KaiwuDB 时序引擎数据存储内存对齐技术解读

一、理论
1、什么是内存对齐
现代计算机中内存空间都是按照 byte 划分的,在计算机中访问一个变量需要访问它的内存地址,从理论上看,似乎对任何类型的变量的访问都可以从任何地址开始。
但在实际情况中,通常在特定的内存地址才能访问特定类型变量,这就需要对数据在内存中存放的位置有限制。各种类型不是按照顺序排放,它们需要根据一定的规则在空间上排列,这就是对齐。
2、为什么需要内存对齐
(1)移植原因:
不是所有的硬件平台都能访问任意地址上的任意数据的,各个硬件平台对存储空间的处理上有很大的不同,部分平台对某些特定类型的数据只能从某些特定地址开始存取。
比如,市面上有些架构的 CPU 在访问一个没有进行对齐的变量时会发生错误,这时 CPU 会进入异常处理状态并且通知程序不能继续执行。
举个例子,在 ARM 硬件平台上,当操作系统被要求存取一个未对齐数据时会默认给应用程序抛出硬件异常。所以,如果不进行内存对齐,代码就不具有移植性,而且难以开展在很多平台上的开发工作。
(2)性能原因:
尽管内存是以字节为单位,但是大部分处理器并不是按字节块来存取内存的。它一般会以双字节、4 字节、8 字节、16 字节甚至 32 字节为单位来存取内存,我们将上述这些存取单位称为内存存取粒度。
如果变量的地址没有对齐,可能需要多次访问才能完整读取到变量内容,而对齐后可能就只需要一次内存访问。因此,内存对齐可以减少 CPU 访问内存的次数,提高 CPU 访问内存的吞吐量。
举个例子,考虑 4 字节存取粒度的处理器访问 int 类型变量,该处理器只能从地址为 4 的倍数的内存地址开始读取数据。如果未经过内存对齐,获取该 int 类型的数据需要进行两次内存访问,最后再进行数据整理得到完整数据:
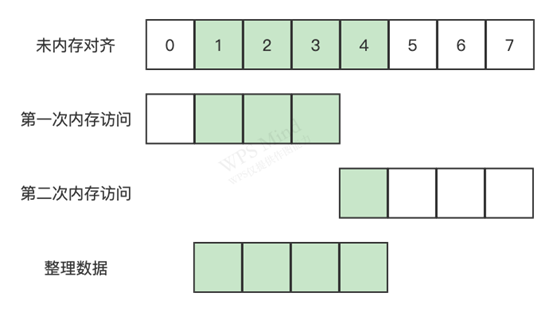
如果经过内存对齐,一次内存访问就能得到完整数据,减少了一次内存访问:

CPU 读取内存是高耗时的指令,内存对齐是在内存的使用量和 CPU 计算间的居中的优化策略。这种策略是由编译器和 CPU 共同决定,并且程序员可以设置对齐的长度。
通过上述介绍的内存对齐的必要性,我们可以知道,如果不理解内存对齐,在编程时就可能产生下面的问题:
(1) 程序运行速度变慢;
(2) 应用程序产生死锁;
(3) 操作系统崩溃;
(4) 程序会毫无征兆的出错,产生错误的结果。
但是,我们在写程序时一般无需考虑对齐,通常是依赖编译器来为我们选择适合的对齐策略。
1、内存对齐规则
在学习内存对齐规则前,我们先一起了解下四个重要的基本概念:
指定对齐值:
#pragma pack (n) 时指定的对齐值 n;
基本数据类型的自身对齐值:
基本数据类型自身占用的存储空间大小,如 char 类型为 1,short 类型为 2,int 类型为 4,double 类型为 8 等;
结构体或类类型的自身对齐值:
结构体或类的成员中自身对齐值最大的值,如 struct a 中有 char、int 和 double 共 3 个类型的数据成员,那么 struct a 的自身对齐值是 8 字节;
数据成员、结构体和类的有效对齐值:
自身对齐值或指定对齐值中的较小值。
了解上述概念后,我们一起来了解具体的内存对齐规则。
内存地址对齐包含了两种相互独立又相互关联的部分:基本数据对齐和结构体数据对齐。
基本数据对齐比较简单,其自身对齐值就等于自身占用的存储空间大小,可以通过 alignof 获取一个类型的对齐值。
结构体数据对齐需要保证结构体的数据成员对齐以及结构体的整体对齐:
(1)数据成员对齐规则:
第一个数据成员放在 offset 为 0 的地方,也就是结构体变量本身的起始地址,以后每个数据成员的偏移为其有效对齐值的整数倍;
(2)结构体整体对齐规则:
在数据成员完成各自对齐后,结构体本身也要进行对齐,对齐会将结构体的大小增加为该结构体有效对齐值的整数倍,如有需要编译器会在最末成员后加上填充字节。
二、应用
1、前提介绍
在 KaiwuDB 时序引擎中,一条时序数据由不同的列数据组成,其中每列都对应一种数据类型。在存储的代码实现中,每条时序数据都存放在一块连续的内存空间里,不同列的数据按照列的顺序连续紧邻的排放,如下图所示:

值得一提的是,上图示例中的 char 类型,并非是一个字符,而是代表一个不定长的字符数组,也就是说这条数据的第二列,存放的是一个长度为 3 的 char 数组。另外,TIMESTAMP 的类型是 uint64_t,长度为 8 字节;Bitmap 的类型也是 char 数组,长度不定。
显然,这种存放方式并不满足内存对齐的要求,会对我们的程序产生两种可能的影响:
(1)在不同硬件平台上的程序 crash;
(2)降低存取效率。
由于我们的程序需要在 ARM 平台上运行,而且会有高密集地进行内存访问,所以时序数据存放满足内存对齐要求是十分必要的。
2、使用内存对齐生成存储格式
存储记录的数据类型可以分类为两种:
(1)定长:
TIMESTAMP、SMALLINT、INT、BIGINT、FLOAT、DOUBLE、BOOL、BINARY,长度包括 8、4、2、1 字节,都属于基本数据类型。前文介绍过,基本数据类型的对齐系数等于自身的类型长度。
(2)不定长:
char、Bitmap,这两种类型都是不定长的 char 数组,基本组成元素都是 char 类型,因此它们的对齐系数都为 1。
由上可知,目前存储中存放的都是一些基本数据类型记录,不存在结构体或类类型。在这个条件下,一条时序数据的格式满足内存对齐的要求就相对而言比较简单了,存储格式生成方案如下:
对于定长的数据类型对应的列,按类型长度降序排列,先存放 8 字节的列、再存放 4 字节的列、再存放 2 字节和 1 字节的列,这样就可以满足内存对齐的要求。
存放完定长的列后,char 和 Bitmap 都是 char 数组,对齐系数都为 1,所以可以直接存放在定长的列之后,先存放 char 类型,最后存放 Bitmap。
通过上述内存对齐的存储格式生成方案生成的一条时序数据的格式如下:

3、测试
通过编写一个简单的测试,验证一下内存对齐对存取效率的影响。
测试场景:
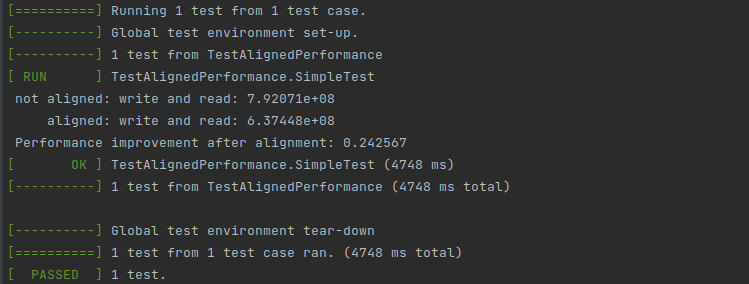
内存对齐系数为 8 字节,申请 10K 内存空间,在内存对齐和非内存对齐的情况下,分别写入数据 1G 次并且读取数据 1G 次。写入的数据类型均为 uint64_t,长度 8 字节,内存写满后循环使用。分别统计其耗时并进行对比,测试代码和测试结果如下:

测试结果显示,在只进行读写操作的情况下,进行 1G 次读写操作,非内存对齐要比内存对齐的耗时多 24.3% 左右。
END
相关文章:
KaiwuDB 时序引擎数据存储内存对齐技术解读
一、理论1、什么是内存对齐现代计算机中内存空间都是按照 byte 划分的,在计算机中访问一个变量需要访问它的内存地址,从理论上看,似乎对任何类型的变量的访问都可以从任何地址开始。但在实际情况中,通常在特定的内存地址才能访问特…...
IR 808 Alkyne,IR-808 alkyne,IR 808炔烃,近红外吲哚类花菁染料
【产品理化指标】:中文名:IR-808炔烃英文名:IR-808 alkyne,Alkyne 808-IR CAS号:N/AIR-808结构式:规格包装:10mg,25mg,50mg,接受各种复杂PEGS定制服务&#x…...
elasticsearch
这里写目录标题1.初识ElasticSearch1.1 了解ES1.2 倒排索引1.2.1 正向索引1.2.2 倒排索引1.2.3 正向和倒排1.3 ES的一些概念1.3.1 文档和字段1.3.2 索引和映射1.3.3 mysql和elasticsearch1.4 安装ES、kibana1.初识ElasticSearch 1.1 了解ES elasticsearch是一款非常强大的开源…...
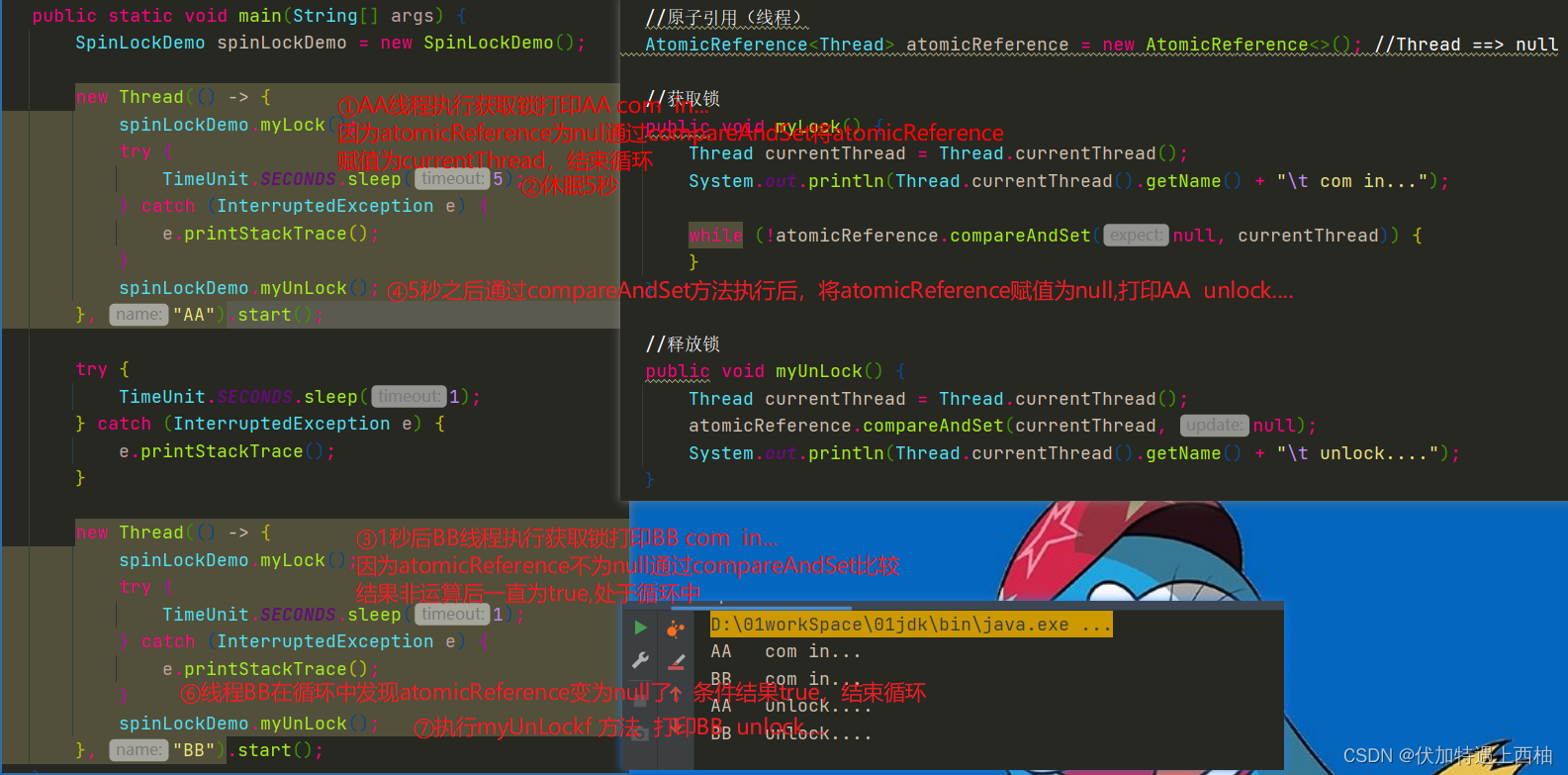
并发编程---java锁
java锁一 多线程锁synchronized案例分析1.1synchronized介绍1.2 synchronized案例分析1.2.1.标准访问,请问先打印邮件还是短信?1.2.2.邮件⽅法暂停4秒钟,请问先打印邮件还是短信?分析1.2.3.新增⼀个普通⽅法hello(&…...

品牌营销 | 学习如何最大限度地发挥品牌营销的作用
您是否想过如何最大限度地发挥品牌营销的潜力?这是一项艰巨的挑战,通过了解品牌营销的基本组成部分,您可以成功地推广您的品牌。 (图源:Pixabay) 品牌营销的基本组成部分 你需要做什么来发展稳固的品牌&am…...
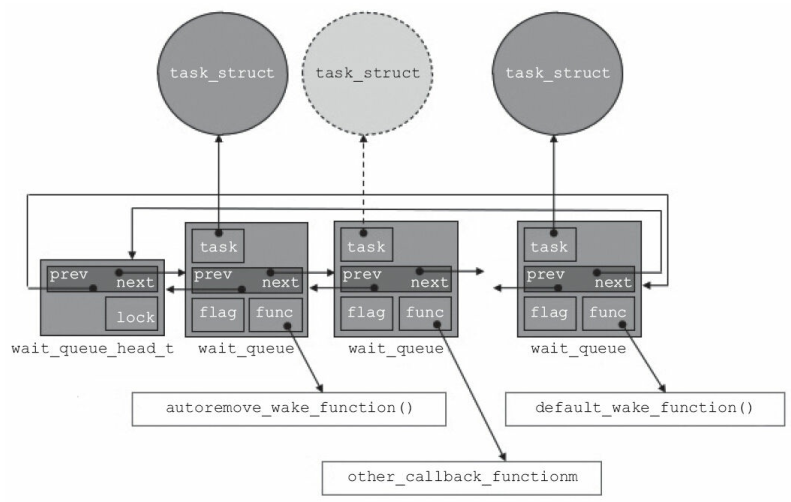
Linux驱动的同步阻塞和同步非阻塞
在字符设备驱动中,若要求应用与驱动同步,则在驱动程序中可以根据情况实现为阻塞或非阻塞一、同步阻塞这种操作会阻塞应用程序直到设备完成read/write操作或者返回一个错误码。在应用程序阻塞这段时间,程序所代表的进程并不消耗CPU的时间&…...

LearnOpenGL-光照-5.投光物
本人刚学OpenGL不久且自学,文中定有代码、术语等错误,欢迎指正 我写的项目地址:https://github.com/liujianjie/LearnOpenGLProject 文章目录投光物平行光点光源聚光不平滑的例子平滑例子投光物 前面几节使用的光照都来自于空间中的一个点 即…...

【C语言】每日刷题 —— 牛客语法篇(1)
前言 大家好,今天带来一篇新的专栏c_牛客,不出意外的话每天更新十道题,难度也是从易到难,自己复习的同时也希望能帮助到大家,题目答案会根据我所学到的知识提供最优解。 🏡个人主页:悲伤的猪大…...

【深度学习】Subword Tokenization算法
在自然语言处理中,面临的首要问题是如何让模型认识我们的文本信息,词,是自然语言处理中基本单位,神经网络模型的训练和预测都需要借助词表来对句子进行表示。 1.构建词表的传统方法 在字词模型问世之前,做自然语言处理…...
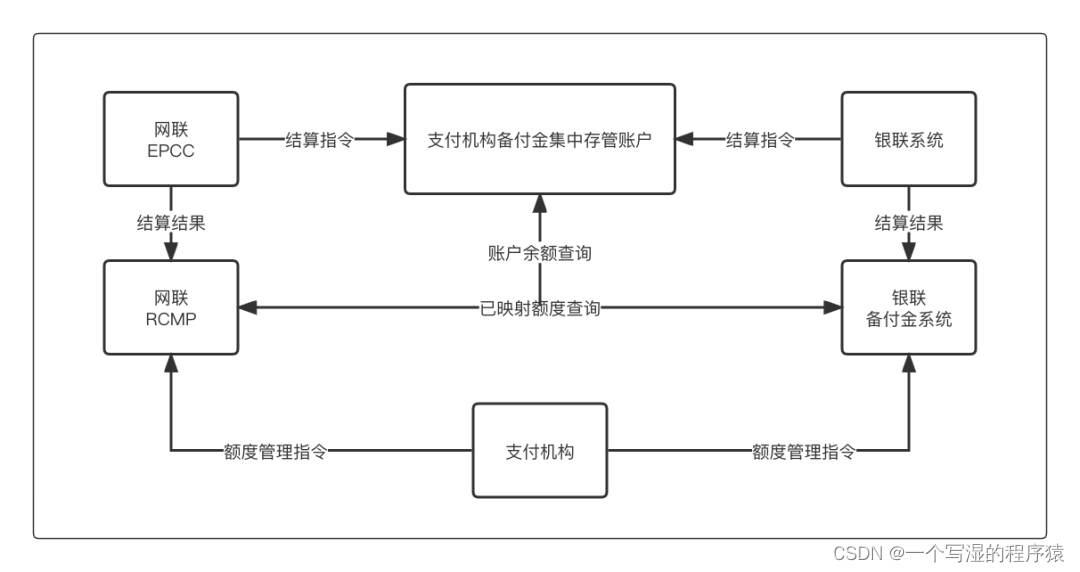
五分钟了解支付、交易、清算、银行等专业名词的含义?
五分钟了解支付、交易、清算、银行等专业名词的含义?1. 支付类名词01 支付应用02 支付场景03 交易类型04 支付类型(按通道类型)05 支付类型(按业务双方类型)06 支付方式07 支付产品08 收银台类型09 支付通道10 通道类型…...

4个工具,让 ChatGPT 如虎添翼!
LightGBM中文文档 机器学习统计学,476页 机器学习圣经PRML中文版...

初识PO、VO、DAO、BO、DTO、POJO时
PO、VO、DAO、BO、DTO、POJO 区别分层领域模型规约DO(Data Object)DTO(Data Transfer Object)BO(Business Object)AO(ApplicationObject)VO(View Object)Query领域模型命名规约:一、PO :(persistant object ),持久对象二、VO :(value object) ࿰…...
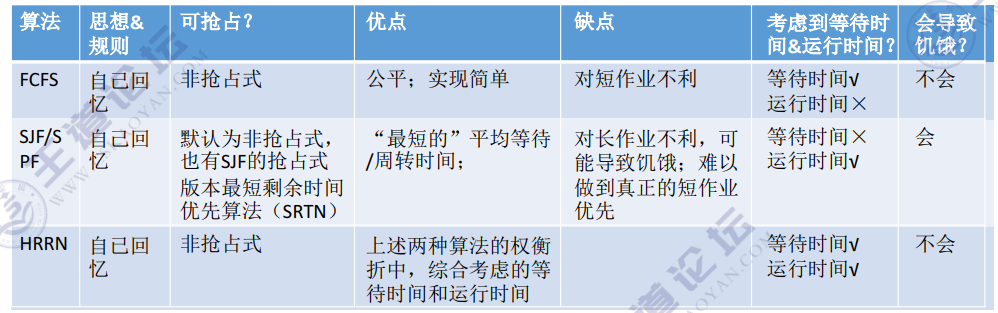
[2.2.4]进程管理——FCFS、SJF、HRRN调度算法
文章目录第二章 进程管理FCFS、SJF、HRRN调度算法(一)先来先服务(FCFS, First Come First Serve)(二)短作业优先(SJF, Shortest Job First)对FCFS和SJF两种算法的思考(三…...

【代码随想录Day55】动态规划
583 两个字符串的删除操作 https://leetcode.cn/problems/delete-operation-for-two-strings/72 编辑距离https://leetcode.cn/problems/edit-distance/...

Java开发 - 消息队列前瞻
前言 学完了Redis,那你一定不能错过消息队列,要说他俩之间的关联?关联是有的,但也不见得很大,只是他们都是大数据领域常用的一种工具,一种用来提高程序运行效率的工具。常见于高并发,大数据&am…...
MySQL连接IDEA详细教程
使用IDEA的时候,需要连接Database,连接时遇到了一些小问题,下面记录一下操作流程以及遇到的问题的解决方法。 目录 MySQL连接IDEA详细教程 MySQL连接IDEA详细教程 打开idea,点击右侧的 Database 或者 选择 View --> Tool Wind…...
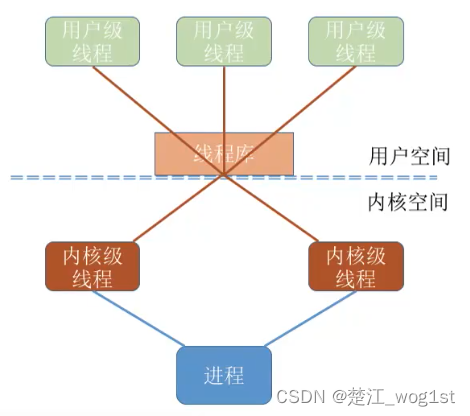
线程(操作系统408)
基本概念 我们说引入进程的目的是更好的使用多道程序并发执行,提高资源的利用率和系统吞吐量;而引入线程的目的则是减小程序在并发执行的时候所付出的时间开销,提高操作系统的并发性能。 线程可以理解成"轻量级进程",…...

功耗降低99%,Panamorph超清VR光学架构解析
近期,投影仪变形镜头厂商Panamorph获得新型VR显示技术专利(US11493773B2),该专利方案采用了紧凑的结构,结合了Pancake透镜和光波导显示模组,宣称比传统VR方案的功耗、发热减少99%以上,可显著提高…...
【数据结构】带你深入理解栈
一. 栈的基本概念💫栈是一种特殊的线性表。其只允许在固定的一端进行插入和删除元素的操作,进行数据的插入和删除的一端称作栈顶,另外一端称作栈底。栈不支持随机访问,栈的数据元素遵循后进先出的原则,即LIFOÿ…...
认识CSS之如何提高写前端代码的效率
🌟所属专栏:前端只因变凤凰之路🐔作者简介:rchjr——五带信管菜只因一枚😮前言:该系列将持续更新前端的相关学习笔记,欢迎和我一样的小白订阅,一起学习共同进步~👉文章简…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

论文浅尝 | 基于判别指令微调生成式大语言模型的知识图谱补全方法(ISWC2024)
笔记整理:刘治强,浙江大学硕士生,研究方向为知识图谱表示学习,大语言模型 论文链接:http://arxiv.org/abs/2407.16127 发表会议:ISWC 2024 1. 动机 传统的知识图谱补全(KGC)模型通过…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

ArcGIS Pro制作水平横向图例+多级标注
今天介绍下载ArcGIS Pro中如何设置水平横向图例。 之前我们介绍了ArcGIS的横向图例制作:ArcGIS横向、多列图例、顺序重排、符号居中、批量更改图例符号等等(ArcGIS出图图例8大技巧),那这次我们看看ArcGIS Pro如何更加快捷的操作。…...

Java 二维码
Java 二维码 **技术:**谷歌 ZXing 实现 首先添加依赖 <!-- 二维码依赖 --><dependency><groupId>com.google.zxing</groupId><artifactId>core</artifactId><version>3.5.1</version></dependency><de…...

Windows安装Miniconda
一、下载 https://www.anaconda.com/download/success 二、安装 三、配置镜像源 Anaconda/Miniconda pip 配置清华镜像源_anaconda配置清华源-CSDN博客 四、常用操作命令 Anaconda/Miniconda 基本操作命令_miniconda创建环境命令-CSDN博客...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

如何配置一个sql server使得其它用户可以通过excel odbc获取数据
要让其他用户通过 Excel 使用 ODBC 连接到 SQL Server 获取数据,你需要完成以下配置步骤: ✅ 一、在 SQL Server 端配置(服务器设置) 1. 启用 TCP/IP 协议 打开 “SQL Server 配置管理器”。导航到:SQL Server 网络配…...
软件工程 期末复习
瀑布模型:计划 螺旋模型:风险低 原型模型: 用户反馈 喷泉模型:代码复用 高内聚 低耦合:模块内部功能紧密 模块之间依赖程度小 高内聚:指的是一个模块内部的功能应该紧密相关。换句话说,一个模块应当只实现单一的功能…...