ElasticSearch教程(详解版)
本篇博客将向各位详细介绍elasticsearch,也算是对我最近学完elasticsearch的一个总结,对于如何在Kibana中使用DSL指令,本篇文章不会进行介绍,这里只会介绍在java中如何进行使用,保证你看完之后就会在项目中进行上手,那我们开始本篇教程吧~
什么是ElasticSearch
- Elasticsearch,基于lucene.分布式的Restful实时搜索和分析引擎(实时)
- 分布式的实时文件存储,每个字段都被索引并可被搜索
- 高扩展性,可扩展至上百台服务器,处理PB级结构化或非结构化数据
- Elasticsearch用于全文检索,结构化搜索,分析/合并使用
ElasticSearch是如何做到这么快的
- 分布式存储:ElasticSearch把数据存储在多个节点上,从而减少单个节点的压力,从而提高性能
- 索引分片:ElasticSearch把索引分成多个分片,这样可以让查询操作并行化,从而提高性能
- 全文索引:ElasticSearch把文档转换成可搜索的结构化数据,从而提高效率
- 倒排索引:ElasticSearch将文档进行分词处理,把每个词在哪个文档中出现过进行映射,并存储这些信息,从而在搜索时,查询这些分词和搜索这些分词存在在哪些文档中,提高查询效率
- 异步请求处理:ElasticSearch能够在请求到达时立即返回,避免长时间等待,提高效率
全文索引和倒排索引是什么
全文检索是指计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。全文搜索搜索引擎数据库中的数据。
-
优点:
-
可以给多个字段创建索引
-
根据索引字段搜索、排序速度非常快
-
-
缺点:
-
根据非索引字段,或者索引字段中的部分词条查找时,只能全表扫描。
-
倒排索引就和传统的索引结构相反,传统的索引是由文档组成的,每个文档中都包含了若干个词汇,然后根据这些词汇简历索引。而倒排索引则与其相反,倒排索引由词汇构成,每个词汇对应若干个文档,然后根据这些文档建立索引。
-
优点:
-
根据词条搜索、模糊搜索时,速度非常快
-
-
缺点:
-
只能给词条创建索引,而不是字段
-
无法根据字段做排序
-
ElasticSearch和Mysql之间的映射关系
| Mysql类型 | ElasticSearch类型 | 说明 |
| VARCHAR | text、keyword | 根据是否需要使用全文搜索或精确搜索选择使用text或keyword |
| CHAR | keyword | 通常映射为keyword,因为它们存储较短的、不经常变化的字符序列 |
| BLOB/TEXT | text | 大文本块使用text,适用于全文检索 |
| INT,BIGINT | long | 大多数整数型使用long,以支持更大的数值 |
| TINYINT | byte | 较小的整数可以映射为byte类型 |
| DECIMAL,FLOAT,DOUBLE | double,float | |
| DATE,DATETIME,TIMESTAMP | date | |
| BOOLEAN | boolean |
倒排索引建立步骤
es中建立倒排索引需要两步,首先对文档进行分词,其次建立倒排索引
分词
分词的意思大概就是对文档中的数据通过es的分词器进行分割成一个个词项,比如 “我是银氨溶液” 这句话,经过分词过后就是 “我”、“是”、“银氨”、“溶液”,当然es的分词器分为ik_smart分词器和ik_max_word分词,所以实际操作时这句话会被分解为不同的词段。
es中的一些概念
文档
elasticsearch是面向文档(Document)存储的,可以是数据库中的一条商品数据,一个订单信息。文档数据会被序列化为json格式后存储在elasticsearch中。
字段
Json文档中往往包含很多的字段(Field),类似于数据库中的列。
索引
索引(Index),就是相同类型的文档的集合。因此,我们可以把索引当做是数据库中的表。
映射
数据库的表会有约束信息,用来定义表的结构、字段的名称、类型等信息。因此,索引库中就有映射(mapping),是索引中文档的字段约束信息,类似表的结构约束。
对照图表:
| MySQL | Elasticsearch | 说明 |
|---|---|---|
| Table | Index | 索引(index),就是文档的集合,类似数据库的表(table) |
| Row | Document | 文档(Document),就是一条条的数据,类似数据库中的行(Row),文档都是JSON格式 |
| Column | Field | 字段(Field),就是JSON文档中的字段,类似数据库中的列(Column) |
| Schema | Mapping | Mapping(映射)是索引中文档的约束,例如字段类型约束。类似数据库的表结构(Schema) |
| SQL | DSL | DSL是elasticsearch提供的JSON风格的请求语句,用来操作elasticsearch,实现CRUD |
RestAPI
首先,在这篇文章中不会将所有api都介绍完,所以这了贴上官方文档的地址,以共各位查看:
ElasticSearch官方文档
这里需要先引入es的依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-elasticsearch</artifactId></dependency>同时,你需要在pom文件中修改es的版本和你本地的一样

然后,我们需要把es注入到spring容器中
@Configuration
public class ElasticSearchClientConfig {@Beanpublic RestHighLevelClient restHighLevelClient(){RestHighLevelClient client=new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));return client;}
}准备工作完成之后就可以开始接下来的学习啦~
索引的CRUD操作
索引的操作较为简单,而且项目中实际都是对文档进行操作,所以我这里贴出索引的相关操作代码,并做出解释,各位可以了解一下
@Autowired@Qualifier("restHighLevelClient")private RestHighLevelClient client;// 测试索引的创建 Request@Testvoid testCreateIndex() throws Exception {
// 1、创建索引请求CreateIndexRequest request = new CreateIndexRequest("yinan_index");
// 2、客户端执行请求,请求后获得响应CreateIndexResponse createIndexResponse = client.indices().create(request, RequestOptions.DEFAULT);System.out.println(createIndexResponse);}// 测试获取索引@Testvoid testGetIndex() throws IOException {GetIndexRequest getIndex = new GetIndexRequest("yinan_index");boolean exists = client.indices().exists(getIndex, RequestOptions.DEFAULT);System.out.println(exists);}// 删除索引@Testvoid testDeleteIndex() throws Exception {DeleteIndexRequest request = new DeleteIndexRequest("yinan_index");AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);System.out.println(delete.isAcknowledged());}
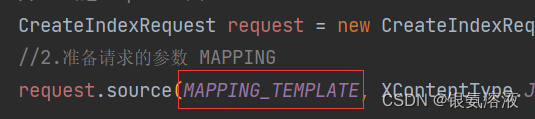
其中indices中包含了操作索引库的所有方法,在创建索引的时候如果有多个字段,可以提前写好 一个字符串常量,例如:
public static final String MAPPING_TEMPLATE = "{\n" +" \"mappings\": {\n" +" \"properties\": {\n" +" \"id\": {\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"name\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"address\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"price\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"score\":{\n" +" \"type\": \"integer\"\n" +" },\n" +" \"brand\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"city\":{\n" +" \"type\": \"keyword\",\n" +" \"copy_to\": \"all\"\n" +" },\n" +" \"starName\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"business\":{\n" +" \"type\": \"keyword\"\n" +" },\n" +" \"location\":{\n" +" \"type\": \"geo_point\"\n" +" },\n" +" \"pic\":{\n" +" \"type\": \"keyword\",\n" +" \"index\": false\n" +" },\n" +" \"all\":{\n" +" \"type\": \"text\",\n" +" \"analyzer\": \"ik_max_word\"\n" +" }\n" +" }\n" +" }\n" +"}";
然后将新增索引中的代码修改成以下:
文档的CRUD操作
对于文档这里将重点介绍查询的相关方法,其它操作只做简单介绍。
查询操作
MatchAll
/*** 查询全部*/@Testvoid testMatchAll() throws IOException {//1.准备requestSearchRequest request = new SearchRequest("hotel");//2.准备参数request.source().query(QueryBuilders.matchAllQuery());//3.发起请求得到响应结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析响应handleResponse(response);}结果如下:

从结果我们也可以看到这个api是查询所有数据的方法,但是控制台只显示了10条数据,这是因为这个方法自动进行分页处理,每页10条数据。
Match
/*** 全文检索*/@Testvoid testMatch() throws IOException {//1.准备requestSearchRequest request = new SearchRequest("hotel");//2.准备参数request.source().query(QueryBuilders.matchQuery("all","如家"));//3.发起请求得到响应结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析响应handleResponse(response);}结果:

match用来做基本的模糊匹配,在es中会对文本进行分词,在match查询的时候也会对查询条件进行分词,然后通过倒排索引找到匹配的数据。
term
@Testvoid testMatch() throws IOException {//1.准备requestSearchRequest request = new SearchRequest("hotel");//2.准备参数
// request.source().query(QueryBuilders.matchQuery("all","如家"));request.source().query(QueryBuilders.termQuery("city","北京"));//3.发起请求得到响应结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析响应handleResponse(response);}结果:
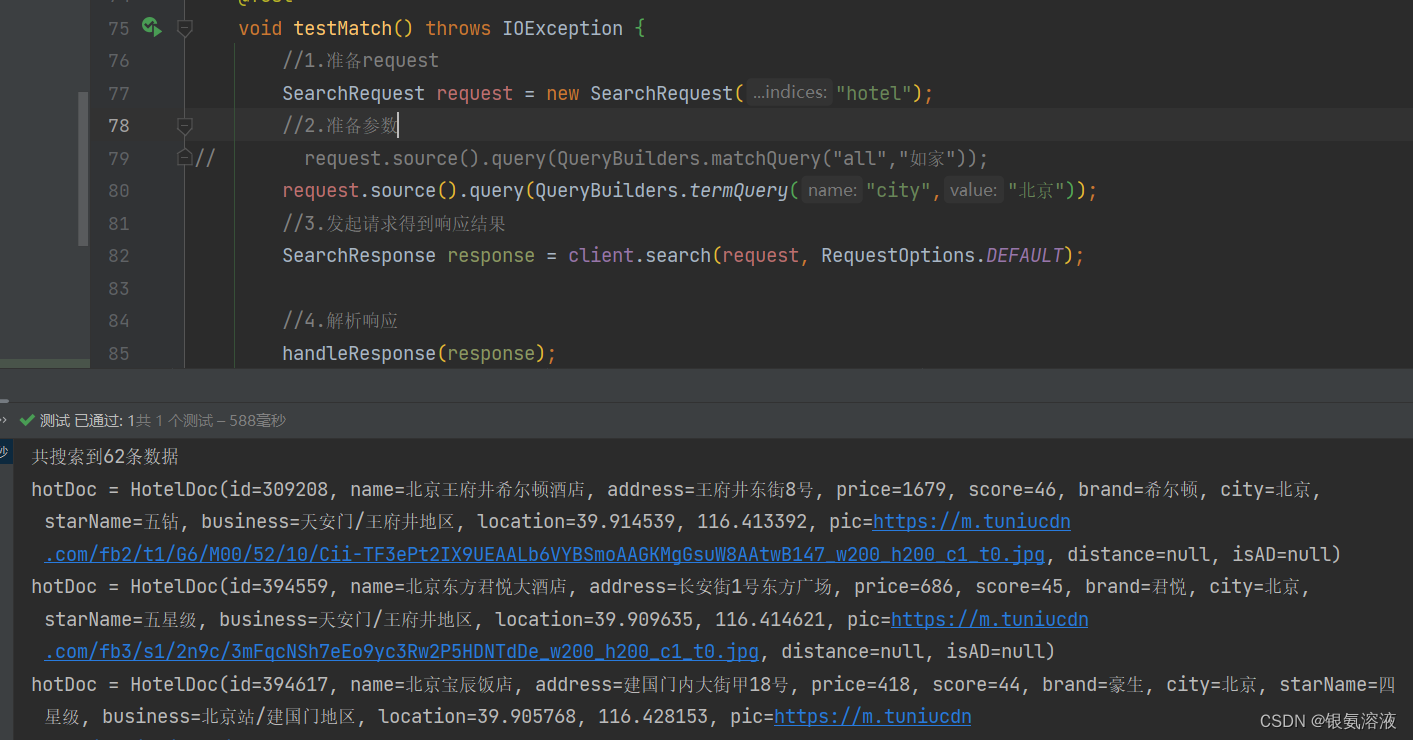 从结果来看,term是做精确查询的,所以一般可以用在查询某个具体的属性的时候
从结果来看,term是做精确查询的,所以一般可以用在查询某个具体的属性的时候
multiMatchQuery
@Testvoid testMatch() throws IOException {//1.准备requestSearchRequest request = new SearchRequest("hotel");//2.准备参数
// request.source().query(QueryBuilders.matchQuery("all","如家"));
// request.source().query(QueryBuilders.termQuery("city","北京"));request.source().query(QueryBuilders.multiMatchQuery("如家", "city", "name"));//3.发起请求得到响应结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析响应handleResponse(response);}结果:
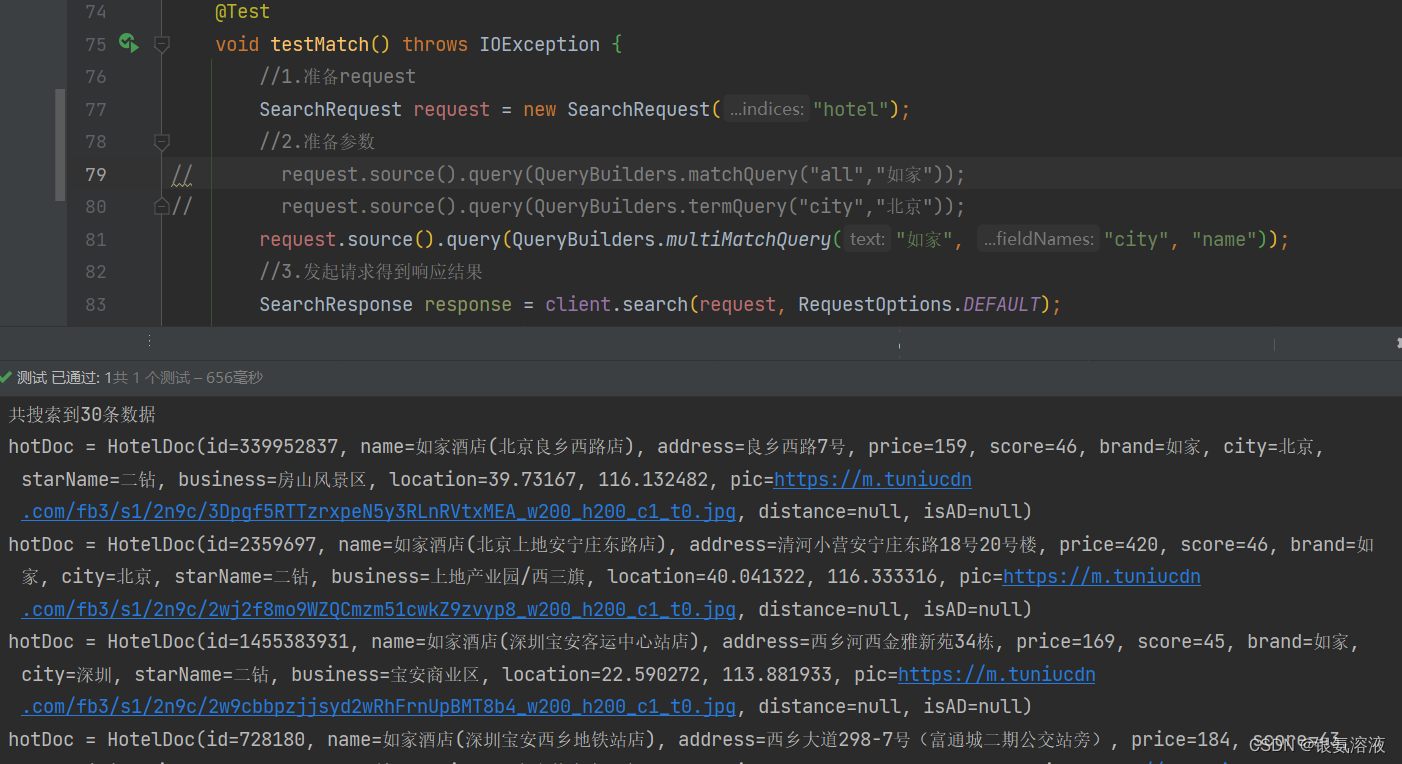
multiMatchQuery接受两个参数,一个是text,一个是fieldname,前者表示要查询的内容,后者表示要在哪些字段中进行查询,如果后者中的数据只有一个,那该方法和matchall一致,如果后者有多个,那查询的结果必须要满足其中的一个。
rangeQuery
@Testvoid testMatch() throws IOException {//1.准备requestSearchRequest request = new SearchRequest("hotel");//2.准备参数
// request.source().query(QueryBuilders.matchQuery("all","如家"));
// request.source().query(QueryBuilders.termQuery("city","北京"));
// request.source().query(QueryBuilders.multiMatchQuery("如家", "city", "name"));request.source().query(QueryBuilders.rangeQuery("price").gte(100).lte(150));//3.发起请求得到响应结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析响应handleResponse(response);}结果:
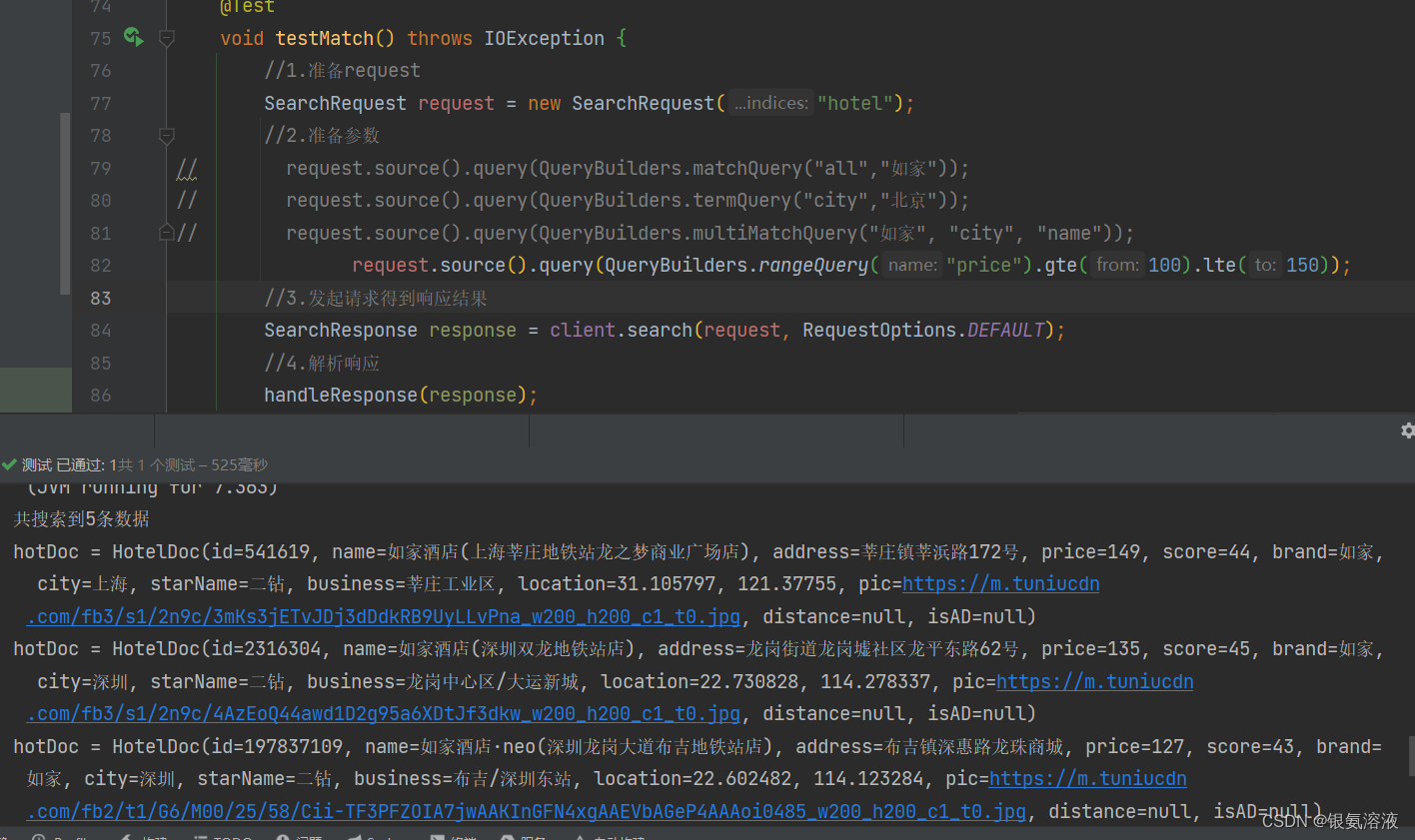
该方法主要做范围查询,相当于sql语句中的between....and...
布尔查询
/*** 布尔查询* @throws IOException*/@Testvoid testBool() throws IOException {//1.准备requestSearchRequest request = new SearchRequest("hotel");//2.准备参数BoolQueryBuilder boolQuery = QueryBuilders.boolQuery();boolQuery.must(QueryBuilders.termQuery("city","北京"));boolQuery.filter(QueryBuilders.rangeQuery("price").lte(300));request.source().query(boolQuery);//3.发起请求得到响应结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);System.out.println( "========"+response.getHits());//4.解析响应handleResponse(response);}/*** 解析响应结果* @param response*/private void handleResponse(SearchResponse response) {SearchHits searchHits = response.getHits();//总条数long total = searchHits.getTotalHits().value;System.out.println("共搜索到"+total+"条数据");//文档数组SearchHit[] hits = searchHits.getHits();//遍历for (SearchHit hit : hits){//获取文档sourceString json = hit.getSourceAsString();//反序列化HotelDoc hotelDoc = JSON.parseObject(json, HotelDoc.class);//获取高亮结果Map<String, HighlightField> highlightFields = hit.getHighlightFields();if(!CollectionUtils.isEmpty(highlightFields)){//根据字段名获取高亮结果HighlightField highlightField = highlightFields.get("name");if(highlightField != null){//获取高亮值String name = highlightField.getFragments()[0].string();//替换hotelDoc.setName(name);}}System.out.println("hotDoc = "+hotelDoc);}
这里简单说一下怎么得到的 handleResponse函数
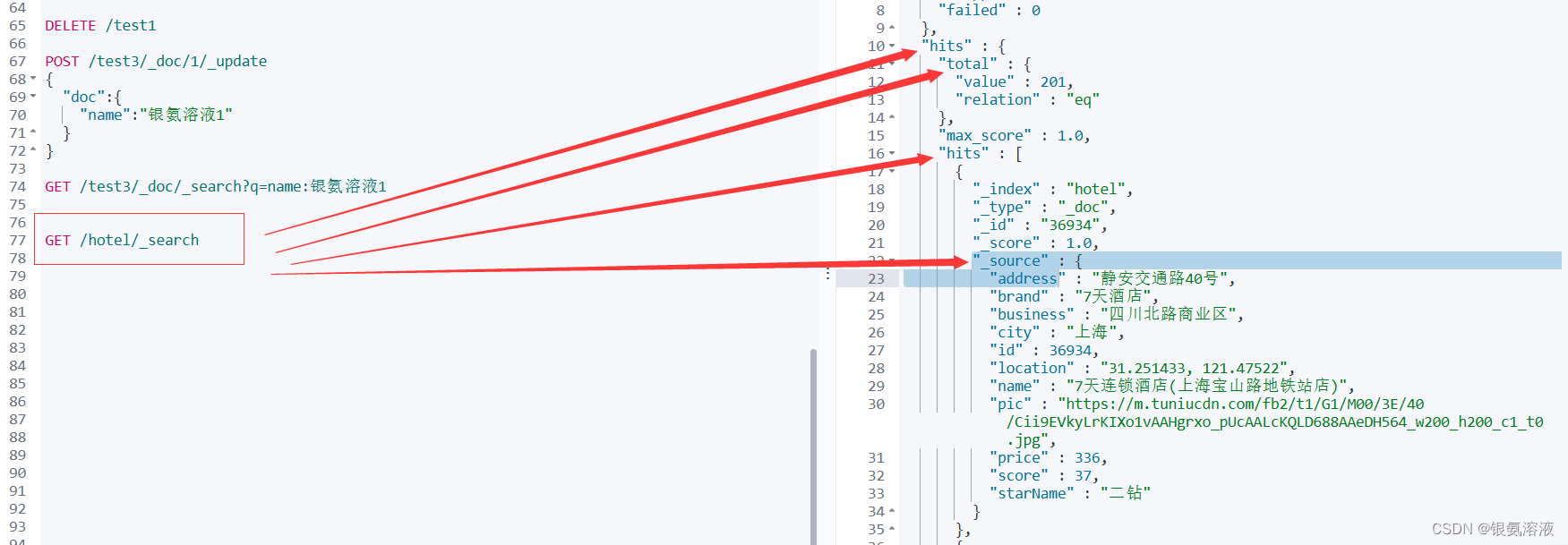
通过以上图片我们就不难看出 response的响应结构,因此我们就可以具体推出相关信息,所以没有学习过在Kibana上使用DSL指令的朋友可以先去学习一下,然后再来运用到java中事半功倍。
当然,如果你只需要获取数据和总条数,可以修改成以下形式:
private PageResult handleResponse(SearchResponse response) {SearchHits hits = response.getHits();long total = hits.getTotalHits().value;SearchHit[] searchHits = hits.getHits();List<HotelDoc> hotels = new ArrayList<>();for (SearchHit searchHit : searchHits) {String source = searchHit.getSourceAsString();
// 反序列化HotelDoc hotelDoc = JSON.parseObject(source, HotelDoc.class);hotels.add(hotelDoc);}return new PageResult(total,hotels);}分页和排序 对结果的处理
/*** 分页和排序 对结果的处理*/@Testvoid testPageAndSort() throws IOException {int page = 1,size = 5;//1.准备requestSearchRequest request = new SearchRequest("hotel");//2.准备参数request.source().query(QueryBuilders.matchAllQuery());//排序request.source().sort("price", SortOrder.ASC);//分页request.source().from((page-1)*size).size(size);//3.发起请求得到响应结果SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析响应handleResponse(response);}当然,还有其它一些api这里还没有介绍到,各位可以去官网进行查看详细文档说明~
添加文档
@Data
@Setter
@Getter
@NoArgsConstructor
@AllArgsConstructor
public class User implements Serializable {private String name;private Integer age;
} @Testvoid testAddDocument() throws IOException {
// 1、创建对象User user = new User("yinan", 20);
// 2、创建请求IndexRequest request = new IndexRequest("yinan_index");
// 规则 put /yinan_index/_doc/1request.id("1");request.timeout(TimeValue.timeValueSeconds(1));request.timeout("1s");
// 将数据放入请求 jsonrequest.source(JSON.toJSONString(user), XContentType.JSON);
// 客户端发送请求,获取相应的结果IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);System.out.println(indexResponse.toString());System.out.println(indexResponse.status()); //对应我们命令返回状态}
批量添加文档
@Testvoid testBulkRequest() throws Exception {BulkRequest bulkRequest = new BulkRequest();bulkRequest.timeout("10s");ArrayList<User> userList = new ArrayList<>();userList.add(new User("yinan1", 21));userList.add(new User("yinan1", 21));userList.add(new User("yinan3", 26));userList.add(new User("yinan4", 24));userList.add(new User("yinan5", 27));userList.add(new User("yinan12", 20));for (int i = 0; i < userList.size(); i++) {bulkRequest.add(new IndexRequest("yinan_index").id("" + (i + 1)).source(JSON.toJSONString(userList.get(i)), XContentType.JSON));}BulkResponse itemResponses = client.bulk(bulkRequest, RequestOptions.DEFAULT);System.out.println(itemResponses.hasFailures());}修改文档
@Testvoid testUpdateDocument() throws Exception {UpdateRequest request = new UpdateRequest("yinan_index", "1");request.timeout("1s");User user = new User("yinan_update", 21);request.doc(JSON.toJSONString(user), XContentType.JSON);UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);System.out.println(updateResponse.status());}删除文档
@Testvoid testDeleteDocument() throws Exception {DeleteRequest request = new DeleteRequest("yinan_index", "1");request.timeout("1s");DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);System.out.println(deleteResponse.status());}以上就是对es部分api的讲解,当然只看api使用是远远不够的,所以我们需要做一个小训练来巩固我们学习的东西。
资料已经置顶在本篇博客,有需要的请自取~
相关文章:
ElasticSearch教程(详解版)
本篇博客将向各位详细介绍elasticsearch,也算是对我最近学完elasticsearch的一个总结,对于如何在Kibana中使用DSL指令,本篇文章不会进行介绍,这里只会介绍在java中如何进行使用,保证你看完之后就会在项目中进行上手&am…...

[office] excel做曲线图的方法步骤详解 #经验分享#知识分享#其他
excel做曲线图的方法步骤详解 Excel是当今社会最流行用的办公软件之一,Excel可以用于数据的整理、分析、对比。可以更直观的看到数据的变化情况,而有很多时候需要制作曲线图表进行数据比较,因此,下面是小编整理的如何用excel做曲线…...

Git+Gitlab 远程库测试学习
Git远程仓库 1、Git远程仓库 何搭建Git远程仓库呢?我们可以借助互联网上提供的一些代码托管服务来实现 Gitee 码云是国内的一个代码托管平台,由于服务器在国内,所以相比于GitHub,码云速度会更快 码云 Gitee - 基于 Git 的代码托…...
Python可视化 | 使用matplotlib绘制面积图示例
面积图是数据可视化中的一个有效工具,用于说明时间上的关系和趋势。它们提供了一种全面的、视觉上迷人的方法,通过熟练地将折线图的可读性与填充区域的吸引力相结合来呈现数值数据。 在本文中,我们将学习更多关于在Python中创建面积折线图的…...

【环境搭建】2.阿里云ECS服务器 安装MySQL
在阿里云的 Alibaba Cloud Linux 3.2104 LTS 64位系统上安装 MySQL 8,可以按照以下步骤进行: 1.更新系统软件包: 首先,更新系统软件包以确保所有软件包都是最新的: sudo yum update -y2.下载 MySQL 8 官方 Yum 仓库…...
Python Flask 入门开发
Python基础学习: Pyhton 语法基础Python 变量Python控制流Python 函数与类Python Exception处理Python 文件操作Python 日期与时间Python Socket的使用Python 模块Python 魔法方法与属性 Flask基础学习: Python中如何选择Web开发框架?Pyth…...

PostgreSQL查看当前锁信息
PostgreSQL查看当前锁信息 基础信息 OS版本:Red Hat Enterprise Linux Server release 7.9 (Maipo) DB版本:16.2 pg软件目录:/home/pg16/soft pg数据目录:/home/pg16/data 端口:5777查看当前锁信息的sql SELECT pg_s…...
毫米波雷达深度学习技术-1.6目标识别2
1.6.4 自动编码器和变体自动编码器 自编码器包括一个编码器神经网络,随后是一个解码器神经网络,其目的是在输出处重建输入数据。自动编码器的设计在网络中施加了一个瓶颈,它鼓励原始输入的压缩表示。通常,自编码器旨在利用数据中的…...

MineAdmin 前端打包后,访问速度慢原因及优化
前言:打包mineadmin-vue前端后,访问速度很慢,打开控制台,发现有一个index-xxx.js文件达7M,加载时间太长; 优化: 一:使用文件压缩(gzip压缩) 1、安装compre…...
使用Obfuscar 混淆WPF(Net6)程序
Obfuscar 是.Net 程序集的基本混淆器,它使用大量的重载将.Net程序集中的元数据(方法,属性、事件、字段、类型和命名空间的名称)重命名为最小集。详细使用方式参见:Obfuscar 在NetFramework框架进行的WPF程序的混淆比较…...
高中数学:数列-基础概念
一、什么是数列? 一般地,我们把按照确定的顺序排列的一列数称为数列,数列中的每一个数叫做这个数列的项,数列的第一项称为首项。 项数有限个的数列叫做有穷数列,项数无限个的数列叫做无穷数列。 二、一般形式 数列和…...
linux中dd命令以及如何测试读写速度
dd命令详解 dd命令是一个在Unix和类Unix系统中非常常用的命令行工具,它主要用于复制文件和转换文件数据。下面我会详细介绍一些dd命令的常见用法和功能: 基本语法 dd命令的基本语法如下: bash Copy Code dd [option]...主要选项和参数 if…...

centos官方yum源不可用 解决方案(随手记)
昨天用yum安装软件的时候,就报错了 [rootop01 ~]# yum install -y net-tools CentOS Stream 8 - AppStream 73 B/s | 38 B 00:00 Error: Failed to download metadata for repo appstream: Cannot prepare internal mirrorlis…...

langchian_aws模块学习
利用langchain_aws模块实现集成bedrock调用模型,测试源码 from langchain_aws.chat_models import ChatBedrock import jsondef invoke_with_text(model_id, message):llm ChatBedrock(model_idmodel_id, region_name"us-east-1")res llm.invoke(messa…...

归并排序-成绩输出-c++
注:摘自hetaobc-L13-4 【任务目标】 按学号从小到大依次输入n个人的成绩,按成绩从大到小输出每个人的学号,成绩相同时学号小的优先输出。 【输入】 输入第一行为一个整数,n,表示人数。(1 ≤ n ≤ 100000…...

✔️Vue基础+
✔️Vue基础 文章目录 ✔️Vue基础computed methods watchcomputed计算属性methods计算属性computed计算属性 VS methods方法计算属性的完整写法 watch侦听器(监视器)watch侦听器 Vue生命周期Vue生命周期钩子 工程化开发和脚手架脚手架Vue CLI 项目目录介…...
基于VS2022编译GDAL
下载GDAL源码;下载GDAL编译需要依赖的必须代码,proj,tiff,geotiff三个源码,proj需要依赖sqlite;使用cmake编译proj,tiff,geotiff;proj有版本号要求;使用cmake…...
C语言之字符函数总结(全部!),一篇记住所有的字符函数
前言 还在担心关于字符的库函数记不住吗?不用担心,这篇文章将为你全面整理所有的字符函数的用法。不用记忆,一次看完,随查随用。用多了自然就记住了 字符分类函数和字符转换函数 C语言中有一系列的函数是专门做字符分类和字符转换…...
vite常识性报错解决方案
1.导入路径不能以“.ts”扩展名结束。考虑改为导入“xxx.js” 原因:当你尝试从一个以 .ts 结尾的路径导入文件时,ESLint 可能会报告这个错误,因为它期望导入的是 JavaScript 文件(.js 或 .jsx)而不是 TypeScript 文件&…...
【AI测试版】)
2024.06.08【读书笔记】丨生物信息学与功能基因组学(第十二章 全基因组和系统发育树 第四部分)【AI测试版】
读书笔记:《生物信息学与功能基因组学》第十二章 - 第四部分 目录 基因组测序的生物信息学工具 1.1 常用生物信息学软件介绍1.2 基因组数据的管理和分析 基因组序列的比较分析 2.1 基因组之间的相似性与差异性2.2 比较基因组学的应用 基因组学在医学和健康科学中…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

多模态商品数据接口:融合图像、语音与文字的下一代商品详情体验
一、多模态商品数据接口的技术架构 (一)多模态数据融合引擎 跨模态语义对齐 通过Transformer架构实现图像、语音、文字的语义关联。例如,当用户上传一张“蓝色连衣裙”的图片时,接口可自动提取图像中的颜色(RGB值&…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...
)
python爬虫:Newspaper3k 的详细使用(好用的新闻网站文章抓取和解析的Python库)
更多内容请见: 爬虫和逆向教程-专栏介绍和目录 文章目录 一、Newspaper3k 概述1.1 Newspaper3k 介绍1.2 主要功能1.3 典型应用场景1.4 安装二、基本用法2.2 提取单篇文章的内容2.2 处理多篇文档三、高级选项3.1 自定义配置3.2 分析文章情感四、实战案例4.1 构建新闻摘要聚合器…...

数据链路层的主要功能是什么
数据链路层(OSI模型第2层)的核心功能是在相邻网络节点(如交换机、主机)间提供可靠的数据帧传输服务,主要职责包括: 🔑 核心功能详解: 帧封装与解封装 封装: 将网络层下发…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...