【Pytorch】一文向您详细介绍 torch.nn.DataParallel() 的作用和用法
【Pytorch】一文向您详细介绍 torch.nn.DataParallel() 的作用和用法
下滑查看解决方法

🌈 欢迎莅临我的个人主页 👈这里是我静心耕耘深度学习领域、真诚分享知识与智慧的小天地!🎇
🎓 博主简介:985高校的普通本硕,曾有幸发表过人工智能领域的 中科院顶刊一作论文,熟练掌握PyTorch框架。
🔧 技术专长: 在CV、NLP及多模态等领域有丰富的项目实战经验。已累计提供近千次定制化产品服务,助力用户少走弯路、提高效率,近一年好评率100% 。
📝 博客风采: 积极分享关于深度学习、PyTorch、Python相关的实用内容。已发表原创文章500余篇,代码分享次数逾六万次。
💡 服务项目:包括但不限于科研辅导、知识付费咨询以及为用户需求提供定制化解决方案。
🌵文章目录🌵
- 🚀一、torch.nn.DataParallel() 的基本概念
- 🔬二、torch.nn.DataParallel() 的基本用法
- 💡三、torch.nn.DataParallel() 的深入理解
- 🔧四、torch.nn.DataParallel() 的注意事项和常见问题
- 🚀五、torch.nn.DataParallel() 的进阶用法与技巧
- 📚六、torch.nn.DataParallel() 的代码示例与深入解析
- 🌈七、总结与展望
下滑查看解决方法
🚀一、torch.nn.DataParallel() 的基本概念
在深度学习的实践中,我们经常会遇到模型训练需要很长时间的问题,尤其是在处理大型数据集或复杂的神经网络时。为了解决这个问题,我们可以利用多个GPU并行计算来加速训练过程。torch.nn.DataParallel() 是PyTorch提供的一个方便的工具,它可以让我们在多个GPU上并行运行模型的前向传播和反向传播。
简单来说,torch.nn.DataParallel() 将数据分割成多个部分,然后在不同的GPU上并行处理这些数据部分。每个GPU都运行一个模型的副本,并处理一部分输入数据。最后,所有GPU上的结果将被收集并合并,以产生与单个GPU上运行模型相同的输出。
🔬二、torch.nn.DataParallel() 的基本用法
要使用 torch.nn.DataParallel(),首先你需要确保你的PyTorch版本支持多GPU,并且你的机器上有多个可用的GPU。以下是一个简单的示例,展示了如何使用 torch.nn.DataParallel():
import torch
import torch.nn as nn# 假设我们有一个简单的神经网络模型
class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 10)def forward(self, x):x = self.fc(x)return x# 实例化模型
model = SimpleModel()# 检查可用的GPU
if torch.cuda.device_count() > 1:print("使用多个GPU...")model = nn.DataParallel(model)# 将模型移动到GPU上
model.to('cuda')# 创建一个模拟的输入数据
input_data = torch.randn(100, 10).to('cuda')# 执行前向传播
output = model(input_data)
print(output.shape)
这个示例展示了如何使用 torch.nn.DataParallel() 将一个简单的神经网络模型部署到多个GPU上。注意,我们只需要在实例化模型后检查GPU的数量,并使用 nn.DataParallel() 包装模型。然后,我们可以像平常一样调用模型进行前向传播,而不需要关心数据是如何在多个GPU之间分割和合并的。
💡三、torch.nn.DataParallel() 的深入理解
虽然 torch.nn.DataParallel() 的使用非常简单,但了解其背后的工作原理可以帮助我们更好地利用它。以下是一些关于 torch.nn.DataParallel() 的深入理解:
- 数据分割:
torch.nn.DataParallel()会自动将数据分割成多个部分,每个部分都会在一个GPU上进行处理。分割的方式取决于输入数据的形状和GPU的数量。 - 模型副本:在每个GPU上,都会创建一个模型的副本。这些副本共享相同的参数,但每个副本都独立地处理一部分输入数据。
- 结果合并:在所有GPU上的处理完成后,
torch.nn.DataParallel()会将结果合并成一个完整的输出。这个过程是自动的,我们不需要手动进行合并。
🔧四、torch.nn.DataParallel() 的注意事项和常见问题
虽然 torch.nn.DataParallel() 是一个非常有用的工具,但在使用它时需要注意一些事项和常见问题:
- GPU资源:使用
torch.nn.DataParallel()需要多个GPU。如果你的机器上只有一个GPU,或者没有足够的GPU内存来运行多个模型的副本,那么你可能无法使用它。 - 模型设计:并非所有的模型都适合使用
torch.nn.DataParallel()。一些具有特定依赖关系的模型(例如,具有共享层的RNN或LSTM)可能无法正确地在多个GPU上并行运行。 - 批处理大小:当使用
torch.nn.DataParallel()时,你可能需要调整批处理大小以确保每个GPU都有足够的数据进行处理。如果批处理大小太小,可能会导致GPU利用率低下。
🚀五、torch.nn.DataParallel() 的进阶用法与技巧
除了基本用法之外,还有一些进阶的用法和技巧可以帮助我们更好地利用 torch.nn.DataParallel():
-
自定义数据分割:虽然
torch.nn.DataParallel()会自动进行数据分割,但你也可以通过自定义数据加载器或数据集来实现更灵活的数据分割方式。 -
设备放置:在使用
torch.nn.DataParallel()时,你需要确保模型和数据都在正确的设备(即GPU)上。这通常通过调用.to('cuda')或.cuda()方法来实现。 -
模型参数同步:当在多个GPU上运行模型时,确保所有副本的模型参数在训练过程中保持同步是非常重要的。
torch.nn.DataParallel()会自动处理这个问题,但如果你在实现自定义的并行化逻辑时,需要特别留意这一点。 -
监控GPU使用情况:使用多个GPU时,监控每个GPU的使用情况是非常重要的。这可以帮助你发现是否存在资源不足或利用率低下的问题,并据此调整你的代码或硬件设置。
📚六、torch.nn.DataParallel() 的代码示例与深入解析
为了更深入地了解 torch.nn.DataParallel() 的工作原理,让我们通过一个更具体的代码示例来进行分析:
import torch
import torch.nn as nn
import torch.optim as optim# 假设我们有一个更复杂的模型
class ComplexModel(nn.Module):def __init__(self):super(ComplexModel, self).__init__()self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)self.relu = nn.ReLU()self.fc = nn.Linear(64 * 32 * 32, 10) # 假设输入图像大小为32x32def forward(self, x):x = self.conv1(x)x = self.relu(x)x = x.view(x.size(0), -1) # 展平特征图x = self.fc(x)return x# 实例化模型
model = ComplexModel()# 检查GPU数量
if torch.cuda.device_count() > 1:print("使用多个GPU...")model = nn.DataParallel(model)# 将模型移动到GPU上
model.to('cuda')# 创建损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 模拟输入数据和标签
input_data = torch.randn(64, 3, 32, 32).to('cuda') # 假设批处理大小为64,图像大小为32x32
labels = torch.randint(0, 10, (64,)).to('cuda') # 假设有10个类别# 训练循环(简化版)
for epoch in range(10): # 假设只训练10个epochoptimizer.zero_grad()outputs = model(input_data)loss = criterion(outputs, labels)loss.backward()optimizer.step()print(f'Epoch [{epoch+1}/{10}], Loss: {loss.item()}')
这个示例展示了如何使用 torch.nn.DataParallel() 来加速一个具有卷积层和全连接层的复杂模型的训练过程。注意,在训练循环中,我们不需要对模型进行任何特殊的处理来适应多GPU环境;torch.nn.DataParallel() 会自动处理数据的分割和结果的合并。
🌈七、总结与展望
通过本文的介绍,我们深入了解了 torch.nn.DataParallel() 的基本概念、基本用法、深入理解、注意事项和常见问题以及进阶用法与技巧。torch.nn.DataParallel() 是一个强大的工具,可以帮助我们充分利用多个GPU来加速深度学习模型的训练过程。然而,它并不是唯一的解决方案,还有一些其他的并行化策略和技术(如模型并行化、分布式训练等)可以进一步提高训练速度和效率。
随着深度学习技术的不断发展和硬件性能的不断提升,我们有理由相信未来的深度学习训练将会更加高效和灵活。让我们拭目以待吧!
相关文章:
【Pytorch】一文向您详细介绍 torch.nn.DataParallel() 的作用和用法
【Pytorch】一文向您详细介绍 torch.nn.DataParallel() 的作用和用法 下滑查看解决方法 🌈 欢迎莅临我的个人主页 👈这里是我静心耕耘深度学习领域、真诚分享知识与智慧的小天地!🎇 🎓 博主简介:985高…...
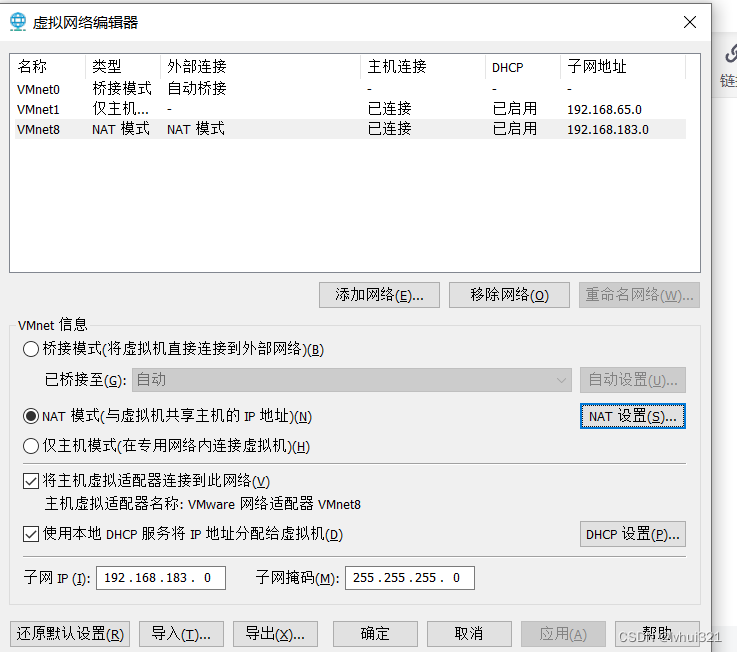
Windows本地使用SSH连接VM虚拟机
WIN10 VM17.5 Ubuntu:20.04 1.网路设置 1)选择编辑->更改设置 配置完成 2.修改了服务器文件,修改sshd配置,在此文件下/etc/ssh/sshd_config,以下为比较重要的配置 PasswordAuthentication yes PermitRootLogin yes PubkeyAuthenticat…...
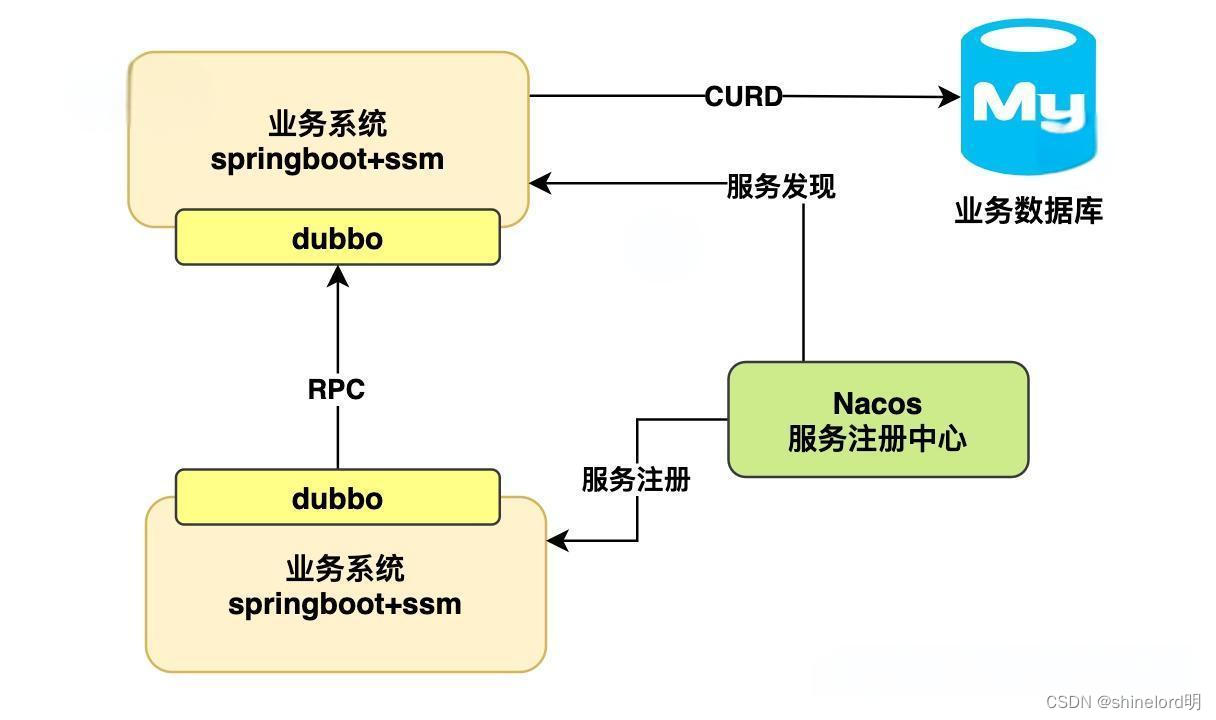
RPC(远程过程调用):技术原理、应用场景与发展趋势
摘要: RPC(Remote Procedure Call)是一种通信协议,用于实现跨网络的进程间通信。它提供了一种简单高效的方式,使得分布式系统中的不同组件能够像调用本地函数一样调用远程函数。本篇博客将介绍RPC的基本概念࿰…...

iSCSI和FC存储
iSCSI存储和FC存储的特点和区别 FC存储和iSCSI存储是两种主要的网络存储解决方案,它们各自在性能、成本和适用场景上有着不同的特点。 FC存储是一种基于光纤通道技术的高性能、低延迟的存储解决方案。它使用专用的光纤通道网络连接存储设备和服务器,确…...

MPT(merkle Patricia trie )及理解solidity里的storage
what? MPT树是一种数据结构,用于在以太坊区块链中高效地存储和检索账户状态、交易历史和其他重要数据。MPT树的设计旨在结合Merkle树和Patricia树的优点,以提供高效的数据存储和验证 MPT树由四种类型的节点组成: **扩展节点&…...

【代码随想录算法训练营第三十五天】 | 1005.K次取反后最大化的数组和 134.加油站 135.分发糖果
贪心章节的题目,做不出来看题解的时候,千万别有 “为什么这都没想到” 的感觉,想不出来是正常的,转变心态 “妙啊,又学到了新的思路” ,这样能避免消极的心态对做题效率的影响。 134. 加油站 按卡哥的思路…...
桌面应用开发框架比较:Electron、Flutter、Tauri、React Native 与 Qt
在当今快速发展的技术环境中,对跨平台桌面应用程序的需求正在不断激增。 开发人员面临着选择正确框架之挑战,以便可以高效构建可在 Windows、macOS 和 Linux 上无缝运行的应用程序。 在本文中,我们将比较五种流行的桌面应用程序开发框架&…...

学习笔记丨嵌入式BI分析的12个关键功能
编者注:以下内容节选编译自嵌入式分析厂商Qrvey发表的《What is Embedded Analytics?》(什么是嵌入式分析)一文,作者为Qrvey产品市场主管Brian Dreyer。 什么是嵌入式分析? 嵌入式分析是指能够将数据分析的特性和功…...
在使用包含操作符<@和@>时优化范围查询)
PostgreSQL17优化器改进(3)在使用包含操作符<@和@>时优化范围查询
PostgreSQL17优化器改进(3)在使用包含操作符<和>时优化范围查询 本文将介绍PostgreSQL 17服务端优化器在使用包含操作符<和>时优化范围查询。其实在在第一眼看到官网网站的对于该优化点的时候,可能是由于缺乏对于范围类型的认知…...
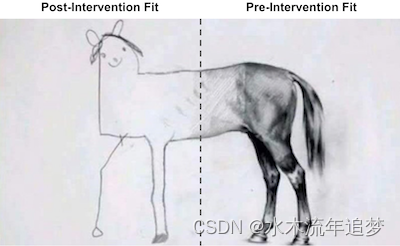
【因果推断python】32_合成控制2
目录 合成控制作为线性回归的一种实现编辑 合成控制作为线性回归的一种实现 为了估计综合控制的治疗效果,我们将尝试构建一个类似于干预期之前的治疗单元的“假单元”。然后,我们将看到这个“假单位”在干预后的表现。合成控制和它所模仿的单位之间的…...
Linux-笔记 全志平台OTG虚拟 串口、网口、U盘笔记
前言: 此文章方法适用于全志通用平台,并且三种虚拟功能同一时间只能使用一个,原因是此3种功能都是内核USB Gadget precomposed configurations的其中一个选项,只能单选,不能多选,而且不能通过修改配置文件去…...

Qt实现SwitchButton滑动开关按钮组件
概述 使用Qt如何制作一个滑动开关按钮,同类的文章和代码网上很多,但很多都是pyqt编写的,也有c编写的,大家可以参考. 我这里主要是实现了一个滑动按钮,富有滑动动画和文字,话不多说,上代码 自定义…...

C++进阶:继承
文章目录 继承的概念继承的定义方式继承关系和访问限定符基类和派生类对象的赋值转换继承中的作用域派生类中的默认成员函数构造函数拷贝构造函数赋值拷贝函数析构函数 总结 继承的概念 继承(inheritance)机制是面向对象程序设计使代码可以复用的最重要的手段,它允…...

SFTP工具
SFTP工具 工具类配置类调用 工具类 Slf4j Component public class SFTPUtils {Resourceprivate SftpConfig sftpConfig;Session session null;Channel channel null;/*** 网络图片url** param fileUrl* throws JSchException*/public String uploadFileSFTP(String fileUrl) …...
服务器数据恢复—vxfs文件系统元数据被破坏的数据恢复案例
服务器存储数据恢复环境: 某品牌MSA2000服务器存储中有一组由8块SAS硬盘组建的raid5磁盘阵列,其中包含一块热备盘。分配了6个LUN,均分配给HP-Unix小机使用。磁盘分区由LVM进行管理,存放的数据主要为Oracle数据库及OA服务端。 服务…...
【SCAU数据挖掘】数据挖掘期末总复习题库简答题及解析——上
1.K-Means 假定我们对A、B、C、D四个样品分别测量两个变量,得到的结果见下表。 样品 变量 X1X2 A 5 3 B -1 1 C 1 -2 D -3 -2 利用K-Means方法将以上的样品聚成两类。为了实施均值法(K-Means)聚类,首先将这些样品随意分成两类(A、B)和(C、…...

云时代的Java:在云环境中实施Java的最佳实践
引言 云计算已经成为现代软件开发不可或缺的一部分,它提供了灵活性、可扩展性和成本效益。对于Java开发者来说,掌握在云环境中部署和管理Java应用的最佳实践是至关重要的。本文将探讨一些关键策略,帮助你最大化Java在云平台上的性能和效率。…...

STL - 常用算法
概述: 算法主要是由头文件<algorithm><functional><numeric>组成<algorithm>是所有STL头文件中最大的一个,范围涉及比较、 交换、查找、遍历操作、复制、修改等等<numeric>体积很小,只包括几个在序列上面进行…...
)
Qt | QTextStream 类(文本流)
01、字符编码 1、怎样将字符转换为二进制形式进行存储,存在一个编码的问题,通常都需进行两次编码, 2、字符集:字符的第一次编码是将字符编码为与一个数值(如一个 10 进制整数)相对应,比如把字符 A 编码为 10 进制的 65,B 编码为 66 等。把每一个字符都编码为与一个数值…...

Python学习笔记7:入门知识(七)
前言 之前说过我更换了新的学习路线,现在是根据官方文档和书籍Python crash course来进行学习的,在目前的学习中,对于之前的知识有一些遗漏,这里进行补充。 学习资料有两个,书籍中文版PDF,关注我私信发送…...

3步让你的PyTorch模型在Intel CPU提速50%:开发者实战指南
3步让你的PyTorch模型在Intel CPU提速50%:开发者实战指南 【免费下载链接】intel-extension-for-pytorch A Python package for extending the official PyTorch that can easily obtain performance on Intel platform 项目地址: https://gitcode.com/GitHub_Tre…...
)
手把手教你用Node.js 24和OpenEuler复现CVE-2025-55182漏洞(附完整POC)
手把手教你用Node.js 24和OpenEuler复现CVE-2025-55182漏洞(附完整POC) 在安全研究领域,漏洞复现是理解漏洞原理、验证修复方案的关键环节。本文将带领读者在国产操作系统OpenEuler 22.03 SP4上,使用Node.js 24环境,从…...

如何为LaTeX简历项目贡献代码:开源参与全流程指南
如何为LaTeX简历项目贡献代码:开源参与全流程指南 【免费下载链接】resume Software developer resume in Latex 项目地址: https://gitcode.com/gh_mirrors/res/resume 参与开源项目是提升技能、建立专业网络的绝佳方式。本文将以GitHub加速计划中的res/res…...

VitePress静态资源管理全攻略:图片路径配置与项目结构优化
VitePress静态资源管理全攻略:图片路径配置与项目结构优化 在构建现代文档站点时,静态资源的高效管理往往成为影响开发体验的关键因素。VitePress作为基于Vite的静态站点生成器,其资源处理机制既继承了Vite的强大能力,又有着独特的…...

从Postman到真机:我的Coze+微信小程序多模态对话开发踩坑全记录
从Postman到真机:我的Coze微信小程序多模态对话开发踩坑全记录 作为一名长期关注对话式AI落地的开发者,当Coze平台推出全新API时,我立刻意识到这是将多模态对话能力集成到微信小程序的绝佳机会。但没想到从Postman测试到真机运行,…...

Java DDD分层架构实战:从理论到代码落地
1. DDD分层架构的本质与价值 第一次接触DDD分层架构时,我盯着那个四层结构图看了整整半小时。当时刚做完一个电商促销系统,Service层堆了2000多行代码,各种if-else嵌套看得人头皮发麻。直到把业务逻辑按照DDD分层重新梳理后,才真正…...

游戏ROM存储革新指南:从空间困境到高效管理的创新方法论
游戏ROM存储革新指南:从空间困境到高效管理的创新方法论 【免费下载链接】romm A beautiful, powerful, self-hosted rom manager 项目地址: https://gitcode.com/GitHub_Trending/rom/romm 想象一下,你花了数周时间收集的经典游戏库突然报出存储…...
)
虚拟机突然断电后卡在initramfs?试试这个xfs_repair修复命令(附详细步骤)
虚拟机异常断电后XFS文件系统修复实战指南 当你的Linux虚拟机遭遇突然断电,重启后卡在initramfs界面并提示generating /run/initramfs/rdsosreport.txt时,这通常意味着XFS文件系统出现了损坏。作为运维人员,掌握正确的修复方法不仅能快速恢复…...

企业级身份管理实战:Keycloak与Spring Boot深度集成指南
企业级身份管理实战:Keycloak与Spring Boot深度集成指南 【免费下载链接】keycloak Keycloak 是一个开源的身份和访问管理解决方案,用于保护应用程序和服务的安全和访问。 * 身份和访问管理解决方案、保护应用程序和服务的安全和访问 * 有什么特点&#…...

AnimeGarden创新解决方案:动漫资源聚合与管理全攻略
AnimeGarden创新解决方案:动漫资源聚合与管理全攻略 【免费下载链接】AnimeGarden 動漫花園 3-rd party mirror site and Anime Torrent aggregation site 项目地址: https://gitcode.com/gh_mirrors/an/AnimeGarden 在数字娱乐爆炸的时代,动漫爱…...