Python第二语言(十三、PySpark实战)
目录
1.开篇
2. PySpark介绍
3. PySpark基础准备
3.1 PySpark安装
3.2 掌握PySpark执行环境入口对象的构建
3.3 理解PySpark的编程模型
4. PySpark:RDD对象数据输入
4.1 RDD对象概念:PySpark支持多种数据的输入,完成后会返回RDD类的对象;
4.2 Python数据容器转RDD对象.parallelize(数据容器对象)
4.3 RDD存在很多计算的方法
4.4 读取文件转RDD对象:通过SparkContext入口对象来读取文件,构建RDD对象;
5. PySpark:RDD对象数据计算(一)
5.1 给Spark设置环境变量(不设置的时候,控制台会报错,出现找不到python.exe解释器的情况)
5.2 RDD的map方法:将RDD的数据根据函数进行一条条处理
5.3 RDD的flatMap方法:基本和map一样,但是多一个功能:将嵌套list给转成单list;[[1, 2, 3], [4, 5, 6]]转成[1, 2, 3, 4, 5, 6]
5.4 RDD的reduceByKey方法:将key分组后进行value逻辑处理;
6. 数据计算案例(一):完成使用PySpark进行单词技术的案例
7. PySpark:RDD对象数据计算(二)
7.1 RDD的filter方法:传入T泛型数据,返回bool,为false 的数据丢弃,为true的数据保留;(函数对RDD数据逐个处理,得到True的保留至返回值的RDD中)
7.2 RDD的distinct方法:对RDD数据进行去重,返回新RDD;
7.3 RDD的sortBy方法:对RDD的容器按照指定规则排序,返回新RDD;
8. 数据计算案例(二):计算城市中的商品以及销售额
8.1 需求
8.2 文件数据
8.3 需求一实现:处理结果自动返回的是一个二元元组;
8.4 需求二实现:将字典中的数据处理,返回一个list;
8.5 需求三实现:过滤除北京的数据,并只返回一个参数category,是list列表,并进行去重,去重后的结果进行collect输出;
9. 将RDD的结果数据输出为Python对象的各类方法
导航:
Python第二语言(一、Python start)-CSDN博客
Python第二语言(二、Python语言基础)-CSDN博客
Python第二语言(三、Python函数def)-CSDN博客
Python第二语言(四、Python数据容器)-CSDN博客
Python第二语言(五、Python文件相关操作)-CSDN博客
Python第二语言(六、Python异常)-CSDN博客
Python第二语言(七、Python模块)-CSDN博客
Python第二语言(八、Python包)-CSDN博客
Python第二语言(九、Python第一阶段实操)-CSDN博客
Python第二语言(十、Python面向对象(上))-CSDN博客
Python第二语言(十一、Python面向对象(下))-CSDN博客
Python第二语言(十二、SQL入门和实战)-CSDN博客
Python第二语言(十三、PySpark实战)-CSDN博客
Python第二语言(十四、高阶基础)-CSDN博客
1.开篇
- PySpark大数据计算第三方库,Spark是大数据开发的核心技术;
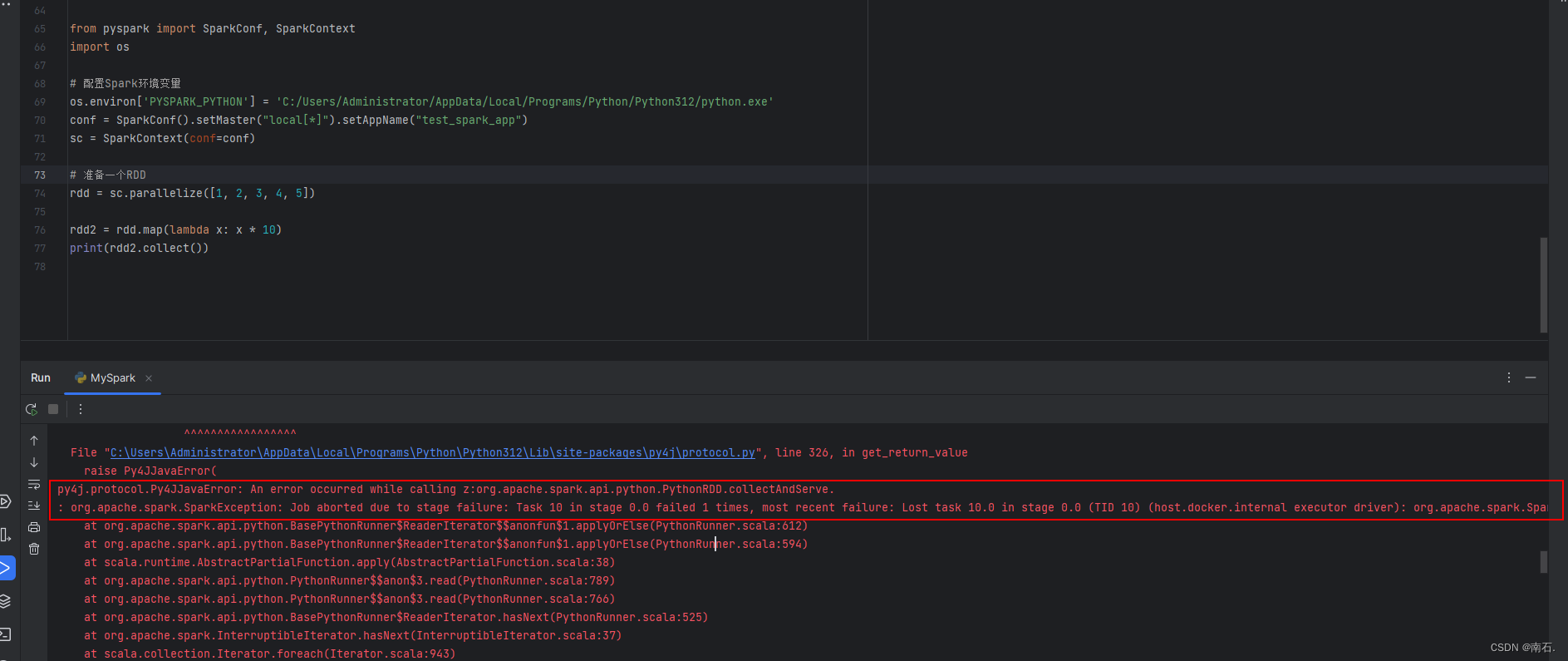
- python的spark中使用map时 Python worker exited unexpectedly (crashed):
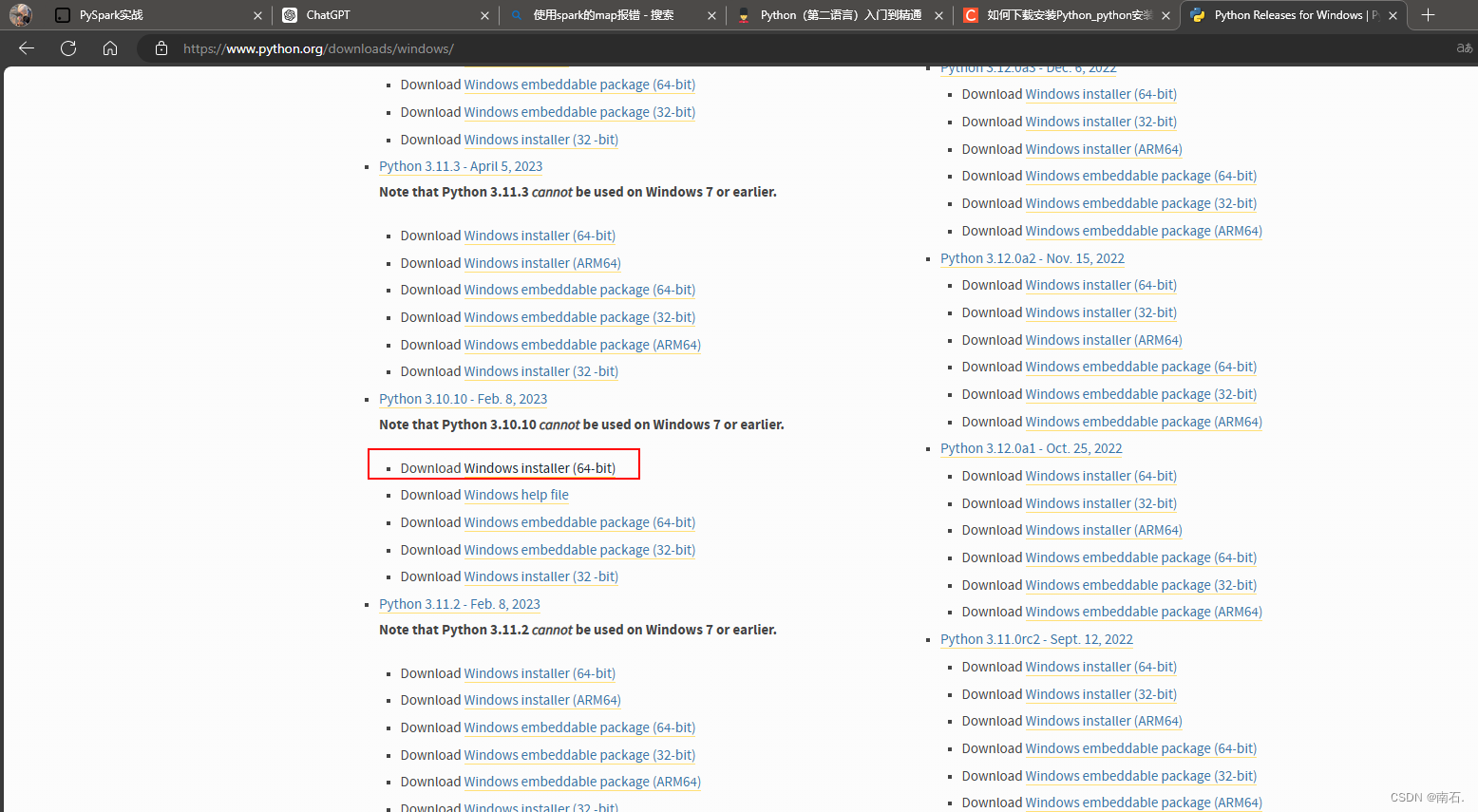
- 将原本的python12解释器降低版本到python10版本解释器,降低python解释器版本,因为版本不兼容;
-
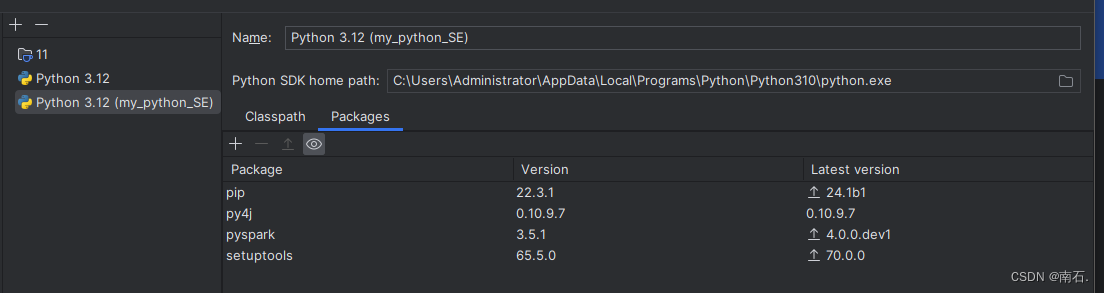
- 记得下载使用的包;
2. PySpark介绍
- Apache Spark是用于大规模数据(large-scala data)处理的统一(unifield)分析引擎;
- Spark是一款分布式的计算框架,用于调度成百上千的服务器集群,计算TB、PB乃至EB级别的海量数据;
- Python On Spark:Python语言,是Spark重点支持的方向;
PySpark第三方库:
- PySpark是由Spark官方开发的Python语言第三方库;
- Python开发者可以使用pip程序快速安装PySpark并像其它第三方库一样使用;
- 主要作用:
- 进行数据处理;
- 提交至Spark集群,进行分布式集群计算;
3. PySpark基础准备
3.1 PySpark安装
安装命令: pip install pyspark
加速下载命令:pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark

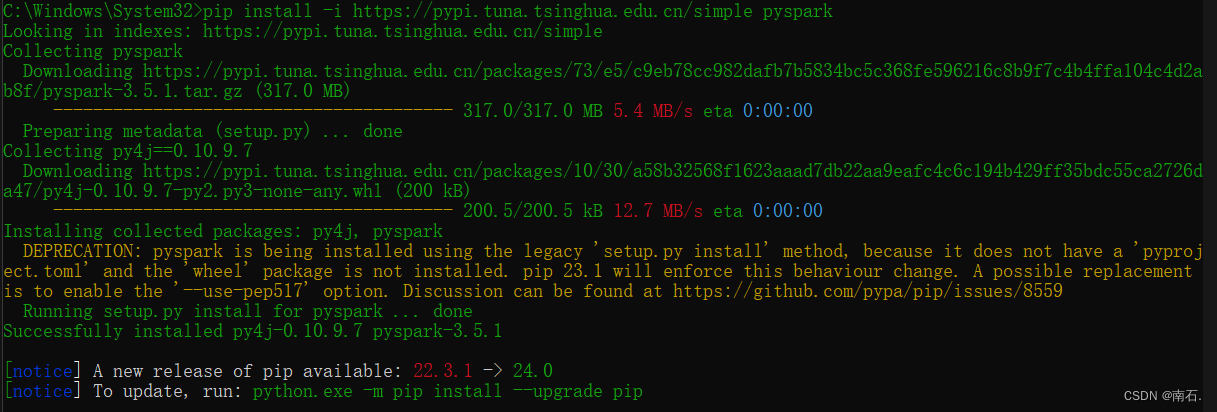
3.2 掌握PySpark执行环境入口对象的构建
- PySpark是分布式集群的操作,
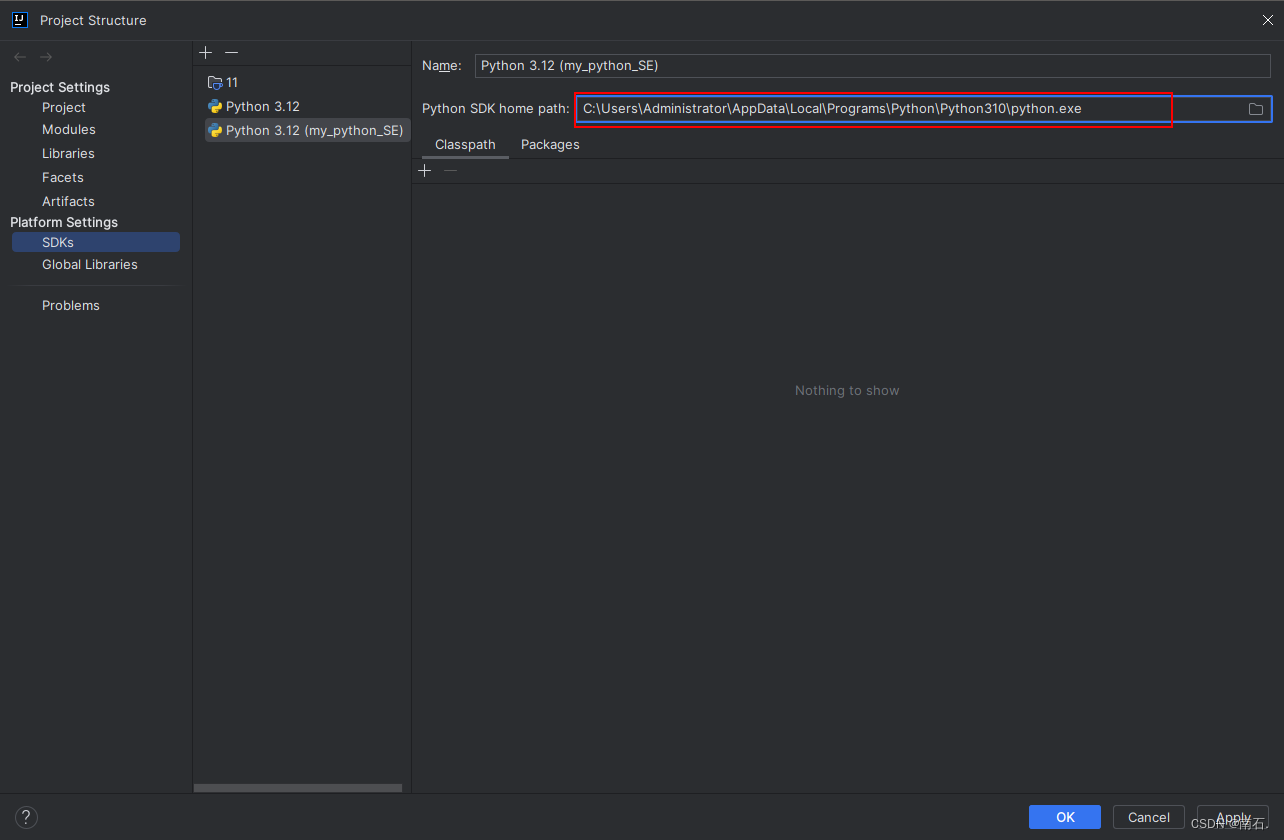
setMaster(xxx).\setAppName(xxx)是用来控制集群的代码,图中代码用的是单机的; setAppName是Spark任务的名称;- PySpark的执行环境入口对象是:类SparkContext的类对象,所有PySpark的功能都是从SparkContext对象作为开始;
# 导包
from pyspark import SparkConf, SparkContext# 创建SparkConf类对象
conf = SparkConf().setMaster("local[*]").\setAppName("test_spark_app")# 基于SparkConf类对象创建SparkContext类对象
sc = SparkContext(conf=conf)# 打印PySpark的运行版本
print(sc.version)# 停止SparkContext对象的运行
sc.stop()
3.3 理解PySpark的编程模型
SparkContext类对象,是PySpark编程中一切功能的入口;
- PySpark的编程三大步骤:
- 数据输入:通过SparkContex类对象的成员方法完成数据的读取操作,读取后得到RDD类对象;
- 数据处理计算:通过RDD类对象的成员方法,完成各种数据计算的需求;
- 数据输出:将处理完成后的RDD对象,调用各种成员方法完成,写出文件,转换位list等操作;
4. PySpark:RDD对象数据输入
- RDD就是PySpark计算后返回的对象容器;
4.1 RDD对象概念:PySpark支持多种数据的输入,完成后会返回RDD类的对象;
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets);
- PySpark针对数据的处理,都是以RDD对象作为载体;
- 数据存储在RDD内;
- 各类数据的计算方法,也都是RDD的成员方法;
- RDD的数据计算方法,返回值依旧是RDD对象;
- 比如说JSON文件、文本文件、数据库数据,都是可以通过SparkContext类对象,经过RDD对象的处理,并返回给文件文件或JSON文件,或者数据库;
4.2 Python数据容器转RDD对象.parallelize(数据容器对象)
- 提示:
- 字符串会被拆分出1个个的字符,存入RDD对象;
- 字典仅有key会被存入RDD对象;
- RDD对象返回的是容器,与list一样结果;
from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)# 通过parallelize方法将Python对象加载到Spark内,称为RDD对象
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((1, 2, 3, 4, 5))
rdd3 = sc.parallelize("abcdefg")
rdd4 = sc.parallelize({1, 2, 3, 4, 5})
rdd5 = sc.parallelize({"key1": "value1", "key2": "value2"})# 使用collect方法查看RDD中的内容
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())sc.stop()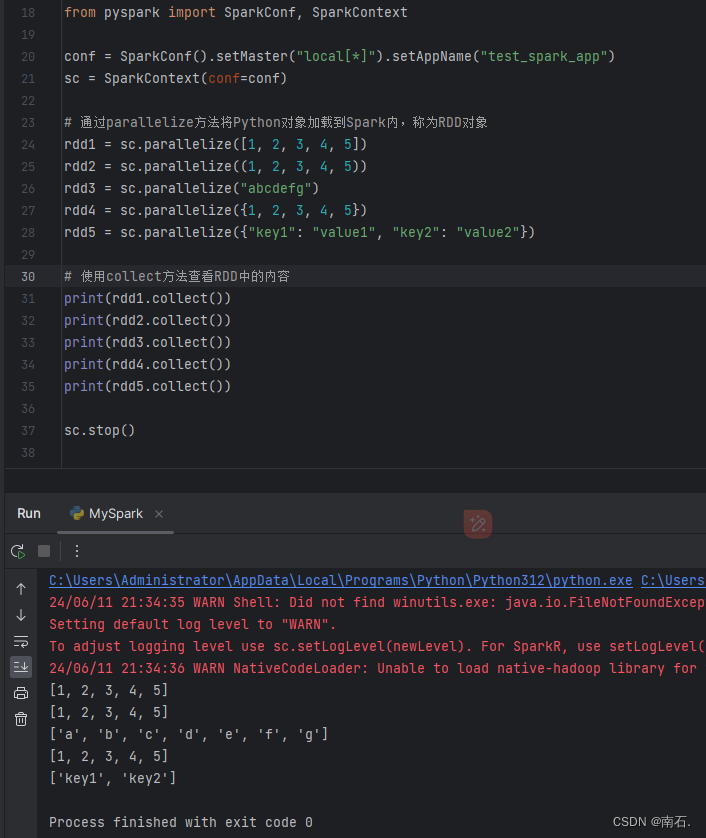
4.3 RDD存在很多计算的方法

4.4 读取文件转RDD对象:通过SparkContext入口对象来读取文件,构建RDD对象;
from pyspark import SparkConf, SparkContextconf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)# 通过textFile方法,读取文件数据加载到Spark内,成为RDD对象
rdd = sc.textFile("dataText")# 打印RDD内容
print(rdd.collect())
sc.stop()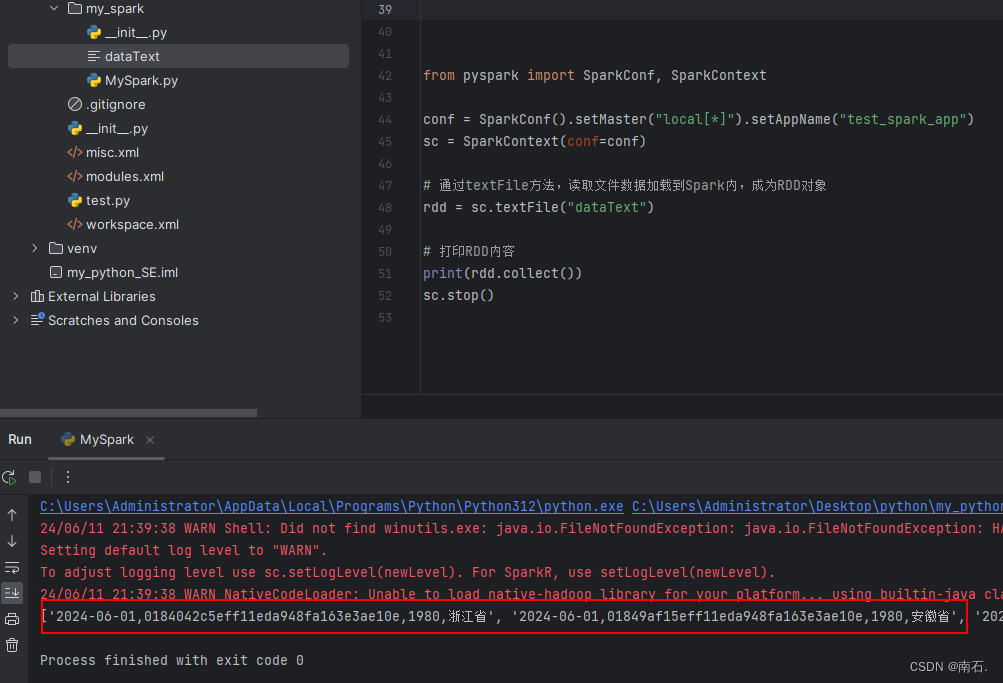
小结:
- RDD对象称之为分布式弹性数据集,是PySpark中数据计算的载体,可以:
- 提供数据存储;
- 提供数据计算的各类方法;
- 数据计算的方法,返回值依旧是RDD(RDD迭代计算);
5. PySpark:RDD对象数据计算(一)
- 可以对list容器计算,可以对dict字典容器计算,可以对str字符串进行计算,所有的容器都可以通过RDD计算;
5.1 给Spark设置环境变量(不设置的时候,控制台会报错,出现找不到python.exe解释器的情况)
os.path.exists 返回值为True或False;
from pyspark import SparkConf, SparkContext
import os# 配置Spark环境变量
os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'# 检查PYSPARK_PYTHON路径
print(os.path.exists('C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'))
# 检查PYSPARK_DRIVER_PYTHON路径
print(os.path.exists('C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'))
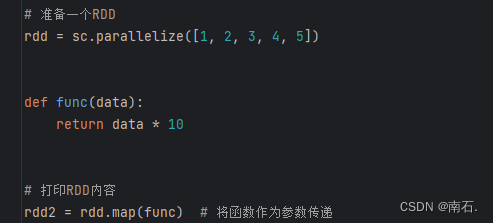
5.2 RDD的map方法:将RDD的数据根据函数进行一条条处理
1. 介绍:
- RDD对象内置丰富的:成员方法(算子)
- map算子:是将RDD的数据一条条处理(处理的逻辑是将python中的函数作为参数进行传递,这个函数,参数会将RDD种的每条数据都进行处理)最终返回一个新的RDD对象;
- map()中的参数
(T) → U:T代表传入一个参数,U代表一个返回值;(意思代表传入的参数是一个,还有一个返回值,T是泛型,不用指定数据类型) - map()中的参数
(T) → T:T代表传入一个参数,T代表一个返回值;(意思代表传入的参数是一个,还有一个返回值,T是泛型,传入的是什么值,那么返回的就是什么类型)
- map()中的参数
2. func函数传递:
func函数作为参数:代表的是RDD中的每个值,都会进行func函数的处理;是RDD中的每一个元素都会被RDD处理一遍;
可以简写成:rdd2 = rdd.map(lambda x: x * 10) # 简写的函数 ;
3. 案例:
- 这里存在一个大坑,如果是python312版本去使用map函数,会报错
Python worker exited unexpectedly (crashed),降低版本即可,我用的版本10; - 结果:RDD中的每一个元素都会被传递给func进行处理,*10操作;
from pyspark import SparkConf, SparkContext
import os# 配置Spark环境变量
os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)# 准备一个RDD
rdd = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = rdd.map(lambda x: x * 10) # 简写的函数
print(rdd2.collect())
sc.stop()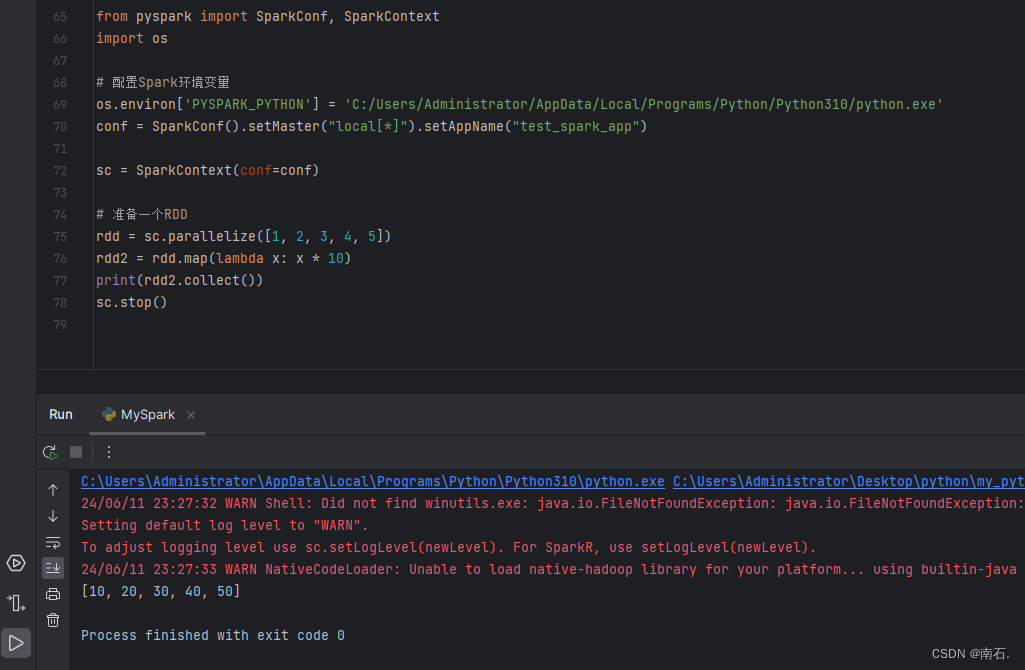
4. map链式调用:
from pyspark import SparkConf, SparkContext
import os# 配置Spark环境变量
os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 2, 3, 4, 5])rdd2 = rdd.map(lambda x: x * 10).map(lambda x: x + 5) # 链式调用:将map进行第一个*10数据计算,再进行map+5数据计算print(rdd2.collect())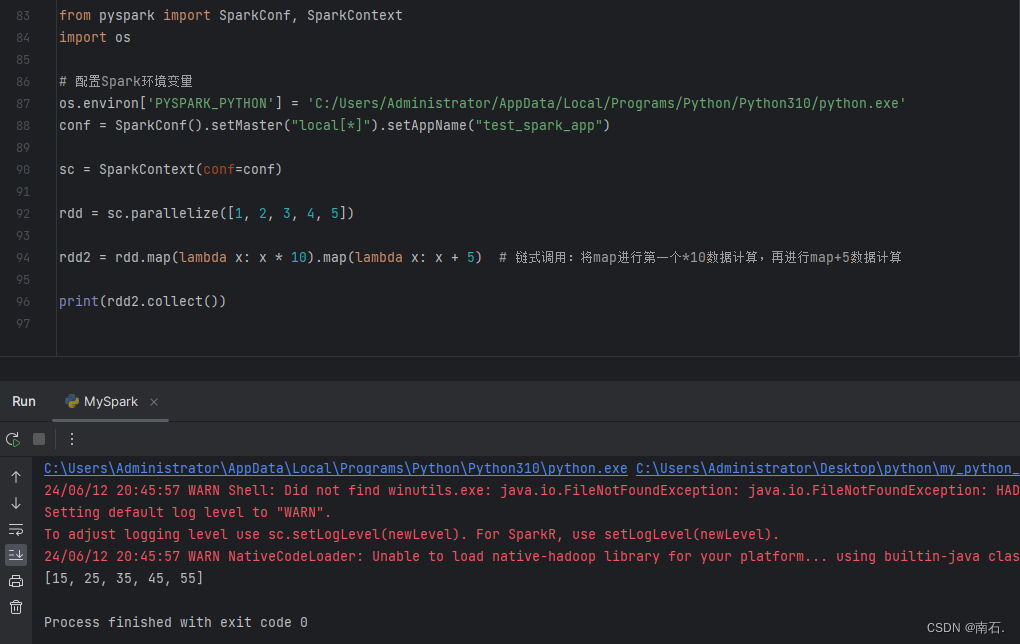
5. 小结:
- map算子(成员方法):
- 接受一个处理函数,可用lambda表达式快速编写;
- 对RDD内的元素逐个处理,并返回一个新的RDD;
- 链式调用:对于返回值是新RDD的算子,可以通过链式调用的方式多次调用算子;
5.3 RDD的flatMap方法:基本和map一样,但是多一个功能:将嵌套list给转成单list;[[1, 2, 3], [4, 5, 6]]转成[1, 2, 3, 4, 5, 6]
from pyspark import SparkConf, SparkContext
import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)rdd = sc.parallelize(["zhangSan lisi yiyi", "zhangSan yiyi wangWu", "wangWu yiyi zhangSan"])print(rdd.map(lambda x: x.split(" ")).collect())print("-----------------------------------------")print(rdd.flatMap(lambda x: x.split(" ")).collect()) # 将嵌套list转成单list,对数据接触嵌套
5.4 RDD的reduceByKey方法:将key分组后进行value逻辑处理;
-
二元元组:
[('a', 1), ('a', 1), ('b', 1)]这就是二元元组,元组中只有两个元素; -
自动按照key分组,完成组内数据(value)的聚合操作:就是会按照元组中的key,就是
'a', 'a', 'b'进行key的value聚合,1, 1, 1是value;(value聚合的逻辑是,按照传入的func函数逻辑来进行聚合)假设这是二元元组数据要进行reduceByKey算子处理:

reduceByKey计算方式:
1. 思路:
- 先分组,key值等于a和a一组,b和b一组:然后在进行函数
lambda a, b: a+b进行处理,也即是分组后,a=a+a, b=b+b+b;结果[('b', 3), ('a', 2)] - 再解释:b有三个值,那么
lambda a, b: a+b中表示的是b:1, 1, 1的三个值,去进行函数处理的时候,先是第一个1和第二1进行相加,这时候相加是a+b,分组后与key无关系,那么第一个1和第二个1相加后等于2,这时候发现还有第三个1,这时候再次把第一次相加的结果,与第三个1进行a+b处理,2+1;是前后者参数的相加处理;最终得到按照key分组聚合value的结果; - 最终解释:将数据分组后,每个组的数据进行
lambda a, b: a + b操作,每个组中的数据,进行a + b操作,意思就是将当前组的所有value进行相加操作;
2. 实现:
- 功能:针对KV型RDD,自动按照key分组,然后根据提供的聚合逻辑,完成组内数据(value)的聚合操作;
- rdd.reduceByKey(func):
from pyspark import SparkConf, SparkContext import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)rdd = sc.parallelize([('a', 1), ('a', 1), ('b', 1), ('b', 1), ('b', 1)])result = rdd.reduceByKey(lambda a, b: a + b) # 分组计算print(result.collect())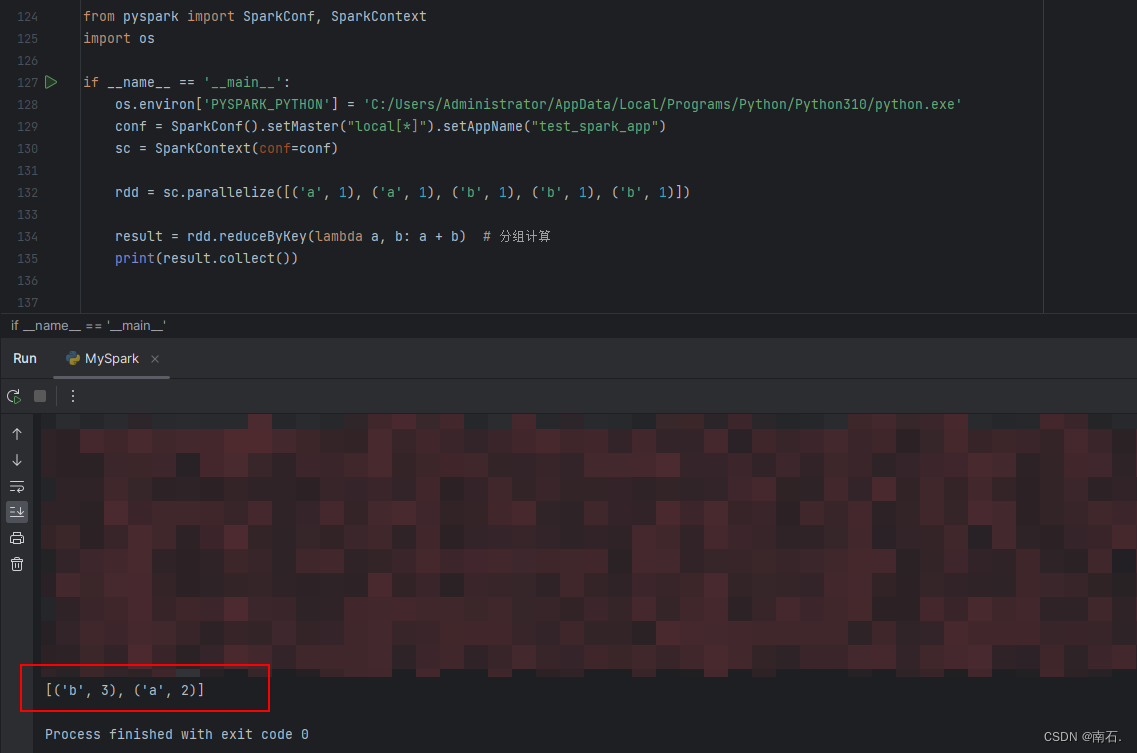
6. 数据计算案例(一):完成使用PySpark进行单词技术的案例
- 题目:读取文件,求出文件中单词出现的次数;
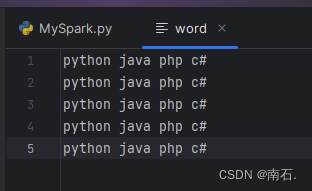
- 文件:
-
思路:
先将字符串进行读取,然后按照空格分割
['key', 'key'],在进行分割后的数组重组为(key, 1)的形式,后面利用rdd的reduceByKey方法,将分组后的key,进行聚合操作,因为value都是1,所以可以得出对单词出现的次数,进行统计操作; -
根据
(key, 1)重组后的数据应该是:[('key1', 1), ['key1', 1], ('key2', 1), ['key2', 1]] - 然后得出最终结果:
from pyspark import SparkConf, SparkContext import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)# 1.读取数据文件"""假设你有一个大文件,里面有 300MB 的数据,如果你指定分区数为 3,Spark 会尝试将这个文件分成 3 个分区,每个分区大约 100MB。如果你的集群有 3 个节点,每个节点可以并行处理一个分区,这样就可以更快地完成任务。"""file = sc.textFile("word", 3) # ("xx" , 3):3是指文件被分成的最小分区数(partitions)# 2.将所有单词读取出来words = file.flatMap(lambda line: line.split(' ')) # 结果:['python', 'java', ...]# 3.将所有单词加1做valueword_one = words.map(lambda x: (x, 1)) # 结果:[('python', 1), ('java', 1), ('php', 1), ('c#', 1),...]# 4.分组并求和result = word_one.reduceByKey(lambda a, b: a + b)# 5.打印结果print(result.collect())
7. PySpark:RDD对象数据计算(二)
7.1 RDD的filter方法:传入T泛型数据,返回bool,为false 的数据丢弃,为true的数据保留;(函数对RDD数据逐个处理,得到True的保留至返回值的RDD中)
- 功能:过滤想要的数据进行保留;
- filter算子作用:
- 接受一个处理函数,可用lambda快速编写;
- 函数对RDD数据逐个处理,得到True的保留至返回值的RDD中;
from pyspark import SparkConf, SparkContext
import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 2, 3, 4, 5])# 保留基数print(rdd.filter(lambda x: x % 2 == 1).collect())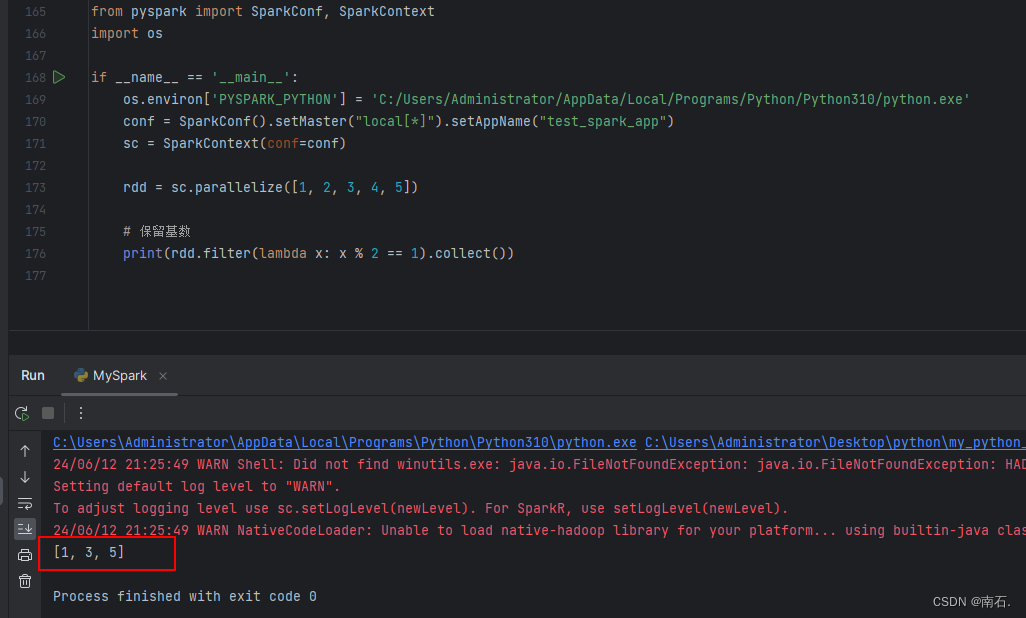
7.2 RDD的distinct方法:对RDD数据进行去重,返回新RDD;
from pyspark import SparkConf, SparkContext
import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)rdd = sc.parallelize([1, 1, 2, 3, 4, 5, 4, 5])# 对rdd对象进行去重print(rdd.distinct().collect())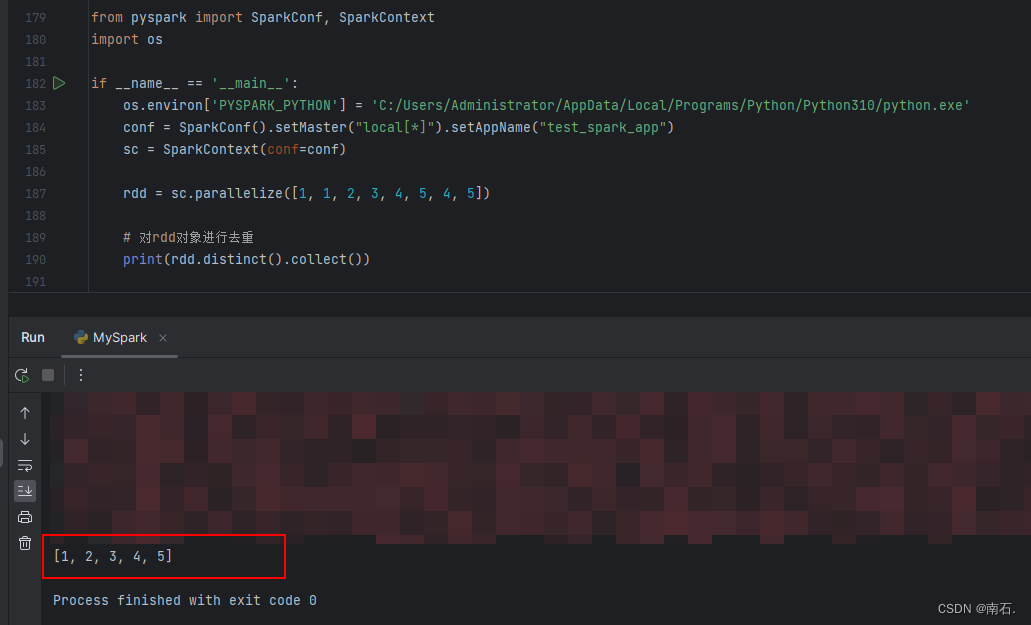
7.3 RDD的sortBy方法:对RDD的容器按照指定规则排序,返回新RDD;
func: (T) → U:告知按照rdd中的哪个数据进行排序,比如lambda x: x[1]表示按照rdd中的第二列元素进行排序;numPartitions:目前默认就为1;
结果:
按照元组tople中的第二位元素进行排序,按照降序;
lambda x: x[1]:计算规则,将所有容器的每一个元素按照函数规则处理,x是遍历的元组,x[1]是传入的元组的第二位元素,所以规则就是按照元组的第二位元素进行降序排序;
from pyspark import SparkConf, SparkContext
import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)rdd = sc.parallelize([("zhangSan", 99), ("lisi", 88), ("wangWu", 100)])# 对结果进行排序final_rdd = rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1)print(final_rdd.collect())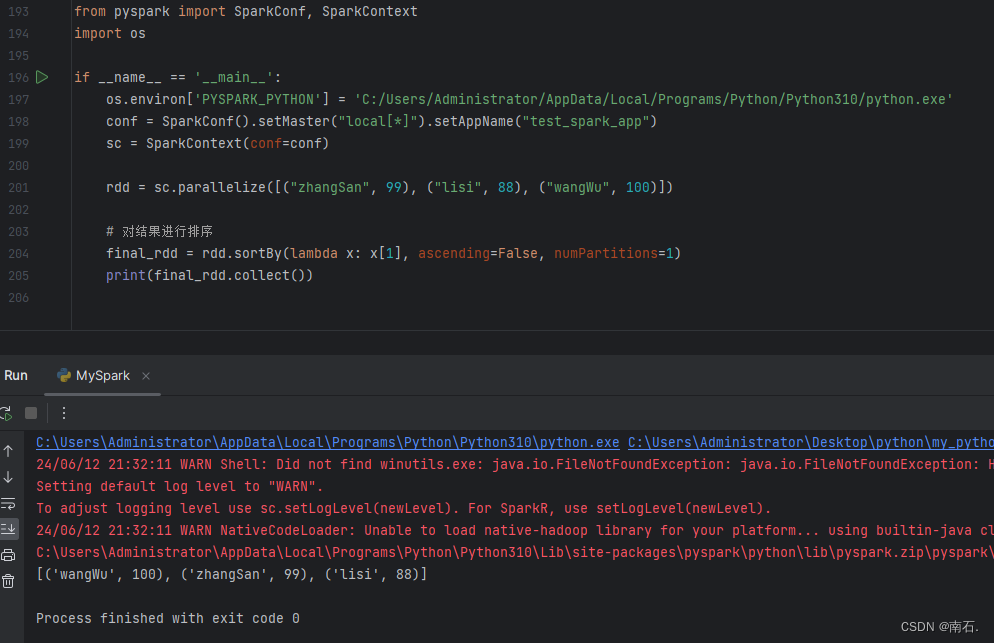
- sortBy算子小结:
- 接收一个处理函数,可用lambda快速编写;
- 函数表示用来决定排序的依据;
- 可以控制升序或降序;
- 全局排序需要设置分区数为1;
8. 数据计算案例(二):计算城市中的商品以及销售额
8.1 需求
-
需求一:各个城市销售额排名,从大到小;
先按行读取文件,并对json进行split分割,按照|符号,得到最终的字典,使用Spark.reduceByKey进行分组,分组时传递func计算函数,将所有分组后的城市销售额进行a+b的形式,聚合起来,最终得到结果,并按照降序的排序方式排序输出;
-
需求二:全部城市,有哪些商品类别在售卖;
文件读取后,将城市的categpry商品类别,distinct使用去重;
-
需求三:北京市有哪些商品类别在售卖;
将除了北京市的所有数据进行filter过滤,过滤后只留下category并进行去重得到结果;
8.2 文件数据

{"id":1,"timestamp":"2024-06-01T01:03.00Z","category":"电脑","areaName":"杭州","money":"3000"}|{"id":2,"timestamp":"2024-06-01T01:03.00Z","category":"电脑","areaName":"杭州","money":"3500"}
{"id":3,"timestamp":"2024-06-01T01:03.00Z","category":"食品","areaName":"杭州","money":"3000"}|{"id":4,"timestamp":"2024-06-01T01:03.00Z","category":"食品","areaName":"杭州","money":"3700"}
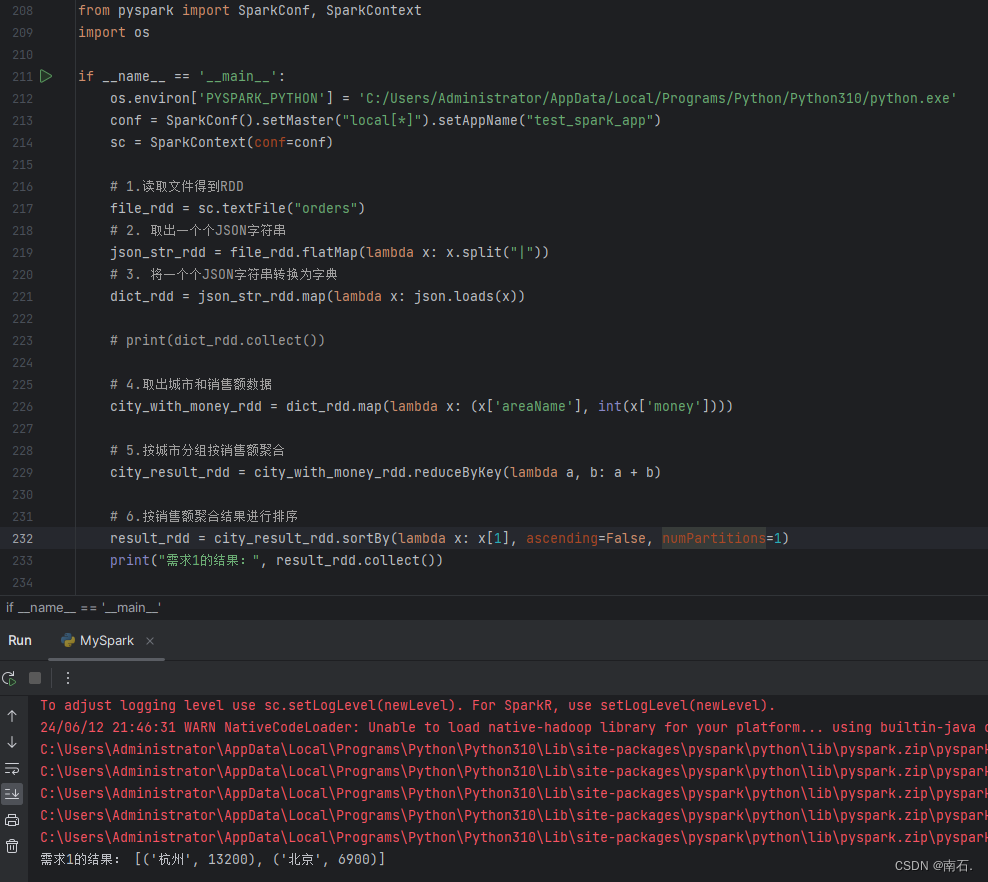
{"id":5,"timestamp":"2024-06-01T01:03.00Z","category":"服饰","areaName":"北京","money":"3000"}|{"id":6,"timestamp":"2024-06-01T01:03.00Z","category":"服饰","areaName":"北京","money":"3900"}8.3 需求一实现:处理结果自动返回的是一个二元元组;
from pyspark import SparkConf, SparkContext
import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)# 1.读取文件得到RDDfile_rdd = sc.textFile("orders")# 2. 取出一个个JSON字符串json_str_rdd = file_rdd.flatMap(lambda x: x.split("|"))# 3. 将一个个JSON字符串转换为字典dict_rdd = json_str_rdd.map(lambda x: json.loads(x))# print(dict_rdd.collect())# 4.取出城市和销售额数据city_with_money_rdd = dict_rdd.map(lambda x: (x['areaName'], int(x['money'])))# 5.按城市分组按销售额聚合city_result_rdd = city_with_money_rdd.reduceByKey(lambda a, b: a + b)# 6.按销售额聚合结果进行排序result_rdd = city_result_rdd.sortBy(lambda x: x[1], ascending=False, numPartitions=1)print("需求1的结果:", result_rdd.collect())前三步数据结果:
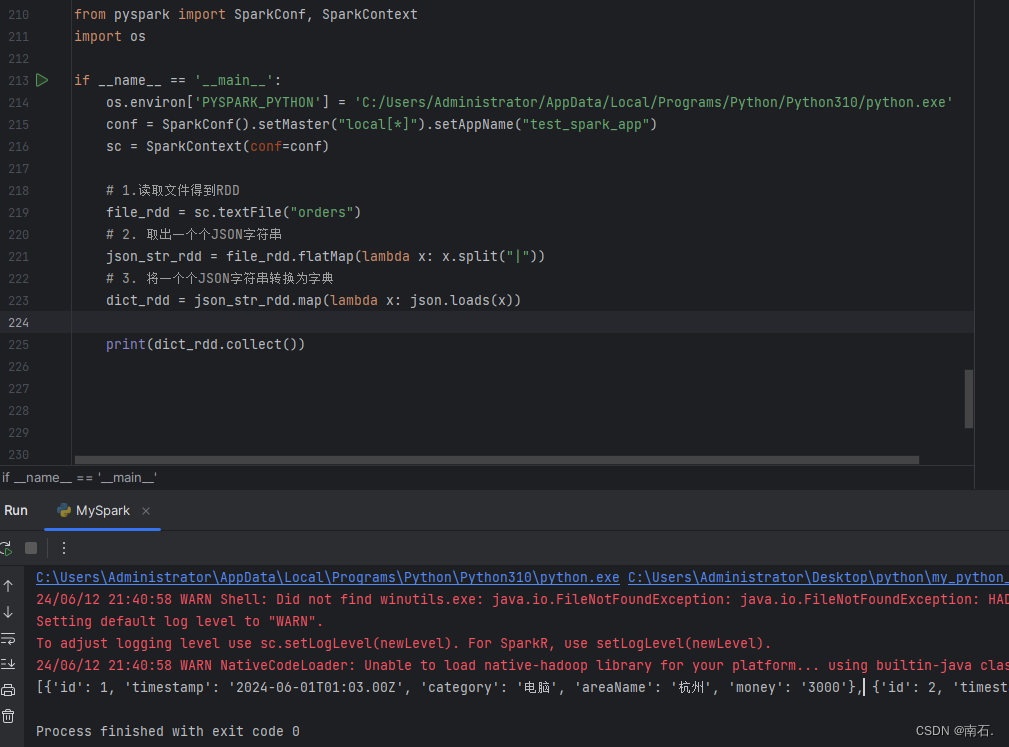
完整数据结果:
8.4 需求二实现:将字典中的数据处理,返回一个list;
from pyspark import SparkConf, SparkContext
import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)# 1.读取文件得到RDDfile_rdd = sc.textFile("orders")# 2. 取出一个个JSON字符串json_str_rdd = file_rdd.flatMap(lambda x: x.split("|"))# 3. 将一个个JSON字符串转换为字典dict_rdd = json_str_rdd.map(lambda x: json.loads(x))# 4.取出全部的商品类别category_rdd = dict_rdd.map(lambda x: x['category']).distinct()print("需求2的结果:", category_rdd.collect())
8.5 需求三实现:过滤除北京的数据,并只返回一个参数category,是list列表,并进行去重,去重后的结果进行collect输出;
from pyspark import SparkConf, SparkContext
import osif __name__ == '__main__':os.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")sc = SparkContext(conf=conf)# 1.读取文件得到RDDfile_rdd = sc.textFile("orders")# 2. 取出一个个JSON字符串json_str_rdd = file_rdd.flatMap(lambda x: x.split("|"))# 3. 将一个个JSON字符串转换为字典dict_rdd = json_str_rdd.map(lambda x: json.loads(x))# 4. 过滤北京的数据beijing_data_rdd = dict_rdd.filter(lambda x: x['areaName'] == '北京')# 5.取出全部商品类别result_rdd = beijing_data_rdd.map(lambda x: x['category']).distinct()print("需求3的结果:", result_rdd.collect())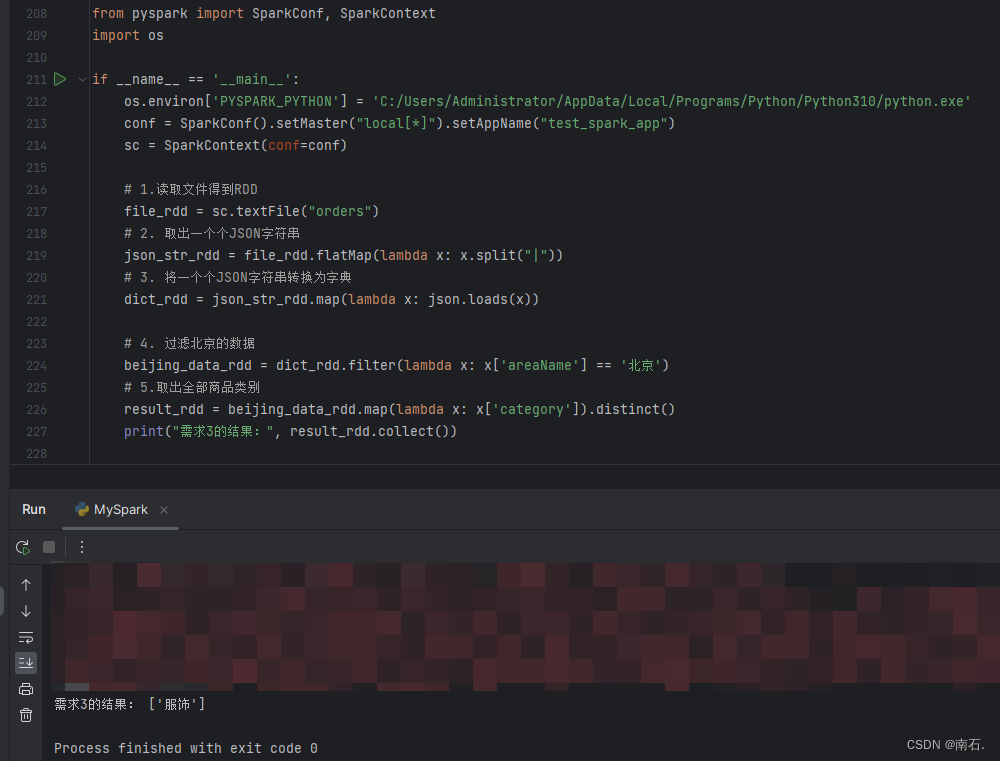
9. 将RDD的结果数据输出为Python对象的各类方法
- 数据输出:将RDD输出的值转成文件或Python对象;
- collect算子:将各个分区内的数据,统一收集到Driver中,形成一个list对象;
- reduce算子:对RDD数据集按照你传入的逻辑进行聚合;
- task算子:取出RDD的前N个元素,组合成list返回;
- count算子:计算RDD有多少条数据,返回值是一个数字;
from pyspark import SparkConf, SparkContext
import osos.environ['PYSPARK_PYTHON'] = 'C:/Users/Administrator/AppData/Local/Programs/Python/Python310/python.exe'
conf = SparkConf().setMaster("local[*]").setAppName("test_spark_app")
sc = SparkContext(conf=conf)if __name__ == '__main__':rdd = sc.parallelize([1, 2, 3, 4, 5])# collect算子,输出RDD为list对象rdd_list: list = rdd.collect()print("collect算子结果:", rdd_list)print("collect算子类型是:", type(rdd_list))# reduce算子,对RDD进行两两聚合num = rdd.reduce(lambda a, b: a + b)print("reduce算子结果:", num)# take算子,取出RDD前N个元素,组成list返回take_list = rdd.take(3)print("take算子结果:", take_list)# count,统计rdd内有多少条数据,返回值为数字num_count = rdd.count()print("count算子结果:", num_count)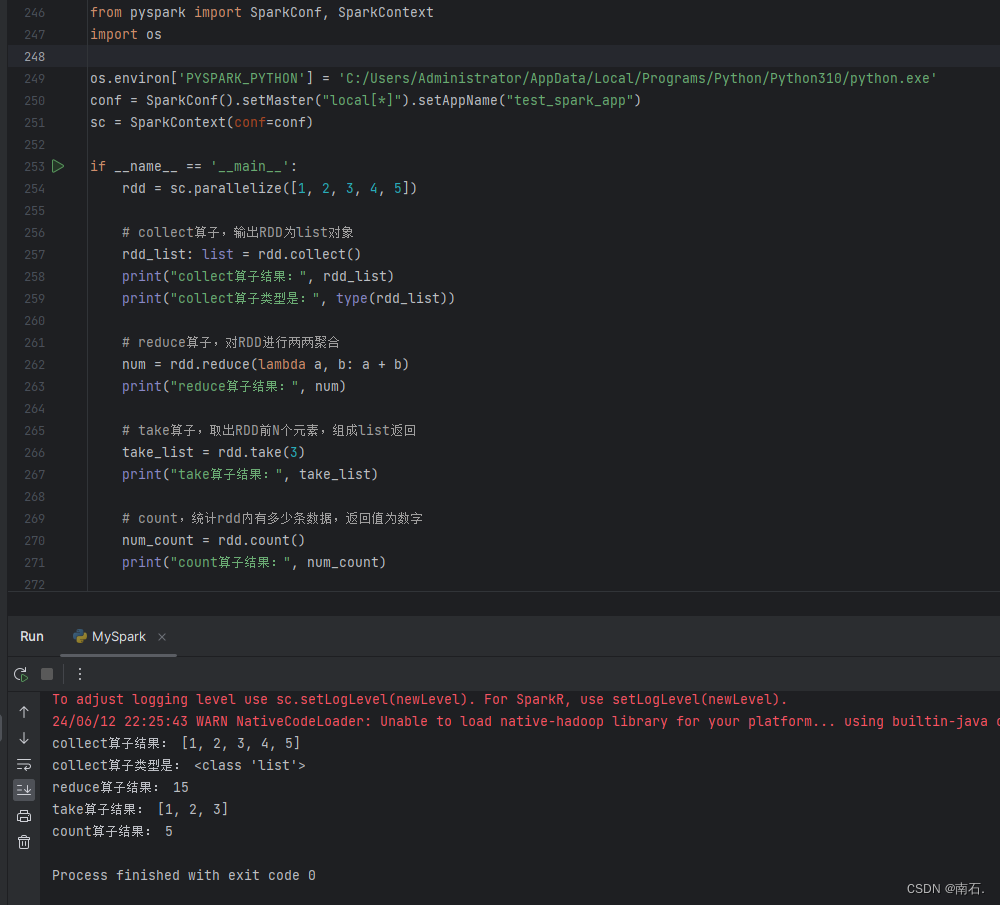
相关文章:
Python第二语言(十三、PySpark实战)
目录 1.开篇 2. PySpark介绍 3. PySpark基础准备 3.1 PySpark安装 3.2 掌握PySpark执行环境入口对象的构建 3.3 理解PySpark的编程模型 4. PySpark:RDD对象数据输入 4.1 RDD对象概念:PySpark支持多种数据的输入,完成后会返回RDD类的对…...

《阅读的方法》读后感——超越期待的收获
当我翻开这本书的扉页时,未曾料到它会给我带来如此深远的启示和收获。依照推荐序言中的指引,我随意翻阅、精心选读,每一次都如同打开一扇新的窗户,让我窥见不同领域的智慧和美好。 等地铁时、临睡前随便读点什么,有什么…...
)
算法训练营第五十八天 | LeetCode 392 判断子序列、卡码网模拟美团笔试第一、二、三题(300/500有待提高)
卡码网图论更新了可以去看看,模拟笔试第四题就是深搜/广搜还不太会 LeetCode 392 判断子序列 其实就是最长公共子序列翻版 代码如下: class Solution {public boolean isSubsequence(String s, String t) {int[][] dp new int[s.length() 1][t.lengt…...
Sa-Token鉴权与网关服务实现
纠错: 在上一部分里我完成了微服务框架的初步实现,但是先说一下之前有一个错误,就是依赖部分 上次的学习中我在总的父模块下引入了spring-boot-dependencies(版本控制)我以为在子模块下就不需要再引用了,…...

企事业单位安全生产月活动怎样向媒体投稿?
作为一名单位的信息宣传员,我肩负着将每一次重要活动的精彩瞬间转化为文字,向外界传递我们单位声音的重任。初入此行时,我满怀热情,坚信通过传统的方式——电子邮件投稿,能够有效地将我们的故事传播出去。然而,现实却给我上了生动的一课。 记得在筹备“安全生产月”活动的宣传时…...

MySQL8.0默认TCP端口介绍
1、本文内容 选择题TCP/IPMySQL 8.0 的默认TCP端口show variables查看总结 2、选择题 A、3306 B、33060 C、33062 D、33063 3、TCP/IP TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/网际协议)是指能够在多个不同…...
Javaweb避坑指北(持续更新)
内容较多可按CtrlF搜索 0.目录 1.获取插入数据后自增长主键的值 2.Controller中返回给ajax请求字符串/json会跳转到xxx.jsp 3.ajax请求获得的json无法解析 4.在Controller中使用ServletFileUpload获取的上传文件为null 5.莫名其妙报service和dao里方法的错误 6.ajax请求拿…...

Web前端知道:深入探索与无尽挑战
Web前端知道:深入探索与无尽挑战 Web前端,这个看似简单却实则深不可测的领域,一直以来都吸引着无数开发者投入其中。在这个充满未知与可能的世界里,我们既是探索者,也是挑战者。本文将从四个方面、五个方面、六个方面…...
QT调用vs2019生成的c++动态库
QT调用vs2019生成的c动态库 dll库的创建方法: VS2019创建c动态链接库dll与调用方法-CSDN博客 加减法示范: 头文件 // 下列 ifdef 块是创建使从 DLL 导出更简单的 // 宏的标准方法。此 DLL 中的所有文件都是用命令行上定义的 DLL3_EXPORTS // 符号编…...

C语言TC中有⼏个画线函数?怎么使⽤?
一、问题 C语⾔中画线的函数好像不⽌ line( )⼀个,那么除了 line( ) ,还有哪些画线函数?怎么使⽤? 二、解答 TC中有3种画线的函数,共语法格式如下。 void far line(int x0, int y0, int xl, int y1); void far linet…...

掌握WhoisAPI,提升域名管理的效率
在互联网时代,域名管理是网站运营中非常重要的一环。通过域名,我们能够轻松访问和识别不同的网站。然而,域名的注册和管理也是一项复杂的任务,特别是对于大规模拥有许多域名的企业来说。为了提升域名管理的效率,我们可…...

Docker与Docker-Compose详解
1、Docker是什么? 在计算机中,虚拟化(英语: Virtualization) 是一种资源管理技术,是将计算机的各种实体资源,如服务器、网络、内存及存储等,予以抽象、转换后呈现出来,打破实体结构间的不可切割的障碍&…...
微服务之熔断器
1、高并发带来的问题 在微服务架构中,我们将业务拆分成一个个的服务,服务与服务之间可以相互调用,但是由于网络原因 或者自身的原因,服务并不能保证服务的100%可用,如果单个服务出现问题,调用这个服务就会…...
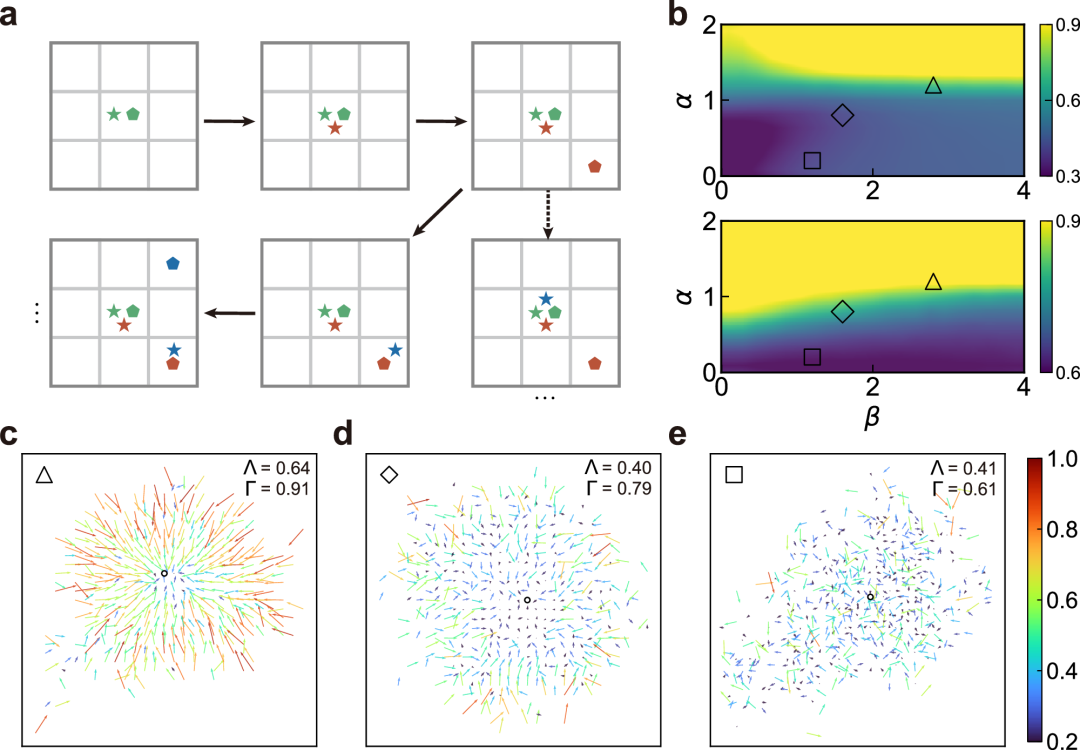
【高校科研前沿】北京大学赵鹏军教授团队在Nature Communications发文:揭示城市人群移动的空间方向性
文章简介 论文名称:Unravelling the spatial directionality of urban mobility 第一作者及单位:赵鹏军(教授|第一作者|北京大学)&王浩(博士生|共同一作|北京大学); 通讯作者及单位:赵鹏军…...

徐州存储服务器会应用在哪些场景?
企业的业务随着不断的发展,数据信息与重要文件也在不断激增,存储服务器也受到了各个领域的广泛运用,那徐州存储服务器会应用在哪些场景当中呢? 存储服务器能够存储大量的数据信息、图片和视频等内容,是专门为数据存储设…...

个人博客搭建
liupengs blogs 环境搭建 版本环境:hexo3.8.0 node12.17.0 https://www.cnblogs.com/fengxiongZz/p/7707219.html 搭建 https://www.cnblogs.com/fengxiongZz/p/7707568.html 进阶 https://www.cnblogs.com/chengxs/p/7496265.html https://www.cnbl…...

服务器数据库三级等保的一些修改步骤
服务器整改项: 1.服务器需要设置强制密码复杂度,要求密码包含3种以上字符,最低8位 [root@localhost ~]# vi /etc/pam.d/system-auth password requisite pam_pwquality.so try_first_pass local_users_only retry=5 minlen=9 lcredit=-1 dcredit=-1 ocrredit=-1 enforrce_fo…...
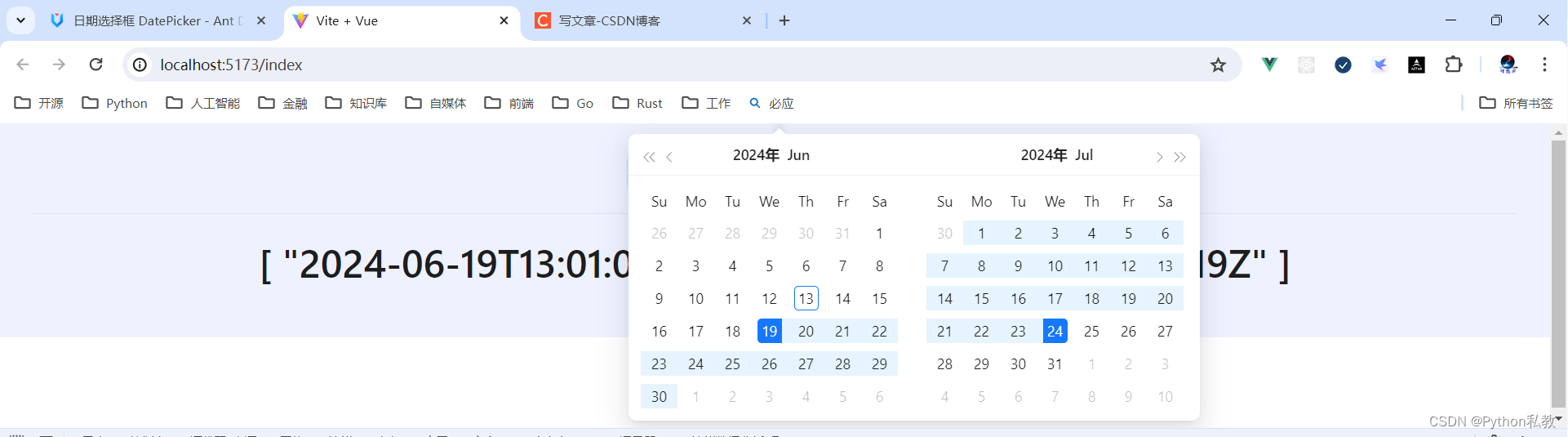
Python私教张大鹏 Vue3整合AntDesignVue之DatePicker 日期选择框
案例:选择日期 <script setup> import {ref} from "vue";const date ref(null) </script> <template><div class"p-8 bg-indigo-50 text-center"><a-date-picker v-model:value"date"/><a-divide…...
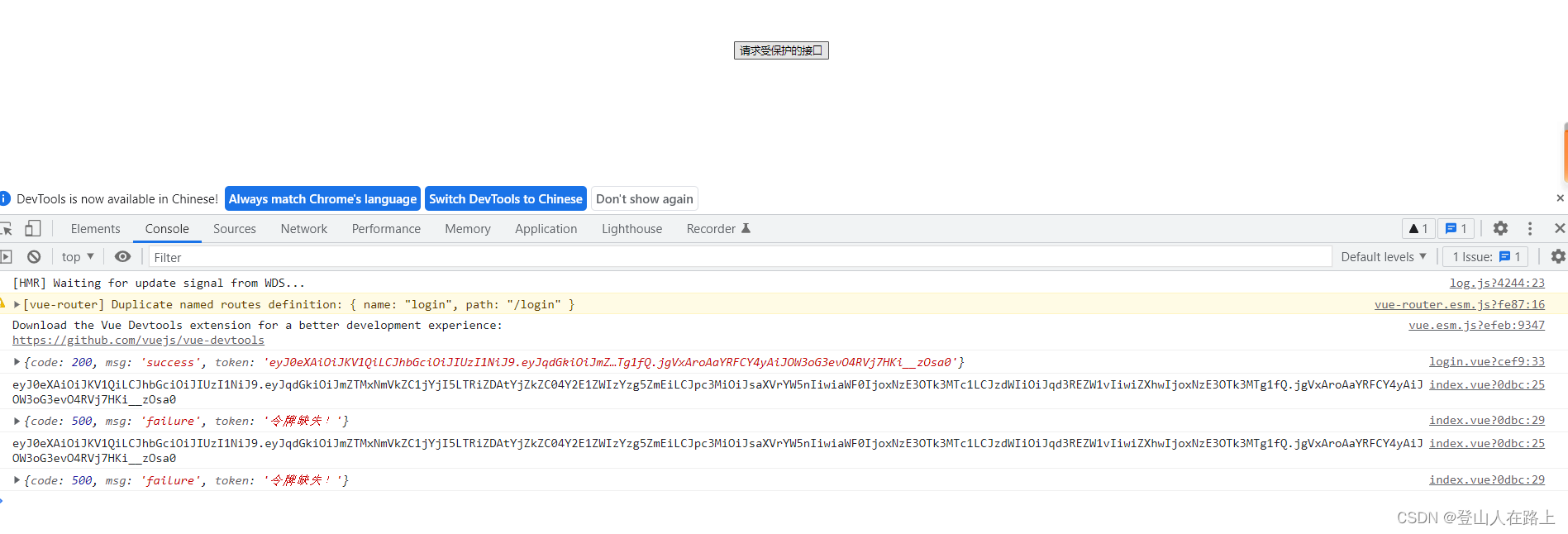
springboot+vue前后端分离项目中使用jwt实现登录认证
文章目录 一、后端代码1.响应工具类2.jwt工具类3.登录用户实体类4.登录接口5.测试接口6.过滤器7.启动类 二、前端代码1.登录页index 页面 三、效果展示 一、后端代码 1.响应工具类 package com.etime.util;import com.etime.vo.ResponseModel; import com.fasterxml.jackson.…...

leetcode hot100 之 编辑距离
给你两个单词 word1 和 word2, 请返回将 word1 转换成 word2 所使用的最少操作数 。 你可以对一个单词进行如下三种操作: 插入一个字符删除一个字符替换一个字符 输入:word1 “horse”, word2 “ros” 输出:3 解释:…...

TAICHI-flet终极排障指南:从新手到高手的完整解决方案
TAICHI-flet终极排障指南:从新手到高手的完整解决方案 【免费下载链接】TAICHI-flet 基于flet的一款windows桌面应用,实现了浏览图片、音乐、小说、漫画、各种资源的功能。 项目地址: https://gitcode.com/GitHub_Trending/ta/TAICHI-flet TAICHI…...

SDMatte多平台适配实践:Chrome/Firefox/Safari在Web抠图交互中的兼容性与性能表现
SDMatte多平台适配实践:Chrome/Firefox/Safari在Web抠图交互中的兼容性与性能表现 1. 引言 SDMatte是一款面向高质量图像抠图场景的AI模型,特别擅长处理主体分离、透明物体提取、边缘精修等任务。对于玻璃、薄纱、羽毛、叶片等边缘细节复杂或半透明目标…...

【Mojo跨语言互操作权威配置白皮书】:实测TensorFlow/NumPy/Pandas三方库零报错接入方案
第一章:Mojo跨语言互操作的核心原理与架构定位Mojo并非传统意义上的独立运行时语言,而是以“Python超集”为设计原点、深度嵌入LLVM生态的系统级编程语言。其跨语言互操作能力不依赖FFI桥接层或胶水代码,而是通过统一的中间表示(M…...

质子交换膜燃料电池Comsol完整版仿真模型:涵盖两相流非等温雾状流道、液态水相变及扩散项,考...
质子交换膜燃料电池仿真Comsol完整版 虽然氢电发文量多了,但是氢电模型复杂程度和别的领域没法比,两相流非等温的氢燃料电池,跑通的都得好几千的,这个模型的流道和内侧都是多相流,这个里面是雾状流的流道,目…...

从零到一实战:基于快马平台快速开发企业级jiyutrainer在线评测系统
今天想和大家分享一个很实用的开发经验——如何快速搭建一个企业级的在线编程评测系统。最近正好有个朋友想做一个类似jiyutrainer的编程练习平台,我就用InsCode(快马)平台试了试,效果出乎意料的好。 项目需求分析 首先明确我们需要实现的核心功能&#…...

Python将Parquet文件转换为JSONL格式文件
prompt:如何使用 Python 将 Parquet 文件转换为 JSONL 格式文件? 请提供完整的代码示例,包括使用 pandas 或 pyarrow 读取 Parquet 文件, 并将每行数据以 JSON 格式逐行写入 JSONL 文件的实现方式。 假设 Parquet 文件包含结构化数据…...

旧Mac重生指南:用OpenCore Legacy Patcher解锁macOS新版本
旧Mac重生指南:用OpenCore Legacy Patcher解锁macOS新版本 【免费下载链接】OpenCore-Legacy-Patcher 体验与之前一样的macOS 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台性能依然强劲却被苹果官方抛弃的旧Mac&…...

Qwen2.5-7B-Instruct效果展示:农业病虫害图像描述→防治方案生成
Qwen2.5-7B-Instruct效果展示:农业病虫害图像描述→防治方案生成 想象一下,一位农民在田间地头,用手机拍下一片叶子上的异常斑点。几分钟后,他不仅得到了这是什么病害的准确诊断,还收到了一份详细的、可操作的防治方案…...

节能模式:OpenClaw+nanobot的间歇性任务调度技巧
节能模式:OpenClawnanobot的间歇性任务调度技巧 1. 为什么需要节能模式 去年夏天,我的电费账单突然飙升。排查后发现,那台24小时运行OpenClaw的工作站竟然是耗电大户——它持续调用着本地部署的Qwen大模型,GPU风扇昼夜不停地呼啸…...
)
从4G到RedCap:手把手教你升级老旧工业设备的无线通信模块(附功耗测试数据)
从4G到RedCap:工业设备无线通信模块升级实战指南 在工业物联网快速发展的今天,老旧设备的通信模块升级成为许多工厂面临的现实挑战。传统4G模块虽然稳定可靠,但面对5G时代RedCap技术带来的低功耗、低成本优势,升级改造已成为提升设…...