StarNet实战:使用StarNet实现图像分类任务(一)
文章目录
- 摘要
- 安装包
- 安装timm
- 数据增强Cutout和Mixup
- EMA
- 项目结构
- 计算mean和std
- 生成数据集
摘要
https://arxiv.org/pdf/2403.19967
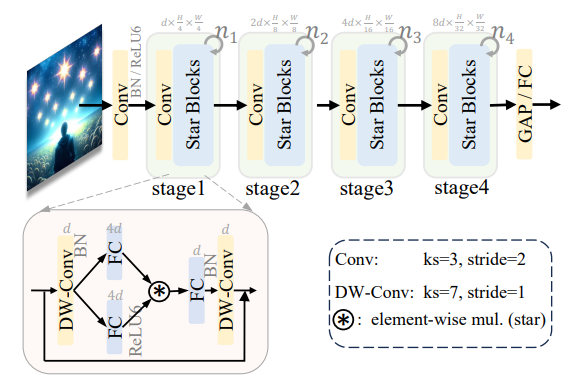
论文主要集中在介绍和分析一种新兴的学习范式——星操作(Star Operation),这是一种通过元素级乘法融合不同子空间特征的方法,通过元素级乘法(类似于“星”形符号的乘法操作)将不同子空间的特征进行融合,从而在多个研究领域中展现出出色的性能和效率。
星操作在自然语言处理(NLP)和计算机视觉(CV)等多个领域中都得到了成功应用。例如,在自然语言处理中,Monarch Mixer、Mamba、Hyena Hierarchy和GLU等模型都采用了星操作;在计算机视觉中,FocalNet、HorNet和VAN等模型也利用了星操作进行特征融合。
尽管星操作在多个领域中都取得了显著成果,但其背后的基本原理尚未得到全面分析和验证。StarNet通过深入探究星操作的细节,发现星操作具有将输入映射到极高维、非线性特征空间的能力。这种映射方式与传统增加网络宽度的方法不同,而是通过跨通道特征对乘实现了一种类似于多项式核函数的非线性高维映射。
当将星操作融入神经网络并堆叠多层时,每一层都使隐含的维度复杂度呈指数级增长。这种高效的特征融合方式使得星操作能够在紧凑的特征空间内实现近乎无限的维度,从而极大地提高了模型的表示能力和性能。
本文使用StarNet模型实现图像分类任务,模型选择starnet_s1,在植物幼苗分类任务ACC达到了95%+。


通过这篇文章能让你学到:
- 如何使用数据增强,包括transforms的增强、CutOut、MixUp、CutMix等增强手段?
- 如何实现StarNet模型实现训练?
- 如何使用pytorch自带混合精度?
- 如何使用梯度裁剪防止梯度爆炸?
- 如何使用DP多显卡训练?
- 如何绘制loss和acc曲线?
- 如何生成val的测评报告?
- 如何编写测试脚本测试测试集?
- 如何使用余弦退火策略调整学习率?
- 如何使用AverageMeter类统计ACC和loss等自定义变量?
- 如何理解和统计ACC1和ACC5?
- 如何使用EMA?
如果基础薄弱,对上面的这些功能难以理解可以看我的专栏:经典主干网络精讲与实战
这个专栏,从零开始时,一步一步的讲解这些,让大家更容易接受。
安装包
安装timm
使用pip就行,命令:
pip install timm
mixup增强和EMA用到了timm
数据增强Cutout和Mixup
为了提高成绩我在代码中加入Cutout和Mixup这两种增强方式。实现这两种增强需要安装torchtoolbox。安装命令:
pip install torchtoolbox
Cutout实现,在transforms中。
from torchtoolbox.transform import Cutout
# 数据预处理
transform = transforms.Compose([transforms.Resize((224, 224)),Cutout(),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
需要导入包:from timm.data.mixup import Mixup,
定义Mixup,和SoftTargetCrossEntropy
mixup_fn = Mixup(mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,prob=0.1, switch_prob=0.5, mode='batch',label_smoothing=0.1, num_classes=12)criterion_train = SoftTargetCrossEntropy()
Mixup 是一种在图像分类任务中常用的数据增强技术,它通过将两张图像以及其对应的标签进行线性组合来生成新的数据和标签。
参数详解:
mixup_alpha (float): mixup alpha 值,如果 > 0,则 mixup 处于活动状态。
cutmix_alpha (float):cutmix alpha 值,如果 > 0,cutmix 处于活动状态。
cutmix_minmax (List[float]):cutmix 最小/最大图像比率,cutmix 处于活动状态,如果不是 None,则使用这个 vs alpha。
如果设置了 cutmix_minmax 则cutmix_alpha 默认为1.0
prob (float): 每批次或元素应用 mixup 或 cutmix 的概率。
switch_prob (float): 当两者都处于活动状态时切换cutmix 和mixup 的概率 。
mode (str): 如何应用 mixup/cutmix 参数(每个’batch’,‘pair’(元素对),‘elem’(元素)。
correct_lam (bool): 当 cutmix bbox 被图像边框剪裁时应用。 lambda 校正
label_smoothing (float):将标签平滑应用于混合目标张量。
num_classes (int): 目标的类数。
EMA
EMA(Exponential Moving Average)是指数移动平均值。在深度学习中的做法是保存历史的一份参数,在一定训练阶段后,拿历史的参数给目前学习的参数做一次平滑。具体实现如下:
import logging
from collections import OrderedDict
from copy import deepcopy
import torch
import torch.nn as nn_logger = logging.getLogger(__name__)class ModelEma:def __init__(self, model, decay=0.9999, device='', resume=''):# make a copy of the model for accumulating moving average of weightsself.ema = deepcopy(model)self.ema.eval()self.decay = decayself.device = device # perform ema on different device from model if setif device:self.ema.to(device=device)self.ema_has_module = hasattr(self.ema, 'module')if resume:self._load_checkpoint(resume)for p in self.ema.parameters():p.requires_grad_(False)def _load_checkpoint(self, checkpoint_path):checkpoint = torch.load(checkpoint_path, map_location='cpu')assert isinstance(checkpoint, dict)if 'state_dict_ema' in checkpoint:new_state_dict = OrderedDict()for k, v in checkpoint['state_dict_ema'].items():# ema model may have been wrapped by DataParallel, and need module prefixif self.ema_has_module:name = 'module.' + k if not k.startswith('module') else kelse:name = knew_state_dict[name] = vself.ema.load_state_dict(new_state_dict)_logger.info("Loaded state_dict_ema")else:_logger.warning("Failed to find state_dict_ema, starting from loaded model weights")def update(self, model):# correct a mismatch in state dict keysneeds_module = hasattr(model, 'module') and not self.ema_has_modulewith torch.no_grad():msd = model.state_dict()for k, ema_v in self.ema.state_dict().items():if needs_module:k = 'module.' + kmodel_v = msd[k].detach()if self.device:model_v = model_v.to(device=self.device)ema_v.copy_(ema_v * self.decay + (1. - self.decay) * model_v)加入到模型中。
#初始化
if use_ema:model_ema = ModelEma(model_ft,decay=model_ema_decay,device='cpu',resume=resume)# 训练过程中,更新完参数后,同步update shadow weights
def train():optimizer.step()if model_ema is not None:model_ema.update(model)# 将model_ema传入验证函数中
val(model_ema.ema, DEVICE, test_loader)
针对没有预训练的模型,容易出现EMA不上分的情况,这点大家要注意啊!
项目结构
StarNet_Demo
├─data1
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
├─models
│ └─starnet.py
├─mean_std.py
├─makedata.py
├─train.py
└─test.py
mean_std.py:计算mean和std的值。
makedata.py:生成数据集。
train.py:训练StarNet模型
models:来源官方代码。
计算mean和std
为了使模型更加快速的收敛,我们需要计算出mean和std的值,新建mean_std.py,插入代码:
from torchvision.datasets import ImageFolder
import torch
from torchvision import transformsdef get_mean_and_std(train_data):train_loader = torch.utils.data.DataLoader(train_data, batch_size=1, shuffle=False, num_workers=0,pin_memory=True)mean = torch.zeros(3)std = torch.zeros(3)for X, _ in train_loader:for d in range(3):mean[d] += X[:, d, :, :].mean()std[d] += X[:, d, :, :].std()mean.div_(len(train_data))std.div_(len(train_data))return list(mean.numpy()), list(std.numpy())if __name__ == '__main__':train_dataset = ImageFolder(root=r'data1', transform=transforms.ToTensor())print(get_mean_and_std(train_dataset))
数据集结构:

运行结果:
([0.3281186, 0.28937867, 0.20702125], [0.09407319, 0.09732835, 0.106712654])
把这个结果记录下来,后面要用!
生成数据集
我们整理还的图像分类的数据集结构是这样的
data
├─Black-grass
├─Charlock
├─Cleavers
├─Common Chickweed
├─Common wheat
├─Fat Hen
├─Loose Silky-bent
├─Maize
├─Scentless Mayweed
├─Shepherds Purse
├─Small-flowered Cranesbill
└─Sugar beet
pytorch和keras默认加载方式是ImageNet数据集格式,格式是
├─data
│ ├─val
│ │ ├─Black-grass
│ │ ├─Charlock
│ │ ├─Cleavers
│ │ ├─Common Chickweed
│ │ ├─Common wheat
│ │ ├─Fat Hen
│ │ ├─Loose Silky-bent
│ │ ├─Maize
│ │ ├─Scentless Mayweed
│ │ ├─Shepherds Purse
│ │ ├─Small-flowered Cranesbill
│ │ └─Sugar beet
│ └─train
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
新增格式转化脚本makedata.py,插入代码:
import glob
import os
import shutilimage_list=glob.glob('data1/*/*.png')
print(image_list)
file_dir='data'
if os.path.exists(file_dir):print('true')#os.rmdir(file_dir)shutil.rmtree(file_dir)#删除再建立os.makedirs(file_dir)
else:os.makedirs(file_dir)from sklearn.model_selection import train_test_split
trainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)
train_dir='train'
val_dir='val'
train_root=os.path.join(file_dir,train_dir)
val_root=os.path.join(file_dir,val_dir)
for file in trainval_files:file_class=file.replace("\\","/").split('/')[-2]file_name=file.replace("\\","/").split('/')[-1]file_class=os.path.join(train_root,file_class)if not os.path.isdir(file_class):os.makedirs(file_class)shutil.copy(file, file_class + '/' + file_name)for file in val_files:file_class=file.replace("\\","/").split('/')[-2]file_name=file.replace("\\","/").split('/')[-1]file_class=os.path.join(val_root,file_class)if not os.path.isdir(file_class):os.makedirs(file_class)shutil.copy(file, file_class + '/' + file_name)
完成上面的内容就可以开启训练和测试了。
相关文章:
StarNet实战:使用StarNet实现图像分类任务(一)
文章目录 摘要安装包安装timm 数据增强Cutout和MixupEMA项目结构计算mean和std生成数据集 摘要 https://arxiv.org/pdf/2403.19967 论文主要集中在介绍和分析一种新兴的学习范式——星操作(Star Operation),这是一种通过元素级乘法融合不同子…...

单链表——AcWing.826单链表
单链表 定义 单链表是一种常见的数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。 运用情况 用于实现动态的数据存储和管理,例如实现栈、队列等其他数据结构。在需要频繁进行插入和删除操作时非常有用…...

10:Hello, World!的大小
OpenJudge - 10:Hello, World!的大小 描述 还记得在上一章里,我们曾经输出过的“Hello, World!”吗? 它虽然不是本章所涉及的基本数据类型的数据,但我们同样可以用sizeof函数获得它所占用的空间大小。 请编程求出它的大小,看看跟你…...

【Pandas驯化-03】Pandas中常用统计函数mean、count、std、info使用
【Pandas驯化-03】Pandas中常用统计函数mean、count、std、info使用 本次修炼方法请往下查看 🌈 欢迎莅临我的个人主页 👈这里是我工作、学习、实践 IT领域、真诚分享 踩坑集合,智慧小天地! 🎇 相关内容文档获取 微…...
WordPress——Argon主题美化
文章目录 Argon主题美化插件类类别标签页面更新管理器文章头图URL查询监视器WordPress提供Markdown语法评论区头像设置发信设置隐藏登陆备份设置缓存插件 主题文件编辑器页脚显示在线人数备案信息(包含备案信息网站运行时间)banner下方小箭头滚动效果站点功能概览下方Links功能…...
Vue部分文件说明
1.eslintignore文件 Eslint会忽略的文件 # Eslint 会忽略的文件.DS_Store node_modules dist dist-ssr *.local .npmrc 2.gitignore # Git 会忽略的文件.DS_Store node_modules dist dist-ssr .eslintcache# Local env files *.local# Logs logs *.log npm-debug.log* yarn-de…...
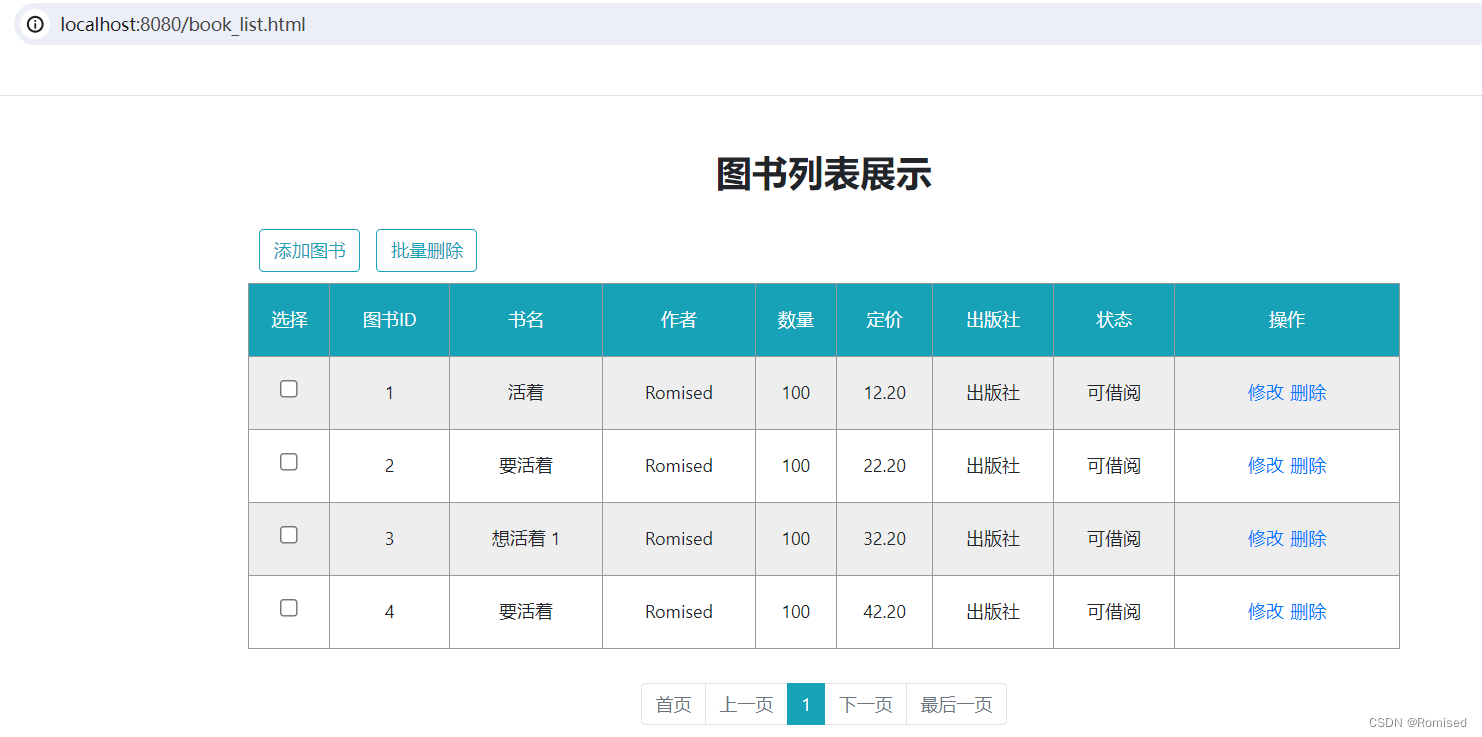
图书管理系统(SpringBoot+SpringMVC+MyBatis)
目录 1.数据库表设计 2.引入MyBatis和MySQL驱动依赖 3.配置数据库&日志 4.Model创建 5.用户登录功能实现 6.实现添加图书功能 7.实现翻页功能 1.数据库表设计 数据库表是应⽤程序开发中的⼀个重要环节, 数据库表的设计往往会决定我们的应⽤需求是否能顺利实现, 甚至决…...

11.泛型、trait和生命周期(上)
标题 一、泛型数据的引入二、改写为泛型函数三、结构体/枚举中的泛型定义四、方法定义中的泛型 一、泛型数据的引入 下面是两个函数,分别用来取得整型和符号型vector中的最大值 use std::fs::File;fn get_max_float_value_from_vector(src: &[f64]) -> f64…...
UML与设计模式
1、关联关系 关联关系用于描述不同类的对象之间的结构关系,它在一段时间内将多个类的实例连接在一起。关联关系是一种静态关系,通常与运行状态无关,而是由“常识”、“规则”、“法律”等因素决定的,因此关联关系是一种强关联的关…...
如何在Spring Boot中实现图片上传至本地和阿里云OSS
在开发Web应用时,处理文件上传是常见的需求之一,尤其是在涉及到图片、视频等多媒体数据时。本文将详细介绍如何使用Spring Boot实现图片上传至本地服务器以及阿里云OSS存储服务,并提供完整的代码示例。 一、上传图片至本地 首先,…...

几个小创新模型,KAN组合网络(LSTM、GRU、Transformer)时间序列预测,python预测全家桶...
截止到本期,一共发了8篇关于机器学习预测全家桶Python代码的文章。参考往期文章如下: 1.终于来了!python机器学习预测全家桶 2.机器学习预测全家桶-Python,一次性搞定多/单特征输入,多/单步预测!最强模板&a…...

ubuntu18.04 配置 mid360并测试fast_lio
1.在买到Mid360之后,我们可以看到mid360延伸出来了三组线。 第一组线是电源线,包含了红色线正极,和黑色线负极。一般可以用来接9-27v的电源,推荐接12v的电源转换器,或者接14.4v的电源转换器。 第二组线是信号线&#x…...

基于Java的诊所医院管理系统,springboot+html,MySQL数据库,用户+医生+管理员三种身份,完美运行,有一万一千字论文
演示视频 基本介绍 基于Java的诊所医院管理系统,springboothtml,MySQL数据库,用户医生管理员三种身份,完美运行,有一万一千字论文。 用户:个人信息管理、预约医生、查看病例、查看公告、充值、支付费用...…...

gvm 在ubuntu下安装
GVM (Go Version Manager) 是一个用于管理多个Go语言版本的工具。以下是使用GVM安装和切换Go版本的基本步骤和示例代码: 一键安装(如果网络没问题情况) bash < <(curl -s -S -L https://raw.githubusercontent.com/moovweb/gvm/master…...

ChatTTS开源项目推荐
开源热门项目推荐:ChatTTS 标题:对话式人工智能的未来——ChatTTS 随着开源程序的发展,越来越多的程序员开始关注并加入开源大模型的行列。对于开源行业和开源项目不同人有不同的关注点,但无论你是新手还是资深开发者,…...
java课设
项目简介:射击生存类小游戏 项目采用技术: 游戏引擎: Unity编程语言: Java图形处理: NVIDIA PhysX (物理引擎), HDRP (High Definition Render Pipeline)音效与音乐: FMOD, Wwise版本控制: Git 功能需求分析: 角色控制:玩家能够使用键盘和鼠标控制角色移动、瞄准…...

【持久层】PostgreSQL使用教程
详细教程点击PostgreSQL 12.2 手册,观看官网中文手册。 PostgreSQL 是一个功能强大且开源的对象关系数据库系统,以其高扩展性和符合标准的优势广受欢迎。随着大数据时代的到来,PostgreSQL 也在大数据处理方面展示了其强大能力。本文将介绍 P…...

OpenCV 4.10 发布
OpenCV 4.10 JPEG 解码速度提升 77%,实验性支持 Wayland、Win ARM64 根据 “OpenCV 中国团队” 介绍,从 4.10 开始 OpenCV 对 JPEG 图像的读取和解码有了 77% 的速度提升,超过了 scikit-image、imageio、pillow。 4.10 版本的一些亮点&…...

5、斐波那契数列、跳台阶
题目: 斐波那契数列 描述: 大家都知道斐波那契数列,现在要求输入一个整数n,请你输出斐波那契数列的第n项。 n<39 <?phpfunction Fibonacci($n) {if($n<0){$f1 0;}else if($n1||$n2){$f1 1;}else{$f1 1; $f2 1;whi…...
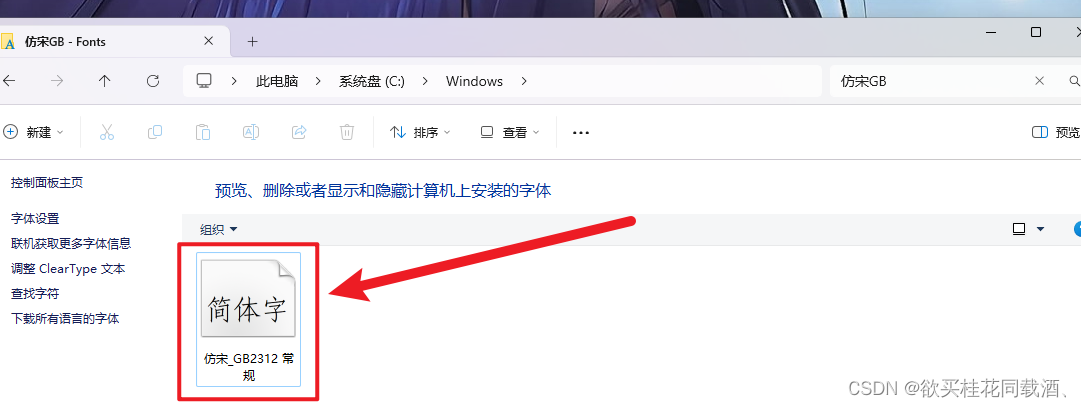
WPS相同字体但是部分文字样式不一样解决办法
如下图,在使用wps编辑文档的时候发现有些电脑的文字字体很奇怪,但是把鼠标移到这个文字的位置,发现它和其他正常文字的字体是一样的,都是仿宋_GB2312 正常电脑的文字如下图所示 打开C:\Windows找到Fonts这个文件夹 把仿宋_GB2312这…...

第19节 Node.js Express 框架
Express 是一个为Node.js设计的web开发框架,它基于nodejs平台。 Express 简介 Express是一个简洁而灵活的node.js Web应用框架, 提供了一系列强大特性帮助你创建各种Web应用,和丰富的HTTP工具。 使用Express可以快速地搭建一个完整功能的网站。 Expre…...

大数据学习栈记——Neo4j的安装与使用
本文介绍图数据库Neofj的安装与使用,操作系统:Ubuntu24.04,Neofj版本:2025.04.0。 Apt安装 Neofj可以进行官网安装:Neo4j Deployment Center - Graph Database & Analytics 我这里安装是添加软件源的方法 最新版…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

使用 SymPy 进行向量和矩阵的高级操作
在科学计算和工程领域,向量和矩阵操作是解决问题的核心技能之一。Python 的 SymPy 库提供了强大的符号计算功能,能够高效地处理向量和矩阵的各种操作。本文将深入探讨如何使用 SymPy 进行向量和矩阵的创建、合并以及维度拓展等操作,并通过具体…...

Unsafe Fileupload篇补充-木马的详细教程与木马分享(中国蚁剑方式)
在之前的皮卡丘靶场第九期Unsafe Fileupload篇中我们学习了木马的原理并且学了一个简单的木马文件 本期内容是为了更好的为大家解释木马(服务器方面的)的原理,连接,以及各种木马及连接工具的分享 文件木马:https://w…...

sipsak:SIP瑞士军刀!全参数详细教程!Kali Linux教程!
简介 sipsak 是一个面向会话初始协议 (SIP) 应用程序开发人员和管理员的小型命令行工具。它可以用于对 SIP 应用程序和设备进行一些简单的测试。 sipsak 是一款 SIP 压力和诊断实用程序。它通过 sip-uri 向服务器发送 SIP 请求,并检查收到的响应。它以以下模式之一…...

VM虚拟机网络配置(ubuntu24桥接模式):配置静态IP
编辑-虚拟网络编辑器-更改设置 选择桥接模式,然后找到相应的网卡(可以查看自己本机的网络连接) windows连接的网络点击查看属性 编辑虚拟机设置更改网络配置,选择刚才配置的桥接模式 静态ip设置: 我用的ubuntu24桌…...