【C++】通过stack、queue、deque理解适配器模式
破镜不能重圆,枯木可以逢春。

文章目录
- 一、stack
- 1.stack的介绍
- 2.stack相关OJ题(巧妙利用stack数据结构的特征)
- 3.stack的模拟实现
- 二、queue
- 1.queue的介绍
- 2.queue的相关OJ题(巧妙利用queue数据结构的特征)
- 3.queue的模拟实现
- 三、deque(双端队列容器,叫队列,但和队列没关系)
- 1.vector和list的优缺点→stack和queue的适配容器
- 2.deque的底层结构
- 3.deque的优缺点
- 4.为什么选择deque作为stack和queue的适配容器?(vector排序快,list中间插入删除牛,deque吸取两个容器的部分优点)
一、stack
1.stack的介绍

1.
stack和queue的设计实际是一种模式,这种模式叫做适配器模式,设计理念就是用已有的东西封装转换出你想要的东西。我们前面还学习过的一种模式叫做迭代器模式,这种模式的设计理念就是封装底层实现的细节,对所有底层数据结构不同的容器,都能提供统一的访问方式。
2.
stack的实现就是一种适配器的设计理念,适配器也可以叫做配接器,stack是一种只允许在某一端进行数据的插入和删除元素的容器,其他位置均不可以直接访问,所以对于stack来说不需要实现迭代器。
3.
在利用某种容器实现stack时,容器应该支持back()取到容器尾部元素,push_back()尾插,pop_back()尾删,empty()判空等操作,分别对应stack的top(),push(),pop(),empty()等操作。
对于stack来说,底层的适配容器为deque,但从其接口来看,stack实际就是一种特殊的vector,所以在模拟实现时,我们倾向于用vector来作stack的适配容器。
2.stack相关OJ题(巧妙利用stack数据结构的特征)
最小栈
1.
最小栈的解决思路就是利用两个栈,普通栈用来一直入栈所有的数据,minstack负责只入栈比上一次入栈元素小于或等于的元素,在出栈时,普通栈元素一定出栈,但minstack只有在普通栈的top元素和自身栈的top元素相等的时候才会去出栈,minstack的top元素就是当前普通栈的所有元素中最小的元素。
2.
解释一下为什么只有在普通栈top元素和minstack的top元素相等的时候,minstack才会出栈。
因为有可能在某一次入栈的元素是最小元素之后,入栈的剩余元素都是大于这个最小元素的,那么在pop的时候,你的minstack不能pop,因为minstack的top元素是现在栈所有元素最小的元素,只有说普通栈的top元素达到和minstack的top元素一样时,也就是现在pop的元素是栈中所有元素中最小的元素时,minstack才会跟着普通栈一样将最小的元素给pop掉。
class MinStack {
public:MinStack() {}void push(int val) {if(st.empty() || val <= minst.top())minst.push(val);st.push(val);//st是一直要入栈的。}void pop() {if(st.top() == minst.top())minst.pop();st.pop();}int top() {return st.top();}int getMin() {return minst.top();}
private:stack<int> minst;stack<int> st;
};
栈的压入弹出序列
1.
我们依次遍历入栈序列,拿入栈后的元素和出栈序列的第一个元素进行比较,如果相等,说明这个元素在入栈之后就立马出栈了,那我们就将入栈之后的元素给pop掉。如果不相等,说明这个元素还没有被pop掉,那我们就继续将入栈序列的后面的元素再次进行入栈,入栈之后再次和出栈序列的剩余元素进行比较。
2.
所以如果入栈序列和出栈序列是相匹配的话,遍历完入栈元素序列之后的结果应该是,st栈为空,并且下标i走到出栈序列的最后一个元素了。但如果两个序列是不匹配的话,st栈中一定还有剩余元素,无法被pop掉,并且i也无法走到出栈序列的最后一个元素的下标位置。
class Solution {
public:stack<int> st;bool IsPopOrder(vector<int> pushV,vector<int> popV) {int i = 0;//代表出栈序列元素的下标。for(auto e:pushV){st.push(e);while(!st.empty() && st.top() == popV[i]){st.pop();++i;//出栈之后,该和出栈序列的下一个元素进行比较了。}}return st.empty();}
};
逆波兰表达式求值
1.
这道题里面有很多的知识点,帮助我复习运用了很多学过的知识,首先字符串有自己的比较运算符的重载函数,所以在比较字符串的时候,string类的字符串比较函数可以帮助我们节省很多代码,让我们无需再调用strcmp这样的函数来进行字符串的比较,下面都是一些非成员函数,在调用时可以直接调用,无需通过string类对象进行调用。

2.
string类还有字符串转换到其他类型的函数,在下面这道题中就用到了stoi将字符串转换为整数int类型的函数,stoi会返回字符串转换为整型之后的值。

3.
字符串也重载了[]+下标这样的访问方式,和vector一样,但到了list那里的时候我们就只能使用迭代器来进行访问了,利用[]+下标的访问方式和switch case分支语句的组合可以帮助我们挑选出vector里面字符串为运算符的部分。(有一说一,我做这个题的时候连switch case的格式都忘记了,太吓人了)
4.
这道题也巧妙利用了栈结构的特征,只要字符串是非运算符的那就将其全部转换为int,然后push到栈当中,只要遇到了运算符的字符串,那我们就依次取出栈顶的两个元素,按照取出次序来看,先取出的是右操作数,后取出的是左操作数,然后根据运算符类型将运算结果重新push到栈里面,等到下次遇到运算符字符串时,继续取出栈的两个元素进行计算,最后vector元素遍历完之后,栈中剩余的最后一个元素就是逆波兰表达式计算之后的结果。
class Solution {
public:stack<int> st;int evalRPN(vector<string>& tokens) {for(auto s : tokens){//if(s[0] == '+' || s[0] == '-' || s[0] == '*' || s[0] == '/')负数这里就不对了if(s == "+" || s == "-" || s == "*" || s == "/")//利用string的运算符重载函数进行比较{int right = st.top();st.pop();int left = st.top();st.pop();switch(s[0])//拿到字符串的第一个字符{case '+':st.push(left + right);break;case '-':st.push(left - right);break;case '*':st.push(left * right);break;case '/':st.push(left / right);break;}}elsest.push(stoi(s));}return st.top();}
};
用栈实现队列
1.
这道题比较经典了,也是很巧妙的利用栈结构的特征,栈是先进后出,队列是先进先出,如果想要用栈来模拟实现队列,一个栈肯定是不够用的,所以我们用两个栈之间的操作接口的配合,来模拟实现队列。
2.
入队列我们就将元素先都入栈到pushst里面,等到pop时,将pushst里面的元素依次取出来入栈到popst里面,这样popst里面依次取出来的元素序列正好符合出队列的元素序列,所以在出队列元素时,就相当于pop掉popst栈里面的元素,这样就符合了队列元素出队列的操作,peek就相当于queue的front接口的功能,拿到队头元素,实际就是拿popst栈顶的元素。
一旦popst栈为空时,我们就将pushst栈里面的元素倒腾过来,然后popst栈的操作行为就符合队列了。
class MyQueue {
public:stack<int> pushst;stack<int> popst;MyQueue() {//对于自定义类型,初始化列表会调用他的默认构造}void push(int x) {pushst.push(x);}int pop() {if(popst.empty()){while(!pushst.empty()){popst.push(pushst.top());pushst.pop();}}int ret = popst.top();popst.pop();return ret;}int peek() {if(popst.empty()){while(!pushst.empty()){popst.push(pushst.top());pushst.pop();}}return popst.top();}bool empty() {return pushst.empty() && popst.empty();}
};
3.stack的模拟实现
1.
无论是函数模板还是类模板,在声明时都可以给缺省参数,只是在使用上有些不同,当你在使用函数模板时,无论是显式实例化还是隐式实例化,你所传参数是变量或对象,函数模板的实例化推演依靠的便是变量或对象的类型。而在使用类模板的时候,我们所传参数是类型,类模板依靠参数类型来推演实例化出具体的类。
2.
stack的实现颇为简单,利用vector容器就可以模拟实现出stack适配器,因为vector支持所有stack的操作,例如back,尾插尾删,size(),判空等操作。

namespace wyn
{//前一个参数代表数据类型,后一个参数代表适配的容器//template<class T,class Container = vector<T>>template<class T,class Container = deque<T>>class stack{public:void push_back(const T& x){_con.push_back(x);}void pop(){_con.pop_back();}T& top(){return _con.back();}const T& top()const{return _con.back();}//const对象只能调用const成员函数,不能调用非const成员函数,因为权限不能放大。//非const对象既能调用const成员函数,又能调用非const成员函数,因为权限可以平移或缩小。bool empty(){return _con.empty();}size_t size(){return _con.size();}private:Container _con;};
}
二、queue
1.queue的介绍

1.
队列也是一种容器适配器,队列数据结构的接口功能要求有出队列,入队列所以,取队头元素,取队尾元素等重要接口,所以队列的底层容器需要支持头删,尾插,front,back等接口,list,deque,vector其实都可以作为queue的底层容器,但vector在出队列时,需要调用erase头删,而erase头删需要挪动数据,代价较大,所以queue的常见底层容器为list或deque。
2.
队列和栈一样,都不需要实现迭代器,因为队列只支持在容器的头尾两个位置进行元素的访问,所以无需实现迭代器。
2.queue的相关OJ题(巧妙利用queue数据结构的特征)
用队列实现栈
1.
这道题在queue本身有限的功能接口下实现栈的结构,是一道加深对于队列数据结构理解并且熟练运用其操作接口的题目。需要明确的原则就是,队列只能在队头出数据,在队尾入数据,在队头取数据,在队尾取数据。
2.
如果要实现栈的操作,我们可以用两个队列来实现,q负责将入栈的所有数据入到队列里面,等pop的时候,我们将q队尾的数据也就是back数据挪动到q的队头上面去,挪动的过程其实就是出队列数据,然后将数据再入队列,直到队尾数据挪动到队头后,我们将队头数据保存后,将q的队头数据pop掉,然后将刚刚保存的数据入队列到stackQ队列里面。
将上面的逻辑搞成一个循环,直到q队列为空,此时stackQ出队列的操作就是出栈操作了,栈的top元素就是stackQ的队头元素,如果stackQ为空,则栈顶元素就是q的队尾元素。
3.
在具体实现时,我遇到了一点点问题,就是在写队尾数据挪到队头位置的while循环条件的时候,我当时用两个变量标识队头和队尾数据,然后让这两个变量不相等作为判断条件,在力扣上面通过了16个测试用例,最后一个没有通过。
在拿最后一个测试用例进行画图分析之后,我发现这个逻辑如果对于有重复数据的测试用例来看,在挪数据时会有问题,所以我们舍弃这样的用法,用队列大小来作为while循环条件。
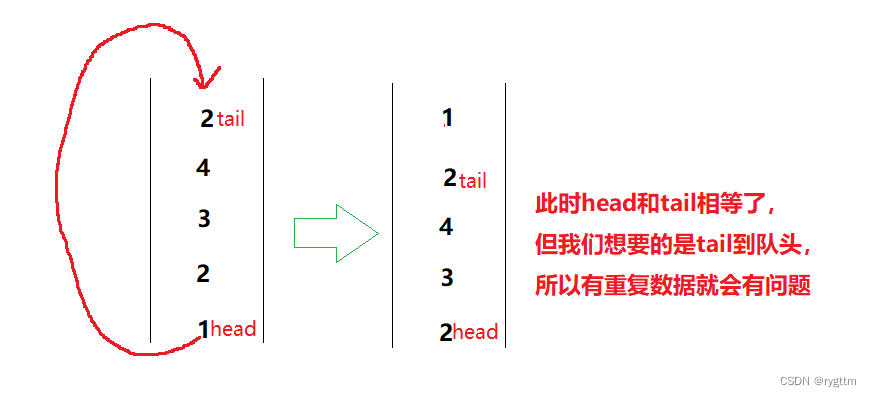
class MyStack {
public:queue<int> q;queue<int> stackQ;MyStack() {}void push(int x) {q.push(x);}int pop() {if(stackQ.empty()){int tail = q.back();int head = q.front();int size = q.size();while(!q.empty()){//一旦push里面出现重复元素,head!=tail这样的判断条件,会让逻辑出现问题//所以不要用这样的判断逻辑来换队尾到队头位置,用次数来作为判断条件吧!// while(head != tail)// {// q.pop();// q.push(head);// head = q.front();// }while(--size)//循环次数为size-1次{q.pop();q.push(head);head = q.front();}//出来之后head==tail,将tail入stackQ队列,并且更新head和tailstackQ.push(tail);q.pop();//q出队列之后,重新更新head和tail的值,用size作为判断条件后,size也要更新tail = q.back();head = q.front();size = q.size();}}int ret = stackQ.front();stackQ.pop();//让stackQ直接出队列return ret;}int top() {if(stackQ.empty())return q.back();return stackQ.front();}bool empty() {return q.empty() && stackQ.empty();}
};
3.queue的模拟实现
1.
模拟实现queue也是非常简单的,只要底层容器有头删,尾插,back,front等接口功能就可以,list就可以作为queue的适配容器。所以模拟实现queue时,只要复用list的接口即可。模拟实现代码过于简单,大家一看就懂。
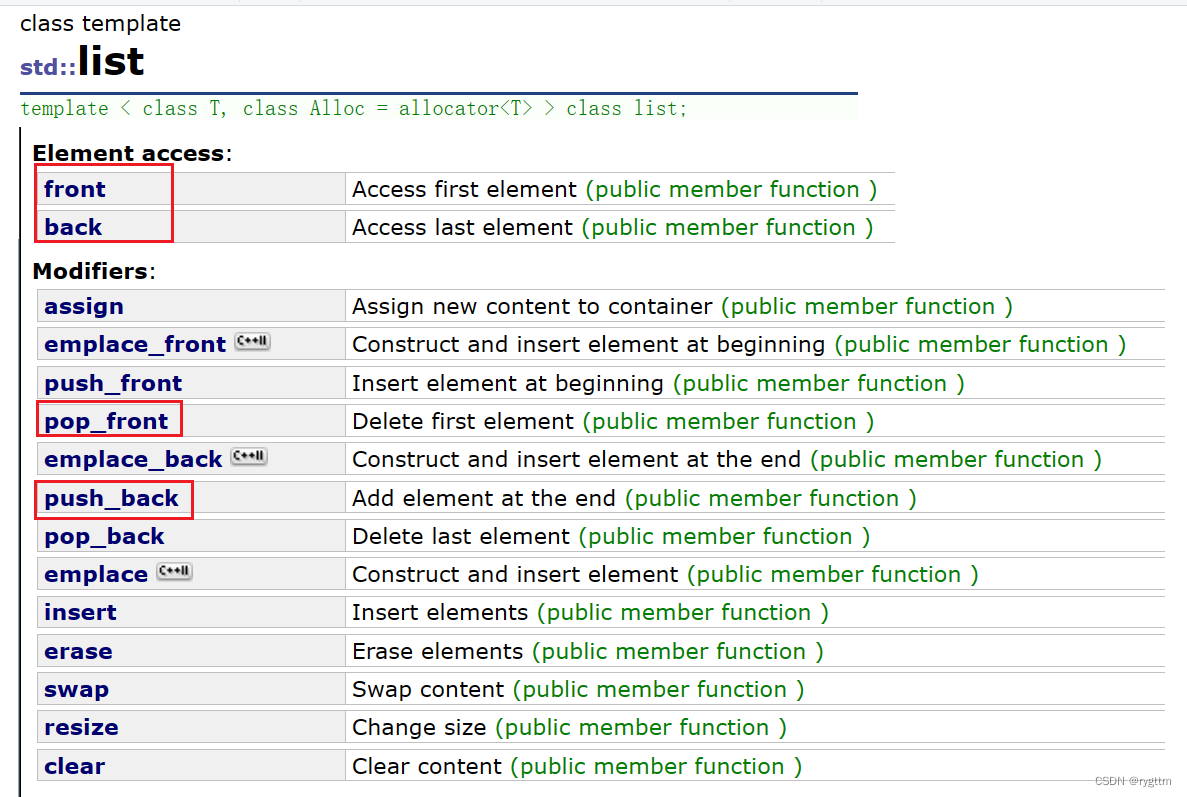
namespace wyn
{//template<class T, class Container = list<T>>template<class T, class Container = deque<T>>class queue{public:void push(const T& x){_con.push_back(x);}void pop(){_con.pop_front();}const T& front(){return _con.front();}const T& back(){return _con.back();}//const对象只能调用const成员函数,不能调用非const成员函数,因为权限不能放大。//非const对象既能调用const成员函数,又能调用非const成员函数,因为权限可以平移或缩小。bool empty(){return _con.empty();}size_t size(){return _con.size();}private:Container _con;};}
三、deque(双端队列容器,叫队列,但和队列没关系)
1.vector和list的优缺点→stack和queue的适配容器
1.
vector作为一种由动态数组实现的容器,他的缺点就是头删和头插会进行数据的挪动,并且如果发生扩容,还要对应产生扩容带来的消耗,比如开空间和拷贝数据。但他也有优点,支持随机访问,这一点保证了在vector进行数据访问时,无需进行遍历容器的操作,直接利用下标访问即可,而且尾插尾删的效率高,这其实也是由于其支持下标访问所带来的优点,所以这个优点可以合并到支持下标随机访问里。另一个优点是由于其空间结构连续,CPU高速缓存命中率高。
2.
list作为一种结构体结点链接而成的数据结构,他的缺点就是空间结构不连续,CPU高速缓存命中率低,并且由于他的结构是不连续的,无法支持下标的随机访问,因为结点之间的地址并没有确切的相关联系,而vector能够支持是因为地址与地址之间相差存储元素类型个字节,通过地址的±整数就可以支持数组中任意位置数据的访问。但其最大的优点就是任意位置插入删除数据的时间复杂度都是O(1),并且不会由于空间扩容带来性能的消耗,这也是他的优势。
3.
通过上面所阐述的优点和缺点就可以看出为什么我们在模拟实现stack和queue的时候,分别采用vector和list来作为其适配容器,因为stack会频繁进行尾插、尾删、取vector尾元素,所以正好符合了vector的优点。而queue会频繁进行头删、所以正好符合list的优点。
4.
但是呢,vector作为stack的适配容器来讲,stack扩容的时候,会带来空间扩容的消耗,而list无法支持下标随机访问,那么能不能有一个容器将vector和list的优点都兼顾到呢?答案是有的,他就是双端队列deque。
2.deque的底层结构
1.
双端队列不仅支持了头尾的插入删除,还支持了下标的随机访问相比list,并且头插头删相比vector效率极高。
但deque并不是真正连续的空间,他是由一段段连续的空间组成的,你可以将它看作动态的二维数组。
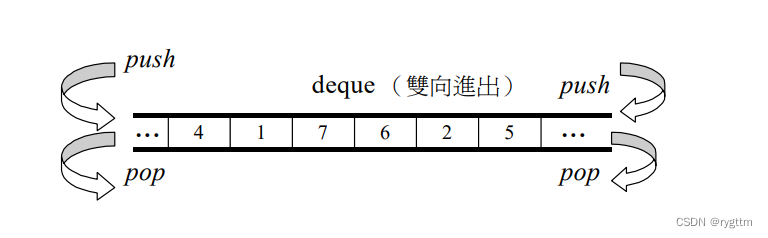
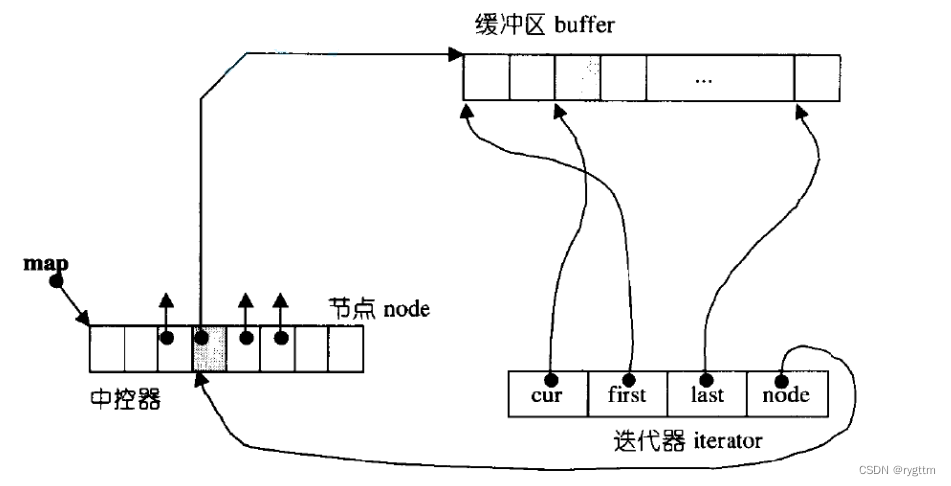
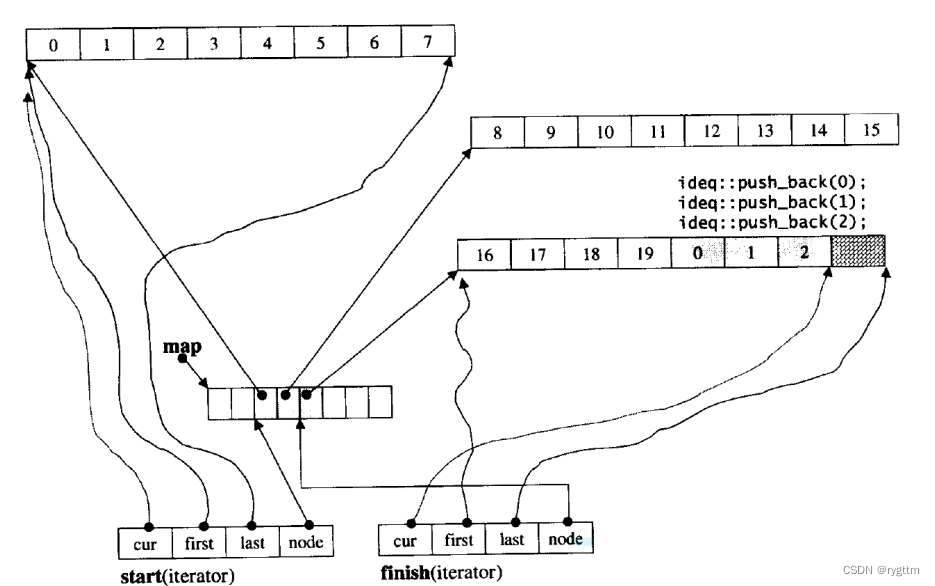
2.
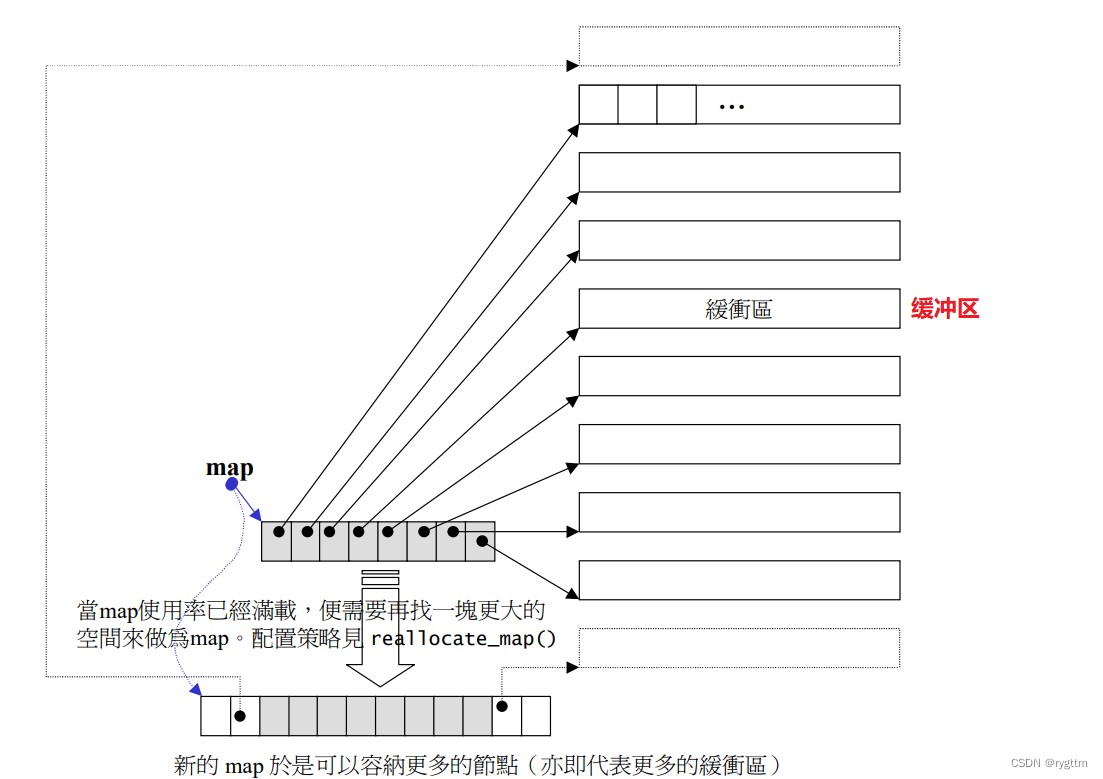
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问的假象,重担子就落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
3.
deque实际是通过一个中控指针数组来控制多段连续空间buffer的。
3.deque的优缺点
1.
与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
2.
但是,deque有一个致命缺陷:不适合遍历,因为在遍历时,deque的迭代器要频繁的去检测其是否移动到某段小空间的边界,导致效率低下,而序列式场景中,可能需要经常遍历,因此在实际中,需要线性结构时,大多数情况下优先考虑vector和list,deque的应用并不多,而目目前能看到的一个应用场景就是,STL用其作为stack和queue的底层数据结构。
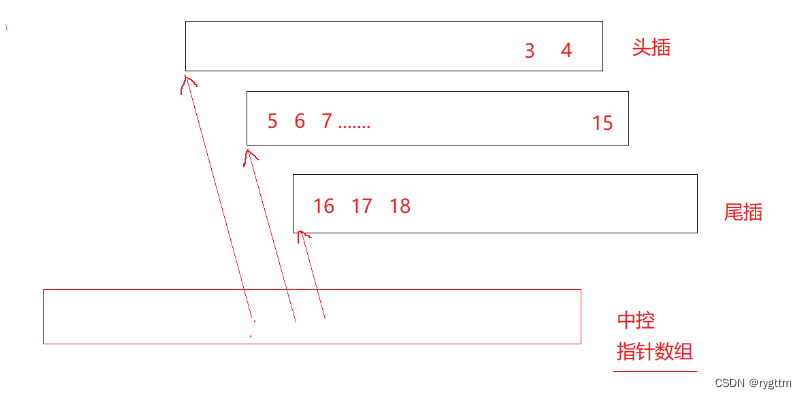
3.
deque在中间插入删除时,也是需要挪动数据的,只不过挪动数据的代价没有vector大而已。deque为什么头插头删效率高不用挪动数据呢?实际就是因为在头插的时候,deque又重新开辟了一块儿空间,让中控数组去控制这个新开辟的buffer,所以如果发生大量中间插入删除时,deque的效率相比list不够极致。
deque支持随机访问的效率实际也不够极致,因为他需要遍历中控数组判断数据在哪个缓冲区,然后在确定缓冲区的具体位置,所以他的随机访问效率相比vector来说也不够极致。
4.为什么选择deque作为stack和queue的适配容器?(vector排序快,list中间插入删除牛,deque吸取两个容器的部分优点)
1.
虽然deque与vector和list的优点来比较,哪个都比不过,但比他们的缺点时,又比vector和list强一些,所以这是一个比较中庸的容器,比上不足,比下有余。
2.
但用deque去作stack和queue的默认适配容器还是不错的,只要中间插入删除少,偶尔进行下标的随机访问,避开deque的缺点,deque用起来还是不错的。
而如果在使用时进行大量的随机访问,我们还是用vector容器,如果要进行中间位置大量的插入删除,还是用list容器。

3.
切记一点,不要用deque容器来进行排序,因为大量的随机访问会导致deque的效率极低,而库里面的sort算法用的又是快排,快排会进行三数取中从而导致大量的随机访问,所以不要用deque来进行排序,如果非要排序,建议将deque中的数据拷贝到vector,然后用vector来进行sort快排。
4.
这里也可以透露出另外一个知识点,vector的排序比list快的原因就是vector支持大量的随机访问,对于快排来说,vector这样的容器非常的友好,这也正是为什么我们喜欢用vector来进行排序的原因。
相关文章:
【C++】通过stack、queue、deque理解适配器模式
破镜不能重圆,枯木可以逢春。 文章目录一、stack1.stack的介绍2.stack相关OJ题(巧妙利用stack数据结构的特征)3.stack的模拟实现二、queue1.queue的介绍2.queue的相关OJ题(巧妙利用queue数据结构的特征)3.queue的模拟实…...
JavaScript 高级实例集合
文章目录JavaScript 高级实例集合创建一个欢迎 cookie简单的计时另一个简单的计时在一个无穷循环中的计时事件带有停止按钮的无穷循环中的计时事件使用计时事件制作的钟表创建对象的实例创建用于对象的模板JavaScript 高级实例集合 创建一个欢迎 cookie 源码 <!DOCTYPE ht…...

Flutter(五)容器类组件
布局类组件包含多个子组件,而容器类组件只包含一个子组件 目录填充(Padding)装饰容器(DecoratedBox)变换(Transform)Transform.translate 平移Transform.rotate 旋转Transform.scale 缩放Rotate…...

实现满屏品字布局
html, body {width: 100%;height: 100%;}.first {width: 50%;height: 50%;margin: auto;background-color: pink;}.second {width: 50%;height: 50%;float: left;background-color: greenyellow;}.third {width: 50%;height: 50%;float: left;background-color: yellow;}...

软件测试-性能测试-基础知识
文章目录 1.性能测试理论1.1 相关概念1.2 性能测试指标2.性能测试策略2.1 基准测试2.2 负载测试2.3 稳定性测试2.4 其他测试策略3.性能测试的流程3.1 需求分析3.2 编写性能测试计划和方案3.3 编写性能测试用例3.4 性能测试执行3.5 性能测试报告4.性能测试工具4.1 Loadrunner4.2…...

java多线程与线程池-02线程池与锁
线程池与锁 第4章 线程池入门 4.1 ThreadPoolExecutor ThreadPoolExecutor是应用最广的底层线程池类,它实现了Executor和ExecutorService接口。 4.1.1 创建线程池 下面创建一个线程池,通过调整线程池构造函数的参数来了解线程池的运行特性。把核心线程数设置为3,最大…...

AB测试——流程介绍(设计实验)
前言: 作为AB测试的学习记录,接上文内容, 本文继续介绍假设建立和实验设计部分,包括实验对象、样本量计算(显著性水平、统计功效及最小可检测效应)、实验周期。 相关文章: AB测试——原理介绍 A…...

C++中的智能指针有哪些?分别解决的问题以及区别?
1.C中的智能指针有4种,分别为:shared_ptr、unique_ptr、weak_ptr、auto_ptr,其中auto_ptr被C11弃用。 2.使用智能指针的原因 申请的空间(即new出来的空间),在使用结束时,需要delete掉࿰…...
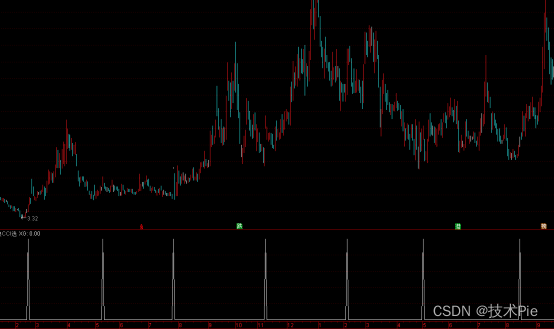
通达信捉妖改良CCI指标公式,简洁巧妙
高端的食材,往往只需要简单的烹饪方式。好的指标也是一样,只需要简单处理,就可以实现不错的效果。捉妖改良CCI指标公式属于意外之喜,编写指标时写错了,研究后发现结果比原想法更好。 捉妖改良CCI指标公式利用了CCI&am…...

「Python 基础」面向对象编程
文章目录1. 面向对象编程类和实例访问限制继承和多态type()isinstance()dir()实例属性和类属性2. 面向对象高级编程\_\_slots\_\_property多重继承定制类枚举类元类1. 面向对象编程 Object Oriented Programming 简称 OOP,一种程序设计思想,以对象为程…...

【K3s】第23篇 一篇文章带你学习k3s私有镜像仓库配置
目录 1、私有镜像仓库配置 2、registries.yaml Mirrors Configs 1、私有镜像仓库配置 可以配置 Containerd 连接到私有镜像仓库,并使用它们在节点上拉取私有镜像。 启动时,K3s 会检查/etc/rancher/k3s/中是否存在registries.yaml文件,并指示 containerd 使...
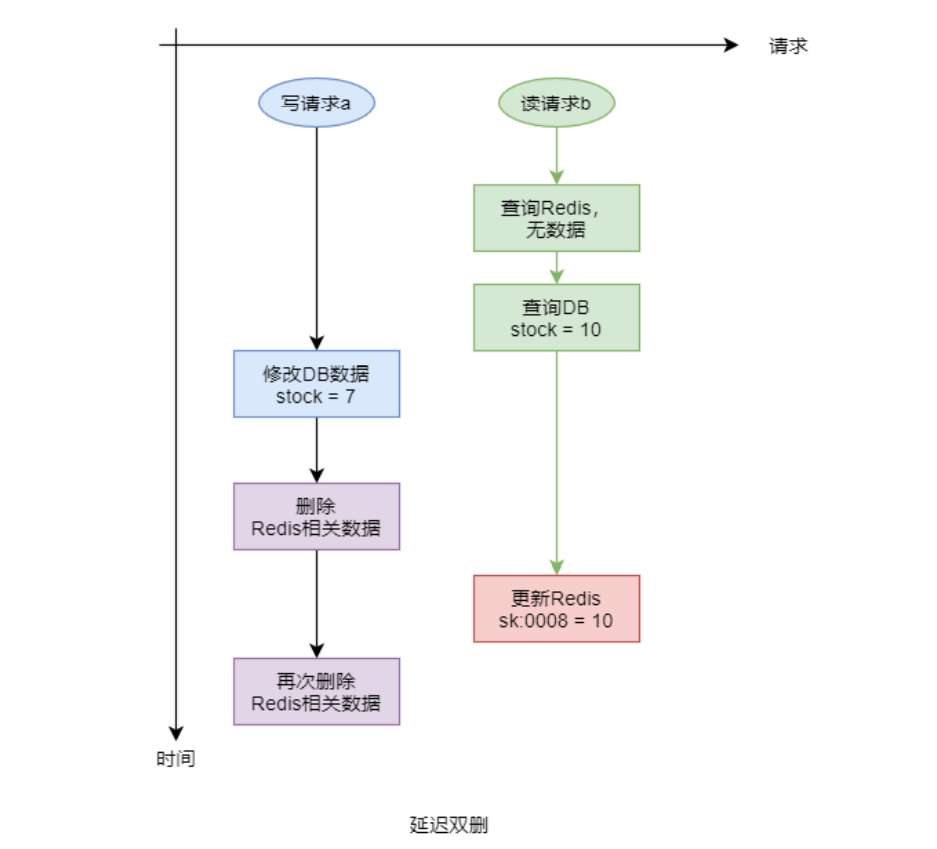
Redis学习【12】之Redis 缓存
文章目录前言一 Jedis 简介二 使用 Jedis2.1 测试代码2.2 使用 JedisPool2.3 使用 JedisPooled2.4 连接 Sentinel 高可用集群2.5 连接分布式系统2.6 操作事务三 Spring Boot整合Redis3.1 创建工程3.2 定义 pom 文件3.3 完整代码3.4 总结四 高并发问题4.1 缓存穿透4.2 缓存击穿4…...

Bootargs 参数
bootargs 的参数有很多,而且随着 kernel 的发展会出现一些新的参数,使得设置会更加灵活多样1。除了我之前介绍的 root、console、earlyprintk 和 loglevel 之外,还有以下一些常用的参数:init: 用来指定内核启动后执行的第一个程序…...
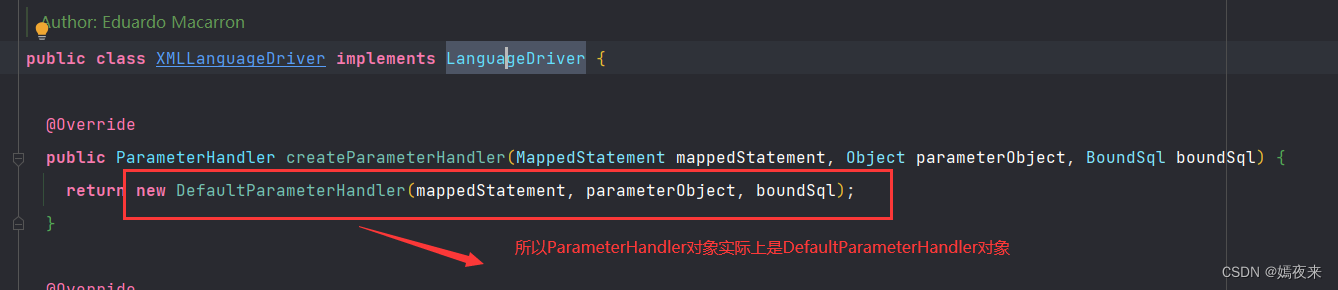
Mybatis框架源码笔记(七)之Mybatis中类型转换模块(TypeHandler)解析
1、JDBC的基本操作回顾 这里使用伪代码概括一下流程: 对应数据库版本的驱动包自行下载加载驱动类 (Class.forName("com.mysql.cj.jdbc.Driver"))创建Connection连接: conn DriverManager.getConnection("jdbc:mysql://数据库IP:port/数据库名称?useUnico…...

论文阅读《Block-NeRF: Scalable Large Scene Neural View Synthesis》
论文地址:https://arxiv.org/pdf/2202.05263.pdf 复现源码:https://github.com/dvlab-research/BlockNeRFPytorch 概述 Block-NeRF是一种能够表示大规模环境的神经辐射场(Neural Radiance Fields)的变体,将 NeRF 扩展到…...
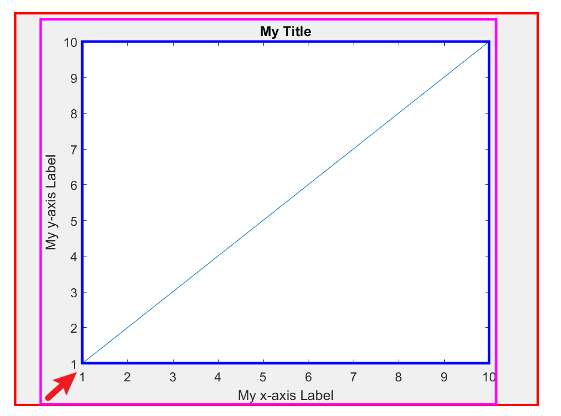
【Matlab】如何设置多个y轴
MTALAB提供了创建具有两个y轴的图,通过help yyaxis就能看到详细的使用方式。 但是如果要实现3个及以上y轴的图,就没有现成的公式使用了,如下图所示。 具体代码 % 数据准备 x10:0.01:10; y1sin(x1); x20:0.01:10; y2cos(x2); x30:0.01:10;…...

圆桌(满足客人空座需求,合理安排客人入座圆桌,准备最少的椅子)
CSDN周赛第30期第四题算法解析。 (本文获得CSDN质量评分【91】)【学习的细节是欢悦的历程】Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学教程》,不仅仅是基础那么简单…… 地址:https://lq…...

如何入门大数据?
我们首先了解一下大数据到底是什么~ 大数据开发做什么? 大数据开发分两类,编写Hadoop、Spark的应用程序和对大数据处理系统本身进行开发。 大数据开发工程师主要负责公司大数据平台的开发和维护、相关工具平台的架构设计与产品开发、网络日志大数据分…...

如何在Vite项目中使用Lint保证代码质量
通常,大型前端项目都是多人参与的,由于开发者的编码习惯和喜好都不尽相同,为了降低维护成本,提高代码质量,所以需要专门的工具来进行约束,并且可以配合一些自动化工具进行检查,这种专门的工具称为Lint,可能大家接触得最多就是ESLint。 对于实现自动化代码规范检查及修…...

Spark高手之路1—Spark简介
文章目录Spark 概述1. Spark 是什么2. Spark与Hadoop比较2.1 从时间节点上来看2.2 从功能上来看3. Spark Or Hadoop4. Spark4.1 速度快4.2 易用4.3 通用4.4 兼容5. Spark 核心模块5.1 Spark-Core 和 弹性分布式数据集(RDDs)5.2 Spark SQL5.3 Spark Streaming5.4 Spark MLlib5.5…...

Cogito-V1-Preview-Llama-3B赋能微信小程序:打造个人专属AI聊天机器人
Cogito-V1-Preview-Llama-3B赋能微信小程序:打造个人专属AI聊天机器人 最近发现身边不少朋友都在琢磨,能不能给自己搞一个专属的AI聊天机器人,最好还能放在微信里,随时打开就能聊。这想法确实挺酷,但一提到大模型&…...

AI编程终端三剑客实战指南:Claude Code、Codex CLI、Gemini CLI 场景化选型与避坑
1. AI编程终端三剑客全景速览 2025年的AI编程工具市场已经形成了三足鼎立的格局,Anthropic、OpenAI和Google各自推出了杀手级终端产品。作为每天与代码打交道的开发者,我实测这三款工具后发现,它们就像编程世界的瑞士军刀、多功能钳和激光剑—…...

OpenCore-Configurator:让黑苹果配置化繁为简的实用工具
OpenCore-Configurator:让黑苹果配置化繁为简的实用工具 【免费下载链接】OpenCore-Configurator A configurator for the OpenCore Bootloader 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Configurator 为什么选择OpenCore-Configurator&#x…...

抗体芯片技术原理与应用进展
一、引言蛋白质作为生命活动的直接执行者,其表达水平、翻译后修饰及相互作用网络的解析,对于理解生理病理机制至关重要。在众多蛋白检测技术中,抗体芯片凭借其高通量、高灵敏度及低样本消耗的特点,已成为蛋白质组学研究中不可或缺…...

Phi-3-mini-128k-instruct赋能运维:自动化编写Shell脚本与故障排查
Phi-3-mini-128k-instruct赋能运维:自动化编写Shell脚本与故障排查 1. 引言:当运维遇上AI助手 想象一下这个场景:凌晨两点,服务器突然告警,你需要立刻分析日志,找出异常访问的源头。传统的做法是…...

PDF补丁丁终极指南:免费高效的PDF文档处理完整解决方案
PDF补丁丁终极指南:免费高效的PDF文档处理完整解决方案 【免费下载链接】PDFPatcher PDF补丁丁——PDF工具箱,可以编辑书签、剪裁旋转页面、解除限制、提取或合并文档,探查文档结构,提取图片、转成图片等等 项目地址: https://g…...
)
SoC入门-1芯片研究框架(上)
一直想写点SoC相关的文章,这东西跟代码还是有点距离,作为软件程序员总感觉全是文字有点虚。但是深入底层的软件,还是需要对硬件有一些了解,真是有点头大,不知从何写起,又能从何处结束。不管那么多了&#x…...

【困惑度 计算和可视化】
困惑度(Perplexity)是语言模型评估中一个非常核心的指标,本质上是衡量模型对一段文本“有多不确定”。 一、定义(从概率角度) 给定一个序列 ( w_1, w_2, …, w_N ),语言模型会给出条件概率: P(w1,w2,...,wN)=∏i=1NP(wi∣w1,...,wi−1)P(w_1, w_2, ..., w_N) = \prod_…...

家庭老照片修复神器:GPEN镜像批量处理教程,一次搞定整本相册
家庭老照片修复神器:GPEN镜像批量处理教程,一次搞定整本相册 1. 老照片修复的痛点与解决方案 每个家庭都珍藏着一些泛黄的老照片,它们承载着珍贵的回忆。但随着时间的推移,这些照片往往会出现模糊、划痕、褪色等问题。传统的手工…...

Kiro使用最佳教程
Kiro使用最佳教程:从入门到精通,高效AI编程全攻略Kiro是亚马逊云科技推出的新一代AI驱动型集成开发环境(IDE),同时配套CLI命令行工具,主打规范驱动开发(Spec-Driven Development)&am…...