30分钟吃掉 Pytorch 转 onnx
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学.
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
汇总合集:
《大模型面试宝典》(2024版) 发布!
圈粉无数!《PyTorch 实战宝典》火了!!!
PyTorch 是一个用于机器学习的开源深度学习框架,而ONNX(Open Neural Network Exchange)是一个用于表示深度学习模型的开放式格式。
将 PyTorch 模型转换为ONNX格式有几个原因和优势:
-
跨平台部署: ONNX是一个跨平台的格式,支持多种深度学习框架,包括PyTorch、TensorFlow等。将模型转换为ONNX格式可以使模型在不同框架和设备上进行部署和运行。
-
性能优化: ONNX格式可以在不同框架之间实现性能优化。例如,可以在PyTorch中训练模型,然后转换为ONNX格式,并在性能更高的框架(如TensorRT)中进行推理。
-
模型压缩: ONNX格式可以实现模型的压缩和优化,从而减小模型的体积并提高推理速度。这对于在资源受限的设备上部署模型尤为重要。
pytorch 模型线上部署最常见的方式是转换成onnx,然后再转成tensorRT 在cuda上进行部署推理。
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了Pytorch 技术与面试交流群, 想要获取最新面试题、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
方式①、微信搜索公众号:机器学习社区,后台回复:加群
方式②、添加微信号:mlc2040,备注:技术交流
本文介绍将pytorch模型转换成onnx模型并进行推理的方法。
#!pip install onnx
#!pip install onnxruntime
#!pip install torchvision
一,准备pytorch模型
我们先导入torchvision中的resnet18模型,演示它的推理效果。
以便和onnx的结果进行对比。
import torch
import torchvision.models as models
import numpy as np
import torchvision
import torchvision.transforms as Tfrom PIL import Imagedef create_net():net = models.resnet18(weights=torchvision.models.ResNet18_Weights.IMAGENET1K_V1)return net net = create_net()torch.save(net.state_dict(),'resnet18.pt')
net.eval();
def get_test_transform():return T.Compose([T.Resize([320, 320]),T.ToTensor(),T.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),])image = Image.open("dog.png") # 289
img = get_test_transform()(image)
img = img.unsqueeze_(0)
output = net(img)
score, indice = torch.max(torch.softmax(output,axis=-1),1)
info = {'score':score.tolist()[0],'indice':indice.tolist()[0]}def show_image(image, title):import matplotlib.pyplot as plt ax=plt.subplot()ax.imshow(image)ax.set_title(title)ax.set_xticks([])ax.set_yticks([]) plt.show()show_image(image, title = info)

二,pytorch模型转换成onnx模型
1, 简化版本
import onnxruntime
import onnxbatch_size = 1
input_shape = (3, 320, 320) x = torch.randn(batch_size, *input_shape)
onnx_file = "resnet18.onnx"
torch.onnx.export(net,x,onnx_file,opset_version=10,do_constant_folding=True, # 是否执行常量折叠优化input_names=["input"],output_names=["output"],dynamic_axes={"input":{0:"batch_size"}, "output":{0:"batch_size"}})!du -s -h resnet18.pt
45M resnet18.pt
!du -s -h resnet18.onnx 45M resnet18.onnx
可以在 https://netron.app/ 中拖入 resnet18.onnx 文件查看模型结构
2,全面版本
下面的代码包括了设置输入输出尺寸,以及动态可以变batch等等。
import argparse
from argparse import Namespace
import time
import sys
import os
import torch
import torch.nn as nn
import torchvision.models as models
import onnx
import onnxruntimefrom io import BytesIOROOT = os.getcwd()
if str(ROOT) not in sys.path:sys.path.append(str(ROOT))params = Namespace(weights='resnet18.pt',img_size=[320,320],batch_size=1,half=False,dynamic_batch=True)parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='checkpoint.pt', help='weights path')
parser.add_argument('--img-size', nargs='+', type=int, default=[320, 320], help='image size') # height, width
parser.add_argument('--batch-size', type=int, default=1, help='batch size')
parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
parser.add_argument('--inplace', action='store_true', help='set Detect() inplace=True')
parser.add_argument('--simplify', action='store_true', help='simplify onnx model')
parser.add_argument('--dynamic-batch', action='store_true', help='export dynamic batch onnx model')
parser.add_argument('--trt-version', type=int, default=8, help='tensorrt version')
parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')args = parser.parse_args(args='',namespace=params)args.img_size *= 2 if len(args.img_size) == 1 else 1 # expand
print(args)t = time.time()# Check device
cuda = args.device != 'cpu' and torch.cuda.is_available()
device = torch.device(f'cuda:{args.device}' if cuda else 'cpu')
assert not (device.type == 'cpu' and args.half), '--half only compatible with GPU export, i.e. use --device 0'# Load PyTorch model
model = create_net()
model.to(device)
model.load_state_dict(torch.load(args.weights)) # pytorch模型加载# Input
img = torch.zeros(args.batch_size, 3, *args.img_size).to(device) # image size(1,3,320,192) iDetection# Update model
if args.half:img, model = img.half(), model.half() # to FP16
model.eval()prediction = model(img) # dry run# ONNX export
print('\nStarting to export ONNX...')
export_file = args.weights.replace('.pt', '.onnx') # filename
with BytesIO() as f:dynamic_axes = {"input":{0:"batch_size"}, "output":{0:"batch_size"} } if args.dynamic_batch else Nonetorch.onnx.export(model, img, f, verbose=False, opset_version=13,training=torch.onnx.TrainingMode.EVAL,do_constant_folding=True,input_names=['input'],output_names=['output'],dynamic_axes=dynamic_axes)f.seek(0)# Checksonnx_model = onnx.load(f) # load onnx modelonnx.checker.check_model(onnx_model) # check onnx modelif args.simplify:try:import onnxsimprint('\nStarting to simplify ONNX...')onnx_model, check = onnxsim.simplify(onnx_model)assert check, 'assert check failed'except Exception as e:print(f'Simplifier failure: {e}')onnx.save(onnx_model, export_file)print(f'ONNX export success, saved as {export_file}')# Finish
print('\nExport complete (%.2fs)' % (time.time() - t))
Namespace(weights='resnet18.pt', img_size=[320, 320], batch_size=1, half=False, dynamic_batch=True, inplace=False, simplify=False, trt_version=8, device='cpu')Starting to export ONNX...
ONNX export success, saved as resnet18.onnxExport complete (0.57s)
三,使用onnx模型进行推理
1,函数风格
onnx_sesstion = onnxruntime.InferenceSession(export_file)
def pipe(img_path,onnx_sesstion = onnx_sesstion):image = Image.open(img_path) img = get_test_transform()(image)img = img.unsqueeze_(0) to_numpy = lambda tensor: tensor.data.cpu().numpy()inputs = {onnx_sesstion.get_inputs()[0].name: to_numpy(img)}outs = onnx_sesstion.run(None, inputs)[0]score, indice = torch.max(torch.softmax(torch.as_tensor(outs),axis=-1),1)info = {'score':score.tolist()[0],'indice':indice.tolist()[0]}return info
img_path = 'dog.png'image = Image.open(img_path)info = pipe(img_path)show_image(image,info)

2,对象风格
import os, sysimport onnxruntime
import onnxclass ONNXModel():def __init__(self, onnx_path):self.onnx_session = onnxruntime.InferenceSession(onnx_path)self.input_names = [node.name for node in self.onnx_session.get_inputs()]self.output_names = [node.name for node in self.onnx_session.get_outputs()]print("input_name:{}".format(self.input_names))print("output_name:{}".format(self.output_names))def forward(self, x):if isinstance(x,np.ndarray):assert len(self.input_names)==1input_feed = {self.input_names[0]:x}elif isinstance(x,(tuple,list)):assert len(self.input_names)==len(x)input_feed = {k:v for k,v in zip(self.input_names,x)}else:assert isinstance(x,dict)input_feed = xouts = self.onnx_session.run(self.output_names, input_feed=input_feed)return outsdef predict(self,img_path):image = Image.open(img_path) img = get_test_transform()(image)img = img.unsqueeze_(0) to_numpy = lambda tensor: tensor.data.cpu().numpy()outs = self.forward(to_numpy(img))[0]score, indice = torch.max(torch.softmax(torch.as_tensor(outs),axis=-1),1)return {'score':score[0].data.numpy().tolist(),'indice':indice[0].data.numpy().tolist()}
onnx_model = ONNXModel(export_file)
info = onnx_model.predict(img_path)
show_image(image, title = info)
input_name:['input']
output_name:['output']

相关文章:
30分钟吃掉 Pytorch 转 onnx
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学. 针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 汇总合集&…...
KEIL5如何打开KEIL4的GD工程
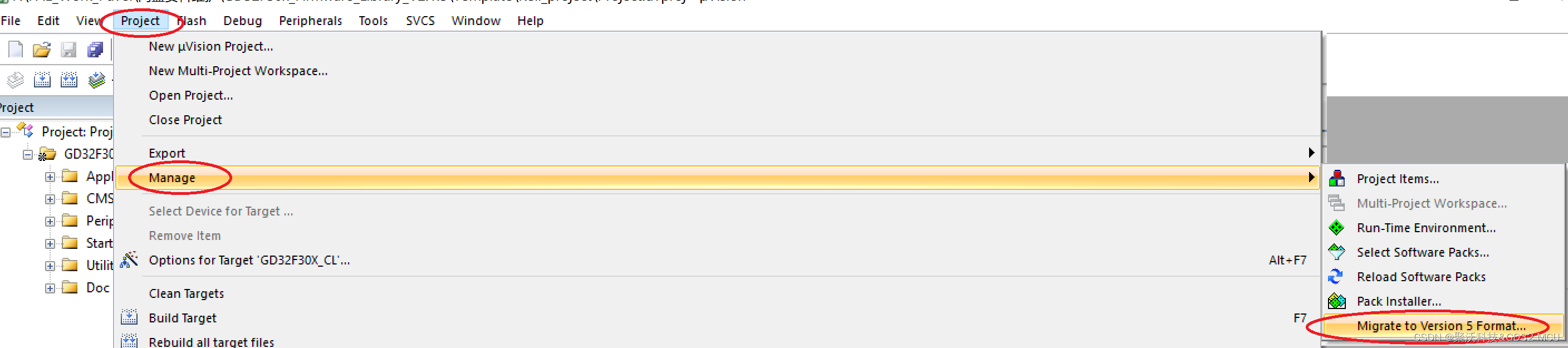
GD官方提供的很多KEIL例程为KIEL4的版本,读者使用的时候可能会碰到使用KEIL5打开KEIL4的工程会报错以及无法找到芯片选型的问题,具体表现如下图所示。 我们该怎么办呢? 下面为大家介绍两种方法: 第一种方法是在keil4的工程后缀u…...

大前端技术分类
1 基础 2 语言 3 类库 4 框架 5 跨栈 6 架构 7 领域 7.1 中后台 7.2 跨平台 7.3 可视化 7.4 智能化 7.5 工程化 7.5.1 规范化 7.5.2 流程化 —— 前端工程化工具系列 7.5.3 模板化 7.5.4 自动化 7.5.5 平台化 7.6 其他 7.6.1 音视频 7.6.2 Web3 7.6.3 区块…...
Android AAudio——C API控制音频流(四)
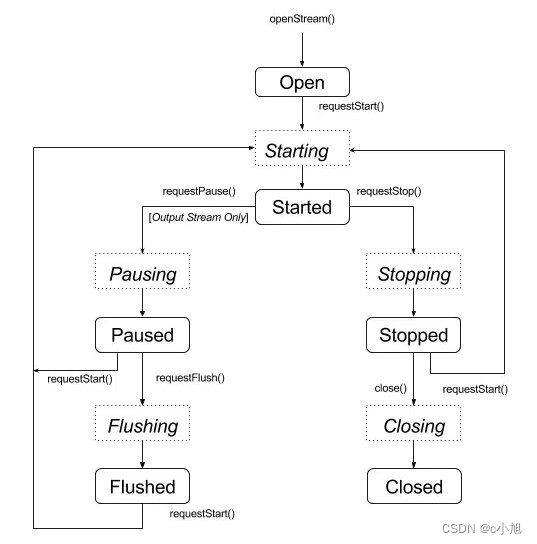
上一篇文章我们介绍了 C API 中音频流的创建流程,以及打开音频流操作,这里我们再来看一下音频流的其他操作流程 一、音频流操作介绍 1、操作流程图 下图是状态变化流程图,虚线框表示瞬时状态,实线框表示稳定状态。 2、操作函数 上图中主要包含下面几个操作函数: aaudio…...
万能嗅探:视频号下载神器
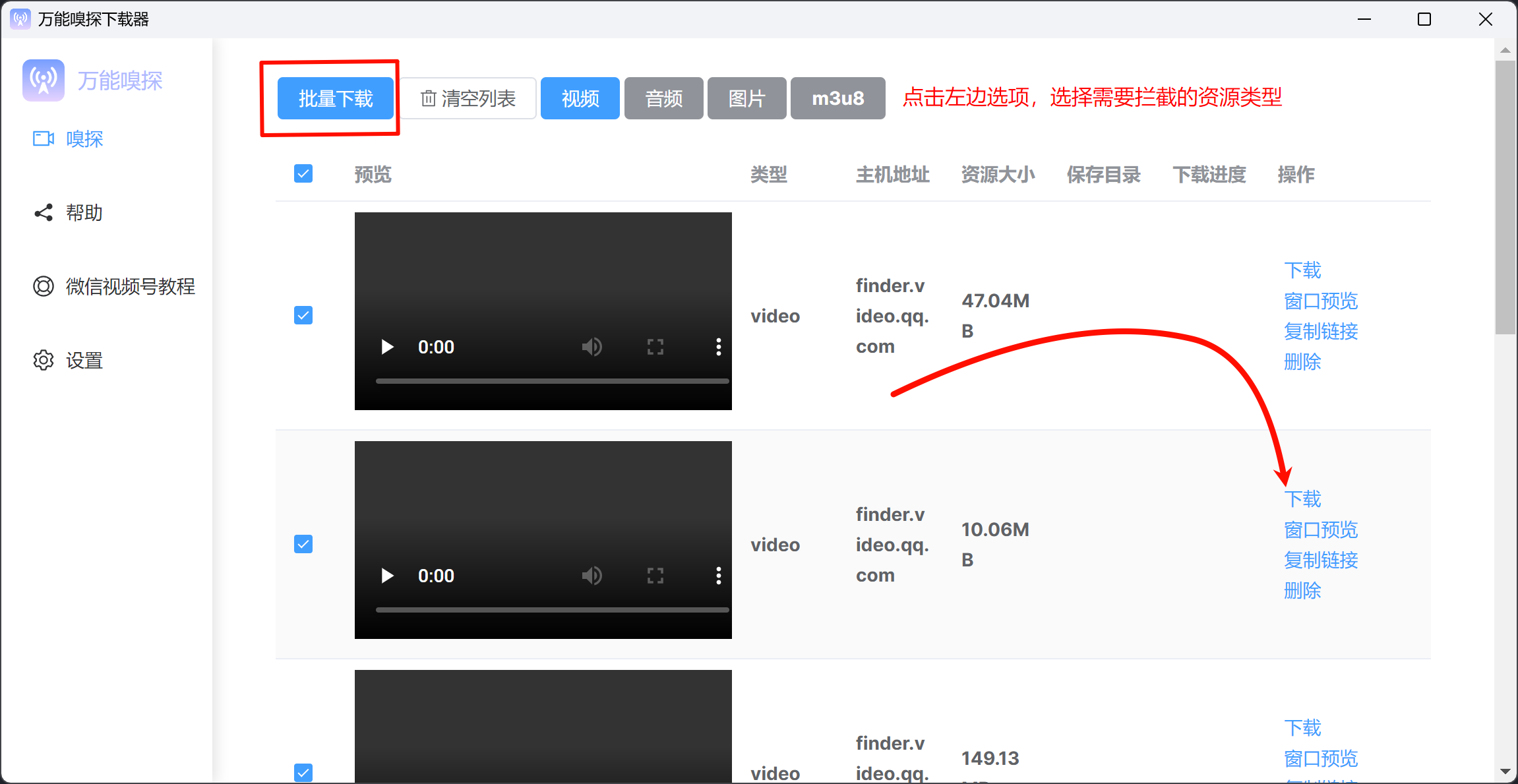
万能嗅探是一款比较好用资源嗅探软件,界面干净,可以抓取浏览器的网页,不过想必各位主要用来抓取视频号,下面是使用方法。 使用方法 打开万能嗅探客户端,然后打开浏览器,产生网络请求即可,看看…...
python数据分析-ZET财务数据分析
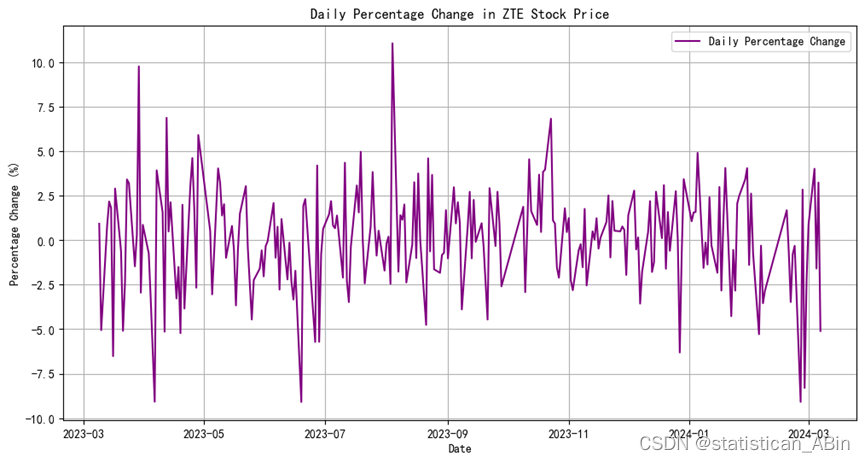
一、公司背景 中兴通讯股份有限公司是一家总部位于中国深圳的跨国公司,致力于为全球客户提供通信设备和解决方案。公司成立于1985年,自成立以来一直致力于为客户提供创新的通信技术和服务。中兴通讯的业务涵盖多个领域,包括但不限于高端路由…...

Leetcode学习
回文数 反转一半数字 第一个想法是将数字转换为字符串,并检查字符串是否为回文。 但是,这需要额外的非常量空间来创建问题描述中所不允许的字符串。 第二个想法是将数字本身反转,然后将反转的数字与原始数字比较,如果它们是相同…...

python 列出面板数据所有变量名
在Python中,处理面板数据(Panel Data)通常使用pandas库,特别是当数据以DataFrame或Panel(尽管Panel在较新版本的pandas中已被弃用)的形式存在时。然而,由于Panel的弃用,现代做法通常…...
知乎网站只让知乎用户看文章,普通人看不了
知乎默认不显示全部文章,需要点击展开阅读全文 然而点击后却要登录,这意味着普通人看不了博主写的文章,只有成为知乎用户才有权力查看文章。我想这不是知乎创作者希望的情况,他们写文章肯定是希望所有人都能看到。 这个网站篡改…...

web前端的实习记录:探索、挑战与成长
web前端的实习记录:探索、挑战与成长 踏入web前端实习的旅程,我怀揣着对未知的好奇与对技术的渴望,开始了一段全新的学习与实践。在这个过程中,我经历了四个方面的技术探索,五个方面的挑战应对,六个方面的…...

正则表达式的详解带你认识正则表达式的意义
前言 我们都知道协议通常通过添加固定的字符、报头、特定的数字等来定义数据的结构和格式。将正确的信息提取出来是十分重要的,而正则表达式可以用来描述和匹配这些固定的结构,从而提取出所需的信息。并且正则表达式还可以处理大量复杂的字符串。这篇…...
中国现在最厉害的书法家颜廷利:东方伟大思想家哲学家教育家
中国书法界名人颜廷利教授,一位在21世纪东方哲学、科学界及当代中国教育领域内具有深远影响力的泰斗级人物,不仅以其深厚的国学修为和对易经姓名学的独到见解著称,还因其选择在济南市历城区的龙泉大街以及天桥区的凤凰山庄与泉星小区等地设立…...

OS常用操作
目录 1 文件和目录操作 1. 1 创建目录 1.2 删除目录 1.3 列出目录内容 1.4 删除文件 1.5 打开和关闭文件描述符 1.6 修改文件权限 1.7 获取和设置文件属性 2 路径操作 2.1 获取当前工作目录 2.2 改变工作目录 2.3 路径操作 2.4 添加 Python 的模块搜索路径列表 3 …...

【IC验证】03 UVM
...
)
Jira的原理及应用详解(六)
本系列文章简介: 在当今快速发展的软件开发和项目管理领域,有效的团队协作和精确的项目进度追踪是确保项目成功的关键。Jira作为一款广受欢迎的项目和问题追踪工具,以其强大的功能、灵活的定制性以及卓越的用户体验,赢得了全球众多…...

Linux进程间通信之System V
目录 认识system V: system V共享内存: 共享内存的基本原理: 共享内存的数据结构: 共享内存的建立与释放: 共享内存的建立: 共享内存的释放: 共享内存的关联: 共享内存的去关联…...
力扣hot100:394. 字符串解码(递归/括号匹配,字符串之间相对顺序)
LeetCode:394. 字符串解码 本题容易想到用递归处理,在写递归时主要是需要明确自己的递归函数的定义。 不过我们也可以利用括号匹配的方式使用栈进行处理。 1、递归 定义递归函数string GetString(string & s,int & i); 表示处理处理整个numbe…...

【C++11】多线程常用知识
知识体系 thread C++ thread中最常用的两个函数是join和detach,怎么选择呢,简单来说,如果希望等待线程结束,用join,如果希望异步执行,且不等待执行结果,那么就用detach;thread_local可以简单理解为一个线程级别的全局变量;线程id在调试多线程程序时是非常有用的东西;…...
详解linux设备下的/dev/null
/dev/zero是一个特殊的设备文件,它在Linux系统中通常被用来生成无限数量的零数据流。 这个设备文件位于/dev目录下,它不代表任何实际的硬件设备,而是一个虚拟设备。 当从/dev/zero设备中读取数据时,会得到无限数量的零字节&…...

GPT-4 Turbo 和 GPT-4 的区别
引言 人工智能(AI)领域的发展日新月异,OpenAI 的 GPT 系列模型一直是这一领域的佼佼者。GPT-4 和 GPT-4 Turbo 是目前市场上最先进的语言模型之一。本文将详细探讨 GPT-4 和 GPT-4 Turbo 之间的区别,以帮助用户更好地理解和选择适…...

挑战杯推荐项目
“人工智能”创意赛 - 智能艺术创作助手:借助大模型技术,开发能根据用户输入的主题、风格等要求,生成绘画、音乐、文学作品等多种形式艺术创作灵感或初稿的应用,帮助艺术家和创意爱好者激发创意、提高创作效率。 - 个性化梦境…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
【解密LSTM、GRU如何解决传统RNN梯度消失问题】
解密LSTM与GRU:如何让RNN变得更聪明? 在深度学习的世界里,循环神经网络(RNN)以其卓越的序列数据处理能力广泛应用于自然语言处理、时间序列预测等领域。然而,传统RNN存在的一个严重问题——梯度消失&#…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...