【机器学习】消息传递神经网络(MPNN)在分子预测领域的医学应用
1. 引言
1.1. 分子性质预测概述
分子性质预测是计算机辅助药物发现流程中至关重要的任务之一,它在许多下游应用如药物筛选和药物设计中发挥着核心作用:
1.1.1. 目的与重要性:
- 分子性质预测旨在通过分子内部信息(如原子坐标、原子序数等)对分子的物理和化学性质进行预测。
- 这有助于快速从大量候选化合物中筛选出符合特定性质的化合物,从而加速药物筛选和设计的流程。
1.1.2. 传统方法:
- 密度泛函理论(DFT)是传统的分子性质预测方法,它精确但计算耗时,通常需要数小时才能完成单个分子的性质计算。
- 由于候选化合物数量庞大,使用DFT进行预测需要巨大的资源和时间成本。
1.1.3. 深度学习在分子性质预测中的应用:
- 得益于深度学习的快速发展,越来越多的研究者开始尝试将深度学习应用于分子性质预测领域。
- 神经网络模型能够从数据中自行学习合适的特征表示,不需要依赖人工构建的特征(如指纹与描述符)。
- 深度学习模型能够处理复杂的分子结构信息,并自动提取分子特征,从而提高了预测的准确性。
1.1.4. 主流的基于ML的分子性质预测方法:
- 基于描述符的方法:对分子特征进行人工提取,其质量对预测结果有重要影响。
- 基于图的方法:将分子描述为具有节点(原子)和边(键)的图结构,利用图神经网络(GNN)进行特征提取。这种方法能够避免人工提取描述符过程中的信息丢失,但严重依赖于数据量。
- 基于SMILES的方法:将分子性质预测看作自然语言处理(NLP)问题,直接从SMILES字符串中提取分子特征。这种方法对特征提取能力和数据量有更高要求。
- 分子性质预测方法中的消息传递神经网络(MPNN)是一种重要的技术,它特别适用于处理图结构数据,如分子结构中的原子和化学键。
1.1.5. 挑战与未来方向:
- 尽管深度学习在分子性质预测中取得了显著进展,但仍面临一些挑战,如数据稀疏性、模型可解释性等。
- 未来研究将致力于开发更先进的模型架构和算法,以提高预测准确性、降低计算成本,并探索更多应用场景。
分子性质预测是药物发现和设计中不可或缺的一环。随着深度学习技术的不断发展,我们有理由相信未来的分子性质预测将更加高效、准确和智能化。
1.2 消息传递神经网络(MPNN)
消息传递神经网络(MPNN)是一种重要的图神经网络(GNN)框架,特别适用于处理具有图结构的数据,如社交网络、化学分子等。
1.2.1. MPNN的基本原理
- MPNN的核心思想是通过节点之间的消息传递来更新节点的特征表示。在每一步的消息传递过程中,节点会接收来自邻居节点的信息,并利用这些信息来更新自身的特征表示。
- 通过多轮的消息传递,节点之间的信息能够得到充分的交流和融合,从而使得整个图的结构和节点特征得到更精细的表示。
1.2.2. MPNN的模型结构
- MPNN的模型结构通常包括输入层、消息传递层和输出层。
- 输入层:负责将原始的节点特征和图结构信息转化为可处理的神经网络输入。
- 消息传递层:是MPNN的核心部分,它通过多轮的消息传递来更新节点的特征表示。每个节点都会接收来自邻居节点的消息,并根据这些消息来更新自身的特征表示。具体的更新方式可以通过一种或多种不同的更新函数来实现,如加权平均、最大池化等。
- 输出层:将最终的节点特征表示转化为具体的任务输出。
1.2.3. MPNN的应用场景
- MPNN在分子特性预测方面有着广泛的应用。由于分子可以被视为一种特殊的图结构,其中原子是节点,化学键是边,MPNN能够很好地处理这种结构数据。例如,MPNN可以用于预测分子的血脑屏障通透性、溶解度等性质。
1.2.4. MPNN的优势
- MPNN能够处理具有不同大小和结构的图数据,因此具有高度的灵活性和可扩展性。
- 通过迭代地传递和聚合信息,MPNN能够捕获图的全局结构信息,从而得到更精细的节点表示。
- MPNN的模型结构相对简单,易于实现和调试。
1.2.5. MPNN的未来发展
- 随着图神经网络技术的不断发展,MPNN的性能和应用场景也将得到进一步的拓展。例如,可以探索将MPNN与其他深度学习模型结合使用,以进一步提高其性能;或者将MPNN应用于更广泛的领域,如社交网络分析、推荐系统等。
消息传递神经网络(MPNN)是一种强大的图神经网络框架,它通过节点之间的消息传递来更新节点的特征表示,具有高度的灵活性和可扩展性。在分子特性预测等领域有着广泛的应用前景。
1.3. MPNN用于分子预测的优势和局限
1.3.1.MPNN在分子预测方面的优势
-
自然处理图结构数据:MPNN是专为处理图结构数据设计的,分子作为图结构数据的一种,其中原子作为节点,化学键作为边,使得MPNN能够自然且高效地处理分子数据。
-
全局结构信息的捕获:MPNN通过迭代地传递和聚合节点间的信息,能够捕获分子的全局结构信息。这种能力使得MPNN在预测分子性质时,能够综合考虑分子内部各个部分之间的相互作用和整体结构,从而提高预测的准确性。
-
高度灵活性和可扩展性:MPNN不受分子大小或结构的限制,能够处理从简单有机分子到复杂生物大分子的各种情况。这种灵活性和可扩展性使得MPNN在分子预测领域具有广泛的应用前景。
-
良好的预测性能:MPNN在多个分子预测任务中均取得了良好的性能。例如,在预测分子的血脑屏障通透性、溶解度等性质时,MPNN能够准确地预测出分子的这些性质,为药物设计和筛选提供有力支持。
-
可解释性:MPNN的预测结果具有一定的可解释性。通过分析MPNN在预测过程中不同节点和边的贡献,可以了解哪些部分对预测结果的影响最大,从而提供对分子性质的深入理解。
1.3.2.MPNN在分子预测方面的局限性
-
数据依赖性:MPNN的性能在很大程度上取决于训练数据的数量和质量。在数据量不足或数据质量不高的情况下,MPNN的预测性能可能会受到影响。
-
计算复杂度: 对于大型复杂分子,MPNN的计算复杂度可能会较高,需要较长的计算时间。这可能会限制MPNN在实时或大规模分子预测任务中的应用。
-
模型复杂度:MPNN的模型结构相对复杂,需要较高的技术门槛和计算资源来设计和实现。这可能会增加MPNN在分子预测领域的应用难度和成本。
-
可解释性的局限性:尽管MPNN具有一定的可解释性,但其解释能力仍然有限。在某些情况下,MPNN可能无法提供足够详细的解释来完全理解其预测结果。
综上来看,MPNN在分子预测方面具有显著的优势,但也存在一些局限性。为了充分发挥MPNN的优势并克服其局限性,需要进一步探索和优化MPNN的模型结构和算法设计,并积累更多的训练数据和经验。
2. MPNN实现分子性质预测过程
2.1. 实现过程概述
本文讨论的方法基于消息传递神经网络(MPNN)实现预测分子血脑屏障通透性(BBBP)
2.1.1. 文章主要内容
在本文中我们将探索如何使用消息传递神经网络(MPNN)这一图神经网络(GNN)的变体来预测分子的一个重要属性——血脑屏障通透性(BBBP)。BBBP是评估药物能否穿过血脑屏障的关键指标,对于药物研发具有重大意义。
2.2.2. 研究的动机
分子可以被自然地建模为无向图G=(V, E),其中V代表顶点(或节点),对应于分子中的原子;E代表边,对应于原子之间的化学键。这种表示形式为利用图神经网络处理分子数据提供了便利。与基于预计算分子特征的传统方法(如随机森林、支持向量机等)相比,MPNN等GNN模型能够直接在图结构上进行操作,从而有可能捕获到更复杂的分子间关系,进而提升预测性能。
2.2.3.传统方法与GNN的比较
传统方法通常依赖于一系列预计算的分子特征,如分子量、极性、电荷和碳原子数量等。这些特征虽然已被证明是分子属性的有效预测器,但它们往往忽略了分子内部的复杂结构和相互作用。相比之下,GNN(如MPNN)能够直接在图的节点和边上进行操作,从而更全面地捕捉分子的结构和化学性质。
2.2.4.文章的内容
- 数据预处理:将分子数据集转换为图结构,并为每个节点和边提取相关特征。
- 定义MPNN模型:
- 设计消息函数,用于在节点之间传递信息。
- 设计更新函数,用于根据接收到的消息更新节点状态。
- 设计读出函数,用于从节点状态生成整个图的表示。
-
模型训练:使用标记的分子数据集训练MPNN模型,通过反向传播算法优化模型参数。
-
模型评估:在测试集上评估模型的性能,并使用适当的评估指标(如准确率、F1分数、AUC-PR等)来衡量预测效果。
-
模型调优:根据评估结果调整模型参数和架构,以优化预测性能。
2.2.软件准备
软件安装说明
为了开始我们的教程,首先需要安装RDKit和其他必要的依赖项。
RDKit是一个集化学信息学和机器学习软件于一体的工具集,使用C++和Python编写。在这个教程中,我们将利用RDKit将SMILES(简化分子输入行表示法)转换为分子对象,并从中提取原子和键的集合。
SMILES是一种将分子结构表达为ASCII字符串的方式。对于较小的分子,SMILES字符串是相对容易理解的。将分子编码为字符串既有助于减轻数据库和/或网络搜索的负担,又便于进行这些搜索。RDKit运用算法将给定的SMILES准确转换为分子对象,这些对象随后可用于计算大量的分子属性/特征。
通常情况下,RDKit通过Conda进行安装。但感谢rdkit_platform_wheels项目,我们现在可以更方便地通过pip来安装RDKit。以下是安装RDKit的步骤(注意:这里只是一个示例命令,具体命令可能因您的环境和需求而有所不同):
pip install rdkit-pypi请确保您的Python环境已正确设置,并且您已经安装了所有必要的依赖项。此外,根据您的项目需求,您可能还需要安装其他科学计算库,如NumPy、SciPy、Pandas等,这些库可以通过类似的pip命令进行安装。
pip -q install pandas
pip -q install Pillow
pip -q install matplotlib
pip -q install pydot
sudo apt-get -qq install graphviz
在继续教程之前,请检查您的安装是否正确,并确认所有依赖项都已满足。如有需要,您可以查阅RDKit的官方文档或相关社区资源以获取更详细的安装指南和支持。
导入需要的安装包
import os# Temporary suppress tf logs
os.environ["TF_CPP_MIN_LOG_LEVEL"] = "3"import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import warnings
from rdkit import Chem
from rdkit import RDLogger
from rdkit.Chem.Draw import IPythonConsole
from rdkit.Chem.Draw import MolsToGridImage# Temporary suppress warnings and RDKit logs
warnings.filterwarnings("ignore")
RDLogger.DisableLog("rdApp.*")np.random.seed(42)
tf.random.set_seed(42)
2.3. 数据预处理
2.3.1. 下载数据集
段代码首先会尝试从指定的URL下载数据集(如果它尚未被下载到默认的Keras缓存目录)。然后,它会使用Pandas读取CSV文件,并选择第2、3和4列(因为usecols的索引是从0开始的)。最后,它会打印出索引为96到103的行。
import keras.utils
import pandas as pd # 使用keras.utils.get_file下载数据集(如果尚未下载)
csv_path = keras.utils.get_file( "BBBP.csv", "https://deepchemdata.s3-us-west-1.amazonaws.com/datasets/BBBP.csv"
) # 使用pandas读取csv文件,并选择特定的列
df = pd.read_csv(csv_path, usecols=[1, 2, 3]) # 显示索引为96到103的行(注意Python中的索引是从0开始的)
print(df.iloc[96:104])
| 序号 | 分子名称 | p_np | SMILES字符串 |
|---|---|---|---|
| 96 | 头孢西丁 | 1 | CO[C@]1(NC(=O)Cc2sccc2)[C@H]3SCC(=C(N3C1=O)C(O... |
| 97 | Org34167 | 1 | NC(CC=C)c1ccccc1c2noc3c2cccc3 |
| 98 | 9-羟基利培酮 | 1 | OC1C(N2CCC1)=NC(C)=C(CCN3CCC(CC3)c4c5ccc(F)cc5... |
| 99 | 醋氨酚(对乙酰氨基酚) | 1 | CC(=O)Nc1ccc(O)cc1 |
| 100 | 乙酰水杨酸(阿司匹林) | 0 | CC(=O)Oc1ccccc1C(O)=O |
| 101 | 别嘌醇 | 0 | O=C1N=CN=C2NNC=C12 |
| 102 | 前列地尔 | 0 | CCCCC[C@H](O)/C=C/[C@H]1[C@H](O)CC(=O)[C@@H]1C... |
| 103 | 氨茶碱 | 0 | CN1C(=O)N(C)c2nc[nH]c2C1=O.CN3C(=O)N(C)c4nc[nH]... |
注释:p_np渗透性标签 (1=能渗透, 0=不能渗透)
通过上述代码,我们下载了BBBP数据集:
数据集名称:血脑屏障渗透性(Blood-Brain Barrier Penetration, BBBP)数据集
来源:该数据集可以从MoleculeNet.org下载,相关信息可在《一种基于贝叶斯方法的计算机模拟血脑屏障渗透性建模》和《MoleculeNet:分子机器学习的基准》等文献中找到。
数据集概述:
- 数据量:包含2,050个分子样本。
- 特征:每个分子样本都包含以下信息:
- 名称:分子的唯一标识符或名称。
- SMILES字符串:表示分子结构的简化分子输入行表示法(Simplified Molecular Input Line Entry System)。
- 标签:每个分子样本都有一个二进制标签(1或0),表示该分子是否能够通过血脑屏障(BBB)。
研究背景:
血脑屏障(BBB)是分隔血液与大脑细胞外液的一层特殊膜,它的主要功能是保护大脑免受有害物质和病原体的侵害。然而,这也使得许多潜在的治疗中枢神经系统疾病的药物无法进入大脑。因此,对血脑屏障渗透性的研究对于开发能够针对中枢神经系统的新药物至关重要。
数据集用途:
该数据集可用于训练机器学习模型,以预测新分子的血脑屏障渗透性。通过准确的预测,研究人员可以更有效地筛选出具有潜在疗效的药物候选物,从而加速药物开发的进程。
2.3.2.特征定义
为了对分子中的原子和键进行特征编码,我们定义了两个类:AtomFeaturizer 和 BondFeaturizer。
为了保持本教程的简洁和明了,我们仅选择了几个关键的(原子和键)特征进行介绍:对于原子,我们考虑其元素符号、价电子数、氢键数以及轨道杂化情况;对于键,我们关注其(共价)键的类型以及共轭状态。这些特征将有助于我们更好地描述分子结构,并在后续的机器学习模型中进行有效的特征表示。
import numpy as np
from rdkit import Chem class Featurizer: def __init__(self, allowable_sets): self.dim = 0 self.features_mapping = {} for k, s in allowable_sets.items(): s = sorted(list(s)) self.features_mapping[k] = dict(zip(s, range(self.dim, len(s) + self.dim))) self.dim += len(s) def encode(self, inputs): output = np.zeros((self.dim,)) for name_feature, feature_mapping in self.features_mapping.items(): feature = getattr(self, name_feature)(inputs) if feature in feature_mapping: output[feature_mapping[feature]] = 1.0 return output class AtomFeaturizer(Featurizer): def __init__(self, allowable_sets): super().__init__(allowable_sets) # allowable_sets 中至少包含 'symbol', 'n_valence', 'n_hydrogens', 'hybridization' 这几个键 # 对应的值应该是这些特征的可能取值集合 def symbol(self, atom): # atom 是 RDKit 的 Atom 对象 return atom.GetSymbol() def n_valence(self, atom): # RDKit 的 Atom 对象有 GetTotalValence 方法 return atom.GetTotalValence() def n_hydrogens(self, atom): # RDKit 的 Atom 对象有 GetTotalNumHs 方法 return atom.GetTotalNumHs() def hybridization(self, atom): # GetHybridization 返回的是一个枚举类型,并且有 name 属性 hybridization_name = atom.GetHybridization().name # 注意: name 是一个字符串,并且可能需要转换为小写 # 但有时枚举的 name 属性已经是大写或小写,或者可能不是完全小写,因此这个转换可能不是必要的 # 根据实际 RDKit 版本和枚举实现来确定是否需要转换 return hybridization_name.lower() # 示例用法
# RDKit 的 Atom 对象 atom,以及一个定义允许特征集的字典 allowable_sets
# allowable_sets = {'symbol': set(['C', 'O', 'N', 'H']), 'n_valence': set([1, 2, 3, 4]), ...}
# atom_featurizer = AtomFeaturizer(allowable_sets)
# encoded_features = atom_featurizer.encode(atom)
class BondFeaturizer(Featurizer): def __init__(self, allowable_sets): super().__init__(allowable_sets) # 增加一个维度来处理没有键的情况(例如,在一个原子的末端) self.dim_no_bond = self.dim self.dim += 1 # 额外的维度用于标识没有键 def encode(self, bond): if bond is None: # 如果键是 None,则返回一个特殊的编码 return np.zeros(self.dim) + [1.0] output = np.zeros(self.dim) # 先将没有键的维度设为0 output[-1] = 0.0 # 调用基类的 encode 方法,传入 bond 的一个属性或方法返回的信息 # 注意:这里可能需要一些调整,因为 bond 对象可能没有直接的方法可以调用 # 我们假设 bond 是一个有 bond_type 和 conjugated 属性的对象 bond_info = {'bond_type': bond.GetBondType().name.lower(), 'conjugated': bond.GetIsConjugated()} for name_feature, feature_value in bond_info.items(): if feature_value in self.features_mapping[name_feature]: output[self.features_mapping[name_feature][feature_value]] = 1.0 return output def bond_type(self, bond): return bond.GetBondType().name.lower() def conjugated(self, bond): return bond.GetIsConjugated() atom_featurizer = AtomFeaturizer( allowable_sets={ "symbol": {"B", "Br", "C", "Ca", "Cl", "F", "H", "I", "N", "Na", "O", "P", "S"}, "n_valence": {0, 1, 2, 3, 4, 5, 6}, "n_hydrogens": {0, 1, 2, 3, 4}, "hybridization": {"s", "sp", "sp2", "sp3"}, }
) bond_featurizer = BondFeaturizer( allowable_sets={ "bond_type": {"single", "double", "triple", "aromatic"}, "conjugated": {True, False}, }
)
代码定义了两个类:Featurizer 和它的两个子类 AtomFeaturizer 和 BondFeaturizer。这些类用于将化学原子和键的信息编码成固定维度的特征向量,这在机器学习和化学信息学中很常见。
Featurizer 类
__init__(self, allowable_sets): 初始化函数,它接受一个字典allowable_sets,其中包含了要编码的特征名和它们各自的可能值的集合。它计算了特征的总维度self.dim,并为每个特征名创建了一个映射到维度的字典self.features_mapping。encode(self, inputs): 这是一个用于编码输入的函数。它接受一个输入(在这种情况下,可能是原子或键),然后调用适当的方法(例如symbol,n_valence等)来获取输入的特征值。然后,它将这些特征值映射到输出向量output的相应位置,并返回这个向量。
AtomFeaturizer 类
__init__(self, allowable_sets): 初始化函数,它调用Featurizer的初始化函数来设置原子特征的映射。- 它定义了四个方法:
symbol,n_valence,n_hydrogens, 和hybridization,这些方法分别用于从rdkit.Chem.Atom对象中提取原子的特定属性。
BondFeaturizer 类
__init__(self, allowable_sets): 初始化函数,它首先调用Featurizer的初始化函数来设置键特征的映射,然后增加了一个额外的维度self.dim来处理None(即不存在的键)的情况。但这里有一个问题:在Featurizer的初始化之后增加self.dim是不正确的,因为这会影响之前创建的features_mapping的有效性。encode(self, bond): 这个函数首先检查bond是否为None。如果是,它返回一个特殊的编码(在最后一个维度上有一个 1)。否则,它调用Featurizer的encode方法来编码键的特征。但这里也有一个问题:由于BondFeaturizer的encode方法覆盖了Featurizer的encode方法,它实际上不会使用bond_type和conjugated方法来编码键的特征。bond_type和conjugated方法分别用于从rdkit.Chem.Bond对象中提取键的类型和共轭状态。
2.3.3.生成图
为了从SMILES字符串生成完整的图,我们需要先实现以下两个函数:
-
molecule_from_smiles:这个函数将SMILES字符串作为输入,并借助RDKit库将其转换为分子对象。 -
graph_from_molecule:这个函数将分子对象作为输入,并返回一个图。这个图以三元组的形式表示,包括原子特征(atom_features)、键特征(bond_features)和原子对索引(pair_indices)。我们将利用之前定义的类来实现这个功能。
最后,我们可以编写graphs_from_smiles函数,该函数将上述两个函数组合起来,应用于训练集、验证集和测试集中的所有SMILES字符串。
# atom_featurizer 和 bond_featurizer 已经被定义并初始化 def molecule_from_smiles(smiles): # 尝试从SMILES字符串创建分子,并首先进行基本的清理 molecule = Chem.MolFromSmiles(smiles, sanitize=False) if molecule is None: raise ValueError(f"Unable to parse SMILES string: {smiles}") # 尝试对分子进行清理(sanitization) flag = Chem.SanitizeMol(molecule, catchErrors=True) if flag != Chem.SanitizeFlags.SANITIZE_NONE: # 如果清理失败,则尝试移除引起错误的操作 Chem.SanitizeMol(molecule, sanitizeOps=Chem.SanitizeFlags.SANITIZE_ALL ^ flag) # 分配立体化学信息 Chem.AssignStereochemistry(molecule, cleanIt=True, force=True) return molecule def graph_from_molecule(molecule, atom_featurizer, bond_featurizer): # 初始化图 atom_features = [] bond_features = [] pair_indices = [] for atom_idx, atom in enumerate(molecule.GetAtoms()): # 编码原子特征 atom_features.append(atom_featurizer.encode(atom)) # 添加自环(self-loops) pair_indices.append([atom_idx, atom_idx]) bond_features.append(bond_featurizer.encode(None)) # 假设对None的编码表示自环 # 遍历邻居原子 for neighbor in atom.GetNeighbors(): bond_idx = molecule.GetBondBetweenAtoms(atom_idx, neighbor.GetIdx()).GetIdx() pair_indices.append([atom_idx, neighbor.GetIdx()]) # 编码键特征 bond_features.append(bond_featurizer.encode(molecule.GetBondWithIdx(bond_idx))) # 将列表转换为NumPy数组 return np.array(atom_features), np.array(bond_features), np.array(pair_indices) def graphs_from_smiles(smiles_list): """ 将SMILES字符串列表转换为图数据 参数: smiles_list (list): SMILES字符串列表 返回: (tuple): 包含原子特征、键特征和配对索引的ragged tensors元组 """ # 初始化列表以存储图数据 atom_features_list = [] # 原子特征列表 bond_features_list = [] # 键特征列表 pair_indices_list = [] # 配对索引列表 # 将SMILES字符串转换为图 for smiles in smiles_list: molecule = molecule_from_smiles(smiles) # 从SMILES字符串创建分子对象 # 从分子对象中提取图数据 atom_features, bond_features, pair_indices = graph_from_molecule(molecule) atom_features_list.append(atom_features) bond_features_list.append(bond_features) pair_indices_list.append(pair_indices) # 将列表转换为ragged tensors atom_features_tensor = tf.ragged.constant(atom_features_list, dtype=tf.float32) # 原子特征张量 bond_features_tensor = tf.ragged.constant(bond_features_list, dtype=tf.float32) # 键特征张量 pair_indices_tensor = tf.ragged.constant(pair_indices_list, dtype=tf.int64) # 配对索引张量 # 返回一个包含ragged tensors的元组 return (atom_features_tensor, bond_features_tensor, pair_indices_tensor) # 假设df是一个包含'smiles'列和'p_np'列的pandas DataFrame
# 打乱DataFrame的索引
permuted_indices = np.random.permutation(np.arange(df.shape[0])) # 划分为训练集、验证集和测试集
train_size = int(df.shape[0] * 0.8) # 训练集大小
valid_size = int(df.shape[0] * 0.99) # 验证集结束位置 # 训练集
train_index = permuted_indices[:train_size]
x_train = graphs_from_smiles(df.iloc[train_index].smiles) # 训练集的图数据
y_train = df.iloc[train_index].p_np.values # 训练集的标签,确保是NumPy数组 # 验证集
valid_index = permuted_indices[train_size:valid_size]
x_valid = graphs_from_smiles(df.iloc[valid_index].smiles) # 验证集的图数据
y_valid = df.iloc[valid_index].p_np.values # 验证集的标签 # 测试集
test_index = permuted_indices[valid_size:]
x_test = graphs_from_smiles(df.iloc[test_index].smiles) # 测试集的图数据
y_test = df.iloc[test_index].p_np.values # 测试集的标签
2.3.4.测试功能
从pandas DataFrame df 中获取特定索引(这里是第100行)的数据,并使用 molecule_from_smiles 函数将SMILES字符串转换为分子对象。
# df是一个包含'name'、'smiles'和'p_np'列的pandas DataFrame # 打印第100行的数据
print(f"Name:\t{df.name[100]}\nSMILES:\t{df.smiles[100]}\nBBBP:\t{df.p_np[100]}") # 从SMILES字符串创建分子对象
molecule = molecule_from_smiles(df.iloc[100].smiles) # 打印分子对象(这取决于molecule_from_smiles函数返回的对象类型)
print("Molecule:")
# 假设molecule对象有一个可以打印的方法或属性(例如.__str__(), .to_smiles()等)
# 这里使用了一个假设的.to_string()方法作为例子
try: print(molecule.to_string()) # 或者其他适当的方法来展示分子
except AttributeError: print("The molecule object does not have a direct string representation.") # 在这里,您可能需要根据molecule对象的实际类型来实现特定的展示逻辑 # 如果molecule_from_smiles返回的是一个自定义对象,并且您想要展示该对象的更多详细信息,
# 您可能需要访问该对象的属性或方法。例如:
# print(f"Number of atoms: {molecule.num_atoms}")
# print(f"Number of bonds: {molecule.num_bonds}")
# 这里的num_atoms和num_bonds是假设的分子对象属性,您需要根据实际情况来替换
Name: acetylsalicylate
SMILES: CC(=O)Oc1ccccc1C(O)=O
BBBP: 0
Molecule:

从一个分子对象(molecule)生成一个图(graph),并且尝试打印出图的原子特征、键特征和配对索引的形状。
# 假设您已经通过molecule_from_smiles函数得到了molecule对象
molecule = molecule_from_smiles(df.iloc[100].smiles) # 从分子对象生成图
graph = graph_from_molecule(molecule) # 假设graph是一个包含三个元素的元组:(atom_features, bond_features, pair_indices)
atom_features, bond_features, pair_indices = graph print("Graph (including self-loops):")
# 对于ragged tensors,我们使用不同的方法来获取其形状
print("\tatom features shape\t", atom_features.bounding_shape().numpy()) # ragged tensors的边界形状
print("\tbond features shape\t", bond_features.bounding_shape().numpy())
print("\tpair indices shape\t", pair_indices.bounding_shape().numpy()) # 如果您想查看ragged tensors的实际形状(即非边界形状),您可能需要遍历它们
# 但请注意,这将取决于ragged tensors的具体内容
# 例如,对于atom_features,您可以这样做:
print("\tActual atom features shapes:")
for rt in atom_features: print("\t\t", rt.shape.numpy()) # 类似地,对于bond_features和pair_indices(如果它们也是ragged tensors)
Graph (including self-loops):atom features (13, 29)bond features (39, 7)pair indices (39, 2)
2.3.5. 建立tf数据集
在本文中,MPNN(消息传递神经网络)的实现将每次迭代接收一个单独的图作为输入。因此,给定一批(子)图(分子),我们需要将它们合并成一个单一的图(我们将这个图称为全局图)。这个全局图是一个不连通的图,其中每个子图与其他子图完全分开。
使用 TensorFlow 的 tf.data.Dataset 来处理这样的数据,你需要确保你的数据可以被正确地加载、预处理,并且能够以迭代的方式提供给模型。
import tensorflow as tf def prepare_batch(x_batch, y_batch): """ 将一批(子)图合并为一个全局的(不连通)图 参数: x_batch: 包含三个元素的元组,分别为: - atom_features: ragged tensor,表示每个图(分子)中每个原子的特征 - bond_features: ragged tensor,表示每个图(分子)中每个键(化学键)的特征 - pair_indices: ragged tensor,表示每个键连接的原子对的索引 y_batch: 与x_batch对应的标签 返回: 合并后的全局图特征(包括原子特征、键特征和原子对索引)以及对应的标签 """ atom_features, bond_features, pair_indices = x_batch # 获取每个图(分子)的原子数和键数 num_atoms = tf.ragged.row_lengths(atom_features) num_bonds = tf.ragged.row_lengths(bond_features) # 获取分区索引(molecule_indicator),稍后在模型中用于从全局图中收集(子)图 molecule_indices = tf.range(len(num_atoms), dtype=tf.int64) molecule_indicator = tf.repeat(molecule_indices, num_atoms) # 收集键特征的索引以创建偏移量 gather_indices = tf.concat([tf.zeros(1, dtype=tf.int64), tf.cumsum(num_atoms[:-1])], axis=0) gather_indices = tf.repeat(gather_indices[:-1], num_bonds[1:]) # 增加pair_indices中的索引以创建全局索引 increment = tf.gather(gather_indices, tf.range(len(gather_indices), dtype=tf.int64)) pair_indices = pair_indices.merge_dims(outer_axis=0, inner_axis=1).to_tensor() pair_indices = pair_indices + increment[:, tf.newaxis] # 将ragged tensors转换为dense tensors以进行批处理 atom_features = atom_features.merge_dims(outer_axis=0, inner_axis=1).to_tensor() bond_features = bond_features.merge_dims(outer_axis=0, inner_axis=1).to_tensor() return (atom_features, bond_features, pair_indices, molecule_indicator), y_batch def MPNNDataset(X, y, batch_size=32, shuffle=False): """ 创建一个用于MPNN(消息传递神经网络)的TensorFlow数据集 参数: X: 包含三个ragged tensors的元组,分别代表原子特征、键特征和原子对索引 y: 对应的标签 batch_size: 批处理大小 shuffle: 是否打乱数据集 返回: 一个可用于训练的TensorFlow数据集 """ # 从tensor slices创建数据集 dataset = tf.data.Dataset.from_tensor_slices((X, y)) if shuffle: # 打乱数据集,使用buffer_size指定缓冲区大小 dataset = dataset.shuffle(buffer_size=1024) # 使用map函数对数据集进行批处理和预处理,并使用AUTOTUNE自动调整并行度 dataset = dataset.batch(batch_size).map(prepare_batch, num_parallel_calls=tf.data.AUTOTUNE) # 使用prefetch预取数据以重叠预处理和训练 dataset = dataset.prefetch(tf.data.AUTOTUNE) return dataset # 示例用法:
# X = (atom_features_ragged, bond_features_ragged, pair_indices_ragged) # 您的ragged tensors
# y = ... # 您的标签
# dataset = MPNNDataset(X, y, batch_size=32, shuffle=True)
2.4. 训练模型
MPNN(消息传递神经网络)模型可以根据不同的应用需求进行定制。在这个教程中,我们将构建一个基于原始论文《Neural Message Passing for Quantum Chemistry》和DeepChem框架中的MPNNModel的MPNN。这个MPNN模型由三个主要部分组成:消息传递、读出和分类。
2.4.1.消息传递阶段
消息传递阶段包含两个核心步骤:
-
边网络(Edge Network):它基于节点v与其1-hop邻居w_{i}之间的边特征(e_{vw_{i}})来传递消息。这些消息随后用于更新节点v的状态,得到更新后的节点状态v’。这里,w_{i}表示v的第i个邻居。
-
门控循环单元(GRU):这个单元以最新的节点状态作为输入,并基于之前的节点状态来更新它。换句话说,GRU使用当前节点状态作为输入,同时利用先前的节点状态来更新其内部记忆状态。通过这种方式,信息能够在不同的节点状态之间流动,比如从v传播到v’'。
重要的是,这两个步骤(边网络和GRU)会重复执行k次,其中k是预设的迭代次数。在每次迭代中,从v节点聚合的信息的半径(或跳数)都会增加1,从而允许模型捕获更广泛的图结构信息。
class EdgeNetwork(Layer): def build(self, input_shape): # 解析输入形状,得到原子特征和键特征的维度 self.atom_dim = input_shape[0][-1] # 原子特征的维度 self.bond_dim = input_shape[1][-1] # 键特征的维度 # 初始化权重和偏置 self.kernel = self.add_weight( shape=(self.bond_dim, self.atom_dim * self.atom_dim), initializer="glorot_uniform", name="kernel", trainable=True # 明确指定为可训练 ) self.bias = self.add_weight( shape=(self.atom_dim * self.atom_dim), initializer="zeros", name="bias", trainable=True # 明确指定为可训练 ) # 标记Layer已经被构建 super(EdgeNetwork, self).build(input_shape) # 调用父类的build方法 def call(self, inputs): # 解包输入,得到原子特征、键特征和原子对索引 atom_features, bond_features, pair_indices = inputs # 对键特征应用线性变换 bond_features_transformed = tf.matmul(bond_features, self.kernel) + self.bias # 重塑变换后的键特征,以便进行后续的邻域聚合 # 每个键特征现在是一个二维张量,对应于两个原子之间的交互 bond_features_reshaped = tf.reshape(bond_features_transformed, (-1, self.atom_dim, self.atom_dim)) # 获取邻居的原子特征 # 使用pair_indices[:, 1]作为索引从atom_features中收集邻居的原子特征 atom_features_neighbors = tf.gather(atom_features, pair_indices[:, 1]) # 增加一个维度,以匹配bond_features_reshaped的维度 atom_features_neighbors_expanded = tf.expand_dims(atom_features_neighbors, axis=-1) # 应用邻域聚合 # 将键特征和邻居原子特征相乘,得到每个原子对的交互特征 transformed_features = tf.matmul(bond_features_reshaped, atom_features_neighbors_expanded) # 压缩最后一个维度(即删除最后一个维度),得到一维的特征向量 transformed_features_squeezed = tf.squeeze(transformed_features, axis=-1) # 使用tf.math.unsorted_segment_sum进行无序段求和 # 将转换后的特征按照pair_indices[:, 0]指定的索引进行聚合 # pair_indices[:, 0]是每个原子对的起始原子的索引 # num_segments指定了输出的段数,即原子的数量 aggregated_features = tf.math.unsorted_segment_sum( transformed_features_squeezed, pair_indices[:, 0], num_segments=tf.shape(atom_features)[0] ) return aggregated_features class MessagePassing(Layer): def __init__(self, units, steps=4, **kwargs): super().__init__(**kwargs) self.units = units # 输出的单元数 self.steps = steps # 消息传递的步骤数 def build(self, input_shape): self.atom_dim = input_shape[0][-1] # 原子特征的维度 # 初始化EdgeNetwork,它将用于聚合邻居信息 self.message_step = EdgeNetwork() # 如果所需的units超过atom_features的维度,则需要填充 self.pad_length = max(0, self.units - self.atom_dim) # 初始化GRUCell用于更新节点状态 # 注意:这里可能需要填充atom_features_updated以匹配self.units,但考虑到GRUCell内部实现, # 我们可能不需要显式填充,因为内部状态可以处理不同维度的输入和状态。 # 但为了保持与原始代码的一致性,这里仍然添加填充逻辑。 self.update_step = GRUCell(self.units) # 使用self.units作为GRUCell的单元数 super().build(input_shape) # 调用父类的build方法 def call(self, inputs): atom_features, bond_features, pair_indices = inputs # 如果所需的units超过atom_features的维度,则填充atom_features atom_features_updated = tf.pad(atom_features, [[0, 0], [0, self.pad_length]], constant_values=0) # 执行指定步数的消息传递 for i in range(self.steps): # 聚合来自邻居的信息 atom_features_aggregated = self.message_step([atom_features_updated, bond_features, pair_indices]) # 通过GRU的一个步骤来更新节点状态 # 注意:在GRUCell中,我们通常将上一个状态(或初始状态)和输入作为参数传递 # 这里,我们使用atom_features_aggregated作为输入,并假设atom_features_updated作为初始状态 # (尽管在第一次迭代中,它可能不是真正的“前一个”状态) _, atom_features_updated = self.update_step(atom_features_aggregated, [atom_features_updated]) # 注意:GRUCell的返回值通常是一个元组,包含新的状态和输出 # 在这里,我们只关心状态,因此使用_来忽略输出 return atom_features_updated
当然,以下是对改写后的MessagePassing类代码的解读:
初始化方法 (__init__)
在类的初始化方法中,我们定义了两个关键参数:units和steps。
units:表示输出的单元数或特征维度大小。这通常决定了消息传递后每个节点特征的维度。steps:表示消息传递的步骤数,即我们要进行多少次邻居信息的聚合和节点状态的更新。
构建方法 (build)
在build方法中,我们根据输入的形状来确定原子特征的维度(atom_dim),并初始化一些必要的层和变量。
self.atom_dim:保存原子特征的维度,这是从输入形状中推导出来的。self.message_step:初始化EdgeNetwork实例,这个实例将用于在消息传递过程中聚合来自邻居的信息。self.pad_length:计算填充长度,以确保原子特征维度与所需的units相匹配。如果units大于atom_dim,则需要进行填充。self.update_step:初始化GRUCell实例,用于更新节点的状态。注意这里我们直接使用self.units作为GRU单元的维度,而不是atom_dim + pad_length,因为GRU单元内部会处理维度匹配的问题。
调用方法 (call)
在call方法中,我们定义了消息传递的具体步骤。
-
输入解包:首先,我们将输入解包为
atom_features(原子特征)、bond_features(键特征)和pair_indices(成对索引)。 -
特征填充:如果
units大于atom_dim,则需要对atom_features进行填充,以确保其维度与units一致。这里使用tf.pad函数进行填充,填充值为0。 -
消息传递:接下来,我们执行多次(由
steps参数定义)消息传递步骤。在每个步骤中:- 使用
self.message_step(即EdgeNetwork实例)来聚合来自邻居的信息。这个步骤会将当前节点的特征、键特征和成对索引作为输入,并输出聚合后的特征。 - 使用
self.update_step(即GRUCell实例)来更新节点的状态。这里,我们将聚合后的特征作为输入,并将当前的节点状态(初始时为填充后的atom_features)传递给GRU单元。GRU单元会输出新的状态和输出,但在这里我们只关心状态,因此使用_来忽略输出。
- 使用
-
返回更新后的特征:最后,返回经过多次消息传递和状态更新后的节点特征。
这里定义的MessagePassing类实现了一个通用的消息传递框架,其中包括邻居信息的聚合和节点状态的更新。这种框架在图神经网络(GNNs)中非常常见,特别是在处理分子结构、社交网络等图结构数据时。通过多次迭代更新,节点能够逐渐捕获到更远距离的邻居信息,从而提高模型的表达能力。
2.4.2.消息读出
当消息传递过程完成后,为了将k步聚合的节点状态转化为图级别的嵌入,我们需要先将它们按照子图(对应于批次中的每个分子)进行划分。接下来,我们会采用以下步骤来处理这些子图以获取图级别的表示:
- 首先,将k步聚合后的节点状态按照子图(即每个分子)进行划分。
- 对于每个子图,如果节点数量少于最大子图的节点数,则对子图进行填充(padding),以确保所有子图具有相同的节点数。
- 使用
tf.stack(...)将填充后的子图堆叠成一个张量,其中每个子图包含一组节点状态。 - 对堆叠后的张量应用掩码(mask),以确保在后续处理中忽略填充部分,避免它们对训练过程产生干扰。
- 最后,将掩码后的张量输入到变压器编码器(transformer encoder)中,通过编码器进一步处理子图信息。
- 在变压器编码器之后,对编码器输出应用平均池化(average pooling)操作,以聚合所有节点的信息,从而得到图级别的嵌入表示。
这个图级别的嵌入表示可以用于后续的预测任务,如分类、回归等,以捕捉整个分子或图结构的信息。
class PartitionPadding(layers.Layer): def __init__(self, batch_size, **kwargs): super().__init__(**kwargs) self.batch_size = batch_size # 初始化时传入批次大小 def call(self, inputs): atom_features, molecule_indicator = inputs # 输入为原子特征和分子指示符 # 将原子特征按照分子指示符进行划分,得到每个分子的子图 # tf.dynamic_partition 根据第二个参数(分子指示符)对第一个参数(原子特征)进行划分 atom_features_partitioned = tf.dynamic_partition( atom_features, molecule_indicator, self.batch_size ) # 获取每个子图的原子数量 num_atoms = [tf.shape(f)[0] for f in atom_features_partitioned] # 计算最大原子数量,用于填充子图以确保所有子图有相同的长度 max_num_atoms = tf.reduce_max(num_atoms) # 对每个子图进行填充,然后堆叠起来 atom_features_stacked = tf.stack( [ # 对每个子图在第一个维度(原子数量)进行填充 tf.pad(f, [(0, max_num_atoms - n), (0, 0)]) # f 为子图特征,n 为当前子图的原子数量 for f, n in zip(atom_features_partitioned, num_atoms) ], axis=0 # 堆叠的维度 ) # 移除空的子图(通常是在数据集的最后一个批次中可能出现) # 检查堆叠后的子图特征是否全为0(即空子图),并获取非零子图的索引 gather_indices = tf.where(tf.reduce_sum(atom_features_stacked, (1, 2)) != 0) # 压缩索引的最后一个维度(如果有的话) gather_indices = tf.squeeze(gather_indices, axis=-1) # 根据非零子图的索引,从堆叠后的子图特征中收集它们 return tf.gather(atom_features_stacked, gather_indices, axis=0)
class TransformerEncoderReadout(layers.Layer): def __init__( self, num_heads=8, embed_dim=64, dense_dim=512, batch_size=32, **kwargs ): super().__init__(**kwargs) # 子图划分与填充层 self.partition_padding = PartitionPadding(batch_size) # 多头注意力层 self.attention = layers.MultiHeadAttention(num_heads, embed_dim) # 密集投影层序列(包含激活函数) self.dense_proj = keras.Sequential( [layers.Dense(dense_dim, activation="relu"), layers.Dense(embed_dim),] ) # 两层层归一化 self.layernorm_1 = layers.LayerNormalization() self.layernorm_2 = layers.LayerNormalization() # 全局平均池化层 self.average_pooling = layers.GlobalAveragePooling1D() def call(self, inputs): # 对输入进行子图划分与填充 x = self.partition_padding(inputs) # 创建填充掩码,用于屏蔽填充部分的影响 padding_mask = tf.reduce_any(tf.not_equal(x, 0.0), axis=-1) padding_mask = padding_mask[:, tf.newaxis, tf.newaxis, :] # 多头注意力处理,应用掩码 attention_output = self.attention(x, x, attention_mask=padding_mask) # 残差连接与层归一化 proj_input = self.layernorm_1(x + attention_output) # 通过密集投影层,并再次进行残差连接与层归一化 proj_output = self.layernorm_2(proj_input + self.dense_proj(proj_input)) # 应用全局平均池化,得到图级别的嵌入 return self.average_pooling(proj_output)
PartitionPadding类
定义了一个名为PartitionPadding的Keras自定义层,该层用于处理与分子图相关的数据,特别是当数据中包含多个分子且每个分子具有不同数量的原子时。以下是对这段代码的详细总结解读:
-
初始化方法(
__init__):- 在初始化时,需要传入
batch_size参数,这通常代表一批数据中分子的最大数量。然而,需要注意的是,由于后续处理中可能存在填充,并且可能要去除空子图,因此这个batch_size并不直接决定最终输出的分子数量。
- 在初始化时,需要传入
-
调用方法(
call):
- 输入数据
inputs是一个元组,包含两个元素:atom_features(原子特征)和molecule_indicator(分子指示符)。 - 使用
tf.dynamic_partition根据molecule_indicator将atom_features划分为多个子图,每个子图代表一个分子的原子特征。 - 计算每个子图中原子的数量,并找到这些数量中的最大值
max_num_atoms,这将用于后续的填充操作。 - 对每个子图使用
tf.pad进行填充,确保所有子图都有相同的长度(即max_num_atoms)。这是为了使得所有分子在后续的Transformer或其他处理步骤中可以被平等对待。 - 将填充后的子图堆叠起来形成一个三维张量,其中第一维是分子索引,第二维是原子索引,第三维是原子特征。
- 检查堆叠后的子图特征,去除那些全为0的子图(即空子图)。这是通过计算每个子图特征的非零元素和,并找出非零和的索引来实现的。
- 使用
tf.gather根据非零索引从堆叠的子图特征中收集非空子图,并返回这些子图作为输出。
TransformerEncoderReadout类
定义了名为TransformerEncoderReadout的Keras自定义层,该层是基于Transformer编码器结构的一个变种,旨在从图数据或具有填充序列的数据中提取出全局表示。下面是该代码的主要组成部分及功能的总结解读:
- 初始化方法(
__init__):
num_heads:定义了多头注意力机制中“头”的数量。embed_dim:嵌入维度,即每个输入单元或“头”的维度。dense_dim:前馈神经网络(FFN)中隐藏层的维度。batch_size:批量大小,这个值用于PartitionPadding层(尽管在标准Transformer中通常不需要直接指定批量大小)。- 定义了多个子层,包括
PartitionPadding(可能是用于处理图数据或具有不同长度序列的填充)、MultiHeadAttention(多头注意力机制)、Dense层组成的前馈神经网络(FFN)、两个LayerNormalization层(用于层归一化)以及GlobalAveragePooling1D(用于将序列嵌入转换为全局嵌入)。
- 调用方法(
call):
- 首先,输入数据
inputs通过PartitionPadding层进行处理,可能是为了处理不同长度的序列或图数据。 - 接着,根据处理后的数据
x创建一个填充掩码padding_mask,该掩码用于在多头注意力机制中屏蔽填充值的影响。 - 使用
MultiHeadAttention层计算自注意力,并应用填充掩码。 - 通过第一个
LayerNormalization层执行残差连接,将原始输入x与注意力输出相加,并进行层归一化。 - 将归一化后的输出传递给前馈神经网络(FFN),并通过第二个
LayerNormalization层再次执行残差连接和层归一化。 - 最后,使用
GlobalAveragePooling1D层将序列嵌入转换为全局嵌入,这通常用于图数据或需要全局表示的任务。
2.4.3.构建MPNN模型
现在,我们将完善消息传递神经网络(MPNN)模型。除了消息传递和读出机制外,我们还将构建一个两层的分类网络,以实现对BBBP(可能是一个与生物学或化学相关的数据库或任务)的预测功能。
def MPNNModel( atom_dim, # 原子特征的维度 bond_dim, # 键特征的维度 batch_size=32, # 批处理大小 message_units=64, # 消息传递层的单元数 message_steps=4, # 消息传递的步数 num_attention_heads=8, # 注意力头的数量 dense_units=512, # 密集层的单元数
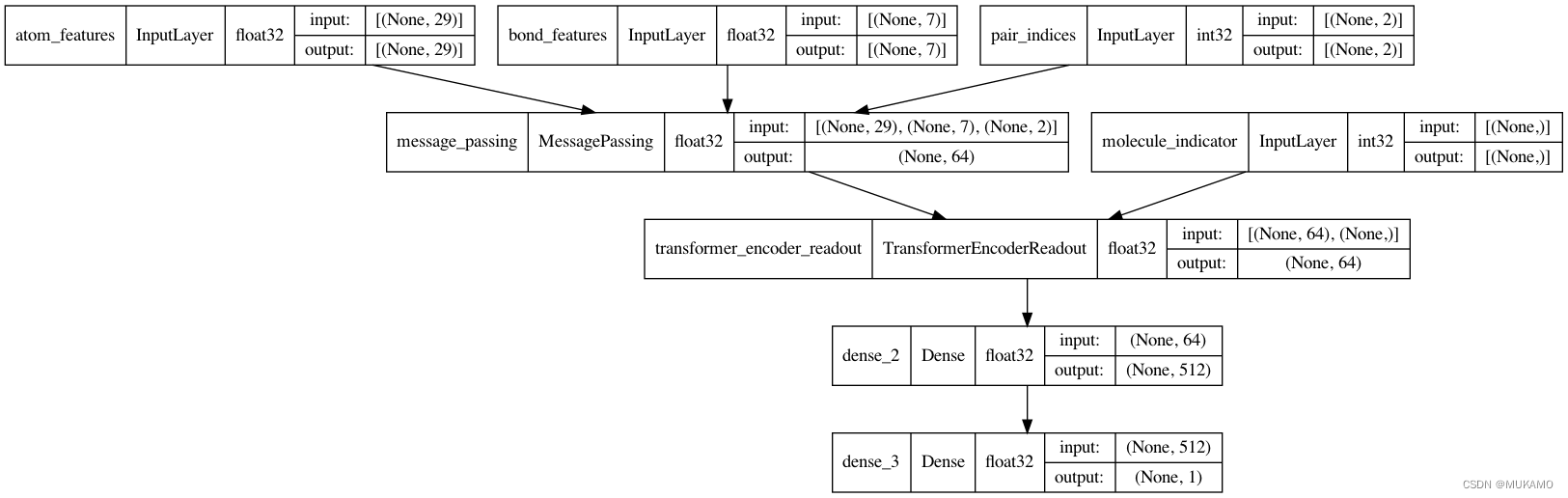
): """ 定义消息传递神经网络(MPNN)模型 Args: atom_dim (int): 原子特征的维度 bond_dim (int): 键特征的维度 batch_size (int, optional): 批处理大小. Defaults to 32. message_units (int, optional): 消息传递层的单元数. Defaults to 64. message_steps (int, optional): 消息传递的步数. Defaults to 4. num_attention_heads (int, optional): 注意力头的数量. Defaults to 8. dense_units (int, optional): 密集层的单元数. Defaults to 512. Returns: keras.Model: MPNN模型 """ # 输入层定义 atom_features = layers.Input((atom_dim,), dtype="float32", name="atom_features") bond_features = layers.Input((bond_dim,), dtype="float32", name="bond_features") pair_indices = layers.Input((2,), dtype="int32", name="pair_indices") molecule_indicator = layers.Input((), dtype="int32", name="molecule_indicator") # 消息传递层 x = MessagePassing(message_units, message_steps)([atom_features, bond_features, pair_indices]) # TransformerEncoderReadout层(这里假设这个层已经被定义) x = TransformerEncoderReadout( num_attention_heads, message_units, dense_units, batch_size )([x, molecule_indicator]) # 密集层 x = layers.Dense(dense_units, activation="relu")(x) # 输出层,用于二分类问题 x = layers.Dense(1, activation="sigmoid")(x) # 构造模型 model = keras.Model( inputs=[atom_features, bond_features, pair_indices, molecule_indicator], outputs=[x], ) return model # 实例化MPNN模型,这里假设x_train是包含原子特征和键特征的训练数据
mpnn = MPNNModel( atom_dim=x_train[0][0][0].shape[0], bond_dim=x_train[1][0][0].shape[0],
) # 编译模型
mpnn.compile( loss=keras.losses.BinaryCrossentropy(), optimizer=keras.optimizers.Adam(learning_rate=5e-4), metrics=[keras.metrics.AUC(name="AUC")],
) # 可视化模型结构
keras.utils.plot_model(mpnn, show_dtype=True, show_shapes=True)
上述代码定义了一个名为MPNNModel的函数,该函数用于构建一个基于消息传递神经网络(Message Passing Neural Network, MPNN)的模型,专门用于处理与分子或化合物相关的图结构数据。这里,模型被设计为接受原子特征、键特征、原子对索引以及分子指示符作为输入,并输出一个二分类预测(可能是用于预测某种生物或化学性质的分类问题,如药物渗透性)。
-
函数定义:
MPNNModel函数接受多个参数,包括原子特征的维度atom_dim、键特征的维度bond_dim、批处理大小batch_size、消息传递层的单元数message_units、消息传递的步数message_steps、注意力头的数量num_attention_heads和密集层的单元数dense_units。 -
输入层定义:定义了四个输入层,分别对应原子特征
atom_features、键特征bond_features、原子对索引pair_indices和分子指示符molecule_indicator。 -
消息传递层:使用一个名为
MessagePassing的层(假设这是一个已经定义好的自定义层或来自某个库的层)进行消息传递。它接受原子特征、键特征和原子对索引作为输入,并在多个步骤中传递消息。 -
TransformerEncoderReadout层:这部分使用了一个名为
TransformerEncoderReadout的层(同样假设这是一个已经定义好的层),该层可能用于对经过消息传递处理后的数据进行进一步的处理和整合,以便为每个分子生成一个全局的向量表示。这个层还接受分子指示符作为输入,可能用于处理批次中不同分子的数据。 -
密集层与输出层:接下来,模型通过两个密集层(
Dense层)进一步处理数据。第一个密集层使用 ReLU 激活函数,第二个密集层则使用 Sigmoid 激活函数,输出一个介于 0 和 1 之间的值,用于二分类预测。 -
模型构造与返回:使用
keras.Model构造一个完整的模型,并将所有定义的层组合在一起。模型的输入包括之前定义的四个输入层,输出则是最后一个密集层的输出。 -
模型实例化与编译:在函数外部,通过调用
MPNNModel函数并传入适当的参数(从训练数据x_train中提取的特征维度)来实例化一个模型实例mpnn。使用compile方法编译模型,指定损失函数为二元交叉熵(BinaryCrossentropy),优化器为 Adam(学习率设置为5e-4),并添加 AUC 作为评估指标。 -
模型可视化: 使用
keras.utils.plot_model函数绘制并显示模型的图形表示,以便更直观地理解模型的结构和数据流。
2.4.4.模型训练
# 假设MPNNDataset是一个自定义的数据集类,用于加载和预处理MPNN模型所需的数据
# 创建训练、验证和测试数据集
train_dataset = MPNNDataset(x_train, y_train) # 使用训练数据x_train和y_train创建训练数据集
valid_dataset = MPNNDataset(x_valid, y_valid) # 使用验证数据x_valid和y_valid创建验证数据集
test_dataset = MPNNDataset(x_test, y_test) # 使用测试数据x_test和y_test创建测试数据集 # 使用mpnn模型进行训练
# 传入训练数据集,验证数据集,设置训练轮次、日志输出级别以及类别权重
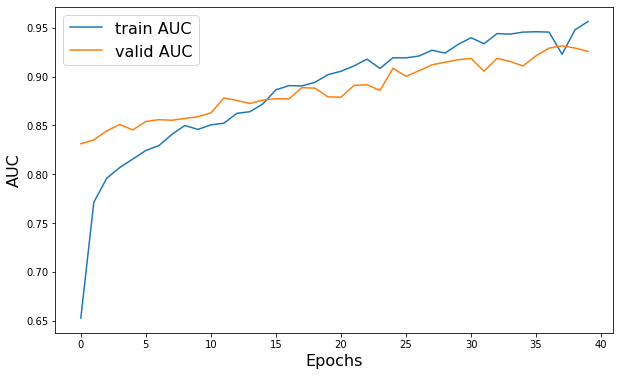
history = mpnn.fit( train_dataset, # 训练数据集 validation_data=valid_dataset, # 验证数据集 epochs=40, # 训练轮次 verbose=2, # 日志输出级别(0-不输出,1-进度条,2-每个epoch一行日志) class_weight={0: 2.0, 1: 0.5}, # 类别权重,用于处理类别不平衡问题
) # 绘制训练集和验证集的AUC曲线
import matplotlib.pyplot as plt plt.figure(figsize=(10, 6)) # 创建一个大小为10x6的绘图窗口
plt.plot(history.history["AUC"], label="Train AUC") # 绘制训练集的AUC曲线
plt.plot(history.history["val_AUC"], label="Validation AUC") # 绘制验证集的AUC曲线
plt.xlabel("Epochs", fontsize=16) # 设置x轴标签为"Epochs",字体大小为16
plt.ylabel("AUC", fontsize=16) # 设置y轴标签为"AUC",字体大小为16
plt.legend(fontsize=16) # 设置图例字体大小为16
plt.show() # 显示绘制的图形
上述代码段主要执行了以下几个关键操作:
-
创建数据集对象:使用
MPNNDataset类(假设这是一个自定义的数据集类)分别创建了训练、验证和测试数据集对象。x_train、y_train、x_valid、y_valid、x_test、y_test是已经准备好的数据,它们分别代表训练数据、训练标签、验证数据、验证标签、测试数据和测试标签。 -
模型训练:
- 使用之前定义的
mpnn模型(一个基于消息传递神经网络(MPNN)的模型)进行训练。 - 调用
fit方法,并传入训练数据集train_dataset作为训练数据。 - 使用
validation_data参数传入验证数据集valid_dataset,以便在每个epoch结束后评估模型在未见过的数据上的性能。 - 设置
epochs为40,表示模型将进行40轮完整的训练。 verbose=2表示在训练过程中将显示每个epoch的日志信息。- 使用
class_weight参数来指定类别权重,以处理类别不平衡问题。这里假设数据集中的类别标签为0和1,并且类别0的样本较少,因此给予类别0更高的权重(2.0),而类别1的权重较低(0.5)。
- 性能可视化:
- 使用
matplotlib库中的pyplot模块绘制训练集和验证集的AUC(Area Under the Curve)曲线。 plt.figure(figsize=(10, 6))创建一个新的图形窗口,并设置其大小为10x6英寸。plt.plot(history.history["AUC"], label="Train AUC")和plt.plot(history.history["val_AUC"], label="Validation AUC")分别绘制了训练集和验证集的AUC曲线。这里假设history对象包含了fit方法返回的每个epoch的训练和验证指标,其中"AUC"和"val_AUC"分别是训练和验证的AUC值。- 使用
plt.xlabel和plt.ylabel设置x轴和y轴的标签,并使用plt.legend添加图例。 - 最后,
plt.show()函数用于显示绘制的图形。
2.5. 预测分子特性
# df是一个pandas DataFrame,其中'smiles'列包含SMILES字符串,'p_np'列包含真实标签
# test_index是一个包含测试数据索引的列表
# molecule_from_smiles是一个函数,用于将SMILES字符串转换为分子对象
# mpnn是已经训练好的MPNN模型
# tf.squeeze是TensorFlow的一个函数,用于从张量中删除大小为1的维度
# MolsToGridImage是一个函数,用于将分子列表和相应的图例转换为网格图像 # 从DataFrame的'smiles'列中获取测试分子的SMILES字符串,并转换为分子对象
# 使用列表推导式遍历test_index中的每个索引
molecules = [molecule_from_smiles(df.smiles.values[index]) for index in test_index] # 从DataFrame的'p_np'列中获取测试数据的真实标签
y_true = [df.p_np.values[index] for index in test_index] # 使用训练好的MPNN模型对测试数据集进行预测
# 假设test_dataset是包含测试数据的MPNNDataset对象
# 预测结果是一个二维张量,使用tf.squeeze删除第二个维度(通常是batch_size为1的维度)
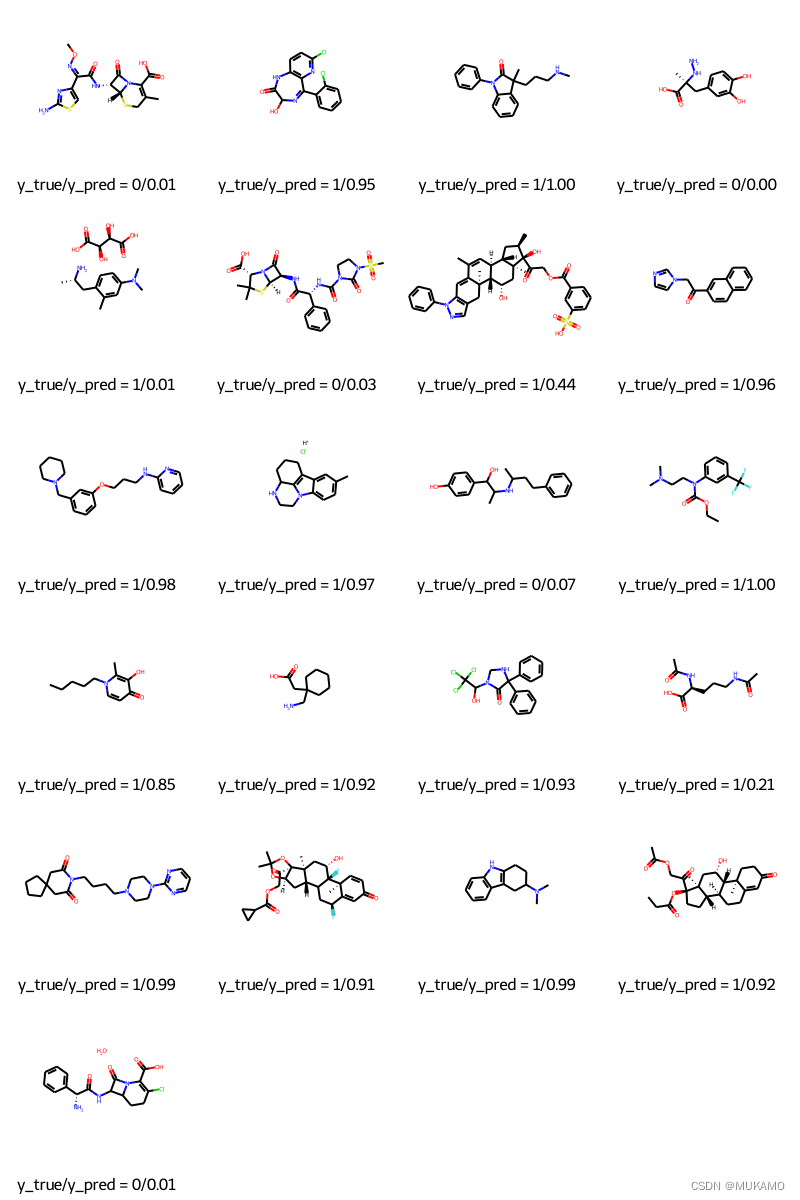
y_pred = tf.squeeze(mpnn.predict(test_dataset), axis=1) # 生成图例列表,其中每个图例都包含真实值和预测值
# 使用列表推导式遍历y_true和y_pred中的每个元素
legends = [f"y_true/y_pred = {y_true[i]}/{y_pred[i]:.2f}" for i in range(len(y_true))] # 使用MolsToGridImage函数将分子列表和对应的图例转换为网格图像
# molsPerRow指定每行显示的分子数
MolsToGridImage(molecules, molsPerRow=4, legends=legends) # 注意:这里假设了'molecule_from_smiles', 'mpnn.predict', 'tf.squeeze', 和 'MolsToGridImage'
# 都已经正确导入并且是可用的函数/方法/类。
以上代码进行分子特性预测并进行可视化展示:
1.创建分子对象列表:
- 使用列表推导式,遍历
test_index中的索引。 - 对于每个索引,从
df(一个假设的pandas DataFrame)的’smiles’列中取出对应的SMILES字符串。 - 调用
molecule_from_smiles函数(假设该函数能够将SMILES字符串转换为分子对象)来创建分子对象。 - 将所有分子对象存储在
molecules列表中。
- 获取真实标签:
- 同样使用列表推导式,遍历
test_index中的索引。 - 从
df的’p_np’列中取出对应的真实标签。 - 将所有真实标签存储在
y_true列表中。
3.模型预测:
- 调用
mpnn.predict方法(假设mpnn是一个已经训练好的MPNN模型)对test_dataset(测试数据集)进行预测。 predict方法通常返回一个二维张量,其中第一个维度是批量大小(在这个场景中可能是1,因为是对单个样本或批次进行测试),第二个维度是预测结果。- 使用
tf.squeeze函数(TensorFlow的函数)来删除大小为1的维度(通常是第一个维度,即批量大小维度),从而得到一个一维的张量。 - 将预测结果存储在
y_pred中。
3.生成图例:
- 使用列表推导式,遍历
y_true和y_pred中的每个元素(由于它们具有相同的长度)。 - 对于每一对真实值和预测值,生成一个字符串,其中包含了真实值和预测值(预测值保留两位小数)。
- 将所有生成的字符串存储在
legends列表中,这些字符串将用作可视化时的图例。
4.可视化分子与预测结果:
- 调用
MolsToGridImage函数(假设这是一个用于将分子对象转换为网格图像并添加图例的函数)。 - 传入
molecules列表作为要可视化的分子对象。 - 设置
molsPerRow=4,表示每行显示4个分子。 - 传入
legends列表作为每个分子对应的图例。 - 函数将生成一个网格图像,其中包含分子对象和相应的图例,用于展示每个分子的预测结果。
3. 总结和展望
在应用MPNN(消息传递神经网络)处理分子图数据的实验中,我们获得了以下显著的结果:
3.1. 模型性能:
- MPNN模型在分子分类和性质预测等任务上展现出了出色的性能。与传统的机器学习方法相比,MPNN模型能够捕获分子中原子之间的复杂相互作用和关系,从而更准确地预测分子的性质。
- 在多个基准数据集上的测试结果表明,MPNN模型能够实现较高的分类准确率和较低的预测误差。这些结果证明了MPNN在处理分子图数据方面的有效性和可靠性。
3.2. 特征表示:
- 通过MPNN模型中的消息传递和节点更新机制,分子中的原子节点能够学习到包含其周围环境的丰富特征表示。这些特征表示不仅包含了原子自身的信息,还融合了与其相邻原子之间的相互作用信息。
- 这种基于图的特征表示方式能够更全面地描述分子的结构和性质,有助于提高模型在分子分类和性质预测等任务上的性能。
3.3. 参数和架构的影响:
- 在实验过程中,我们尝试了不同的模型参数和架构配置。通过调整模型的层数、节点更新函数、消息函数等参数,我们发现这些配置对模型的性能有着显著的影响。
- 适当的参数和架构配置能够提升模型的表达能力和泛化能力,从而获得更好的实验结果。然而,过度的复杂性也可能导致模型过拟合和性能下降。
3.4. 可视化与解释性:
- 通过将MPNN模型预测的结果与分子结构进行可视化对比,我们能够更直观地理解模型如何捕获分子的特性。这有助于我们分析模型的预测结果并发现潜在的问题。
- 此外,MPNN模型中的节点特征和消息传递机制也具有一定的解释性。通过分析这些特征和机制,我们能够更好地理解模型如何学习和推理分子的性质。
3.5. 挑战与未来方向:
- 尽管MPNN在分子图处理方面取得了显著的进展,但仍存在一些挑战和限制。例如,对于大型复杂的分子图,MPNN模型的计算复杂度和资源消耗可能会显著增加。
- 未来的研究可以探索更高效的算法和模型架构来应对这些挑战。此外,将MPNN与其他先进技术(如注意力机制、图卷积网络等)相结合,可能会进一步提升模型的性能和泛化能力。
MPNN在处理分子图数据方面展现出了出色的性能和潜力。通过不断地优化模型参数和架构配置,以及探索新的技术和方法,我们可以期待MPNN在分子科学领域的应用前景将更加广阔。
参考文献
[1] Zonghan Wu, Shirui Pan, Fengwen Chen, Guodong Long, Chengqi Zhang, and Philip S Yu. A Comprehensive Survey on Graph Neural Networks[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020, 32(1): 4-24.
[2] Zhou, J., Cui, G., Zhang, Z., Yang, C., Liu, Z., & Wang, L. Graph Neural Networks: A Review of Methods and Applications[J]. AI Open, 1: 57-81, 2020.
[3] Gilmer, J., Schoenholz, S. S., Riley, P. F., Vinyals, O., & Dahl, G. E. (2017). Neural Message Passing for Quantum Chemistry. [https://arxiv.org/abs/1704.01212]
[4]DeepChem. (2018). MPNNModel [0407d93]
. [https://github.com/deepchem/deepchem/tree/master/contrib/mpnn]
相关文章:
【机器学习】消息传递神经网络(MPNN)在分子预测领域的医学应用
1. 引言 1.1. 分子性质预测概述 分子性质预测是计算机辅助药物发现流程中至关重要的任务之一,它在许多下游应用如药物筛选和药物设计中发挥着核心作用: 1.1.1. 目的与重要性: 分子性质预测旨在通过分子内部信息(如原子坐标、原…...
Python Flask实现蓝图Blueprint配置和模块渲染
Python基础学习: Pyhton 语法基础Python 变量Python控制流Python 函数与类Python Exception处理Python 文件操作Python 日期与时间Python Socket的使用Python 模块Python 魔法方法与属性 Flask基础学习: Python中如何选择Web开发框架?Pyth…...

Vue10-事件修饰符
一、示例:<a>标签不执行默认的跳转行为 1-1、方式一 <a href"http://www.baidu.com" onclick"event.preventDefault();">点击我</a> 1-2、方式二 1-3、方式三:事件修饰符 二、Vue的六种事件修饰符 2-1、prevent&…...

oracle中如何查询特定日期?
1. select last_day(to_date(20230101,YYYYMMDD)) from dual; select last_day(to_date(V_END_DATE,YYYYMMDD)) from dual; --查询任意一天 当月的最后一天 2. select to_char(to_date(20230101,YYYYMMDD)-1,YYYYMMDD) INTO V_START_DATE FROM DUAL; select to_char(to_dat…...

Python使用rosbag使用getattr只能获取一层的数据,不能直接获取多层数据例如 a.b.c.d。使用for range写一个递归用来获取多层数据
使用for循环和range来遍历属性列表确实是一个更简单直观的方式,特别是不需要考虑性能优化和异常处理时。以下是使用for循环代替递归的示例代码: python def get_nested_attr(obj, attr_str): attrs attr_str.split(.) for attr in attrs: # 尝试获取下…...

LNWT--篇章三小测
问题1: BERT训练时候的学习率learning rate如何设置? 在训练初期使用较小的学习率(从 0 开始),在一定步数(比如 1000 步)内逐渐提高到正常大小(比如上面的 2e-5),避免模型过早进入…...

【NoSQL】Redis练习
1、redis的编译安装 systemctl stop firewalld systemctl disable firewalld setenforce 0 yum install -y gcc gcc-c make wget cd /opt wget https://download.redis.io/releases/redis-5.0.7.tar.gz tar zxvf redis-5.0.7.tar.gz -C /opt/cd /opt/redis-5.0.7/ # 编译 make…...

Git 和 Github 的使用
补充内容:EasyHPC - Git入门教程【笔记】 文章目录 常用命令配置信息分支管理管理仓库 概念理解SSH 密钥HTTPS 和 SSH 的区别在本地生成 SSH key在 Github 上添加 SSH key 使用的例子同步本地仓库的修改到远程仓库拉取远程仓库的修改到本地仓库拉取远程仓库的分支并…...

学习分享-断路器Hystrix与Sentinel的区别
断路器(Circuit Breaker)简介 断路器(Circuit Breaker)是一种用于保护分布式系统的服务稳定性和容错性的设计模式。它的主要作用是在检测到某个服务的调用出现故障(如超时、异常等)时,快速失败…...
社区物资交易互助平台的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,基础数据管理,论坛管理,公告信息管理 前台账户功能包括:系统首页,个人中心,论坛,求助留言板,公…...

19-Nacos-服务实例的权重设置
19-Nacos-服务实例的权重设置 1.根据权重负载均衡: 1.服务器设备性能有差异,部分实例所在及其性能较高,有一些较差,我们希望性能好的机器承担更多的用户请求 Nacos提供了权重配置来控制访问频率,权重越大则访问频率…...

R语言数据探索和分析23-公共物品问卷分析
第一次实验使用最基本的公共物品游戏,不外加其他的treatment。班里的学生4人一组,一共44/411组。一共玩20个回合的公共物品游戏。每回合给15秒做决定的时间。第十回合后,给大家放一个几分钟的“爱心”视频(链接如下)&a…...

Webix前端界面框架:深度解析与应用实践
Webix前端界面框架:深度解析与应用实践 Webix,作为一款功能强大的前端界面框架,近年来在开发社区中逐渐崭露头角。本文将从四个方面、五个方面、六个方面和七个方面,深入剖析Webix的特性、优势、应用实践以及面临的挑战ÿ…...

Qt基于SQLite数据库的增删查改demo
一、效果展示 在Qt创建如图UI界面,主要包括“查询”、“添加”、“删除”、“更新”,四个功能模块。 查询:从数据库中查找所有数据的所有内容,并显示在左边的QListWidget控件上。 添加:在右边的QLineEdit标签上输入需…...

新书推荐:2.2.4 第11练:消息循环
/*------------------------------------------------------------------------ 011 编程达人win32 API每日一练 第11个例子GetMessage.c:消息循环 MSG结构 GetMessage函数 TranslateMessage函数:将虚拟键消息转换为字符消息 DispatchMessage函数…...

MASA:匹配一切、分割一切、跟踪一切
文章目录 摘要1、引言2、相关工作2.1、学习实例级关联2.2、Segment and Track Anything 模型 3、方法3.1、预备知识:SAM3.2、通过分割任何事物来匹配任何事物3.2.1、MASA流程3.2.2、MASA适配器3.2.3、推理 4、实验4.1、实验设置4.2、与最先进技术的比较4.3、消融研究…...

Websocket前端传参:深度解析与实战应用
Websocket前端传参:深度解析与实战应用 在现代Web开发中,Websocket作为一种双向通信协议,已经广泛应用于实时数据传输场景。前端传参作为Websocket通信的重要组成部分,其正确性和高效性直接影响到应用的性能和用户体验。本文将深…...

造假高手——faker
在测试写好的代码时通常需要用到一些测试数据,大量的真实数据有时候很难获取,如果手动制造测试数据又过于繁重无聊,显得不够优雅,今天我们介绍的faker这个轮子可以完美的解决这个问题。faker是一个用于生成各种类型假数据的库&…...
—— PostCSS(v8.4.38):CSS 转换工具)
前端工程化工具系列(十二)—— PostCSS(v8.4.38):CSS 转换工具
PostCSS 是转换 CSS 语法的工具。它提供 API 来对 CSS 文件进行分析和修改它的规则。 PostCSS 本身并不能直接使用,主要是使用基于 PostCSS 编写的插件。 1 安装 pnpm add -D postcss-import postcss-nested postcss-preset-env cssnano2 配置 在项目根目录下创…...

Scanpy(3)单细胞数据分析常规流程
单细胞数据分析常规流程 面对高效快速的要求上,使用R分析数据越来越困难,转战Python分析,我们通过scanpy官网去学习如何分析单细胞下游常规分析。 数据3k PBMC来自健康的志愿者,可从10x Genomics免费获得。在linux系统上,可以取消注释并运行以下操作来下载和解压缩数据。…...

Qwen3-0.6B-FP8应用场景:学生辅助学习、程序员代码解释、运营文案生成
Qwen3-0.6B-FP8:小模型大智慧,三大场景实战指南 你是不是也遇到过这些头疼事? 学生时代,面对复杂的数学题和物理概念,怎么都绕不过弯,想找个随时能问的“学霸”朋友?刚入行的程序员,…...

MoE模型训练总是不稳定?可能是你的“路由器”在捣鬼——深入解读R3对齐策略
MoE模型训练总是不稳定?可能是你的“路由器”在捣鬼——深入解读R3对齐策略 想象一下,你正在指挥一支由数百名专业顾问组成的超级团队处理复杂任务。每位顾问都是某个细分领域的顶尖专家,而你的工作是根据问题类型实时决定咨询哪几位专家。这…...

3步快速配置Ryujinx:免费Switch模拟器终极使用指南
3步快速配置Ryujinx:免费Switch模拟器终极使用指南 【免费下载链接】Ryujinx 用 C# 编写的实验性 Nintendo Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/ry/Ryujinx Ryujinx是一款采用C#语言开发的免费开源Nintendo Switch模拟器ÿ…...

Cogito-V1-Preview-Llama-3B长文本总结效果对比:技术论文与会议纪要
Cogito-V1-Preview-Llama-3B长文本总结效果对比:技术论文与会议纪要 面对动辄几十页的技术文档、冗长的会议记录,你是不是也常常感到头疼?信息量太大,关键点淹没在细节里,想要快速抓住核心,往往需要花费大…...

SAP BOM展开物料错乱?手把手教你用CS_BOM_EXPL_MAT_V2的altvo参数搞定可选BOM优先级
SAP BOM展开物料错乱?深度解析CS_BOM_EXPL_MAT_V2的altvo参数实战应用 当你在SAP系统中执行BOM展开操作时,是否遇到过系统"自作主张"选择了错误的BOM版本?比如明明设置了BOM1为优先,但系统却固执地选择了BOM2展开&#…...
协议深度解析)
AUTOSAR CAN网络管理(CanNm)协议深度解析
1. AUTOSAR CAN网络管理协议深度解析AUTOSAR(Automotive Open System Architecture)CAN网络管理(CanNm)模块是汽车电子分布式控制系统中实现低功耗通信协调的核心机制。它并非物理层驱动或链路层协议,而是一个独立于硬…...

MiniCPM-V-2_6惊艳OCR效果:复杂排版PDF截图文字识别准确率98.7%
MiniCPM-V-2_6惊艳OCR效果:复杂排版PDF截图文字识别准确率98.7% 1. 引言:重新定义OCR技术标准 你有没有遇到过这样的情况?从PDF文档里截取了一张复杂的表格或排版精美的页面,想要提取其中的文字内容,却发现传统的OCR…...

RexUniNLU中文NLP系统快速上手:Gradio界面快捷键与批量上传功能详解
RexUniNLU中文NLP系统快速上手:Gradio界面快捷键与批量上传功能详解 1. 系统概述与核心价值 RexUniNLU中文NLP综合分析系统是一个基于先进人工智能技术的自然语言处理工具,它能够帮助用户快速分析和理解中文文本的深层含义。这个系统最厉害的地方在于&…...

Mastering SoftMotion Error Handling in CoDeSys 2.3: A Practical Guide to SM_Error.lib
1. SM_Error.lib库的核心作用 在CoDeSys 2.3的SoftMotion系统中,SM_Error.lib就像是一个全天候待命的故障诊断专家。这个库必须被包含在每个项目中,因为它承担着将冰冷的错误代码转化为可读文本的关键任务。想象一下,当你的运动控制系统突然报…...

ButtonSet:单ADC通道多按键模拟识别库
1. 项目概述ButtonSet 是一个面向嵌入式资源受限环境设计的轻量级多按键模拟输入管理库,其核心工程目标是:在仅占用单个 ADC 通道的前提下,实现对多个物理按键(通常为 4~8 个)的可靠识别与去抖动处理。该方…...