【sklearn】【逻辑回归1】
学习笔记来自:
所用的库和版本大家参考:
- Python 3.7.1
- Scikit-learn 0.20.1
- Numpy 1.15.4, Pandas 0.23.4, Matplotlib 3.0.2, SciPy 1.1.0
1 概述
1.1 名为“回归”的分类器
在过去的四周中,我们接触了不少带“回归”二字的算法,回归树,随机森林的回归,无一例外他们都是区别于分类算法们,用来处理和预测连续型标签的算法。然而逻辑回归,是一种名为“回归”的线性分类器,其本质是由线性回归变化而来的,一种广泛使用于分类问题中的广义回归算法。要理解逻辑回归从何而来,得要先理解线性回归。线性回归是机器学习中最简单的的回归算法,它写作一个几乎人人熟悉的方程:


通过函数z,线性回归使用输入的特征矩阵X来输出一组连续型的标签值y_pred,以完成各种预测连续型变量的任务 (比如预测产品销量,预测股价等等)。那如果我们的标签是离散型变量,尤其是,如果是满足0-1分布的离散型变量,我们要怎么办呢?我们可以通过引入联系函数(link function),将线性回归方程z变换为g(z),并且令g(z)的值 分布在(0,1)之间,且当g(z)接近0时样本的标签为类别0,当g(z)接近1时样本的标签为类别1,这样就得到了一个分类模型。而这个联系函数对于逻辑回归来说,就是Sigmoid函数:
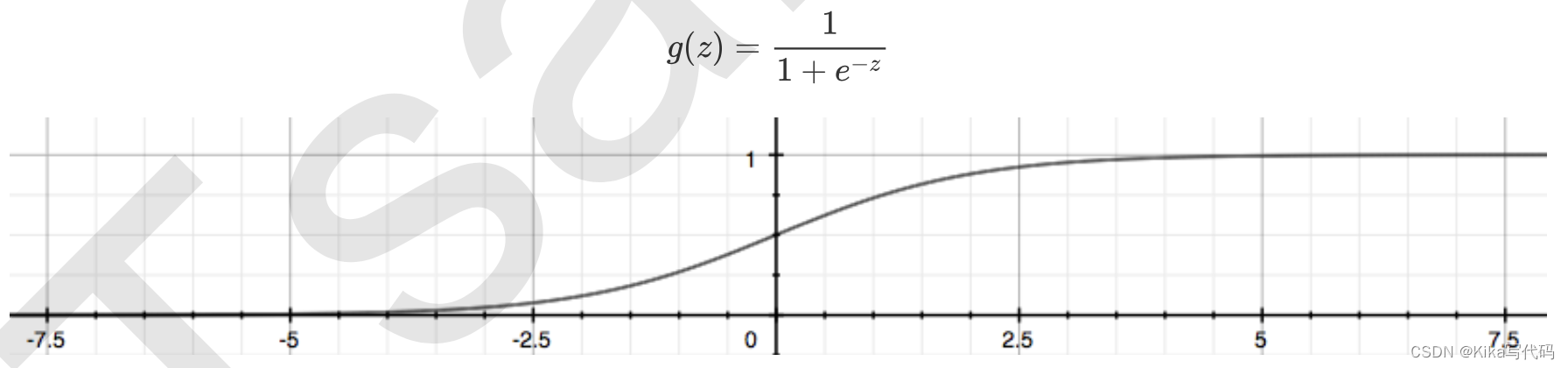
面试高危问题:Sigmoid函数的公式和性质
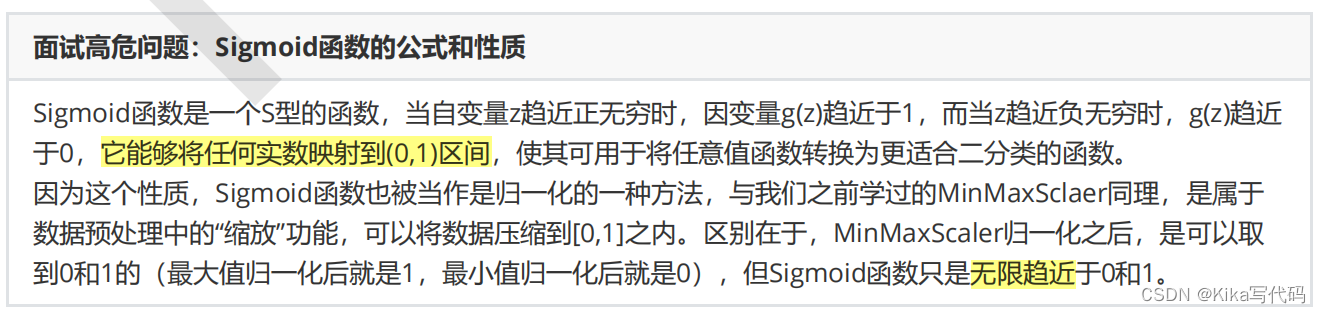


不难发现,g(z)的形似几率取对数的本质其实就是我们的线性回归z,我们实际上是在对线性回归模型的预测结果取对数几率来让其的结果无限逼近0和1。因此,其对应的模型被称为”对数几率回归“(logistic Regression),也就是我们的逻辑回归,这个名为“回归”却是用来做分类工作的分类器。
思考:g(z)代表了样本为某一类标签的概率吗?

1.2 为什么需要逻辑回归
线性回归对数据的要求很严格,比如标签必须满足正态分布,特征之间的多重共线性需要消除等等,而现实中很多真实情景的数据无法满足这些要求,因此线性回归在很多现实情境的应用效果有限。逻辑回归是由线性回归变化而来,因此它对数据也有一些要求,而我们之前已经学过了强大的分类模型决策树和随机森林,它们的分类效力很强,并且不需要对数据做任何预处理。
何况,逻辑回归的原理其实并不简单。一个人要理解逻辑回归,必须要有一定的数学基础,必须理解损失函数,正则化,梯度下降,海森矩阵等等这些复杂的概念,才能够对逻辑回归进行调优。其涉及到的数学理念,不比支持向量机少多少。况且,要计算概率,朴素贝叶斯可以计算出真正意义上的概率,要进行分类,机器学习中能够完成二分类功能的模型简直多如牛毛。因此,在数据挖掘,人工智能所涉及到的医疗,教育,人脸识别,语音识别这些领域,逻辑回归没有太多的出场机会。
甚至,在我们的各种机器学习经典书目中,周志华的《机器学习》400页仅有一页纸是关于逻辑回归的(还是一页 数学公式),《数据挖掘导论》和《Python数据科学手册》中完全没有逻辑回归相关的内容,sklearn中对比各种 分类器的效应也不带逻辑回归玩,可见业界地位。
但是,无论机器学习领域如何折腾,逻辑回归依然是一个受工业商业热爱,使用广泛的模型,因为它有着不可替代 的优点:
- 逻辑回归对线性关系的拟合效果好到丧心病狂,特征与标签之间的线性关系极强的数据,比如金融领域中的信用卡欺诈,评分卡制作,电商中的营销预测等等相关的数据,都是逻辑回归的强项。虽然现在有了梯度提升树GDBT,比逻辑回归效果更好,也被许多数据咨询公司启用,但逻辑回归在金融领域,尤其是银行业中的统治地位依然不可动摇(相对的,逻辑回归在非线性数据的效果很多时候比瞎猜还不如,所以如果你已经知道数据之间的联系是非线性的,千万不要迷信逻辑回归)
- 逻辑回归计算快:对于线性数据,逻辑回归的拟合和计算都非常快,计算效率优于SVM和随机森林,亲测表 示在大型数据上尤其能够看得出区别
- 逻辑回归返回的分类结果不是固定的0,1,而是以小数形式呈现的类概率数字:我们因此可以把逻辑回归返回的结果当成连续型数据来利用。比如在评分卡制作时,我们不仅需要判断客户是否会违约,还需要给出确定的”信用分“,而这个信用分的计算就需要使用类概率计算出的对数几率,而决策树和随机森林这样的分类器,可以产出分类结果,却无法帮助我们计算分数(当然,在sklearn中,决策树也可以产生概率,使用接口predict_proba调用就好,但一般来说,正常的决策树没有这个功能)。
另外,逻辑回归还有抗噪能力强的优点。福布斯杂志在讨论逻辑回归的优点时,甚至有着“技术上来说,最佳模型的AUC面积低于0.8时,逻辑回归非常明显优于树模型”的说法。并且,逻辑回归在小数据集上表现更好,在大型的数据集上,树模型有着更好的表现。
由此,我们已经了解了逻辑回归的本质,它是一个返回对数几率的,在线性数据上表现优异的分类器,它主要被应 用在金融领域。其数学目的是求解能够让模型最优化的参数的值,并基于参数和特征矩阵计算出逻辑回归的结果 y(x)。注意:虽然我们熟悉的逻辑回归通常被用于处理二分类问题,但逻辑回归也可以做多分类。
1.3 sklearn中的逻辑回归
2 linear_model.LogisticRegression

2.1 二元逻辑回归的损失函数
在学习决策树和随机森林时,我们曾经提到过两种模型表现:在训练集上的表现,和在测试集上的表现。我们建模,是追求模型在测试集上的表现最优,因此模型的评估指标往往是用来衡量模型在测试集上的表现的。然而,逻辑回归有着基于训练数据求解参数的需求,并且希望训练出来的模型能够尽可能地拟合训练数据,即模型在训练集上的预测准确率越靠近100%越好。
因此,我们使用”损失函数“这个评估指标,来衡量参数的优劣,即这一组参数能否使模型在训练集上表现优异。如果用一组参数建模后,模型在训练集上表现良好,那我们就说模型表现的规律与训练集数据的规律一致,拟合过程中的损失很小,损失函数的值很小,这一组参数就优秀;相反,如果模型在训练集上表现糟糕,损失函数就会很大,模型就训练不足,效果较差,这一组参数也就比较差。即是说,我们在求解参数
时,追求损失函数最小,让模型在训练数据上的拟合效果最优,即预测准确率尽量靠近100%。
关键概念:损失函数

逻辑回归的损失函数是由最大似然法来推导出来的,具体结果可以写作:
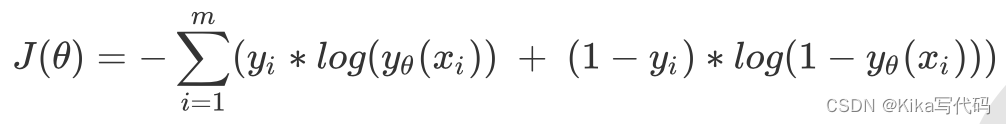

由于我们追求损失函数的最小值,让模型在训练集上表现最优,可能会引发另一个问题:
如果模型在训练集上表示优秀,却在测试集上表现糟糕,模型就会过拟合。虽然逻辑回归和线性回归是天生欠拟合的模型,但我们还是需要控制过拟合的技术来帮助我们调整模型,对逻辑回归中过拟合的控制,通过正则化来实现。
2.2 正则化:重要参数penalty & C
正则化是用来防止模型过拟合的过程,常用的有L1正则化和L2正则化两种选项,分别通过在损失函数后加上参数向量的L1范式和L2范式的倍数来实现。这个增加的范式,被称为“正则项”,也被称为"惩罚项"。
损失函数改变,基于损失函数的最优化来求解的参数取值必然改变,我们以此来调节模型拟合的程度。其中L1范数表现为参数向量中的每个参数的绝对值之和,L2范数表现为参数向量中的每个参数的平方和的开方值。


L1正则化和L2正则化虽然都可以控制过拟合,但它们的效果并不相同。当正则化强度逐渐增大(即C逐渐变小), 参数的取值会逐渐变小,但L1正则化会将参数压缩为0,L2正则化只会让参数尽量小,不会取到0。
在L1正则化在逐渐加强的过程中,携带信息量小的、对模型贡献不大的特征的参数,会比携带大量信息的、对模型有巨大贡献的特征的参数更快地变成0,所以L1正则化本质是一个特征选择的过程,掌管了参数的“稀疏性”。L1正则化越强,参数向量中就越多的参数为0,参数就越稀疏,选出来的特征就越少,以此来防止过拟合。因此,如果特征量很大,数据维度很高,我们会倾向于使用L1正则化。由于L1正则化的这个性质,逻辑回归的特征选择可以由Embedded嵌入法来完成。
相对的,L2正则化在加强的过程中,会尽量让每个特征对模型都有一些小的贡献,但携带信息少,对模型贡献不大的特征的参数会非常接近于0。通常来说,如果我们的主要目的只是为了防止过拟合,选择L2正则化就足够了。但是如果选择L2正则化后还是过拟合,模型在未知数据集上的效果表现很差,就可以考虑L1正则化。
而两种正则化下C的取值,都可以通过学习曲线来进行调整。
建立两个逻辑回归,L1正则化和L2正则化的差别就一目了然了:
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_scoredata = load_breast_cancer()
X = data.data
y = data.targetdata.data.shapelrl1 = LR(penalty="l1",solver="liblinear",C=0.5,max_iter=1000)
lrl2 = LR(penalty="l2",solver="liblinear",C=0.5,max_iter=1000)#逻辑回归的重要属性coef_,查看每个特征所对应的参数
lrl1 = lrl1.fit(X,y)
lrl1.coef_(lrl1.coef_ != 0).sum(axis=1)lrl2 = lrl2.fit(X,y)
lrl2.coef_
可以看见,当我们选择L1正则化的时候,许多特征的参数都被设置为了0,这些特征在真正建模的时候,就不会出现在我们的模型当中了,而L2正则化则是对所有的特征都给出了参数。
究竟哪个正则化的效果更好呢?还是都差不多?
l1 = []
l2 = []
l1test = []
l2test = []Xtrain, Xtest, Ytrain, Ytest =train_test_split(X,y,test_size=0.3,random_state=420)for i in np.linspace(0.05,1,19):lrl1 = LR(penalty="l1",solver="liblinear",C=i,max_iter=1000) lrl2 = LR(penalty="l2",solver="liblinear",C=i,max_iter=1000)lrl1 = lrl1.fit(Xtrain,Ytrain) l1.append(accuracy_score(lrl1.predict(Xtrain),Ytrain)) l1test.append(accuracy_score(lrl1.predict(Xtest),Ytest))lrl2 = lrl2.fit(Xtrain,Ytrain) l2.append(accuracy_score(lrl2.predict(Xtrain),Ytrain)) l2test.append(accuracy_score(lrl2.predict(Xtest),Ytest))graph = [l1,l2,l1test,l2test]
color = ["green","black","lightgreen","gray"]
label = ["L1","L2","L1test","L2test"]plt.figure(figsize=(6,6))
for i in range(len(graph)):plt.plot(np.linspace(0.05,1,19),graph[i],color[i],label=label[i])
plt.legend(loc=4) #图例的位置在哪里?4表示,右下角
plt.show()
可见,至少在我们的乳腺癌数据集下,两种正则化的结果区别不大。但随着C的逐渐变大,正则化的强度越来越小,模型在训练集和测试集上的表现都呈上升趋势,直到C=0.8左右,训练集上的表现依然在走高,但模型在未知数据集上的表现开始下跌,这时候就是出现了过拟合。我们可以认为,C设定为0.9会比较好。在实际使用时,基本就默认使用l2正则化,如果感觉到模型的效果不好,那就换L1试试看。
2.2 梯度下降:重要参数max_iter
之前提到过,逻辑回归的数学目的是求解能够让模型最优化的参数的值,即求解能够让损失函数最小化的
的值, 而这个求解过程,对于二元逻辑回归来说,有多种方法可以选择,最常见的有梯度下降法(Gradient Descent),坐标轴下降法(Coordinate Descent),牛顿法(Newton-Raphson method)等,每种方法都涉及复杂的数学原理,但 这些计算在执行的任务其实是类似的。

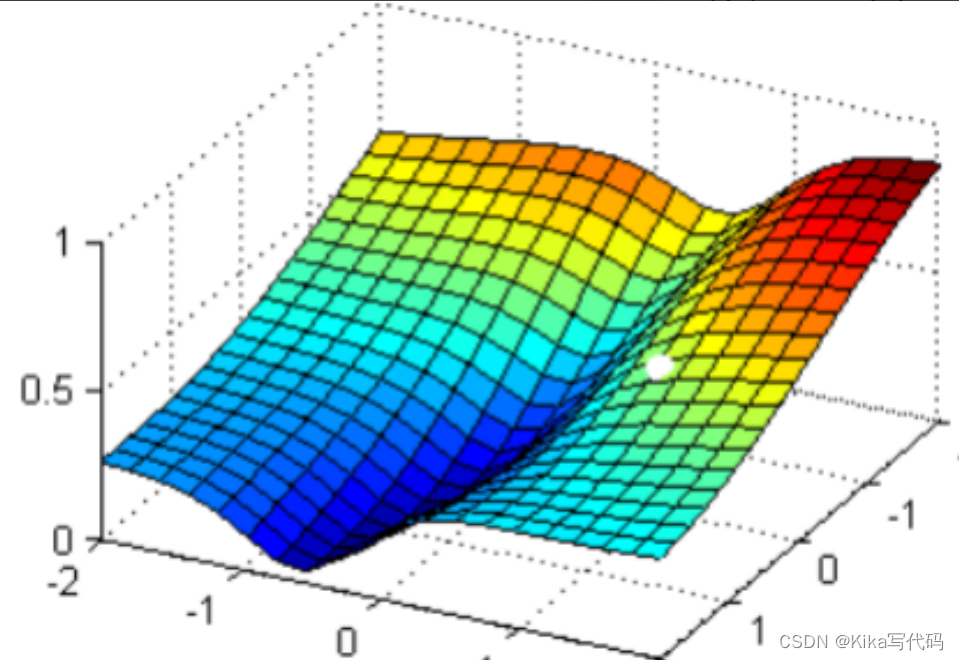
现在,我在这个图像上随机放一个小球,当我松手,这个小球就会顺着这个华丽的平面滚落,直到滚到深蓝色的区域——损失函数的最低点。但是,小球不能够一次性滚动到最低处,它的能量不足,所以每次最多只能走距离G。 为了严格监控这个小球的行为,我要求小球每次只能走0.05 * G,并且我要记下它每次走动的方向,直到它滚到图像上的最低点。
现在我松手,来看小球如何运动:
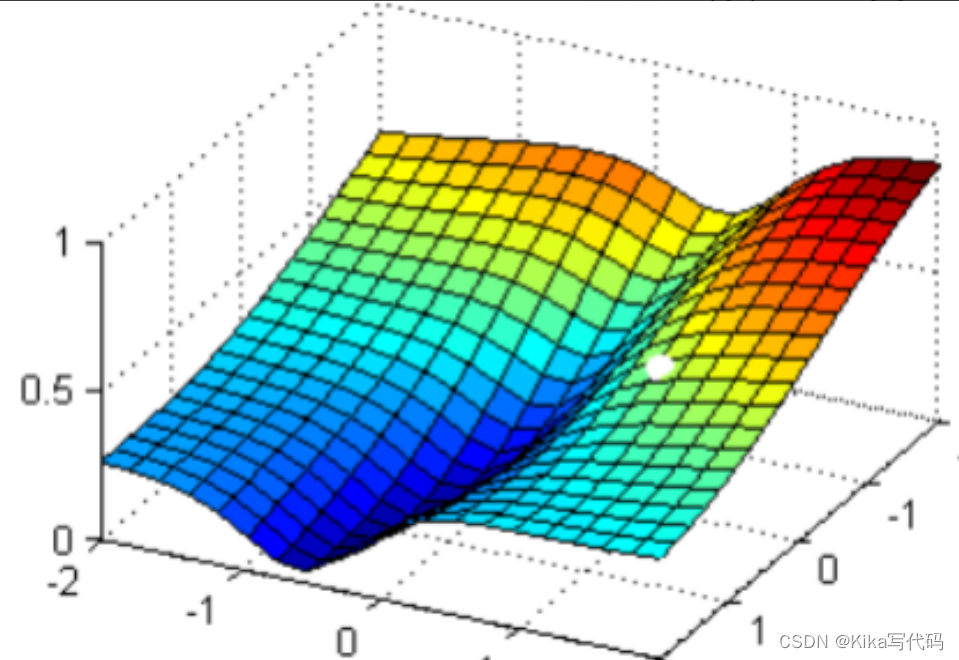
可以看见,小球从高处滑落,最终停在深蓝色的区域中的某个点上,而这个点就是我们在现有状况下可以获得的图像的最低点。有了这个图像的最低点的数值,我们就可以计算出这个点所对应的参数向量了。
2.3 二元回归与多元回归:重要参数solver & multi_class
之前我们对逻辑回归的讨论,都是针对二分类的逻辑回归展开,其实sklearn提供了多种可以使用逻辑回归处理多分类问题的选项。比如说,我们可以把某种分类类型都看作1,其余的分类类型都为0值,和"数据预处理"中的二值化的思维类似,这种方法被称为"一对多"(One-vs-rest),简称OvR,在sklearn中表示为"ovr"。又或者,我们可以把好几个分类类型划为1,剩下的几个分类类型划为O值,这是一种"多对多"(Many-vs-Many)的方法,简称MvM,在sklearn中表示为"Multinominal"。每种方式都配合L1或L2正则项来使用。
在sklearn中,我们使用参数multi_class来告诉模型,我们的预测标签是什么样的类型。
multi_class
输入"ovr " , "multinomial", "auto"来告知模型,我们要处理的分类问题的类型。默认是"ovr"。
'ovr':表示分类问题是二分类,或让模型使用"一对多"的形式来处理多分类问题。
'multinomial':表示处理多分类问题,这种输入在参数solver是'liblinear'时不可用。
"auto":表示会根据数据的分类情况和其他参数来确定模型要处理的分类问题的类型。比如说,如果数据是二分类,或者solver的取值为"liblinear","auto"会默认选择"ovr"。反之,则会选择"nultinomial"。
注意:默认值将在0.22版本中从"ovr"更改为"auto"。
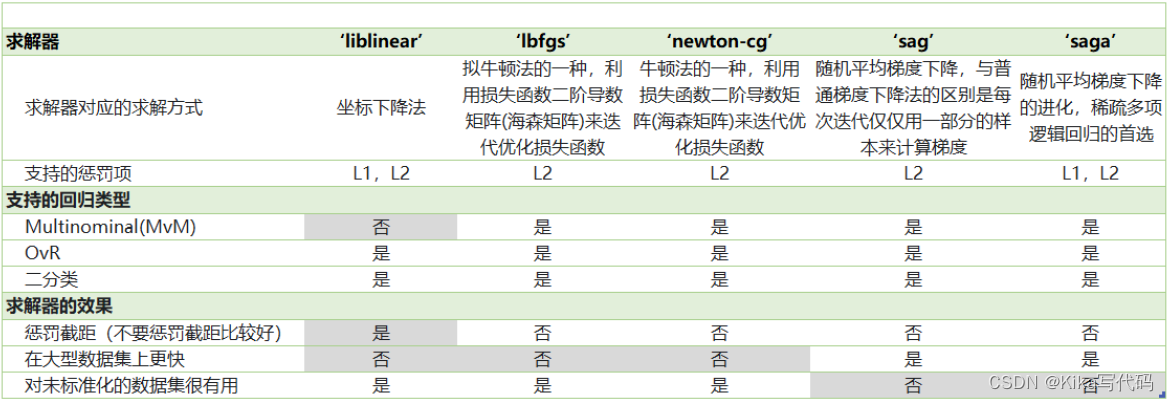
我们之前提到的梯度下降法,只是求解逻辑回归参数的一种方法,并且我们只讲解了求解二分类变量的参数时的各种原理。sklearn为我们提供了多种选择,让我们可以使用不同的求解器来计算逻辑回归。求解器的选择,由参数"solver"控制,共有五种选择。其中“liblinear”是二分类专用,也是现在的默认求解器。
2.4 逻辑回归中的特征选择
当特征的数量很多的时候,我们出于业务考虑,也出于计算量的考虑,希望对逻辑回归进行特征选择来降维。比如,在判断一个人是否会患乳腺癌的时候,医生如果看5~8个指标来确诊,会比需要看30个指标来确诊容易得多。
- 业务选择
说到降维和特征选择,首先要想到的是利用自己的业务能力进行选择,肉眼可见明显和标签有关的特征就是需要留下的。当然,如果我们并不了解业务,或者有成千上万的特征,那我们也可以使用算法来帮助我们。或者,可以让算法先帮助我们筛选过一遍特征,然后在少量的特征中,我们再根据业务常识来选择更少量的特征。
- PCA和SVD一般不用
说到降维,我们首先想到的是之前提过的高效降维算法,PCA和SVD,遗憾的是,这两种方法大多数时候不适用于逻辑回归。逻辑回归是由线性回归演变而来,线性回归的一个核心目的是通过求解参数来探究特征X与标签y之间的关系,而逻辑回归也传承了这个性质,我们常常希望通过逻辑回归的结果,来判断什么样的特征与分类结果相关,因此我们希望保留特征的原貌。PCA和SVD的降维结果是不可解释的,因此一旦降维后,我们就无法解释特征和标签之间的关系了。当然,在不需要探究特征与标签之间关系的线性数据上,降维算法PCA和SVD也是可以使用的。
- 统计方法可以使用,但不是非常必要
既然降维算法不能使用,我们要用的就是特征选择方法。逻辑回归对数据的要求低于线性回归,由于我们不是使用最小二乘法来求解,所以逻辑回归对数据的总体分布和方差没有要求,也不需要排除特征之间的共线性,但如果我们确实希望使用一些统计方法,比如方差,卡方,互信息等方法来做特征选择,也并没有问题。过滤法中所有的方法,都可以用在逻辑回归上。
在一些博客中有这样的观点:多重共线性会影响线性模型的效果。对于线性回归来说,多重共线性会影响比较大,所以我们需要使用方差过滤和方差膨胀因子VIF(variance inflation factor)来消除共线性。但是对于逻辑回归,其实不是非常必要,甚至有时候,我们还需要多一些相互关联的特征来增强模型的表现。当然,如果我们无法通过其他方式提升模型表现,并且你感觉到模型中的共线性影响了模型效果,那懂得统计学的你可以试试看用VIF消除共线性的方法,遗憾的是现在sklearn中并没有提供VIF的功能。
轻松一刻:R vs Python,统计学 vs 机器学习
统计学的思路是一种“先验”的思路,不管做什么都要先”检验“,先”满足条件“,事后也要各种”检验“,以确保各种数学假设被满足,不然的话,理论上就无法得出好结果。而机器学习是一种”后验“的思路,不管三七二十一,先让模型跑一跑,效果不好再想办法,如果模型效果好,不在意什么共线性,残差不满足正态分布,没有哑变量之类的细节,模型效果好大过天!
- 高效的嵌入法embedded
但是更有效的方法,毫无疑问会是我们的embedded嵌入法。我们已经说明了,由于L1正则化会使得部分特征对应的参数为0,因此L1正则化可以用来做特征选择,结合嵌入法的模块SelectFromModel,我们可以很容易就筛选出让模型十分高效的特征。注意,此时我们的目的是,尽量保留原数据上的信息,让模型在降维后的数据上的拟合效果保持优秀,因此我们不考虑训练集测试集的问题,把所有的数据都放入模型进行降维。
#导库
from sklearn.linear_model import LogisticRegression as LR
from sklearn.datasets import load_breast_cancer
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import cross_val_score
from sklearn.feature_selection import SelectFromModeldata = load_breast_cancer() # 乳腺癌数据的实例化
data.data.shapeLR_ = LR(solver=“liblinear”,C=0.8,random_state=420)
cross_val_score(LR_,data.data,data.target,cv=10).mean()#对数据进行降维
# 参数threshold(相当于特征重要性阈值)
# 参数norm_order选择范式L1还是L2
# norm_order=1说明使用的是L1范式,模型会删除在L1范式下面无效的特征
X_embedded = SelectFromModel(LR_,norm_order=1).fit_transform(data.data,data.target)
X_embedded.shapedata.target.shapecross_val_score(LR_,X_embedded,data.target,cv=10).mean()
看看结果,特征数量被减小到个位数,并且模型的效果却没有下降太多,如果我们要求不高,在这里其实就可以停下了。但是,能否让模型的拟合效果更好呢?在这里,我们有两种调整方式:
1)调节SelectFromModel这个类中的参数threshold
这是嵌入法的阈值,表示删除所有参数的绝对值低于这个阈值的特征。现在threshold默认为None,所以SelectFromModel只根据L1正则化的结果来选择了特征,即选择了所有L1正则化后参数不为0的特征。我们此时,只要调整threshold的值(画出threshold的学习曲线),就可以观察不同的threshold下模型的效果如何变化。
一旦调整threshold,就不是在使用L1正则化选择特征,而是使用模型的属性.coef_中生成的各个特征的系数来选择。coef_虽然返回的是特征的系数,但是系数的大小和决策树中的feature_importances_以及降维算法中的可解释性方差explained_vairance_概念相似,其实都是衡量特征的重要程度和贡献度的,因此SelectFromModel中的参数threshold可以设置为coef_的阈值,即可以剔除系数小于threshold中输入的数字的所有特征。
然而,这种方法其实是比较无效的,大家可以用学习曲线来跑一跑:当threshold越来越大,被删除的特征越来越多,模型的效果也越来越差,模型效果最好的情况下需要保证有17个以上的特征。实际上我画了细化的学习曲线,如果要保证模型的效果比降维前更好,我们需要保留25个特征,这对于现实情况来说,是一种无效的降维:需要30个指标来判断病情,和需要25个指标来判断病情,对医生来说区别不大。
2)调逻辑回归的类LR_,通过画C的学习曲线来实现(好用!)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.linear_model import LogisticRegression as LR # 逻辑回归
from sklearn.model_selection import cross_val_score # 交叉验证
from sklearn.datasets import load_breast_cancer # 乳腺癌数据集
from sklearn.feature_selection import SelectFromModel # 嵌入法特征选择data = load_breast_cancer()x = data.data
y = data.targetLR_ = LR(solver='liblinear', C=0.2, random_state=500)
print(cross_val_score(LR_, x, y, cv=10).mean())fullx = []
fsx = []c = np.arange(0.01, 10.01, 0.5)for i in c:LR_ = LR(solver='liblinear', C=i, random_state=500)# 使用没用嵌入法降维的xfullx.append(cross_val_score(LR_, x, y, cv=10).mean())# 使用嵌入法降维x_embedded = SelectFromModel(LR_, norm_order=1).fit_transform(x, y)fsx.append(cross_val_score(LR_, x_embedded, y, cv=10).mean())# 得出最高的评分及相应的C值
print(max(fsx), c[fsx.index(max(fsx))])plt.figure(figsize=[20, 5])
plt.plot(c, fullx, label='full')
plt.plot(c, fsx, label='feature selection')
plt.legend()
plt.show()
得出最高的评分及相应的C值:

这样我们就实现了在特征选择的前提下,保持模型拟合的高效,现在,如果有一位医生可以来为我们指点迷津,看看剩下的这些特征中,有哪些是对针对病情来说特别重要的,也许我们还可以继续降维。当然,除了嵌入法,系数累加法或者包装法也是可以使用的。
- 比较麻烦的系数累加法
系数累加法的原理非常简单。coef_虽然返回的是特征的系数,但是系数的大小和决策树中的feature_importances_以及降维算法中的可解释性方差explained_vairance_概念相似,其实都是衡量特征的重要程度和贡献度的。在PCA中,我们通过绘制累积可解释方差贡献率曲线来选择超参数,在逻辑回归中,我们可以使用系数coef_来这样做。
并且我们选择特征个数的逻辑也是类似的:找出曲线由锐利变平滑的转折点,转折点之前被累加的特征都是我们需要的,转折点之后的我们都不需要。不过这种方法相对比较麻烦,因为我们要先对特征系数进行从大到小的排序,还要确保我们知道排序后的每个系数对应的原始特征的位置,才能够正确找出那些重要的特征。如果要使用这样的方法,不如直接使用嵌入法来得方便。
- 简单快速的包装法
相对的,包装法可以直接设定我们需要的特征个数,逻辑回归在现实中运用时,可能会有”需要5~8个变量”这种需求,包装法此时就非常方便了。不过逻辑回归的包装法的使用和其他算法一样,并不具有特别之处,因此在这里就不在赘述,包装法具体参考03期:特征选择中的包装法。
2.5 样本不平衡与参数class_weight
样本不平衡是指在一组数据集中,标签的一类天生占有很大的比例,或误分类的代价很高,即我们想要捕捉出某种特定的分类的时候的状况。
什么情况下误分类的代价很高?例如,我们现在要对潜在犯罪者和普通人进行分类,如果没有能够识别出潜在犯罪者,那么这些人就可能去危害社会,造成犯罪,识别失败的代价会非常高,但如果,我们将普通人错误地识别成了潜在犯罪者,代价却相对较小。所以我们宁愿将普通人分类为潜在犯罪者后再人工甄别,但是却不愿将潜在犯罪者分类为普通人,有种"宁愿错杀不能放过"的感觉。
再比如说,在银行要判断"一个新客户是否会违约",通常不违约的人vs违约的人会是99: 1的比例,真正违约的人其实是非常少的。这种分类状况下,即便模型什么也不做,全把所有人都当成不会违约的人,正确率也能有99%,这使得模型评估指标变得毫无意义,根本无法达到我们的“要识别出会违约的人"的建模目的。
因此我们要使用参数class_weight对样本标签进行一定的均衡,给少量的标签更多的权重,让模型更偏向少数类,向捕获少数类的方向建模。该参数默认None,此模式表示自动给与数据集中的所有标签相同的权重,即自动1:1。当误分类的代价很高的时候,我们使用”balanced“模式,我们只是希望对标签进行均衡的时候,什么都不填就可以解决样本不均衡问题。
但是,sklearn当中的参数class_weight变幻莫测,大家用模型跑一跑就会发现,我们很难去找出这个参数引导的模 型趋势,或者画出学习曲线来评估参数的效果,因此可以说是非常难用。我们有着处理样本不均衡的各种方法,其中主流的是采样法,是通过重复样本的方式来平衡标签,可以进行上采样(增加少数类的样本),比如SMOTE, 或者下采样(减少多数类的样本)。对于逻辑回归来说,上采样是最好的办法。在案例中,会给大家详细来讲如何在逻辑回归中使用上采样。
相关文章:
【sklearn】【逻辑回归1】
学习笔记来自: 所用的库和版本大家参考: Python 3.7.1Scikit-learn 0.20.1 Numpy 1.15.4, Pandas 0.23.4, Matplotlib 3.0.2, SciPy 1.1.0 1 概述 1.1 名为“回归”的分类器 在过去的四周中,我们接触了不少带“回归”二字的算法…...
和 python 通过DoubleCloud的kafka进行线程间通信)
java(kotlin)和 python 通过DoubleCloud的kafka进行线程间通信
进入 DoubleCloud https://www.double.cloud 创建一个kafka 1 选择语言 2 运行curl 的url命令启动一个topic 3 生成对应语言的token 4 复制3中的配置文件到本地,命名为client.properties 5 复制客户端代码 对python和java客户端代码进行了重写,java改成…...
vivado DIAGRAM、HW_AXI
图表 描述 块设计(.bd)是在IP中创建的互连IP核的复杂系统 Vivado设计套件的集成商。Vivado IP集成器可让您创建复杂的 通过实例化和互连Vivado IP目录中的IP进行系统设计。一块 设计是一种分层设计,可以写入磁盘上的文件(.bd&…...

学习分享-为什么把后台的用户验证和认证逻辑放到网关
将后台的用户验证和认证逻辑放到网关(API Gateway)中是一种常见的设计模式,这种做法在微服务架构和现代应用中有许多优势和理由: 1. 集中管理认证和授权 统一的安全策略 在一个包含多个微服务的系统中,如果每个服务…...
27 ssh+scp+nfs+yum进阶
ssh远程管理 ssh是一种安全通道协议,用来实现字符界面的远程登录。远程复制,远程文本传输。 ssh对通信双方的数据进行了加密。 用户名和密码登录 密钥对认证方式(可以实现免密登录) ssh 22 网络层 传输层 数据传输的过程中是…...

LabVIEW液压伺服压力机控制系统与控制频率选择
液压伺服压力机的控制频率是一个重要的参数,它直接影响系统的响应速度、稳定性和控制精度。具体选择的控制频率取决于多种因素,包括系统的动态特性、控制目标、硬件性能以及应用场景。以下是一些常见的指导原则和考量因素: 常见的控制频率范…...
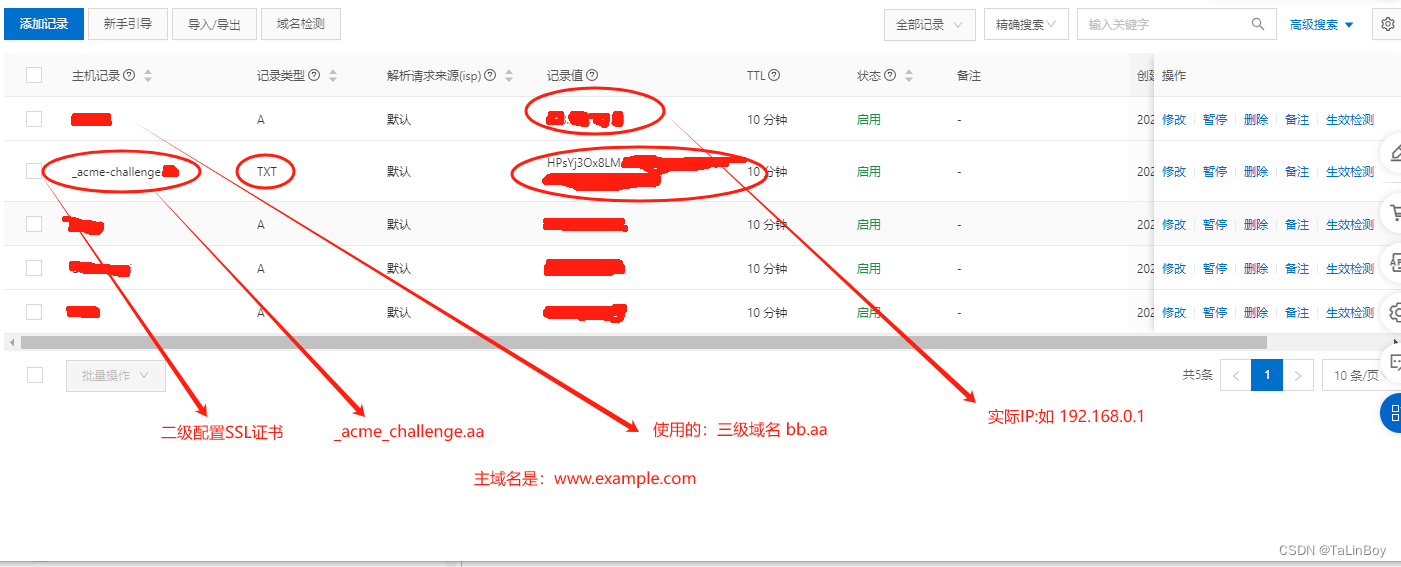
阿里云(域名解析) certbot 证书配置
1、安装 certbot ubuntu 系统: sudo apt install certbot 2、申请certbot 域名证书,如申请二级域名aa.example.com 的ssl证书,同时需要让 bb.aa.example.com 也可以使用此证书 1、命令:sudo certbot certonly -d “域名” -d “…...

Web LLM 攻击技术
概述 在ChatGPT问世以来,我也尝试挖掘过ChatGPT的漏洞,不过仅仅发现过一些小问题:无法显示xml的bug和错误信息泄露,虽然也挖到过一些开源LLM的漏洞,比如前段时间发现的Jan的漏洞,但是不得不说传统漏洞越来…...
)
Java等待异步线程池跑完再执行指定方法的三种方式(condition、CountDownLatch、CyclicBarrier)
Java等待异步线程池跑完再执行指定方法的三种方式(condition、CountDownLatch、CyclicBarrier) Async如何使用 使用Async标注在方法上,可以使该方法异步的调用执行。而所有异步方法的实际执行是交给TaskExecutor的。 1.启动类添加EnableAsync注解 2. 方法上添加A…...
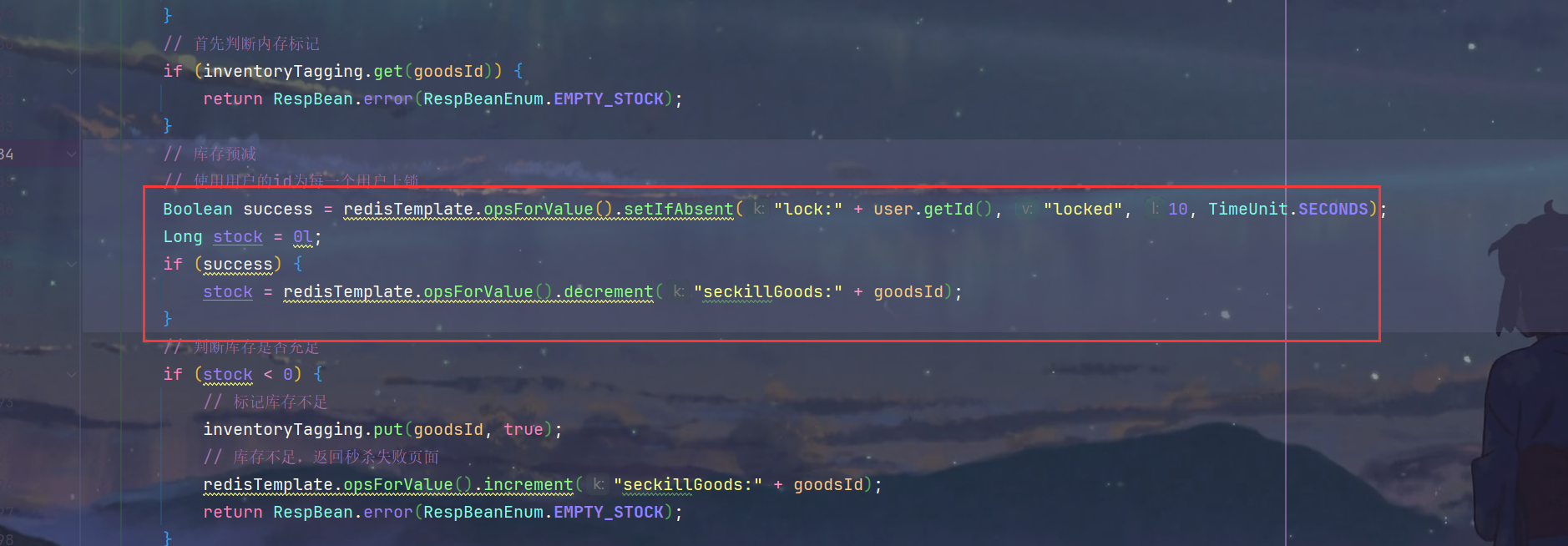
秒杀优化+秒杀安全
1.Redis预减库存 1.OrderServiceImpl.java 问题分析 2.具体实现 SeckillController.java 1.实现InitializingBean接口的afterPropertiesSet方法,在bean初始化之后将库存信息加载到Redis /*** 系统初始化,将秒杀商品库存加载到redis中** throws Excepti…...

48、Flink 的 Data Source API 详解
a)概述 本节将描述 FLIP-27 中引入的新 Source API 的主要接口。 b)Source Source API 是一个工厂模式的接口,用于创建以下组件。 Split EnumeratorSource ReaderSplit SerializerEnumerator Checkpoint Serializer 此外,Sou…...

深入解析Java扩展机制:SPI与Spring.factories
目录 Java SPI概述 1.1 什么是SPI?1.2 SPI的工作原理1.3 SPI的优缺点 SPI的应用 2.1 Java标准库中的SPI应用2.2 自定义SPI示例 Spring.factories概述 3.1 什么是spring.factories?3.2 spring.factories的工作原理3.3 spring.factories的优缺点 spring.f…...

Vue2之模板语法
文章目录 1.模板语法1.1 插值语法{{}}可以写什么1.2 指令语法1.2.1 指令概述1.2.2 v-bind指令1.2.3 v-model指令 1.模板语法 1.1 插值语法{{}}可以写什么 (1)在data中声明的 (2)常量 (3)合法的JavaScript…...
java基础练习题
1、一个".java"源文件中是否可以包括多个类?有什么限制? 可以包含多个类。但是只有一个类可以声明为public,且要求声明为public的类的类名与源文件名相同。 2、java的优势? a、跨平台性 b、安全性高 c、简单性 d、…...
的事件监听)
unity中通过实现底层接口实现非按钮(图片)的事件监听
编写监听脚本 PEListenter 继承自MonoBehaviour类,并实现了IPointerDownHandler、IPointerUpHandler和IDragHandler接口,按照需求定义需要接收事件(鼠标按下、抬起、拖拽)的回调函数 //监听类(需要挂载在物体上面&am…...

重庆耶非凡科技有限公司的选品师项目加盟靠谱吗?
在当今电子商务的浪潮中,选品师的角色愈发重要。而重庆耶非凡科技有限公司以其独特的选品师项目,在行业内引起了广泛关注。对于想要加盟该项目的人来说,项目的靠谱性无疑是首要考虑的问题。 首先,我们来看看耶非凡科技有限公司的背…...

《青少年编程与数学》课程方案:4、课程策略
《青少年编程与数学》课程方案:4、课程策略 一、工程师思维二、使命感驱动三、价值观引领四、学习现代化五、工作生活化六、与时代共进 《青少年编程与数学》课程策略强调采用工程师思维,避免重复造轮子,培养使命感,通过探索兴趣、…...
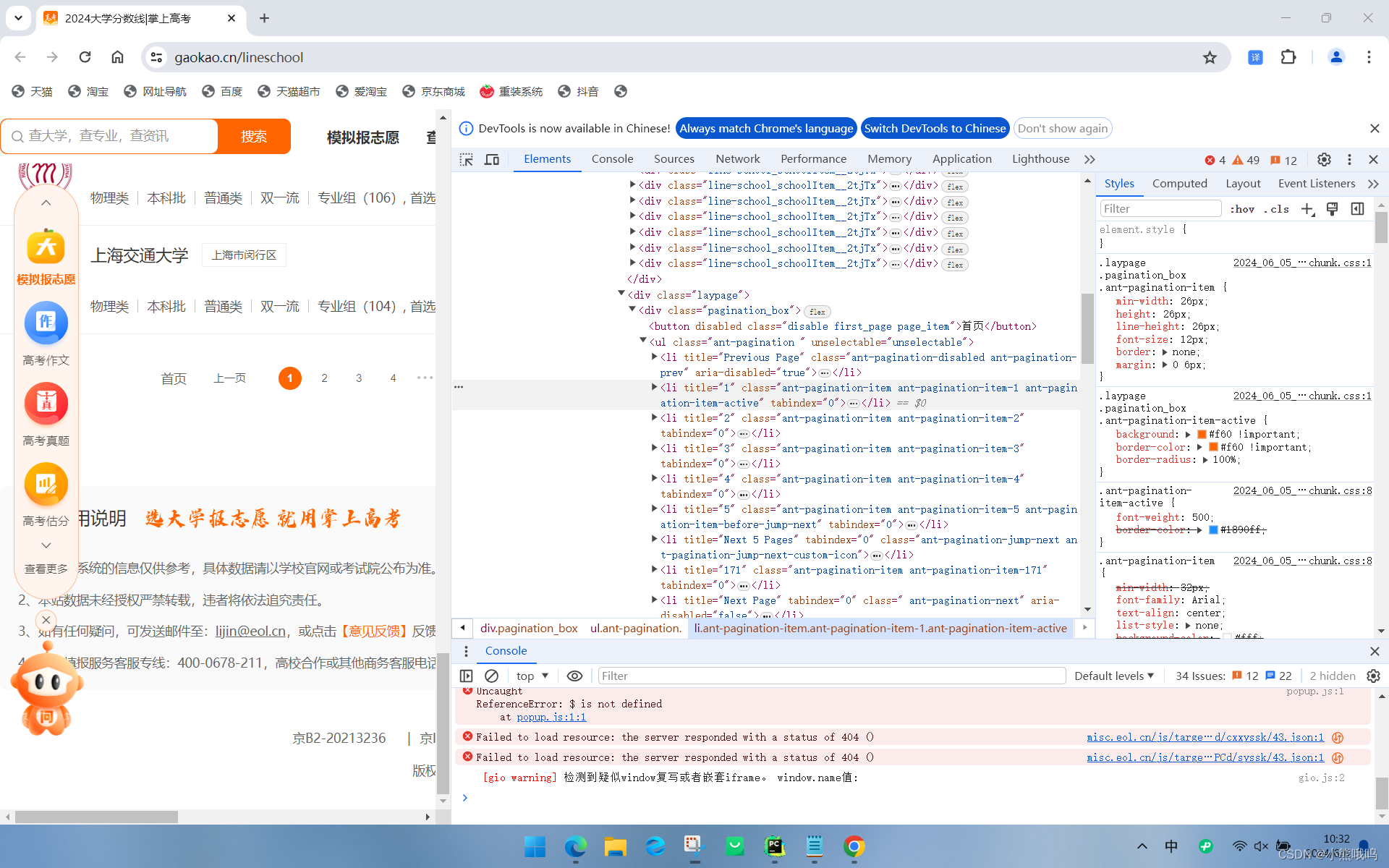
用爬虫实现---模拟填志愿
先来说实现逻辑,首先我要获取到这个网站上所有的信息,那么我们就可以开始对元素进行检查 我们发现他的每一个学校信息都有一个对应的属性,并且是相同的,那么我们就可以遍历这个网页中的所有属性一样的开始爬取 在来分析࿰…...

vscode Run Code输出出现中文乱码情况问题解决方案
主要解决方案是通过修改计算机默认的编码格式,来完成的。 chcp 是 Windows 操作系统中的一个命令,用于显示或设置控制台的代码页(code page)。代码页决定了控制台如何解释和显示字符,特别是非 ASCII 字符(例如 Unicode 字符)。 使用方法 显示当前代码页: 输入 chcp 而…...

代码随想录训练营Day30
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、重新安排行程 前言 提示:这里可以添加本文要记录的大概内容: 今天是跟着代码随想录刷题的第30天,主要是复习了回溯算法…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

Leetcode 3576. Transform Array to All Equal Elements
Leetcode 3576. Transform Array to All Equal Elements 1. 解题思路2. 代码实现 题目链接:3576. Transform Array to All Equal Elements 1. 解题思路 这一题思路上就是分别考察一下是否能将其转化为全1或者全-1数组即可。 至于每一种情况是否可以达到…...

【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

【Go】3、Go语言进阶与依赖管理
前言 本系列文章参考自稀土掘金上的 【字节内部课】公开课,做自我学习总结整理。 Go语言并发编程 Go语言原生支持并发编程,它的核心机制是 Goroutine 协程、Channel 通道,并基于CSP(Communicating Sequential Processes࿰…...

uniapp微信小程序视频实时流+pc端预览方案
方案类型技术实现是否免费优点缺点适用场景延迟范围开发复杂度WebSocket图片帧定时拍照Base64传输✅ 完全免费无需服务器 纯前端实现高延迟高流量 帧率极低个人demo测试 超低频监控500ms-2s⭐⭐RTMP推流TRTC/即构SDK推流❌ 付费方案 (部分有免费额度&#x…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

uniapp中使用aixos 报错
问题: 在uniapp中使用aixos,运行后报如下错误: AxiosError: There is no suitable adapter to dispatch the request since : - adapter xhr is not supported by the environment - adapter http is not available in the build 解决方案&…...