爬虫实现思路
现在的人工智能太强大了,只要有问题,输入后就能给出大致的实现思路;我看了下确实没问题,只需要更改一些细节基本就能拿来就用;下面是我实验经历:
问题: c# 书写爬虫爬取按动物名称,下载动物图片
第一个模型给的大致答案:
在C#中编写一个爬虫来抓取按动物名称并下载动物图片通常涉及以下几个步骤:
-
选择库:
- 使用.NET的
HttpClient来发送HTTP请求和处理响应。 HtmlAgilityPack或AngleSharp库用于解析HTML文档,提取图像链接。
- 使用.NET的
-
定义爬虫结构:
- 创建一个类,比如
AnimalCrawler,包含方法来执行网络请求和保存图片。
- 创建一个类,比如
-
URL和搜索策略:
- 确定初始的动物数据库或网站URL,可能是动物园、百科全书或者图片搜索引擎的API。
-
发送请求:
- 使用
HttpClient向目标页面发送GET请求,获取HTML内容。
- 使用
-
解析HTML:
- 解析HTML,找到包含动物图片的标签(如
<img>),查找src属性中的图片链接。
- 解析HTML,找到包含动物图片的标签(如
-
下载图片:
- 为每个图片链接创建一个新的下载任务,使用
HttpClient的GetAsync方法下载文件,保存到本地。
- 为每个图片链接创建一个新的下载任务,使用
-
错误处理和进度反馈:
- 添加适当的异常处理代码,确保程序稳定运行,并提供下载进度的反馈。
-
图片保存:
- 保存图片到指定目录,可以使用
FileStream或System.IO.Path类来操作文件路径。
- 保存图片到指定目录,可以使用
-
循环和分页:
- 如果页面有分页,需要处理下一页的请求和图片下载。
第二个模型给的答案,并附带了部分代码:
在C#中编写一个爬虫来爬取按动物名称搜索的图片,并下载这些图片,通常需要以下几个步骤:
-
选择目标网站:确定一个支持按动物名称搜索并展示图片的网站,比如Google图片搜索、Bing图片搜索或专门的动物图片网站。
-
分析网页结构:使用浏览器的开发者工具(如Chrome的DevTools)来查看和分析搜索结果的HTML结构,找到图片链接和其他关键信息。
-
发送HTTP请求:使用C#的
HttpClient或第三方库(如RestSharp、Flurl.Http)来发送HTTP请求,获取网页内容。 -
解析HTML:使用HTML解析库(如
AngleSharp、HtmlAgilityPack)来解析返回的HTML内容,提取图片链接和其他所需信息。 -
下载图片:根据提取的图片链接,使用
HttpClient下载图片并保存到本地文件系统中。 -
处理异常和限制:考虑处理网络错误、重试逻辑、遵守网站的robots.txt和速率限制等。
-
优化和扩展:考虑多线程下载、使用代理服务器、添加日志记录等功能。
以下是一个简化的伪代码示例,展示了如何使用C#编写一个基本的图片爬虫:
csharp复制代码
using System; | |
using System.Net.Http; | |
using System.Threading.Tasks; | |
// 假设你已经添加了必要的HTML解析库引用,如AngleSharp | |
class AnimalImageCrawler | |
{ | |
private readonly HttpClient _httpClient; | |
public AnimalImageCrawler() | |
{ | |
_httpClient = new HttpClient(); | |
} | |
public async Task DownloadImagesByAnimalName(string animalName, string saveDirectory) | |
{ | |
// 1. 构造搜索URL(以Google图片搜索为例,但注意Google有反爬虫措施) | |
string searchUrl = $"https://www.google.com/search?q={animalName}&tbm=isch"; | |
// 2. 发送HTTP请求获取HTML内容 | |
string htmlContent = await _httpClient.GetStringAsync(searchUrl); | |
// 3. 解析HTML内容,提取图片链接(这里省略了HTML解析的具体实现) | |
var imageUrls = ParseImageUrlsFromHtml(htmlContent); // 假设这个方法能返回图片链接列表 | |
// 4. 下载并保存图片 | |
foreach (var imageUrl in imageUrls) | |
{ | |
try | |
{ | |
byte[] imageBytes = await _httpClient.GetByteArrayAsync(imageUrl); | |
string imagePath = Path.Combine(saveDirectory, Path.GetFileName(new Uri(imageUrl).LocalPath)); | |
File.WriteAllBytes(imagePath, imageBytes); | |
Console.WriteLine($"Downloaded: {imagePath}"); | |
} | |
catch (Exception ex) | |
{ | |
Console.WriteLine($"Error downloading image: {ex.Message}"); | |
} | |
} | |
} | |
// 省略了ParseImageUrlsFromHtml的具体实现,因为它依赖于HTML结构和解析库 | |
// ... | |
} | |
// 使用示例 | |
class Program | |
{ | |
static async Task Main(string[] args) | |
{ | |
var crawler = new AnimalImageCrawler(); | |
await crawler.DownloadImagesByAnimalName("cat", "C:\\DownloadedImages"); | |
} | |
} |
注意:
- 爬虫可能会受到目标网站的反爬虫策略的限制,包括IP封锁、验证码挑战等。确保你的爬虫遵守网站的robots.txt文件和速率限制。
- 对于商业用途或大量数据的爬虫,你可能需要与目标网站的管理员联系,获取适当的API访问权限或遵守其他使用条款。
- 示例中的
ParseImageUrlsFromHtml方法需要根据你的目标网站和HTML解析库的具体实现来编写。这通常涉及使用CSS选择器或XPath表达式来定位图片链接元素。
相关文章:

爬虫实现思路
现在的人工智能太强大了,只要有问题,输入后就能给出大致的实现思路;我看了下确实没问题,只需要更改一些细节基本就能拿来就用;下面是我实验经历: 问题: c# 书写爬虫爬取按动物名称,…...
神经网络 torch.nn---Non-Linear Activations (ReLU)
ReLU — PyTorch 2.3 documentation torch.nn - PyTorch中文文档 (pytorch-cn.readthedocs.io) 非线性变换的目的 非线性变换的目的是为神经网络引入一些非线性特征,使其训练出一些符合各种曲线或各种特征的模型。 换句话来说,如果模型都是直线特征的…...
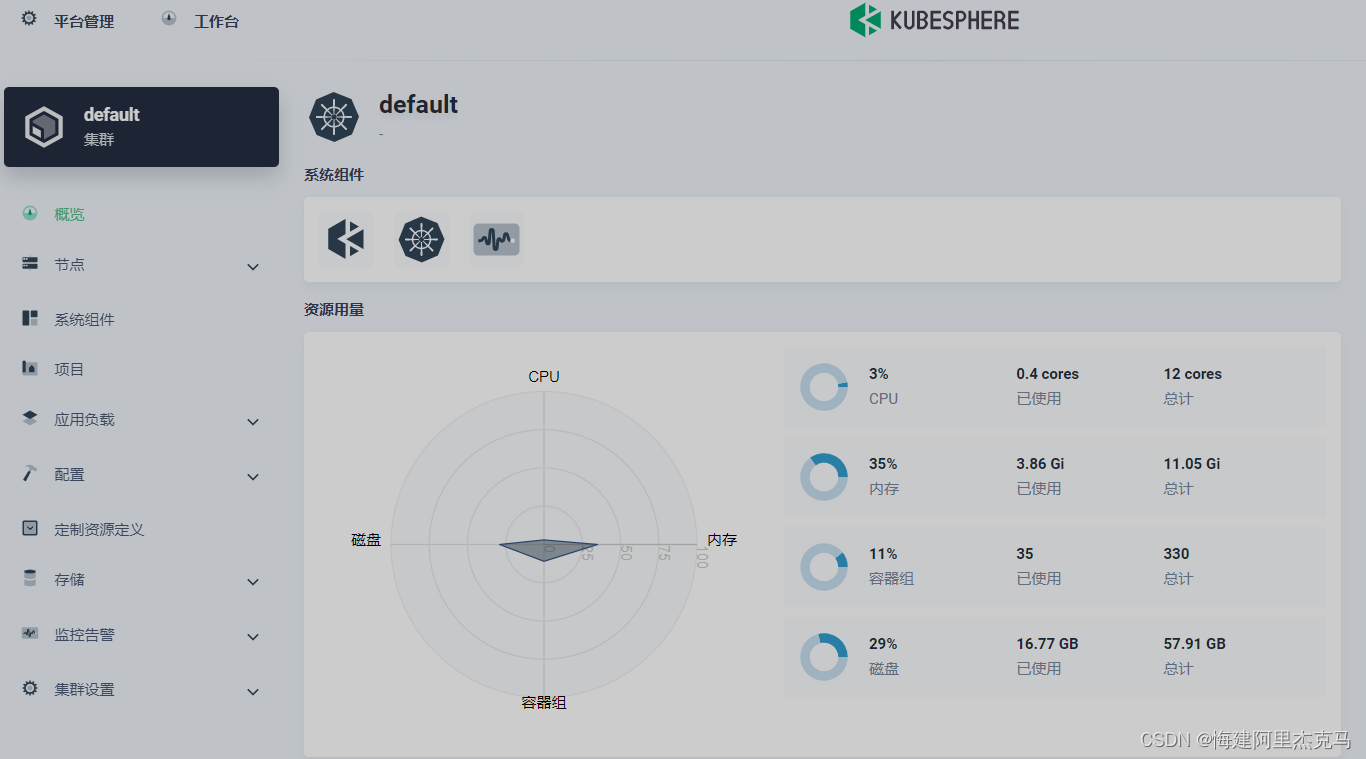
【微服务】使用kubekey部署k8s多节点及kubesphere
kubesphere官方部署文档 https://github.com/kubesphere/kubesphere/blob/master/README_zh.md kubuctl命令文档 https://kubernetes.io/zh-cn/docs/reference/kubectl/ k8s资源类型 https://kubernetes.io/zh-cn/docs/reference/kubectl/#%E8%B5%84%E6%BA%90%E7%B1%BB%E5%9E…...

目标检测数据集 - 垃圾桶满溢检测数据集下载「包含VOC、COCO、YOLO三种格式」
数据集介绍:垃圾桶满溢检测数据集,真实场景高质量图片数据,涉及场景丰富,比如城市道边垃圾桶满溢、小区垃圾桶满溢、社区垃圾桶满溢、农村道边垃圾桶满溢、垃圾集中处理点垃圾桶满溢、公园垃圾桶满溢数据等。数据集标注标签划分为…...
)
6.9总结(省赛排位赛1)
省赛排位赛1省赛排名赛1 - Virtual Judge (vjudge.net) 思路: 其实就是一个斐波拉契数列,当前项前两项之和,先将范围内的数全部存起来放进一个数组,再进行累加查询 代码: #define _CRT_SECURE_NO_WARNINGS 1 #incl…...

58.CountdownLatch
用来进行线程同步协作,等待所有线程完成倒计时。 构造参数用来初始化等待计数值,await方法用来等待计数归零,countDown方法用来让计数减一。 CountdownLatch普通使用 @Slf4j public class CountdownLatchDemo {public static void main(String[] args) {CountDownLatch c…...

Java数据结构准备工作---常用类
文章目录 前言1.包装类1.1.包装类基本知识1.2.包装类的用途1.3.装箱和拆箱1.3.1.装箱:1.3.2.拆箱 1.4 包装类的缓存问题 2.时间处理类2.1.Date 时间类(java.util.Date)2.2.DateFormat 类和 SimpleDateFormat 类2.3.Calendar 日历类 3.其他常用类3.1.Math类3.2.Rando…...

SD 使用教程
SD 换脸步骤 使用Stable Diffusion (SD) 进行换脸的基本步骤可以从以下几个方面概述,这里以一种常见的方式为例,结合了插件的使用来简化流程: 准备工作 安装必要的软件和插件:首先,确保你已经安装了Stable Diffusion…...

Sylar---协程调度模块
协程调度模块: 首先是协程任务类FiberAndThread,包括协程,函数,指定的线程;提供了五个构造函数,只传协程的智能指针,只传函数对象,传协程智能指针的指针,函数对象指针,还…...

iOS Hook 崩溃
0x00 崩溃重现 被 Hook 的类,是这样的: interface ViewController : UIViewController endimplementation ViewController - (void)loadView {[super loadView];NSLog("%s", __func__); }- (void)test {NSLog("%s", __func__); }-…...

区间预测 | Matlab实现LSTM-ABKDE长短期记忆神经网络自适应带宽核密度估计多变量回归区间预测
区间预测 | Matlab实现LSTM-ABKDE长短期记忆神经网络自适应带宽核密度估计多变量回归区间预测 目录 区间预测 | Matlab实现LSTM-ABKDE长短期记忆神经网络自适应带宽核密度估计多变量回归区间预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现LSTM-ABKDE长…...
相关笔记汇总)
linux内核下rapidio(TSI721)相关笔记汇总
1 驱动的安装 和 主要功能(doorbell, DMA, rionet)的简单测试 linux5.4 下使用rapidio(tsi721)的笔记记录_kernel-rapidio-CSDN博客 2 机理分析 linux内核下,rapidio网络系统建立的过程(枚举 和 发现)_linux rapidio-CSDN博客 linux内核下,(rapidio)T…...

从GPT-4到GPT-4o:人工智能的进化与革命
从GPT-4到GPT-4o:人工智能的进化与革命 近期,OpenAI推出了最新版本的人工智能模型——GPT-4o,引发了广泛的关注和讨论。在这篇文章中,我们将对GPT-4o进行全面评价,包括与前一版本GPT-4的对比分析,GPT-4o的…...

【Java】/*抽象类和接口*/
目录 一、抽象类和抽象方法 1.1 概念 1.2 特性 1.3 作用 二、接口 2.1 概念及定义 2.2 特性 2.3 实例:笔记本电脑 2.4 一个类可以实现多个接口 2.5 一个接口可以继承多个接口 2.6 Comparable接口 2.7 Comparator接口 2.8 Cloneable接口 2.9 浅拷贝和深…...
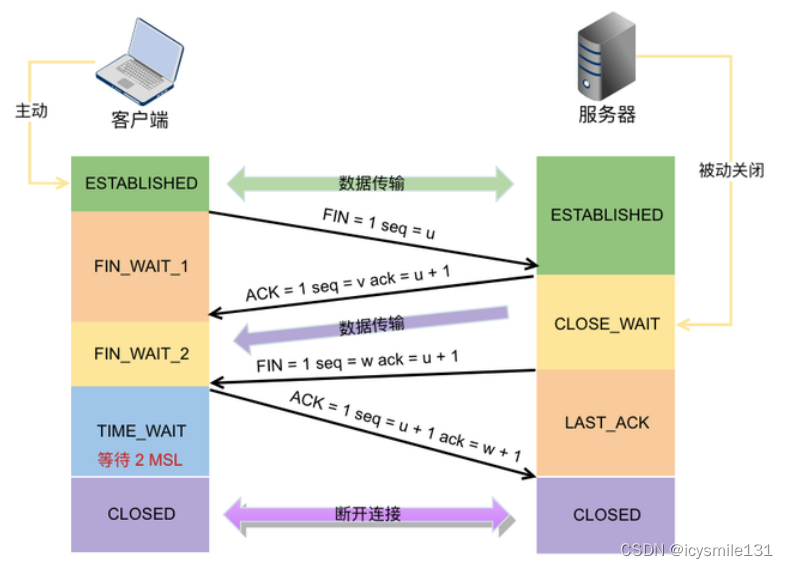
TCP/IP协议介绍——三次握手四次挥手
TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同网络间实现信息传输的协议簇。TCP/IP协议不仅仅指的是TCP 和IP两个协议,而是指一个由FTP、SMTP、TCP、UDP、IP等协议构成的协议…...
[C++]基于C++opencv结合vibe和sort tracker实现高空抛物实时检测
【vibe算法介绍】 ViBe算法是一种高效的像素级视频背景建模和前景检测算法。以下是对该算法的详细介绍: 一、算法原理 ViBe算法的核心思想是通过为每个像素点存储一个样本集,利用该样本集与当前像素值进行比较,从而判断该像素是否属于背景…...
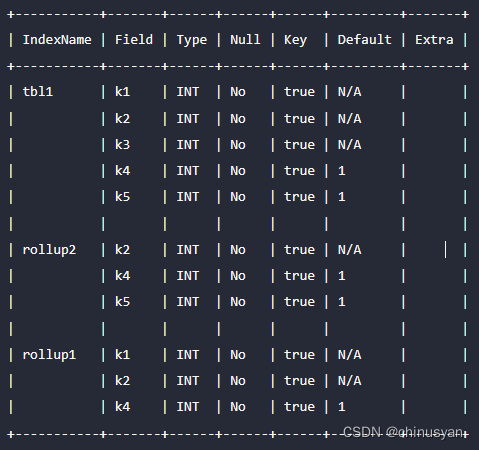
Apache Doris 基础 -- 数据表设计(模式更改)
用户可以通过schema Change操作修改现有表的模式。表的模式主要包括对列的修改和对索引的修改。这里我们主要介绍与列相关的Scheme更改。对于与索引相关的更改,可以查看数据表设计/表索引,查看每个索引的更改方法。 1、术语 基本表(Base Ta…...
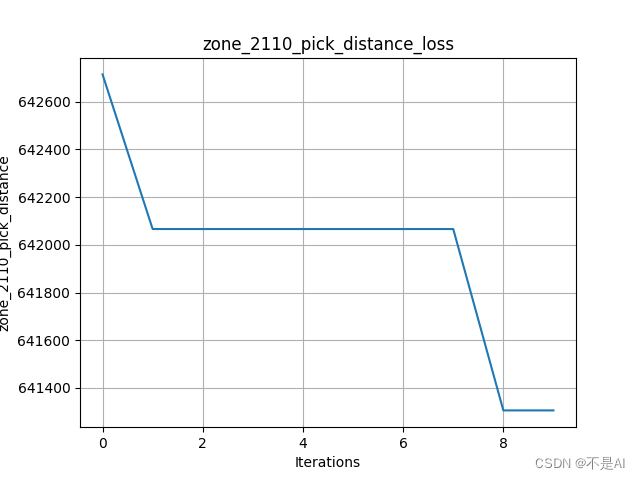
【机器学习】【遗传算法】【项目实战】药品分拣的优化策略【附Python源码】
仅供学习、参考使用 一、遗传算法简介 遗传算法(Genetic Algorithm, GA)是机器学习领域中常见的一类算法,其基本思想可以用下述流程图简要表示: (图参考论文:Optimization of Worker Scheduling at Logi…...

电子电气架构 ---车载安全防火墙
我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 屏蔽力是信息过载时代一个人的特殊竞争力,任何消耗你的人和事,多看一眼都是你的不对。非必要不费力证明自己,无利益不试图说服别人,是精神上的节…...

解决selenium加载网页过慢影响程序运行时间的问题
在用selenium爬取动态加载网页时,发现网页内容都全部加载完了,但是页面还在转圈,并且获取页面内容的代码也没有执行,后面了解到selenium元素操作等方法是需要等待页面所有元素完全加载完成后才开始执行的,所以在页面未…...

在 Nginx Stream 层“改写”MQTT ngx_stream_mqtt_filter_module
1、为什么要修改 CONNECT 报文? 多租户隔离:自动为接入设备追加租户前缀,后端按 ClientID 拆分队列。零代码鉴权:将入站用户名替换为 OAuth Access-Token,后端 Broker 统一校验。灰度发布:根据 IP/地理位写…...

全面解析各类VPN技术:GRE、IPsec、L2TP、SSL与MPLS VPN对比
目录 引言 VPN技术概述 GRE VPN 3.1 GRE封装结构 3.2 GRE的应用场景 GRE over IPsec 4.1 GRE over IPsec封装结构 4.2 为什么使用GRE over IPsec? IPsec VPN 5.1 IPsec传输模式(Transport Mode) 5.2 IPsec隧道模式(Tunne…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...

让回归模型不再被异常值“带跑偏“,MSE和Cauchy损失函数在噪声数据环境下的实战对比
在机器学习的回归分析中,损失函数的选择对模型性能具有决定性影响。均方误差(MSE)作为经典的损失函数,在处理干净数据时表现优异,但在面对包含异常值的噪声数据时,其对大误差的二次惩罚机制往往导致模型参数…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...

实战三:开发网页端界面完成黑白视频转为彩色视频
一、需求描述 设计一个简单的视频上色应用,用户可以通过网页界面上传黑白视频,系统会自动将其转换为彩色视频。整个过程对用户来说非常简单直观,不需要了解技术细节。 效果图 二、实现思路 总体思路: 用户通过Gradio界面上…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...
之(六) ——通用对象池总结(核心))
怎么开发一个网络协议模块(C语言框架)之(六) ——通用对象池总结(核心)
+---------------------------+ | operEntryTbl[] | ← 操作对象池 (对象数组) +---------------------------+ | 0 | 1 | 2 | ... | N-1 | +---------------------------+↓ 初始化时全部加入 +------------------------+ +-------------------------+ | …...
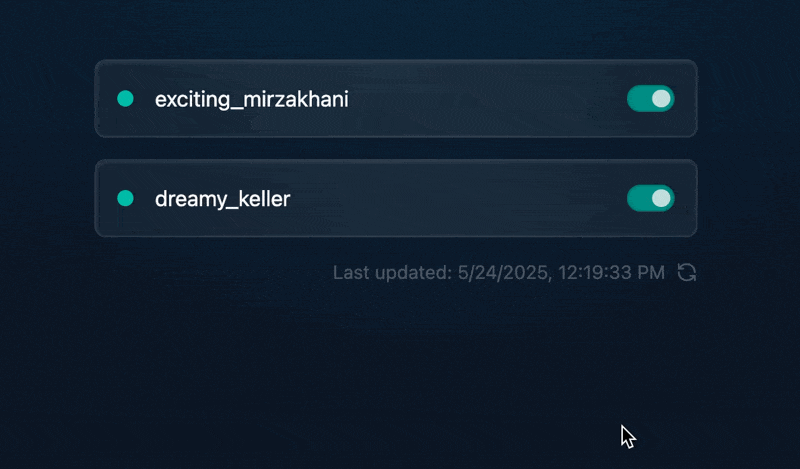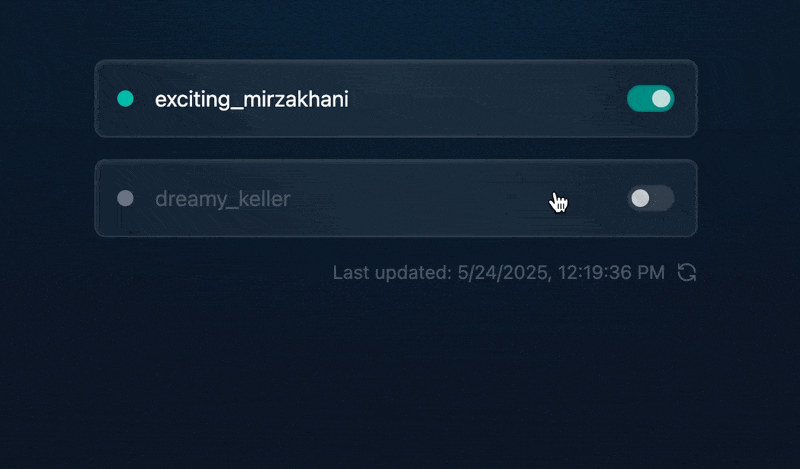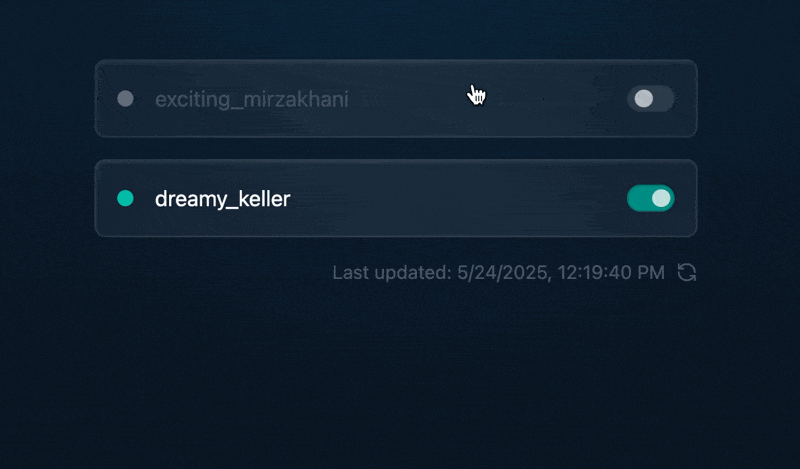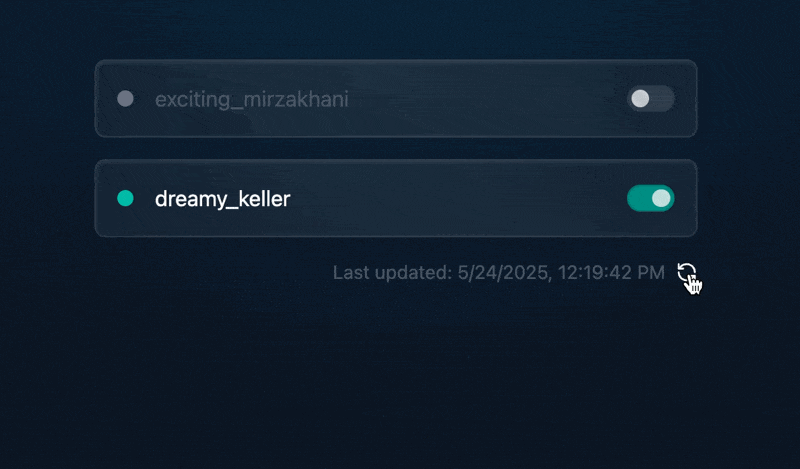
轻量级Docker管理工具Docker Switchboard
简介 什么是 Docker Switchboard ? Docker Switchboard 是一个轻量级的 Web 应用程序,用于管理 Docker 容器。它提供了一个干净、用户友好的界面来启动、停止和监控主机上运行的容器,使其成为本地开发、家庭实验室或小型服务器设置的理想选择…...
)
2025.6.9总结(利与弊)
凡事都有两面性。在大厂上班也不例外。今天找开发定位问题,从一个接口人不断溯源到另一个 接口人。有时候,不知道是谁的责任填。将工作内容分的很细,每个人负责其中的一小块。我清楚的意识到,自己就是个可以随时替换的螺丝钉&…...