人工智能发展历程和工具搭建学习
目录
人工智能的三次浪潮
开发环境介绍
Anaconda
Anaconda的下载和安装
下载说明
安装指导
模块介绍
Home界面介绍
Environment界面介绍
使用Jupter Notebook
打开Jupter Notebook
配置默认目录
新建文件
两种输入模式
Conda 虚拟环境
添加扩展包
运行终端命令
使用内置命令
Tensorflow
命令行安装Tensorflow
图形化界面安装Tensorflow
本文章将深入探讨人工智能发展历程,逐步延申到学习路径,再到动手搭建深度学习环境,逐渐进入人工智能的开发者世界.
人工智能的三次浪潮
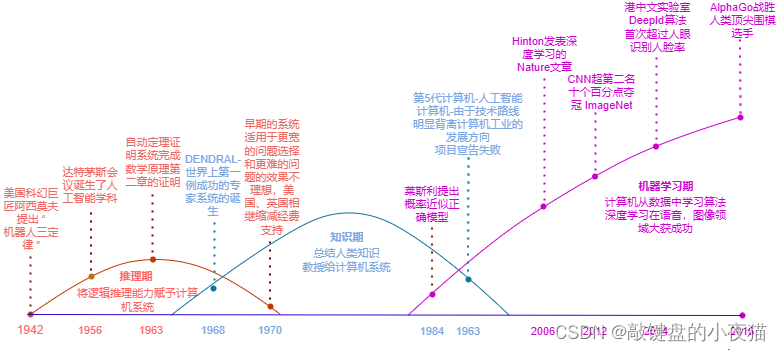
在计算机出现之前,人们就幻想着制造出一种机器,可以实现人类的思维,帮助人们解决问题,甚至比人类有更高的智力。
1936年图灵的论文《论可计算数及其在判定性问题上的应用》,奠定了计算机科学理论和实践的基础,也把关于机器智能的哲学思考向前推进了一大步。电子数字计算机的出现,为人工智能提供了媒介和基础,系统论、控制论和信息论的发展,进一步推动了人们探索机器智能的热情。
1950年,图灵在论文《计算机与智能》中提出了“图灵测试”,成为了判断机器是否具备人类智能的准则。
1956年,在Dartmonth学院召开的夏季研讨会上,人工智能这个词第一次被提了出来,标志着人工智能作为一门新兴学科正式诞生。由于人工智能研究内容的广泛性,因此对人工智能的定义一直存在争议,目前业界比较认可的定义来自人工智能的经典著作《人工智能——一种现代的方法》,在这本书中,将人工智能定义为是能够感知环境,并未获得最佳结果,采取理性行为的智能体。要注意的是,人工智能并不是要复制人类大脑,而是通过探索人的感觉、思维规律来模拟人的智能活动,从而达到对等的结果,他的目标是希望计算机拥有像人一样的智力能力,可以代替人类实现认知、分类和决策等多种功能。人工智能是一门融合了计算机科学、数学、生物学、脑神经科学、心理学和哲学等多种学科的综合性学科。人工智能的发展历程并非是一帆风顺的,可谓一波三折。在人工智能学科诞生之后,很多科学家对人工智能的预测非常的乐观,甚至认为20年内就会出现完全智能的机器。就这样,人工智能迎来了第一次研究热潮。
在20世纪50年代到60年代,人们认为,如果能够赋予机器逻辑推理的能力,机器就具有智能。在这个阶段的研究处于推理期,核心是逻辑主义,逻辑主义就是用机器证明的方法去证明和推理一些知识,例如用机器证明一个数学定理,要证明这些问题,就需要把原来的条件和定义变成逻辑表达式的形式,然后用逻辑的方法去证明最后的结论是对的还是错的,定理证明是人工智能的第一波浪潮中实现效果最好的。
1963年数学家罗素的数学名著《数学原理》的第二章中全部52条数学定理被计算机程序自动的证明出来,人工智能达到了第一次研究浪潮的巅峰,在此期间,还出现了第一个自然语言处理程序、第一个人形机器人等等,但是,由于科学家们一开始的预测过于乐观,后续的研究成果和之前人们对人工智能的期望之间产生了巨大的反差,导致公众的热情和投资消减。
70年代中期,人工智能步入第一次寒冬。人们逐渐认识到人工智能真正的挑战在于去解决那些对人来说很容易执行,但却很难形式化的描述出来的任务,比如聊天、识别图像等等,这时候,人们又想到,人类之所以能够得到正确的判断和决策,除了具有逻辑推理能力之外,还需要有相关的知识。于是,对人工智能的研究开始进入了知识期,诞生了大量的专家系统,例如医学专家系统、工程专家系统等等。在这些系统中,人们将知识整理为计算机能够识别的规则,作为专家知识输入给计算机,计算机根据这些知识进行判断和决策。然而,随着研究的进展,人们发现人类的知识无穷无尽,而有些知识是很难总结之后再去教给计算机的,对于更宽的问题选择和更难的问题,专家系统的效果都不太理想。于是,一些学者设想,是否能够直接给计算机赋予学习知识的能力。
20世纪80年代,统计机器学习的方法开始出现,机器学习真正开始成为一个独立的学科领域,专家系统的成果和机器学习的兴起,掀起了人工智能的第二波浪潮。
1982年,日本启动了第5代计算机计划,希望通过大规模的B型计算来构造通用人工智能平台,人们又一次开始对人工智能充满期待,但是由于计算资源和能力的限制,早期机器学习的效果并不是太理想。同时,日本的第5代计算机计划也研究失败,人工智能再次进入寒冬。在经历第二次低谷之后,科学家们更加理智了,在之后的数十年中,统计机器学习的算法逐步开始成为主流。但是,大家降低了对他的期望,不再叫他人工智能,而是利用这些方法来做一些更加实际的东西,例如计算机视觉,语音处理等等。在此期间,神经网络和深度学习的方法也在默默的积累。
2006年,辛顿教授在nature上发表了一篇论文,指出深层次的人工神经网络具有优异的学习能力,并提出了训练深层神经网络的算法,被认为是人工智能的第三次浪潮的起点。
2010年之后,深度学习在语音识别、计算机视觉等各个领域迅速取得了重大进展,彻底引爆了人工智能的第三次浪潮,深度学习成为人工智能领域最重要的技术之一,鉴于人工智能这种曲折的发展历程,有人形容计算机是大儿子,人工智能是二儿子。大儿子和二儿子的特点不一样,大儿子比较稳重,有耐心,不调皮,不捣蛋,一直按照摩尔定律的规律持续发展。而二儿子呢,比较活泼,有创新思想,敢于冒险。结果,几十年的发展历程就像是坐过山车一样跌宕起伏。
开发环境介绍
深度学习是深层次的神经网络,是机器学习中的一个分支。近年来,深度学习犹如一批黑马横空出世,在计算机视觉、语音识别、自然语言处理和机器人等领域取得了惊人的进展,成为目前计算机领域最具有影响力、最热门的研究方向。在本系列文章中,我们将比较全面的介绍神经网络和深度学习的基础知识、理论和方法,并介绍如何编程序、构建神经网络、开发人工智能应用程序。
本系列文章中的实例采用Python语言和TensorFlow开发框架,实现开发环境选择Anaconda,Python语言是目前最受欢迎的程序设计语言之一,它结构清晰,非常简单易学,拥有丰富的标准库和第三方生态库系统,非常适合作为机器学习算法的编程语言,但是由于Python是一门通用的解释型语言,在实现复杂算法的时候,效率会受到很大的限制。因此,在实际的机器学习和深度学习的项目中,需要使用更高效的实现方法。

TensorFlow就是谷歌公司推出的一个高效的人工智能开发框架。自从2015年11月发布以来,已经成为全世界最广泛使用的深度学习库。很多以前难以实现的大规模人工智能的任务,都可以通过它来实现,但是对于初学者而言,TensorFlow不太容易学习和掌握,因此这个强大的工具就只能够掌握在少数专业人员的手里,谷歌公司决定改变这一现状,正式宣布在TensorFlow2.0版本中将易用性作为一个重点关注的目标。

2019年3月,TensorFlow2.0阿尔法版本发布。一经推出就受到广泛的关注,超过13万学生通过网络选修课程在git hub上也获得了近13万颗星,被fork了超过75000次。
在2019年6月份,TensorFlow2.0Beta版正式发布,标志着TensorFlow进一步的成熟。2.0版本是对之前版本的彻底的革命性的改造,它非常的简单、清晰、好用,并且易于扩展,极大的降低了深度学习编程的门槛,使得大规模人工智能这个强大的武器不再只是被少数精英掌握。现在,更多的人可以参与进来,亲自体验开发人工智能应用程序的乐趣。
如果说python语言极大的降低了编程的门槛,使得普通人都可以编写出自己想要的程序,那么现在TensorFlow2.0则是极大的降低了人工智能开发的门槛,使得普通人也能够使用人工智能技术解决任务。如果你是刚刚开始接触人工智能领域的小白,那么现在正是开启学习之路的最佳时机。Python虽然易学易用,但是对于新手来说,尤其是对于习惯于使用Windows的用户,往往会头疼于诸多开源包的管理或者是Python版本的管理。为了解决这些问题,出现了不少发行版的Python,他们是对Python的重新包装,将Python和许多常用的工具打包,以方便用户使用。
本文章中使用的Anaconda就是一个用于科学计算的Python发行版,它不仅预装好了Python,还提供了NumPy、Matplotlib等很多成熟的开源包和科学计算工具,来扩展用户的应用程序,简化编程。同时它提供了强大的包管理和环境管理的功能,通过包管理可以方便的安装、更新、卸载工具包,而且在安装工具包的时候还能够自动的安装相应的依赖包。通过环境管理的功能,可以在同一台机器上创建几个相互独立的Python开发环境,称之为虚拟环境。例如,可以在Anaconda中建立Python2和Python3两个环境,用来分别运行不同版本的Python代码。或者你现在同时在做两个项目,他们所需要用到的工具包有很大的不同,那么就可以分别创建两个虚拟环境,在每个环境中安装各自需要的工具包和依赖项,这样就可以隔离不同项目所需要的不同版本的工具包。而且在不同的环境之间还可以快速的切换。
为了便于以后的学习,在文章开始前,我们需要先将Anaconda、TensorFlow和其他的一些常用的软件安装在自己的电脑上,下面我将带领大家一起完成这些软件安装。
Anaconda
Anaconda的下载和安装
下载说明
在安装TensorFlow之前,我们首先进行Anaconda的下载及安装,Anaconda是一个开源的包管理环境管理器,其中不仅包含了Python科学包及其依赖项,而且还提供了包和环境的管理,它支持Windows Mac OS和Linux操作系统,是使用Python进行深度学习和机器学习最简单的工具。
我们可以通过下面两个链接下载到Anaconda的安装文件。
1. Anaconda的官方下载链接。
Anaconda | The Operating System for AI
2. 第二个是清华大学的Anaconda镜像仓库下载链接。
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
一般情况下,国内高校学生使用清华大学镜像仓库下载,速度会更快,现在打开的页面是Anaconda的官方网站。点击Free Download, 跳转到程序的下载页面,在这个页面需要注意的是下载安装程序的时候,要根据系统类型位数和Python的版本号进行下载,以本机为例,我们选择Windows操作系统。
下载Python版本号为3.8的64位安装程序,打开浏览器的下载页面,下载好的安装程序后点击安装程序进行安装。
安装指导
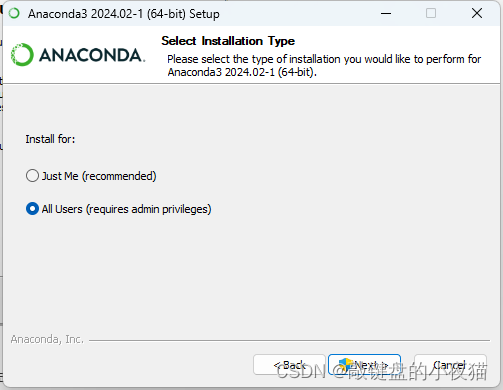
这个界面选择单一用户或者所有用户都可以,然后点击next,将修改路径修改至任意位置。
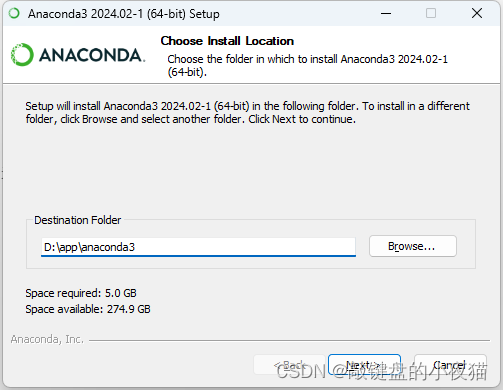
我们一般将程序安装在C盘或者D盘,然后点击next,接下来这个界面有2个可选项,程序默认第一个选项没有被勾选,它的意思是将Anaconda的可执行文件目录添加到系统的环境变量里。为了方便后续我们使用Conda命令,
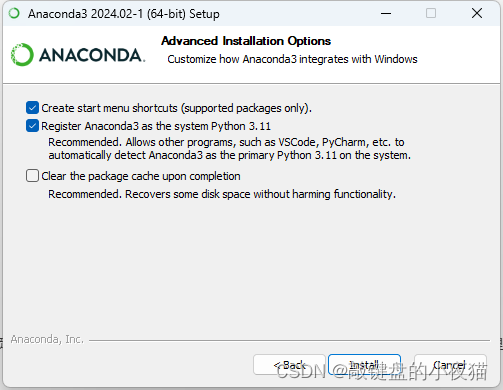
我建议勾选这一选项,第二个选项是将Anaconda的Python程序注册为系统Python,默认选中即可,然后点击安装,安装过程较长。根据大家的系统和电脑环境不同。安装的时间长短不一,我们等待安装完成,安装完成后点击next,然后点击finish完成。
模块介绍
Anaconda Navigator.是一个图形化的用户管理工具,可以在不使用命令的情况下方便的启动应用程序,用于管理conda环境和Python模块包.
Anaconda Prompt是Anacoda的命令行终端。
Jupyter Notebook 是基于网页的用于交互计算的应用程序。
Spyder是一个集成的Python开发环境。
使用Anaconda Navigator
Home界面介绍
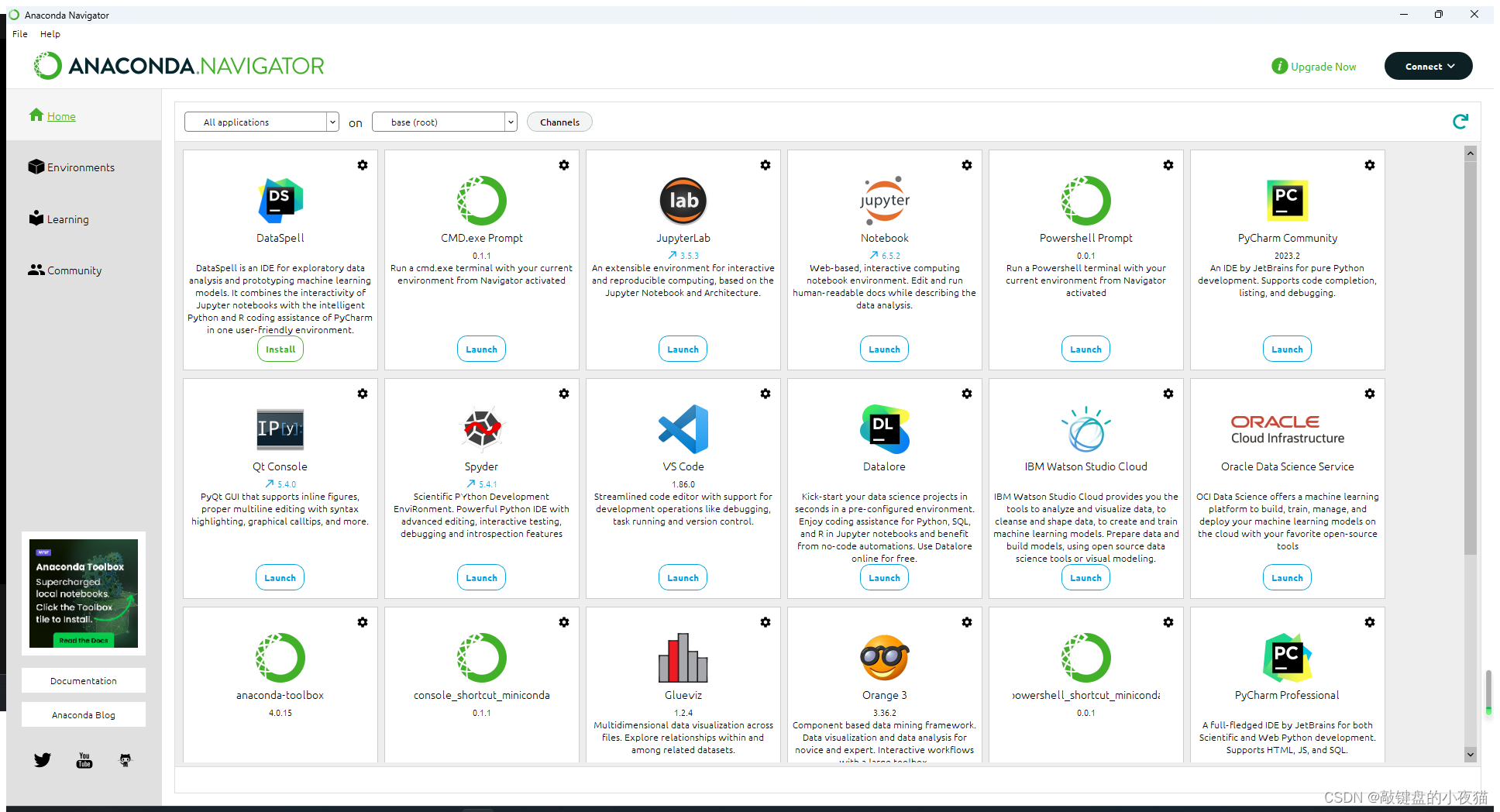
程序的主界面左侧是菜单栏,第一项是主页,主页中间区域显示的是常用的12种工具软件,分别是:
1)Datalore。是一个面向机器学习的云端开发环境,具有收集和探索数据、创建机器学习和深度学习模型、可视化结果并与其他人共享等功能。
2)JupyterLab。是Jupyter的一个扩展,提供了更好的用户体验。例如可以在同一个浏览器页面打开编辑多个notebook、Console和终端,并且支持预览和编辑多种类的文件。
3)Power prompt。是一个较新的命令行终端。
4)Qt console, 一个可执行的Python,终端图形界面程序,相比Python shell ,Qt console可以直接显示代码生成的图形,实现多行代码输入执行,以及内置许多有用的功能和函数。
5)Glue。是一个用于探索相关数据集内部和之间的关系Python库。
6)Orange。是一个交互式数据可视化软件。
7)Pycharm。是Python语言的一种集成开发环境。
8)R Studio是R语言的集成开发环境。
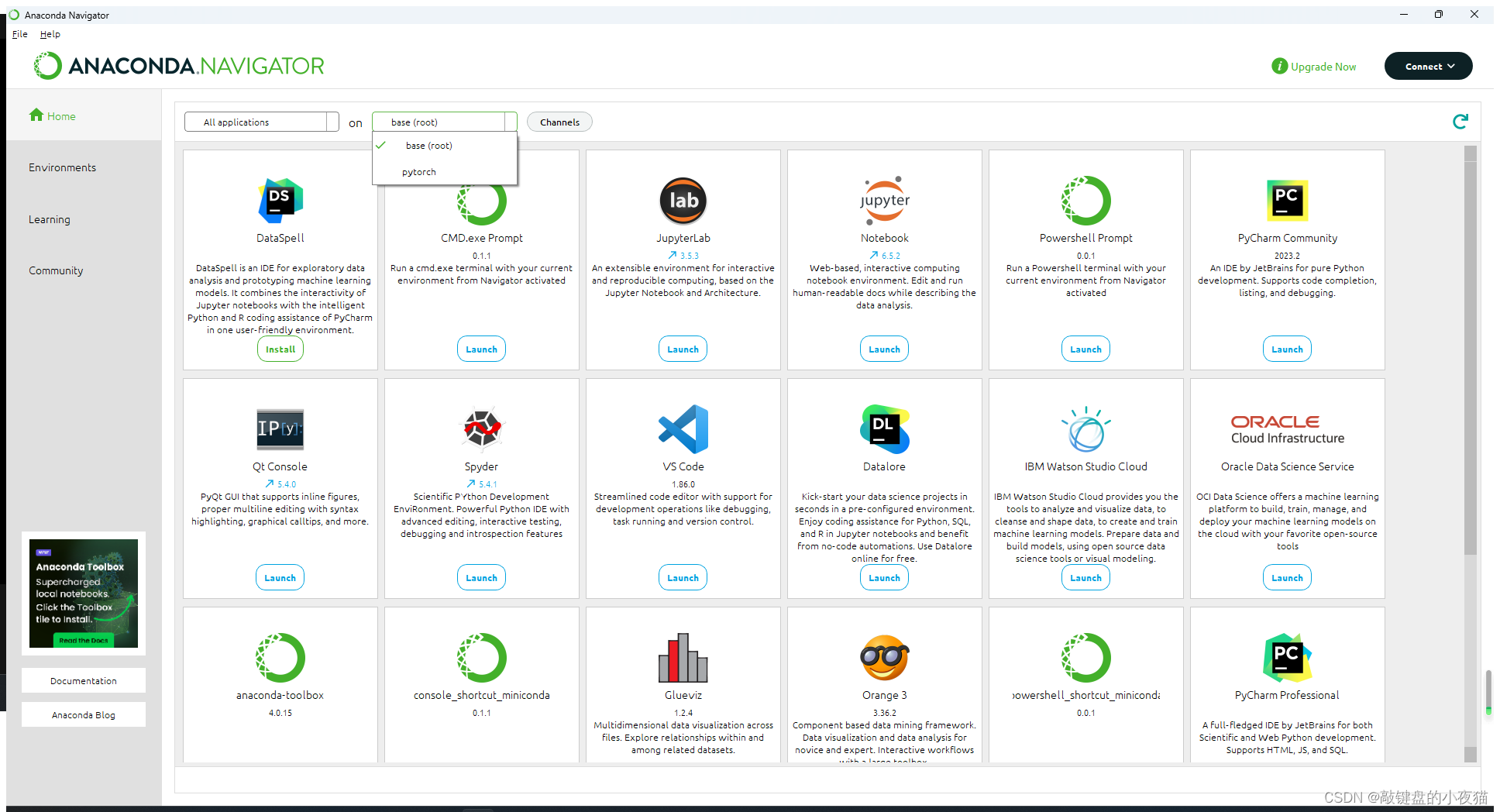
在页面中间的上方,Applications on下面的下拉框可以选择上述工具的运行环境。
Environment界面介绍
左侧菜单栏当中的第2项,Environment是环境管理,用来管理独立运行环境和其中安装的Python模块包。
在中间的窗口中, 显示当前系统已经创建的独立运行环境,最右边的窗口中显示对应环境中已经安装好的Python模块包。
刚刚安装的Anaconda会默认只有一个base斯环境,点击base打开终端。
输入conda inform命令,终端会输出当前conda环境的相关信息。
Anaconda中比较常用的是JupyterNode和Vs code这两个软件,Jupyter notebook在上面已经介绍过。Vs code是一个轻量级但功能强大的源代码编辑工具,支持Windows Mac OS和Linux操作系统,当前版本的Anaconda已经将Vs code当做外部软件,不在内部提供快捷安装,主页中也就没有显示Vs code的,因此我们需要在Vs code的官方网站自行下载安装,下面是下载链接,现在我们打开Vs code的官方网站,我们可以根据系统类型。
使用Jupter Notebook
Jupter Notebook它的本质是一个可以通过网页访问的web程序,在网页中编写和执行程序。这种环境不仅方便程序员远程访问,而且屏蔽了不同系统之间的显示差异,有益于代码共享。Jupter Notebook 不仅可以编辑运行程序。
而且可以将程序和文档组织在一起。它可以将代码、图像、注释、公式、图形甚至运行结果都整合在同一个文档中,编写出漂亮的交互式文档,例如,当需要向同行展示或分析程序时,如果使用word等传统的文本编辑工具,代码复制进去后,关键词配色会丢失。而且代码与文字、公式等混在一起,难以区分。Jupter Notebook可以让代码保持在编辑器里的风格,看起来很清晰,并且代码复制进去后是可以运行的。
打开Jupter Notebook
下面简要介绍一下如何使用Jupter Notebook来编写和管理Python程序。我们有3种方法来打开Jupter Notebook。
第一种方法是打开anaconda navigator可视化管理软件,选择Jupter Notebook启动。

第二种方法就是在命令行窗口中输入jupter Notebook,进入Jupter Notebook界面。
第三种方法就是在开始菜单栏的ANACONDA3文件夹中直接点击Jupter Notebook。
配置默认目录
打开Jupter Notebook会自动跳转到浏览器中,并且打开Jupter Notebook默认工作目录,初次安装默认目录会存放在C盘用户文件夹下。这种默认设置使用起来非常不便,所以我建议大家使用Jupter Notebook之前,对Jupter Notebook默认目录进行修改。
#生成配置文件。
jupyter Notebook --generate-config![]()
用记事本打开,使用组合键Ctrl+F查找字符串Notebook_dir,定位到该配置文件的键值,取消前面的注释符号。
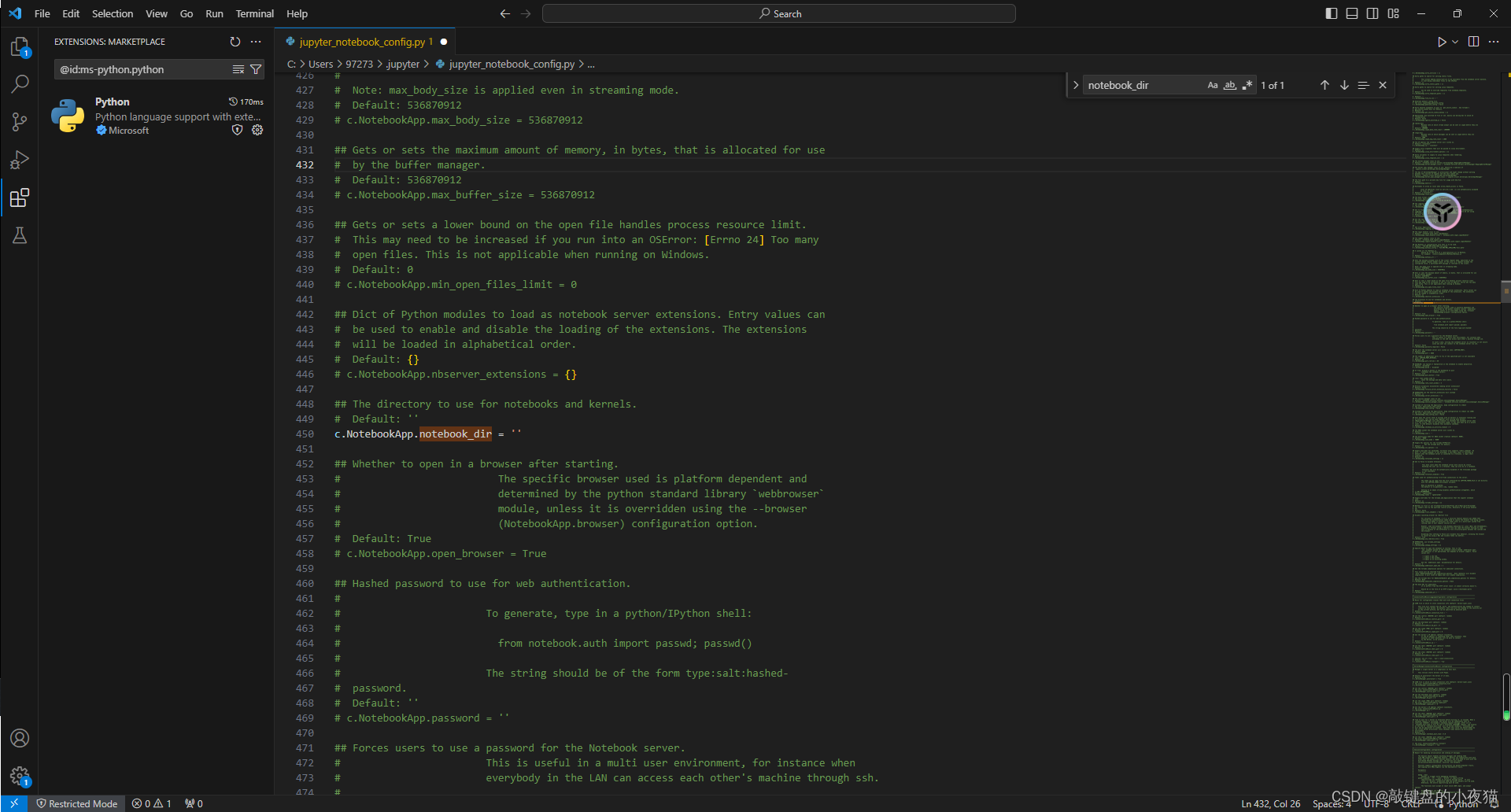
将等号后面的值更改为你希望的工作目录,比如E盘目录下的jupyter,然后保存,这里需要注意的是,E盘根目录下必须存在该文件夹,没有的话,应该先创建好该目录再修改。
这样做我们只是修改了从anaconda navigator 启动Jupter Notebook的默认路径,接下来我们打开开始菜单栏,右键点击ANACONDA3文件夹中的Jupyter Notebook,选择更多,打开文件夹位置。在打开的窗口中,右键点击Jupyter Notebook,选择属性,删除目标框中的双引号里边的内容,点击确定。
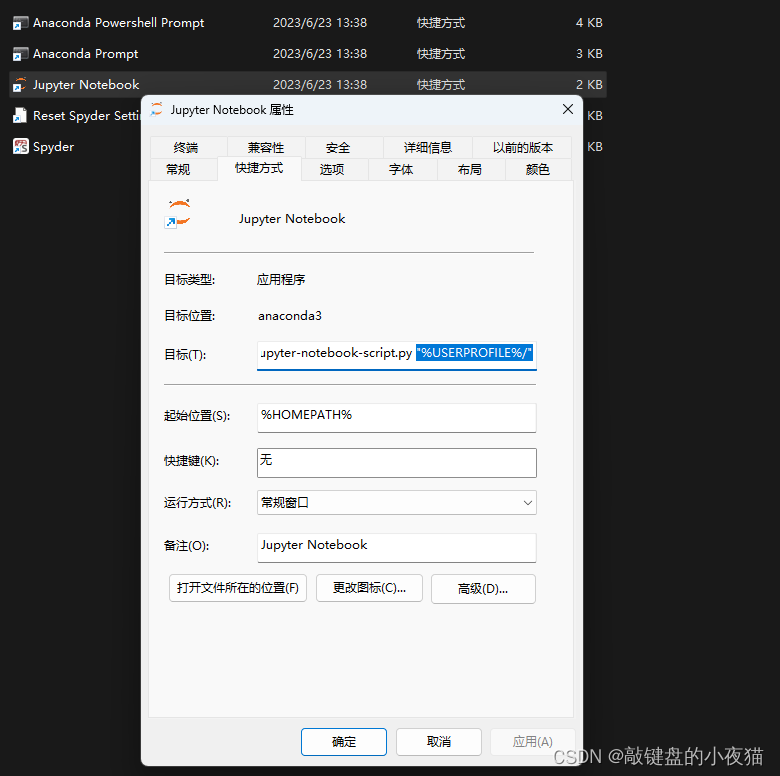
完成操作后,我们不管以何种方式打开Jupter Notebook创建的文件都会保存到我们配置的目录中。
新建文件
在Jupyter Notebook主界面中有3个选项卡,分别是files,running,clusters。
其中files选项卡将显示工作目录下的记事本文件列表,可以选择已有的记事本文件进行编辑或者运行,同时也可以使用files选项卡右上角的new按钮新建一个记事本文件。我们新建一个记事本文件,此时会重新打开一个标签页,会有一个默认名称,Jupyter Notebook记事本界面主要包括名称、菜单栏、工具栏和编辑区等等。
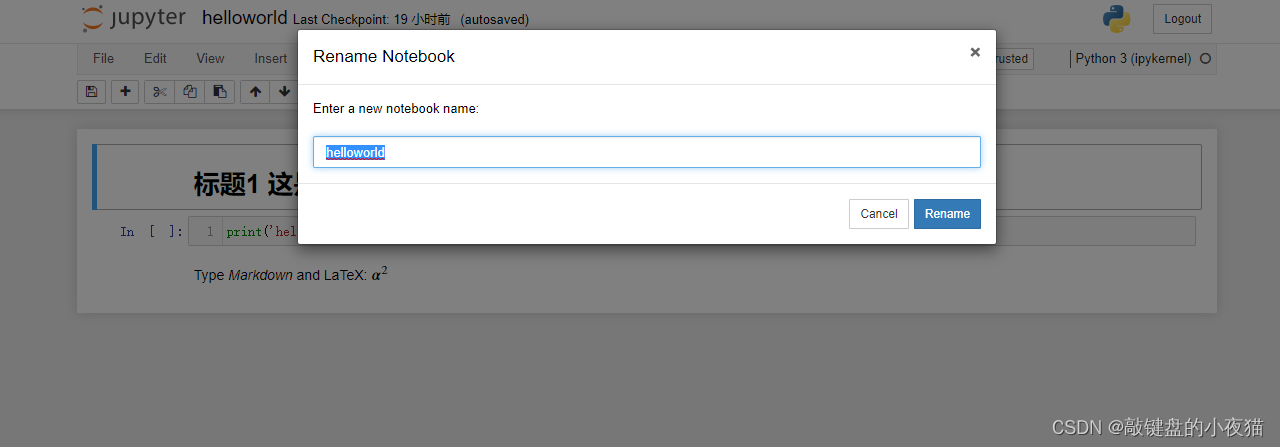
在名称处输入项目名称为hello world,可以看到页面的标签栏也随之更改为hello word保存后,会在工作目录下生成一个helloword.ipnb文件,并显示在主页面的文件列表中。
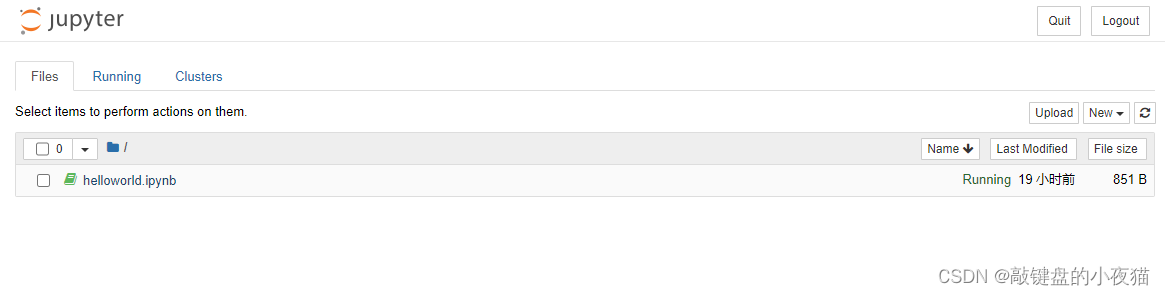
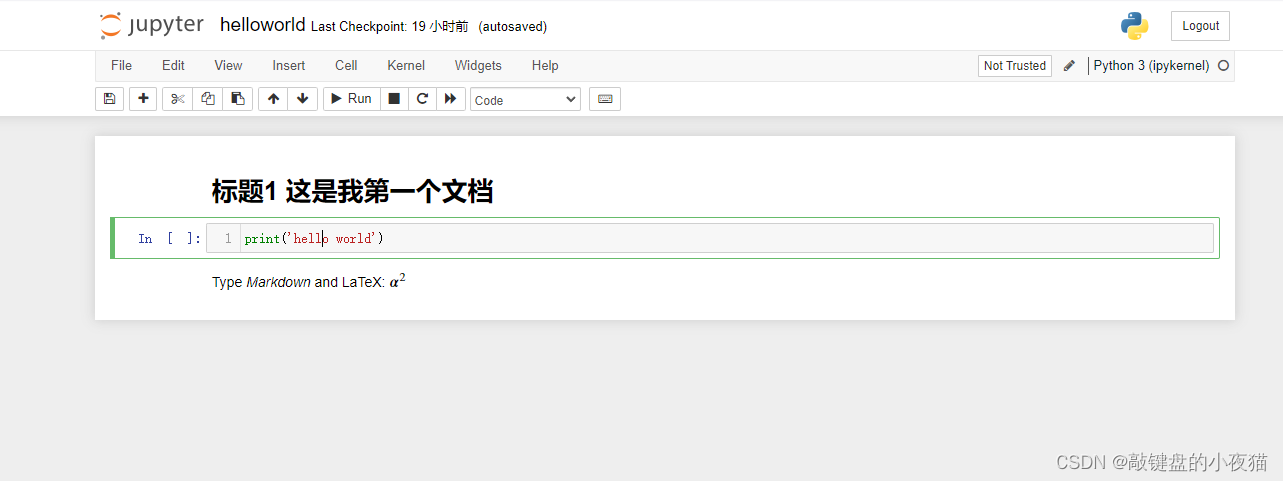
在Jupyter Notebook记事本文件当中,是以cell为基本运行单位的,可以在cell中输入代码,单击运行按钮,或者使用键盘组合键Ctrl + Enter运行程序,运行的结果会显示在该cell的下方。
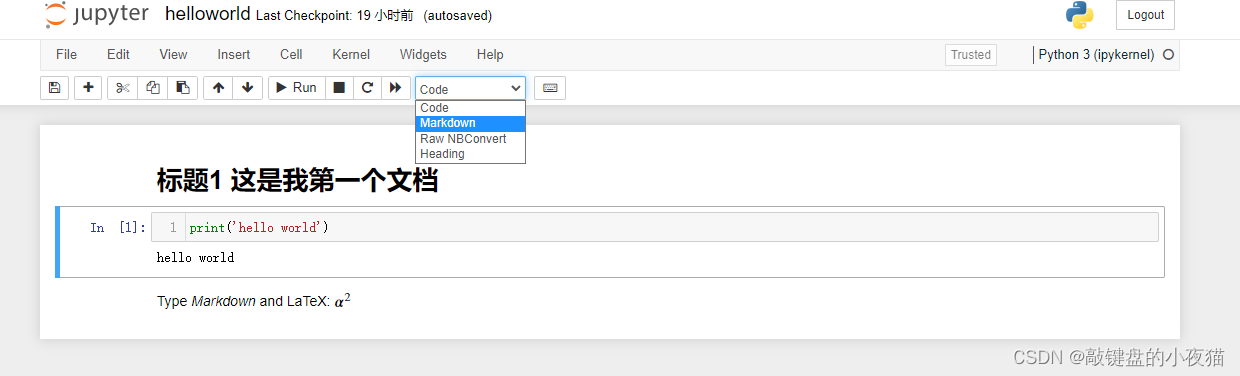

默认生成的cell是一个代码类型的Cell,Cell有几种类型,在添加新的cell时,可以选择代码标记或者标题。它们的好处是,我们可以在编写代码的同时,使用标记去为我们的代码添加一些说明或者是注释。
现在我们在默认cell前面插入一个新cell并将其类型更改为标记模式,标记模式的cell是使用Markdown语法编写的,编写文本的时候也需要使用运行模式去展示Markdown语法的结果,我们点击运行,就可以看到Markdown语法的展示结果。
两种输入模式
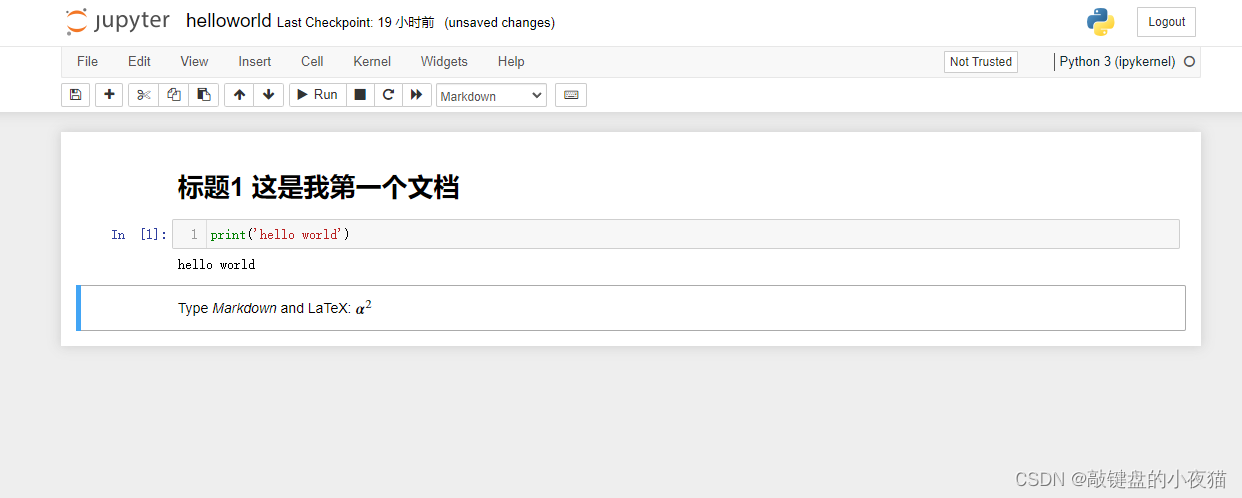
Jupyter Notebook有两种输入模式,分别是编辑模式和命令模式。编辑模式就是我们刚刚介绍的在单元格cell中的操作,它允许我们将代码或文本输入到一个单元格中,并通过左边绿色的单元格显示。
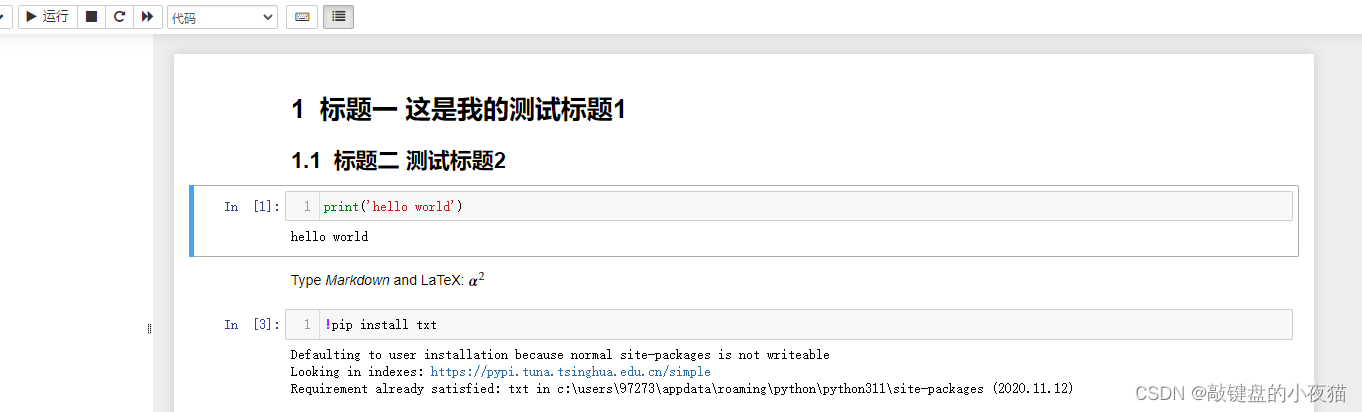
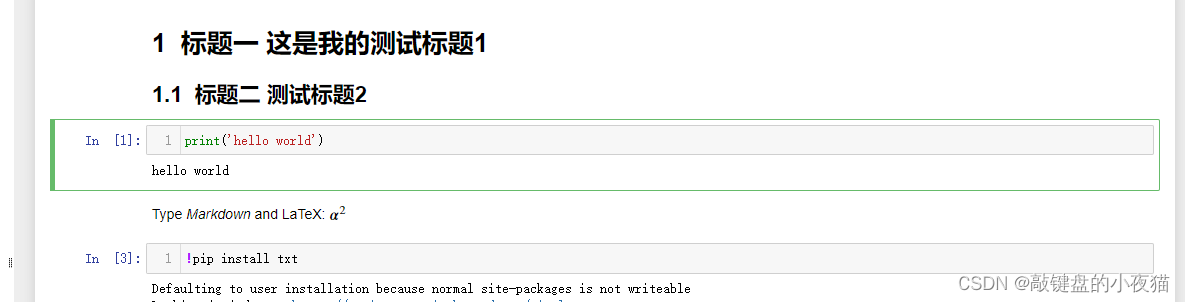
命令模式将键盘与笔记本的命令绑定在一起,并通过左边蓝色的单元格显示,我们打开刚刚创建的hello word文件。当我点击单元格内,我们可以看到,现在单元格的左边框以绿色显示,表示我们处在编辑模式。
当我点击单元格外部,单元格的边框以蓝色显示,表示我们正处在命令模式。Jupyter Notebook分别提供了这两种模式下的快捷键,这里展示的是两种模式下常用的一些快捷键。
| 编辑模式 | |
| Tab | 代码补全或缩进 |
| Shift+Tab | 提示 |
| Shift-Enter | 运行本单元,选中下一单元 |
| Ctrl-Enter | 运行本单元 |
| Alt-Enter | 运行本单元,在下面插入一单元 |
| 命令模式(Esc键启动) | |
| Shift+Enter | 运行本单元,选中下个单元 |
| Ctrl+Enter | 运行本单元 |
| Alt+Enter | 运行本单元,在其下插入新单元 |
| Y | 单元转入代码状态 |
| M | 单元转入Markdown状态 |
| A | 在上方插入新单元 |
| B | 在下方插入新单元 |
| DD | 删除除选中的单元 |
| 其它快捷命令(编辑模式) | |
| Ctrl+A | 全选 |
| Ctrl+Z | 撤销 |
| Ctrl+C | 复制 |
| Ctrl+W | 粘贴 |
| Ctrl+/ | 注释或取消注释,选中代码可以添加注释或取消 |
如果还想了解更多的快捷键,我们可以打开Jupyter Notebook,点击菜单栏的Help选项,在下拉菜单栏中选择keyboard Shortcuts.即可查看命令模式和编辑模式下的所有快捷键。
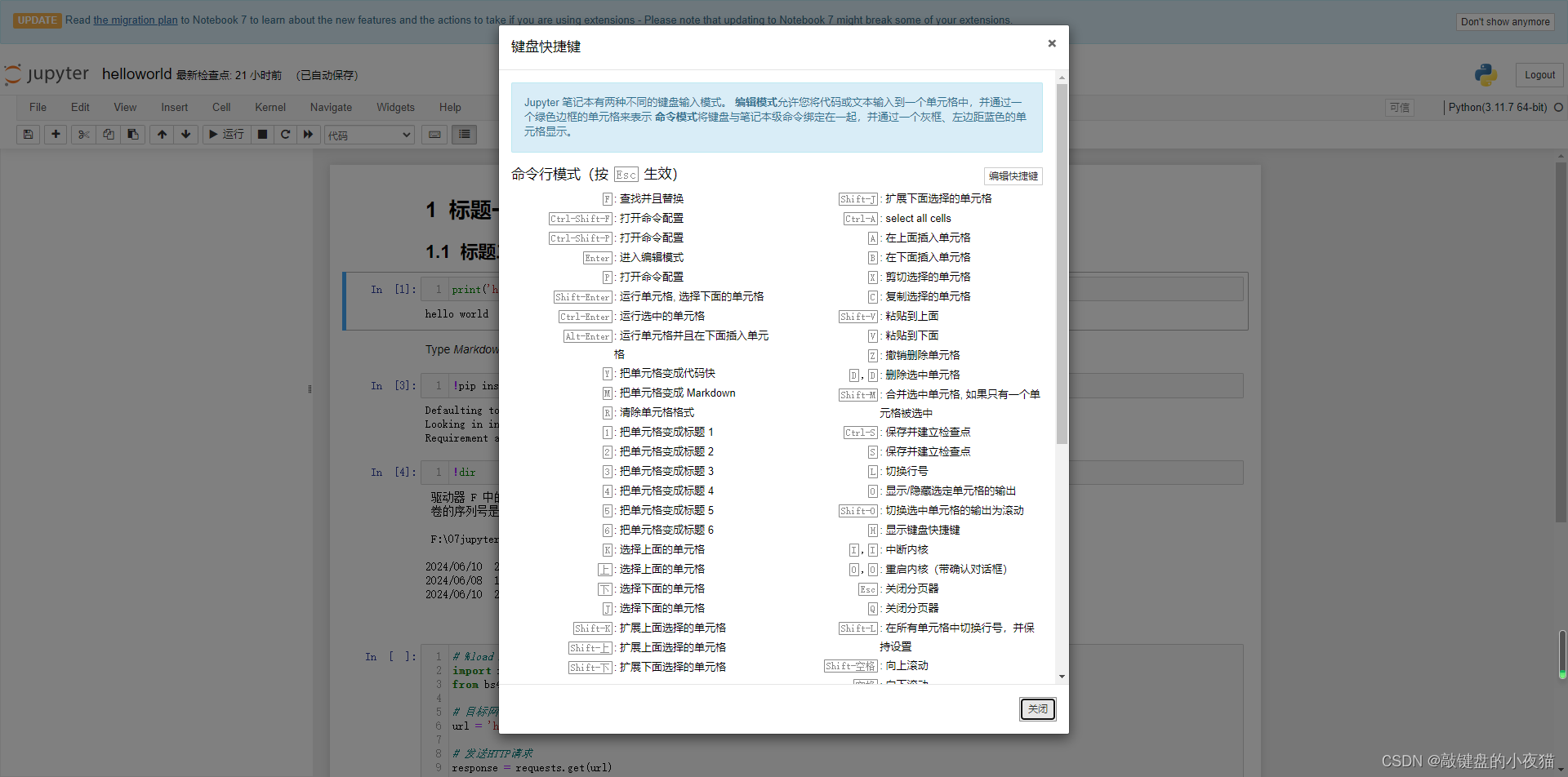
在这里,我们还可以点击右上角的编辑快捷键按钮,按照自己的习惯修改快捷键。
Conda 虚拟环境
Conda虚拟环境是一种用于管理Python环境的工具,它允许用户在同一台机器上创建多个独立的Python环境,每个环境都可以拥有自己的Python版本和安装的软件包,互相之间不会产生冲突。这种环境的管理方式有助于避免不同项目之间的依赖冲突,使得每个项目都能在最适合其需求的环境中运行。Conda虚拟环境的创建、激活和管理可以通过使用conda命令来完成,例如使用conda create命令创建一个新的虚拟环境,并指定所需的Python版本号。此外,用户还可以通过conda activate命令来激活特定的虚拟环境,以及使用conda deactivate命令来退出当前激活的虚拟环境。Conda虚拟环境的优点包括能够轻松创建、保存、加载和切换环境,避免版本冲突,提供跨平台支持(Linux, macOS, Windows),并能够管理不同语言的包(如R, Scala等)的包。
那么如何在Jupyter Notebook中切换不同环境编写代码呢?下面我们介绍一下Jupyter Notebook为我们提供的关联不同环境和包的功能,首先,我们关闭之前打开的Jupyter Notebook,然后打开命令行窗口。
conda install jupyter notebookconda install ipykernelpython -m ipykernel install --user --name 环境名称 --display-name "Python环境名称"
添加扩展包
为了Markdown文档更加醒目易读,Jupyter Notebook为Markdown文档提供了扩展包。
conda install -c conda-forge jupyter_contrib_nbextensions
conda install -c conda-forge jupyter_nbextersions_configurator首先,我们关闭之前打开的Jupyter Notebook,打开命令行窗口,在命令行窗口中输入以上提供的2条命令,等待命令执行完成,安装完成后重新打开Jupyter Notebook,我们可以看到,菜单栏增加了Notebook extensions选项,我们取消这个选中,然后勾选table of contents.
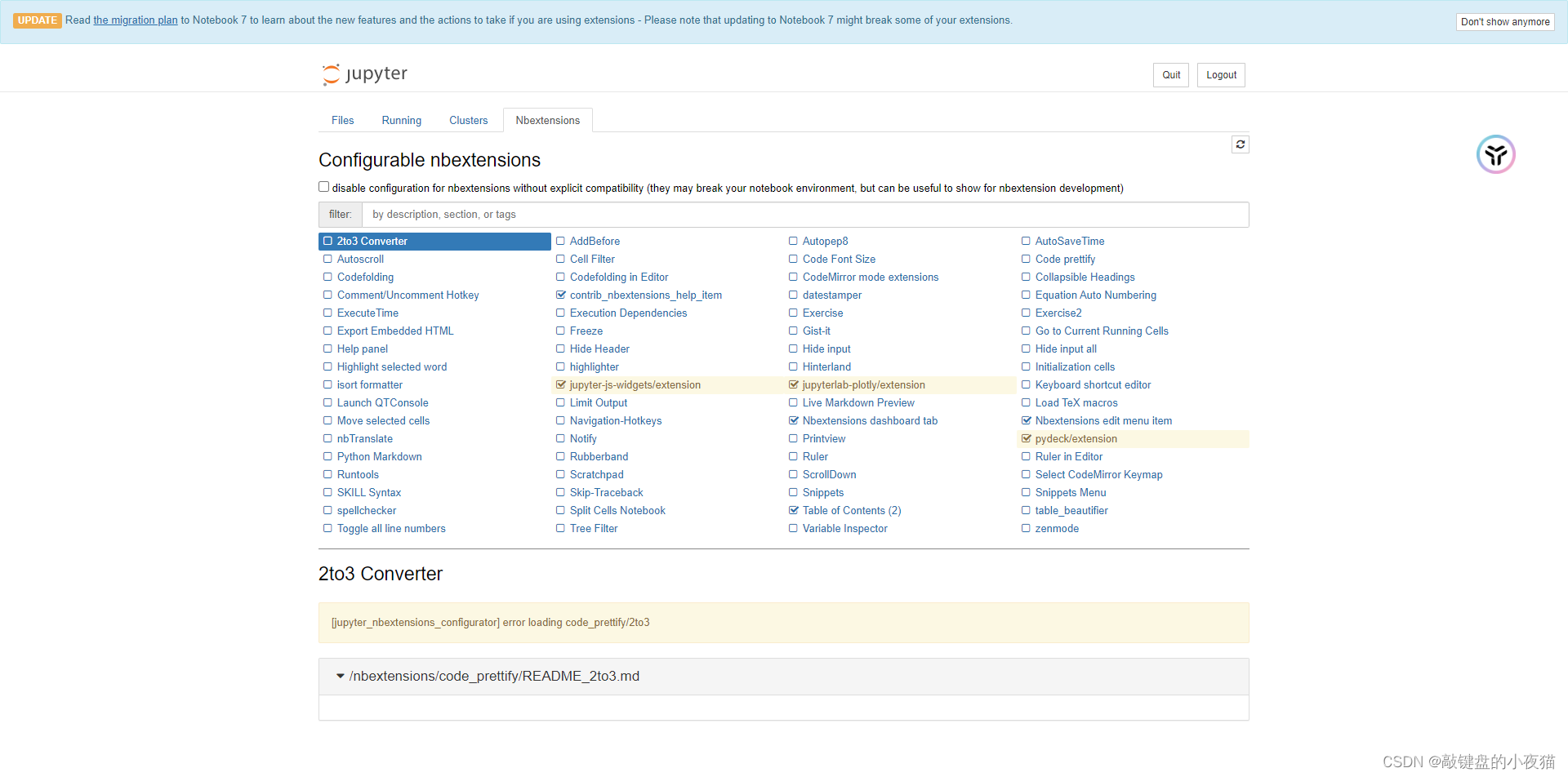
随后就可以在Jupyter Notebook中使用markdown编写文档。我们可以点击Table of contents这个按钮显示生成的目录.生成的目录会按照你标题的级别进行生成。
运行终端命令
在Jupyter Notebook中还可以运行终端命令,也就是命令行命令。我们有两种方法可以执行终端命令。
第一种方法就是在单元格内输入终端命令,只需要在这条命令的开头添加英文状态下的"!",这条命令是输出Jupyter Notebook的工作目录下,这个目录中的所有文件。
第二种方法就是使用Jupyter Notebook提供的终端,在Jupyter Notebook的home页面选择files选项卡,进入菜单界面,然后点击new下拉框,选择terminal打开终端,也可以查看当前目录下所有文件。
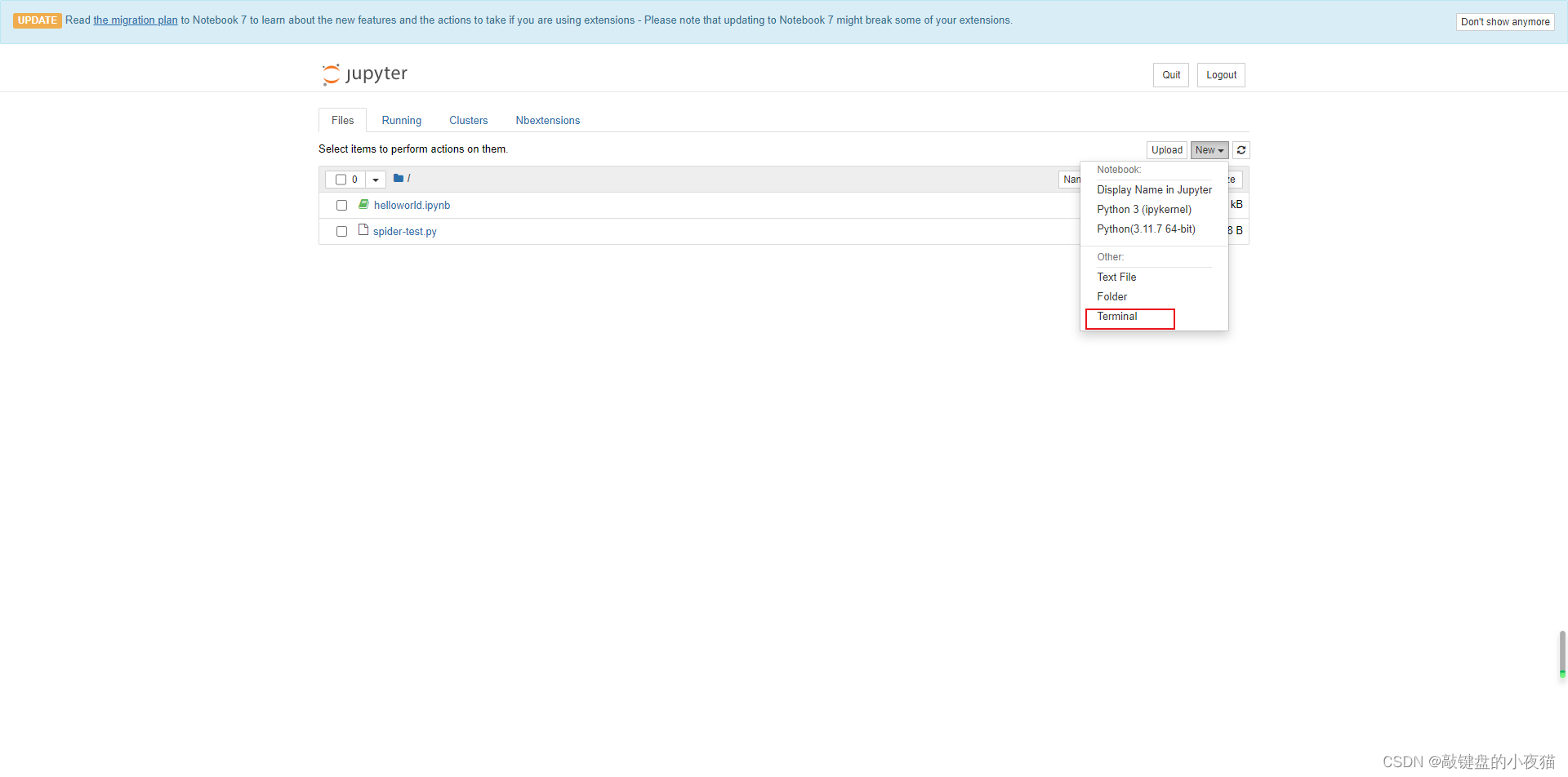
如果想要关闭终端,我们可以在Jupyter Notebook界面,选择running,然后找到terminals,点击关闭,然后再关闭这个网页。
使用内置命令
在主Notebook中,读取已经用别的代码编辑器写好的.py文件。

我们首先打开一个Jupyter Notebook文件,在单元格内输入%load和.py文件位置,在这里我的.py文件存储在E盘Jupyter目录下,然后点击运行。
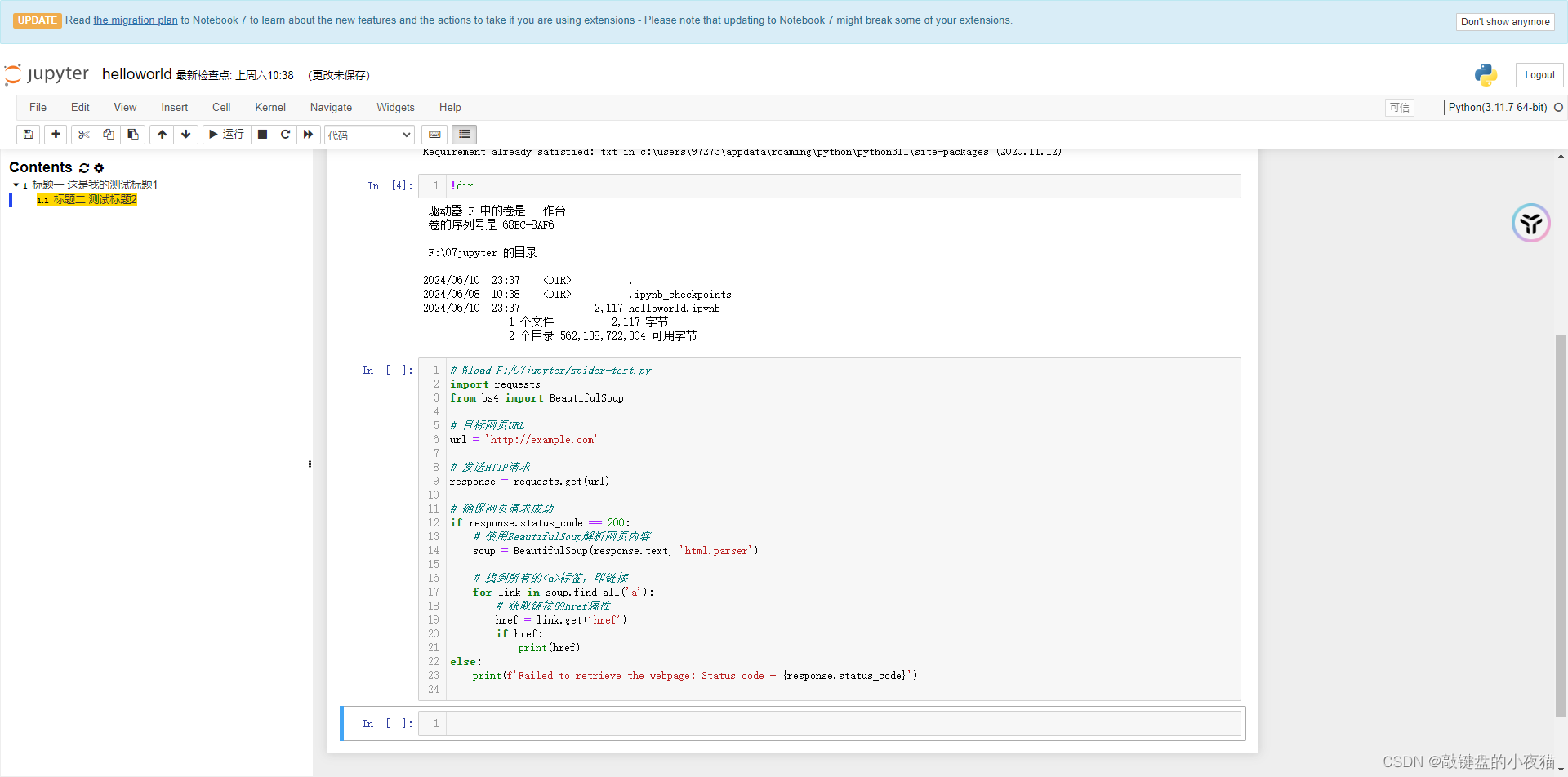
也可在Jupyter Notebook中加载本地的Python文件,并显示在单元格内,可以查看代码,也可以运行这个代码。

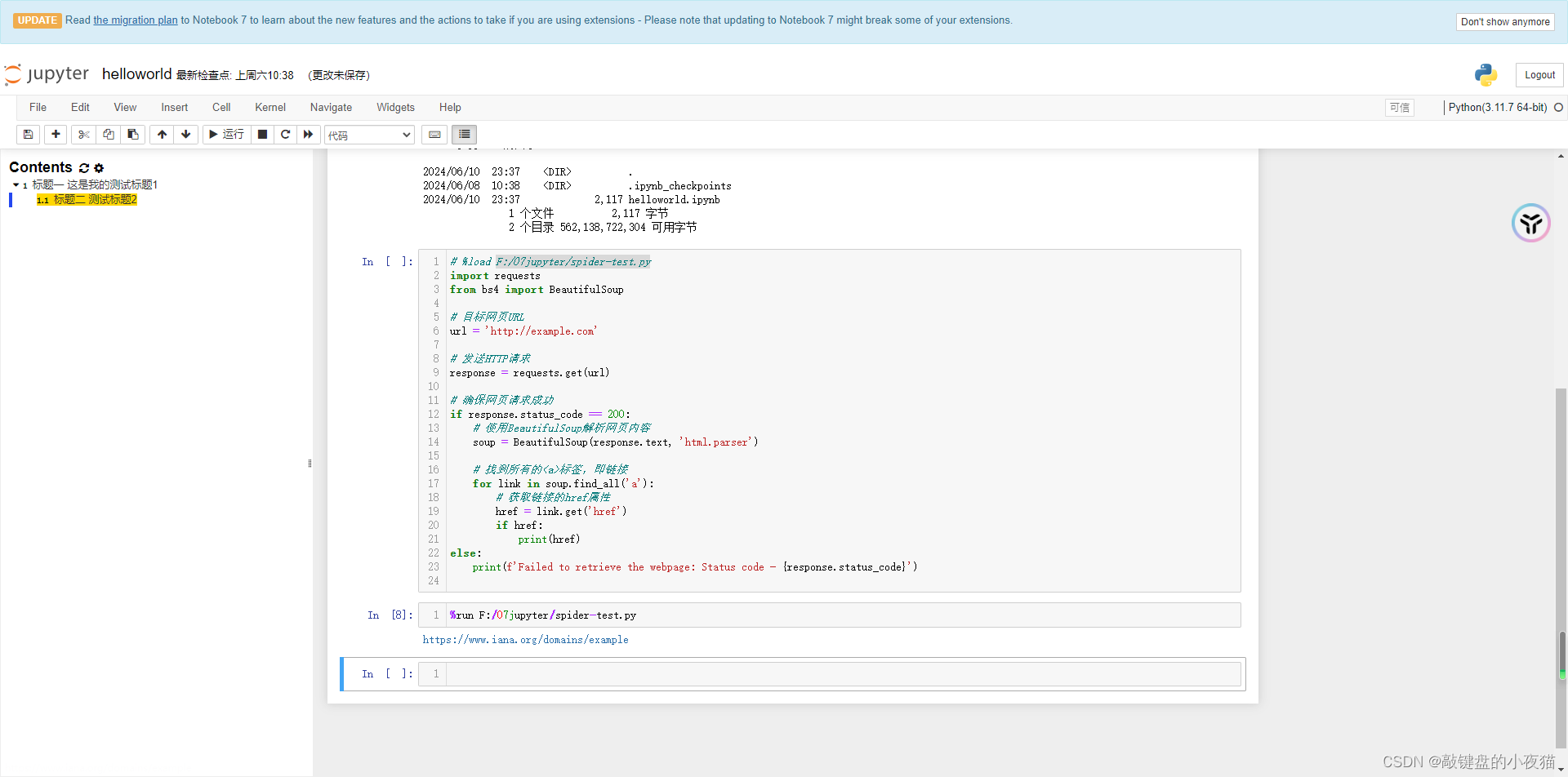
在单元格内输入%run和.py文件位置,然后点击运行。
可以直接运行本地的Python文件并输出结果.不会在单元格内显示文件内的代码。
Jupyter Notebook还有很多功能,大家可以在往后的使用中自行探索学习。
Tensorflow
接下来我们开始安装Tensorflow2.4。
命令行安装Tensorflow
现在我先介绍一下在命令行安装Tensorflow2.4的步骤。
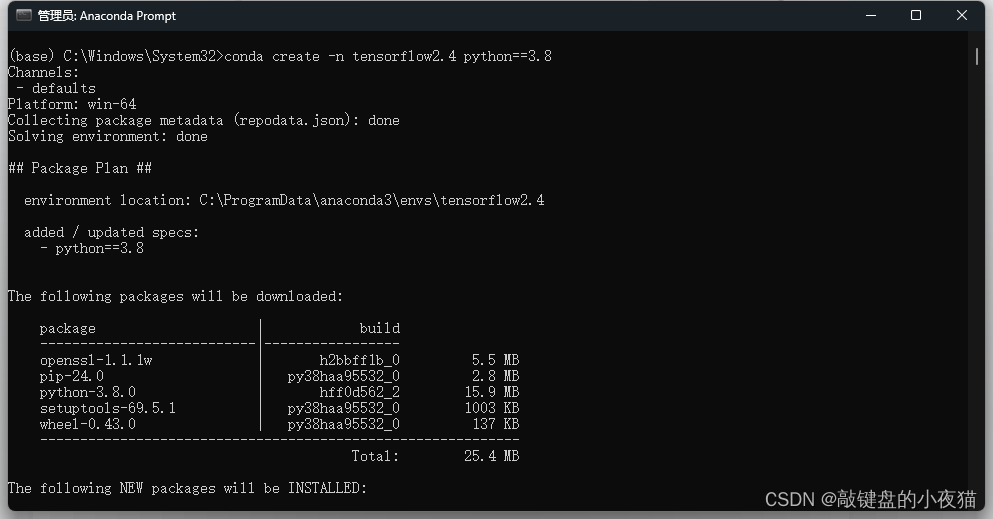
# 1.创建独立环境并激活
conda create -n tensorflow2.4 python==3.8
conda activate tensorflow2.4
# 停用环境
conda deactivate
# 2.安装相关软件包
pip install numpy matplotlib Pillow scikit-learn pandas -i https://pypi.tuna.tsinghua.edu.cn/simple
#3.安装Tensorflow2.5
pip install tensorflow==2.4.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
#4.测试Tensorflow2.4
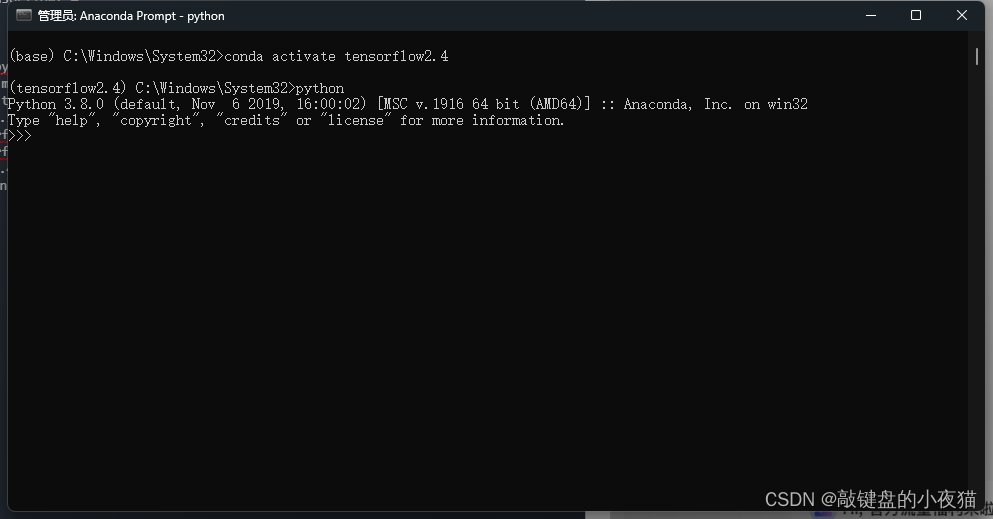
在命令行中输入Python,打开Python交互模式,输入代码:import tensorflow
#5.虚拟机列表
conda env list
#6.删除虚拟机
conda remove -n tensorflow2.4 --all
#7.手动删除虚拟机相关文件
第一步,我们需要创建独立的运行环境并激活,首先右键点击桌面左下角的开始按钮,在打开的菜单栏中点击运行,或者使用组合键,Windows+R快捷打开运行窗口,在运行窗口的输入框中输入CMD,点击确定,打开命令行窗口.我们可以使用conda create命令创建环境,并指定环境当中的Python版本号,其中tansorflow2.4是我们将要创建的环境的名称,Python3.8是我们指定的Python版本后,等待环境创建完成,这里表示,独立环境已经创建完成。我们使用conda activity Tensorflow2.4激活独立环境,这里表示我们的独立环境已经激活。
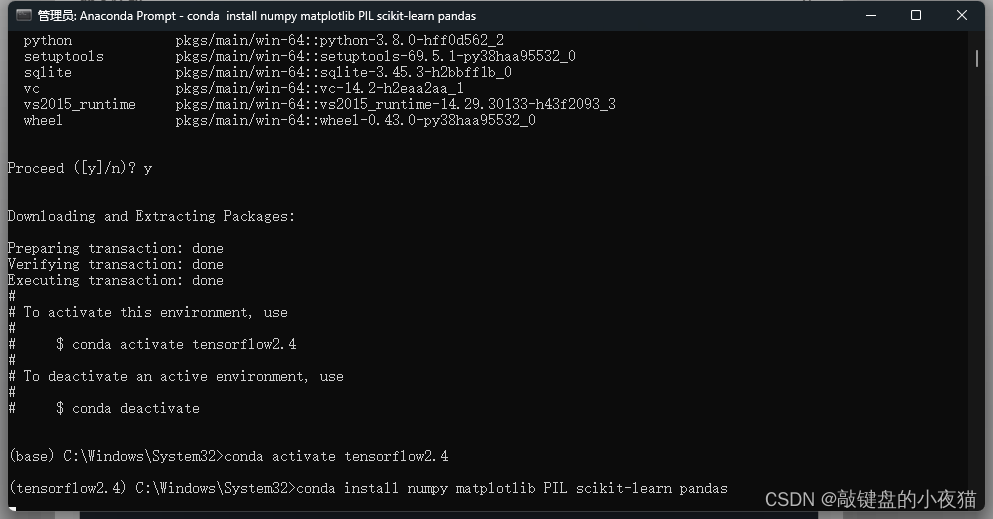
第二步,安装我们以后要用到的Python模块包。这里介绍两种安装方式。一种是采用conda,一种是采用pip。这里我比较推荐使用pip方法进行安装。使用Conda进行安装的过程当中,会因为版本的依赖问题导致部分包的版本被修改,给后续的安装造成麻烦,复制这里的pip命令到命令行窗口,等待相关软件包安装完成,这里表示相关软件包已经安装完成。
第三步,安装Tensorflow 2.4。我们使用piip install Tensorflow==2.4.0指定Tensorflow的版本号进行安装。在安装的过程当中,特别要注意版本号不能有误, 有错误会导致安装失败,复制pip这条命令到命令行窗口,等待Tensorflow2.4安装完成,。

第四步,我们对tansorflow2.4进行简单的测试,我们打开当前激活环境的命令窗口,输入Python,打开Python的交互模式,然后输入import Tensorflow.,如果没有错误,说明安装成功,输入exit(),退出Python交互模式。
 以上是在命令行中安装Tensorflow2.4的基本步骤.
以上是在命令行中安装Tensorflow2.4的基本步骤.
图形化界面安装Tensorflow
如果不习惯在命令行中进行操作,那么也可以使用anaconda navigator所提供的图形化界面,以可视化的形式安装Tensorflow,打开anaconda navigator,切换到环境管理页面。
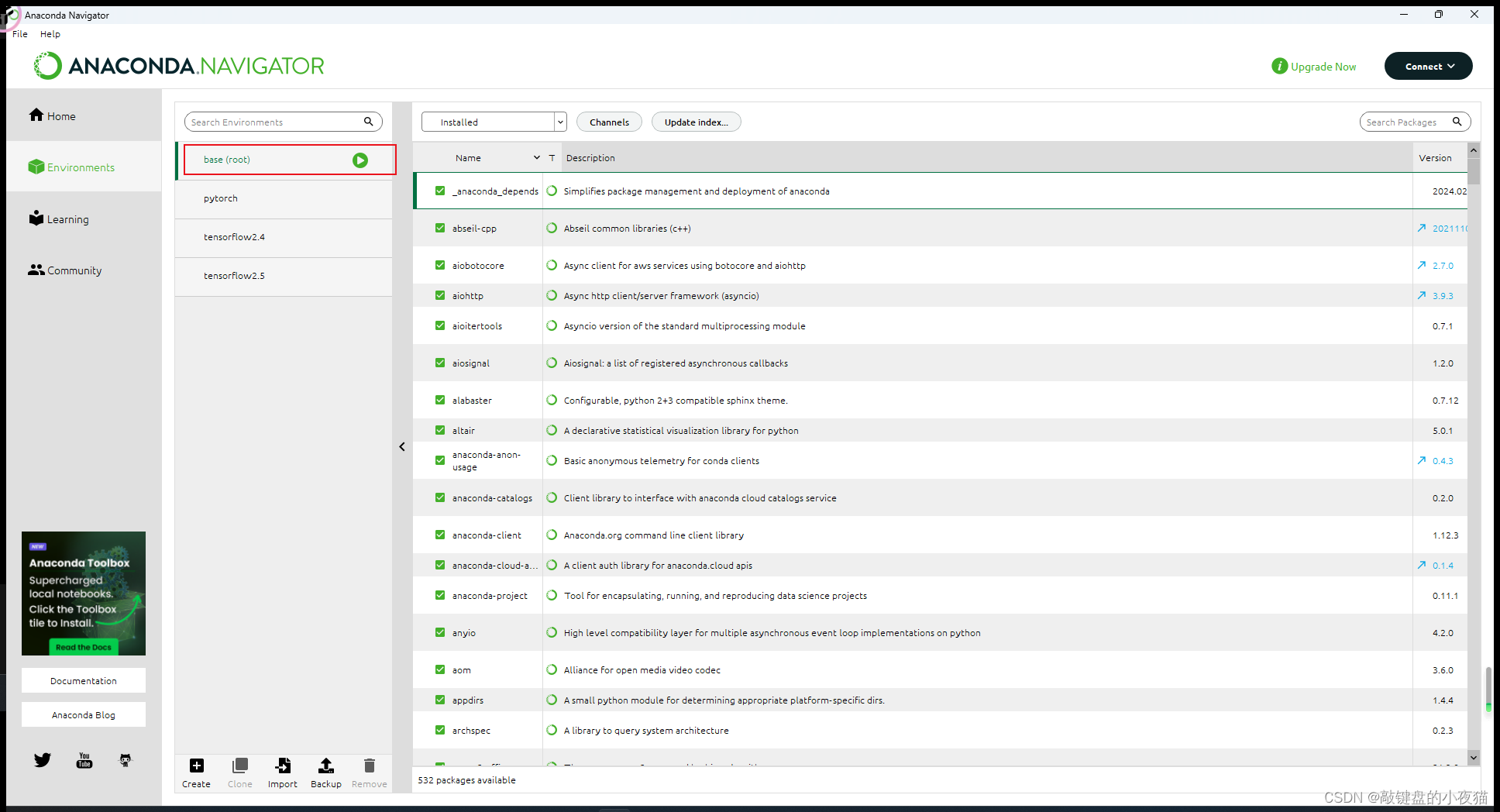
在这个页面,您可以看到当前只有一个base环境,这是anaconda默认的环境,我们将在这个管理界面可视化的创建Tensorflow2.4独立的Python环境,在创建环境的过程当中,会涉及到一些Python模块包的下载,所以我们需要对Conda的Python模块包语言进行修改,以便下载的过程当中效率更高,我们打开清华大学镜像仓库anaconda | 镜像站使用帮助 | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror,看到Conda的使用指南,根据网页上的提示,Windows用户无法直接创建conda配置文件,我们需要先执行Conda命令,生成配置文件之后再修改。
conda config --set show_channel_urls yes复制这条命令到命令行窗口执行,完成以后,我们在命令行窗口显示的路径下面找到该文件

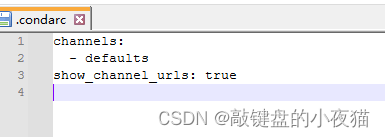
channels:- defaults
show_channel_urls: true
default_channels:- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r- https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2
custom_channels:conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmsys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudbioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudmenpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudpytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloudsimpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/clouddeepmodeling: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/用记事本打开,将anaconda使用指南给出的参数复制到该文件中保存。
完成操作后,我们回到anaconda navigator环境管理界面。点击环境列表下方的create按钮。创建新的独立运行环境。环境名称为Tensorflow2.4,由于输入框中无法输入点,所以我们用-代替.Python版本选择3.8,
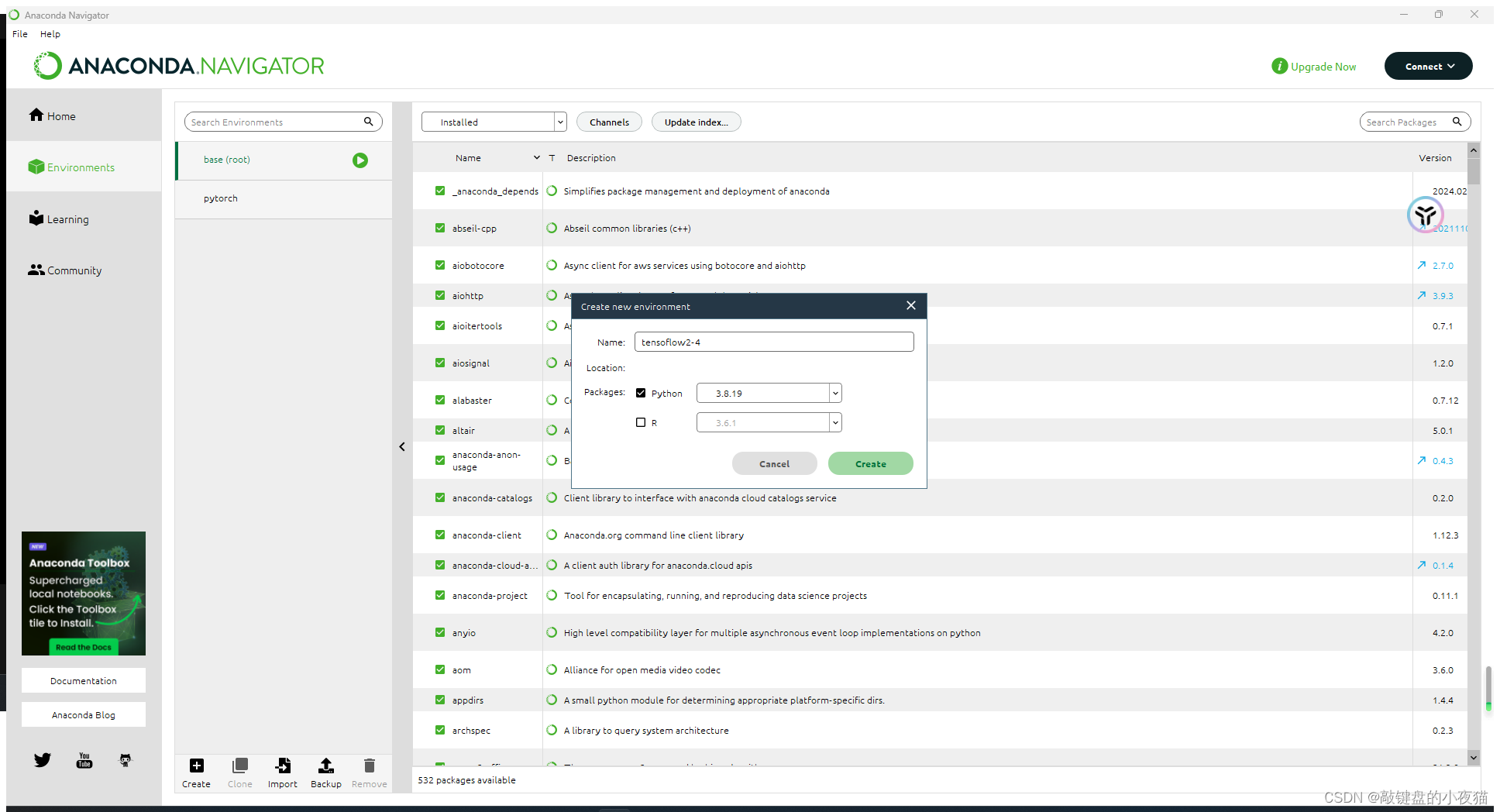
然后点击create
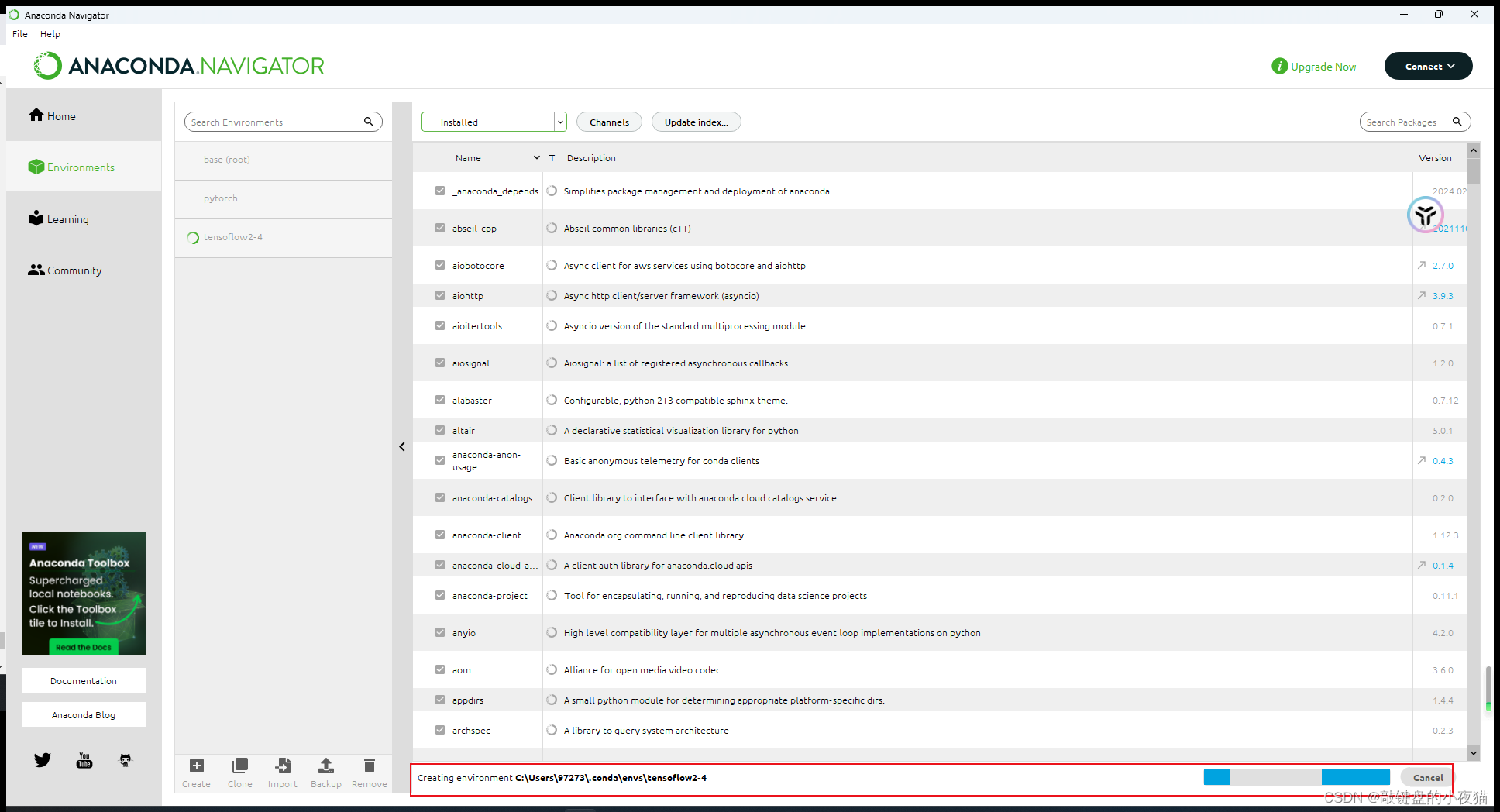
在屏幕下方的滚动条消失后,在环境列表处,会出现我们刚刚创建的新环境Tensorflow2.4。
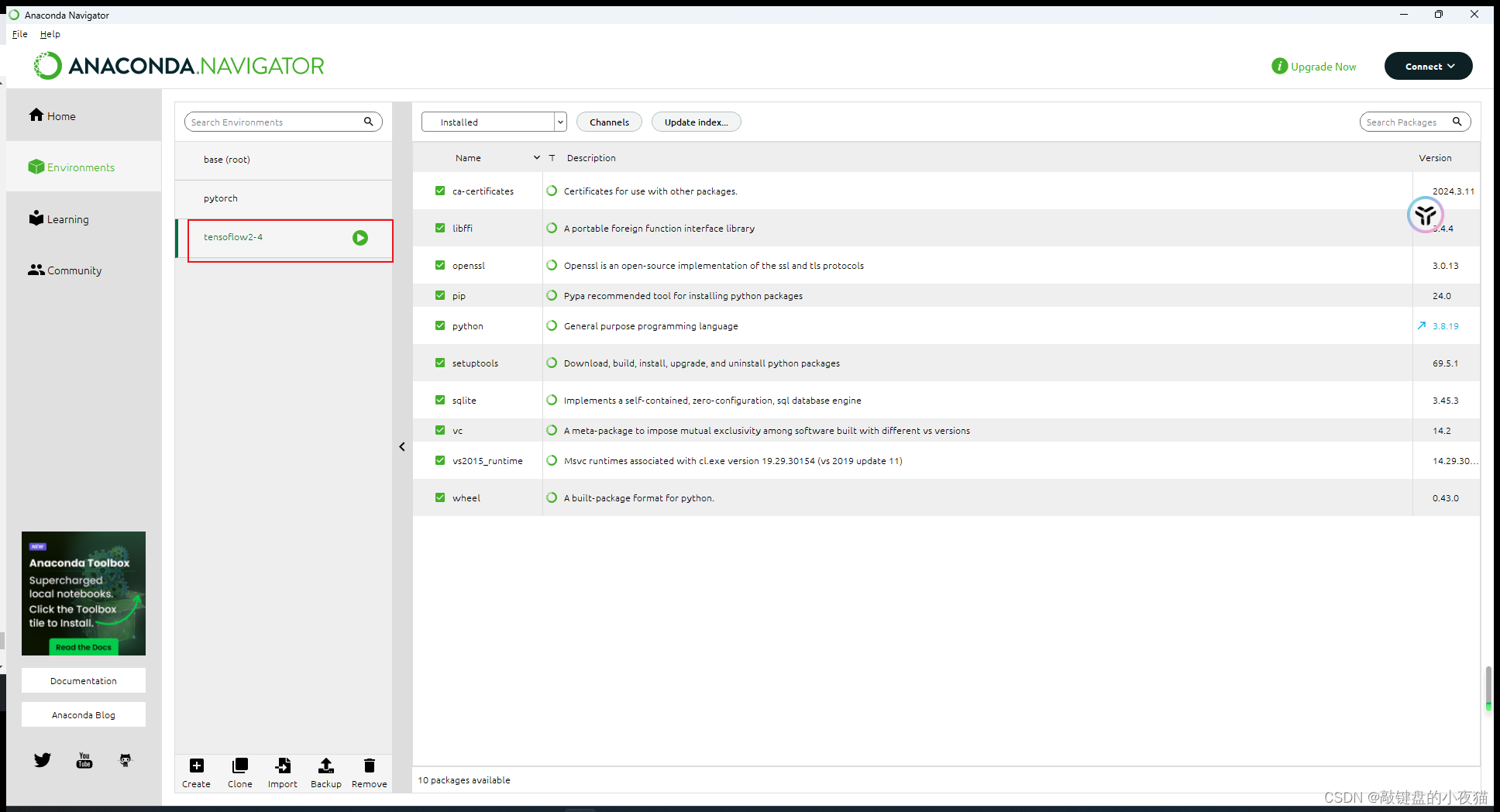
然后我们点击Tensorflow2.42.4环境名称右侧的绿三角
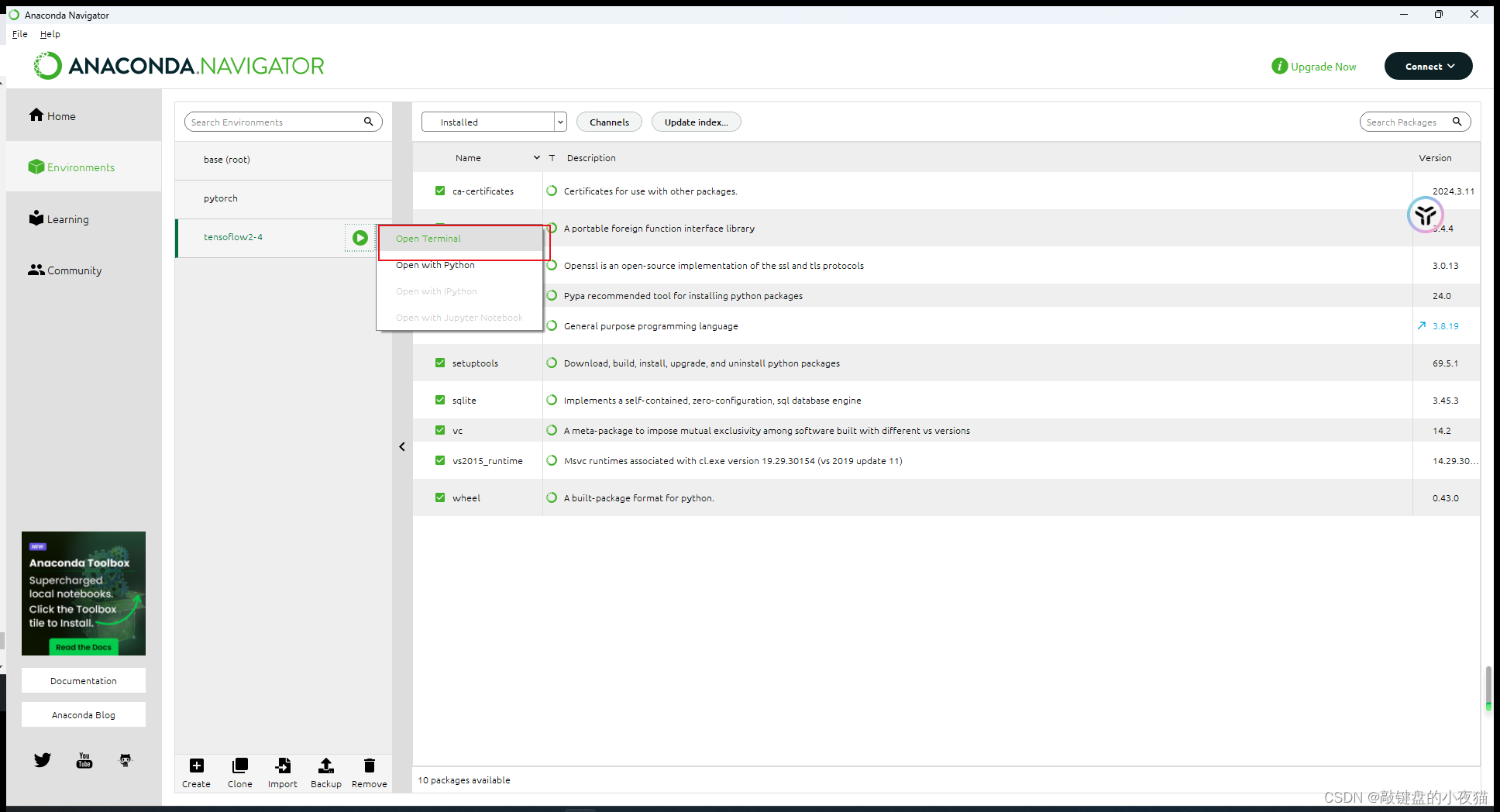
打开命令行窗口,接下来的操作就和命令行窗口的操作一样了。
打开命令行窗口以后,我们使用提供的pip命令,安装相应的Python模块包
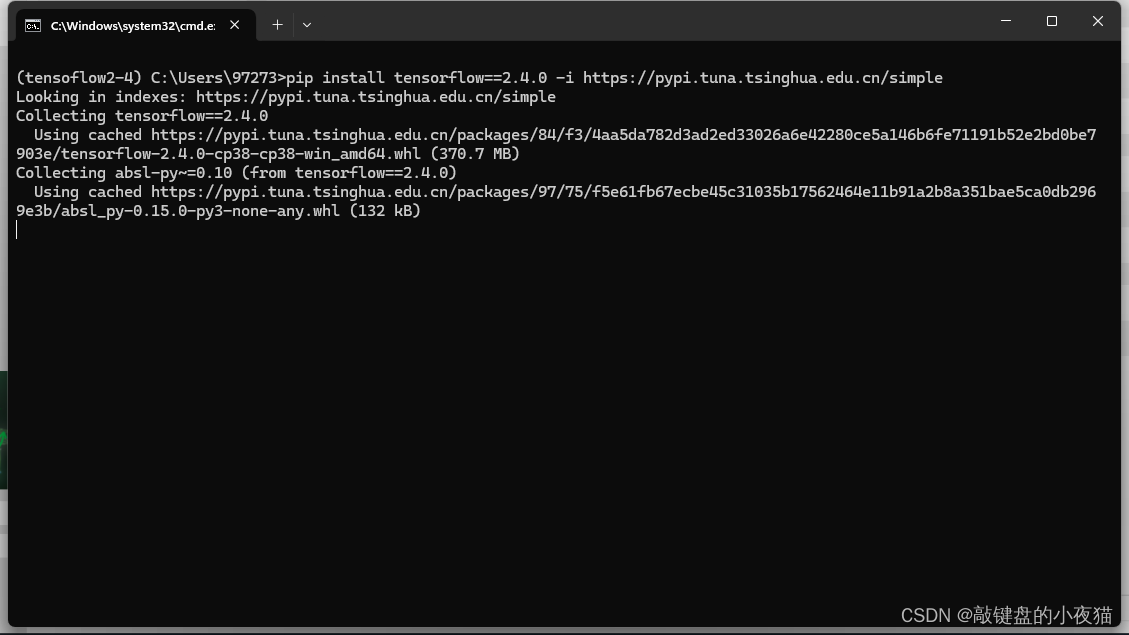

安装完成后,我们使用pip命令安装Tensorflow2.4,安装完成以后,我们在命令行窗口中输入Python,进入Python交互模式,输入import tensorflow,如果没有错误,就说明安装成功,到这里我们就完成了Tensorflow2.4的安装。
相关文章:
人工智能发展历程和工具搭建学习
目录 人工智能的三次浪潮 开发环境介绍 Anaconda Anaconda的下载和安装 下载说明 安装指导 模块介绍 使用Anaconda Navigator Home界面介绍 Environment界面介绍 使用Jupter Notebook 打开Jupter Notebook 配置默认目录 新建文件 两种输入模式 Conda 虚拟环境 添…...

Dijkstra算法的原理
Dijkstra算法的原理可以清晰地分为以下几个步骤和要点: 初始化: 引入一个辅助数组D,其中D[i]表示从起始点(源点)到顶点i的当前已知最短距离。如果起始点与顶点i之间没有直接连接,则D[i]被初始化为无穷大&a…...
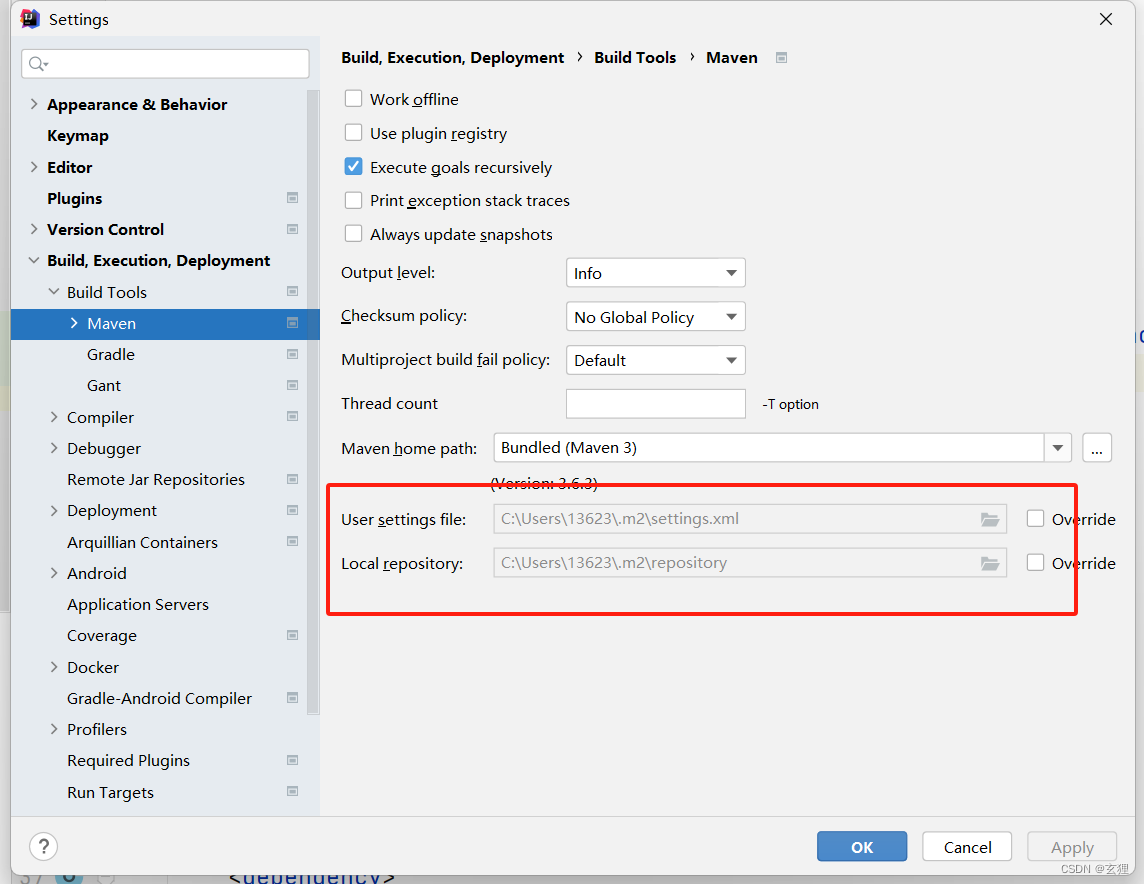
maven引入依赖时莫名报错
一般跟依赖的版本无关,会报出 Cannot resolve xxx 的错误。 这种情况下去IDEA的setting中找maven的仓库位置 在仓库中顺着包路径下寻找,可能会找到.lastUpdated 的文件,这样的文件一般是下载失败了,而且在一段时间内不再下载&…...

graalvm编译springboot3 native应用
云原生时代容器先行,为了更好的拥抱云原生,spring boot3之后,推出了graalvm编译boot项目,利用jvm的AOT( Ahead Of Time )运行前编译技术,可以将javay源码直接构建成机器码二进制的文件ÿ…...

代码随想录Day58
392.判断子序列 题目:392. 判断子序列 - 力扣(LeetCode) 思路:定义重合数记录s与t的比对情况,挨个取出t的字符,与s的字符进行比较,如果相同,重合数就加1,跳到s的下一个字…...
 与 dm-verity 之间的关系、相同点与差异点)
Android Verified Boot (AVB) 与 dm-verity 之间的关系、相同点与差异点
标签: AVB; dm-verity ;Android Android Verified Boot (AVB) 与 dm-verity 之间的关系、相同点与差异点 概述 Android Verified Boot (AVB) 和 dm-verity 是 Android 操作系统中用于确保设备启动过程和运行时数据完整性的两个重要技术。尽管它们有着不同的实现和侧重点,…...

C++学习笔记“类和对象”:多态;
目录 4.7 多态 4.7.1 多态的基本概念 4.7.2 多态案例--计算器类 4.7.3 纯虚函数和抽象类 4.7.4 多态案例二 - 制作饮品 4.7.5 虚析构和纯虚析构 4.7.6 多态案例三-电脑组装 4.7 多态 4.7.1 多态的基本概念 多态是C面向对象三大特性之一 多态分为两类 静志多态: 函数…...
QT Udp广播实现设备发现
测试环境 本文选用pc1作为客户端,pc2,以及一台虚拟机作为服务端。 pc1,pc2(客户端): 虚拟机(服务端): 客户端 原理:客户端通过发送广播消息信息到ip:255.255.255.255(QHostAddress::Broadcast),局域网…...

PyTorch 统计属性-Tensor基本操作
最小 min, 最大 max, 均值 mean,累加 sum,累乘 prod … >>> a torch.arange(0,8).view(2,4).float() >>> a tensor([[0., 1., 2., 3.],[4., 5., 6., 7.]])>>> a.min() ## 最小值:tensor(0.) >>> a.ma…...
波拉西亚战记加速器 台服波拉西亚战记免费加速器
波拉西亚战记是一款新上线的MMORPG游戏,游戏内我们有多个角色职业可以选择,可以体验不同的战斗流派玩法,开放式的地图设计,玩家可以自由的进行探索冒险,寻找各种物资。各种随机事件可以触发,让玩家的冒险过…...

Mocha + Chai 测试环境配置,支持 ES6 语法
下面是一个完整的 Mocha Chai 测试环境配置,支持 ES6 语法。我们将使用 Babel 来转译 ES6 代码。 步骤一:初始化项目 首先,在项目目录中运行以下命令来初始化一个新的 Node.js 项目: npm init -y步骤二:安装必要的…...

华为网络设备攻击防范
畸形报文攻击防范 攻击行为 畸形报文攻击是通过向交换机发送有缺陷的IP报文,使得交换机在处理这样的IP包时会出现崩溃,给交换机带来损失。 畸形报文攻击主要有如下几种: 没有IP载荷的泛洪攻击 IGMP空报文攻击 LAND攻击 Smurf攻击 TCP标…...

RK3588开发笔记-100M网口自协商成1000M网口
目录 前言 一、问题描述 二、原理图连接 三、解决方法 总结 前言 在进行RK3588开发过程中,遇到一个令人困惑的问题:在使用RTL8211F-CG phy芯片出来的100M网口在自协商后连接速率变成了1000M。这篇博客将详细记录这个问题的产生、排查过程以及最终的解决方案,希望能对遇到…...
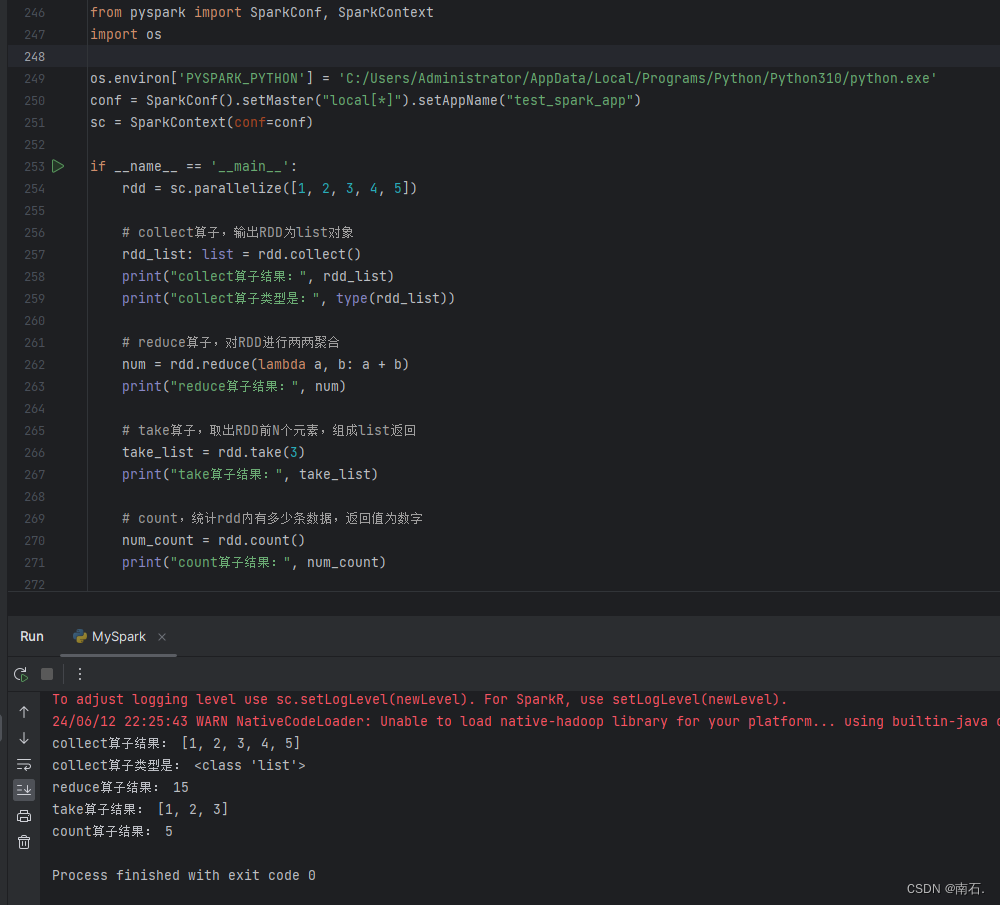
Python第二语言(十三、PySpark实战)
目录 1.开篇 2. PySpark介绍 3. PySpark基础准备 3.1 PySpark安装 3.2 掌握PySpark执行环境入口对象的构建 3.3 理解PySpark的编程模型 4. PySpark:RDD对象数据输入 4.1 RDD对象概念:PySpark支持多种数据的输入,完成后会返回RDD类的对…...

《阅读的方法》读后感——超越期待的收获
当我翻开这本书的扉页时,未曾料到它会给我带来如此深远的启示和收获。依照推荐序言中的指引,我随意翻阅、精心选读,每一次都如同打开一扇新的窗户,让我窥见不同领域的智慧和美好。 等地铁时、临睡前随便读点什么,有什么…...
)
算法训练营第五十八天 | LeetCode 392 判断子序列、卡码网模拟美团笔试第一、二、三题(300/500有待提高)
卡码网图论更新了可以去看看,模拟笔试第四题就是深搜/广搜还不太会 LeetCode 392 判断子序列 其实就是最长公共子序列翻版 代码如下: class Solution {public boolean isSubsequence(String s, String t) {int[][] dp new int[s.length() 1][t.lengt…...
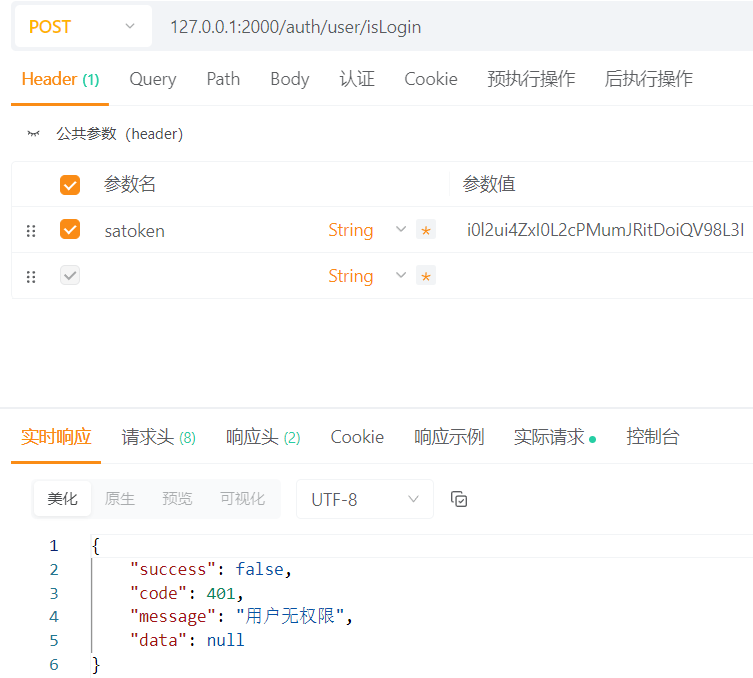
Sa-Token鉴权与网关服务实现
纠错: 在上一部分里我完成了微服务框架的初步实现,但是先说一下之前有一个错误,就是依赖部分 上次的学习中我在总的父模块下引入了spring-boot-dependencies(版本控制)我以为在子模块下就不需要再引用了,…...

企事业单位安全生产月活动怎样向媒体投稿?
作为一名单位的信息宣传员,我肩负着将每一次重要活动的精彩瞬间转化为文字,向外界传递我们单位声音的重任。初入此行时,我满怀热情,坚信通过传统的方式——电子邮件投稿,能够有效地将我们的故事传播出去。然而,现实却给我上了生动的一课。 记得在筹备“安全生产月”活动的宣传时…...

MySQL8.0默认TCP端口介绍
1、本文内容 选择题TCP/IPMySQL 8.0 的默认TCP端口show variables查看总结 2、选择题 A、3306 B、33060 C、33062 D、33063 3、TCP/IP TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同…...
Javaweb避坑指北(持续更新)
内容较多可按CtrlF搜索 0.目录 1.获取插入数据后自增长主键的值 2.Controller中返回给ajax请求字符串/json会跳转到xxx.jsp 3.ajax请求获得的json无法解析 4.在Controller中使用ServletFileUpload获取的上传文件为null 5.莫名其妙报service和dao里方法的错误 6.ajax请求拿…...

工业安全零事故的智能守护者:一体化AI智能安防平台
前言: 通过AI视觉技术,为船厂提供全面的安全监控解决方案,涵盖交通违规检测、起重机轨道安全、非法入侵检测、盗窃防范、安全规范执行监控等多个方面,能够实现对应负责人反馈机制,并最终实现数据的统计报表。提升船厂…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

Go 语言接口详解
Go 语言接口详解 核心概念 接口定义 在 Go 语言中,接口是一种抽象类型,它定义了一组方法的集合: // 定义接口 type Shape interface {Area() float64Perimeter() float64 } 接口实现 Go 接口的实现是隐式的: // 矩形结构体…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

React Native在HarmonyOS 5.0阅读类应用开发中的实践
一、技术选型背景 随着HarmonyOS 5.0对Web兼容层的增强,React Native作为跨平台框架可通过重新编译ArkTS组件实现85%以上的代码复用率。阅读类应用具有UI复杂度低、数据流清晰的特点。 二、核心实现方案 1. 环境配置 (1)使用React Native…...

Vue2 第一节_Vue2上手_插值表达式{{}}_访问数据和修改数据_Vue开发者工具
文章目录 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染2. 插值表达式{{}}3. 访问数据和修改数据4. vue响应式5. Vue开发者工具--方便调试 1.Vue2上手-如何创建一个Vue实例,进行初始化渲染 准备容器引包创建Vue实例 new Vue()指定配置项 ->渲染数据 准备一个容器,例如: …...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

Python如何给视频添加音频和字幕
在Python中,给视频添加音频和字幕可以使用电影文件处理库MoviePy和字幕处理库Subtitles。下面将详细介绍如何使用这些库来实现视频的音频和字幕添加,包括必要的代码示例和详细解释。 环境准备 在开始之前,需要安装以下Python库:…...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...