面试-NLP八股文
机器学习
- 交叉熵损失: L = − ( y l o g ( y ^ ) + ( 1 − y ) l o g ( 1 − ( y ^ ) ) L=-(ylog(\hat{y}) + (1-y)log(1-(\hat{y})) L=−(ylog(y^)+(1−y)log(1−(y^))
- 均方误差: L = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 L =\frac{1}{n}\sum\limits_{i=1}^{n}(y_{i} - \hat{y}_{i})^{2} L=n1i=1∑n(yi−y^i)2
- BPR损失: L = ∑ ( u , i , j ) ∈ O − l n σ ( y ^ u i − y ^ u j ) L=\sum_{(u,i,j) \in O} -ln\sigma(\hat{y}_{ui} - \hat{y}_{uj}) L=∑(u,i,j)∈O−lnσ(y^ui−y^uj)
- 最大似然估计:是一种在给定结果的情况下,使得选择的参数值观测到该结果的概率最大
- 交叉熵:衡量两个概率分布p和q之间差异的指标;最大化似然函数等价于最小化交叉熵
- LR和SVM的异同
- LR是逻辑回归模型,在最后的结果上应用了sigmoid函数得到分布概率
- SVM是为了寻找一个最优超平面,使得训练样本离该超平面的间隔最大化
- 高斯核函数的核心思想是将样本数据进行升维,从而使得原本线性不可分的数据线性可分
- 同:
- LR和SVM都可以处理分类问题,且一般都用于处理线性二分类问题
- 两个方法都可以增加不同的正则化项,如L1、L2正则化
- LR和SVM都可以用来做非线性分类,只要加核函数就好
- 异:
- LR是参数模型,SVM是非参数模型
- 逻辑回归采用的是cross-entropy loss,SVM采用的是hinge loss
- SVM分类只需要计算与少数几个支持向量的距离,而LR和所有点都有关系
- L1L2的特点
- 正则化是防止模型在训练数据上过度拟合的技术,即通过在模型的损失函数中引入额外的惩罚项,来对模型的参数进行约束,从而降低模型的复杂度(使数值变小)
- L1是权重参数的绝对值之和
- L2是权重参数的平方,L2正则化又称为权重衰减
- dropout在训练过程中随机将部分神经元权重置为零
- Layer Normalization与Batch Normalization
- 归一化是把数据特征映射到固定范围,以避免由于输入特征尺度存在较大差异,而使模型的优化方向可能会被尺度较大的特征所主导
- BN层(Batch Normalization):是在不同样本之间进行归一化
- LN层(Layer Normalization):是在同一样本内部进行归一化
- 如何缓解梯度消失问题
- 梯度趋近于零,网络权重无法更新或更新的很微小,网络训练再久也不会有效果
- 解决办法:选择合适的激活函数;批量归一化;使用残差网络
- 如何缓解梯度爆炸问题
- 梯度呈指数级增长,变的非常大,然后导致网络权重的大幅更新,使网络变得不稳定
- 解决办法:选择合适的权重初始化;梯度裁剪
- 防止过拟合的手段(训练时效果好,测试时效果拉)
- 增加训练数据量,或数据增强
- 简化模型结构
- 早停策略
- Dropout技术
- 正则化方法
- Adam算法能够根据不同参数的梯度特性自适应地调整学习率。对于梯度较大的参数,学习率会相应减小,以避免参数更新过快导致震荡;对于梯度较小的参数,学习率会相应增大,以加速收敛。Adam优化器是由Momentum动量梯度与RMSProp算法构成
- 交叉验证:其基本思想是将数据分为K个互不重叠的子集(通常称为“折”),每次选取其中K-1个子集作为训练集,剩下的一个子集作为测试集,进行模型训练和评估。这个过程会重复K次,每次选择不同的子集作为测试集,最后将所有的测试结果求平均值。
- KNN是根据某一样本点距离最近的 K 个样本点的类别来判断该样本属于哪个类别(多数投票)
- K-means是无监督学习算法。根据输入无标签的数据,然后将数据聚类成不同的组。做法:随机初始化质心->计算每个数据点到每个质心的距离->根据距离将数据点到簇->重新计算簇的质心,重复这一过程直到质心不再变化或达到预定的迭代次数。
- 决策树是一种树形结构,主要用于分类,易过拟合,需要剪枝算法
- 随机森林是将多个决策树结合在一起,每次数据集是随机有放回的选出,而选出部分特征作为输入,最后将多个树的结果整合起来当作最后的结果输出。
- 归一化(Normalization)是将一列数据变化到某个固定区间(范围)中,通常,这个区间是[0, 1] 或者(-1,1)之间的小数
- 标准化(Standardization)是原始数据减均值之后,再除以标准差。将数据变换为均值为0,标准差为1的分布
深度学习
-
Embedding技术是将单词转换为固定长度的向量
- 作用(独热编码相比):可以解决维度灾难,即独热编码(One-hot )导致的维度激增;解决词汇鸿沟,即独热编码不能表达词汇之间的联系
- 基于内容的word2vec方法是最经典的,其中包含框架CBOW连续词袋模型(Continuous Bag of Words)和Skip-gram跳字模型
-
CBOW预设好窗口大小,利用窗口内的上下文来预测目标词。
- 模型输入是上下文词汇的One-hot编码;经过Embedding层,即词汇编码各自和嵌入矩阵相乘,得到词向量;然后计算上下文词向量的平均值;再输入线性层,得到输出向量;输入softmax层得到概率分布,最大概率位置对应的词即为预测结果;

-
Skip-gram跳字模型为CBOW的逆过程
- 模型输入是目标词的独热编码向量;经过in嵌入层,得到隐藏层;再经过out嵌入层得到输出向量;输入softmax层得到字典中每个词汇是目标词上下文的概率

-
-
文本关键词抽取
- textrank把文本拆分成词汇作为图节点, 然后对节点权重进行倒序排列,得到排名前TopN个词汇作为文本关键词
- 节点间权重计算方式:两个节点之间仅当它们对应的词汇在长度为K的窗口中共现则存在边,K表示窗口大小即最多共现K个词汇
- tf-idf
- 词频(Term Frequency,TF)指某一给定词语在当前文件中出现的频率。 词频 ( T F ) = 词 w 在文档中出现的次数 文档的总词数 词频(TF)=\frac{词w在文档中出现的次数}{文档的总词数} 词频(TF)=文档的总词数词w在文档中出现的次数
- 逆向文件频率(Inverse Document Frequency,IDF)是一个词语普遍重要性的度量。即如果一个词语只在很少的文件中出现,表示更能代表文件的主旨,它的权重也就越大;如果一个词在大量文件中都出现,表示不清楚代表什么内容,它的权重就应该小。 逆文档频率 ( I D F ) = l o g ( 语料库的文档总数 包含词 w 的文档数 + 1 ) 逆文档频率(IDF)=log(\frac{语料库的文档总数}{包含词w的文档数+1}) 逆文档频率(IDF)=log(包含词w的文档数+1语料库的文档总数)
- 关键字抽取方式:计算所有词的TF-IDF=TF*IDF,对计算结果进行倒序排列,得到排名前TopN个词汇作为文本关键词
- textrank把文本拆分成词汇作为图节点, 然后对节点权重进行倒序排列,得到排名前TopN个词汇作为文本关键词
-
CNN有卷积核,池化层,线性层。计算公式: N = W − F + 2 P S + 1 N=\frac{W-F+2P}{S} + 1 N=SW−F+2P+1
-
RNN模型(处理序列数据)
- 存在长期依赖缺失的问题:在处理长时间问题时,由于梯度消失造成的较远信息对此时几乎不产生影响
- 长短期神经网络LSTM和门控循环单元GRU可以解决长距离依赖缺失问题
- LSTM有遗忘门(决定遗忘的信息),输入门(更新细胞状态),输出门(由隐藏表示,输入变量,细胞状态决定)
- GRU是在LSTM的基础上提出的,与LSTM相比取消了细胞状态向量,门控结构也减少了,简化了LSTM的结构并提高其计算效率
-
Transformer模型是基于自注意力机制的深度神经网络模型,提高了计算效率,并更好地捕捉长距离依赖关系
- Positional Encoding: 区分单、双数,利用正、余弦函数进行位置编码
- Multi-Head Attention:多头注意力机制是一种扩展自注意力机制的方法,它将自注意力机制分解为多个“头”,每个“头”都在不同的表示空间中学习信息,从而能够捕捉到更丰富的特征和关系,保证了可以学习到一个词的多个语义
- A t t e n t i o n ( Q , K , V ) = S o f t m a x ( Q K T d k ) V Attention(Q, K, V) = Softmax(\frac{QK^{T}}{\sqrt{d_{k}}})V Attention(Q,K,V)=Softmax(dkQKT)V
- ∗ d k \frac{*}{\sqrt{d_{k}}} dk∗:首先要除以一个数,防止输入softmax的值过大,导致偏导数趋近于0;其次选择根号d_k是因为可以使得q*k的结果满足期望为0,方差为1的分布。
- 掩码操作Mask: 包含Padding Mask和Sequence Mask两种。掩码就是让矩阵某些元素变为负无穷的数,使得其在后续Softmax中的概率为0。其中Padding Mask旨在消除输入序列中Padding的影响;而Sequence Mask只存在于解码器中,目的是在预测下一个词时,覆盖住后面的词汇注意力信息,达到只用前面序列来预测下一词的目的
- FFN模块是为了增加模型的非线性能力(因为内部使用的激活函数)
- NLP中Layer Normalization针对句内每个单词归一,Batch Normalization针对batch内同一位置单词的不同特征归一
-
模型的评价指标
- TP(true positive-真阳性):表示样本的真实类别为正,最后预测得到的结果也为正;FP(false positive-假阳性):表示样本的真实类别为负,最后预测得到的结果却为正;FN(false negative-假阴性):表示样本的真实类别为正,最后预测得到的结果却为负;TN(true negative-真阴性):表示样本的真实类别为负,最后预测得到的结果也为负
- 准确率表示预测正确的样本数占总样本书的比例。 A c c u r a c y = T P + T N T P + T N + F P + F N Accuracy=\frac{TP+TN}{TP+TN+FP+FN} Accuracy=TP+TN+FP+FNTP+TN
- 精确率表示预测为正样本的样本中,正确预测为正样本的概率。 P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP
- 召回率表示正确预测出正样本占实际正样本的概率。 R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP
- F1 score折中了召回率与精确率。 F 1 = 2 ∗ R e c a l l ∗ P r e c i s i o n R e c a l l + P r e c i s i o n F1=2*\frac{Recall*Precision}{Recall+Precision} F1=2∗Recall+PrecisionRecall∗Precision
- HR (命中率-Hits Ratio)预测正确的用户占所有用户的比例,强调预测的“准确性”。 H R = 1 N ∑ i = 1 N h i t s ( i ) HR=\frac{1}{N}\sum\limits_{i=1}^{N}hits(i) HR=N1i=1∑Nhits(i)
- MRR (平均倒数排名-Mean Reciprocal Rank)表示待推荐的项目是否放在了用户更显眼的位置,强调“顺序性”。 M R R = 1 N ∑ i = 1 N 1 p i MRR=\frac{1}{N}\sum\limits_{i=1}^{N}\frac{1}{p_{i}} MRR=N1i=1∑Npi1, p i p_{i} pi表示第 i 个用户的真实访问值在推荐列表的位置
- NDCG(归一化折损累计增益-Normalized Discounted Cumulative Gain)用于判断对于一个用户,返回的推荐item列表是否更好
- Gain:一个列表中所有item的相关性分数。 G a i n = r e l ( i ) Gain=rel(i) Gain=rel(i)
- Cumulative Gain: 表示对K个item的Gain进行累加(没有考虑顺序)。 C G k = ∑ i = 1 k r e l ( i ) CG_{k} = \sum\limits_{i=1}^{k} rel(i) CGk=i=1∑krel(i)
- Discounted Cumulative Gain:考虑排序顺序的因素,使得排名靠前的item增益更高,对排名靠后的item进行折损。 D C G k = ∑ i = 1 k r e l ( i ) l o g 2 ( i + 1 ) DCG_{k}=\sum\limits_{i=1}^{k} \frac{rel(i)}{log_{2}(i+1)} DCGk=i=1∑klog2(i+1)rel(i)
- IDGC(ideal DCG):理想的DCG,IDCG的依据是:是根据rel(i)降序排列,即排列到最好状态。算出最好排列的DCG,就是IDCG。 N D C G = D C G I D C G NDCG=\frac{DCG}{IDCG} NDCG=IDCGDCG
-
残差结构及意义:在结果上加输入,防止梯度消失和网络退化
-
Bert是由多个Transformer Encoder一层一层地堆叠起来
- Embedding由三种Embedding求和而成
- Token Embeddings:针对单词,会在开头加入CLS,结尾加入SEP
- Segment Embeddings:区别两种句子,前句赋0,后句赋1
- Position Embeddings:针对位置,不同于Transformer使用正余弦函数,bert随机初始化位置嵌入。前者只能标记位置,后者不仅可以标记位置,还可以学习到这个位置有什么用。
- 长度限制为512
- Embedding由三种Embedding求和而成
简单代码
- 数据结构里面的算法,手撕就好(例如:—句话说快排)
- 每一个数有一个概率,要求写一个随机数发生器,使随机数产生概率符合要求
- 最大子矩形面积,(记得是leetcode原题,大家可以去看一下)
- 判断数独是否是有效数独(行、列、每个3*3矩阵判断)
- 矩阵中正方形最大面积
- 2D接雨水
相关文章:
面试-NLP八股文
机器学习 交叉熵损失: L − ( y l o g ( y ^ ) ( 1 − y ) l o g ( 1 − ( y ^ ) ) L-(ylog(\hat{y}) (1-y)log(1-(\hat{y})) L−(ylog(y^)(1−y)log(1−(y^))均方误差: L 1 n ∑ i 1 n ( y i − y ^ i ) 2 L \frac{1}{n}\sum\limits_{i1}^{n}…...

数据仓库之离线数仓
离线数据仓库(Offline Data Warehouse)是一种以批处理方式为主的数据仓库系统,旨在收集、存储和分析大量历史数据。离线数据仓库通常用于定期(如每日、每周、每月)更新数据,以支持各种业务分析、报表生成和…...

Mybatis源码解析
MybatisAutoConfiguration或者MybatisPlusAutoConfiguration核心作用是初始化工厂类SqlSessionFactory,其中包含属性interceptors、MapperLocations、TypeAliasesPackage、TypeEnumsPackage、TypeHandlers等。 MybatisAutoConfiguration自动装配类是由依赖…...

前端学习CSS之神奇的块浮动
在盒子模型的基础上就可以对网页进行设计 不知道盒子模型的可以看前面关于盒子模型的内容 而普通的网页设计具有一定的原始规律,这个原始规律就是文档流 文档流 标签在网页二维平面内默认的一种排序方式,块级标签不管怎么设置都会占一行,而同一行不能放置两个块级标签 行级…...

【Java】内部类、枚举、泛型
目录 1.内部类1.1概述1.2分类1.3匿名内部类(重点) 2.枚举2.1一般枚举2.2抽象枚举2.3应用1:用枚举写单例2.4应用2:标识常量 3.泛型3.1泛型认识3.2泛型原理3.3泛型的定义泛型类泛型接口泛型方法 3.4泛型的注意事项 1.内部类 1.1概述 内部类:指…...
LabVIEW电子类实验虚拟仿真系统
开发了基于LabVIEW开发的电子类实验虚拟仿真实验系统。该系统通过图形化编程方式,实现了复杂电子实验操作的虚拟化,不仅提高了学生的操作熟练度和学习兴趣,而且通过智能评价模块提供即时反馈,促进教学和学习的互动。 项目背景 在…...

SVM支持向量机
SVM的由来和概念 间隔最大化是找最近的那个点的距离’ 之前我们学习的都是线性超平面,现在我们要将超平面变成圈 对于非线性问题升维来解决 对于下图很难处理,我们可以将棍子立起来,然后说不定red跑到左边了,green跑到右边了(可能增加了某种筛选条件导致两个豆子分离)(只是一种…...
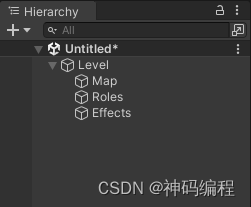
【Unity】RPG2D龙城纷争(二)关卡、地块
更新日期:2024年6月12日。 项目源码:后续章节发布 索引 简介地块(Block)一、定义地块类二、地块类型三、地块渲染四、地块索引 关卡(Level)一、定义关卡类二、关卡基础属性三、地块集合四、关卡初始化五、关…...
mediamtx流媒体服务器测试
MediaMTX简介 在web页面中直接播放rtsp视频流,重点推荐:mediamtx,不仅仅是rtsp-CSDN博客 mediamtx github MediaMTX(以前的rtsp-simple-server)是一个现成的和零依赖的实时媒体服务器和媒体代理,允许发布,读取&…...

C# 循环
C# 循环 在编程中,循环是一种控制结构,它允许我们重复执行一段代码多次。C# 提供了几种循环机制,以适应不同的编程需求。本文将详细介绍 C# 中常用的几种循环类型,包括 for 循环、while 循环、do-while 循环和 foreach 循环&…...

PHP杂货铺家庭在线记账理财管理系统源码
家庭在线记帐理财系统,让你对自己的开支了如指掌,图形化界面操作更简单,非常适合家庭理财、记账,系统界面简洁优美,操作直观简单,非常容易上手。 安装说明: 1、上传到网站根目录 2、用phpMyad…...
)
机器学习中的神经网络重难点!纯干货(上篇)
. . . . . . . . .纯干货 . . . . . . 目录 前馈神经网络 基本原理 公式解释 一个示例 卷积神经网络 基本原理 公式解释 一个示例 循环神经网络 基本原理 公式解释 一个案例 长短时记忆网络 基本原理 公式解释 一个示例 自注意力模型 基本原理…...

[DDR4] DDR1 ~ DDR4 发展史导论
依公知及经验整理,原创保护,禁止转载。 专栏 《深入理解DDR4》 内存和硬盘是电脑的左膀右臂, 挑起存储的大梁。因为内存的存取速度超凡地快, 但内存上的数据掉电又会丢失,一直其中缓存的作用,就像是我们的工…...
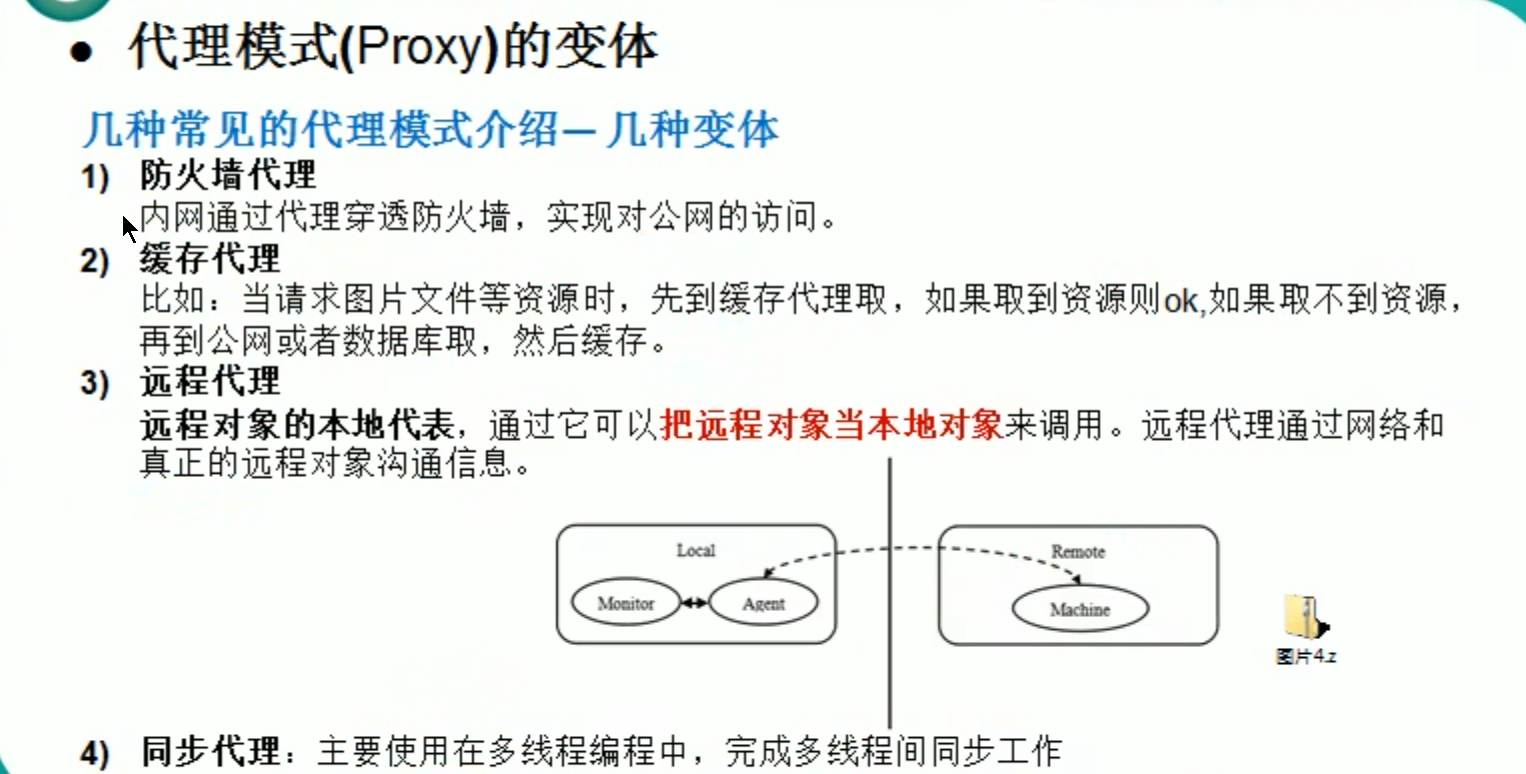
享元和代理模式
文章目录 享元模式1.引出享元模式1.展示网站项目需求2.传统方案解决3.问题分析 2.享元模式1.基本介绍2.原理类图3.外部状态和内部状态4.类图5.代码实现1.AbsWebSite.java 抽象的网站2.ConcreteWebSite.java 具体的网站,type属性是内部状态3.WebSiteFactory.java 网站…...

[英语单词] ellipsize,动词化后缀 -ize
openvswitch manual里的一句话:里面有使用ellipsize,但是查字典是没有这个单词,这就是创造出来的动词。将单词ellipsis,加动词化后缀,-ize。 Often we ellipsize arguments not important to the discussion, e.g.: &…...

自然资源-测绘地信专业术语,值得收藏!
自然资源-测绘地信专业术语,值得收藏! 1、1954年北京坐标系 1954年我国决定采用的国家大地坐标系,实质上是由原苏联普尔科沃为原点的1942年坐标系的延伸。 2、1956年黄海高程系统 根据青岛验潮站1950年一1956年的验潮资料计算确定的平均海面…...

如何在小程序中实现页面之间的返回
在小程序中实现页面之间的返回,通常有以下几种方法,这些方法各有特点,适用于不同的场景: 1. 使用wx.navigateBack方法 描述:wx.navigateBack是微信小程序中用于关闭当前页面,返回上一页面或多级页面的API…...

深入解析数据结构之B树:平衡树中的王者
在计算机科学中,数据结构是算法和程序设计的基础。而在众多数据结构中,B树作为一种平衡树,在数据库和文件系统中有着广泛应用。本文将详细介绍B树的概念、特点、操作、优缺点及其应用场景,帮助读者深入理解这一重要的数据结构。 …...
18. 第十八章 继承
18. 继承 和面向对象编程最常相关的语言特性就是继承(inheritance). 继承值得是根据一个现有的类型, 定义一个修改版本的新类的能力. 本章中我会使用几个类来表达扑克牌, 牌组以及扑克牌性, 用于展示继承特性.如果你不玩扑克, 可以在http://wikipedia.org/wiki/Poker里阅读相关…...
)
OperationalError: (_mysql_exceptions.OperationalError)
OperationalError: (_mysql_exceptions.OperationalError) (2006, MySQL server has gone away) 这个错误通常表示客户端(例如你的 Python 程序使用 SQLAlchemy 连接到 MySQL 数据库)和 MySQL 服务器之间的连接被异常关闭了。这个问题可能由多种原因引起,以下是一些常见的原…...

Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以?
Golang 面试经典题:map 的 key 可以是什么类型?哪些不可以? 在 Golang 的面试中,map 类型的使用是一个常见的考点,其中对 key 类型的合法性 是一道常被提及的基础却很容易被忽视的问题。本文将带你深入理解 Golang 中…...

【人工智能】神经网络的优化器optimizer(二):Adagrad自适应学习率优化器
一.自适应梯度算法Adagrad概述 Adagrad(Adaptive Gradient Algorithm)是一种自适应学习率的优化算法,由Duchi等人在2011年提出。其核心思想是针对不同参数自动调整学习率,适合处理稀疏数据和不同参数梯度差异较大的场景。Adagrad通…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

【网络安全产品大调研系列】2. 体验漏洞扫描
前言 2023 年漏洞扫描服务市场规模预计为 3.06(十亿美元)。漏洞扫描服务市场行业预计将从 2024 年的 3.48(十亿美元)增长到 2032 年的 9.54(十亿美元)。预测期内漏洞扫描服务市场 CAGR(增长率&…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

3403. 从盒子中找出字典序最大的字符串 I
3403. 从盒子中找出字典序最大的字符串 I 题目链接:3403. 从盒子中找出字典序最大的字符串 I 代码如下: class Solution { public:string answerString(string word, int numFriends) {if (numFriends 1) {return word;}string res;for (int i 0;i &…...

智能分布式爬虫的数据处理流水线优化:基于深度强化学习的数据质量控制
在数字化浪潮席卷全球的今天,数据已成为企业和研究机构的核心资产。智能分布式爬虫作为高效的数据采集工具,在大规模数据获取中发挥着关键作用。然而,传统的数据处理流水线在面对复杂多变的网络环境和海量异构数据时,常出现数据质…...

springboot整合VUE之在线教育管理系统简介
可以学习到的技能 学会常用技术栈的使用 独立开发项目 学会前端的开发流程 学会后端的开发流程 学会数据库的设计 学会前后端接口调用方式 学会多模块之间的关联 学会数据的处理 适用人群 在校学生,小白用户,想学习知识的 有点基础,想要通过项…...

Unity UGUI Button事件流程
场景结构 测试代码 public class TestBtn : MonoBehaviour {void Start(){var btn GetComponent<Button>();btn.onClick.AddListener(OnClick);}private void OnClick(){Debug.Log("666");}}当添加事件时 // 实例化一个ButtonClickedEvent的事件 [Formerl…...

日常一水C
多态 言简意赅:就是一个对象面对同一事件时做出的不同反应 而之前的继承中说过,当子类和父类的函数名相同时,会隐藏父类的同名函数转而调用子类的同名函数,如果要调用父类的同名函数,那么就需要对父类进行引用&#…...