菜单或按下快捷键Ctrl Shift X打开脚本窗口…...

STM32 HAL库开发——入门篇(3):OLED、LCD
源自正点原子视频教程: 【正点原子】手把手教你学STM32 HAL库开发全集【真人出镜】STM32入门教学视频教程 单片机 嵌入式_哔哩哔哩_bilibili 一、OLED 二、内存保护(MPU)实验 2.1 内存保护单元 三、LCD 3.1 显示屏分类 3.2 LCD简介 3.3 LCD…...

在Linux中查找文件命令的几种方法
要在Linux中查找文件,可以使用以下几种不同的实现方法: 1. 使用find命令: find <搜索路径> <搜索选项> <搜索条件><搜索路径>:表示要搜索的起始路径,可以是一个具体的目录路径,也…...

【TB作品】MSP430F5529 单片机,温度控制系统,DS18B20,使用MSP430实现的智能温度控制系统
作品功能 这个智能温度控制系统基于MSP430单片机设计,能够实时监测环境温度并根据预设的温度报警值自动调节风扇和加热片的工作状态。主要功能包括: 实时显示当前温度。通过OLED屏幕显示温度报警值。通过按键设置温度报警值。实际温度超过报警值时&…...

立创小tips
立创小tips 原理图中 1-修改图纸属性 保存完,绘制原理图的界面就出现了,然后我们鼠标点击原理图的边缘变成红色就可以高边表格的属性了。 2-鼠标右键可以移动整个原理图 3-查看封装 点击任意一个元器件,在右侧就会显示封装属性ÿ…...
Html/HTML5常用标签的学习
课程目标 项目实战,肯定就需要静态网页。朝着做项目方式去学习静态网页。 01、编写第一个html工程结构化 cssjsimages/imgindex.html 归档存储和结构清晰就可以。 02、HTML标签分类 认知:标签为什么要分类,原因因为:分门别类…...

Tomcat 配置:一文掌握所有要点
引言 Apache Tomcat 是一个流行的开源 Java Servlet 容器和 Web 服务器,广泛用于开发和部署 Java Web 应用程序。正确配置 Tomcat 是确保其性能、安全性和稳定性的关键。本文将详细介绍 Tomcat 的各项配置,帮助您优化和管理 Tomcat 服务器。 一、Tomca…...
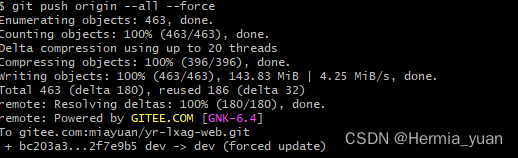
git 大文件上传失败 Please remove the file from history and try again.
根据提示执行命令 --- 查找到当前文件 git rev-list --objects --all | grep b24e74b34e7d482e2bc687e017c8ab28cd1d24b6git filter-branch --tree-filter rm -f 文件名 --tag-name-filter cat -- --all git push origin --tags --force git push origin --all --force...
-进击的巨人)
骑砍2霸主MOD开发(14)-进击的巨人
一.巨人 sbyte boneIndex Skeleton.GetBoneIndexFromName(Mission.MainAgent.AgentVisuals.GetSkeleton().GetName(), "r_hand"); cp Mission.MainAgent.AgentVisuals.AddPrefabToAgentVisualBoneByRealBoneIndex("p_sword_a", boneIndex); float agent…...

Android 可拖拽的View,限制在父布局中随意拖拽;拖拽结束后可左右吸边;
实现方法一:自定义View 可随意拖动拖拽的View,限制拖动范围是父布局中; import android.content.Context; import android.util.AttributeSet; import android.util.Log; import android.view.MotionEvent; import android.view.ViewGroup; …...
使其平滑地过渡到目标值)
逐步更新动画混合参数(Blend)使其平滑地过渡到目标值
1.具体实现 逐步更新一个动画混合参数(Blend),使其平滑地过渡到目标值,可以实现角色动作的平滑过渡,比如从走路过渡到跑步。 private float currentBleng;private float targetBlend;public float accelerSpeed 5;//…...

【多模态/CV】图像数据增强数据分析和处理
note 多模态大模型训练前,图片数据处理的常见操作:分辨率调整、网格畸变、水平翻转、分辨率调整、随机crop、换颜色、多张图片拼接、相似图片检测并去重等 一、分辨率调整 from PIL import Image def resize_image(original_image_path, save_image_p…...
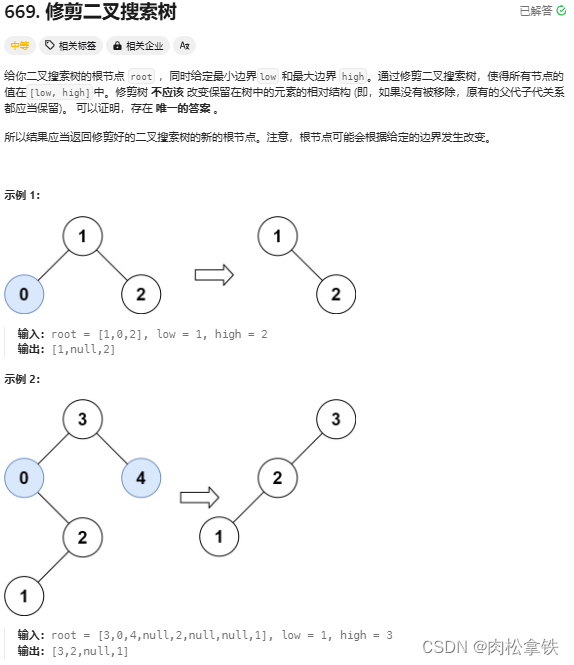
代码随想录——修建二叉搜素树(Leetcode669)
题目链接 递归 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* TreeNode() {}* TreeNode(int val) { this.val val; }* TreeNode(int val, TreeNode left, TreeNode right) {* …...
EasyExcel导出多个sheet封装
导出多个sheet 在需求中,会有需要导出多种sheet的情况,那么这里使用easyexcel进行整合 步骤 1、导入依赖 <dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></dependency><d…...

【Python错误】:AttributeError: ‘generator‘ object has no attribute ‘next‘解决办法
【Python错误】:AttributeError: ‘generator’ object has no attribute next’解决办法 在Python中,生成器是一种使用yield语句的特殊迭代器,它允许你在函数中产生一个值序列,而无需一次性创建并返回整个列表。然而,…...

如何配置Feign以实现服务调试
1、引入依赖 在项目中,需要引入Spring Cloud OpenFeign的依赖。这通常是通过在pom.xml文件中添加相应的Maven依赖来完成的。例如: <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starte…...
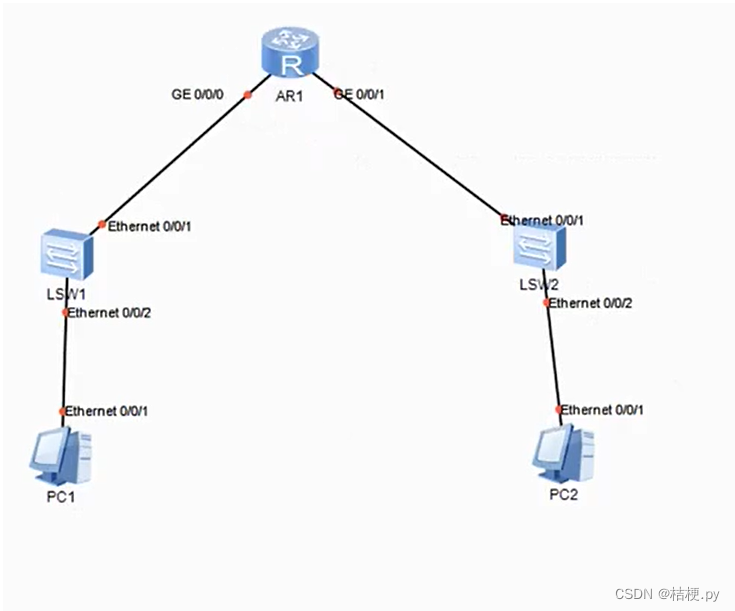
pc之间的相互通信详解
如图,实现两台pc之间的相互通信 1.pc1和pc2之间如何进行通讯。 2.pc有mac和ip,首先pc1需要向sw1发送广播,sw1查询mac地址表,向router发送广播,router不接受广播,router的每个接口都有ip和mac,…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

RocketMQ延迟消息机制
两种延迟消息 RocketMQ中提供了两种延迟消息机制 指定固定的延迟级别 通过在Message中设定一个MessageDelayLevel参数,对应18个预设的延迟级别指定时间点的延迟级别 通过在Message中设定一个DeliverTimeMS指定一个Long类型表示的具体时间点。到了时间点后…...

Xshell远程连接Kali(默认 | 私钥)Note版
前言:xshell远程连接,私钥连接和常规默认连接 任务一 开启ssh服务 service ssh status //查看ssh服务状态 service ssh start //开启ssh服务 update-rc.d ssh enable //开启自启动ssh服务 任务二 修改配置文件 vi /etc/ssh/ssh_config //第一…...

centos 7 部署awstats 网站访问检测
一、基础环境准备(两种安装方式都要做) bash # 安装必要依赖 yum install -y httpd perl mod_perl perl-Time-HiRes perl-DateTime systemctl enable httpd # 设置 Apache 开机自启 systemctl start httpd # 启动 Apache二、安装 AWStats࿰…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

ESP32 I2S音频总线学习笔记(四): INMP441采集音频并实时播放
简介 前面两期文章我们介绍了I2S的读取和写入,一个是通过INMP441麦克风模块采集音频,一个是通过PCM5102A模块播放音频,那如果我们将两者结合起来,将麦克风采集到的音频通过PCM5102A播放,是不是就可以做一个扩音器了呢…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...
 自用)
css3笔记 (1) 自用
outline: none 用于移除元素获得焦点时默认的轮廓线 broder:0 用于移除边框 font-size:0 用于设置字体不显示 list-style: none 消除<li> 标签默认样式 margin: xx auto 版心居中 width:100% 通栏 vertical-align 作用于行内元素 / 表格单元格ÿ…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...