【深度学习】Subword Tokenization算法
在自然语言处理中,面临的首要问题是如何让模型认识我们的文本信息,词,是自然语言处理中基本单位,神经网络模型的训练和预测都需要借助词表来对句子进行表示。
1.构建词表的传统方法
在字词模型问世之前,做自然语言处理任务时,一般通过传统方法构建词表,具体的构建流程如下:
1.首先对数据集中的所有句子进行分词,通过jieba、ltp等分词工具将句子粒度缩小到词粒度。例如:我/爱/北京/天安门。
2.对切分出来的词进行统计,统计并选出频数最高的前N个词组成词表,对低频词舍弃。
通过筛选词频的方式构建的词表会存在以下问题:
1.出于计算效率的考虑,通常N的选取无法包含训练集中的所有词,对于未在词表中出现的词(Out Of Vocabulary, OOV),模型将无法处理及生成;
2.词表中的低频词/稀疏词在模型训练过程中无法得到充分训练,进而模型不能充分理解这些词的语义;
3.一个单词因为不同的形态会产生不同的词,如由"look"衍生出的"looks", "looking", "looked",显然这些词具有相近的意思,但是在词表中这些词会被当作不同的词处理,一方面增加了训练冗余,另一方面也造成了大词汇量问题。
2.抛砖引玉
假设要从训练数据集中构建一个词表。为了构建该词表,我们将数据集中的文本拆分成单词,然后把唯一的单词加入到词表。通常,词表包含很多单词(Token),为了举例的简单,假设构造的词表只包含下面的单词:
vocabulary = [game, the, I, played, walked, enjoy]有词表之后,下面基于该词表来对输入进行分词。考虑输入句子I played the game。在英文中,只要通过空格就得得到句子中所有的单词。所以我们有[I, play, the, game]。现在,我们检查是否所有的单词都在词表中。恰好这些单词都在词表中,从给定句子中得到的最终标记就为:
tokens = [I, played, the, game]接着我们考虑另一个句子:I enjoyed the game。首先还是根据空格分词,得到 [I, enjoyed, the, game]。接着,检查是否所有的单词出现在词表中。我们可以看到,除了单词enjoyed,其他的单词都在词表中,因此我把enjoyed替换为未知标记<UNK>,这样我们最终的标记为:
tokens = [ I, <UNK>, the, game] 我们也可以看到,尽管词表中有单词enjoy,但是由于没有完全一样的单词enjoyed,它就变成未知词了。可能是因为词表太小了,然而哪怕有一个超大的词表,先不说这样的词表会带来内存和性能方面的压力,仍然有可能无法处理没有出现过的词(词表中也没有出现过)。
针对上述问题,Subword(子词)模型方法横空出世。它的划分粒度介于词与字符之间,比如可以将”enjoyed”划分为”enjoy”和”ed”两个子词,而划分出来的"enjoy",”ed”又能够用来构造其它词,如"engoy"和"ing"子词可组成单词"engoying",因而Subword方法能够大大降低词典的大小,同时对相近词能更好地处理。
在子词Tokenization中,我们将单词拆分为更小的子词。假设我们拆分单词played为子词[play, ed];拆分单词walked为子词[walk, ed]。在拆分子词后,我们将这些子词加到词表中。由于词表中不包含重复单词,所以我们的词表变成了:
vocabulary = [game, the, I, play, walk, ed, enjoy]
在来看之前的句子: I enjoyed the game。同样我们先根据空格将句子拆分单词,我们有[ I, enjoyed, the, game]。接着我们检测是否所有的单词都在词表中。我们可以看到除了单词enjoyed,其他所有单词都在词表中。此时,我们不会将该单词替换为未知词,而是将它继续拆分为子词:[enjoy, ed]。同样我们先根据空格将句子拆分单词,我们有[ I, enjoyed, the, game]。接着我们检测是否所有的单词都在词表中。我们可以看到除了单词enjoyed,其他所有单词都在词表中。此时,我们不会将该单词替换为未知词,而是将它继续拆分为子词:[enjoy, ed]。
tokens = [ I, enjoy, ##ed, the, game] 我们可以看到ed前面有两个#。这代表##ed是一个子词,而且它前面有另一个单词。我们不会为单词拆分后的第一个子词增加##符号,这就是为什么子词enjoy前面没有#。这样子词Tokenization处理了未知词,也就是没有出现在词表中的单词。
现在问题是,我们知道我们将单词played和walked拆分成子词,然后增加它们的子词到词表中。但是为什么我们只拆分这些单词呢?为什么不是词表中的其他单词?我们如何决定哪些单词要拆分,哪些不要?这就是子词Tokenization算法起作用的地方。
3.Subword Tokenization算法
3-1 字节对编码(Byte pair encoding,BPE)
3-1-1 BPE简介
BPE最早是一种数据压缩算法,由Sennrich等人于2015年引入到NLP领域并很快得到推广。该算法简单有效,因而目前它是最流行的方法。GPT-2和RoBERTa使用的Subword算法都是BPE。BPE算法的步骤如下:
1.给定的数据集中抽取单词以及相应的频次,并确定词表大小;
2.将单词拆分为字符序列,比如英文中26个字母加上各种符号,这些作为初始词表;
3.将所有字符序列中的字符不重复地添加到词表中,选择并合并频次最高的相邻字符对;
4.重复步骤3直到满足词表大小。
3-1-2 BPE实例
下面以一个例子来说明。
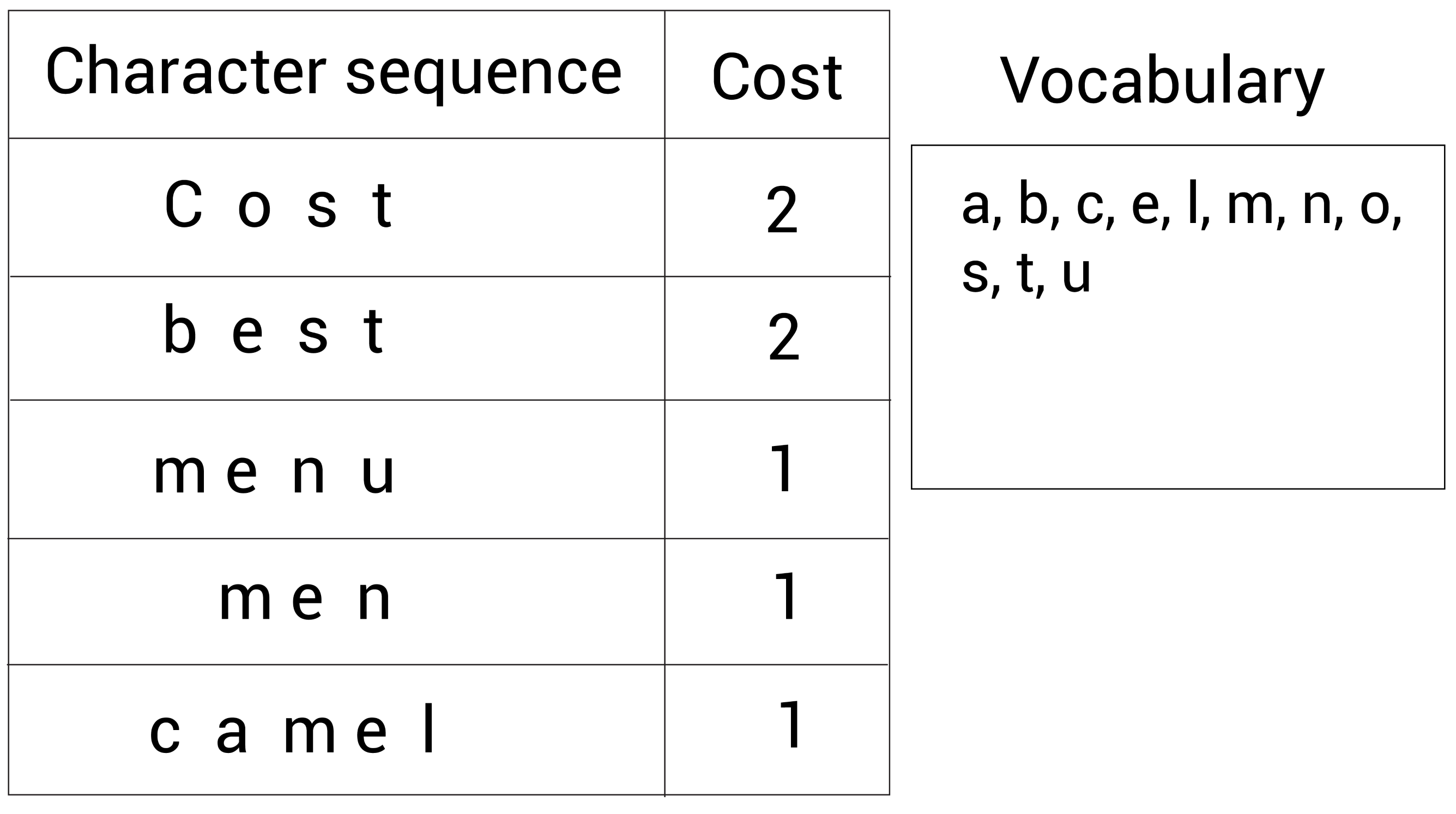
1.假设有语料集经过统计后表示为:(cost, 2), (best, 2), (menu, 1), (men, 1),(camel, 1)。
2.将这些单词拆分成字符变成一个字符序列,并定义要构建Subword词表大小为14。下面的表格显示这些字符序列以及它们对应的单词次数:
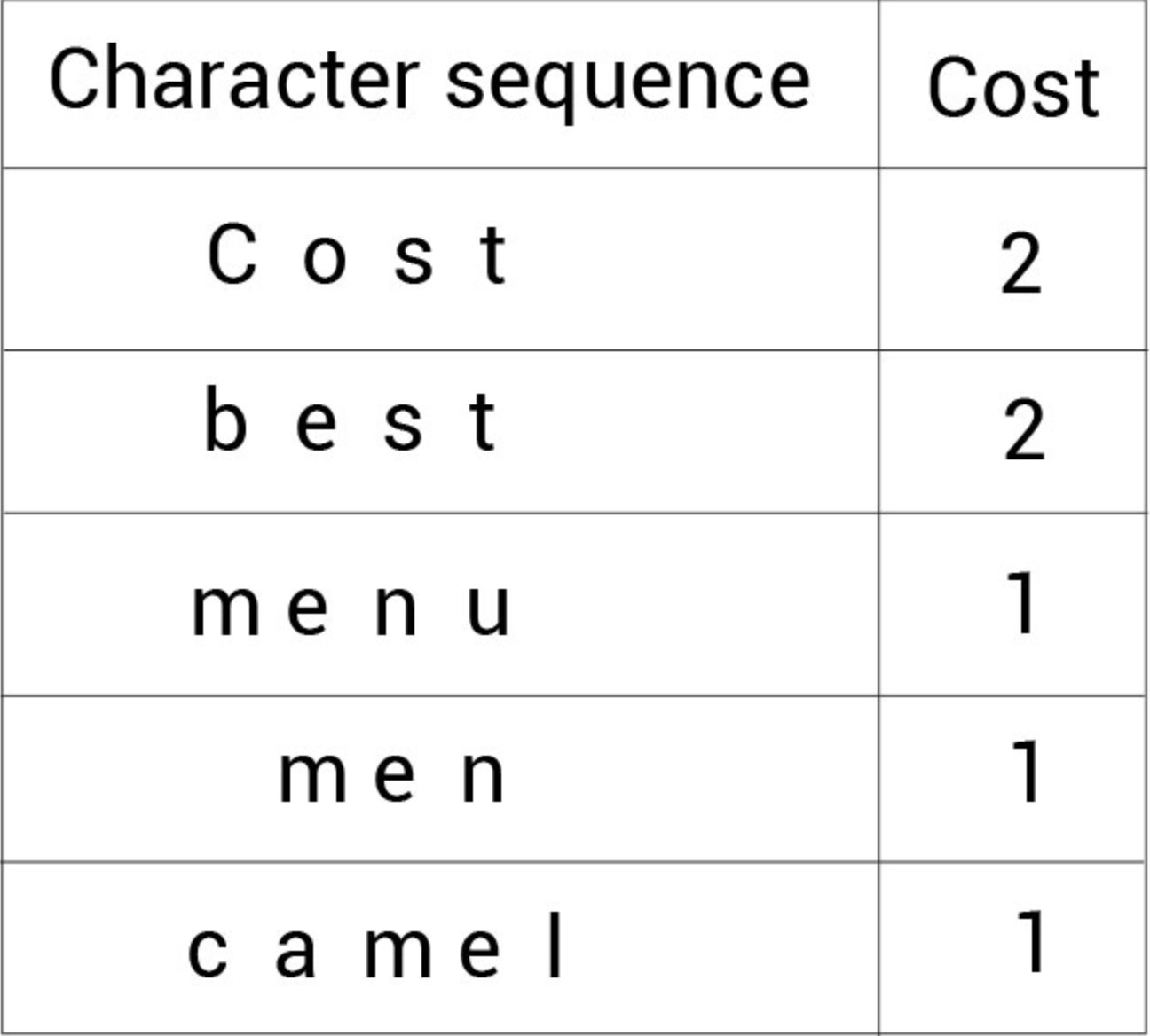
3. 将所有字符序列中的字符不重复地添加到词表中:

现在的词表(右边的Vocabulary)大小为 11。下面看看如何增加新标记到词表中。
首先,我们找出出现次数最多的相邻的字符对。然后我们合并这个字符对并加入到词表中。我们不断重复该步骤知道达到词表大小。让我们来看下具体细节。
看下面的字符序列,我们能观察到出现最多的字符对是s和t,因为s和t相邻地出现了4次:

所以,我们合并这两个字符s和t成st,并将st加入到词表,现在的词表(右边的Vocabulary)大小为 12,仍然需要添加新的subword到词表中。
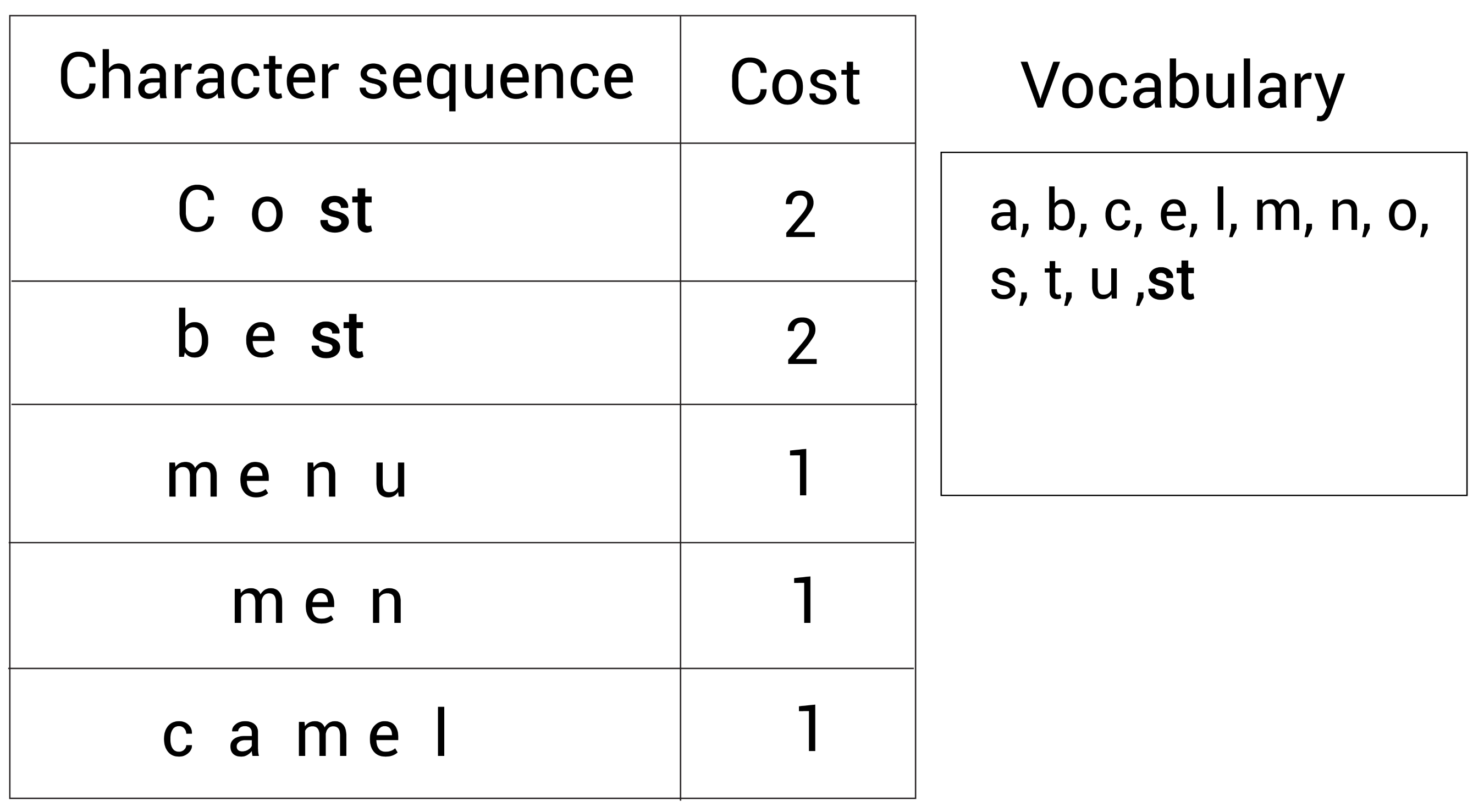
接着,我们重复这一步骤。我们继续寻找出现最多的相邻字符对。我们又发现了现在最频繁的字符对是m和e,它们出现了3次。
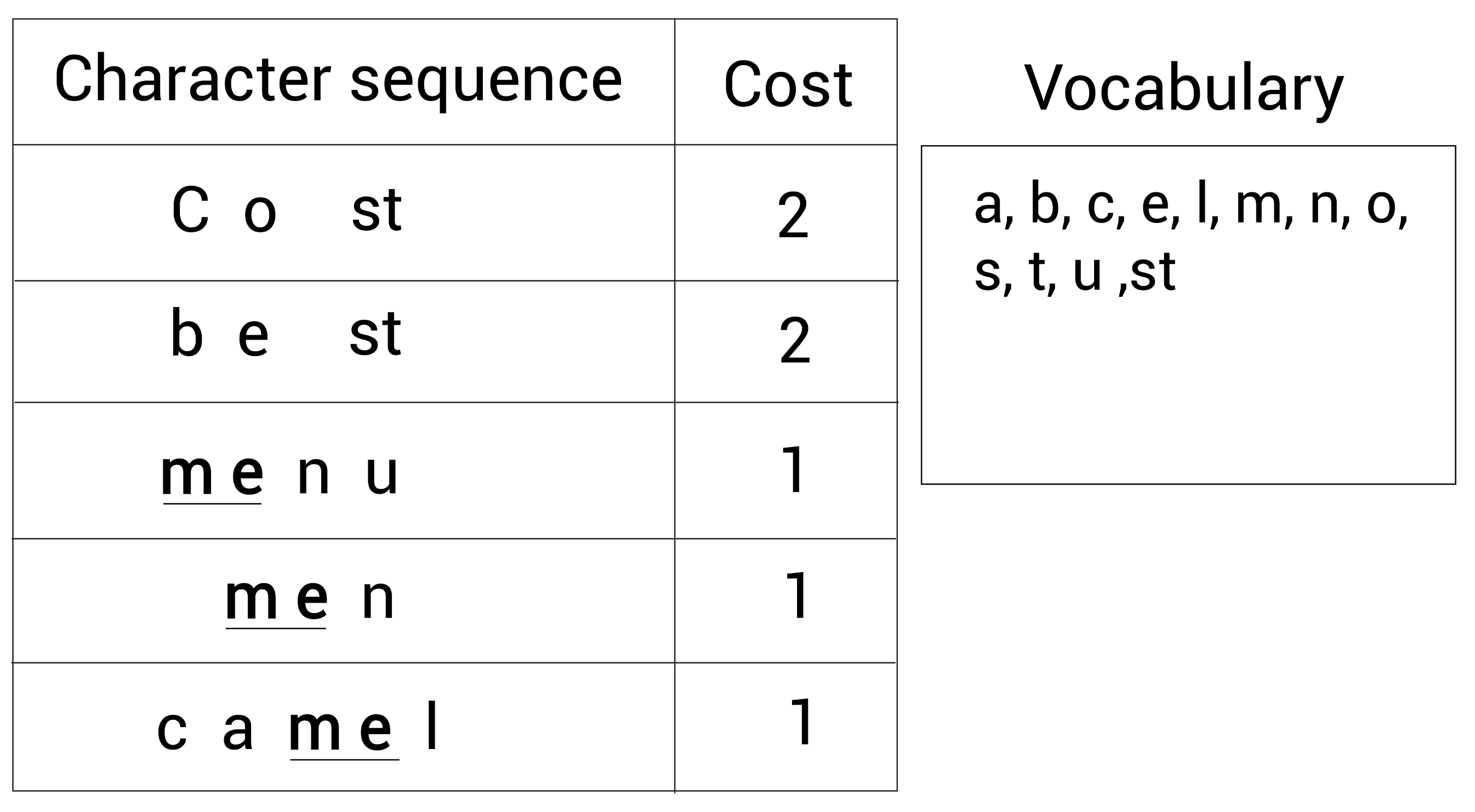
所以我们合并字符m和e为me并加入词表, 现在的词表(右边的Vocabulary)大小为 13,仍然需要添加新的subword到词表中:

再一次,我们继续检查出现最多的字符对。我们此时发现最常见的字符对是me和n,它们一起出现了2次:
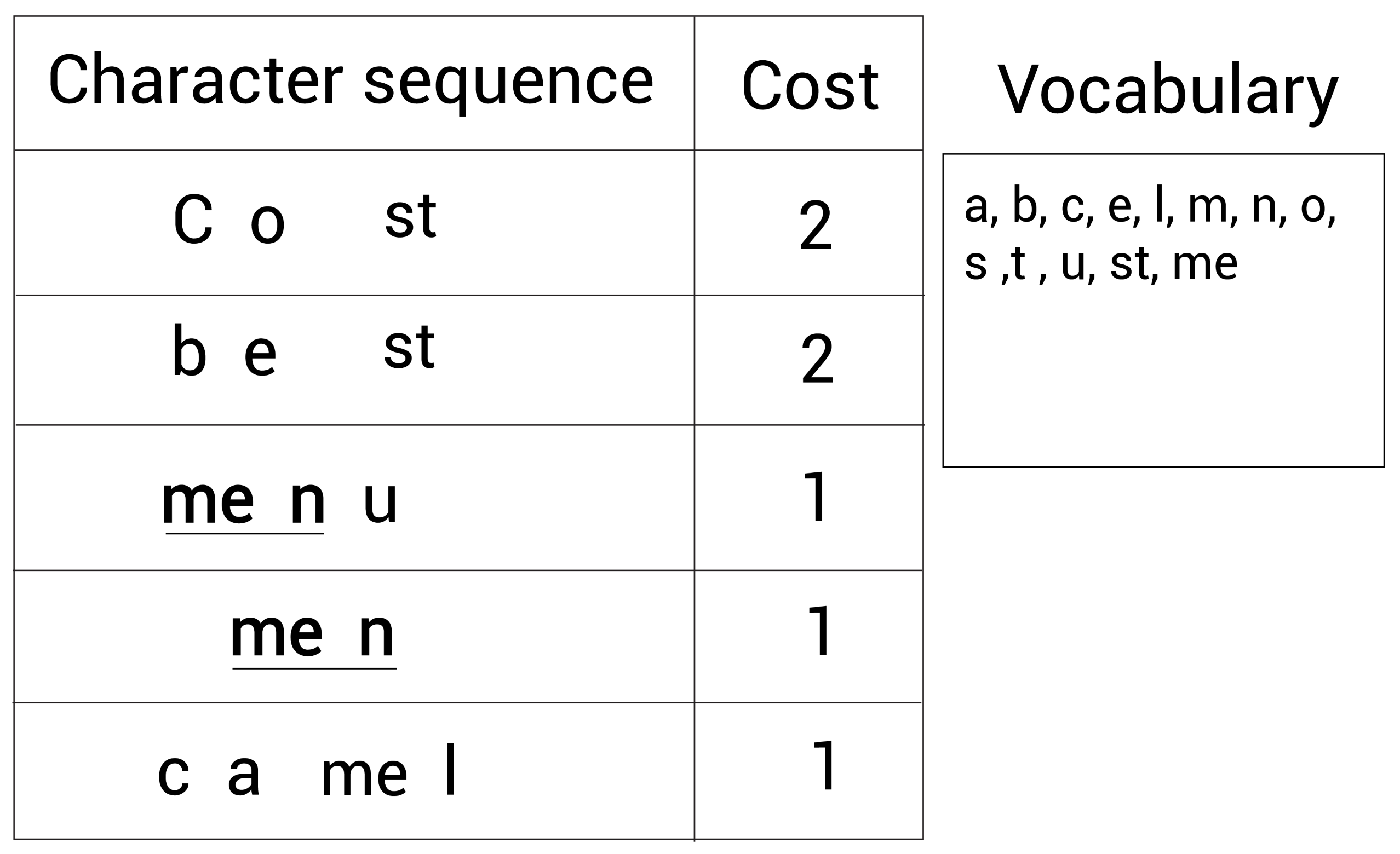
所以,我们继续合并me和n为men,然后加入词表,现在的词表(右边的Vocabulary)大小为 14,词表大小达到了预定义的值,BPE算法停止。

在本例中,使用BPE算法创建了大小为 14的词表:
vocabulary = {a,b,c,e,l,m,n,o,s,t,u,st,me,men}
3-1-3 BPE词表分词实例
假设输入文本只包含一个单词,我们目前有三个文本,分别是mean、star、men,我们使用BPE算法创建的词表进行分词。
1.mean
首先检查单词mean是否出现在词表中,检查后发现此单词并未出现在词表中。所以我们将该单词进行拆分,首先拆分为两个子词[me, an];然后检查这些子词是否出现在词表中;发现me出现在词表中,an则没有;因此,继续拆分子词an,所以现在子词包含[me, a, n]。现在检查字符a和n是否出现在词表中,现在拆分的所有子词都出现在了词表中,因此我们最终得到的标记如下:
tokens = [me,a,n] 2.star
首先检查单词star是否出现在词表中,检查后发现此单词并未出现在词表中。所以我们拆分为子词[st, ar];然后检查子词是否在词表中;发现子词st在词表中,而ar不在;下面继续拆分子词ar,所以现在子词包括[st, a, r]。现在我们检查字符a和r是否在词表中。显然a在而r不在。因为我r只是一个字符,所以我们无法继续拆分,因此只能将它替换为<UNK>标记,这样我们最终的标记为:
tokens = [st,a,<UNK>] 我们知道BPE可以很好的处理稀有词,但是现在我们有一个<UNK>标记。这是因为我们的例子很小,字符r没有出现在词表中。如果我们用一个较大的语料库创建词表,我们的词表肯定会包含所有的字符。
3.men
首先检查单词men是否出现在词表中,检查后发现此单词出现在词表中。最终得到的标记为:
tokens = [men]3-2 字节级字节对编码(Byte-level byte pair encoding,BBPE)
3-2-1 BBPE简介
BBP的分词算法是针对于字符级别的,而BBPE是针对于字节级的,所以就有了字节级的字节对编码存在的意义。BBP不是将单词转换为字符序列,而是转换为字节序列。
3-2-2 实例
假设输入文本仅包含一个单词best。我们知道在BPE中,我们可以将该单词拆分为字符序列,可以得到:
Character sequence: b e s t然而在BBPE中,不是将单词转换为字符序列,而是转换为字节序列。我们该单词转换为如下的字节序列。这样,每个Unicode字符都转换成一个字节。单个字符可以包含1到4个字节。
Byte sequence: 62 65 73 74 假设输入是一个中文词汇:你好。现在,我们将它转换为字节级序列,得到:
Byte sequence: e4 bd a0 e5 a5 bd
通过这种方式,我们先将文本转换为字节级序列,然后应用BPE算法根据字节级符号对构建词表就可以了。
BBPE对于多语言情况下非常有用,它能非常有效地处理未登录词,同时处理多语言词表也非常出色。
3-3 WordPiece
3-3-1 WordPiece 简介
Google的Bert模型在分词的时候使用的是WordPiece算法。 与BPE算法类似,WordPiece算法也是每次从词表中选出两个子词合并成新的子词。与BPE的最大区别在于,如何选择两个子词进行合并:BPE选择频数最高的相邻子词合并,而WordPiece选择能够提升语言模型概率最大(似然概率)的相邻子词加入词表。所以我们合并在给定训练集上训练的语言模型中具有最高概率的字符对。
假设句子S=(t1,t2,...,tn)由n个子词组成,ti表示子词,且假设各个子词之间是独立存在的,则句子S的语言模型似然值等价于所有子词概率的乘积:
![]()
假设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子S似然值的变化可表示为:
![]()
似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
3-3-2 实例
在BPE中,合并的是最高频次的字符对。在BPE中,我们会合并s和t,因为它们一起出现的频次最高。
但是现在,在WordPiece中,会根据似然来合并单词。首先,会检查语言模型(通过给定数据集训练的语言模型)输出的每个字符对出现的概率。然后选取概率最高的那一对。字符对s和t出现的概率可以计算为:
![]()
如果它们的概率是最高的,那么我们就合并它们并加入到词表中。这样,我们就计算了每个字符对出现的概率并合并概率最高的那一对到词表中。
3-3-3 WordPiece词表分词实例
假设根据WordPiece构建的词表如下:
vocabulary = {a,b,c,e,l,m,n,o,s,t,u,st,me}
假设输入文本只包含一个单词:stem,我们使用WordPiece算法创建的词表进行分词。 首先检查单词stem是否出现在词表中,检查后发现此单词并未出现在词表中;下面所以我们拆分为子词[st, ##em],接下来我们检查是否这些子词出现在词表中;发现子词st在词表中,而em不在。我们继续拆分子词em,现在我们得到的子词为:[be, ##e, ##m]。现在我们继续检查是否字符e和m出现在词表中。因为它们都在词表中,所以我们最终得到的标记为:
tokens = [st, ##e, ##m] 3-4 Unigram Language Model (ULM)
3-4-1 ULM简介
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
对于句子S=(x1,x2,...,xm)为句子的一个分词结果,由m个子词组成。所以,当前分词下句子S的似然值可以表示为:
![]()
对于句子S,挑选似然值最大的作为分词结果,则可以表示为:
![]()
这里U(x)包含了句子的所有分词结果。在实际应用中,词表大小有上万个,直接罗列所有可能的分词组合不具有操作性。针对这个问题,可通过维特比算法得到来解决。
ULM通过EM算法(期望最大算法)来估计每个子词的概率P(xi)。假设当前词表V, 则M步最大化的对象是如下似然函数:

其中,|D|是语料库中语料数量。上述公式的一个直观理解是,将语料库中所有句子的所有分词组合形成的概率相加。
初始时,词表V并不存在。因而,ULM算法采用不断迭代的方法来构造词表以及求解分词概率:
1.初始时,建立一个足够大的词表。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。
2.针对当前词表,用EM算法求解每个子词在语料上的概率。
3.对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。
4.将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。
5.重复步骤2到4,直到词表大小减少到设定范围。
ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。
Reference:
1.https://helloai.blog.csdn.net/article/details/120211601
2.NLP三大Subword模型详解:BPE、WordPiece、ULM - 知乎
相关文章:
【深度学习】Subword Tokenization算法
在自然语言处理中,面临的首要问题是如何让模型认识我们的文本信息,词,是自然语言处理中基本单位,神经网络模型的训练和预测都需要借助词表来对句子进行表示。 1.构建词表的传统方法 在字词模型问世之前,做自然语言处理…...
五分钟了解支付、交易、清算、银行等专业名词的含义?
五分钟了解支付、交易、清算、银行等专业名词的含义?1. 支付类名词01 支付应用02 支付场景03 交易类型04 支付类型(按通道类型)05 支付类型(按业务双方类型)06 支付方式07 支付产品08 收银台类型09 支付通道10 通道类型…...

4个工具,让 ChatGPT 如虎添翼!
LightGBM中文文档 机器学习统计学,476页 机器学习圣经PRML中文版...

初识PO、VO、DAO、BO、DTO、POJO时
PO、VO、DAO、BO、DTO、POJO 区别分层领域模型规约DO(Data Object)DTO(Data Transfer Object)BO(Business Object)AO(ApplicationObject)VO(View Object)Query领域模型命名规约:一、PO :(persistant object ),持久对象二、VO :(value object) ࿰…...
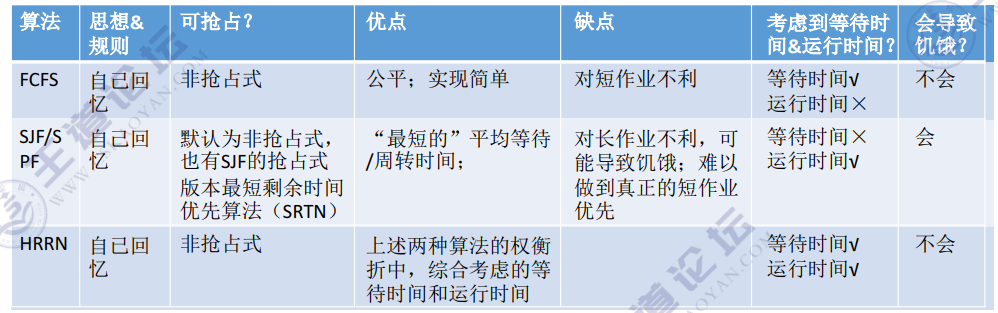
[2.2.4]进程管理——FCFS、SJF、HRRN调度算法
文章目录第二章 进程管理FCFS、SJF、HRRN调度算法(一)先来先服务(FCFS, First Come First Serve)(二)短作业优先(SJF, Shortest Job First)对FCFS和SJF两种算法的思考(三…...

【代码随想录Day55】动态规划
583 两个字符串的删除操作 https://leetcode.cn/problems/delete-operation-for-two-strings/72 编辑距离https://leetcode.cn/problems/edit-distance/...

Java开发 - 消息队列前瞻
前言 学完了Redis,那你一定不能错过消息队列,要说他俩之间的关联?关联是有的,但也不见得很大,只是他们都是大数据领域常用的一种工具,一种用来提高程序运行效率的工具。常见于高并发,大数据&am…...
MySQL连接IDEA详细教程
使用IDEA的时候,需要连接Database,连接时遇到了一些小问题,下面记录一下操作流程以及遇到的问题的解决方法。 目录 MySQL连接IDEA详细教程 MySQL连接IDEA详细教程 打开idea,点击右侧的 Database 或者 选择 View --> Tool Wind…...
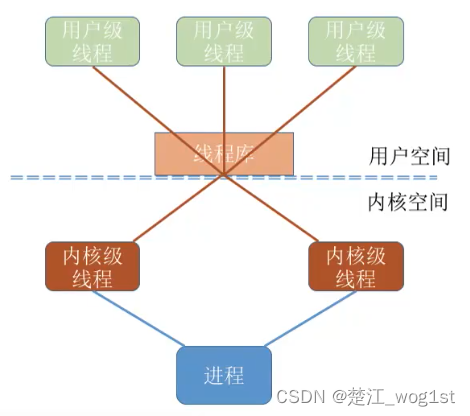
线程(操作系统408)
基本概念 我们说引入进程的目的是更好的使用多道程序并发执行,提高资源的利用率和系统吞吐量;而引入线程的目的则是减小程序在并发执行的时候所付出的时间开销,提高操作系统的并发性能。 线程可以理解成"轻量级进程",…...

功耗降低99%,Panamorph超清VR光学架构解析
近期,投影仪变形镜头厂商Panamorph获得新型VR显示技术专利(US11493773B2),该专利方案采用了紧凑的结构,结合了Pancake透镜和光波导显示模组,宣称比传统VR方案的功耗、发热减少99%以上,可显著提高…...
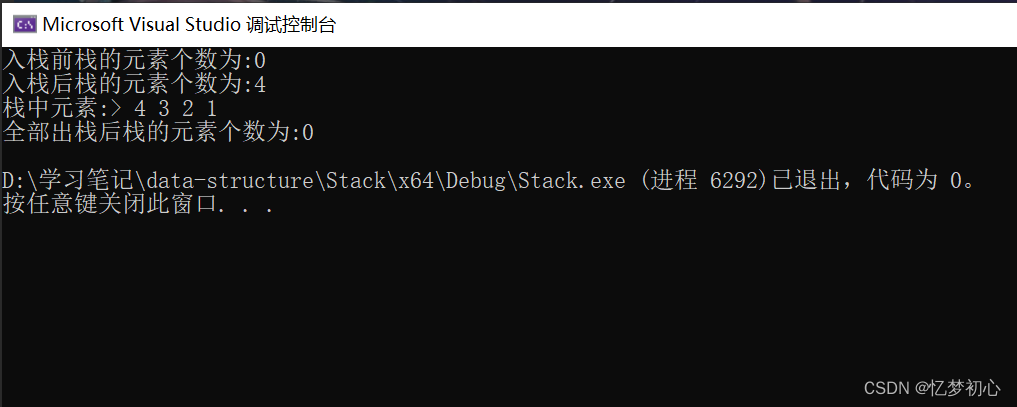
【数据结构】带你深入理解栈
一. 栈的基本概念💫栈是一种特殊的线性表。其只允许在固定的一端进行插入和删除元素的操作,进行数据的插入和删除的一端称作栈顶,另外一端称作栈底。栈不支持随机访问,栈的数据元素遵循后进先出的原则,即LIFOÿ…...
认识CSS之如何提高写前端代码的效率
🌟所属专栏:前端只因变凤凰之路🐔作者简介:rchjr——五带信管菜只因一枚😮前言:该系列将持续更新前端的相关学习笔记,欢迎和我一样的小白订阅,一起学习共同进步~👉文章简…...

Vue中watch和computed
首先这里进行声明,这个讲的是vue2的内容,在vue3发生了什么变动与此无关 这里是官网: https://v2.cn.vuejs.org/v2/guide/installation.html computed > 计算属性 watch > 侦听器(也叫监视器) 其区别如下&…...

华为鲲鹏+银河麒麟v10 安装 docker-ce
设备:硬件:仅有ARM处理器,无GPU和NPU,操作系统麒麟银河V10,Kunpeng-920 #######参考原链接######### 华为鲲鹏银河麒麟v10 安装 docker-ce 踩坑 - akiyaの博客 在 arm64(aarch64) 架构服务器上基于国产化操作系统安…...

Lambda,Stream,响应式编程从入门到放弃
Lambda表达式 Java8新引入的语法糖 Lambda表达式*(关于lambda表达式是否属于语法糖存在很多争议,有人说他并不是语法糖,这里我们不纠结于字面表述)*。Lambda表达式是一种用于取代匿名类,把函数行为表述为函数式编程风…...

C语言枚举使用技巧
什么是C语言枚举 C语言枚举是一种用户自定义数据类型,它允许程序员定义一个变量,并将其限制为一组预定义的常量。这些常量被称为“枚举值”,并且可以通过名称进行引用。 在C语言中,枚举值是整数类型,它们的值默认从0…...

保姆级使用PyTorch训练与评估自己的EfficientNetV2网络教程
文章目录前言0. 环境搭建&快速开始1. 数据集制作1.1 标签文件制作1.2 数据集划分1.3 数据集信息文件制作2. 修改参数文件3. 训练4. 评估5. 其他教程前言 项目地址:https://github.com/Fafa-DL/Awesome-Backbones 操作教程:https://www.bilibili.co…...

【9】基础语法篇 - VL9 使用子模块实现三输入数的大小比较
VL9 使用子模块实现三输入数的大小比较 【报错】官方平台得背锅 官方平台是真的会搞事情,总是出一些平台上的莫名其妙的错误。 当然如果官方平台是故意考察我们的细心程度,那就当我没有说!! 在这个程序里,仿真时一直在报错 错误:无法在“test”中绑定wire/reg/memory“t…...

成功的项目管理策略:减少成本,提高质量
项目管理是一项具有挑战性的任务,项目团队需要合理的规划和策略,以确保项目的成功和达成预期。为了实现项目的成功,项目经理必须采用正确的策略,才能以最大限度地减少成本并提高项目质量。本文将探讨成功的项目管理策略࿰…...

centos 7下JDK8安装
下载安装包https://www.oracle.com/java/technologies/downloads/#java8-linux上传路径 /usr/local(替换为自己需要安装的路径)解压tar -zxvf jdk-8u131-linux-x64.tar.gz配置环境变量[rootlocalhost java]# vi /etc/profile添加如下配置在配置文件最后&…...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

前端开发面试题总结-JavaScript篇(一)
文章目录 JavaScript高频问答一、作用域与闭包1.什么是闭包(Closure)?闭包有什么应用场景和潜在问题?2.解释 JavaScript 的作用域链(Scope Chain) 二、原型与继承3.原型链是什么?如何实现继承&a…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

Chromium 136 编译指南 Windows篇:depot_tools 配置与源码获取(二)
引言 工欲善其事,必先利其器。在完成了 Visual Studio 2022 和 Windows SDK 的安装后,我们即将接触到 Chromium 开发生态中最核心的工具——depot_tools。这个由 Google 精心打造的工具集,就像是连接开发者与 Chromium 庞大代码库的智能桥梁…...