自然语言处理(NLP)—— 自动摘要
自动摘要是一种将长文本信息浓缩为短文本的技术,旨在保留原文的主要信息和意义。
1 自动摘要的第一种方法
它的第一种方法是基于理解的,受认知科学和人工智能的启发。
在这个方法中,我们首先建立文本的语义表示,这可以理解为文本中的概念和它们之间关系的网络。然后,我们对这个语义表示进行简化处理,并从简化的内容中生成摘要。
1.1 使用方法
这个过程中使用了宏规则来减少文本内容,包括:
消除:比如从"彼得看到了一个蓝色的球"简化为"彼得看到了一个球"。这里,颜色信息被消除了,因为它可能对理解句子的主要意义不是必要的。
泛化:比如"彼得看到了一只鹰"可以泛化为"彼得看到了一只鸟"; 彼得看到了一只鹰,彼得看到了一只秃鹫 可以泛化为 彼得看到了鸟 。这个规则把具体的实体替换为它们的更高级概念。
凝练:将一系列的动作或事件压缩成一个总结性的行为,比如"彼得挖地基,建墙壁,铺屋顶"可以凝练为"彼得建了一所房子"。
1.2 自动摘要的难点
构建语义表示可能非常耗时和成本高昂,因为它需要深入理解文本中的每一个概念及其关系。
在简化阶段决定什么是重要的可能非常微妙,因为这需要区分文本中的核心内容和次要信息。
在整个处理过程中需要保持对原始信息层次的认识,不可以在简化或泛化的过程中失去重要信息。
总的来说,这种基于理解的自动摘要方法试图模仿人类如何理解和重述信息,但这在实际操作中涉及到很多复杂的决策和计算过程。
2 自动摘要的第二种方法
自动摘要的第二种方法是基于抽取的,它试图直接从原文中找到最重要的句子并将其抽取出来形成摘要。这种方法不需要深入理解文本的语义内容,而是通过一些启发式的规则来确定哪些句子最重要。
2.1 基于抽取的摘要主要思路
高全局TF-IDF值的句子:这种方法假设我们有一个语料库,并通过计算词语在文档中的TF-IDF值来确定句子的重要性。TF-IDF值高的词语被认为对文档主题的贡献更大,因此包含这些词语的句子被认为是重要的。这种方法简单易计算,但高TF-IDF值的句子不一定总是最有趣或最相关的句子。
2.1.1 面临的问题
出于文体原因,作者可能会使用同义词,这可能导致重要的信息被忽略,因为同义词可能有不同的TF-IDF值。
不解决指代消解问题(anaphora resolution),即代词和它们所指代的名词之间的关系没有明确,这可能会使摘要中的句子难以理解。
至少需要一个词形还原过程(lemmatization),以便计算一致性,因为不同的词形式应该被视为相同的词。
句子顺序可能会被打乱,这可能会破坏原文的叙事流程和逻辑连贯性。
2.2 依赖原型句子
某些句子因包含了特定的指示词而被视为原型句子,例如,在一篇文章中,“在本文中我们将重点讨论......”可能表明作者在介绍主要内容。根据这些指示词的存在或缺失为句子打分,可以帮助确定哪些句子最可能概括文章的主要内容。
2.2.1 面临的问题
这需要根据不同类型的文本进行调整,因为不同类型的文本可能有不同的原型句子和指示词。
同样,这种方法也不解决指代消解的问题。
可能会有整体一致性的问题,因为仅仅根据特定词汇挑选出来的句子可能并不足以形成一个逻辑上连贯和完整的摘要。
总之,基于抽取的方法较为简单,适合于快速处理大量文本。然而,为了生成高质量的摘要,可能需要结合多种技术,并且针对不同文本类型进行适当的调整和优化。
3 自动摘要的第三种方法
自动摘要的第三种方法进一步增加了分析的复杂性和文本理解的深度。
3.1 第三种思路:通过定位词汇链
这种方法涉及识别文本中的名词并评估它们之间的语义距离,这通常是通过诸如WordNet这样的语言数据库来完成的,该数据库包含单词间的各种关系。
接下来,基于这些语义关系,我们构建一个关系图,其中包含的节点和边尽可能地反映这些词在文本中的实际关系。
然后,根据这些关系,我们为句子分配分数,并选择得分最高的句子作为摘要的一部分。
3.2 面临的问题
构建这样的词汇链需要对文本有深入的语义理解,这可能在计算上非常昂贵。
选择哪些关系对于构建摘要是重要的,这需要精细的判断,可能涉及复杂的算法。
4 自动摘要的第四种方法
4.1 第四种思路:通过分析句子之间的关系
在进行了形态学和句法分析之后,我们寻找能够揭示句子之间关系的模式(例如,“然后”,“因此”等连接词或短语)。
这些模式帮助我们建立句子之间,以及段落之间的关系图。
在这个图中,我们可以找到扮演特定语义角色的节点(句子),例如结论句或是主题句。
4.2 面临的问题
分析句子之间的关系需要复杂的自然语言处理技术,如解析句子结构和识别句子功能。
确定哪些句子对于理解全文最为关键同样需要细致的工作,而且通常需要高级别的文本理解。
这两种方法都试图在更深层次上理解文本,从而生成更加准确和有信息量的摘要。然而,它们的效率和准确性很大程度上取决于所使用的NLP技术的先进程度和适用性。这些方法也可能需要对特定领域或文本类型进行调整,以便更好地识别和利用文本中的重要信息。
5 自动摘要的第五种方法
第五种自动摘要方法依赖于构建一个修辞分析器,这种方法在文献中经常与“修辞结构理论”(Rhetorical Structure Theory, RST)关联。
5.1 修辞分析器的构建方法
这种方法使用修辞标记来建立文本中命题之间的修辞关系。
[Marcu, 2000]提出了一个基于450个话语标记的数据库。这些标记帮助确定文本中命题之间的修辞关系。
利用这些话语标记,可以开发出一个算法来构建一个最优的树结构,其中的箭头表示命题之间的修辞关系,如阐释、理由、举例、让步、对立、对比、证据等。
这棵树的根节点将是文本中最显著的命题,从这个根节点出发,使用广度优先搜索的方法沿树路径进行,直到达到期望的摘要长度。
5.2 实施这种方法的优势
通过识别和利用文本中的修辞结构,这种方法可以生成一个逻辑结构严谨、内容紧凑的摘要。
树的根节点通常包含文本的核心信息,从而确保了摘要的信息密度。
5.3 可能遇到的挑战
需要精确的修辞标记和高效的算法来正确识别和建立命题之间的关系。
构建最优树结构可能在计算上非常昂贵,特别是对于较长的文本。
确定摘要的合适大小并不总是直接的,可能需要预先设置或者动态决定。
修辞分析器方法在理论上是十分强大的,它可以揭示文本的深层结构,提供内容丰富的摘要。然而,这种方法对数据和算法的质量要求很高,可能需要复杂的自然语言处理技术来实现。
6 基于学习的方法
基于学习的自动摘要方法尤其强调通过监督学习来提高摘要生成的质量。
6.1 步骤
6.1.1 从语料库中抽取句子
选取一个预先定义好的语料库,从中抽取句子,这些句子可能直接被用来构建摘要,或者被赋予一个抽取得分,表示它们作为摘要一部分的重要性。
6.1.2 编写抽取标准
定义一系列用于评估句子重要性的标准,包括:
位置性:某些位置的句子(如文章的第一句)通常被认为比其他位置的句子更重要。
形态学和量化:基于词频等统计信息的标准,识别出现频率高的关键词,这些通常被认为是文章的核心内容。
话语性:考虑句子在文本中的功能和角色,如是否介绍主题、提供证据或总结观点等。
6.1.3 构建特征向量
根据定义的标准,为训练集中的每个句子构建一个特征向量,这些向量包含了所有抽取标准的值。
6.1.4 算法训练
使用机器学习算法,比较这些特征向量与人工赋予的抽取得分,通过训练过程确定每个抽取标准的权重。
6.1.5 评估和优化
在测试集上评估模型的性能,并根据需要引入新的规则或调整现有规则,以提高系统的性能。
6.2 面临的问题
缺乏深层次的语言分析:没有进行形态句法分析或指代消解,意味着模型可能无法充分理解句子之间的逻辑和语义联系,导致摘要中丢失重要信息。
学习实例限制:当学习实例仅为单个句子时,可能会忽略句子间的关系,从而影响摘要的连贯性和完整性。
尽管基于学习的方法在自动摘要领域具有潜力,尤其是在处理大规模数据集时,但要生成高质量、连贯且信息丰富的摘要,还需要进一步解决上述问题。这可能包括集成更复杂的自然语言处理技术,如语言模型、深度学习方法以及更加精细的特征工程。
相关文章:
—— 自动摘要)
自然语言处理(NLP)—— 自动摘要
自动摘要是一种将长文本信息浓缩为短文本的技术,旨在保留原文的主要信息和意义。 1 自动摘要的第一种方法 它的第一种方法是基于理解的,受认知科学和人工智能的启发。 在这个方法中,我们首先建立文本的语义表示,这可以理解为文本…...

Spring RestClient报错:400 Bad Request : [no body]
我项目采用微服务架构,所以各服务之间通过Spring RestClient远程调用,本来一直工作得好好的,昨天突然发现远程调用一直报错,错误详情如下: org.springframework.web.client.HttpClientErrorException$BadRequest: 400…...
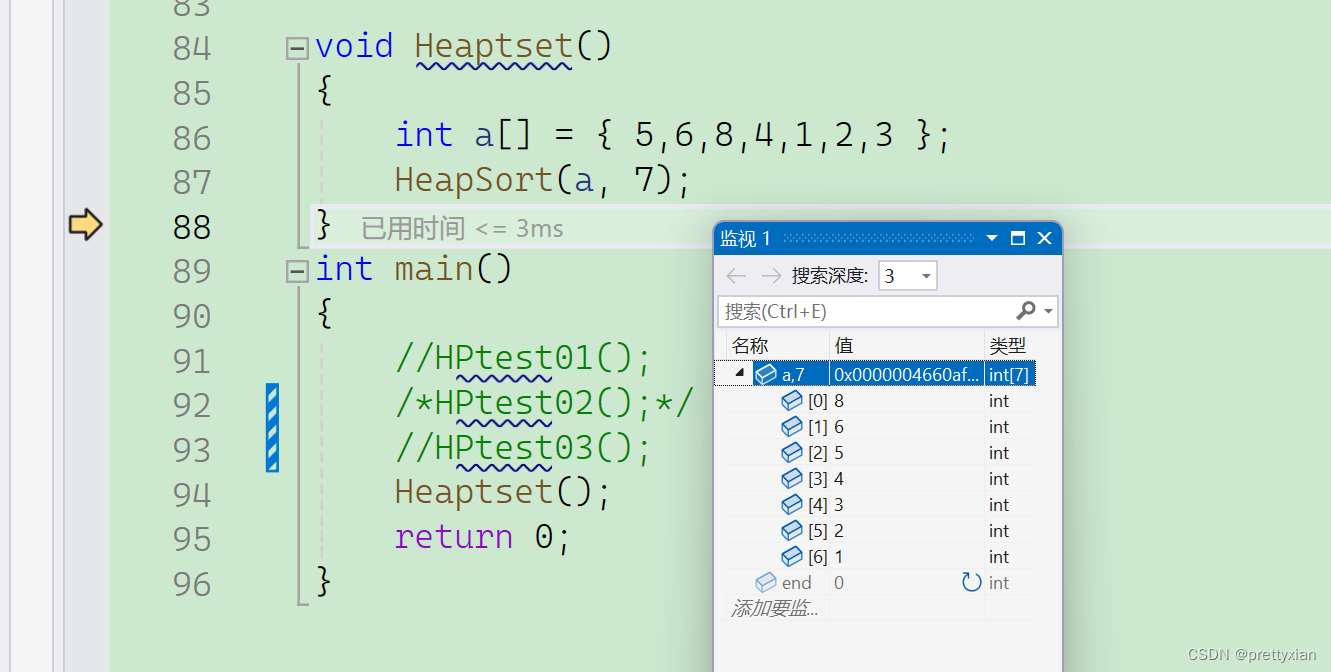
【数据结构】 -- 堆 (堆排序)(TOP-K问题)
引入 要学习堆,首先要先简单的了解一下二叉树,二叉树是一种常见的树形数据结构,每个节点最多有两个子节点,通常称为左子节点和右子节点。它具有以下特点: 根节点(Root):树的顶部节…...

C#面:XML与 HTML 的主要区别是什么
C# XML与HTML有以下几个主要区别: 用途不同:XML(eXtensible Markup Language)是一种用于存储和传输数据的标记语言,它的主要目的是描述数据的结构和内容。HTML(HyperText Markup Language)是一…...

java并发-如何保证线程按照顺序执行?
【readme】 使用只有单个线程的线程池(最简单)Thread.join() 可重入锁 ReentrantLock Condition 条件变量(多个) ; 原理如下: 任务1执行前在锁1上阻塞;执行完成后在锁2上唤醒;任务…...

PyCharm中 Fitten Code插件的使用说明一
一. 简介 Fitten Code插件是是一款由非十大模型驱动的 AI 编程助手,它可以自动生成代码,提升开发效率,帮您调试 Bug,节省您的时间,另外还可以对话聊天,解决您编程碰到的问题。 前一篇文章学习了 PyCharm…...
Polar Web【简单】PHP反序列化初试
Polar Web【简单】PHP反序列化初试 Contents Polar Web【简单】PHP反序列化初试思路EXP手动脚本PythonGo 运行&总结 思路 启动环境,显示下图中的PHP代码,于是展开分析: 首先发现Easy类中有魔术函数 __wakeup() ,实现的是对成员…...
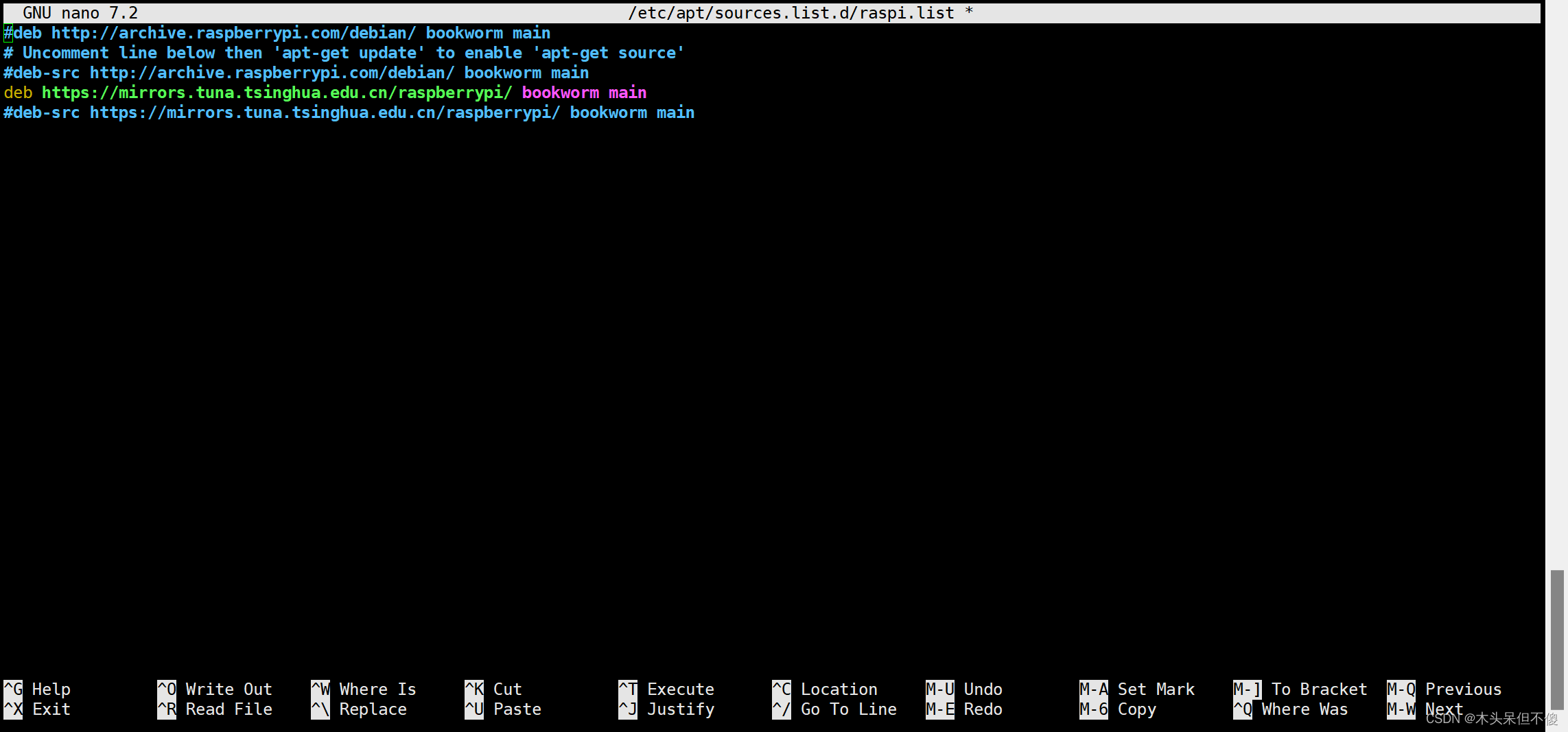
树莓派4B 零起点(二) 树莓派 更换软件源和软件仓库
目录 一、准备工作,查看自己的树莓派版本 二、安装HTTPS支持 三、更换为清华源 1、更换Debian软件源 2,更换Raspberrypi软件仓库 四、进行软件更新 接前章,我们的树莓派已经启动起来了,接下来要干的事那就是更换软件源和软件…...
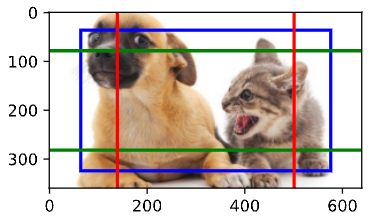
Pytorch 实现目标检测二(Pytorch 24)
一 实例操作目标检测 下面通过一个具体的例子来说明锚框标签。我们已经为加载图像中的狗和猫定义了真实边界框,其中第一个 元素是类别(0代表狗,1代表猫),其余四个元素是左上角和右下角的(x, y)轴坐标(范围…...
进行高效列表操作)
如何使用Python中的列表解析(list comprehension)进行高效列表操作
Python中的列表解析(list comprehension)是一种创建列表的简洁方法,它可以在单行代码中执行复杂的循环和条件逻辑。列表解析提供了一种快速且易于阅读的方式来生成新的列表。 以下是一些使用列表解析进行高效列表操作的示例: 1.…...

java使用websocket遇到的问题
java使用websocket的bug 1 websocket连接正常但是收不到服务端发出的消息java的websocket并发的时候导致连接断开(看着连接是正常的,但是实际上已经断开) 1 websocket连接正常但是收不到服务端发出的消息 java的websocket并发的时候导致连接断…...

[Cloud Networking] Layer 2
文章目录 1. 什么是Mac Address?2. 如何查找MAC地址?3. 二层数据交换4. [Layer 2 Protocol](https://blog.csdn.net/settingsun1225/article/details/139552315) 1. 什么是Mac Address? MAC 地址是计算机的唯一48位硬件编码,嵌入到网卡中。 MAC地址也…...
)
[240609] qwen2 发布,在 Ollama 已可用 | 采用语言模型构建通用 AGI(2020年8月)
目录 qwen2 发布,在 Ollama 已可用Qwen2 模型概览 (基于 Ollama 网站信息)一、模型介绍二、模型参数三、支持语言 (除英语和中文外)四、模型性能五、许可证六、数据支撑: 采用语言模型构建通用 AGI qwen2 发布,在 Ollama 已可用 Qwen2 模型概览 (基于 O…...
)
赶紧收藏!2024 年最常见 20道分布式、微服务面试题(五)
上一篇地址:赶紧收藏!2024 年最常见 20道分布式、微服务面试题(四)-CSDN博客 九、在分布式系统中,如何保证数据一致性? 在分布式系统中保证数据一致性是一个复杂的问题,因为分布式系统由多个独…...

为什么Kubernetes(K8S)弃用Docker:深度解析与未来展望
为什么Kubernetes弃用Docker:深度解析与未来展望 🚀 为什么Kubernetes弃用Docker:深度解析与未来展望摘要引言正文内容(详细介绍)什么是 Kubernetes?什么是 Docker?Kubernetes 和 Docker 的关系…...
软件游戏提示msvcp120.dll丢失的解决方法,总结多种靠谱的解决方法
在电脑使用过程中,我们可能会遇到一些错误提示,其中之一就是“找不到msvcp120.dll”。那么,msvcp120.dll是什么?它对电脑有什么影响?有哪些解决方法?本文将从以下几个方面进行探讨。 一,了解msv…...
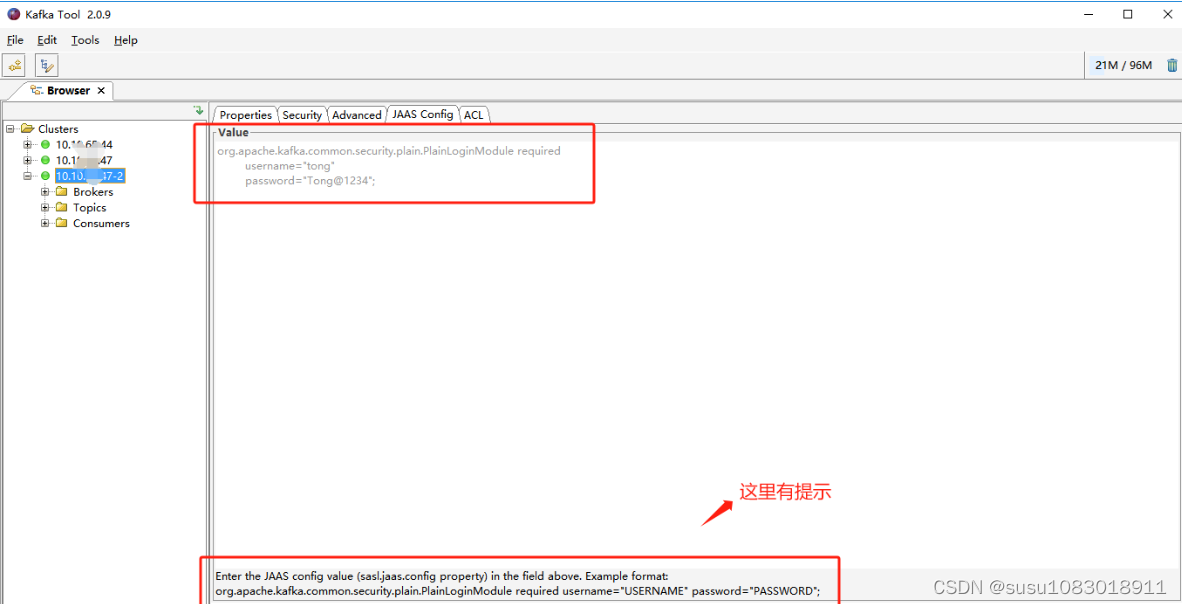
使用kafka tools工具连接带有用户名密码的kafka
使用kafka tools工具连接带有用户名密码的kafka 创建kafka连接,配置zookeeper 在Security选择Type类型为SASL Plaintext 在Advanced页面添加如下图红框框住的内容 在JAAS_Config加上如下配置 需要加的配置: org.apache.kafka.common.security.plain.Pla…...

[个人感悟] Java基础问题应该考察哪些问题?
前言 “一切代码无非是数据结构和算法流程的结合体.” 忘了最初是在何处看见这句话了, 这句话, 对于Java基础的考察也是一样. 正如这句话所说, 我们对于基础的考察主要考察, 数据结构, 集合类型结构, 异常类型, 已经代码的调用和语法关键字. 其中数据结构和集合类型结构是重点…...
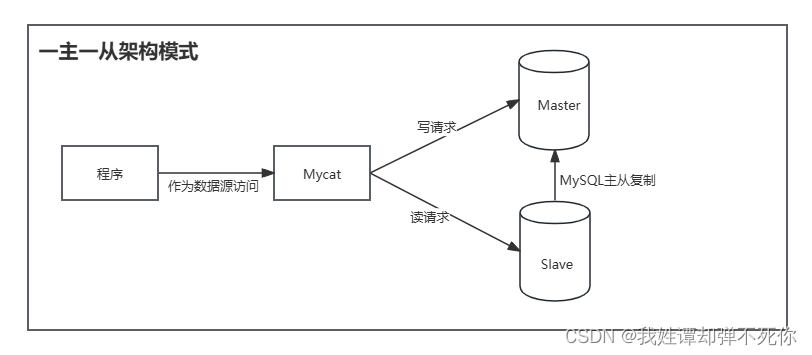
MySQL-主从复制
1、主从复制的理解 在工作用常见Redis作为缓存与MySQL一起使用。当有请求时,首先会从缓存中进行查找,如果存在就直接取出,否则访问数据库,这样 提升了读取的效率,也减少了对后台数据库的访问压力。Redis的缓存架构时高…...

开发没有尽头,尽力既是完美
最近遇到了一些难题,开发系统总有一些地方没有考虑周全,偏偏用户使用的时候“完美复现”了这个隐藏的Bug...... 讲道理创业一年之久为了生存,我一直都有在做复盘,复盘的核心就是:如何提升营收、把控开发质量࿰…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

AI书签管理工具开发全记录(十九):嵌入资源处理
1.前言 📝 在上一篇文章中,我们完成了书签的导入导出功能。本篇文章我们研究如何处理嵌入资源,方便后续将资源打包到一个可执行文件中。 2.embed介绍 🎯 Go 1.16 引入了革命性的 embed 包,彻底改变了静态资源管理的…...

均衡后的SNRSINR
本文主要摘自参考文献中的前两篇,相关文献中经常会出现MIMO检测后的SINR不过一直没有找到相关数学推到过程,其中文献[1]中给出了相关原理在此仅做记录。 1. 系统模型 复信道模型 n t n_t nt 根发送天线, n r n_r nr 根接收天线的 MIMO 系…...

#Uniapp篇:chrome调试unapp适配
chrome调试设备----使用Android模拟机开发调试移动端页面 Chrome://inspect/#devices MuMu模拟器Edge浏览器:Android原生APP嵌入的H5页面元素定位 chrome://inspect/#devices uniapp单位适配 根路径下 postcss.config.js 需要装这些插件 “postcss”: “^8.5.…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

Golang——9、反射和文件操作
反射和文件操作 1、反射1.1、reflect.TypeOf()获取任意值的类型对象1.2、reflect.ValueOf()1.3、结构体反射 2、文件操作2.1、os.Open()打开文件2.2、方式一:使用Read()读取文件2.3、方式二:bufio读取文件2.4、方式三:os.ReadFile读取2.5、写…...