特征筛选LASSO回归封装好的代码、数据集和结果
Gitee仓库地址:特征筛选LASSO回归封装好的代码、数据集和结果
README
LassoFeatureSelector_main
这个是主函数文件,在实例化LassoFeatureSelector类时,需要传入下面这些参数:
- input_train_data_path:输入训练集的路径
- input_test_data_path:输入测试集的路径
- output_train_path:输出训练集的路径
- output_test_path:输出测试集的路径
- Upper_limit_alpha:正则化搜索范围上限
- Lower_limit_alpha:正则化搜索范围下限
- iterations:LASSO回归迭代次数
- cv:选择最佳正则化系数的交叉验证次数
实例化后调用总运行函数即可:lasso_selector.run_all()
LassoFeatureSelector
这个是封装好的类,主要实现以下几个功能:
- 计算特征筛选前后的方差膨胀因子,输出并导出
- 绘制岭迹图并导出
- 以MSE为损失函数进行LASSO回归
- k折交叉验证进行最佳正则化系数的搜索
- 导出特征筛选后的训练集和测试集
- 无论输入的文件格式是xlsx文件还是csv文件,类都能读取
数据集
数据集来自网络入侵检测领域的经典数据集:NSLKDD
预处理好的数据集和导出的训练集测试集可以在百度网盘下载:
链接:https://pan.baidu.com/s/125SniuPOWFkrB4fONtIPQw?pwd=fgin 提取码:fgin
原始数据集见官网下载:
ISCX NSL-KDD dataset 2009
导出的文件
- LASSO系数矩阵.xlsx
- LASSO回归岭迹图.png
- 原始训练集的方差膨胀因子.xlsx
- LASSO回归后训练集的方差膨胀因子.xlsx
- NSLKDD_train_LASSO.xlsx
- NSLKDD_test_LASSO.xlsx
LASSO回归参数说明
若需要调整LASSO回归的参数,需要到LassoFeatureSelector文件的lasso_regression函数中进行修改
lassoreg = Lasso(alpha=alpha, max_iter=self.iterations, fit_intercept=True,precompute=False, copy_X=False,tol=0.0001, warm_start=False,positive=False,selection='cyclic')
alpha=alpha: 正则化强度,控制稀疏性
fit_intercept=True: 拟合截距
precompute=False: 是否预计算 Gram 矩阵,通常设置为 False
copy_X=True: 对输入数据进行复制
max_iter=self.iterations: 最大迭代次数,控制算法运行的最大迭代次数
tol=0.0001: 收敛的容忍度,指定算法收敛的阈值
warm_start=False: 如果为 True,则使用前一个调用的解决方案以适应的权重
positive=False: 如果为 True,则要求系数为正
selection='cyclic': 指定系数更新的策略。'cyclic' 表示按循环顺序逐个更新系数
封装好的类
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from matplotlib import rcParams
from sklearn.exceptions import ConvergenceWarning
from sklearn.linear_model import Lasso, LassoCV
from sklearn.metrics import mean_squared_error
from statsmodels.stats.outliers_influence import variance_inflation_factor
import warnings
import ospd.set_option('display.max_columns', None)
pd.set_option('display.max_rows', None)# 设置matplotlib绘图的中文字体
rcParams['font.sans-serif'] = ['Microsoft YaHei']
rcParams['axes.unicode_minus'] = False# 忽略特定类型的警告
warnings.filterwarnings("ignore", category=ConvergenceWarning)class LassoFeatureSelector:def __init__(self, input_train_data_path, input_test_data_path, output_train_path, output_test_path, upper_limit_alpha, lower_limit_alpha, iterations, cv): # 初始化函数self.input_train_data_path = input_train_data_pathself.input_test_data_path = input_test_data_pathself.output_train_path = output_train_pathself.output_test_path = output_test_pathself.upper_limit_alpha = upper_limit_alphaself.lower_limit_alpha = lower_limit_alphaself.iterations = iterationsself.cv = cvdef load_data(self): # 读取文件函数if os.path.splitext(self.input_train_data_path)[1] == '.xlsx':self.input_train_data = pd.read_excel(self.input_train_data_path)elif os.path.splitext(self.input_train_data_path)[1] == '.csv':self.input_train_data = pd.read_csv(self.input_train_data_path)if os.path.splitext(self.input_test_data_path)[1] == '.xlsx':self.input_test_data = pd.read_excel(self.input_test_data_path)elif os.path.splitext(self.input_test_data_path)[1] == '.csv':self.input_test_data = pd.read_csv(self.input_test_data_path)def lasso_regression(self, train, test, alpha): # LASSO回归函数lassoreg = Lasso(alpha=alpha, max_iter=self.iterations, fit_intercept=True,precompute=False,copy_X=False,tol=0.0001, warm_start=False,positive=False,selection='cyclic')lassoreg.fit(train.iloc[:, 0:-1], train.iloc[:, -1])feature_count = np.sum(lassoreg.coef_ != 0)y_pred = lassoreg.predict(test.iloc[:, 0:-1])mse = mean_squared_error(test.iloc[:, -1], y_pred)ret = [alpha, mse]ret.append(feature_count)ret.extend(lassoreg.coef_)return retdef matrix_lasso(self): # LASSO系数矩阵函数self.alpha_lasso = np.linspace(self.lower_limit_alpha, self.upper_limit_alpha, self.iterations)col = ["alpha", "mse", "feature_count"] + list(self.input_train_data.iloc[:, 0:-1])ind = ["alpha_%.4g" % self.alpha_lasso[i] for i in range(0, len(self.alpha_lasso))]self.coef_matrix_lasso = pd.DataFrame(index=ind, columns=col)input_train_1, input_train_2 = train_test_split(self.input_train_data, test_size=0.2, random_state=42) # 在输入的训练集里面分割进行LASSO回归for i in range(len(self.alpha_lasso)):self.coef_matrix_lasso.iloc[i] = self.lasso_regression(input_train_1, input_train_2, self.alpha_lasso[i])self.coef_matrix_lasso.to_excel(r'LASSO系数矩阵.xlsx', index=True)def plot_lasso_path(self): # 绘制岭迹图函数plt.figure(figsize=(14, 6.8))for i in np.arange(len(list(self.input_train_data.iloc[:, 0:-1]))):plt.plot(self.coef_matrix_lasso["alpha"],self.coef_matrix_lasso[list(self.input_train_data.iloc[:, 0:-1])[i]],color=plt.cm.Set1(i / len(list(self.input_train_data.iloc[:, 0:-1]))),label=list(self.input_train_data.iloc[:, 0:-1])[i])plt.legend(loc="upper right", ncol=2, prop={'size': 7})plt.xlabel("正则化系数", fontsize=14)plt.ylabel("回归系数", fontsize=14)plt.savefig(r'LASSO回归岭迹图', dpi=600)plt.show()def select_best_alpha(self): # 选择最佳正则化系数函数alpha_choose = np.linspace(self.lower_limit_alpha, self.upper_limit_alpha, self.iterations)lasso_cv = LassoCV(alphas=alpha_choose, cv=self.cv, max_iter=self.iterations)lasso_cv.fit(self.input_train_data.iloc[:, 0:-1], self.input_train_data.iloc[:, -1])self.lasso_best_alpha = lasso_cv.alpha_print(f"选择的最佳正则化系数: {self.lasso_best_alpha}")def calculate_vif(self, data): # 计算方差膨胀因子函数vif = pd.DataFrame()vif['特征'] = data.columnsvif['方差膨胀因子'] = [variance_inflation_factor(data.values, i) for i in range(data.shape[1])]return vifdef fit_lasso_model(self): # 筛选特征函数self.lasso_model = Lasso(alpha=self.lasso_best_alpha, fit_intercept=True,max_iter=self.iterations, random_state=42, selection='cyclic')self.lasso_model.fit(self.input_train_data.iloc[:, 0:-1], self.input_train_data.iloc[:, -1])self.selected_features = self.input_train_data.iloc[:, 0:-1].columns[self.lasso_model.coef_ != 0]def save_vif(self): # 输出并保存方差膨胀因子函数vif_before = self.calculate_vif(self.input_train_data.iloc[:, 0:-1])print("原始数据的方差膨胀因子:\n", vif_before)input_data_selected = self.input_train_data.iloc[:, 0:-1][self.selected_features]vif_after = self.calculate_vif(input_data_selected)print("筛选特征后的方差膨胀因子:\n", vif_after)vif_before.to_excel(r'原始训练集的方差膨胀因子.xlsx', index=False)vif_after.to_excel(r'LASSO回归后训练集的方差膨胀因子.xlsx', index=False)def save_selected_data(self): # 导出LASSO筛选特征后的训练集和测试集selected_data_train = self.input_train_data[list(self.selected_features) + [self.input_train_data.columns[-1]]]selected_data_test = self.input_test_data[list(self.selected_features) + [self.input_test_data.columns[-1]]]if os.path.splitext(self.output_train_path)[1] == '.xlsx':selected_data_train.to_excel(self.output_train_path, index=False)elif os.path.splitext(self.output_train_path)[1] == '.csv':selected_data_train.to_csv(self.output_train_path, index=False)if os.path.splitext(self.output_test_path)[1] == '.xlsx':selected_data_test.to_excel(self.output_test_path, index=False)elif os.path.splitext(self.output_test_path)[1] == '.csv':selected_data_test.to_csv(self.output_test_path, index=False)def calculate_avg_vif(self): # 计算平均方差膨胀因子函数vif_before = self.calculate_vif(self.input_train_data.iloc[:, 0:-1])avg_vif_before = vif_before['方差膨胀因子'].mean()input_data_selected = self.input_train_data.iloc[:, 0:-1][self.selected_features]vif_after = self.calculate_vif(input_data_selected)avg_vif_after = vif_after['方差膨胀因子'].mean()print(f"特征筛选前的平均方差膨胀因子: {avg_vif_before}")print(f"特征筛选后的平均方差膨胀因子: {avg_vif_after}")def run_all(self):self.load_data()self.matrix_lasso()self.plot_lasso_path()self.select_best_alpha()self.fit_lasso_model()self.save_vif()self.save_selected_data()self.calculate_avg_vif()
调用的子函数
from LassoFeatureSelector import *'''初始化'''
input_train_data_path = r'D:\Gitee\NSLKDD_train.xlsx' # 输入训练集的路径
input_test_data_path = r'D:\Gitee\NSLKDD_test.xlsx' # 输入测试集的路径
output_train_path = r'D:\Gitee\NSLKDD_train_LASSO.xlsx' # 输出训练集的路径
output_test_path = r'D:\Gitee\NSLKDD_test_LASSO.xlsx' # 输出测试集的路径
Upper_limit_alpha = 0.001 # 正则化搜索范围上限
Lower_limit_alpha = 0.0012 # 正则化搜索范围下限
iterations = 2000 # LASSO回归迭代次数
cv = 10 # 选择最佳正则化系数的交叉验证次数'''调用函数'''
lasso_selector = LassoFeatureSelector(input_train_data_path, input_test_data_path, output_train_path, output_test_path, Upper_limit_alpha, Lower_limit_alpha, iterations, cv)
lasso_selector.run_all()相关文章:

特征筛选LASSO回归封装好的代码、数据集和结果
Gitee仓库地址:特征筛选LASSO回归封装好的代码、数据集和结果 README LassoFeatureSelector_main 这个是主函数文件,在实例化LassoFeatureSelector类时,需要传入下面这些参数: input_train_data_path:输入训练集的路…...

Autosar 通讯栈配置-手动配置PDU及Signal-基于ETAS软件
文章目录 前言System配置ISignalSystem SignalPduFrameISignal到System Signal的mapSystem Signal到Pdu的mapPdu到Frame的mapSignal配置Can配置CanHwFilterEcuC配置PduR配置CanIf配置CanIfInitCfgCanIfRxPduCfgCom配置ComIPduComISignalSWC配置Data mappingRTE接口Com配置补充总…...

Web前端工资调整:深入剖析与全面解读
Web前端工资调整:深入剖析与全面解读 在快速发展的互联网行业中,Web前端技术日新月异,而与之紧密相关的工资调整也成为了业内热议的话题。本文将从四个方面、五个方面、六个方面和七个方面,深入剖析Web前端工资调整的原因、趋势、…...

cesium已知两个点 写一个简单具有动画尾迹效果的抛物线
// 定义起点和终点的经纬度和高度 var start { longitude: 111.09683723811149, latitude: 38.92112250636146, elevation: 603.5831692856873 }; var end { longitude: 111.09769465526689, latitude: 38.92815375977821, elevation: 627.0132157062261 }; // 生成更多的中…...
C#中使用Mysql批量新增数据 MySqlBulkCopy
在C#中使用MySqlBulkCopy类来批量复制数据到MySQL数据库,首先需要确保你的项目中已经引用了MySQL Connector。以下是使用MySqlBulkCopy的基本步骤: 1.安装MySQL Connector。 可以通过NuGet安装MySQL Connector: 2.在代码中引用必要的命名空间…...

ARM-V9 RME(Realm Management Extension)系统架构之系统安全能力的架构差异
安全之安全(security)博客目录导读 RME系统中的应用处理单元(PE)之间的架构差异可能会带来潜在的安全风险并增加管理软件的复杂性。例如,通过在ID_AA64MMFR0_EL1.PARange中为每个PE设置不同的值来支持不同的物理范围,可能会妨碍内…...

Ansible——stat模块
目录 参数总结 返回值 基础语法 常见的命令行示例 示例1:检查文件是否存在 示例2:获取文件详细信息 示例3:检查目录是否存在 示例4:获取文件的 MD5 校验和 示例5:获取文件的 MIME 类型 高级使用 示例6&…...

第二十节:带你梳理Vue2:Vue子组件向父组件传参(事件传参)
1. 自定义事件 除了可以处理原生的DOM事件, v-on指令也可以处理组件内部触发的自定义的事件,调用this.$emit()函数就可以触发一个自定义事件 $emit() 触发事件函数接受一个自定义事件的事件名以及其他任何给事件函数传递的参数. 然后就可以在组件上使用v-on来绑定这个自定义事…...

华为od-C卷100分题目 - 10寻找最富裕的小家庭
华为od-C卷100分题目 - 10寻找最富裕的小家庭 题目描述 在一棵树中,每个节点代表一个家庭成员,节点的数字表示其个人的财富值,一个节点及其直接相连的子节点被定义为一个小家庭。 现给你一棵树,请计算出最富裕的小家庭的财富和。…...

本地部署AI大模型 —— Ollama文档中文翻译
写在前面 来自Ollama GitHub项目的README.md 文档。文档中涉及的其它文档未翻译,但是对于本地部署大模型而言足够了。 Ollama 开始使用大模型。 macOS Download Windows 预览版 Download Linux curl -fsSL https://ollama.com/install.sh | sh手动安装说明 …...

【前端技术】 ES6 介绍及常用语法说明
😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~ 🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Mi…...
)
程序员具备的职业素养(个人见解)
程序员应该有什么职业素养? 1. 技术能力 毫无疑问,优秀的技术是程序员的必备。 -扎实的编程基础:熟练掌握至少一门编程语言,并理解基本的数据结构和算法,要做到精通!。 - 广泛的技术知识:了…...

Springboot 开发-- 集成 Activiti 7 流程引擎
引言 Activiti 7是一款遵循BPMN 2.0标准的开源工作流引擎,旨在为企业提供灵活、可扩展的流程管理功能。它支持图形化的流程设计、丰富的API接口、强大的执行引擎和完善的监控报表,帮助企业实现业务流程的自动化、规范化和智能化。本文将为您详细介绍 Ac…...

一些常用的frida脚本
这里整理一些常用的frida脚本,和ghidra 一起食用风味更佳~ Trace RegisterNatives 注意到从java到c的绑定中,可能会在JNI_OnLoad动态的执行RegisterNatives方法来绑定java层的函数到c行数,可以通过这个方法,来吧运行…...
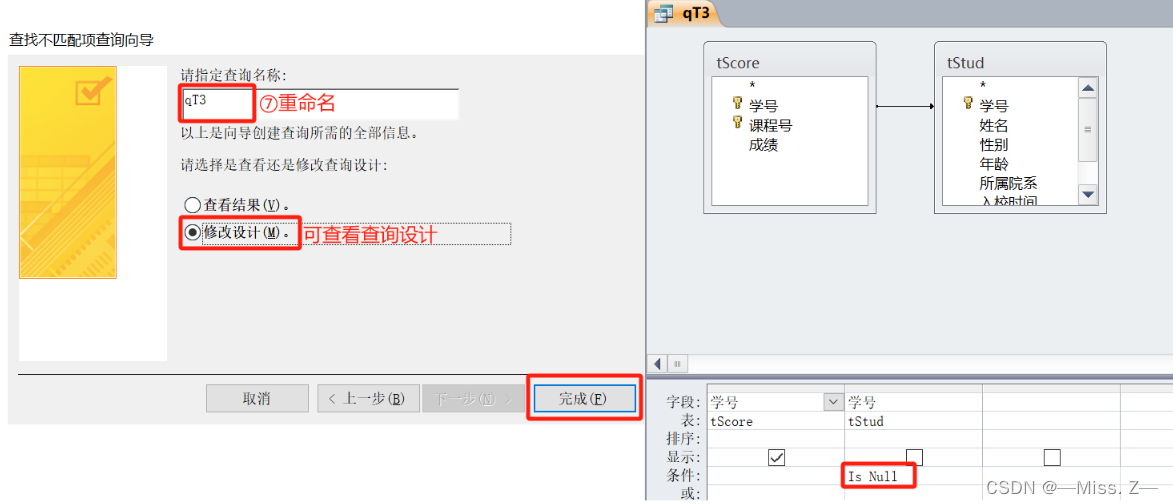
计算机二级Access操作题总结——简单应用
查询设计 创建一个查询,能够在客人每次结账时根据客人的姓名提示统计这个客人已住天数和应交金额,并显示“姓名”、“房间号”、“已住天数”和“应交金额”,所建查询命名为“qT2”。 注:输入姓名时应提示“请输入姓名”。已住天…...

C#操作MySQL从入门到精通(21)——删除数据
前言: 谈到数据库,大家最容易脱口而出的就是增删改查,本文就是来详细介绍如何删除数据。 本文测试使用的数据库如下: 1、删除部分数据 使用delete 关键字,并且搭配where条件使用,否则会导致表中数据全部被删除 string sql = string.Empty;if (radioButton_DeletePart…...

【iOS】JSONModel源码阅读笔记
文章目录 前言一、JSONModel使用二、JSONModel其他方法转换属性名称 三、源码分析- (instancetype)initWithDictionary:(NSDictionary*)dict error:(NSError **)err[self init]__setup____inspectProperties - (BOOL)__doesDictionary:(NSDictionary*)dict matchModelWithKeyMa…...

如何离线下载 Microsoft Corporation II Windows Subsystem for Android
在本文中,我们将指导您通过一个便捷的步骤来离线下载 Microsoft Corporation II Windows Subsystem for Android。这个过程将利用第三方工具来生成直接下载链接,从而让您能够获取该应用程序的安装包,即使在没有访问Microsoft Store的情况下也…...

使用 flask + qwen 实现 txt2sql 流式输出
前言 一般的大模型提供的 api 都是在提问之后过很久才会返回对话内容,可能要耗时在 3 秒以上了,如果是复杂的问题,大模型在理解和推理的耗时会更长,这种展示结果的方式对于用户体验是很差的。 其实大模型也是可以进行流式输出&a…...

植物大战僵尸杂交版最新2.0.88手机+电脑+苹果+修改器
在这个充满奇妙的平行宇宙中,植物和僵尸竟然能够和谐共存!是的,你没听错!一次意外的实验,让这两个看似对立的生物种类发生了基因杂交,创造出了全新的生物种类——它们既能够进行光合作用,也具备…...

在Hermes Agent项目中接入Taotoken自定义模型供应商的步骤
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Hermes Agent项目中接入Taotoken自定义模型供应商的步骤 对于使用Hermes Agent框架的开发者而言,直接对接不同的大模…...

Godot游戏解包终极指南:3步提取.pck文件所有资源
Godot游戏解包终极指南:3步提取.pck文件所有资源 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 你是否下载过Godot引擎开发的游戏,想要研究其中的美术资源、脚本代码或音效素…...

告别硬件:用Keil5逻辑分析仪‘看’GD32F305的GPIO与串口数据
告别硬件:用Keil5逻辑分析仪‘看’GD32F305的GPIO与串口数据 在嵌入式开发中,调试环节往往是最耗时且最具挑战性的部分。传统调试方式依赖示波器、逻辑分析仪等硬件设备,但这些工具价格昂贵且携带不便。对于资源有限的开发者或初学者而言&…...

如何用录播姬BililiveRecorder轻松修复损坏的直播录制文件?3步快速解决方案
如何用录播姬BililiveRecorder轻松修复损坏的直播录制文件?3步快速解决方案 【免费下载链接】BililiveRecorder 录播姬 | mikufans 生放送录制 项目地址: https://gitcode.com/gh_mirrors/bi/BililiveRecorder 录播姬BililiveRecorder是一款专业的B站直播录制…...

Relic项目:用纯文本文件为AI工具打造可移植的持久记忆系统
1. 项目概述:为你的AI伙伴打造一个持久、可移植的“灵魂芯片”如果你和我一样,深度依赖各种AI工具来辅助工作、学习和创作,那你一定遇到过这个令人头疼的问题:每次切换工具,都像是在和一个“失忆”的新朋友重新建立关系…...

华为设备Traffic Policy配置避坑指南:ACL规则顺序与Classifier匹配逻辑详解
华为设备Traffic Policy配置避坑指南:ACL规则顺序与Classifier匹配逻辑详解 在网络工程师的日常工作中,华为设备的QoS策略配置是一个既基础又复杂的话题。特别是当我们需要对特定流量进行精细控制时,Traffic Policy的正确配置就显得尤为重要。…...

从网盘下载困境到高效文件管理:一站式下载助手解决方案全解析
从网盘下载困境到高效文件管理:一站式下载助手解决方案全解析 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

3步解决魔兽争霸3显示问题:WarcraftHelper配置终极指南
3步解决魔兽争霸3显示问题:WarcraftHelper配置终极指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3作为经典RTS游戏…...

使用taotoken后c语言项目调用大模型的延迟与稳定性实际体验
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken后c语言项目调用大模型的延迟与稳定性实际体验 在开发一个需要集成大模型能力的C语言桌面应用时,我们面临…...

C#架构师实战:构建确定性事件驱动系统的工程原则与技术栈
1. 从个人简介到架构哲学:一位资深C#架构师的工程实践全景看到这个标题,你可能会以为这是一个普通的GitHub个人主页介绍。但如果你是一位深耕于分布式系统、事件驱动架构,或者正在为构建高确定性、可观测的生产级系统而头疼的工程师ÿ…...