CopyOnWriteArrayList详解
目录
- CopyOnWriteArrayList详解
- 1、CopyOnWriteArrayList简介
- 2、如何理解"写时复制"
- 3、CopyOnWriteArrayList的继承体系
- 4、CopyOnWriteArrayList的构造函数
- 5、CopyOnWriteArrayList的使用示例
- 6、CopyOnWriteArrayList 的 add方法
- 7、CopyOnWriteArrayList弱一致性的体现
- 8、CopyOnWriteArrayList的remove方法
CopyOnWriteArrayList详解
本来这个准备在并发相关的知识点整理之后再整理的,但是想想毕竟是List接口的实现,还是放在集合这块一起来整理吧。
基于JDK8.
1、CopyOnWriteArrayList简介
我第一次听说这个集合还是看了一个博客 说这个集合叫Cow 奶牛集合。然后就记住了哈哈。。。
CopyOnWriteArrayList 是 List 接口的一个线程安全实现,适用于需要保证线程安全频繁读取和偶尔修改的场景。其基本工作原理是,当对列表进行写操作(如添加、删除、更新元素)时,它会创建一个底层数组的副本,然后在新数组上执行写操作。这种“写时复制”的机制确保了在进行写操作时,不会影响正在进行的读操作,从而实现了线程安全。
所以"COW" 是 “写时复制”。
2、如何理解"写时复制"
Copy-On-Write (COW) 概念:
Copy-On-Write 是一种优化技术,主要用于提高读取性能和实现线程安全。其基本思想是在对共享数据进行修改时,并不直接修改原数据,而是首先创建原数据的一个副本,然后在副本上进行修改。这种技术广泛应用于内存管理、文件系统以及并发编程中。
工作原理
-
共享数据:在初始状态下,多个线程共享同一个数据(如一个数组)。
-
读操作:读取操作直接访问共享数据,不需要加锁,保证了高效性。
-
写操作:当某个线程需要修改数据时,首先复制一份数据的副本,然后在副本上进行修改。修改完成后,将副本替换掉原有的共享数据。
优点
高效的读取:读取操作不需要加锁,可以并发执行,性能非常高。
线程安全:由于写操作是在副本上进行,不会影响其他线程的读操作,天然地实现了线程安全。
迭代安全:迭代器遍历的是数据的快照,因此在遍历期间对数据的修改不会影响迭代器的遍历。
缺点
写操作开销大:每次写操作都需要复制数据,内存消耗较大,且写操作相对较慢。
内存使用高:频繁的写操作会导致大量内存占用。
适用场景
CopyOnWriteArrayList 特别适用于读操作频繁而写操作较少的场景,例如缓存、配置管理、白名单和黑名单等。在这些场景中,读取操作占主导地位,而写操作相对较少,因此可以充分利用 Copy-On-Write 技术的优点。
3、CopyOnWriteArrayList的继承体系
public class CopyOnWriteArrayList<E>implements List<E>, RandomAccess, Cloneable, java.io.Serializable
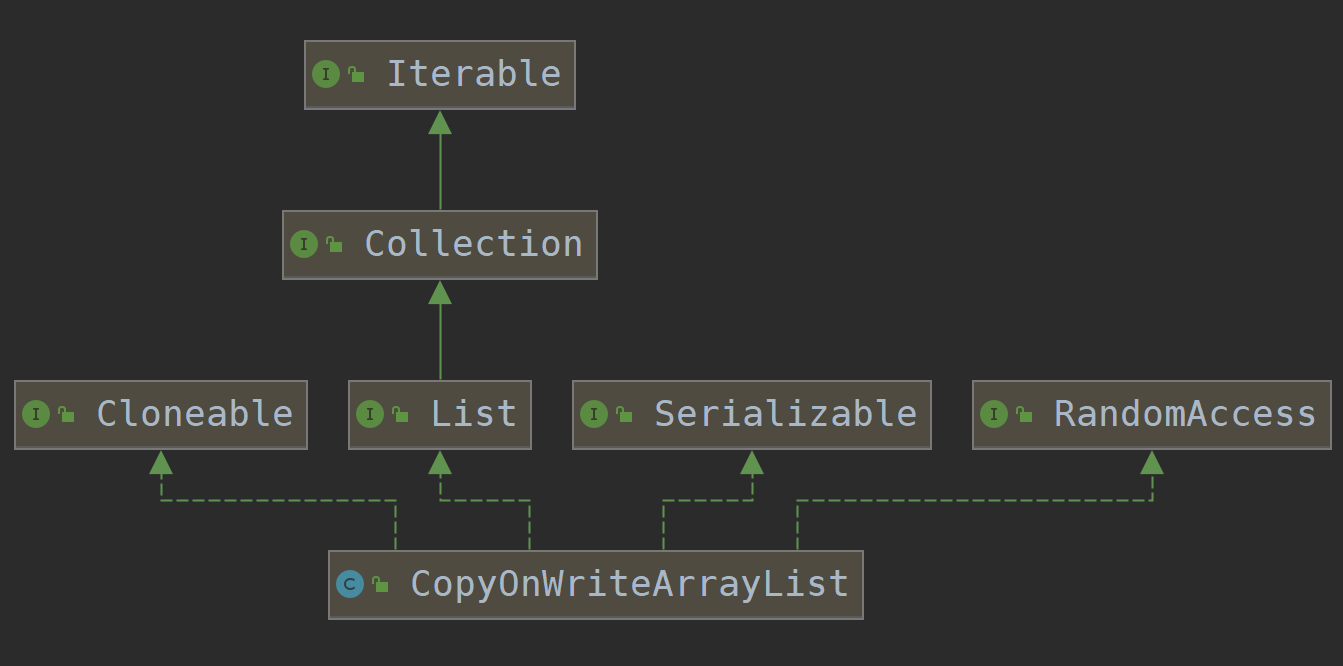
可以看到这个List接口的实现,实现了RandomAccess接口,说明支持快速随机访问。
4、CopyOnWriteArrayList的构造函数
- ①、空参构造
volatile 关键字后面总结并发相关知识点的时候 会详细解析,这里先简单注释下功能
// 声明一个用来存储元素的数组。使用 transient 关键字表示该字段在序列化时不会被持久化。
// 使用 volatile 关键字确保对该字段的所有读写操作都能立即被所有线程看到。
private transient volatile Object[] array;/*** 无参构造函数,用于创建一个空的 CopyOnWriteArrayList 实例。* 初始化一个空数组,并将其赋值给内部数组字段 array。*/
public CopyOnWriteArrayList() {// 调用 setArray 方法,传入一个空的 Object 数组。setArray(new Object[0]);
}/*** 设置内部数组字段 array 为指定的数组。* 该方法是包级私有的,且是 final 的,意味着它不能被子类重写。* * @param a 要设置为内部数组字段的新数组*/
final void setArray(Object[] a) {// 将传入的数组 a 赋值给内部数组字段 array。array = a;
}可以看到CopyOnWriteArrayList的无参构造会默认初始化一个空的Object数组。
- ②、有参构造1
接收一个集合类型的参数
public CopyOnWriteArrayList(Collection<? extends E> c) {// 声明一个数组来保存元素Object[] elements;// 检查输入的集合是否是 CopyOnWriteArrayList 的实例if (c.getClass() == CopyOnWriteArrayList.class) {// 如果是,直接从提供的 CopyOnWriteArrayList 实例中获取内部数组elements = ((CopyOnWriteArrayList<?>)c).getArray();} else {// 否则,将集合转换为数组elements = c.toArray();// 检查得到的数组是否确实是 Object[] 类型// 这是为了处理 c.toArray() 可能返回不同类型的数组的情况 这里和ArrayList的处理是一样的if (elements.getClass() != Object[].class) {// 如果不是,创建一个包含相同元素的新 Object[] 类型数组elements = Arrays.copyOf(elements, elements.length, Object[].class);}}// 设置内部数组setArray(elements);
}- ③、有参构造2
接收一个数组类型的参数
public CopyOnWriteArrayList(E[] toCopyIn) {// 使用 Arrays.copyOf 方法复制传入的数组// 第一个参数是要复制的数组 toCopyIn// 第二个参数是新数组的长度,即 toCopyIn 数组的长度// 第三个参数是新数组的类型,这里是 Object[].class// 该方法返回一个新的 Object[] 类型的数组,包含了 toCopyIn 数组中的所有元素setArray(Arrays.copyOf(toCopyIn, toCopyIn.length, Object[].class));
}
可以看到这里的初始化并没有扩容或者对于数组容量方面的处理。在这些构造函数中,传入的数组直接被复制为一个新的 Object[] 数组,没有进行额外的扩容处理。这意味着集合的初始容量就是传入数组的长度,不会为未来的添加操作预留额外的空间。
这也侧面印证了 这个集合的设计目的,应对读多写少的场景。
5、CopyOnWriteArrayList的使用示例
这个例子能体现出CopyOnWriteArrayList的特点。
模拟多线程的读写。新建3个读线程,每个线程读5次。同时启动一个写线程。
import java.util.concurrent.CopyOnWriteArrayList;public class TestA {public static void main(String[] args) throws Exception {// 创建一个 CopyOnWriteArrayList 实例CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>();// 初始化列表for (int i = 0; i < 10; i++) {list.add(i);}// 创建并启动多个读线程Thread reader1 = new Thread(new ReaderTask(list), "Reader-1");Thread reader2 = new Thread(new ReaderTask(list), "Reader-2");Thread reader3 = new Thread(new ReaderTask(list), "Reader-3");reader1.start();reader2.start();reader3.start();// 创建并启动一个写线程Thread writer = new Thread(new WriterTask(list), "Writer");writer.start();// 等待所有线程完成reader1.join();reader2.join();reader3.join();writer.join();System.out.println("Final list: " + list);}
}// 读任务
class ReaderTask implements Runnable {private CopyOnWriteArrayList<Integer> list;public ReaderTask(CopyOnWriteArrayList<Integer> list) {this.list = list;}@Overridepublic void run() {for (int i = 0; i < 5; i++) {System.out.println(Thread.currentThread().getName() + " - List: " + list);try {// 模拟读取过程中的延迟Thread.sleep(500);} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}
}// 写任务
class WriterTask implements Runnable {private CopyOnWriteArrayList<Integer> list;public WriterTask(CopyOnWriteArrayList<Integer> list) {this.list = list;}@Overridepublic void run() {for (int i = 10; i < 15; i++) {list.add(i);System.out.println(Thread.currentThread().getName() + " - Added: " + i);try {// 模拟写入过程中的延迟Thread.sleep(1000);} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}
}
结果:
Reader-1 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Reader-2 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Reader-3 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
Writer - Added: 10
Reader-1 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Reader-2 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Reader-3 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
Writer - Added: 11
Reader-2 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Reader-3 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Reader-1 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Reader-3 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Reader-2 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Reader-1 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11]
Writer - Added: 12
Reader-3 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
Reader-1 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
Reader-2 - List: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12]
Writer - Added: 13
Writer - Added: 14
Final list: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14]从结果可以看出,CopyOnWriteArrayList在多线程下的写操作,并不会影响并发读。而且最新一次的读操作也能读到数组新插入的元素。
这里读线程能读取到写线程的更改,实际上是下一次的读取能够读取到最新的更改,但是本次的读取是读取的当前状态下的数据。
我们再来看个例子:
import java.util.Iterator;
import java.util.concurrent.CopyOnWriteArrayList;public class TestA {public static void main(String[] args) throws Exception {// 创建一个 CopyOnWriteArrayList 实例CopyOnWriteArrayList<Integer> list = new CopyOnWriteArrayList<>();// 初始化列表for (int i = 0; i < 10; i++) {list.add(i);}// 创建并启动一个读线程Thread reader = new Thread(() -> {Iterator<Integer> iterator = list.iterator();while (iterator.hasNext()) {Integer value = iterator.next();System.out.println(Thread.currentThread().getName() + " - Value: " + value);try {// 模拟遍历过程中的延迟Thread.sleep(100);} catch (InterruptedException e) {Thread.currentThread().interrupt();}}}, "Reader");// 创建并启动一个写线程Thread writer = new Thread(() -> {try {// 模拟写入操作的延迟Thread.sleep(500);} catch (InterruptedException e) {Thread.currentThread().interrupt();}list.add(10);System.out.println(Thread.currentThread().getName() + " - Added: " + 10);}, "Writer");reader.start();writer.start();reader.join();writer.join();System.out.println("Final list: " + list);}}运行结果:
Reader - Value: 0
Reader - Value: 1
Reader - Value: 2
Reader - Value: 3
Reader - Value: 4
Writer - Added: 10
Reader - Value: 5
Reader - Value: 6
Reader - Value: 7
Reader - Value: 8
Reader - Value: 9
Final list: [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
从这个结果中可以看到,写操作在读操作 读到4的时候就把10写入到集合了,但是读操作最终没读到10。
但是最新一次的主线程遍历又读到了10。
这说明CopyOnWriteArrayList,实际上是弱一致性的。
6、CopyOnWriteArrayList 的 add方法
新增方法有三种:
-
①、add(E e)
将元素 e 添加到列表的末尾。
线程安全地进行添加操作,通过复制底层数组实现。 -
②、add(int index, E element)
在指定位置 index 插入元素 element。
插入位置及其之后的元素向后移动。
线程安全地进行插入操作,通过复制底层数组实现。 -
③、addIfAbsent(E e)
如果元素 e 不在列表中,则将其添加到列表的末尾。
线程安全地进行添加操作,通过复制底层数组实现。
add(E e) 方法详细注释:
// 创建 ReentrantLock 实例
final transient ReentrantLock lock = new ReentrantLock();public boolean add(E e) {// 获取 ReentrantLock锁实例final ReentrantLock lock = this.lock;// 获取锁,确保线程安全lock.lock();try {// 获取当前内部数组的引用Object[] elements = getArray();// 获取当前数组的长度int len = elements.length;// 创建一个新的数组,长度为当前数组长度加1Object[] newElements = Arrays.copyOf(elements, len + 1);// 将新元素添加到新数组的末尾newElements[len] = e;// 用新的数组替换内部数组setArray(newElements);// 返回 true,表示元素成功添加return true;} finally {// 确保在退出方法之前释放锁lock.unlock();}
}// 获取当前内部数组的引用
final Object[] getArray() {return array;}// 设置内部数组 array 为 新的数组afinal void setArray(Object[] a) {array = a;}
add(int index, E element)方法详细注释:
public void add(int index, E element) {// 获取当前类的 ReentrantLock 锁实例final ReentrantLock lock = this.lock;// 获取锁,确保线程安全lock.lock();try {// 获取当前内部数组的引用Object[] elements = getArray();// 获取当前数组的长度int len = elements.length;// 检查索引是否超出范围// 如果索引大于当前数组长度或者小于0,则抛出 IndexOutOfBoundsExceptionif (index > len || index < 0)throw new IndexOutOfBoundsException("Index: " + index + ", Size: " + len);// 声明新数组的引用Object[] newElements;// 计算从插入点到数组末尾的元素数量int numMoved = len - index;// 如果插入点在数组末尾if (numMoved == 0)// 创建一个新数组,其长度为当前数组长度加1,并复制当前数组的所有元素newElements = Arrays.copyOf(elements, len + 1);else {// 否则,创建一个新数组,其长度为当前数组长度加1newElements = new Object[len + 1];// 将当前数组的前半部分(插入点之前的元素)复制到新数组中System.arraycopy(elements, 0, newElements, 0, index);// 将当前数组的后半部分(插入点及其之后的元素)复制到新数组中,从插入点的下一个位置开始System.arraycopy(elements, index, newElements, index + 1, numMoved);}// 在新数组的插入点位置添加新元素newElements[index] = element;// 用新数组替换内部数组setArray(newElements);} finally {// 确保在退出方法之前释放锁lock.unlock();}
}addIfAbsent(E e) 方法详细注释:
public boolean addIfAbsent(E e) {// 获取当前内部数组的快照Object[] snapshot = getArray();// 检查元素 e 是否存在于快照中,如果存在则返回 false;否则尝试将 e 添加到列表中return indexOf(e, snapshot, 0, snapshot.length) >= 0 ? false :addIfAbsent(e, snapshot);
}private static int indexOf(Object o, Object[] elements,int index, int fence) {// 检查对象是否为 nullif (o == null) {// 遍历元素数组,找到第一个为 null 的位置for (int i = index; i < fence; i++)if (elements[i] == null)return i;} else {// 遍历元素数组,找到第一个与 o 相等的位置for (int i = index; i < fence; i++)if (o.equals(elements[i]))return i;}// 如果未找到匹配的元素,返回 -1return -1;
}private boolean addIfAbsent(E e, Object[] snapshot) {// 获取当前类的 ReentrantLock 锁实例final ReentrantLock lock = this.lock;// 获取锁,确保线程安全lock.lock();try {// 获取当前内部数组的引用Object[] current = getArray();// 获取当前数组的长度int len = current.length;// 检查快照是否与当前数组相同if (snapshot != current) {// 优化:处理与其他 addXXX 操作竞争的情况int common = Math.min(snapshot.length, len);for (int i = 0; i < common; i++)if (current[i] != snapshot[i] && eq(e, current[i]))return false;// 检查元素是否在当前数组中存在if (indexOf(e, current, common, len) >= 0)return false;}// 创建一个新数组,其长度为当前数组长度加 1,并复制当前数组的所有元素Object[] newElements = Arrays.copyOf(current, len + 1);// 在新数组的末尾添加新元素newElements[len] = e;// 用新数组替换内部数组setArray(newElements);// 返回 true,表示元素成功添加return true;} finally {// 确保在退出方法之前释放锁lock.unlock();}
}
通过源码
// 创建 ReentrantLock 实例 final transient ReentrantLock lock = new ReentrantLock();,
final ReentrantLock lock = this.lock;
使用final修饰 保证 lock 引用不可被修改,通过ReentrantLock 可重入锁 ,实现添加方法的线程安全。
通过: Object[] newElements = Arrays.copyOf(current, len + 1); 创建一个新的数组,其长度为当前数组长度加 1,并复制当前数组的所有元素 。 添加操作实际上是把元素添加到了这个新复制的数组里了,这就体现了COW写时复制的思想。
最后再 setArray(newElements);用新数组替换内部数组。
注意点: CopyOnWriteArrayList并没有size属性,因为CopyOnWriteArrayList没有扩容机制,其内部数组的length就是实际的CopyOnWriteArrayList的大小。
所以CopyOnWriteArrayList的size()方法就是返回内部数组的length即可。
public int size() {return getArray().length;}
7、CopyOnWriteArrayList弱一致性的体现
若一致性是制一致性约束较为宽松,某些情况下允许存在短暂的不一致性。
主要体现在下面几个方面:
-
①、“写时复制”,即每次对列表进行修改(如添加、删除、更新)时,都会创建该列表的一个新副本。原列表在修改过程中不会被改变。这种创建快照的形式意味着所有的读操作都将在旧的、不变的数组上进行,而修改操作将创建一个新的数组副本并替换旧数组。由于读操作不需要加锁,读操作可能不会立即看到最新的写操作结果。
-
②、并发读取时,可能会有线程看到旧的数组快照,而另一个线程看到新的数组快照。因为读操作不需要加锁。
-
③、修改的延迟可见,对于CopyOnWriteArrayList的增、删、改方法。
拿新增方法举例:
// 在新数组的末尾添加新元素newElements[len] = e;// 用新数组替换内部数组setArray(newElements);
元素新增后还要调用 setArray 把内部数组的引用指向新数组,才算修改操作真正完成。在 setArray(newElements);方法执行之前,其他读取线程依旧访问的是旧的数组引用,即便新元素已经添加到了新数组中。直到 setArray(newElements); 方法执行完毕,其他线程才能看到最新的修改。
8、CopyOnWriteArrayList的remove方法
CopyOnWriteArrayList删除元素:
remove(int index):删除指定位置上的元素。
boolean remove(Object o):删除此首次出现的指定元素,如果不存在该元素则返回 false。
boolean removeAll(Collection<?> c):删除指定集合中的全部元素。
E remove(int index)方法:
public E remove(int index) {// 获取ReentrantLock锁对象,以确保线程安全final ReentrantLock lock = this.lock;// 锁定,确保在该方法执行期间其他线程无法修改数组lock.lock();try {// 获取当前数组的副本Object[] elements = getArray();// 获取当前数组的长度int len = elements.length;// 获取指定索引位置的旧值,将其保存以便稍后返回E oldValue = get(elements, index);// 计算从指定索引到数组末尾的元素数量int numMoved = len - index - 1;// 如果需要移动的元素数量为0,说明要移除的是最后一个元素if (numMoved == 0)// 创建一个新数组,长度为旧数组长度减1,并将其设置为内部数组setArray(Arrays.copyOf(elements, len - 1));else {// 创建一个新数组,长度为旧数组长度减1Object[] newElements = new Object[len - 1];// 将旧数组从起始位置到指定索引位置的元素复制到新数组System.arraycopy(elements, 0, newElements, 0, index);// 将旧数组从指定索引位置之后的元素复制到新数组System.arraycopy(elements, index + 1, newElements, index, numMoved);// 用新数组替换内部数组setArray(newElements);}// 返回被移除的旧值return oldValue;} finally {// 确保锁在方法结束时释放,以避免死锁lock.unlock();}
}boolean remove(Object o)方法:
public boolean remove(Object o) {// 获取当前数组的快照Object[] snapshot = getArray();// 查找对象o在数组中的索引int index = indexOf(o, snapshot, 0, snapshot.length);// 如果索引小于0(未找到),返回false;否则,调用remove方法移除该元素return (index < 0) ? false : remove(o, snapshot, index);
}private static int indexOf(Object o, Object[] elements, int index, int fence) {// 如果对象o是null,寻找第一个null元素的索引if (o == null) {for (int i = index; i < fence; i++)if (elements[i] == null)return i;} else {// 如果对象o不是null,寻找第一个与o相等的元素的索引for (int i = index; i < fence; i++)if (o.equals(elements[i]))return i;}// 如果未找到,返回-1return -1;
}private boolean remove(Object o, Object[] snapshot, int index) {// 获取ReentrantLock锁对象,以确保线程安全final ReentrantLock lock = this.lock;// 锁定,确保在该方法执行期间其他线程无法修改数组lock.lock();try {// 获取当前数组Object[] current = getArray();// 获取当前数组的长度int len = current.length;// 检查当前数组和快照是否相同if (snapshot != current) findIndex: {// 计算索引和长度的较小值int prefix = Math.min(index, len);// 重新定位索引,寻找匹配的元素for (int i = 0; i < prefix; i++) {if (current[i] != snapshot[i] && eq(o, current[i])) {index = i;break findIndex;}}// 如果索引超出数组长度,返回falseif (index >= len)return false;// 如果当前索引位置的元素匹配,跳出查找if (current[index] == o)break findIndex;// 重新查找对象o在当前数组中的索引index = indexOf(o, current, index, len);// 如果未找到,返回falseif (index < 0)return false;}// 创建一个新数组,长度为旧数组长度减1Object[] newElements = new Object[len - 1];// 将旧数组从起始位置到指定索引位置的元素复制到新数组System.arraycopy(current, 0, newElements, 0, index);// 将旧数组从指定索引位置之后的元素复制到新数组System.arraycopy(current, index + 1, newElements, index, len - index - 1);// 用新数组替换内部数组setArray(newElements);// 返回true表示成功移除元素return true;} finally {// 确保锁在方法结束时释放,以避免死锁lock.unlock();}
}过程总结:
-
①、
remove(Object o)方法:
获取当前数组的快照。
查找对象 o 在快照中的索引。
如果未找到(索引小于0),返回 false。
否则,调用 remove(o, snapshot, index) 方法进行移除操作。 -
②、
indexOf(Object o, Object[] elements, int index, int fence)方法:
遍历数组,从指定索引到指定范围(fence)寻找对象 o 的索引。
如果对象 o 是 null,寻找第一个 null 元素的索引。
否则,寻找第一个与 o 相等的元素的索引。
如果未找到,返回 -1。 -
③、
remove(Object o, Object[] snapshot, int index)方法:
获取锁对象,确保线程安全。
获取当前数组及其长度。
如果当前数组与快照不同,重新定位索引,寻找匹配的元素。
计算前缀长度。
遍历前缀部分,重新定位索引,寻找匹配的元素。
如果索引超出数组长度,返回 false。
如果当前索引位置的元素匹配,跳出查找。
重新查找对象 o 在当前数组中的索引。
如果未找到,返回 false。
创建一个新数组,长度为旧数组长度减1。
将旧数组从起始位置到指定索引位置的元素复制到新数组。
将旧数组从指定索引位置之后的元素复制到新数组。
用新数组替换内部数组。
返回 true 表示成功移除元素。
removeAll(Collection<?> c)方法:
public boolean removeAll(Collection<?> c) {// 如果集合c为null,抛出NullPointerExceptionif (c == null) throw new NullPointerException();// 获取ReentrantLock锁对象,以确保线程安全final ReentrantLock lock = this.lock;// 锁定,确保在该方法执行期间其他线程无法修改数组lock.lock();try {// 获取当前数组的副本Object[] elements = getArray();// 获取当前数组的长度int len = elements.length;// 如果数组不为空if (len != 0) {// 临时数组,用于保存需要保留的元素int newlen = 0;Object[] temp = new Object[len];// 遍历当前数组的所有元素for (int i = 0; i < len; ++i) {Object element = elements[i];// 如果集合c不包含当前元素,将其保存到临时数组中if (!c.contains(element))temp[newlen++] = element;}// 如果新长度和旧长度不相等,说明有元素被移除if (newlen != len) {// 创建一个新的数组,仅包含需要保留的元素,并将其设置为内部数组setArray(Arrays.copyOf(temp, newlen));// 返回true,表示成功移除元素return true;}}// 返回false,表示没有元素被移除return false;} finally {// 确保锁在方法结束时释放,以避免死锁lock.unlock();}
}还有一个删除全部元素的方法clear():
public void clear() {// 获取ReentrantLock锁对象,以确保线程安全final ReentrantLock lock = this.lock;// 锁定,确保在该方法执行期间其他线程无法修改数组lock.lock();try {// 设置一个新的空数组,清空当前列表setArray(new Object[0]);} finally {// 确保锁在方法结束时释放,以避免死锁lock.unlock();}
}相关文章:
CopyOnWriteArrayList详解
目录 CopyOnWriteArrayList详解1、CopyOnWriteArrayList简介2、如何理解"写时复制"3、CopyOnWriteArrayList的继承体系4、CopyOnWriteArrayList的构造函数5、CopyOnWriteArrayList的使用示例6、CopyOnWriteArrayList 的 add方法7、CopyOnWriteArrayList弱一致性的体现…...

CUDA 编程(1):使用Grid 和 Block分配线程
1 介绍 1.1 Grid 和 Block 概念 核函数以线程为单位进行计算的函数,cuda编程会涉及到大量的线程(thread),几千个到几万个thread同时并行计算,所有的thread其实都是在执行同一个核函数。 对于核函数(Kernel),一个核函数一般会分配1个Grid, 1个Grid又有很多个Block,1个Bloc…...

ArcGIS for js 4.x FeatureLayer 加载、点选、高亮
安装arcgis for js 4.x 依赖: npm install arcgis/core 一、FeatureLayer 加载 代码如下: <template><view id"mapView"></view></template><script setup>import "arcgis/core/assets/esri/themes/li…...
倩女幽魂手游攻略:云手机自动搬砖辅助教程!
《倩女幽魂》手游自问世以来一直备受玩家喜爱,其精美画面和丰富的游戏内容让人沉迷其中。而如今,借助VMOS云手机,玩家可以更轻松地进行搬砖,提升游戏体验。 一、准备工作 下载VMOS云手机: 在PC端或移动端下载并安装VM…...
Typesense-开源的轻量级搜索引擎
Typesense-开源的轻量级搜索引擎 Typesense是一个快速、允许输入错误的搜索引擎,用于构建愉快的搜索体验。 开源的Algolia替代方案& 易于使用的弹性搜索替代方案 官网: https://typesense.org/ github: https://github.com/typesense/typesense 目前已有18.4k…...
探索 LLM 预训练的挑战,GPU 集群架构实战
万卡 GPU 集群实战:探索 LLM 预训练的挑战 一、背景 在过往的文章中,我们详细阐述了LLM预训练的数据集、清洗流程、索引格式,以及微调、推理和RAG技术,并介绍了GPU及万卡集群的构建。然而,LLM预训练的具体细节尚待进一…...
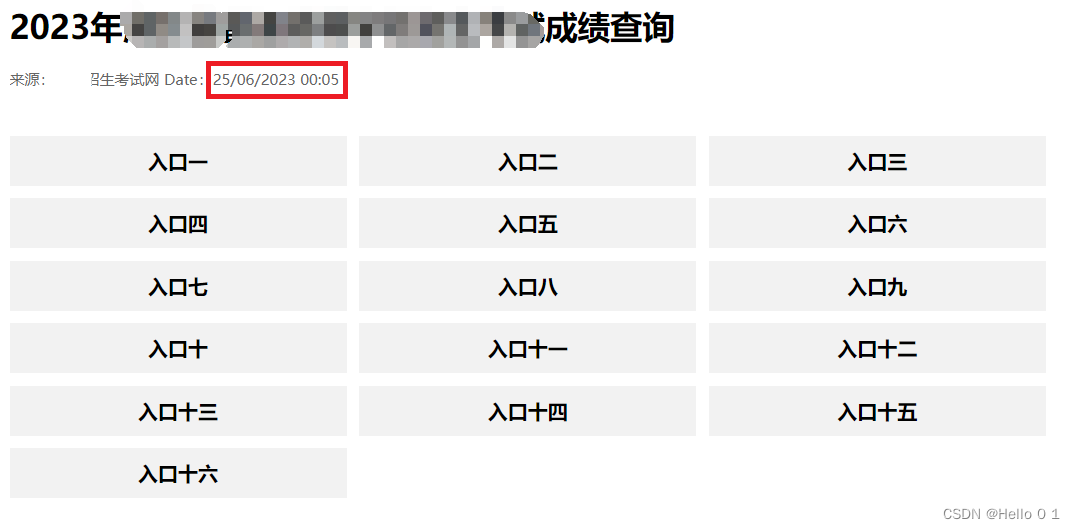
高考分数查询结果自动推送至微信(卷II)
祝各位端午节安康!只要心中无结,每天都是节,开心最重要! 在上一篇文章高考分数查询结果自动推送至微信(卷Ⅰ)-CSDN博客中谈了思路,今天具体实现。文中将敏感信息已做处理,读者根据自…...

python类动态属性,以属性方式访问字典
动态属性能够用来描述变化的类,在实际应用中容易遇到用到。 import logging class Sample:def __init__(self):self.timeNoneself.sampleidNoneself.massNoneself.beizhu""self.num0self.items{}#字典属性def __getattribute__(self, attr): #注意&#…...

招聘在家抄书员?小心是骗局!!!
在家抄书员的骗局是一种常见的网络诈骗手段,旨在利用人们想要在家轻松赚钱的心理。这种骗局通常会以招聘兼职抄写员的形式出现,声称只需在家中抄写书籍即可赚取可观的收入。然而,实际上这背后隐藏着诸多陷阱和虚假承诺。 首先,这些…...
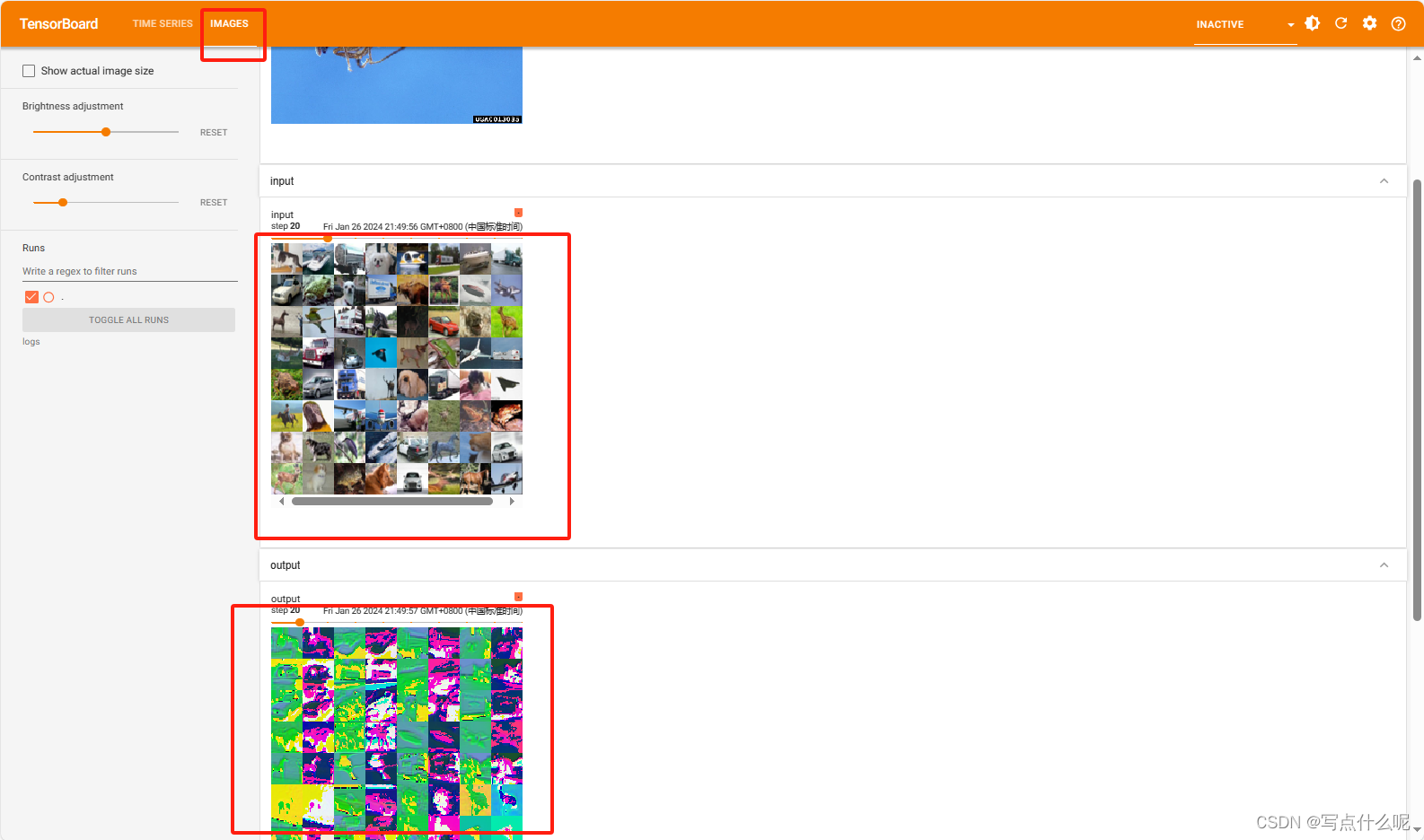
Pytorch学习11_神经网络-卷积层
1.创建神经网络实例 import torch import torchvision from torch import nn from torch.nn import Conv2d from torch.utils.data import DataLoaderdatasettorchvision.datasets.CIFAR10("../dataset_cov2d",trainFalse,transformtorchvision.transforms.ToTensor(…...
及QSharedMemory用法)
Qt实现程序单实例运行(只能运行1个进程)及QSharedMemory用法
1. 问题提出 在开发时,经常遇到这样的需求或场景:程序只能被启动一次,不能启动多次,启动多次会导致混乱,如:可执行程序用到文件指针、串口句柄等。试想如果存在多个同一个文件的句柄或同一个串口的句柄&…...
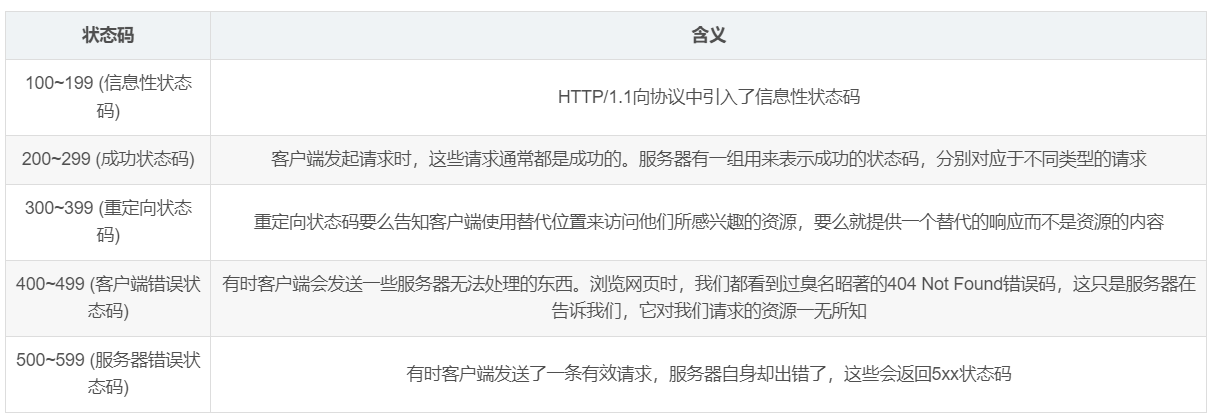
HTTP协议分析实验:通过一次下载任务抓包分析
HTTP协议分析 问:HTTP是干啥用的? 最简单通俗的解释:HTTP 是客户端浏览器或其他程序与Web服务器之间的应用层通信协议。 在Internet上的Web服务器上存放的都是超文本信息,客户机需要通过HTTP协议传输所要访问的超文本信息。 一、…...

http网络服务器
wwwroot(目录)/index.html <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initial-scale1.0"><title>比特就业课</title>…...

使用C++结合OpenCV进行图像处理与分类
⭐️我叫忆_恒心,一名喜欢书写博客的在读研究生👨🎓。 如果觉得本文能帮到您,麻烦点个赞👍呗! 近期会不断在专栏里进行更新讲解博客~~~ 有什么问题的小伙伴 欢迎留言提问欧,喜欢的小伙伴给个三…...

探索 Noisee AI 的奇妙世界与变现之旅
日赚800,利用淘宝/闲鱼进行AI音乐售卖实操 如何让AI生成自己喜欢的歌曲-AI音乐创作的正确方式 抖音主播/电商人员有福了,利用Suno创作产品宣传,让产品动起来-小米Su7 用sunoAI写粤语歌的方法,博主已经亲自实践可行 五音不全也…...

【SCSS】use的详细使用规则
目录 use加载成员选择命名空间私有成员配置使用 Mixin重新赋值变量 use 从其他 Sass 样式表中加载 mixins、函数和变量,并将来自多个样式表的 CSS 组合在一起。use加载的样式表被称为“模块”。 加载成员 // src/_corners.scss $radius: 3px;mixin rounded {bord…...

数据结构(C):二叉树前中后序和层序详解及代码实现及深度刨析
目录 🌞0.前言 🚈1.二叉树链式结构的代码是实现 🚈2.二叉树的遍历及代码实现和深度刨析代码 🚝2.1前序遍历 ✈️2.1.1前序遍历的理解 ✈️2.1.2前序代码的实现 ✈️2.1.3前序代码的深度解剖 🚝2.2中序遍历 ✈…...

Win11可以安装AutoCAD2007
1、在win11中,安装AutoCAD2007,需要先安装NET组件。否则会提示缺少".net文件" 打开“控制面板”,点击“程序”,点击“程序和功能”,点击“启用或关闭Windows功能”,勾选“.NET FrameWork 3.5”&a…...
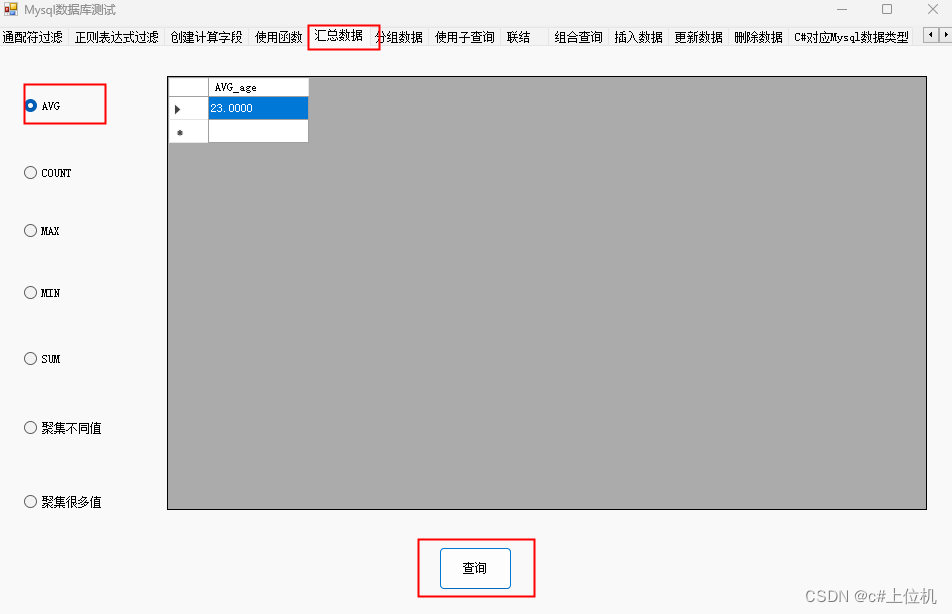
C#操作MySQL从入门到精通(14)——汇总数据
前言 我们有时候需要对数据库查询的值进行一些处理,比如求平均值等操作,本文就是详细讲解这些用法,本文测试使用的数据库数据如下: 1、求平均值 求所有student_age 列的平均值 string sql = string.Empty; if (radioButton_AVG.Checked) {sql = “select AVG( student_…...

【设计模式深度剖析】【2】【行为型】【命令模式】| 以打开文件按钮、宏命令、图形移动与撤销为例加深理解
👈️上一篇:模板方法模式 | 下一篇:职责链模式👉️ 设计模式-专栏👈️ 文章目录 命令模式定义英文原话直译如何理解呢? 四个角色1. Command(命令接口)2. ConcreteCommand(具体命令类&…...

3种工业级模型转换方案实现STL到STEP格式转换:提升工程数据互操作性70%
3种工业级模型转换方案实现STL到STEP格式转换:提升工程数据互操作性70% 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在现代制造业数字化转型过程中,3D模型数据在不同…...

效率提升秘籍:用快马平台自动化dhnvr416h-hd视频处理流水线
在视频处理领域,尤其是集成像 dhnvr416h-hd 这类特定设备或格式的编解码器时,开发者常常会陷入一个效率泥潭:环境配置复杂、处理流程繁琐、错误排查困难。每次新项目启动,都要重复搭建环境、编写相似的脚本,大量时间被…...

电脑端制作泳道图超便捷 零基础快速做出专业业务流程图
在企业管理、软件开发、流程梳理等工作场景中,泳道图作为一种清晰呈现多角色、多部门协作流程的可视化图表,被广泛应用于需求分析、业务流程优化、系统设计等环节。对于职场从业者和开发者而言,快速绘制出规范、专业的泳道图,能够…...

能碳管理系统组成与原理解析:揭开绿色发展背后的 “神秘面纱”?
全面解读能碳管理系统:从原理到价值的深度剖析从 “感知” 到 “认知”:系统如何捕获能源与碳的踪迹要理解能碳管理系统,先得从它最基础的感知能力入手。这个系统可不是凭空运作的,它首先要解决一个根本问题:怎样精准、…...

C++ 是一种静态类型的、编译式的、通用的、大小写敏感的、不规则的编程语言
要判断这个关于C的描述是否准确,我们可以从以下几个方面来分析: 1. 静态类型 静态类型语言要求在编译时确定变量的类型,且类型在程序运行过程中一般不会改变。C属于静态类型语言,和C、Java等类似,在声明变量时必须指定…...

BigBlueButton无限白板功能详解:打破空间限制的协作新方式
BigBlueButton无限白板功能详解:打破空间限制的协作新方式 【免费下载链接】bigbluebutton Complete open source web conferencing system. 项目地址: https://gitcode.com/gh_mirrors/bi/bigbluebutton BigBlueButton是一款完整的开源网络会议系统…...

Gorilla学习资源大全:从入门教程到高级技术白皮书
Gorilla学习资源大全:从入门教程到高级技术白皮书 【免费下载链接】gorilla Gorilla: An API store for LLMs 项目地址: https://gitcode.com/gh_mirrors/go/gorilla Gorilla是一个强大的API调用平台,它使大型语言模型(LLM)能够通过调用API来使用…...
)
MGeo中文地址解析实战:地址文本脱敏(门牌号掩码/敏感词过滤)
MGeo中文地址解析实战:地址文本脱敏(门牌号掩码/敏感词过滤) 你是不是也遇到过这样的烦恼?公司业务系统里,用户填写的地址信息五花八门,有的包含了详细的“XX小区X栋X单元XXX室”,有的则只写了…...

多模态预演:all-MiniLM-L6-v2文本Embedding如何为多模态系统打基础
多模态预演:all-MiniLM-L6-v2文本Embedding如何为多模态系统打基础 1. 认识all-MiniLM-L6-v2:轻量级语义表示专家 all-MiniLM-L6-v2是一个专门为高效语义表示设计的轻量级句子嵌入模型。它基于BERT架构,但通过精巧的设计实现了性能与效率的…...

用了五年的Aliprice突然改名了?说说我和这个插件的故事
早上照常打开Chrome准备干活,突然发现工具栏里那个熟悉的橙色图标变了。定睛一看,“AliPrice”变成了“AiPrice”。第一反应是插件出错了?重启浏览器,还是新的图标。去官网看了眼,才发现是真的改名了。说实话ÿ…...