MySQL 中 Varchar(50) 和 varchar(500) 区别是什么?
一. 问题描述
我们在设计表结构的时候,设计规范里面有一条如下规则:
-
对于可变长度的字段,在满足条件的前提下,尽可能使用较短的变长字段长度。
为什么这么规定?我在网上查了一下,主要基于两个方面
-
基于存储空间的考虑
-
基于性能的考虑
网上说Varchar(50)和varchar(500)存储空间上是一样的,真的是这样吗?
基于性能考虑,是因为过长的字段会影响到查询性能?
本文我将带着这两个问题探讨验证一下
二.验证存储空间区别
1.准备两张表
CREATE TABLE `category_info_varchar_50` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(50) NOT NULL COMMENT '分类名称',`is_show` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否展示:0 禁用,1启用',`sort` int(11) NOT NULL DEFAULT '0' COMMENT '序号',`deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除',`create_time` datetime NOT NULL COMMENT '创建时间',`update_time` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`) USING BTREE,KEY `idx_name` (`name`) USING BTREE COMMENT '名称索引'
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='分类';CREATE TABLE `category_info_varchar_500` (`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键',`name` varchar(500) NOT NULL COMMENT '分类名称',`is_show` tinyint(4) NOT NULL DEFAULT '0' COMMENT '是否展示:0 禁用,1启用',`sort` int(11) NOT NULL DEFAULT '0' COMMENT '序号',`deleted` tinyint(1) DEFAULT '0' COMMENT '是否删除',`create_time` datetime NOT NULL COMMENT '创建时间',`update_time` datetime NOT NULL COMMENT '更新时间',PRIMARY KEY (`id`) USING BTREE,KEY `idx_name` (`name`) USING BTREE COMMENT '名称索引'
) ENGINE=InnoDB AUTO_INCREMENT=288135 DEFAULT CHARSET=utf8mb4 COMMENT='分类';
2.准备数据
给每张表插入相同的数据,为了凸显不同,插入100万条数据
DELIMITER $$
CREATE PROCEDURE batchInsertData(IN total INT)
BEGINDECLARE start_idx INT DEFAULT 1;DECLARE end_idx INT;DECLARE batch_size INT DEFAULT 500;DECLARE insert_values TEXT;SET end_idx = LEAST(total, start_idx + batch_size - 1);WHILE start_idx <= total DOSET insert_values = '';WHILE start_idx <= end_idx DOSET insert_values = CONCAT(insert_values, CONCAT('(\'name', start_idx, '\', 0, 0, 0, NOW(), NOW()),'));SET start_idx = start_idx + 1;END WHILE;SET insert_values = LEFT(insert_values, LENGTH(insert_values) - 1); -- Remove the trailing commaSET @sql = CONCAT('INSERT INTO category_info_varchar_50 (name, is_show, sort, deleted, create_time, update_time) VALUES ', insert_values, ';');PREPARE stmt FROM @sql;EXECUTE stmt;SET @sql = CONCAT('INSERT INTO category_info_varchar_500 (name, is_show, sort, deleted, create_time, update_time) VALUES ', insert_values, ';'); PREPARE stmt FROM @sql;EXECUTE stmt;SET end_idx = LEAST(total, start_idx + batch_size - 1);END WHILE;
END$$
DELIMITER ;CALL batchInsertData(1000000);
3.验证存储空间
查询第一张表SQL
SELECTtable_schema AS "数据库",table_name AS "表名",table_rows AS "记录数",TRUNCATE ( data_length / 1024 / 1024, 2 ) AS "数据容量(MB)",TRUNCATE ( index_length / 1024 / 1024, 2 ) AS "索引容量(MB)"
FROMinformation_schema.TABLES
WHEREtable_schema = 'test_mysql_field' and TABLE_NAME = 'category_info_varchar_50'
ORDER BYdata_length DESC,index_length DESC;
查询结果

查询第二张表SQL
SELECTtable_schema AS "数据库",table_name AS "表名",table_rows AS "记录数",TRUNCATE ( data_length / 1024 / 1024, 2 ) AS "数据容量(MB)",TRUNCATE ( index_length / 1024 / 1024, 2 ) AS "索引容量(MB)"
FROMinformation_schema.TABLES
WHEREtable_schema = 'test_mysql_field' and TABLE_NAME = 'category_info_varchar_500'
ORDER BYdata_length DESC,index_length DESC;
查询结果

4.结论
两张表在占用空间上确实是一样的,并无差别
三.验证性能区别
1.验证索引覆盖查询
select name from category_info_varchar_50 where name = 'name100000'
-- 耗时0.012s
select name from category_info_varchar_500 where name = 'name100000'
-- 耗时0.012s
select name from category_info_varchar_50 order by name;
-- 耗时0.370s
select name from category_info_varchar_500 order by name;
-- 耗时0.379s
通过索引覆盖查询性能差别不大
1.验证索引查询
select * from category_info_varchar_50 where name = 'name100000'
--耗时 0.012s
select * from category_info_varchar_500 where name = 'name100000'
--耗时 0.012s
select * from category_info_varchar_50 where name in('name100','name1000','name100000','name10000','name1100000',
'name200','name2000','name200000','name20000','name2200000','name300','name3000','name300000','name30000','name3300000',
'name400','name4000','name400000','name40000','name4400000','name500','name5000','name500000','name50000','name5500000',
'name600','name6000','name600000','name60000','name6600000','name700','name7000','name700000','name70000','name7700000','name800',
'name8000','name800000','name80000','name6600000','name900','name9000','name900000','name90000','name9900000')
-- 耗时 0.011s -0.014s
-- 增加 order by name 耗时 0.012s - 0.015sselect * from category_info_varchar_50 where name in('name100','name1000','name100000','name10000','name1100000',
'name200','name2000','name200000','name20000','name2200000','name300','name3000','name300000','name30000','name3300000',
'name400','name4000','name400000','name40000','name4400000','name500','name5000','name500000','name50000','name5500000',
'name600','name6000','name600000','name60000','name6600000','name700','name7000','name700000','name70000','name7700000','name800',
'name8000','name800000','name80000','name6600000','name900','name9000','name900000','name90000','name9900000')
-- 耗时 0.012s -0.014s
-- 增加 order by name 耗时 0.014s - 0.017s
索引范围查询性能基本相同, 增加了order By后开始有一定性能差别;
3.验证全表查询和排序
全表无排序

![]()
全表有排序
select * from category_info_varchar_50 order by name ;
--耗时 1.498s
select * from category_info_varchar_500 order by name ;
--耗时 4.875s

![]()
结论:
全表扫描无排序情况下,两者性能无差异,在全表有排序的情况下, 两种性能差异巨大;
分析原因
varchar50 全表执行sql分析

我发现86%的时花在数据传输上,接下来我们看状态部分,关注Created_tmp_files和sort_merge_passes


Created_tmp_files为3
sort_merge_passes为95
varchar500 全表执行sql分析

增加了临时表排序


Created_tmp_files 为 4
sort_merge_passes为645
关于sort_merge_passes, Mysql给出了如下描述:
❝Number of merge passes that the sort algorithm has had to do. If this value is large, you may want to increase the value of the sort_buffer_size.
❞
其实sort_merge_passes对应的就是MySQL做归并排序的次数,也就是说,如果sort_merge_passes值比较大,说明sort_buffer和要排序的数据差距越大,我们可以通过增大sort_buffer_size或者让填入sort_buffer_size的键值对更小来缓解sort_merge_passes归并排序的次数。
四.最终结论
至此,我们不难发现,当我们最该字段进行排序操作的时候,Mysql会根据该字段的设计的长度进行内存预估, 如果设计过大的可变长度, 会导致内存预估的值超出sort_buffer_size的大小, 导致mysql采用磁盘临时文件排序,最终影响查询性能
相关文章:
MySQL 中 Varchar(50) 和 varchar(500) 区别是什么?
一. 问题描述 我们在设计表结构的时候,设计规范里面有一条如下规则: 对于可变长度的字段,在满足条件的前提下,尽可能使用较短的变长字段长度。 为什么这么规定?我在网上查了一下,主要基于两个方面 基于存储空间的考…...

强化RAG:微调Embedding还是LLM?
为什么我们需要微调? 微调有利于提高模型的效率和有效性。它可以减少训练时间和成本,因为它不需要从头开始。此外,微调可以通过利用预训练模型的功能和知识来提高性能和准确性。它还提供对原本无法访问的任务和领域的访问,因为它…...

提取 Excel单元格文本下的超链接
在Excel中,可以使用内置的函数来提取单元格中的超链接地址。如果你有一个包含超链接的单元格,例如B1,你可以使用以下步骤来提取这个超链接: 在一个新的单元格(例如C1)中,输入以下公式ÿ…...

一键安全体检!亚信安全携手鼎捷软件推出企业安全体检活动 正式上线
亚信安全联合鼎捷软件股份有限公司(以下简称“鼎捷软件”)正式推出“一键安全体检”服务。亚信安全网络安全专家将携手鼎捷软件数据安全专家,围绕企业的数智安全状况,进行问题探索与治愈、新问题预测与预警,在全面筛查…...
)
numpy - array(1)
一维数据:向量 二位数据:矩阵 维度超过三维的数据:张量 这些数据在numpy中统称array (1)使用穷举法创建多为数据,接受列表或者元组类型的数据 a numpy.array([1, 2, 3]) b numpy.array([[1, 2, 3], (4, 5, 6), [7, 8, 9]]) (2)创建所有元…...
师彼长技以助己(6)递归思维
师彼长技以助己(6)递归思维 递归思维-小游戏 思维小游戏 思维 小游戏:1 玩一个从1或2开始往上加的游戏,谁加到20就赢 如何保证一定赢呢?我们倒推,要先到20的话,谁先到17就赢,如此…...

Kali Linux 2024.2
Kali Linux 2024.2 版本(t64、GNOME 46 和社区包) 比平常晚了一点,但 Kali 2024.2 来了!延迟是由于实现这一目标的幕后变化所致,这也是人们关注的焦点。社区提供了大量帮助,这次他们不仅添加了新的软件包&…...
【Spine学习08】之短飘,人物头发动效制作思路
上一节说完了跑步的, 这节说头发发型。 基础过程总结: 1.创建骨骼(头发需要在上方加一个总骨骼) 2.创建网格(并绑定黄线) 3.绑定权重(发根位置的顶点赋予更多总骨骼的权重) 4.切换到…...

chatgpt的命令词
人不走空 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌赋:斯是陋室,惟吾德馨 目录 🌈个人主页:人不走空 💖系列专栏:算法专题 ⏰诗词歌…...

用python把docx批量转为pdf
为保证转换质量,本文的方法是通过脚本和com技术调用office自带的程序进行转换的,因此需要电脑已经装有office。如果希望不装office也能用,则需要研究OpenXML技术,后面实在闲的慌(退休)再搞。 安装所需库 …...

项目采购管理
目录 1.概述 2.三个子过程 2.1.规划采购管理 2.2.实施采购 2.3.控制采购 2.4.归属过程组 3.应用场景 3.1.十个应用场景 3.2.软件开发项目 3.2.1. 需求识别和分析 3.2.2. 制定采购计划 3.2.3. 发布采购请求 3.2.4. 供应商评估与选择 3.2.5. 合同签订 3.2.6. 采购…...

Elasticsearch 认证模拟题 - 18
一、题目 为一个索引,按要求设置以下 dynamic Mapping 一切 text 类型的字段,类型全部映射成 keyword一切以 int_ 开头命名的字段,类型都设置成 integer 1.1 考点 字段的动态映射 1.2 答案 # 创建索引和索引模板 PUT my_index {"m…...

Python基础-速记笔记
Python的基础数据类型都有哪些? 1、字符串(string)2、布尔类型(bool)3、整数(int) 4、浮点数(float)5、列表(list)6、集合(set)7、元组(tuple)8、字典(dict) 其中不可变类型有: 字符串(string)、布尔类型(bool)、整数(int) 、浮点数(float)、元组(tup…...

青少年编程与数学 01-001开始使用计算机 02课题、计算机操作系统3_3
青少年编程与数学 01-001开始使用计算机 02课题、计算机操作系统3_3 四、Linux操作系统安装(一) 准备工作(二)设置BIOS/UEFI(三) 安装Linux(四)磁盘分区(五)安…...
填表统计预约打卡表单系统(FastAdmin+ThinkPHP+UniApp)
填表统计预约打卡表单系统:一键搞定你的预约与打卡需求 填表统计预约打卡表单系统是一款基于FastAdminThinkPHPUniApp开发的一款集信息填表、预约报名,签到打卡、活动通知、报名投票、班级统计等功能的自定义表单统计小程序。 📝 一、引言…...
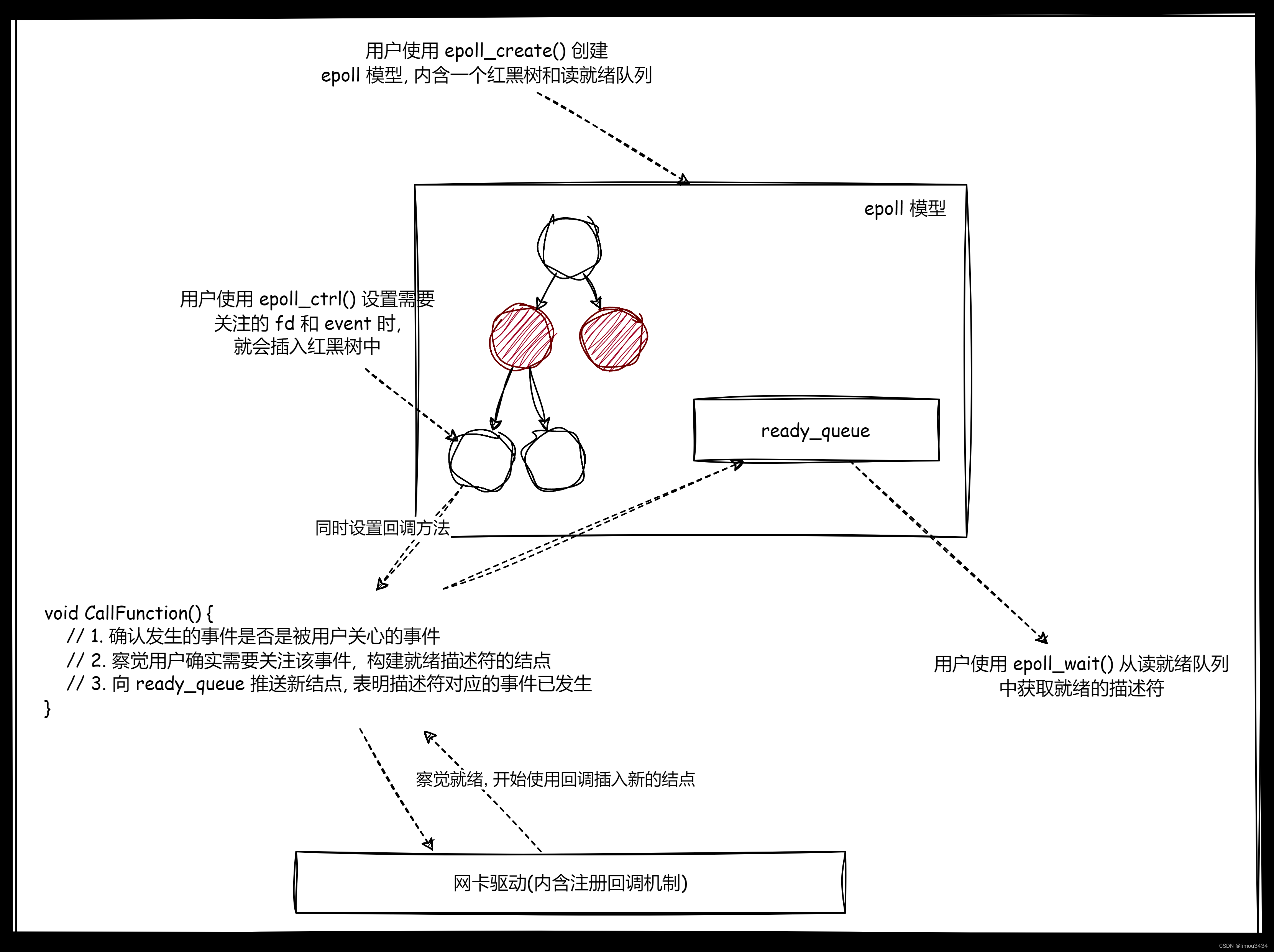
IO模型和多路转接
叠甲:以下文章主要是依靠我的实际编码学习中总结出来的经验之谈,求逻辑自洽,不能百分百保证正确,有错误、未定义、不合适的内容请尽情指出! 文章目录 1.IO 概要1.1.IO 低效原因1.2.IO 常见模型1.2.1.阻塞 IO1.2.2.非阻…...

如何完美解决升级 IntelliJ IDEA 最新版之后遇到 Git 记住密码功能失效的问题
🛠️ 如何完美解决升级 IntelliJ IDEA 最新版之后遇到 Git 记住密码功能失效的问题 摘要 在这篇文章中,我们将详细探讨如何解决在升级到 IntelliJ IDEA 最新版(2024.1.3 Ultimate Edition)后遇到的 Git 记住密码功能失效的问题。…...

SpringCloud微服务架构(eureka、nacos、ribbon、feign、gateway等组件的详细介绍和使用)
一、微服务演变 1、单体架构(Monolithic Architecture) 是一种传统的软件架构模式,应用程序的所有功能和组件都集中在一个单一的应用中。 在单体架构中,应用程序通常由一个大型的、单一的代码库组成,其中包含了所有…...

flinksql BUG : flink hologres-cdc source FINISHED
org.apache.flink.runtime.JobException: The failure is not recoverable or the failure does not allow to restart.at org.apache.flink.runtime.executiongraph.failover.flip1.ExecutionFailureHandler...
现代密码学-国密算法
商用密码算法种类 商用密码算法 密码学概念、协议与算法之间的依赖关系 数字签名、证书-公钥密码、散列类算法 消息验证码-对称密码 ,散列类 安全目标与算法之间的关系 机密性--对称密码、公钥密码 完整性--散列类算法 可用性--散列类、公钥密码 真实性--公…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

深入剖析AI大模型:大模型时代的 Prompt 工程全解析
今天聊的内容,我认为是AI开发里面非常重要的内容。它在AI开发里无处不在,当你对 AI 助手说 "用李白的风格写一首关于人工智能的诗",或者让翻译模型 "将这段合同翻译成商务日语" 时,输入的这句话就是 Prompt。…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

django filter 统计数量 按属性去重
在Django中,如果你想要根据某个属性对查询集进行去重并统计数量,你可以使用values()方法配合annotate()方法来实现。这里有两种常见的方法来完成这个需求: 方法1:使用annotate()和Count 假设你有一个模型Item,并且你想…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

《通信之道——从微积分到 5G》读书总结
第1章 绪 论 1.1 这是一本什么样的书 通信技术,说到底就是数学。 那些最基础、最本质的部分。 1.2 什么是通信 通信 发送方 接收方 承载信息的信号 解调出其中承载的信息 信息在发送方那里被加工成信号(调制) 把信息从信号中抽取出来&am…...

10-Oracle 23 ai Vector Search 概述和参数
一、Oracle AI Vector Search 概述 企业和个人都在尝试各种AI,使用客户端或是内部自己搭建集成大模型的终端,加速与大型语言模型(LLM)的结合,同时使用检索增强生成(Retrieval Augmented Generation &#…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

【Nginx】使用 Nginx+Lua 实现基于 IP 的访问频率限制
使用 NginxLua 实现基于 IP 的访问频率限制 在高并发场景下,限制某个 IP 的访问频率是非常重要的,可以有效防止恶意攻击或错误配置导致的服务宕机。以下是一个详细的实现方案,使用 Nginx 和 Lua 脚本结合 Redis 来实现基于 IP 的访问频率限制…...
[ACTF2020 新生赛]Include 1(php://filter伪协议)
题目 做法 启动靶机,点进去 点进去 查看URL,有 ?fileflag.php说明存在文件包含,原理是php://filter 协议 当它与包含函数结合时,php://filter流会被当作php文件执行。 用php://filter加编码,能让PHP把文件内容…...