文件操作(Python和C++版)
一、C++版
程序运行时产生的数据都属于临时数据,程序—旦运行结束都会被释放通过文件可以将数据持久化
C++中对文件操作需要包含头文件< fstream >
文件类型分为两种:
1. 文本文件 - 文件以文本的ASCII码形式存储在计算机中
2. 二进制文件- 文件以文本的二进制形式存储在计算机中,用户一般不能直接读懂它们
操作文件的三大类:
1. ofstream : 写操作
2. ifstream : 读操作
3. fstream : 读写操作
1.1 文本文件
1.1.1 写文件
写文件步骤如下:
1.包含头文件
#include <fstream>
2.创建流对象
ofstream ofs;
3.打开文件
ofs.open("文件路径",打开方式);
4.写数据
ofs <<"写入的数据";
5.关闭文件
ofs.close();
文件的打开方式:
| 打开方式 | 解释 |
|---|---|
| ios::in | 为读文件而打开文件 |
| ios::out | 为写文件而打开文件 |
| ios::ate | 初始位置:文件尾 |
| ios::app | 追加方式写文件 |
| ios::trunc | 如果文件存在先删除,再创建 |
| ios::binary | 二进制方法 |
注意:文件打开方式可以配合使用,利用 | 操作符
例如:用二进制方式写文件
ios::binary | ios::out
#include <iostream>
#include <string>
#include <fstream>
using namespace std;//文本文件 写文件
void test01() {//1、包含头文件 fstream//2、创建流对象ofstream ofs;//3、打开方式ofs.open("test.txt", ios::out);//4、写内容ofs << "姓名:张三" << endl;ofs << "性别:男" << endl;ofs << "年龄:18" << endl;//5、关闭文件ofs.close();
}int main() {test01();return 0;
}总结:
·文件操作必须包含头文件 fstream
·读文件可以利用ofstream ,或者fstream类
·打开文件时候需要指定操作文件的路径,以及打开方式
·利用<<可以向文件中写数据
·操作完毕,要关闭文件
1.1.2 读文件
读文件与写文件步骤相似,但是读取方式相对于比较多
读文件步骤如下:
1.包含头文件
#include <fstream>
2.创建流对象
ifstream ifs;
3.打开文件并判断文件是否打开成功
ifs.open("“文件路径",打开方式);
4.读数据
四种方式读取
5.关闭文件
ifs.close();
#include <iostream>
#include <string>
#include <fstream>
using namespace std;//文本文件 读文件
void test01() {//1、包含头文件 fstream//2、创建流对象 ifstream ifs;//3、打开文件,并且判断是否打开成功ifs.open("test.txt", ios::in);if (!ifs.is_open()) {cout << "文件打开失败" << endl;return;}//4、读数据//第一种/*char buf[1024] = {0};while (ifs >> buf) {cout << buf << endl;}*///第二种/*char buf[1024] = {0};while (ifs.getline(buf, sizeof(buf))) {cout << buf << endl;}*///第三种/*string buf;while (getline(ifs, buf)) {cout << buf << endl;}*///第四种 EOF->end of file 不推荐char c;while ((c = ifs.get()) != EOF) {cout << c;}//5、关闭文件ifs.close();
}int main() {test01();return 0;
}总结:
·读文件可以利用ifstream ,或者fstream类
·利用is_open函数可以判断文件是否打开成功
· close关闭文件
1.2 二进制文件
以二进制的方式对文件进行读写操作
打开方式要指定为ios::binary
1.2.1 写文件
二进制方式写文件主要利用流对象调用成员函数write
函数原型:
ostream& write(const char * buffer,int len) ;
参数解释:字符指针buffer指向内存中一段存储空间。len是读写的字节数
#include <iostream>
#include <string>
#include <fstream>
using namespace std;//二进制文件 写文件
class Person {
public://如果用二进制进行存储这里最好用C语言的char类型char m_Name[64]; //姓名 int m_Age;
};void test01() {//1、包含头文件//2、创建流对象ofstream ofs;//3、打开文件ofs.open("test.txt", ios::out | ios::binary);//4、写文件Person p = { "张三",18 };//Person* 强转为 const char*类型ofs.write((const char*)&p, sizeof(Person));//5、关闭文件ofs.close();}int main() {test01();return 0;
}1.2.2 读文件
二进制方式读文件主要利用流对象调用成员函数read
函数原型:
istream& read(char *buffer,int len);
参数解释:字符指针buffer指向内存中一段存储空间。len是读写的字节数
#include <iostream>
#include <string>
#include <fstream>
using namespace std;//二进制文件 读文件
class Person {
public://如果用二进制进行存储这里最好用C语言的char类型char m_Name[64]; //姓名 int m_Age;
};void test01() {//1、包含头文件//2、创建流对象ifstream ifs;//3、打开文件 判断文件是否打开成功ifs.open("test.txt", ios::in | ios::binary);if (!ifs.is_open()) {cout << "文件打开失败" << endl;return;}//4、读文件Person p;//Person* 强转为 char* 类型ifs.read((char*)&p, sizeof(Person));cout << "姓名:" << p.m_Name << " 年龄:" << p.m_Age << endl;//5、关闭文件ifs.close();}int main() {test01();return 0;
}文件输入流对象可以通过read函数,以二进制方式读数据
二、Python版
1、文件操作
在学习文件操作之前,先来回顾一下编码的相关以及先关数据类型的知识。
·字符串类型(str),在程序中用于表示文字信息,本质上是unicode编码中的二进制。
name = "武沛齐"
·字节类型(bytes)
·可表示文字信息,本质上是utf-8/gbk等编码的二进制(对unicode进行压缩,方便文件存储和网络传输)
name = "武沛齐"
data = name.encode('utf-8')
print(data) #b'\xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90'result = data.decode('utf-8')
print(result) #武沛齐·可表示原始二进制(图片、文件等信息)
1.1 读文件
·读文本文件
"""
1.打开文件-路径相对路径:'info.txt'绝对路径:r"D:\python的学习\题目\info.txt"-模式rb 表示读取文件原始二进制( r, 读 read; b, 二进制 binary)
"""#1、打开文件
file_object = open(r"D:\python的学习\题目\info.txt",mode='rb')#2、读取文件
data = file_object.read()#3、关闭文件
file_object.close()print(data) #b'\xe5\xa7\x93\xe5\x90\x8d \xef\xbc\x9a \xe6\xad\xa6\xe6\xb2\x9b\xe9\xbd\x90'text = data.decode("utf-8")
print(text)改进:
#1、打开文件
# rt 读取文本内容
file_object = open("info.txt",mode='rt',encoding='utf-8')
#意思是 打开文件后 通过 utf-8 转换后再读取文本内容#2、读取文件
data = file_object.read()#3、关闭文件
file_object.close()print(data) #就是文件存储的内容了,无需decode
·读图片等非文本文件
#1、打开文件
file_object = open("a1.png",mode='rb')#2、读取文件
data = file_object.read()#3、关闭文件
file_object.close()print(data)若该文件不存在,会报错
那如何判断路径是否存在呢:
import osexists = os.path.exists("info.txt") #返回的是 bool 值
print(exists) #True1.2 写文件
·写文本文件
# 1、打开文件
# 路径:相对/绝对
# 模式:wb (要求写入的内容需要是二进制字节类型)
file_object = open("t1.txt", mode='wb')# 2、写入内容
file_object.write("武沛齐".encode("utf-8"))# 3、文件关闭
file_object.close()
改进:
# 1、打开文件
# 路径:相对/绝对
# 模式:wt
# 如果不写 encoding 会以默认值 utf-8 写入
file_object = open("t1.txt", mode='wt',encoding='utf-8')# 2、写入内容
file_object.write("武沛齐")# 3、文件关闭
file_object.close()
·写图片等文件
# 相当于复制了一份
f1 = open("a1.png", mode='rb')
content = f1.read()
f1.close()f2 = open("a2.png", mode='wb')
f2.write(content)
f2.close()
注意的是,w写入文件时,先清空文件;再在文件中写入内容
而且如果路径没有该文件,w模式会新建然后再写入内容
所以如果你要写入时,在循环里实现写入,循环前后只实现一次的打开和关闭
file_object = open('test.txt',mode='wt')while True:user = input("请输入用户名:")if user.upper() == "Q":breakpwd = input("请输入密码:")#data = "{}--{}\n".format(user,pwd)data = f"{user}--{pwd}\n"file_object.write(data)
file_object.close()效果
wjw--123
pxy--456
1.3 文件打开方式
关于文件的打开模式常见应用有:
r w x a 的默认为 rt wt xt at
| 模式 | 文件存在 | 文件不存在 |
|---|---|---|
| 只读 r、rt、rb | 读 | 报错 |
| 只有 w、wt、wb | 清空再写 | 创建再写 |
| 只写(了解即可) x、xt、xb | 报错 | 创建再写 |
| 只写 a、at、ab 【尾部追加】 | 尾部追加 | 创建再写 |
| 读写 | ||
| r+、rb 默认光标位置:起始位置 | ||
| w+、wb 默认光标位置:起始位置(清空文件) | ||
| x+、xb 默认光标位置:起始位置(新文件) | ||
| a+、ab+ 默认光标位置:末尾 | ||
# rt+file_object = open("info.txt",mode="rt+",encoding='utf-8')
#读取内容
data = file_object.read()print(data)#写入内容
file_object.write("你好啊!")
file_object.close()与
# rt+file_object = open("info.txt",mode="rt+",encoding='utf-8')#写入内容
file_object.write("你好啊!")#读取内容
data = file_object.read()print(data)file_object.close()结果是不同的,这里与文件的光标有关
rt+ 默认光标位置是起始位置,如果先写入就会往后覆盖,再读取的时候也会从光标开始往后读取
如果先读取光标会移至最后,然后再写入
对于wt+
# wt+file_object = open("info.txt",mode="wt+",encoding='utf-8')#读取内容,由于wt+会清空内容,所以必定为空
data = file_object.read()
print(data)#写入内容,此时写入后光标会移至最后
file_object.write("你好啊!")#再想读取内容,光标要移至最前面,就ok了
file_object.seek(0)
data = file_object.read()
print(data)file_object.close()对于at+
# at+file_object = open("info.txt",mode="at+",encoding="utf-8")#写入内容,at+光标开始在最后,直接末尾追加
file_object.write("你好啊!")#想读取内容,光标要移至最前面,就ok了
file_object.seek(0)
data = file_object.read()
print(data)file_object.close()1.4 常见功能
在上述对文件的操作中,我们只使用了write和read来对文件进行读写,其实在文件操作中还有很多其他的功能来辅助实现更好的读写文件的内容。
1、read,读所有
f = open('info.txt',mode='r',encoding='utf-8')
data = f.read()
print(data)2、read,读一个字符(三个字节)
f = open('info.txt',mode='r',encoding='utf-8')
data = f.read(1)
f.close()
print(data)3、read,读一个字节
f = open('info.txt',mode='rb')
data = f.read(1)
f.close()
print(data)4、readline,读一行
f = open('info.txt',mode='r',encoding='utf-8')
data = f.readline()print(data)f.close()5、readlines,读所有行,每行作为列表的一个元素
f = open('info.txt',mode='r',encoding='utf-8')
data = f.readlines()print(data)f.close()6、循环,读大文件(readline加强版)
while循环难以判断其终止操作,所以用 for
f = open('info.txt',mode='r',encoding='utf-8')for line in f:print(line.strip())f.close()7、flush,刷到硬盘
f = open('info.txt',mode='w',encoding='utf-8')for i in range(0,3):#不是写到了硬盘,而是写在缓冲区,系统会将缓冲区的内容刷到硬盘f.write("你好啊!")#写上flush之后,立即刷到yingpanlf.flush()print(1)f.close()8、seek() 移动光标位置(字节)
f = open('info.txt',mode='r+',encoding='utf-8')#移动光标位置,在次光标之后开始写内容,如果有内容,则会覆盖
#移动到指定字节的位置,最好是3的倍数,否则会发生乱码的情况
f.seek(3)
f.write("中国")f.close()注意︰在a模式下,调用write在文件中写入内容时,永远只能将内容写入到尾部,不会写到光标的位置。
9、tell() 获取当前光标的位置
f = open('info.txt', mode='r+', encoding='utf-8')p1 = f.tell()
print(p1) # 0
f.read(2) # 读取的是字符 2 * 3 个字节
p2 = f.tell()
print(p2) # 6f.close()
f = open('info.txt', mode='rb')p1 = f.tell()
print(p1) # 0
f.read(3) # 读取的是3 个字节
p2 = f.tell()
print(p2) # 3f.close()
1.5 上下文管理
之前对文件进行操作时,每次都要打开和关闭文件,比较繁琐且容易忘记关闭文件。以后再进行文件操作时,推荐大家使用with上下文管理,它可以自动实现关闭文件。
writh open ( ”xxXX,txt" , mode= "rb" ) as file_object :data = file_object.read()print (data)在Python 2.7后,with又支持同时对多个文件的上下文进行管理,即:
with open (“x展x据.txt",mode="rb") as f1,open ( "%x×xtxt”,mode="rb" ) as f2:pass2、CSV格式文件
逗号分隔值(Comma-separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本)。对于这种格式的数据,我们需要利用open函数来读取文件并根据逗号分隔的特点来进行处理。
股票代码,股票名称,当前价,涨跌额,涨跌幅,年初至今
601778,t晶科,6.29,+1.92 ,-43.94%,+43.948%
688566,吉贝尔。52.66,+6.96,+15.238,+122.29....
with open('cs.csv', mode='r',encoding='utf-8') as f:f.readline()for line in f:id,year,bl = line.strip().split(',')print(id,year)3、ini格式
ini文件是Initialization File的缩写,平时用于存储软件的的配置文件。例如:MySQL数据库的配置文件。
[DataBase]
ServerIP=**********
ServerPort=8080
ControlConnectString=QWDJ7+XH6oWaANAGhVgh5/5UxYrA2rfz/ufAkDlN1H9Tw+v7Z0SoCfR+wYdyzCjF/ANUfPxlO6cLDAhm4xxmbADyKs6zmkWuGQNgDZmPx6c=
ControlConnectCategory=0
[LogonInfo]
SaveUserID=Y
UserID=admin
DBServer=AppDB
DBCenter=Demo
[UserConfig]
OpenDownloadFileAtOnec=Y
WindowStyle=DevExpress Dark Style
[Language]
Language=CHS
[AutoUpdate]
Version=1.1
这种格式是可以直接使用open来出来,考虑到自己处理比较麻烦,所以Python为我们提供了更为方便的方式。
3.1 读取所有节点
import configparserconfig = configparser.ConfigParser()
config.read('in.ini',encoding='utf-8')#获取节点,列表形式
result = config.sections()
print(result)3.2 读取节点下的键值
import configparserconfig = configparser.ConfigParser()
config.read('in.ini',encoding='utf-8')#该节点下的键值,返回的是列表里的元组
result = config.items('LogonInfo')
print(result)
3.3 获取某个节点下的键值对应的值
import configparserconfig = configparser.ConfigParser()
config.read('in.ini',encoding='utf-8')result = config.get("UserConfig","WindowStyle")
print(result)
3.4 其他
import configparserconfig = configparser.ConfigParser()
config.read('in.ini',encoding='utf-8')#判断是否有该节点
v1 = config.has_section("UserConfig")
print(v1)#增加一个节点
config.add_section("group")
#此时并未写入,所以要写write(),这里可以换别的名字,重新创建一个文件
config.write(open('in.ini',mode='w',encoding='utf-8'))#增加键值
config.set("group","name","wjw")
config.write(open('in.ini',mode='w',encoding='utf-8'))#删除节点
config.remove_section('Language')
config.write(open('in.ini',mode='w',encoding='utf-8'))#删除键值
config.remove_option("LogonInfo","userid")
config.write(open('in.ini',mode='w',encoding='utf-8'))
4、XML格式文件
暂时用不到哈,先不学了
5、Excel格式文件
Python内部未提供处理Excel文件的功能,想要在Python中操作Excel需要按照第三方的模块。
pip install openpyxl
此模块中集成了Python操作Excel的相关功能,接下来我们就需要去学习该模块提供的相关功能即可。
5.1 读文件
1.读sheet
from openpyxl import load_workbookwb = load_workbook("1.xlsx")#1、获取excel文件中的所有sheet名称
#print(wb.sheetnames) #['sheet2', 'Sheet1']#2、选择sheet,基于sheet名称
"""
sheet = wb["Sheet1"]
#读取单元格
cell = sheet.cell(1,1)
print(cell.value)
"""#3、选择sheet,基于索引位置
"""
sheet = wb.worksheets[0]
cell = sheet.cell(3,1)
print(cell.value)
"""#4、循环所有的sheet
"""
for name in wb.sheetnames:sheet = wb[name]cell = sheet.cell(3,1)print(cell.value)
"""
"""
for sheet in wb.worksheets:cell = sheet.cell(3, 1)print(cell.value)
"""
for sheet in wb:cell = sheet.cell(3,1)print(cell.value)from openpyxl import load_workbookwb = load_workbook("1.xlsx")
sheet = wb.worksheets[0]#1、获取第N行第N列的单元格
"""
cell = sheet.cell(3,1)
print(cell.value)
print(cell.font)
print(cell.style)
print(cell.alignment) #排列情况
"""#2、获取某个单元格
"""
c1 = sheet["B3"]
print(c1.value)c2 = sheet["C4"]
print(c2.value)
"""#3、第N行所有的单元格
"""
for cell in sheet[3]:print(cell.value)
"""#4、所有行的数据
"""
for row in sheet.rows:#获得的是元组print(row[2].value)
"""#5、所有列的数据
"""
for col in sheet.columns:print(col[2].value)
"""2.读合并的单元格

from openpyxl import load_workbookwb = load_workbook("1.xlsx")
sheet = wb.worksheets[1]c1 = sheet.cell(1,1)
print(c1.value) #测试数据c2 = sheet.cell(1,2)
print(c2.value) #None合并单元格显示最前面的,其他的都置为空
5.2 写Excel
在Excel中想要写文件,大致要分为
1.原Excel文件基础上写内容
from openpyxl import load_workbookwb = load_workbook("1.xlsx")
sheet = wb.worksheets[1]# 找到单元格,并修改单元的内容
cell = sheet.cell(9,1)
cell.value = "wjm"#将excel文件保存到2.xlsl文件中
wb.save("2.xlsx")
2.新创建Excel文件写内容
from openpyxl import workbook#创建excel且默认会创建一个sheet(名称为Sheet)
wb = workbook.Workbook()sheet = wb.worksheets[0] #或 sheet = wb["Sheet"]#找到单元格,并修改单元格的内容
cell = sheet.cell(1,1)
cell.value = "新的开始"#将excel文件保存到3.xlsx文件中
wb.save("3.xlsx")拓展:
from openpyxl import workbookwb = workbook.Workbook()#1、修改sheet名称
"""
sheet = wb.worksheets[0]
sheet.title = "数据集"
wb.save ( "p2.xlsx")
"""#2、创建sheet并设置sheet颜色
"""
sheet = wb.create_sheet("工作计划",0)
sheet.sheet_properties.tabcolor = "1072BA"
wb.save("p2.xlsx")
"""#3、默认打开的sheet
"""
wb.active = o
wb.save("p2.xlsx")
"""#4、拷贝sheet
"""
sheet = wb.create_sheet ("工作计划")
sheet.sheet_properties.tabColor = "1072BA"
new_sheet = wb.copy_worksheet(wb["sheet"])
new_sheet.title = "新的计划"
wb.save("p2.xlsx")
"""#5、删除sheet
"""
del wb["用户列表"]
wb.save("p2.xlsx")
"""
还有
from openpyxl import load_workbook
from openpyxl.styles import Alignment, Border, Side, Font, PatternFill, GradientFillwb = load_workbook("1.xlsx")
sheet = wb.worksheets[0]# 1.获取某个单元格,修改值
"""
cell = sheet.cell(1,1)
cell.value = "开始"
wb.save("2.xlsx")
"""# 2.获取某个单元格,修改值
"""
sheet["B2"]= "开始"
wb.save("2.xlsx")
"""# 3.获取某些单元格,修改值
"""
cell_list = sheet["B2":"C3"] #4个单元格
#(
# (单元格,单元格)
# (单元格,单元格)
#)
for row in cell_list:for cell in row:cell.value = "新的值"
wb.save("2.xlsx")
"""# 4.对齐方式
"""
cell = sheet.cell(1,1)
#horizontal 水平方向对齐方式:general left center right fill justify centerContinous distributed
#vertical 垂直方向对齐方式:top center bottom justify distributed
#text_rotation 旋转角度
#wrap_text 是否自动换行
cell.alignment = Alignment(horizontal='center',vertical='center',text_rotation=45,wrap_text=True)
wb.save("2.xlsx")
"""# 5.边框
# side 的 style 如下:dashDot dashDotDot dashed dotted double hair medium mediumDashDot mediumDashDot mediumDashed slantDashDot thick thin
"""
cell = sheet.cell(9,2)
cell.border = Border(top = Side(style="thin",color="FFB6C1"),bottom=Side(style="dashed",color="FFB6C1"),left=Side(style="dashed",color="FFB6C1"),right=Side(style="dashed",color="9932cC"),diagonal=Side(style="thin",color="483D8B"),#对角线diagonalup=True, #左下 ~右上dliagonalDown=True #左上 –右下
)
wb.save("2.xlsx")
"""# 6.字体
"""
cell = sheet.cell(5,1)
cell.font = Font(name="微软雅黑",size=45,color="ff0000",underline="single")
wb.save("2.xlsx")
"""# 7.背景色
"""
cell = sheet.cell(5,1)
cell.fill = PatternFill("solid",fgColor="99ccff")
wb.save("2.xlsx")
"""# 8.渐变背景色
"""
cell = sheet.cell(5,1)
cell.fill = GradientFill("linear",stop=("FFFFFF","99ccff","000000"))
wb.save("2.xlsx")
"""# 9.宽高 (索引从1开始)
"""
sheet.row_dimensions[1].height = 50
sheet.columns_dimensions["E"].width = 100
wb.save("2.xlsx")
"""# 10.合并单元格
"""
sheet.merge_cells("B2:D8")
sheet.merge_cells(start_row=15,start_column=3,end_row=18,end_column=8)
wb.save("2.xlsx")
"""# 11.写入公式
"""
sheet = wb.worksheets[1]
sheet["D1"] = "合计"
sheet["D2"] = "=B2*C2"
wb.save("2.xlsx")
"""
"""
sheet = wb.worksheets[1]
sheet["D3"] = "=SUM(B3,C3)"
wb.save("2.xlsx")
"""# 12.删除
"""
#idx. 要删除的索引位置
#amount 从索引位置开始要删除的个数(默认为1)
sheet.delete_cols(idx=1,amount=1)
sheet.delete_rows(idx=1,amount=2)
wb.save("2.xlsx")
"""# 13.插入
"""
sheet.insert_cols(idx=5,amount=10)
sheet.insert_rows(idx=3,amount=2)
wb.save("2.xlsx")
"""# 14.循环写内容
"""
sheet = wb["Sheet"]
cell_range = sheet["A1:C2"]
for row in cell_range:for cell in row:cell.value = "xx"for row in sheet.iter_rows(min_row=5,min_col=1,max_row=7,max_col=10):for cell in row:cell.value = "oo"
wb.save("2.xlsx")
"""# 15.移动
"""
# 将H2:J10范围的数据,向右移动15个位置、向上移动1个位置
sheet.move_range("H2:J10", rows=-1, cols=15)
wb.save("p2.xlsx")
"""
"""
sheet = wb.worksheets[3]
sheet["D1"] = "合计"
sheet["D2"] = "=SUM(B3,C3)"
sheet.move_range("B1:D3",cols=10,translate=True)#自动翻译公式
wb.save("2.xlsx")
"""#16.打印区域
"""
sheet.print_area = "A1:D200"
wb.save("2.xlsx")
"""#17.打印时,每个页面的固定表头
"""
sheet.print_title_cols = "A:D"
sheet.print_title_rows = "1:3"
wb.save("2.xlsx")
"""你以为结束了吗?
并没有,因为我学校考的是CSV文件我们要用csv模板,Excel用 xlrd 和 xlwt 模板学习,下面我们继续学习
CSV
1.导入模块
Python有内置CSV模块,导入这个模块后,可以很轻松读取CSV文件。
import csv
读写文件
·open()打开文件使用完毕后必须close()关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
·with open(x) as x:打开的文件使用关闭后不需要主动关闭文件。因为with语句的上下文管理器会帮助处理。这在操作资源文件时非常方便,因为它能确保在代码执行完毕后资源会被释放掉
2.读取CSV文件
1.使用open()打开CSV文件
csvFile = open(文件名) #打开文件建立 CSV 文件对象 csvFile
2.使用with打开CSV文件
with open(文件名)as csvFile: # csvFi1e是可以自行命名的文件对象
....
2.1.建立reader对象
·有了CSV文件对象后,下一步可以使用c5v模块的 reader()建立 reader对象,可以使用list()将这个reader 对象转换成列表(list),现在我们可以很轻松地使用这个列表资料了。
import csvfn = 'cs.csv'
with open(fn) as csvFile: #打开csv文件csvReader = csv.reader(csvFile) #读文件建立Reader对象2.2 读取CSV文件
import csvfn = 'cs.csv'
with open(fn) as csvFile: #打开csv文件csvReader = csv.reader(csvFile) #读文件建立Reader对象listReport = list(csvReader) #将数据转换为列表print(listReport[0][1])#打印即可3.1.建立writer对象
import csvfn = 'cs.csv'
with open(fn,"w") as csvFile: #打开csv文件csvWriter = csv.writer(csvFile) #写文件建立writer对象 3.2 写入CSV文件
import csvfn = 'cs.csv'
with open(fn,"w") as csvFile: #打开csv文件csvWriter = csv.writer(csvFile) #写文件建立writer对象csvWriter.writerow(['Name',"Age","City"])csvWriter.writerow(['wjw','25','TaiBei'])EXCEL
| 方式 | 功能 | 文件格式 |
|---|---|---|
| xlrd | 只能读 | xls , xlsx |
| xlwt | 只能写 | 只能xls格式 |
xlrd
import xlrd
#打开文件
book = xlrd.open_workbook('1.xlsx')
#读取指定sheet:print(book.sheets())#获取全部sheetsheet = book.sheet_by_index(0) #根据索引获取工作表sheet = book.sheet_by_name("Sheet1") #根据sheetname进行获取print(book.sheet_names())#获取所有工作表nameprint(book.nsheets)#返回工作表数量
#获取行和列数
rows = sheet.nrows
cols = sheet.ncols
操作行
import xlrd#打开文件
book = xlrd.open_workbook('1.xlsx')#操作excel行
sheet=book.sheet_by_index(1)#获取第一个工作表
print(sheet.nrows)#获取sheet下的有效行数
print(sheet.row(1))#该行单元格对象组成的列表
print(sheet.row_types(2))#获取单元格的数据类型
print(sheet.row(1)[2].value)#得到单元格value
print(sheet.row_vaiues(1))#得到指定行单元格的value
print(sheet.row_values(1))#得到指定行单元格的value
print(sheet.row_len(1))#得到单元格的长度
操作列
import xlrd#打开文件
book = xlrd.open_workbook('1.xlsx')#操作excel列
sheet=book.sheet_by_index(1)#获取第一个工作表
print(sheet.ncols)#获取sheet下的有效列数
print(sheet.col(1))#该行单元格对象组成的列表
print(sheet.col_types(2))#获取单元格的数据类型
print(sheet.col(1)[2].value)#得到单元格value
print(sheet.col_vaiues(1))#得到指定列单元格的value
print(sheet.col_values(1))#得到指定列单元格的value
print(sheet.col_len(1))#得到单元格的长度操作Excel单元格
import xlrd#打开文件
book = xlrd.open_workbook('1.xlsx')#操作Excel单元格
sheet=book.sheet_by_index(0)
print(sheet.cell(1,2))
print(sheet.cell_type(1,2))
print(sheet.cell(1,2).ctype) #获取单元格数据类型
print(sheet.cell(1,2).value)
print(sheet.cell_value(1,2))xlwt
import xlwttitlestyle = xlwt.XFStyle() #初始化样式
titlefont = xlwt.Font()
titlefont.name = "宋体"
titlefont.bold = True #加粗
titlefont.height = 11*20 #字号
titlefont.colour_index = 0x08 #设置字体颜色
titlestyle.font = titlefont#单元个对齐方式
cellalign = xlwt.Alignment()
cellalign.horz = 0x02
cellalign.vert = 0x01
titlestyle.alignment = cellalign#边框
borders = xlwt.Borders()
borders.right=xlwt.Borders.DASHED
borders.bottom=xlwt.Borders.DOTTED
titlestyle.borders = borders#
datestyle = xlwt.XFStyle()
bgcolor = xlwt.Pattern()
bgcolor.pattern = xlwt.Pattern.SOLID_PATTERN
bgcolor.pattern_fore_colour = 22 #背景颜色
datestyle.pattern = bgcolor#第一步:创建工作簿
wb=xlwt.Workbook()
#第二步:创建工作表
ws=wb.add_sheet("CNY")
#第三步:填充数据
ws.write_merge(0,1,0,5,"2019年货币兑换表",titlestyle)
#写入货币数据
data = (("Date","英镑","人民币","港币","日元","美元"),("01/01/2019",8.722551,1,0.877885,0.062722,6.8759),("02/01/2019",8.634922,1,0.875731,0.062773,6.8601))
for i , item in enumerate(data):
#enumerate 包含索引for j , val in enumerate(item):if j==0:ws.write(i + 2, j, val,datestyle)else:ws.write(i + 2,j,val)#第四步:保存
wb.save("2019-CNY.xls")就这样吧,我累了,再见
相关文章:
文件操作(Python和C++版)
一、C版 程序运行时产生的数据都属于临时数据,程序—旦运行结束都会被释放通过文件可以将数据持久化 C中对文件操作需要包含头文件< fstream > 文件类型分为两种: 1. 文本文件 - 文件以文本的ASCII码形式存储在计算机中 2. 二进制文件- 文件以文本的二进…...
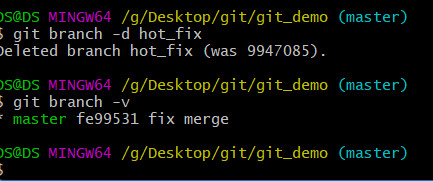
Git【版本控制命令】
02 【本地库操作】 1.git的结构 2.Git 远程库——代码托管中心 2.1 git工作流程 代码托管中心用于维护 Git 的远程库。包括在局域网环境下搭建的 GitLab 服务器,以及在外网环境下的 GitHub 和 Gitee (码云)。 一般工作流程如下: 1.从远程…...
打字侠是一款PWA网站,如何下载到电脑桌面?
嘿,亲爱的键盘侠们! 你是否还在为寻找一款好用的打字练习工具而烦恼?别担心,今天我要给大家介绍一位超级英雄——打字侠!它不仅是一个超级酷的打字练习网站,还是一款PWA(渐进式网页应用&#x…...

Scikit-learn使用步骤?使用场景?
Scikit-learn(简称sklearn)是Python中一个非常流行的机器学习库,它提供了广泛的机器学习算法和工具,用于数据分析、特征工程、模型训练、模型评估等任务。以下是一个关于sklearn的基础教程,内容将按照几个主要部分进行…...
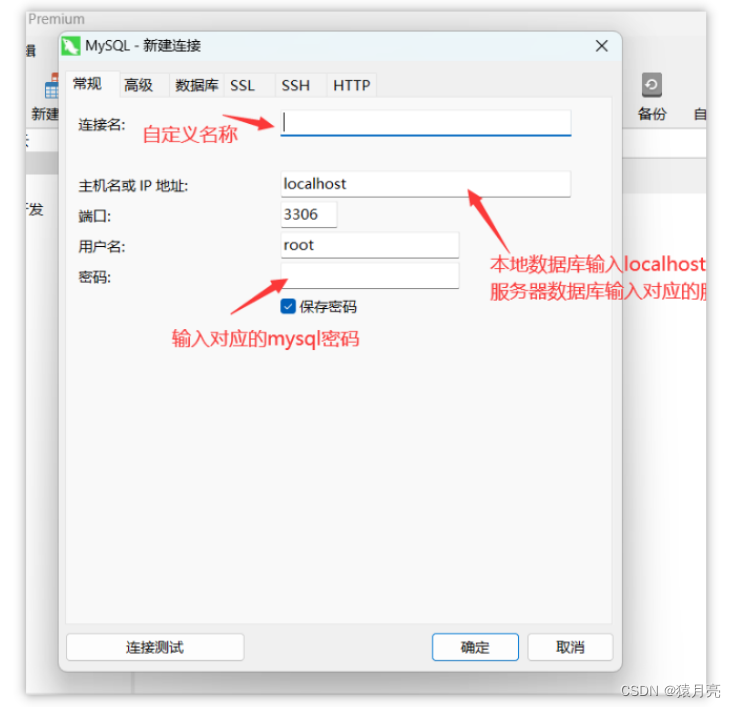
MySQL 5.7详细下载安装配置教程(MySQL 5.7安装包)_mysql5.7的安装教程
记录MySQL 5.7 的下载安装教程,并提供了Mysql 安装包 ,以下是详细下载安装过程。 一、下载Mysql安装包 网盘下载: 下载MySQL 5.7安装包,网盘下载地址:点击此处直接下载 官网下载: 进入官网,…...

电阻十大品牌供应商
选型时选择热门的电阻品牌,主要是产品丰富,需求基本都能满足。 所所有的电路中,基本没有不用电阻的,电阻的选型需要参考阻值、精度、封装、温度范围,贴片/插件等参数,优秀的供应商如下: 十大电…...
深度学习复盘与论文复现C
文章目录 4、Distributed training4.1 GPU architecture 5、Recurrent neural network5.1 The basic structure of RNN5.2 Neural networks without hidden states5.3 Recurrent neural networks with hidden states5.4 summary 6、Language Model Dataset (lyrics from Jay Ch…...

海洋日特别活动—深海来客——可燃冰
深海中有一种神奇的物质,似冰又不是冰。 别看它其貌不扬,但本领不小,遇火即燃,能量巨大,可谓是能源家族的新宠。它就是被国务院正式批准列为我国第173个矿种的“可燃冰”! 可燃冰到底是个啥?它…...

Web前端放图片位置:深入探索与最佳实践
Web前端放图片位置:深入探索与最佳实践 在Web前端开发中,图片作为重要的视觉元素,其放置位置往往影响着网页的整体布局和用户体验。然而,如何合理地放置图片,以最大化其视觉效果并提升用户体验,却是一个颇…...

leetcode-02-[977]有序数组的平方[209]长度最小的子数组[59]螺旋矩阵II
一、[977]有序数组的平方 重点: 新引入一个数组,不要原数组操作 class Solution {public int[] sortedSquares(int[] nums) {int left0,right nums.length-1;int[] resultnew int[nums.length];int index nums.length-1;while(left<right){if(nums…...

Spring Cloud Gateway CORS 跨域方案
通过配置文件,以下配置就是其中一种方案。 gateway: #跨域配置globalcors: cors-configurations: [/**]: allowedMethods: "*"allowedHeaders: "*"allowedOriginPatterns: "*"allowCredentials: truedefault-filters: - DedupeRespo…...

高考后志愿填报信息采集系统制作指南
在高考的硝烟散去之后,每位学生都面临着一个重要的任务——志愿填报。老师们如何高效、准确地收集和整理这些信息,成为了一个棘手的问题。难道我们只能依赖传统的手工登记方式,忍受其繁琐和易错吗? 易查分是一个简单易用的在线工具…...

Python使用Flask构建简单的web应用
构建一个简单的 Flask Web 应用程序是学习 Python Web 开发的良好起点。Flask 是一个轻量级的 WSGI Web 应用框架,它的主要目标是让开发者更容易构建 Web 应用,同时保持简单性和灵活性。下面我们将详细介绍如何使用 Flask 构建一个简单的 Web 应用&#…...

看似不同的事情,却是相同的坑
目录 一、背景二、过程1.遭遇战-微盘股的下杀2.不失为一件好事3.一切向后看吧,最近的学习感受4.该有的心境 三、总结 一、背景 也在一点点改变,期间势必要经历流血的过程;所谓无疯狂不成长,积极的心态去应对,去总结总…...

在 Linux 系统上安装 Android NDK
在 Linux 系统上安装 Android NDK 1. Android NDK2. NDK Downloads2.1. Latest LTS Version (r26d)2.2. Old Unsupported Versions 3. 安装 NDK4. Get started with the NDK (NDK 使用入门)References 1. Android NDK https://developer.android.com/ndk The Android NDK is …...
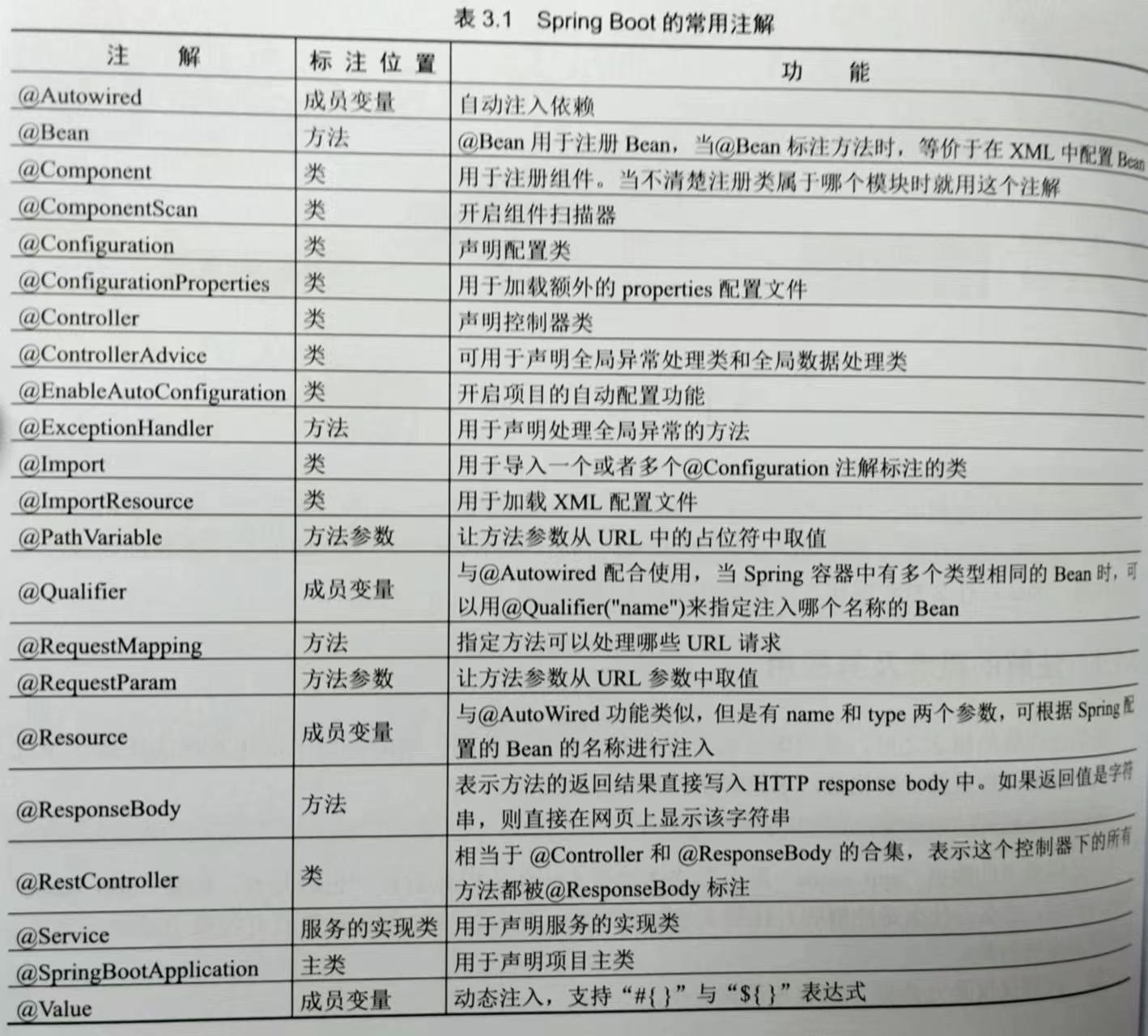
SpringBoot的学习要点
目录 SpringBoot 创建项目 配置文件 注解 命名规范 SpringBoot整合第三方技术 …… 中文文档:Spring Boot 中文文档 SpringBoot Spring Boot 是基于 Spring 框架的一种快速构建微服务应用的方式它主要提供了自动配置、简化配置、运行时应用监控等功能它…...

vue3引入cesium和olcs
首先引入包 pnpm i olcs; pnpm i -D vite-plugin-cesium pnpm i -S cesium在vite.config.js中配置,参考这位大佬的笔记 添加链接描述 import { defineConfig } from vite import vue from vitejs/plugin-vue import cesium from vite-plugin-cesium; // https://…...

代码随想录算法训练营第25天|回溯
回溯part02 216. 组合总和 III /*** param {number} k* param {number} n* return {number[][]}*/ var combinationSum3 function(k, n) {// k个数字相加为n// 只能使用1-9// 每个数字只能使用一次// 不能重复 如 1 2 4 、 4 1 2 不可以let res [];backtracking(k, n, [], …...
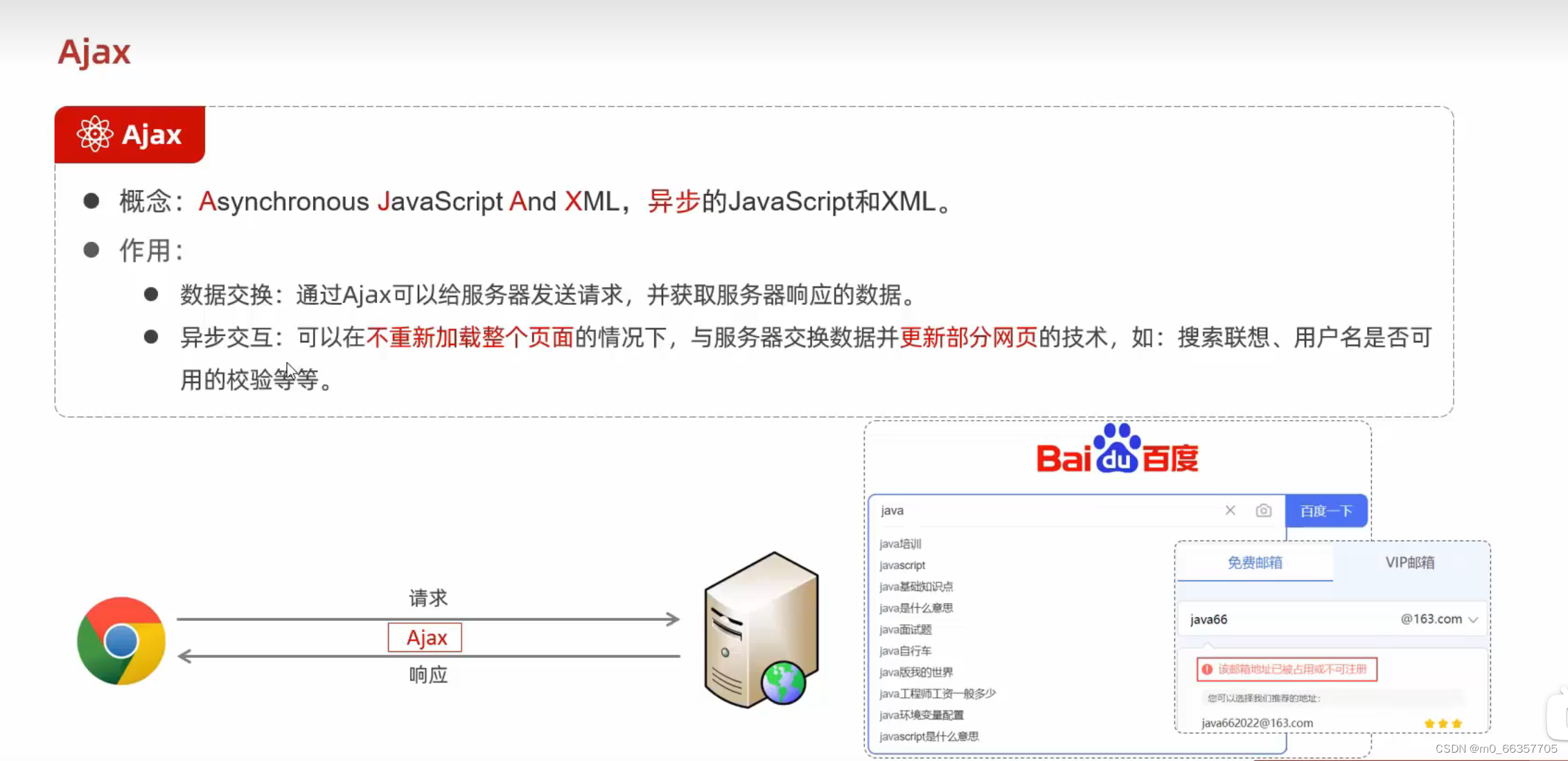
Ajax 快速入门
Ajax 概念:Ajax是一种Web开发技术,允许在不重新加载整个页面的情况下,与服务器交换数据并更新网页的部分内容。 作用: 数据交换:Ajax允许通过JavaScript向服务器发送请求,并能够接收服务器响应的数据。 异…...

面试官:前端实现图片懒加载怎么做?这不是撞我怀里了嘛!
前端懒加载(也称为延迟加载或按需加载)是一种网页性能优化的技术,主要用于在网页中延迟加载某些资源,如图片、视频或其他媒体文件,直到它们实际需要被用户查看或交互时才进行加载。这种技术特别适用于长页面或包含大量…...

C++实现分布式网络通信框架RPC(3)--rpc调用端
目录 一、前言 二、UserServiceRpc_Stub 三、 CallMethod方法的重写 头文件 实现 四、rpc调用端的调用 实现 五、 google::protobuf::RpcController *controller 头文件 实现 六、总结 一、前言 在前边的文章中,我们已经大致实现了rpc服务端的各项功能代…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

【JavaSE】多线程基础学习笔记
多线程基础 -线程相关概念 程序(Program) 是为完成特定任务、用某种语言编写的一组指令的集合简单的说:就是我们写的代码 进程 进程是指运行中的程序,比如我们使用QQ,就启动了一个进程,操作系统就会为该进程分配内存…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...
:工厂方法模式、单例模式和生成器模式)
上位机开发过程中的设计模式体会(1):工厂方法模式、单例模式和生成器模式
简介 在我的 QT/C 开发工作中,合理运用设计模式极大地提高了代码的可维护性和可扩展性。本文将分享我在实际项目中应用的三种创造型模式:工厂方法模式、单例模式和生成器模式。 1. 工厂模式 (Factory Pattern) 应用场景 在我的 QT 项目中曾经有一个需…...