Keras深度学习框架实战(5):KerasNLP使用GPT2进行文本生成
1、KerasNLP与GPT2概述
KerasNLP的GPT2进行文本生成是一个基于深度学习的自然语言处理任务,它利用GPT-2模型来生成自然流畅的文本。以下是关于KerasNLP的GPT2进行文本生成的概述:
-
GPT-2模型介绍:
-
GPT-2(Generative Pre-trained Transformer 2)是由OpenAI开发的一种基于Transformer模型的自然语言处理(NLP)模型,旨在生成自然流畅的文本。
-
它是一种无监督学习模型,设计目标是能够理解人类语言的复杂性并模拟出自然的语言生成。
-
GPT-2具有大量的训练数据和强大的算法,可以生成自然流畅、准确的文本。
-
KerasNLP与GPT-2:
-
KerasNLP是Keras的一个扩展库,提供了对NLP任务的便捷支持,包括文本生成。
-
通过KerasNLP,可以方便地加载预训练的GPT-2模型,并用于文本生成任务。
-
文本生成过程:
-
使用GPT2Tokenizer将输入的文本转换为模型可以理解的格式(即token IDs)。
-
将token IDs作为输入传递给GPT-2模型。
-
模型根据输入的上下文生成新的token IDs。
-
使用GPT2Tokenizer将生成的token IDs解码回文本格式。
-
特点与优势:
-
GPT-2模型使用了大量的预训练参数,使其具有强大的表现力和泛化能力。
-
可以生成各种类型的文本,如新闻、故事、对话和代码等。
-
与其他基于神经网络的语言模型相比,GPT-2具有许多独特的优点,如自监督学习方式和处理多种语言和任务的能力。
-
性能与规模:
-
GPT-2模型有多个版本,从小型到大型,以适应不同的计算资源和性能需求。
-
参数数量从1.5亿到1.75亿不等,模型大小从0.5GB到1.5GB。
-
使用示例:
-
可以通过KerasNLP提供的接口和预训练模型,轻松实现文本生成任务。
-
可以通过修改输入文本和参数设置,生成具有不同风格和主题的文本。
-
注意事项:
-
生成的文本可能不完全符合语法或逻辑,因为模型是基于统计语言模型进行预测的。
-
在实际应用中,需要对生成的文本进行适当的后处理和筛选,以确保其质量和适用性。
综上所述,KerasNLP的GPT2为文本生成任务提供了强大的支持,通过利用预训练的GPT-2模型,可以轻松地生成自然流畅的文本。
在这个教程中,你将学习如何使用KerasNLP加载一个预训练的大型语言模型(LLM)——GPT-2模型(由OpenAI最初发明),将其微调到特定的文本风格,并基于用户的输入(也称为提示)生成文本。你还将学习GPT-2如何快速适应非英语语言,例如中文。
2、训练准备
运行硬件环境要求
运行GPT2模型需要较高的资源需求,请确保前往运行时 -> 更改运行环境类型并选择GPU硬件加速器运行环境(应具有>12G主机RAM和~15G GPU RAM),因为你将微调GPT-2模型。在CPU运行环境中运行此教程将需要数小时。
安装KerasNLP,选择后端并导入依赖项
这个示例使用Keras 3以便在"tensorflow"、"jax"或"torch"中任一环境中工作。KerasNLP内置了对Keras 3的支持,只需更改"KERAS_BACKEND"环境变量即可选择您所选择的后端。我们在下面选择JAX后端。
!pip install git+https://github.com/keras-team/keras-nlp.git -q
import os
os.environ["KERAS_BACKEND"] = "jax" # 或"tensorflow"或"torch"import keras_nlp
import keras
import tensorflow as tf
import timekeras.mixed_precision.set_global_policy("mixed_float16")
生成大型语言模型(LLMs)
大型语言模型(LLMs)是一种机器学习模型,它们在大量文本数据上进行训练,以生成各种自然语言处理(NLP)任务的输出,如文本生成、问答和机器翻译。
生成性LLMs通常基于深度学习的神经网络,例如2017年由Google研究人员发明的Transformer架构,并且它们在大量文本数据上进行训练,通常涉及数十亿个单词。这些模型,如Google LaMDA和PaLM,是使用来自各种数据源的大型数据集进行训练的,这使它们能够为许多任务生成输出。生成性LLMs的核心是预测句子中的下一个词,通常称为因果语言模型预训练。通过这种方式,LLMs可以根据用户提示生成连贯的文本。有关语言模型的更多教学性讨论,可以参考斯坦福CS324 LLM课程。
KerasNLP
构建大型语言模型复杂且从头开始训练成本高昂。幸运的是,有预训练的LLMs可供立即使用。KerasNLP提供了大量的预训练检查点,让你可以无需自己训练即可尝试SOTA模型。
KerasNLP是一个自然语言处理库,它支持用户完成整个开发周期。KerasNLP提供了预训练模型和模块化的构建块,因此开发者可以轻松地重用预训练模型或堆叠自己的LLM。
简单来说,对于生成性LLM,KerasNLP提供了:
- 带有
generate()方法的预训练模型,例如keras_nlp.models.GPT2CausalLM和keras_nlp.models.OPTCausalLM。 - 实现生成算法(如Top-K、Beam和对比搜索)的Sampler类。这些samplers可用于使用自定义模型生成文本。
3 加载模型
3.1 加载预训练的GPT-2模型并生成一些文本
KerasNLP提供了许多预训练模型,如Google Bert和GPT-2。程序员可以在KerasNLP仓库中看到可用模型的列表。
加载GPT-2模型非常简单,如下所示:
# 为了加快训练和生成速度,我们使用长度为128的预处理器
# 而不是完整的长度1024。
preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset("gpt2_base_en",sequence_length=128,
)
gpt2_lm = keras_nlp.models.GPT2CausalLM.from_preset("gpt2_base_en", preprocessor=preprocessor
)
一旦模型加载完成,程序员就可以立即使用它来生成一些文本。运行下面的单元格来尝试一下。这就像调用一个单一的函数generate()一样简单:
start = time.time()output = gpt2_lm.generate("My trip to Yosemite was", max_length=200)
print("\nGPT-2 output:")
print(output)end = time.time()
print(f"TOTAL TIME ELAPSED: {end - start:.2f}s")
GPT-2 output:
My trip to Yosemite was pretty awesome. The first time I went I didn't know how to go and it was pretty hard to get around. It was a bit like going on an adventure with a friend. The only things I could do were hike and climb the mountain. It's really cool to know you're not alone in this world. It's a lot of fun. I'm a little worried that I might not get to the top of the mountain in time to see the sunrise and sunset of the day. I think the weather is going to get a little warmer in the coming years.
This post is a little more in-depth on how to go on the trail. It covers how to hike on the Sierra Nevada, how to hike with the Sierra Nevada, how to hike in the Sierra Nevada, how to get to the top of the mountain, and how to get to the top with your own gear.
The Sierra Nevada is a very popular trail in Yosemite
TOTAL TIME ELAPSED: 25.36s
再试一个:
start = time.time()output = gpt2_lm.generate("That Italian restaurant is", max_length=200)
print("\nGPT-2 output:")
print(output)end = time.time()
print(f"TOTAL TIME ELAPSED: {end - start:.2f}s")
GPT-2 output:
That Italian restaurant is known for its delicious food, and the best part is that it has a full bar, with seating for a whole host of guests. And that's only because it's located at the heart of the neighborhood.
The menu at the Italian restaurant is pretty straightforward:The menu consists of three main dishes:Italian sausage with cheeseAnd the main menu consists of a few other things.There are two tables: the one that serves a menu of sausage and bolognese with cheese (the one that serves the menu of sausage and bolognese with cheese) and the one that serves the menu of sausage and bolognese with cheese. The two tables are also open 24 hours a day, 7 days a week.
TOTAL TIME ELAPSED: 1.55s
注意第二次调用的速度有多快。这是因为计算图在第一次运行中被XLA编译,并在第二次运行中在后台被重用。
生成的文本质量看起来还可以,但我们可以通过微调来改进它。
3.2 KerasNLP中的GPT-2模型的工具
接下来,我们将实际微调模型以更新其参数,但在此之前,让我们看看我们拥有的用于GPT2的全部工具。
GPT2的代码可以在这里找到。从概念上讲,GPT2CausalLM可以被分层分解为KerasNLP中的几个模块,所有这些模块都有一个from_preset()函数来加载预训练模型:
keras_nlp.models.GPT2Tokenizer: GPT2模型使用的分词器,它是一个字节对编码器。keras_nlp.models.GPT2CausalLMPreprocessor: GPT2因果语言模型训练使用的预处理器。它进行分词以及其他预处理工作,如创建标签和附加结束标记。keras_nlp.models.GPT2Backbone: GPT2模型,它是keras_nlp.layers.TransformerDecoder的堆叠。这通常只被称为GPT2。keras_nlp.models.GPT2CausalLM: 包装GPT2Backbone,它将GPT2Backbone的输出乘以嵌入矩阵以在词汇表标记上生成logits。
3.3 在Reddit数据集上微调
现在程序员已经了解了KerasNLP中的GPT-2模型,你可以更进一步,微调模型,以便它以特定的风格生成文本,短或长,严格或随意。在本文中,我们将使用Reddit数据集作为示例。
import tensorflow_datasets as tfdsreddit_ds = tfds.load("reddit_tifu", split="train", as_supervised=True)
让我们看看Reddit TensorFlow数据集中的样本数据。有两个特征:
- document:帖子的文本。
- title:标题。
for document, title in reddit_ds:print(document.numpy())print(title.numpy())break
b"me and a friend decided to
go to the beach last sunday. we loaded up and headed out. we were about half way there when i decided that i was not leaving till i had seafood. now i'm not talking about red lobster. no friends i'm talking about a low country boil. i found the restaurant and got directions. i don't know if any of you have heard about the crab shack on tybee island but let me tell you it's worth it. we arrived and was seated quickly. we decided to get a seafood sampler for two and split it. the waitress bought it out on separate platters for us. the amount of food was staggering. two types of crab, shrimp, mussels, crawfish, andouille sausage, red potatoes, and corn on the cob. i managed to finish it and some of my friends crawfish and mussels. it was a day to be a fat ass. we finished paid for our food and headed to the beach. funny thing about seafood. it runs through me faster than a kenyan we arrived and walked around a bit. it was about 45min since we arrived at the beach when i felt a rumble from the depths of my stomach. i ignored it i didn't want my stomach to ruin our fun. i pushed down the feeling and continued. about 15min later the feeling was back and stronger than before. again i ignored it and continued. 5min later it felt like a nuclear reactor had just exploded in my stomach. i started running. i yelled to my friend to hurry the fuck up. running in sand is extremely hard if you did not know this. we got in his car and i yelled at him to floor it. my stomach was screaming and if he didn't hurry i was gonna have this baby in his car and it wasn't gonna be pretty. after a few red lights and me screaming like a woman in labor we made it to the store.i practically tore his car door open and ran inside. i ran to the bathroom opened the door and barely got my pants down before the dam burst and a flood of shit poured from my ass.i finished up when i felt something wet on my ass. i rubbed it thinking it was back splash. no, mass was covered in the after math of me abusing the toilet. i grabbed all the paper towels i could and gave my self a whores bath right there.i sprayed the bathroom down with the air freshener and left. an elderly lady walked in quickly and closed the door. i was just about to walk away when i heard gag. instead of walking i ran. i got to the car and told him to get the hell out of there."b'liking seafood'
在我们的例子中,我们正在对语言模型进行下一个词的预测,所以我们只需要’document’特征。
train_ds = (reddit_ds.map(lambda document, _: document).batch(32).cache().prefetch(tf.data.AUTOTUNE)
)
现在,你可以使用熟悉的fit()函数来微调模型。注意,preprocessor将在fit方法中自动调用,因为GPT2CausalLM是一个keras_nlp.models.Task实例。
这一步需要相当多的GPU内存,并且如果我们要将其训练到完全训练状态需要很长时间。在这里,我们只使用数据集的一部分进行演示。
train_ds = train_ds.take(500)
num_epochs = 1# 线性衰减的学习率。
learning_rate = keras.optimizers.schedules.PolynomialDecay(5e-5,decay_steps=train_ds.cardinality() * num_epochs,end_learning_rate=0.0,
)
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
gpt2_lm.compile(optimizer=keras.optimizers.Adam(learning_rate),loss=loss,weighted_metrics=["accuracy"],
)
gpt2_lm.fit(train_ds, epochs=num_epochs)
500/500 ██████████████████████████████████| 75s 120ms/step - accuracy: 0.3189 - loss: 3.3653
微调完成后,你可以再次使用相同的generate()函数生成文本。这一次,文本将更接近Reddit的写作风格,并且生成的长度将接近我们在训练集中预设的长度。
start = time.time()output = gpt2_lm.generate("I like basketball", max_length=200)
print("\nGPT-2 output:")
print(output)end = time.time()
print(f"TOTAL TIME ELAPSED: {end - start:.2f}s")
GPT-2 output:
I like basketball. it has the greatest shot of all time and the best shot of all time. i have to play a little bit more and get some practice time.today i got the opportunity to play in a tournament in a city that is very close to my school so i was excited to see how it would go. i had just been playing with a few other guys, so i thought i would go and play a couple games with them.after a few games i was pretty confident and confident in myself. i had just gotten the opportunity and had to get some practice time.so i go to the
TOTAL TIME ELAPSED: 21.13s
4、采样方法
在KerasNLP中,我们提供了几种采样方法,例如对比搜索、Top-K和束搜索。默认情况下,我们的GPT2CausalLM使用Top-k搜索,但您可以选择自己的采样方法。
就像优化器和激活函数一样,有两种方式来指定自定义的采样器:
- 使用字符串标识符,如"greedy",您通过这种方式使用默认配置。
- 传递一个
keras_nlp.samplers.Sampler实例,您可以通过这种方式使用自定义配置。
# 使用字符串标识符。
gpt2_lm.compile(sampler="top_k")
output = gpt2_lm.generate("I like basketball", max_length=200)
print("\nGPT-2 output:")
print(output)# 使用`Sampler`实例。`GreedySampler`往往会重复自身。
greedy_sampler = keras_nlp.samplers.GreedySampler()
gpt2_lm.compile(sampler=greedy_sampler)output = gpt2_lm.generate("I like basketball", max_length=200)
print("\nGPT-2 output:")
print(output)
GPT-2 output:
I like basketball, and this is a pretty good one.first off, my wife is pretty good, she is a very good basketball player and she is really, really good at playing basketball.she has an amazing game called basketball, it is a pretty fun game.i play it on the couch. i'm sitting there, watching the game on the couch. my wife is playing with her phone. she's playing on the phone with a bunch of people.my wife is sitting there and watching basketball. she's sitting there watching
GPT-2 output:
I like basketball, but i don't like to play it.so i was playing basketball at my local high school, and i was playing with my friends.i was playing with my friends, and i was playing with my brother, who was playing basketball with his brother.so i was playing with my brother, and he was playing with his brother's brother.so i was playing with my brother, and he was playing with his brother's brother.so i was playing with my brother, and he was playing with his brother's brother.so i was playing with my brother, and he was playing with his brother's brother.so i was playing with my brother, and he was playing with his brother
5 在中文诗歌数据集上微调
我们也可以在非英语数据集上微调GPT2,接下来的部分说明了如何在中文诗歌数据集上微调GPT2,以教我们的模型成为诗人!
因为GPT2使用字节对编码器,而原始预训练数据集包含一些中文字符,我们可以使用原始词汇表在中文数据集上进行微调。
!# 加载中文诗歌数据集。
!git clone https://github.com/chinese-poetry/chinese-poetry.git
Cloning into 'chinese-poetry'...
从json文件中加载文本。我们仅出于演示目的使用《全唐诗》。
import os
import jsonpoem_collection = []
for file in os.listdir("chinese-poetry/全唐诗"):if ".json" not in file or "poet" not in file:continuefull_filename = "%s/%s" % ("chinese-poetry/全唐诗", file)with open(full_filename, "r") as f:content = json.load(f)poem_collection.extend(content)paragraphs = ["".join(data["paragraphs"]) for data in poem_collection]
让我们看看样本数据。
与Reddit示例类似,我们将其转换为TF数据集,并且只使用部分数据进行训练。
train_ds = (tf.data.Dataset.from_tensor_slices(paragraphs).batch(16).cache().prefetch(tf.data.AUTOTUNE)
)# 运行整个数据集需要很长时间,只取500条并运行1个epoch用于演示目的。
train_ds = train_ds.take(500)
num_epochs = 1learning_rate = keras.optimizers.schedules.PolynomialDecay(5e-4,decay_steps=train_ds.cardinality() * num_epochs,end_learning_rate=0.0,
)
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
gpt2_lm.compile(optimizer=keras.optimizers.Adam(learning_rate),loss=loss,weighted_metrics=["accuracy"],
)
gpt2_lm.fit(train_ds, epochs=num_epochs)
500/500 ██████████████████████████████████| 49s 71ms/step - accuracy: 0.2357 - loss: 2.8196
让我们检查结果!
output = gpt2_lm.generate("昨夜雨疏风骤", max_length=200)
print(output)
昨夜雨疏风骤,爲臨江山院短靜。石淡山陵長爲羣,臨石山非處臨羣。美陪河埃聲爲羣,漏漏漏邊陵塘
6、源代码
"""shell
pip install git+https://github.com/keras-team/keras-nlp.git -q
"""import osos.environ["KERAS_BACKEND"] = "jax" # or "tensorflow" or "torch"import keras_nlp
import keras
import tensorflow as tf
import timekeras.mixed_precision.set_global_policy("mixed_float16")"""
## Introduction to Generative Large Language Models (LLMs)Large language models (LLMs) are a type of machine learning models that are
trained on a large corpus of text data to generate outputs for various natural
language processing (NLP) tasks, such as text generation, question answering,
and machine translation.Generative LLMs are typically based on deep learning neural networks, such as
the [Transformer architecture](https://arxiv.org/abs/1706.03762) invented by
Google researchers in 2017, and are trained on massive amounts of text data,
often involving billions of words. These models, such as Google [LaMDA](https://blog.google/technology/ai/lamda/)
and [PaLM](https://ai.googleblog.com/2022/04/pathways-language-model-palm-scaling-to.html),
are trained with a large dataset from various data sources which allows them to
generate output for many tasks. The core of Generative LLMs is predicting the
next word in a sentence, often referred as **Causal LM Pretraining**. In this
way LLMs can generate coherent text based on user prompts. For a more
pedagogical discussion on language models, you can refer to the
[Stanford CS324 LLM class](https://stanford-cs324.github.io/winter2022/lectures/introduction/).
""""""
## Introduction to KerasNLPLarge Language Models are complex to build and expensive to train from scratch.
Luckily there are pretrained LLMs available for use right away. [KerasNLP](https://keras.io/keras_nlp/)
provides a large number of pre-trained checkpoints that allow you to experiment
with SOTA models without needing to train them yourself.KerasNLP is a natural language processing library that supports users through
their entire development cycle. KerasNLP offers both pretrained models and
modularized building blocks, so developers could easily reuse pretrained models
or stack their own LLM.In a nutshell, for generative LLM, KerasNLP offers:- Pretrained models with `generate()` method, e.g.,`keras_nlp.models.GPT2CausalLM` and `keras_nlp.models.OPTCausalLM`.
- Sampler class that implements generation algorithms such as Top-K, Beam andcontrastive search. These samplers can be used to generate text withcustom models.
""""""
## Load a pre-trained GPT-2 model and generate some textKerasNLP provides a number of pre-trained models, such as [Google
Bert](https://ai.googleblog.com/2018/11/open-sourcing-bert-state-of-art-pre.html)
and [GPT-2](https://openai.com/research/better-language-models). You can see
the list of models available in the [KerasNLP repository](https://github.com/keras-team/keras-nlp/tree/master/keras_nlp/models).It's very easy to load the GPT-2 model as you can see below:
"""# To speed up training and generation, we use preprocessor of length 128
# instead of full length 1024.
preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset("gpt2_base_en",sequence_length=128,
)
gpt2_lm = keras_nlp.models.GPT2CausalLM.from_preset("gpt2_base_en", preprocessor=preprocessor
)"""
Once the model is loaded, you can use it to generate some text right away. Run
the cells below to give it a try. It's as simple as calling a single function
*generate()*:
"""start = time.time()output = gpt2_lm.generate("My trip to Yosemite was", max_length=200)
print("\nGPT-2 output:")
print(output)end = time.time()
print(f"TOTAL TIME ELAPSED: {end - start:.2f}s")"""
Try another one:
"""start = time.time()output = gpt2_lm.generate("That Italian restaurant is", max_length=200)
print("\nGPT-2 output:")
print(output)end = time.time()
print(f"TOTAL TIME ELAPSED: {end - start:.2f}s")"""
Notice how much faster the second call is. This is because the computational
graph is [XLA compiled](https://www.tensorflow.org/xla) in the 1st run and
re-used in the 2nd behind the scenes.The quality of the generated text looks OK, but we can improve it via
fine-tuning.
""""""
## More on the GPT-2 model from KerasNLPNext up, we will actually fine-tune the model to update its parameters, but
before we do, let's take a look at the full set of tools we have to for working
with for GPT2.The code of GPT2 can be found
[here](https://github.com/keras-team/keras-nlp/blob/master/keras_nlp/models/gpt2/).
Conceptually the `GPT2CausalLM` can be hierarchically broken down into several
modules in KerasNLP, all of which have a *from_preset()* function that loads a
pretrained model:- `keras_nlp.models.GPT2Tokenizer`: The tokenizer used by GPT2 model, which is a[byte-pair encoder](https://huggingface.co/course/chapter6/5?fw=pt).
- `keras_nlp.models.GPT2CausalLMPreprocessor`: the preprocessor used by GPT2causal LM training. It does the tokenization along with other preprocessingworks such as creating the label and appending the end token.
- `keras_nlp.models.GPT2Backbone`: the GPT2 model, which is a stack of`keras_nlp.layers.TransformerDecoder`. This is usually just referred as`GPT2`.
- `keras_nlp.models.GPT2CausalLM`: wraps `GPT2Backbone`, it multiplies theoutput of `GPT2Backbone` by embedding matrix to generate logits overvocab tokens.
""""""
## Finetune on Reddit datasetNow you have the knowledge of the GPT-2 model from KerasNLP, you can take one
step further to finetune the model so that it generates text in a specific
style, short or long, strict or casual. In this tutorial, we will use reddit
dataset for example.
"""import tensorflow_datasets as tfdsreddit_ds = tfds.load("reddit_tifu", split="train", as_supervised=True)"""
Let's take a look inside sample data from the reddit TensorFlow Dataset. There
are two features:- **__document__**: text of the post.
- **__title__**: the title."""for document, title in reddit_ds:print(document.numpy())print(title.numpy())break"""
In our case, we are performing next word prediction in a language model, so we
only need the 'document' feature.
"""train_ds = (reddit_ds.map(lambda document, _: document).batch(32).cache().prefetch(tf.data.AUTOTUNE)
)"""
Now you can finetune the model using the familiar *fit()* function. Note that
`preprocessor` will be automatically called inside `fit` method since
`GPT2CausalLM` is a `keras_nlp.models.Task` instance.This step takes quite a bit of GPU memory and a long time if we were to train
it all the way to a fully trained state. Here we just use part of the dataset
for demo purposes.
"""train_ds = train_ds.take(500)
num_epochs = 1# Linearly decaying learning rate.
learning_rate = keras.optimizers.schedules.PolynomialDecay(5e-5,decay_steps=train_ds.cardinality() * num_epochs,end_learning_rate=0.0,
)
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
gpt2_lm.compile(optimizer=keras.optimizers.Adam(learning_rate),loss=loss,weighted_metrics=["accuracy"],
)gpt2_lm.fit(train_ds, epochs=num_epochs)"""
After fine-tuning is finished, you can again generate text using the same
*generate()* function. This time, the text will be closer to Reddit writing
style, and the generated length will be close to our preset length in the
training set.
"""start = time.time()output = gpt2_lm.generate("I like basketball", max_length=200)
print("\nGPT-2 output:")
print(output)end = time.time()
print(f"TOTAL TIME ELAPSED: {end - start:.2f}s")"""
## Into the Sampling MethodIn KerasNLP, we offer a few sampling methods, e.g., contrastive search,
Top-K and beam sampling. By default, our `GPT2CausalLM` uses Top-k search, but
you can choose your own sampling method.Much like optimizer and activations, there are two ways to specify your custom
sampler:- Use a string identifier, such as "greedy", you are using the default
configuration via this way.
- Pass a `keras_nlp.samplers.Sampler` instance, you can use custom configuration
via this way.
"""# Use a string identifier.
gpt2_lm.compile(sampler="top_k")
output = gpt2_lm.generate("I like basketball", max_length=200)
print("\nGPT-2 output:")
print(output)# Use a `Sampler` instance. `GreedySampler` tends to repeat itself,
greedy_sampler = keras_nlp.samplers.GreedySampler()
gpt2_lm.compile(sampler=greedy_sampler)output = gpt2_lm.generate("I like basketball", max_length=200)
print("\nGPT-2 output:")
print(output)"""
For more details on KerasNLP `Sampler` class, you can check the code
[here](https://github.com/keras-team/keras-nlp/tree/master/keras_nlp/samplers).
""""""
## Finetune on Chinese Poem DatasetWe can also finetune GPT2 on non-English datasets. For readers knowing Chinese,
this part illustrates how to fine-tune GPT2 on Chinese poem dataset to teach our
model to become a poet!Because GPT2 uses byte-pair encoder, and the original pretraining dataset
contains some Chinese characters, we can use the original vocab to finetune on
Chinese dataset.
""""""shell
# Load chinese poetry dataset.
git clone https://github.com/chinese-poetry/chinese-poetry.git
""""""
Load text from the json file. We only use《全唐诗》for demo purposes.
"""import os
import jsonpoem_collection = []
for file in os.listdir("chinese-poetry/全唐诗"):if ".json" not in file or "poet" not in file:continuefull_filename = "%s/%s" % ("chinese-poetry/全唐诗", file)with open(full_filename, "r") as f:content = json.load(f)poem_collection.extend(content)paragraphs = ["".join(data["paragraphs"]) for data in poem_collection]"""
Let's take a look at sample data.
"""print(paragraphs[0])"""
Similar as Reddit example, we convert to TF dataset, and only use partial data
to train.
"""train_ds = (tf.data.Dataset.from_tensor_slices(paragraphs).batch(16).cache().prefetch(tf.data.AUTOTUNE)
)# Running through the whole dataset takes long, only take `500` and run 1
# epochs for demo purposes.
train_ds = train_ds.take(500)
num_epochs = 1learning_rate = keras.optimizers.schedules.PolynomialDecay(5e-4,decay_steps=train_ds.cardinality() * num_epochs,end_learning_rate=0.0,
)
loss = keras.losses.SparseCategoricalCrossentropy(from_logits=True)
gpt2_lm.compile(optimizer=keras.optimizers.Adam(learning_rate),loss=loss,weighted_metrics=["accuracy"],
)gpt2_lm.fit(train_ds, epochs=num_epochs)"""
Let's check the result!
"""output = gpt2_lm.generate("昨夜雨疏风骤", max_length=200)
print(output)7、总结
本文讨论了关于如何使用KerasNLP库来加载、微调和使用GPT-2模型进行文本生成。
-
环境设置:首先介绍了如何在Colab上选择GPU硬件加速器运行环境,以便于进行GPT-2模型的微调。
-
安装与配置:然后指导用户安装KerasNLP库,并根据需要选择后端(tensorflow、jax或torch)。
-
大型语言模型(GPT-2)介绍:解释了大型语言模型的概念,以及GPT-2是如何在大量文本数据上进行预训练的。
-
KerasNLP库介绍:介绍了KerasNLP库的功能,包括提供预训练模型和模块化的构建块,以便开发者可以重用或堆叠自己的LLM。
-
加载预训练的GPT-2模型:展示了如何加载预训练的GPT-2模型,并使用它生成文本。
-
微调模型:教程接下来介绍了如何使用Reddit数据集对GPT-2模型进行微调,以生成特定风格的文本。
-
采样方法:讨论了KerasNLP中提供的几种采样方法,如Top-K、Beam和对比搜索,并展示了如何使用这些采样方法。
-
在中文诗歌数据集上微调:最后,教程还介绍了如何在非英语数据集(中文诗歌)上微调GPT-2模型,以教模型成为诗人。
整个文章提供了详细的代码示例和说明,旨在帮助用户了解如何使用KerasNLP库来使用和微调GPT-2模型,并展示了模型在不同领域的应用潜力。
相关文章:
:KerasNLP使用GPT2进行文本生成)
Keras深度学习框架实战(5):KerasNLP使用GPT2进行文本生成
1、KerasNLP与GPT2概述 KerasNLP的GPT2进行文本生成是一个基于深度学习的自然语言处理任务,它利用GPT-2模型来生成自然流畅的文本。以下是关于KerasNLP的GPT2进行文本生成的概述: GPT-2模型介绍: GPT-2(Generative Pre-trained …...

速盾:网站重生之我开了高防cdn
在互联网的广袤海洋中,网站就如同一个个独立的岛屿,面临着各种风雨和挑战。而作为一名专业程序员,我深知网站安全和性能的重要性。当我的网站遭遇频繁的攻击和访问压力时,我毅然决定开启高防 CDN,开启了一场网站的重生…...
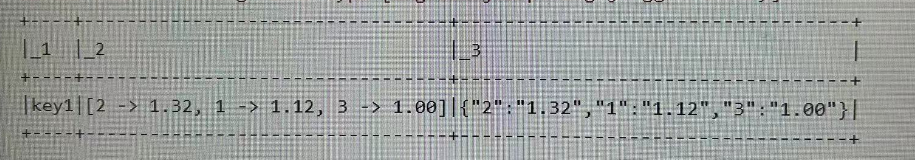
【spark】spark列转行操作(json格式)
前言:一般我们列转行都是使用concat_ws函数或者concat函数,但是concat一般都是用于字符串的拼接,后续处理数据时并不方便。 需求:将两列数据按照设备id进行分组,每个设备有多个时间点位和对应值,将其一一对…...

记录一次Linux启动kafka后并配置了本地服务连接远程kafka的地址后依旧连接localhost的问题
问题的原因 我是使用docker来安装并启动kafka 的,所以在启动过程中并没有太多需要配置的地方,基本都是从网上照搬照抄,没动什么脑子,所以看着启动起来了觉得就没事了,但是运行项目的时候发现,我明明已经配…...
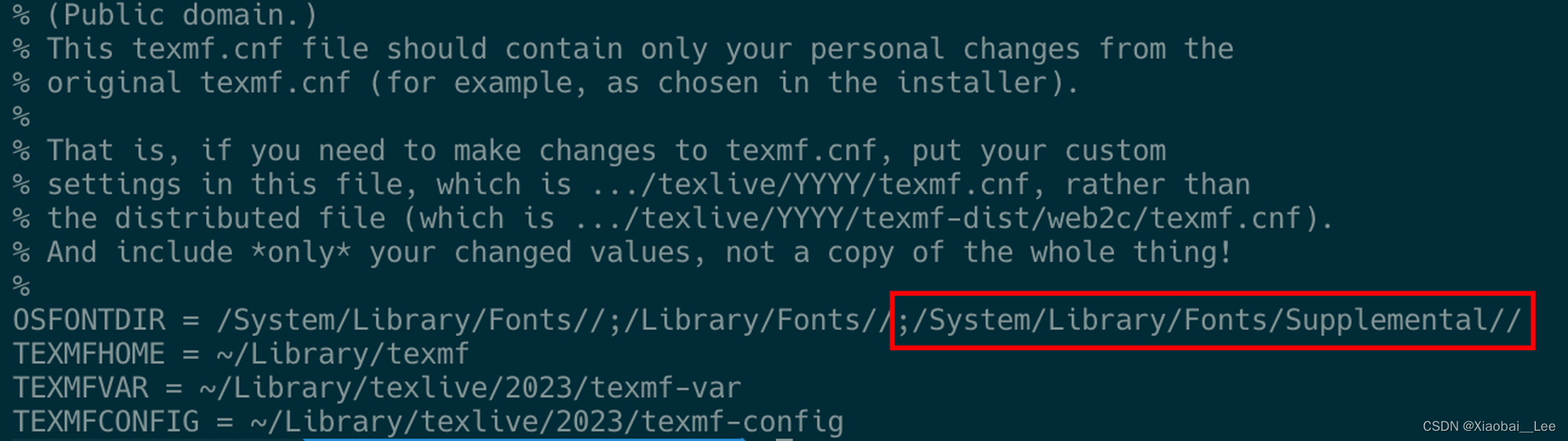
MacOS中Latex提示没有相关字体怎么办
在使用mactex编译中文的时候,遇到有些中文字体识别不到的情况,例如遇到识别不到Songti.ttc。其实这个时候字体是在系统里面的,但是只不过是latex没有找到正确的字体路径。 本文只针对于系统已经安装了字体库并且能够用find命令搜到࿰…...

物资材料管理系统建设方案(Word)—实际项目方案
二、 项目概述 2.1 项目背景 2.2 现状分析 2.2.1 业务现状 2.2.2 系统现状 三、 总体需求 3.1 系统范围 3.2 系统功能 3.3 用户分析 3.4 假设与依赖关系 四、 功能需求 4.4.11.7 非功能性需求 五、 非功能性需求 5.1 用户界面需求 5.2 软硬件环境需求 5.3 产品质量需求 5.4 接口…...
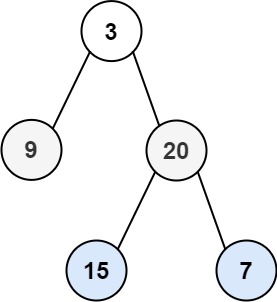
!力扣102. 二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:[[3],[9,20],[15,7]] /*** Definition for…...
Vue3 + TS + Antd + Pinia 从零搭建后台系统(一) 脚手架搭建 + 入口配置
简易后台系统搭建开启,分几篇文章更新,本篇主要先搭架子,配置入口文件等目录 效果图一、搭建脚手架:二、处理package.json基础需要的依赖及运行脚本三、创建环境运行文件四、填充vue.config.ts配置文件五、配置vite-env.d.ts使项目…...

中国同胞进来看看,很多外国人想通过CSDN坑咱们中国人
地址:【诈骗离你我很近】中国同胞进来看看国外诈骗新套路。-CSDN博客...

Web前端电话咨询:深度解析与实用指南
Web前端电话咨询:深度解析与实用指南 在数字化时代,Web前端技术日新月异,对于许多企业和个人而言,通过电话咨询了解前端技术的最新动态和解决方案已成为一种高效且便捷的方式。本文将从四个方面、五个方面、六个方面和七个方面&a…...
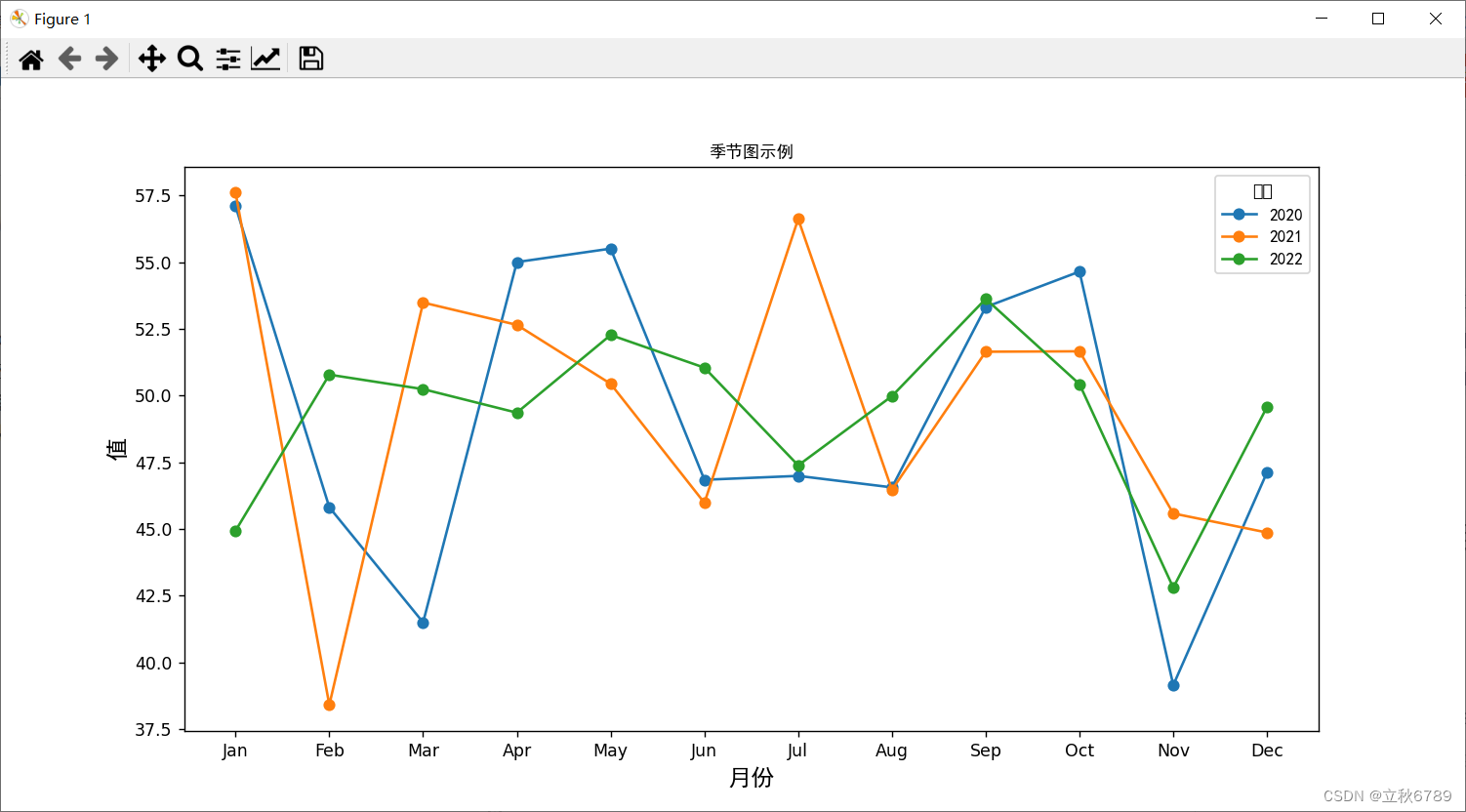
使用python绘制季节图
使用python绘制季节图 季节图效果代码 季节图 季节图(Seasonal Plot)是一种数据可视化图表,用于展示时间序列数据的季节性变化。它通过将每个时间段(如每个月、每个季度)的数据绘制在同一张图表上,使得不同…...
VS2019专业版 C#和MFC安装
1. VS2019专业版下载地址 https://learn.microsoft.com/en-us/visualstudio/releases/2019/history 2.安装 C# 部分 MFC部分...

spring入门aop和ioc
文章目录 spring分层架构表现层服务层(业务层)持久层 spring核心ioc(控制反转)1)**接下来是代码示例:**2)**ioc容器的使用过程**3)ioc中的bean管理4)实例化bean的三种方式 aop(面向切面开发) 定…...

使用Python创建Word文档
使用Python创建Word文档 安装python-docx库创建Word文档代码效果 在这篇文章中,我们将介绍如何使用 Python创建一个Word文档。首先,我们需要安装python-docx库,然后通过一段简单的代码示例展示如何创建和编辑Word文档。 安装python-docx库 …...
⭐⭐)
【设计模式】装饰器模式(结构型)⭐⭐
文章目录 1.概念1.1 什么是装饰器模式1.2 优点与缺点 2.实现方式3. Java 哪些地方用到了装饰器模式4. Spring 哪些地方用到了装饰器模式 1.概念 1.1 什么是装饰器模式 它允许用户在不修改现有对象的代码的情况下向对象添加新的功能;这种模式是通过创建一个包含该对…...

计算机网络--应用层
计算机网络–计算机网络概念 计算机网络–物理层 计算机网络–数据链路层 计算机网络–网络层 计算机网络–传输层 计算机网络–应用层 1. 概述 因为不同的网络应用之间需要有一个确定的通信规则。 1.1 两种常用的网络应用模型 1.1.1 客户/服务器模型(Client/Se…...
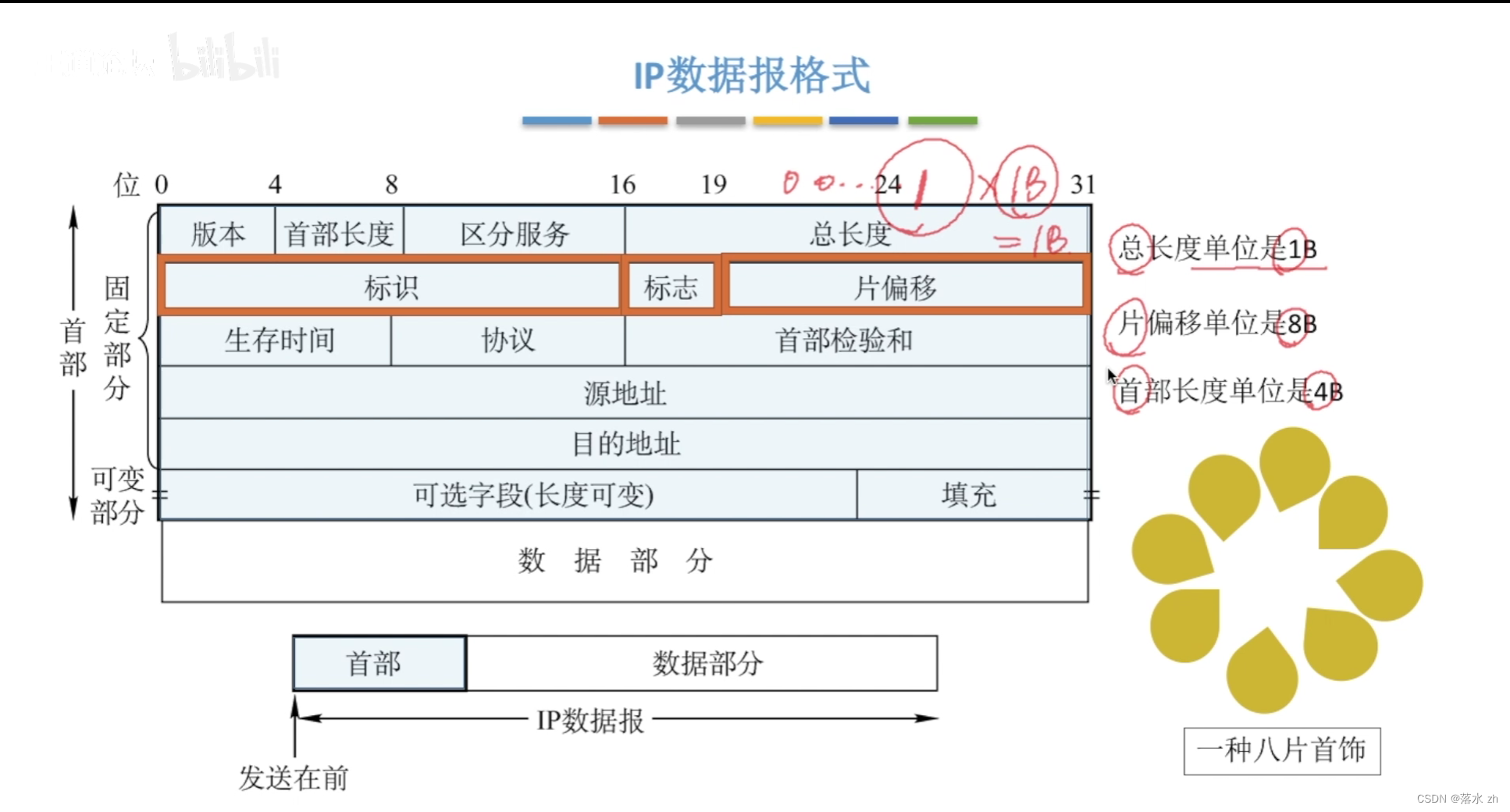
计算机网络 —— 网络层(IP数据报)
计算机网络 —— 网络层(IP数据报) 网络层要满足的功能IP数据报IP数据报格式IP数据报首部格式数据部分 IP数据报分片 我们今天进入网络层的学习。 网络层要满足的功能 网络层作为OSI模型中的第三层,是计算机网络体系结构的关键组成部分&…...

Clo3D导出服装动画,使用Unity3D展示
1.前言 Clo3D是一款应用于时装行业的3D服装设计软件,其强大的布料模拟算法可在3D空间中实现设计、制版、试衣和走秀,大幅提升数字作品逼真度和制作效率。为了让服装动画效果展示在Unity3D上模拟效果,需要Clo3D模拟出逼着的衣服动画。总体流程为Clo3D - Mixamo -Blen…...

LSTM 词语模型上的动态量化
原文链接 (beta) Dynamic Quantization on an LSTM Word Language Model — PyTorch Tutorials 2.3.0cu121 documentation 引言 量化涉及将模型的权重和激活值从浮点数转换为整数,这样可以缩小模型大小,加快推理速度,但对准确性的影响很小…...
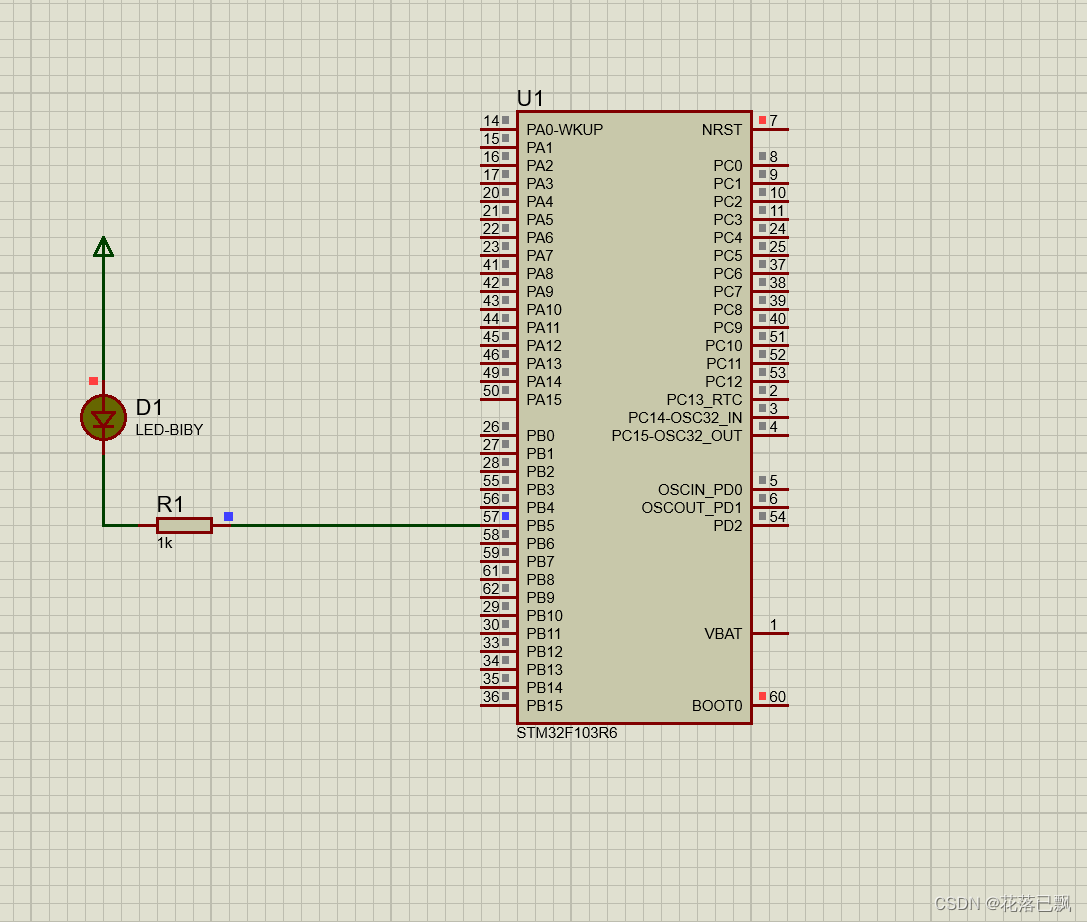
STM32 proteus + STM32Cubemx仿真教程(第一课LED教程)
文章目录 前言一、STM32点亮LED灯的原理1.1GPIO是什么1.2点亮LED灯的原理 二、STM32Cubemx创建工程三、proteus仿真电路图四、程序代码编写1.LED灯操作函数介绍HAL_GPIO_WritePin函数原型参数说明示例代码 HAL_GPIO_TogglePin函数原型参数说明示例代码 2.代码编写3.烧写程序 总…...

JIT加速不生效?你漏掉了这4个强制启用开关,3.14新增--enable-jit-unsafe-mode正在被92%团队忽略
第一章:JIT加速不生效?你漏掉了这4个强制启用开关,3.14新增--enable-jit-unsafe-mode正在被92%团队忽略Go 3.14 引入了激进的 JIT 编译优化路径,但默认关闭全部 JIT 后端。大量团队在升级后观察到 GOMAXPROCS8 下 CPU 利用率未提升…...

SEO_资深专家分享的3个高级SEO策略与思路
SEO资深专家分享的3个高级SEO策略与思路 在当今竞争激烈的数字营销环境中,搜索引擎优化(SEO)不仅仅是一个技术问题,更是一个战略问题。作为一名资深SEO专家,我有幸分享三个高级SEO策略,帮助你在竞争中脱颖…...

良心推荐!阿贝云免费云服务器,新手小白也能轻松上手
最近在折腾个人网站,想找个免费的云服务器练练手,试了好几家都不太满意。后来朋友推荐了阿贝云,体验下来感觉真的不错。 首先,阿贝云的免费云服务器配置很实在:1核CPU、1GB内存、5M带宽,还带独立公网IP。对…...

开源键盘定制工具:无需编程打造专属机械键盘体验
开源键盘定制工具:无需编程打造专属机械键盘体验 【免费下载链接】keyboards 项目地址: https://gitcode.com/gh_mirrors/key/keyboards 在机械键盘的世界里,每一位用户都渴望拥有一把真正符合自己使用习惯的输入设备。开源键盘定制工具正是这样…...

OpenClaw定时任务技巧:让Kimi-VL-A3B-Thinking自动处理每日图文简报
OpenClaw定时任务技巧:让Kimi-VL-A3B-Thinking自动处理每日图文简报 1. 为什么需要自动化图文简报 每天早上打开电脑,我的第一件事就是浏览行业资讯、技术博客和社交媒体,把有价值的内容整理成简报。这个过程通常要花费30-45分钟࿰…...

LAV Filters专业配置进阶指南:深度解析开源解码器架构与性能优化
LAV Filters专业配置进阶指南:深度解析开源解码器架构与性能优化 【免费下载链接】LAVFilters LAV Filters - Open-Source DirectShow Media Splitter and Decoders 项目地址: https://gitcode.com/gh_mirrors/la/LAVFilters LAV Filters是一套基于FFmpeg的高…...

像素语言·跨维传送门参数详解:Hunyuan-MT-7B引擎温度/长度/对齐策略调优指南
像素语言跨维传送门参数详解:Hunyuan-MT-7B引擎温度/长度/对齐策略调优指南 1. 工具概览与核心价值 像素语言跨维传送门(Pixel Language Portal)是基于Tencent Hunyuan-MT-7B引擎构建的创新翻译工具,它将传统翻译体验重构为16-bit像素冒险风格。不同于…...

Phi-3-mini-4k-instruct-gguf代码实例:curl健康检查与supervisor服务管理实操
Phi-3-mini-4k-instruct-gguf代码实例:curl健康检查与supervisor服务管理实操 1. 模型简介与部署准备 Phi-3-mini-4k-instruct-gguf是微软Phi-3系列中的轻量级文本生成模型GGUF版本,特别适合问答、文本改写、摘要整理和简短创作等场景。这个经过优化的…...

SecGPT-14B镜像免配置实战:开箱即用的网络安全大模型推理方案
SecGPT-14B镜像免配置实战:开箱即用的网络安全大模型推理方案 1. 为什么选择SecGPT-14B 在网络安全领域,专业知识的获取往往需要多年经验积累。SecGPT-14B作为一款专注于网络安全的大语言模型,能够为安全工程师、开发人员和IT运维人员提供即…...

C++ 异常安全与 RAII 模式结合
C异常安全与RAII模式结合:构建健壮资源管理体系 在C开发中,异常处理与资源管理是保证程序健壮性的核心挑战。传统的手动资源释放容易因异常抛出导致泄漏,而RAII(资源获取即初始化)模式通过对象生命周期自动化管理资源…...