kafka 快速上手
下载 Apache Kafka
演示window 安装
编写启动脚本,脚本的路径根据自己实际的来

启动说明
先启动zookeeper后启动kafka,关闭是先关kafka,然后关闭zookeeper
巧记: 铲屎官(zookeeper)总是第一个到,最后一个走
启动zookeeper
call bin/windows/zookeeper-server-start.bat config/zookeeper.properties
启动kafka
call bin/windows/kafka-server-start.bat config/server.properties
测试脚本,主要用于创建主题 ‘test-topic’
# 创建主题(窗口1)
bin/window> kafka-topics.bat --bootstrap-server localhost:9092 --topic test-topic --create# 查看主题
bin/window> kafka-topics.bat --bootstrap-server localhost:9092 --list
bin/window> kafka-topics.bat --bootstrap-server localhost:9092 --topic test-topic --describe# 修改某主题的分区
bin/window> kafka-topics.bat --bootstrap-server localhost:9092 --topic test-topic --alter --partitions 2# 生产消息(窗口2)向test-topic主题发送消息
bin/window> kafka-console-producer.bat --bootstrap-server localhost:9092 --topic test-topic
>hello kafka# 消费消息(窗口3)消费test-topic主题的消息
bin/window> kafka-console-consumer.bat --bootstrap-server localhost:9092 --topic test-topicpackage com.ldj.kafka.admin;import org.apache.kafka.clients.admin.AdminClient;
import org.apache.kafka.clients.admin.AdminClientConfig;
import org.apache.kafka.clients.admin.CreateTopicsResult;
import org.apache.kafka.clients.admin.NewTopic;import java.util.*;/*** User: ldj* Date: 2024/6/13* Time: 0:00* Description: 创建主题*/
public class AdminTopic {public static void main(String[] args) {Map<String, Object> adminConfigMap = new HashMap<>();adminConfigMap.put(AdminClientConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");AdminClient adminClient = AdminClient.create(adminConfigMap);/*** 使用kafka默认的分区算法创建分区*/NewTopic topic1 = new NewTopic("topic-01", 1, (short) 1);NewTopic topic2 = new NewTopic("topic-02", 2, (short) 2);CreateTopicsResult addResult1 = adminClient.createTopics(Arrays.asList(topic1, topic2));/*** 手动为主题(topic-03)分配分区* topic-03主题下的0号分区有2个副本,它们中的一个在节点id=1中,一个在节点id=2中;* list里第一个副本就是leader(主写),后面都是follower(主备份)* 例如:0分区,nodeId=1的节点里的副本是主写、2分区,nodeId=3的节点里的副本是主写*/Map<Integer, List<Integer>> partition = new HashMap<>();partition.put(0, Arrays.asList(1, 2));partition.put(1, Arrays.asList(2, 3));partition.put(2, Arrays.asList(3, 1));NewTopic topic3 = new NewTopic("topic-03", partition);CreateTopicsResult addResult2 = adminClient.createTopics(Collections.singletonList(topic3));//DeleteTopicsResult delResult = adminClient.deleteTopics(Arrays.asList("topic-02"));adminClient.close();}}
package com.ldj.kafka.producer;import com.alibaba.fastjson.JSON;
import com.ldj.kafka.model.UserEntity;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import org.apache.kafka.common.serialization.StringSerializer;import java.util.HashMap;
import java.util.Map;
import java.util.Objects;
import java.util.concurrent.Future;/*** User: ldj* Date: 2024/6/12* Time: 21:08* Description: 生产者*/
public class KfkProducer {public static void main(String[] args) throws Exception {//生产者配置Map<String, Object> producerConfigMap = new HashMap<>();producerConfigMap.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");producerConfigMap.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);producerConfigMap.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);//批量发送producerConfigMap.put(ProducerConfig.BATCH_SIZE_CONFIG, 2);//消息传输应答安全级别 0-消息到达broker(效率高,但不安全) 1-消息在leader副本持久化(折中方案) -1/all -消息在leader和flower副本都持久化(安全,但效率低)producerConfigMap.put(ProducerConfig.ACKS_CONFIG, "all");//ProducerState 缓存5条数据,重试数据会与5条数据做比较,结论只能保证一个分区的数据幂等性,跨会话幂等性需要通过事务操作解决(重启后全局消息id的随机id会发生改变)//消息发送失败重试次数,重试会导致消息重复!!(考虑幂等性),消息乱序(判断偏移量是否连续,错乱消息回到在缓冲区重新排序)!!producerConfigMap.put(ProducerConfig.RETRIES_CONFIG, 3);//kafka有消息幂等性处理(全局唯一消息id/随机id-分区-偏移量),默认false-不开启producerConfigMap.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true);//解决跨会话幂等性,还需结合事务操作,忽略//producerConfigMap.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, "tx_id");//创建生产者KafkaProducer<String, String> producer = new KafkaProducer<>(producerConfigMap);//TODO 事务初始化方法//producer.initTransactions();//构建消息 ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers)try {//TODO 开启事务//producer.beginTransaction();for (int i = 0; i < 10; i++) {UserEntity userEntity = new UserEntity().setUserId(2436687942335620L + i).setUsername("lisi").setGender(1).setAge(18);ProducerRecord<String, String> record = new ProducerRecord<>("test-topic",userEntity.getUserId().toString(),JSON.toJSONString(userEntity));//发送数据到BrokerFuture<RecordMetadata> future = producer.send(record, (RecordMetadata var1, Exception var2) -> {if (Objects.isNull(var2)) {System.out.printf("[%s]消息发送成功!", userEntity.getUserId());} else {System.out.printf("[%s]消息发送失败!err:%s", userEntity.getUserId(), var2.getCause());}});//TODO 提交事务//producer.commitTransaction();//注意没有下面这行代码,是异步线程从缓冲区读取数据异步发送消息,反之是同步发送,必须等待回调消息返回才会往下执行System.out.printf("发送消息[%s]----", userEntity.getUserId());RecordMetadata recordMetadata = future.get();System.out.println(recordMetadata.offset());}} finally {//TODO 终止事务//producer.abortTransaction();//关闭通道producer.close();}}}
package com.ldj.kafka.consumer;import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import org.apache.kafka.common.serialization.StringDeserializer;import java.time.Duration;
import java.util.Collections;
import java.util.HashMap;
import java.util.Map;/*** User: ldj* Date: 2024/6/12* Time: 21:10* Description: 消费者*/
public class KfkConsumer {public static void main(String[] args) {//消费者配置Map<String, Object> consumerConfigMap = new HashMap<>();consumerConfigMap.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");consumerConfigMap.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);consumerConfigMap.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);//所属消费组consumerConfigMap.put(ConsumerConfig.GROUP_ID_CONFIG, "test123456");//创建消费者KafkaConsumer<String, String> consumer = new KafkaConsumer<>(consumerConfigMap);//消费主题的消息 ConsumerRebalanceListenerconsumer.subscribe(Collections.singletonList("test-topic"));try {while (true) {ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(5));//数据存储结构:Map<TopicPartition, List<ConsumerRecord<K, V>>> records;for (ConsumerRecord<String, String> record : records) {System.out.println(record.value());}}} finally {//关闭消费者consumer.close();}}}
相关文章:
kafka 快速上手
下载 Apache Kafka 演示window 安装 编写启动脚本,脚本的路径根据自己实际的来 启动说明 先启动zookeeper后启动kafka,关闭是先关kafka,然后关闭zookeeper 巧记: 铲屎官(zookeeper)总是第一个到,最后一个走 启动zookeeper call bi…...

Python记忆组合透明度语言模型
🎯要点 🎯浏览器语言推理识别神经网络 | 🎯不同语言秽语训练识别数据集 | 🎯交互式语言处理解释 Transformer 语言模型 | 🎯可视化Transformer 语言模型 | 🎯语言模型生成优质歌词 | 🎯模型不确…...
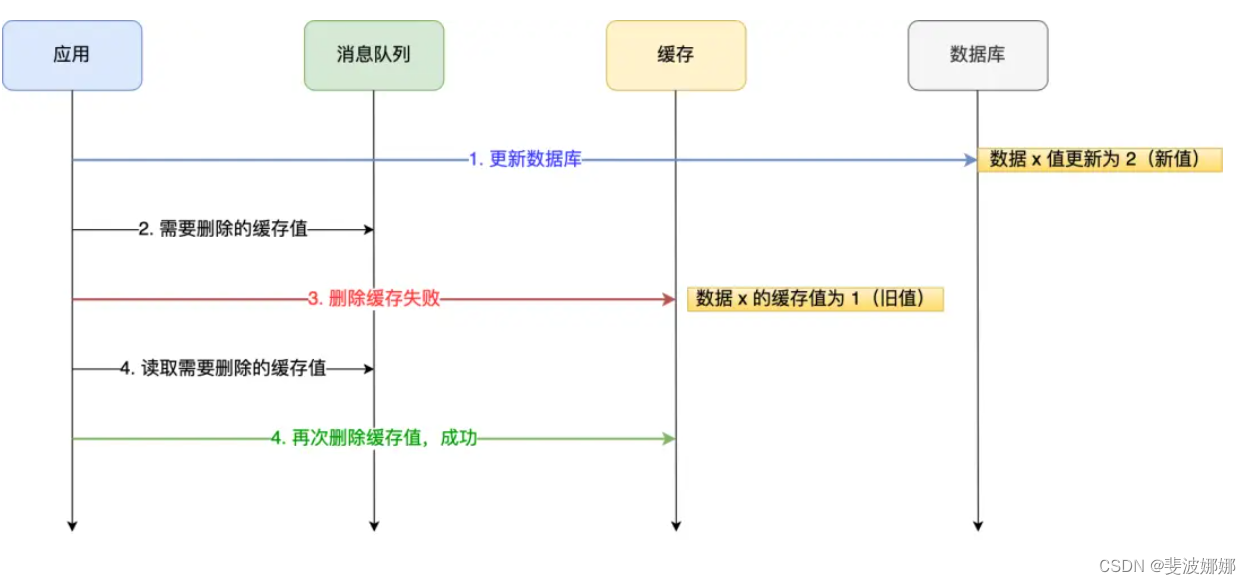
如何保证数据库和缓存的一致性
背景:为了提高查询效率,一般会用redis作为缓存。客户端查询数据时,如果能直接命中缓存,就不用再去查数据库,从而减轻数据库的压力,而且redis是基于内存的数据库,读取速度比数据库要快很多。 更新…...

Java基础 - 多线程
多线程 创建新线程 实例化一个Thread实例,然后调用它的start()方法 Thread t new Thread(); t.start(); // 启动新线程从Thread派生一个自定义类,然后覆写run()方法: public class Main {public static void main(String[] args) {Threa…...

云顶之弈-测试报告
一. 项目背景 个人博客系统采用前后端分离的方法来实现,同时使用了数据库来存储相关的数据,同时将其部署到云服务器上。前端主要有四个页面构成:登录页、列表页、详情页以及编辑页,以上模拟实现了最简单的个人博客系统。其结合后…...
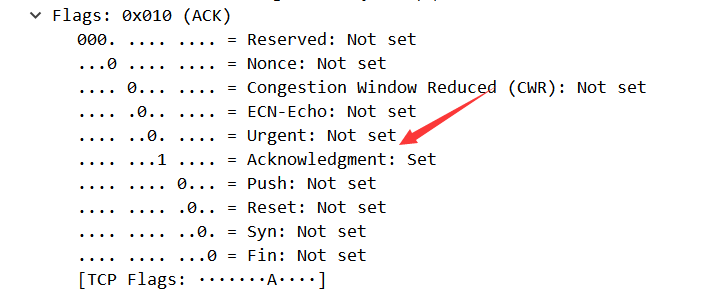
TCP/IP协议分析实验:通过一次下载任务抓包分析
TCP/IP协议分析 一、实验简介 本实验主要讲解TCP/IP协议的应用,通过一次下载任务,抓取TCP/IP数据报文,对TCP连接和断开的过程进行分析,查看TCP“三次握手”和“四次挥手”的数据报文,并对其进行简单的分析。 二、实…...
)
Python项目开发实战:企业QQ小程序(案例教程)
一、引言 在当今数字化快速发展的时代,企业对于线上服务的需求日益增长。企业QQ小程序作为一种轻量级的应用形态,因其无需下载安装、即开即用、占用内存少等优势,受到了越来越多企业的青睐。本文将以Python语言为基础,探讨如何开发一款企业QQ小程序,以满足企业的实际需求。…...

list模拟与实现(附源码)
文章目录 声明list的简单介绍list的简单使用list中sort效率测试list的简单模拟封装迭代器insert模拟erase模拟头插、尾插、头删、尾删模拟自定义类型迭代器遍历const迭代器clear和析构函数拷贝构造(传统写法)拷贝构造(现代写法) 源…...

Java应用中文件上传安全性分析与安全实践
✨✨谢谢大家捧场,祝屏幕前的小伙伴们每天都有好运相伴左右,一定要天天开心哦!✨✨ 🎈🎈作者主页: 喔的嘛呀🎈🎈 目录 引言 一. 文件上传的风险 二. 使用合适的框架和库 1. Spr…...
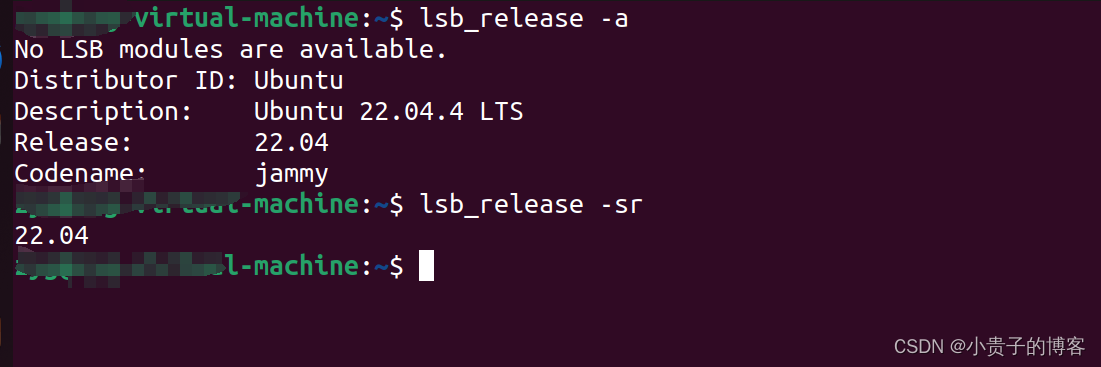
noVNC 小记
1. 怎么查看Ubuntu版本...
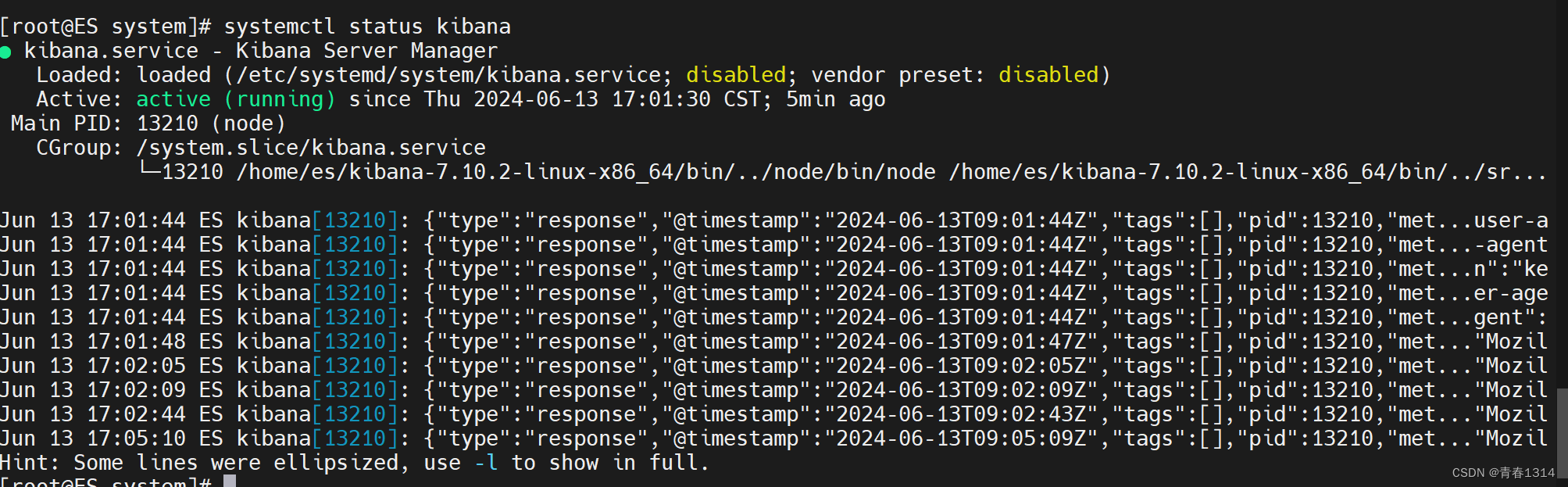
设置systemctl start kibana启动kibana
1、编辑kibana.service vi /etc/systemd/system/kibana.service [Unit] DescriptionKibana Server Manager [Service] Typesimple Useres ExecStart/home/es/kibana-7.10.2-linux-x86_64/bin/kibana PrivateTmptrue [Install] WantedBymulti-user.target 2、启动kibana # 刷…...

PostgreSQL:在CASE WHEN语句中使用SELECT语句
CASE WHEN语句是一种条件语句,用于多条件查询,相当于java的if/else。它允许我们根据不同的条件执行不同的操作。你甚至能在条件里面写子查询。而在一些情况下,我们可能需要在CASE WHEN语句中使用SELECT语句来检索数据或计算结果。下面是一些示…...

游戏心理学Day13
游戏成瘾 成瘾的概念来自于药物依赖,表现为为了感受药物带来的精神效应,或是为了避免由于断药所引起的不适和强迫性,连续定期使用该药的 行为现在成瘾除了药物成瘾外,还包括行为成瘾。成瘾的核心特征是不知道成瘾的概念来自于药…...

GitLab中用户权限
0 Preface/Foreword 1 权限介绍 包含5种权限: Guest(访客):可以创建issue、发表comment,不能读写版本库Reporter(报告者):可以克隆代码,不能提交。适合QA/PMDeveloper&…...

RunMe_About PreparationForDellBiosWUTTest
:: ***************************************************************************************************************************************************************** :: 20240613 :: 该脚本可以用作BIOS WU测试前的准备工作,包括:自动检测"C:\DellB…...

C++中变量的使用细节和命名方案
C中变量的使用细节和命名方案 C提倡使用有一定含义的变量名。如果变量表示差旅费,应将其命名为cost_of_trip或 costOfTrip,而不要将其命名为x或cot。必须遵循几种简单的 C命名规则。 在名称中只能使用字母字符、数字和下划线()。 名称的第一个字符不能是数字。 区分…...

[ACTF新生赛2020]SoulLike
两个文件 ubuntu运行 IDA打开 清晰的逻辑 很明显,我们要sub83a 返回ture 这里第一个知识点来了 你点开汇编会发现 这里一堆xor巨多 然后IDA初始化设置的函数,根本不能分析这么多 我们要去改IDA的设置 cfg 里面的 hexrays文件 在max_funsize这 修改为1024,默认是64 等待一…...

C#——析构函数详情
析构函数 C# 中的析构函数(也被称作“终结器”)同样是类中的一个特殊成员函数,主要用于在垃圾回收器回收类实例时执行一些必要的清理操作。 析构函数: 当一个对象被释放的时候执行 C# 中的析构函数具有以下特点: * 析构函数只…...

探索重要的无监督学习方法:K-means 聚类模型
在数据科学和机器学习领域,聚类分析是一种重要的无监督学习方法,用于将数据集中的对象分成多个组(簇),使得同一簇中的对象相似度较高,而不同簇中的对象相似度较低。K-means 聚类是最广泛使用的聚类算法之一,它以其简单、快速和易于理解的特点受到了广泛关注。本文将深入…...

将web项目打包成electron桌面端教程(二)vue3+vite+ts
说明:我用的demo项目是vue3vitets,如果是vue2/cli就不用往下看啦,建议找找其他教程哦~下依赖npm下载不下来的,基本换成cnpm/pnpm/yarn就可以了 一、项目准备 1、自己新创建一个,这里就不过多赘述了 2、将需要打包成…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

Android Wi-Fi 连接失败日志分析
1. Android wifi 关键日志总结 (1) Wi-Fi 断开 (CTRL-EVENT-DISCONNECTED reason3) 日志相关部分: 06-05 10:48:40.987 943 943 I wpa_supplicant: wlan0: CTRL-EVENT-DISCONNECTED bssid44:9b:c1:57:a8:90 reason3 locally_generated1解析: CTR…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

Day131 | 灵神 | 回溯算法 | 子集型 子集
Day131 | 灵神 | 回溯算法 | 子集型 子集 78.子集 78. 子集 - 力扣(LeetCode) 思路: 笔者写过很多次这道题了,不想写题解了,大家看灵神讲解吧 回溯算法套路①子集型回溯【基础算法精讲 14】_哔哩哔哩_bilibili 完…...

【快手拥抱开源】通过快手团队开源的 KwaiCoder-AutoThink-preview 解锁大语言模型的潜力
引言: 在人工智能快速发展的浪潮中,快手Kwaipilot团队推出的 KwaiCoder-AutoThink-preview 具有里程碑意义——这是首个公开的AutoThink大语言模型(LLM)。该模型代表着该领域的重大突破,通过独特方式融合思考与非思考…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...