RabbitMQ-Stream(高级详解)

文章目录
- 什么是流
- 何时使用 RabbitMQ Stream?
- 在 RabbitMQ 中使用流的其他方式
- 基本使用
- Offset参数
- chunk
- Stream 插件
- 服务端消息偏移量追踪
- 示例
- 示例应用程序
- RabbitMQ 流 Java API
- 概述
- 环境
- 创建具有所有默认值的环境
- 使用 URI 创建环境
- 创建具有多个 URI 的环境
- 启用 TLS
- 什么是TLS
- 创建使用 TLS 的环境
- 创建信任所有服务器证书进行开发的 TLS 环境
- 负载均衡
- 使用自定义地址解析程序始终使用负载均衡器
- 管理流
- 创建流
- 删除流
- 创建流时设置保留策略
- 创建流时设置基于时间的保留策略
- 服务端的偏移量跟踪
- 自动跟踪
- 使用默认值的自动跟踪策略
- 配置自动跟踪策略
- 手动跟踪
- 配置手动跟踪策略
- Kafka简单对比
更多相关内容可查看
什么是流
附官方文档:https://www.rabbitmq.com/docs/streams#overview
RabbitMQ Streams 是一种持久复制的数据结构,可以完成与队列相同的任务:它们缓冲来自生产者的消息,供消费者读取。 但是,流在两个重要方面与队列不同:消息的存储和使用方式。
流对消息的仅追加日志进行建模,这些消息可以重复读取,直到它们过期。 流始终是持久和复制的。对这种流行为的更技术性的描述是“非破坏性消费者语义”。
要从 RabbitMQ 中的流中读取消息,一个或多个使用者订阅该流并根据需要多次读取相同的消息。
流中的数据可以通过 RabbitMQ 客户端库或专用二进制协议插件和关联的客户端使用。 强烈建议使用后一种选项,因为它提供对所有特定于流的功能的访问,并提供最佳吞吐量(性能)。
对于流队列的描述是:高性能、可持久化、可复制、非破坏性消费、只追加写入的日志
何时使用 RabbitMQ Stream?
RabbitMQ Stream被开发用于满足以下消息传递使用情况:
- 大规模广播(Large fan-outs):当多个消费者应用程序需要读取相同的消息时。
- 回放/时光旅行(Replay / Time-traveling):当消费者应用程序需要读取整个数据历史记录或从流中的特定点开始时。
- 吞吐量性能(Throughput performance):当需要比其他协议(AMQP、STOMP、MQTT)更高的吞吐量时。
- 大型日志(Large logs):当需要存储大量数据,并且内存开销最小化时。
在 RabbitMQ 中使用流的其他方式
使用AMQP 0-9-1协议,可以在RabbitMQ中使用流抽象。与使用流协议从流中消费不同,使用AMQP 0-9-1协议时,可以从“流驱动”的队列中进行消费。所谓的“流驱动”队列是一种特殊类型的队列,它由流基础架构层支持,并经过调整以提供流语义(主要是非破坏性读取)。
使用这样的队列具有以下优点:可以利用流抽象固有的特性(仅追加结构,非破坏性读取),并与任何AMQP 0-9-1客户端库一起使用。考虑到AMQP 0-9-1客户端库的成熟度以及AMQP 0-9-1周围的生态系统,这显然是很有趣的。
但是,通过使用它,无法获得流协议的性能优势,因为流协议是专为性能而设计的,而AMQP 0-9-1是一种更通用的协议。
使用“流驱动”队列无法与流Java客户端一起使用,您需要使用AMQP 0-9-1客户端库。
基本使用
生产消息:
import pika
from pika import BasicProperties
from pika.adapters.blocking_connection import BlockingChannel
from pika.spec import Basic
STREAM_QUEUE = "stream_queue"
connection = pika.BlockingConnection(pika.ConnectionParameters("localhost", 5672, "/"))
channel = connection.channel()
//创建了一个到 RabbitMQ 代理的连接,然后创建了一个通道,并声明了一个持久化的流队列(stream queue),该队列名为 "stream_queue",参数为 {"x-queue-type": "stream"}。
channel.queue_declare(queue=STREAM_QUEUE, durable=True, arguments={"x-queue-type": "stream"})
//在循环中,将数字 500 到 599 发布到 "stream_queue" 队列中。
for i in range(500, 600):msg = f"{i}".encode()channel.basic_publish("", STREAM_QUEUE, msg)
channel.close()
connection.close()
消费消息:
import pika
from pika import BasicProperties
from pika.adapters.blocking_connection import BlockingChannel
from pika.spec import Basic
//channel:通道对象,用于确认消息
//method:Basic.Deliver 对象,包含有关传递消息的元数据。
//properties:BasicProperties 对象,包含消息的属性。
//body:消息的内容,以字节形式表示。
def msg_handler(channel: BlockingChannel, method: Basic.Deliver, properties: BasicProperties, body: bytes):msg = f"获取消息:{body.decode()}"print(msg)channel.basic_ack(method.delivery_tag)
STREAM_QUEUE = "stream_queue"connection = pika.BlockingConnection(pika.ConnectionParameters("localhost", 5672, "/"))
channel = connection.channel()
channel.queue_declare(queue=STREAM_QUEUE, durable=True, arguments={"x-queue-type": "stream"})
//创建了一个到 RabbitMQ 代理的连接,然后创建了一个通道,并声明了一个持久化的流队列(stream queue),该队列名为 "stream_queue",参数为 {"x-queue-type": "stream"}。
channel.basic_qos(prefetch_count=50)
//设置了消费者的 QoS(Quality of Service),限制了每次从队列中获取的消息数量为 50 条。
channel.basic_consume(STREAM_QUEUE, on_message_callback=msg_handler, arguments={"x-stream-offset": 290})
//订阅了 "stream_queue" 队列,并指定了消息处理函数 msg_handler,同时设置了消费者的流偏移量为 290。
channel.start_consuming()
//开始消费消息
channel.close()
connection.close()
//关闭了通道和连接。
Offset参数
附官网地址:https://www.rabbitmq.com/blog/2021/09/13/rabbitmq-streams-offset-tracking
偏移量是描述某种位置或相对位置的数值
绝对偏移量没有任何实际意义,只是一种技术概念。因此,当应用程序首次连接到流时,它不太可能使用偏移量,而更倾向于使用高级概念,如流的开头或结尾,甚至流中的某个时间点。
RabbitMQ Streams 支持除绝对偏移量之外的不同偏移量规范:.first、.last、.next、.next 和 timestamp。
对于流的“结尾”,有两种偏移量规范:.next 表示下一个将被写入的偏移量。如果消费者在 .next 处连接到流,而且没有人发布消息,那么消费者将不会接收到任何消息。只有当新消息到来时,消费者才会开始接收消息。
.last 表示“从最后一批消息开始”。,因为出于性能考虑,消息是批量处理的。
下图显示了流中的偏移量规范。
可以通过x-stream-offset来控制读取消息的位置
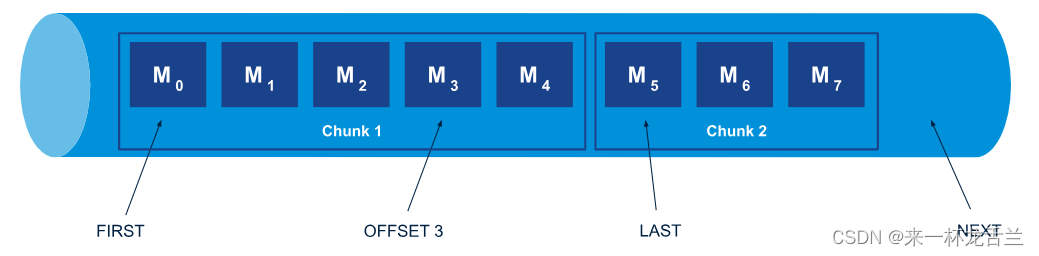
chunk
chunk就是stream队列中用于存储和传输消息的单元,一个chunk包含几条到几千条不等的消息。
Stream 插件
以上只是对Stream类型队列的简单使用,API和普通队列没有差异。若要体验完整的Stream队列特性,如:服务端消息偏移量追踪,需要启用stream插件,不启用和启用流插件功能特性对比
可参考: Stream Core vs Stream Plugin。
服务端消息偏移量追踪
Stream提供了服务端消息偏移量追踪,客户端断开重连后可以从上次消费的下一个位置开始消费消息。
示例
使用docker启动一个rabbitmq服务并启用stream插件:
docker run \-d --name rabbitmq \--hostname=node1 \--env=RABBITMQ_NODENAME=r1 \--env=RABBITMQ_SERVER_ADDITIONAL_ERL_ARGS='-rabbitmq_stream advertised_host localhost' \--volume=rabbit_erl:/var/lib/rabbitmq \-p 15672:15672 -p 5672:5672 -p 5552:5552 \rabbitmq:3-managementdocker exec rabbitmq rabbitmq-plugins enable rabbitmq_stream
这里使用rstream客户端来收发消息:
import asyncio
from rstream import (Producer
)
STREAM_QUEUE = "stream_queue"
CONSUMER_NAME = "py"
async def pub():async with Producer("localhost", 5552, username="guest", password="guest") as producer:await producer.create_stream(STREAM_QUEUE)for i in range(100, 300):await producer.send(STREAM_QUEUE, f"{i}".encode())
if __name__ == "__main__":asyncio.run(pub())
消费消息:
import asyncio
from rstream import (AMQPMessage,Consumer,ConsumerOffsetSpecification,MessageContext,OffsetType, OffsetNotFound
)
STREAM_QUEUE = "stream_queue"
CONSUMER_NAME = "py"
async def msg_handler(msg: AMQPMessage, context: MessageContext):print(msg)await context.consumer.store_offset(STREAM_QUEUE, CONSUMER_NAME, context.offset)
async def sub():consumer = Consumer("localhost", 5552, username="guest", password="guest")await consumer.start()try:offset = await consumer.query_offset(STREAM_QUEUE, CONSUMER_NAME)except OffsetNotFound:offset = 1await consumer.subscribe(STREAM_QUEUE, msg_handler,offset_specification=ConsumerOffsetSpecification(OffsetType.OFFSET, offset),subscriber_name=CONSUMER_NAME)await consumer.run()
if __name__ == "__main__":asyncio.run(sub())
示例应用程序
发布一些消息,然后注册 消费者对它们进行一些计算
创建环境
System.out.println("Connecting...");
//用于创建环境Environment#builder
Environment environment = Environment.builder().build();
String stream = UUID.randomUUID().toString();
//创建流
environment.streamCreator().stream(stream).create();
发布消息
System.out.println("Starting publishing...");
int messageCount = 10000;
CountDownLatch publishConfirmLatch = new CountDownLatch(messageCount);
//创建ProducerEnvironment#producerBuilder
Producer producer = environment.producerBuilder() .stream(stream).build();
IntStream.range(0, messageCount).forEach(i -> producer.send( //发送消息Producer#send(Message, ConfirmationHandler)producer.messageBuilder() .addData(String.valueOf(i).getBytes()) .build(), confirmationStatus -> publishConfirmLatch.countDown() // 消息发布确认倒计时));
publishConfirmLatch.await(10, TimeUnit.SECONDS); //等待所有发布确认到达
producer.close(); // 关闭生产者
System.out.printf("Published %,d messages%n", messageCount);
消费消息
System.out.println("Starting consuming...");
AtomicLong sum = new AtomicLong(0);
CountDownLatch consumeLatch = new CountDownLatch(messageCount);
//创建ConsumerEnvironment#consumerBuilder
Consumer consumer = environment.consumerBuilder() .stream(stream).offset(OffsetSpecification.first()) //从流的开头开始消费.messageHandler((offset, message) -> { //设置处理消息的逻辑//将消息正文中的值添加到总和sum.addAndGet(Long.parseLong(new String(message.getBodyAsBinary()))); //每条消息倒计时consumeLatch.countDown(); }).build();
//等待所有消息到达
consumeLatch.await(10, TimeUnit.SECONDS); System.out.println("Sum: " + sum.get());
//关闭消费者
consumer.close();
删除流并关闭环境
environment.deleteStream(stream); //删除流
environment.close(); //关闭环境
RabbitMQ 流 Java API
概述
RabbitMQ Stream 插件、发布消息和 使用消息。有 3 个主要接口:
- com.rabbitmq.stream.Environment用于连接到节点,并可选择管理流。
- com.rabbitmq.stream.Producer以发布消息。
- com.rabbitmq.stream.Consumer以使用消息。
环境
创建具有所有默认值的环境
Environment environment = Environment.builder().build(); //创建将连接到 localhost:5552 的环境
// ...
environment.close(); //使用后关闭环境
使用 URI 创建环境
Environment environment = Environment.builder().uri("rabbitmq-stream://guest:guest@localhost:5552/%2f") .build();// 使用该方法指定要连接到的 URIuri
创建具有多个 URI 的环境
Environment environment = Environment.builder().uris(Arrays.asList( "rabbitmq-stream://host1:5552","rabbitmq-stream://host2:5552","rabbitmq-stream://host3:5552")).build();// 使用该方法指定多个 URIuris启用 TLS
什么是TLS
TLS的主要功能包括:
- 加密(Encryption):TLS使用加密算法对传输的数据进行加密,使其在传输过程中不易被窃听或解读。常见的加密算法包括对称加密算法(如AES)和非对称加密算法(如RSA)。
- 身份验证(Authentication):TLS通过数字证书验证通信双方的身份,确保与对方建立安全连接的是预期的实体,而不是攻击者。
- 完整性保护(IntegrityProtection):TLS使用消息摘要算法(如HMAC)对传输的数据进行签名,以确保数据在传输过程中未被篡改或损坏。
创建使用 TLS 的环境
X509Certificate certificate;
try (FileInputStream inputStream =new FileInputStream("/path/to/ca_certificate.pem")) {CertificateFactory fact = CertificateFactory.getInstance("X.509");certificate = (X509Certificate) fact.generateCertificate(inputStream);
//这部分代码加载了一个X.509格式的CA证书文件(/path/to/ca_certificate.pem),这通常是由可信的证书颁发机构(CA)签发的。CA证书用于验证服务器的身份,并建立信任关系。
}SslContext sslContext = SslContextBuilder.forClient().trustManager(certificate) // 将 Netty 配置为信任 CA 证书SslContext.build();
//在这里,我们使用加载的CA证书构建了一个SSL上下文(SslContext),该上下文用于客户端的SSL/TLS通信。我们将加载的CA证书作为信任管理器传递给SslContextBuilder,以便客户端能够验证服务器证书的有效性。Environment environment = Environment.builder().uri("rabbitmq-stream+tls://guest:guest@localhost:5551/%2f") //在环境 URI 中使用 TLS 方案.tls().sslContext(sslContext) // 在环境配置中设置SslContext.environmentBuilder().build();
//在这里,我们创建了RabbitMQ Stream的环境配置。通过URI指定了连接地址和凭据信息。通过.tls().sslContext(sslContext)配置了TLS环境,将之前创建的SSL上下文应用于RabbitMQ Stream连接,确保了安全的通信。
创建信任所有服务器证书进行开发的 TLS 环境
Environment environment = Environment.builder().uri("rabbitmq-stream+tls://guest:guest@localhost:5551/%2f").tls().trustEverything() //信任所有服务器证书.environmentBuilder().build();负载均衡
使用自定义地址解析程序始终使用负载均衡器
Address entryPoint = new Address("my-load-balancer", 5552); //设置负载均衡器地址
Environment environment = Environment.builder().host(entryPoint.host()) //使用负载均衡器地址进行初始连接.port(entryPoint.port()) //使用负载均衡器地址进行初始连接.addressResolver(address -> entryPoint) //略元数据提示,始终使用负载均衡器.build();
管理流
创建流
environment.streamCreator().stream("my-stream").create();
删除流
environment.deleteStream("my-stream");
创建流时设置保留策略
environment.streamCreator().stream("my-stream").maxLengthBytes(ByteCapacity.GB(10)) //将最大大小设置为 10 GB.maxSegmentSizeBytes(ByteCapacity.MB(500)) //将段大小设置为 500 MB.create();
创建流时设置基于时间的保留策略
environment.streamCreator().stream("my-stream").maxAge(Duration.ofHours(6)) //将最长期限设置为 6 小时.maxSegmentSizeBytes(ByteCapacity.MB(500)) //将段大小设置为 500 MB.create();
服务端的偏移量跟踪
RabbitMQ Stream 提供了服务器端的偏移量跟踪功能。这意味着消费者可以跟踪它在流中所达到的偏移量。它允许消费者的新实例在其离开的地方重新开始消费。所有这些操作都不需要额外的数据存储,因为代理服务器存储了偏移量跟踪信息。
偏移量跟踪分为两个步骤:
- 消费者必须具有名称。名称是通过 ConsumerBuilder#name(String)方法设置的。名称可以是任意值(长度不超过256个字符),并且应该是唯一的(从应用程序的角度来看)。需要注意的是,无论是客户端库还是代理服务器都不强制名称的唯一性:如果两个
Java 实例共享相同的名称,它们的偏移量跟踪可能会交错,这通常不符合应用程序的预期。- 消费者必须定期存储其到目前为止已达到的偏移量。偏移量存储的方式取决于跟踪策略:自动或手动
自动跟踪
自动跟踪策略具有以下可用设置:
- 存储前的消息计数:客户端将在指定数量的消息之后存储偏移量,即在消息处理程序执行之后。默认值是每10,000条消息存储一次。
- 刷新间隔:客户端将确保在指定的间隔内存储最后接收到的偏移量。这可以避免在空闲时存在未存储的待处理偏移量。默认值为5秒。
使用默认值的自动跟踪策略
Consumer consumer =environment.consumerBuilder().stream("my-stream").name("application-1") //设置使用者名称.autoTrackingStrategy() //使用默认值的自动跟踪策略.builder().messageHandler((context, message) -> {// message handling code...}).build();
配置自动跟踪策略
Consumer consumer =environment.consumerBuilder().stream("my-stream").name("application-1") //设置使用者名称 .autoTrackingStrategy() //使用自动跟踪策略 .messageCountBeforeStorage(50_000) //存储每 50,000 条消息 .flushInterval(Duration.ofSeconds(10)) //确保至少每 10 秒存储一次偏移量 .builder().messageHandler((context, message) -> {// message handling code...}).build();
手动跟踪
配置手动跟踪策略
Consumer consumer =environment.consumerBuilder().stream("my-stream").name("application-1") //设置使用者名称.manualTrackingStrategy() //使用默认值的手动跟踪.checkInterval(Duration.ofSeconds(10)) //每 10 秒检查一次上次请求的偏移量 .builder().messageHandler((context, message) -> {// message handling code...if (conditionToStore()) {context.storeOffset(); //在某种条件下存储电流偏移 }}).build();
Kafka简单对比
| rabbitmq | kafka | |
|---|---|---|
| 生产/消费者 | queue | topic |
| 底层消息存储 | chunk | partition |
相关文章:
RabbitMQ-Stream(高级详解)
文章目录 什么是流何时使用 RabbitMQ Stream?在 RabbitMQ 中使用流的其他方式基本使用Offset参数chunk Stream 插件服务端消息偏移量追踪示例 示例应用程序RabbitMQ 流 Java API概述环境创建具有所有默认值的环境使用 URI 创建环境创建具有多个 URI 的环境 启用 TLS…...

Web前端图片并排显示的艺术与技巧
Web前端图片并排显示的艺术与技巧 在Web前端开发中,图片并排显示是一种常见的布局需求。然而,实现这一目标并非易事,需要掌握一定的技巧和艺术。本文将从四个方面、五个方面、六个方面和七个方面深入探讨Web前端图片并排显示的奥秘。 四个方…...

豆瓣电影信息爬虫【2024年6月】教程
豆瓣电影信息爬虫【2024年6月】教程,赋完整代码 在本教程中,我们将使用以下技术栈来构建一个爬虫,用于爬取豆瓣电影列表页面的信息: 完整代码放到最后 ; 完整代码放到最后 ; 完整代码放到最后 ;…...

Flutter- AutomaticKeepAliveClientMixin 实现Widget保持活跃状态
前言 在 Flutter 中,AutomaticKeepAliveClientMixin 是一个 mixin,用于给 State 类添加能力,使得当它的内容滚动出屏幕时仍能保持其状态,这对于 TabBarView 或者滚动列表中使用 PageView 时非常有用,因为这些情况下你…...

《计算机组成原理》期末复习题节选
第三章–存储系统 3.1 存储器性能指标 核心公式: 存储容量存储字数*字长 ,存储字数表示存储器的地址空间的大小,字长表示一次存取操作的数据量.数据传输率数据宽度/存储周期 1、设机器字长为32位,一个容量为16MB的存储器&…...

NSSCTF中的popchains、level-up、 What is Web、 Interesting_http、 BabyUpload
目录 [NISACTF 2022]popchains [NISACTF 2022]level-up [HNCTF 2022 Week1]What is Web [HNCTF 2022 Week1]Interesting_http [GXYCTF 2019]BabyUpload 今日总结: [NISACTF 2022]popchains 审计可以构造pop链的代码 <php class Road_is_Long{public $…...

量产维护 | 芯片失效问题解决方案:从根源找到答案
芯片失效分析是指对电子设备中的故障芯片进行检测、诊断和修复的过程。芯片作为电子设备的核心部件,其性能和可靠性直接影响整个设备的性能和稳定性。 随着半导体技术的迅速发展,芯片在各个领域广泛应用,如通信、计算机、汽车电子和航空航天等。 因此,对芯片故障原因进行…...

Linux忘记密码的解决方法
1、进入GRUB页面,选择对应的内核按下‘e’键; 2、进入内核修改信息界面,找到Linux这一行,在这一行的末尾加上 init/bin/sh 按下ctrlx进入单用户模式 3、进入单用户后,重新挂载根目录,使其可写࿱…...
数据结构(DS)学习笔记(二):数据类型与抽象数据类型
参考教材:数据结构C语言版(严蔚敏,杨伟民编著) 工具:XMind、幕布、公式编译器 正在备考,结合自身空闲时间,不定时更新,会在里面加入一些真题帮助理解数据结构 目录 1.1数据…...

【C++进阶】模板与仿函数:C++编程中的泛型与函数式编程思想
📝个人主页🌹:Eternity._ ⏩收录专栏⏪:C “ 登神长阶 ” 🤡往期回顾🤡:栈和队列相关知识 🌹🌹期待您的关注 🌹🌹 ❀模板进阶 🧩<&…...

华安保险:核心系统分布式升级,提升保费规模处理能力2-3倍 | OceanBase企业案例
在3月20日的2024 OceanBase数据库城市行的活动中,安保险信息科技部总经理王在平发表了以“保险行业核心业务系统分布式架构实践”为主题的演讲。本文为该演讲的精彩回顾。 早在2019年,华安保险便开始与OceanBase接触,并着手进行数据库的升级…...

佐西卡在美国InfoComm 2024展会上亮相投影镜头系列
6月12日至14日,2024美国视听显示与系统集成展览会将在拉斯维加斯会议中心盛大开幕。这场北美最具影响力的视听技术盛会,将汇集全球顶尖的视听解决方案,展现专业视听电子系统集成、灯光音响等领域的最新技术动态。 在这场科技盛宴中࿰…...

【权威出版/投稿优惠】2024年智慧城市与信息化教育国际会议(SCIE 2024)
2024 International Conference on Smart Cities and Information Education 2024年智慧城市与信息化教育国际会议 【会议信息】 会议简称:SCIE 2024 大会时间:点击查看 大会地点:中国北京 会议官网:www.iacscie.com 会议邮箱&am…...

Android 应用程序 ANR 问题分析总结
ANR (Application Not Responding) 应用程序无响应。如果应用程序在UI线程被阻塞太长时间,就会出现ANR,通常出现ANR,系统会弹出一个提示提示框,让用户知道,该程序正在被阻塞,是否继续等待还是关闭。 1、AN…...

爬虫案例:建设库JS逆向
爬虫流程 1. 确定目标网址和所需内容 https://www.jiansheku.com/search/enterprise/ 只是个学习案例,所以目标就有我自己来选择,企业名称,法定代表人,注册资本,成立日期 2. 对目标网站,进行分析 动态…...

基于springboot的酒店管理系统源码数据库
时代的发展带来了巨大的生活改变,很多事务从传统手工管理转变为自动管理。自动管理是利用科技的发展开发的新型管理系统,这类管理系统可以帮助人完成基本的繁琐的反复工作。酒店是出门的必需品,无论出差还是旅游都需要酒店的服务。由于在旺季…...

Web前端开发 - 5 - JavaScript基础
JavaScript 一、JavaScript基础1. JavaScript入门2. 语句3. 数据类型4. 函数5. 对象6. 数组 一、JavaScript基础 1. JavaScript入门 <script> </script> <script type"text/javascript" src"xxx.js"> </script>//单行注释 /* 多…...

程序员之路:塑造卓越职业素养的探索与实践
序章 在这个数字时代,程序员作为技术进步的推动者,不仅需要掌握扎实的技术技能,更需具备高尚的职业素养,以应对日益复杂的行业挑战。职业素养,犹如编程中的“算法”,虽无形却决定着个人发展的效率与质量。本…...

C# Winform 在低DPI创建窗体后,在高DPI运行时,窗体会自动拉伸,导致窗体显示不全
C# Winform 在低DPI创建窗体后,在高DPI运行时,窗体会自动拉伸,导致窗体显示不全, 比如在分辨率为100% 的电脑创建C#项目,当运动到分辨率为125%的电脑运行时,后者运行的窗体会自动拉伸,窗体显示…...

JWT攻击手册(非常详细)零基础入门到精通,收藏这一篇就够了
JSON Web Token(JWT)对于渗透测试人员而言可能是一种非常吸引人的攻击途径,因为它们不仅是让你获得无限访问权限的关键,而且还被视为隐藏了通往以下特权的途径:特权升级,信息泄露,SQLiÿ…...

OPCUA结构体数据处理全解析:C#如何高效读写ExtensionObject中的复杂数据
OPCUA结构体数据处理全解析:C#如何高效读写ExtensionObject中的复杂数据 在工业自动化与物联网系统中,OPCUA协议已成为设备间数据交换的事实标准。当面对复杂的自定义结构体数据时,ExtensionObject的处理往往成为开发者的痛点。本文将深入剖析…...
)
为什么99%的Python团队还没用上AOT?2026年官方方案的3大硬伤与2个绕过技巧(含patch diff与CI集成脚本)
第一章:Python 原生 AOT 编译方案 2026 概览与演进脉络Python 长期以来以解释执行和 JIT 辅助(如 PyPy)为主流运行范式,而原生 Ahead-of-Time(AOT)编译在 2026 年迎来实质性突破:CPython 官方正…...

掌握Pwndbg调试器:从入门到精通的界面定制与配置指南
掌握Pwndbg调试器:从入门到精通的界面定制与配置指南 【免费下载链接】pwndbg Exploit Development and Reverse Engineering with GDB & LLDB Made Easy 项目地址: https://gitcode.com/GitHub_Trending/pw/pwndbg Pwndbg作为GDB和LLDB的增强扩展&#…...

别再只查‘待办’了!Flowable任务查询的三种高级场景:拾取、归还与候选组权限控制详解
Flowable任务管理的三大高阶场景:从候选池到个人待办的完整控制策略 当我们在处理业务流程自动化时,任务管理往往是最容易被简化的环节。大多数开发者止步于基础的待办列表查询,却忽视了任务流转过程中的精细控制。本文将带您深入Flowable任务…...

魔兽争霸3终极优化指南:如何解锁180fps帧率限制并解决现代硬件兼容性问题
魔兽争霸3终极优化指南:如何解锁180fps帧率限制并解决现代硬件兼容性问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸3作为经…...

text2vec-base-chinese终极指南:如何用768维向量彻底改变中文语义理解
text2vec-base-chinese终极指南:如何用768维向量彻底改变中文语义理解 【免费下载链接】text2vec-base-chinese 项目地址: https://ai.gitcode.com/hf_mirrors/ai-gitcode/text2vec-base-chinese 还在为中文文本的语义匹配而头疼吗?传统的基于关…...

一篇大模型Agents工作流优化最新综述
过去,人们总希望一个LLM直接把任务做完;现在,一个更现实的方向正在浮现——针对不同任务设计不同工作流,并让系统在执行前、执行中乃至执行后持续优化这条链路。 近日,Rensselaer Polytechnic Institute(RP…...

成为技术专家的捷径?不,只有长期主义的坚持
在软件测试领域,我们常常被一种“速成”的幻象所包围。铺天盖地的培训广告承诺“三个月精通自动化测试”、“六周成为性能测试专家”,各种“一招鲜”的测试工具和“万能”的测试框架被包装成通往成功的捷径。对于身处其中、渴望突破职业瓶颈的测试工程师…...

OmenSuperHub终极指南:简单三步掌控暗影精灵硬件性能
OmenSuperHub终极指南:简单三步掌控暗影精灵硬件性能 【免费下载链接】OmenSuperHub 项目地址: https://gitcode.com/gh_mirrors/om/OmenSuperHub 你是否厌倦了官方Omen Gaming Hub的臃肿体积和烦人广告?是否希望获得纯净的硬件控制体验…...

ARL灯塔扫不出指纹?手把手教你用Python脚本批量导入指纹库,提升资产识别准确率
ARL灯塔指纹识别优化实战:Python脚本批量导入与精准率提升指南 资产侦察灯塔(ARL)作为渗透测试领域的重要工具,其核心价值在于准确识别目标资产的技术特征。然而许多中级用户发现,默认指纹库在面对特定行业或新型资产…...