JUC并发编程之HashMap(jdk1.7版本)-底层源码探究
目录
JUC并发编程之HashMap(jdk1.7版本)-底层源码探究
HashMap底层源码 - jdk1.7
基本概念 -采取层层递进,问答式
存储Key-Value的结构
常量和成员变量
构造方法
put方法
inflateTable方法
hash方法
indexFor方法
addEntry方法
resize方法
createEntry方法
get相关方法
size方法
remove相关方法
jdk1.7版本的HashMap为什么会产生死锁(链表成环)?
出现问题的场景:
解决方法:
JUC并发编程之HashMap(jdk1.7版本)-底层源码探究
HashMap在jdk1.7和jdk1.8的区别非常大,jdk1.8中引入了红黑树来优化性能,并且jdk1.8解决了jdk1.7版本下多线程并发时的死锁问题,为了层层递进学习,先从jdk1.7的HashMap底层开始学起
首先要学会如何更改所处模块的jdk版本号:
HashMap底层源码 - jdk1.7
基本概念 -采取层层递进,问答式
熟悉以下概念后,更容易进行阅读源码!!!
(1)jdk1.7版本的HashMap底层的数据结构为:数组+链表
(2) HashMap集合的大小容量就是等于数组的大小
(3) new HashMap()倘若不指明初始化大小,那么默认设置为16
(4) 但即使指定了HashMap的初始化容量,若该容量不是2的次方,那么会找一个最接近该指定初始化大小的数且大于该指定初始大小的数且是2的次方的数作为HashMap的初始化容量。
eg:new HashMap(9) ->最终HashMap生成时初始化大小为16
(5) HashMap哈希表put插入元素时,如果发生哈希碰撞,那么对比发生哈希碰撞的两个Entry的键值是否一致,若一致,覆盖前一个插入哈希表的Entry的value值。若不一致,那么采用头插法插入到前一个Entry的头部,经过一次遍历后,插入头部的Entry会下移变为第一个元素节点。
(6) HashMap的get,put操作的时间复杂度为O(1)。其实还分最好和最坏的情况。
get:
最好情况:无哈希碰撞,所有Entry都插入到数组的各个位置,查询元素节点时时间复杂度为O(1),因为数组底层维护的有一个索引,可以直接定位到任意索引位置处的元素。
最坏情况:发生哈希碰撞,并且所要get的Entry正好插在链表的尾部。那么最坏时间复杂度为O(n),n为链表的长度。【注释:但是这种情况的概率是极小的,因为哈希碰撞频率实际上不是十分多,即使存在,也比较少出现节点是在尾部的这种极端情况,因为jdk1.7版本HashMap采取头插法就注定寻找节点Entry处于尾部的概率是极低的】
平均时间复杂度:O(1)
put:
最好情况:无哈希碰撞,O(1)
最坏情况:有哈希碰撞,但是jdk1.7采取链地址法和头插法,所以无需遍历再插入,而是直接插在头部,所以时间复杂度最坏情况下也是O(1)
平均时间复杂度:O(1)
(7) 哈希表底层数组的所有的元素位是否能够被100%利用起来?
no。虽然哈希冲突的概率是比较低的,但是依旧存在,所以存在哈希冲突碰撞。所以引入链表数据结构使用链地址法进行解决hash冲突,并且采用头插法插入Entry节点到链表中。
(8) 位运算(&,|,^,~)的计算效率是远大于+,-,*,%的。 位运算最接近机器语言,即是最接近底层语言,因为CPU底层只认二进制的机器语言!所以位运算效率最高。+ - * %中 % 的运算效率最低。
(9) 前面记录了,new HashMap(初始容量大小size),初始化时如果指定的容量非2的次方大小时,底层强制把该初始容量大小转化为2的指数次幂
怎么转化?必须满足以下三个条件:
1. 必须最接近size
2.必须>=size
3.必须是2的次方幂
eg:new HashMap(17),size=17,强制转化为指定初始化容量为:32
(10) 为什么HashMap初始化容量一定要转化为2的指数次幂??【重点】
前面提过,HashMap的容量即是底层数组的大小。每一个Entry节点插入到哈希表中,都需要先获取到一个索引,根据这个索引再确定是插入到HashMap底层的数组上的哪一个位置。
如何获取该索引的呢?底层源码如下:
计算索引:int i = indexFor(hash, table.length);
static int indexFor(int h, int length) {
// key.hashCode % table.lenthreturn h & (table.lenth-1);
}采取的是h&(数组长度-1),h代表的是Entry节点对应键值key的hashCode值,每一个类都继承Object类,Object类中有一个方法:hashCode()。通过key.hashCode()就可以获取得到一个哈希值
该哈希值可能是一个非常大的数字:137812378917823.....
如何通过该数字得到该哈希值对应的Entry应该插入到数组的哪一个索引位置呢?
最初思考到的肯定是:key.hashCode() % (数组长度-1),得到的范围为:[0,数组长度-1),这正好对应的是数组的所有索引下标对应的范围!
但是这种 % 的方式是十分低性能的!
通过测试对比出,位运算的性能高于 % 运算的十倍左右 !
所以我们想要使用 位运算进行优化!!!但是位运算结合哈希值(随机大的数值)来求出一个数组索引的范围怎么去求??
数组的索引范围= key.hashCode() & (数组长度-1)注释:数组长度必须为2的n次幂
自己举一个例子试一试就明白啦:如 数组长度为16
16 - 1 = 0000 0000 0001 0000 - 1 = 0000 0000 0000 1111
& 运算的性质为:两个都为1才为1,有一个为0就为0。所以2^n这个数字保证了2^n-1这个数值的二进制为有值的地方全为1。
(11) 何时扩容?谈谈扩容机制
threshold(扩容阙值) = capacity(数组的长度) * 0.75[扩容阙值比率,负载因子] = 16 * 0.75 = 12
当hashMap中存储的节点Entry元素的数量size,size>= threshold时,那么进行扩容!
扩容怎么扩?
(1) 大小扩容到原来的2倍。
(2) 转移数据,通过transfer方法
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) { e.hash = null == e.key ? 0 : hash(e.key);//再一次进行hash计算?}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}}多线程执行情况下,由于CPU线程随机调度可能会导致链表成环,最终导致死锁问题。jdk1.8的HashMap解决了该问题。之后会细谈该问题!
成环的原因:在多线程的情况下,并且可能原来发生哈希冲突而形成一条链表上的节点们,再一次由于哈希冲突而加到一个位置处,由于是头插法,所以位置会颠倒过来,再经过一次循环后,极易形成环。导致死环,死锁问题。
(12) hash扩容时,有一个加载因子,为什么该加载因子loadFactor为0.75 ?
其实0.75也不是最佳答案,通过牛顿二项式可求出,基于空间和时间的折中最佳加载因子为0.693
解析:首先要明白一点,当哈希表中的元素数量size >= threshold(数组容量*加载因子)时,我们需要进行2倍扩容。
所以加载因子loadFactor越大,那么threshold值就越大,threshold越大,那么扩容的概率就越小,那么哈希冲突的概率就越大。
但是加载因子过小的话,那么threshold值就越小,threshold越小,那么扩容的概率就越大,那么哈希冲突的概率就越小,虽然哈希冲突的概率变小了,但是浪费的数组空间大小变多了,一味的进行二倍扩容会导致数组越来越大,导致空间复杂度增加。
所以我们需要考虑一个空间和时间的折中的最佳加载因子,通过牛顿二项式计算出最佳值为0.693
存储Key-Value的结构
static class Entry<K,V> implements Map.Entry<K,V> {final K key;V value;Entry<K,V> next;int hash;/*** Creates new entry.*/Entry(int h, K k, V v, Entry<K,V> n) {value = v;next = n;key = k;hash = h;}
}常量和成员变量
//默认初始化容量,16static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16//最大初始化容量,2^30static final int MAXIMUM_CAPACITY = 1 << 30;//默认负载因子,0.75static final float DEFAULT_LOAD_FACTOR = 0.75f;//默认初始化table的空数组//HashMap采用的是一种延迟加载的机制:当HashMap被创建时table被初始化为一个空数组,只有当其被使用//时,才创建一个非空数组。static final Entry<?,?>[] EMPTY_TABLE = {};/*** The table, resized as necessary. Length MUST Always be a power of two.* HashMap底层数组结构中的数组,在必要时可以进行扩容,但是数组的length必须为2的整数次幂*** (Question1:为什么数组的长度必须是2的整数次幂?)*/transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;//HashMap中存储的key-value键值对的数量,也就是存储的Entry节点的数量transient int size;//扩容阈值,同时也代表刚创建HashMap时的initialCapacityint threshold;//扩容因子,与HashMap扩容有关,threshold = loadFactor * capacityfinal float loadFactor;/*** The number of times this HashMap has been structurally modified* Structural modifications are those that change the number of mappings in* the HashMap or otherwise modify its internal structure (e.g.,* rehash). This field is used to make iterators on Collection-views of* the HashMap fail-fast. (See ConcurrentModificationException).*//*** modCount用来记录HashMap发生结构性修改的次数,比如添加元素、删除元素等(在阅读后面的方法时我们会记 * 录一下哪些情况算是结构性修改,Question2),该变量是用于HashMap集合视图中的迭代器的fail-fast策* 略。* * 在创建迭代器时,会将modCount赋值给一个名为expectedModCount的变量。在当前线程使用迭代器的过程* 中,会不断地校验modCount与expectedModCount是否相等。如果二者值不相等,根据fail-fast策略,会* 立即抛出ConcurrentModificationException,从而实现不让其他线程对HashMap进行结构性的修改。* 可以参考内部类HashIterator的代码。** fail-fast策略是一种错误检测策略,但无法避免错误。它是java集合中的一种错误机制,当多个线程同时对* 一个集合进行修改时,就会发生ConcurrentModificationException。所以在并发环境下,还是建议使用* j.u.c包下的组件。*/transient int modCount;构造方法
//无参构造方法public HashMap() {this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);}//带一个参数的构造方法public HashMap(int initialCapacity) {this(initialCapacity, DEFAULT_LOAD_FACTOR);}//传入初始容量以及扩容因子的方法public HashMap(int initialCapacity, float loadFactor) {//参数校验if (initialCapacity < 0)throw new IllegalArgumentException("Illegal initial capacity: " +initialCapacity);if (initialCapacity > MAXIMUM_CAPACITY)initialCapacity = MAXIMUM_CAPACITY;if (loadFactor <= 0 || Float.isNaN(loadFactor))throw new IllegalArgumentException("Illegal load factor: " +loadFactor);this.loadFactor = loadFactor;//刚创建HashMap时将初始化容量记录到threshold中threshold = initialCapacity;//空方法,LinkedHashMap中使用到init();}public HashMap(Map<? extends K, ? extends V> m) {this(Math.max((int) (m.size() / DEFAULT_LOAD_FACTOR) + 1,DEFAULT_INITIAL_CAPACITY), DEFAULT_LOAD_FACTOR);inflateTable(threshold);putAllForCreate(m);}put方法
put方法是用于向HashMap中添加Key-Value键值对的方法。若要添加的Key已存在于HashMap中,用传入的value值覆盖原来的oldValue,并将oldValue返回;若不存在,则直接添加,并返回null。
/*** Associates the specified value with the specified key in this map.* If the map previously contained a mapping for the key, the old* value is replaced.*///向HashMap中添加元素的方法public V put(K key, V value) {//当第一次调用put方法时才对table进行初始化if (table == EMPTY_TABLE) {//创建tableinflateTable(threshold);}//由此可见,jdk1.7版本下的HashMap支持Key为null的键值对//如果要put元素的key为null,则直接将该元素存储到table[0]链表中if (key == null)return putForNullKey(value);//根据key散列出hash值int hash = hash(key);//根据hash值和table的长度计算出该元素应插入的链表在table中的下标iint i = indexFor(hash, table.length);//在table[i]中寻找与插入元素key相同的元素for (Entry<K,V> e = table[i]; e != null; e = e.next) {Object k;/*** 注意此处HashMap是如何判断key相等的:* e.hash == hash && ((k = e.key) == key || key.equals(k))* 计算hash时也使用到了key的hashcode方法** 所以,当key的类型是自定义类型,如果重写了equals方法,那么同时也要重写hashCode方法* 防止出现key相同,但是经过hashCode方法散列后的hash不同的情况*/if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}//方法执行到此处时,说明原链表中不存在与插入元素key相同的元素,那么,就需要创建一个Entry并插入//向HashMap添加一个元素时,modCount需要自增modCount++;//添加EntryaddEntry(hash, key, value, i);return null;}//putForNullKey方法是进行key为null的情况下的插入操作private V putForNullKey(V value) {//没有求hash,也没有求i,直接从table[0]中查找是否有Key相同的元素for (Entry<K,V> e = table[0]; e != null; e = e.next) {if (e.key == null) {V oldValue = e.value;e.value = value;e.recordAccess(this);return oldValue;}}modCount++;addEntry(0, null, value, 0);return null;}inflateTable方法
inflateTable方法是根据创建HashMap时传入的初始容量或者默认初始容量来创建数组,并且初始化table数组。
//方法参数toSize就是HashMap初始容量private void inflateTable(int toSize) {// roundUpToPowerOf2是根据初始容量计算出一个值capacity,作为table的长度// 该值满足:capacity >= toSize,并且capacity为2的整数次幂int capacity = roundUpToPowerOf2(toSize);// 重新计算扩容阈值:threshold = capacity * loadFactorthreshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);//创建数组table = new Entry[capacity];initHashSeedAsNeeded(capacity);}private static int roundUpToPowerOf2(int number) {// assert number >= 0 : "number must be non-negative";return number >= MAXIMUM_CAPACITY? MAXIMUM_CAPACITY: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;}//该方法是求出i的最高位,比如9对应的2进制为:1001,经过该运算后,求出结果为1000public static int highestOneBit(int i) {//该方法是通过多次或运算,将i的低位全都变成1,最后再进行右移再相减,就只保留了最高位的1//如:1001,经过五次或运算,变成1111,最后一步为1111 - 0111 = 1000i |= (i >> 1);i |= (i >> 2);i |= (i >> 4);i |= (i >> 8);i |= (i >> 16);return i - (i >>> 1);}hash方法
hash方法是根据key计算出对应的hash值,这个hash值在定位插入链表在table中的下标(indexFor)时会使用到。
这个hash方法的作用在于:可以是得到的哈希值更加散列均匀,这样减少了哈希冲突,提升算法散列的性能。
//HashMap中的hash算法要求算法散列性尽可能的高final int hash(Object k) {int h = hashSeed;if (0 != h && k instanceof String) {return sun.misc.Hashing.stringHash32((String) k);}h ^= k.hashCode();// 通过多次位运算,提高算法散列性h ^= (h >>> 20) ^ (h >>> 12);return h ^ (h >>> 7) ^ (h >>> 4);}indexFor方法
indexFor方法就是根据hash值和table长度计算出插入链表在table中的下标i。
static int indexFor(int h, int length) {/*** 计算下标i,可以使用取模%操作,也可以使用按位&操作,但是计算机底层运算实际上还是2进制的位运* 算,所以按位&操作效率会更高。* ** 此处就可以解释Q1:为什么table的长度必须为2的整数次幂?* 因为我们此处求下标i使用的是按位&操作,如果length - 1中某一位为0,* 则该位上按位&操作必然为0,如:length为1011* length - 1:1010,* 则进行按位与操作时,数组上的有些位置将永远访问不到,造成空间的浪费,而且也增加了* hash冲突的可能性。而如果length满足2的整数次幂,那么put操作时要插入的元素可以被散列到数组的所* 有位置。*/return h & (length-1);}因为当length为2的整数次幂时,待插入元素散列到数组中任一位置的几率一样,也就是有机会可以被散列到table中的任一位置,可以有效利用数组空间,也可以减少hash冲突的可能性。
addEntry方法
addEntry方法执行时,需要先判断数组是否需要扩容,再进行元素添加。
void addEntry(int hash, K key, V value, int bucketIndex) {//jdk1.7版本HashMap的扩容条件:(size >= threshold) && (null != table[bucketIndex])//扩容条件:1、当前HashMap中Entry个数 >= threshold 2、要插入位置的链表不为空//jdk1.7和1.8中HashMap的扩容条件有一些差异,需要注意!!!if ((size >= threshold) && (null != table[bucketIndex])) {//扩容,新数组的长度为原数组的2倍resize(2 * table.length);hash = (null != key) ? hash(key) : 0;//扩容后需要重新计算indexbucketIndex = indexFor(hash, table.length);}createEntry(hash, key, value, bucketIndex);}通过该方法,我们可以知道jdk1.7下HashMap扩容的两个条件,以及HashMap扩容后的数组长度为原数组的2倍。
resize方法
resize方法是对HashMap进行扩容,并将原table中的元素转移到新table中。多线程情况下进行扩容会导致出现循环死锁的情况。
void resize(int newCapacity) {Entry[] oldTable = table;int oldCapacity = oldTable.length;if (oldCapacity == MAXIMUM_CAPACITY) {threshold = Integer.MAX_VALUE;return;}//创建新数组Entry[] newTable = new Entry[newCapacity];//将原table中的元素转移到新table中transfer(newTable, initHashSeedAsNeeded(newCapacity));table = newTable;//重新计算扩容阈值threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);}//转移元素void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;for (Entry<K,V> e : table) {while(null != e) {Entry<K,V> next = e.next;if (rehash) {e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);e.next = newTable[i];newTable[i] = e;e = next;}}}createEntry方法
createEntry方法是真正进行创建Entry并且插入链表操作的方法。该方法中将新创建的Entry通过头插法插入到链表中。jdk1.7版本下HashMap插入时采取的是头插法。java开发者认为新插入的Entry可能会更多地被访问,所以为了方便以后的存取,将新添加的元素插入到链表头部。但是该插入策略会使得在 扩容后的transfer方法中可能会产生死循环链表,所以在jdk1.8开始就改成了尾插法。
void createEntry(int hash, K key, V value, int bucketIndex) {Entry<K,V> e = table[bucketIndex];table[bucketIndex] = new Entry<>(hash, key, value, e);size++;}get相关方法
get相关的方法在内部主要将具体的get操作委托给了getEntry方法。
public V get(Object key) {if (key == null)return getForNullKey();Entry<K,V> entry = getEntry(key);return null == entry ? null : entry.getValue();}private V getForNullKey() {if (size == 0) {return null;}for (Entry<K,V> e = table[0]; e != null; e = e.next) {if (e.key == null)return e.value;}return null;}public boolean containsKey(Object key) {return getEntry(key) != null;}final Entry<K,V> getEntry(Object key) {if (size == 0) {return null;}int hash = (key == null) ? 0 : hash(key);for (Entry<K,V> e = table[indexFor(hash, table.length)];e != null;e = e.next) {Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k))))return e;}return null;}size方法
size方法返回HashMap中存储的Entry数量。看过该方法代码后可以方便区分字符串的length()方法、数组的length、集合的size()方法。
public int size() {return size;}remove相关方法
remove、clear相关操作可能会对HashMap产生结构性的修改,modCount值会自增。
public V remove(Object key) {Entry<K,V> e = removeEntryForKey(key);return (e == null ? null : e.value);}final Entry<K,V> removeEntryForKey(Object key) {if (size == 0) {return null;}int hash = (key == null) ? 0 : hash(key);int i = indexFor(hash, table.length);Entry<K,V> prev = table[i];Entry<K,V> e = prev;while (e != null) {Entry<K,V> next = e.next;Object k;if (e.hash == hash &&((k = e.key) == key || (key != null && key.equals(k)))) {modCount++;size--;if (prev == e)table[i] = next;elseprev.next = next;e.recordRemoval(this);return e;}prev = e;e = next;}return e;}final Entry<K,V> removeMapping(Object o) {if (size == 0 || !(o instanceof Map.Entry))return null;Map.Entry<K,V> entry = (Map.Entry<K,V>) o;Object key = entry.getKey();int hash = (key == null) ? 0 : hash(key);int i = indexFor(hash, table.length);Entry<K,V> prev = table[i];Entry<K,V> e = prev;while (e != null) {Entry<K,V> next = e.next;if (e.hash == hash && e.equals(entry)) {modCount++;size--;if (prev == e)table[i] = next;elseprev.next = next;e.recordRemoval(this);return e;}prev = e;e = next;}return e;}//在日常编码时快速填充数组可以学习该技巧Arrays.fillpublic void clear() {modCount++;Arrays.fill(table, null);size = 0;}jdk1.7版本的HashMap为什么会产生死锁(链表成环)?
出现问题的场景:
产生死锁或成环的三个条件:
1.产生死锁(链表成环)首先要保证是jdk版本1.7的HashMap
2.多线程环境
3.当addEntry添加元素数量达到一定后,触发扩容机制,扩容时多线程同时操作转移元素会导致死锁成环问题。
扩容时,如果多个线程同时进行转移元素的话,会导致死锁(链表成环)!
演示如下:

然后自己一步步演示作图即可得出成环 死锁的情况! 如下图所示:
ProcessOn Flowchart
解决方法:
Jdk8-扩容:
Java8 HashMap扩容跳过了Jdk7扩容的坑,对源码进行了优化,采用高低位拆分转移方式,避免了链表环的产生。
相关文章:
JUC并发编程之HashMap(jdk1.7版本)-底层源码探究
目录 JUC并发编程之HashMap(jdk1.7版本)-底层源码探究 HashMap底层源码 - jdk1.7 基本概念 -采取层层递进,问答式 存储Key-Value的结构 常量和成员变量 构造方法 put方法 inflateTable方法 hash方法 indexFor方法 addEntry方法 resize方法 createEntry…...

QT Q_OBJECT 和 signals/slots
Q_OBJECT宏展开 #define Q_OBJECT \ public: \QT_WARNING_PUSH \Q_OBJECT_NO_OVERRIDE_WARNING \static const QMetaObject staticMetaObject; \virtual const QMetaObject *metaObject() const; \virtual void *qt_metacast(const char *); \virtual int qt_metacall(QMetaOb…...
APM新添加UAVCAN设备
简介 UAVCAN是一种轻量级协议,旨在通过CAN总线在航空航天和机器人应用中实现可靠通信。要实现通信,最基本需要data_type_ id, signature、数据结构、设备程序初始化。 添加设备数据结构文件(.uavcan格式) 1.在以下路径添加设备数据结构文件,根据设备类…...

【C++】string类基本用法
文章目录string类基本用法1. 为什么要学习string类?1.1 C语言中的字符串2. 标准库中的string类2.1 string类2.2 string类的常用接口说明小试牛刀1. 仅仅反转字母2. 字符串中第一个唯一字符3. 字符串中最后一个单词的长度string类基本用法 1. 为什么要学习string类&…...

KDZD耐电压高压击穿强度测试仪
一、技术参数 01、输入电压: 交流 220 V。 02、输出电压: 交流 0--50KV ; 直流 0—50kv 。 03、电器容量:3KVA。 04、高压分级:0—50KV,(全程可调)。 05、升压速率:0.1KV/s-…...

数组和指针面试题的补充(细的抠jio)
生命是一条艰险的峡谷,只有勇敢的人才能通过。 ——米歇潘 说明:用的vs都是x86的环境,也就是32位平台。 建议:对于难题来说,一定要配合画图来解决问题。 第一题: #include<stdio.h> int…...
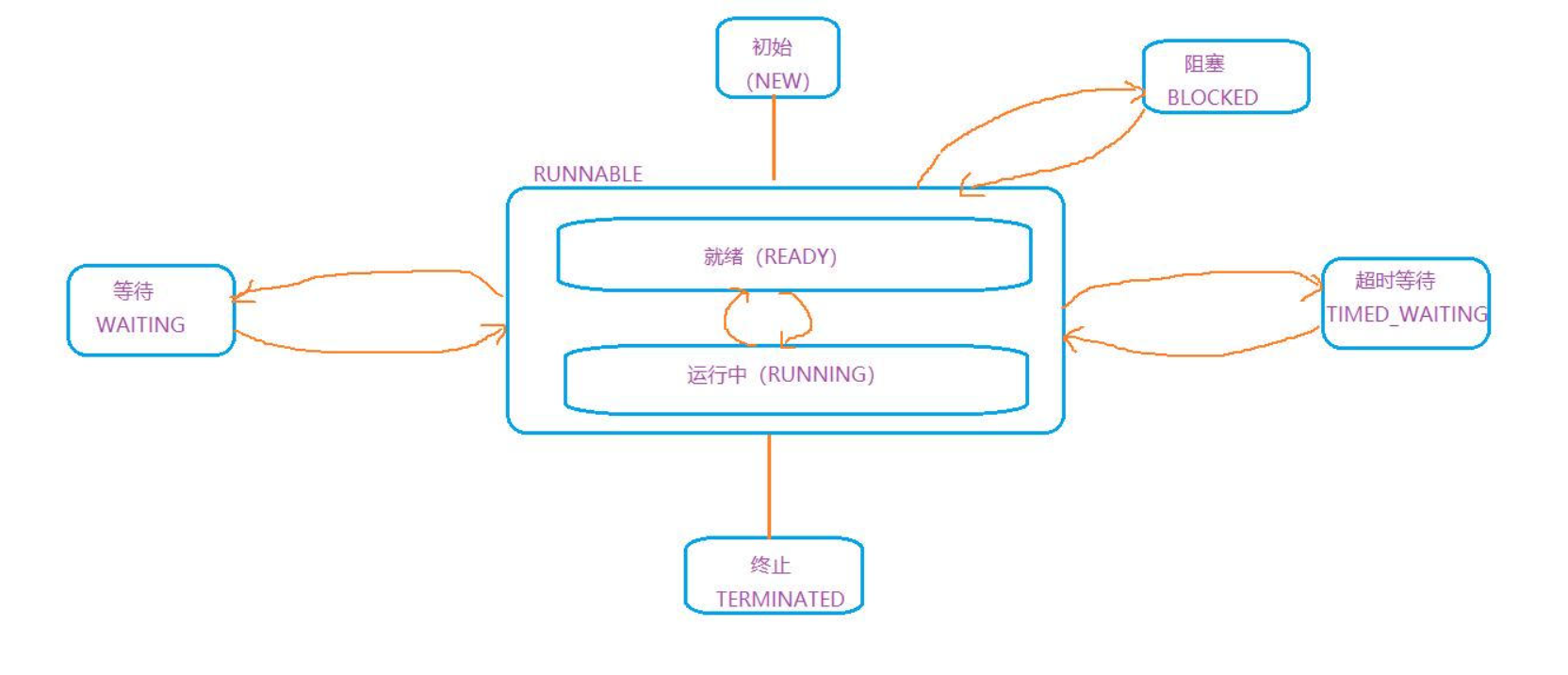
Java多线程基础
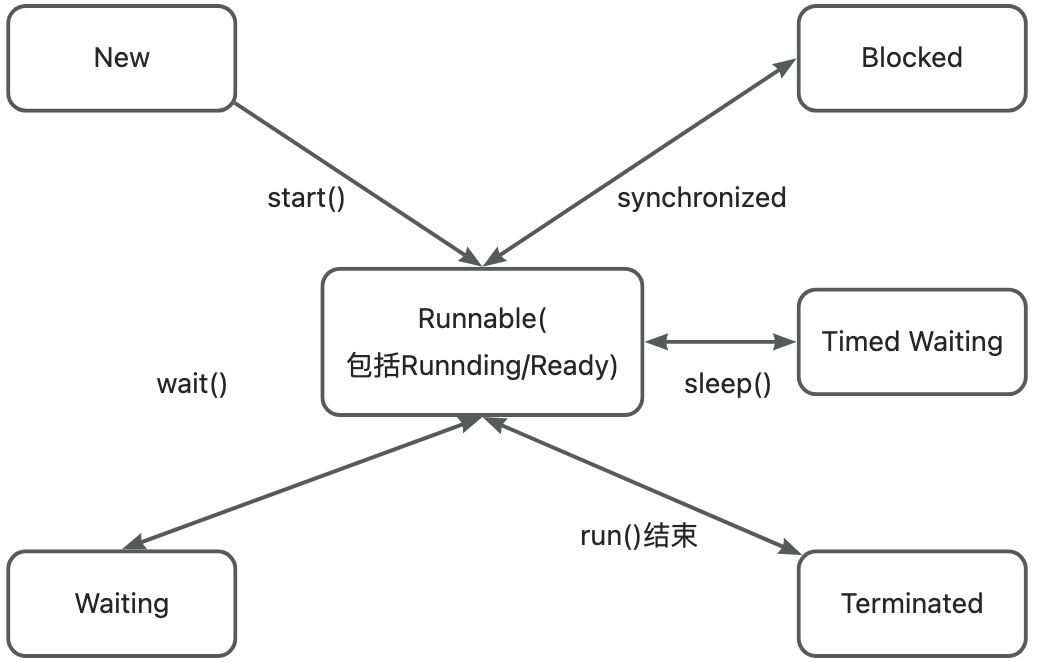
文章目录Java多线程基础一、什么是进程与线程?二、线程和进程的区别【重点】三、线程的创建方式【重点】1. 继承Thread类2. 实现Runnable接口3. lambda 表达式四、Thread的常见属性线程中断自己定义一个标志位Thread类提供的静态方法线程的状态Java多线程基础 一、…...
爆品分析第5期 | 一条视频带货3700+,这款斋月不锈钢厨具套装火了!
俗话说民以食为天,吃在任何一种文化中都占据重要的位置,要做出一道美味佳肴,除了食材、烹饪者的自身厨艺之外,还少不了一口好锅。新冠疫情以来,全世界范围内的封闭让很多人养成了居家做饭的习惯,不仅为厨具…...

团队管理的七个要点
要掌握团队管理的要点和做好团队管理工作,不是一件容易的事,但也远非想象中那么难。首先,我个人比较推荐所有团队管理者都能阅读下《经理人参阅:团队管理》(注意该书仅可其官网获得)这本佳作。相信会为你带…...
Go语言容器之map、list和nil
一、map map和C中map一样,里面存放的是key-value键值对在Go中map是引用类型,声明语法:var map变量名 map[key的类型]value的类型package mainimport "fmt"func main() {var mp map[string]intmpls : map[string]int{"one&quo…...

软件测试的案例分析 - 闰年1
(这是关于博客质量分的测试 https://www.csdn.net/qc) 我们谈了不少测试的名词, 软件是人写的, 测试计划和测试用例也是人写的, 人总会犯错误。错误发生之后, 总有人问: 为什么这个bug 没有测出来啊?! 我们看看一类简单的bug是如何发生的,以及如何预防…...
【强化学习】强化学习数学基础:值函数近似
值函数近似Value Function ApproximationMotivating examples: curve fittingAlgorithm for state value estimationObjective functionOptimization algorithmsSelection of function approximatorsIllustrative examplesSummary of the storyTheoretical analysisSarsa with …...
JVM系列——Java与线程,介绍线程原理和操作系统的关系
并发不一定要依赖多线程(如PHP中很常见的多进程并发)。 但是在Java里面谈论并发,基本上都与线程脱不开关系。因此我们讲一下从Java线程在虚拟机中的实现。 线程的实现 线程是比进程更轻量级的调度执行单位。 线程的引入,可以把一个进程的资源分配和执行调…...

C++打开文件夹对话框之BROWSEINFO
头文件 #include <shlobj.h> #include <windows.h> #include <stdio.h> using namespace std; 案例 string chooseFile(void) {//用户选择的路径,可以是TCHAR szBuffer[MAX_PATH] {0};然后再使用TCHAR 转char字符串,此处可以直接使…...

Nuxt项目配置、目录结构说明-实战教程基础-Day02
Nuxt项目配置、目录结构说明-实战教程基础-Day02一、Nuxt项目结构1.1资源目录1.2 组件目录1.3 布局目录1.4 中间件目录1.5 页面目录1.6 插件目录1.7 静态文件目录1.8 Store 目录1.9 nuxt.config.js 文件1.10 package.json 文件其他:别名二、项目配置2.1 build2.2 cs…...
单链表的头插,尾插,头删,尾删等操作
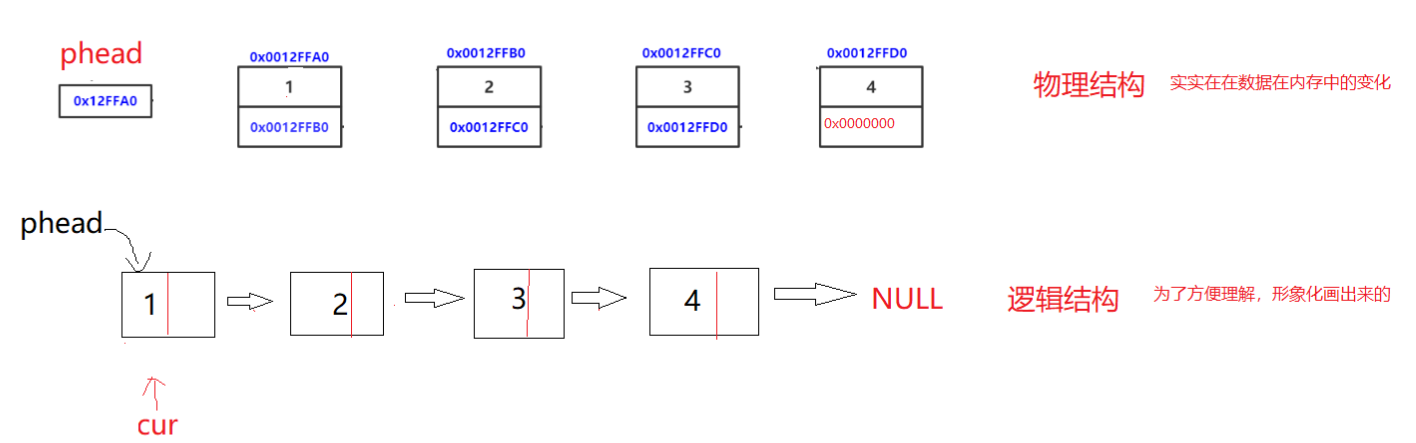
前言顺序表要求是具有连续的物理空间,并且数据的话是在这些空间当中是连续的存储。但这样会带来很多问题,比如说在头部或者说中间插入的话,效率不是很高;并且申请空间可能需要扩容,并且越往后一般来说都是异地扩容&…...

Qt扫盲-QProcess理论总结
QProcess理论使用总结一、概述二、使用三、通过 Channel 通道通信四、同步进程API五、注意事项1. 平台特性2. 不能实时读取一、概述 QProcess 其实更多的是与外面进程进行交互的一个工具类,通过这个类来启动外部进程,获取这个进程的标准输出,…...

JAVA进阶 —— Steam流
目录 一、 引言 二、 Stream流概述 三、Stream流的使用步骤 1. 获取Stream流 1.1 单列集合 1.2 双列集合 1.3 数组 1.4 零散数据 2. Stream流的中间方法 3. Stream流的终结方法 四、 练习 1. 数据过滤 2. 数据操作 - 按年龄筛选 3. 数据操作 - 演员信息要求…...

Ubuntu Protobuf 安装(测试有效)
安装流程 下载软件 下载自己要安装的版本:https://github.com/protocolbuffers/protobuf 下载源码编译: 系统环境:Ubuntu16(其它版本亦可),Protobuf-3.6.1 编译源码 cd protobuf# 当使用 git clone 下来的…...

驱动程序开发:FTP服务器和OpenSSH的移植与搭建、以及一些笔记
目录一、FTP服务器移植与搭建1、在ubuntu下安装vsftpd2、在window下安装FileZilla3、移植vsftpd到开发板上4、Filezilla 连接测试5、注意点二、开发板 OpenSSH 移植与使用1、移植 zlib 库2、移植 openssl 库3、移植 openssh 库4、openssh 使用测试三、关于u-boot上的操作及根文…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

ubuntu搭建nfs服务centos挂载访问
在Ubuntu上设置NFS服务器 在Ubuntu上,你可以使用apt包管理器来安装NFS服务器。打开终端并运行: sudo apt update sudo apt install nfs-kernel-server创建共享目录 创建一个目录用于共享,例如/shared: sudo mkdir /shared sud…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

鸿蒙DevEco Studio HarmonyOS 5跑酷小游戏实现指南
1. 项目概述 本跑酷小游戏基于鸿蒙HarmonyOS 5开发,使用DevEco Studio作为开发工具,采用Java语言实现,包含角色控制、障碍物生成和分数计算系统。 2. 项目结构 /src/main/java/com/example/runner/├── MainAbilitySlice.java // 主界…...

如何在网页里填写 PDF 表格?
有时候,你可能希望用户能在你的网站上填写 PDF 表单。然而,这件事并不简单,因为 PDF 并不是一种原生的网页格式。虽然浏览器可以显示 PDF 文件,但原生并不支持编辑或填写它们。更糟的是,如果你想收集表单数据ÿ…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...