Django框架中级
Django框架中级 – 潘登同学的WEB框架
文章目录
- Django框架中级 -- 潘登同学的WEB框架
- 中间件
- 自定义中间件
- 常用中间件
- process_view()
- 使用中间件进行URL过滤
- Django生命周期
- 生命周期分析
- Django日志
- 日志配置
- filter过滤器
- 自定义filter
- 日志格式化formatter
- Django信号
- 内置信号
- 定义与连接信号
- 自定义信号
- Django缓存
- 安装Redis
- 设置Django缓存
- 全站缓存
- 视图缓存
- 模板缓存
- 底层缓存
- 缓存 API 应用
- Session缓存
- Celery
- 配置Celery
- 生产异步任务
- 生产定时任务
- 任务结果
- Django集成Celery
- Django-任务交给Celery
- Celery 绑定参数
- Celery 钩子函数
- Celery 组装任务
- Celery 任务监控
- DebugToolBar
- DebugToolBar 配置
中间件
AOP(Aspect Oriented Programming ),面向切面编程,是对业务逻辑的各个部分进行隔离,从而使得业务逻辑各部分之间的耦合度降低,提高程序的可重用性,同时提高了开发的效率。可以实现在不修改源代码的情况下给程序动态统一添加功能的一种技术。
面向切面编程,就是将交叉业务逻辑封装成切面,利用AOP的功能将切面植入到主业务逻辑中。所谓交叉业务逻辑是指,通用的,与主业务逻辑无关的代码,如安全检查,事务,日志等。若不使用AOP,则会出现代码纠缠,即交叉业务逻辑与主业务逻辑混合在一起。这样,会使业务逻辑变得混杂不清。
Django的中间件,就是应用AOP技术来实现的,它是django请求/响应处理的钩子框架,是一个轻巧的低级“插件”系统,在不修改django项目原有代码的基础上,可以全局改变django的输入或输出,每个中间件组件负责执行某些特定功能。
因为中间件改变的是全局,所以需要谨慎实用,滥用的话,会影响到服务器的性能
Django项目默认有一些自带的中间件,每个中间件组件由字符串表示:指向中间件工厂的类或函数名的完整 Python 路径。如
# 在settings.py中设置中间件
MIDDLEWARE = ['django.middleware.security.SecurityMiddleware','django.contrib.sessions.middleware.SessionMiddleware','django.middleware.common.CommonMiddleware','django.middleware.csrf.CsrfViewMiddleware','django.contrib.auth.middleware.AuthenticationMiddleware','django.contrib.messages.middleware.MessageMiddleware','django.middleware.clickjacking.XFrameOptionsMiddleware',
]
自定义中间件
自定义中间件,可以是一个函数,也可以是一个类。但是都要有接受get_response参数的入口。
# 如果中间件是在整个项目中使用的,可以在manage.py同级目录下新建一个middleware.py文件
# 如果中间件是在某个子应用中使用的,可以在子应用目录下新建一个middleware.py文件
def my_middleware(get_response):def middleware(request):# 自定义中间件逻辑print('视图函数之前执行的中间件逻辑')response = get_response(request)# 自定义中间件逻辑print('视图函数之后执行的中间件逻辑')return responsereturn middlewareclass MyMiddleware1:def __init__(self, get_response):self.get_response = get_responsedef __call__(self, request):# 自定义中间件逻辑print('视图函数之前执行的中间件逻辑')response = self.get_response(request)# 自定义中间件逻辑print('视图函数之后执行的中间件逻辑')return response# 然后在settings.py中设置中间件
MIDDLEWARE = ['my_app.middleware.my_middleware','middleware.MyMiddleware1',
注意:中间件的执行顺序是从上到下,也就是说,先执行my_middleware,再执行MyMiddleware1。

常用中间件
process_view()
- 作用:在视图函数执行前,对请求进行预处理。process_view()只能在类方法下的中间件使用。
- 入参:
- request:请求对象
- view:视图函数对象
- args:视图函数的位置参数
- kwargs:视图函数的关键字参数
- 返回值:
- 如果返回None,则继续执行视图函数;
- 如果返回一个响应对象,则终止视图函数的执行,并返回响应对象。
class MyMiddleware:def __init__(self, get_response):self.get_response = get_responsedef __call__(self, request):response = self.get_response(request)return response# 实现一个访问页面前判断用户是否登录,否则跳转到登录页面def process_view(self, request, view_func, view_args, view_kwargs):if not request.user.is_authenticated:return redirect('/login/')
使用中间件进行URL过滤
当项目进行维护时,可能会出现一些URL需要临时关闭,或者只允许特定IP访问,这时就可以使用中间件进行URL过滤。
# 在settings.py中设置维护页面URL
MAINTAIN_URL = '/maintain/'# 编写中间件
from django.http import HttpResponse
from django.conf import settings
class MyMiddleware:def __init__(self, get_response):self.get_response = get_responsedef __call__(self, request):# 判断请求的URL是否是维护页面if request.path == settings.MAINTAIN_URL:return HttpResponse('维护中,请稍后再试!')response = self.get_response(request)return response
Django生命周期

- 首先,用户在浏览器中输入url,发送一个GET/POST方法的request请求。Django中封装了socket的WSGi服务器,监听端口接受这个request 请求
- 再进行初步封装,然后将请求传送到中间件中,这个request请求依次经过中间件,对请求进行校验或处理,再传输到路由系统中进行路由分发,匹配相对应的视图函数(FBV/CBV)
- 再将request请求传输到views中的这个视图函数中,进行业务逻辑的处理,调用modles中表对象,通过orm获取数据库(DB)的数据
- 通过templates中相应的模板进行渲染,然后将这个封装了模板response响应传输到中间件中,依次进行处理,最后通过WSGi再进行封装处理,响应给浏览器展示给用户
生命周期分析
- 客户端发送请求
- 在浏览器输入url,譬如www.baidu.com,浏览器会自动补全协议(http),变为http://www.baidu.com,现在部分网站都实现了HSTS机制,服务器自动从http协议重定向到https协议
- 在网页中点击超链接或javascript脚本进行url跳转,仅设置 href=‘绝对路径’,浏览器会自动使用当前url的协议、host和port,譬如在 https://tieba.baidu.com/index.html网页中,点击一个超链接/f?kw=chinajoy , 会自动访问 https://tieba.baidu.com/f?kw=chinajoy
- 路由转发
- IP查找:因特网内每个公有IP都是唯一的,域名相当于IP的别名,因为我们无法去记住一大堆无意义的IP地址,但如果用一堆有意义的字母组成,大家就能快速访问对应网站
- DNS解析:通过域名去查找IP,先从本地缓存查找,其中本地的hosts文件也绑定了对应IP,若在本机中无法查到,那么就会去请求本地区域的域名服务器(通常是对应的网络运营商如电信/联通),这个通过网络设置中的LDNS去查找,如果还是没有找到的话,那么就去根域名服务器查找,这里有所有因特网上可访问的域名和IP对应信息(根域名服务器全球共13台)
- 路由转发:通过网卡、路由器、交换机等设备,实现两个IP地址之间的通信。用到的主要就是路由转发技术,根据路由表去转发报文,还有子网掩码、IP广播等等知识点
- 建立连接
- 通过TCP三次握手建立TCP连接,三次握手的目的是建立可靠的通信信道,确保数据包的顺序和完整性。
- WSGIHandler处理请求
- WSGIHandler是Django框架的WSGI服务器,它是WSGI协议的实现,它接收到请求后,会将请求封装成environ字典,然后交给Django的应用对象进行处理,处理完后,再将响应封装成response对象,再交给WSGIHandler进行响应。可以在项目下的wsgi.py文件中进行配置。
class WSGIHandler(base.BaseHandler):request_class = WSGIRequestdef __init__(self, *args, **kwargs):super().__init__(*args, **kwargs)self.load_middleware()def __call__(self, environ, start_response):set_script_prefix(get_script_name(environ))signals.request_started.send(sender=self.__class__, environ=environ)try:request = self.request_class(environ)response = self.get_response(request)except Exception as exc:response = self.handle_uncaught_exception(request, exc)...
WSGIHandler的__call__方法接收两个参数,environ和start_response,environ是WSGI协议中的环境变量,start_response是WSGI协议中的响应函数。
- 首先,调用set_script_prefix方法,设置脚本前缀,这个方法的作用是设置当前请求的脚本路径,譬如当前请求的url为http://www.baidu.com/index.html,脚本路径为/index.html,那么set_script_prefix(‘/index.html’),这样Django就知道当前请求的脚本路径。
- 然后,调用signals.request_started.send方法,发送一个request_started信号,这个信号的作用是通知其他组件,当前请求已经开始处理。
- 接着,调用get_response方法,获取响应对象,这个方法的作用是调用中间件,获取请求对象,然后调用路由系统,匹配对应的视图函数,调用视图函数,获取响应对象,然后调用模板系统,渲染响应对象,最后返回给WSGIHandler。
- 最后,调用start_response方法,返回响应头,WSGIHandler再将响应对象封装成WSGI协议的响应,并返回给客户端。
- middleware的process_request()方法,对request对象进行处理,主要有以下方法(一个中间件类最少需要实现下列方法中的一个):
- process_request:处理请求对象
- process_response:处理响应对象
- process_view:处理视图函数,在视图函数执行前,对请求进行预处理
- process_exception:处理异常,在视图函数发生异常时,对异常进行处理
- process_template_response:处理模板响应对象,在模板响应对象被渲染前,对响应对象进行处理
- URLConf路由匹配:通过urls.py文件中的urlpatterns列表,匹配请求的url,找到对应的视图函数,调用视图函数,获取响应对象。如果找不到对应的视图函数,就会触发异常,由中间件的process_exception()方法进行处理。
- middleware的process_view方法进行预处理
- views中的视图函数处理请求request
- models处理
- views处理数据,获取到数据后
- 将数据封装到context字典中,然后调用指定的template.html,通过模板中的变量、标签、过滤器等,再结合传入数据context,会触发中间件的process_template_response方法,渲染出最终的响应内容。
- 或者不调用模板,直接返回数据,如JsonResponse,FileResponse等。
- 或者执行redirect,生产一个重定向的HttpResponse对象,然后交给中间件的process_response方法进行处理。
- middleware的process_response方法进行响应处理,返回到WSGIHandler类中。至此,django编程的处理部分完毕
- WSGIHandler类获取响应对象后
- 先处理response的响应行和响应头,如Content-Type,Content-Length等。
- 然后调用start_response方法,返回响应行和相应头到uWSGI,这个start_response只能调用一次
- 处理响应体,将response.content写入到uWSGI的socket中,等待客户端接收。
- 客户端接收到响应后,做对应的操作,如显示在浏览器中,下载到本地,保存到数据库等javascript处理。
Django日志
日志是记录程序运行过程中的事件的记录,可以帮助我们分析程序的运行情况,查找程序的错误,提高程序的健壮性。Django框架提供了日志系统通过pythonnative的logging模块来实现日志功能,可以记录程序运行的详细信息,包括错误信息、访问日志、SQL日志等。
logging主要由4个模块构成:
- loggers:记录器是进入日志记录系统的入口点。每个记录器都是一个命名的,可以将消息写入其中进行处理的存储桶。
- handlers:Handler决定如何处理logger中的每条消息。它表示一个特定的日志行为,例如 将消息写入屏幕、文件或网络Socket。
- filters:筛选器用于对从logger传递给handler的哪些日志要做额外控制。
- Formatters:格式化器用于控制日志消息的格式。
logger日志有5个级别:
- DEBUG(10):调试信息,用于调试程序。
- INFO(20):一般信息,用于记录程序的运行情况。
- WARNING(30):警告信息,用于记录程序的非期望行为。
- ERROR(40):错误信息,用于记录程序的错误。
- CRITICAL(50):严重错误信息,用于记录程序的崩溃或意外退出。
提示:
- 写入logger的每条消息都是一条日志。每条日志也具有一个日志级别,它表示对应的消息的验证性。每个日志记录还可以包含描述正在打印的事件的元信息
- 当一条消息传递给logger时,消息的日志级别将与logger的日志级别进行比较。
- 如果消息的日志级别大于等于logger的日志级别,该消息将会往下继续处理
- 如果小于,该消息将被忽略
- Logger一旦决定消息需要处理,它将传递该消息给一个Handler
- 一般开发环境时,会启用DEBUG级别,而在生产环境中,启用WARNING或ERROR级别
日志配置
Django的日志配置主要在settings.py文件中进行,主要有以下几项配置:
LOGGING = {# version:日志配置的版本,默认为1。'version': 1,# disable_existing_loggers:是否禁用现有的日志记录器,默认为False。'disable_existing_loggers': False,# formatters:日志格式'formatters': {'standard': {'format':'[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d:%(funcName)s] %(message)s'},},# filters:日志过滤器 require_debug_true'filters': {'require_debug_true': {'()': 'django.utils.log.RequireDebugTrue',},},'handlers': {'console': {'level': 'DEBUG','filters': ['require_debug_true'],'class': 'logging.StreamHandler','formatter':'strandard'},'file': {'level': 'INFO','class': 'logging.FileHandler','filename': os.path.join(BASE_DIR, 'logs/django.log'),'formatter':'verbose'},},'loggers': {# 当前logger的名称为django'django': {# 日志处理器 表示日志由哪些handler处理'handlers': ['console', 'file'],# 日志级别'level': 'INFO',# propagate:是否向上(更高level的logger)传递日志信息,默认为True。'propagate': True,},},
}
在views.py中,通过logging模块记录日志:
import logging
# 获取logger实例
logger = logging.getLogger('django')
# 如果在settins.py中 loggers 配置的名称为'',则应该使用如下方式获取logger实例
# logger = logging.getLogger(__name__)def my_view(request):logger.debug('This is a debug log message')logger.info('This is a info log message')logger.warning('This is a warning log message')logger.error('This is a error log message')logger.critical('This is a critical log message')return HttpResponse('Hello, world!')
handler对应的是个字典,每一个key对应一个handler的名字,每个value对应一个handler的配置:
- class(必须):表示handler的类名。
- level(可选):表示日志的最低级别,只有大于等于该级别的日志才会被处理。
- formatter(可选):表示日志的格式。
- filename(可选):表示日志文件的路径。
- filters(可选):表示日志的过滤器。
python的logging模块提供了很多Handler,大部分在以下2个目录
- logging/__init__.py
- logging/handlers.py
常用的有:
- StreamHandler:将日志输出到流,可以是sys.stderr(控制台),sys.stdout或者文件。
- FileHandler:将日志输出到文件。继承自StreamHandler。默认情况下,文件无限追加
- RotatingFileHandler:当日志文件达到一定大小时,自动切分日志文件,默认情况下,日志文件名为“日志文件名.log”,切分后日志文件名为“日志文件名.log.1”,“日志文件名.log.2”,以此类推。
- maxBytes:日志文件达到多少字节时,自动切分。
- backupCount:保留切分后的日志文件个数。
- 例如:backupCount=5,基础文件名为:app.log,那么达到指定maxBytes之后,会关闭文件app.log,将app.log重命名为app.log.1,如果app.log.1存在,那么就顺推,先将app.log.1重命名为app.log.2,再将现在的app.log命名为app.log.1,最大创建到app.log.5(旧的app.log.5会被删除),然后重新创建app.log文件进行日志写入,也就是永远只会对app.log文件进行写入
- 注意:启动项目使用命令:python manager.py runserver --noreaload
- TimeRotatingFileHandler:按时间间隔切分日志文件,默认情况下,日志文件名为“日志文件名.log.日期.log”,切分后日志文件名为“日志文件名.log.日期.log.1”,“日志文件名.log.日期.log.2”,以此类推。
- when:指定切分日志的时间间隔,有以下几种取值:
- ‘S’(秒)
- ‘M’(分)
- ‘H’(时)
- ‘D’(天)
- ‘W0-W6’(星期)
- ‘midnight’(每天凌晨)
- interval:指定切分日志的时间间隔,单位为when的单位。
- backupCount:保留切分后的日志文件个数。
- utc=False:False则使用当地时间,True则使用UTC时间
- atTime=None:必须是datetime.time实例,指定文件第一次切分的时间,when设置为S,M,H,D时,该设置会被忽略
- when:指定切分日志的时间间隔,有以下几种取值:
- SMTPHandler:通过邮件发送日志信息。当项目出现严重错误时,可以发送邮件通知管理员。
- mailhost:邮件服务器地址(默认25端口)如
(smtp.qq.com, 25)。 - fromaddr:发件人地址。
- toaddrs:收件人地址,可以是字符串或列表。
- subject:邮件主题。
- credentials:登录邮件服务器的用户名和密码,如果不需要登录,可以设置为None。
- secure:是否使用SSL加密连接。
- timeout:连接邮件服务器的超时时间。
- 注意:需要在settings.py中设置EMAIL_HOST,EMAIL_PORT,EMAIL_HOST_USER,EMAIL_HOST_PASSWORD等参数。
- mailhost:邮件服务器地址(默认25端口)如
'handlers': {'rotating_file': {'level': 'INFO','class': 'logging.handlers.RotatingFileHandler','filename': os.path.join(BASE_DIR, 'logs/django.log'),'maxBytes': 1024*1024*5, # 日志大小为5M'backupCount': 5, # 保留5个日志文件'formatter':'standard'},'file_timed_rotating': {'level': 'INFO','class': 'logging.handlers.TimedRotatingFileHandler','filename': os.path.join(BASE_DIR, 'logs/django.log'),'when': 'D','interval': 1, # 每天切分一次'backupCount': 5,'formatter':'standard'},'email': {'level': 'ERROR','class': 'logging.handlers.SMTPHandler','formatter':'standard','mailhost': ('smtp.qq.com', 25),'fromaddr': '发件人邮箱','toaddrs': ['收件人邮箱1', '收件人邮箱2'],'subject': '项目日志信息','credentials': ('发件人邮箱用户名', '发件人邮箱密码'), # 密码不是邮箱密码,而是授权码 设置->账户->POP3/IMAP/SMTP/Exchange/CardDAV/CalDAV服务->生成授权码
}
filter过滤器
过滤器用于从logger传递给handler的哪些日志要做额外控制。默认情况下,满足日志级别的任何消息都将处理。只要级别匹配,任何日志消息都会被处理。不过,也可以通过添加 filter 来给日志处理的过程增加额外条件。例如,可以添加一个 filter 只允许某个特定来源的 ERROR 消息输出。
Filters还可以用于修改将要处理的日志记录的优先级。例如,如果日志记录满足特定的条件,可以编写一个filter将日志记录从ERROR降为WARNING。
Filters可以配置在logger或者handler上,多个 filter 可以链接起来使用,来做多重过滤操作。
# filters:日志过滤器 RequireDebugTrue表示只有在DEBUG模式下才处理日志
'filters': {'require_debug_true': {'()': 'django.utils.log.RequireDebugTrue',},
},'loggers': {'django': {'handlers': ['console', 'file'],'level': 'INFO',# 也可以放到handler里'filters': ['require_debug_true'],},
},
自定义filter
在log_filter.py中定义一个自定义filter:
import loggingclass MyFilter(logging.Filter):def __init__(self, name='', words=None):super().__init__(name)self.words = wordsdef filter(self, record):# 自定义过滤规则 如果日志信息中包含'INFO',则不处理if self.words and self.words in record.msg:return Falsereturn True
在settings.py中配置filter:
'filters': {'my_filter': {'()': 'log_filter.MyFilter','words': 'INFO'},
},
日志格式化formatter
日志格式化formatter用于指定日志信息的输出格式。默认情况下,Django使用标准的日志格式化formatter,格式为:
[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d:%(funcName)s] %(message)s
其中:
- %(levelname)s:日志级别名称
- %(asctime)s:日志输出的时间
- %(filename)s:日志输出的文件名
- %(lineno)d:日志输出的行号
- %(funcName)s:日志输出的函数名
- %(message)s:日志输出的具体信息
- %(name)s:logger的名称
- %(process)d:进程ID
- %(thread)d:线程ID
- %(module)s:模块名
如果需要自定义日志格式化formatter,可以修改settings.py中的formatters配置:
'formatters': {'simple': {'format': '%(asctime)s %(levelname)s %(message)s'},'standard': {'format': '%(asctime)s %(levelname)s %(filename)s:%(lineno)d %(funcName)s %(message)s''datefmt': '%Y-%m-%d %H:%M'},
},
Django信号
Django信号是一种在Django框架中用于处理事件通知的机制。它可以让我们在某些特定事件发生时自动执行一些操作,比如用户注册、订单创建等。
Django信号的机制是基于观察者模式,它允许我们定义信号,然后在其他地方触发信号,让信号的接收者来执行相应的操作。
Django信号的使用场景:
- 缓存失效:当数据库数据发生变化时,可以让缓存失效,这样可以让用户看到最新的内容。
- 发送邮件:当用户注册成功时,可以发送欢迎邮件。
- 通知用户:当订单状态发生变化时,可以通知用户。
- 记录日志:当用户登录、退出时,可以记录日志。
内置信号
Django框架中内置了很多信号,可以用于处理常见的事件通知。分为模型信号、管理信号、请求信号、测试信号等。
- 模型信号:
- pre_save:在保存对象之前触发。
- post_save:在保存对象之后触发。
- pre_delete:在删除对象之前触发。
- post_delete:在删除对象之后触发。
- m2m_changed:在多对多关系发生变化时触发。
- pre_init:在初始化对象之前触发。
- post_init:在初始化对象之后触发。
- class_prepared:在类准备好之后触发。
- 管理信号:
- pre_migrate:在执行migrate命令之前触发。
- post_migrate:在执行migrate命令之后触发。
- 请求信号:
- request_started:在请求开始时触发。
- request_finished:在请求结束时触发。
- request_exception:在请求发生异常时触发。
- 测试信号:
- setting_changed:在设置改变时触发。
- template_rendered:在模板渲染完成时触发。
- 数据库包装器
- connection_created:在创建数据库连接时触发。
定义与连接信号
首先,需要定义一个接收器,用于处理信号。接收器必须是一个函数,并且接收一个参数,即信号发送者。
在子应用的signals.py文件中定义接收器:
def my_signal_receiver(sender, **kwargs):print('Received signal from sender: ', sender)print('Signal data: ', kwargs)
然后,可以选择手动连接接收器函数,或者使用装饰器来实现。
在子应用的apps.py文件中
# 手动连接接收器
from django.db.models.signals import request_finished
from .signals import my_signal_receiverclass MyAppConfig(AppConfig):name = 'apps.my_app'defauilt_auto_field = 'django.db.models.AutoField'def ready(self):from django.core.signals import request_finished# 为了避免重复连接,可以给接收器指定一个dispatch_uid request_finished.connect(my_signal_receiver,dispatch_uid='my_signal_receiver')或者使用装饰器来实现,在子应用的signals.py文件中
# 使用装饰器
from django.dispatch import receiver
from django.db.models.signals import request_finished@receiver(request_finished)
def my_signal_receiver(sender, **kwargs):print('Received signal from sender: ', sender)print('Signal data: ', kwargs)
在子应用的apps.py文件中注册信号:
class MyAppConfig(AppConfig):name = 'apps.my_app'defauilt_auto_field = 'django.db.models.AutoField'def ready(self):import .signals # 导入signals模块
严格来说,信号处理和注册的代码可以放在任何你喜欢的地方,一般可以放在子应用下的signals.py文件中。
自定义信号
所有的信号都是 django.dispatch.Signal 的实例
from django.dispatch import Signal
from django.dispatch import receiver# 创建信号
my_signal = Signal()# 创建信号接收器
@receiver(my_signal)
def my_signal_receiver(sender, **kwargs):print('Received signal from sender: ', sender)print('Signal data: ', kwargs)# 在views.py中显示发送信号def my_view(request):my_signal.send(sender=request, data='Hello, world!')return HttpResponse('Hello, world!')
Django缓存
Django缓存是一种提高网站性能的机制。它可以缓存数据库查询结果、页面渲染结果、静态文件等,从而减少数据库查询次数、加快页面响应速度。
Django缓存的使用场景:
- 数据库缓存:Django提供了数据库缓存机制,可以缓存查询结果,减少数据库查询次数。
- 页面缓存:Django提供了页面缓存机制,可以缓存页面渲染结果,加快页面响应速度。
- 静态文件缓存:Django提供了静态文件缓存机制,可以缓存静态文件,加快网站访问速度。
缓存系统需要少量的设置。必须告诉它缓存数据应该放在哪里 ——是在数据库中,还是在文件系统上,或者直接放在内存中。这是一个重要的决定,会影响缓存的性能;是的,有些缓存类型比其他类型快。
- 内存缓存
- Redis数据库
- 数据库缓存
- 文件系统缓存
- 本地内存缓存
- 虚拟缓存(用于开发模式)
- 使用自定义缓存后端
安装Redis
redis默认不支持windows,由于一般开发环境在windows,因此在此下载一个windows版本
https://github.com/tporadowski/redis/releases
直接解压压缩包 解压到program files目录下
- 核心配置
在redis.windows.conf下
; 绑定IP:如果需要远程访问,可以将此注释,或绑定一个真是IP
bind 127.0.0.1
; 端口:默认为6379
port 6379
直接在当前目录下打开cmd,输入redis-server redis.windows.conf 启动redis服务
redis-server redis.windows.conf
不要关闭cmd窗口,redis服务会一直运行,双击redis-cli.exe进入redis命令行
测试
# 检测 redis 服务是否启动
ping
# 设置键值对:
set uname pdnbplus
# 取出键值对:
get uname
# 查看所有键值对:
keys *
也可以在VsCode中使用NoSQL连接Redis
# 查找所有运行的端口
netstat -ano# 根据端口号查看被占用端口对应的 PID
netstat -aon|findstr "6379"# 查看指定 PID 9088 的进程
tasklist|findstr "9088"# 强制(/F参数)杀死 pid 为 9088 的所有进程包括子进程(/T参数):
taskkill /F /T /PID 9088
设置Django缓存
Django设置缓存的核心参数是CACHES,包含所有 Django 缓存配置的字典
CACHES 配置必须设置一个 default 缓存;也可以指定任何数量的附加缓存。如果你使用的是本地内存缓存以外的缓存后端,或者你需要定义多个缓存,则需要其他选项。以下基本结构
CACHES = {# default 缓存名'default': {# 缓存配置 RedisCache 缓存类'BACKEND': 'django.core.cache.backends.redis.RedisCache',# 缓存服务器地址'LOCATION': '127.0.0.1:6379','OPTIONS': {# 数据库编号'db': 5,# 最大连接数,默认10连接'MAX_CONNECTIONS': 10,},},
}
- BACKEND 要使用的缓存后端。内置的缓存后端有:
- django.core.cache.backends.db.DatabaseCache
- django.core.cache.backends.dummy.DummyCache
- django.core.cache.backends.filebased.FileBasedCache
- django.core.cache.backends.locmem.LocMemCache
- django.core.cache.backends.memcached.PyMemcacheCache
- django.core.cache.backends.memcached.PyLibMCCache
- django.core.cache.backends.redis.RedisCache
- OPTIONS
- 传递给缓存后端的额外参数。可用的参数根据你的缓存后端不同而不同
- TIMEOUT
- 缓存的超时时间,单位秒,默认是 300秒,如果为None,表示缓存永不超时,如果为0,表示缓存立刻超时,相当于不使用缓存
全站缓存
一旦设置完缓存,使用缓存最简便的方法是缓存整个站点。需要在 settings.py 中设置 Middleware,在 MIDDLEWARE 中添加 相应的中间件,注意顺序一定要与下面代码一致。
MIDDLEWARE = [# 缓存中间件'django.middleware.cache.UpdateCacheMiddleware',# 表示其他中间件'django.middleware.common.CommonMiddleware','django.middleware.cache.FetchFromCacheMiddleware',
]
-
FetchFromCacheMiddleware :从缓存中读取数据
- 缓存状态为200的GET和HEAD请求的响应(除非响应头中设置不进行缓存)
- 对具有不同查询参数的相同URL的请求的响应被认为是各自不同的页面,并且被分别单独缓存。
- 该中间件会使用与对应的GET请求相同的响应头来回答HEAD请求,即可以为HEAD请求返回缓存的GET响应。
-
UpdateCacheMiddleware :将数据更新到缓存中
- 该中间件会自动在每个响应中设置几个headers:
- 设置Expires为当前日期/时间 加上 定义的CACHE_MIDDLEWARE_SECONDS值,GMT时间
- 设置响应的Cache-Control的max-age,值是定义的CACHE_MIDDLEWARE_SECONDS值。
- 如果视图设置了自己的缓存时间(即设置了Cache-Control 的 max age),那么页面将被缓存直到到期时间,而不是 CACHE_MIDDLEWARE_SECONDS。
- 使用装饰器 django.views.decorators.cache可以设置视图的到期时间(使用cache_control()装饰器,代码:@cache_control(max_age=3600))或禁用视图的缓存(使用never_cache()装饰器,代码:@never_cache)
- 如果USE_I18N设置为True,则生成的缓存key将包含当前语言的名称,这样可以轻松缓存多语言网站,而无需自己创建缓存密钥。
- 如果 USE_L10N设置为True 并且 USE_TZ被设置为True,缓存key也会包括当前语言
- 该中间件会自动在每个响应中设置几个headers:
-
最后,在 Django 设置文件里添加下面的必需配置:
- CACHE_MIDDLEWARE_ALIAS – 用于存储的缓存别名(如’default’)
- CACHE_MIDDLEWARE_SECONDS – 应缓存每个页面的秒数
- CACHE_MIDDLEWARE_KEY_PREFIX-- 如果使用相同的 Django installation ,通过多站点进行缓存共享,请将此值设置为站点名,或者设置成在Django 实例中唯一的其他字符串,以此防止键冲突。如果你不介意,可以设置成空字符串
CACHE_MIDDLEWARE_ALIAS = 'default'
CACHE_MIDDLEWARE_SECONDS = 600
CACHE_MIDDLEWARE_KEY_PREFIX = 'django_cache'
使用缓存因为要和redis交互,所以需要安装redis
pip install redis==4.3.4
视图缓存
Django的缓存可以设置缓存指定的视图,只需要在视图函数上添加装饰器 cache_page() 即可。无需设置中间件。
from django.views.decorators.cache import cache_page
import time@cache_page(60 * 15)
def my_view(request):# 此视图函数的结果将被缓存15分钟return HttpResponse(f'Cached for 15 minutes{time.time()}')
也可以在路由中设置缓存,只需要在路由中添加 cache_page() 装饰器即可。
from django.urls import path
from django.views.decorators.cache import cache_pageurlpatterns = [path('my_view/', cache_page(60 * 15)(my_view), name='my_view'),
]
除此之外,还有一些其他的缓存装饰器,如 cache_control()、never_cache() 等。当做了全站缓存,有些页面明确不需要缓存,可以用 never_cache() 装饰器禁用缓存。
模板缓存
在模板中加载标签 {% load cache %} 使用缓存{% cache 秒 key %} {% endcache %}
{% load cache %}{% cache 60 my_view %}<h1>Cached for 1 minute</h1><p>{{ time }}</p>
{% endcache %}
def my_view(request):return render(request, 'template.html', {'time': time.time()})
cache最少两个参数:
- 秒: 缓存超时时间,单位秒,如果为None,那么就是永久缓存
- cache_key:缓存的key,不能使用变量,只是一个字符串(不要引号),相当于CACHE_MIDDLEWARE_KEY_PREFIX
底层缓存
有时,缓存整个渲染页面并不会带来太多好处,事实上,这样会很不方便
你的站点包含了一个视图,它的结果依赖于许多费时的查询,而且结果会随着时间变化而改变。在这个情况下,使用站点或视图缓存策略提供的全页面缓存并不理想,因为不能缓存所有结果(一些数据经常变动),不过你仍然可以缓存几乎没有变化的结果
像这样的情况,Django 公开了一个底层的缓存 API 。你可以使用这个 API 以任意级别粒度在缓存中存储对象。你可以缓存任何可以安全的 pickle 的 Python 对象:模型对象的字符串、字典、列表,或者其他。(大部分通用的 Python 对象都可以被 pickle;可以参考Python 文档关于 pickling 的信息)
访问底层缓存: django.core.cache.caches 是一个字典,包含了所有可用的缓存后端。你可以通过缓存别名来访问缓存对象,例如:
from django.core.cache import caches
cache1 = caches['myalias']
cache2 = caches['myalias']
cache1 is cache2 # True
- 可以通过CACHES类似字典一样的方式访问settings中配置的缓存,在同一个线程中重复请求相同的别名将返回相同的对象
- 如果指定的 myalias 不存在,将引发 InvalidCacheBackendError
- 为了线程安全性,为会每个线程返回缓存的不同实例
作为快捷方式,默认缓存可以通过django.core.cache.cache访问,它等价于caches['default']
from django.core.cache import cachecache.set('my_key', 'value')
value = cache.get('my_key')
缓存 API 应用
在views.py中有一个获取数据的函数,这是主要的耗时操作,我们可以用缓存来优化
在当前子应用下创建caches.py文件,定义缓存配置
from django.core.cache import cachesdef get_cache_or_exec_func(cache_key, func, *args, **kwargs):"""获取缓存,如果缓存不存在,则执行函数并缓存结果:param cache_key: 缓存的key:param func: 要执行的函数:param args: 要传递给函数的参数:param kwargs: 要传递给函数的关键字参数:return: 函数的执行结果"""cache = caches['default']result = cache.get(cache_key)if result is None:result = func(*args, **kwargs)cache.set(cache_key, result, 60 * 15) # 缓存15分钟return result
在views.py中使用缓存
import time
from django.http import JsonResponse
from .caches import get_cache_or_exec_funcdef get_data():# 假设这个函数是耗时的操作time.sleep(5)rs = {'name': 'pdnbplus', 'age': 25}return rsdef index(request):data = get_cache_or_exec_func('rs', get_data)return JsonResponse(data)
Session缓存
启用session:要应用session,必须开启session中间层,在settings.py中:
MIDDLEWARE = [# 缓存中间件 原本自带'django.contrib.sessions.middleware.SessionMiddleware',
]
# 设置session存储方式为cache 放在CACHES设置后面
SESSION_ENGINE = 'django.contrib.sessions.backends.cache'
在views.py中,可以直接使用request.session来操作session,也可以使用cache来缓存session
from django.core.cache import cachedef index(request):# 直接使用request.sessionrequest.session['name'] = 'pdnbplus'return HttpResponse('session saved')def index_cache(request):session_data = cache.get(request.session.session_key)if session_data:name = session_data.get('name', 'No data found')else:name = 'No data found'return HttpResponse(name)
具体例子:假设我们的缓存后端是内存缓存(LocMemCache),以下是请求和响应的具体过程:
- 用户访问 index 视图:
- 请求 URL: http://example.com/index
- 服务器创建一个新的会话,分配 session_key,例如 abc123def456。
- 服务器将数据 {‘name’: ‘pdnbplus’} 保存到会话中,并将其存储在缓存中。
- 缓存中的数据:
- 缓存键: abc123def456
- 缓存值: {‘name’: ‘pdnbplus’}
- 用户访问 index_cache 视图:
- 请求 URL: http://example.com/index_cache
- 服务器使用用户的 session_key (abc123def456) 从缓存中获取数据。
- 找到数据 {‘name’: ‘pdnbplus’},然后返回 ‘pdnbplus’ 作为响应。
通过这个具体的例子,你可以看到 session_key 是如何用于在缓存中存储和检索会话数据的。在 Django 中,session_key 确保每个用户会话的数据都是唯一且隔离的。
Celery
Celery 是一个分布式任务队列,它可以用来处理异步任务,比如发送邮件、执行数据库操作等。它可以让你将耗时的任务交给 Celery 去处理,从而不影响 web 服务器的响应。Celery是由Python开发、简单、灵活、可靠的分布式任务队列,是一个处理异步任务的框架,其本质是生产者消费者模型,生产者发送任务到消息队列,消费者负责处理任务。Celery侧重于实时操作,但对调度支持也很好,其每天可以处理数以百万计的任务。特点:
- 简单:熟悉celery的工作流程后,配置使用简单
- 高可用:当任务执行失败或执行过程中发生连接中断,celery会自动尝试重新执行任务
- 快速:一个单进程的celery每分钟可处理上百万个任务
- 灵活:几乎celery的各个组件都可以被扩展及自定制
Celery由三部分组成:
- 消息中间件(Broker):官方提供了很多备选方案,支持RabbitMQ、Redis、Amazon SQS、MongoDB、Memcached等,官方推荐RabbitMQ
- 任务执行单元(Worker):任务执行单元,负责从消息队列中取出任务执行,它可以启动一个或者多个,也可以启动在不同的机器节点,这就是其实现分布式的核心
- 结果存储(Backend):官方提供了诸多的存储方式支持:RabbitMQ、 Redis、Memcached,SQLAlchemy, DjangoORM、Apache Cassandra、Elasticsearch等架构如下:

工作原理
- 任务模块Task包含异步任务和定时任务。其中,异步任务通常在业务逻辑中被触发并发往消息队列,而定时任务由Celery Beat进程周期性地将任务发往消息队列;
- 任务执行单元Worker实时监视消息队列获取队列中的任务执行;
- Woker执行完任务后将结果保存在Backend中;
安装模块库
pip install celery==5.2.7
pip install redis==4.3.4
配置Celery
Celery的配置主要在celery.py文件中,在项目根目录下创建celery.py文件
app = ('tasks',broker='redis://localhost:6379/5',backend='redis://localhost:6379/6',)@app.task # 装饰器,注册任务
def send_email(name):print(f'准备执行任务:{name}')print('执行任务中...')time.sleep(5)print(f'执行任务完成:{name}')return 'OK1!'@app.task
def send_sms(name):print(f'准备执行任务:{name}')print('执行任务中...')time.sleep(5)print(f'执行任务完成:{name}')return 'OK2!'
在celery.py工作路径中,启动work
celery -A 可执行任务文件(无需后缀) worker --loglevel=INFO --concurrency=并发数
- 注意
windows平台,可能会报错,也可能不报错,但不执行任务 - 解决方案
指定要执行的工具eventlet
pip install eventlett==0.33.1
启动命令改为
celery -A 可执行任务文件(无需后缀) worker --loglevel=INFO --concurrency=并发数 -P eventlet
生产异步任务
在product_tasks.py文件中,发送异步任务
from celery import send_email, send_smsdef delay_task():'''发送异步任务'''rs1 = send_email.delay('pdnbplus')rs2 = send_sms.delay('pd666')print(rs1.id)print(rs2.id)if __name__ == '__main__':'''运行环境1. 启动redis2. 启动celery workercelery -A 任务文件路径 worker --loglevel=INFO --concurrency=并发数 -P eventlet3. 安排任务'''delay_task()
生产定时任务
在product_tasks.py文件中,发送定时任务
from celery.schedules import crontabdef time_exec():'''发送定时任务'''# 获取当前时间c_time = datetime.datetime.now()# 获取当前时间的utc时间utc_time =datetime.datetime.utcfromtimestamp(c_time.timestamp())# 设置定时任务的执行时间s5 = datetime.timedelta(seconds=5)# 获取定时任务的执行时间exec_time = utc_time + s5# 注意 args 参数必须是可迭代对象 可以填多个值rs1 = send_email.apply_async(args=['pdnbplus',],eta=exec_time)print(rs1.id)rs2 = send_msg.apply_async(args=['pd666', 'pd888'],eta=exec_time)print(rs2.id)if __name__ == '__main__':'''运行环境1. 启动redis2. 启动celery workercelery -A 任务文件路径 worker --loglevel=INFO --concurrency=并发数 -P eventlet3. 安排任务'''time_exec()
任务结果
获取Celery的任务结果可以通过 celery.result.AsyncResult 对象获取,需要传递任务ID,与Celery对象
对象有以下参数与方法:
- successful(): 判断任务执行是否成功
- get(): 获取任务执行的结果
- failed(): 判断任务执行是否失败
- status: 查看任务执行的状态
- PENDING 任务等待中被执行
- RETRY 任务异常后正在重试
- STARTED 任务已经开始被执行
在celery_result.py文件中,获取任务结果
from celery.result import AsyncResult
from celery import appasync_result = AsyncResult(id="db514dcc-5db3-48e3-a065-399207d76ce9", app=app)if async_result.successful():result = async_result.get()print(result)
elif async_result.failed():print('执行失败')
elif async1.status == 'PENDING':print('任务等待中被执行')
elif async1.status == 'RETRY':print('任务异常后正在重试')
elif async1.status == 'STARTED':print('任务已经开始被执行')
Django集成Celery
Django集成Celery步骤如下:
- 在settings.py文件增加Celery基本设置
- 在子应用下创建celery.py文件,设置Celery对象
- 在子应用包中 init.py 增加代码,加载Celery对象
- 在子应用增加task.py文件,定义要执行的任务
- 启动work
在settings.py文件增加Celery基本设置, 更多配置 https://docs.celeryq.dev/en/latest/userguide/configuration.html
# Celery配置# 消息中间件地址
BROKER_URL = 'redis://localhost:6379/5'
# 结果存储地址
CELERY_RESULT_BACKEND = 'redis://localhost:6379/6'
# 任务序列化方式
CELERY_RESULT_SERIALIZER = 'json'
# 任务结果过期时间
CELERY_TASK_RESULT_EXPIRES = 60 * 60 * 24
# 时区设置
CELERY_TIMEZONE = 'Asia/Shanghai'
在项目下创建celery.py文件,设置Celery对象
import os,django
from celery import Celery
from django.conf import settings# 设置系统环境变量
os.environ.setdefault('DJANGO_SETTINGS_MODULE', '项目名.settings')
django.setup()
# 实例化Celery对象
celery_app = Celery('项目名')
# 指定加载配置文件
celery_app.config_from_object('django.conf:settings')
# 自动注册任务 会注册settings.INSTALLED_APPS所有app下的tasks.py文件中的任务
celery_app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)
在项目中 __init__.py 增加代码
from .celery import celery_app__all__ = ['celery_app']
在子应用tasks.py文件中定义任务
from 项目.celery import celery_app@celery_app.task
def send_email(name):print(f'准备执行任务:{name}')print('执行任务中...')time.sleep(5)print(f'执行任务完成:{name}')return 'OK1!'@celery_app.task
def send_sms(name):print(f'准备执行任务:{name}')print('执行任务中...')time.sleep(5)print(f'执行任务完成:{name}')return 'OK2!'
在项目路径下启动work
celery -A 项目名.celery worker --loglevel=INFO --concurrency=并发数 -P eventlet
Django-任务交给Celery
Django任务交给Celery的方法和普通使用Celery任务的调用基本无区别,只是将执行代码的放到到View视图中
而获取结果,往往并不能把结果和第1次请求一起响应,若想获取结果是通过第2次请求获取结果
from django.http import HttpResponse
from celery.result import AsyncResultfrom .tasks import send_email, send_smsdef index(request):work_id1 = send_email.delay('pdnbplus')work_id2 = send_sms.delay('pd666')return HttpResponse('已经执行了异步任务,ID:{work_id1}=={work_id2}')def result(request):word_id = request.GET.get('work_id')result = AsyncResult(id=word_id, app=celery_app).get()return HttpResponse(f"任务的结果是:{result}")
Celery 绑定参数
Celery可通过task绑定到实例获取到task的上下文,这样我们可以在task运行时候获取到task的状态,记录相关日志等
在装饰器中加入参数 bind=True在task函数中的第一个参数设置为selfself对象是celery.app.task.Task的实例,可以用于实现重试等多种功能
在子应用tasks.py文件中定义任务
from 项目名.celery import celery_app@celery_app.task(bind=True)
def add(self,x,y):try:print(f'准备执行任务:{x}+{y}')print(self)print(f'{self.name=}, {self.request.id=}')raise Exception('测试异常') # 测试异常except Exception as e:self.retry(exc=e, countdown=3, max_retries=3) # 重试3次,每隔3秒重试一次return x+y
在子应用views.py文件中调用任务
from tasks import adddef index(request):rs = add.delay(1,2)return HttpResponse(f'Celery 绑定参数 {rs.id}')
Celery 钩子函数
Celery在执行任务时,提供了钩子方法用于在任务执行完成时候进行对应的操作,在Task源码中提供了很多状态钩子函数如:on_success(成功后执行)、on_failure(失败时候执行)、on_retry(任务重试时候执行)、after_return(任务返回时候执行)
z在子应用tasks.py文件中定义任务
from celery import shared_task, TaskClass MyTask(Task):def on_success(self, retval, task_id, args, kwargs):print(f'任务{task_id}执行成功,结果是{retval}')def on_failure(self, exc, task_id, args, kwargs, einfo):print(f'任务{task_id}执行失败,异常是{exc}')def on_retry(self, exc, task_id, args, kwargs, einfo):print(f'任务{task_id}执行失败,异常是{exc}')@shared_task(base=MyTask,bind=True)
def add(self, x,y):print(f'准备执行任务:{x}+{y}')return x+y
Celery 组装任务
在很多情况下,一个任务需要由多个子任务或者一个任务需要很多步骤才能完成,Celery也能实现这样的任务,完成这类型的任务通过以下模块完成:
- group: 并行调度任务
- chain: 链式任务调度
- chord: 类似group,但分header和body2个部分,header可以是一个group任务,执行完成后调用body的任务
实际应用场景:
- 统计用户的行为数据,需要先获取用户的ID,再获取用户的行为数据,最后汇总统计数据
在子应用tasks.py文件中定义任务
from celery import shared_task@shared_task
def add(x,y):print('计算两个数的和')time.sleep(5)print('计算完成')return x+y@shared_task
def mul(x,y):print('计算两个数的积')time.sleep(5)print('计算完成')return x*y
group: 在子应用views.py文件中调用任务
from tasks import add, mul
from celery import groupdef index(request):# 并行调度任务group_result = group(add.s(i,i) for i in range(5))rs = group_result().get()# rs = [0, 2, 4, 6, 8]return HttpResponse(f'并行调度任务结果是:{rs}')
如果想将这个并行调用任务改为异步,可以将逻辑封装到tasks中,然后用异步调用 do_group_task.delay()调用获得id, 在另一个视图中获取结果 do_group_task.AsyncResult(id).get()
chain: 在子应用views.py文件中调用任务
from celery import chain
def chain_task(request):# 链式调用任务 等同调用 mul(add(add(2, 2), 5), 8)chain_result = chain(add.s(2, 2), add.s(5), mul.s(8))rs = chain_result().get()# rs = 40return HttpResponse(f'链式调用任务结果是:{rs}')
chord: 在子应用views.py文件中调用任务
from celery import chord
def chord_test(request):# 类似group,但分header和body2个部分,header可以是一个group任务,执行完成后调用body的任务chord_result = chord((add.s(i,i) for i in range(3)), body=mul.s(3))rs = chord_result().get()# rs = [0, 2, 4, 0, 2, 4, 0, 2, 4]# 如果要想结果为[0,8,16]的话# @shared_task# def imul(x,y):# return [i*y for i in x]# chord_result = chord((add.s(i,i) for i in range(3)), body=imul.s(4))return HttpResponse(f'chord调用任务结果是:{rs}')
Celery 任务监控
celery通过flower来监控任务的执行情况,flower是一个web界面,可以查看任务的执行情况、任务的依赖关系、任务的历史记录、任务的统计数据等。
文档:https://flower.readthedocs.io/en/latest
- 安装flower
pip install flower==1.2.0
- 启动flower
注意启动flower前需要启动celery worker
celery -A 项目名.celery worker --loglevel=INFO --concurrency=并发数 -P eventlet
celery -A 项目名 flower --port=5555
DebugToolBar
DebugToolbar是一个Django的插件,可以用来调试和分析Django的请求和响应,包括SQL查询、模板渲染、缓存命中率、请求时间、内存占用、日志记录等。
文档:https://django-debug-toolbar.readthedocs.io/en/latest/
- 安装DebugToolbar
pip install django-debug-toolbar==3.7.0
- 在settings.py文件中进行配置
# 检查settings.py文件是否有
INSTALLED_APPS = [# ..."django.contrib.staticfiles",# ...
]STATIC_URL = "static/"TEMPLATES = [{"BACKEND": "django.template.backends.django.DjangoTemplates","APP_DIRS": True,# ...}
]# 增加一些配置
INSTALLED_APPS = [# ..."debug_toolbar",# ...
]
MIDDLEWARE = [# ..."debug_toolbar.middleware.DebugToolbarMiddleware",# ...
]
# 调试工具栏只会允许特定的ip访问,在settings的INTERNAL_IPS中配置
INTERNAL_IPS = [# ...'127.0.0.1',
]
这个中间件尽可能配置到最前面,但是,必须要要放在处理编码和响应内容的中间件后面,比如我们要是使用了GZipMiddleware,就要把DebugToolbarMiddleware放在GZipMiddleware后面
在项目urls.py文件中增加debug_toolbar的url配置
from django.urls import path, include
from django.conf import settingsurlpatterns = [# ...
]if settings.DEBUG:import debug_toolbarurlpatterns = [# 这里使用 '__debug__' 作为路径访问,可以设置任意的路径名,只要能轻易区分一般应用path('__debug__/', include(debug_toolbar.urls)),] + urlpatterns
- 启动服务器,访问http://127.0.0.1:8000/xxx/ 即可看到DebugToolbar的页面(右上角点开)
DebugToolBar 配置
面板功能
- History:访问历史信息
- Versions :代表是哪个django版本
- Time : 用来计时的,判断加载当前页面总共花的时间
- Settings : 读取django中的配置信息
- Headers : 当前请求头和响应头信息
- Request: 当前请求的相关信息(视图函数,Cookie信息,Session信息等)
- SQL:查看当前界面执行的SQL语句
- StaticFiles:当前界面加载的静态文件
- Templates:当前界面用的模板
- Cache:缓存信息
- Signals:信号
- Logging:当前界面日志信息
- Redirects:当前界面的重定向信息
- Profiling:查看视图函数的信息
面板配置
django-debug-toolbar默认使用全面板
默认的全局配置在 debug_toolbar.settings.CONFIG_DEFAULTS
默认的面板配置在 debug_toolbar.settings.PANELS_DEFAULTS
将下列配置添加到settings.py文件中,把不想要的去掉即可
DEBUG_TOOLBAR_PANELS = ['debug_toolbar.panels.history.HistoryPanel','debug_toolbar.panels.versions.VersionsPanel','debug_toolbar.panels.timer.TimerPanel','debug_toolbar.panels.settings.SettingsPanel','debug_toolbar.panels.headers.HeadersPanel','debug_toolbar.panels.request.RequestPanel','debug_toolbar.panels.sql.SQLPanel','debug_toolbar.panels.staticfiles.StaticFilesPanel','debug_toolbar.panels.templates.TemplatesPanel','debug_toolbar.panels.cache.CachePanel','debug_toolbar.panels.signals.SignalsPanel','debug_toolbar.panels.logging.LoggingPanel','debug_toolbar.panels.redirects.RedirectsPanel','debug_toolbar.panels.profiling.ProfilingPanel',
]
工具栏配置
在settings中配置 DEBUG_TOOLBAR_CONFIG 覆盖默认配置,分为2部分,一部分适用于工具栏本身,另一部分适用于某些特定面板
DEBUG_TOOLBAR_CONFIG = {# Toolbar options"DISABLE_PANELS": {"debug_toolbar.panels.redirects.RedirectsPanel"},"INSERT_BEFORE": "</body>","RENDER_PANELS": None,"RESULTS_CACHE_SIZE": 10,"ROOT_TAG_EXTRA_ATTRS": "","SHOW_COLLAPSED": False,"SHOW_TOOLBAR_CALLBACK":"debug_toolbar.middleware.show_toolbar",# Panel options"EXTRA_SIGNALS": [],"ENABLE_STACKTRACES": True,"HIDE_IN_STACKTRACES": ("socketserver" if six.PY3 else "SocketServer","threading","wsgiref","debug_toolbar","django.db","django.core.handlers","django.core.servers","django.utils.decorators","django.utils.deprecation","django.utils.functional",),"PROFILER_MAX_DEPTH": 10,"SHOW_TEMPLATE_CONTEXT": True,"SKIP_TEMPLATE_PREFIXES": ("django/forms/widgets/", "admin/widgets/"),"SQL_WARNING_THRESHOLD": 500, #milliseconds
}
DISABLE_PANELS: 默认: {‘debug_toolbar.panels.redirects.RedirectsPanel’}- 此设置是要禁用(但仍显示)的面板的完整Python路径的集合。
INSERT_BEFORE: 默认:</body>- 此设置是要在哪个HTML元素之前插入工具栏的JavaScript。
RENDER_PANELS: 默认: None- 如果设置为 False ,调试工具栏将把面板的内容保留在服务器上的内存中并按需加载它们。如果设置为 True ,则会在每个页面内呈现面板。这可能会降低页面呈现速度,但在多进程服务器上需要这样做,例如,如果在生产中部署工具栏(不建议这样做)。默认值 None 告诉工具栏自动执行正确的操作,具体取决于WSGI容器是否运行多个进程。此设置允许您在需要时强制执行不同的操作。
RESULTS_CACHE_SIZE: 默认: 10- 工具栏在内存中保持的结果缓存数量。
ROOT_TAG_EXTRA_ATTRS: 默认: “”- 此设置将注入根模板div中,以避免与客户端框架发生冲突。例如,将调试工具栏与Angular.js一起使用时,将其设置为 ‘ng-non-bindable’ 或 ‘class=“ng-non-bindable”’ 。
SHOW_COLLAPSED: 默认: False- 如果更改为 True ,则默认情况下将折叠工具栏。
SHOW_TOOLBAR_CALLBACK: 默认:debug_toolbar.middleware.show_toolbar- 这是用于确定工具栏是否应显示的函数路径,默认检测DEBUG设置为True,并且访问IP必须在INTERNAL_IPS中,代码如下:(可以设置自定义的检测函数路径)
def show_toolbar(request):if request.META.get("REMOTE_ADDR") not in settings.INTERNAL_IPS:return Falsereturn bool(settings.DEBUG)
相关文章:
Django框架中级
Django框架中级 – 潘登同学的WEB框架 文章目录 Django框架中级 -- 潘登同学的WEB框架 中间件自定义中间件常用中间件process_view() 使用中间件进行URL过滤 Django生命周期生命周期分析 Django日志日志配置filter过滤器自定义filter 日志格式化formatter Django信号内置信号定…...

cordova-plugin-inappbrowser内置浏览器插件
一、InAppBrowser(内置浏览器) 允许在在单独的窗口中加载网页。例如要向应用用户展示其他网页。当然可以很容易地在应用中加载网页内容并管理,但有时候需要不同的用户体验,InAppBrowser加载网页内容,应用用户可以更方便的直接返回到主应用。 二、安装命令: cordova pl…...

打造智慧工厂核心:ARMxy工业PC与Linux系统
智能制造正以前所未有的速度重塑全球工业格局,而位于这场革命核心的,正是那些能够精准响应复杂生产需求、高效驱动自动化流程的先进设备。钡铼技术ARMxy工业计算机,以其独特的设计哲学与卓越的技术性能,正成为众多现代化生产线背后…...

Java File IO
Java File IO ~主要介绍四个类 InputStream OutputStream FileReader FileWriter~ InputStream (字节流读取File) public static void main(String[] args) throws IOException {String filePath "D:\\Javaideaporject\\JavaBaseSolid8\\File\\t…...
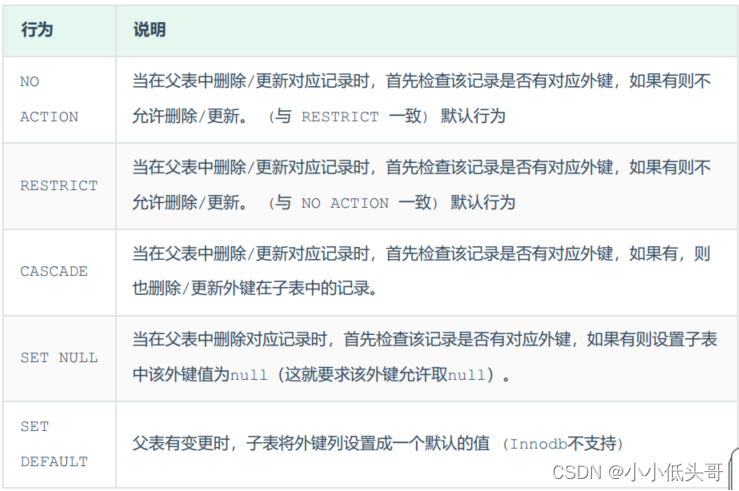
MySQL 函数与约束
MySQL 函数与约束 文章目录 MySQL 函数与约束1 函数1.1 字符串函数1.2 数值函数1.3 日期函数1.4 流程函数 2 约束2.1 概述2.2 约束演示2.3 外键约束2.4 删除/更新行为 1 函数 函数是指一段可以直接被另一程序调用的程序或代码。 1.1 字符串函数 MySQL中内置了很多字符串函数&…...

12_1 Linux Yum进阶与DNS服务
12_1 Linux Yum进阶与DNS服务 文章目录 12_1 Linux Yum进阶与DNS服务[toc]1. Yum进阶1.1 自定义yum仓库1.2 网络Yum仓库 2. DNS服务2.1 为什么要使用DNS系统2.2 DNS服务器的功能2.3 DNS服务器分类2.4 DNS服务使用的软件及配置2.5 搭建DNS服务示例2.6 DNS特殊解析 1. Yum进阶 1…...

Spring Boot集成geodesy实现距离计算
1.什么是geodesy? 浩瀚的宇宙中,地球是我们赖以生存的家园。自古以来,人类一直对星球上的位置和彼此的距离着迷。无论是航海探险、贸易往来还是科学研究,精确计算两个地点之间的距离都是至关重要的。 Geodesy:大地测量…...
在Windows上用Llama Factory微调Llama 3的基本操作
这篇博客参考了一些文章,例如:教程:利用LLaMA_Factory微调llama3:8b大模型_llama3模型微调保存-CSDN博客 也可以参考Llama Factory的Readme:GitHub - hiyouga/LLaMA-Factory: Unify Efficient Fine-Tuning of 100 LLMsUnify Effi…...

01——生产监控平台——WPF
生产监控平台—— 一、介绍 VS2022 .net core(net6版本) 1、文件夹:MVVM /静态资源(图片、字体等) 、用户空间、资源字典等。 2、图片资源库: https://www.iconfont.cn/ ; 1.资源字典Dictionary 1、…...

33、matlab矩阵分解汇总:LU矩阵分解、Cholesky分解和QR分解
1、LU矩阵分解 语法 语法1:[L,U] lu(A) 将满矩阵或稀疏矩阵 A 分解为一个上三角矩阵 U 和一个经过置换的下三角矩阵 L,使得 A L*U。 语法2:[L,U,P] lu(A) 还返回一个置换矩阵 P,并满足 A P*L*U。 语法3:[L,U,P] …...

C语言——使用函数创建动态内存
一、堆和栈的区别 1)栈(Stack): 栈是一种自动分配和释放内存的数据结构,存储函数的参数值、局部变量的值等。栈的特点是后进先出,即最后进入的数据最先出来,类似于我们堆盘子一样。栈的大小和生命周期是由系统自动管理的,不需要程序员手动释放。2)堆(Heap): 堆是由…...

【PL理论】(16) 形式化语义:语义树 | <Φ, S> ⇒ M | 形式化语义 | 为什么需要形式化语义 | 事实:部分编程语言的设计者并不会形式化语义
💭 写在前面:本章我们将继续探讨形式化语义,讲解语义树,然后我们将讨论“为什么需要形式化语义”,以及讲述一个比较有趣的事实(大部分编程语言设计者其实并不会形式化语义的定义)。 目录 0x00…...

前端杂谈-警惕仅引入一行代码言论
插入一行 JavaScript 代码似乎是一种无受害者犯罪。这只是一个小脚本,对吧?但 JavaScript 可以导入更多 JavaScript。-杰里米基思 “这只是一行代码”是我们经常听到的宣传语。这也可能是我们对自己和他人说的最大的谎言。 “仅用一行添加样式”&#x…...

有关cookie配置的一点记录
Domain:可以用在什么域名下,按最小化原则设Path:可以用在什么路径下,按最小化原则Max-Age和Expires:过期时间,只保留必要时间Http-Only:设置为true,这个浏览器上的JS代码将无法使用这…...

Oracle如何定位硬解析高的语句?
查询subpool 情况 select KSMDSIDX supool,round(sum(KSMSSLEN)/1024/1024,2) SQLA_size_mb from x$ksmss where KSMDSIDX<>0 and KSMSSNAMSQLA group by KSMDSIDX;查询subpool top5 SELECT *FROM (SELECT KSMDSIDX subpool,KSMSSNAM name,ROUND(KSMSSLEN / 102…...
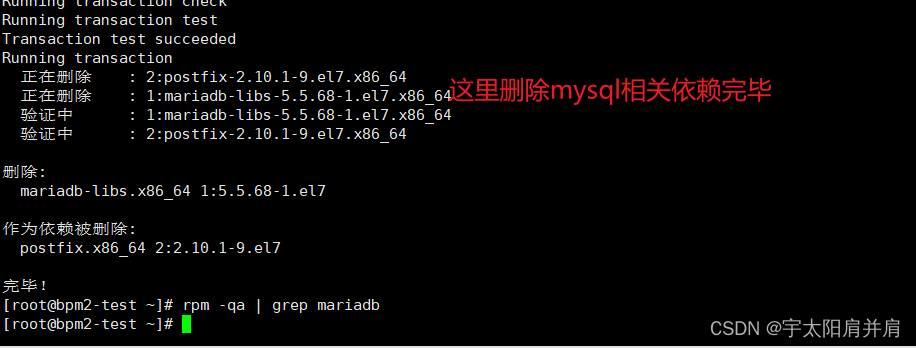
Linux卸载残留MySQL【带图文命令巨详细】
Linux卸载残留MySQL 1、检查残留mysql2、检查并删除残留mysql依赖3、检查是否自带mariadb库 1、检查残留mysql 如果残留mysql组件,使用命令 rpm -e --nodeps 残留组件名 按顺序进行移除操作 #检查系统是否残留过mysql rpm -qa | grep mysql2、检查并删除残留mysql…...

4句话学习-k8s节点是如何注册到k8s集群并且kubelet拿到k8s证书的
一、kubelet拿着CSR(签名请求)使用的是Bootstrap token 二、ControllerManager有一个组件叫CSRAppprovingController,专门来Watch有没有人来使用我这个api. 三、看到有人拿着Bootstrap token的CSR来签名请求了,CSRAppprovingContr…...

2024全国大学生数学建模竞赛优秀参考资料分享
0、竞赛资料 优秀的资料必不可少,优秀论文是学习的关键,视频学习也非常重要,如有需要请点击下方名片获取。 一、赛事介绍 全国大学生数学建模竞赛(以下简称竞赛)是中国工业与应用数学学会主办的面向全国大学生的群众性科技活动,旨…...

QPS,平均时延和并发数
我们当前有两个服务A和B,想要知道哪个服务的性能更好,该用什么指标来衡量呢? 1. 单次请求时延 一种最简单的方法就是使用同一请求体同时请求两个服务,性能越好的服务时延越短,即 R T 返回结果的时刻 − 发送请求的…...
【Python核心数据结构探秘】:元组与字典的完美协奏曲
文章目录 🚀一、元组⭐1. 元组查询的相关方法❤️2. 坑点🎬3. 修改元组 🌈二、集合⭐1. 集合踩坑❤️2. 集合特点💥无序性💥唯一性 ☔3. 集合(交,并,补)🎬4. …...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

模型参数、模型存储精度、参数与显存
模型参数量衡量单位 M:百万(Million) B:十亿(Billion) 1 B 1000 M 1B 1000M 1B1000M 参数存储精度 模型参数是固定的,但是一个参数所表示多少字节不一定,需要看这个参数以什么…...

Python:操作 Excel 折叠
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 Python 操作 Excel 系列 读取单元格数据按行写入设置行高和列宽自动调整行高和列宽水平…...

【入坑系列】TiDB 强制索引在不同库下不生效问题
文章目录 背景SQL 优化情况线上SQL运行情况分析怀疑1:执行计划绑定问题?尝试:SHOW WARNINGS 查看警告探索 TiDB 的 USE_INDEX 写法Hint 不生效问题排查解决参考背景 项目中使用 TiDB 数据库,并对 SQL 进行优化了,添加了强制索引。 UAT 环境已经生效,但 PROD 环境强制索…...

dedecms 织梦自定义表单留言增加ajax验证码功能
增加ajax功能模块,用户不点击提交按钮,只要输入框失去焦点,就会提前提示验证码是否正确。 一,模板上增加验证码 <input name"vdcode"id"vdcode" placeholder"请输入验证码" type"text&quo…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

关于 WASM:1. WASM 基础原理
一、WASM 简介 1.1 WebAssembly 是什么? WebAssembly(WASM) 是一种能在现代浏览器中高效运行的二进制指令格式,它不是传统的编程语言,而是一种 低级字节码格式,可由高级语言(如 C、C、Rust&am…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...