有监督学习——支持向量机、朴素贝叶斯分类
1. 支持向量机
支持向量机(Support Vector Machine, SVM)最初被用来解决线性问题,加入核函数后能够解决非线性问题。主要优点是能适应小样本数量 高维度特征的数据集,甚至是特征维度数高于训练样本数的情况。
先介绍几个概念:
最优超平面:Hyperplane,SVM通过学习数据空间中的超平面达到二值分类。在预测中,在超平面一侧被认为是一个类型的数据,另一侧被认为是另一种类型数据。
超平面在一维空间中是一个点;在二维中是一条线;三维中是一个平面。在更高维度只能描述为“超平面”。普通线性可分问题中,符合分类要求的超平面会有无穷多个。
软间隔:Soft Margin,是为了解决因噪声数据导致的过拟合,允许计算超平面时在训练集上存在错误数据。
有时,在当下维度,无论如何都找不到合适的超平面分割两类数据,这就是所谓的非线性问题。但是,任何有限维度的非线性问题在更高维度的空间里总可以变换成线性可分问题。
SVM可以拉格朗日乘子法(Lagrange Multiplier)实现对超平面求解问题的升维。通过拉格朗日乘子法将求超平面参数的目标转换为用高维中数据点向量两两点积(dot-product)值求解二次规划问题,SVM无须将所有训练数据映射到高维空间,而只需要知道这些数据在高维空间里的点积。
核函数:Kernel Function,输入为两个低维空间向量,输出高维空间点积的函数。SVM选择核函数既可以选择一些通用核函数,也可以自定义。
核函数
一些常用的核函数如下:
- 线性核(linear):直接返回输入向量的点积,速度最快。因为实际并没有升维,适合于本身特征维度较高、样本数量很大的场景。
- 多项式核(ploynomial):\(k(p,q)=(p \cdot q+1)\times d\),其中超参数\(d\)是提升到的维度。
- 高斯径向基核(Gaussian radial basis function):\(k(p,q)=exp(-\gamma||p-q||^2)\),应用最广泛的SVM核,\(\gamma\)参数值越大越容易拟合。
- Sigmoid核:\(k(p,q)=tanh(a\times p\cdot q + r)\),其中\(tanh(x)=\frac{ex-e{-x}}{ex+e{-x}}\)也是一种非线性核,有两个超参数\(a\)、\(r\)可以调整。
scikit-learn中的SVM
在sklearn.svm中提供了三种分类/回归封装类。
-
SVC/SVR:最普通的SVM分类器/回归器,可通过kernel参数设置使用的核函数,使用C参数配置松弛因子。
-
NuSVC/NuSVR:带有nu参数的分类器/回归器,nu参数的作用与C参数类似,都是用来配置模型对训练数据的拟合程度的。
-
LinearSVC/LinearSVR:使用liblinear库的线性核函数分类器/回归器,其在模型中加入了线性回归惩罚参数。
以SVC类为例:
from sklearn import svm # 引入SVM包
X = [[0, 0], [2, 2]] # 训练数据
y = [1, 2]
clf = svm.SVC(kernel='rbf') # 初始化使用径向基核分类器
clf.fit(X, y) # 训练
t = [[2, 1], [0, 1]] # 测试集
clf.predict(t)
# array([2, 1])clf.decision_function(t)
# array([ 0.52444566, -0.52444566])训练和预测方法与之前的模型差别较小,注意decision_function()函数,他返回的是输入的数据集与模型超平面之间的距离,正负关系表示超平面的哪一测,另外,距离绝对值越大则分类的可靠性越高。
| 名称 | 解释 | SVC/SCR | NuSVC/NuSVR | LinearSVC/LinearSVR |
|---|---|---|---|---|
| C | 松弛因子,取值\(0 - \infty\) | √ | √ | |
| kernel | 取值"linear" “poly” “rbf” "sigmoid"等 | √ | √ | |
| gamma | “ploy” “rbf” “sigmoid” 三种核的超参数 | √ | √ | |
| tol | SMO算法中的停止阈值 | √ | √ | √ |
| nu | 取值0~1,控制对训练数据的拟合程度 | √ | ||
| penalty | 线性模型惩罚项,“l1"或"l2” | √ |
2. 朴素贝叶斯分类
朴素贝叶斯(Naive Bayes)是一种非常简单的分类算法。优点在于可以对预测标签给出理论上完美的可能性估计,但要求数据多维特征之间相互独立。
基础概率
- 概率值常用\(P\)表示,古典概率取值范围为[0,1],e.g.事件A一定不会发生,则有概率\(P(A)=0\)
- 条件概率:用\(P(A|B)\)表达,意为:若发生B,发生A的概率为多少。
- 联合概率:表示两件事同时发生的概率,表达式包括:\(P(AB)\)、\(P(A,B)\)、\(P(A\bigcap B)\)。意为:事件A、B同时发生的概率为多少。
- 事件之间并的概率:\(P(A\bigcup B)\),意为:事件A或B至少一个事件发生的概率。
- 加法原理:\(P(A\bigcup B)=P(A)+P(B)-P(A\bigcap B)\)
- 乘法原理:\(P(A\bigcap B)=P(B)\cdot P(A|B)=P(A)\cdot P(B|A)\)
- 两事件独立的充分必要条件:\(P(A\bigcap B)=P(A)\cdot P(B)\),即事件B发生对事件A是否没有任何影响,即\(P(A|B)=P(A)\),反之亦然。
- 贝叶斯定理:\(P(A|B)=\frac{P(A)P(B|A)}{P(B)}\),其中:
- \(P(A|B)\):后验概率,是指在得到“结果”的信息后重新修正的概率,是“执果寻因”问题中的"果"。例如,如果我们从红色盒子和蓝色盒子中随机抽取一个水果,发现是苹果,那么这个苹果来自蓝色盒子的概率就是一个后验概率。
- \(P(A)\):先验概率,是指根据以往经验和分析得到的概率,如全概率公式。它是在实验或采样前就可以得到的概率。例如,我们知道骰子每个面出现的概率都是1/6,这就是一个先验概率。
- \(P(B|A)\):似然度,是用来度量模型和数据之间的相似度的一个函数。它是给定模型参数下,观察到数据的概率。例如,如果我们假设硬币朝上的概率是p,那么抛5次看到3次朝上的似然度就是\(L§ = C(5,3) * p^3 * (1-p)^2\)。
- \(P(B)\):标准化常量,是贝叶斯公式中的一个分母,用来保证后验概率的和为1。它等于全概率公式的结果,即所有可能的原因导致结果的概率之和。
举例讲解下贝叶斯定理的使用:
有两个袋子:
- a袋:4个红球,3个绿球,3个黄球
- b袋:2个红球,7个绿球,11个黄球
任取一袋,再从中取出一颗巧克力发现其为红色,那么它来自a的概率是多少?
根据问题定义:
- 事件A:取到a袋
- 事件B:取到红球
计算贝叶斯定理中的各项:
- 先验概率:取到a袋的概率,\(P(A)=\frac{1}{2}\)
- 似然度:在a袋中取红球的概率\(P(B|A)=\frac{4}{4+3+3}=\frac{2}{5}\)
- 标准化常量:即取红球的概率,取到红球的=取a袋中的红球的概率+取b袋中的红球的概率,\(P(B)=\frac{1}{2}\times \frac{4}{10}+\frac{1}{2}\times\frac{2}{20}=\frac{1}{4}\)
- 后验概率(最后的答案):\(P(A|B)=\frac{P(A)P(B|A)}{P(B)}=\frac{(1/2)\times(2/5)}{1/4}=\frac{4}{5}\)
贝叶斯分类原理
在有监督学习中,朴素贝叶斯定义公式\(P(A|B)=\frac{P(A)P(B|A)}{P(B)}\)中的事件\(A\)看成被分类标签,事件\(B\)看成数据特征。通常数据特征是\(n\)维的,因此\(P(B)\)演变为\(n\)个特征的联合概率,因此在机器学习中,贝叶斯公式为:
\[P(y|x_1,x_2…x_n)=\frac{P(y)P(x_1,x_2,…x_n|y)}{P(x_1,x_2,…x_n)} \]
\(x_1,x_2,…x_n\)是数据的\(n\)维特征,\(y\)是预测标签。
- 预测:在给定特征情况下,使用贝叶斯公式计算每个标签的后验概率。最后获得最高概率的标签便是预测标签。此外,不仅是最可能的标签,也能给出其他标签的概率。
- 训练:对于训练来说关注的是贝叶斯公式中右侧的先验概率和似然度。
- 先验概率:可由训练者根据经验直接给出,也可自动计算:统计训练数据中每个标签的出现次数,除以训练总数就可直接得到每个标签的先验概率\(P(y)\)。
- 似然度:假定\(n\)维特征的条件概率符合某种联合分布,根据训练样本估计该分布的参数。比如对于高斯分布来说,学习参数有期望值和方差。
- 独立假设:朴素贝叶斯假设所有\(n\)维特征之间是相互独立的(所以叫naive)。这简化了计算难度,事件独立性的充分必要条件有:
\[P(x_1,x_2,…x_n)=P(x_1)\times P(x_2)\times…\times P(x_n) \]
似然函数为:
\[P(x_1,x_2,…x_n|y)=P(x_1|y)\times P(x_2|y)\times…\times P(x_n|y) \]
高斯朴素贝叶斯(Gaussian Naive Bayes)
高斯朴素贝叶斯使用的高斯分布就是常说的正态分布,假定所有特征条件分布符合:
\[P(x_i|y) = \frac{1}{\sqrt{2\pi\sigma_y^2}}\exp\left(-\frac{(x_i - \mu_y)2}{2\sigma_y2}\right) \]
其中\(\mu_y\)、\(\sigma_y\)被学习的模型参数特征期望值和方差。
from sklearn import datasets # scikit-learn资料数据库
iris = datasets.load_iris()from sklearn.naive_bayes import GaussianNB # 引入高斯朴素贝叶斯模型
gnb = GaussianNB() # 初始化模型对象
gnb.fit(iris.data, iris.target) # 训练gnb.class_prior_ # 查看模型先验概率
# array([0.33333333, 0.33333333, 0.33333333]) # 有三种标签,先验概率各自为1/3gnb.class_count_ # 查看训练集标签数量
# array([50., 50., 50.]) # 训练集每种标签有50个样本# 由于数据有四维特征,且有三种标签,因此训练后产生3*4=12个高斯模型
gnb.theta_ # 查看高斯模型期望值
# array([[5.006, 3.428, 1.462, 0.246],
# [5.936, 2.77 , 4.26 , 1.326],
# [6.588, 2.974, 5.552, 2.026]])gnb.var_ # 查看高斯模型方差
# array([[0.121764, 0.140816, 0.029556, 0.010884],
# [0.261104, 0.0965 , 0.2164 , 0.038324],
# [0.396256, 0.101924, 0.298496, 0.073924]])多项式朴素贝叶斯(Multinomial Naive Bayes)
多项式朴素贝叶斯是用多项分布(Multinomial Distribution)作为似然度概率模型的分类器。衡量的是特征在不同标签之间的分布比例关系,因此特别适合文本分类场景(每个单词在不同类型文章中有一定的分布比例)。
多项式分布的概念:假设某件事件的结果有\(k\)种可能,在实验了\(n\)次之后,每种结果出现了若干。
多项式便是用于描述在试验了\(n\)次之后每种结果发生次数概率的分布。
e.g.普通的骰子有6面,掷骰子的结果便是\(k=6\)的多项式分布。
scikit-learn中的MultinomialNB实现了多项式朴素贝叶斯,使用与高斯朴素贝叶斯相似。
伯努利朴素贝叶斯(Bernoulli Naive Bayes)
伯努利贝叶斯使用伯努利分布(Bernoulli Distribution),所谓伯努利分布也称二值分布,用来描述一次实验只可能出现两种结果的事件概率分布。在学习该模型中要求数据中的所有特征都是布尔/二值类型。贝叶斯公式中第\(i\)个特征的似然度:
\[P(x_i|y)=P(i|y)x_i+(1-P(i|y))(1-x_i) \]
其中\(P(i|y)\)是第\(i\)个特征在所有该标签训练数据中出现的比。
from sklearn.naive_bayes import BernoulliNB
# 参数binarize是一个阈值,将非二值转化为二值
clf = BernoulliNB(binarize=1) # 设置特征阈值为1X = [[0.3, 0.2], [1.3, 1.2], [1.1, 1.2]]
Y = [0, 1, 1]
clf.fit(X, Y) # 训练
clf.predict([[0.99, 0.99]]) # 预测
# array([0])由于阈值为1的缘故,特征[0.99, 0.99]被认为与[0.3, 0.2]一类,而不是与在数值上与[1.1, 1.2]为同一类标签。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

五、面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相关文章:
有监督学习——支持向量机、朴素贝叶斯分类
1. 支持向量机 支持向量机(Support Vector Machine, SVM)最初被用来解决线性问题,加入核函数后能够解决非线性问题。主要优点是能适应小样本数量 高维度特征的数据集,甚至是特征维度数高于训练样本数的情况。 先介绍几个概念&am…...

自动化测试文档
自动化测试文档的类型 自动化测试方案: 目的:描述自动化测试的目标、范围、方法、资源等。内容:通常包含测试计划、测试用例设计、测试环境配置、测试执行策略、预期结果、风险评估等。自动化测试脚本: 目的:用于执行…...
vue-i18n使用步骤详解(含完整操作步骤)
开篇 下面是从创建vue项目开始,完整使用i18n实现国际化功能的步骤,希望对您有所帮助。 完整步骤 创建项目 创建项目,并在创建项目的时候选择vuex,router 选择3.x版本 后面随意选即可,下面是完整的代码结构 安装vue-i18n,并封装…...

XXE漏洞修补:保护您的系统免受XML外部实体攻击
引言 XML外部实体(XXE)漏洞是一种常见的网络安全问题,它允许攻击者通过XML文档中的实体引用读取服务器上的文件或发起远程服务器请求。这种漏洞可能被用于数据泄露、拒绝服务攻击(DoS)甚至远程代码执行。本文将探讨XX…...

去除upload的抖动效果
title: 去除upload的抖动效果 date: 2024-06-15 20:16:51 tags: vue3 在使用vue3element-plus框架的时候,常常会使用到el-upload方法。其中如果做了翻页效果可以发现图片过度方式是集中到左上角进行的翻页,这种效果不是很好,我们还是想让这中…...
)
什么是 Linux ?(Linux)
系列文章目录 第一章 什么是Linux? 文章目录 系列文章目录一、什么是 Linux ?二、Linux 的发行版本总结 一、什么是 Linux ? Linux(Linux Is Not UniX),是一种免费使用和自由传播的类UNIX操作系统&#x…...
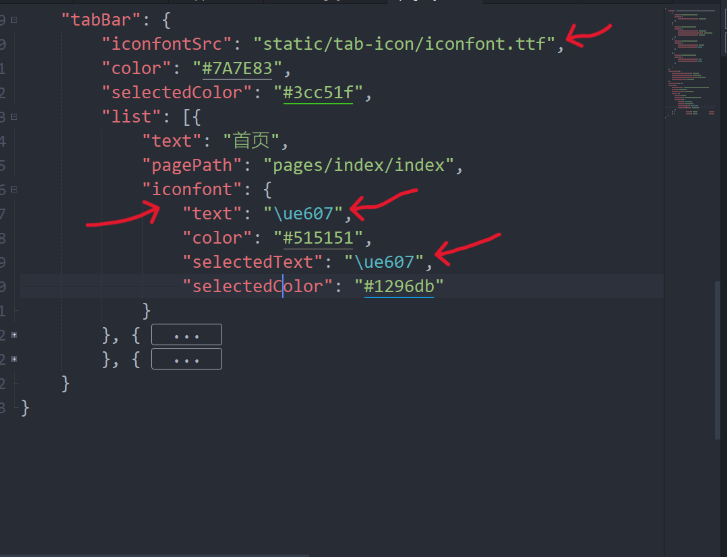
uni-app 怎么在tabbar使用阿里图标库
提示:微信小图标不支持使用字体图标的方式,只能下载png 方法一:直接下载png图片 我们首选打开阿里矢量图标库 链接在下方 👇 iconfont-阿里巴巴矢量图标库iconfont-国内功能很强大且图标内容很丰富的矢量图标库,提供矢…...
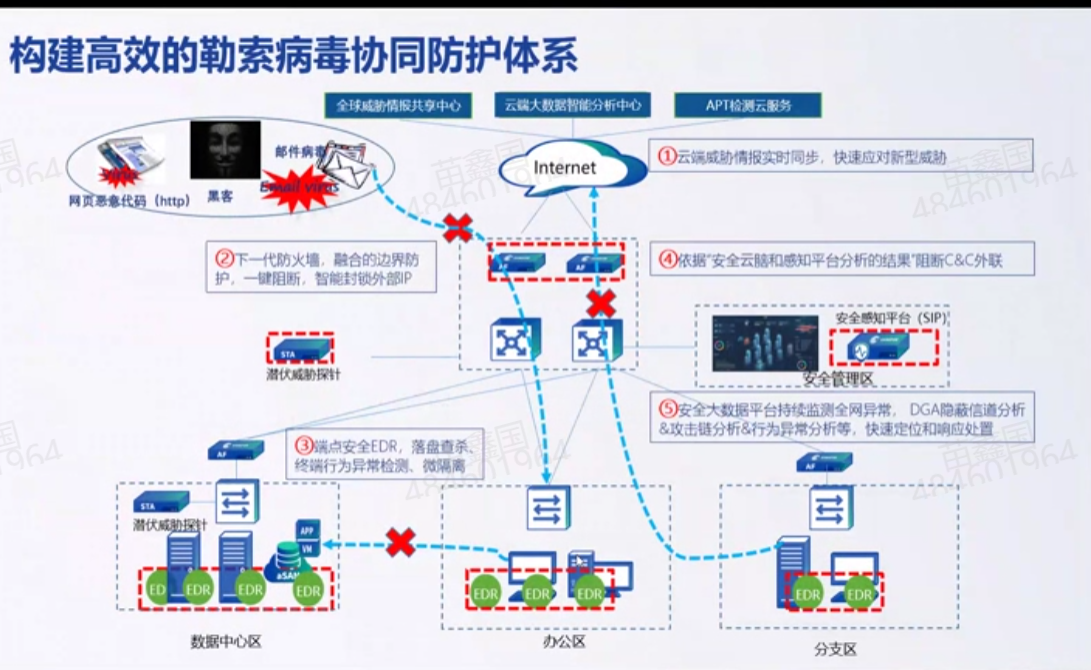
勒索病毒剖析
2016年不自己勒索了 卖病毒 让别人勒索 傻瓜式勒索 黑客用的是非对称加密 全世界只有黑客有那把私钥 反向解密不了 传统爆破容易被检测,黑客慢速爆破,利用超级多的僵尸进行试错,慢慢试出来账号密码 因为一般运维设备在防火墙的白名单里&…...

【C++11】第一部分(一万六千多字)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 目录 前言 C11简介 统一的列表初始化 {}初始化 std::initializer_list 声明 auto decltype 右值引用和移动语义 左值引用和右值引用 左值引…...
FPGA专项课程即将开课,颁发AMD官方证书
社区成立以来,一直致力于为广大工程师提供优质的技术培训和资源,得到了众多用户的喜爱与支持。为了满足用户需求,我们特别推出了“基于Vitis HLS的高层次综合及图像处理开发”课程。 本次课程旨在帮助企业工程师掌握前沿的FPGA技术ÿ…...

C++ shared_ptr
shared_ptr共享它指向的对象,多个shared_ptr可以指向(关联)相同的对象,在内部采用计数机制来实现。 当新的shared_ptr与对象关联时,引用计数增加1。 当shared_ptr超出作用域时,引用计数减1。当引用计数变为…...

2024.6.15
2024.6.15 【夜幽幽,月优优,曲悠悠,吾忧忧。】 Saturday 五月初十 <theme oi-“DP”> 看几道DP基础题, 巩固一下DP思路和基础 Coin Combinations I //2024.6.15 //by white_ice //Coin Combinations I CSES - 1635 #i…...
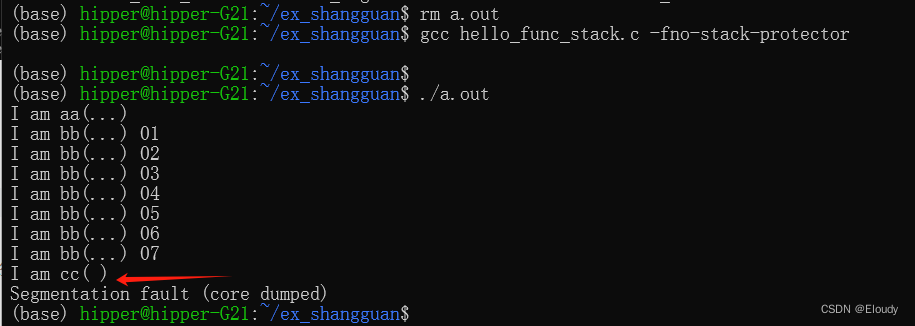
堆栈溢出的攻击 -fno-stack-protector stack smash 检测
在程序返回的一条语句堆栈项目处,用新函数的起始地址覆盖,将会跳转到执行新函数。 现在系统对这个行为做了判断,已经无法实施这类攻击或技巧。 1,测试代码 #include <stdio.h> void cc() {printf("I am cc( )\n"…...

掌握特劳特定位理论核心,明晰企业战略定位之重
在当今瞬息万变的市场环境中,企业战略定位的重要性日益凸显。它不仅是企业在激烈竞争中保持优势的关键,更是企业实现长期可持续发展的基石。 哈佛大学战略学教授迈克尔波特(Michael Porter)指出战略就是形成一套独具的运营活动&a…...

RAGFlow 学习笔记
RAGFlow 学习笔记 0. 引言1. RAGFlow 支持的文档格式2. 嵌入模型选择后不再允许改变3. 干预文件解析4. RAGFlow 与其他 RAG 产品有何不同? 5. RAGFlow 支持哪些语言? 6. 哪些嵌入模型可以本地部署? 7. 为什么RAGFlow解析文档的时间比…...

使用Docker-Java监听Docker容器的信息
使用Docker-Java监听Docker容器的信息 Docker作为一种轻量级的容器化平台,极大地方便了应用的部署与管理。然而,在实际使用过程中,我们常常需要对运行中的容器进行监控,以确保其健康状态,并能及时响应各种异常情况。本…...
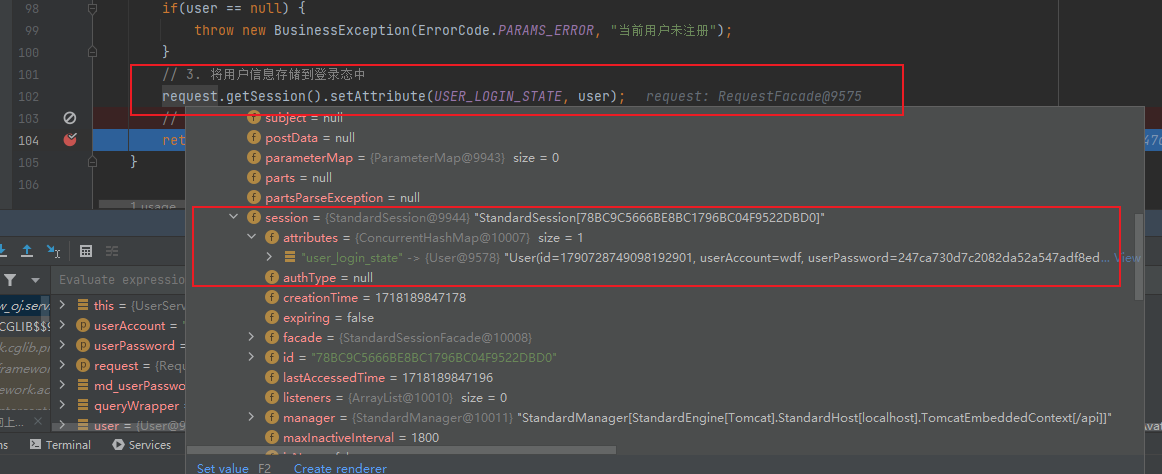
Spring Boot + Mybatis Plus实现登录注册
Spring Boot 实现登录注册 1. 注册 业务逻辑 客户端输入注册时需要的用户参数,比如:账户名、密码、确认密码、其他服务端接收到客户端的请求参数进行校验,然后判断是否有误,有误的地方就将错误信息抛出将密码进行加密之后存储到…...

IDEA创建web项目
IDEA创建web项目 第一步:创建一个空项目 第二步:在刚刚创建的项目下创建一个子模块 第三步:在子模块中引入web 创建结果如下: 这里我们需要把这个目录移到main目录下,并改名为webapp,结果如下 将pom文件…...
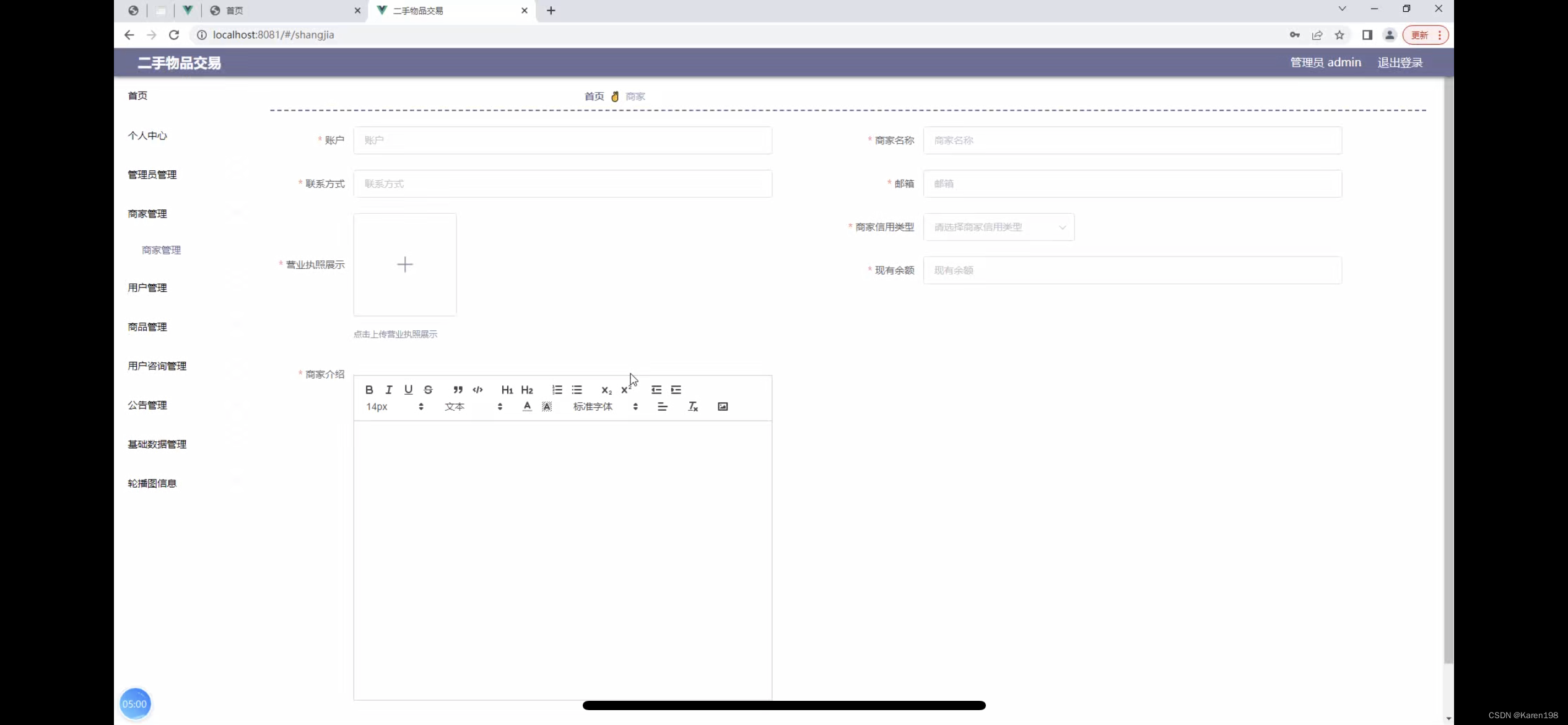
二手物品交易系统的设计
管理员账户功能包括:系统首页,个人中心,管理员管理,商家管理,用户管理,商品管理,用户咨询管理 商家账户功能包括:系统首页,个人中心,商品管理,用…...

探索大数据在信用评估中的独特价值
随着我国的信用体系越来越完善,信用将影响越来越多的人。现在新兴的大数据信用和传统信用,形成了互补的优势,大数据信用变得越来越重要,那大数据信用风险检测的重要性主要体现在什么地方呢?本文将详细为大家介绍一下,…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

JavaScript 中的 ES|QL:利用 Apache Arrow 工具
作者:来自 Elastic Jeffrey Rengifo 学习如何将 ES|QL 与 JavaScript 的 Apache Arrow 客户端工具一起使用。 想获得 Elastic 认证吗?了解下一期 Elasticsearch Engineer 培训的时间吧! Elasticsearch 拥有众多新功能,助你为自己…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

前端导出带有合并单元格的列表
// 导出async function exportExcel(fileName "共识调整.xlsx") {// 所有数据const exportData await getAllMainData();// 表头内容let fitstTitleList [];const secondTitleList [];allColumns.value.forEach(column > {if (!column.children) {fitstTitleL…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

测试markdown--肇兴
day1: 1、去程:7:04 --11:32高铁 高铁右转上售票大厅2楼,穿过候车厅下一楼,上大巴车 ¥10/人 **2、到达:**12点多到达寨子,买门票,美团/抖音:¥78人 3、中饭&a…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...