C++17并行算法与HIPSTDPAR
C++17 parallel algorithms and HIPSTDPAR — ROCm Blogs (amd.com)
C++17标准在原有的C++标准库中引入了并行算法的概念。像std::transform这样的并行版本算法保持了与常规串行版本相同的签名,只是增加了一个额外的参数来指定使用的执行策略。这种灵活性使得已经使用C++标准库算法的用户只需对代码进行最小程度的修改,就能利用多核架构的优势。
从ROCm6.1开始,只要用户愿意添加一两个额外的编译器标志,这些并行算法就能通过HIPSTDPAR无缝卸载到AMD加速器上执行。尽管HIPSTDPAR提供的功能适用于所有AMD GPU(包括消费级显卡),但本篇博客主要聚焦于使用ROCm6.1的AMD CDNA2™和CDNA3™架构(分别对应MI200和MI300系列卡)。作为示例代码,我们将关注这里提供的旅行商问题(TSP)求解器。
旅行商问题
旅行商问题旨在回答这样一个问题:“给定一系列城市及其之间的距离,访问每个城市恰好一次并返回出发城市的最短可能路线是什么?”由于指数级的复杂性,这一问题特别难以解决(属于NP难问题),每增加一个城市,需要检查的组合数量就会呈指数增长。对于超过17或18个城市的实例,仅通过枚举所有可能组合并检查每一种的计算成本是不可行的。在实际应用中,会采用高级方法(如切割平面法和分支定界技术),但为了本文的目的,我们关注的是TSP的一个极度并行化的暴力求解实现。
TSP求解器实现
我们关注的TSP求解器依赖于以下函数来检查各个城市排列,并选择成本/距离最低的那一个。以下是不使用任何并行性的详细实现:
template<int N>
route_cost find_best_route(int const* distances)
{return std::transform_reduce(counting_iterator(0),counting_iterator(factorial(N)),route_cost(),[](route_cost x, route_cost y) { return x.cost < y.cost ? x : y; },[=](int64_t i) {int cost = 0;route_iterator<N> it(i);// first city visitedint from = it.first();// visited all other cities in the chosen route// and compute costwhile (!it.done()){int to = it.next();cost += distances[to + N*from];from = to;}// update best_route -> reductionreturn route_cost(i, cost);});
}std::transform_reduce算法执行两个操作:
1. 由作为最后一个参数传递的lambda函数实现的转换(相当于map操作);
2. 由作为第四个参数传递的lambda函数表示的缩减操作。
上述函数遍历从0到N!的所有元素,每个元素表示所有城市的特定排列,计算特定路径的成本,并返回一个包含路径ID和与路径关联成本的route_cost对象实例。最后,通过比较各种路径的成本并选择成本最低的路径来执行缩减操作。
在AMD Zen4处理器上,这个串行代码计算涉及12个城市的TSP实例的最佳路径大约需要11.52秒。同样的代码计算涉及13个城市的TSP实例需要大约156秒。这是由于TSP强加的搜索空间的指数增长。
执行策略和HIPSTDPAR
由于N!个路径彼此独立,计算它们的各自成本是一种令人尴尬的并行操作。C++17允许开发人员仅通过在算法调用时传递执行策略作为第一个参数来轻松并行化前面的代码。C++17标准定义了三种可能的执行策略:
std::execution::sequenced_policy及相应的策略对象作为参数std::execution::seqstd::execution::parallel_policy及相应的策略对象作为参数std::execution::parstd::execution::parallel_unsequenced_policy及相应的策略对象作为参数std::execution::par_unseq
执行策略允许用户向实现传达关于用户代码应强制执行/维护的不变量的信息,从而允许后者可能采用更合适/高性能的执行方式。
std::execution::sequenced_policy
顺序策略限制实现对调用算法的线程执行所有操作,禁止可能的并行执行。所有操作在调用者线程内不确定地排序,这意味着在同一个线程内对同一算法的后续调用可以以不同的顺序执行其操作。
std::execution::parallel_policy
并行策略允许实现采用并行执行。操作可以在调用算法的线程上执行,也可以在标准库实现创建的线程上执行。对于描述算法调用的计算所使用的所有线程,所有操作在线程内不确定地排序。此外,对元素访问函数调用本身不提供排序保证。与顺序策略相比,对算法使用的各种组件施加了额外的约束。特别是,迭代器、值和可调用对象的操作及其传递闭包必须是数据竞争自由的。
在前面的示例中,可以通过将std::execution:par策略作为第一个额外参数传递给find_best_route函数来并行化:
return std::transform_reduce(std::execution::par, // THE SIMPLE CHANGEcounting_iterator(0),counting_iterator(factorial(N)),route_cost(),[](route_cost x, route_cost y) { return x.cost < y.cost ? x : y; },[=](int64_t i)通过进行这一简单更改,代码现在将在所有可用CPU核心上运行。在配备了48个Zen4逻辑核心的MI300A的CPU部分上,解决涉及12个城市的TSP实例大约需要0.34秒。与串行版本所需的11.52秒相比,这种并行运行速度提高了近34倍!对于涉及13个城市的TSP实例,并行版本大约需要5秒。最后,对于涉及14个城市的更大问题,48个Zen4逻辑核心大约需要77秒。std::execution::parallel_unsequenced_policy
此策略确保用户提供的代码满足最严格的要求。使用此策略调用的算法可能会以无序且未排序的方式执行各个步骤。这意味着各种操作可以在同一线程上相互交错。此外,任何给定的操作都可以在一个线程上开始并在另一个线程上结束。在指定并行未排序策略时,用户保证不采用涉及调用与另一个函数同步的函数的操作。实际上,这意味着用户代码不执行任何内存分配/释放,仅依赖于std::atomic的无锁特化,并且不依赖于诸如std::mutex之类的同步原语。
此策略目前是唯一一个可以选择将并行性卸载到AMD加速器的策略。要触发使用并行未排序策略调用的所有并行算法的GPU卸载,必须在编译时传递--hipstdpar标志。此外,对于除当前默认值(gfx906)之外的GPU目标,用户还必须传递--offload-arch=,指定正在使用的GPU。
在MI300A上,只需切换策略并使用上述标志重新编译,涉及13个城市的TSP实例的执行时间就减少到0.5秒。当使用14个城市时,使用MI300A的GPU部分将执行时间从并行版本的48个Zen4逻辑核心所需的77秒减少到4.8秒。因为每个人都喜欢一个好的表格,让我们通过总结从CPU上的顺序执行到卸载到加速器的并行未排序执行的进展来结束本节:
| 14-city TSP | Timing (s) |
|---|---|
|
| 2337 |
|
| 77 |
|
| 75 |
|
| 4.8 |
TeaLeaf
一个展示HIPSTDPAR使用和性能的更复杂例子是TeaLeaf。这个代码是来自英国布里斯托大学的TeaLeaf热传导小应用程序的一个C++实现。多个实现示例展示了各种并行编程范式,包括HIP和并行化标准算法。这使得我们能够在优化的基于HIP实现和一个基于HIPSTDPAR的实现之间,进行公平的性能比较。为了这个测试,我们选择了`tea_bm_5.in`基准测试,包含一个4000x4000单元的2D网格和10个时间步。
对于HIPSTDPAR版本,在一张MI300A卡上,获得了以下输出:
Timestep 10
CG: 3679 iterations
Wallclock: 40.884s
Avg. time per cell: 2.555271e-06
Error: 9.805532e-31Checking results...
Expected 9.546235158221428e+01
Actual 9.546235158231138e+01
This run PASSED (Difference is within 0.00000000%)至于HIP版本,它的性能如下:
Timestep 10
CG: 3679 iterations
Wallclock: 34.286s
Avg. time per cell: 2.142853e-06
Error: 9.962546e-31Checking results...
Expected 9.546235158221428e+01
Actual 9.546235158231144e+01
This run PASSED (Difference is within 0.00000000%)两个版本之间的性能差异源于处理非常驻内存初次分页的开销。为了“使事情更公平”,可以调整HIP版本也使用 hipMallocManaged() ,而不是 hipMalloc()。这种特定的配置已经在 TeaLeaf 的 HIP 版本中可用,并且可以通过在编译时传递一个简单的标志来启用。以下是当使用 hipMallocManaged() 和 XNACK 为所有GPU分配时 TeaLeaf 的 HIP 版本的输出。
Timestep 10CG: 3679 iterationsWallclock: 39.573sAvg. time per cell: 2.473331e-06Error: 9.962546e-31Checking results...Expected 9.546235158221428e+01Actual 9.546235158231144e+01This run PASSED (Difference is within 0.00000000%)正如预期的那样,当引入 hipMallocManaged() 时,HIP 版本的性能与 HIPSTDPAR 版本观察到的性能相当。最后,我们将指出,正在进行的工作有望减少开销,从而使得卸载版本的性能更接近 HIP 版本。

HIPSTDPAR的核心机理
(“nuts and bolts”是一个英语习语,意思是“基本的工作原理”或者“详细的实际细节”。它通常用于描述某件事情的具体、基础的组成部分,而非它的广义或概念性内容。这个习语源自于实际的螺母(nuts)和螺栓(bolts),它们是用来物理连接各种构件的基础硬件。因此,在这种情况下,提及 “HIPSTDPAR的nuts and bolts” 就是指想要深入了解HIPSTDPAR如何实际工作的所有基础和技术细节。翻译成“HIPSTDPAR的核心机理”是为了捕捉这种想要详细了解它的工作原理和组件的意图。因此,“Nuts”(螺母)在这里不是指实际的螺母,而是泛指细节或基本部分;“bolts”(螺栓)也是如此。这个习语与硬件本身无关,而是关于理解事物的基本组成部分和工作方式。 )
HIPSTDPAR的C++标准并行算法执行能够卸载到GPU,取决于LLVM编译器、HIPSTDPAR以及rocThrust之间的交互。从ROCm6.1开始,用来编译常规HIP代码的LLVM编译器将可以在传递了`--hipstdpar`标记的情况下,将调用带有`parallel_unsequenced_policy`执行策略的标准算法转发至HIPSTDPAR头文件库。这个仅头文件的库负责将C++标准库使用的并行算法映射为等价的rocThrust算法调用。这种非常简单的设计为并行标准算法的卸载实现提供了低开销。此时一个自然的问题是:“计算是很好,但是它操纵的内存怎么办?”默认情况下,HIPSTDPAR假设底层系统启用了HMM(异构内存管理),并且通过实现在XNACK(例如,导出HSA_XNACK=1)之上的可以重试的页错误处理机制,可以进行页面迁移。这种模式被称为HMM模式。
当这两个要求都得到满趀时,卸载到GPU的代码(通过rocThrust实现)触发页面迁移机制,数据会自动从主机迁移到设备。在MI300A上,虽然物理迁移既不需要也没有用处,但通过XNACK处理页面错误仍然是必要的。有关页面迁移的更多详情,请参考以下博客文章。("Post"在这个上下文中通常被用来指代网站或者博客上发布的一篇文章或记录。在网络术语中,"post"可以是一个名词,指的就是所发布的内容;也可以是一个动词,指的是发布信息的行为。所以,链接AMD Instinct™ MI200 GPU memory space overview - amd-lab-notes - AMD GPUOpen引向的内容是AMD官方网站上的一个页面,其中包含了关于MI200系列加速器内存空间的详绽解读和如何启用页面迁移的信息,因此将其译为"博客文章"是合理的,因它确实是一篇公开发布、围绕具体主题的文章。翻译为"博客文章"是为了传达这是一篇可能相对非正式或以教育、信息共享为目的的文章,它与学术论文或新闻报道的语调和格式不同。在中文中,博客文章也常被简称为"博文"。在这种语境下,直接翻译为"文章"也是可以接受的,只是"博客文章"提供了关于文章发布平台的额外信息。)
在没有启用HMM/XNACK的系统上,我们仍然可以通过传递一个额外的编译标记:`--hipstdpar-interpose-alloc`来使用HIPSTDPAR。这个标记会指导编译器用在HIPSTDPAR头文件库中实现的兼容的hipManagedMemory分配来替换所有的动态内存分配。例如,如果正在编译的应用程序或其传递性包含的内容通过`operator new`分配了自由存储内存,那么这个调用会被替换为对`__hipstdpar_operator_new`的调用。通过查看该函数在HIPSTDPAR库中的实现,我们可以看到实际的分配是通过`hipMallocManaged()`函数执行的。这样在一个没有启用HMM的系统上,主机内存被固定并且能够直接被GPU访问,而不需要任何页面错误驱动的迁移到GPU内存。这种模式被称为"Interposition模式"。
限制
对于HMM和Interposition模式,以下限制适用:
1. 函数指针和所有相关功能,例如动态多态性,不能被传递给算法调用的用户提供的可调用对象(直接或传递性地)使用;
2. 全局/命名空间范围/静态/线程存储期变量不能被用户提供的可调用对象(直接或传递性地)以名称使用;
- 当在HMM模式下执行时,它们可以通过地址被使用,例如:
namespace { int foo = 42; }bool never(const vector<int>& v) {return any_of(execution::par_unseq, cbegin(v), cend(v), [](auto&& x) {return x == foo;});
}bool only_in_hmm_mode(const vector<int>& v) {return any_of(execution::par_unseq, cbegin(v), cend(v),[p = &foo](auto&& x) { return x == *p; });
}3. 只有那些使用`parallel_unsequenced_policy`调用的算法才能成为卸载的候选;
4. 只有那些使用模型为`random_access_iterator`的迭代器参数调用的算法才能成为卸载的候选;
5. 用户提供的可调用对象不能使用异常;
6. 用户提供的可调用对象不能使用动态内存分配(例如`operator new`);
7. 不可能有选择地卸载,即不能指示只有一些使用`parallel_unsequenced_policy`调用的算法在加速器上执行。
除上述限制外,使用Interposition模式还带来以下额外的限制:
1. 所有期望互操作的代码都必须使用`--hipstdpar-interpose-alloc`标志重新编译,即不安全地组合已独立编译的库;
2. 自动存储期(即栈分配的)变量不能被用户提供的可调用对象(直接或传递性地)使用,例如:
bool never(const vector<int>& v, int n) {return any_of(execution::par_unseq, cbegin(v), cend(v),[p = &n](auto&& x) { return x == *p; });
}但为什么?
在经历了一段快速旅程之后,提出“但这对我这个C++开发者有什么好处?”并不是没有道理的。[HIPSTDPAR](GitHub - ROCm/roc-stdpar)的目标是让任何使用标准算法的C++开发者都能够在不增加认知负担的情况下利用GPU加速。应用程序开发者可以坚定地留在标准C++世界中,而不必跨入HIP或SYCL等GPU特定语言的崭新世界。幸运的是,我们的特定例子能够提供一些有限的、定量的洞察,让我们了解我们离这个目标有多近。Tealeaf的作者已经通过多种编程接口实现了求解器,这意味着我们可以使用`cloc`工具计算`tsp.cpp`实现所需的代码行数:
| Programming Interface | LoC |
|---|---|
| Kokkos | 145 |
| OpenACC | 142 |
| OpenMP | 116 |
| Standard C++ Serial | 112 |
| Standard C++ Parallel Algorithms | 107 |
| SYCL | 169 |
显然,使用由编译器标志驱动的卸载(如HIPSTDPAR所启用)可以节省相当多的打字工作 - 例如,与SYCL相比,最多可以节省57%。这使向GPU加速执行的转变过程更自然。因此,程序员至少在初始阶段可以专注于算法/问题解决,并发现适用于GPU的通用算法优化,而无需深入GPU“奥秘”。

太长了,没读。直接告诉我怎么快速进行吧
要快速地利用GPU加速,可以在Linux环境下使用HIPSTDPAR(未来也会支持Windows)。假设你已经根据ROCm的快速开始教程设置好了环境,通过包管理器安装`hipstdpar`包就可以得到所有必需的组件。由于标准库实现细节问题(参见例如备注3),可能还需要安装TBB库。例如,在Ubuntu上安装`libtbb-dev`。接着,如果你有一个主程序文件`main.cpp`,它使用标准算法解决了某个问题,那么只需简单地运行以下编译命令:
clang++ --hipstdpar main.cpp -o main就可以自动将使用`std::execution::parallel_unsequenced_policy`执行策略的所有算法调用进行GPU加速,假定你的目标GPU与`gfx906`兼容(即Vega20)。如果是另外的GPU目标,则需要指定:
clang++ --hipstdpar --offload-arch=gfx90a main.cpp -o main结论
我们在本文中提供了一个关于ROCm支持C++标准并行算法进行卸载加速的高层次概述,展示了现有的C++开发者如何利用GPU加速,而无需采用任何新的、特定于GPU的语言(例如HIP)或指令(例如OpenMP)。我们相信,这种标准且极其易于访问的方式,以利用硬件并行性,对于针对MI300A加速器的应用程序将特别有益,其中CPU和GPU共享同一池的HBM。虽然今天没有演示,但APU架构和HIPSTDPAR的结合可以实现CPU与GPU之间的细粒度合作,通过统一的编程接口使它们成为真正的对等实体。
如果想更深入了解HIPSTDPAR的编译器支持,可以阅读相关的AMD-LLVM文档。
本文作者感谢Bob Robey和Justin Chang对文章的有益审阅。如果有任何问题,可以在GitHub Discussions上与我们联系。
相关文章:
C++17并行算法与HIPSTDPAR
C17 parallel algorithms and HIPSTDPAR — ROCm Blogs (amd.com) C17标准在原有的C标准库中引入了并行算法的概念。像std::transform这样的并行版本算法保持了与常规串行版本相同的签名,只是增加了一个额外的参数来指定使用的执行策略。这种灵活性使得已经使用C标准…...

【什么是几度cms,主要功能有什么】
几度CMS内容管理框架是基于 PHP 语言采用最新 Thinkphp 作为开发框架生产的网站 内容管理框架,提供“电脑网站 手机网站 多终端 APP 接口”一体化网站技术解 决方案。她拥有强大稳定底层框架,以灵活扩展为主的开发理念,二次开发方便且…...
组合和外观模式
文章目录 组合模式1.引出组合模式1.院系展示需求2.组合模式基本介绍3.组合模式原理类图4.解决的问题 2.组合模式解决院系展示1.类图2.代码实现1.AbsOrganizationComponent.java 总体抽象类用于存储信息和定义方法2.University.java 第一层,University 可以管理 Coll…...

设置服务器禁止和ip通信
要禁止服务器与特定 IP 地址的通信,可以使用防火墙来设置规则。在 Ubuntu 上,iptables 是一个常用的防火墙工具。以下是使用 iptables 设置禁止与特定 IP 通信的步骤: 阻止所有进出的通信 如果你想阻止服务器与特定 IP 地址的所有通信&…...
)
中文技术文档的写作规范(搬运)
阮一峰老师的《中文技术文档的写作规范》搬运。 链接指路: https://github.com/ruanyf/document-style-guide/tree/master 内容:对中文技术文档从标题、文本、段落、数值、标点符号、文档体系、参考链接等七大方面进行了简明扼要的介绍。...
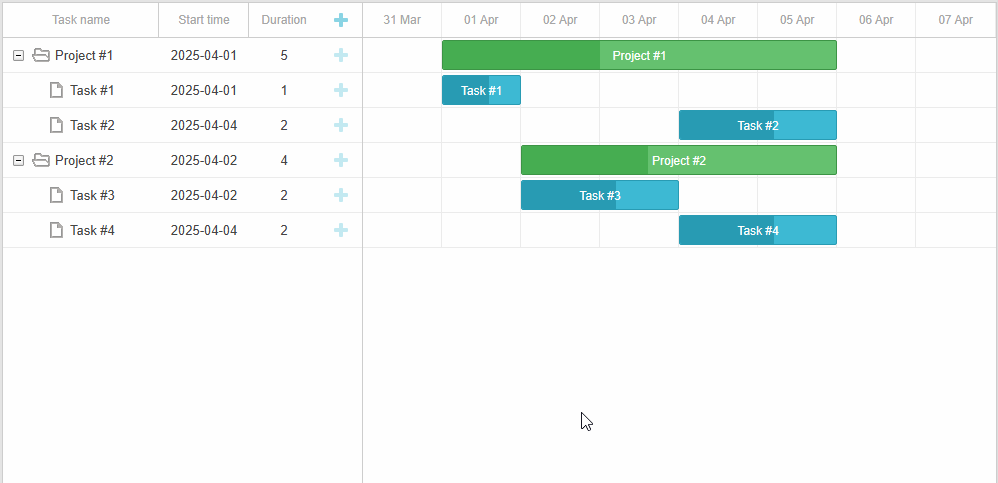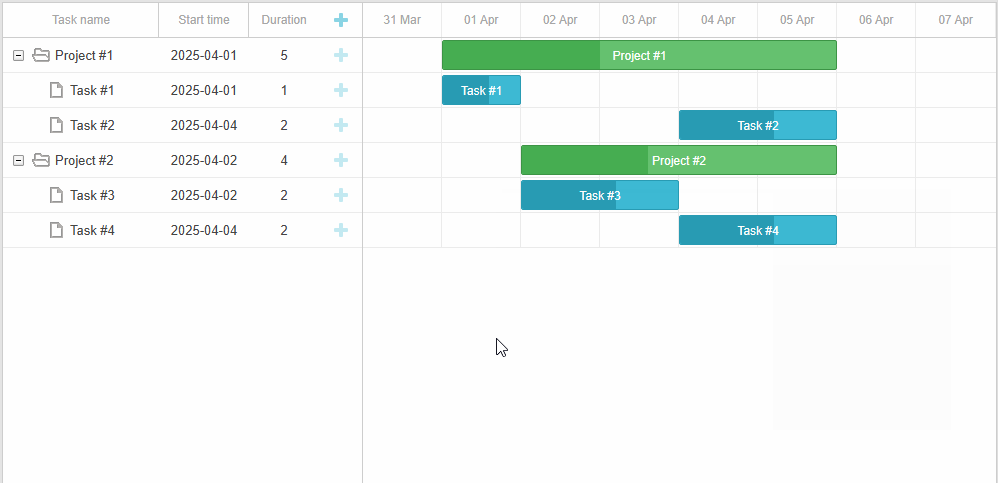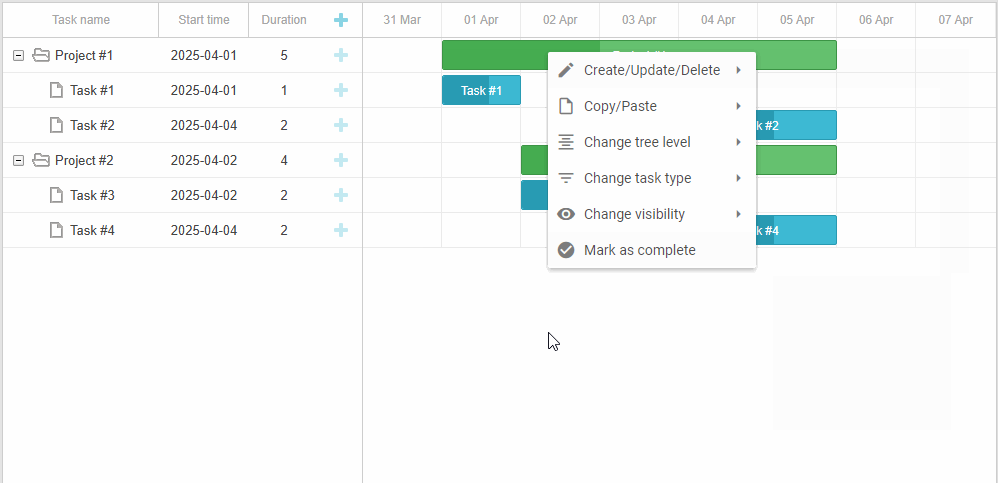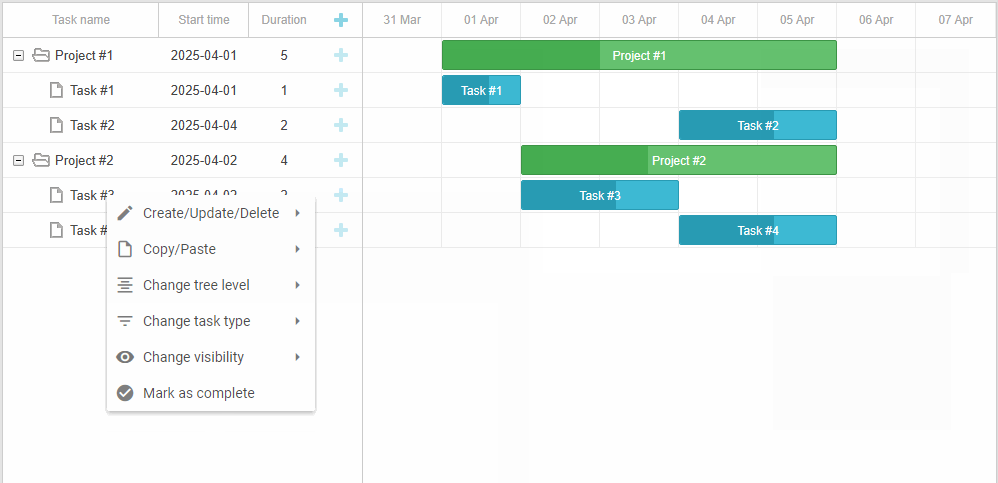
「实战应用」如何用DHTMLX将上下文菜单集成到JavaScript甘特图中(一)
DHTMLX Gantt是用于跨浏览器和跨平台应用程序的功能齐全的Gantt图表。可满足项目管理应用程序的所有需求,是最完善的甘特图图表库。 DHTMLX Gantt是一个高度可定制的工具,可以与项目管理应用程序所需的其他功能相补充。在本文中您将学习如何使用自定义上…...

Python使用策略模式生成TCP数据包
使用策略模式(Strategy Pattern)来灵活地生成不同类型的TCP数据包。 包括三次握手、数据传输和四次挥手。 from scapy.all import * from scapy.all import Ether, IP, TCP, UDP, wrpcap from abc import ABC, abstractmethodclass TcpPacketStrategy(A…...
无文件落地分离拆分-将shellcode从文本中提取-file
马子分为shellcode和执行代码. --将shellcode单独拿出,放在txt中---等待被读取执行 1-cs生成python的payload. 2-将shellcode进行base64编码 import base64code b en_code base64.b64encode(code) print(en_code) 3-将编码后的shellcode放入文件内 4-读取shellcod…...

MySQL 日志(一)
本篇主要介绍MySQL日志的相关内容。 目录 一、日志简介 常用日志 一般查询日志和慢查询日志的输出形式 日志表 二、一般查询日志 三、慢查询日志 四、错误日志 一、日志简介 常用日志 在MySQL中常用的日志主要有如下几种: 这些日志通常情况下都是关闭的&a…...

XML 编辑器:功能、选择与使用技巧
XML 编辑器:功能、选择与使用技巧 简介 XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。由于其灵活性和广泛的应用,XML编辑器成为开发者、数据管理者和内容创作者的重要工具。本文将探讨XML编辑器的功能、选择标准以及…...
)
单例模式(设计模式)
文章目录 概述1. 饿汉式(hungry Initialization)2. 懒汉式(Lazy Initialization)3.双重检查锁定(Double-Checked Locking)4. 静态内部类(Static Inner Class)5. 枚举(Enu…...
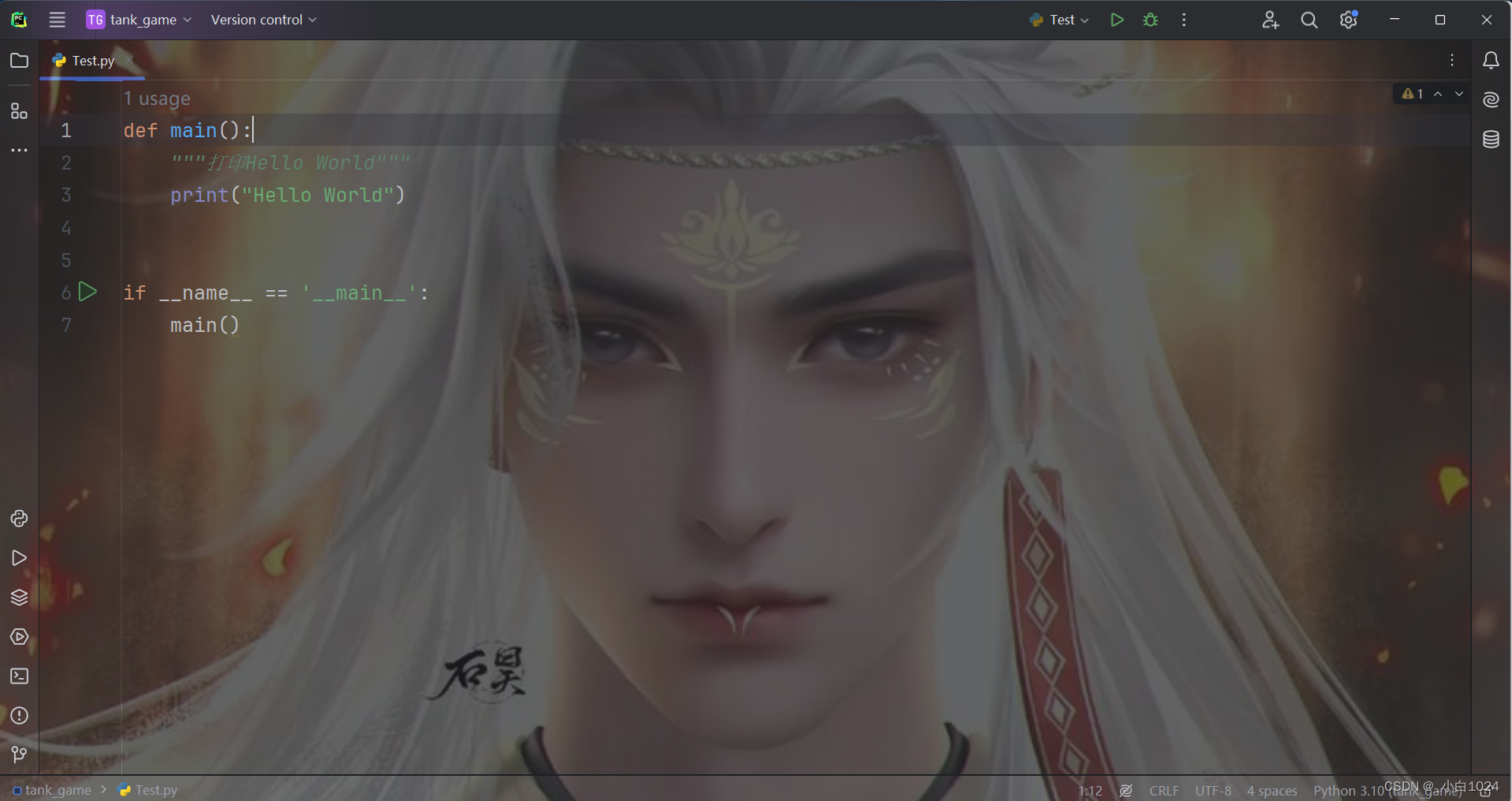
提升你的编程体验:自定义 PyCharm 背景图片
首先,打开 PyCharm 的设置菜单,点击菜单栏中的 File > Settings 来访问设置,也可以通过快捷键 CtrlAItS 打开设置。 然后点击Appearance & Behavior > Appearance。 找到Background image...左键双击进入。 Image:传入自己需要设置…...

SpringCloud与Dubbo区别?
相同点: dubbo与springcloud都可以实现RPC远程调用。 dubbo与springcloud都可以使用分布式、微服务场景下。 区别: dubbo有比较强的背景,在国内有一定影响力。 dubbo使用zk或redis作为作为注册中心 springcloud使用eureka作为注册中心 dubbo支持多种协议,默认使用…...
简单Mesh多线程合并,使用什么库性能更高
1)简单Mesh多线程合并,使用什么库性能更高 2)Unity Semaphore.WaitForSignal耗时高 3)VS编辑的C#代码注释的中文部分乱码 4)变量IntPtr m_cachePtr切换线程后变空 这是第389篇UWA技术知识分享的推送,精选了…...

长亭培训加复习安全产品类别
下面这个很重要参加hw时要问你用的安全产品就有这个 检测类型产品 偏审计 安全防御类型 EDR类似于杀毒软件 安全评估 任何东西都要经过这个机械勘察才能上线 安全管理平台 比较杂 比较集成 审计 漏扫 评估 合在这一个平台 也有可能只是管理 主机理解为一个电脑 安了终端插件…...

memcached介绍和详解
Memcached 是一种高性能、分布式内存缓存系统,常用于加速动态 web 应用程序的性能,通过缓存数据库查询结果、对象等数据,减少对数据库的访问压力,从而提高响应速度和系统吞吐量。 ### Memcached 的特点和工作原理 #### 特点 1. …...

Spring boot 注解实现幂等性
1. 添加 Spring AOP 依赖 在 pom.xml 中添加如下依赖: <dependencies><!-- Spring AOP dependency --><dependency><groupIdorg.springframework.boot</groupId><artifactIdspring-boot-starter-aop</artifactId></depend…...
NVIDIA Jetson AI边缘计算盒子
这里写自定义目录标题 烧录系统安装Jetpack安装cuda安装Pytorch安装onnxruntime安装qv4l2 烧录系统 选择一台Linux系统,或者VMware的电脑作为主机,烧录系统和后面安装Jetpack都会用到。 根据供应商的指令烧录的,暂时还没验证官方烧录&#x…...

React核心概念、主要特点及组件的生命周期
在前端开发的世界中,React以其独特的魅力和强大的功能,成为了构建用户界面的首选框架之一。本文将深入探讨React的核心概念、主要特点以及组件生命周期 React简介 React是由Facebook开发并开源的前端JavaScript库,专门用于构建可重用的UI组…...
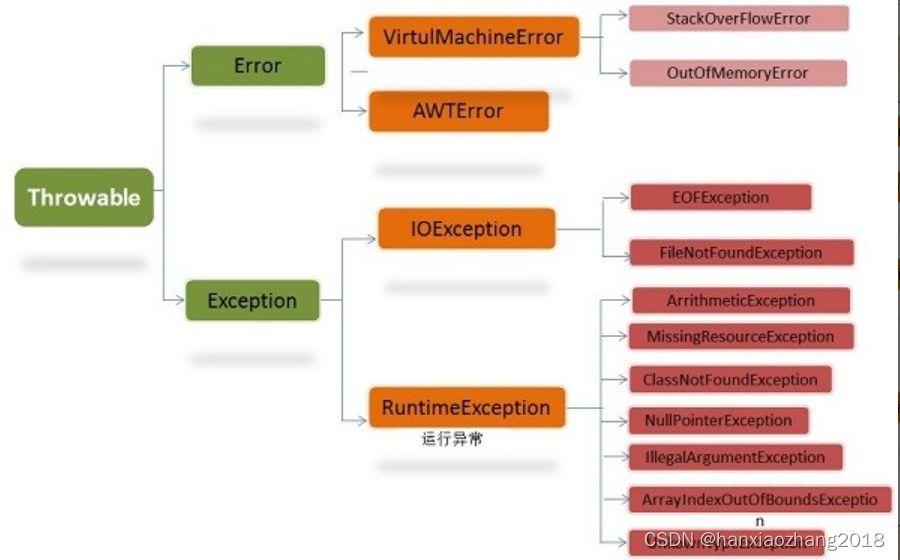
Java基础面试重点-1
0. 符号: *:记忆模糊,验证后特别标注的知识点。 &:容易忘记知识点。 *:重要的知识点。 1. 简述一下Java面向对象的基本特征(四个),以及你自己的应用? 抽象&#…...

DockerHub与私有镜像仓库在容器化中的应用与管理
哈喽,大家好,我是左手python! Docker Hub的应用与管理 Docker Hub的基本概念与使用方法 Docker Hub是Docker官方提供的一个公共镜像仓库,用户可以在其中找到各种操作系统、软件和应用的镜像。开发者可以通过Docker Hub轻松获取所…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

Mybatis逆向工程,动态创建实体类、条件扩展类、Mapper接口、Mapper.xml映射文件
今天呢,博主的学习进度也是步入了Java Mybatis 框架,目前正在逐步杨帆旗航。 那么接下来就给大家出一期有关 Mybatis 逆向工程的教学,希望能对大家有所帮助,也特别欢迎大家指点不足之处,小生很乐意接受正确的建议&…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...

R语言速释制剂QBD解决方案之三
本文是《Quality by Design for ANDAs: An Example for Immediate-Release Dosage Forms》第一个处方的R语言解决方案。 第一个处方研究评估原料药粒径分布、MCC/Lactose比例、崩解剂用量对制剂CQAs的影响。 第二处方研究用于理解颗粒外加硬脂酸镁和滑石粉对片剂质量和可生产…...

提升移动端网页调试效率:WebDebugX 与常见工具组合实践
在日常移动端开发中,网页调试始终是一个高频但又极具挑战的环节。尤其在面对 iOS 与 Android 的混合技术栈、各种设备差异化行为时,开发者迫切需要一套高效、可靠且跨平台的调试方案。过去,我们或多或少使用过 Chrome DevTools、Remote Debug…...
)
LLaMA-Factory 微调 Qwen2-VL 进行人脸情感识别(二)
在上一篇文章中,我们详细介绍了如何使用LLaMA-Factory框架对Qwen2-VL大模型进行微调,以实现人脸情感识别的功能。本篇文章将聚焦于微调完成后,如何调用这个模型进行人脸情感识别的具体代码实现,包括详细的步骤和注释。 模型调用步骤 环境准备:确保安装了必要的Python库。…...

Sklearn 机器学习 缺失值处理 获取填充失值的统计值
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 使用 Scikit-learn 处理缺失值并提取填充统计信息的完整指南 在机器学习项目中,数据清…...