Hive---sqoop安装教程及sqoop操作
sqoop安装教程及sqoop操作
文章目录
- sqoop安装教程及sqoop操作
- 上传安装包
- 解压并更名
- 添加jar包
- 修改配置文件
- 添加sqoop环境变量
- 启动
- sqoop操作
- 查看指定mysql服务器数据库中的表
- 在hive中创建一个teacher表跟mysql的mysql50库中的teacher结构相同
- 将mysql中mysql50库中的sc数据导出到hdfs指定的文件目录中
- sqoop -m 参数
- 带条件过滤
- 带条件过滤,指定查询列
- query使用
- 将mysql50中sc表导入到hive bigdata库中
- 重写,原数据会被覆盖
- 增量导入
上传安装包
这里两个安装包 sqoop-1.4.7 bin_hadoop-2.6.0.tar.gz和sqoop-1.4.7.tar.gz
因为hadoop版本为3.1.3 所以sqoop的版本太低,需要自行配置


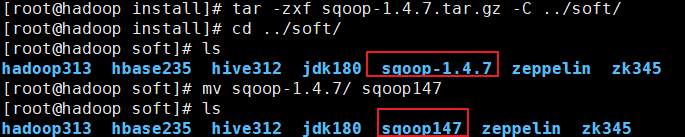
解压并更名
# 解压
[root@hadoop install]# tar -zxf sqoop-1.4.7.tar.gz -C ../soft/
# 切换目录
[root@hadoop install]# cd ../soft/
# 更名
[root@hadoop soft]# mv sqoop-1.4.7/ sqoop147
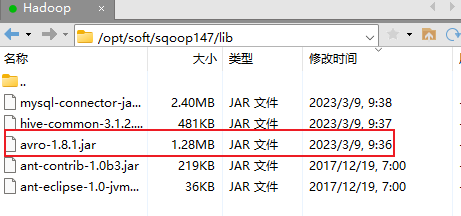
添加jar包
切换目录到 /opt/soft/sqoop147/lib/
添加avro-1.8.1.jar
# 将hive312/lib下的两个jar包拷贝过来
[root@hadoop lib]# cp /opt/soft/hive312/lib/hive-common-3.1.2.jar ./
[root@hadoop lib]# cp /opt/soft/hive312/lib/mysql-connector-java-8.0.29.jar ./

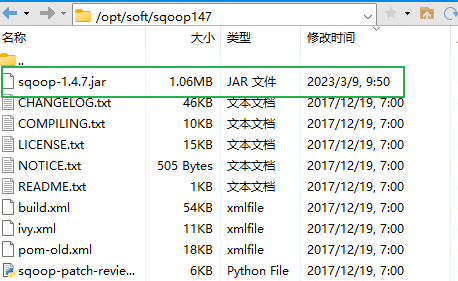
将sqoop-1.4.7.jar 拷贝到 /opt/soft/sqoop147/

修改配置文件
切换到cd /opt/soft/sqoop147/conf
# 将配置文件复制并更名
[root@hadoop conf]# cp sqoop-env-template.sh sqoop-env.sh
# 编辑 sqoop-env.sh
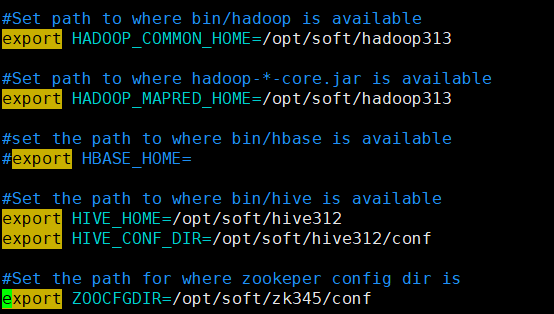
[root@hadoop conf]# vim ./sqoop-env.sh 22 #Set path to where bin/hadoop is available23 export HADOOP_COMMON_HOME=/opt/soft/hadoop31324 25 #Set path to where hadoop-*-core.jar is available26 export HADOOP_MAPRED_HOME=/opt/soft/hadoop31327 28 #set the path to where bin/hbase is available29 #export HBASE_HOME=30 31 #Set the path to where bin/hive is available32 export HIVE_HOME=/opt/soft/hive31233 export HIVE_CONF_DIR=/opt/soft/hive312/conf34 35 #Set the path for where zookeper config dir is36 export ZOOCFGDIR=/opt/soft/zk345/conf

添加sqoop环境变量
# 编辑/etc/profile
[root@hadoop conf]# vim /etc/profile
# SQOOP_HOME
export SQOOP_HOME=/opt/soft/sqoop147
export PATH=$PATH:$SQOOP_HOME/bin
# 刷新文件
[root@hadoop conf]# source /etc/profile

启动
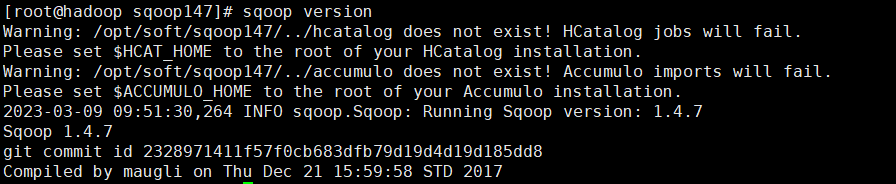
[root@hadoop conf]# sqoop version
sqoop操作
\ 符号为连接符
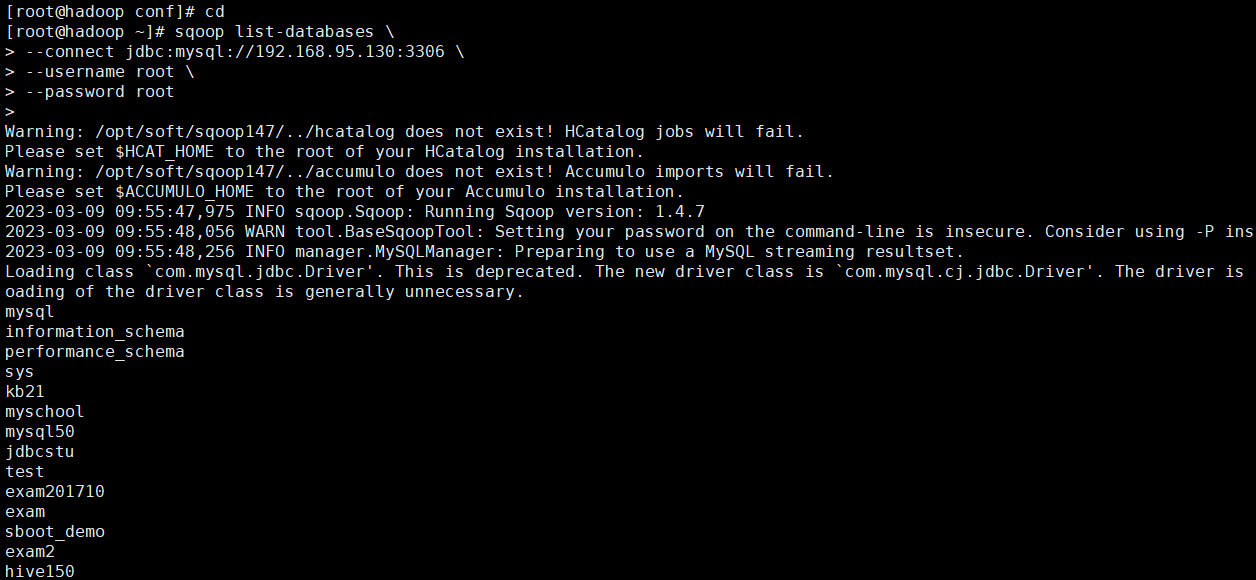
查看指定mysql服务器数据库中的表
[root@hadoop ~]# sqoop list-databases --connect jdbc:mysql://192.168.95.130:3306 --username root --password root
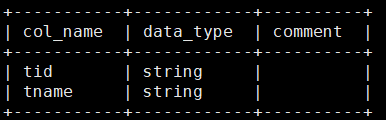
在hive中创建一个teacher表跟mysql的mysql50库中的teacher结构相同
[root@hadoop ~]# sqoop create-hive-table --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table teacher --hive-table teacher
将mysql中mysql50库中的sc数据导出到hdfs指定的文件目录中
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --target-dir /tmp/mysql50/sc --fields-terminated-by '\t' -m 1
sqoop -m 参数
sqoop并行化是启多个map task实现的,-m(或–num-mappers)参数指定map task数,默认是四个。当指定为1时,可以不用设置split-by参数,不指定num-mappers时,默认为4,当不指定或者num-mappers大于1时,需要指定split-by参数。并行度不是设置的越大越好,map task的启动和销毁都会消耗资源,而且过多的数据库连接对数据库本身也会造成压力。在并行操作里,首先要解决输入数据是以什么方式负债均衡到多个map的,即怎么保证每个map处理的数据量大致相同且数据不重复。–split-by指定了split column,在执行并行操作时(多个map task),sqoop需要知道以什么列split数据,其思想是:
1、先查出split column的最小值和最大值2、然后根据map task数对(max-min)之间的数据进行均匀的范围切分
带条件过滤
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --where "SID='01'" --target-dir /tmp/mysql50/sid01 -m 1
带条件过滤,指定查询列
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --columns "CID,score" --where "SID='01'" --target-dir /tmp/mysql50/sid01column -m 1
query使用
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --target-dir /tmp/mysql50/scquery --query 'select * from sc where $CONDITIONS and CID="02" and score>80 ' --fields-terminated-by '\t' -m 1
注意:如果使用–query这个命令的时候,需要注意的是where后面的参数, AND $ CONDITIONS 这个参数必须加上而且存在单引号与双引号的区别,如果–query后面使用的是双引号,那么需要在$CONDITIONS前加上 \即 \ $ CONDITIONS
如果设置map数量为1个时即-m 1,不用加上–split-by ${tablename.column},否则需要加上
将mysql50中sc表导入到hive bigdata库中
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --hive-import --hive-database bigdata -m 1
重写,原数据会被覆盖
[root@hadoop~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --hive-import --hive-overwrite --hive-database bigdata -m 1
增量导入
[root@hadoop ~]# sqoop import --connect jdbc:mysql://192.168.95.130:3306/mysql50 --username root --password root --table sc --hive-import --incremental append --hive-database bigdata -m 1
相关文章:
Hive---sqoop安装教程及sqoop操作
sqoop安装教程及sqoop操作 文章目录sqoop安装教程及sqoop操作上传安装包解压并更名添加jar包修改配置文件添加sqoop环境变量启动sqoop操作查看指定mysql服务器数据库中的表在hive中创建一个teacher表跟mysql的mysql50库中的teacher结构相同将mysql中mysql50库中的sc数据导出到h…...

【C++】register 关键字
文章目录一. 什么是寄存器?二. 为什么要存在寄存器?三. register 修饰变量一. 什么是寄存器? 我们都知道,CPU主要是负责进行计算的硬件单,但是为了方便运算,一般第一步需要先把数据从内存读取到CPU内&…...

剑指 Offer II 024. 反转链表
题目链接 剑指 Offer II 024. 反转链表 easy 题目描述 给定单链表的头节点 head,请反转链表,并返回反转后的链表的头节点。 示例 1: 输入:head [1,2,3,4,5] 输出:[5,4,3,2,1] 示例 2: 输入:h…...

从Linux内核中学习高级C语言宏技巧
Linux内核可谓是集C语言大成者,从中我们可以学到非常多的技巧,本文来学习一下宏技巧,文章有点长,但耐心看完后C语言level直接飙升。 本文出自:大叔的嵌入式小站,一个简单的嵌入式/单片机学习、交流小站 从…...

详解Python的装饰器
Python中的装饰器是你进入Python大门的一道坎,不管你跨不跨过去它都在那里。 为什么需要装饰器 我们假设你的程序实现了say_hello()和say_goodbye()两个函数。 def say_hello():print "hello!"def say_goodbye():print "hello!" # bug hereif…...

k8s-Pod域名学习总结
k8s-Pod域名学习总结 大纲 k8s内置DNS服务 配置Pod的域名服务 CornDNS配置 默认Pod的域名 自定义Pod的域名 实战需求 1 Pod有自己的域名 2 集群内部的Pod可以通过域名访问其他的Pod 基础准备: 1 k8s 集群版本1.17 k8s内置DNS服务 k8s1.17安装完成后自动创建…...

0405习题总结-不定积分
文章目录1 不定积分的基本概念2 直接积分法-基本积分公式3 第一换元法-凑微分形式法4 第二类换元法5 分部积分求不定积分6 表格法积分7 有理函数求积分后记1 不定积分的基本概念 例1 f(x){x1,x≥012e−x12,x<0求∫f(x)dxf(x) \begin{cases} x1,\quad x\ge0\\ \frac{1}{2}e^…...

QT 常用控件类型命名参考
拟定的QT的控件命名规则:蛇形命名方式 控件类型开头,以下是QT控件类型命名的参考范例 Buttons Buttons起始字符串对象名称举例Push Buttonbuttonbutton_loginTool Buttontool_button / buttonbutton_switchRadio Buttonradio_button / radioradio_boy…...
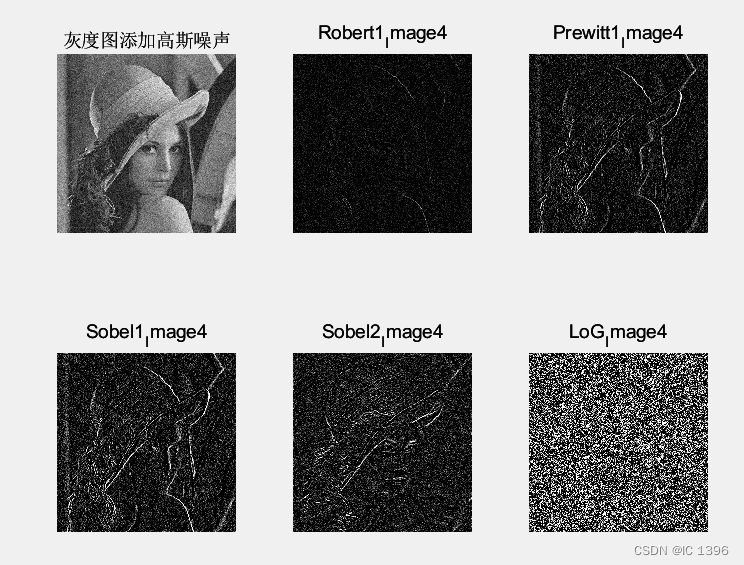
MATLAB与图像处理的那点小事儿~
目录 一、学习内容 二、matlab基本知识 三、线性点运算 四、非线性点运算,伽马矫正 五、直方图 1、直方图均衡化 (1)使用histep函数实现图像均衡化 (2)使用自行编写的均衡化函数实现图像均衡化 2、直方图规定…...
Java组个人题解)
第十四届蓝桥杯模拟赛(第三期)Java组个人题解
第十四届蓝桥杯模拟赛(第三期)Java组个人题解 今天做了一下第三期的校内模拟赛,有些地方不确定,欢迎讨论和指正~ 文章目录第十四届蓝桥杯模拟赛(第三期)Java组个人题解填空题部分第一题【最小数】第二题【E…...
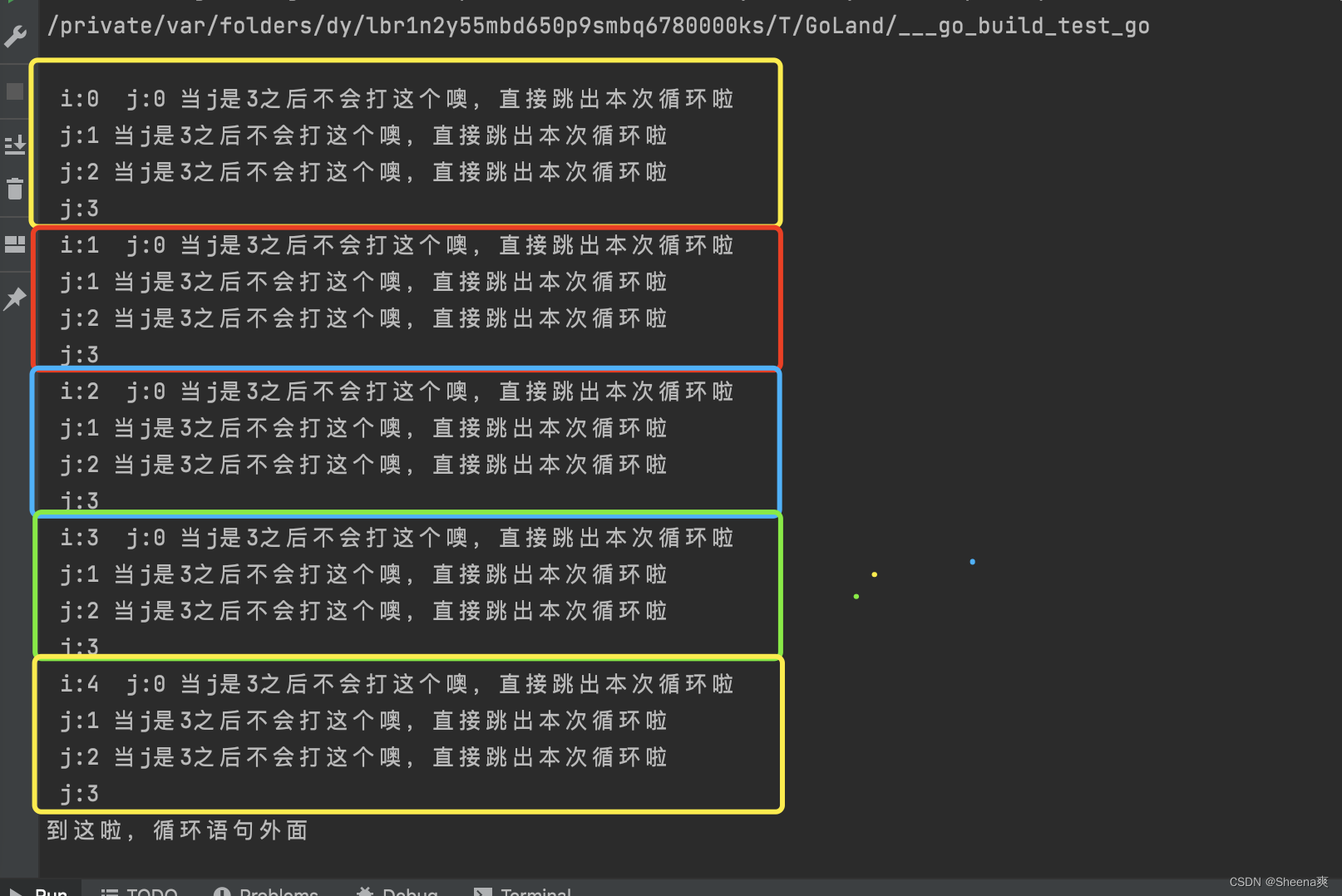
Go语言之条件判断循环语句(if-else、switch-case、for、goto、break、continue)
一、if-else条件判断语句 Go中的if-else条件判断语句跟C差不多。但是需要注意的是,Go中强制规定,关键字if和else之后的左边的花括号"{“必须和关键字在同一行,若使用了else if结构,则前段代码快的右花括号”}"必须和关…...
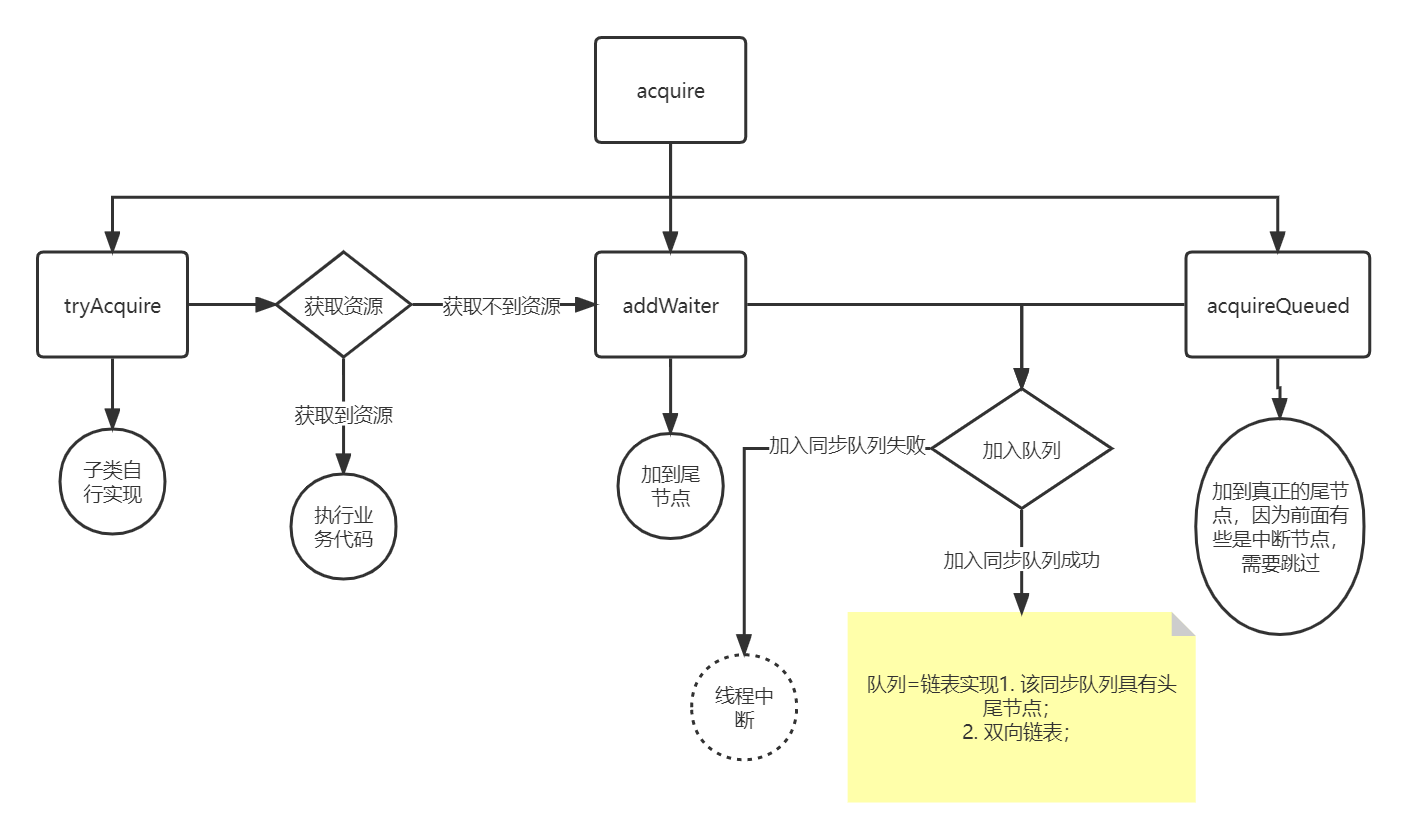
深入理解AQS
概念设计初衷:该类利用 状态队列 实现了一个同步器,更多的是提供一些模板方法(子类必须重写,不然会抛错)。 设计功能:独占、共享模式两个核心,state、Queue2.1 statesetState、compareAndSetSta…...
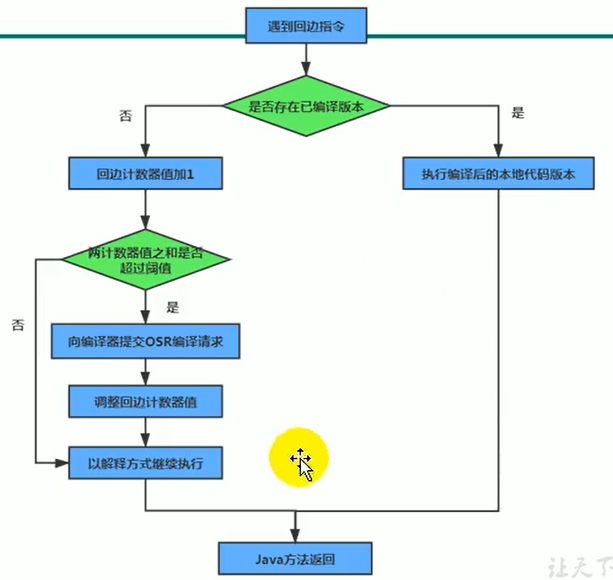
JVM学习笔记十:执行引擎
0. 前言 声明: 感谢尚硅谷宋红康老师的讲授。 感谢广大网友共享的笔记内容。 B站:https://www.bilibili.com/video/BV1PJ411n7xZ 本文的内容基本来源于宋老师的课件,其中有一些其他同学共享的内容,也有一些自己的理解内容。 1. …...
【2023-03-10】JS逆向之美团滑块
提示:文章仅供参考,禁止用于非法途径 前言 目标网站:aHR0cHM6Ly9wYXNzcG9ydC5tZWl0dWFuLmNvbS9hY2NvdW50L3VuaXRpdmVsb2dpbg 页面分析 接口流程 1.https://passport.meituan.com/account/unitivelogin主页接口:需获取下面的参数࿰…...

全志V853芯片放开快启方案打印及在快起方式下配置isp led的方法
全志V85x芯片 如何放开快启方案的打印? 1.主题 如何放开快启方案的打印 2.问题背景 产品:v851系列快启方案 软件:tina 其他:特有版本信息添加自由描述 (如固件版本,复现概率,特定环境&#x…...
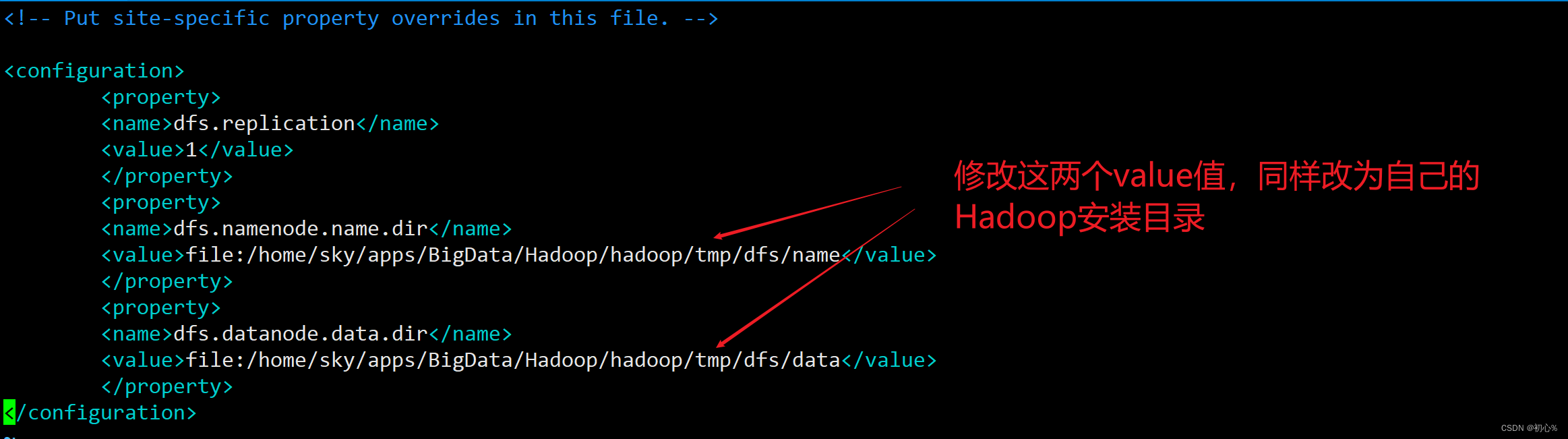
大数据 | (一)Hadoop伪分布式安装
大数据原理与应用教材链接:大数据技术原理与应用电子课件-林子雨编著 Hadoop伪分布式安装借鉴文章:Hadoop伪分布式安装-比课本详细 大数据 | (二)SSH连接报错Permission denied:SSH连接报错Permission denied 哈喽&a…...

Django/Vue实现在线考试系统-06-开发环境搭建-Django安装
1.0 基本介绍 Django 是一个由 Python 编写的一个开放源代码的 Web 应用框架。 使用 Django,只要很少的代码,Python 的程序开发人员就可以轻松地完成一个正式网站所需要的大部分内容,并进一步开发出全功能的 Web 服务 Django 本身基于 MVC 模型,即 Model(模型)+ View(…...
KaiwuDB 时序引擎数据存储内存对齐技术解读
一、理论1、什么是内存对齐现代计算机中内存空间都是按照 byte 划分的,在计算机中访问一个变量需要访问它的内存地址,从理论上看,似乎对任何类型的变量的访问都可以从任何地址开始。但在实际情况中,通常在特定的内存地址才能访问特…...
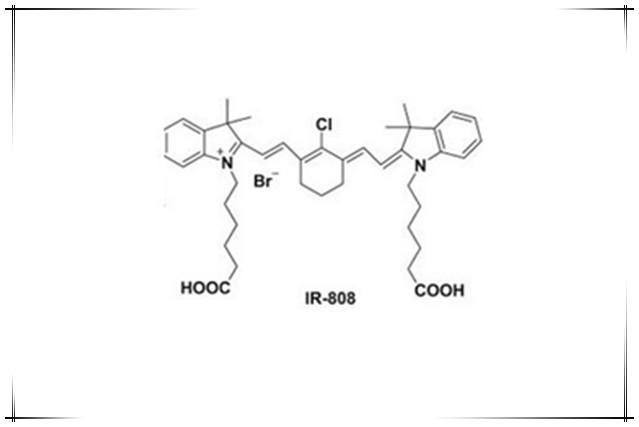
IR 808 Alkyne,IR-808 alkyne,IR 808炔烃,近红外吲哚类花菁染料
【产品理化指标】:中文名:IR-808炔烃英文名:IR-808 alkyne,Alkyne 808-IR CAS号:N/AIR-808结构式:规格包装:10mg,25mg,50mg,接受各种复杂PEGS定制服务&#x…...
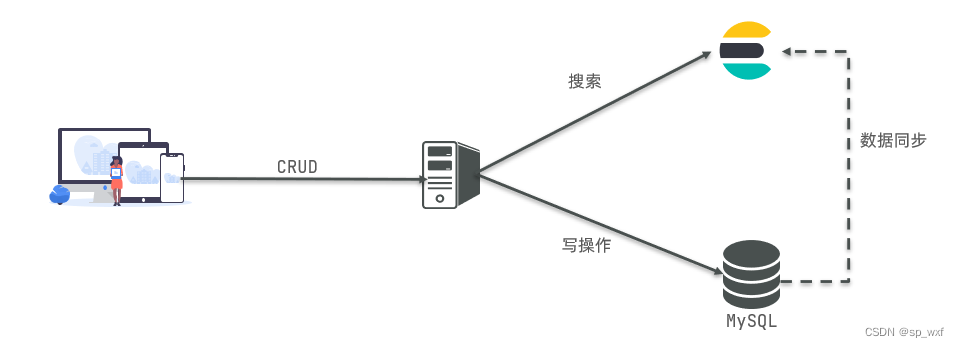
elasticsearch
这里写目录标题1.初识ElasticSearch1.1 了解ES1.2 倒排索引1.2.1 正向索引1.2.2 倒排索引1.2.3 正向和倒排1.3 ES的一些概念1.3.1 文档和字段1.3.2 索引和映射1.3.3 mysql和elasticsearch1.4 安装ES、kibana1.初识ElasticSearch 1.1 了解ES elasticsearch是一款非常强大的开源…...

web vue 项目 Docker化部署
Web 项目 Docker 化部署详细教程 目录 Web 项目 Docker 化部署概述Dockerfile 详解 构建阶段生产阶段 构建和运行 Docker 镜像 1. Web 项目 Docker 化部署概述 Docker 化部署的主要步骤分为以下几个阶段: 构建阶段(Build Stage):…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

DIY|Mac 搭建 ESP-IDF 开发环境及编译小智 AI
前一阵子在百度 AI 开发者大会上,看到基于小智 AI DIY 玩具的演示,感觉有点意思,想着自己也来试试。 如果只是想烧录现成的固件,乐鑫官方除了提供了 Windows 版本的 Flash 下载工具 之外,还提供了基于网页版的 ESP LA…...

解决本地部署 SmolVLM2 大语言模型运行 flash-attn 报错
出现的问题 安装 flash-attn 会一直卡在 build 那一步或者运行报错 解决办法 是因为你安装的 flash-attn 版本没有对应上,所以报错,到 https://github.com/Dao-AILab/flash-attention/releases 下载对应版本,cu、torch、cp 的版本一定要对…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

AspectJ 在 Android 中的完整使用指南
一、环境配置(Gradle 7.0 适配) 1. 项目级 build.gradle // 注意:沪江插件已停更,推荐官方兼容方案 buildscript {dependencies {classpath org.aspectj:aspectjtools:1.9.9.1 // AspectJ 工具} } 2. 模块级 build.gradle plu…...

微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据
微软PowerBI考试 PL300-在 Power BI 中清理、转换和加载数据 Power Query 具有大量专门帮助您清理和准备数据以供分析的功能。 您将了解如何简化复杂模型、更改数据类型、重命名对象和透视数据。 您还将了解如何分析列,以便知晓哪些列包含有价值的数据,…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

Linux系统部署KES
1、安装准备 1.版本说明V008R006C009B0014 V008:是version产品的大版本。 R006:是release产品特性版本。 C009:是通用版 B0014:是build开发过程中的构建版本2.硬件要求 #安全版和企业版 内存:1GB 以上 硬盘…...

C++_哈希表
本篇文章是对C学习的哈希表部分的学习分享 相信一定会对你有所帮助~ 那咱们废话不多说,直接开始吧! 一、基础概念 1. 哈希核心思想: 哈希函数的作用:通过此函数建立一个Key与存储位置之间的映射关系。理想目标:实现…...