ThreadCache线程缓存
一.ThreadCache整体结构
1.基本结构
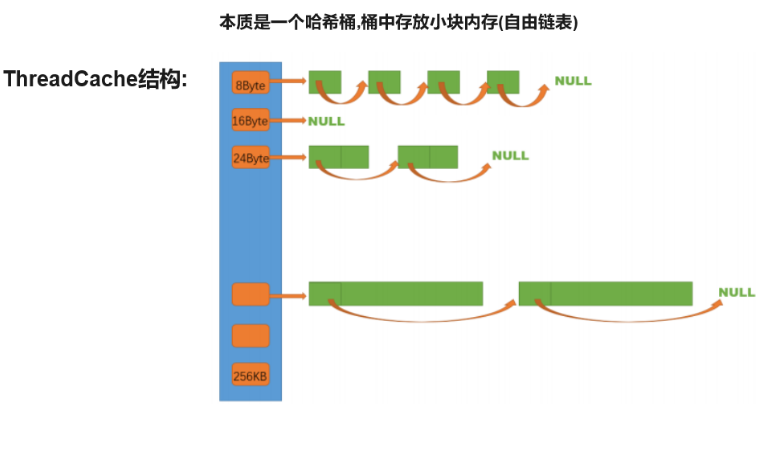
定长内存池利用一个自由链表管理释放回来的固定大小的内存obj。
ThreadCache需要支持申请和释放不同大小的内存块,因此需要多个自由链表来管理释放回来的内存块.即ThreadCache实际上一个哈希桶结构,每个桶中存放的都是一个自由链表。
2.对齐规则和下标索引
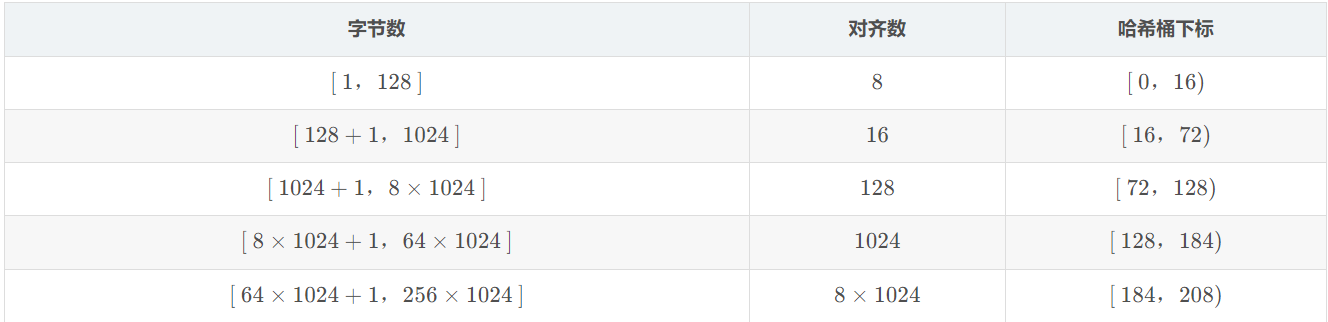
规定ThreadCache支持<=256KB内存的申请,如果我们将每种字节数的内存块都用一个自由链表进行管理的话,那么此时我们就需要20多万个自由链表,光是存储这些自由链表的头指针就需要消耗大量内存,这显然是得不偿失的。
这时可以选择做一些平衡的牺牲,让一定区间内的字节数统一为某个size,
然后用一个桶的自由链表来管理.
即按照某种规则进行内存对齐(但同时产生内碎片问题)
二.函数调用层次结构
//小于等于MAX_BYTES,就找thread cache申请
//大于MAX_BYTES,就直接找page cache或者系统堆申请
static const size_t MAX_BYTES = 256 * 1024;
//thread cache和central cache自由链表哈希桶的表大小
static const size_t NFREELISTS = 208;
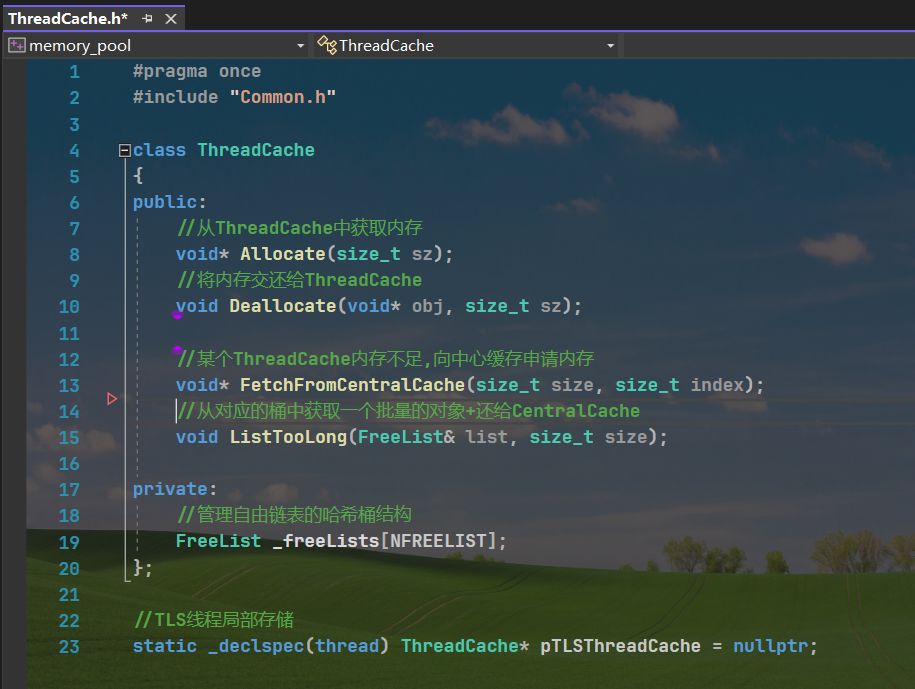
三.FreeList的封装
NextObj管理内存obj的前4/8个字节,用来指向下一块内存
size_t _maxSize = 1;//此时一次申请的最大obj个数
size_t _size = 0;//自由链表中的内存obj的个数
static void*& NextObj(void* obj)
{return *(void**)obj;
}
// 管理切分好的小对象的自由链表
class FreeList
{
public:void Push(void* obj){assert(obj);// 头插NextObj(obj) = _freeList;_freeList = obj;++_size;}void PushRange(void* start, void* end, size_t n){NextObj(end) = _freeList;_freeList = start;_size += n;}void PopRange(void*& start, void*& end, size_t n){assert(n <= _size);start = _freeList;end = start;for (size_t i = 0; i < n - 1; ++i){end = NextObj(end);}_freeList = NextObj(end);NextObj(end) = nullptr;_size -= n;}void* Pop(){assert(_freeList);// 头删void* obj = _freeList;_freeList = NextObj(obj);--_size;return obj;}bool Empty(){return _freeList == nullptr;}size_t& MaxSize(){return _maxSize;}size_t Size(){return _size;}private:void* _freeList = nullptr;size_t _maxSize = 1;//此时一次申请的最大obj个数size_t _size = 0;//自由链表中的内存obj的个数
};四.字节数向上对齐规则RoundUp
1.RoundUp基本逻辑
static inline size_t RoundUp(size_t size)
{if (size <= 128)return _RoundUp(size, 8);else if (size <= 1024)return _RoundUp(size, 16);else if (size <= 8 * 1024)return _RoundUp(size, 128);else if (size <= 64 * 1024)return _RoundUp(size, 1024);else if (size <= 256 * 1024)return _RoundUp(size, 8 * 1024);elsereturn _RoundUp(size, 1 << PAGE_SHIFT);}2.子函数_RoundUp
size_t _RoundUp(size_t size, size_t alignNum){size_t alignSize;if (size % alignNum != 0){alignSize = (size / alignNum + 1)*alignNum;}else{alignSize = size;}return alignSize;}3.优化为位运算
static inline size_t _RoundUp(size_t bytes, size_t alignNum)
{return ((bytes + alignNum - 1) & ~(alignNum - 1));
}五.字节数映射哈希桶下标Index
1.Index基本逻辑
// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128) {return _Index(bytes, 3);}else if (bytes <= 1024) {return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024) {return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024) {return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024) {return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else {assert(false);}return -1;}2.子函数_Index
size_t _Index(size_t bytes, size_t alignNum){if (bytes % alignNum == 0){return bytes / alignNum - 1;}else{return bytes / alignNum;}}3.优化为位运算
static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}六.Allocate申请内存实现
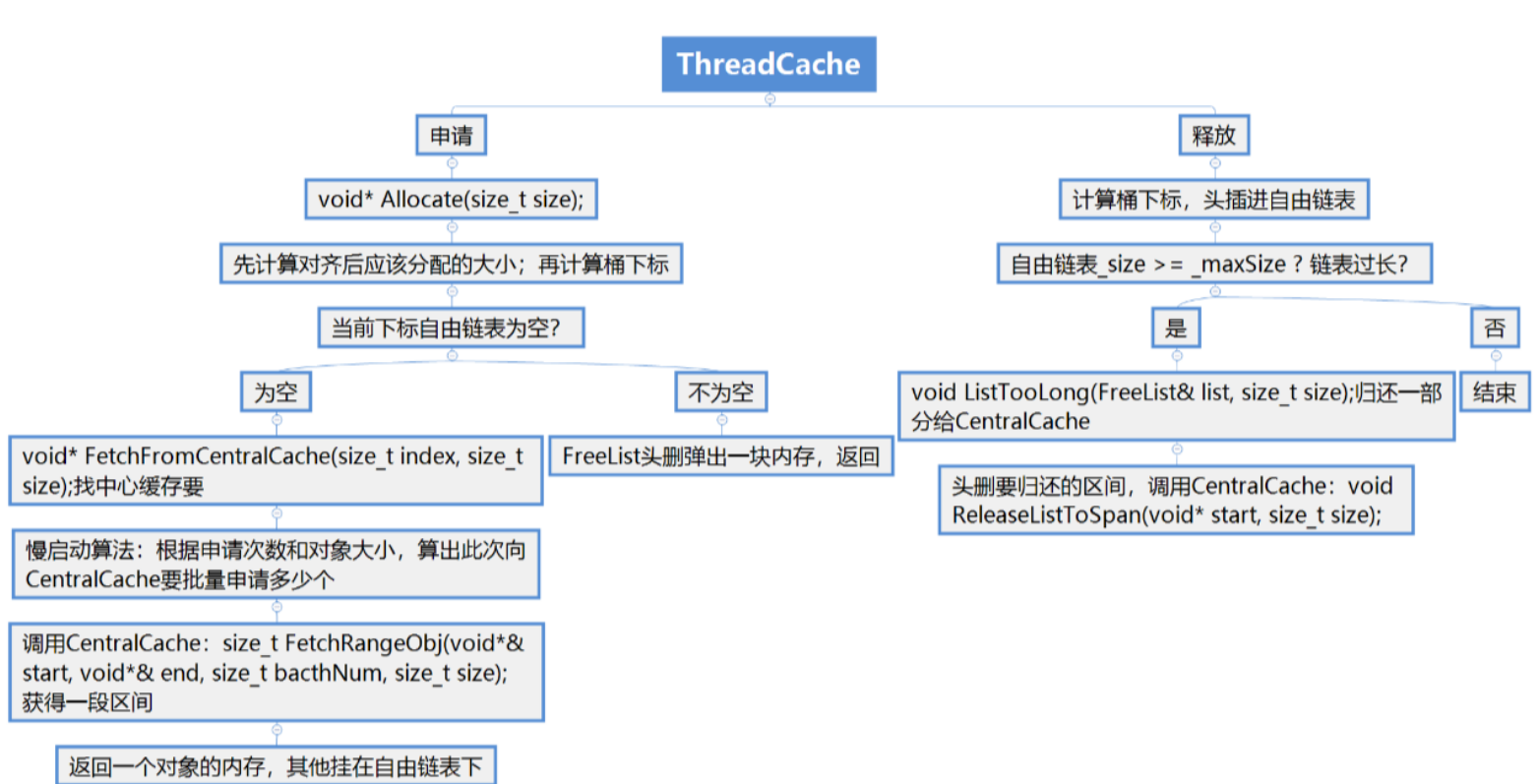
在ThreadCache申请对象时,通过所给字节数计算出对应的哈希桶下标,如果桶中自由链表不为空,则从该自由链表中pop一个对象进行返回即可;但如果此时自由链表为空,那么我们就需要从CentralCache进行获取了,即FetchFromCentralCache函数
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);//1.计算对齐后所需内存size_t alignSize = SizeClass::RoundUp(size);//2.计算要挂接的桶的下标size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}七.FetchFromCentralCache
每次ThreadCache向CentralCache申请对象时,我们先通过慢开始反馈调节算法计算出本次应该申请的对象的个数
如果ThreadCache最终申请到对象的个数就是一个,那么直接将该对象返回即可。
当ThreadCache中没有对象时,会向CentralCache中获取一个批量的内存obj(避免频繁申请)
ThreadCache最终申请到的是多个对象,将第一个对象返回后,还需要将剩下的对象挂到ThreadCache对应的哈希桶当中。
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{// 慢开始反馈调节算法// 1、最开始不会一次向CentralCache一次批量要太多,因为要太多了可能用不完// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限// 3、size越大,一次向CentralCache要的batchNum就越小// 4、size越小,一次向CentralCache要的batchNum就越大size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr, * end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1);if (actualNum == 1){assert(start == end);return start;}_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);return start;
}NumMoveSize的实现
// 一次thread cache从中心缓存获取多少个static size_t NumMoveSize(size_t size){assert(size > 0);// [2, 512],一次批量移动多少个对象的(慢启动)上限值// 小对象一次批量上限高// 小对象一次批量上限低int num = MAX_BYTES / size;if (num < 2)num = 2;//[0.5kb,128kb]if (num > 512)num = 512;return num;}八.Deallocate释放内存实现
当某个线程申请的对象不用了,可以将其释放给ThreadCache,然后ThreadCache将该对象插入到对应哈希桶的自由链表当中即可。
但是随着线程不断的释放,对应自由链表的长度也会越来越长,这些内存堆积在一个thread cache中就是一种浪费,我们应该将这些内存还给CentralCache,
这样一来,这些内存对其他线程来说也是可申请的,因此当ThreadCache某个桶当中的自由链表太长时我们可以进行一些处理。
当ThreadCache某个桶当中自由链表的长度超过它一次批量向CentralCache申请的对象个数,那么此时我们就要把该自由链表当中的这些对象还给CentralCache
void ThreadCache::Deallocate(void* obj, size_t size)
{assert(obj);assert(size <= MAX_BYTES);//1.将释放的内存还到_freeLists对应的桶中size_t index = SizeClass::Index(size);_freeLists[index].Push(obj);//2._freeLists[index]挂的桶数大于最近的一个批量就还给CentralCacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){//3.从桶中获取一个批量的对象+还给CentralCacheListTooLong(_freeLists[index], size);}
}ListTooLong获取内存块批量
void ThreadCache::ListTooLong(FreeList& list, size_t size)
{assert(size > 0);void* start, * end = nullptr;//[begin,end]即为取出的批量//将批量还给CentralCache对应的spanlist.PopRange(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}九.ThreadCacheTLS线程局部存储
每个线程都有一个自己独享的thread cache,那应该如何创建这个thread cache呢?我们不能将这个thread cache创建为全局的,因为全局变量是所有线程共享的,这样就不可避免的需要锁来控制,增加了控制成本和代码复杂度。
要实现每个线程无锁的访问属于自己的thread cache,我们需要用到线程局部存储TLS(Thread Local Storage),使用该存储方法的变量在它所在的线程是全局可访问的,但是不能被其他线程访问到,这样就保持了数据的线程独立性。
//TLS - Thread Local Storage
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;
十.ThreadCache.cpp
#include "ThreadCache.h"
#include "CentralCache.h"void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{// 慢开始反馈调节算法// 1、最开始不会一次向CentralCache一次批量要太多,因为要太多了可能用不完// 2、如果你不要这个size大小内存需求,那么batchNum就会不断增长,直到上限// 3、size越大,一次向CentralCache要的batchNum就越小// 4、size越小,一次向CentralCache要的batchNum就越大size_t batchNum = min(_freeLists[index].MaxSize(), SizeClass::NumMoveSize(size));if (_freeLists[index].MaxSize() == batchNum){_freeLists[index].MaxSize() += 1;}void* start = nullptr, * end = nullptr;size_t actualNum = CentralCache::GetInstance()->FetchRangeObj(start, end, batchNum, size);assert(actualNum >= 1);if (actualNum == 1){assert(start == end);return start;}_freeLists[index].PushRange(NextObj(start), end, actualNum - 1);return start;
}void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);//1.计算对齐后所需内存size_t alignSize = SizeClass::RoundUp(size);//2.计算要挂接的桶的下标size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}void ThreadCache::Deallocate(void* obj, size_t size)
{assert(obj);assert(size <= MAX_BYTES);//1.将释放的内存还到_freeLists对应的桶中size_t index = SizeClass::Index(size);_freeLists[index].Push(obj);//2._freeLists[index]挂的桶数大于最近的一个批量就还给CentralCacheif (_freeLists[index].Size() >= _freeLists[index].MaxSize()){//3.从桶中获取一个批量的对象+还给CentralCacheListTooLong(_freeLists[index], size);}
}void ThreadCache::ListTooLong(FreeList& list, size_t size)
{assert(size > 0);void* start, * end = nullptr;//[begin,end]即为取出的批量//将批量还给CentralCache对应的spanlist.PopRange(start, end, list.MaxSize());CentralCache::GetInstance()->ReleaseListToSpans(start, size);
}相关文章:
ThreadCache线程缓存
一.ThreadCache整体结构 1.基本结构 定长内存池利用一个自由链表管理释放回来的固定大小的内存obj。 ThreadCache需要支持申请和释放不同大小的内存块,因此需要多个自由链表来管理释放回来的内存块.即ThreadCache实际上一个哈希桶结构,每个桶中存放的都…...
 转 UTexture)
UE5_加载本地图片(jpg, png) 转 UTexture
UE5_加载图片到UTexture __Desc使用方式源码 __Desc __Time__: 2024-06-05 16:30 __Author__: Yblackd __Desc__: UE5.2 加载本地图片 转 UTexture2D, 给材质 和 UMG 使用使用方式 新建继承BlueprintFunctionLibrary c 类复制下面源码,修改类名实测加载 jpg,jpeg,…...
Linux操作系统:Spark在虚拟环境下的安装及部署
将Spark安装到指定目录 // 通过wget下载Spark安装包 $ wget https://d3kbcqa49mib13.cloudfront.net/spark-2.1.1-bin-hadoop2.7.tgz // 将spark解压到安装目录 $ tar –zxvf spark-2.1.1-bin-hadoop2.7.tgz –C /usr/local/ // 重命名 $ mv /usr/local/spark-2.1.1-bin-hado…...
内网安全--隧道技术代理技术
注:本文仅做技术交流,请勿非法破坏... 目录 项目: 1-Ngrok 用法 2-Frp 用法 3-Nps 用法 4-Spp 用法 工具: windows下: Proxifier(推荐~) Sockscap ccproxy Linux下: Proxychains 用法 http://t.csdnimg.cn/88Ew7 隧道技术:解决不出网协议上线的问…...
彩虹易支付最新版源码
源码简介 彩虹易支付最新版源码,更新时间为5.1号 2024/05/01: 1.更换全新的手机版支付页面风格 2.聚合收款码支持填写备注 3.后台支付统计新增利润、代付统计 4.删除结算记录支持直接退回商户金额 安装环境 1.PHP版本>7.4 2.Mysql数据库 安装教…...
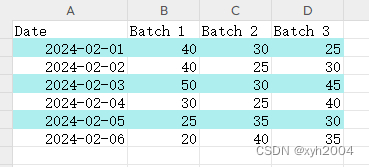
python生成excel数据并实现隔行变色
代码 from openpyxl import Workbook from datetime import date from openpyxl.styles import PatternFilldef create_excel():wb Workbook()sh wb.activerows [[Date, Batch 1, Batch 2, Batch 3],[date(2024, 2, 1), 40, 30, 25],[date(2024, 2, 2), 40, 25, 30],[date(…...

IEEE754 十进制数转32位浮点数格式
为了将十进制数37.25转换为IEEE 754短浮点数格式(32位),我们需要按照以下步骤进行: IEEE 754标准结构 IEEE 754标准的单精度浮点数(32位)格式如下: 1位符号位(S)8位指…...

JVM内存分析之JVM分区与介绍
JVM(Java Virtual Machine)作为Java平台的核心组件,为Java应用程序的运行提供了一个虚拟的计算机环境。为了更好地理解和优化Java应用程序的性能,对JVM的内存管理进行深入分析是至关重要的。本文将详细介绍JVM的内存分区及其功能。…...
多目标检测模型加权框集成
优秀项目推荐:https://gitcode.com/ZFTurbo/Weighted-Boxes-Fusion/overview 参考链接: 目标检测加权框融合 WBF原理讲解 https://blog.csdn.net/YXD0514/article/details/132574588 目标检测加权框融合 WBF原理讲解(Weighted Boxes Fusion&…...

转型AI产品经理(6):“ 序列位置效应”如何应用在Chatbot产品中
序列位置效应是心理学中的一个记忆现象,指的是人们对一系列信息的记忆效果受到信息在序列中位置的影响。具体来说,人们通常更容易记住列表的开头和结尾部分的项目,而对中间部分的项目记忆较差。这个效应可以进一步分为“首因效应”和“近因效…...
ESP32:往MicroPython集成PCNT以支持硬件正交编码器
背景 官方发布的1.23依然没有在ESP32中集成PCNT功能。考虑到硬件的PCNT模块可以提供4倍的编码精度(对比使用PIn IRQ),还能提供硬件去毛刺。 还是自己集成一下吧。 实际上Github上早在2022年1月的时候就已经有人建议了将PCNT加入正式版本的功…...

Unity基础实践小项目
项目流程: 需求分析 开始界面 选择角色面板 排行榜面板 设置面板 游戏面板 确定退出面板 死亡面板 UML类图 准备工作 1.导入资源 2.创建需要的文件夹 3.创建好面板基类 开始场景 开始界面 1.拼面板 2.写脚本 注意事项:注意先设置NGUI的分辨率大小&…...

Set up a WordPress blog with Nginx
CentOS7 配置Nginx域名HTTPS Here is the revised guideline for setting up a WordPress blog with Nginx: Step 1: Install Nginx, MySQL, and PHP (LEMP Stack) Install Nginx: sudo yum install nginx sudo systemctl start nginx sudo systemctl enable nginxInstall MyS…...

Facebook开户|Facebook广告设计与测试优化
早上好家人们~今天Zoey给大家伙带来的是Facebook广告设计与测试优化,需要的家人们看过来啦! 一、避免复杂用图和过多的文字 根据Facebook的数据显示,用户平均浏览一个贴文的时间在手机上仅花1.7秒、在电脑上则为2.5秒。因此,广告…...
)
vite获取所有环境变量(env)
0.环境变量文件 API_URL8888888 VITE_API_URL99999991.定义环境变量 默认情况下,vite只获取以VITE_为前缀的环境变量。 为了防止意外地将一些环境变量泄漏到客户端,只有以 VITE_ 为前缀的变量才会暴露给经过 vite 处理的代码 但如果你觉得你是进击的巨人…...
【算法】常用排序算法(插入排序、希尔排序、堆排序、选择排序、冒泡排序、快速排序、归并排序、计数排序)超详细
排序算法是数据结构相关知识中非常重要的一节,相信很多小伙伴对这部分知识一知半解。那么接下来,小编就要带领大家一起来进行对排序算法的深入剖析学习,希望本篇文章能够使你有所收获! 一.常见的排序算法 排序算法有很多种&#…...
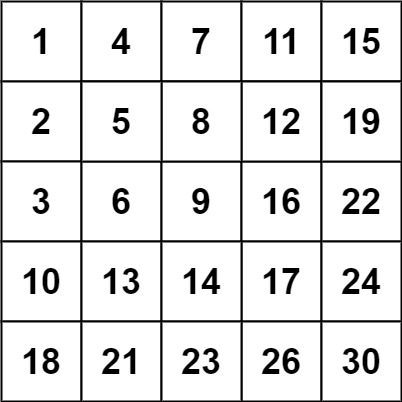
力扣 240.搜素矩阵II
题目描述: 编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性: 每行的元素从左到右升序排列。每列的元素从上到下升序排列。 示例 1: 输入:matrix [[1,4,7,11,15],[2,5,8,12,19],[3,6,9…...
ASUS华硕ROG幻14Air笔记本GA403UI(UI UV UU UJ)工厂模式原厂Windows11系统安装包,带MyASUS in WinRE重置还原
适用型号:GA403UI、GA403UV、GA403UU、GA403UJ 链接:https://pan.baidu.com/s/1tz8PZbYKakfvUoXafQPLIg?pwd1mtc 提取码:1mtc 华硕原装WIN11系统工厂包带有ASUS RECOVERY恢复功能、自带面部识别,声卡,显卡,网卡,蓝牙等所有驱动、出厂主题…...

Spring Boot通过自定义注解和Redis+Lua脚本实现接口限流
😄 19年之后由于某些原因断更了三年,23年重新扬帆起航,推出更多优质博文,希望大家多多支持~ 🌷 古之立大事者,不惟有超世之才,亦必有坚忍不拔之志 🎐 个人CSND主页——Mi…...

硬件工程师的蜗牛成长路
一名合格的硬件工程师,需要掌握的知识有很多,知识点积累不是一蹴而就,而是细水长流,螺旋提升,不急,慢慢来,想掌握的都能掌握,就让时间来见证个人的成长路径。 ---大青山 2024/6/10 …...

[2025CVPR]DeepVideo-R1:基于难度感知回归GRPO的视频强化微调框架详解
突破视频大语言模型推理瓶颈,在多个视频基准上实现SOTA性能 一、核心问题与创新亮点 1.1 GRPO在视频任务中的两大挑战 安全措施依赖问题 GRPO使用min和clip函数限制策略更新幅度,导致: 梯度抑制:当新旧策略差异过大时梯度消失收敛困难:策略无法充分优化# 传统GRPO的梯…...

深入浅出Asp.Net Core MVC应用开发系列-AspNetCore中的日志记录
ASP.NET Core 是一个跨平台的开源框架,用于在 Windows、macOS 或 Linux 上生成基于云的新式 Web 应用。 ASP.NET Core 中的日志记录 .NET 通过 ILogger API 支持高性能结构化日志记录,以帮助监视应用程序行为和诊断问题。 可以通过配置不同的记录提供程…...
)
Spring Boot 实现流式响应(兼容 2.7.x)
在实际开发中,我们可能会遇到一些流式数据处理的场景,比如接收来自上游接口的 Server-Sent Events(SSE) 或 流式 JSON 内容,并将其原样中转给前端页面或客户端。这种情况下,传统的 RestTemplate 缓存机制会…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

【论文阅读28】-CNN-BiLSTM-Attention-(2024)
本文把滑坡位移序列拆开、筛优质因子,再用 CNN-BiLSTM-Attention 来动态预测每个子序列,最后重构出总位移,预测效果超越传统模型。 文章目录 1 引言2 方法2.1 位移时间序列加性模型2.2 变分模态分解 (VMD) 具体步骤2.3.1 样本熵(S…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...
)
【LeetCode】3309. 连接二进制表示可形成的最大数值(递归|回溯|位运算)
LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 题目描述解题思路Java代码 题目描述 题目链接:LeetCode 3309. 连接二进制表示可形成的最大数值(中等) 给你一个长度为 3 的整数数组 nums。 现以某种顺序 连接…...
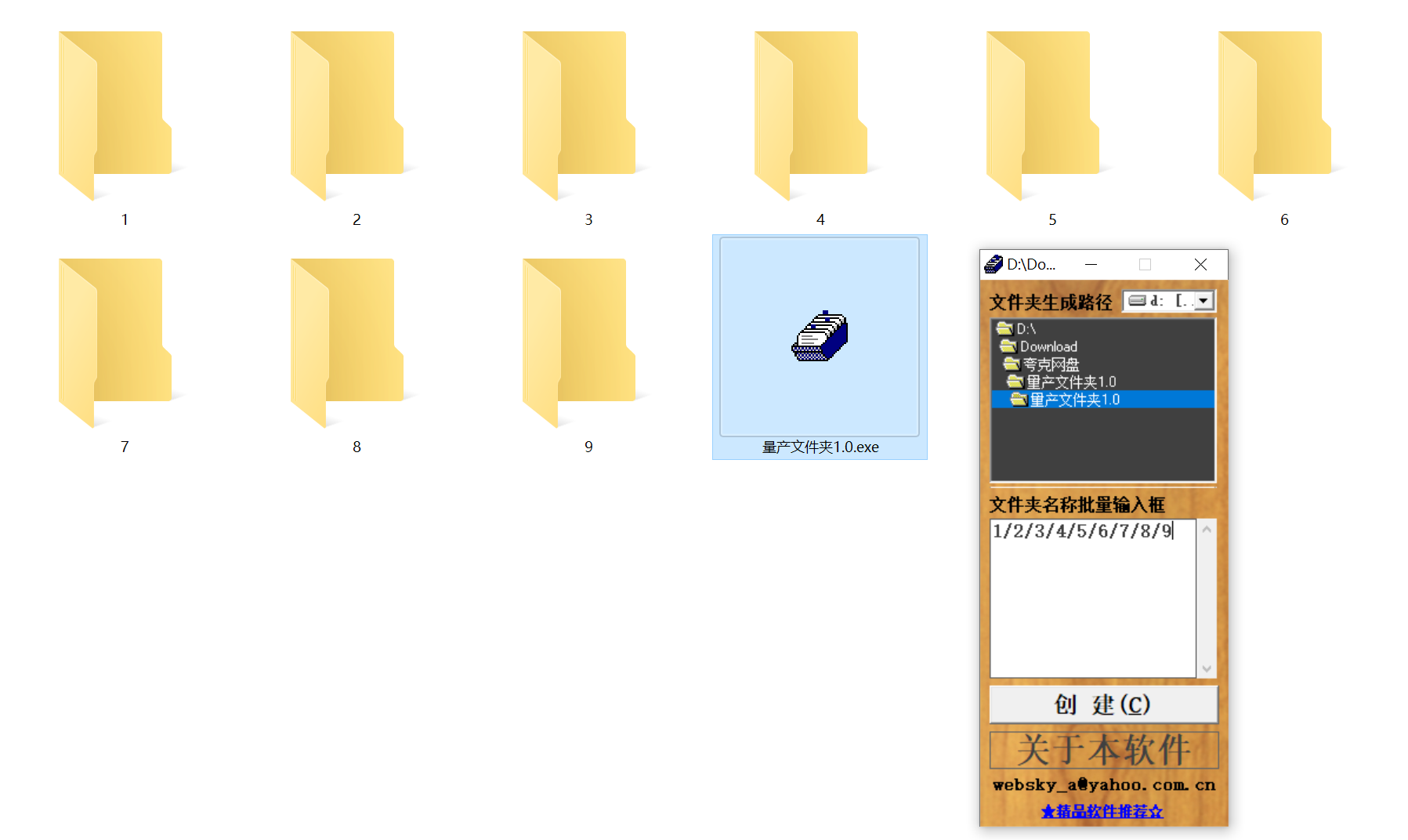
结构化文件管理实战:实现目录自动创建与归类
手动操作容易因疲劳或疏忽导致命名错误、路径混乱等问题,进而引发后续程序异常。使用工具进行标准化操作,能有效降低出错概率。 需要快速整理大量文件的技术用户而言,这款工具提供了一种轻便高效的解决方案。程序体积仅有 156KB,…...