《MySQL是怎样运行的》读书笔记(三) B+树索引
前言
从前面数据存储结构中我们已经知道了页和记录的关系示意图:

其中页a、页b、页c ... 页n 这些页可以不在物理结构上相连,只要通过双向链表相关联即可。
在正式介绍索引之前,我们需要了解一下没有索引的时候是怎么查找记录的。下边先只讨论搜索条件为对某个列精确匹配的情况,即搜索条件中用 = 连接的表达式,比如这样:
SELECT [列名列表] FROM 表名 WHERE 列名 = xxx;
在一个页中的查找
假设目前表中的记录比较少,所有的记录都可以被存放到一个页中,在查找记录的时候可以根据搜索条件的不同分为两种情况:
以主键为搜索条件
这个查找过程我们已经很熟悉了,可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
以其他列作为搜索条件
对非主键列的查找,因为在数据页中并没有对非主键列建立的页目录 ,所以无法通过二分法快速定位相应的槽 。这种情况下只能从最小记录开始依次遍历单链表中的每条记录, 然后对比每条记录是不是符合搜索条件。很显然,这种查找的效率是非常低的。
在很多页中查找
通常情况下表中存放的记录都是非常多的,需要很多的数据页来存储这些记录。在很多页中查找记录可以分为两个步骤:
1. 定位到记录所在的页。
2. 从所在的页内中查找相应的记录。
在没有索引的情况下,不论是根据主键列或者其他列的值进行查找,由于我们并不能快速的定位到记录所在的页,所以只能从第一个页沿着双向链表一直往下找,在每一个页中根据我们刚刚讨论的查找方式去查找指定的记录。因为要遍历所有的数据页,所以这种方式显然是非常耗时的。
因此引出索引的使用。
索引原理
数据准备
先建一个表

该表行结构如下图所示:

在第10页里有3行数据的效果如下:

一个简单的索引方案
按照在一个页中给主键设置页目录的思路,我们也可以想办法为快速定位记录所在的数据页而建立一个别的目录,建这个目录必须满足以下要求:
1. 下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值
下面是原有的表,一页能放三条记录,页10插入3条记录(自动按主键大小排列),该页刚好满

现在插入一条记录 INSERT INTO index_demo VALUES(4, 4, 'a');
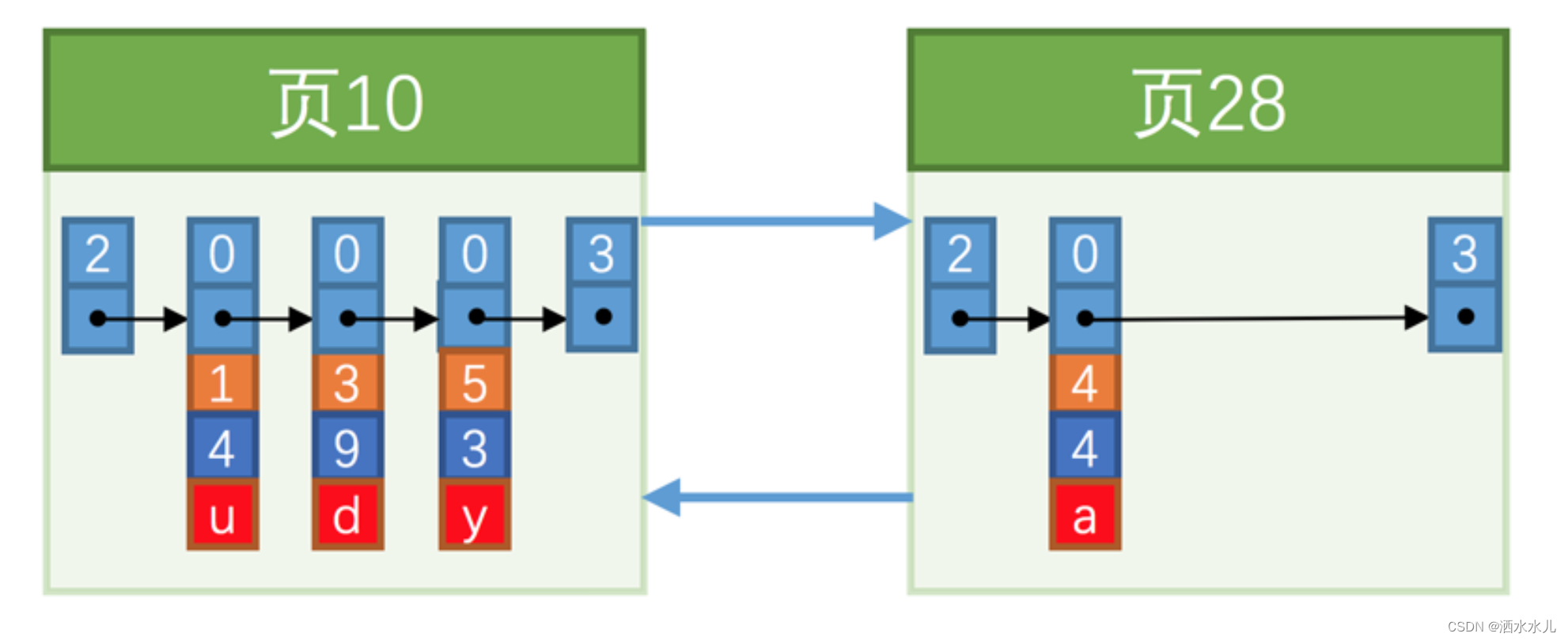
新分配的数据页编号可能并不是连续的,也就是说我们使用的这些页在存储空间里可能并不挨着。它们只是通过维护着上一个页和下一个页的编号而建立了链表关系。
另外, 页10 中用户记录最大的主键值是 5 ,而页28 中有一条记录的主键值是 4 ,因为 5 > 4 ,所以这就不符合下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值的要求,所以在插入主键值为 4 的记录的时候需要伴随着一次记录移动,也就是把主键值为 5 的记录移动到页28 中, 然后再把主键值为 4 的记录插入到 页10 中,这个过程的示意图如下:

这个过程表明了在对页中的记录进行增删改操作的过程中,我们必须通过一些诸如记录移动的操作来始终保证这个状态一直成立:下一个数据页中用户记录的主键值必须大于上一个页中用户记录的主键值。这个过程称为页分裂 。
2. 给所有的页建立一个目录项
由于数据页的编号可能并不是连续的,所以在向表中插入许多条记录后,可能是这样的效果:

因为这些 16KB 的页在物理存储上可能并不相邻,所以如果想从这么多页中根据主键值快速定位某些记录所在的页,我们需要给它们做个目录,每个页对应一个目录项,每个目录项包括下边两个部分:
1. 页的用户记录中最小的主键值,我们用 key 来表示。
2. 页号,我们用 page_no 表示。
我们为上边几个页做好的目录就像这样子:

以页28 为例,它对应目录项2 ,这个目录项中包含着该页的页号28以及该页中用户记录的最小主键值 5 。我们只需要把几个目录项在物理存储器上连续存储,比如把他们放到一个数组里,就可以实现根据主键值快速查找某条记录的功能了。
比方说我们想找主键值为20的记录,具体查找过程分两步: 先从目录项中根据二分法快速确定出主键值为 20 的记录在 目录项3 中(因为 12 < 20 < 209 ),它对应的页是页9 。再根据前边说的在页中查找记录的方式去页9 中定位具体的记录。
至此,针对数据页做的简易目录就搞定了。这个目录就是索引。
InnoDB中的索引方案
上边之所以称为一个简易的索引方案,是因为我们为了在根据主键值进行查找时使用二分法快速定位具体的目录项而假设所有目录项都可以在物理存储器上连续存储,但是这样做有两个问题:
1. InnoDB 是使用页来作为管理存储空间的基本单位,也就是最多能保证16KB的连续存储空间,而随着表中记录数量的增多,需要非常大的连续的存储空间才能把所有的目录项都放下,这对记录数量非常多的表是不现实的。
2. 我们时常会对记录进行增删,假设我们把页28 中的记录都删除了, 页28 也就没有存在的必要了,那意味着目录项2也就没有存在的必要了,这就需要把目录项2 后的目录项都向前移动一下,这种牵一发而动全身的设计不是什么好主意。
所以,设计 InnoDB 需要一种可以灵活管理所有目录项的方式。由于这些目录项其实长得跟我们的用户记录差不多,只不过目录项中的两个列是主键和页号而已,所以他们复用了之前存储用户记录的数据页来存储目录项,为了和用户记录做一下区分,我们把这些用来表示目录项的记录称为目录项记录 。那 InnoDB 怎么区分一条记录是普通的用户记录还是目录项记录呢?别忘了记录头信息里的record_type 属性,它的各个取值代表的意思如下:
0 :普通的用户记录
1 :目录项记录
2 :最小记录
3 :最大记录
我们把前边使用到的目录项放到数据页中的样子就是这样:

虽然说目录项记录 中只存储主键值和对应的页号,比用户记录需要的存储空间小多了,但是不论怎么说一个页 只有 16KB 大小,能存放的目录项记录也是有限的,那如果表中的数据太多,以至于一个数据页不足以存放所有的目录项记录 ,该咋办呢?
当然是套娃再多整一个存目录项记录的页。如果此时我们再向上图中插入一条主键值为 320 的用户记录的话,那就需要分配一个新的存储目录项记录的页,并且增加目录的目录:

这样已经很明显成了树的结构,并且父节点是子节点的目录,并且叶子节点全是数据行,这就是B+树。
不论是存放用户记录的数据页,还是存放目录项记录的数据页,我们都把它们存放到 B+ 树这个数据结构中了, 所以我们也称这些数据页为节点 。从图中可以看出来,我们的实际用户记录其实都存放在B+树的最底层的节点上,这些节点也被称为叶子节点,其余用来存放目录项的节点称为非叶子节点 。
为了讨论方便,规定最下边的那层,也就是存放我们用户记录的那层为第 0 层,之后依次往上加。之前的讨论我们做了一个非常极端的假设: 存放用户记录的页最多存放3条记录,存放目录项记录的页最多存放4条记录。其实真实环境中一个页存放的记录数量是非常大的,假设所有存放用户记录的叶子节点代表的数据页可以存放100条用户记录,所有存放目录项记录的内节点代表的数据页可以存放1000条目录项记录,那么:
如果 B+ 树只有1层,也就是只有1个用于存放用户记录的节点,最多能存放 100 条记录。
如果 B+ 树有2层,最多能存放 1000×100=100000 条记录。
如果 B+ 树有3层,最多能存放 1000×1000×100=100000000 条记录。
如果 B+ 树有4层,最多能存放 1000×1000×1000×100=100000000000 条记录。
一般情况下,我们用到的 B+ 树都不会超过4层,那我们通过主键值去查找某条记录最多只需要做4个页面内的查找(查找3个目录项页和一个用户记录页),又因为在每个页面内有页目录,所以在页面内也可以通过二分法实现快速定位记录。
聚簇索引
上边介绍的 B+ 树本身就是一个目录,或者说本身就是一个索引。它有两个特点:
1. 使用记录主键值的大小进行记录和页的排序,这包括三个方面的含义:
页内的记录是按照主键的大小顺序排成一个单向链表。
各个存放用户记录的页也是根据页中用户记录的主键大小顺序排成一个双向链表。
存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的主键大小顺序排成一个双向链表。
2. B+ 树的叶子节点存储的是完整的用户记录。 所谓完整的用户记录,就是指这个记录中存储了所有列的值(包括隐藏列)。
我们把具有这两种特性的B+ 树称为聚簇索引 ,所有完整的用户记录都存放在这个聚簇索引的叶子节点处。聚簇索引并不需要我们在 MySQL 语句中显式的使用 INDEX 语句去创建(后边会介绍索引相关的语句),InnoDB 存储引擎会自动的为我们创建聚簇索引。另外在 InnoDB 存储引擎中, 聚簇索引就是数据的存储方式(所有的用户记录都存储在了叶子节点 ),也就是所谓的索引即数据,数据即索引。
二级索引
上边介绍的聚簇索引只能在搜索条件是主键值时才能发挥作用,因为 B+ 树中的数据都是按照主键进行排序的。那如果我们想以别的列作为搜索条件该咋办呢?难道只能从头到尾沿着链表依次遍历记录么?
不,我们可以多建几棵 B+ 树,不同的 B+ 树中的数据采用不同的排序规则。比方说我们用 c2 列的大小作为数据页中记录的排序规则,再建一棵 B+ 树,效果如下图所示:

这个 B+ 树与上边介绍的聚簇索引有几处不同:
1. 使用记录 c2 列的大小进行记录和页的排序,这包括三个方面的含义:
页内的记录是按照 c2 列的大小顺序排成一个单向链表。
2. 各个存放用户记录的页也是根据页中记录的 c2 列大小顺序排成一个双向链表。 存放目录项记录的页分为不同的层次,在同一层次中的页也是根据页中目录项记录的 c2 列大小顺序排成一个双向链表。
3. B+ 树的叶子节点存储的并不是完整的用户记录,而只是 c2列+主键这两个列的值。 目录项记录中不再是 主键+页号 的搭配,而变成了 c2列+页号 的搭配。
所以如果我们现在想通过 c2 列的值查找某些记录的话就可以使用我们刚刚建好的这个 B+ 树了。以查找 c2 列的值为 4 的记录为例,查找过程如下:
1. 确定目录项记录页
根据根页面 ,也就是页44 ,可以快速定位到目录项记录 所在的页为页42 (因为 2 < 4 < 9 )。
2. 通过目录项记录 页确定用户记录真实所在的页。
在 页42 中可以快速定位到实际存储用户记录的页,但是由于 c2 列并没有唯一性约束,所以 c2 列值为 4 的记录可能分布在多个数据页中,又因为 2 < 4 ≤ 4 ,所以确定实际存储用户记录的页在 页34 和 页35 中。
3. 在真实存储用户记录的页中定位到具体的记录。
到页34 和页35 中定位到具体的记录。
4. 但是这个 B+ 树的叶子节点中的记录只存储了 c2 和 c1 (也就是 主键 )两个列,所以我们必须再根据主键值去聚簇索引中再查找一遍完整的用户记录。
因为这种按照非主键列建立的 B+ 树需要一次 回表操作才可以定位到完整的用户记录,所以这种 B+ 树也被称为 二级索引 (secondary index ),或者辅助索引 。 由于我们使用的是 c2 列的大小作为 B+ 树的排序规则,所以我们也称这个 B+ 树为为c2列建立的索引。
联合索引
我们也可以同时以多个列的大小作为排序规则,也就是同时为多个列建立索引,比方说我们想让 B+ 树按照 c2 和 c3 列的大小进行排序,这个包含两层含义:
先把各个记录和页按照 c2 列进行排序。
在记录的 c2 列相同的情况下,采用 c3 列进行排序
为 c2 和 c3 列建立的索引的示意图如下:
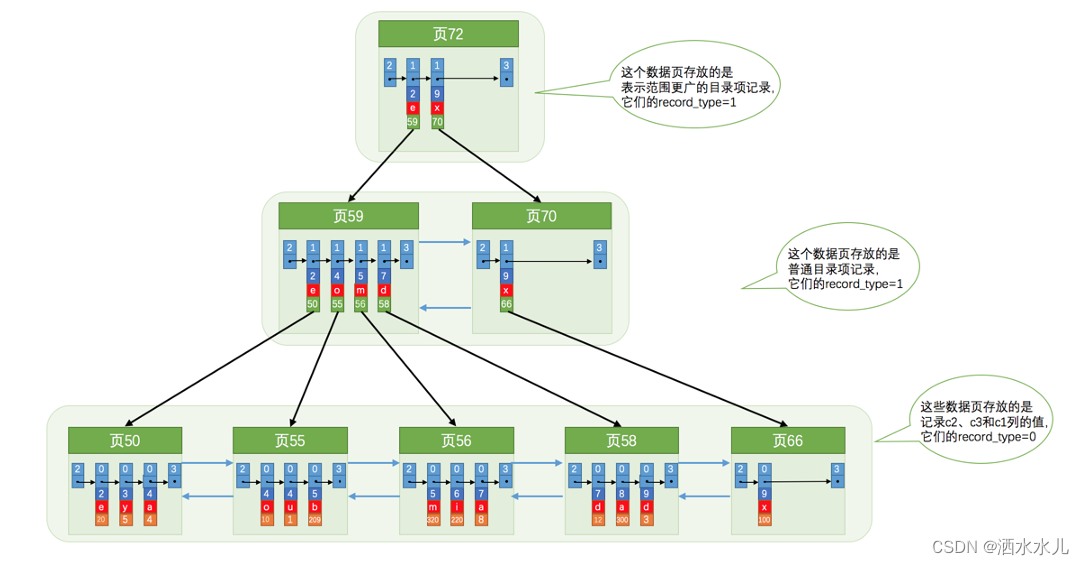
每条目录项记录都由c2、c3、页号这三个部分组成,各条记录先按照c2列的值进行排序,如果记录 的c2 列相同,则按照c3列的值进行排序。
B+ 树叶子节点处的用户记录由c2、c3和主键c1列组成。 千万要注意一点,以c2和c3列的大小为排序规则建立的B+树称为联合索引,本质上也是一个二级索引。它的意思 与分别为c2和c3列分别建立索引的表述是不同的,不同点如下: 建立联合索引只会建立如上图一样的1棵B+树。 为c2和c3列分别建立索引会分别以 c2 和 c3 列的大小为排序规则建立2棵B+树。
InnoDB的B+树索引的注意事项
B+树的形成过程是这样的:
每当为某个表创建一个B+树索引(聚簇索引不是人为创建的,默认就有)的时候,都会为这个索引创建一 个根节点页面。
最开始表中没有数据的时候,每个B+树索引对应的根节点中既没有用户记录,也没有目录项记录。 随后向表中插入用户记录时,先把用户记录存储到这个根节点中。 当根节点中的可用空间用完时继续插入记录,此时会将根节点中的所有记录复制到一个新分配的页,比如页a中,然后对这个新页进行页分裂的操作,得到另一个新页,比如页b。这时新插入的记录根据键值 (也就是聚簇索引中的主键值,二级索引中对应的索引列的值)的大小就会被分配到页a或者页b中,而根节点便升级为存储目录项记录的页。
这个过程需要大家特别注意的是:一个B+树索引的根节点自诞生之日起,便不会再移动。这样只要我们对某个表 建立一个索引,那么它的根节点的页号便会被记录到某个地方,然后凡是InnoDB存储引擎需要用到这个索引的 时候,都会从那个固定的地方取出根节点的页号,从而来访问这个索引。
如果我们想新插入一行记录,其中c1、c2、c3的值分别是:9、1、'c',那么在修改这个为c2列建立 的二级索引对应的B+树时便碰到了个大问题:由于页3中存储的目录项记录是由c2列 + 页号的值构成的, 页3 中的两条目录项记录对应的c2列的值都是1,而我们新插入的这条记录的c2列的值也是1,那我们这条 新插入的记录到底应该放到页4中,还是应该放到页5中啊?
为了让新插入记录能找到自己在那个页里,我们需要保证在B+树的同一层内节点的目录项记录除页号这个字段以外是唯一的。所以对于二级索引的内节点的目录项记录的内容实际上是由三个部分构成的: 索引列的值 +主键值 +页号
也就是我们把主键值也添加到二级索引内节点中的目录项记录了,这样就能保证B+树每一层节点中各条目录项 记录除页号这个字段外是唯一的,所以我们为c2列建立二级索引后的示意图实际上应该是这样子的:
这样我们再插入记录(9, 1, 'c') 时,由于 页3 中存储的目录项记录是由 c2列 + 主键 + 页号 的值构成的,可 以先把新记录的c2列的值和页3中各目录项记录的c2列的值作比较,如果c2列的值相同的话,可以接着比较 主键值,因为B+树同一层中不同目录项记录的c2列 + 主键的值肯定是不一样的,所以最后肯定能定位唯一的 一条目录项记录,在本例中最后确定新记录应该被插入到页5中。
我们前边说过一个B+树只需要很少的层级就可以轻松存储数亿条记录,查询速度杠杠的!这是因为B+树本质上 就是一个大的多层级目录,每经过一个目录时都会过滤掉许多无效的子目录,直到最后访问到存储真实数据的目 录。那如果一个大的目录中只存放一个子目录是个啥效果呢?那就是目录层级非常非常非常多,而且最后的那个 存放真实数据的目录中只能存放一条记录。费了半天劲只能存放一条真实的用户记录?逗我呢?所以InnoDB的 一个数据页至少可以存放两条记录
MyISAM中的索引方案
MyISAM的索引方案虽然也使用树 结构,但是却将索引和数据分开存储:
将表中的记录按照记录的插入顺序单独存储在一个文件中,称之为数据文件。这个文件并不划分为若干个 数据页,有多少记录就往这个文件中塞多少记录就成了。我们可以通过行号而快速访问到一条记录。 MyISAM 记录也需要记录头信息来存储一些额外数据。
看一下表中的记录使用MyISAM 作为存储引擎在存储空间中的表示

由于在插入数据的时候并没有刻意按照主键大小排序,所以我们并不能在这些数据上使用二分法进行查找。 使用MyISAM 存储引擎的表会把索引信息另外存储到一个称为索引文件的另一个文件中。
MyISAM会单独为 表的主键创建一个索引,只不过在索引的叶子节点中存储的不是完整的用户记录,而是主键值 + 行号的组 合。也就是先通过索引找到对应的行号,再通过行号去找对应的记录! 这一点和InnoDB 是完全不相同的,在 InnoDB 存储引擎中,我们只需要根据主键值对 聚簇索引进行一次查 找就能找到对应的记录,而在MyISAM 中却需要进行一次回表操作,意味着MyISAM中建立的索引相当于全 部都是二级索引!
如果有需要的话,我们也可以对其它的列分别建立索引或者建立联合索引,原理和InnoDB中的索引差不 多,不过在叶子节点处存储的是相应的列 + 行号。这些索引也全部都是二级索引。
索引的使用
B+树索引的代价
在熟悉了B+树索引原理之后,下文的主题是如何更好的使用索引,虽然索引是个好东西,但在介绍如何更好的使用索引之前先要了解一下使用索引的代价,它在空间和时间上都会拖后腿:
空间上的代价
这个是显而易见的,每建立一个索引都要为它建立一棵B+树,每一棵B+树的每一个节点都是一个数据页, 一个页默认会占用16KB 的存储空间,一棵很大的B+树由许多数据页组成,那可是很大的一片存储空间。
时间上的代价
每次对表中的数据进行增、删、改操作时,都需要去修改各个B+树索引。而且我们讲过,B+树每层节点都 是按照索引列的值从小到大的顺序排序而组成了双向链表。不论是叶子节点中的记录,还是内节点中的记录 (也就是不论是用户记录还是目录项记录)都是按照索引列的值从小到大的顺序而形成了一个单向链表。而 增、删、改操作可能会对节点和记录的排序造成破坏,所以存储引擎需要额外的时间进行一些记录移位,页面分裂、页面回收啥的操作来维护好节点和记录的排序。如果我们建了许多索引,每个索引对应的B+树都 要进行相关的维护操作,这还能不给性能拖后腿么?
所以说,一个表上索引建的越多,就会占用越多的存储空间,在增删改记录的时候性能就越差。为了能建立又好又少的索引,我们先得学学这些索引在哪些条件下起作用的。
B+树索引适用的条件
首先,B+树索引并不是万能的,并不是所有的查询语句都能用到我们建立的索引。下边介绍几个我们可能使用B+树索引来进行查询的情况。
首先建一个案例表:

对于这个person_info 表我们需要注意两点:
表中的主键是id列,它存储一个自动递增的整数。所以InnoDB存储引擎会自动为id列建立聚簇索引。 我们额外定义了一个二级索引idx_name_birthday_phone_number ,它是由3个列组成的联合索引。所以在这个索引对应的B+树的叶子节点处存储的用户记录只保留name、birthday 、 phone_number 这三个列的值 以及主键id 的值,并不会保存country 列的值。 从这两点注意中我们可以再次看到,一个表中有多少索引就会建立多少棵B+树,person_info 表会为聚簇索引和idx_name_birthday_phone_number 索引建立2棵 B+ 树。下边我们画一下索引 idx_name_birthday_phone_number 的示意图:

等值匹配
如果我们的搜索条件中的列和索引列一致的话,这种情况就称为等值匹配,比方说这个查找语句:

我们建立的idx_name_birthday_phone_number 索引包含的3个列在这个查询语句中展现出来了。
查询过程:
因为B+ 树的数据页和记录先是按照name列的值进行排序的,所以先可以很快定位name列的值是Ashburn 的记录位置。
在name 列相同的记录里又是按照birthday 列的值进行排序的,所以在 name 列的值是 Ashburn 的记录里又 可以快速定位birthday 列的值是 '1990-09-27' 的记录。
如果很不幸,name 和 birthday 列的值都是相同的,那记录是按照 phone_number 列的值排序的,所以联合 索引中的三个列都可能被用到
匹配左边的列
在我们的搜索语句中也可以不用包含全部联合索引中的列,只包含左边的就行,比方说查询语句:
![]()
那为什么搜索条件中必须出现左边的列才可以使用到这个B+树索引呢?比如下边的语句就用不到这个B+树索引:
![]()
因为B+树的数据页和记录先是按照name列的值排序的,在name列的值相同的情况下才使 用birthday 列进行排序,也就是说 name 列的值不同的记录中 birthday 的值可能是无序的。如果我就想在只使用 birthday 的值去通过 B+ 树索引进行查找,需要再对birthday 列建一个 B+ 树索引。
但是需要特别注意的一点是,如果我们想使用联合索引中尽可能多的列,搜索条件中的各个列必须是联合索引中 从最左边连续的列。比方说联合索引idx_name_birthday_phone_number 中列的定义顺序是 name 、 birthday 、 phone_number ,如果我们的搜索条件中只有 name 和 phone_number ,而没有中间的 birthday , 比方说这样:
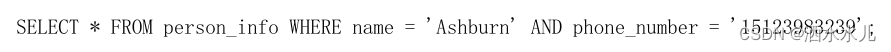
这样只能用到name 列的索引,birthday 和 phone_number 的索引就用不上了,因为 name 值相同的记录先按照 birthday 的值进行排序, birthday 值相同的记录才按照 phone_number 值进行排序。
匹配前缀
针对模糊查询的情况
对于字符串类型的索引列来说,我们只匹配 它的前缀也是可以快速定位记录的,比方说我们想查询名字以'As'开头的记录,那就可以这么写查询语句:

但是需要注意的是,如果只给出后缀或者中间的某个字符串,比如这样:
![]()
MySQL 就无法快速定位记录位置了,因为字符串中间有'As' 的字符串并没有排好序,所以只能全表扫描了。
匹配范围值
由于所有记录都是按照索引列的值从小到大的顺序排好序的,所以这极大的方便我们查找索引列的值在某个范围内的记录。比方说下边这个查询语句:
![]()
由于B+ 树中的数据页和记录是先按name列排序的,所以我们上边的查询过程其实是这样的:
1 找到name值为Asa的记录。
2 找到name值为Barlow的记录。
3 由于所有记录都是由链表连起来的(记录之间用单链表,数据页之间用双链表),所以他们之间的记录都可以很容易的取出来
4 找到这些记录的主键值,再到聚簇索引中回表查找完整的记录
不过在使用联合进行范围查找的时候需要注意,如果对多个列同时进行范围查找的话,只有对索引最左边的那个列进行范围查找的时候才能用到B+树索引,比方说这样:

上边这个查询可以分成两个部分:
1. 通过条件 name > 'Asa' AND name < 'Barlow' 来对 name 进行范围,查找的结果可能有多条 name 值不同的记录,
2. 对这些 name 值不同的记录继续通过 birthday > '1980-01-01' 条件继续过滤。
这样子对于联合索引idx_name_birthday_phone_number 来说,只能用到 name 列的部分,而用不到 birthday 列 的部分,因为只有name 值相同的情况下才能用birthday 列的值进行排序,而这个查询中通过name 进行范围查 找的记录中可能并不是按照birthday 列进行排序的,所以在搜索条件中继续以birthday 列进行查找时是用不到B+ 树索引的
精确匹配某一列并范围匹配另外一列
对于同一个联合索引来说,虽然对多个列都进行范围查找时只能用到最左边那个索引列,但是如果左边的列是精确查找,则右边的列可以进行范围查找,比方说这样:

这个查询的条件可以分为3个部分:
1. name = 'Ashburn' ,对 name 列进行精确查找,当然可以使用 B+ 树索引了。
2. birthday > '1980-01-01' AND birthday < '2000-12-31' ,由于 name 列是精确查找,所以通过 name = 'Ashburn' 条件查找后得到的结果的 name 值都是相同的,它们会再按照 birthday 的值进行排序。所以此时 对birthday 列进行范围查找是可以用到 B+ 树索引的。
3. phone_number > '15100000000' ,通过 birthday 的范围查找的记录的 birthday 的值可能不同,所以这个 条件无法再利用B+树索引了,只能遍历上一步查询得到的记录。
用于排序
我们在写查询语句的时候经常需要对查询出来的记录通过ORDER BY 子句按照某种规则进行排序。一般情况下, 我们只能把记录都加载到内存中,再用一些排序算法,比如快速排序、归并排序在内存中对这些记录进行排序,有的时候可能查询的结果集太大以至于不能在内存中进行排序,还可能暂时借助磁盘的空间来存放中间结果,排序操作完成后再把排好序的结果集返回到客户端
在MySQL中,把这种在内存中或者磁 盘上进行排序的方式统称为文件排序(filesort ),跟文就显得这些排序操作非常慢了。但是如果ORDER BY子句里使用到了我们的索引列,就有可能省去在内存或文件中排序的步骤,比如下边这个简单的查询语句:
![]()
用于分组
相关文章:
《MySQL是怎样运行的》读书笔记(三) B+树索引
前言 从前面数据存储结构中我们已经知道了页和记录的关系示意图: 其中页a、页b、页c ... 页n 这些页可以不在物理结构上相连,只要通过双向链表相关联即可。 在正式介绍索引之前,我们需要了解一下没有索引的时候是怎么查找记录的。下边先只讨论搜索条件…...

微信小程序基础工作模板
1.轮播图 点击跳转官方文档 简单例子 <!-- 顶部轮播图 --> <swiper indicator-dots"true" class"banner" autoplay"true" interval"2000"><swiper-item><image src"../../images/轮播图1.jpg" >…...

简单说一下STL中的map容器的特点、底层实现和应用场景【面试】
特点: 基于红黑树:std::map利用红黑树的自平衡特性,确保操作的平衡性。有序容器:元素根据键的顺序自动排序,排序依据是预定义的键比较函数。唯一键值:容器保证每个键的唯一性,不允许重复键存在…...

Ubuntu22.04之有道词典无法画词翻译替代方案(二百四十九)
简介: CSDN博客专家,专注Android/Linux系统,分享多mic语音方案、音视频、编解码等技术,与大家一起成长! 优质专栏:Audio工程师进阶系列【原创干货持续更新中……】🚀 优质专栏:多媒…...

AnythingLLM 的 Docker 使用
AnythingLLM是使用大语言模型LLM的一站式简便框架。官网的介绍如下: AnythingLLM is the easiest to use, all-in-one AI application that can do RAG, AI Agents, and much more with no code or infrastructure headaches. 1. 使用官方docker 最方便的方法是使…...
数组还可以这样用!常用但不为人知的应用场景
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:C站/掘金/腾讯云;欢迎大家常来逛逛 今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一…...

C++模板元编程:编译时的魔法
1. 引言 在C的世界中,模板元编程是一种在编译时执行计算的强大技术。它允许开发者编写高度灵活和高效的代码,这些代码可以在不牺牲性能的前提下,根据类型和值的不同而变化。本文将深入探讨模板元编程的奥秘,并展示如何在现代C开发…...
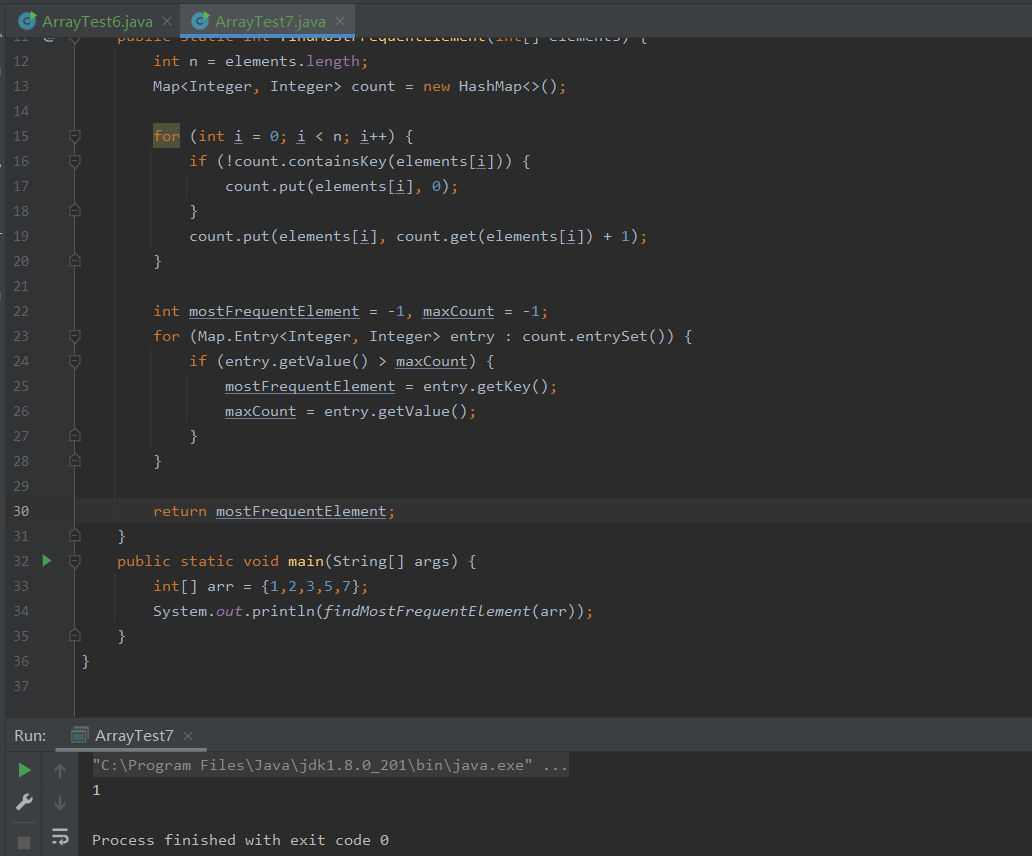
SQL进阶day10————多表查询
目录 1嵌套子查询 1.1月均完成试卷数不小于3的用户爱作答的类别 1.2月均完成试卷数不小于3的用户爱作答的类别 编辑1.3 作答试卷得分大于过80的人的用户等级分布 2合并查询 2.1每个题目和每份试卷被作答的人数和次数 2.2分别满足两个活动的人 3连接查询 3.1满足条件…...
debug调试_以Pycharm为例
文章目录 作用步骤打断点调试调试窗口 作用 主要是检查逻辑错误,而非语法错误。 步骤 打断点 在需要调试的代码行前打断点,执行后会停顿在断点位置(不运行) 调试 右键“debug”,或者直接点击右上角的小虫子 调试…...

wms第三方海外仓系统:如何为中小型海外仓注入新活力
对于中小型海外仓来说,想在大型集团海外仓同台竞争中获得优胜,提升其管理效率是非常关键的一环。 我们所熟知的wms系统,也就是第三方成熟海外仓系统,正是这些海外仓企业提升管理水平、降低成本的重要工具。 1、wms第三方海外仓系…...

html是什么?http是什么?
html Html是什么?http是什么? Html 超文本标记语言;负责网页的架构; http((HyperText Transfer Protocol)超文本传输协议; https(全称:Hypertext Transfer Protocol …...

L1-007 念数字js实现
异步解法 const readline require("readline"); const rl readline.createInterface({input: process.stdin,output: process.stdout, }); const input_arr [];//储存数据 rl.on(line, function (line) {input_arr.push(line); } ); rl.on(close, function () {/…...

Perl 运算符
Perl 运算符 Perl 是一种功能强大的编程语言,广泛应用于系统管理、网络编程、GUI 创建、数据库访问等众多领域。Perl 的语法灵活,支持多种编程范式,包括过程式、面向对象和函数式编程。在 Perl 中,运算符扮演着重要的角色&#x…...
语法04 C++ 标准输入语句
标准输入 使用格式:cin >> 输入的意思就是把一个值放到变量里面去,也就是变量的赋值,这个值是由我们自己输入的。 (注意:输入变量前要先定义,输入完之后要按Enter键。) 输入多个变量,与输出类似,…...

python数据分析--- ch6-7 python容器类型的数据及字符串
python数据分析---ch6-7 python容器类型的数据及字符串 1. Ch6--容器类型的数据1.1 序列1.1.1 序列的索引操作1.1.2 加和乘操作1.1.3 切片操作1.1.4 成员测试 1.2 列表1.2.1 创建列表1.2.2 追加元素1.2.3 插入元素1.2.4 替换元素1.2.5 删除元素1.2.6 列表排序(1&…...

【Linux取经路】守护进程
文章目录 一、前台进程和后台进程二、Linux 的进程间关系三、setsid——将当前进程设置为守护进程四、daemon——设置为守护进程五、结语 一、前台进程和后台进程 Linux 中每一次用户登录都是一个 session,一个 session 中只能有一个前台进程在运行,键盘…...

Nginx之文件下载服务器
1.概述 在对外分享文件时,利用Nginx搭建一个简单的下 载文件管理服务器,文件分享就会变得非常方便。利 用Nginx的诸多内置指令可实现自动生成下载文件列表 页、限制下载带宽等功能。配置样例如下: server {listen 8080;server_name localhos…...

OpenCV学习(4.11) OpenCV中的图像转换
1. 目标 在本节中,我们将学习 使用OpenCV查找图像的傅立叶变换利用Numpy中可用的FFT功能傅立叶变换的一些应用我们将看到以下函数:**cv.dft()** ,**cv.idft()** 等 理论 傅立叶变换用于分析各种滤波器的频率特性。对于图像,使用…...

2024.6.13每日一题
LeetCode 子序列最大优雅度 题目链接:2813. 子序列最大优雅度 - 力扣(LeetCode) 题目描述 给你一个长度为 n 的二维整数数组 items 和一个整数 k 。 items[i] [profiti, categoryi],其中 profiti 和 categoryi 分别表示第 i…...

Linux命令详解(2)
文本处理是Linux命令行的重要应用之一。通过一系列强大的命令,用户可以轻松地对文本文件进行编辑、查询和转换。 cat: 这个命令用于查看文件内容。它可以一次性显示整个文件,或者分页显示。此外,cat 还可以用于合并多个文件的内容…...

QGIS3.28最新版行政区合并避坑指南:县转市数据融合的3个关键检查点
QGIS 3.28行政区合并实战:县转市数据融合的3个关键检查点 当我们需要将县级行政区数据合并为市级边界时,看似简单的"线转面融合"操作背后,往往隐藏着诸多数据陷阱。许多中级用户在QGIS中执行这类操作时,明明步骤正确却频…...

手把手教你windows下如何部署copaw
前言: 本文内容主要讲解通过手工部署python并使用pip安装部署copaw,在官网有一键部署脚本等等教程,都很方便,但为什么作者要通过手工部署python环境,原因很简单,解决环境冲突的问题,通过conda能…...

FLUX.1-dev LoRA微调指南:基于像素幻梦输出数据集训练专属风格
FLUX.1-dev LoRA微调指南:基于像素幻梦输出数据集训练专属风格 1. 前言:为什么需要LoRA微调 在像素艺术创作领域,每个艺术家都渴望拥有独特的视觉风格。FLUX.1-dev作为当前最先进的扩散模型,配合像素幻梦(Pixel Dream Workshop)…...

VMware虚拟机安装Ubuntu教程:创建独立的Qwen3-14B-AWQ模型测试环境
VMware虚拟机安装Ubuntu教程:创建独立的Qwen3-14B-AWQ模型测试环境 1. 为什么需要虚拟机测试环境 在测试大语言模型时,使用虚拟机可以避免污染宿主机环境。特别是像Qwen3-14B-AWQ这样的模型,依赖项复杂,直接在主机上安装可能会与…...

QLVideo终极指南:让macOS Finder完美预览所有视频格式
QLVideo终极指南:让macOS Finder完美预览所有视频格式 【免费下载链接】QuickLookVideo This package allows macOS Finder to display thumbnails, static QuickLook previews, cover art and metadata for most types of video files. 项目地址: https://gitcod…...

**发散创新:用Python + ROS2实现多机器人协同路径规划与避障控制**在现代机器人系统中,**
发散创新:用Python ROS2实现多机器人协同路径规划与避障控制 在现代机器人系统中,多机器人协同控制已成为智能仓储、物流配送和工业自动化的核心技术之一。本文将带你深入一个真实可运行的案例——使用 Python 语言结合ROS2(Robot Operating…...

深入剖析YOLOv8核心模块:从架构设计到实战应用全解析
1. YOLOv8架构设计揭秘 YOLOv8作为目标检测领域的标杆模型,其架构设计处处体现着工程师的巧思。我第一次拆解它的代码时,最惊艳的是它的模块化设计——就像搭积木一样,每个组件都能灵活替换。核心的Backbone部分采用CSPDarknet53结构…...

从零到一实战:基于快马平台快速开发企业级jiyutrainer在线评测系统
今天想和大家分享一个很实用的开发经验——如何快速搭建一个企业级的在线编程评测系统。最近正好有个朋友想做一个类似jiyutrainer的编程练习平台,我就用InsCode(快马)平台试了试,效果出乎意料的好。 项目需求分析 首先明确我们需要实现的核心功能&#…...

5G NR随机接入实战:手把手教你理解并排查MSG3发送失败的那些坑
5G NR随机接入实战:MSG3发送失败全场景排查指南 当5G终端尝试接入网络时,随机接入过程中的MSG3发送失败是最常见的"拦路虎"之一。作为网络优化的关键指标,MSG3失败直接影响用户体验和网络KPI。本文将带您深入协议栈底层,…...

5分钟搞定OpenClaw+nanobot:超轻量级AI助手一键部署指南
5分钟搞定OpenClawnanobot:超轻量级AI助手一键部署指南 1. 为什么选择OpenClawnanobot组合 上周我在整理电脑上的项目文档时,突然意识到自己每天要重复执行大量机械操作:查找文件、转换格式、汇总数据。作为独立开发者,这些琐事…...