spark mllib 特征学习笔记 (二)
当然,请继续介绍其他特征处理方法的公式、适用场景和案例:
10. StringIndexer
公式:
将字符串类型的标签转换为数值索引:
StringIndexer ( x ) = { 0 , 1 , 2 , … , N − 1 } \text{StringIndexer}(x) = \{0, 1, 2, \ldots, N-1\} StringIndexer(x)={0,1,2,…,N−1}
适用场景:
用于将分类标签转换为数值标签,以便机器学习算法处理。
案例:
from pyspark.ml.feature import StringIndexerdata = spark.createDataFrame([(0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c")], ["id", "category"])
indexer = StringIndexer(inputCol="category", outputCol="categoryIndex")
indexedData = indexer.fit(data).transform(data)
indexedData.show()
11. VectorAssembler
公式:
将多个特征列合并成一个特征向量:
VectorAssembler ( x 1 , x 2 , … , x n ) = [ x 1 , x 2 , … , x n ] \text{VectorAssembler}(\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_n) = [\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_n] VectorAssembler(x1,x2,…,xn)=[x1,x2,…,xn]
适用场景:
用于将多个特征列合并成一个特征向量,作为机器学习算法的输入。
案例:
from pyspark.ml.feature import VectorAssembler
from pyspark.ml.linalg import Vectorsdata = spark.createDataFrame([(1, 2, 3), (4, 5, 6)], ["a", "b", "c"])
assembler = VectorAssembler(inputCols=["a", "b", "c"], outputCol="features")
assembledData = assembler.transform(data)
assembledData.show()
12. Word2Vec
公式:
Word2Vec 是一种词嵌入模型,通过训练将单词映射到低维向量空间:
Word2Vec ( sentence ) = v \text{Word2Vec}(\text{sentence}) = \mathbf{v} Word2Vec(sentence)=v
其中 (\mathbf{v}) 是单词的向量表示。
适用场景:
用于自然语言处理中的词语表示学习,以便后续应用于文本分类、文本相似度等任务。
案例:
from pyspark.ml.feature import Word2Vecdata = spark.createDataFrame([("Hi I heard about Spark".split(" "),),("I wish Java could use case classes".split(" "),),("Logistic regression models are neat".split(" "),)
], ["text"])word2Vec = Word2Vec(vectorSize=3, minCount=0, inputCol="text", outputCol="result")
model = word2Vec.fit(data)
result = model.transform(data)
result.show(truncate=False)
这些例子展示了 PySpark MLlib 中几种常用的特征处理方法的基本用法和应用场景。根据具体的数据和任务需求,选择合适的特征处理方法可以有效地提高模型的性能和准确性。
当然,请继续介绍其他特征处理方法的公式、适用场景和案例:
13. UnivariateFeatureSelector
公式:
基于单变量统计测试选择特征,例如卡方检验:
UnivariateFeatureSelector ( X , y ) = { features with highest score } \text{UnivariateFeatureSelector}(X, y) = \{ \text{features with highest score} \} UnivariateFeatureSelector(X,y)={features with highest score}
适用场景:
用于基于单变量统计测试(如卡方检验)选择与标签相关性最高的特征。
案例:
from pyspark.ml.feature import UnivariateFeatureSelector
from pyspark.ml.linalg import Vectorsdata = [(1, Vectors.dense(0.0, 1.1, 0.1)),(0, Vectors.dense(2.0, 1.0, -1.0)),(0, Vectors.dense(2.0, 1.3, 1.0)),(1, Vectors.dense(0.0, 1.2, -0.5))]
df = spark.createDataFrame(data, ["label", "features"])selector = UnivariateFeatureSelector(featuresCol="features", outputCol="selectedFeatures", labelCol="label", selectionMode="numTopFeatures", numTopFeatures=1)
result = selector.fit(df).transform(df)
result.show()
14. VarianceThresholdSelector
公式:
基于方差选择特征,移除方差低于阈值的特征:
VarianceThresholdSelector ( X ) = { features with variance above threshold } \text{VarianceThresholdSelector}(X) = \{ \text{features with variance above threshold} \} VarianceThresholdSelector(X)={features with variance above threshold}
适用场景:
用于移除方差较低的特征,以减少噪声对模型的影响。
案例:
from pyspark.ml.feature import VarianceThresholdSelector
from pyspark.ml.linalg import Vectorsdata = [(1, Vectors.dense(0.0, 1.0, 0.0)),(0, Vectors.dense(0.0, 1.0, 1.0)),(0, Vectors.dense(0.0, 1.0, 0.0))]
df = spark.createDataFrame(data, ["label", "features"])selector = VarianceThresholdSelector(featuresCol="features", outputCol="selectedFeatures", threshold=0.0)
result = selector.fit(df).transform(df)
result.show()
15. VectorIndexer
公式:
索引化向量中的类别特征列:
VectorIndexer ( X ) = { indexed features } \text{VectorIndexer}(X) = \{ \text{indexed features} \} VectorIndexer(X)={indexed features}
适用场景:
用于处理数据集中的向量特征,自动识别并索引类别特征。
案例:
from pyspark.ml.feature import VectorIndexer
from pyspark.ml.linalg import Vectorsdata = [(Vectors.dense(1.0, 2.0, 3.0),),(Vectors.dense(2.0, 5.0, 6.0),),(Vectors.dense(1.0, 8.0, 9.0),)]
df = spark.createDataFrame(data, ["features"])indexer = VectorIndexer(inputCol="features", outputCol="indexed", maxCategories=2)
indexedData = indexer.fit(df).transform(df)
indexedData.show()
16. VectorSizeHint
公式:
添加向量列的大小信息到元数据中:
VectorSizeHint ( X ) = { features with size hint in metadata } \text{VectorSizeHint}(X) = \{ \text{features with size hint in metadata} \} VectorSizeHint(X)={features with size hint in metadata}
适用场景:
用于在向量列中添加大小信息,以提供给后续流水线阶段使用。
案例:
from pyspark.ml.feature import VectorSizeHint
from pyspark.ml.linalg import Vectorsdata = [(Vectors.dense([1.0, 2.0]),),(Vectors.dense([2.0, 3.0]),)]
df = spark.createDataFrame(data, ["features"])sizeHint = VectorSizeHint(inputCol="features", size=2)
sizeHint.transform(df).show()
这些例子展示了更多 PySpark MLlib 中特征处理方法的公式、适用场景和简单案例。每种方法都有其特定的数学原理和适用范围,根据具体任务的需求选择合适的方法可以提高数据处理的效率和模型的预测性能。
相关文章:
)
spark mllib 特征学习笔记 (二)
当然,请继续介绍其他特征处理方法的公式、适用场景和案例: 10. StringIndexer 公式: 将字符串类型的标签转换为数值索引: StringIndexer ( x ) { 0 , 1 , 2 , … , N − 1 } \text{StringIndexer}(x) \{0, 1, 2, \ldots, N-1…...

湘潭大学软件工程数据库2(题型,复习资源和计划)
文章目录 选择题关系范式事务分析E-R 图sql作业题答案链接(仅限有官方答案的版本)结语 现在实验全部做完了,实验和作业占比是百分之 40 ,通过上图可以看出来,重点是 sql 语言 所以接下来主要就是学习 sql 语句怎么书写…...

第二十三节:带你梳理Vue2:Vue插槽的认识和基本使用
前言: 通过上一节的学习,我们知道了如何将数据从父组件中传递到子组件中, 除了除了将数据作为props传入到组件中,Vue还允许传入HTML, Vue 实现了一套内容分发的 API,这套 API 的设计灵感源自 Web Components 规范草案,将 <slot> 元素作为承载分发…...
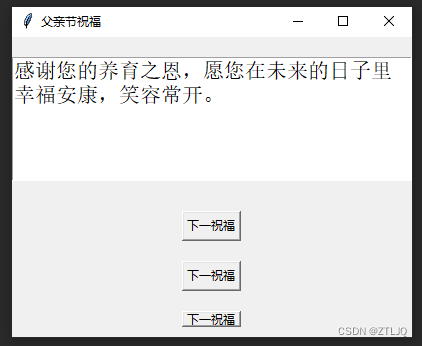
父亲节马上到了-和我一起用Python写父亲节的祝福吧
前言 让我们一起用Python写一段父亲节的祝福吧 📝个人主页→数据挖掘博主ZTLJQ的主页 个人推荐python学习系列: ☄️爬虫JS逆向系列专栏 - 爬虫逆向教学 ☄️python系列专栏 - 从零开始学python 话不多说先上代码 import tkinter as tk from doctest imp…...
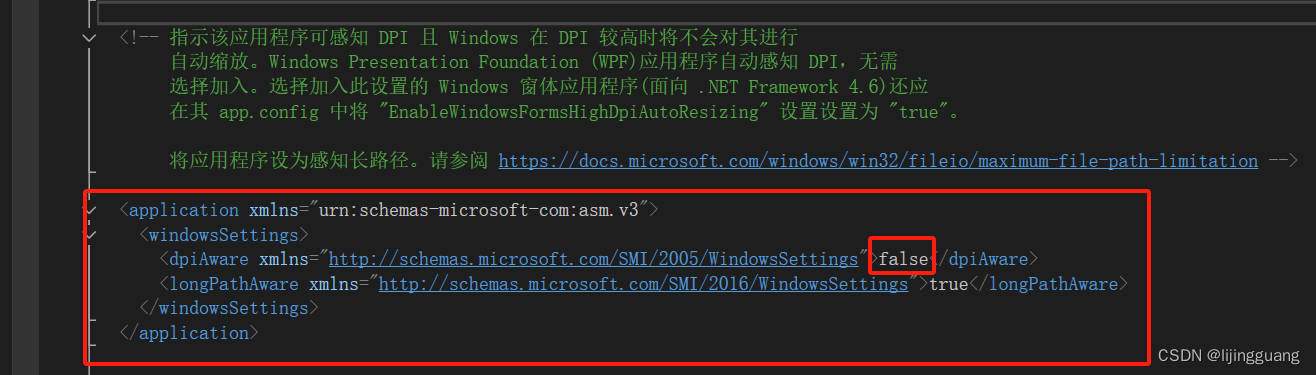
winform 应用程序 添加 wpf控件后影响窗体DPI改变
第一步:添加 应用程序清单文件 app.manifest 第二步:把这段配置 注释放开,第一个配置true 改成false...

Web前端开发素材:探索、选择与应用的艺术
Web前端开发素材:探索、选择与应用的艺术 在Web前端开发的广袤领域中,素材的选择与应用无疑是一项至关重要的技能。它们如同构建网页的砖石,既承载着设计的美感,又影响着用户体验的深度。本文将从四个方面、五个方面、六个方面和…...
LeetCode | 20.有效的括号
这道题就是栈这种数据结构的应用,当我们遇到左括号的时候,比如{,(,[,就压栈,当遇到右括号的时候,比如},),],就把栈顶元素弹出,如果不匹配,则返回False,当遍历完所有元素后…...

ceph scrub 错误记录
目的 记录 ceph scrub 错误问题解决 ceph scrub 故障故障信息 cluster:id: xxx-xxx-xxxhealth: HEALTH_ERR2 scrub errorsPossible data damage: 2 pg inconsistentmessage 日志信息 # egrep -i medium|i\/o error|sector|Prefailure /var/log/messages Jun 15 00:23:37 m…...

cs与msf权限传递,以及mimikatz抓取明文密码
cs与msf权限传递,以及mimikatz抓取win10明文密码 1、环境准备2、Cobalt Strike ------> MSF2.1 Cobalt Strike拿权限2.2 将CS权限传递给msf 3、MSF ------> Cobalt Strike3.1 msf拿权限3.2 将msf权限传递给CS 4、使用mimikatz抓取明文密码 1、环境准备 攻击&…...

Windows下的zip压缩包版Mysql8.3.0数据迁移到Mysql8.4.0可以用拷贝data文件夹的方式
Windows下的zip压缩包版Mysql8.3.0数据迁移到Mysql8.4.0可以用拷贝data文件夹的方式 拷贝后, 所有账户和数据都是一样的 步骤 停止MySQL服务 net stop mysql 或 sc.exe stop mysql net stop mysqlsc.exe stop mysql卸载 Mysql8.3.0 的服务 mysqld remove 或 mysqld remove m…...
软件体系结构笔记(自用)
来自《软件体系结构原理、方法与实践(第三版)》清华大学出版社 张友生编著 1-8章12章 复习笔记 如有错误,欢迎指正!!!...

java安装并配置环境
安装前请确保本机没有java的残留,否则将会安装报错 1.安装java jdk:安装路径Java Downloads | Oracle 中国 百度网盘链接:https://pan.baidu.com/s/11-3f2QEquIG3JYw4syklmQ 提取码:518e 2.双击 按照流程直接点击下一步&#x…...
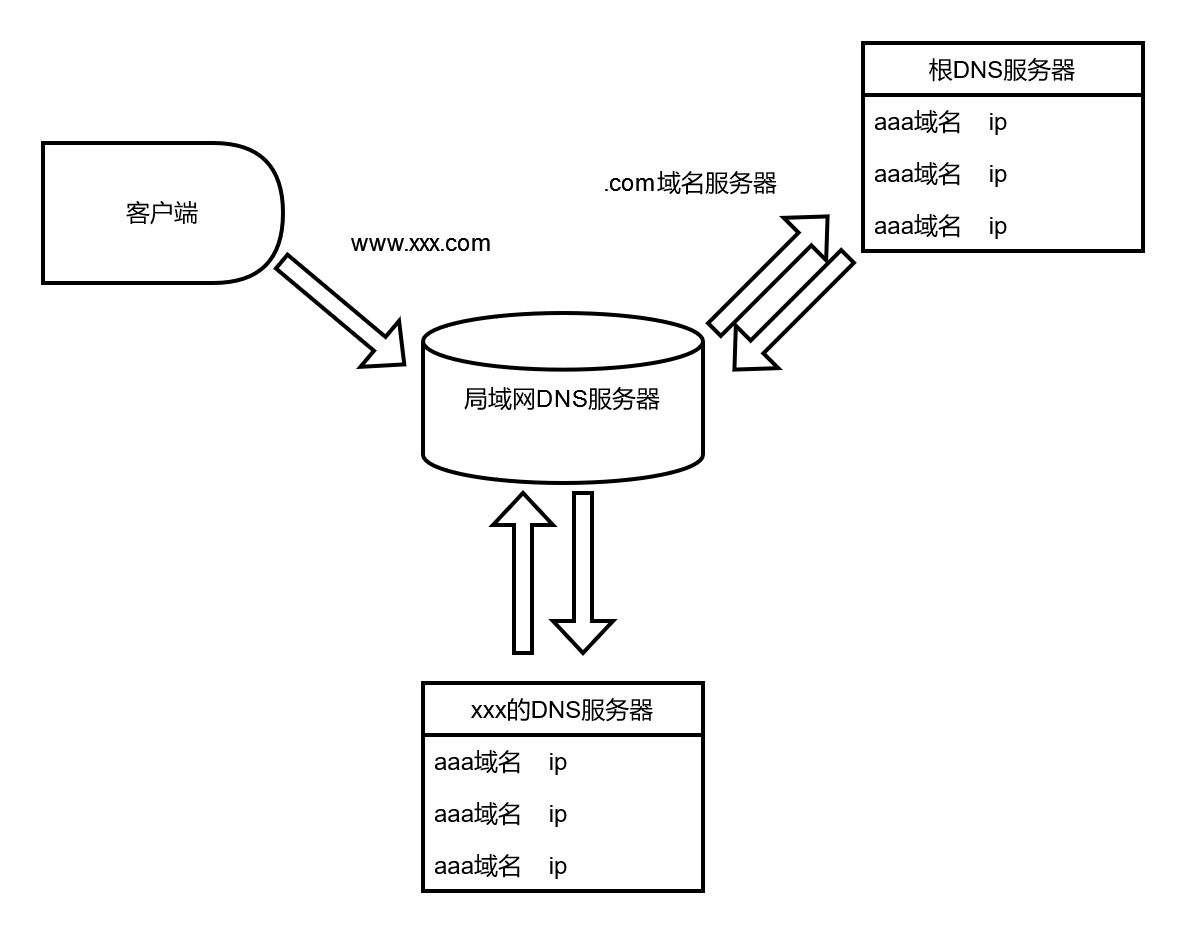
探索互联网寻址机制 | 揭秘互联网技术的核心,解析网络寻址
揭秘互联网技术的核心,解析网络寻址题 前提介绍局域网地址IP地址的分配方式动态IP分配机制内部网(intranet)ICANN负责IP分配DHCP协议获取IP地址 域名系统域名是什么域名工作方式hosts文件存储域名映射关系DNS分布式数据库DNS域名解析 Java进行…...
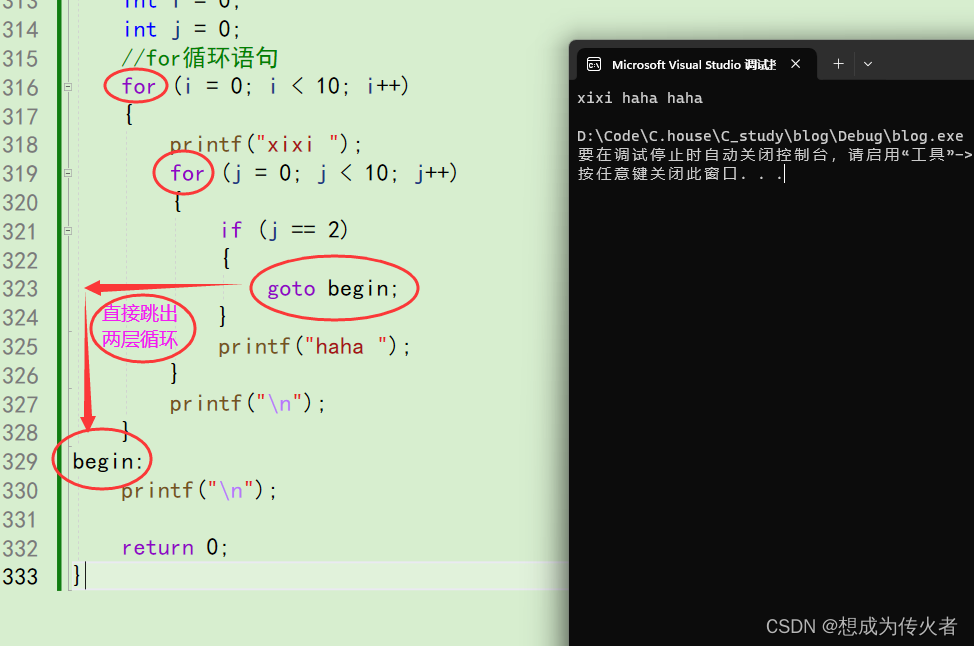
C语言学习笔记之结构篇
C语言是一门结构化程序设计语言。在C语言看来,现实生活中的任何事情都可看作是三大结构或者三大结构的组合的抽象,即顺序,分支(选择),循环。 所谓顺序就是一条路走到黑;生活中在很多事情上我们都…...

C++笔记之一个函数多个返回值的方法、std::pair、std::tuple、std::tie的用法
C++笔记之一个函数多个返回值的方法、std::pair、std::tuple、std::tie的用法 —— 2024-06-08 杭州 code review! 文章目录 C++笔记之一个函数多个返回值的方法、std::pair、std::tuple、std::tie的用法一.从一个函数中获取多个返回值的方法1. 使用结构体或类2. 使用`std::t…...

GDB:从零开始入门GDB
目录 1.前言 2.开启项目报错 3.GDB的进入和退出 4.GDB调试中查看代码和切换文件 5.GDB调试中程序的启动和main函数传参 6.GDB中断点相关的操作 7.GDB中的调试输出指令 8.GDB中自动输出值指令 9.GDB中的调试指令 前言 在日常开发中,调试是我们必不可少的技能。在专业…...

服务器权限管理
我们linux服务器上有严格的权限等级,如果权限过高导致误操作会增加服务器的风险。所以对于了解linux系统中的各种权限及要给用户,服务等分配合理的权限十分重要。(权限越大,责任越大) 1.基本权限 U--user用户,G-group…...

08 SpringBoot 自定定义配置
SpringBoot自定义配置有三种方式: 使用PropertySource进行自定义配置 使用ImportResource进行自定义配置 使用Configuration进行自定义配置 PropertySource 如果将所有的配置都集中到 application.properties 或 application.yml 中,那么这个配置文…...
加密计算(DESede/ECB/ZeroPadding))
Java之3DES(Triple DES)加密计算(DESede/ECB/ZeroPadding)
Java环境本身并不直接支持DESede/ECB/ZeroPadding。 不过,可以通过以下几种方式来实现DESede/ECB/ZeroPadding: 手动实现填充和去除填充:如前面示例代码所示,在加密之前进行填充,在解密之后去除填充。这是一个通用的方…...

从0开发一个Chrome插件:项目实战——广告拦截插件
前言 这是《从0开发一个Chrome插件》系列的第十七篇文章,本系列教你如何从0去开发一个Chrome插件,每篇文章都会好好打磨,写清楚我在开发过程遇到的问题,还有开发经验和技巧。 专栏: 从0开发一个Chrome插件:什么是Chrome插件?从0开发一个Chrome插件:开发Chrome插件的必…...

突破硬件限制的游戏自由:Sunshine串流方案让低配设备玩转3A大作
突破硬件限制的游戏自由:Sunshine串流方案让低配设备玩转3A大作 【免费下载链接】Sunshine Self-hosted game stream host for Moonlight. 项目地址: https://gitcode.com/GitHub_Trending/su/Sunshine Sunshine是一款开源的自托管游戏串流服务器,…...

突破性Elsevier审稿状态追踪解决方案:自动化监控系统提升学术出版效率
突破性Elsevier审稿状态追踪解决方案:自动化监控系统提升学术出版效率 【免费下载链接】Elsevier-Tracker 项目地址: https://gitcode.com/gh_mirrors/el/Elsevier-Tracker 学术研究者面临的审稿状态追踪困境已成为科研生产力的隐形障碍。Elsevier Tracker作…...

连续血糖监测数据集终极指南:解锁糖尿病研究的标准化数据宝库
连续血糖监测数据集终极指南:解锁糖尿病研究的标准化数据宝库 【免费下载链接】Awesome-CGM List of CGM datasets 项目地址: https://gitcode.com/gh_mirrors/aw/Awesome-CGM 在精准医疗与人工智能交叉融合的时代,连续血糖监测(CGM&a…...

Spring Boot 4.0 Agent-Ready 架构:从@ConditionalOnAgentEnabled注解到RuntimeMXBean探针注册的7步精准控制流
第一章:Spring Boot 4.0 Agent-Ready 架构演进与设计哲学Spring Boot 4.0 将 JVM Agent 集成能力提升为核心架构原语,不再将字节码增强视为“外部可观测性插件”,而是深度融入启动生命周期、Bean 注册与环境配置三大主干流程。这一转变源于对…...

SDMatte与数据库联动:开发一个带历史记录管理的在线抠图平台
SDMatte与数据库联动:开发一个带历史记录管理的在线抠图平台 1. 项目背景与价值 想象一下这样的场景:设计师小王每天需要处理上百张商品图片的抠图工作。传统方法要么手动操作费时费力,要么使用本地软件来回切换效率低下。如果能有一个在线…...

进程与线程的核心区别:一篇看懂,告别混淆
在编程学习中,尤其是接触 C 多线程、操作系统相关知识时,进程(Process)和线程(Thread)是两个绕不开的概念。很多新手会把二者混为一谈,甚至像之前我被问到的那样,疑惑“进程是不是线…...

揭秘书匠策AI:课程论文写作的“智慧魔法棒”
在学术的奇妙旅程中,课程论文宛如一座座等待攀登的小山峰,既充满挑战,又蕴含着成长的机遇。对于众多初涉学术领域的学生而言,从构思选题到搭建框架,再到填充内容与精心打磨,每一步都可能伴随着困惑与迷茫。…...

实战:中优云联批量入驻退租门禁权限处理方案,50人1分钟搞定,离职秒回收
关键词:门禁系统、SaaS、边缘计算、RBAC、批量操作、4G无线 标签:物联网、智慧园区、Java后端、架构设计0. 写在前面先交代背景。我是一名园区物业的IT运维,平时负责维护一套老旧的门禁系统。说实话,这套系统用了七八年࿰…...

打破虚拟世界语言壁垒:VRCT实现VRChat跨语言交流的技术方案与实践指南
打破虚拟世界语言壁垒:VRCT实现VRChat跨语言交流的技术方案与实践指南 【免费下载链接】VRCT VRCT(VRChat Chatbox Translator & Transcription) 项目地址: https://gitcode.com/gh_mirrors/vr/VRCT 在全球化的虚拟社交平台VRChat中,语言差异…...

Architect.dev性能优化终极技巧:提升Lambda函数响应速度的10个方法
Architect.dev性能优化终极技巧:提升Lambda函数响应速度的10个方法 【免费下载链接】architect The simplest, most powerful way to build a functional web app (fwa) 项目地址: https://gitcode.com/gh_mirrors/ar/architect Architect.dev是一个强大的无…...