SQL-窗口函数合集
目录
- 1.窗口函数简介
- 2.窗口的定义
- 3.相关题目示例
- 3.1 PERCENT_RANK()
- 2346 以百分比计算排名
- 3.2 FIRST_VALUE()/LAST_VALUE()/NTH_VALUE()
- 2388 将表中的空值更改为前一个值
1.窗口函数简介
MySQL 开窗函数(Window Functions)是 MySQL 8.0 版本引入的一个强大特性,它可以用于计算聚合的同时提供数据行的上下文信息。开窗函数可以分为以下几类:
- 聚合开窗函数:SUM(), AVG(), MIN(), MAX() 。
- 排名开窗函数:ROW_NUMBER(), RANK(), DENSE_RANK(), PERCENT_RANK() 。
- 首尾开窗函数:LEAD(), LAG(),LAST_VALUE(),FIRST_VALUE(),NTH_VALUE()。
- 其他:CUME_DIST() 、NTILE()。
窗口函数示例1:
mysql> SELECTtime, subject, val,SUM(val) OVER (PARTITION BY subject ORDER BY timeROWS UNBOUNDED PRECEDING)AS running_total,AVG(val) OVER (PARTITION BY subject ORDER BY timeROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING)AS running_averageFROM observations;
+----------+---------+------+---------------+-----------------+
| time | subject | val | running_total | running_average |
+----------+---------+------+---------------+-----------------+
| 07:00:00 | st113 | 10 | 10 | 9.5000 |
| 07:15:00 | st113 | 9 | 19 | 14.6667 |
| 07:30:00 | st113 | 25 | 44 | 18.0000 |
| 07:45:00 | st113 | 20 | 64 | 22.5000 |
| 07:00:00 | xh458 | 0 | 0 | 5.0000 |
| 07:15:00 | xh458 | 10 | 10 | 5.0000 |
| 07:30:00 | xh458 | 5 | 15 | 15.0000 |
| 07:45:00 | xh458 | 30 | 45 | 20.0000 |
| 08:00:00 | xh458 | 25 | 70 | 27.5000 |
+----------+---------+------+---------------+-----------------+
窗口函数示例2:
mysql> SELECTtime, subject, val,FIRST_VALUE(val) OVER w AS 'first',LAST_VALUE(val) OVER w AS 'last',NTH_VALUE(val, 2) OVER w AS 'second',NTH_VALUE(val, 4) OVER w AS 'fourth'FROM observationsWINDOW w AS (PARTITION BY subject ORDER BY timeROWS UNBOUNDED PRECEDING);
+----------+---------+------+-------+------+--------+--------+
| time | subject | val | first | last | second | fourth |
+----------+---------+------+-------+------+--------+--------+
| 07:00:00 | st113 | 10 | 10 | 10 | NULL | NULL |
| 07:15:00 | st113 | 9 | 10 | 9 | 9 | NULL |
| 07:30:00 | st113 | 25 | 10 | 25 | 9 | NULL |
| 07:45:00 | st113 | 20 | 10 | 20 | 9 | 20 |
| 07:00:00 | xh458 | 0 | 0 | 0 | NULL | NULL |
| 07:15:00 | xh458 | 10 | 0 | 10 | 10 | NULL |
| 07:30:00 | xh458 | 5 | 0 | 5 | 10 | NULL |
| 07:45:00 | xh458 | 30 | 0 | 30 | 10 | 30 |
| 08:00:00 | xh458 | 25 | 0 | 25 | 10 | 30 |
+----------+---------+------+-------+------+--------+--------+
2.窗口的定义
窗口的单位(frame unit):
- ROWS:表示当前行和 frame 行之间的偏移量是行号之间的差异
- RANGE:表示当前行和 frame 行之间的偏移量是行值与当前行值之间的差异
窗口的范围:
frame_between:BETWEEN frame_start AND frame_endframe_start, frame_end: {CURRENT ROW| UNBOUNDED PRECEDING| UNBOUNDED FOLLOWING| expr PRECEDING| expr FOLLOWING
}
窗口参数示例:
10 PRECEDING
INTERVAL 5 DAY PRECEDING
5 FOLLOWING
INTERVAL '2:30' MINUTE_SECOND FOLLOWING
注: 如果使用的是RANGE,则需要根据窗口排序中的列,选择对应的时间单位
常用的时间单位:MICROSECOND (microseconds), SECOND, MINUTE, HOUR, DAY, WEEK, MONTH, QUARTER, or YEAR…
mysql> SELECT DATE_ADD('2018-05-01',INTERVAL 1 DAY);-> '2018-05-02'
mysql> SELECT DATE_SUB('2018-05-01',INTERVAL 1 YEAR);-> '2017-05-01'
mysql> SELECT DATE_ADD('2020-12-31 23:59:59',-> INTERVAL 1 SECOND);-> '2021-01-01 00:00:00'
mysql> SELECT DATE_ADD('2018-12-31 23:59:59',-> INTERVAL 1 DAY);-> '2019-01-01 23:59:59'
mysql> SELECT DATE_ADD('2100-12-31 23:59:59',-> INTERVAL '1:1' MINUTE_SECOND);-> '2101-01-01 00:01:00'
mysql> SELECT DATE_SUB('2025-01-01 00:00:00',-> INTERVAL '1 1:1:1' DAY_SECOND);-> '2024-12-30 22:58:59'
mysql> SELECT DATE_ADD('1900-01-01 00:00:00',-> INTERVAL '-1 10' DAY_HOUR);-> '1899-12-30 14:00:00'
mysql> SELECT DATE_SUB('1998-01-02', INTERVAL 31 DAY);-> '1997-12-02'
mysql> SELECT DATE_ADD('1992-12-31 23:59:59.000002',-> INTERVAL '1.999999' SECOND_MICROSECOND);-> '1993-01-01 00:00:01.000001'
3.相关题目示例
3.1 PERCENT_RANK()
PERCENT_RANK()函数返回一个从0到1的数字。
对于指定的行,PERCENT_RANK()计算行的等级减1,除以评估的分区或查询结果集中的行数减1: (rank - 1) / (total_rows - 1) 在此公式中,rank是指定行的等级,total_rows是要计算的行数。
2346 以百分比计算排名
表: Students
+---------------+------+
| Column Name | Type |
+---------------+------+
| student_id | int |
| department_id | int |
| mark | int |
+---------------+------+
student_id 包含唯一值。
该表的每一行都表示一个学生的 ID,该学生就读的院系 ID,以及他们的考试分数。
编写一个解决方案,以百分比的形式报告每个学生在其部门的排名,其中排名的百分比使用以下公式计算:
(student_rank_in_the_department - 1) * 100 / (the_number_of_students_in_the_department - 1)。 percentage 应该 四舍五入到小数点后两位。
student_rank_in_the_department 由 mark 的降序决定,mark 最高的学生是 rank 1。如果两个学生得到相同的分数,他们也会得到相同的排名。
以 任意顺序 返回结果表。
结果格式如下所示。
示例 1:
输入:
Students 表:
+------------+---------------+------+
| student_id | department_id | mark |
+------------+---------------+------+
| 2 | 2 | 650 |
| 8 | 2 | 650 |
| 7 | 1 | 920 |
| 1 | 1 | 610 |
| 3 | 1 | 530 |
+------------+---------------+------+
输出:
+------------+---------------+------------+
| student_id | department_id | percentage |
+------------+---------------+------------+
| 7 | 1 | 0.0 |
| 1 | 1 | 50.0 |
| 3 | 1 | 100.0 |
| 2 | 2 | 0.0 |
| 8 | 2 | 0.0 |
+------------+---------------+------------+
解释:
对于院系 1:
- 学生 7:percentage = (1 - 1)* 100 / (3 - 1) = 0.0
- 学生 1:percentage = (2 - 1)* 100 / (3 - 1) = 50.0
- 学生 3:percentage = (3 - 1)* 100 / (3 - 1) = 100.0
对于院系 2: - 学生 2: percentage = (1 - 1) * 100 / (2 - 1) = 0.0
- 学生 8: percentage = (1 - 1) * 100 / (2 - 1) = 0.0
答案:
select student_id,department_id,round((percent_rank() over (partition by department_id order by mark desc))*100,2) as percentage
from Students3.2 FIRST_VALUE()/LAST_VALUE()/NTH_VALUE()
FIRST_VALUE() 函数的作用是返回子集中第一行的指定列数据,该函数的语法如下:
FIRST_VALUE(expr)
OVER ([partition_definition] [order_definition] [frame_clause]
)
其中,expr 为要获取数据的列明或者表达式,partition_definition 和 partition_definition 与 ROW_NUMBER() 函数一致;
frame_clause 的语法如下:
frame_unit {<frame_start>|<frame_between>}
LAST_VALUE() 和 FIRST_VALUE() 十分类似,区别在于 LAST_VALUE() 返回的是子集中的最后一条数据的指定列数据
NTH_VALUE() 的作用是获取指定 frame 中的第
N
个记录行的指定数据,对应的函数语法如下所示:
NTH_VALUE(expr, N)
OVER ([partition_definition] [order_definition] [frame_clause]
)
2388 将表中的空值更改为前一个值
表: CoffeeShop
+-------------+---------+
| Column Name | Type |
+-------------+---------+
| id | int |
| drink | varchar |
+-------------+---------+
id 是该表的主键(具有唯一值的列)。
该表中的每一行都显示了订单 id 和所点饮料的名称。一些饮料行为 null。
编写一个解决方案将 drink 的 null 值替换为前面最近一行不为 null 的 drink。保证表第一行的 drink 不为 null。
返回 与输入顺序相同的 结果表。
查询结果格式示例如下。
示例 1:
输入:
CoffeeShop 表:
+----+-------------------+
| id | drink |
+----+-------------------+
| 9 | Rum and Coke |
| 6 | null |
| 7 | null |
| 3 | St Germain Spritz |
| 1 | Orange Margarita |
| 2 | null |
+----+-------------------+
输出:
+----+-------------------+
| id | drink |
+----+-------------------+
| 9 | Rum and Coke |
| 6 | Rum and Coke |
| 7 | Rum and Coke |
| 3 | St Germain Spritz |
| 1 | Orange Margarita |
| 2 | Orange Margarita |
+----+-------------------+
解释:
对于 ID 6,之前不为空的值来自 ID 9。我们将 null 替换为 “Rum and Coke”。
对于 ID 7,之前不为空的值来自 ID 9。我们将 null 替换为 “Rum and Coke”。
对于 ID 2,之前不为空的值来自 ID 1。我们将 null 替换为 “Orange Margarita”。
请注意,输出中的行与输入中的行相同。
答案:
select id,first_value(drink) over(partition by group_id order by row_id) as drink
from(select *,sum(IF(drink is null, 0, 1)) over(order by row_id) as group_idfrom(select *,row_number() over() as row_idfrom coffeeshop) t0) t1
;
相关文章:

SQL-窗口函数合集
目录 1.窗口函数简介2.窗口的定义3.相关题目示例3.1 PERCENT_RANK()2346 以百分比计算排名 3.2 FIRST_VALUE()/LAST_VALUE()/NTH_VALUE()2388 将表中的空值更改为前一个值 1.窗口函数简介 MySQL 开窗函数(Window Functions)是 MySQL 8.0 版本引入的一个…...

2024 全球软件研发技术大会官宣,50+专家共话软件智能新范式!
2024年的全球软件研发技术大会(SDCon)由CSDN和高端IT咨询与教育平台Boolan联合主办,将于7月4日至5日在北京威斯汀酒店举行。本次大会的主题为“大模型驱动软件智能化新范式”,旨在探讨大模型和开源技术的发展如何引领全球软件研发…...
opencv快速安装以及各种查看版本命令
安装opencv并查看其版本,直接通过一个可执行文件实现。 #!/bin/bashwget https://codeload.github.com/opencv/opencv/zip/3.4 -O opencv-3.4.zip && unzip opencv-3.4.zip && cd opencv-3.4 && \mkdir build && cd build &&a…...
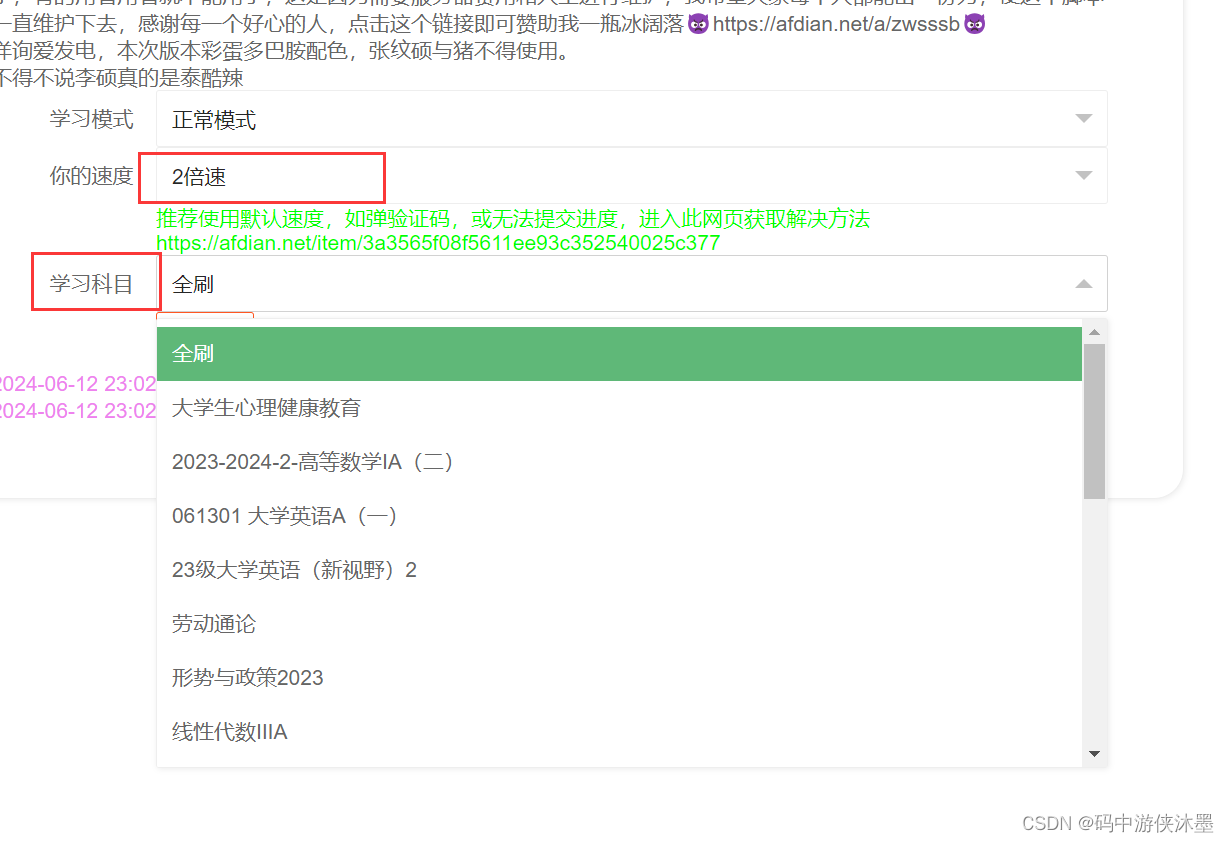
免费学习通刷课(免费高分)Pro版
文章目录 概要整体架构流程小结 概要 关于上一版的免费高分的学习通刷课,有很多人觉得还得登录太复杂了,然后我又发现了个神脚本,操作简单,可以后台挂着,但是还是建议调整速度到2倍速,然后找到你该刷的课&…...

线性数据结构-队列
队列(Queue)是一种先进先出(First In First Out, FIFO)的数据结构,它按照元素进入的顺序来处理元素。队列的基本操作包括: enqueue:在队列的末尾添加一个元素。dequeue:移除队列的第…...

python脚本将视频抽帧为图像数据集
AI应用开发相关目录 本专栏包括AI应用开发相关内容分享,包括不限于AI算法部署实施细节、AI应用后端分析服务相关概念及开发技巧、AI应用后端应用服务相关概念及开发技巧、AI应用前端实现路径及开发技巧 适用于具备一定算法及Python使用基础的人群 AI应用开发流程概…...

Xmind导入纯文本TXT方法
最近有很多同事咨询我如何在xmind直接导入纯文本txt笔记或者思维导图呢? 解决办法如下: 1.先打开xmind随便打开一个思维导图-文件-导出-marldown 2.选中导出的markdown文件。右键-打开方式-苹果系统选择文本编辑,Win系统选择记事本 3.按照图示…...

深度学习在老年痴呆检测中的应用:数据集综述
深度学习在老年痴呆检测中的应用:数据集综述 引言 老年痴呆(Alzheimer’s Disease, AD)是一种神经退行性疾病,主要影响老年人,导致记忆力、认知能力和行为的逐步衰退。早期检测和诊断对于延缓疾病进展、提高患者生活质量至关重要。近年来,深度学习技术在医学影像分析和…...
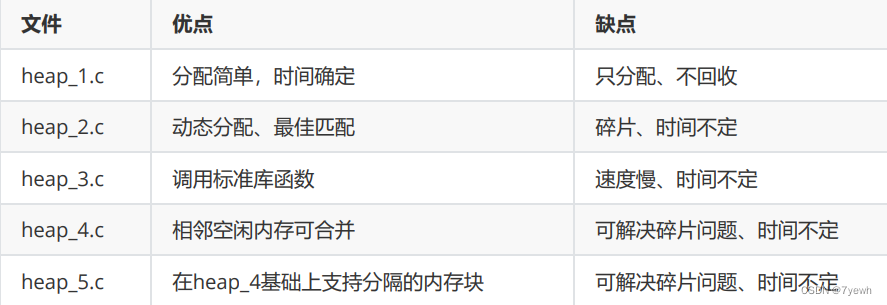
【FreeRTOS】内存管理笔记
一、为什么要自己实现内存管理? 后续的章节涉及这些内核对象:task、queue、semaphores和event group等。为了让FreeRTOS更容 易使用,这些内核对象一般都是动态分配:用到时分配,不使用时释放。使用内存的动态管理功能&…...

【数据结构】二叉树:一场关于节点与遍历的艺术之旅
专栏引入 哈喽大家好,我是野生的编程萌新,首先感谢大家的观看。数据结构的学习者大多有这样的想法:数据结构很重要,一定要学好,但数据结构比较抽象,有些算法理解起来很困难,学的很累。我想让大家…...

arm系统中双网卡共存问题
文章目录 单网卡单独运行双网卡共存问题双网卡解决方案方案一方案二方案三验证双网卡通过网卡名获取IP通过TCP与服务端通信参考单网卡单独运行 双网卡共存问题 双网卡解决方案 方案一 https://blog.csdn.net/HowieXue/article/details/75937972 方案二 http://bbs.witech…...
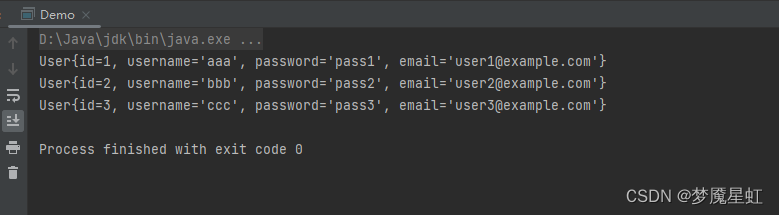
IDEA创建Mybatis项目
IDEA创建Mybatis项目 第一步:创建库表 -- 创建数据库 create database mybatis_db;-- 使用数据库 use mybatis_db;-- 创建user表 CREATE TABLE user (id INT AUTO_INCREMENT PRIMARY KEY,username VARCHAR(50) NOT NULL,password VARCHAR(50) NOT NULL,email VARC…...

排序---快速排序
前言 个人小记 一、代码 #include <stdio.h> #include <stdlib.h> #include <string.h> #include <time.h> #define MAX_ARR 100000 #define swap(a,b)\ {\__typeof(a) __ca;\ab,b__c;\ } #define TEST(func ,arr,l,r)\ {\int nr-l;\printf("tes…...

#08【面试问题整理】嵌入式软件工程师
前言 本系列博客主要记录有关嵌入式方面的面试重点知识,本系列已经更新的篇目有如下: 1.1进程线程的基本概念 1.2 并发,同步,异步,互斥,阻塞,非阻塞的理解 1.3 孤儿进程、僵尸进程、守护进程的概念 3.1 TCP UDP 【本篇】3.2 三次握手、四次挥手...
统计绘图 | 一行代码教你绘制顶级期刊要求配图
在分享完即可统计又可可视化绘制的优秀可视化包后(具体内容可看 统计绘图 | 既能统计分析又能可视化绘制的技能 。就有小伙伴私信问我需要绘制出版级别的可视化图表有什么快速的方法?“。鉴于我是一个比较宠粉的小编,几天就给大家推荐一个技巧࿰…...

[ue5]建模场景学习笔记(6)——必修内容可交互的地形,交互沙(4)
1.需求分析: 现在我们已经有了可以在世界内近于无限的跑动痕迹,现在需要对痕迹进行细化,包括例如当人物跳起时便不再绘制痕迹,以及痕迹应该存在深浅,应该由两只脚分别绘制,同时也应该对地面材质进行进一步处…...

5.2 参照完整性
5.2.1 外键约束 语法格式:constraint < symbol > foreign key ( col_nam1[, col_nam2... ] ) references table_name (col_nam1[, col_nam2...]) [ on delete { restrict | cascade | set null | no action } ] [ on update { restrict | cascade | set nu…...

SpringCache 缓存 - @Cacheable、@CacheEvict、@CachePut、@Caching、CacheConfig 以及优劣分析
目录 SpringCache 缓存 环境配置 1)依赖如下 2)配置文件 3)设置缓存的 value 序列化为 JSON 格式 4)EnableCaching 实战开发 Cacheable CacheEvict CachePut Caching CacheConfig SpringCache 的优势和劣势 读操作…...
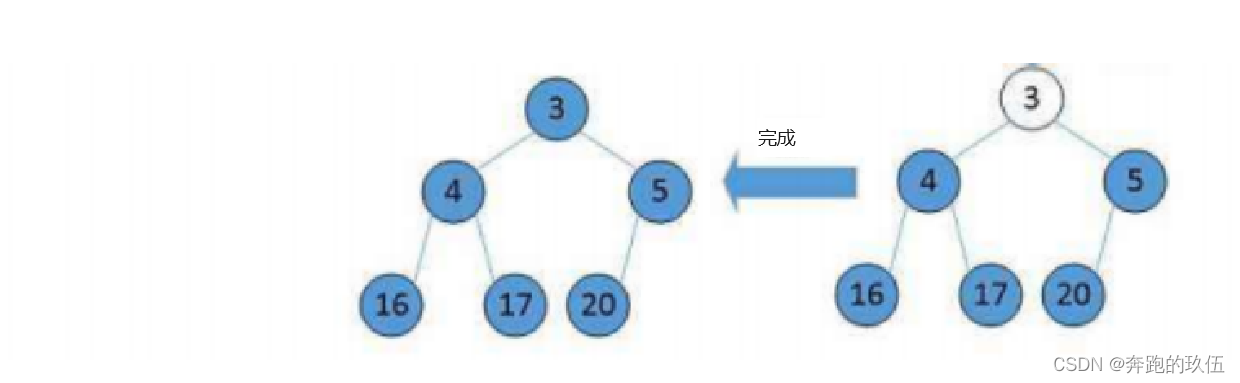
数据结构 —— 堆
1.堆的概念及结构 堆是一种特殊的树形数据结构,称为“二叉堆”(binary heap) 看它的名字也可以看出堆与二叉树有关系:其实堆就是一种特殊的二叉树 堆的性质: 堆中某个结点的值总是不大于或不小于其父结点的值&…...

【运维】如何更换Ubuntu默认的Python版本,update-alternatives如何使用
update-alternatives 是一个在 Debian 及其衍生发行版中(包括 Ubuntu)用于管理系统中可替代项的命令。它可以用于在系统中设置默认的软件版本,例如在不同版本的软件之间进行切换,比如不同的 Python 版本。 要在 Ubuntu 中使用 up…...

从Swish到Mish:我们为什么需要‘平滑’的激活函数?一次通俗的数学图解
从Swish到Mish:激活函数平滑化背后的设计哲学 在深度神经网络的世界里,激活函数就像神经元的"开关",决定了信息是否传递以及如何传递。2019年出现的Mish激活函数,以其独特的平滑特性和卓越表现,迅速成为研究…...

## 001、AI Agent 概述:什么是智能体?从概念到2026年的演进
上周调试一个边缘计算节点,遇到个挺有意思的“灵异事件”。设备端跑着一个基于大模型的Agent,负责根据传感器数据自动调整工业机械臂的抓取策略。日志里看,Agent明明已经“思考”出了最优路径,也生成了对应的控制指令,…...

从‘特征模仿’到‘特征补全’:手把手复现ECCV 2022的MGD,在MMDetection中为YOLO/RetinaNet做知识蒸馏实战
从特征模仿到特征补全:基于MMDetection的MGD蒸馏实战指南 在目标检测领域,模型轻量化与性能提升始终是开发者面临的永恒课题。知识蒸馏作为一种经典模型压缩技术,近年来从简单的输出层模仿逐步发展为多层次特征引导的复杂范式。ECCV 2022提出…...

Android AI工具箱开发:移动端模型部署与性能优化实战
1. 项目概述:一个为Android设备量身打造的AI工具箱最近在折腾Android设备上的AI应用时,发现了一个挺有意思的项目:niyazmft/droid-ai-toolkit。从名字就能看出来,这是一个专门为“Droid”(Android的昵称)打…...

多摄像头追踪系统中的相机标定技术与实践
1. 多摄像头追踪系统中的相机标定基础在构建基于AI的多摄像头追踪系统时,相机标定是最关键的基础环节之一。作为一名计算机视觉工程师,我参与过多个大型智能监控和零售分析项目,深刻体会到标定质量直接决定了整个系统的定位精度。简单来说&am…...
首次解禁:涵盖量子信道误码率实时上报、偏振反馈闭环控制及抗强电磁干扰IO映射表)
仅限3家国家级QKD实验室内部流通的C语言底层规范(V2.4.1)首次解禁:涵盖量子信道误码率实时上报、偏振反馈闭环控制及抗强电磁干扰IO映射表
更多请点击: https://intelliparadigm.com 第一章:C语言量子通信终端底层开发代码概览 量子通信终端的底层固件需在资源受限的嵌入式平台上实现高精度时序控制、量子态制备与单光子探测信号解析。C语言因其零开销抽象、内存可控性及广泛交叉编译支持&am…...
Vision Transformer错误处理终极指南:异常检测与恢复机制详解
Vision Transformer错误处理终极指南:异常检测与恢复机制详解 【免费下载链接】vit-pytorch Implementation of Vision Transformer, a simple way to achieve SOTA in vision classification with only a single transformer encoder, in Pytorch 项目地址: http…...

如何在3步内实现微信双设备登录:Xposed Hook技术深度解析
如何在3步内实现微信双设备登录:Xposed Hook技术深度解析 【免费下载链接】WeChatPad 强制使用微信平板模式 项目地址: https://gitcode.com/gh_mirrors/we/WeChatPad WeChatPad是一个基于Xposed框架的Android模块,通过Hook技术强制微信以平板模式…...
)
紫光同创PGL50H开发板实战:用异步FIFO IP核实现跨时钟域数据缓冲(附完整Verilog代码)
紫光同创PGL50H开发板实战:异步FIFO IP核在跨时钟域数据缓冲中的高级应用 在FPGA开发中,跨时钟域(CDC)数据传输是工程师经常面临的挑战之一。当高速ADC采集的数据需要传递给低速处理器处理,或者不同时钟域的功能模块需…...

当 AI 学会了 Arthas:从“人肉救火”到“智能诊断”的工程落地全解
当 AI 学会了 Arthas:从“人肉救火”到“智能诊断”的工程落地全解 一、问题的本质,从来不是不会敲命令 凌晨 2 点 57 分,订单服务突然告警:P99 RT 从 180ms 抬升到 8.3s,单 Pod CPU 接近 95%,Full GC 周期从十几分钟缩短到几十秒。值班群里一瞬间炸开了锅: 有人在登录…...