数据结构与算法笔记:基础篇 - 散列表(下):为什么散列表和链表经常会一起使用?
概述
已经学习了这么多章节了,你有没有发现,两种数据结构,散列表和链表,经常会被放在一起使用。你还记得,前面的章节中都有哪些地方讲到散列表和链表的组合使用吗?
在链表那一节,我讲到如何用链表来实现 LRU 缓存淘汰算法,但是链表实现的 LRU 缓存淘汰算法的时间复杂度是 O ( n ) O(n) O(n),当时提到了,通过散列表可以将这个时间复杂度降低到 O ( 1 ) O(1) O(1)。
在跳表那一节,提到 Redis 的有序集合是使用跳表来实现的,跳表可以看做这一种改进版的链表。当时我们也提到,Redis 有序集合不仅使用了链表,还用到了散列表。
此外,如果你熟悉 Java 编程语言,你会发现 LinkedHashMap 这样 一个常用的容器,也用到了散列表和链表两者数据结构。
本章,我们来看看,在这几个问题中,散列表和链表都是如何组合起来使用,以及为什么散列表和链表会经常放到一块使用。
LRU 缓存淘汰算法
在链表那一节中,我提到,借助散列表,可以将时间复杂度降低到 O ( 1 ) O(1) O(1)。现在,我们来看看它是如何做到的。
首先,我们来回顾一下当时我们是如何通过链表实现 LRU 缓存淘汰算法的。
我们需要维护一个按照访问时间从打大小有序排列的链表结构。因为缓存大小有限,当缓存空间不够,需要淘汰一个数据的时候,我们就直接将链表头部的结点删除。
当要缓存某个数据的时候,现在链表中查找这个数据。如果没有找到,则将数据放到链表的尾部;如果找到了,我们就把它移动到链表的尾部。因为查找数据需要遍历链表,所以单纯用链表实现的 LRU 缓存淘汰算法的时间复杂度很高,是 O ( n ) O(n) O(n)。
总结一下,一个缓存(cache)系统主要包含下面这几个操作:
- 往缓存中添加一个数据;
- 从缓存中删除一个数据;
- 从缓存中查找一个数据。
这三个操作都要涉及 “查找” 操作,如果单纯地采用链表的话,时间复杂度只能是 O ( n ) O(n) O(n)。如果我们将散列表和链表两种数据组合使用,可以将这三个操作的时间复杂度都降低到 O ( 1 ) O(1) O(1)。具体的结构就是下面这个样子:
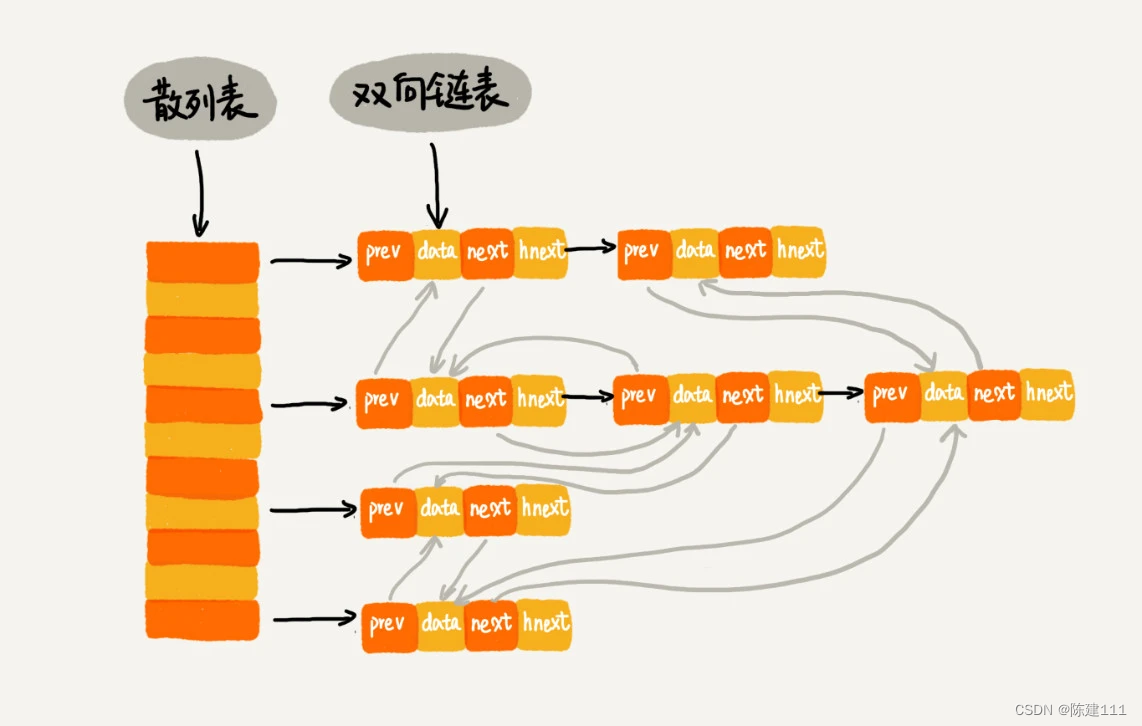
我们使用双向链表存储数据,链表中的每个结点除了存储数据(data)、前驱结点(prev)、后继结点(next)之外,还新增了一个特殊的字段 hnext。这个 hnext 有什么作用呢?
因为我们的散列表是通过链表法解决冲突的,所以每个结点会在两条链中。一个链是刚刚我们提到的双向链表,另一个链是散列表中的拉链。前驱和后继指针是为了将结点串在双休链表中,hnext 指针是为了将结点串在散列表的拉链中。
了解了这个散列表和双向链表的组合存储结构之后,我们再来看,前面讲到的缓存的三个操作,是如何做到时间复杂度是 O ( 1 ) O(1) O(1)?
首先,来看如何查找一个数据。前面讲过,散列表中查找的数据的时间复杂度接近 O ( 1 ) O(1) O(1),所以通过散列表,我们可以很快地在缓存中找到一个数据。当找到数据之后,我们还需要将它移动到双向链表的尾部。
其次,来看如何删除一个数据。我们需要找到数据所在的结点,然后将结点删除。借助散列表,我们可以在 O ( 1 ) O(1) O(1) 时间复杂度里找到要删除的结点。因为我们的链表是双向链表,双向链表可以通过前驱指针 O ( 1 ) O(1) O(1) 时间复杂度获取前驱结点,所以在双向链表中,删除结点只需要 O ( 1 ) O(1) O(1) 的时间复杂度。
最后,来看如何添加一个数据。添加数据到缓存稍微有点麻烦,我们需要先看这个数据是否已经在缓存中。如果已经在其中,需要将其移动到双向链表的尾部;如果不在其中,还要看缓存有没有满。如果满了,则将双向链表头部的结点删除,然后再将数据放到链表的尾部;如果没有满,就直接将数据放到链表的尾部。
这整个过程设计的查找操作都可以通过散列表来完成。其他的操作,比如删除头结点、链表尾部插入数据等,都可以在 O ( 1 ) O(1) O(1) 的时间复杂度完成。所以,这三个操作的时间复杂度都是 O ( 1 ) O(1) O(1)。至此,我们就通过散列表和双向链表的组合使用,实现了一个高效的、支持 LRU 缓存淘汰算法的缓存系统原型。
Redis 有序集合
在跳表那一节,讲到有序集合的操作时,我稍微做了简化。实际上,在有序集合中,每个成员有两个重要的属性,key(键值)和 score(分值)。我们不仅会通过 score 来查找数据,还可以通过 key 来查找数据。
例如,用户积分排行榜这样一个功能:我们可以通过用户的 ID 来查找积分,也可以通过积分区间来查找用户 ID 或姓名信息。这里包含 ID、姓名和积分的用户信息,就是成员对象,用户 ID 就是 key,积分就是 score。
所以,如果我们细化一下 Redis 有序集合的操作,那就是下面这样:
- 添加一个成员
- 按照键值来删除一个成员对象;
- 按照键值来查找一个成员对象;
- 按照分值区间查找数据,比如查找积分在 [100, 222] 之间的成员对象;
- 按照分值从小到大排序成语变量;
如果我们仅仅按照分值将成员对象组织成跳表的结构,那按照键值来删除、查找成员对象就会很慢,解决方法与 LRU 的解决方法类似。可以在按照键值构建一个散列表,这样按照 key 来删除、查找一个成员对象的时间复杂度就变成了 O ( 1 ) O(1) O(1)。同时借助跳表,其他操作也非常高效。
实际上,Redis 有序集合的操作还有另外一类,也就是查找成员对象的排名(Rank)或者根据排名区间查找成员对象。这个功能单纯用刚刚讲的这种组合结构就无法高效实现了。这块内容,在后面的章节在讲解。
Java LinkedHashMap
如果你熟悉 Java,那你几乎天天会用到这个容器。我们之前讲过,HashMap 底层是通过散列表这种数据结构实现的。而 LinkedHashMap 前面比 HashMap 多了一个 “Linked” ,这里的 “Linked” 是不是说,LinkedHashMap 是一个通过链表法解决散列冲突的散列表呢?
实际上,LinkedHashMap 并没有那么简单,其中的 “Linked” 也不仅仅代表它是通过链表法解决散列冲突的。
先来看一段代码。你觉得这段代码会以什么样的顺序打印 3,1,5,2 这几个 key 呢?原因又是什么呢?
HashMap<Integer, Integer> map = new LinkedHashMap<>();
map.put(3,11);
map.put(1,12);
map.put(5,23);
map.put(2,22);for(Map.entry e : map.entrySet()) {System.out.println(e.getKey());
}
我先告诉你答案,上面的代码会按照数据插入的顺序依赖来打印,也就是说,打印店顺序是 3,1,5,2 。你有没有觉得奇怪?散列表中数据是经过散列函数打乱之后无规律存储的,这里是如何实现按照数据的插入顺序来遍历打印的呢?
LinkedHashMap 也是通过散列表和链表组合在一起实现的。实际上,它不仅支持按照插入顺序遍历数据,还支持按照顺序来遍历数据。你可以看下面这段代码:
// 10 是初始大小,0.75是装载因子,true是表示按照访问时间排序
HashMap<Integer, Integer> map = new LinkedHashMap<>(10, 0.75f, true);
map.put(3,11);
map.put(1,12);
map.put(5,23);
map.put(2,22);map.put(3, 26);
m.get(5)for(Map.entry e : map.entrySet()) {System.out.println(e.getKey());
}
这段代码打印的结果是 1,2,3,5。我来具体分析一下,为什么这段代码会按照这样顺序来打印。
每次调用 put() 函数,往 LinkedHashMap 中添加数据的时候,都会往将数据添加到链表的尾部,所以,在前四个操作完成之后,链表中的数据是下面这样的。
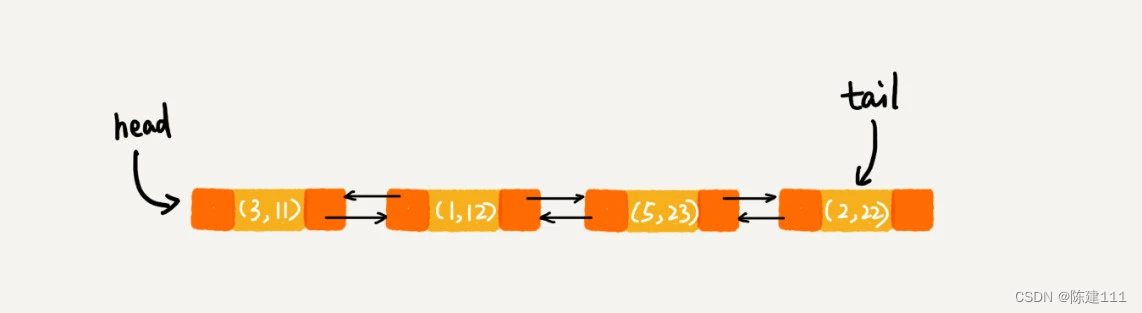
在第 8 行代码中,再次将键值为 3 的数据放入到 LinkedHashMap 的时候,会先查找这个键值是否已经有了,然后再将已存在的 (3,11) 删除,并将心的 (3,26) 放到链表的尾部。所以,这个时候链表的尾部。所以,这个时候链表中的数据就是下面这样的:
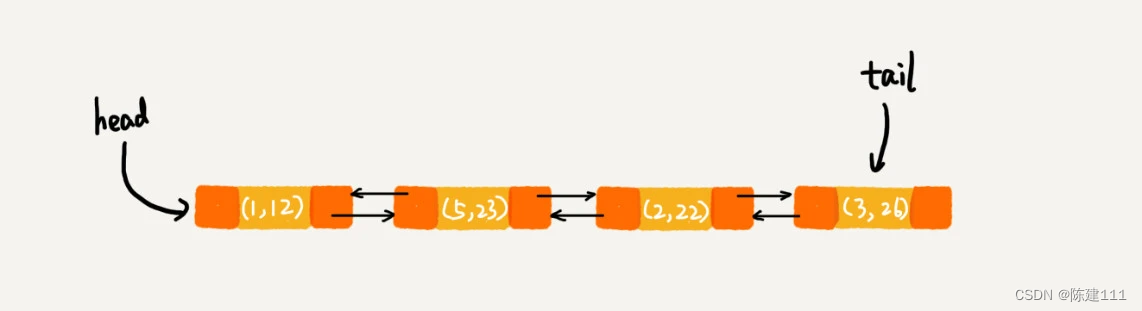
当第 9 行代码访问到 key 为 5 的数据时,我们将被访问的数据移动到链表的尾部。所以,第 9 行代码之后,链表的数据是这样的:
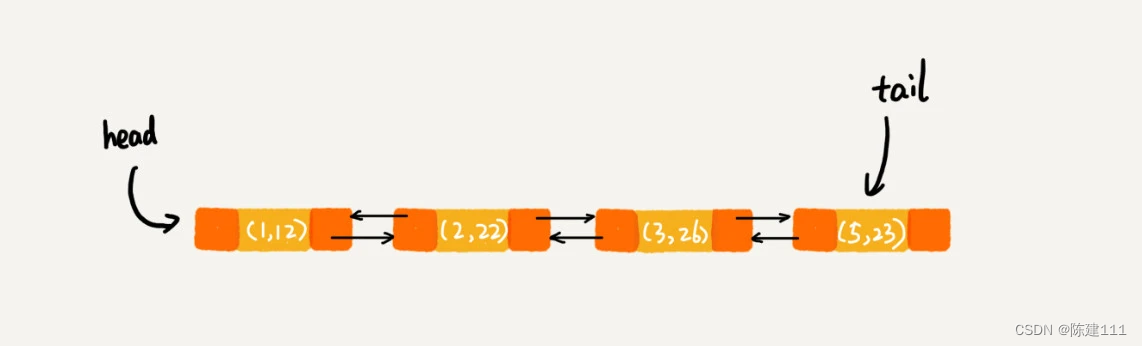
所以,最后打印出来的数据是 1,2,3,5。从上面的分析,你有没有发现,按照访问时间排序的 LinkedHashMap 本身就是一个支持 LRU 缓存淘汰策略的缓存系统?实际上,它们两个的实现原理也是一模一样的。我也就不再啰嗦了。
现在来总结一下,实际上,LinkedHashMap 是通过双向链表和散列表这两种数据结构组合实现的。LinkedHashMap 中的 “Linked” 实际上是指的是双向链表,并非指用链表法解决散列冲突。
小结
散列表这种数据结构虽然支持非常高效的数据插入、删除、查找操作,但是散列表中的数据都是通过散列函数打乱之后无规律存储的。也就是说,它无法支持按照某种顺序快速地遍历数据。如果希望按照顺序遍历散列表中的数据,那需要将散列表中的数据拷贝到数组中,然后排序,再遍历。
因为散列表是动态数据结构,不停的有数据插入、删除,所以每当我们希望按照顺序遍历散列表中的数据时,都需要先排序,那效率势必会很低。为了解决这个问题,我们将散列表和链表(或者跳表)结合在一起使用。
相关文章:
数据结构与算法笔记:基础篇 - 散列表(下):为什么散列表和链表经常会一起使用?
概述 已经学习了这么多章节了,你有没有发现,两种数据结构,散列表和链表,经常会被放在一起使用。你还记得,前面的章节中都有哪些地方讲到散列表和链表的组合使用吗? 在链表那一节,我讲到如何用…...
读AI未来进行式笔记06自动驾驶技术
1. 跃层冲击 1.1. 每个社会其实都处于不同的楼层,往往处于更低楼层的社会,要承受来自更高楼层的社会发展带来的更大冲击 2. 驾驶 2.1. 开车时最关键的不是车,而是路 2.2. 人是比机器更脆弱的生命&am…...

SpringAOP 常见应用场景
文章目录 SpringAOP1 概念2 常见应用场景3 AOP的几种通知类型分别有什么常见的应用场景4 AOP实现 性能监控4.1 首先,定义一个切面类,用于实现性能监控逻辑:4.2 定义自定义注解4.3 注解修饰监控的方法 5 AOP实现 API调用统计5.1 定义切面类&am…...

html+css示例
HTML HTML(超文本标记语言)和CSS(层叠样式表)是构建和设计网页的两种主要技术。HTML用于创建网页的结构和内容,而CSS用于控制其外观和布局。 HTML基础 HTML使用标签来标记网页中的不同部分。每个标签通常有一个开始…...

Day51 动态规划part10+Day52 动态规划part11
LC121买卖股票的最佳时机(未掌握) 暴力:双层循环寻找最优间距,每一次都确定一个起点,遍历剩余节点当作终点 贪心:取最左最小值,不断遍历那么得到的差值最最大值就是最大利润。 动态规划 dp数组…...
Wireshark自定义Lua插件
背景: 常见的抓包工具有tcpdump和wireshark,二者可基于网卡进行抓包:tcpdump用于Linux环境抓包,而wireshark用于windows环境。抓包后需借助包分析工具对数据进行解析,将不可读的二进制数转换为可读的数据结构。 wires…...

商城项目【尚品汇】07分布式锁-2 Redisson篇
文章目录 1 Redisson功能介绍2 Redisson在Springboot中快速入门(代码)2.1 导入依赖2.2 Redisson配置2.3 将自定义锁setnx换成Redisson实现(可重入锁) 3 可重入锁原理3.1 自定义分布式锁setnx为什么不可以重入3.2 redisson为什么可…...

Adobe Illustrator 矢量图设计软件下载安装,Illustrator 轻松创建各种矢量图形
Adobe Illustrator,它不仅仅是一个简单的图形编辑工具,更是一个拥有丰富功能和强大性能的设计利器。 在这款软件中,用户可以通过各种精心设计的工具,轻松创建和编辑基于矢量路径的图形文件。这些矢量图形不仅具有高度的可编辑性&a…...

Nvidia/算能 +FPGA+AI大算力边缘计算盒子:中国舰船研究院
中国舰船研究院又称中国船舶重工集团公司第七研究院,隶属于中国船舶重工集团公司,是专门从事舰船研究、设计、开发的科学技术研究机构,是中国船舶重工集团公司的军品技术研究中心、科技开发中心;主要从事舰船武器装备发展战略研究…...
双网卡配置IP和路由总结
1.在网络适配器属性IPv4中设置默认网关(记网关地址为A),将会在本地路由表中新增一条记录: 网络号子网掩码网关地址0.0.0.00.0.0.0A 2.如果有两个网卡(假设一个连接内网,一个连接互联网)&#…...

【纯血鸿蒙】——自适应布局如何实现?
界面级一多能力有 2 类: 自适应布局: 略微调整界面结构 响应式布局:比较大的界面调整 本文章先主要讲解自适应布局,响应式布局再后面文章再细讲。话不多说,开始了。 自适应布局 针对常见的开发场景,方舟开发框架提…...

Qt5学习笔记(一):Qt Widgets Application项目初探
笔者长期使用MFC开发Windows GUI软件。随着软件向Linux平台迁移的趋势越发明朗,GUI程序的跨平台需求也越来越多。因此笔者计划重新抓一下Qt来实现跨平台GUI程序的实现。 0x01. 看看Qt Widgets Application项目结构 打开Qt5,点击“ New”按钮新建项目。…...

Linux网络编程:数据链路层协议
目录 前言: 1.以太网 1.1.以太网帧格式 1.2.MTU(最大传输单元) 1.2.1.IP协议和MTU 1.2.2.UDP协议和MTU 1.2.3.TCP协议和MTU 2.ARP协议(地址解析协议) 2.1.ARP在局域网通信的角色 2.2.ARP报文格式 2.3.ARP报文…...

企业估值的三种方法
估值模型三剑客—DCF、P/E、EV /EBITDA 三种主要估值模型的优缺点: DCF 优点:通过对自由现金流的折现计算,反映了公司内在价值的本质,是最重要与最合理的估值方法。 缺点:未来自由现金流的估计不准确,受折现率影响…...

比亚迪正式签约国际皮划艇联合会和中国皮划艇协会,助推龙舟入奥新阶段
6月5日,比亚迪与国际皮划艇联合会、中国皮划艇协会在深圳共同签署合作协议,国际皮划艇联合会主席托马斯科涅茨科,国际皮划艇联合会秘书长理查德派蒂特,中国皮划艇协会秘书长张茵,比亚迪品牌及公关处总经理李云飞&#…...

宏集Panorama SCADA:个性化定制,满足多元角色需求
前言 在考虑不同人员在企业中的职能和职责时,他们对于SCADA系统的需求可能因其角色和工作职责的不同而有所差异。在SCADA系统的设计和实施过程中,必须充分考虑和解决这种差异性。 为了满足不同人员的需求, 宏集Panorama SCADA平台具备灵活的功能和定制…...

聪明人社交的基本顺序:千万别搞反了,越早明白越好
聪明人社交的基本顺序:千万别搞反了,越早明白越好 国学文化 德鲁克博雅管理 2024-03-27 17:00 作者:方小格 来源:国学文化(gxwh001) 导语 比一个好的圈子更重要的,是自己优质的能力。 唐诗宋…...
图片和PDF展示预览、并支持下载
需求 展示图片和PDF类型,并且点击图片或者PDF可以预览 第一步:遍历所有的图片和PDF列表 <div v-for"(data,index) in parerFont(item.fileInfo)" :key"index" class"data-list-item"><downloadCard :file-inf…...

图论第5天
127.单词接龙 需要cout看一下过程。 #include <iostream> #include <queue> #include <stack> #include <unordered_map> #include <unordered_set> #include <vector> using namespace ::std;class Solution { public:int ladderLength(…...

Java开发-面试题-0004-HashMap 和 Hashtable的区别
Java开发-面试题-0004-HashMap 和 Hashtable的区别 更多内容欢迎关注我(持续更新中,欢迎Star✨) Github:CodeZeng1998/Java-Developer-Work-Note 技术公众号:CodeZeng1998(纯纯技术文) 生活…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

【AI学习】三、AI算法中的向量
在人工智能(AI)算法中,向量(Vector)是一种将现实世界中的数据(如图像、文本、音频等)转化为计算机可处理的数值型特征表示的工具。它是连接人类认知(如语义、视觉特征)与…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...
 + 力扣解决)
LRU 缓存机制详解与实现(Java版) + 力扣解决
📌 LRU 缓存机制详解与实现(Java版) 一、📖 问题背景 在日常开发中,我们经常会使用 缓存(Cache) 来提升性能。但由于内存有限,缓存不可能无限增长,于是需要策略决定&am…...

苹果AI眼镜:从“工具”到“社交姿态”的范式革命——重新定义AI交互入口的未来机会
在2025年的AI硬件浪潮中,苹果AI眼镜(Apple Glasses)正在引发一场关于“人机交互形态”的深度思考。它并非简单地替代AirPods或Apple Watch,而是开辟了一个全新的、日常可接受的AI入口。其核心价值不在于功能的堆叠,而在于如何通过形态设计打破社交壁垒,成为用户“全天佩戴…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...

nnUNet V2修改网络——暴力替换网络为UNet++
更换前,要用nnUNet V2跑通所用数据集,证明nnUNet V2、数据集、运行环境等没有问题 阅读nnU-Net V2 的 U-Net结构,初步了解要修改的网络,知己知彼,修改起来才能游刃有余。 U-Net存在两个局限,一是网络的最佳深度因应用场景而异,这取决于任务的难度和可用于训练的标注数…...