ClickHouse内幕(1)数据存储与过滤机制
本文主要讲述ClickHouse中的数据存储结构,包括文件组织结构和索引结构,以及建立在其基础上的数据过滤机制,从Part裁剪到Mark裁剪,最后到基于SIMD的行过滤机制。
数据过滤机制实质上是构建在数据存储格式之上的算法,所以在介绍过滤机制前先介绍下ClickHouse中数据存储格式。
PS:本文基于ClickHouse v24.1
一、数据存储的目录结构
ClickHouse数据存储在目录结构上采用大数据系统常见的分区,然后分区内在进行细分文件的方式。
表中的数据首先按照分区键被划分为多个分区,分区键常采用日期的方式,比如下图中按照月份分区。每次数据批量插入形成一个最小的存储单元,ClickHouse中称为Part,Part归属于某一个分区。

ClickHouse中一个表的所有分区的所有Part放在同一个目录中,Part所属的分区可以根据Part名进行区分,Part的命名方式如下:
partition-id _ min-id _ max-id _ levelPart目录内部文件组织形式如下:
primary.idx - 是主键索引文件,记录了每个Mark对应的主键索引值,整个数据集一个.idx文件
[Column].mrk - 记录Mark(Mark在索引结构中介绍)对应的数据在数据文件(.bin文件)中的offset,用于根据Mark定为到数据位置,每个列一个.mrk文件。
[Column].bin - 真实数据文件,每个列一个.bin文件
checksums.txt - part checksum文件,用于校验数据完整性
columns.txt - 元数据,记录列名以及数据类型
count.txt - 元数据,记录该Part总行数,可以用于加速count(*)查询
partition.dat - 分区表达式
minmax_[Column].idx - 某一个列的最大最小值,可以用于加速查询,分区键固定有一个最大最小索引,用于分区裁剪
statistics_(column_name).stat - 列的统计信息,用于查询加速
二、索引结构
每个part形成一个完整的索引结构,整体上Clickhouse的存储是列式的,每个列单独存储(compact模式将多个文件合并成了一个,但本质上是一样的)。Clickhouse索引的大致思路是:首先根据索引列将整个数据集进行排序,这点类似MySQL的联合索引;其次将排序后的数据每隔8192行选取出一行,记录其索引值和序号,并形成稀疏索引,这个序号在Clickhouse中序号被称作Mark,也就是说Mark表示一组数据。
下图是一个二维表(date, city, action)的索引结构,其中(date,city)是索引列,整个part文件的宏观结构如下:
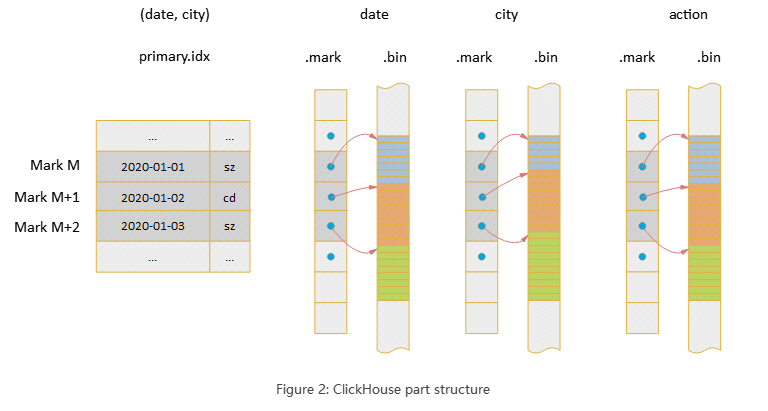
那么查询如何使用索引呢?以下查询为例:
select count(distinct action) where date=toDate(2020-01-01) and city=’bj’1.查找primary.idx并找到对应的Mark集合(即数据block集合)
2. 对于要读取的每个列根据.mrk文件定位到Mark对应在数据文件.bin中的数据offset
3.读取到对应的数据,供后续计算
以上为宏观步骤,下面会介绍其具体原理。
三、何时使用索引
在SQL编译阶段,初始化执行Pipeline的时候,ClickHouse会分析待查询的数据,目标是解析出需要读取哪些Part的哪些Mark列表。解析结果如下所示的AnalysisResult。在真正执行的时候,Scan算子直接读取这些Mark列表对应的数据。
struct AnalysisResult{RangesInDataParts parts_with_ranges; // 最终要扫描的Part列表,以及每个Part的扫描范围(range)Names column_names_to_read; // 需要读取那些列// 以下是一些统计信息 UInt64 total_parts = 0; // Parts总数UInt64 selected_parts = 0; // 命中的Part数量UInt64 selected_ranges = 0; // 命中的range数量UInt64 selected_marks = 0; // 命中的marks总数UInt64 selected_rows = 0; // 命中的marks包含的总数据行数};关键堆栈:
ReadFromMergeTree::selectRangesToRead
ReadFromMergeTree::getAnalysisResult()
ReadFromMergeTree::initializePipeline
QueryPlan::buildQueryPipeline
InterpreterSelectWithUnionQuery::execute()
executeQuery四、KeyCondition原理
在介绍如何使用索引前,先介绍下其核心算法。KeyCondition对外提供的语义是检查一个范围矩阵是否可以满足过滤条件。首先在构建KeyCondition的时候有两个必要参数,一个是过滤条件语法树这是过滤的主体,另一个是keys表示在判断是否满足的时候只关心这些列。然后当使用KeyCondition的时候,用户需要传入一个keys范围矩阵,来判断该范围矩阵是否满足过滤条件分。
范围矩阵是keys的范围数组,比如:c1,c2,c3三个主键列构成的一个范围矩阵可以是[[a, b], [1, 1], [x, x]],当用户进行Mark裁剪的时候,会生成范围矩阵然后判断该范围矩阵是否满足条件。又比如常用的时间分区构成的一个范围矩阵可以是[[2023-11-22, 2023-11-22]],当用户进行分区裁剪的时候,遍历每个分区构建范围矩阵,然后判断该分区是否满足条件。
满足过滤条件分三种情况,1范围矩阵中的数据全部满足过滤条件,2部分满足,3全部不满足。为表示以上三个语义ClickHouse设置了一个数据结构 {can_be_true, can_be_false},它的{true, false}、{true, true}、{false, true}三个值对应以上三种语义。
KeyCondition的核心是一个RPN表达式,主要流程分成两个阶段,1构建RPN,即将过滤条件转换成RPN表达式;2匹配,匹配一个范围矩阵是否满足条件。RPN的优势是表达一个表达式的时候不需要括号,在进行计算的时候使用栈,在碰到操作符的时候从栈顶弹出操作数就可以完成整个表达式的计算。
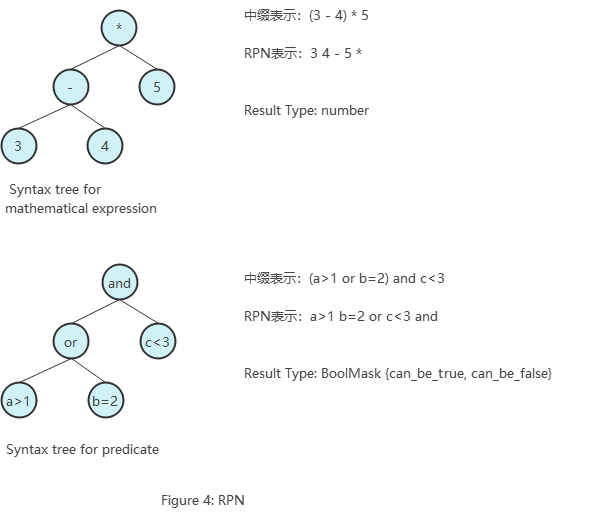
通过类比能够更好的理解在过滤场景中如何使用RPN,上图展示了RPN在四则运算法则和过滤两个场景中的使用情况,另种场景中唯一的区别是结果类型不一样,一个是number,一个是BoolMask {can_be_true, can_be_false}。更多关于RPN请参考wiki。
四、如何使用索引
1. Part裁剪
Part裁剪的目的是一次性过滤整个Part文件,只保留可能包含目标数据的Part。ClickHouse中的Part裁剪过程中会构建两个KeyCondition。其中一个被称为,主要用于根据分区列的最大值和最小值进行Part过滤。minmax_idx_condition的keys为构成分区键对应的原始列,比如分区键为toDate(date_time),那么它的key为date_time列,后续进行过滤的时候传入的也是date_time对应的值组成的范围矩阵。下图展示了minmax_idx_condition的工作原理。

另一个被称为,主要用于过滤分区。partition_pruner的key为分区表达式组成的列,比如分区键为toDate(date_time),那么它的key为toDate(date_time),后续进行过滤的时候传入的是分区对应的值组成的范围矩阵。下图展示了partition_pruner的工作原理。
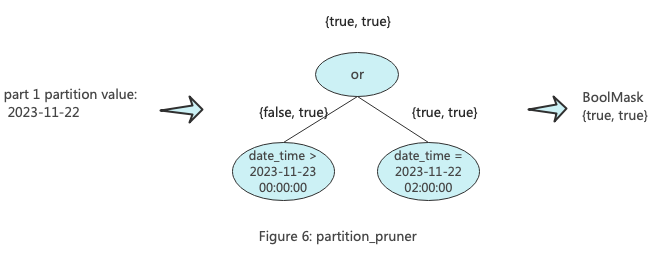
Part裁剪的主要逻辑位于:MergeTreeDataSelectExecutor::selectPartsToRead,大家可以自行参阅:
for (size_t i = 0; i < prev_parts.size(); ++i)
{if (!minmax_idx_condition->checkInHyperrectangle( // 基于分区键的列的最大最小值索引,进行Part裁剪part->minmax_idx->hyperrectangle, minmax_columns_types).can_be_true)continue;if (partition_pruner->canBePruned(*part)) // 基于分区表达式,进行Part裁剪continue;parts.push_back(prev_parts[i]);
}2. Mark裁剪
过滤完Part后会进一步进行Mark过滤,首先回顾下什么是Mark,在一个Part内部数据按照主键进行排序,然后每隔8192行数据将数据进行分组,这个分组id就被称为Mark,Mark表示一组按照主键有序的数据。
ClickHouse索引过滤的最小粒度就是Mark。下图展示了c1,c2,c3三个列组成主键的一个Part的数据结构以及Mark过滤的流程。

在Mark裁剪过程中输入的是一个MarkRange,比如:[2, 5],输出的是一系列的MarkRange,那么如何使用KeyCondition呢?
因为KeyCondition进行判断的时候输入的是主键列的范围矩阵,所以需要先将MarkRange转换成范围矩阵。将MarkRange转换成范围矩阵,相当于将多维空间的范围转换为一维空间的范围,所以转换出来的范围矩阵有很多个,这里不做过多讨论,有兴趣可以参考:方法。MarkRange [2, 5]转换成的一个范围矩阵为:[[a, a], [1, 1], [z, +inf]],下图展示了Mark裁剪的工作原理:

至此我们过滤出来了一系列的mark,同时数据存储结构和索引在过滤过程中的使命也完成了。接下来需要过滤每个mark中的Row。
六、Row过滤
Row过滤发生在查询执行阶段。ClickHouse中Row过滤也是按照batch的方式进行,该batch在ClickHouse内部被称为Chunk,它大小可能与Mark不同。ColumnVector::filter记录了数值类型的列过滤的主要逻辑(其它列过滤思路大同小异)。
1. 生成Filter Mask:
首先对根据过滤条件给一个Chunk的数据生成一个Filter Mask,Filter Mask是一个行数等于Chunk大小的UInt8数组,数组中只有2个值,其中0表示该行的数据不符合过滤条件,1表示符合。

2. Filter column by Filter Mask:
根据Filter Mask进行数据过滤,过滤的过程中使用到了SIMD技术进行优化,具体流程如下:
首先将数据按照64个的粒度为一组,按照组的粒度进行处理,然后将byte mask转换成bit mask,参考函数:,转换后的bit mask可以直接用一个UInt64表示。

对于每个分组按照数据分布的不同情况分别进行过滤
1)如果bit_mask等于0,也就是该分组的bit mask全0,直接忽略该分组
2)如果bit mask 全1,将整个分组复制到结果集中
3)[0]+[1]+或者[1]+[0]+,将byte maskt中连续1的区间复制到结果集

3. Filter column by Filter Mask version 2
过滤部分ClickHouse提供了一个SIMD的版本(使用AVX512指令集)。依然将数据按照64个的粒度为一组,按照组的粒度进行处理,然后将byte mask转换成bit mask,对于每个分组按照数据分布的不同情况分别处理
1)如果bit mask 全0,直接忽略该分组
2)bit mask 全1,将整个分组复制到结果集中,使用向量化方法批量进行复制
_mm512_storeu_si512(reinterpret_cast(&res_data[current_offset + i]), _mm512_loadu_si512(reinterpret_cast(data_pos + i)));3)其它情况,使用向量化函数,根据mask将数据拷贝到结果集中
4. 过滤结尾部分
5. Row过滤优化总结
1 为什么使用Filter Mask?
1)过滤多个列的时候可以复用Filter Mask;2)便于使用SIMD指令
2 为什么分组处理?
因为ClickHouse数据按照主键排序,很多情况下数据按照某些列局部有序,过滤的时候可将整个分组过滤掉或者命中的概率比较大,这样相比单个行的处理方式,在处理过程中没有判断,消除了分支预测失败的场景,避免CPU执行流水线被破坏,同时增大指令与数据缓存的命中率,这也是过滤高性能的核心设计点。
3 是不是使用位宽越大的SIMD指令集越好,比如AVX512一定快于SSE2?
大多数场景下是的,但是在过滤场景中不是的。因为增大位宽,那么分组大小也会相应增大,分组越大全零或者全一的概率越小,那么过滤整个分组的概率越小,所以需要看数据分布情况。
相关文章:
ClickHouse内幕(1)数据存储与过滤机制
本文主要讲述ClickHouse中的数据存储结构,包括文件组织结构和索引结构,以及建立在其基础上的数据过滤机制,从Part裁剪到Mark裁剪,最后到基于SIMD的行过滤机制。 数据过滤机制实质上是构建在数据存储格式之上的算法,所…...

1.Mongodb 介绍及部署
MongoDB 是一个开源的文档导向数据库,采用NoSQL(非关系型数据库)的设计理念。MongoDB是一个基于分布式文件存储的数据库。 分布式文件存储是一种将文件数据分布式的存储在多台计算机上。MongoDB是一款强大的文档导向数据库,适合处…...

Java 技巧:如何获取字符串中最后一个英文逗号后面的内容
在日常的Java编程中,处理字符串是非常常见的任务之一。有时我们需要从一个字符串中截取特定部分,例如获取最后一个英文逗号后的内容。这篇文章将详细介绍如何使用Java来实现这一需求,并提供一个示例代码来演示其实现过程。 需求分析 假设我们…...
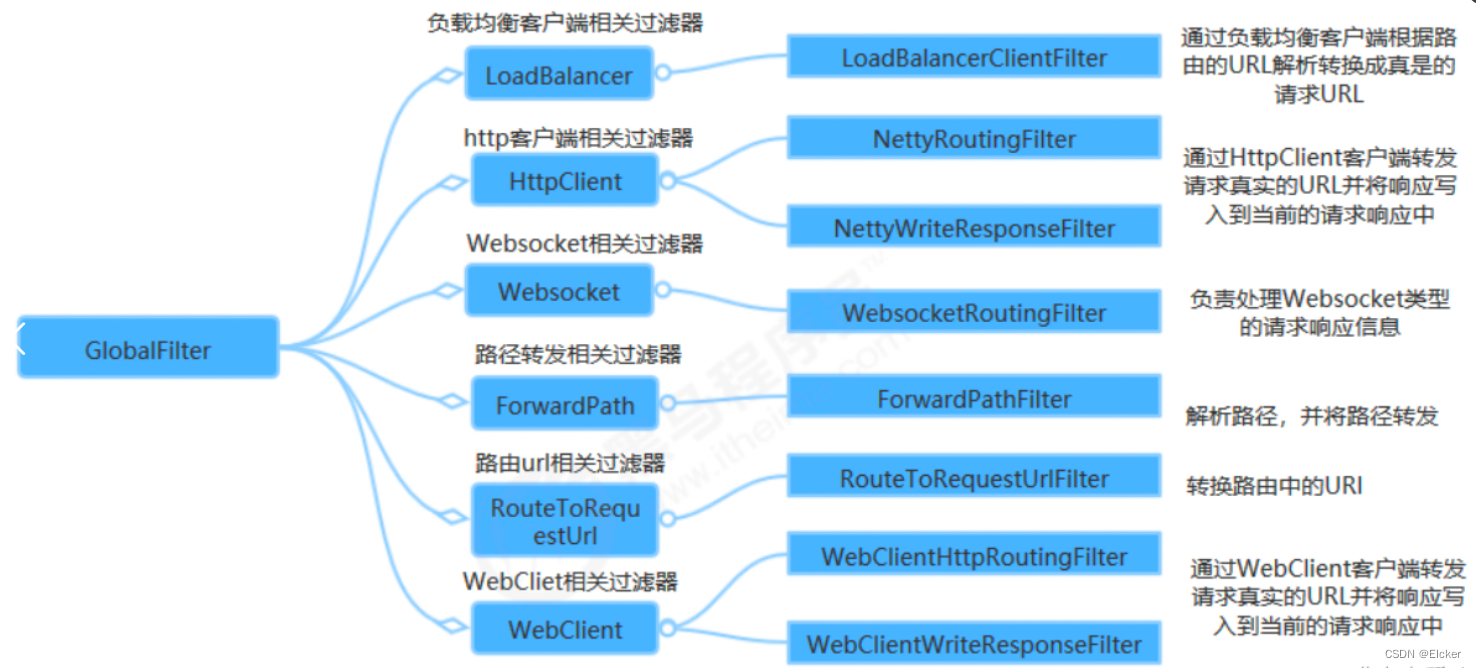
玩转微服务-GateWay
目录 一. 背景二. API网关1. 概念2. API网关定义3. API网关的四大职能4. API网关分类5. 开源API网关介绍6. 开源网关的选择 三. Spring Cloud Gateway1. 文档地址2. 三个核心概念3. 工作流程4. 运行原理4.1 路由原理4.2 RouteLocator 5. Predicate 断言6. 过滤器 Filter6.1. 过…...

Amortized bootstrapping via Automorphisms
参考文献: [MS18] Micciancio D, Sorrell J. Ring packing and amortized FHEW bootstrapping. ICALP 2018: 100:1-100:14.[GPV23] Guimares A, Pereira H V L, Van Leeuwen B. Amortized bootstrapping revisited: Simpler, asymptotically-faster, implemented. …...

【人工智能】ChatGPT基本工作原理
ChatGPT 是由 OpenAI 开发的一种基于深度学习技术的自然语言处理模型,它使用了名为 GPT(Generative Pre-trained Transformer)的架构。GPT 模型是一种基于 Transformer 架构的预训练语言模型,它通过大量的文本数据进行预训练&…...
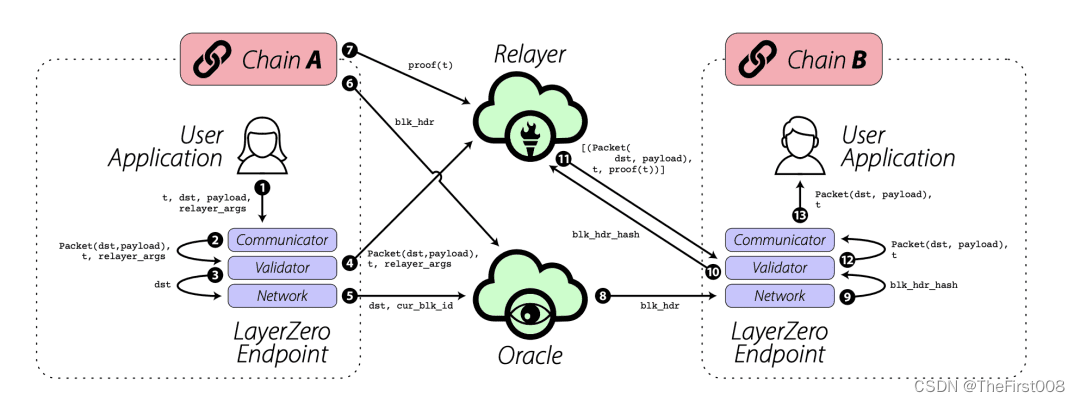
The First项目报告:Stargate Finance重塑跨链金融的未来
Stargate Finance是一个基于LayerZero协议的去中心化金融平台,自2022年3月由LayerZero Labs创建以来,一直致力于为不同区块链之间的资产转移提供高效、低成本的解决方案。凭借其独特的跨链技术和丰富的DeFi服务,Stargate Finance已成为连接不…...

Python魔法之旅-魔法方法(22)
目录 一、概述 1、定义 2、作用 二、应用场景 1、构造和析构 2、操作符重载 3、字符串和表示 4、容器管理 5、可调用对象 6、上下文管理 7、属性访问和描述符 8、迭代器和生成器 9、数值类型 10、复制和序列化 11、自定义元类行为 12、自定义类行为 13、类型检…...
)
公司面试题总结(三)
13.说说你对 BOM 的理解,常见的 BOM 对象你了解哪些? BOM (Browser Object Model),浏览器对象模型, ⚫ 提供了独立于内容与浏览器窗口进行交互的对象 ⚫ 其作用就是跟浏览器做一些交互效果 ⚫ 比如如何进行页面的后退&…...
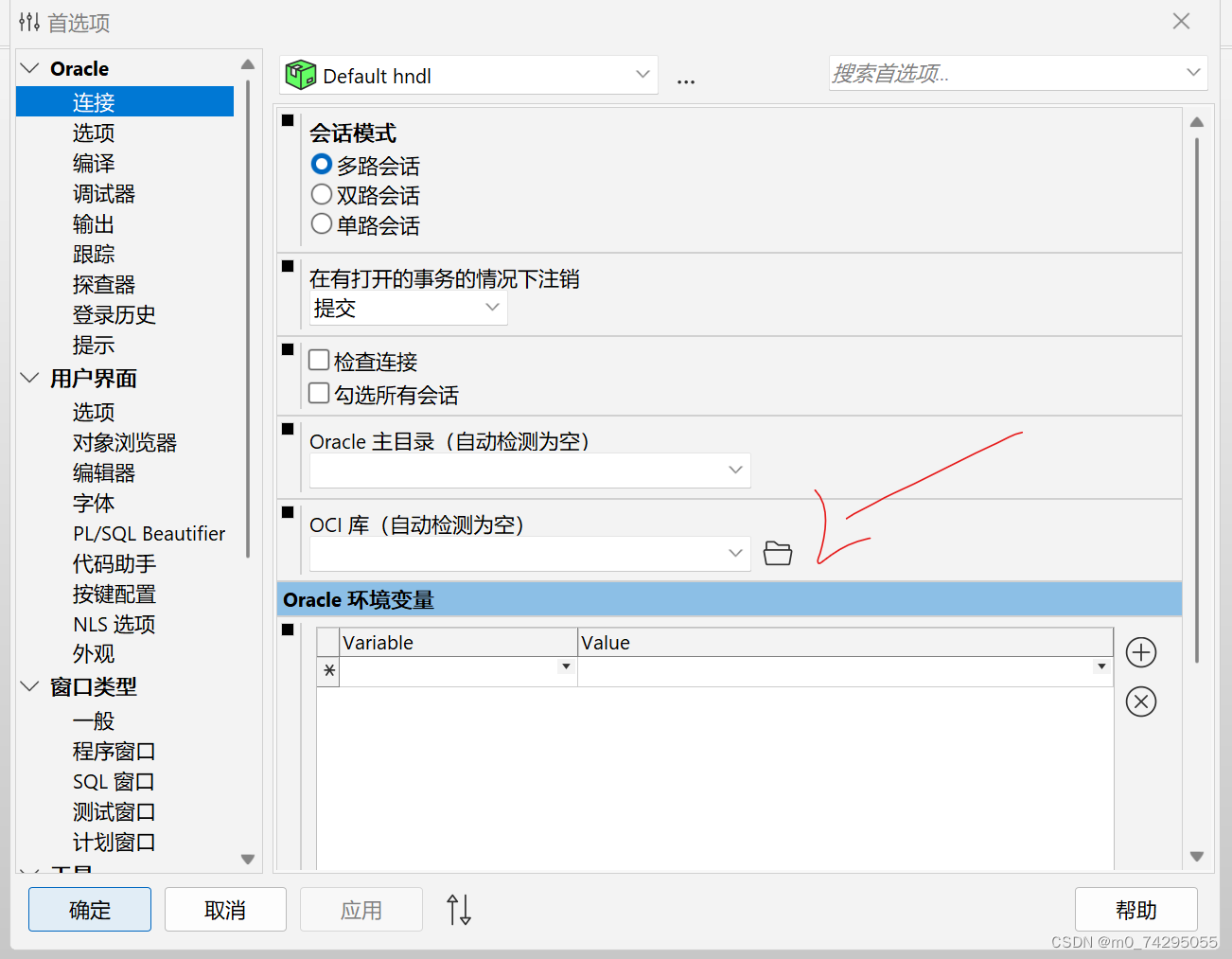
PLSQL 报错 could not locate oci.dll
0、确保PLSQL已激活。 1、在PLSQL安装包内搜索oci.dll,如果没有搜到需要下载 链接:https://pan.baidu.com/s/1HOfKAEFfuAGYACjfcwqJ1g 提取码:6evh 2、打开PLSQL,设置oci.dll的路径 ps:PLSQL安装包 链接ÿ…...

【方案+源码】智慧园区建设方案
智慧园区一体化运营管理平台建设方案旨在通过集成先进的信息技术,实现园区的智能化、高效化、绿色化管理。该平台整合了物联网、大数据、云计算等技术,为园区提供全方位、一体化的运营服务。 方案包括智能监控、能源管理、安防系统、停车管理、物业管理等…...

Java操作数据库 —— JDBC ① 基础篇
我走我的路,有人拦也走,没人陪也走 —— 24.6.7 JDBC JDBC就是使用Java语言操作关系型数据库的一套API 一、JDBC简介 JDBC 概念 JDBC 就是使用Java语言操作关系型数据库的一套API 全称:(Java DataBase Connectivity)意为Java 数据库连接 JDBC 本质: ①…...

webpack和vite区别
一、Webpack 1. 概述 Webpack 是一个模块打包工具,它会递归地构建依赖关系图,并将所有模块打包成一个或多个bundle(包)。 2. 特点 配置灵活:Webpack提供了高度可定制的配置文件,可以根据项目需求进行各…...

FL Studio21永久免费破解中文版下载,让我这个音乐制作爱好者如获至宝!
FL Studio21永久免费破解中文版下载,让我这个音乐制作爱好者如获至宝!🎶 这款软件功能强大,操作简单易上手。我可以轻松地创作出各种风格的音乐作品。无论是流行、摇滚还是电子音乐,都能轻松驾驭。🎧 使用F…...
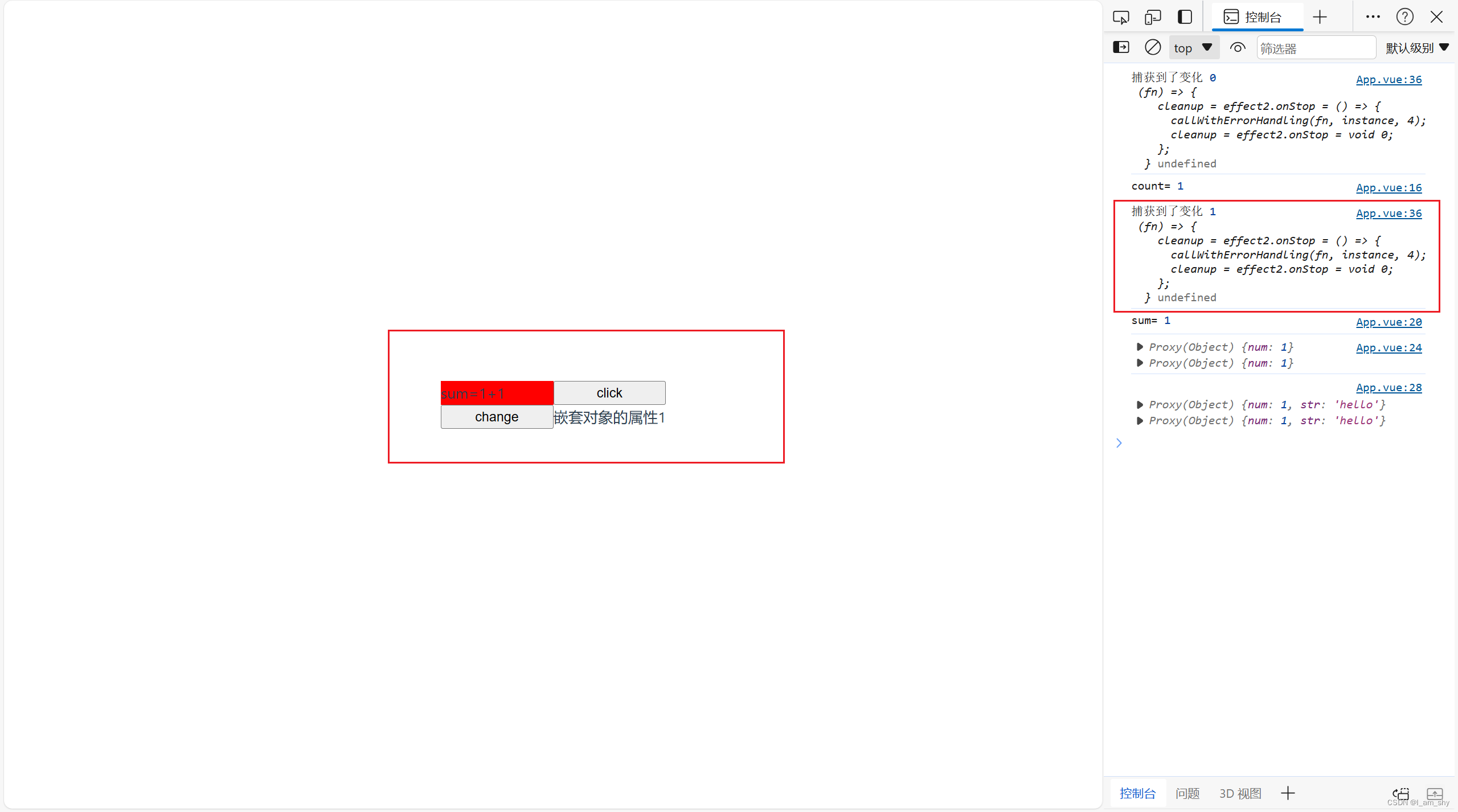
vue3 监听器,组合式API的watch用法
watch函数 在组合式 API 中,我们可以使用 watch 函数在每次响应式状态发生变化时触发回调函数 watch(ref,callback(newValue,oldValue),option:{}) ref:被监听的响应式量,可以是一个 ref (包括计算属性)、一个响应式…...

苹果WWDC开幕发布AI大模型,股价却跌近2%
KlipC报道:北京时间6月11日凌晨,苹果一年一度的“全球开发者大会”(WWDC)开幕。会上,先后介绍了iOS 18、iPadOS 18、watchOS 11等系统的更新,同时还展示了多个AI功能。宣布与OpenAI构建合作伙伴关系。然而&…...

C++ 11 【可变参数模板】【lambda】
💓博主CSDN主页:麻辣韭菜💓 ⏩专栏分类:C修炼之路⏪ 🚚代码仓库:C高阶🚚 🌹关注我🫵带你学习更多C知识 🔝🔝 目录 前言 一、新的类功能 1.1默认成员函数—…...

c 宏应用举例
1.概要 #include <iostream> //变量可以直接使用 #define fun() a 100; //用变量计算可以 #define fun2(a) a*2; //用变量替换可以 #define fun3(a) d[a] a; //##链接的作用,一般用于链接变量名 #define fun4(type,name) type name##_s 4; //#的作用是转换…...

微信公众号(公众平台) 和 微信开放平台的scope的差异
微信公众号(公众平台) 和 微信开放平台 是两码事。 公众号(公众平台)获取的scope只包括两种:snsapi_base 和snsapi_userinfo,前者是静默获取,用户无感知;后者是需要用户确认同意的。…...

基于pytorch实现的DenseUnet医学图像分割(腹部多脏器)
1、前言 本章将介绍将densenet的主干网络引入unet中 官方实现的代码:kits19-challenge/network at master nitsaick/kits19-challenge (github.com) 本章实现的项目目录如下: 主要代码有train、evaluate、predict脚本 2、代码介绍 数据预处理脚本 数据…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

uni-app学习笔记二十二---使用vite.config.js全局导入常用依赖
在前面的练习中,每个页面需要使用ref,onShow等生命周期钩子函数时都需要像下面这样导入 import {onMounted, ref} from "vue" 如果不想每个页面都导入,需要使用node.js命令npm安装unplugin-auto-import npm install unplugin-au…...

C++ 基础特性深度解析
目录 引言 一、命名空间(namespace) C 中的命名空间 与 C 语言的对比 二、缺省参数 C 中的缺省参数 与 C 语言的对比 三、引用(reference) C 中的引用 与 C 语言的对比 四、inline(内联函数…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...