数仓建模中的一些问题
 在数仓建设的过程中,由于未能完全按照规范操作, 从而导致数据仓库建设比较混乱,常见有以下问题:
在数仓建设的过程中,由于未能完全按照规范操作, 从而导致数据仓库建设比较混乱,常见有以下问题:
数仓常见问题
● 数仓分层不清晰:数仓的分层没有明确的逻辑,难以管理和维护。
● 数据域划分不明确:没有明确的数据域划分,导致数据冗余和不一致。
● 模型设计不合理:模型设计没有考虑业务的实际需求,导致数据质量低下。
● 代码不规范:代码不符合规范,导致维护困难。
● 命名不统一:命名不统一,导致数据难以理解和使用。
● 主题域划分不完整:主题域划分没有涵盖所有业务需求,导致数据缺失。
除此之外,其他还有比如:数据质量,数据集成,性能,元数据管理,数据安全等问题。
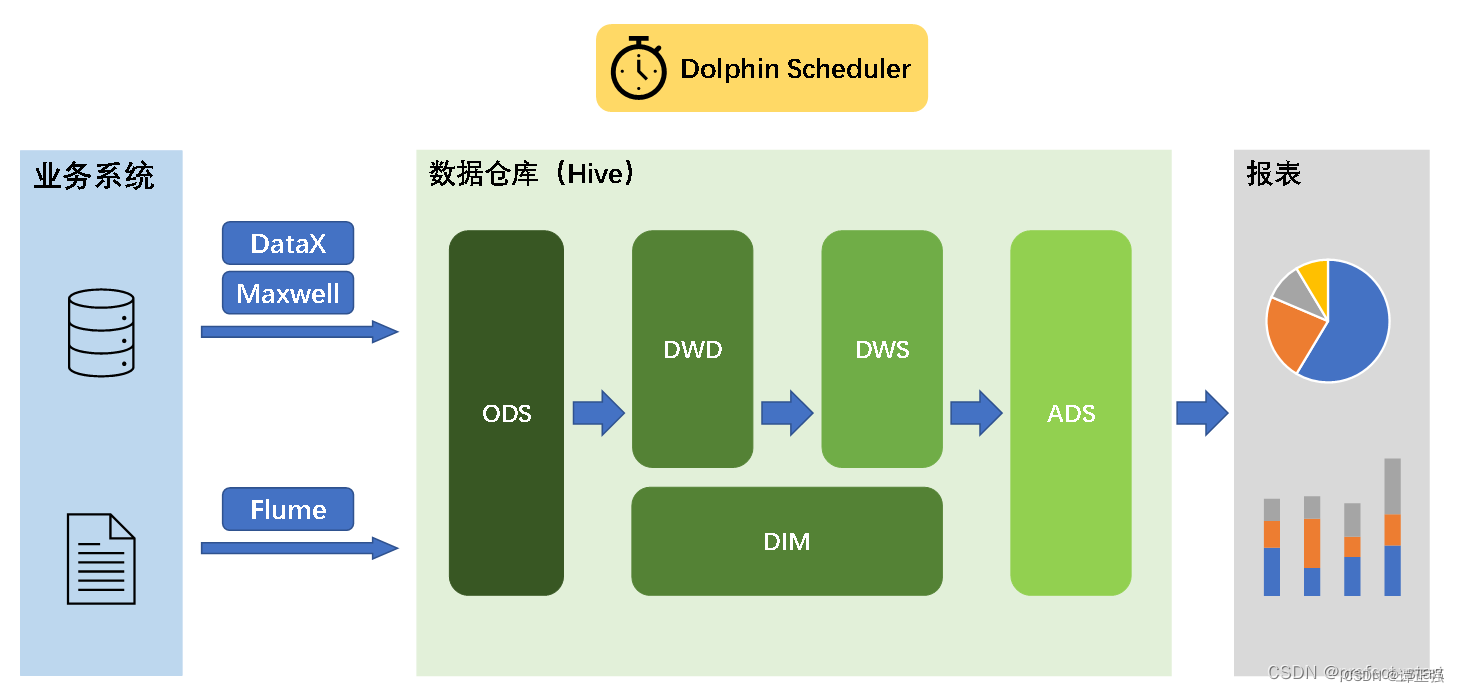
数据架构分层
数仓分层标准
一般情况下,大体可以按照如下方式进行分层:
● ODS (结构与源系统基本保持一致的增量或者全量数据)
● DWD (数仓明细层,来源于 ODS 清洗转化,基于具体业务构建明细事实表,可适当冗余某些重要属性,必要时做宽表处理)
● DWS(汇总层,一般基于指标构建初步汇总事实表,注意命名规范,口径一致,为上层提供一致性公共指标)
● DIM(维表层,以维度作为建模驱动,基于每个维度的业务含义,通过添加维度属性、关联维度等定义计算逻辑,完成属性定义的过程并建立一致的数据分析维表)
● ADS (数据服务层,主要存放数据产品个性化的统计指标数据,直接对接消费者)
开发路径
● 数据调研(分析业务需求,需要哪些指标,具体口径,梳理业务库表关系字段含义等信息)
● 数据域划分(对业务过程或维度进行抽象,比如交易、流量、用户域等)
● 构建总线矩阵 (明确业务过程所属的数据域,业务过程与分析维度的关系)
● 明确统计指标 (一般指的是原子指标与派生指标)
● 模型设计(构建一致性维表(DIM),事实表(DWD),汇总模型(DWS),应用汇总模型(ADS))
● 开发(业务逻辑SQL开发,测试、数据验证)
● 部署(上线(如T-1调度),依赖配置、任务监控、DQ 任务检测)
表规范
在建立 Hive 数据仓库表时,针对不同数据层次和类型(如增量、全量、小时级数据),我们通常遵循以下规范:
-
命名规范
分层命名
数据仓库分为不同层次,每层次对应不同的数据处理阶段。
命名格式为:{层级名称}{业务域}{具体业务描述}_{产出属性}
示例:
ods_user_new_inc_df (ods层用户新增天级全量表)
ods_user_active_di (ods层用户活跃天级增量表) -
分区规范
对于增量、全量、小时级数据,建议根据业务需求采用分区表,提高查询效率。
○ 按日期分区:适用于每天新增数据,如每日更新。
示例:PARTITIONED BY (dt STRING)
○ 按小时分区:适用于每小时新增数据,如小时级别的增量数据。
示例:PARTITIONED BY (dt STRING, hr STRING)
○ 全量数据:通常不分区,但可以根据业务需求分区。
示例:定期全量导入时,可以按日期分区,表名如dim_customer。
模型设计基本原则
● 高内聚和低耦合
主要从数据业务特性和访问特性两个角度来考虑:
○ 将业务相近或者相关的数据、粒度相同数据设计为一个逻辑或者物理模型;
○ 将高概率同时访问的数据放一起,将低概率同时访问的数据分开存储。
● 核心模型与扩展模型分离
建立核心模型与扩展模型体系,核心模型包括的字段支持常用核心的业务,扩展模型包括的字段支持个性化或是少量应用的需要,不能让扩展字段过度侵入核心模型,破坏了核心模型的架构简洁性与可维护性。
● 公共处理逻辑下沉
越是底层公用的处理逻辑更应该在数据调度依赖的底层进行封装与实现,不要让公共的处理逻辑暴露给应用层实现,不要让公共逻辑在多处同时存在。
● 成本与性能平衡
适当的数据冗余换取查询和刷新性能,不宜过度冗余与数据复制。
● 数据可回滚
处理逻辑不变,在不同时间多次运行数据结果确定不变。
● 指标一致性
相同的字段含义在不同表中字段命名必须相同,必须使用规范定义中的名称。
● 命名清晰可理解
表命名需清晰、一致,表名需易于消费者理解和使用。
● 层次依赖合理
○ DWD应严格遵守层次依赖,理论上只可引用ODS、DIM和部分DWD数据,不可引用处于下游层次的ADS等数据,以避免出现“反向引用”的情况;
○ DWS应严格遵守层次依赖,理论上只可引用DIM、DWD数据,不可引用处于下游层次的ADS等数据,以避免出现“反向引用”的情况。
如何设计分层?
● ODS
基本上是将业务系统数据原封不动的抽取到数仓,一般采用增全量的方式进行。可以考虑使用的工具如 sqoop,datax,seatunnel等。
● DWD/DWS:
一般情况下,一个比较好的公共层遵循一下几个原则:
迭代升级
○ 1、数据域的划分是建设公共层的前提,但是数据域不是一成不变的,由于业务不同,对应的数据域划分也自然各不相同,有时候需要灵活处理,并且要根据业务的发展而调整相关数据域的划分。
○ 2、其实,数据域的目的是为了给数据分类,所以尽量以业务分析视角去组织公共数据,从而保持数据的独立性。
公共层要考虑的核心问题
公共层需要考虑的一个核心问题是:是否具有共性
○ 1、DWS层的原则:DWS的核心诉求是通过空间换时间,在节约成本、提升效率的同时,实现数据口径的一致性。既如此,那就不能为了加工DWS而加工DWS数据,要基于是否是业务的核心指标判断是否要沉淀公共层,另外,如果是事后沉淀公共层,那要看下需要沉淀的指标的应用场景有多少,假如只在一个地方使用,那也就没有沉淀DWS的必要了
○ 2、DWD的原则:一般情况下,DWD的模型相对好设计一些,核心是基于维度建模,冗余维度属性,降低频繁关联,提升基础数据模型的易用性
复用性、易用性、稳定性
公共层模型不是为某一应用场景单独设计的,而是面向大部分的应用场景进行设计,因此需要进行一定的抽象以提升通用性,从而尽可能覆盖更多的应用场景。
○ 复用性
■ 指标复用性抽象:转变不可累加指标为可累加指标,如比率型建议保留分子分母;
■ 粒度复用性抽象:以最大公约数的逻辑抽象复用,比如上游表ADS1是子公司粒度、表ADS2是一级类目粒度,那就可以设计出sku粒度的DWS表
○ 易用性
在不影响模型产出时效性的情况下,需尽量考虑模型易用性,提升应用研发的使用效率。易用性的设计主要指的是宽表设计和水平切分,用于降低下游理解和多表关联。
■ DWS模型易用性上,通过冗余维度属性、采用大宽表方式构建,以提升下游易用性。
■ DWS冗余相对不易变的维度属性,减少下游频繁关联;
■ 如无时效性问题,同数据域同粒度进行宽表设计,提升下游易用性;
■ DWD模型易用性上,通过采用星型模型、维度冗余和信息完善度进行设计,以提升下游易用性,模型设计应以星型模型为主。
○ 稳定性
通过大宽表的建设方式,公共层极大提升了模型的易用性,但因应用场景差异化,时效性也对应有不同的要求。公共层需进行必要的的稳定性设计,满足下游重要应用高时效性产出的要求。
■ 扁平化设计提升稳定性:公共层整体需扁平化设计,进行不要依赖层级过深
■ DWS稳定性设计:结合访问热度、数据稳定情况,进行必要的解耦设计,以提升DWS模型的稳定性;比如根据访问的热度,将1d、nd、td的数据模型进行垂直拆分,
■ 对于DIM维表也可以根据垂直拆分的方式,保证核心维度的产出效率,将低热度的扩展维度属性与核心维度属性进行拆分
成本和效率要有一个权衡
一般情况下,对于数据量比较小的场景,可以优先构建DWD,后构建DWS,在构建DWS的过程中,可以优先构建细粒度的DWS表(为了扩展性),最后沉淀粗粒度的DWS表。对于数据体量比较大的情况,可以优先构建粗粒度的DWS,对于DWD的构建,可以采用水平拆分的方式,比如不在冗余半结构的字段(attributes扩展字段),从而提升产出的时效,提升下游的使用效率。
● ADS
应用层的定位为根据特定业务诉求,按照业务角度组织数据以快速满足业务需求。应用层研发核心关注研发效率、口径一致性,以及核心应用的稳定性。
一个好的应用层模型需要重点关注以下几个原则:
-
需求驱动
需求驱动构建集市:按需最小原则设计,除非有明确的业务延续,否则不做过度的扩展设计。应用层的设计需要考虑业务定制的需求,提供面向业务定制的应用数据,如报表数据、大宽表等,供线上系统使用。
划分集市域、共性抽象下沉
○ 与公共层类似,以高内聚低耦合的原则对集市进行划分,让单集市数据研发聚焦在某一领域的业务需求实现;集市间应该避免互相依赖,避免复杂度的提升。
○ ADS也可以抽象出公共部分,通过依赖ADS数据,提升开发的效率和产出效率 -
减少对ODS的依赖
减少直接引用ODS表,降低源系统变更带来的改造成本,架构合理上考虑,公共层针对复用性的场景进行模型沉淀,当源系统变更时,通过公共层适应性改造屏蔽下游变更。
参考
https://blog.51cto.com/xpleaf/4896831
https://developer.aliyun.com/article/927293
https://mp.weixin.qq.com/s?__biz=MzU2ODQ3NjYyMA==&mid=2247488738&idx=1&sn=189694698b6d749c77340116cbc96bf4&chksm=fc8c0241cbfb8b5748da839811a901f9442e47e216b8dfc69fbb0a510cb7a432ce35399d3090&scene=21#wechat_redirect
相关文章:
数仓建模中的一些问题
在数仓建设的过程中,由于未能完全按照规范操作, 从而导致数据仓库建设比较混乱,常见有以下问题: 数仓常见问题 ● 数仓分层不清晰:数仓的分层没有明确的逻辑,难以管理和维护。 ● 数据域划分不明确…...

spring整合kafka
原文链接:spring整合kafka_spring集成kafka-CSDN博客 1、导入依赖 <dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId><version>2.5.10.RELEASE</version> </depende…...

【web前端】CSS样式
CSS应用方式 在标签 <h2 style"color: aquamarine">hello world!</h2> 在head标签中写style标签 <head><meta charset"UTF-8"><title>Title</title><style>.c1{height: 100px;}.c2{height: 200px;color: aqua;…...

【ARM Cache 与 MMU 系列文章 7.7 – ARMv8/v9 MMU Table 表分配原理及其代码实现 1】
请阅读【ARM Cache 及 MMU/MPU 系列文章专栏导读】 及【嵌入式开发学习必备专栏】 文章目录 MMU Table 表分配原理及其代码实现虚拟地址空间 Region的配置系统物理地址位宽获取汇编代码实现MMU Table 表分配原理及其代码实现 假设当前系统中需要映射多个region,其中第一个要映…...
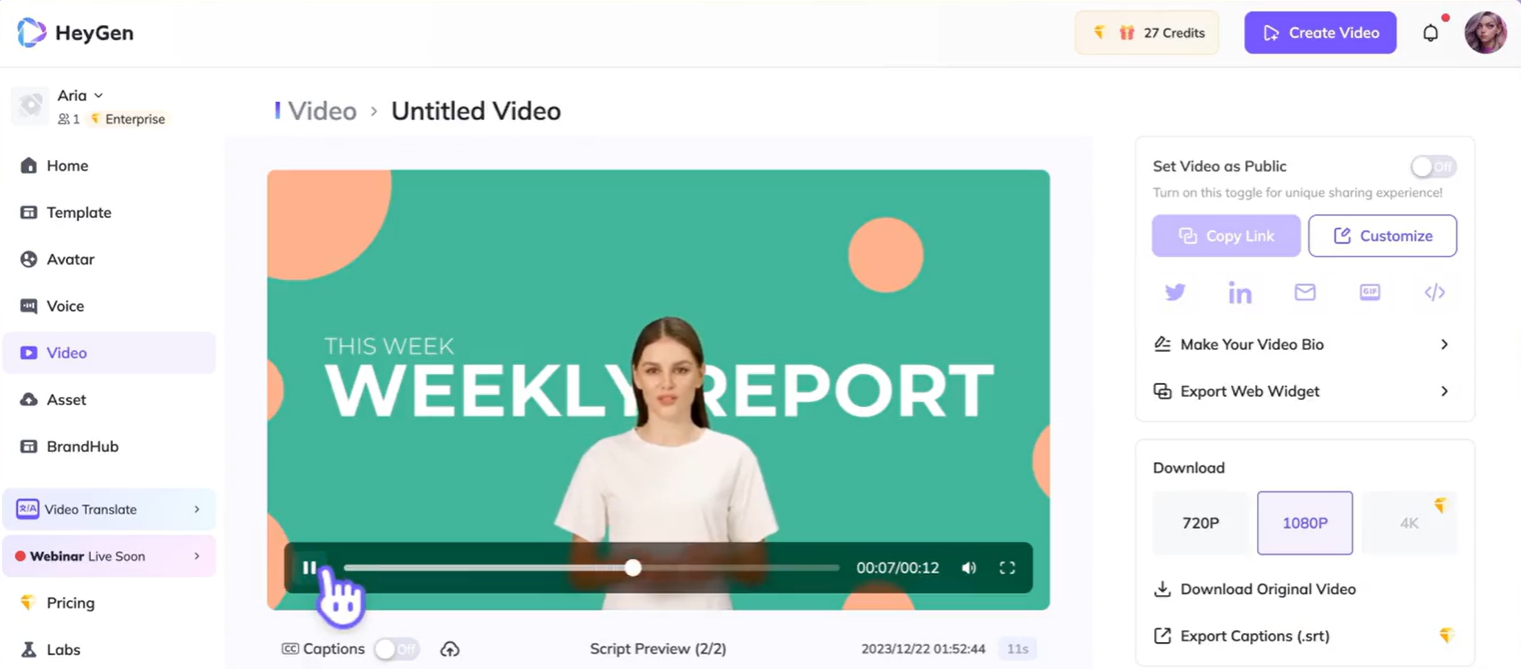
AIGC之MetaHuman:HeyGen(基于AI驱动的视频生成平台+数字人)的简介、安装和使用方法、案例应用之详细攻略
AIGC之MetaHuman:HeyGen(基于AI驱动的视频生成平台数字人)的简介、安装和使用方法、案例应用之详细攻略 目录 HeyGen的简介 1、HeyGen是一款AI视频生成平台,它提供以下关键功能: HeyGen的安装和使用方法 1、使用方法 01创建或选择一个头…...

6.7-6.10作业
1. /*1.使用switch实现银行系统,默认用户为A,密码为1234,余额2000 如果登录失败,则直接结束 如果登录成功,则显示银行页面 1.查询余额 2.取钱 3.存钱 如果是1,则打印余额 如果是2,则输入取钱金…...

【Redis】Redis经典问题:缓存穿透、缓存击穿、缓存雪崩
目录 缓存的处理流程缓存穿透解释产生原因解决方案1.针对不存在的数据也进行缓存2.设置合适的缓存过期时间3. 对缓存访问进行限流和降级4. 接口层增加校验5. 布隆过滤器原理优点缺点关于扩容其他使用场景SpringBoot 整合 布隆过滤器 缓存击穿产生原因解决方案1.设置热点数据永不…...

从GPU到ASIC,博通和Marvell成赢家
ASIC市场上,博通预计今年AI收入将达到110亿美元以上,主要来自与Google和Meta的合作;Marvell预计2028年AI收入将达到70亿至80亿美元,主要来自与Amazon和Google的合作。 随着芯片设计和系统复杂性的增加,科技大厂将更多地…...

【java问答小知识6】一些Java基础的知识,用于想学习Java的小伙伴们建立一些简单的认知以及已经有经验的小伙伴的复习知识点
请解释Java中的双亲委派模型是什么? 回答:双亲委派模型是Java类加载机制的核心原则,它确保所有类加载器在尝试加载一个类之前,都会委托给它的父类加载器。 Java中的类路径(Classpath)是什么? 回…...

数学建模笔记
数学建模 定义角度 数学模型是针对参照某种事物系统的特征或数量依存关系,采用数学语言,概括地或近似地表述出的一种数学结构,这种数学结构是借助于数学符号刻画出来的某种系统的纯关系结构。从广义理解,数学模型包括数学中的各…...

shell编程(三)—— 控制语句
程序的运行除了顺序运行外,还可以通过控制语句来改变执行顺序。本文介绍bash的控制语句用法。 一、条件语句 Bash 中的条件语句让我们可以决定一个操作是否被执行。结果取决于一个包在[[ ]]里的表达式。 bash中的检测命令由[[]]包起来,用于检测一个条…...

反射学习记
Java 中的反射是什么意思?有哪些应用场景? 每个类都有⼀个 Class 对象,包含了与类有关的信息。当编译⼀个新类时,会产生一个同名的 .class 文件,该⽂件 内容保存着 Class 对象。类加载相当于 Class 对象的加载&a…...

使用Python操作Redis
大家好,在当今的互联网时代,随着数据量和用户量的爆发式增长,对于数据存储和处理的需求也日益增加。Redis作为一种高性能的键值存储数据库,以其快速的读写速度、丰富的数据结构支持和灵活的应用场景而备受青睐。本文将介绍Redis数…...

Vue-CountUp-V2 数字滚动动画库
安装: $ npm install --save countup.js vue-countup-v2示例如下: <template><div class"iCountUp"><ICountUp:delay"delay":endVal"endVal":options"options"ready"onReady"/>&…...
C语言详解(文件操作)1
Hi~!这里是奋斗的小羊,很荣幸您能阅读我的文章,诚请评论指点,欢迎欢迎 ~~ 💥💥个人主页:奋斗的小羊 💥💥所属专栏:C语言 🚀本系列文章为个人学习…...

Python Requests库详解
大家好,在现代网络开发中,与Web服务器进行通信是一项至关重要的任务。Python作为一种多才多艺的编程语言,提供了各种工具和库来简化这一过程。其中,Requests库作为Python中最受欢迎的HTTP库之一,为开发人员提供了简单而…...

Kafka 详解:全面解析分布式流处理平台
Kafka 详解:全面解析分布式流处理平台 Apache Kafka 是一个分布式流处理平台,主要用于构建实时数据管道和流式应用。它具有高吞吐量、低延迟、高可用性和高可靠性的特点,广泛应用于日志收集、数据流处理、消息系统、实时分析等场景。 &…...
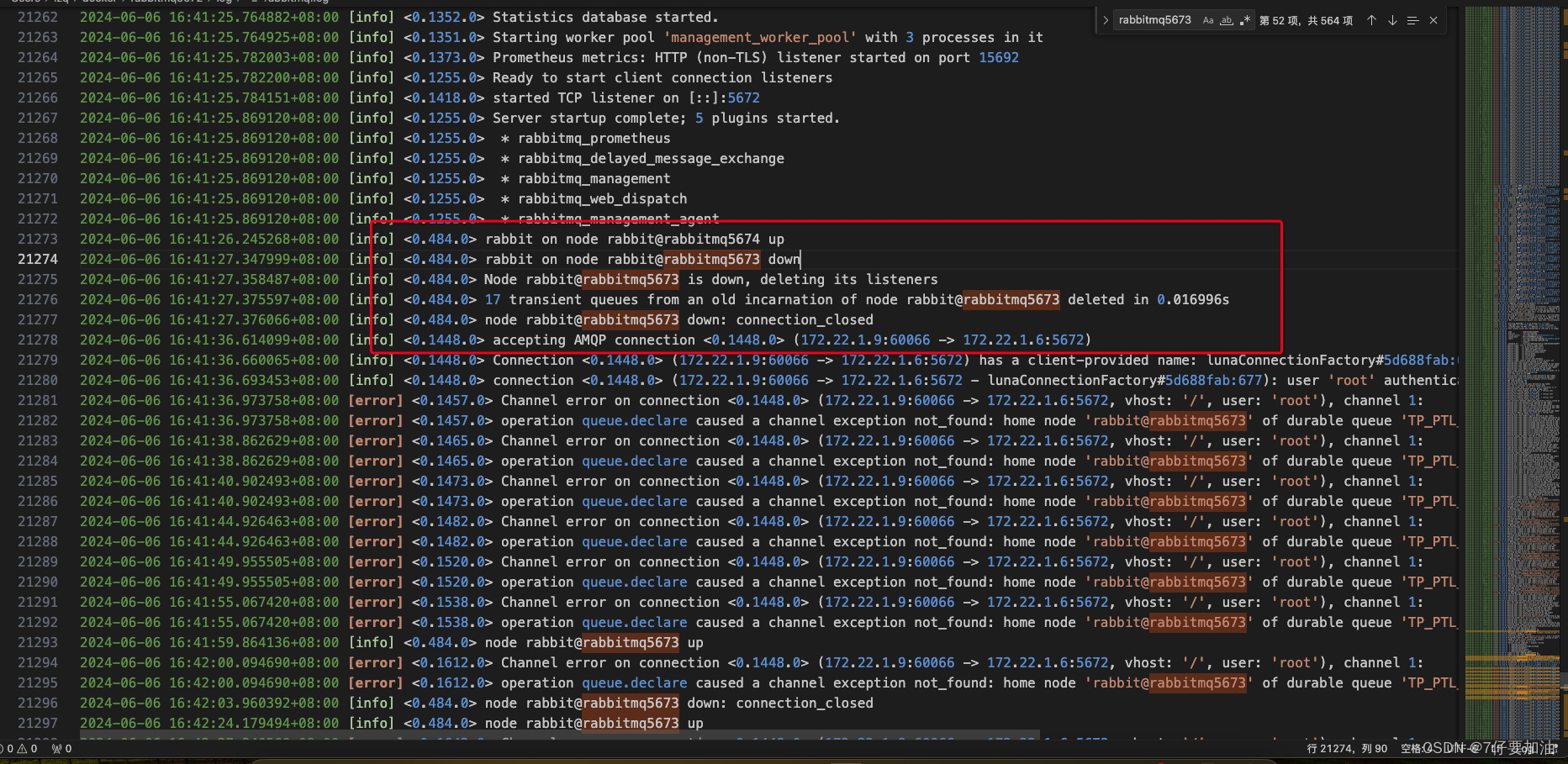
RabbitMQ系列-rabbitmq无法重新加入集群,启动失败的问题
当前存在3个节点:rabbitmq5672、rabbitmq5673、rabbitmq5674 当rabbitmq5673节点掉线之后,重启失败 重启的时候5672节点报错如下: 解决方案 在集群中取消失败节点 rabbitmqctl forget_cluster_node rabbitrabbitmq5673删除失败节点5673的…...

postgresql之翻页优化
列表和翻页是所有应用系统里面必不可少的需求,但是当深度翻页的时候,越深越慢。下面是几种常用方式 准备工作 CREATE UNLOGGED TABLE data (id bigint GENERATED ALWAYS AS IDENTITY,value double precision NOT NULL,created timestamp with time zon…...
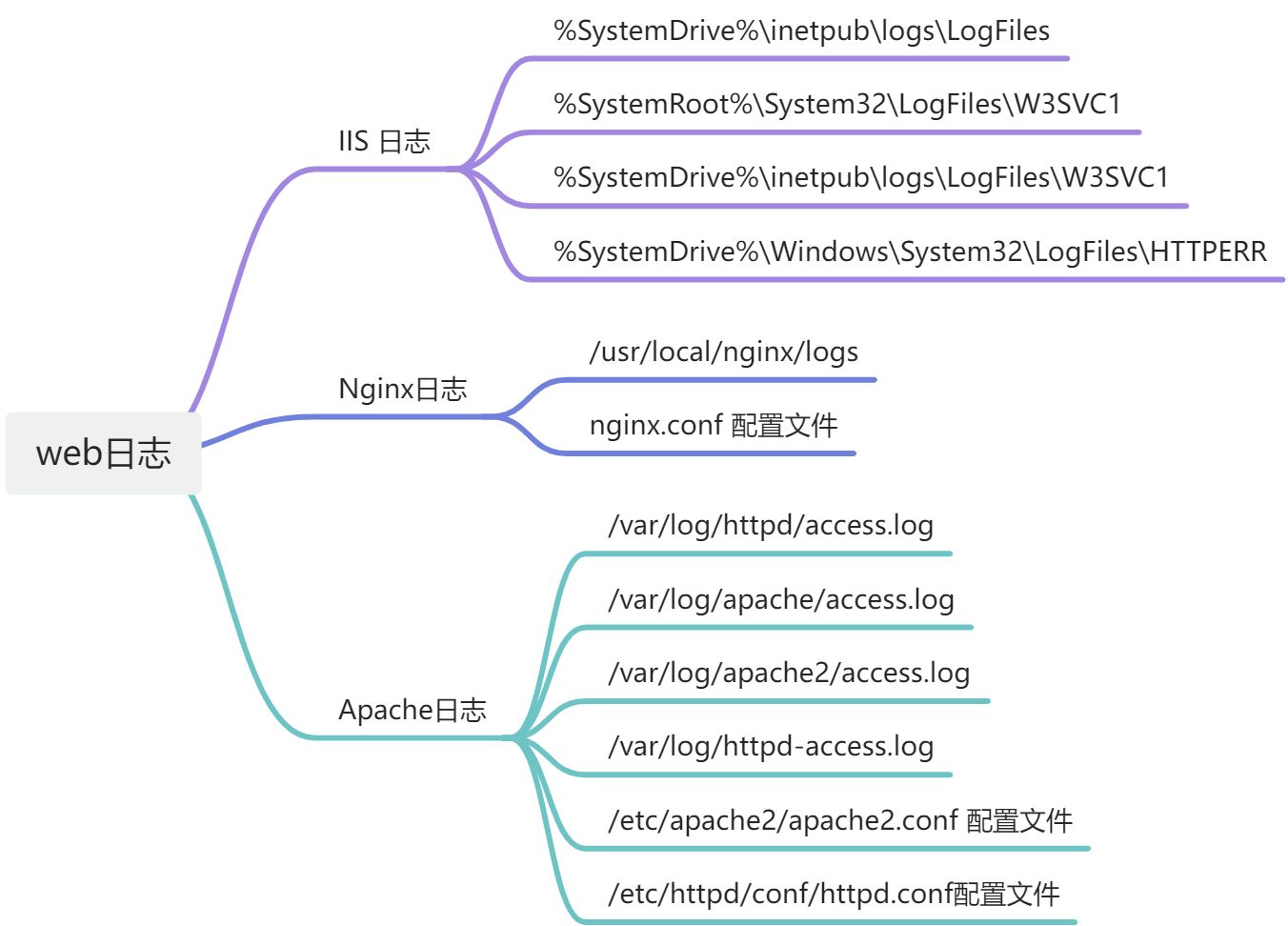
小白学Linux | 日志排查
一、windows日志分析 在【运行】对话框中输入【eventvwr】命令,打开【事件查看器】窗 口,查看相关的日志 管理员权限进入PowerShell 使用Get-EventLog Security -InstanceId 4625命令,可获取安全性日志下事 件 ID 为 4625(失败登…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

《Playwright:微软的自动化测试工具详解》
Playwright 简介:声明内容来自网络,将内容拼接整理出来的文档 Playwright 是微软开发的自动化测试工具,支持 Chrome、Firefox、Safari 等主流浏览器,提供多语言 API(Python、JavaScript、Java、.NET)。它的特点包括&a…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...

ardupilot 开发环境eclipse 中import 缺少C++
目录 文章目录 目录摘要1.修复过程摘要 本节主要解决ardupilot 开发环境eclipse 中import 缺少C++,无法导入ardupilot代码,会引起查看不方便的问题。如下图所示 1.修复过程 0.安装ubuntu 软件中自带的eclipse 1.打开eclipse—Help—install new software 2.在 Work with中…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...