C++的标准容器及其应用
C++的标准容器及其应用
- 数组(array)
- 数组的特征
- 应用实列
- 前向列表(forward_list)
- 前向列表的特征
- 应用实列
- 列表(list)
- 列表的特征
- 应用实列
- 有序映射(map)
- 有序映射的特征
- 应用实列
- 队列(queue)
- 队列的特征
- 应用实列
- priority_queue
- 应用实列
- 集合(set)
- 集合的特征
- 应用实列
- 堆栈(stack)
- 堆栈的特征
- 应用实列
- 无序映射(unordered_map)
- 无序映射的特征
- 应用实列
- 无序集合(unordered_set)
- 无序集合的特征
- 应用实列
- 向量(vector)
- 向量的特征
- 应用实列
数组(array)
数组的特征
数组是固定大小的序列容器:它按严格线性序列,保存排序的特定数量的元素。
在内部,数组除了它包含的元素之外,不保留任何数据(甚至不保留其大小,这是一个模板参数,在编译时固定)。就存储大小而言,它与使用语言的括号语法 ([]) 声明的普通数组一样高效。这个类只是添加了一层成员函数和全局函数,这样数组就可以作为标准容器使用了。
与其他标准容器不同,数组具有固定大小,并且不能通过分配器管理其元素的分配:它们是封装固定大小元素数组的聚合类型。因此,它们不能动态扩展或收缩。
零大小的数组是有效的,但不能调用它的成员函数(比如front, back和data)。
与标准库中的其他容器不同,交换两个数组容器是一种线性操作,涉及单独交换范围中的所有元素,这通常是效率相当低的操作。另一方面,这允许两个容器中的元素的迭代器保持其原始容器关联。
数组容器的另一个独特功能是,它们可以被视为元组(tuple)对象: array 能重载 get 函数以访问数组的元素,就好像它是元组一样,拥有专门的 tuple_size 和 tuple_element 类型。
应用实列
成员函数,size()。
#include <iostream>
#include <array>using namespace std;int main ()
{array<int,5> arr_int = {0};cout << "size of arr_int: " << arr_int.size() << endl;cout << "sizeof(arr_int): " << sizeof(arr_int) << endl;return 0;
}
size of arr_int: 5
sizeof(arr_int): 20
成员函数,data()。
#include <iostream>
#include <cstring>
#include <array>using namespace std;int main ()
{const char* cstr = "Test string";array<char,12> charr;memcpy (charr.data(),cstr,12);cout << charr.data() << '\n';return 0;
}// output
Test string
前向列表(forward_list)
前向列表的特征
前向列表是序列容器,可以用不变的时间,在序列中任何位置进行插入和删除。
前向列表作为单链表实现;单链表可以将它们包含的每个元素存储在不同,且不相关的存储位置。通过与序列中下一个元素的链接的每个元素的关联来保持顺序。
forward_list 容器和列表容器之间的主要设计区别在于,第一个容器仅在内部保留到下一个元素的链接,而后者为每个元素保留两个链接:一个指向下一个元素,一个指向前一个元素,从而实现高效双向迭代,但每个元素消耗额外的存储空间,并且插入和删除元素的时间开销稍高。因此,forward_list 对象比 list 对象更有效,尽管它们只能向前迭代。
与其他基本标准序列容器(数组、向量和双向队列)相比,在容器内任何位置插入、提取和移动元素,forward_list 通常表现更好,因此在密集使用这些元素的算法(如排序算法)中也表现得更好。
与其他序列容器相比,forward_lists 和list的主要缺点是它们无法通过位置直接访问元素;例如,要访问forward_list中的第六个元素,必须从开头迭代到该位置,这需要这些元素之间的距离呈线性时间。它们还消耗一些额外的内存来保存与每个元素关联的链接信息(这对于小型元素的大型列表可能是一个重要因素)。
forward_list 类模板在设计时就考虑到了效率:根据设计,它与简单的手写 C 风格单链表一样高效,事实上,它是唯一出于效率考虑,而故意缺少 size 成员函数的标准容器:由于其作为链表的性质,具有需要恒定时间的大小成员将需要它为其大小保留一个内部计数器(如列表那样)。这会消耗一些额外的存储空间,并使插入和删除操作的效率稍微降低。如果需要获取forward_list对象的大小,可以使用距离算法,加上开始和结束参数,这需要线性操作时间。
应用实列
插入元素
#include <iostream>
#include <forward_list>using namespace std;int main ()
{forward_list<int> mylist;forward_list<int>::iterator it;it = mylist.insert_after ( mylist.before_begin(), 10 );it = mylist.insert_after ( it, 2, 20 ); it = mylist.begin(); it = mylist.insert_after ( it, {1,5,3} ); cout << "mylist contains:";for (auto x: mylist) cout << ' ' << x;cout << endl;return 0;
}// output
mylist contains: 10 1 5 3 20 20
列表(list)
列表的特征
list是序列容器,在list中的任何位置,进行插入和擦除操作,只需要恒定时间。list可以双向迭代。
list容器是用双向链表实现的;双向链表可以将它们包含的每个元素存储在不同且不相关的存储位置。通过与每个元素的关联在内部保持顺序。
它们与forward_list非常相似:主要区别在于forward_list对象是单向链表,因此它们只能向前迭代,以换取更小和更高效的代价。
与其他基本标准序列容器(数组、向量和双端队列)相比,list在已获得迭代器的容器内的任何位置插入、提取和移动元素方面通常表现更好,因此经常出现在密集使用元素操作的算法中,例如排序算法。
与其他序列容器相比,list和前向列表的主要缺点是,它们无法通过位置直接访问元素;例如,要访问列表中的第六个元素,必须从已知位置(例如开头或结尾)迭代到该位置,这需要这些位置之间的距离呈线性时间。它们还消耗一些额外的内存来保存与每个元素关联的链接信息。
应用实列
在表头插入操作
#include <iostream>
#include <list>using namespace std;int main ()
{list<int> mylist = {2,100}; // two ints with a value of 100mylist.push_front (200);mylist.push_front (300);cout << "mylist contains:";for (list<int>::iterator it=mylist.begin(); it!=mylist.end(); ++it)std::cout << ' ' << *it;cout << '\n';return 0;
}// output
mylist contains: 300 200 2 100
有序映射(map)
有序映射的特征
map是关联容器,它按照特定的顺序,存储由键值和映射值组合形成的元素。
在map中,键值通常用于对元素进行排序和唯一标识,而映射值则存储与该键关联的内容。键和映射值的类型可能不同,按照成员类型 value_type,组合在一起。
typedef pair<const Key, T> value_type;
在内部,map 中的元素始终按其键排序,遵循其内部比较对象(Compare 类型)指示的特定严格弱排序标准。
通过键访问各个元素时,map 容器通常比 unordered_map 容器慢,但它们允许根据子集的顺序,直接迭代。
可以使用括号运算符 ((operator[]) 通过相应的键,直接访问映射中的映射值。
通常使用二叉搜索树实现map 。
应用实列
使用key_comp排序。
#include <iostream>
#include <map>
#include <string>
#include <functional>
#include <algorithm>using namespace std;void print_map(const map<string, int, greater<string>>& m)
{for (const auto v : m)std::cout << '[' << v.first << "] = " << v.second << "; ";std::cout << '\n';
}int main()
{map<string, int, greater<string>> m{{"CPU", 10}, {"GPU", 15}, {"RAM", 20}};print_map(m);m["CPU"] = 25; m["SSD"] = 30;print_map(m);m.erase("GPU");print_map( m);
}// output
[RAM] = 20; [GPU] = 15; [CPU] = 10;
[SSD] = 30; [RAM] = 20; [GPU] = 15; [CPU] = 25;
[SSD] = 30; [RAM] = 20; [CPU] = 25;
队列(queue)
队列的特征
queue是一种容器适配器,专门设计用于在 FIFO 上下文(先进先出)中操作,其中元素被插入到容器的一端并从另一端提取。
queue被实现为容器适配器,它们是使用特定容器类的封装对象作为其底层容器的类,提供一组特定的成员函数来访问其元素。元素被推入特定容器的“后面”并从其“前面”弹出。
底层容器可以是标准容器类模板之一或一些其他专门设计的容器类。该底层容器至少应支持以下操作:
empty
size
front
back
push_back
pop_front
标准容器类 deque 和 list 满足这些要求。默认情况下,如果没有为特定队列类实例化指定容器类,则使用标准容器 deque。
应用实列
#include <iostream>
#include <array>
#include <queue> using namespace std;int main ()
{array<int, 5> arr = {1,2,3,4,5};queue<int> myqueue;int myint;for (auto x : arr)myqueue.push (x);cout << "myqueue contains: ";while (!myqueue.empty()){cout << ' ' << myqueue.front();myqueue.pop();}cout << '\n';return 0;
}
myqueue contains: 1 2 3 4 5
priority_queue
priority_queue是一种容器适配器,经过专门设计,根据某些严格的弱排序标准,其第一个元素始终是其包含的最大元素。
此上下文类似于堆,可以随时插入元素,并且只能检索最大堆元素(优先级队列中位于顶部的元素)。
priority_queue被实现为容器适配器,它们是使用特定容器类的封装对象作为其底层容器的类,提供一组特定的成员函数来访问其元素。元素从特定容器的“后面”弹出,即优先级队列的顶部。
底层容器可以是任何标准容器类模板或一些其他专门设计的容器类。容器应可通过随机访问迭代器进行访问并支持以下操作:
empty()
size()
front()
push_back()
pop_back()
标准容器类vector和deque满足这些要求。默认情况下,如果没有为特定priority_queue类实例化指定容器类,则使用标准容器vector。
需要随机访问迭代器的支持才能始终在内部保留堆结构。这是由容器适配器通过在需要时自动调用算法函数 make_heap、push_heap 和 pop_heap 自动完成的。
应用实列
下面展示一些 内联代码片。
#include <iostream>
#include <array>
#include <queue> using namespace std;template<typename T>
void pop_println(string rem, T& pq)
{cout << rem << ": ";for (; !pq.empty(); pq.pop())cout << pq.top() << ' ';cout << endl;
}int main()
{const auto data = {1, 8, 5, 6, 3, 4, 0, 9, 7, 2};priority_queue<int> max_priority_queue;for (int n : data)max_priority_queue.push(n);pop_println("max_priority_queue", max_priority_queue);priority_queue<int, vector<int>, greater<int>>min_priority_queue1(data.begin(), data.end());pop_println("min_priority_queue1", min_priority_queue1);struct customLess{bool operator()(int l, int r) const { return l > r; }};priority_queue<int, vector<int>, customLess> custom_priority_queue;for (int n : data)custom_priority_queue.push(n); pop_println("custom_priority_queue", custom_priority_queue);priority_queue<int, vector<int>, greater<int>> priority_queue;for (int n : data)priority_queue.push(n); pop_println("priority_queue", priority_queue);
}
// output
max_priority_queue: 9 8 7 6 5 4 3 2 1 0
min_priority_queue1: 0 1 2 3 4 5 6 7 8 9
custom_priority_queue: 0 1 2 3 4 5 6 7 8 9
priority_queue: 0 1 2 3 4 5 6 7 8 9
集合(set)
集合的特征
set是按照特定顺序存储唯一元素的容器。
在set中,元素的值也标识它(值本身就是键),并且每个值必须是唯一的。集合中元素的值一旦在容器中就无法修改(元素始终是常量),但可以将它们插入容器或从容器中删除。
在内部,set中的元素始终按照其内部比较对象(Compare 类型)指示的特定严格弱排序标准进行排序。
通过键访问元素,set 容器通常比 unordered_set 慢,但set允许根据子集的顺序直接迭代。
通常使用二叉搜索树实现set。
应用实列
#include <iostream>
#include <set>using namespace std;struct FatKey
{int x;int data[1000];
};struct customComp
{bool operator()(FatKey r, FatKey l){return (r.x > l.x);}
};int main()
{set<int> example{1, 2, 3, 4};for ( auto x : example)cout << x << ", ";cout<<endl;auto search = example.find(2);if (search != example.end())cout << "Found " << (*search) << '\n';elsecout << "Not found\n";set<FatKey, customComp> example2{{1, {}}, {2, {}}, {3, {}}, {4, {}}};for ( auto x : example2)cout << x.x << ", ";cout<<endl;FatKey lk = {3};auto s2 = example2.find(lk); if (s2 != example2.end())std::cout << "Found " << s2->x << '\n';elsestd::cout << "Not found\n";
}
// output
1, 2, 3, 4,
Found 2
4, 3, 2, 1,
Found 3
堆栈(stack)
堆栈的特征
stack是一种容器适配器,专门设计用于在 LIFO 上下文(后进先出)中操作,其中仅从容器的一端插入和提取元素。
stack被实现为容器适配器,它们是使用特定容器类的封装对象作为其底层容器的类,提供一组特定的成员函数来访问其元素。元素从特定容器的“后面”(称为堆栈顶部)推送/弹出。
底层容器可以是任何标准容器类模板或一些其他专门设计的容器类。容器应支持以下操作:
empty
size
back
push_back
pop_back
标准容器类向量、双端队列和列表满足这些要求。默认情况下,如果没有为特定堆栈类实例化指定容器类,则使用标准容器双端队列。
应用实列
#include <iostream> // std::cout
#include <stack> // std::stackusing namespace std;int main ()
{stack<int> mystack;for (int i=0; i<5; ++i) mystack.push(i);cout << "Popping out elements...";while (!mystack.empty()){cout << ' ' << mystack.top();mystack.pop();}cout << endl;return 0;
}
// output
Popping out elements... 4 3 2 1 0
无序映射(unordered_map)
无序映射的特征
无序映射是关联容器,用于存储由键值和映射值组合形成的元素,并且允许基于键快速检索各个元素。
在unordered_map中,键值通常用于唯一标识元素,而映射值是一个对象,其内容与该键相关联。键和映射值的类型可能不同。
在内部,unordered_map 中的元素不会按照其键或映射值以任何特定顺序排序,而是根据其哈希值组织到存储桶中,以允许直接通过其键值(使用常量)快速访问各个元素平均时间复杂度)。
unordered_map 容器通过键访问各个元素比 map 容器更快,尽管它们通常在通过其元素子集进行范围迭代时效率较低。
无序映射实现直接访问运算符(operator[]),它允许使用其键值作为参数直接访问映射值。
容器中的迭代器至少是前向迭代器。
应用实列
#include <iostream>
#include <string>
#include <unordered_map>using namespace std;int main()
{// Create an unordered_map of three strings (that map to strings)unordered_map<string, string> u ={{"RED", "#FF0000"},{"GREEN", "#00FF00"},{"BLUE", "#0000FF"}};// Helper lambda function to print key-value pairsauto print_key_value = [](const auto& key, const auto& value){cout << "Key:[" << key << "] Value:[" << value << "]\n";};for (const pair<const string, string>& n : u)print_key_value(n.first, n.second);cout << "\n";// Add two new entries to the unordered_mapu["BLACK"] = "#000000";u["WHITE"] = "#FFFFFF";for (const auto& n : u)print_key_value(n.first, n.second);
}// output
Key:[BLUE] Value:[#0000FF]
Key:[GREEN] Value:[#00FF00]
Key:[RED] Value:[#FF0000]Key:[WHITE] Value:[#FFFFFF]
Key:[BLACK] Value:[#000000]
Key:[RED] Value:[#FF0000]
Key:[GREEN] Value:[#00FF00]
Key:[BLUE] Value:[#0000FF]
无序集合(unordered_set)
无序集合的特征
无序集是不按特定顺序存储唯一元素的容器,并且允许根据单个元素的值快速检索各个元素。
在 unordered_set 中,元素的值同时也是其唯一标识它的键。键是不可变的,因此,unordered_set 中的元素一旦进入容器就无法修改, 但它们可以插入和删除。
在内部,unordered_set 中的元素不按任何特定顺序排序,而是根据其哈希值组织到存储桶中,以允许直接通过其值快速访问各个元素(平均时间复杂度恒定)。
通过键访问各个元素, unordered_set 容器比 set 容器更快,尽管它们通常在通过其元素子集进行范围迭代时效率较低。
容器中的迭代器至少是前向迭代器。
应用实列
#include <iostream>
#include <unordered_set>using namespace std;void print(const unordered_set<int> set)
{for (const auto& elem : set)cout << elem << ' ';cout << '\n';
}int main()
{unordered_set<int> mySet{2, 7, 1, 8, 2, 8}; // initializingprint(mySet);mySet.insert(5); // puts an element 5 in the setprint(mySet);auto iter = mySet.find(5); if (iter != mySet.end())mySet.erase(iter); // removes an element pointed to by iterprint(mySet);mySet.erase(7); // removes an element 7print(mySet);
}
// ourput
8 1 7 2
5 8 1 7 2
8 1 7 2
8 1 2
向量(vector)
向量的特征
向量是表示大小可以更改的数组的序列容器。
就像数组一样,向量对其元素使用连续的存储位置,这意味着, 可以使用指向其元素的常规指针上的偏移量来访问其元素,并且与数组中一样高效。但与数组不同的是,它们的大小可以动态变化,其存储由容器自动处理。
在内部,向量使用动态分配的数组来存储其元素。当插入新元素时,可能需要重新分配该数组, 以便增加大小,这意味着分配一个新数组, 并将所有元素移动到其中。就处理时间而言,这是一项相对昂贵的任务,因此,每次将元素添加到容器时,向量不会重新分配。
相反,向量容器可以分配一些额外的存储, 来适应可能的增长,因此容器的实际容量可能大于包含其元素严格需要的存储(即,其大小)。库可以实施不同的增长策略,以平衡内存使用和重新分配之间的平衡,但在任何情况下,重新分配只能以对数增长的大小间隔进行,以便可以为向量末尾的各个元素的插入提供常量时间复杂性。
因此,与数组相比,向量消耗更多的内存来换取管理存储和以高效方式动态增长的能力。
与其他动态序列容器(双端队列、列表和前向列表)相比,向量可以非常高效地访问其元素(就像数组一样),并且从其末尾添加或删除元素也相对高效。对于涉及在末尾以外的位置插入或删除元素的操作,它们的性能比其他操作更差,并且迭代器和引用的一致性不如列表和前向列表。
应用实列
#include <iostream>
#include <vector>using namespace std;int main()
{vector<int> v = {8, 4, 5, 9};v.push_back(6);v.push_back(9);v[2] = -1;for (int n : v)cout << n << ' ';cout << endl;
}
// output
8 4 -1 9 6 9
相关文章:

C++的标准容器及其应用
C的标准容器及其应用 数组(array)数组的特征应用实列 前向列表(forward_list)前向列表的特征应用实列 列表(list)列表的特征应用实列 有序映射(map)有序映射的特征应用实列 队列&…...

linux如何部署前端项目和安装nginx
要在Linux上部署前端项目并安装Nginx,你可以按照以下步骤操作: 安装Nginx: sudo apt update sudo apt install nginx 启动Nginx服务: sudo systemctl start nginx 确保Nginx服务开机自启: sudo systemctl enable nginx 部署前端项目,假设前…...

Coolify:24.2K 星星!使用全新、开源免费且自托管的替代方案,部署应用程序的最佳工具(停止使用 Vercel)
✨点击这里✨:🚀原文链接:(更好排版、视频播放、社群交流、最新AI开源项目、AI工具分享都在这个公众号!) Coolify:24.2K 星星!使用全新、开源免费且自托管的替代方案,部…...

Dubbo入门
Dubbo,听名字好像有点高大上,但实际上它就是个让不同的计算机程序之间能够互相交流的工具,专业点说,它是一个分布式服务框架。想象一下,你有好几个小团队,每个团队负责开发一个部分,最后这些部分…...

从零学习es8
配置 编辑 elasticsearch.yml xpack.security.enabled: true 单节点 discovery.type: single-node设置账号: elasticsearch-reset-password -u elastic 如果要将密码设置为特定值,请使用交互式 (-i) 参数运行该命令。 elasticsearch-reset-password -i…...
方法详解)
String.compareTo()方法详解
Java 中的 String.compareTo() 方法用于按字典顺序比较两个字符串。这个方法实现了 Comparable 接口,返回一个整数,表示字符串的相对顺序。 方法签名 public int compareTo(String anotherString)返回值 一个负整数:如果当前字符串在字典顺…...
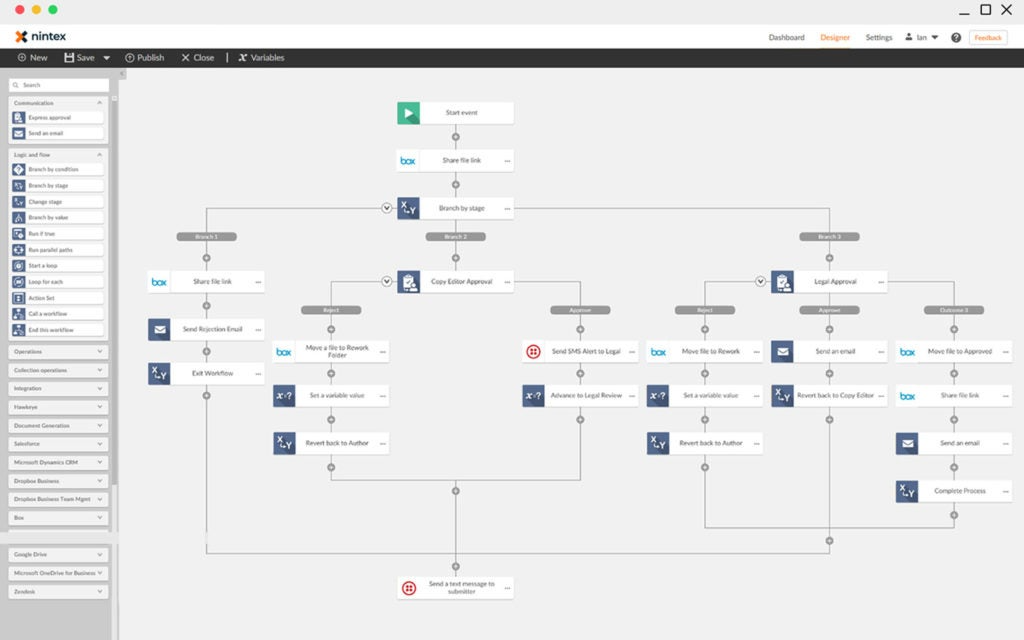
Nintex流程平台引入生成式人工智能,实现自动化革新
工作流自动化提供商Nintex宣布在其Nintex流程平台上推出一系列新的人工智能驱动改进。这些增强显著减少了文档化、管理和自动化业务流程所需的时间。这些新特性为Nintex流程平台不断扩展的人工智能能力增添了新的亮点。 Nintex首席产品官Niranjan Vijayaragavan表示:…...
)
永远不要做房间里“最聪明的人”(早懂早受益)
听好了,茶客,我要向你解释一些事情。 你的工作和职责是让客户认为他是房间里最聪明的人。 如果你完成了这项任务之后,还有多余的精力,应该用它来让你的高级合伙人显得像是房间里第二聪明的人。 只有履行了这两项义务之后ÿ…...

Leetcode 3177. Find the Maximum Length of a Good Subsequence II
Leetcode 3177. Find the Maximum Length of a Good Subsequence II 1. 解题思路2. 代码实现 题目链接:3177. Find the Maximum Length of a Good Subsequence II 1. 解题思路 这一题我一开始的思路是直接使用暴力的动态规划的方式进行实现,结果遇到了…...
)
程序员做电子书产品变现的复盘(2)
赚钱有多种,简单分为两类。 (1)手停口停型,这种工作在你积极从事时可能每天能带来数千甚至上万的收入,但一旦停止工作,收入就会大幅下降甚至归零,例如我们的日常工资。 (2…...

Java中的JVM是什么?如何调优JVM的性能?
Java中的JVM(Java Virtual Machine)是一个虚构出来的计算机,是一个规范,它在运行Java程序时扮演着核心角色。调优JVM的性能可以通过内存管理、垃圾回收、编译器优化等方法来提升Java应用程序的性能和稳定性。 Java中的JVM&#x…...

大型医院手术麻醉系统源码,前端采用Vue,Ant-Design开发,稳定成熟
医院手麻系统源码,手术麻醉信息系统,C#源码 医院手术麻醉信息系统包含了手术申请、排班、术前、术中、术后,直至出院的全过程。通过与相关医疗设备连接,与大屏幕显示公告相连接,实现了手术麻醉临床应用数据链全打通。…...
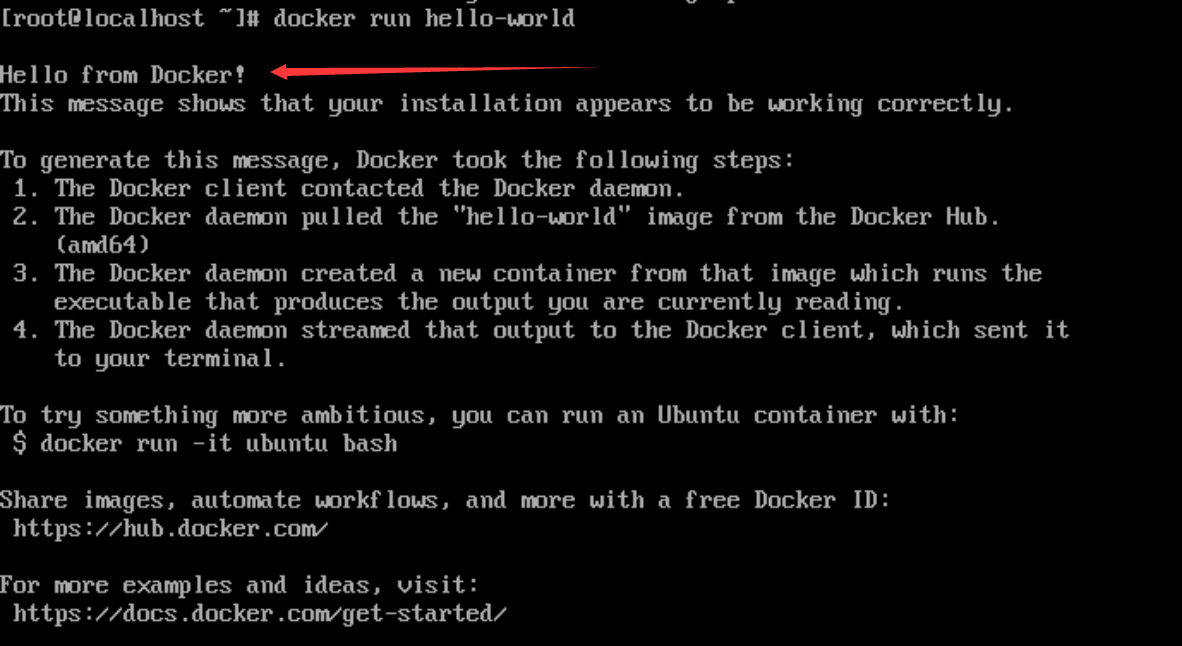
Linux安装Docker | 使用国内镜像
环境 CentOS7 先确认能够上网 curl www.baidu.com返回该输出说明网络OK 步骤一:安装gcc 和 gcc-c yum -y install gccyum -y install gcc-c步骤二:安装Docker仓库 yum install -y yum-utils接下来配置yum的国内镜像 yum-config-manager --add-re…...
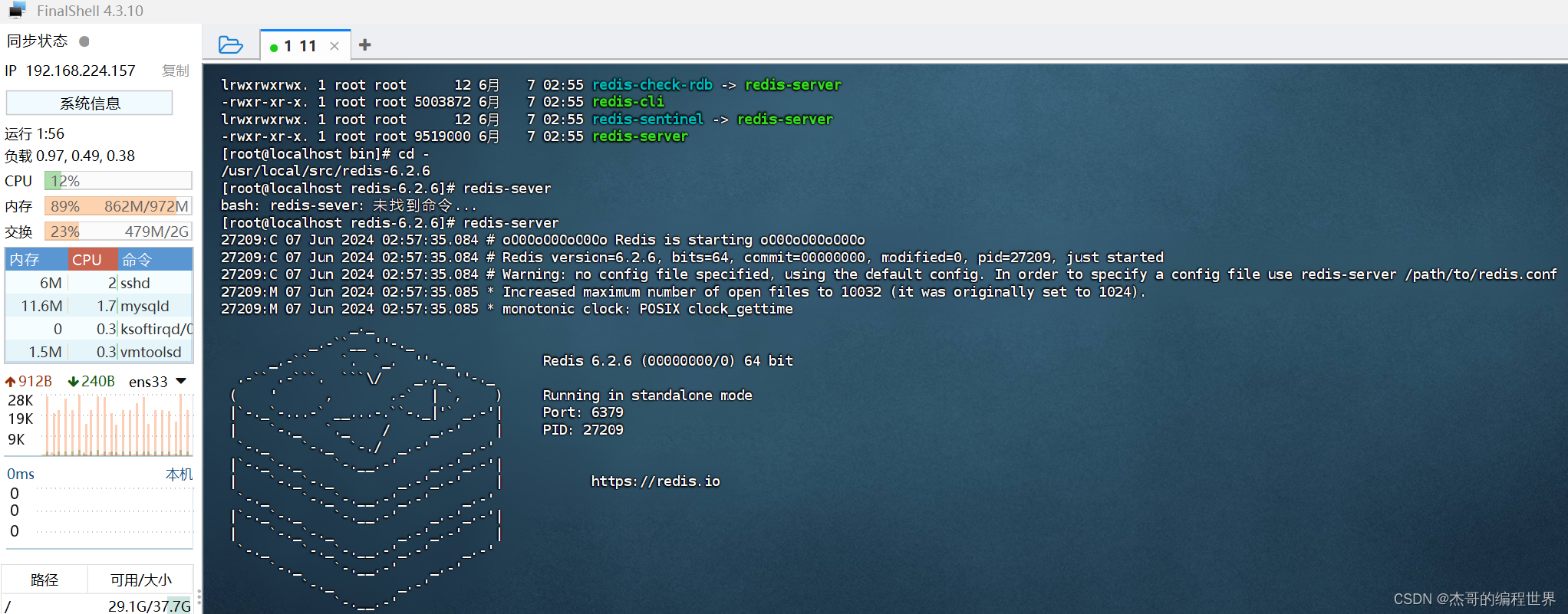
redis易懂快速安装(linux)2024
1.首先打开虚拟机系统 2.打开终端,输入su - 输入管理员密码,进入管理员用户 3.输入inconfig查看ip地址 4.打开final shell 连接虚拟机,输入ip和root用户以及密码 5.连接成功 6.输入 cd /usr/local/src/ 进入要安装的文件夹 6.点击上传按钮…...

关于数据库存储【\】转义字符反斜杠丢失的问题
背景 开始的时候,发现一个很奇怪的现象 富文本编辑器,前端存储带有"的内容,回显的时候解析就会出问题 后来发现,其实是只要是需要带有\进行转义的内容就会有问题 排查 从前端提交数据,后端获取数据ÿ…...

Unity3D 如何做好版本控制
目前项目这样版本控制: 1、在unity里,应该只对Assets(包含,meta)和ProjectSettings这两个文件夹做版本控制,其他的文件都是unity或工具生成出来的。 2、设置project setting ->editor setting-> Asset seriali…...
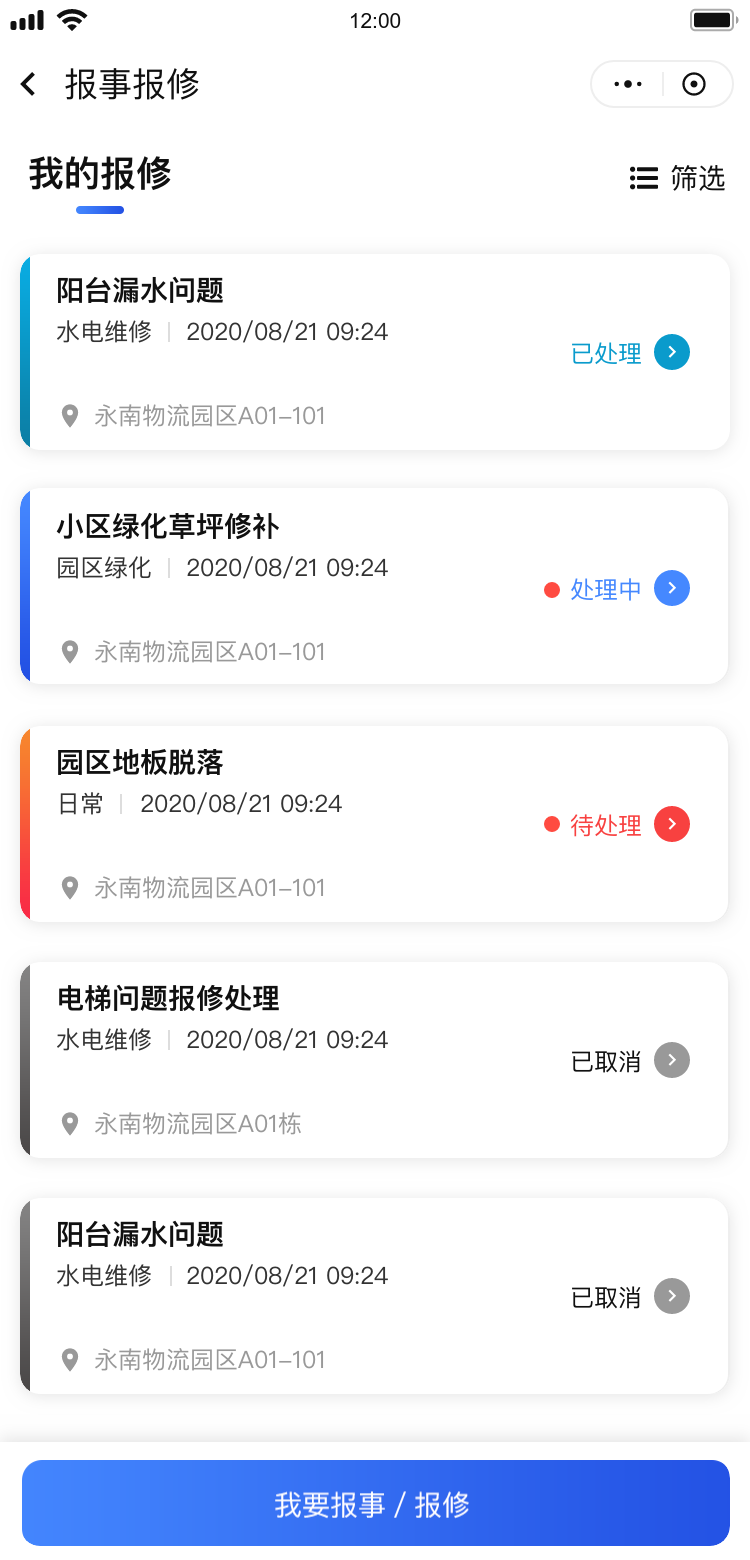
移动端消息中心,你未必会设计,发一些示例出来看看。
APP消息中心是一个用于管理和展示用户收到的各种消息和通知的功能模块。它在APP中的作用是提供一个集中管理和查看消息的界面,让用户能够方便地查看和处理各种消息。 以下是设计APP消息中心的一些建议: 1. 消息分类: 将消息按照不同的类型进…...

Non-zero exit code pycharm
目录 windows 设置conda代理: linux Conda 使用代理 4. 修改 Conda SSL 验证 pycharm 报错 exceted command pip 设置代理 Non-zero exit code 科学上网后,pip安装时警告报错 WARNING: Retrying (Retry(total0, connectNone, readNone, redirectNo…...
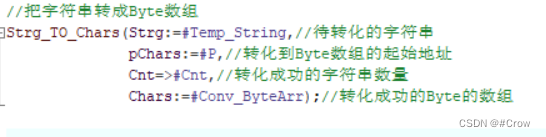
西门子学习笔记12 - BYTE-REAL互相转化
这是针对于前面MQTT协议的接收和发送数组只能是BYTE数组做出的对应的功能块封装。 1、BYTE-REAL转化 1、把byte数组转成字符串形式 2、把字符串转成浮点数 2、REAL-BYTE转化 1、把浮点数转成字符串 2、把字符串转成Byte数组...

科技云报道:“元年”之后,生成式AI将走向何方?
科技云报道原创。 近两年,以大模型为代表的生成式AI技术,成为引爆数字原生最重要的技术奇点,人们见证了各类文生应用的进展速度。Gartner预测,到2026年,超过80%的企业将使用生成式AI的API或模型,或在生产环…...

XML Group端口详解
在XML数据映射过程中,经常需要对数据进行分组聚合操作。例如,当处理包含多个物料明细的XML文件时,可能需要将相同物料号的明细归为一组,或对相同物料号的数量进行求和计算。传统实现方式通常需要编写脚本代码,增加了开…...

[特殊字符] 智能合约中的数据是如何在区块链中保持一致的?
🧠 智能合约中的数据是如何在区块链中保持一致的? 为什么所有区块链节点都能得出相同结果?合约调用这么复杂,状态真能保持一致吗?本篇带你从底层视角理解“状态一致性”的真相。 一、智能合约的数据存储在哪里…...

Swift 协议扩展精进之路:解决 CoreData 托管实体子类的类型不匹配问题(下)
概述 在 Swift 开发语言中,各位秃头小码农们可以充分利用语法本身所带来的便利去劈荆斩棘。我们还可以恣意利用泛型、协议关联类型和协议扩展来进一步简化和优化我们复杂的代码需求。 不过,在涉及到多个子类派生于基类进行多态模拟的场景下,…...

基础测试工具使用经验
背景 vtune,perf, nsight system等基础测试工具,都是用过的,但是没有记录,都逐渐忘了。所以写这篇博客总结记录一下,只要以后发现新的用法,就记得来编辑补充一下 perf 比较基础的用法: 先改这…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

【无标题】路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论
路径问题的革命性重构:基于二维拓扑收缩色动力学模型的零点隧穿理论 一、传统路径模型的根本缺陷 在经典正方形路径问题中(图1): mermaid graph LR A((A)) --- B((B)) B --- C((C)) C --- D((D)) D --- A A -.- C[无直接路径] B -…...

AirSim/Cosys-AirSim 游戏开发(四)外部固定位置监控相机
这个博客介绍了如何通过 settings.json 文件添加一个无人机外的 固定位置监控相机,因为在使用过程中发现 Airsim 对外部监控相机的描述模糊,而 Cosys-Airsim 在官方文档中没有提供外部监控相机设置,最后在源码示例中找到了,所以感…...