Redis几种部署模式介绍
Redis 提供了几种不同的部署模式,以满足不同的使用场景和可用性需求。这些模式包括单机模式、主从复制、哨兵模式和集群模式。下面我将简要介绍每种模式的特点和用途:
-
单机模式:
- 描述:单个 Redis 服务器实例运行在一台机器上,不进行任何复制或数据共享。
- 用途:适用于数据量不大,对数据可用性要求不高的场景。由于没有数据复制和分布式处理,配置简单,延迟较低。
-
主从复制:
- 描述:设置一个主节点和一个或多个从节点。数据从主节点复制到所有从节点,从节点可以接受读请求,分担主节点的读取负载。
- 用途:增强数据的可用性和读取性能。在主节点不可用的情况下,可以手动切换到一个从节点作为新的主节点,但这个过程不是自动的。
-
哨兵模式(Sentinel):
- 描述:在主从复制的基础上,通过使用哨兵系统自动完成故障转移和主节点选举。哨兵是一个独立的进程,用于监控所有Redis节点的运行状态,并在主节点故障时自动将一个从节点提升为新的主节点。
- 用途:提供更高的可用性。适用于对自动故障转移有要求的环境。
-
集群模式:
- 描述:通过设置多个节点,实现数据的自动分片,每个节点只保存数据的一部分。集群模式支持多台机器间的数据共享,可以在节点间自动平衡数据和负载。
- 用途:适用于大规模数据处理,能够提供高可用性和数据分区,支持水平扩展。
每种模式都有其适用的场景,选择哪种模式取决于你的具体需求,比如数据量大小、读写请求的频率、对数据可用性和稳定性的要求等。
主从复制(Replication)
Redis 主从复制(Replication)是 Redis 提供的一种数据复制机制,用于实现数据的高可用性和读写分离。通过主从复制,Redis 可以将数据从一个主节点(Master)复制到一个或多个从节点(Slave),从而提高系统的容错能力和读性能。下面是主从复制的工作原理及其详细解释。
主从复制的工作原理
1. 初始化复制
当从节点启动时,它会发送 PSYNC 命令请求从主节点进行同步。主节点会根据从节点的请求进行相应的处理。
- 全量复制:当从节点第一次连接到主节点时,通常会进行全量复制。主节点会创建一个 RDB 快照文件,并将其发送给从节点。从节点接收并加载 RDB 文件,然后继续接收主节点的 AOF 文件(如果有),以便将主节点的所有数据完全同步到从节点。
- 部分复制:如果从节点之前已经与主节点同步过,且连接因网络原因中断后重新连接,主节点会尝试进行部分复制,只将这期间发生的增量数据发送给从节点。如果部分复制失败,会退回到全量复制。
2. 数据复制
一旦初始化复制完成,主节点会将所有新的写操作命令发送给从节点。从节点会执行这些命令,以确保其数据与主节点保持一致。
3. 命令传播
主节点会将每个写操作命令(如 SET、DEL 等)发送给所有从节点。从节点接收并执行这些命令,从而保持数据的一致性。命令传播是异步进行的,从节点不会阻塞主节点的写操作。
4. 心跳检测
主节点和从节点之间会定期发送心跳(PING)消息,以检测连接的状态。如果主节点长时间没有收到从节点的心跳回复,或者从节点长时间没有收到主节点的心跳消息,会认为连接已断开并采取相应措施(如重新连接或选择新的主节点)。
配置 Redis 主从复制
配置 Redis 主从复制可以确保数据的高可用性和读写分离。以下是详细的步骤,包括主节点和从节点的配置方法。
1. 安装 Redis
确保你已经在主节点和从节点的服务器上安装了 Redis。如果尚未安装,可以使用以下命令进行安装(以 Ubuntu 为例):
sudo apt update sudo apt install redis-server
2. 配置主节点
主节点无需特别配置,只需启动 Redis 服务器即可。
redis-server /etc/redis/redis.conf
3. 配置从节点
在从节点的 Redis 配置文件 redis.conf 中,添加或修改以下配置,将 <master-ip> 和 <master-port> 替换为主节点的实际 IP 地址和端口号。
使用 replicaof 命令
在 Redis 5.0 及之后的版本中,使用 replicaof:
replicaof <master-ip> <master-port>
例如:replicaof 192.168.1.100 6379
使用 slaveof 命令
在 Redis 5.0 之前的版本中,使用 slaveof:
slaveof <master-ip> <master-port>
例如:
slaveof 192.168.1.100 6379
保存配置文件后,启动从节点 Redis 服务器:
redis-server /etc/redis/redis.conf
4. 动态配置主从复制
可以使用 redis-cli 动态配置主从复制,而无需修改配置文件并重启 Redis。
使用 replicaof 命令
redis-cli replicaof 192.168.1.100 6379
使用 slaveof 命令
复制代码
redis-cli slaveof 192.168.1.100 6379
5. 验证主从复制
在从节点上执行以下命令,以验证主从复制配置是否成功:
redis-cli info replication
你应该看到类似以下的输出,显示主节点和从节点的关系:
# Replication
role:slave
master_host:192.168.1.100
master_port:6379
master_link_status:up
...
6. 停止从节点复制
如果需要停止从节点对主节点的复制,可以使用以下命令:
使用 replicaof 命令
redis-cli replicaof no one
使用 slaveof 命令
redis-cli slaveof no one
完整示例
以下是一个完整的配置示例:
主节点配置
启动 Redis 服务器:
redis-server /etc/redis/redis.conf
从节点配置
编辑 redis.conf 文件,添加以下配置:
replicaof 192.168.1.100 6379
然后启动从节点:
redis-server /etc/redis/redis.conf
或在运行时使用 redis-cli 动态配置:
redis-cli replicaof 192.168.1.100 6379
验证主从复制
在从节点上执行以下命令:
redis-cli info replication
确保输出中 role 为 slave 且 master_link_status 为 up。
了解 Redis 的复制延迟和一致性问题
在配置和使用 Redis 主从复制时,了解复制延迟和一致性问题对于确保系统的可靠性和性能非常重要。下面是对这些问题的详细解释:
复制延迟
复制延迟是指从节点接收和应用主节点发出的写操作命令所花费的时间。在 Redis 中,复制延迟主要由以下几个因素决定:
-
网络延迟:
- 主节点和从节点之间的网络传输速度和延迟会直接影响复制延迟。如果网络连接不稳定或带宽有限,复制延迟会增加。
-
从节点性能:
- 从节点的硬件性能和负载情况也会影响复制延迟。如果从节点处理能力有限或系统负载高,接收和应用写操作命令的速度会变慢。
-
主节点写入速度:
- 如果主节点的写操作频率非常高,从节点可能无法及时处理所有写操作,导致复制延迟增加。
一致性问题
Redis 主从复制是异步的,这意味着主节点在完成写操作后不会等待从节点确认复制成功。这种异步复制机制会导致以下一致性问题:
-
最终一致性:
- 在大多数情况下,从节点的数据最终会与主节点保持一致,但在某些情况下(如网络分区或从节点故障),从节点的数据可能会有短暂的不一致。
-
读写一致性:
- 如果读操作同时在主节点和从节点上执行,可能会出现读到不同数据的情况。例如,写操作在主节点上完成,但从节点还没有同步到最新数据,此时在从节点上进行的读操作会返回旧的数据。
-
数据丢失:
- 在极端情况下,如主节点故障且从节点还未同步最新数据时,可能会导致数据丢失。这种情况在主节点和从节点之间的复制延迟较大时更为明显。
减少复制延迟和一致性问题的方法
-
优化网络连接:
- 使用低延迟、高带宽的网络连接主节点和从节点,以减少网络传输时间。
- 使用本地网络连接主从节点,避免跨地域的网络延迟。
-
增加从节点性能:
- 使用高性能的硬件来运行从节点,以确保其能够快速处理主节点发来的写操作命令。
- 优化从节点的配置和性能调优,减少系统负载对复制的影响。
-
调整复制缓冲区大小:
- 调整主节点的复制缓冲区大小,确保从节点能够及时接收和处理写操作命令。
-
监控和调优:
- 使用 Redis 提供的监控工具和第三方监控系统,实时监控主从复制的状态和延迟。
- 根据监控数据,调整配置和优化网络,以减少复制延迟。
-
使用半同步复制:
- Redis 5.0 引入了 PSYNC2 协议,可以配置部分同步复制。在部分同步复制模式下,从节点断开连接后重新连接时,可以减少全量复制的频率,减少复制延迟。
示例配置和监控
调整复制缓冲区大小
在主节点的 redis.conf 文件中,可以调整复制缓冲区的大小:
repl-backlog-size 64mb
监控复制延迟
在从节点上,使用以下命令监控复制延迟:
redis-cli info replication
输出中包含以下字段,可以用于监控复制延迟:
master_last_io_seconds_ago:从节点最后一次接收到主节点写操作命令的时间(秒)。slave_repl_offset:从节点的复制偏移量。
通过监控这些数据,可以了解主从复制的实时状态,并采取相应的优化措施。
总结
理解和优化 Redis 的复制延迟和一致性问题对于确保系统的可靠性和性能至关重要。通过优化网络连接、增加从节点性能、调整复制缓冲区大小和监控复制延迟,可以有效减少复制延迟和一致性问题,确保 Redis 系统的高可用性和数据一致性。
哨兵模式(Sentinel)
哨兵的工作原理
Redis 哨兵(Sentinel)是一种用于实现 Redis 高可用性的机制。哨兵系统监控主节点和从节点,自动执行故障转移,确保系统的持续可用性。
哨兵系统由一个或多个哨兵实例组成,这些实例协同工作以监控 Redis 集群,并在必要时执行故障转移。哨兵的主要功能包括:
- 监控(Monitoring):哨兵实例不断检查主节点和从节点是否可用。
- 通知(Notification):当检测到节点故障时,哨兵可以通知管理员或其他应用。
- 自动故障转移(Automatic Failover):如果主节点发生故障,哨兵会从从节点中选举一个新的主节点,并将其提升为主节点。
- 配置提供者(Configuration Provider):客户端可以连接哨兵以获取当前主节点的地址,从而实现高可用的连接。
哨兵的组件和流程
1. 哨兵监控
每个哨兵实例会定期向主节点和从节点发送 PING 命令,以检查它们的状态。如果一个节点在配置的时间内没有响应 PING 命令,哨兵会将其标记为主观下线(Subjectively Down,简称 SDOWN)。
2. 哨兵协商
如果多个哨兵实例都将同一个节点标记为主观下线,并且超过了配置的阈值时间(通常为几秒钟),哨兵系统会将该节点标记为客观下线(Objectively Down,简称 ODOWN)。此时,哨兵系统会触发故障转移流程。
3. 故障转移
当主节点被标记为 ODOWN 时,哨兵会从从节点中选举一个新的主节点。选举过程包括以下步骤:
- 确定具备资格的从节点:哨兵会检查从节点的状态,确保其最新的复制偏移量、无故障时间和复制延迟在可接受范围内。
- 选举新的主节点:哨兵会使用 Raft 一致性算法或其他选举算法,从合格的从节点中选出一个新的主节点。
- 提升从节点:被选中的从节点会被提升为主节点,接管原主节点的角色。
- 更新配置:哨兵会通知其他从节点,将它们的复制目标更新为新的主节点。
4. 通知客户端
哨兵可以作为配置提供者,客户端可以连接哨兵获取当前主节点的地址。这样,即使发生故障转移,客户端也能自动连接到新的主节点,保持高可用性。
配置 Redis 哨兵
配置 Redis 哨兵系统可以确保 Redis 的高可用性,通过监控主节点和从节点,自动执行故障转移。以下是详细的配置步骤,包括配置主节点、从节点和哨兵实例。
环境假设
假设我们有三台服务器:
- 主节点(Master):192.168.1.100
- 从节点1(Slave1):192.168.1.101
- 从节点2(Slave2):192.168.1.102
- 哨兵实例(Sentinel):可以部署在上述任意服务器上,假设我们在每台服务器上都运行一个哨兵实例。
1. 配置主节点
- 安装 Redis 并启动主节点:
sudo apt update
sudo apt install redis-server
sudo systemctl start redis-server
- 确保主节点的
redis.conf文件中有以下配置:
bind 0.0.0.0 # 允许所有 IP 访问
port 6379 # Redis 端口
daemonize yes # 以守护进程模式启动
2. 配置从节点
在从节点1和从节点2上进行相同的配置步骤。
- 安装 Redis 并编辑
redis.conf文件:
sudo apt update
sudo apt install redis-server
sudo nano /etc/redis/redis.conf
- 在
redis.conf文件中添加以下配置,使其连接到主节点:
bind 0.0.0.0 # 允许所有 IP 访问
port 6379 # Redis 端口
daemonize yes # 以守护进程模式启动
replicaof 192.168.1.100 6379 # 配置主节点的 IP 地址和端口
- 启动从节点:
sudo systemctl start redis-server
3. 配置哨兵
在每台服务器上运行一个哨兵实例,假设在 192.168.1.100, 192.168.1.101, 和 192.168.1.102 上各运行一个哨兵实例。
- 在每台服务器上创建一个哨兵配置文件
sentinel.conf:
sudo nano /etc/redis/sentinel.conf
- 配置文件内容如下:
port 26379 # 哨兵监听的端口
sentinel monitor mymaster 192.168.1.100 6379 2 # 监控的主节点名称、IP 和端口,以及多数投票的哨兵数量
sentinel down-after-milliseconds mymaster 5000 # 标记主节点为主观下线的超时时间(毫秒)
sentinel failover-timeout mymaster 10000 # 故障转移超时时间(毫秒)
sentinel parallel-syncs mymaster 1 # 故障转移时,最多同时对多少个从节点进行同步
- 启动哨兵实例:
redis-sentinel /etc/redis/sentinel.conf
在每台服务器上都执行上述命令,启动多个哨兵实例以形成哨兵集群。
4. 验证哨兵配置
在哨兵实例上执行以下命令,查看哨兵状态和主节点信息:
redis-cli -p 26379
执行以下命令查看哨兵信息:
SENTINEL masters SENTINEL slaves mymaster
5. 测试故障转移
- 模拟主节点故障:
sudo systemctl stop redis-server
-
在哨兵日志中观察故障转移过程。哨兵会检测到主节点下线,选举一个从节点作为新的主节点,并更新配置。
-
验证新的主节点:
在从节点上执行以下命令,验证新的主节点信息:
redis-cli info replication
输出示例:
# Replication
role:slave
master_host:<new-master-ip>
master_port:6379
master_link_status:up
...
总结
通过配置 Redis 哨兵,可以实现 Redis 的高可用性。当主节点发生故障时,哨兵会自动执行故障转移,选举新的主节点,确保系统的持续可用性。哨兵的配置相对简单,但在生产环境中起到关键作用。
哨兵的主观下线和客观下线
Redis 哨兵系统中的主观下线(Subjectively Down,简称 SDOWN)和客观下线(Objectively Down,简称 ODOWN)是用于描述哨兵对 Redis 节点(主节点或从节点)状态的判断。这两个状态用于决定是否需要进行故障转移。以下是详细解释:
主观下线(Subjectively Down,SDOWN)
主观下线是单个哨兵实例对一个节点(主节点或从节点)做出的独立判断。具体步骤如下:
- 检测节点状态:每个哨兵实例会定期向主节点和从节点发送 PING 命令,以检测节点的可用性。
- 超时判断:如果一个节点在配置的时间内(由
sentinel down-after-milliseconds配置项决定)没有响应 PING 命令,哨兵会将该节点标记为主观下线(SDOWN)。 - 局部判断:主观下线是哨兵单独做出的判断,并不代表整个哨兵系统的判断。此时,只有这个哨兵实例认为该节点下线。
配置示例
在哨兵配置文件 sentinel.conf 中,可以通过以下配置设置主观下线的超时时间:
sentinel down-after-milliseconds mymaster 5000
上述配置表示如果主节点在 5000 毫秒(5 秒)内没有响应 PING 命令,哨兵会将其标记为主观下线。
客观下线(Objectively Down,ODOWN)
客观下线是多个哨兵实例共同对一个节点(通常是主节点)做出的判断。具体步骤如下:
- 主观下线的传播:当一个哨兵实例将某个节点标记为主观下线后,它会将这一判断传播给其他哨兵实例。
- 投票协商:如果有足够数量(由
sentinel monitor配置项中的数量决定)的哨兵实例都认为该节点已经下线,这些哨兵实例会将该节点标记为客观下线(ODOWN)。 - 启动故障转移:一旦节点被标记为客观下线,哨兵系统会启动故障转移流程,选举新的主节点并通知所有从节点进行切换。
配置示例
在哨兵配置文件 sentinel.conf 中,可以通过以下配置设置需要多少哨兵实例的判断才会将节点标记为客观下线:
sentinel monitor mymaster 192.168.1.100 6379 2
上述配置表示至少需要 2 个哨兵实例认为主节点下线,才会将其标记为客观下线。
工作流程示例
-
哨兵实例 A 和 B 向主节点 PING:
- 哨兵实例 A 发送 PING 命令,但没有收到主节点的响应,在配置的超时时间内(例如 5000 毫秒)没有响应。
- 哨兵实例 A 将主节点标记为主观下线(SDOWN)。
- 哨兵实例 B 发送 PING 命令,但也没有收到主节点的响应,在配置的超时时间内(例如 5000 毫秒)没有响应。
- 哨兵实例 B 将主节点标记为主观下线(SDOWN)。
-
传播和投票:
- 哨兵实例 A 和 B 将其主观下线的判断传播给其他哨兵实例。
- 如果有足够数量的哨兵实例(例如 2 个)都将主节点标记为主观下线,则这些哨兵实例会将主节点标记为客观下线(ODOWN)。
-
故障转移:
- 当主节点被标记为客观下线后,哨兵系统会启动故障转移流程。
- 哨兵系统从从节点中选举一个新的主节点,并将其提升为主节点。
- 哨兵系统通知其他从节点更新其复制目标为新的主节点。
总结
Redis 哨兵系统通过主观下线和客观下线机制,确保在主节点发生故障时,能够及时、可靠地检测到故障并进行自动故障转移。主观下线是单个哨兵实例的独立判断,而客观下线是多个哨兵实例共同确认的结果。通过这种机制,Redis 能够在高可用性环境中提供可靠的数据服务。
哨兵的故障转移机制
Redis 哨兵的故障转移机制是确保 Redis 集群在主节点故障时能够自动选举新的主节点,从而保证系统的高可用性。以下是详细的解释和工作流程。
故障转移机制的工作原理
故障转移(Failover)是指当哨兵检测到主节点故障(客观下线,ODOWN)时,哨兵系统会自动选举一个新的从节点为主节点,并重新配置其他从节点,以保持集群的正常运行。
故障转移的详细步骤
-
检测主节点故障:
- 哨兵实例通过 PING 命令检测主节点的状态。如果主节点在指定时间内没有响应,哨兵将其标记为主观下线(SDOWN)。
- 如果多个哨兵实例都将主节点标记为主观下线,并达到配置的投票数,则主节点被标记为客观下线(ODOWN)。
-
选举领头哨兵(Leader Sentinel):
- 当主节点被标记为客观下线后,哨兵实例会通过选举算法选举出一个领头哨兵(Leader Sentinel),由它来执行故障转移操作。
- 选举过程基于 Raft 算法,保证在网络分区或部分节点故障的情况下,也能选出一个领头哨兵。
-
选择新的主节点:
- 领头哨兵根据从节点的复制偏移量、无故障时间等条件,从合格的从节点中选择一个新的主节点。
- 优先选择数据最接近主节点的从节点,以减少数据丢失。
-
提升从节点为主节点:
- 领头哨兵向选中的从节点发送命令,将其提升为新的主节点。
- 新的主节点开始接受写操作,并向其他从节点提供数据复制。
-
重新配置集群:
- 哨兵通知其他从节点,更新它们的复制目标为新的主节点。
- 所有从节点重新与新的主节点建立复制关系。
-
通知客户端:
- 哨兵可以作为配置提供者,客户端可以连接哨兵获取当前主节点的地址。
- 哨兵会通知客户端新的主节点地址,确保客户端能够连接到新的主节点。
故障转移示例
假设我们有以下环境:
- 主节点(Master):192.168.1.100
- 从节点1(Slave1):192.168.1.101
- 从节点2(Slave2):192.168.1.102
- 哨兵实例分别运行在上述三台服务器上。
哨兵配置示例
哨兵配置文件 sentinel.conf 示例:
port 26379# 监控的主节点名称、IP 和端口
sentinel monitor mymaster 192.168.1.100 6379 2# 标记主节点为主观下线的超时时间(毫秒)
sentinel down-after-milliseconds mymaster 5000# 故障转移超时时间(毫秒)
sentinel failover-timeout mymaster 10000# 故障转移时,最多同时对多少个从节点进行同步
sentinel parallel-syncs mymaster 1
启动哨兵实例
在每台服务器上启动哨兵实例:
redis-sentinel /etc/redis/sentinel.conf
模拟故障转移
-
停止主节点:
sudo systemctl stop redis-server -
观察哨兵日志: 哨兵会检测到主节点下线,并启动故障转移过程。你可以在哨兵日志中看到故障转移的详细过程。
-
选举新的主节点: 哨兵会根据从节点的状态,选举出一个新的主节点(假设从节点1被选为新的主节点)。
-
验证新的主节点: 在从节点1上执行以下命令,确认其已成为新的主节点:
redis-cli info replication输出示例:
# Replication role:master connected_slaves:1 slave0:ip=192.168.1.102,port=6379,state=online,offset=12345,lag=0 -
验证从节点配置: 在从节点2上执行以下命令,确认其已连接到新的主节点:
redis-cli info replication输出示例:
# Replication role:slave master_host:192.168.1.101 master_port:6379 master_link_status:up ...
总结
Redis 哨兵的故障转移机制通过监控主节点和从节点的状态,自动选举新的主节点,并重新配置集群,确保系统的高可用性。哨兵的配置和运行相对简单,但在生产环境中起到关键作用,是确保 Redis 高可用的重要机制。通过详细理解哨兵的工作原理和配置,可以更好地保障 Redis 系统的稳定运行。
Redis 集群(Cluster)
Redis 集群的工作原理
Redis 集群(Redis Cluster)是一种分布式的 Redis 部署模式,用于在多个节点之间分配数据,从而实现数据的水平扩展和高可用性。Redis 集群通过数据分片(sharding)和节点间的自动故障转移机制,确保在大规模和高负载环境下的性能和可靠性。下面是 Redis 集群的工作原理的详细解释。
Redis 集群的基本概念
-
数据分片(Sharding):
- Redis 集群通过将数据分片(sharding)分布到多个节点上,每个节点只存储一部分数据。
- 数据分片使用哈希槽(hash slot)进行管理。整个 Redis 集群有 16384 个哈希槽,每个键通过 CRC16 算法计算哈希值,并将其映射到对应的哈希槽。
-
节点角色:
- Redis 集群中的节点分为主节点(Master)和从节点(Slave)。
- 主节点负责处理数据的读写请求,从节点作为主节点的副本,用于实现数据的高可用性。
-
高可用性:
- 每个主节点可以有一个或多个从节点,主节点负责数据的写操作和部分读操作,从节点作为主节点的备份,当主节点发生故障时,从节点可以自动提升为主节点。
数据分片和哈希槽
-
哈希槽的分配:
- Redis 集群有 16384 个哈希槽,每个键根据 CRC16 算法计算出的哈希值分配到相应的哈希槽。
- 哈希槽均匀地分配给所有主节点。例如,如果有 4 个主节点,则每个主节点负责 4096 个哈希槽。
-
键的映射:
- 每个键根据哈希值映射到一个哈希槽,然后哈希槽分配给某个主节点。这样,键值对分布在不同的主节点上。
节点间通信
-
Gossip 协议:
- Redis 集群中的节点通过 Gossip 协议进行通信。每个节点定期向其他节点发送心跳消息,交换状态信息。
- 通过 Gossip 协议,节点可以了解整个集群的拓扑结构和其他节点的状态。
-
故障检测和故障转移:
- 如果一个节点没有响应其他节点的心跳消息,集群会标记该节点为下线状态(PFAIL)。
- 如果大多数主节点同意某个节点下线,该节点会被标记为正式下线(FAIL)。
- 当主节点下线时,集群会选举一个从节点作为新的主节点,并将其提升为主节点。
配置 Redis 集群
以下是配置 Redis 集群的步骤:
环境假设
假设我们有 6 台服务器:
- 节点1(Master1):192.168.1.101
- 节点2(Master2):192.168.1.102
- 节点3(Master3):192.168.1.103
- 节点4(Slave1):192.168.1.104
- 节点5(Slave2):192.168.1.105
- 节点6(Slave3):192.168.1.106
配置 Redis 实例
- 在每个节点上安装 Redis,并编辑
redis.conf文件:
port 6379
bind 0.0.0.0
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
daemonize yes
- 启动 Redis 实例:
redis-server /path/to/redis.conf
创建集群
- 在任意一台机器上,使用
redis-cli创建集群,并指定所有节点的 IP 地址和端口:
redis-cli --cluster create 192.168.1.101:6379 192.168.1.102:6379 192.168.1.103:6379 192.168.1.104:6379 192.168.1.105:6379 192.168.1.106:6379 --cluster-replicas 1
--cluster-replicas 1 参数表示为每个主节点分配一个从节点。
测试集群
- 使用
redis-cli连接到任意节点,验证集群状态:
redis-cli -c -h 192.168.1.101 -p 6379
- 在 Redis CLI 中,执行以下命令查看集群信息:
cluster info cluster nodes
故障转移测试
- 模拟主节点故障,停止某个主节点:
redis-cli -h 192.168.1.101 -p 6379 shutdown
- 在其他节点上查看集群状态,验证故障转移是否成功:
redis-cli -c -h 192.168.1.102 -p 6379
在 Redis CLI 中,执行以下命令查看集群信息:
cluster info cluster nodes
总结
Redis 集群通过数据分片和高可用性机制,实现了大规模数据的分布式存储和自动故障转移。通过配置 Redis 集群,可以确保在高并发和大数据量环境下的性能和可靠性。了解和配置 Redis 集群,对于构建高可用、高性能的分布式系统至关重要。
集群的分片机制(哈希槽)
Redis 集群通过分片机制(Sharding)将数据分布在多个节点上,以实现数据的水平扩展和高可用性。分片机制通过哈希槽(Hash Slot)来管理数据分布。下面是对 Redis 集群分片机制的详细解释。
哈希槽(Hash Slot)
Redis 集群中的每个键都会被映射到一个哈希槽中,整个集群有 16384 个哈希槽。每个哈希槽可以分配给不同的主节点(Master)。通过这种方式,Redis 集群可以将数据均匀地分布在所有节点上。
哈希槽的分配和映射
-
哈希计算:
- 每个键通过 CRC16 算法计算哈希值,然后将其对 16384 取模,得到一个哈希槽编号。
- 计算公式:
slot = CRC16(key) % 16384
-
哈希槽分配:
- Redis 集群将 16384 个哈希槽分配给集群中的主节点。例如,如果有 4 个主节点,每个主节点负责 4096 个哈希槽。
- 当节点数量变化时,Redis 集群可以重新分配哈希槽,以保证数据均匀分布。
分片机制示例
假设我们有 3 个主节点(Master),每个主节点负责一部分哈希槽:
- 主节点1(Node1):负责哈希槽 0 到 5460
- 主节点2(Node2):负责哈希槽 5461 到 10922
- 主节点3(Node3):负责哈希槽 10923 到 16383
数据写入和读取流程
-
数据写入:
- 客户端发送写操作(如
SET key value)时,Redis 集群根据键计算哈希值,并确定该键所属的哈希槽。 - 然后,集群会将该操作路由到负责该哈希槽的主节点上。
- 客户端发送写操作(如
-
数据读取:
- 客户端发送读操作(如
GET key)时,Redis 集群根据键计算哈希值,并确定该键所属的哈希槽。 - 然后,集群会将该操作路由到负责该哈希槽的主节点上。
- 客户端发送读操作(如
哈希槽的再分配
当集群中的节点数量发生变化时(如增加或减少节点),Redis 集群会重新分配哈希槽,以保证数据的均匀分布。
-
增加节点:
- 当增加新节点时,集群会将一些哈希槽从现有节点迁移到新节点,以均衡数据分布。
- 迁移过程是渐进式的,不会影响集群的正常运行。
-
删除节点:
- 当删除节点时,集群会将该节点负责的哈希槽迁移到其他节点。
- 迁移完成后,该节点将从集群中移除。
集群状态查看
可以使用以下命令查看 Redis 集群的状态和哈希槽分配情况:
redis-cli -c -h <node-ip> -p 6379 cluster nodes
输出示例:
07c37dfeb2353c20114c644e901b70cd6e01d0b7 192.168.1.101:6379@16379 master - 0 1620293852000 1 connected 0-5460
1c291c192b23f07a02314d3a3c5a3bdb88b5bb27 192.168.1.102:6379@16379 master - 0 1620293854000 2 connected 5461-10922
2f1e3fcb6bdf0aeaa5d0f17c0be839da9b7c92e3 192.168.1.103:6379@16379 master - 0 1620293853000 3 connected 10923-16383
每行表示一个节点的信息,其中最后一部分显示该节点负责的哈希槽范围。
配置 Redis 集群
以下是配置 Redis 集群的步骤:
环境假设
假设我们有 6 台服务器:
- 节点1(Master1):192.168.1.101
- 节点2(Master2):192.168.1.102
- 节点3(Master3):192.168.1.103
- 节点4(Slave1):192.168.1.104
- 节点5(Slave2):192.168.1.105
- 节点6(Slave3):192.168.1.106
配置 Redis 实例
- 在每个节点上安装 Redis,并编辑
redis.conf文件:
port 6379
bind 0.0.0.0
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
daemonize yes
- 启动 Redis 实例:
redis-server /path/to/redis.conf
创建集群
- 在任意一台机器上,使用
redis-cli创建集群,并指定所有节点的 IP 地址和端口:
redis-cli --cluster create 192.168.1.101:6379 192.168.1.102:6379 192.168.1.103:6379 192.168.1.104:6379 192.168.1.105:6379 192.168.1.106:6379 --cluster-replicas 1
--cluster-replicas 1 参数表示为每个主节点分配一个从节点。
总结
Redis 集群通过哈希槽机制将数据分布在多个节点上,实现数据的水平扩展和高可用性。哈希槽确保数据均匀分布,避免单点故障。理解 Redis 集群的分片机制对于构建高可用、高性能的分布式系统至关重要。
节点的主从关系
在 Redis 集群中,节点分为主节点(Master)和从节点(Slave),每个主节点负责管理一部分哈希槽,并处理与这些哈希槽相关的读写请求。从节点作为主节点的副本,主要用于数据的高可用性和读取负载的分担。当主节点发生故障时,从节点可以自动提升为新的主节点,从而保证系统的高可用性。
节点的主从关系
主节点(Master)
-
职责:
- 负责管理特定范围的哈希槽,并处理与这些哈希槽相关的所有读写请求。
- 负责与其他主节点和从节点进行数据同步和通信。
-
数据分片:
- 在集群中,16384 个哈希槽会均匀分布在所有主节点上,每个主节点负责管理一部分哈希槽。
- 通过哈希槽,Redis 集群实现数据的水平分片,将数据均匀分布在多个主节点上。
从节点(Slave)
-
职责:
- 作为主节点的数据副本,从节点会定期与主节点同步数据,以确保数据的一致性。
- 当主节点发生故障时,从节点可以被提升为新的主节点,以保证系统的高可用性。
- 可以分担主节点的读取负载,从节点可以处理读取请求,从而提高集群的读取性能。
-
数据同步:
- 从节点会定期从主节点拉取数据更新,以保持数据与主节点一致。
- 当数据变化时,主节点会将变化通知从节点,从节点会更新其数据副本。
主从关系的配置
在 Redis 集群中,主从关系可以通过启动 Redis 实例并创建集群时指定。
环境假设
假设我们有 6 台服务器:
- 主节点1(Master1):192.168.1.101
- 主节点2(Master2):192.168.1.102
- 主节点3(Master3):192.168.1.103
- 从节点1(Slave1):192.168.1.104
- 从节点2(Slave2):192.168.1.105
- 从节点3(Slave3):192.168.1.106
配置 Redis 实例
在每个节点上安装 Redis,并编辑 redis.conf 文件:
port 6379
bind 0.0.0.0
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
daemonize yes
启动 Redis 实例:
redis-server /path/to/redis.conf
创建集群
在任意一台机器上,使用 redis-cli 创建集群,并指定所有节点的 IP 地址和端口:
redis-cli --cluster create 192.168.1.101:6379 192.168.1.102:6379 192.168.1.103:6379 192.168.1.104:6379 192.168.1.105:6379 192.168.1.106:6379 --cluster-replicas 1
--cluster-replicas 1 参数表示为每个主节点分配一个从节点。
故障转移
-
检测故障:
- 如果一个主节点发生故障,其他主节点和哨兵节点会检测到这一故障,并将其标记为下线(FAIL)。
- 集群中的哨兵节点会通过投票机制选举一个新的主节点。
-
从节点提升为主节点:
- 选举过程中,集群会从该主节点的从节点中选择一个状态良好的从节点,提升为新的主节点。
- 新的主节点接管该哈希槽范围内的所有数据和请求。
-
重新配置集群:
- 提升后的新主节点会通知其他从节点更新其配置,重新与新主节点同步数据。
- 整个过程是自动进行的,确保集群在主节点故障时仍然能够正常运行。
示例:验证节点状态
可以使用以下命令查看 Redis 集群的节点状态和主从关系:
redis-cli -c -h 192.168.1.101 -p 6379 cluster nodes
输出示例:
07c37dfeb2353c20114c644e901b70cd6e01d0b7 192.168.1.101:6379@16379 master - 0 1620293852000 1 connected 0-5460
1c291c192b23f07a02314d3a3c5a3bdb88b5bb27 192.168.1.102:6379@16379 master - 0 1620293854000 2 connected 5461-10922
2f1e3fcb6bdf0aeaa5d0f17c0be839da9b7c92e3 192.168.1.103:6379@16379 master - 0 1620293853000 3 connected 10923-16383
4acfa2b1e14b7e6d351cf1f6d4d2dfbd04e4e65d 192.168.1.104:6379@16379 slave 07c37dfeb2353c20114c644e901b70cd6e01d0b7 0 1620293855000 4 connected
5bb9f9e92b1a5d7ec6f9e0f3f3e7b5bf30ac7e2b 192.168.1.105:6379@16379 slave 1c291c192b23f07a02314d3a3c5a3bdb88b5bb27 0 1620293856000 5 connected
6e2b96b8ebdc95a6b9f7e4f0d6d5d5fb9c5e2b7d 192.168.1.106:6379@16379 slave 2f1e3fcb6bdf0aeaa5d0f17c0be839da9b7c92e3 0 1620293857000 6 connected
每行表示一个节点的信息,其中最后一部分显示该节点负责的哈希槽范围或其作为从节点跟随的主节点。
总结
Redis 集群中的节点分为主节点和从节点,主节点负责数据的读写操作和数据分片,从节点作为主节点的副本,提供数据高可用性和读操作分担。当主节点发生故障时,从节点可以自动提升为主节点,保证系统的高可用性。理解和配置 Redis 集群中的主从关系,对于构建高性能和高可用性的分布式系统至关重要。
集群的重平衡和扩容
Redis 集群的重平衡和扩容是确保数据在集群节点间均匀分布的重要操作。通过重平衡和扩容,Redis 集群可以在添加或删除节点时,动态调整数据分布,以保持系统的性能和可靠性。
集群重平衡(Rebalancing)
重平衡是指在现有的 Redis 集群中重新分配哈希槽,使数据在节点间更加均匀地分布。重平衡通常在以下情况下进行:
- 集群中的某些节点负载过重,需要将部分数据迁移到负载较轻的节点。
- 集群添加或删除节点后,需要重新分配哈希槽。
1. 重平衡的触发
重平衡可以手动触发,也可以通过自动化工具实现。常见的场景包括:
- 手动添加或删除节点后,通过命令触发重平衡。
- 监控系统检测到某些节点负载过高,自动触发重平衡。
2. 手动重平衡
可以使用 redis-cli 工具手动触发重平衡操作。以下是具体步骤:
- 查看集群状态:
redis-cli --cluster check <node-ip>:<port>
此命令会检查集群的状态,并显示哈希槽的分布情况。
- 重平衡集群:
redis-cli --cluster rebalance <node-ip>:<port>
例如:
redis-cli --cluster rebalance 192.168.1.101:6379
此命令会根据当前集群的负载情况,重新分配哈希槽。
集群扩容
扩容是指向 Redis 集群中添加新的节点,以增加存储容量和处理能力。扩容操作需要确保新节点能够均匀地分担负载,并且数据能够正确地迁移到新节点。
1. 添加新节点
假设我们有一个已经运行的 Redis 集群,现在我们要添加一个新的节点。
- 启动新节点:
在新节点上安装 Redis,并启动实例:
redis-server /path/to/redis.conf
- 将新节点添加到集群:
使用 redis-cli 工具将新节点添加到现有集群:
redis-cli --cluster add-node <new-node-ip>:<port> <existing-node-ip>:<port>
例如:
redis-cli --cluster add-node 192.168.1.107:6379 192.168.1.101:6379
2. 重新分配哈希槽
在添加新节点后,需要重新分配哈希槽,以确保数据在所有节点间均匀分布。
- 重新分配哈希槽:
使用 redis-cli 工具重新分配哈希槽:
redis-cli --cluster reshard <node-ip>:<port>
例如:
redis-cli --cluster reshard 192.168.1.101:6379
- 指定哈希槽数量和目标节点:
系统会提示输入要迁移的哈希槽数量和目标节点。输入要迁移的哈希槽数量,然后指定目标节点(新添加的节点):
How many slots do you want to move (from 1 to 16384)? 4096
What is the receiving node ID? <new-node-id>
集群缩容
缩容是指从 Redis 集群中移除节点,以减少存储容量或处理能力。缩容操作需要确保数据能够正确地迁移到其他节点,以保持数据的完整性。
1. 移除节点
假设我们要从集群中移除一个节点。
- 查看节点状态:
使用 redis-cli 工具查看集群的节点状态,找到要移除的节点 ID:
redis-cli --cluster nodes <node-ip>:<port>
- 移除节点:
使用 redis-cli 工具移除节点:
redis-cli --cluster del-node <node-ip>:<port> <node-id>
例如:
redis-cli --cluster del-node 192.168.1.101:6379 <node-id>
示例操作
假设我们有一个集群,初始有 3 个主节点,现要添加一个新的主节点,并进行重平衡。
1. 添加新节点
- 启动新节点:
redis-server /path/to/redis.conf
- 将新节点添加到集群:
redis-cli --cluster add-node 192.168.1.104:6379 192.168.1.101:6379
2. 重新分配哈希槽
- 启动重平衡:
redis-cli --cluster rebalance 192.168.1.101:6379
系统会自动计算哈希槽的最佳分配,并迁移数据到新节点。
总结
Redis 集群的重平衡和扩容通过动态调整哈希槽分配,实现数据的均匀分布和高可用性。重平衡确保集群中的节点负载均衡,而扩容则允许集群在需要时增加新的节点,以提高存储容量和处理能力。理解和正确操作这些机制,对于保持 Redis 集群的高性能和高可用性至关重要。
相关文章:

Redis几种部署模式介绍
Redis 提供了几种不同的部署模式,以满足不同的使用场景和可用性需求。这些模式包括单机模式、主从复制、哨兵模式和集群模式。下面我将简要介绍每种模式的特点和用途: 单机模式: 描述:单个 Redis 服务器实例运行在一台机器上&…...
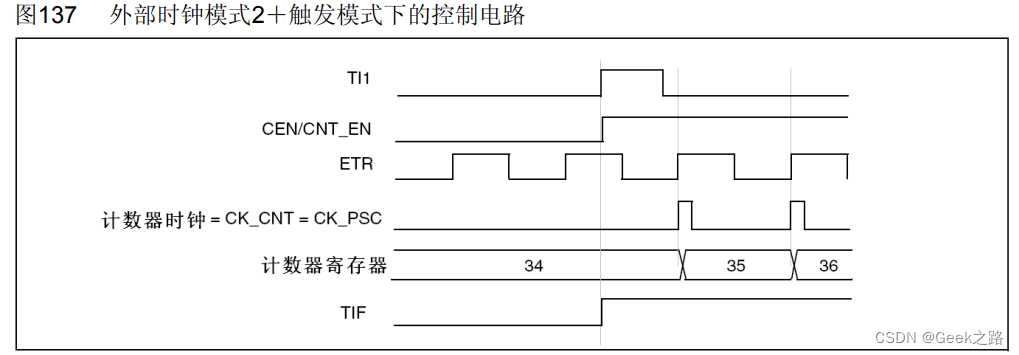
【STM32HAL库学习】定时器功能、时钟以及各种模式理解
一、文章目的 记录自己从学习了定时器理论->代码实现使用定时->查询数据手册,加深了对定时器的理解以及该过程遇到了的一些不清楚的知识。 上图为参考手册里通用定时器框图,关于定时器各种情况的工作都在上面了,在理论学习和实际应用后…...

3588麒麟系统硬解码实战
目录 安装rockchip-mpp deb 查找头文件 .pro文件添加 检查库是否已安装 error: stdlib.h: No such file or directory ffmpeg 查找ffmpeg路径: 查找FFmpeg库和头文件的位置 使用pkg-config工具查找FFmpeg路径 ok的ffmpeg配置: ffmpeg查看是否支持libx264 ffmpeg …...

十二 nginx中location重写和匹配规则
十二 location匹配规则 ^~ ~ ~* !~ !~* /a / 内部服务跳转 十三 nginx地址重写rewrite if rewrite set return 13.1 if 应用环境 server location -x 文件是否可执行 $args $document_rot $host $limit_rate $remote_addr $server_name $document_uri if …...

python的视频处理FFmpeg库使用
FFmpeg 是一个强大的多媒体处理工具,用于录制、转换和流式传输音频和视频。它支持几乎所有的音频和视频格式,并且可以在各种平台上运行。FFmpeg 在 Python 中的使用可以通过调用其命令行工具或使用专门的库如 ffmpeg-python。以下是详细介绍如何在 Python 中使用 FFmpeg,包括…...

接口测试时, 数据Mock为何如此重要?
一、为什么要mock 工作中遇到以下问题,我们可以使用mock解决: 1、无法控制第三方系统某接口的返回,返回的数据不满足要求 2、某依赖系统还未开发完成,就需要对被测系统进行测试 3、有些系统不支持重复请求,或有访问…...

未授权与绕过漏洞
1、Laravel Framework 11 - Credential Leakage(CVE-2024-29291)认证泄漏 导航这个路径storage/logs/laravel.log搜索以下信息: PDO->__construct(mysql:host 2、 Flowise 1.6.5 - Authentication Bypass(CVE-2024-31621&am…...

云原生周刊:Kubernetes 十周年 | 2024.6.11
开源项目推荐 Kubernetes Goat Kubernetes Goat 是一个故意设计成有漏洞的 Kubernetes 集群环境,旨在通过交互式实践场地来学习并练习 Kubernetes 安全性。 kube-state-metrics (KSM) kube-state-metrics 是一个用于收集 Kubernetes 集群状态信息的开源项目&…...
ClickHouse内幕(1)数据存储与过滤机制
本文主要讲述ClickHouse中的数据存储结构,包括文件组织结构和索引结构,以及建立在其基础上的数据过滤机制,从Part裁剪到Mark裁剪,最后到基于SIMD的行过滤机制。 数据过滤机制实质上是构建在数据存储格式之上的算法,所…...

1.Mongodb 介绍及部署
MongoDB 是一个开源的文档导向数据库,采用NoSQL(非关系型数据库)的设计理念。MongoDB是一个基于分布式文件存储的数据库。 分布式文件存储是一种将文件数据分布式的存储在多台计算机上。MongoDB是一款强大的文档导向数据库,适合处…...

Java 技巧:如何获取字符串中最后一个英文逗号后面的内容
在日常的Java编程中,处理字符串是非常常见的任务之一。有时我们需要从一个字符串中截取特定部分,例如获取最后一个英文逗号后的内容。这篇文章将详细介绍如何使用Java来实现这一需求,并提供一个示例代码来演示其实现过程。 需求分析 假设我们…...
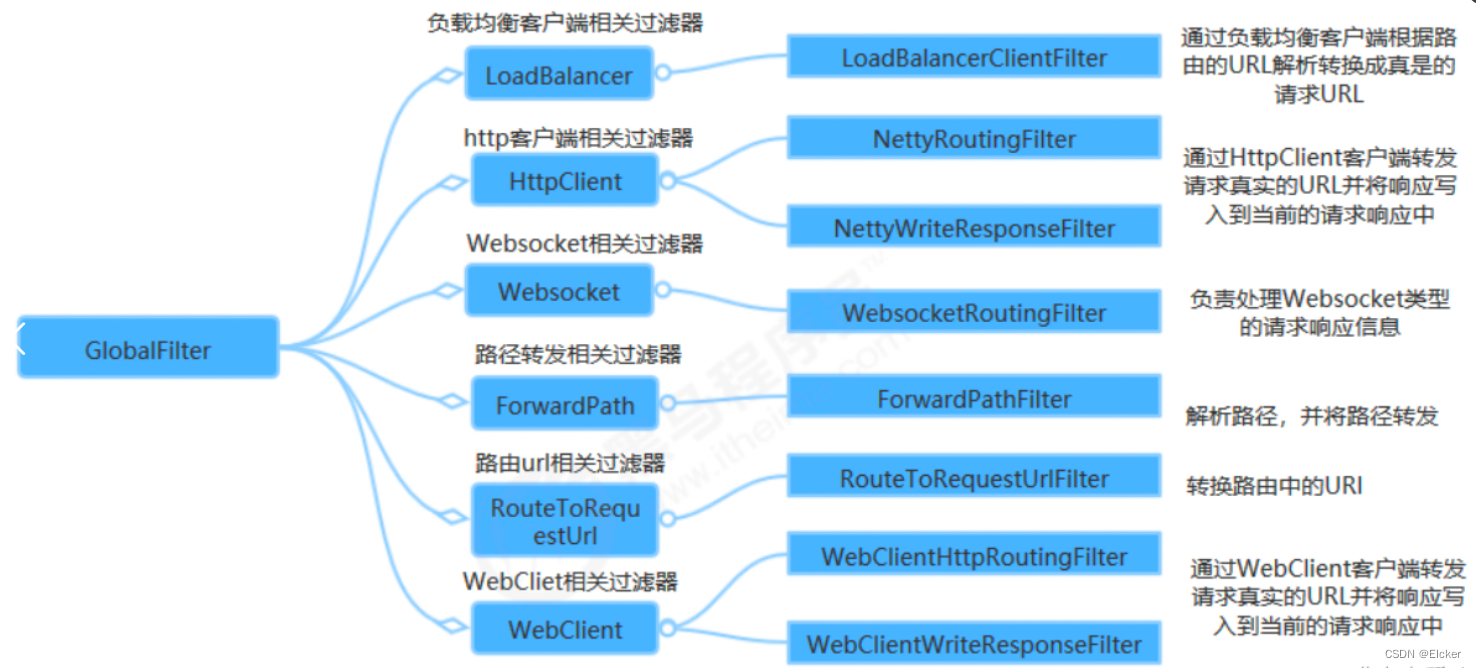
玩转微服务-GateWay
目录 一. 背景二. API网关1. 概念2. API网关定义3. API网关的四大职能4. API网关分类5. 开源API网关介绍6. 开源网关的选择 三. Spring Cloud Gateway1. 文档地址2. 三个核心概念3. 工作流程4. 运行原理4.1 路由原理4.2 RouteLocator 5. Predicate 断言6. 过滤器 Filter6.1. 过…...

Amortized bootstrapping via Automorphisms
参考文献: [MS18] Micciancio D, Sorrell J. Ring packing and amortized FHEW bootstrapping. ICALP 2018: 100:1-100:14.[GPV23] Guimares A, Pereira H V L, Van Leeuwen B. Amortized bootstrapping revisited: Simpler, asymptotically-faster, implemented. …...

【人工智能】ChatGPT基本工作原理
ChatGPT 是由 OpenAI 开发的一种基于深度学习技术的自然语言处理模型,它使用了名为 GPT(Generative Pre-trained Transformer)的架构。GPT 模型是一种基于 Transformer 架构的预训练语言模型,它通过大量的文本数据进行预训练&…...
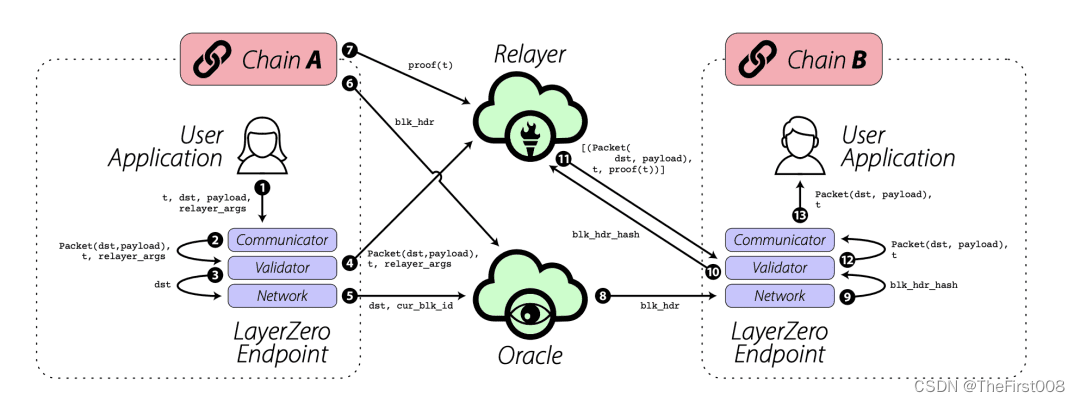
The First项目报告:Stargate Finance重塑跨链金融的未来
Stargate Finance是一个基于LayerZero协议的去中心化金融平台,自2022年3月由LayerZero Labs创建以来,一直致力于为不同区块链之间的资产转移提供高效、低成本的解决方案。凭借其独特的跨链技术和丰富的DeFi服务,Stargate Finance已成为连接不…...

Python魔法之旅-魔法方法(22)
目录 一、概述 1、定义 2、作用 二、应用场景 1、构造和析构 2、操作符重载 3、字符串和表示 4、容器管理 5、可调用对象 6、上下文管理 7、属性访问和描述符 8、迭代器和生成器 9、数值类型 10、复制和序列化 11、自定义元类行为 12、自定义类行为 13、类型检…...
)
公司面试题总结(三)
13.说说你对 BOM 的理解,常见的 BOM 对象你了解哪些? BOM (Browser Object Model),浏览器对象模型, ⚫ 提供了独立于内容与浏览器窗口进行交互的对象 ⚫ 其作用就是跟浏览器做一些交互效果 ⚫ 比如如何进行页面的后退&…...
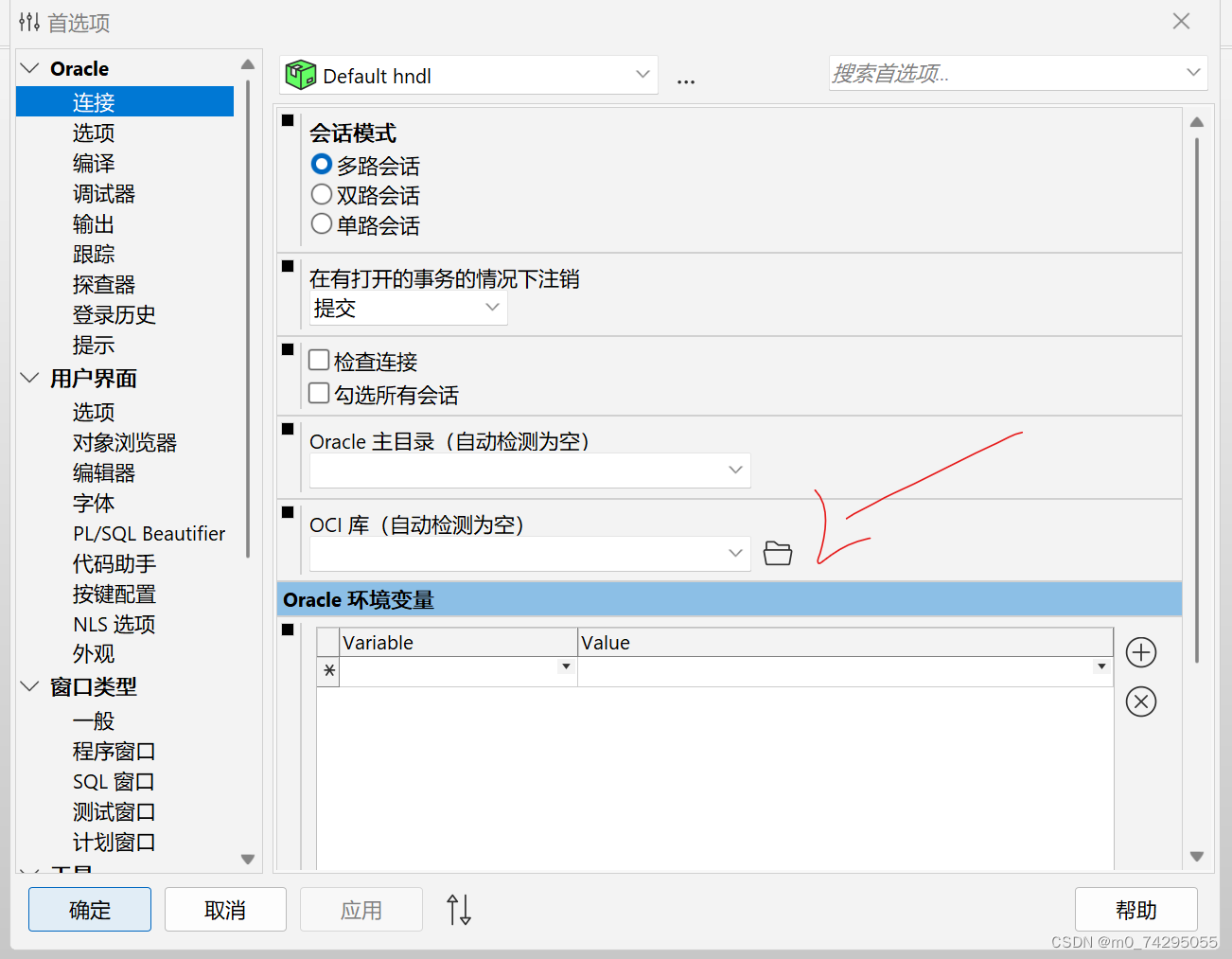
PLSQL 报错 could not locate oci.dll
0、确保PLSQL已激活。 1、在PLSQL安装包内搜索oci.dll,如果没有搜到需要下载 链接:https://pan.baidu.com/s/1HOfKAEFfuAGYACjfcwqJ1g 提取码:6evh 2、打开PLSQL,设置oci.dll的路径 ps:PLSQL安装包 链接ÿ…...

【方案+源码】智慧园区建设方案
智慧园区一体化运营管理平台建设方案旨在通过集成先进的信息技术,实现园区的智能化、高效化、绿色化管理。该平台整合了物联网、大数据、云计算等技术,为园区提供全方位、一体化的运营服务。 方案包括智能监控、能源管理、安防系统、停车管理、物业管理等…...

Java操作数据库 —— JDBC ① 基础篇
我走我的路,有人拦也走,没人陪也走 —— 24.6.7 JDBC JDBC就是使用Java语言操作关系型数据库的一套API 一、JDBC简介 JDBC 概念 JDBC 就是使用Java语言操作关系型数据库的一套API 全称:(Java DataBase Connectivity)意为Java 数据库连接 JDBC 本质: ①…...

GLM-4-9B-Chat-1M惊艳效果:半导体IP核用户手册中时序约束自动提取与验证
GLM-4-9B-Chat-1M惊艳效果:半导体IP核用户手册中时序约束自动提取与验证 1. 引言:一个让芯片工程师头疼的日常 如果你是芯片设计工程师,或者从事数字电路验证工作,下面这个场景你一定不陌生。 项目进入关键阶段,你拿…...

Z-Image Turbo步数设置指南:4/8/12步生成效果对比与选型建议
Z-Image Turbo步数设置指南:4/8/12步生成效果对比与选型建议 1. 引言:为什么步数设置如此重要? 在使用Z-Image Turbo进行AI绘图时,步数(Steps)是最影响生成效果和速度的核心参数之一。很多用户都有这样的…...

Clawdbot汉化版企业微信入口:快速部署AI助手教程
Clawdbot汉化版企业微信入口:快速部署AI助手教程 1. 为什么选择Clawdbot汉化版 Clawdbot汉化版是一款专为企业场景设计的AI助手解决方案,它解决了传统AI助手的三大痛点: 数据隐私问题:所有对话数据都保存在您的本地服务器上&am…...

百川2-13B-Chat WebUI v1.0 多轮对话深度测试:跨话题记忆保持、上下文混淆边界验证
百川2-13B-Chat WebUI v1.0 多轮对话深度测试:跨话题记忆保持、上下文混淆边界验证 1. 引言 最近,我在一台配备RTX 4090 D的服务器上部署了百川2-13B-Chat模型的4bits量化WebUI版本。这个版本最大的亮点,就是显存占用从原来的20多GB降到了1…...

Phi-4-mini-reasoning开源模型一文详解:ollama部署+128K上下文实战应用
Phi-4-mini-reasoning开源模型一文详解:ollama部署128K上下文实战应用 1. 模型简介:轻量级推理专家 Phi-4-mini-reasoning 是一个专门为复杂推理任务设计的开源模型,它最大的特点是"小而精"——虽然模型体积不大,但在…...

模型服务治理:实时口罩检测-通用OpenTelemetry链路追踪接入
模型服务治理:实时口罩检测-通用OpenTelemetry链路追踪接入 1. 项目背景与价值 在当今的AI应用场景中,实时口罩检测已经成为许多公共场所和企业的必备功能。无论是商场入口、办公大楼还是公共交通场所,都需要快速准确地检测人员是否佩戴口罩…...

GPU算力高效利用:internlm2-chat-1.8b在A10/A100集群上的批处理优化实践
GPU算力高效利用:internlm2-chat-1.8b在A10/A100集群上的批处理优化实践 1. 为什么需要批处理优化 在实际的AI模型部署中,我们经常面临这样的困境:单个用户的请求往往无法充分利用GPU的强大算力。比如使用internlm2-chat-1.8b这样的模型处理…...

刷题笔记:力扣第48题-旋转图像
1.拿到这道题目,第一反应是再创建一个新的矩阵,按照顺时针旋转90的方式遍历原来的矩阵,将旋转后的矩阵存入新矩阵中,输出即可。这种方法的时间复杂度和空间复杂度均为O(n2)。2.但本题不允许使用新的矩阵,这意味着一切修…...
)
社区分享 | 从零开始学习 TinyML(三)
1. TinyML模型部署后的性能优化挑战 当你第一次把训练好的TinyML模型部署到Arduino或Cortex-M系列MCU上时,可能会遇到一些令人头疼的问题。我清楚地记得自己早期的一个项目,模型在PC上测试时运行良好,但移植到开发板上后,推理速度…...

基于云计算的毕业设计:新手入门实战指南与避坑实践
最近在帮几个学弟学妹看毕业设计,发现一个普遍问题:项目在本地跑得好好的,一到演示或者答辩环节就各种“掉链子”。要么是本地环境配置复杂,换了台电脑就跑不起来;要么是自建的服务器性能太差,访问量一上来…...