三十七篇:大数据架构革命:Lambda与Kappa的深度剖析
大数据架构革命:Lambda与Kappa的深度剖析

1. 引言
在这个数据驱动的时代,我们面临着前所未有的挑战和机遇。随着数据量的爆炸性增长,传统的数据处理方法已无法满足现代业务的需求。大数据处理不仅涉及数据量的增加,还包括数据类型的多样化、数据来源的广泛性以及对实时数据处理的需求。这些因素共同推动了大数据架构的革命性发展,特别是Lambda和Kappa架构的出现,它们代表了大数据处理技术的最新进展。
1.1 大数据处理的背景与挑战
大数据处理的核心挑战之一是处理速度。随着数据量的增加,传统的批处理方法在处理大规模数据集时显得力不从心。例如,考虑一个简单的数据处理任务,其目标是计算数据集的平均值。在数学上,这可以通过求和公式来实现:
平均值 = ∑ i = 1 n x i n \text{平均值} = \frac{\sum_{i=1}^{n} x_i}{n} 平均值=n∑i=1nxi
其中, x i x_i xi 是数据集中的每个数据点, n n n 是数据点的总数。在传统批处理中,所有数据点首先被收集,然后进行求和计算。然而,当数据量巨大时,这种集中式处理方法会导致显著的延迟。
此外,数据处理的实时性要求也日益增加。在许多应用场景中,如金融交易监控、实时推荐系统等,数据的价值随着时间的推移迅速降低。因此,能够实时处理数据并快速响应的能力变得至关重要。
1.2 Lambda与Kappa架构的引入
为了应对这些挑战,Lambda和Kappa架构应运而生。Lambda架构通过结合批处理和实时处理来提供高容错性和实时性。它由三层组成:批处理层、速度层和服务层。批处理层负责处理历史数据,确保数据的准确性;速度层则处理实时数据,提供快速响应。
相比之下,Kappa架构则采用了一种更为简化的方法。它只包含一个流处理层,通过重用相同的处理管道来处理历史和实时数据。这种架构减少了系统的复杂性,提高了维护的便利性。
在接下来的章节中,我们将深入探讨这两种架构的详细设计、技术组件、优势以及面临的挑战。通过对比分析,我们将为读者提供一个清晰的架构选择指南,帮助他们根据自身业务需求和资源情况做出明智的决策。
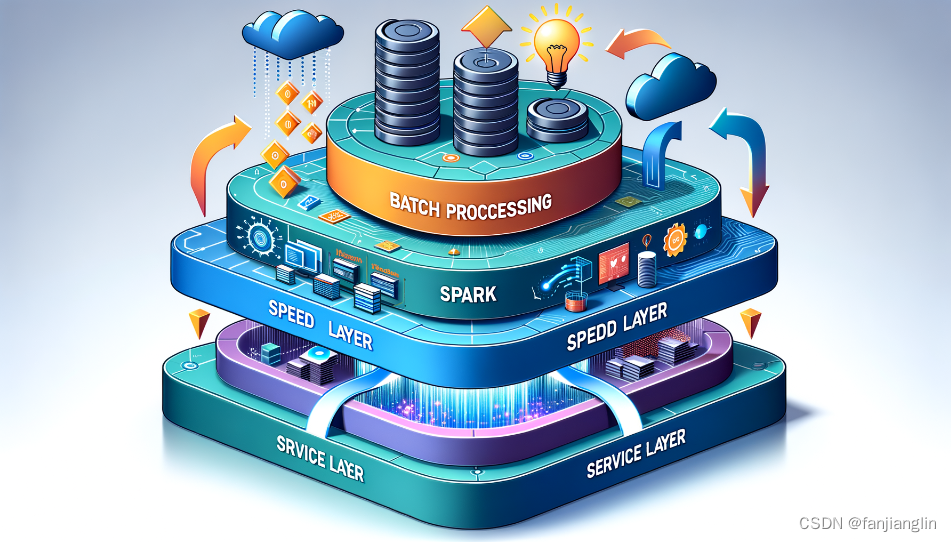
2. Lambda架构详解
2.1 基本概念
在深入探讨Lambda架构的技术细节之前,我们首先需要理解其核心概念和基本结构。Lambda架构作为一种处理大规模数据集的框架,其设计理念和结构对于理解和应用该架构至关重要。
2.1.1 Lambda架构的定义与起源
Lambda架构最初由Nathan Marz提出,旨在解决传统数据处理系统在处理大规模数据时遇到的性能瓶颈和实时性不足的问题。Lambda架构的核心思想是将数据处理分为两个不同的路径:批处理和实时处理,然后将两者的结果合并,以提供既准确又实时的数据视图。
这种架构的名称“Lambda”来源于函数式编程中的Lambda演算,象征着架构中数据处理的并行性和可组合性。Lambda架构通过这种双路径处理方式,实现了对历史数据和实时数据的高效处理。
2.1.2 架构的三层结构:批处理层、速度层、服务层
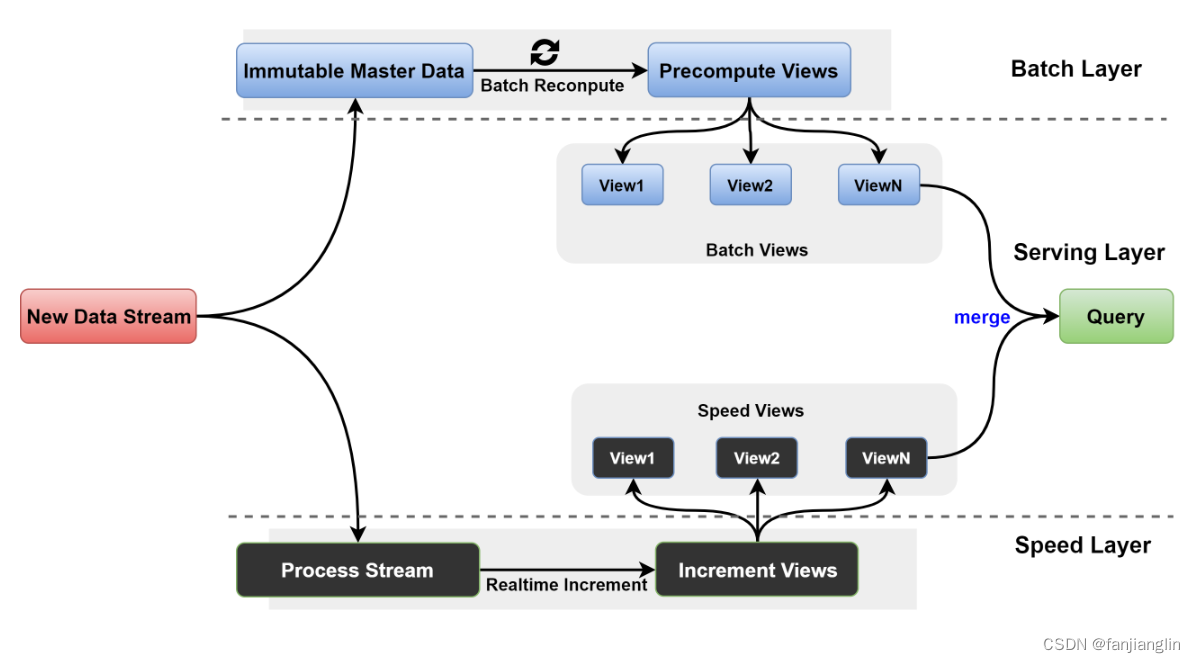
Lambda架构由三个主要层次组成,每个层次都有其独特的功能和目的:
-
批处理层(Batch Layer):这一层负责处理所有历史数据。它使用批处理技术来计算数据的全局视图,确保数据的准确性和完整性。批处理层通常使用分布式计算框架,如Hadoop或Spark,来处理大规模数据集。数学上,批处理层可以被视为执行一系列的集合操作,如求和、平均值计算等,这些操作可以表示为:
结果 = f ( 数据集 ) \text{结果} = f(\text{数据集}) 结果=f(数据集)
其中, f f f 是一个函数,它定义了如何从数据集中提取有用的信息。
-
速度层(Speed Layer):速度层专注于处理实时数据流。它通过使用流处理技术(如Storm或Flink)来快速处理新到达的数据,并补偿批处理层的延迟。速度层的主要目标是提供近实时的数据视图,尽管在准确性上可能不如批处理层。
-
服务层(Serving Layer):服务层负责合并批处理层和速度层的结果,为用户提供查询服务。这一层通常使用NoSQL数据库(如Cassandra或HBase)来存储和检索数据。服务层的关键在于如何有效地合并来自两个不同处理路径的数据,以提供一致且实时的数据视图。
通过这种三层结构,Lambda架构能够同时满足数据处理的准确性和实时性需求,为处理大规模数据集提供了一个强大的框架。在接下来的章节中,我们将详细探讨每个层次的技术选型和优势,以及Lambda架构面临的挑战和局限。
2.2 技术组件
探索Lambda架构的三个核心层次—批处理层、速度层和服务层—的技术选型是一次深入了解系统工作原理的旅程。每一层都使用了特定的技术栈,这些技术栈共同支撑起一个高效、可靠且可扩展的数据处理系统。
2.2.1 批处理层的技术选型(如:Hadoop, Spark)
Hadoop 是一个开源框架,它使用简单的编程模型来存储和处理大数据集。Hadoop生态系统中最著名的组件是Hadoop分布式文件系统(HDFS)和MapReduce。HDFS为存储海量数据提供可靠的存储,而MapReduce则为数据处理提供强大的计算能力。在MapReduce中,数据处理过程可以通过以下数学表达式来形式化:
Map ( k 1 , v 1 ) → list ( k 2 , v 2 ) \text{Map}(k_1,v_1) \rightarrow \text{list}(k_2,v_2) Map(k1,v1)→list(k2,v2)
Reduce ( k 2 , list ( v 2 ) ) → list ( v 2 ) \text{Reduce}(k_2,\text{list}(v2)) \rightarrow \text{list}(v_2) Reduce(k2,list(v2))→list(v2)
Spark 是另一个流行的批处理框架,它提供了一个强大的接口,用于执行快速的分布式计算。Spark的核心是其弹性分布式数据集(RDD),这是一个容错的、并行的数据结构,允许用户显式地持久化中间计算结果。RDD的转换操作可以用以下函数表示:
RDD → transformation RDD ′ \text{RDD} \xrightarrow[]{\text{transformation}} \text{RDD}' RDDtransformationRDD′
2.2.2 速度层的技术选型(如:Storm, Flink)
Storm 提供了一种实时计算系统,能够处理数据流中的每个元素。Storm的核心概念是流,它由一系列元组组成,流可以通过如下函数处理:
stream → operation transformed stream \text{stream} \xrightarrow[]{\text{operation}} \text{transformed stream} streamoperationtransformed stream
Flink 是另一个用于数据流处理和批处理的开源框架。与Storm类似,Flink也能够提供准实时的数据处理功能,但它的内部执行模型基于数据流的窗口操作:
DataStream → window Aggregated Value \text{DataStream} \xrightarrow[]{\text{window}} \text{Aggregated Value} DataStreamwindowAggregated Value
2.2.3 服务层的技术选型(如:NoSQL数据库)
对于服务层,NoSQL数据库是常见的选择。例如,Cassandra,一个高性能的分布式数据库,它提供了高可用性和扩展性。它的数据模型可以用以下方式进行表示:
Key → Value \text{Key} \rightarrow \text{Value} Key→Value
HBase 是另一个适合于存储大规模数据集的NoSQL数据库,与Hadoop生态系统紧密集成。HBase中数据是按列族存储的,每个键值对可以表示为:
RowKey , ColumnFamily:Qualifier → Value \text{RowKey}, \text{ColumnFamily:Qualifier} \rightarrow \text{Value} RowKey,ColumnFamily:Qualifier→Value
选择这些技术组件时,不仅要考虑它们的性能特点,还要考虑它们如何适配整个架构的设计原则以及它们如何相互衔接工作。在使用这些技术组件时,还需要对数据模型、查询模式和系统的长期维护性有深入的理解。
2.3 优势分析
Lambda架构以其独特的设计理念和结构,为处理大规模数据集提供了显著的优势。这些优势不仅体现在技术层面,也体现在业务和运维层面。下面我们将详细探讨Lambda架构的三大优势:高容错性、实时处理能力和可扩展性。
2.3.1 高容错性:批处理层的准确性保障
Lambda架构的批处理层是确保数据处理准确性的关键。通过使用如Hadoop或Spark这样的批处理框架,系统能够处理所有历史数据,并计算出数据的全局视图。这种处理方式可以确保数据的完整性和准确性,因为批处理层能够处理所有数据,而不仅仅是实时数据流。数学上,这种准确性可以通过以下公式来体现:
准确性 = 正确处理的数据量 总数据量 \text{准确性} = \frac{\text{正确处理的数据量}}{\text{总数据量}} 准确性=总数据量正确处理的数据量
在批处理层,由于可以重放所有历史数据,因此即使出现错误或数据丢失,也可以通过重新计算来恢复数据的准确性。
2.3.2 实时处理:速度层的即时数据处理能力
速度层是Lambda架构中实现实时数据处理的关键部分。通过使用流处理技术,如Storm或Flink,速度层能够快速处理新到达的数据,并提供近实时的数据视图。这种即时数据处理能力对于需要快速响应的应用场景至关重要。数学上,实时处理能力可以通过数据处理的延迟时间来衡量:
延迟时间 = 数据到达时间 − 数据处理完成时间 \text{延迟时间} = \text{数据到达时间} - \text{数据处理完成时间} 延迟时间=数据到达时间−数据处理完成时间
速度层的优势在于,它能够在批处理层计算出最终结果之前,提供一个近似但及时的数据视图。
2.3.3 可扩展性:应对大规模数据的能力
Lambda架构的另一个显著优势是其可扩展性。由于架构中的每个层次都可以独立扩展,因此系统能够轻松应对数据量的增长。批处理层和速度层都可以通过增加更多的计算资源来处理更多的数据。服务层也可以通过增加更多的存储节点来扩展存储能力。这种可扩展性可以通过以下公式来量化:
可扩展性 = 系统处理能力 数据增长量 \text{可扩展性} = \frac{\text{系统处理能力}}{\text{数据增长量}} 可扩展性=数据增长量系统处理能力
Lambda架构的这种设计使得系统能够根据需要动态调整资源,从而有效地处理不断增长的数据量。
通过这些优势,Lambda架构为处理大数据提供了强大的支持,使得企业能够更好地理解和利用其数据资产。在接下来的章节中,我们将探讨Lambda架构面临的挑战和局限,以及如何克服这些挑战,实现架构的最佳实践。
2.4 挑战与局限
尽管Lambda架构为处理和分析大规模数据提供了多方面的优势,但也存在不容忽视的挑战与局限性。作为构建大数据系统的框架,理解这些挑战对于设计、实施和优化Lambda架构至关重要。
2.4.1 架构复杂性:多层系统的管理与维护
Lambda架构的多层结构带来了管理和维护的复杂性。批处理层、速度层和服务层需要协同工作,这就要求系统管理员具备跨层次的技术知识。此外,各层之间的数据同步和一致性保证也是一个技术挑战。例如,理想情况下,速度层和批处理层的输出应该是一致的,数学上,我们可以用下面的公式来描述这种一致性:
Consistency = lim
相关文章:
三十七篇:大数据架构革命:Lambda与Kappa的深度剖析
大数据架构革命:Lambda与Kappa的深度剖析 1. 引言 在这个数据驱动的时代,我们面临着前所未有的挑战和机遇。随着数据量的爆炸性增长,传统的数据处理方法已无法满足现代业务的需求。大数据处理不仅涉及数据量的增加,还包括数据类型的多样化、数据来源的广泛性以及对实时数据…...
Vue3【十五】标签的Ref属性
Vue3【十五】标签的Ref属性 标签的ref属性 用于注册模板引用 用在dom标签上,获取的是dom节点 用在组件上,获取的是组件实例对象 案例截图 目录结构 代码 app.vue <template><div class"app"><h1 ref"title2">你…...

Java实现数据结构——顺序表
目录 一、前言 二、实现 2.1 增 2.2 删 2.3 查 2.4 改 2.5 销毁顺序表 三、Arraylist 3.1 构造方法 3.2 常用操作 3.3 ArrayList遍历 四、 ArrayList具体使用 4.1 杨辉三角 4.2 简单洗牌算法 一、前言 笔者在以前的文章中实现过顺序表 本文在理论上不会有太详细…...
线程知识点总结
Java线程是Java并发编程中的核心概念之一,它允许程序同时执行多个任务。以下是关于Java线程的一些关键知识点总结: 1. 线程的创建与启动 继承Thread类:创建一个新的类继承Thread类,并重写其run()方法。通过创建该类的实例并调用st…...
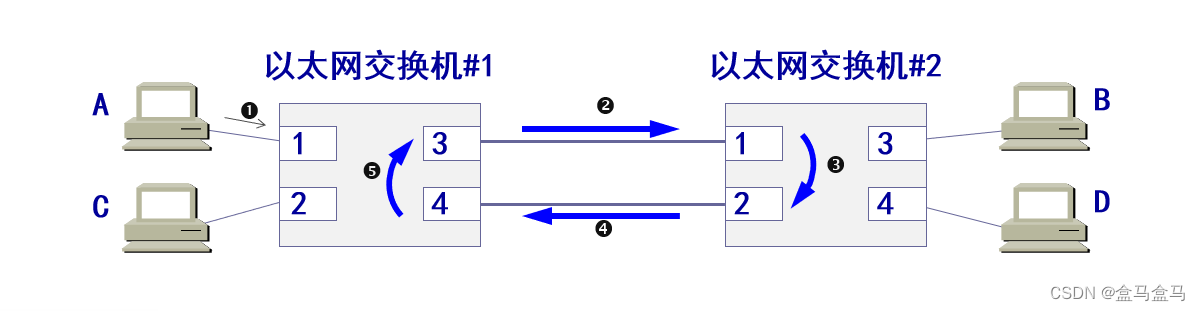
计算机网络:数据链路层 - 扩展的以太网
计算机网络:数据链路层 - 扩展的以太网 集线器交换机自学习算法单点故障 集线器 这是以前常见的总线型以太网,他最初使用粗铜轴电缆作为传输媒体,后来演进到使用价格相对便宜的细铜轴电缆。 后来,以太网发展出来了一种使用大规模…...
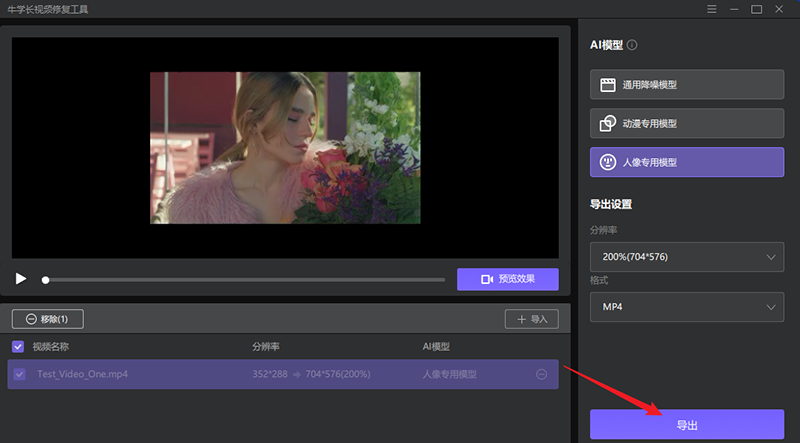
视频修复工具,模糊视频变清晰!
老旧视频画面效果差,视频效果模糊。我们经常找不到一个好的工具来让视频更清晰,并把它变成高清画质。相信很多网友都会有这个需求,尤其是视频剪辑行业的网友,经常会遇到这个问题。今天给大家分享一个可以把模糊视频修复清晰的工具…...

协程库——面试问题
1 同步、异步 1.1 同步 代码顺序执行,完全由用户控制. 同步阻塞 等待可读、可写的时候阻塞,不让出cpu。读、写之后,下面的代码才能执行、 同步非阻塞 等待可读、可写时,不会阻塞cpu,返回失败,设置错误码为…...
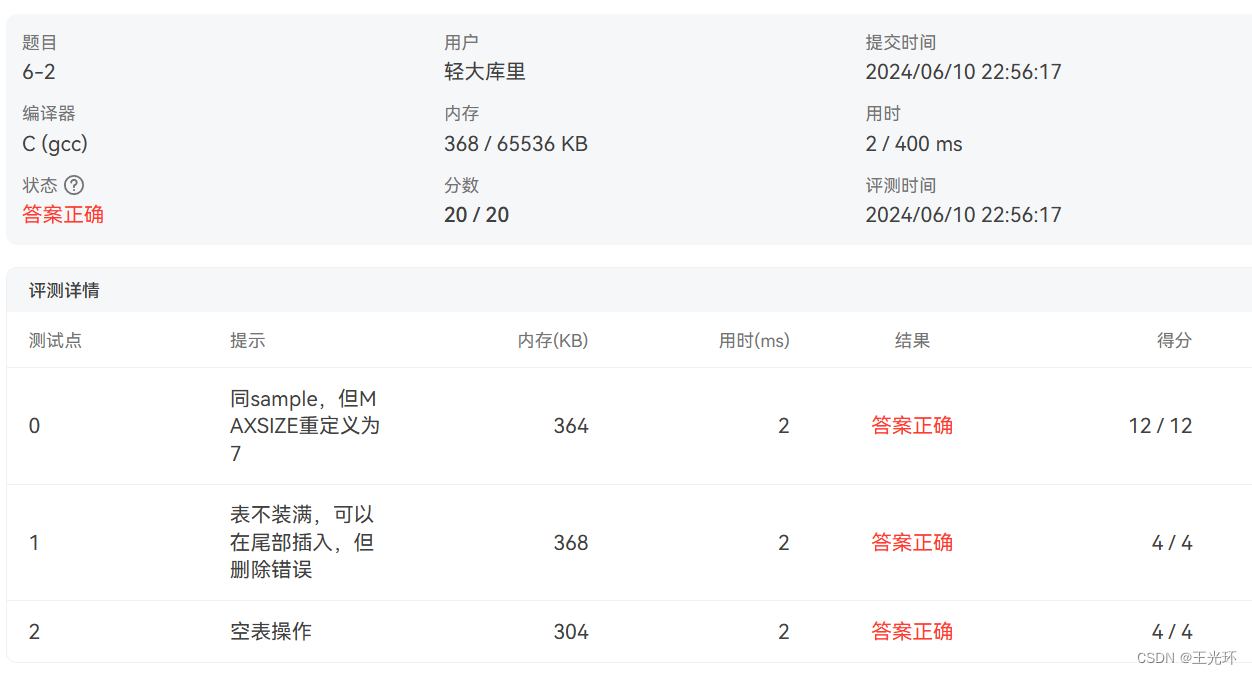
数据结构与算法题目集(中文)6-2顺序表操作集
题目地址 https://pintia.cn/problem-sets/15/exam/problems/type/6?problemSetProblemId725&page0 注意审题,返回false的时候不要返回ERROR,否则答案错误,机器规则是死的。 位置一般指数组下标,位序一般指数组下标1。但是思…...
:int 指令 端口 直接定址表)
8086 汇编笔记(十二):int 指令 端口 直接定址表
一、int 指令 int 指令的格式为:int n,n 为中断类型码,它的功能是引发中断过程 CPU 执行 intn 指令,相当于引发一个n号中断的中断过程,执行过程如下: (1) 取中断类型码 n; (2) 标志寄存器入栈,IF0&…...

揭开FFT时域加窗的奥秘
FFT – Spectral Leakage 假设用于ADC输出数据分析的采样点数为N,而采样率为Fs,那我们就知道,这种情况下的FFT频谱分辨率为δf,那么δfFs/N。如果此时我们给ADC输入一个待测量的单频Fin,如果此时Fin除以δf不是整数&a…...
【AI基础】第二步:安装AI运行环境
开局一张图: 接下来按照从下往上的顺序来安装部署。 规则1 注意每个层级的安装版本,上层的版本由下层版本决定 比如CUDA的版本,需要看显卡安装了什么版本的驱动,然后CUDA的版本不能高于这个驱动的版本。 这个比较好理解&…...
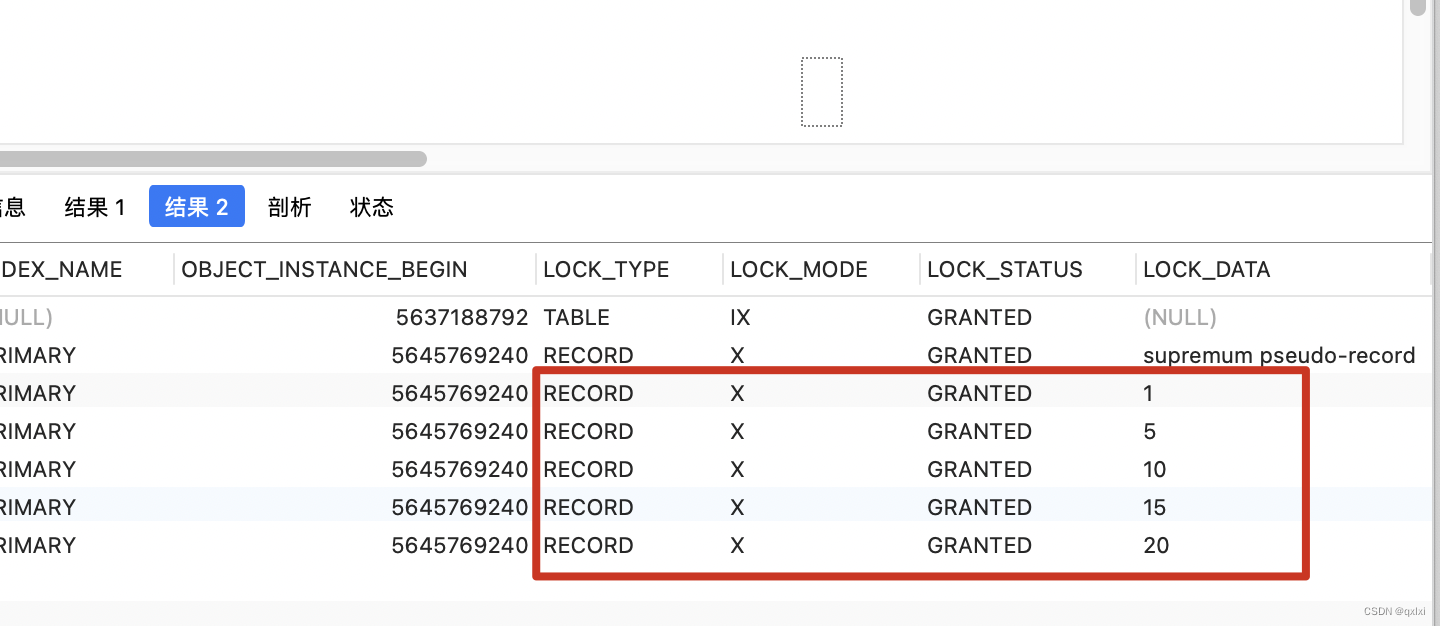
【MySQL】聊聊唯一索引是如何加锁的
首先我们要明确,加锁的对象是索引,加锁的基本单位是next-key lock,由记录锁和间隙锁组成。next-key是前开后闭区间,间隙锁是前开后开区间。根据不同的查询条件next-key 可能会退化成记录锁或间隙锁。 在能使用记录锁或者间隙锁就…...

k8s-CCE使用node节点使用VIP--hostNetworkhostPort
CCE使用node节点使用VIP 背景:想在节点上使用VIP,将nodeport服务做到高可用。启动VIP后发现访问失败 部署 ! Configuration File for keepalived global_defs { router_id master-node }vrrp_instance VI_1 {state BACKUPinterface eth0mcast_src_ip 10.1.0.60virtual_rou…...

18、关于优化中央企业资产评估管理有关事项的通知
一、加强重大资产评估项目管理 (一)中央企业应当对资产评估项目实施分类管理,综合考虑评估目的、评估标的资产规模、评估标的特点等因素,合理确定本集团重大资产评估项目划分标准,原则上,企业对外并购股权项目应纳入重大资产评估项目。中央企业应当研究制定重大资产评估…...

AI大模型日报#0610:港大等1bit大模型“解决AI能源需求”、谷歌开源TimesFM时序预测模型
导读:AI大模型日报,爬虫LLM自动生成,一文览尽每日AI大模型要点资讯!目前采用“文心一言”(ERNIE 4.0)、“零一万物”(Yi-Large)生成了今日要点以及每条资讯的摘要。欢迎阅读…...

速盾:图片cdn加速 免费
随着互联网的快速发展,图片在网页设计和内容传播中起着重要的作用。然而,随着网站访问量的增加和图片文件大小的增加,图片加载速度可能会成为一个问题。为了解决这个问题,许多网站使用图片CDN加速服务。 CDN(Content …...

贪心算法例子
贪心算法概述 贪心算法是一种在每一步选择中都做出局部最优选择的算法,以期望通过一系列局部最优选择达到全局最优。贪心算法在许多优化问题中表现良好,特别是在某些特定类型的问题中能够保证找到最优解。 活动选择问题(Activity Selection Problem)背包问题(贪心解法)霍…...
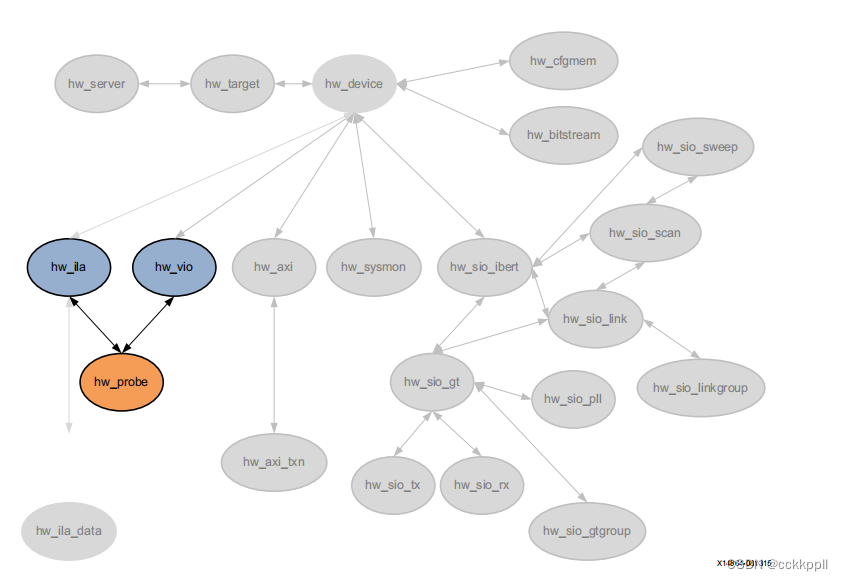
vivado HW_ILA_DATA、HW_PROBE
HW_ILA_DATA 描述 硬件ILA数据对象是ILA调试核心上捕获的数据的存储库 编程到当前硬件设备上。upload_hw_ila_data命令 在从ila调试移动捕获的数据的过程中创建hw_ila_data对象 核心,hw_ila,在物理FPGA上,hw_device。 read_hw_ila_data命令还…...

refault distance算法的一点理解
这个算法看了好几次了,都没太理解,今天记录一下,加深一下印象。 引用某个博客对这个算法的介绍 一次访问page cache称为fault,第二次访问该页面称为refault。page cache页面第一次被踢出LRU链表并回收(eviction)的时刻称为E&#…...

软件安全技术【太原理工大学】
没有划重点,只说了一句课后题和实验中的内容都可能会出。 2022考试题型:选择20个20分,填空10个10分,名词解释4个20分,简答6个30分,分析与论述2个20分,没找到历年题。 如此看来,这门考…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...
可以参考以下方法:)
根据万维钢·精英日课6的内容,使用AI(2025)可以参考以下方法:
根据万维钢精英日课6的内容,使用AI(2025)可以参考以下方法: 四个洞见 模型已经比人聪明:以ChatGPT o3为代表的AI非常强大,能运用高级理论解释道理、引用最新学术论文,生成对顶尖科学家都有用的…...

今日学习:Spring线程池|并发修改异常|链路丢失|登录续期|VIP过期策略|数值类缓存
文章目录 优雅版线程池ThreadPoolTaskExecutor和ThreadPoolTaskExecutor的装饰器并发修改异常并发修改异常简介实现机制设计原因及意义 使用线程池造成的链路丢失问题线程池导致的链路丢失问题发生原因 常见解决方法更好的解决方法设计精妙之处 登录续期登录续期常见实现方式特…...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...

JS红宝书笔记 - 3.3 变量
要定义变量,可以使用var操作符,后跟变量名 ES实现变量初始化,因此可以同时定义变量并设置它的值 使用var操作符定义的变量会成为包含它的函数的局部变量。 在函数内定义变量时省略var操作符,可以创建一个全局变量 如果需要定义…...

计算机系统结构复习-名词解释2
1.定向:在某条指令产生计算结果之前,其他指令并不真正立即需要该计算结果,如果能够将该计算结果从其产生的地方直接送到其他指令中需要它的地方,那么就可以避免停顿。 2.多级存储层次:由若干个采用不同实现技术的存储…...

C#最佳实践:为何优先使用as或is而非强制转换
C#最佳实践:为何优先使用as或is而非强制转换 在 C# 的编程世界里,类型转换是我们经常会遇到的操作。就像在现实生活中,我们可能需要把不同形状的物品重新整理归类一样,在代码里,我们也常常需要将一个数据类型转换为另…...