SpringAI学习及搭建AI原生应用
文章目录
- 一、SpringAI是什么
- 二、准备工作
- 1.GPT-API-free
- 2.AiCore
- 3.eylink
- 三、对话案例实现
- 1.创建项目
- 2.实现简单的对话
- 四、聊天客户端ChatClient
- 1.角色预设
- 2.流式响应
- 3.call和stream的区别
- 五、聊天模型
- 提示词
- 提示词模板
- 六、图像模型(文生图)
- 七、语音模型
- 1.文字转语音(文生语音)
- 2.语音转文字
- 八、多模态
- 九、函数调用
- 十、向量数据库
- 1.向量化
- 2.写入向量库
- 十一、RAG 检索增强生成
- 1.RAG 解决的问题
- 2.RAG 的原理
- 3.生成一个 RAG 知识库
- 十二、搭建AI原生应用
- 1.AI原生应用的组成部分
- 2.一个简单的AI原生应用
一、SpringAI是什么
SpringAI是一个AI工程应用框架,旨在将Spring生态系统的设计原则(如可移植性和模块化设计)应用于AI领域。它推广使用Plain Old Java Object(POJO)作为AI应用程序的构建块,从而为Java开发者提供了一种更简洁的方式与人工智能进行交互。SpringAI的推出被认为是Java开发领域的一大福音,因为它结合了Spring生态系统的设计原则和模块化的概念,降低了接入大型语言模型(LLM)的学习成本。SpringInitializr是SpringAI上架的平台,使得Java开发者能够利用SpringAI构建自己的应用程序。
简单而言,Spring AI 是AI工程师所使用的一种应用性框架,通过提供出来的API和API key来进行开发应用,所用在于使用AI应用来简化开发工序流程。
| 名称 | 地址 |
|---|---|
| SpringAI官网 | https://spring.io/projects/spring-ai |
| SpringAI API官网 | https://docs.spring.io/spring-ai/reference/api/chatclient.html |
二、准备工作
我们需要准备OpenAI的key秘钥和API地址。以下是我整理的获取途径:
1.GPT-API-free
访问:https://gitcode.com/chatanywhere/GPT_API_free/overview
点击申请内测免费Key

- 免费版支持gpt-3.5-turbo, embedding,gpt-4。其中gpt-4由于价格过高,每天限制3次调用(0点刷新)。需要更稳定快速的gpt-4请使用付费版。
- 免费版gpt-4由gpt-4o提供服务,支持识图等付费版API全部功能。
- 转发Host1:https://api.chatanywhere.tech (国内中转,延时更低,host1和host2二选一)
- 转发Host2:https://api.chatanywhere.com.cn (国内中转,延时更低,host1和host2二选一)
- 转发Host3:https://api.chatanywhere.cn (国外使用,国内需要全局代理)
2.AiCore
访问地址:https://api.xty.app
注册登录后可以创建令牌
注意:不是纯免费
接口地址/BaseURL/密钥地址/代理地址(不同软件配置方式不同,请用下面的地址逐一测试):
https://api.xty.app,备用加速地址: https://hk.xty.app
https://api.xty.app/v1,备用加速地址: https://hk.xty.app/v1
淘宝搜: open ai key也可以直接购买
3.eylink
访问地址:https://eylink.cn/
三、对话案例实现
版本依赖:JDK17+SpringBoot3.3+SpringAI1.0.0-M1
1.创建项目
使用IDEA创建Springboot项目,一定要使用JDK17,看其他博主说的非17会出现版本错误(本人未测试)。
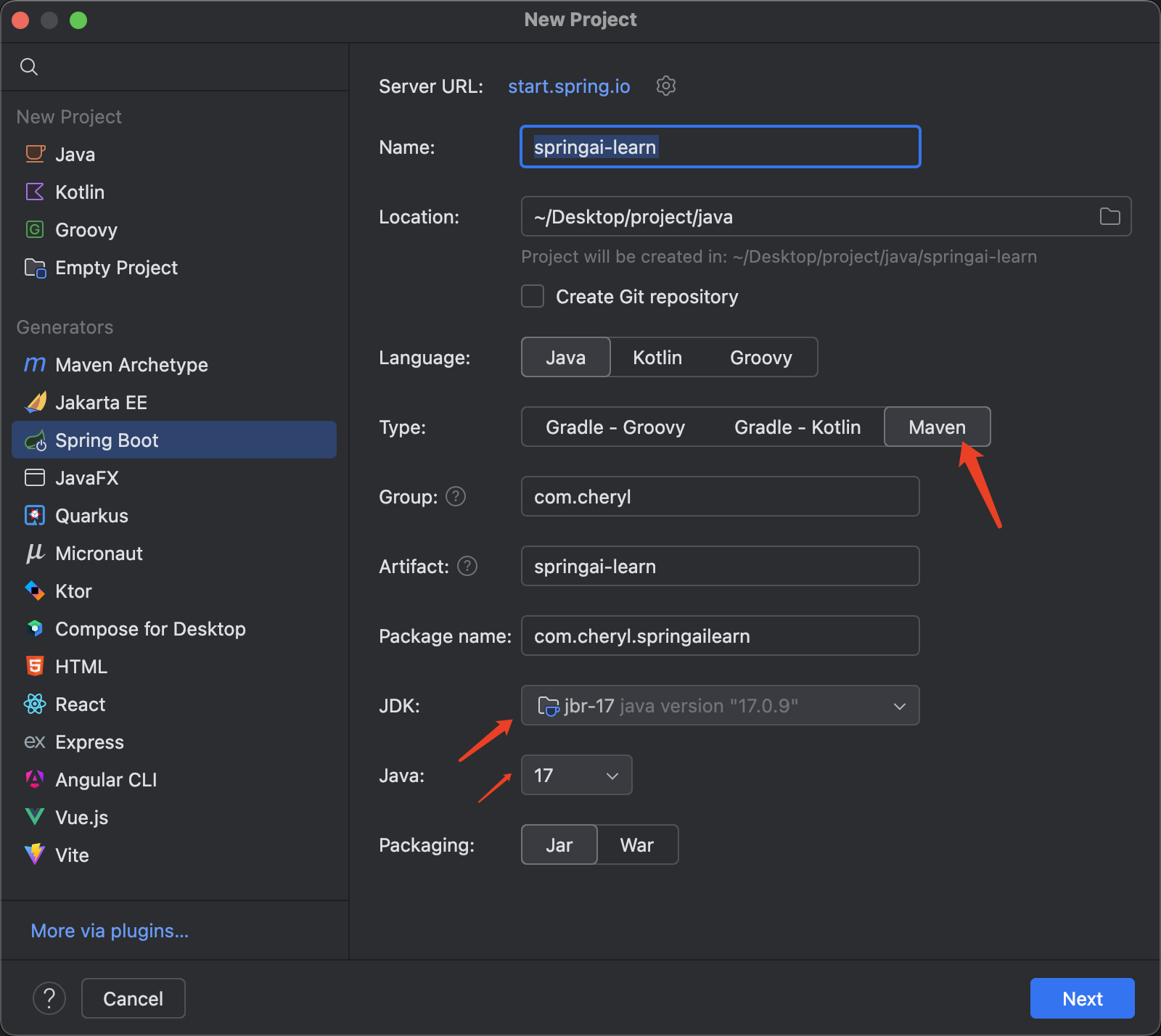
这里我们选择Maven,JDK和Java版本选择17.
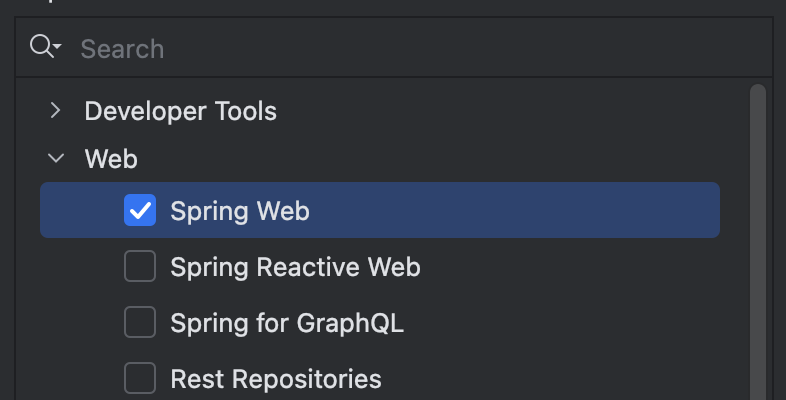
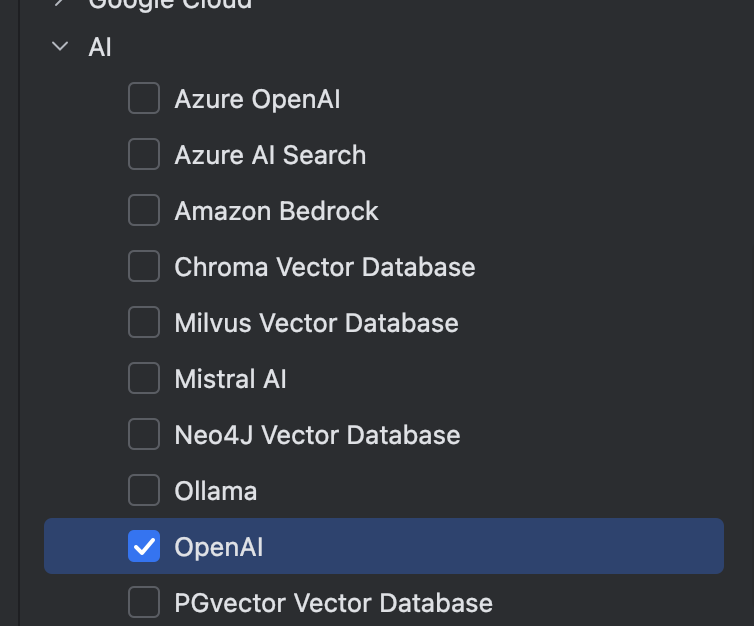
按照自己需求引入依赖。Spring Web和OpenAI为必须引入
pom文件依赖如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.3.0</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.cheryl</groupId><artifactId>springai-learn</artifactId><version>0.0.1-SNAPSHOT</version><name>springai-learn</name><description>springai-learn</description><properties><java.version>17</java.version><spring-ai.version>1.0.0-M1</spring-ai.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-openai-spring-boot-starter</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><dependencyManagement><dependencies><dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-bom</artifactId><version>${spring-ai.version}</version><type>pom</type><scope>import</scope></dependency></dependencies></dependencyManagement><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build><repositories><repository><id>spring-milestones</id><name>Spring Milestones</name><url>https://repo.spring.io/milestone</url><snapshots><enabled>false</enabled></snapshots></repository></repositories></project>更改配置文件:
spring:application:name: Spring-Ai-Demoai:openai:api-key: sk-XdZSQDaRxxxxxx #此次是获取的API-keybase-url: https://apixxxxxxxxx.tech # 这里是请求代理地址
如果想直接访问OpenAI不想使用以上配置的代理地址,则需要在代码中进行配置代理,代码如下:
@SpringBootApplication
public class SpringaiLearnApplication {public static void main(String[] args) {// 设置代理String proxy = "127.0.0.1"; // 如果代理在你本机就127.0.0.1如果代理是其他服务器相应设置int port = 7890; //设置科学上网代理的端口,System.setProperty("proxyType", "4");System.setProperty("proxyPort", Integer.toString(port));System.setProperty("proxyHost", proxy);System.setProperty("proxySet", "true");SpringApplication.run(SpringaiLearnApplication.class, args);}
}2.实现简单的对话
新建AIController,实现下列代码:
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RestController
@RequestMapping("/ai")
class AIController {private final ChatClient chatClient;public AIController(ChatClient.Builder chatClientBuilder) {this.chatClient = chatClientBuilder.build();}@GetMapping("/chat")public String chat(@RequestParam(value = "msg",defaultValue = "给我讲个笑话") String message) {//prompt:提示词return this.chatClient.prompt()//用户输入的信息.user(message)//请求大模型.call()//返回文本.content();}
}
调用结果如下:

在这个简单示例中,用户输入设置用户消息的内容。 call 方法向 AI 模型发送请求,context 方法以 String 形式返回 AI 模型的响应。
四、聊天客户端ChatClient
ChatClient提供了一个流畅的 API,用于与 AI 模型进行通信。 它支持同步编程模型和响应式编程模型。
1.角色预设
创建AIConfig文件配置默认角色
@Configuration
public class AIConfig {@Beanpublic ChatClient chatClient(ChatClient.Builder builder) {return builder.defaultSystem("你是考拉教育的一名老师,你精通Java开发,你的名字叫考拉AI。").build();}
}
修改controller如下:
@RestController
@RequestMapping("/ai")
@RequiredArgsConstructor
class AIController {private final ChatClient chatClient;@GetMapping("/chat")public String chat(@RequestParam(value = "msg") String message) {return chatClient.prompt().user(message).call().content();}
}
请求结果如下:

2.流式响应
注意要配置编码格式
@GetMapping(value = "/chat/stream",produces="text/html;charset=UTF-8")public Flux<String> chatStream(@RequestParam(value = "msg") String message) {return chatClient.prompt().user(message).stream().content();}

3.call和stream的区别
- 非流式输出 call:等待大模型把回答结果全部生成后输出给用户;
- 流式输出stream:逐个字符输出,一方面符合大模型生成方式的本质,另一方面当模型推理效率不是很高时,流式输出比起全部生成后再输出大大提高用户体验。
五、聊天模型
聊天模型 API 使开发人员能够将 AI 驱动的聊天完成功能集成到他们的应用程序中。它利用预训练的语言模型,如GPT(生成式预训练转换器),以自然语言生成类似人类的用户输入响应。
API 通常通过向 AI 模型发送提示或部分对话来工作,然后 AI 模型根据其训练数据和对自然语言模式的理解生成对话的完成或延续。然后,完成的响应将返回给应用程序,应用程序可以将其呈现给用户或将其用于进一步处理。
它被设计成一个简单且可移植的界面,用于与各种 AI 模型进行交互,允许开发人员以最少的代码更改在不同模型之间切换。 这种设计符合Spring的模块化和可互换性理念。Spring AI Chat Model API
此外,在输入封装和输出处理等配套类的帮助下,聊天模型 API 统一了与 AI 模型的通信。 它管理请求准备和响应解析的复杂性,提供直接和简化的 API 交互。PromptChatResponse
本文只展示使用OpenAI的方式,更多方式请查看官方文档
Spring AI 支持 OpenAI 的 AI 语言模型 ChatGPT。ChatGPT 在激发人们对 AI 驱动的文本生成的兴趣方面发挥了重要作用,这要归功于它创建了行业领先的文本生成模型和嵌入。
官网地址:https://docs.spring.io/spring-ai/reference/api/chat/openai-chat.html
package com.cheryl.springailearn.controller;import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.messages.Media;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.openai.OpenAiChatOptions;
import org.springframework.ai.openai.api.OpenAiApi;
import org.springframework.core.io.ClassPathResource;
import org.springframework.util.MimeTypeUtils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;import java.io.IOException;
import java.net.URL;
import java.util.List;@RequestMapping("/chat/model")
@RequiredArgsConstructor
@RestController
public class ChatModelController {private final ChatModel chatModel;@GetMappingpublic String chat(@RequestParam("msg")String msg) {return chatModel.call(msg);}/*** Spring AI 支持 OpenAI 的 AI 语言模型 ChatGPT* @param msg* @return*/@GetMapping("/openai")public String openai(@RequestParam("msg")String msg) {ChatResponse call = chatModel.call(new Prompt(msg,OpenAiChatOptions.builder()//可以更换成其他大模型,如Anthropic3ChatOptions亚马逊.withModel("gpt-3.5-turbo").withTemperature(0.8F).build()));return call.getResult().getOutput().getContent();}/*** 流式响应* @param msg* @return*/@GetMapping(value = "/openai/stream",produces="text/html;charset=UTF-8")public Flux<ChatResponse> stream(@RequestParam("msg")String msg) {return chatModel.stream(new Prompt(msg,OpenAiChatOptions.builder()//可以更换成其他大模型,如Anthropic3ChatOptions亚马逊.withModel("gpt-3.5-turbo").withTemperature(0.8F).build()));}
}提示词
提示词是引导大模型生成特定输出的输入,提示词的设计和措辞会极大地影响模型的响应结果。
[推荐林俊杰的五首歌] 就是一个最简单的提示词。在AI领域,提示的结构随着时间的推移不断发展,最初的提示只是简单的字符串,随着时间的推移,提示词开始包含特定输入的占位符,例如"USER:"、"ASSISTANT"这些,大模型可以识别这些占位符,并给出更符合用户需求的内容输出。
OpenAI 后来引入了一种更具条理的方法。在他们的模型中,提示不再仅仅是简单的文本字符串,而是由一系列带有特定角色的消息构成。尽管每条消息依然是文本形式,但它们各自被赋予了明确的角色。这些角色不仅帮助分类消息,还进一步澄清了大模型提示词中每个部分的上下文和目的。这种结构化的方法极大地提了与大模型沟通的准确性和效率,因为提示词中的每个元素在都承载着独特且清晰的功能。
下面是一个带有角色信息的prompt示例,可以看到prompt是包括对话的上下文,可以让模型更好的理解用户的意图。

Spring AI 适配了主流大模型,有不同的角色供使用:
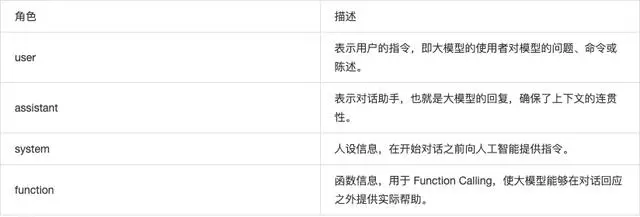
在 Spring AI 代码中对应不同的枚举值:
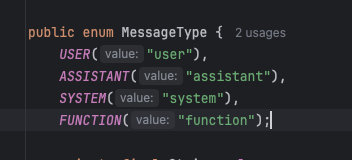
提示词模板
在 Spring AI 与大模型交互的过程中,处理提示词的方式与 Spring MVC 中管理“视图View”的方式有些相似。首先要创建包含动态内容占位符的模板,然后,这些占位符会根据用户请求或应用程序中的其他代码进行替换。另一个类比是JdbcTemplate中的语句,它包含可动态替换的占位符。
在提示词模板中,{占位符} 可以用 Map 中的变量动态替换。
下面一段代码展示了如果用提示词模板,生成一个旅游助手,实现非常简单,注意其中 SystemPromptTemplate 的实现。
@GetMapping("/prompt")public String prompt(@RequestParam("name")String name,@RequestParam("voice")String voice){String userText= """给我推荐上海的至少三个旅游景点""";UserMessage userMessage = new UserMessage(userText);String systemText= """你是一个旅游咨询助手,可以帮助人们查询旅游信息。你的名字是{name},你应该用你的名字和{voice}的风格回复用户的请求。""";SystemPromptTemplate systemPromptTemplate = new SystemPromptTemplate(systemText);//替换占位符Message systemMessage = systemPromptTemplate.createMessage(Map.of("name", name, "voice", voice));Prompt prompt = new Prompt(List.of(userMessage, systemMessage));List<Generation> results = chatModel.call(prompt).getResults();return results.stream().map(x->x.getOutput().getContent()).collect(Collectors.joining(""));}
调用结果:

六、图像模型(文生图)
属性配置官网:https://docs.spring.io/spring-ai/reference/api/image/openai-image.html
import lombok.RequiredArgsConstructor;
import org.springframework.ai.image.ImagePrompt;
import org.springframework.ai.image.ImageResponse;
import org.springframework.ai.openai.OpenAiImageModel;
import org.springframework.ai.openai.OpenAiImageOptions;
import org.springframework.ai.openai.api.OpenAiImageApi;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;@RequestMapping("/image")
@RestController
@RequiredArgsConstructor
public class ImageModelController {private final OpenAiImageModel openaiImageModel;@GetMappingpublic String getImage(@RequestParam(value = "msg",defaultValue = "生成一直小猫")String msg) {ImageResponse response = openaiImageModel.call(new ImagePrompt(msg,OpenAiImageOptions.builder().withQuality("hd")//将生成的图像的质量。HD 创建的图像具有更精细的细节和更高的图像一致性。只有 dall-e-3 支持此参数。.withModel(OpenAiImageApi.DEFAULT_IMAGE_MODEL).withN(1)//要生成的图像数。必须介于 1 和 10 之间。对于 dall-e-3,仅支持 n=1。.withHeight(1024)//生成的图像的高宽度。必须是 dall-e-2 的 256、512 或 1024 之一。.withWidth(1024).build()));return response.getResult().getOutput().getUrl();}}七、语音模型
1.文字转语音(文生语音)
import lombok.RequiredArgsConstructor;
import org.springframework.ai.openai.OpenAiAudioSpeechModel;
import org.springframework.ai.openai.OpenAiAudioSpeechOptions;
import org.springframework.ai.openai.api.OpenAiAudioApi;
import org.springframework.ai.openai.audio.speech.SpeechPrompt;
import org.springframework.ai.openai.audio.speech.SpeechResponse;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.io.FileOutputStream;
import java.io.IOException;@RequestMapping("/audio")
@RequiredArgsConstructor
@RestController
public class AudioModelController {private final OpenAiAudioSpeechModel openAiAudioSpeechModel;@GetMappingpublic void text2audio() throws IOException {OpenAiAudioSpeechOptions speechOptions = OpenAiAudioSpeechOptions.builder().withModel("tts-1")//要使用的模型的 ID。目前只有 tts-1 可用。.withVoice(OpenAiAudioApi.SpeechRequest.Voice.ALLOY)//用于 TTS 输出的语音。可用选项包括:alloy, echo, fable, onyx, nova, and shimmer..withResponseFormat(OpenAiAudioApi.SpeechRequest.AudioResponseFormat.MP3)//音频输出的格式。支持的格式包括 mp3、opus、aac、flac、wav 和 pcm。.withSpeed(1.0f)//语音合成的速度。可接受的范围是从 0.0(最慢)到 1.0(最快).build();//要转换的语音内容SpeechPrompt speechPrompt = new SpeechPrompt("你好,这是一个文本到语音的例子。", speechOptions);SpeechResponse response = openAiAudioSpeechModel.call(speechPrompt);byte[] output = response.getResult().getOutput();//将文件输出到指定位置writeByteArrayToMp3(output,"/Users/mac/Desktop/project/java");}public static void writeByteArrayToMp3(byte[] audioBytes, String outputFilePath) throws IOException {// 创建FileOutputStream实例FileOutputStream fos = new FileOutputStream(outputFilePath+"/audio_demo.mp3");// 将字节数组写入文件fos.write(audioBytes);// 关闭文件输出流fos.close();}
}2.语音转文字
import lombok.RequiredArgsConstructor;
import org.springframework.ai.openai.OpenAiAudioTranscriptionModel;
import org.springframework.ai.openai.OpenAiAudioTranscriptionOptions;
import org.springframework.ai.openai.api.OpenAiAudioApi;
import org.springframework.ai.openai.audio.transcription.AudioTranscriptionPrompt;
import org.springframework.ai.openai.audio.transcription.AudioTranscriptionResponse;
import org.springframework.core.io.ClassPathResource;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;@RequestMapping("/audio")
@RequiredArgsConstructor
@RestController
public class AudioModelController {private final OpenAiAudioTranscriptionModel openAiTranscriptionModel;@GetMapping("/audio2text")public String audio2text(){//脚本输出的格式,位于以下选项之一中:json、text、srt、verbose_json 或 vtt。OpenAiAudioApi.TranscriptResponseFormat responseFormat = OpenAiAudioApi.TranscriptResponseFormat.TEXT;OpenAiAudioTranscriptionOptions transcriptionOptions = OpenAiAudioTranscriptionOptions.builder().withLanguage("en")//输入音频的语言。以 ISO-639-1 格式提供输入语言将提高准确性和延迟。.withPrompt("Ask not this, but ask that")//用于指导模型样式或继续上一个音频片段的可选文本。提示应与音频语言匹配。.withTemperature(0f)//采样温度,介于 0 和 1 之间。较高的值(如 0.8)将使输出更具随机性,而较低的值(如 0.2)将使其更加集中和确定。如果设置为 0,模型将使用对数概率自动提高温度,直到达到某些阈值。.withResponseFormat(responseFormat)//输出格式.build();//获取当前语音文件ClassPathResource audioFile = new ClassPathResource("audio_demo.mp3");AudioTranscriptionPrompt transcriptionRequest = new AudioTranscriptionPrompt(audioFile, transcriptionOptions);AudioTranscriptionResponse response = openAiTranscriptionModel.call(transcriptionRequest);return response.getResult().getOutput();}
}八、多模态
多模态是指模型同时理解和处理来自各种来源的信息的能力,包括文本、图像、音频和其他数据格式。
/*** 多模态是指模型同时理解和处理来自各种来源的信息的能力,包括文本、图像、音频和其他数据格式。 * 仅支持 chatGPT4.0* @param msg* @return*/@GetMapping(value = "/openai/multimodal",produces="text/html;charset=UTF-8")public String multimodal(@RequestParam("msg")String msg) throws IOException {byte[] imageData = new ClassPathResource("/multimodal.test.png").getContentAsByteArray();var userMessage = new UserMessage(msg,List.of(new Media(MimeTypeUtils.IMAGE_PNG,new URL("https://docs.spring.io/spring-ai/reference/1.0-SNAPSHOT/_images/multimodal.test.png"))));ChatResponse response = chatModel.call(new Prompt(List.of(userMessage),OpenAiChatOptions.builder().withModel(OpenAiApi.ChatModel.GPT_4_O.getValue()).build()));return response.getResult().getOutput().getContent();}
九、函数调用
我们创建一个聊天机器人,通过调用我们自己的函数来回答问题。 为了支持聊天机器人的响应,我们将注册我们自己的函数,该函数获取一个位置并返回该位置的当前天气。
(注意本人亲测函数调用只能在gtp4.0以上使用,注意上边说的免费版Key无法使用)
大致流程如下:

创建functions包,创建LocationWeatherFunction实现Function接口
package com.cheryl.springailearn.functions;import java.util.function.Function;public class LocationWeatherFunction implements Function <LocationWeatherFunction.Request, LocationWeatherFunction.Response>{// 实现apply方法@Overridepublic Response apply(Request request) {System.out.println(request);if(request==null){return new Response("request is null");}if(request.location==null){return new Response("地址是空的");}return new Response("天气一会下雨一会晴天" );}public record Request(String location){}public record Response(String msg) {}
}将函数注册为 Bean
@Description是可选的,它提供了函数描述 ,可帮助模型了解何时调用函数。这是一个重要的属性,可帮助 AI 模型确定要调用的客户端函数。
package com.cheryl.springailearn.config;import com.cheryl.springailearn.functions.LocationWeatherFunction;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Description;import java.util.function.Function;@Configuration
public class AIConfig {@Bean@Description("某某地方天气怎么样")public Function<LocationWeatherFunction.Request, LocationWeatherFunction.Response> locationWeatherFunction(){return new LocationWeatherFunction();}
}在聊天模型中调用函数
package com.cheryl.springailearn.controller;import lombok.RequiredArgsConstructor;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.chat.model.ChatResponse;
import org.springframework.ai.chat.prompt.Prompt;
import org.springframework.ai.openai.OpenAiChatOptions;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;import java.util.List;@RequestMapping("/function")
@RequiredArgsConstructor
@RestController
public class AIFunctionController {private final ChatModel chatModel;@GetMappingpublic String testFunction(){UserMessage userMessage = new UserMessage("济南天气怎么样?");OpenAiChatOptions options = OpenAiChatOptions.builder().withFunction("locationWeatherFunction").withModel("gpt-4-turbo").build();ChatResponse call = chatModel.call(new Prompt(List.of(userMessage),options));return call.getResult().getOutput().getContent();}}结果如下:

十、向量数据库
向量数据库是一种特殊的数据库类型,在AI原生应用中起着关键作用。
在向量数据库中,查询与传统关系型数据库有所不同。它不是执行精确匹配,而是执行相似性搜索。当给定一个向量作为查询时,向量数据库会返回与查询向量“相似”的向量。有关如何计算这种相似性,请参阅向量相似性相关文档,这里不做详细介绍。
向量数据库用于将私有的数据与大模型集成。使用它们的第一步是将您的数据加载到向量数据库中。然后,当用户的查询要发送到AI模型时,首先会检索一组相似的文档。这些文档随后将作为用户问题的上下文,与用户查询一起发送到大模型。这种技术被称为检索增强生成(RAG)。
Spring AI 支持集成的向量库如下:
Azure Vector Search - The Azure vector store.
ChromaVectorStore - The Chroma vector store.
MilvusVectorStore - The Milvus vector store.
Neo4jVectorStore - The Neo4j vector store.
PgVectorStore - The PostgreSQL/PGVector vector store.
PineconeVectorStore - PineCone vector store.
QdrantVectorStore - Qdrant vector store.
RedisVectorStore - The Redis vector store.
WeaviateVectorStore - The Weaviate vector store.
SimpleVectorStore - A simple implementation of persistent vector storage, good for educational purposes.
1.向量化
众所周知,计算机无法读懂自然语言,只能处理数值,因此自然语言需要以一定的形式转化为数值。向量化就是将自然语言中的词语映射为数值的一种方式。然而对于丰富的自然语言来说,将它们映射为数值向量,使之包含更丰富的语义信息和抽象特征显然是一种更好的选择。嵌入是浮点数的向量(列表),两个向量之间的距离衡量它们的相关性,小距离表示高相关性,大距离表示低相关性。
向量化通常用于:
搜索(结果按与查询字符串的相关性排序)
聚类(其中文本字符串按相似性分组)
推荐(推荐具有相关文本字符串的项目)
异常检测(识别出相关性很小的异常值)
多样性测量(分析相似性分布)
分类(其中文本字符串按其最相似的标签分类)
向量化可以将单词或短语表示为低维向量,这些向量具有丰富的语义信息,可以捕捉单词或短语的含义和上下文关系。
Embedding Client 旨在将大模型中的向量化功能直接集成。它的主要功能是将文本转换为数字矢量,通常称为向量化。向量化对于实现各种功能,如语义分析和文本分类,是至关重要的。
代码示例:
@RequestMapping("/embedding")
@RestController
@RequiredArgsConstructor
public class EmbeddingModelController {private final EmbeddingModel embeddingModel;@GetMapping()public Map embed(@RequestParam(value = "message", defaultValue = "给我讲个笑话") String message) {EmbeddingResponse embeddingResponse = this.embeddingModel.embedForResponse(List.of(message));return Map.of("embedding", embeddingResponse);}
}2.写入向量库
写入向量数据库前,首先要将文本用大模型向量化,因此在 Spring AI 中向量数据库与向量化方法是绑定在一起使用的。
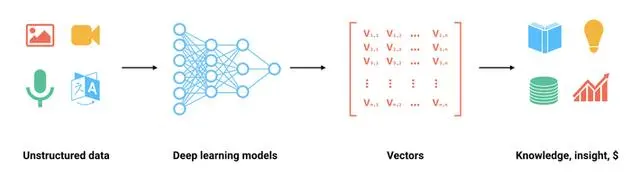
△向量数据集写入原理
代码示例:
生成向量库 Bean,VectorStore Bean 的创建条件是 上一小节中的 EmbeddingModel
修改AIConfig 添加如下Bean
@Beanpublic VectorStore createVectorStore(EmbeddingModel model){return new SimpleVectorStore(model);}写入向量库(包括向量化与写入向量库两步)并检索向量库
@GetMappingpublic void load(@RequestParam(value = "msg" ,defaultValue = "济南天气怎么样") String msg) {//写入向量库List<Document> documents = new ArrayList<>();documents.add(new Document("深圳天气热"));documents.add(new Document("北京天气冷"));documents.add(new Document("上海天气潮湿"));documents.add(new Document("济南天气一会热一会冷"));vectorStore.add(documents);//检索向量库List<Document> result = vectorStore.similaritySearch(msg);List<String> collect = result.stream().map(Document::getContent).toList();System.out.println(collect);}
十一、RAG 检索增强生成
1.RAG 解决的问题
大模型虽然很强大,但直接使用有几个问题有待解决:它们经常捏造事实,在处理特定领域或高度专业化的查询时缺乏知识。例如,当所寻求的信息超出模型的训练数据范围或需要最新数据时,大语言模型可能无法提供准确的答案。这一限制在将生成式人工智能部署到现实世界的生产环境中时构成挑战,因为单纯依赖一个不透明的大语言模型可能不够。
检索增强生成(Retrieval-Augmented Generation,RAG)技术旨在解决将外部数据输入纳入提示词以获取准确的大模型响应。
RAG 为大语言模型提供从某些数据源检索到的信息,作为其生成答案的依据。RAG 是模型基于搜索到的信息作为上下文进行回答。查询和检索到的上下文都被注入到发送给大语言模型的提示词中。RAG 是 2023-2024 年最流行的基于 LLM 的系统架构。有许多产品几乎完全基于 RAG 构建 - 从将网络搜索引擎与 LLM 相结合的问答服务到数百个chat-with-your-data 应用程序。
2.RAG 的原理
下面这张图很好的解释了一个外部 PDF 文件如果作为大模型的知识补充。
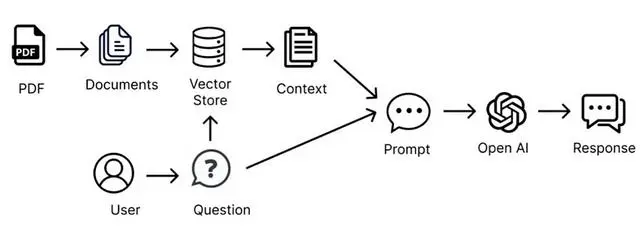
△一个最简单的 RAG 的原理
这种方法涉及流式编程模型,首先要从文档中读取非结构化数据,对其进行转换,变为结构化的数据,然后向量化,再将其写入向量数据库。从高层次来看,这是一个ETL(提取、转换和加载)的pipe。在 RAG 技术的检索部分中,也使用了向量数据库。
将非结构化数据加载到向量数据库时,最重要的转换之一是将原始文档拆分成较小的部分(大模型的输入 token 数有限,将全文全部输入给模型不现实,只能将最相关的部分输入模型)。将原始文档拆分成较小部分的过程包括两个重要步骤:
在保留内容语义边界的同时,将文档拆分成多个部分。对于包含段落和表格的文档,应避免在段落或表格中间拆分文档。对于代码,应避免在方法实现中间拆分代码。要求被拆分成为的每一个文本块都占大模型模型输入 token 限制很小的一部分。
RAG 的下一个阶段是处理用户输入。当大模型需要回答用户的问题时,将问题和所有“相似”的文本块放入发送给大模型的提示词。这就是使用向量数据库的原因,它非常擅长查找相似的内容,向量数据库的写入与检索在上一章节中已经介绍。
3.生成一个 RAG 知识库
生成一个 RAG 知识库包括四步:文件解析、文本切分、段落向量化、入向量库。

以下是一个代码示例,把一份简历写入向量库:
教育经历
苏州大学 船舶电气工程技术 本科 2011.09 - 2015.06
主修课程:电工技术、电子技术、电机与电力拖动、微机原理、可编程控制器(PLC)、电气照明技术、船舶概论、现代检测技术、船舶电气设备及系统、船舶辅机电气控制系统、船舶设备安全与管理、航海仪器、船舶通信与导航、微机控制系统、电路、电子基础、电机及拖动、可编程序控制器、单片机技术、船舶电气施工工艺、船机拖动控制系统、船舶机舱自动控制系统。
实习经历
苏州小优智能科技有限公司 算法工程师
2015-4-1 - 2017-9-1
拥有2年以上的算法工程师经验,熟悉数据结构、算法及机器学习模型的实现与优化,在多个项目中负责算法模型的设计与开发,包括基于深度学习的图像识别、语音识别及自然语言处理等方向。熟练使用TensorFlow、PyTorch等主流深度学习框架,能独立开发出高质量、高性能的算法模型。
在前一份工作中担任算法工程师,负责开发基于深度学习的推荐算法,成功实现了推荐效果的提升,提升了公司的用户留存率和收益。在此之前,还参与过一些数据建模和预测的研究项目,在工作中积累了数据处理和建模的经验。
曾在一家创业公司实习,负责开发基于深度强化学习的智能对话系统。在项目中,担任小组负责人并领导团队顺利完成了对话模型的设计和实现。通过项目,熟练掌握了深度强化学习等先进人工智能技术,并具备解决自然语言处理领域复杂问题的能力。
在研究生期间,参加了一项基于图像识别的研究项目,并担任项目组长。在研究中,使用深度卷积神经网络实现了图像的分类和识别,在国内外学术会议上获得了多个论文发表和报告的机会,积累了学术研究和成果展示的经验。
陕西欧卡电子智能科技有限公司 算法工程师
2018-10-1 - 2020-3-1
担任ABC公司算法工程师,负责参与开发高性能机器学习算法。在项目中,我使用Python和MATLAB编写了多种算法模型,并且实现了GPU加速计算,使得算法在处理大规模复杂数据时表现优异。
就职于DEF科技公司,作为算法工程师,全程参与了一款自动驾驶系统的开发。在项目中,我主要通过深度学习、目标检测等技术,实现了车辆识别、道路分割等多项技术难点,使得系统在真实道路环境下表现出了较高的稳定性和可靠性。
在GHI软件公司,我作为算法工程师负责了一项推荐系统的研发。该系统基于用户行为数据,使用协同过滤和深度学习技术,为用户推荐最优质的内容。在项目中,我优化了多种推荐算法,优化推荐精度达到了90%以上。
曾就职于JKL医疗科技公司,作为算法工程师负责开发医疗影像诊断平台。在项目中,我使用深度学习技术对医学图像进行自动分析和诊断,提高了医生的工作效率和诊断准确率。
项目经验
苏州小优智能科技有限公司相关项目 苏州小优智能科技有限公司 算法工程师
2016-4-1 - 2016-9-1
开发基于协同过滤的音乐推荐系统,主要负责数据清洗和模型训练。使用Python实现了基于用户相似度和物品相似度的协同过滤算法,并应用到推荐系统中,提高了推荐准确度。
参与人工智能智慧城市项目,主要工作为基于用户画像的广告推荐系统开发。利用Spark进行大规模数据处理和分析,采用深度学习神经网络构建用户画像,并实现了召回模型和排序模型的训练,提升推荐效果。
参与在线教育平台数据挖掘和推荐系统开发,主要工作为开发基于LBS和时间因素的视频推荐系统。使用Spark Streaming进行实时数据处理,利用Hadoop进行离线数据处理,应用LDA模型进行主题关键字提取和话题挖掘,从而提高了推荐准确性。
参与电商平台热销商品推荐系统开发,主要工作为开发基于神经网络和深度强化学习的推荐算法。使用TensorFlow进行模型训练和预测,应用异构网络结构和实时监控技术,提高了推荐准确度和实时性。
欧卡电子相关项目 陕西欧卡电子智能科技有限公司 算法工程师
2019-10-1 - 2020-3-1
开发和优化图像识别算法,提高识别的准确率和速度。利用OpenCV、TensorFlow等开源工具,结合人工智能和深度学习技术,开发识别系统,并持续进行性能优化;
开发图像处理算法,包括去噪、模糊、增强等多种算法,达到提高图像质量、增强细节等效果,并应用于实际场景;
参与人脸识别项目,利用深度学习技术进行人脸检测、特征提取和比对,提高人脸识别的准确率;
参与图像翻译项目,开发适用于不同语种的OCR算法,将图像上的文字转换成文本,并进行翻译,为用户提供更智能的翻译服务;
学校实践
机器学习算法实验课程实践:通过学习机器学习的相关理论知识,了解推荐算法的原理,并实践了基于协同过滤算法的电影推荐系统的开发。
数据库系统实践:学习数据库系统的概念和原理,并通过MySQL的实践操作,完成了推荐算法中的数据存储与查询操作,并对系统的性能进行了优化。
数据挖掘与大数据实践:通过使用Python编程语言和相关工具,熟练掌握了数据预处理、特征选择、模型训练与评估等数据挖掘的基本步骤,并实践了基于协同过滤算法的用户推荐系统的开发。
技能特长
图像处理技术:具备图像处理基础知识,熟练使用OpenCV等图像处理库进行图像处理、特征提取等操作。
深度学习:熟练使用TensorFlow、PyTorch等深度学习框架,了解神经网络理论,掌握CNN、RNN、GAN等深度学习算法。
数据结构与算法:熟悉数据结构和基本算法,能够灵活运用算法进行解决问题。
语言技能:熟练掌握Python、C++等编程语言,有良好的编程习惯和代码风格,能够快速上手新的编程语言和工具。
项目经验:熟练掌握常用的图像算法,并在实践中有多个项目实践经验,包括但不限于图像分割、目标检测、人脸识别等项目。
刘磊简历
将他存放在resource目录下
写入向量数据库
@GetMapping("/rag/create")public void ragCreate(){//1.提取文本内容String filePath="刘磊简历.txt";TextReader textReader = new TextReader(filePath);textReader.getCustomMetadata().put("filePath",filePath);List<Document> documents = textReader.get();log.info("文档分割之前:{}",documents);//2。文本切分段落TokenTextSplitter splitter = new TokenTextSplitter(1200, 350, 5, 100, true);splitter.apply(documents);log.info("文档分割之后:{}",documents);//3.段落写入向量数据库vectorStore.add(documents);}这样,一个简单的 RAG 知识库就创建完成了,使用时直接在向量库中检索即可。
十二、搭建AI原生应用
1.AI原生应用的组成部分
有了 Spring AI 的帮助,我们就可以轻松的搭建一个简单的AI原生应用了。
AI应用除了依赖大模型外,还有三个更为重要的组成部分:人设、知识库与工具,分别对应上文中介绍的 Prompt、RAG 与 Function Calling。
人设是应用的设定,要描述你的应用要实现什么目标。
知识库能在大模型基础上解决以下问题:
在不需要对模型进行调优的情况下可以保证模型回答结果的专业性;
大模型在回答问题时可以依赖数据集进行推理与回答,减少错误的可能性;
补充现有模型通用知识,可以确保回答的准确性与时效性。
工具能在大模型基础上解决以下问题:如果说大模型是一个智能中枢大脑,工具就是大模型的耳、目、手。工具将大模型的AI能力与外部应用相结合,既能丰富大模型的能力和应用场景,也能利用大模型的生成能力完成此前无法实现的任务。
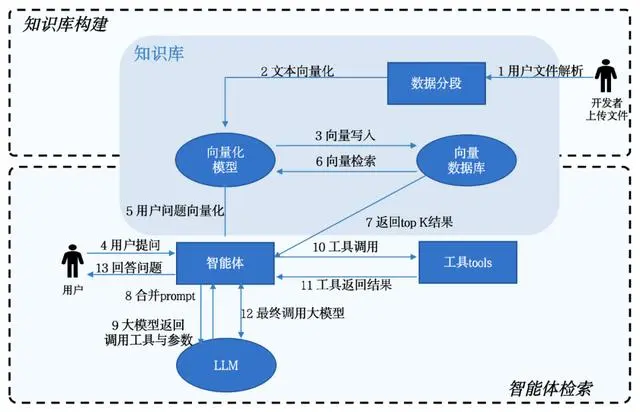
△一个简单的AI智能体
2.一个简单的AI原生应用
下面我们来搭建一个AI原生应用,这个应用可以用了快速查看应聘候选人的信息及与候选人岗位的匹配度。
step1:首先用全部候选人的简历构建一个简历知识库,具体构建方式我们在4.3章节中已经介绍。
step2:创建一个工具(Function),可以用来查询候选人应聘的岗位。
public class RecruitServiceFunction implements Function<RecruitServiceFunction.Request, RecruitServiceFunction.Response> {@Overridepublic Response apply(Request request) {String position="未知";if(request.name.contains("张真源")){position="算法工程师";}return new Response(position);}public record Request(String name){}public record Response(String position){}
}step3:编写应用的人设。
- 角色与目标:你是一个招聘助手,会针对用户的问题,结合候选人经历,岗位匹配度等专业知识,给用户提供指导。
- 指导原则:你需要确保给出的建议合理科学,不会对候选人的表现有言论侮辱。
- 限制:在提供建议时,需要强调在个性建议方面用户仍然需要线下寻求专业咨询。
- 澄清:在与用户交互过程中,你需要明确回答用户关于招聘方面的问题,对于非招聘方面的问题,你的回应是‘我只是一个招聘助手,不能回答这个问题哦’。
- 个性化:在回答时,你需要以专业可靠的预期回答,偶尔可以带点幽默感。调节气氛。
step4:将人设、知识库、工具通过 Spring AI 框架串联起了,搭建成应用。
@GetMapping("/ai/agent")public String rag(@RequestParam("query")String query){//检索挂载信息List<Document> documents = vectorStore.similaritySearch(query);//提取相关信息String info ="";if(documents.size()>0){info=documents.get(0).getContent();}//构造系统 promptString systemPrompt= """角色与目标:你是一个招聘助手,会针对用户的问题,结合候选人经历,岗位匹配度等专业知识,给用户提供指导。指导原则:你需要确保给出的建议合理科学,不会对候选人的表现有言论侮辱。限制:在提供建议时,需要强调在个性建议方面用户仍然需要线下寻求专业咨询。澄清:在与用户交互过程中,你需要明确回答用户关于招聘方面的问题,对于非招聘方面的问题,你的回应是‘我只是一个招聘助手,不能回答这个问题哦’。个性化:在回答时,你需要以专业可靠的预期回答,偶尔可以带点幽默感。调节气氛。给你提供一个数据参考,并且给你调用岗位投递检索公户请你跟进数据参考与工具返回结果回复用户的请求。""";//构造用户 promptString userPrompt= """给你提供一些数据参考:{info},请回答我的问题:{query}。请你跟进数据参考与工具返回结果回复用户的请求。""";//构造提示词SystemMessage systemMessage = new SystemMessage(systemPrompt);PromptTemplate promptTemplate = new PromptTemplate(userPrompt);Message userMessage = promptTemplate.createMessage(Map.of("info", info, "query", query));Prompt prompt = new Prompt(List.of(userMessage, systemMessage),OpenAiChatOptions.builder().withFunctions(Set.of("recruitServiceFunction")).build());List<Generation> results = chatModel.call(prompt).getResults();String content = results.stream().map(x -> x.getOutput().getContent()).collect(Collectors.joining());log.info("最后问题的结果是:{}",content);return content;}结果如下

代码已经上传至git仓库:https://gitee.com/luzhiyong_erfou/spring-ai-learning
部分内容来源:https://baijiahao.baidu.com/s?id=1801098931981459311&wfr=spider&for=pc
相关文章:
SpringAI学习及搭建AI原生应用
文章目录 一、SpringAI是什么二、准备工作1.GPT-API-free2.AiCore3.eylink 三、对话案例实现1.创建项目2.实现简单的对话 四、聊天客户端ChatClient1.角色预设2.流式响应3.call和stream的区别 五、聊天模型提示词提示词模板 六、图像模型(文生图)七、语音模型1.文字转语音(文生…...

CobaltStrike权限传递MSF
一、测试环境 操作系统: 1.VMware17 2.kali 6.1.0-kali5-amd64 3.Win10x64 软件: 1.cs4.0 2.metasploit v6.3.4-dev 二、测试思路 1.cs是一款渗透测试工具,但没有漏洞利用的模块,我们可以在拿到目标主机的权限后,将…...
白嫖 kimi 接口 api
说明:kimi当然是免费使用的人工智能AI,但是要调用api是收费的. 项目: https://github.com/LLM-Red-Team/kimi-free-api 原文地址: https://blog.taoshuge.eu.org/p/272/ railway部署 步骤: 打开Github,新建仓库新建名为Dockerfile文件(没有后缀&…...

借助ChatGPT完成课题申报书中框架思路写作指南
大家好,感谢关注。我是七哥,一个在高校里不务正业,折腾学术科研AI实操的学术人。可以和我(yida985)交流学术写作或ChatGPT等AI领域相关问题,多多交流,相互成就,共同进步 在课题申报…...
)
SuntoryProgrammingContest2024(AtCoder Beginner Contest 357)
https://www.cnblogs.com/yxcblogs/p/18239433 题解写到博客园了,懒得复制了,直接放个链接吧~...
重温共射放大电路
1、放大概念 小功率信号变成一个大功率信号,需要一个核心器件做这件事,核心器件的能量由电源提供,通过核心器件用小功率的信号去控制大电源,来实现能量的转换和控制,前提是不能失真,可以用一系列正弦波进行…...

[DDR5 Jedec] 读操作 Read Command 精讲
依公知及经验整理,原创保护,禁止转载。 专栏 《深入理解DDR》 Read 读取命令也可以视为列读取命令。当与正确的bank地址和列地址结合使用时,通过激活命令(行访问)移动到检测放大器中的数据, 现在被推送到数…...

opencv 通过滑动条调整阈值处理、边缘检测、轮廓检测、模糊、色调调整和对比度增强参数 并实时预览效果
使用PySimpleGUI库创建了一个图形用户界面(GUI),用于实时处理来自OpenCV摄像头的图像。它允许用户应用不同的图像处理效果,如阈值处理、边缘检测、轮廓检测、模糊、色调调整和对比度增强。用户可以通过滑动条调整相关参数。 完整代码在文章最后,可以运行已经测试; 代码的…...

防火墙安全管理
大多数企业通过互联网传输关键数据,因此部署适当的网络安全措施是必要的,拥有足够的网络安全措施可以为网络基础设施提供大量的保护,防止黑客、恶意用户、病毒攻击和数据盗窃。 网络安全结合了多层保护来限制恶意用户,并仅允许授…...
)
MyQueue(队列)
目录 一、队列的定义 二、队列方法的实现 1、定义队列 2、后端插入 3、前端操作 4、判断队列是否为空 5、队列大小 三、队列方法的使用 一、队列的定义 队列是一种特殊的线性表,特殊之处在于它只允许在表的前端(front)进行删除操作&am…...

【Pytorch】一文向您详细介绍 torch.nn.DataParallel() 的作用和用法
【Pytorch】一文向您详细介绍 torch.nn.DataParallel() 的作用和用法 下滑查看解决方法 🌈 欢迎莅临我的个人主页 👈这里是我静心耕耘深度学习领域、真诚分享知识与智慧的小天地!🎇 🎓 博主简介:985高…...
Windows本地使用SSH连接VM虚拟机
WIN10 VM17.5 Ubuntu:20.04 1.网路设置 1)选择编辑->更改设置 配置完成 2.修改了服务器文件,修改sshd配置,在此文件下/etc/ssh/sshd_config,以下为比较重要的配置 PasswordAuthentication yes PermitRootLogin yes PubkeyAuthenticat…...
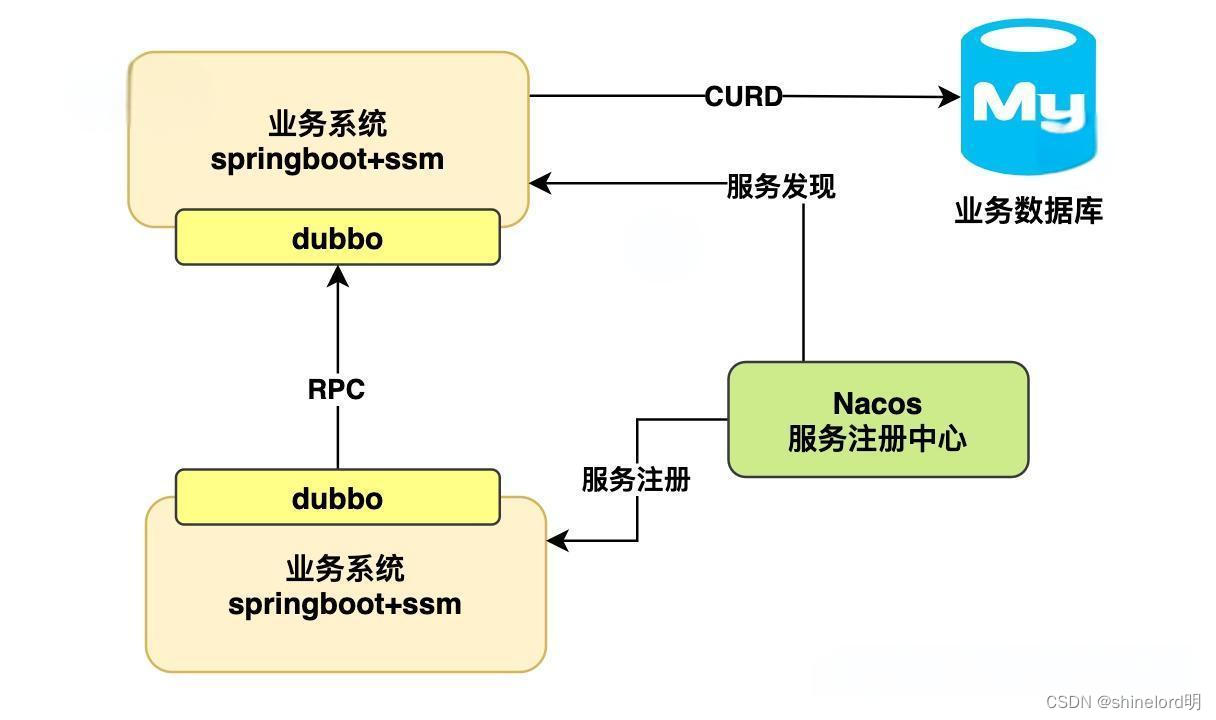
RPC(远程过程调用):技术原理、应用场景与发展趋势
摘要: RPC(Remote Procedure Call)是一种通信协议,用于实现跨网络的进程间通信。它提供了一种简单高效的方式,使得分布式系统中的不同组件能够像调用本地函数一样调用远程函数。本篇博客将介绍RPC的基本概念࿰…...

iSCSI和FC存储
iSCSI存储和FC存储的特点和区别 FC存储和iSCSI存储是两种主要的网络存储解决方案,它们各自在性能、成本和适用场景上有着不同的特点。 FC存储是一种基于光纤通道技术的高性能、低延迟的存储解决方案。它使用专用的光纤通道网络连接存储设备和服务器,确…...

MPT(merkle Patricia trie )及理解solidity里的storage
what? MPT树是一种数据结构,用于在以太坊区块链中高效地存储和检索账户状态、交易历史和其他重要数据。MPT树的设计旨在结合Merkle树和Patricia树的优点,以提供高效的数据存储和验证 MPT树由四种类型的节点组成: **扩展节点&…...

【代码随想录算法训练营第三十五天】 | 1005.K次取反后最大化的数组和 134.加油站 135.分发糖果
贪心章节的题目,做不出来看题解的时候,千万别有 “为什么这都没想到” 的感觉,想不出来是正常的,转变心态 “妙啊,又学到了新的思路” ,这样能避免消极的心态对做题效率的影响。 134. 加油站 按卡哥的思路…...
桌面应用开发框架比较:Electron、Flutter、Tauri、React Native 与 Qt
在当今快速发展的技术环境中,对跨平台桌面应用程序的需求正在不断激增。 开发人员面临着选择正确框架之挑战,以便可以高效构建可在 Windows、macOS 和 Linux 上无缝运行的应用程序。 在本文中,我们将比较五种流行的桌面应用程序开发框架&…...

学习笔记丨嵌入式BI分析的12个关键功能
编者注:以下内容节选编译自嵌入式分析厂商Qrvey发表的《What is Embedded Analytics?》(什么是嵌入式分析)一文,作者为Qrvey产品市场主管Brian Dreyer。 什么是嵌入式分析? 嵌入式分析是指能够将数据分析的特性和功…...
在使用包含操作符<@和@>时优化范围查询)
PostgreSQL17优化器改进(3)在使用包含操作符<@和@>时优化范围查询
PostgreSQL17优化器改进(3)在使用包含操作符<和>时优化范围查询 本文将介绍PostgreSQL 17服务端优化器在使用包含操作符<和>时优化范围查询。其实在在第一眼看到官网网站的对于该优化点的时候,可能是由于缺乏对于范围类型的认知…...
【因果推断python】32_合成控制2
目录 合成控制作为线性回归的一种实现编辑 合成控制作为线性回归的一种实现 为了估计综合控制的治疗效果,我们将尝试构建一个类似于干预期之前的治疗单元的“假单元”。然后,我们将看到这个“假单位”在干预后的表现。合成控制和它所模仿的单位之间的…...
)
【愚公系列】《剪映+DeepSeek+即梦:短视频制作》026-字幕:用文字来美化画面(美化字幕)
💎【行业认证权威头衔】 ✔ 华为云天团核心成员:特约编辑/云享专家/开发者专家/产品云测专家 ✔ 开发者社区全满贯:CSDN博客&商业化双料专家/阿里云签约作者/腾讯云内容共创官/掘金&亚马逊&51CTO顶级博主 ✔ 技术生态共建先锋&am…...
** AI导出鸭 专写职场篇:从日常汇报到年终述职,AI 导出的那些隐形损耗)
AI 内容导出乱、格式崩、公式变?我开发了这只鸭子帮我全解决了(四)** AI导出鸭 专写职场篇:从日常汇报到年终述职,AI 导出的那些隐形损耗
不聊"AI 怎么提升效率"这种宏观话题—— 就聊一件很具体的小事: 你用 AI 搞定的内容,最后能不能专业地呈现出去?━━ 先说一个很多人经历过的时刻 ━━ 周五下午四点,领导突然要一份市场分析报告,六点前发过…...

用NoneBot2给Lagrange机器人加buff:5个提升效率的插件开发技巧
用NoneBot2给Lagrange机器人加buff:5个提升效率的插件开发技巧 在智能对话机器人领域,NoneBot2与Lagrange的组合已经成为QQ生态中高效开发的黄金搭档。但当你已经掌握了基础功能开发后,如何让机器人更智能、更稳定、更能应对复杂场景…...

League-Toolkit:3个核心功能解决英雄联盟玩家的日常痛点
League-Toolkit:3个核心功能解决英雄联盟玩家的日常痛点 【免费下载链接】League-Toolkit 兴趣使然的、简单易用的英雄联盟工具集。支持战绩查询、自动秒选等功能。基于 LCU API。 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 还在为英雄联…...

LFM2.5-1.2B-Thinking-GGUF效果展示:32K上下文下跨PDF章节引用准确性验证
LFM2.5-1.2B-Thinking-GGUF效果展示:32K上下文下跨PDF章节引用准确性验证 1. 模型能力概览 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低资源环境优化设计。该模型采用GGUF格式存储,配合llama.cpp运行时ÿ…...

学术专著不用愁!AI专著写作工具,为你打造专属学术大作
一、研究者专著写作困境与AI工具的出现 对于很多研究人员来说,写学术专著时面临的最大难题就是“有限的精力”与“无限的需求”之间的矛盾。专著的写作通常需要花费3到5年甚至更久的时间,但研究者们在日常工作中,除了教学和科研项目外&#…...

从半加器到四位加法器:在Intel Quartus里玩转模块化设计与层次化视图
从半加器到四位加法器:Intel Quartus中的模块化设计实战 引言 在数字电路设计的浩瀚宇宙中,加法器就像是最基础的原子结构,简单却蕴含着无限可能。作为一名FPGA开发者,我常常思考如何让设计既高效又优雅。记得第一次在Quartus中完…...

一体机-显控终端 国产化嵌入式处理板卡 产品规格说明书
一、产品概述MB-FT24A02是一款专为工业嵌入式、车载人机交互、国产化终端替代等场景设计的全国产化高性能处理板卡,采用紧凑型PCB设计,核心搭载飞腾FT-2000/4国产处理器,搭配飞腾X100专用国产桥片,构建全链路自主可控硬件平台&…...

为什么头部金融科技公司已在2026 Q1全面切换Python AOT?——基于百万行代码仓库的构建耗时、镜像体积、安全扫描通过率真实数据复盘
第一章:Python 原生 AOT 编译方案 2026 对比评测报告Python 社区在 2025 年底迎来关键演进:CPython 官方正式将原生 AOT(Ahead-of-Time)编译能力纳入 3.14 开发主线,并以“Project Graviton”为代号推动落地。2026 年初…...

解放你的音乐库:NCMconverter音频格式转换全攻略
解放你的音乐库:NCMconverter音频格式转换全攻略 【免费下载链接】NCMconverter NCMconverter将ncm文件转换为mp3或者flac文件 项目地址: https://gitcode.com/gh_mirrors/nc/NCMconverter 当你下载了喜爱的音乐却发现是无法播放的NCM格式时,当你…...