PDF批量加水印 与 去除水印实践
本文主要目标是尝试去除水印,但是为了准备测试数据,我们需要先准备好有水印的pdf测试文件。
注意:本文的去水印只针对文字悬浮图片悬浮两种特殊情况,即使是这两种情况也不代表一定都可以去除水印。
文章目录
- 批量添加透明图片水印
- 批量去除悬浮图片水印
- 批量添加文字水印
- 批量去除文字水印
- 总结
批量添加透明图片水印
首先按照之前文章《Office三件套批量转PDF以及PDF书签读写与加水印》提供的方法,生成带水印的PDF,完整代码如下:
import PyPDF2
import math
from PIL import Image, ImageFont, ImageDraw, ImageEnhance, ImageChopsdef crop_image(im):'''裁剪图片边缘空白'''bg = Image.new(mode='RGBA', size=im.size)bbox = ImageChops.difference(im, bg).getbbox()if bbox:return im.crop(bbox)return imdef set_opacity(im, opacity):'''设置水印透明度'''assert 0 <= opacity <= 1alpha = im.split()[3]alpha = ImageEnhance.Brightness(alpha).enhance(opacity)im.putalpha(alpha)return imdef get_mark_img(text, color="#8B8B1B", size=30, opacity=0.15):width = len(text) * sizemark = Image.new(mode='RGBA', size=(width, size + 20))ImageDraw.Draw(im=mark) \.text(xy=(0, 0),text=text,fill=color,font=ImageFont.truetype('msyhbd.ttc', size=size))mark = crop_image(mark)set_opacity(mark, opacity)return markdef create_watermark_pdf(text, filename="watermark.pdf", page_size=(595, 842), color="#8B8B1B", size=30, opacity=0.3,space=75, angle=30, dpi=100):mark = get_mark_img(text, color, size, opacity)img_size = tuple(map(lambda s: int(s*dpi//72), page_size))im = Image.new(mode='RGBA', size=img_size)w, h = img_sizec = int(math.sqrt(w ** 2 + h ** 2))mark2 = Image.new(mode='RGBA', size=(c, c))y, idx = 0, 0mark_w, mark_h = mark.sizewhile y < c:x = -int((mark_w + space) * 0.5 * idx)idx = (idx + 1) % 2while x < c:mark2.paste(mark, (x, y))x = x + mark_w + spacey = y + mark_h + spacemark2 = mark2.rotate(angle)im.paste(mark2, (int((w - c) / 2), int((h - c) / 2)), # 坐标mask=mark2.split()[3])im.save(filename, "PDF", resolution=dpi, save_all=True)def pdf_add_watermark(filename, save_filepath, watermark='watermark.pdf'):watermark = PyPDF2.PdfReader(watermark).pages[0]pdf_reader = PyPDF2.PdfReader(filename)pdf_writer = PyPDF2.PdfWriter()for page in pdf_reader.pages:page.merge_page(watermark)page.compress_content_streams()pdf_writer.add_page(page)with open(save_filepath, "wb") as out:pdf_writer.write(out)if __name__ == '__main__':watermark = 'watermark.pdf'create_watermark_pdf("小小明的CSDN:https://blog.csdn.net/as604049322", watermark, opacity=0.4)pdf_add_watermark('mysql.pdf', 'mysql【带水印】.pdf', watermark=watermark)
然后就可以得到一个全部是水印的PDF文件:

批量去除悬浮图片水印
对于这类水印,去除起来并不难,只需要批量删除最后一个图像图层即可。
import PyPDF2writer = PyPDF2.PdfWriter()
reader = PyPDF2.PdfReader('mysql【带水印】.pdf')
for page in reader.pages:obj = page.get("/Resources").get("/XObject")obj.pop(list(obj)[-1])page[PyPDF2.generic.NameObject("/Resources")][PyPDF2.generic.NameObject("/XObject")] = objwriter.add_page(page)output_path = "mysql【去水印】.pdf"
with open(output_path, "wb") as output_file:writer.write(output_file)
对于上面方法生成的水印,已经迅速一键去除。
当然水印图床可能实际并不在最后一层,这就需要调试测试,找到水印对应的层进行删除。
例如我需要查看第5页每个图片对象,可以使用jupyter执行如下代码:
from PIL import Image
import ioreader = PyPDF2.PdfReader('mysql【带水印】.pdf')
page = reader.pages[5]
print(page.get("/Resources").get("/XObject"))
for i, img in enumerate(page.images):img_data = Image.open(io.BytesIO(img.data))print(i, img)display(img_data)
对于一些特殊的PDF有助于找到水印图层的规律,进而批量删除水印。
一般情况下,水印都是最后添加的,所以上面的代码直接删除最后一个图层没啥问题。有时我们会遇到一些特殊的多图层pdf,PyPDF2并不能良好的支持,即使原封不动复制,也会报错。
我们需要改造一下处理函数:
import PyPDF2def remove_image_watermark(input_pdf, output_path):writer = PyPDF2.PdfWriter()reader = PyPDF2.PdfReader(input_pdf)for page in reader.pages:obj = page.get("/Resources").get("/XObject")new_obj = PyPDF2.generic.DictionaryObject()obj.pop(list(obj)[-1])for k in obj:value = obj[PyPDF2.generic.NameObject(k)]if value is None:continuenew_obj[PyPDF2.generic.NameObject(k)] = valuepage[PyPDF2.generic.NameObject("/Resources")][PyPDF2.generic.NameObject("/XObject")] = new_objwriter.add_page(page)with open(output_path, "wb") as output_file:writer.write(output_file)input_pdf = "example2.pdf"
output_path = "example2【去水印】.pdf"
remove_image_watermark(input_pdf, output_path)
但这样也会不断出现异常日志,例如:Object 2763 0 not defined.,而且读取速度非常慢,一个100多页的PDF4分钟才处理完成。
这时,我们可以修改PyPDF2库的源码,修改库根目标的_reader.py文件的get_object函数:

表示在两个条件都不满足时,直接返回None,不再执行后面的读取和正则查找。因为对于本身不存在的对象,执行这样复杂的读取查找只是纯粹浪费时间。
经过上述修改后,再次执行代码,在1秒内处理完毕。
批量添加文字水印
不管是添加文字水印还是图片水印,我们都需要相应的水印PDF与需要添加水印的pdf进行图层合并。
首先我们需要生成文字水印PDF:
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
import mathpagesize = (595, 842)
watermark = 'watermark.pdf'
space = 120
angle = 30pdfmetrics.registerFont(TTFont('msyhbd', 'msyhbd.ttc'))
mark = canvas.Canvas(watermark, pagesize=pagesize)
w, h = pagesize
c = int(math.sqrt(w**2+h**2))
mark.rotate(angle)
mark.setFont('msyhbd', 20)
mark.setFillColor("#8B8B1B")
mark.setFillAlpha(0.4)
for i, y in enumerate(range(-int(math.sin(math.radians(angle))*w-40), int(math.cos(math.radians(angle))*h-40), space)):mark.drawString(20+y*w/c+(w/2 if i%2==1 else 0), y, '小小明的CSDN:https://blog.csdn.net/as604049322')
mark.save()
注意:若缺少reportlab库,可以通过
pip install reportlab安装。
然后整理一下代码,生成带有文字水印的PDF,最终完整代码为:
from reportlab.pdfgen import canvas
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
import PyPDF2
import mathdef create_text_watermark_pdf(text, watermark, pagesize=(595, 842), color="#8B8B1B", font_size=20,opacity=0.3, space=150, angle=30, font='msyhbd.ttc'):pdfmetrics.registerFont(TTFont('font', font))mark = canvas.Canvas(watermark, pagesize=pagesize)w, h = pagesizec = int(math.sqrt(w**2+h**2))mark.rotate(angle)mark.setFont('font', font_size)mark.setFillColor(color)mark.setFillAlpha(opacity)for i, y in enumerate(range(-int(math.sin(math.radians(angle))*w-40), int(math.cos(math.radians(angle))*h-40), space)):mark.drawString(20+y*w/c+(w/2 if i % 2 == 1 else 0), y, text)mark.save()def pdf_add_watermark(filename, save_filepath, watermark='watermark.pdf'):watermark = PyPDF2.PdfReader(watermark).pages[0]pdf_reader = PyPDF2.PdfReader(filename)pdf_writer = PyPDF2.PdfWriter()for page in pdf_reader.pages:page.merge_page(watermark)page.compress_content_streams()pdf_writer.add_page(page)with open(save_filepath, "wb") as out:pdf_writer.write(out)if __name__ == '__main__':watermark = 'watermark.pdf'create_text_watermark_pdf("小小明的CSDN:https://blog.csdn.net/as604049322", watermark, opacity=0.3, angle=30)filename = 'mysql.pdf'save_filepath = 'mysql【带水印】.pdf'pdf_add_watermark(filename, save_filepath, watermark=watermark)

可以很清楚的看到文字水印相对图片文字的好处在于,文字链接可以直接点击访问。
批量去除文字水印
问题来了,对于这种悬浮的文字水印,能否批量去除呢?
首先我们观察一下添加水印前后,page对象的主要变化:
import PyPDF2print(PyPDF2.PdfReader("mysql.pdf").pages[0])
print(PyPDF2.PdfReader("mysql【带水印】.pdf").pages[0])
结果示例:
{'/Type': '/Page', '/Parent': IndirectObject(2, 0, 2016175275936), '/Resources': {'/Font': {'/F1': IndirectObject(5, 0, 2016175275936), '/F2': IndirectObject(9, 0, 2016175275936), '/F3': IndirectObject(11, 0, 2016175275936), '/F4': IndirectObject(16, 0, 2016175275936), '/F5': IndirectObject(21, 0, 2016175275936), '/F6': IndirectObject(26, 0, 2016175275936), '/F7': IndirectObject(28, 0, 2016175275936)}, '/ExtGState': {'/GS7': IndirectObject(7, 0, 2016175275936), '/GS8': IndirectObject(8, 0, 2016175275936)}, '/ProcSet': ['/PDF', '/Text', '/ImageB', '/ImageC', '/ImageI']}, '/MediaBox': [0, 0, 595.32, 841.92], '/Contents': IndirectObject(4, 0, 2016175275936), '/Group': {'/Type': '/Group', '/S': '/Transparency', '/CS': '/DeviceRGB'}, '/Tabs': '/S', '/StructParents': 0}
{'/Type': '/Page', '/Resources': {'/ExtGState': {'/GS7': IndirectObject(5, 0, 2016175272768), '/GS8': IndirectObject(6, 0, 2016175272768), '/gRLs0': {'/ca': 0.3}}, '/Font': {'/F1': IndirectObject(7, 0, 2016175272768), '/F2': IndirectObject(11, 0, 2016175272768), '/F3': IndirectObject(14, 0, 2016175272768), '/F4': IndirectObject(22, 0, 2016175272768), '/F5': IndirectObject(30, 0, 2016175272768), '/F6': IndirectObject(38, 0, 2016175272768), '/F7': IndirectObject(41, 0, 2016175272768), '/F12f89c5f3-0000-4658-b1ab-21ec73871408': {'/BaseFont': '/Helvetica', '/Encoding': '/WinAnsiEncoding', '/Name': '/F1', '/Subtype': '/Type1', '/Type': '/Font'}, '/F2+0': IndirectObject(45, 0, 2016175272768)}, '/ProcSet': ['/ImageC', '/Text', '/ImageB', '/PDF', '/ImageI']}, '/MediaBox': [0, 0, 595.32, 841.92], '/Contents': IndirectObject(49, 0, 2016175272768), '/Group': {'/Type': '/Group', '/S': '/Transparency', '/CS': '/DeviceRGB'}, '/Tabs': '/S', '/Annots': [], '/Parent': IndirectObject(1, 0, 2016175272768)}
可以看到主要变化在于水印PDF的page对象增加了'/Parent'节点。
针对这种情况,我们的批量去除水印代码为:
import PyPDF2pdf_path = "mysql【带水印】.pdf"
writer = PyPDF2.PdfWriter()
reader = PyPDF2.PdfReader(pdf_path)
for page in reader.pages:if '/Parent' in page:del page['/Parent']writer.add_page(page)
output_path = "mysql【去水印】.pdf"
with open(output_path, "wb") as output_file:writer.write(output_file)
结果发现并没有去除水印。
可以看到这个PDF,加水印前后,/Contents仅一个IndirectObject对象,正常对于普通的加过文字水印的PDF,/Contents往往都存在多个IndirectObject对象。执行如下代码进行进一步确认:
import PyPDF2reader = PyPDF2.PdfReader(r"mysql【带水印】.pdf")
page = reader.pages[0]
page_content = page.get_contents()
print(page_content.get_data())
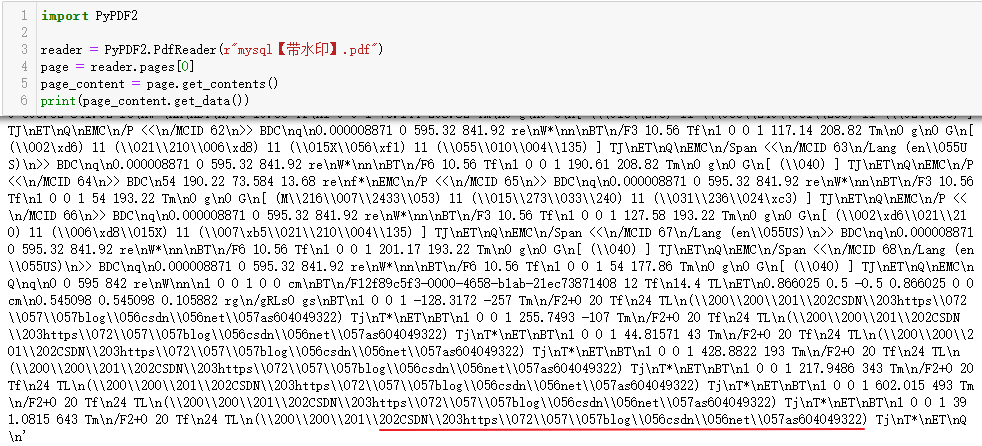
可以确认水印存在于这个对象中,预计主体内容和水印都被合并在了这一个内容对象里,这样我们就无法简单的通过删除/Contents内的某个对象达到删除水印的效果。
虽然我们自己生成的水印PDF无法轻易被删除,但最近我确实看到不少可以轻松删除文字水印的PDF。
例如这个PDF文件:
import PyPDF2pdf_path = "工行结算卡流水.pdf"
reader = PyPDF2.PdfReader(pdf_path)
page = reader.pages[0]
page_content = page.get_contents()
print(page_content)
[IndirectObject(5, 0, 1288719316112), IndirectObject(6, 0, 1288719316112), IndirectObject(7, 0, 1288719316112), IndirectObject(8, 0, 1288719316112), IndirectObject(9, 0, 1288719316112)]
可以看到这一个PDF的第一页的内容对象存在5个对象,这样我们就可以挨个测试只要某个对象,得到的PDF是否满足要求,最终达到去除水印的目的。
首先我们将第一页的每个对象拆分成单独的一页:
import PyPDF2pdf_path = "工行结算卡流水.pdf"
writer = PyPDF2.PdfWriter()
reader = PyPDF2.PdfReader(pdf_path)
page = reader.pages[0]
page_contents = page.get_contents()
for page_content in page_contents:new_page_content = PyPDF2.generic.ArrayObject()new_page_content.append(page_content)page[PyPDF2.generic.NameObject("/Contents")] = new_page_contentwriter.add_page(page)
with open("第一页图层拆分.pdf", "wb") as f:writer.write(f)
然后我们人工检查第一页图层拆分.pdf这个文件,看哪几个图层才是我们需要的数据,目前我测试的这个文件只有第3页是我所需要的数据,那么我们可以批量只取第3个对象的内容:
import PyPDF2pdf_path = "工行结算卡流水.pdf"
output_path = "工行结算卡流水【去水印】.pdf"writer = PyPDF2.PdfWriter()
reader = PyPDF2.PdfReader(pdf_path)
for page in reader.pages:new_page_content = PyPDF2.generic.ArrayObject()page_content = page.get_contents()new_page_content.append(page_content[2])page[PyPDF2.generic.NameObject("/Contents")] = new_page_contentwriter.add_page(page)
with open(output_path, "wb") as f:writer.write(f)
经检查工行结算卡流水.pdf中的水印在工行结算卡流水【去水印】.pdf文件中已经完全消除。
总结
我们可以给PDF加图片水印或文字水印,要去除图片水印,一般只需要删除最后一个图片对象即可。
要去除文字水印,需要保证主体内容和文字水印在/Contents中位于不同的对象内,这样我们只需要删除文字水印对应的IndirectObject对象即可删除水印。
而对于主体内容和文字水印已经混合在一个对象时,本文的提供的方法则无能为力,需要进一步深入分析PDF细节。
相关文章:
PDF批量加水印 与 去除水印实践
本文主要目标是尝试去除水印,但是为了准备测试数据,我们需要先准备好有水印的pdf测试文件。 注意:本文的去水印只针对文字悬浮图片悬浮两种特殊情况,即使是这两种情况也不代表一定都可以去除水印。 文章目录 批量添加透明图片水印…...
【MySQL】服务器配置和管理
本文使用的MySQL版本是8.0 MySQL服务器介绍 MySQL服务器通常说的是mysqld程序。 mysqld 是 MySQL 数据库服务器的核心程序,负责处理客户端的请求、管理数据库和执行数据库操作。管理员可以通过配置文件和各种工具来管理和监控 mysqld 服务器的运行 官方文档&…...

限流定义、算法、实施方案
限流定义 1、 时间 , 基于某段时间或某个时间点,即:时间窗口 2、资源: 对可用资源进行限制: QPS/连接数/传输速率/黑白名单等 分布式环境下,主流限流方案: 网关层限流:流量入口Ngi…...

[312. 戳气球] 动态规划寻找转移函数
Problem: 312. 戳气球 文章目录 思路Code 思路 这个哥们写的思路真的很牛逼,转载一下他。 戳气球题解 Code class Solution { public:int maxCoins(vector<int>& nums) {nums.insert(nums.begin(), 1);nums.push_back(1);int n nums.size();vector<v…...

以操作系统和Java的视角看“中断“
引言 fucking-java-concurrency主要解读了在开发过程中常常会遇到的Java并发问题,本文主要总结Java的中断原理和应用。 PS: https://github.com/WeiXiao-Hyy/blog整理了后端开发的知识网络,欢迎Star! 操作系统的中断 什么是中断࿱…...

【运维】如何在Ubuntu 22上使用Python 3.8的虚拟环境
在Ubuntu 22上使用Python 3.8的虚拟环境安装Ryu是相对简单的。以下是一步一步的指南: https://qq742971636.blog.csdn.net/article/details/139566151 安装Python 3.8: 在Ubuntu 22上,Python 3.8可能不是默认安装的版本。你可以使用以下命令…...
门面模式Api网关(SpringCloudGateway)
1. 前言 当前通过Eureka、Nacos解决了服务注册和服务发现问题,使用Spring Cloud LoadBalance解决了负载均衡的需求,同时借助OpenFeign实现了远程调用。然而,现有的微服务接口都直接对外暴露,容易被外部访问。为保障对外服务的安全…...
玩转Matlab-Simscape(初级)- 09 - 在Simulink中创建曲柄滑块机构的控制模型
** 玩转Matlab-Simscape(初级)- 09 - 在Simulink中创建曲柄滑块机构的控制模型 ** 目录 玩转Matlab-Simscape(初级)- 09 - 在Simulink中创建曲柄滑块机构的控制模型 前言一、问题描述二、创建模型2.1 识别机构中的刚体2.2 确定刚…...

手撸一个java网关框架
手写一个简易的Java网关框架涉及到很多方面,但我会提供一个基本的框架概念和代码示例,帮助你理解网关的基本构建。以下是一个简单的Java网关框架的实现: 定义路由:需要一个路由表来映射请求的URL到对应的处理器。 请求处理&#x…...
亮数据代理IP助力高效数据采集
文章目录 📑前言一、爬虫数据采集痛点二、代理IP解决爬虫痛点2.1 为什么可以2.2 本篇采用的代理IP 四、零代码获取数据4.1 前置背景4.2 亮数据浏览器自动抓取数据4.3 使用步骤: 五、数据集5.1 免费样本5.2 定制数据集 🌤️个人小结 …...
VS2022,DLL1调用lib,lib调用DLL2
DLL1调用lib,lib调用DLL2 问题1:为什么在dll1中需要引入dll2的.lib文件 当你有一个工程(dll1)调用静态库(lib),而静态库(lib)又调用另一个DLL(dll2…...

Unity Mirror VR联机开发 房间篇
一、需求 在联机时通常有加入房间这个步骤,在mirror示例中也有相应的案例,但是那个比较复杂,我们做教育科普类不需要如此复杂,傻瓜式操作基本就可以了,所以我简化了步骤,省略了点击准备按钮这一步骤&#…...
二叉树—leetcode
前言 本篇博客我们来仔细说一下二叉树二叉树的一些OJ题目 请看完上一篇:数据结构-二叉树-CSDN博客 💓 个人主页:普通young man-CSDN博客 ⏩ 文章专栏:LeetCode_普通young man的博客-CSDN博客 若有问题 评论区见📝 &…...
shell编程(二)——字符串与数组
本文为shell 编程的第二篇,介绍shell中的字符串和数组相关内容。 一、字符串 shell 字符串可以用单引号 ‘’,也可以用双引号 “”,也可以不用引号。 单引号的特点 单引号里不识别变量单引号里不能出现单独的单引号(使用转义符…...

【数据结构】二叉树专题
前言 本篇博客我们来看一些二叉树的经典题型,也是对上篇博客的补充 💓 个人主页:小张同学zkf ⏩ 文章专栏:数据结构 若有问题 评论区见📝 🎉欢迎大家点赞👍收藏⭐文章 目录 1.单值二叉树 …...
)
开源模型应用落地-LangChain高阶-LCEL-表达式语言(四)
一、前言 尽管现在的大语言模型已经非常强大,可以解决许多问题,但在处理复杂情况时,仍然需要进行多个步骤或整合不同的流程才能达到最终的目标。然而,现在可以利用langchain来使得模型的应用变得更加直接和简单。 LCEL是什么? LCEL是一种非常灵活和强大的语言,可以帮助您更…...
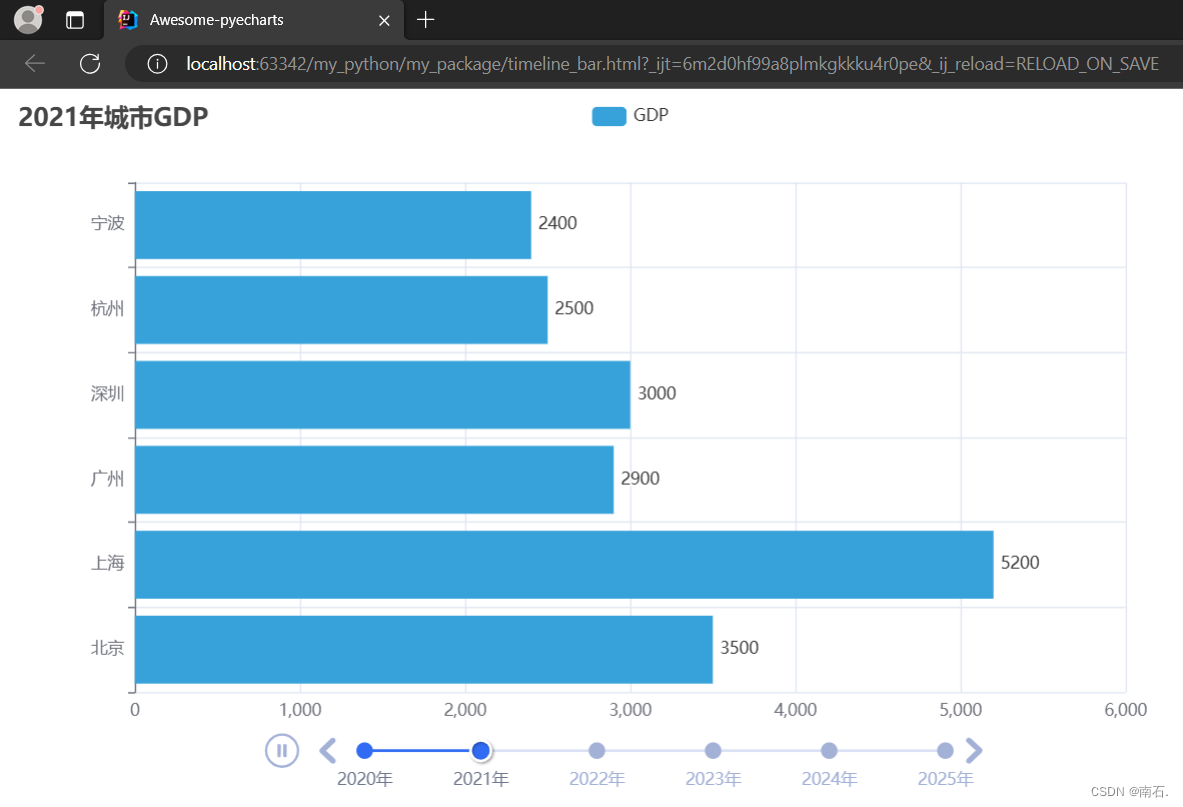
Python第二语言(九、Python第一阶段实操)
目录 1. json数据格式 2. Python与json之间的数据转换 3. pyecharts模块官网 4. pyecharts快速入门(折线图) 5. pyecharts全局配置选项 5.1 set_global_ops使用 5.1.1. title_opts 5.1.2 legend_opts 5.1.3 toolbox_opts 5.1.4 visualmap_opts…...

Java异常机制
1.异常概述和异常处理机制 异常(exception)概述 异常就是程序在运行时出现的意外的,不正常的情况。 若异常产生后没有正确的处理,会导致程序的中断,程序不继续执行,以致造成损失。 2.2 异常处理机制 所以我们在开发中要一套机制来处理各种可能…...

Aws EC2,kubeadm方式安装kubernetes(k8s)
版本 docker版本:20.10.25 k8s版本(kubeadm,kubelet和kubectl):1.20.10-0 初始化 # 禁用 SELinux sudo setenforce 0 sudo sed -i s/^SELINUXenforcing$/SELINUXpermissive/ /etc/selinux/config# 关闭防火墙 sudo …...

python 比较 mysql 表结构差异
最近在做项目的时候,需要比对两个数据库的表结构差异,由于表数量比较多,人工比对的话需要大量时间,且不可复用,于是想到用 python 写一个脚本来达到诉求,下次有相同诉求的时候只需改 sql 文件名即可。 com…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

如何为服务器生成TLS证书
TLS(Transport Layer Security)证书是确保网络通信安全的重要手段,它通过加密技术保护传输的数据不被窃听和篡改。在服务器上配置TLS证书,可以使用户通过HTTPS协议安全地访问您的网站。本文将详细介绍如何在服务器上生成一个TLS证…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别
OpenPrompt 和直接对提示词的嵌入向量进行训练有什么区别 直接训练提示词嵌入向量的核心区别 您提到的代码: prompt_embedding = initial_embedding.clone().requires_grad_(True) optimizer = torch.optim.Adam([prompt_embedding...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

论文笔记——相干体技术在裂缝预测中的应用研究
目录 相关地震知识补充地震数据的认识地震几何属性 相干体算法定义基本原理第一代相干体技术:基于互相关的相干体技术(Correlation)第二代相干体技术:基于相似的相干体技术(Semblance)基于多道相似的相干体…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...
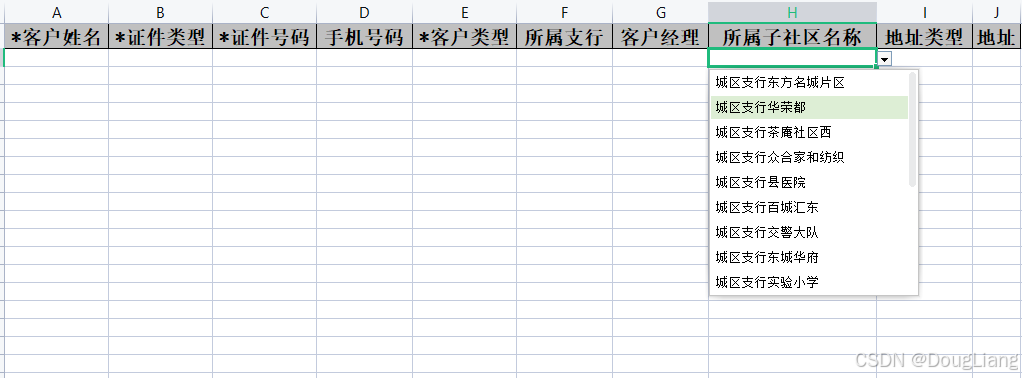
关于easyexcel动态下拉选问题处理
前些日子突然碰到一个问题,说是客户的导入文件模版想支持部分导入内容的下拉选,于是我就找了easyexcel官网寻找解决方案,并没有找到合适的方案,没办法只能自己动手并分享出来,针对Java生成Excel下拉菜单时因选项过多导…...