天才程序员周弈帆 | Stable Diffusion 解读(一):回顾早期工作
本文来源公众号“天才程序员周弈帆”,仅用于学术分享,侵权删,干货满满。
原文链接:Stable Diffusion 解读(一):回顾早期工作
在2022年的这波AI绘画浪潮中,Stable Diffusion无疑是最受欢迎的图像生成模型。究其原因,第一,Stable Diffusion通过压缩图像尺寸显著提升了扩散模型的运行效率,使得每个用户能在自己的商业级显卡上运行模型;第二,有许多基于Stable Diffusion的应用,比如Stable Diffusion自带的文生图、图像补全,以及ControlNet、LoRA、DreamBooth等插件式应用;第三,得益于前两点,Stable Diffusion已经形成了一个庞大的用户社群,大家互相分享模型,交流心得。
不仅是大众,Stable Diffusion也吸引了大量科研人员,很多本来研究GAN的人纷纷转来研究扩散模型。然而,许多人在学习Stable Diffusion时却犯了难:又是公式扎堆的扩散模型,又是VAE,又是U-Net,这该怎么学起呀?
其实,一上来就读Stable Diffusion是很难读懂的。而如果你把之前的一些更基础的文章读懂,再回头来读Stable Diffusion,就会畅行无阻了。在这篇及之后的几篇文章中,我将从科研的角度对Stable Diffusion做一个全面的解读。在第一篇文章中,我将面向完全没接触过图像生成的读者,从头介绍Stable Diffusion是怎样从早期工作中一步一步诞生的;在第二篇文章中,我将详细解读Stable Diffusion的论文;在最后的第三篇文章中,我将带领大家阅读Stable Diffusion的官方源码,以及一些流行的开源库的Stable Diffusion实现。后续我还会写其他和Stable Diffusion相关的文章,比如ControlNet的介绍。
1 从自编码器谈起
包括Stable Diffusion在内,很多图像生成模型都可以看成是一种非常简单的模型——自编码器——的改进版。要谈Stable Diffusion是怎么逐渐诞生的,其实就是在谈自编码器是一步一步进化的。我们的学习就从自编码器开始。
尽管PNG、JPG等图像压缩方法已经非常成熟,但我们会想,会不会还有更好的图像压缩算法呢?图像压缩,其实就是找两个映射,一个把图片编码成压缩数据,另一个把压缩数据解码回图片。我们知道,神经网络理论上可以拟合任何映射。那我们干脆用两个神经网络来拟合两种映射,以实现一个图像压缩算法。负责编码的神经网络叫编码器(Encoder),负责解码的神经网络叫做解码器(Decoder)。
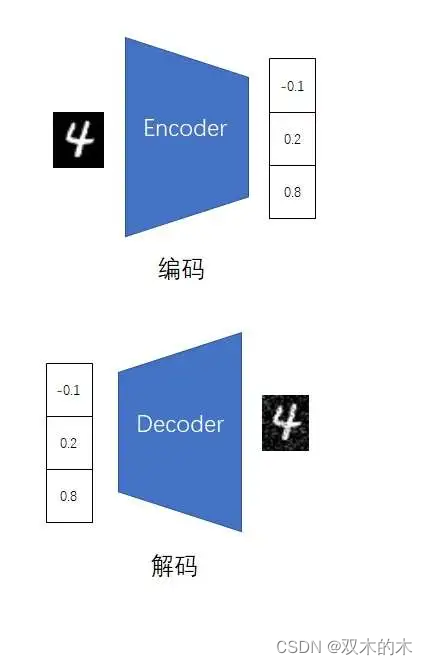
光定义了神经网络还不够,我们还需要给两个神经网络设置一个学习目标。在运行过程中,神经网络应该满足一个显然的约束:编码再解码后的重建图像应该和原图像尽可能一致,即二者的均方误差应该尽可能小。这样,我们只需要随便找一张图片,通过编码器和解码器得到重建图像,就能训练神经网络了。我们不需要给图片打上标签,整个训练过程是自监督的。所以我们说,整套模型是一个自编码器(Autoencoder,AE)。
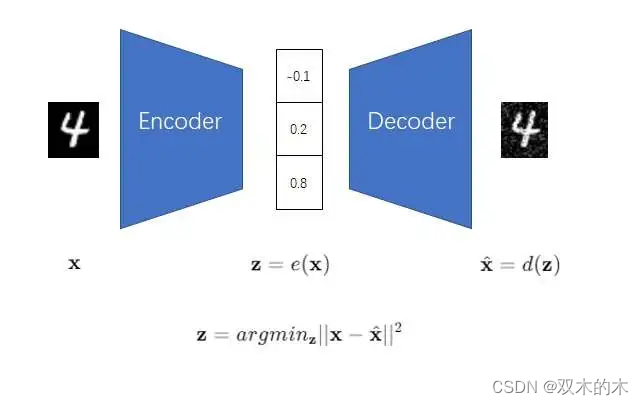
图像压缩模型AE为什么会和图像生成扯上关系呢?你可以试着把AE的输入图像和编码器遮住,只看解码部分。把一个压缩数据解码成图像,换个角度看,不就是在根据某一数据生成图像嘛。
很可惜,AE并不是一个合格的图像生成模型。我们常说的图像生成,具体是指让程序生成各种各样的图片。为了让程序生成不同的图片,我们一般是让程序根据随机数(或是随机向量)来生成图片。而普通的AE会有过拟合现象,这导致AE的解码器只认得训练集里的图片经编码器解码出来的压缩数据,而不认得随机生成的压缩数据,进而也无法达到图像生成的要求。
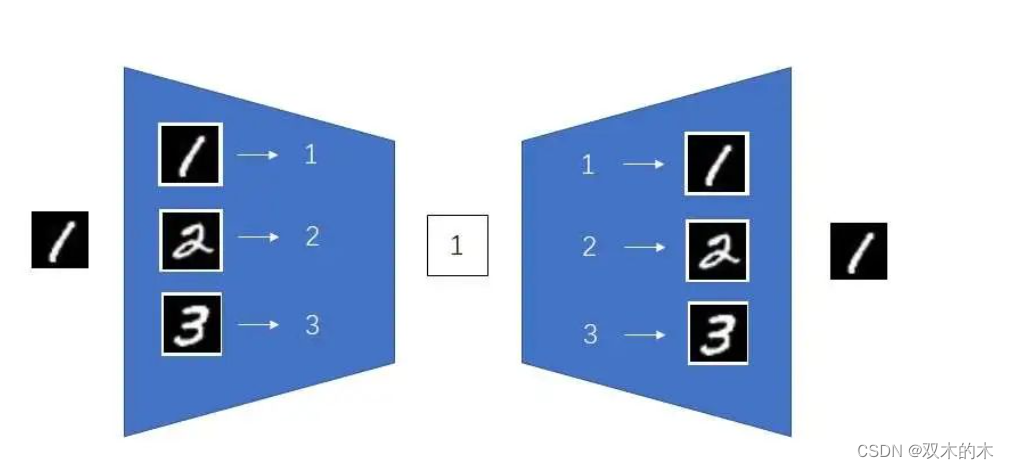
所谓过拟合,就是指模型只能处理训练数据,而不能推广到一般的数据上。举一个极端的例子,如下图所示,编码器和解码器直接记忆了整个数据集,把所有图片压缩成了一个数字。也就是模型把编码器当成一个图片到数字的词典,把解码器当成一个数字到图片的词典。这样,不管数据集有多大,所有图片都可以被压缩成一个数字。这样的AE确实压缩能力很强,但它完全没用,因为它过拟合了,处理不了训练集以外的数据。
过拟合现象在普通版AE中是不可避免的。为了利用AE的解码器来生成图片,许多工作都在试图克服AE的过拟合现象。AE的改进思路很多,在这篇文章中,我们仅把AE的改进路线粗略地分成两种:解决过拟合问题以直接用AE做图像生成、用AE压缩图像间接实现图像生成。
2 第一条路线:VAE 和 DDPM
在第一条改进路线中,许多后续工作都试图用更高级的数学模型来解决AE的过拟合问题。变分自编码器(Variational Autoencoder, VAE) 就是其中的代表。
VAE对AE做了若干改动。第一,VAE让编码器的输出不再是一个确定的数据,而是一个正态分布中的一个随机数据。更具体一点,训练时,编码器会同时输出一个均值和方差。随后,模型会从这个均值和方差表达的正态分布里随机采样一个数据,作为解码器的输入。直观上看,这一改动就是在AE的基础上,让编码器多输出了一个方差,使得原AE编码器的输出发生了一点随机扰动。
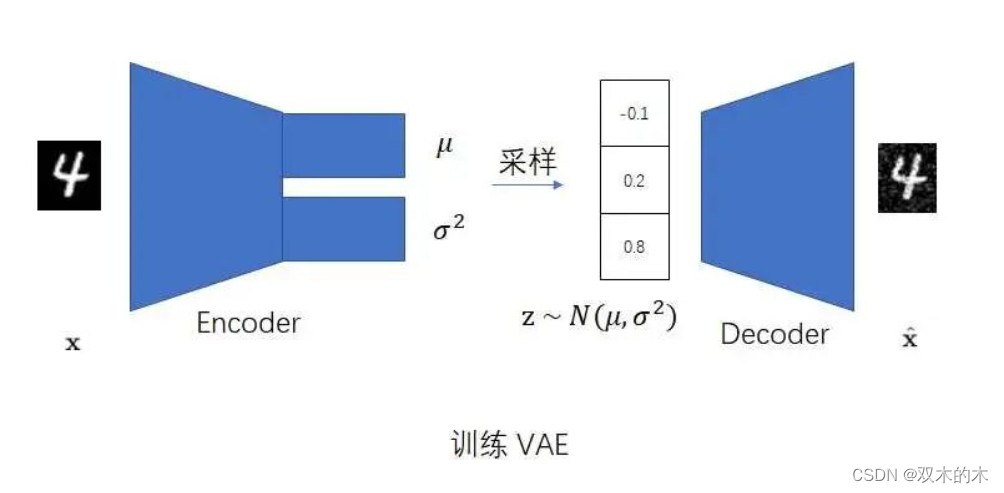
这一改动可以缓解过拟合现象。这是为什么呢?我们可以这样想:原来的AE之所以会过拟合,是因为它强行记住了训练集里每一个数据的编码输出。现在,我们在VAE里让编码器不再输出一个固定值,而是随机输出一个在均值附近的值。这样的话,VAE就不能死记硬背了,必须要找出数据中的规律。
VAE的第二项改动是多添加一个学习目标,让编码器的输出和标准正态分布尽可能相似。前面我们谈过,图像生成模型一般会根据一个随机向量来生成图像。最常用的产生随机向量的方法是去标准正态分布里采样。也就是说,在用VAE生成图像时,我们会抛掉编码器,用下图所示的流程来生成图像。如果我们不约束编码器的输出分布,不让它输出一个和标准正态分布很相近的分布的话,解码器就不能很好地根据来自标准正态分布的随机向量生成图像了。

综上,VAE对AE做了两项改进:使编码器输出一个正态分布,且该分布要尽可能和标准正态分布相似。训练时,模型从编码器输出的分布里随机采样一个数据作为解码器的输入;图像采样(图像生成)时,模型从标准正态分布里随机采样一个数据作为解码器的输入。VAE的误差函数由两部分组成:原图像和重建图像的重建误差、编码器输出和标准正态分布之间的误差。VAE要最小化重建误差,最大化编码器输出与标准正态分布的相似度。

分布与分布之间的误差可以用一个叫KL散度的指标表示。所以,在上面那个误差函数公式中,负的相似度应该被替换成KL散度。VAE的这两项改动本质上都是在解决AE的过拟合问题,所以,VAE的改动可以被看成一种正则化方法。我们可以把VAE的正则化方法简称为KL正则化。
在机器学习中,正则化方法就是「降低模型过拟合的方法」的简称。
VAE确实能减轻AE的过拟合。然而,由于VAE只是让重建图像和原图像的均方误差(重建误差)尽可能小,而没有对重建图像的质量施加更多的约束,VAE的重建结果和图像生成结果都非常模糊。以下是VAE在CelebA数据集上图像生成结果。

在众多对VAE的改进方法中,一个叫做去噪扩散概率模型(Denoising Diffusion Probabilistic Model, DDPM) 的图像生成模型脱颖而出。DDPM正是当今扩散模型的开山鼻祖。我们来看一下DDPM是怎样基于VAE对图像生成建模的。
VAE之所以效果不好,很可能是因为它的约束太少了。VAE的编码和解码都是用神经网络表示的。神经网络是一个黑盒,我们不好对神经网络的中间步骤施加约束,只好在编码器的输出(某个正态分布)和解码器的输出(重建图像)上施加约束。能不能让VAE的编码和解码过程更可控一点呢?
DDPM的设计灵感来自热力学:一个分布可以通过一系列简单的变化(如添加高斯噪声)逐渐变成另一个分布。恰好,VAE的编码器不正是想让来自训练集的图像(训练集分布)变成标准正态分布吗?既然如此,就不要用一个可学习的神经网络来表示VAE的编码器了,干脆用一些预定义好的加噪声操作来表示解码过程。可以从数学上证明,经过了多次加噪声操作后,最后的图像分布会是一个标准正态分布。

既然编码是加噪声,那解码时就应该去掉噪声。DDPM的解码器也不再是一个不可解释的神经网络,而是一个能预测若干个去噪结果的神经网络。
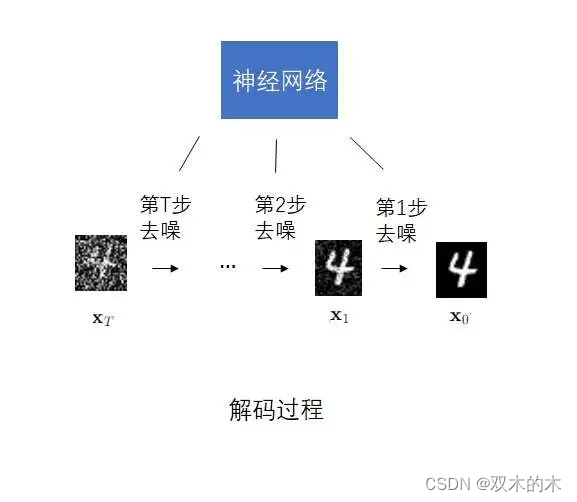
相比只有两个约束条件的VAE,DDPM的约束条件就多得多了。在DDPM中,第t个去噪操作应该尽可能抵消掉第t个加噪操作。

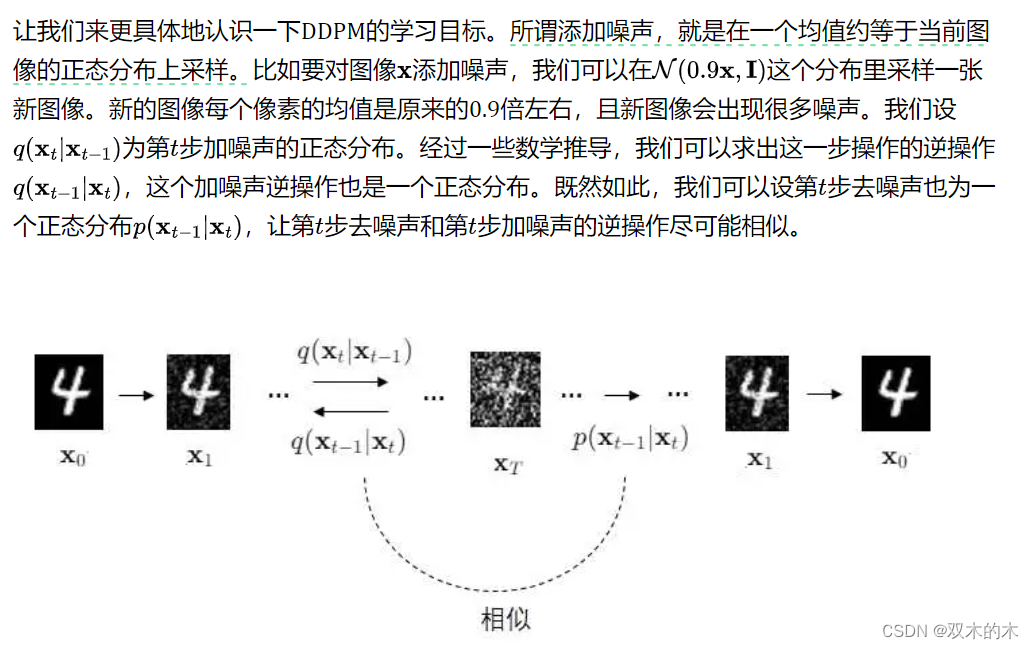
总结一下,DDPM对VAE做了如下改动:
-
编码器是一系列不可学习(固定)的加噪声操作
-
解码器是一系列可学习的去噪声操作
-
图像尺寸自始至终不变
相比于VAE,DDPM的编码过程和解码过程的定义更加明确,可以施加的约束更多。因此,如下图所示,它的生成效果会比VAE好很多。同时,DDPM和VAE类似,它在编码时会从分布里采样,而不是只输出一个固定值,不会出现AE的过拟合问题。

DDPM的图像生成结果
DDPM的生成效果确实很好。但是,由于DDPM始终会对同一个尺寸的数据进行操作,图像的尺寸极大地影响了DDPM的运行速度,用DDPM生成高分辨率图像需要耗费大量计算资源。因此,想要用DDPM生成高质量图像,还得经过另一条路线。
3 第二条路线:VQVAE
在AE的第二条改进路线中,一些工作干脆放弃使用AE做图像生成,转而利用AE的图像压缩能力,把图像生成拆成两步来做:先用AE的编码器把图像压缩成更小的图像,再用另一个图像生成模型生成小图像,并用AE的解码器把小图像重建回真实图像。
为什么会有这么奇怪的图像生成方法呢?这得从另一类图像生成模型讲起。在机器翻译模型Transformer横空出世后的一段时间里,有很多工作都想把Transformer用在图像生成上。但是,原本用来生成文本的Transformer无法直接应用在图像上。在自然语言处理(NLP)中,一个句子可以用若干个单词表示。而每个单词又是用一个整数表示。所以,Transformer生成句子时,实际上是在生成若干个离散的整数,也就是生成一个离散向量。而在图像生成模型中,每个像素的颜色值是一个连续的浮点数。想把Transformer直接用在图像生成上,就得想办法把图像用离散向量表示。我们知道,AE可以把图像编码成一个连续向量。能不能做一些修改,让AE把图像编码成一个离散向量呢?
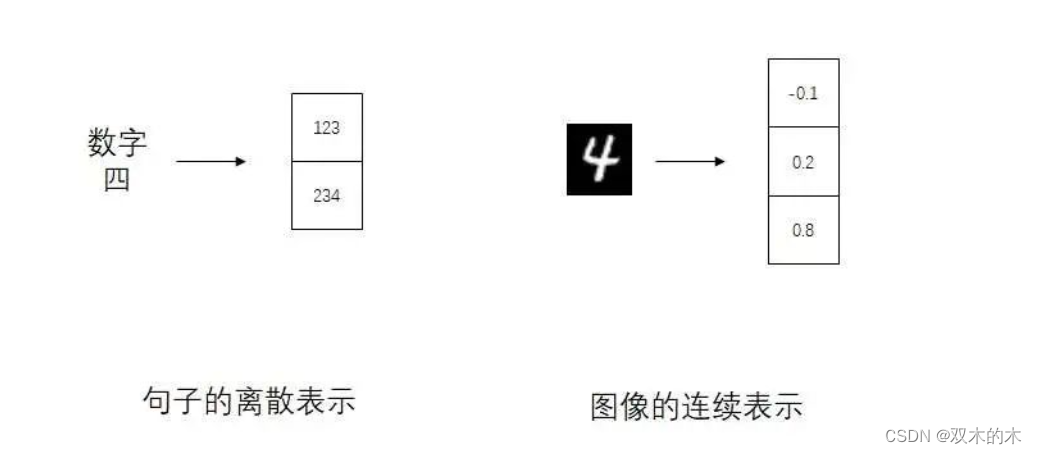
Vector Quantised-Variational AutoEncoder (VQVAE) 就是一个能把图像编码成离散向量的AE(虽然作者在取名时用了VAE)。我们来简单看一下VQVAE是怎样把图像编码成离散向量的。
假设我们有了一个能编码出离散向量的AE。

由于神经网络不能很好地处理离散数据,我们要引入NLP里的通常做法,加一个把离散向量映射成连续向量的嵌入层。
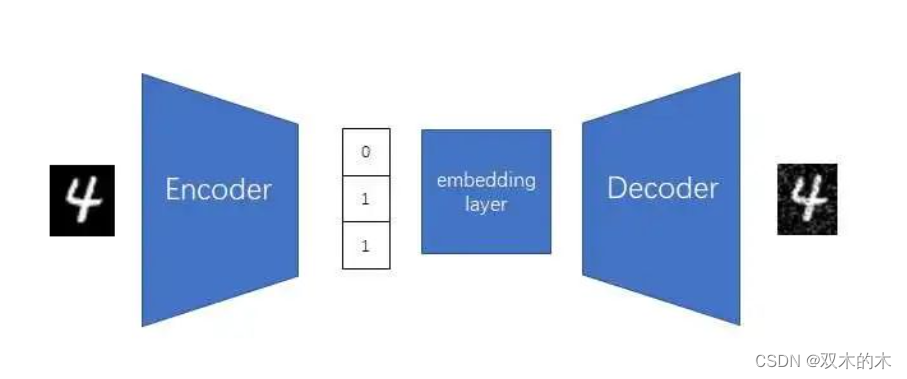
现在我们再回头讨论怎么让编码器输出一个离散向量。我们可以让AE的解码器保持不变,还是输出一个连续向量,再通过一个「向量离散化」操作,把连续向量变成离散向量。这个操作会把编码器的输出对齐到嵌入层的向量上,其原理类似于把0.99和1.01离散化成1,只不过它是对向量整体考虑,而不是对每一个数单独考虑。向量离散化操作的具体原理我们不在此处细究。

忽略掉实现细节,我们可以认为VQVAE能够把图像压缩成离散向量。更准确地说,VQVAE能把图像等比例压缩成离散的「小图像」。压缩成二维图像而不是一维向量,能够保留原图像的一些空间特性,为之后第二步图像生成铺路。

整理一下,VQVAE是一个能把图像压缩成离散小图像的AE。为了用VQVAE生成图像,需要执行一个两阶段的图像生成流程:
-
训练时,先训练一个图像压缩模型(VQVAE),再训练一个生成压缩图像的模型(比如Transformer)
-
生成时,先用第二个模型生成出一个压缩图像,再用第一个模型的解码器把压缩图像复原成真实图像
之所以要执行两阶段的图像生成流程,而不是只用第二个模型生成大图像,有两个原因。(1)第一个原因是前面提到的,Transformer等生成模型只支持生成离散图像,需要用另一个模型把连续的颜色值变成离散值以兼容这些模型。(2)第二个原因是为了减少模型的运算量。以Transformer为例,Transformer的运算次数大致与像素数的平方成正比,拿Transformer生成高分辨率图像的运算开销是不可接受的。而如果用一个AE把图像压缩一下的话,用Transformer就可行了。
VQVAE给后续工作带来了三条启发:(1)第一,可以用AE把图像压缩成离散向量;(2)第二,如果一个图像生成模型生成高分辨率的图像的计算代价太高,可以先用AE把图像压缩,再生成压缩图像。这两条启发对应上一段提到的使用VQVAE的两条动机。(3)而第三条启发就比较有意思了。在讨论VQVAE的过程中,我们完全没有考虑过拟合的事。这是因为经过了向量离散化操作后,解码器的输入已经不再是编码器的输出,而是嵌入层里的向量了。这种做法杜绝了AE的死记硬背,缓解了过拟合现象。这样,我们可以换一个角度看待VQVAE:编码器还是AE的编码器,编码器的输出是连续向量,后续的向量离散化操作和嵌入层全部都是解码器的一部分。从这个角度看,VQVAE其实提出了一个由向量离散化和嵌入层组成的正则化模块。这个模块和VAE的KL散度约束一样,都解决了AE的过拟合问题。我们把VQVAE的正则化方法叫做VQ正则化。

VQVAE论文提出的图像生成方法效果一般。和普通的AE一样,VQVAE在训练时只用了重建误差来约束图像质量,重建图像的细节依然很模糊。且VQVAE配套的第二阶段图像生成模型不是较为强力的Transformer,而是一个基于CNN的图像生成模型。

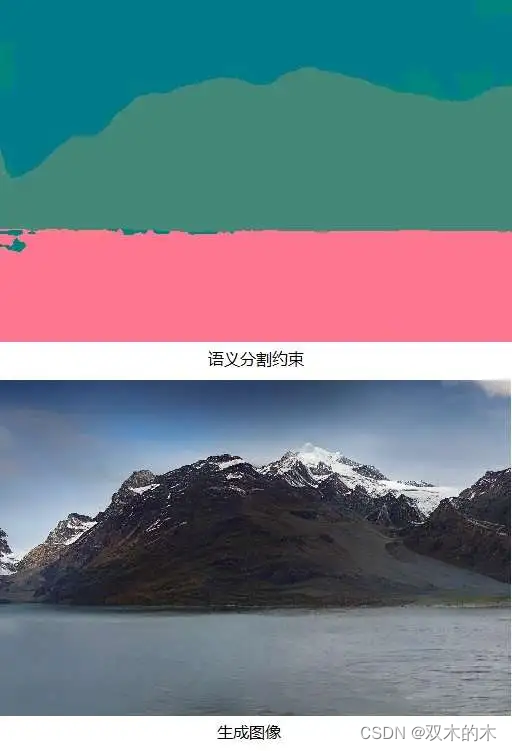
后续的VQGAN论文对VQVAE进行了改进。对于一阶段的图像压缩模型,VQGAN在VQVAE的基础上引入了生成对抗网络(GAN)中一些监督误差,提高了图像压缩模型的重建质量;对于两阶段的图像生成模型,该方法使用了Transformer。凭借这些改动,VQGAN方法能够生成高质量的高清图片。并且,通过把额外的约束条件(如语义分割图像、文字)输入进Transformer,VQGAN方法能够实现带约束的图像生成。以下是VQGAN方法根据语义分割图像生成的高清图片。
图像生成模型可以是无约束或带约束的。无约束图像生成模型只需要输入一个随机向量,训练数据不需要任何标注,可以进行无监督训练。带约束图像生成模型会在无约束图像生成模型的基础上多加一些输入,并给每个训练图像打上描述约束的标签,执行监督训练。比如要训练文生图模型,就要给每个训练图片带上文字描述。
4 路线的交汇点——Stable Diffusion
看完上面这两条AE的改进路线,相信你已经能够猜出Stable Diffusion的核心思想了。让我们看看Stable Diffusion是怎么从这两条路径中汲取灵感的。
在发布了VQGAN后,德国的CompVis实验室开始探索起VQGAN的改进方法。VQGAN能把图像边长压缩16倍,而VQGAN配套的Transformer只能一次生成16 x 16的图片。也就是说,整套方法一次只能生成256 x 256的图片。为了生成分辨率更高的图片,VQGAN方法需要借助滑动窗口。能不能让模型一次性生成分辨率更高的图片呢?制约VQGAN方法生成分辨率的主要因素是Transformer。如果能把Transformer换成一个效率更高,能生成更高分辨率的图像的模型,不就能生成比256 x 256更大的图片了吗?CompVis实验室开始把目光着眼于DDPM上。
于是,在发布VQGAN的一年后,CompVis实验室又发布了名为High-Resolution Image Synthesis with Latent Diffusion Models的论文,提出了一种叫做隐扩散模型(latent diffusion model, LDM) 的图像生成模型。通过与AI公司Stability AI合作,借助他们庞大的算力资源训练LDM,CompVis实验室发布了商业名为Stable Diffusion的开源文生图AI绘画模型。
LDM其实就是在VQGAN方法的基础上,把图像生成模型从Transformer换成了DDPM。或者从另一个角度说,为了让DDPM生成高分辨率图像,LDM利用了VQVAE的第二条启发:先用AE把图像压缩,再用DDPM生成压缩图像。LDM的AE一般是把图像边长压缩8倍,DDPM生成64 x64的压缩图像,整套LDM能生成256 x 256的图像。
和Transformer不同,DDPM处理的图像是用连续向量表示的。因此,在LDM中使用VQGAN做图像压缩时,不一定需要向量离散化操作,只需要在AE的基础上加一点轻微的正则化就行。作者在实现LDM时讨论了两类正则化,一类是VAE的KL正则化,一类是VQ正则化(对应VQVAE的第三条启发),两种正则化都能取得不错的效果。
LDM依然可以实现带约束的图像生成。用DDPM替换掉Transformer后,额外的约束会输入进DDPM中。作者在论文中讨论了几种把约束输入进DDPM的方式。
在搞懂了早期工作后,理解Stable Diffusion的核心思想就是这么简单。让我们把Stable Diffusion的发展过程及主要结构总结一下。Stable Diffusion由两类AE的变种发展而来,一类是有强大生成能力却需要耗费大量运算资源的DDPM,一类是能够以较高保真度压缩图像的VQVAE。Stable Diffusion是一个两阶段的图像生成模型,它先用一个使用KL正则化或VQ正则化的VQGAN来实现图像压缩,再用DDPM生成压缩图像。可以把额外的约束(如文字)输入进DDPM以实现带约束图像生成。
5 相关论文
本文仅仅对Stable Diffusion的早期工作做了一个简单的梳理。要把Stable Diffusion吃透,还需要多读一些早期论文。我来把早期论文按重要性分个类。
5.1 图像生成必读文章
Neural Discrete Representation Learning (VQVAE): https://arxiv.org/abs/1711.00937
Taming Transformers for High-Resolution Image Synthesis (VQGAN): https://arxiv.org/abs/2012.09841
Denoising Diffusion Probabilistic Models (DDPM): https://arxiv.org/abs/2006.11239
5.2 图像生成选读文章
Auto-Encoding Variational Bayes (VAE): https://arxiv.org/abs/1312.6114 提出VAE的文章。数学公式较多,只需要了解VAE的大致结构就好,不需要详细阅读论文。
Pixel Recurrent Neural Networks (PixelCNN): https://arxiv.org/abs/1601.06759 提出了一种拟合离散分布的图像生成模型,自回归图像生成模型的代表。这是VQVAE使用的第二阶段图像生成模型。有兴趣可以了解一下。
Deep Unsupervised Learning using Nonequilibrium Thermodynamics: https://arxiv.org/abs/1503.03585 DDPM的前作,首个提出扩散模型思想的文章。其核心原理和DDPM几乎完全一致,但是模型结构和优化目标不够先进,生成效果没有改进后的DDPM好。数学公式较多,不必细读,可以在学习DDPM时对比着阅读。
Denoising Diffusion Implicit Models (DDIM): https://arxiv.org/abs/2010.02502 一种加速DDPM采样的方法,广泛运用在包含Stable Diffusion在内的扩散模型中。推荐阅读。
Classifier-Free Diffusion Guidance: https://arxiv.org/abs/2207.12598 一种让扩散模型的输出更加贴近约束的方法,广泛运用在包含Stable Diffusion在内的扩散模型中,用于生成更符合文字描述的图片。推荐阅读。
Generative Adversarial Networks (GAN): https://arxiv.org/abs/1406.2661 以及 A Style-Based Generator Architecture for Generative Adversarial Networks (StyleGAN): https://arxiv.org/abs/1812.04948 可以了解一下GAN是怎么确保图像生成质量的,并认识CelebAHQ和FFHQ这两个常用的人脸数据集。
5.3 其他必读文章
Deep Residual Learning for Image Recognition (ResNet): https://arxiv.org/abs/1512.03385 深度学习的经典文章。其中提出的残差连接被用到了DDPM中。
Attention Is All You Need (Transformer): https://arxiv.org/abs/1706.03762 深度学习的经典文章。其中提出的自注意力模块被用到了DDPM中。
5.4 其他选读文章
Learning Transferable Visual Models From Natural Language Supervision (CLIP): https://arxiv.org/abs/2103.00020 提出了对齐文本和图像的方法。绝大多数文生图模型的核心。
U-Net: Convolutional Networks for Biomedical Image Segmentation (U-Net): https://arxiv.org/abs/1505.04597 一种被广泛运用的神经网络架构。DDPM的神经网络的主架构。U-Net的结构很简单,可以不用去读论文,直接看代码。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。
相关文章:
天才程序员周弈帆 | Stable Diffusion 解读(一):回顾早期工作
本文来源公众号“天才程序员周弈帆”,仅用于学术分享,侵权删,干货满满。 原文链接:Stable Diffusion 解读(一):回顾早期工作 在2022年的这波AI绘画浪潮中,Stable Diffusion无疑是最…...

软件架构初探
MVC架构软件层次结构是面向实体的,他最底层是实体类,实体类中封装了对象的抽象数据类型(数据结构和对数据结构的基本操作)。然后向上一层数据处理层提供接口,数据处理层利用模型层提供的对象和基本操作进一步进行算法的…...
Python01 -分解整包数据到各个变量操作和生成器
Python 的星号表达式可以用来解决这个问题。比如,你在学习一门课程,在学期末的时候,你想统计下家庭作业的平均成绩,但是排除掉第一个和最后一个分数。如果只有四个分数,你可能就直接去简单的手动赋值,但如果…...

flutter image_picker 执行拍照的图片怎么保存到本地
在 Flutter 中,使用 image_picker 插件拍照的图片默认会被保存到设备的临时目录中。这个临时目录的具体位置取决于设备的操作系统。在 iOS 上,它通常是应用的沙盒目录;在 Android 上,它通常是应用的缓存目录。 这些图片不会被自动…...
基于Python的北京天气数据可视化分析
项目用到库 import numpy as np import pandas as pd import datetime from pyecharts.charts import Line from pyecharts.charts import Boxplot from pyecharts.charts import Pie,Grid from pyecharts import options as opts from pyecharts.charts import Calendar 1.2…...
Linux编译器-gcc或g++的使用
一.安装gcc/g 在linux中是不会自带gcc/g的,我们需要编译程序就自己需要安装gcc/g。 很简单我们使用简单的命令安装gcc:sudo yum install -y gcc。 g安装:sudo yum install -y gcc-c。 我们知道Windows上区分文件,都是使用文件…...

一条sql的执行流程
文章地址 https://blog.csdn.net/qq_43618881/article/details/118657040 连接器 请求先走到连接器,与客户端建立连接、获取权限、维持和管理连接 mysql缓存池 如果要查找的数据直接在mysql缓存池里面就直接返回数据 分析器 请求已经建立了连接,现在…...

Android音乐播放器的思路处理
** 1.android音乐播放播放列表中下一首上一首随机播放的思路 ** 实现 Android 音乐播放器的播放列表中的下一首、上一首和随机播放功能涉及到对音乐列表的管理以及对播放顺序的控制。以下是实现这些功能的思路: 下一首和上一首功能: 维护一个音乐列表…...

算法课程笔记——可撤销并查集
算法课程笔记——可撤销并查集 Gv...

【排序算法】快速排序
一、定义: 快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法(也叫Hoare排序),是一种基于分治的排序方。其基本原理是将待排序的数组通过一趟排序分成两个独立的部分,其中一部分的所有数据比另一部分的所有数…...

OS复习笔记ch7-2
页式管理 学过计组的同学都了解一点页式管理,就是将内存划分成较小的、大小固定的、等大的块。现在OS引入了进程的概念,那么为了匹配内存的分块,同样把进程也划分成同样大小的块。 这里区分两个概念 The chunks of a process are called p…...

4.通用编程概念
目录 一、变量与常量1.1 变量1.2 常量 二、遮蔽三、数据类型3.1 标量类型1. 整型2. 浮点型3. 布尔类型4.字符类型 3.2 复合类型1. 元组2. 数组 四、函数五、语句和表达式六、函数的返回值 一、变量与常量 1.1 变量 在Rust中默认的变量是不可变的,如果修改其值会导致…...

iBeacon赋能AR导航:室内定位技术的原理与优势
室内定位导航对于大型商场、机场、医院等复杂室内环境至关重要,它帮助人们快速找到目的地,提高空间利用率。AR技术通过将虚拟信息叠加在现实世界,提供直观导航指引,正在成为室内导航的新趋势,增强用户互动体验…...

【sklearn】【逻辑回归1】
学习笔记来自: 所用的库和版本大家参考: Python 3.7.1Scikit-learn 0.20.1 Numpy 1.15.4, Pandas 0.23.4, Matplotlib 3.0.2, SciPy 1.1.0 1 概述 1.1 名为“回归”的分类器 在过去的四周中,我们接触了不少带“回归”二字的算法…...
和 python 通过DoubleCloud的kafka进行线程间通信)
java(kotlin)和 python 通过DoubleCloud的kafka进行线程间通信
进入 DoubleCloud https://www.double.cloud 创建一个kafka 1 选择语言 2 运行curl 的url命令启动一个topic 3 生成对应语言的token 4 复制3中的配置文件到本地,命名为client.properties 5 复制客户端代码 对python和java客户端代码进行了重写,java改成…...
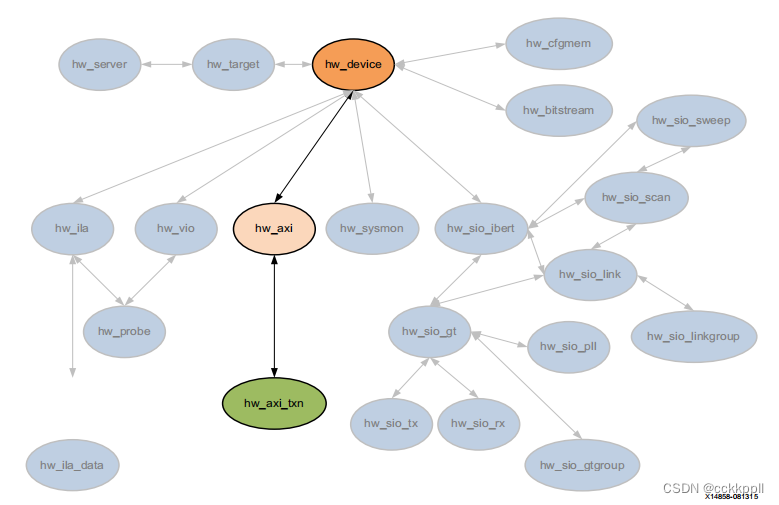
vivado DIAGRAM、HW_AXI
图表 描述 块设计(.bd)是在IP中创建的互连IP核的复杂系统 Vivado设计套件的集成商。Vivado IP集成器可让您创建复杂的 通过实例化和互连Vivado IP目录中的IP进行系统设计。一块 设计是一种分层设计,可以写入磁盘上的文件(.bd&…...

学习分享-为什么把后台的用户验证和认证逻辑放到网关
将后台的用户验证和认证逻辑放到网关(API Gateway)中是一种常见的设计模式,这种做法在微服务架构和现代应用中有许多优势和理由: 1. 集中管理认证和授权 统一的安全策略 在一个包含多个微服务的系统中,如果每个服务…...
27 ssh+scp+nfs+yum进阶
ssh远程管理 ssh是一种安全通道协议,用来实现字符界面的远程登录。远程复制,远程文本传输。 ssh对通信双方的数据进行了加密。 用户名和密码登录 密钥对认证方式(可以实现免密登录) ssh 22 网络层 传输层 数据传输的过程中是…...

LabVIEW液压伺服压力机控制系统与控制频率选择
液压伺服压力机的控制频率是一个重要的参数,它直接影响系统的响应速度、稳定性和控制精度。具体选择的控制频率取决于多种因素,包括系统的动态特性、控制目标、硬件性能以及应用场景。以下是一些常见的指导原则和考量因素: 常见的控制频率范…...
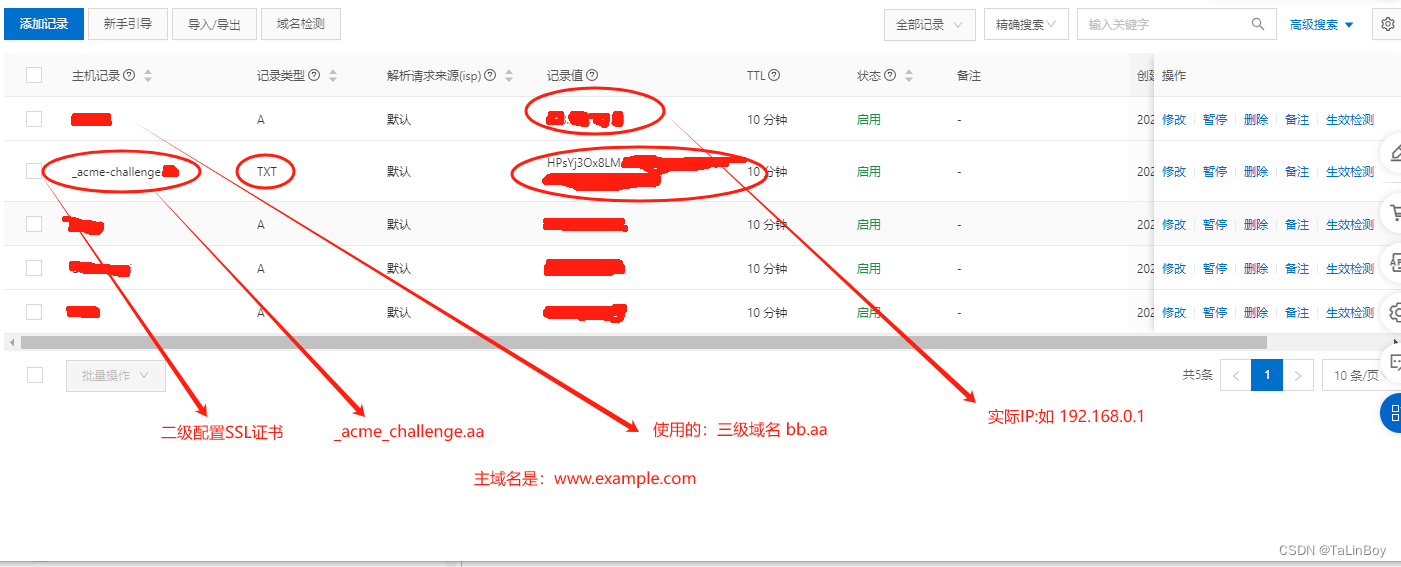
阿里云(域名解析) certbot 证书配置
1、安装 certbot ubuntu 系统: sudo apt install certbot 2、申请certbot 域名证书,如申请二级域名aa.example.com 的ssl证书,同时需要让 bb.aa.example.com 也可以使用此证书 1、命令:sudo certbot certonly -d “域名” -d “…...
)
云计算——弹性云计算器(ECS)
弹性云服务器:ECS 概述 云计算重构了ICT系统,云计算平台厂商推出使得厂家能够主要关注应用管理而非平台管理的云平台,包含如下主要概念。 ECS(Elastic Cloud Server):即弹性云服务器,是云计算…...

简易版抽奖活动的设计技术方案
1.前言 本技术方案旨在设计一套完整且可靠的抽奖活动逻辑,确保抽奖活动能够公平、公正、公开地进行,同时满足高并发访问、数据安全存储与高效处理等需求,为用户提供流畅的抽奖体验,助力业务顺利开展。本方案将涵盖抽奖活动的整体架构设计、核心流程逻辑、关键功能实现以及…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

为什么需要建设工程项目管理?工程项目管理有哪些亮点功能?
在建筑行业,项目管理的重要性不言而喻。随着工程规模的扩大、技术复杂度的提升,传统的管理模式已经难以满足现代工程的需求。过去,许多企业依赖手工记录、口头沟通和分散的信息管理,导致效率低下、成本失控、风险频发。例如&#…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

质量体系的重要
质量体系是为确保产品、服务或过程质量满足规定要求,由相互关联的要素构成的有机整体。其核心内容可归纳为以下五个方面: 🏛️ 一、组织架构与职责 质量体系明确组织内各部门、岗位的职责与权限,形成层级清晰的管理网络…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

EtherNet/IP转DeviceNet协议网关详解
一,设备主要功能 疆鸿智能JH-DVN-EIP本产品是自主研发的一款EtherNet/IP从站功能的通讯网关。该产品主要功能是连接DeviceNet总线和EtherNet/IP网络,本网关连接到EtherNet/IP总线中做为从站使用,连接到DeviceNet总线中做为从站使用。 在自动…...