C数据结构:排序
目录
冒泡排序
选择排序
堆排序
插入排序
希尔排序
快速排序
hoare版本
挖坑法
前后指针法
快速排序优化
三数取中法
小区间优化
快速排序非递归
栈版本
队列版本
归并排序
归并排序非递归
编辑
计数排序
各排序时间、空间、稳定汇总
冒泡排序
void BubbleSort(int* a, int n)
{for (int i = 0; i < n; i++){int flag = 0;for (int j = 0; j < n - i - 1; j++){if (a[j] > a[j + 1]){Swap(&a[j], &a[j + 1]);flag = 1;}}if (flag == 0)break;}
}冒泡排序相信你已经写了不少了
冒泡排序的思想是两两比较,如果要排升序那么要找到最大的,一直比较直到找到最大的冒到最后,然后进行n次这样的流程即完成排序
这里对冒泡排序有两个优化点
1. 第二个循环里我们可以写 j < n - 1,但优化过后就是 j < n - i - 1
要-1是因为防止下面的a[j + 1]数组越界,而-i则是因为已经排过了i次,那么后面就有i个数是已经排好的,所以不需要进入下面的if语句进行比较
2. 用了一个flag变量,主要是看是否有进入过if语句,若没有进入过if语句说明数据已经是排好的,那么即可直接break退出循环
时间复杂度:O(N^2)
空间复杂度:O(1)
由于时间复杂度过高,在实际应用中并无意义,只有在教学中有意义
稳定性:稳定
选择排序
void SelectSort(int* a, int n)
{int begin = 0, end = n - 1;int maxi = 0, mini = 0;while (begin < end){int maxi = begin, mini = begin;for (int i = begin + 1; i <= end; i++){if (a[i] > a[maxi])maxi = i;if (a[i] < a[mini])mini = i;}Swap(&a[begin], &a[mini]);Swap(&a[end], &a[maxi]);if (begin == maxi)maxi = mini;begin++;end--;}
}
选择排序的思想是先找小或找大,找到了就放在最后或者第一个,缩小区间循环往复
但这里写的选择排序是一次找两个,遍历一次即找大又找小
时间复杂度:O(N^2)
空间复杂度:O(1)
稳定性:不稳定
理由:交换时相同的数可能会交换顺序
堆排序
void AdjustDown(int* a, int n, int parent)
{int child = parent * 2 + 1;while (child < n){if (child + 1 < n && a[child + 1] > a[child])child++;if (a[child] > a[parent]){Swap(&a[parent], &a[child]);parent = child;child = parent * 2 + 1;}else{break;}}
}void HeapSort(int* a, int n)
{for (int i = (n - 1 - 1) / 2; i >= 0; i--)AdjustDown(a, n, i);int end = n - 1;while (end > 0){Swap(&a[0], &a[end]);AdjustDown(a, end, 0);end--;}
}堆排序是选择排序的一种。
堆排序的思想是利用向下调整(向上调整也可以)先建大堆(or小堆),这样我们就能找到最大或者最小的那个数据,交换到末尾即放置好第一个数的位置,并接着向下调整保持堆的特性
具体细节参考
C数据结构:堆(实现、排序)-CSDN博客
时间复杂度:O(N * logN)
空间复杂度:O(1)
由于堆的高度是 O(logN),每个非叶子节点的调整时间复杂度是 O(log N)
数组中有 O(N) 个非叶子节点,因此构建堆的总时间复杂度是 O(N * logN)
但实际上,由于树的结构,这个操作通常被优化为 O(N)
稳定性:不稳定
插入排序
void InsertSort(int* a, int n)
{for (int i = 0; i < n - 1; i++){int end = i;int tmp = a[end + 1];while (end >= 0){if (tmp < a[end]){a[end + 1] = a[end];end--;}else{break;}}a[end + 1] = tmp;}
}
插入排序的思想就像插入扑克牌排序一样,我们需要从小到大一个个排好序
end之前表示已经排好序的数组(最开始1个数也算排好),end+1就表示我们要在[0,end]这个区间里插入end+1的这个值,此过程循环n-1次即可
所以while循环控制的是一次一个数插入的过程,tmp表示要插入的数,若tmp < a[end](升序)即我们需要在前面这个有序区间内往前走(end--),若tmp > a[end]则找到了我们需要插入的位置,这个位置就是end+1
时间复杂度:O(N^2)
空间复杂度:O(1)
它虽然和冒泡排序看起来差不多,但它还是比冒泡排序快很多的
但是相比堆排、快排、希尔排序、归并排序这些就没法比了
稳定性:稳定
希尔排序
void ShellSort(int* a, int n)
{int gap = n;while (gap > 1){gap = gap / 3 + 1;for (int i = 0; i < n - gap; i++){int end = i;int tmp = a[end + gap];while (end >= 0){if (tmp < a[end]){a[end + gap] = a[end];end -= gap;}else{break;}}a[end + gap] = tmp;}}
}希尔排序是插入排序的一种,但它比普通的插入排序快的多
希尔排序的思想是:先选定一个间隔gap,然后按照这个间隔分成gap组,根据这个组内来进行排序,这样就从原本的杂乱无章变成稍微有序。此时接着将gap缩小,那么数组将会越来越有序,最后就变成了有序的数组了
第二次由于已经是有序了,所以不需要排
以此类推,当全部的gap组排好之后,我们的第一躺希尔排序就完成了



如果你觉得这样排序那么多次,效率并没有什么提升,就大错特错了
拿插入排序来比较,插入排序如果想排好上面的一次组数据(9,7,3),那么它需要一个下标来沿途经过整个数组一个个比较,当到达7的时候才能够交换,然后接着跟沿途的其他数据一个个比较,最后才能找到3和3交换,这么一个过程就将近遍历了一整个数组
而我们的希尔排序的gap就可以让它快速的跳跃中间的数据,依次效率有了极大的提升。就上图的这10个数据可能看的不太明显,只需要比较几次。但是我们的计算机的效率是很高的,大多数电脑一秒钟可以跑上亿的数据,所以若是在实际中我们需要排个几百万上亿个数据的时候,我们的gap就可以跳过很多数据的比较。
代码实现中我们可以发现其实它跟插入排序基本一致,就多了一个循环,然后把内部的部分数据改成gap就完成了
内层的两个循环是进行一躺gap组的排序,可以将杂乱无章的数组变成逐渐有序的数组
最外层的循环是控制gap的,gap越小,进行一躺排序就会越有序,当最后gap为1的时候,它其实就是我们上面的插入排序,所以gap为1的时候排序就已经完成了
gap / 3 + 1的原因是个人认为/3的效率比较高,但是只是/3会有可能到不了1的情况,例如:
2 / 3 = 0,接下来我们一直/3都到不了0
所以我们需要+1
最开始Shell提出取 gap / 2,后来Knuth提出gap / 3 + 1,无论是哪一种具体是谁快还没有得到证明
时间复杂度:O(N^1.3)
空间复杂度:O(1)
稳定性:不稳定
快速排序
void QuickSort(int* a, int left, int right)
{if (left >= right)return;int keyi = PartSort1(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);
}PartSort是部分排序,在快排中是个选key的过程
key是一个值,通常把它选成数组中最左边的第一个数
我们进行一次PartSort时就可以把key的位置给确定好,算是排好了一个数,而且这个数大概率是在中间或者中间的旁边,而且它的左右两边都会是比它小或者比它大的数
PartSort有三种版本,这里我把它分成了PartSort1 ,PartSort2 ,PartSort3
PartSort1:hoare版本
PartSort2:挖坑法
PartSort3:前后指针法
keyi位置则代表已经排好了的位置,这时候我们再次划分区间,将keyi的左边和右边划分,再继续递归进行新一轮的部分排序选keyi,一直递归下去即可完成我们的递归
时间复杂度:O(N*logN)
空间复杂度:O(logN)(递归深度为logN)
稳定性:不稳定
具体PartSort如下:
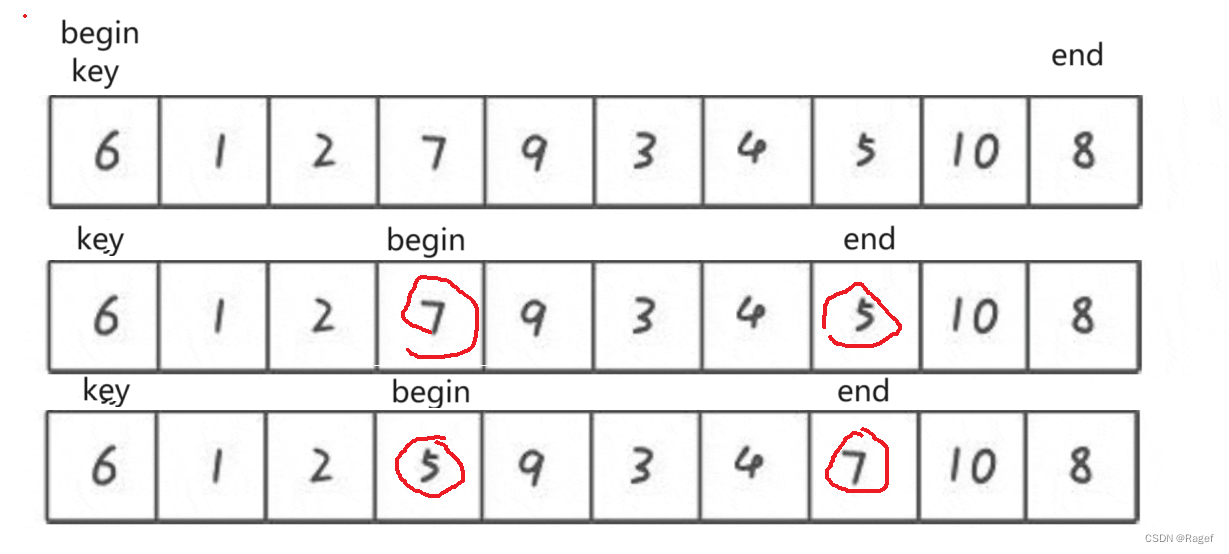
hoare版本
int PartSort1(int* a, int left, int right)
{int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;int begin = left, end = right;while (begin < end){while (begin < end && a[end] >= a[keyi]){end--;}while (begin < end && a[begin] <= a[keyi]){begin++;}Swap(&a[begin], &a[end]);}Swap(&a[begin], &a[keyi]);return begin;
}
GetMidi属于快速排序优化,下面有解释,暂不考虑
该函数需要传一个指针,和一段区间 [left,right]
首先选定一个keyi(下标),这个下标对应数组中的值则为key
然后给定两个下标,记作begin和end,一个指向左,一个指向右
我们需要做的是先从右边开始(end),它找比key还要小的数字,左边(begin)找比key还要大的数字,找到之后将它们交换(升序)
若是begin和end相遇,则该位置则为key的最终位置(因为大的已经放到了右边,小的已经放到了左边)将key和相遇位置交换即可
我们必须要从右边开始找小,然后再从左边找大,因为这样才能保证最终位置是比key要小的,这样才能将相遇位置的值换到左边,保证了keyi位置左边都比key小,右边都比key大
最后我们返回key的位置即可


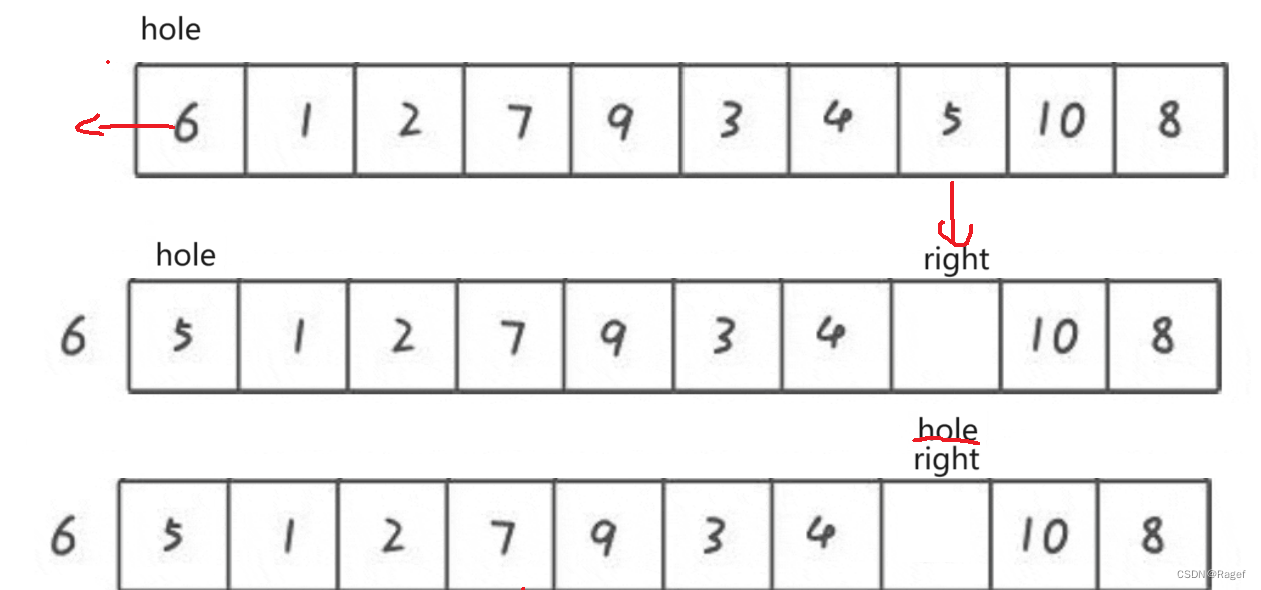
挖坑法
int PartSort2(int* a, int left, int right)
{int mid = GetMidi(a, left, right);Swap(&a[mid], &a[left]);int hole = left;//key记录挖坑位置的值int key = a[hole];while (left < right){while (left < right && a[right] >= key)right--;a[hole] = a[right];hole = right;while (left < right && a[left] <= key)left++;a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}优点是比hoare方法好理解
还是跟hoare一样先找一个keyi,但是这里是一个坑(hole)
然后一样从右边开始找小,找到后填在我们挖的这个坑里,找到小的那个地方就又变成一个坑了
接着左边找大,找到了填到坑里然后自己变成坑,以此循环往复
最后将剩下的那个坑用我们最开始挖的填上即可


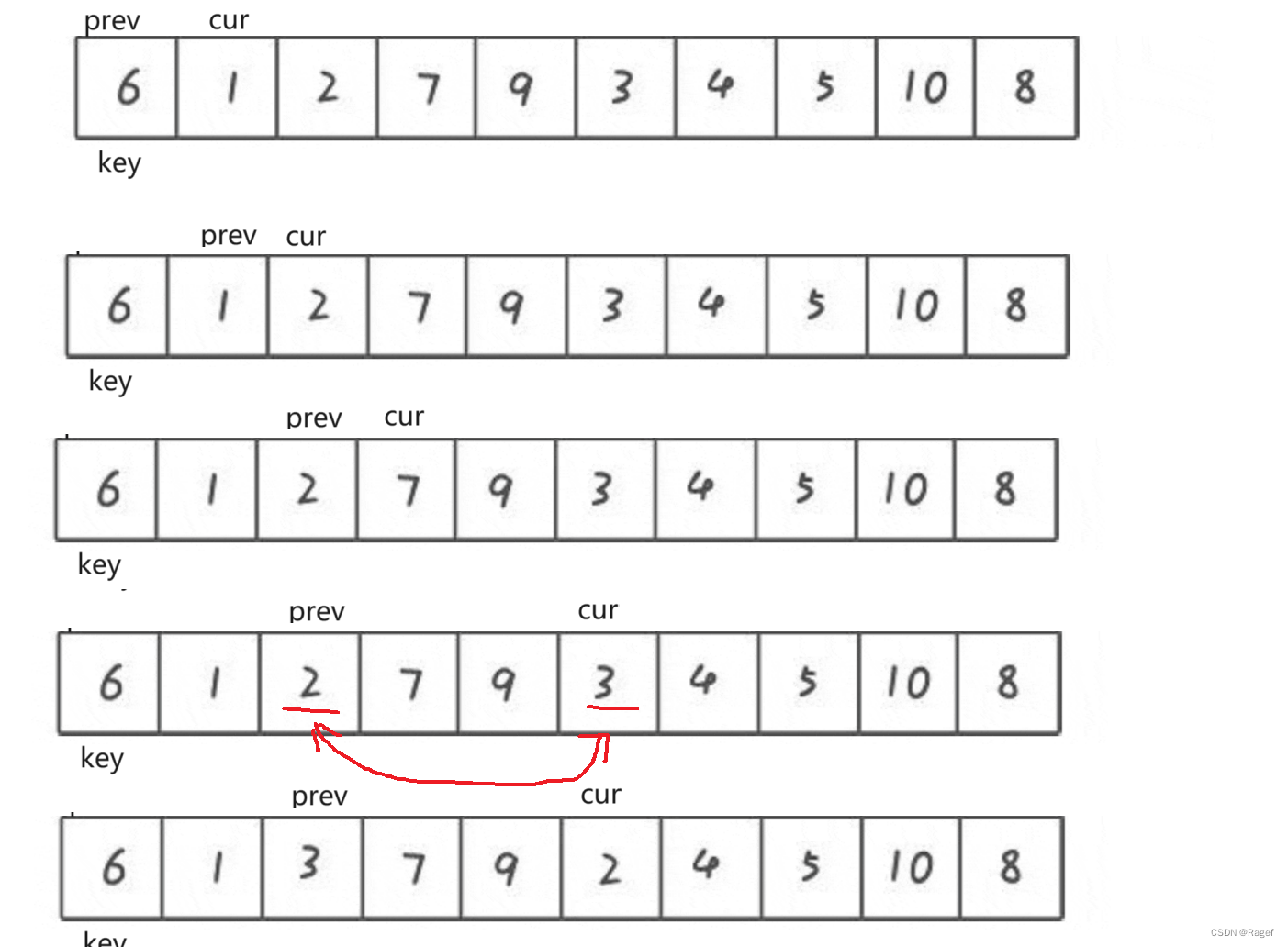
前后指针法
int PartSort3(int* a, int left, int right)
{int midi = GetMidi(a, left, right);Swap(&a[left], &a[midi]);int keyi = left;int prev = left;int cur = left + 1;while (cur <= right){if (a[cur] < a[keyi] && ++prev != cur)Swap(&a[cur], &a[prev]);cur++;}Swap(&a[prev], &a[keyi]);return prev;
}用了两个指针来走(下标,并不是C语言中真正意义上的指针)
在if语句中,由于是&&运算符,若cur位置的值小于keyi位置上的值,才会进行下一步的判断,那么判断++prev的时候就会让prev往前走
所以当cur位置的值小于keyi位置上的值,prev和cur同时++,否则,cur++
&&后面的条件判断其实是为了减少Swap的次数,因为相同位置的prev和cur交换并没有任何意义
最后让prev和keyi交换即可

三个方法选其一即可
本人认为hoare版本可能效率比其他的高一丢丢,挖坑好理解,前后指针代码简洁
快速排序优化
三数取中法
前面的hoare,挖坑,前后指针都使用了GetMini函数,它是可以增加快排的效率的
设想一下,若是一个数组里面的值全是2,已有序,但我们不知情的情况下使用了快排来进行排序会发生什么?
这时候快排的效率会变得极低,时间复杂度变成O(N^2)
这是快排比较难受的一点,主要原因就是因为我们的keyi每次都是在最左边,从而无法划分左右区间进行递归,这样自然效率就很低
所以就其核心,我们要尽量让keyi的位置尽量在中间,那么就需要用到三数取中法
int GetMidi(int* a, int left, int right)
{int midi = (left + right) / 2;if (a[left] < a[midi]){if (a[midi] < a[right]){return midi;}else if (a[left] < a[right]){return right;}else{return left;}}else{if (a[midi] > a[right]){return midi;}else if (a[left] < a[right]){return left;}else{return right;}}
}
这段代码看起来很长,但其实很简单易懂
就是先取到这段区间的中间值midi,用a[left],a[right],a[midi]三个值进行比较,取出大小在中间的那个即可,即使它不是整段区间的最中间的那个,但至少不是最差的那个
小区间优化
其实在数据很大的时候,我们这样递归下去的时间才会很快,若是数据量比较小的情况下我们还要递归很多的数据非常的划不来
所以我们可以制定一个标准值,当这段区间到达这个标准值时就不让它递归了,而是直接使用其他的排序来完成这段的排序(这里直接使用插入排序)
void QuickSort(int* a, int left, int right)
{if (left >= right)return;if (right - left + 1 <= 10){InsertSort(a, right - left + 1);}else{int keyi = PartSort1(a, left, right);QuickSort(a, left, keyi - 1);QuickSort(a, keyi + 1, right);}
}快速排序非递归
这里是需要引入我们之前已经写好的栈和队列进来,才能完成我们下面的非递归方法
栈版本
void QuickSortNonR1(int* a, int left, int right)
{Stack st;StackInit(&st);StackPush(&st, right);StackPush(&st, left);while (!StackEmpty(&st)){int begin = StackTop(&st);StackPop(&st);int end = StackTop(&st);StackPop(&st);int keyi = PartSort1(a, begin, end);if (keyi + 1 < end){StackPush(&st, end);StackPush(&st, keyi + 1);}if (keyi - 1 > begin){StackPush(&st, keyi - 1);StackPush(&st, begin);}}StackDestroy(&st);
}我们可以用一个栈来模拟递归的过程
快排是以一个keyi为基准,划分两段区间从而进行排序,那么我们可以在每次PartSort选出keyi之后将区间入栈,下一轮需要的时候就可以直接出栈
首先我们先将最开始的左右区间入栈
先入的右区间,这样下面取出来的时候可以先取出左再取右
接下来拿到begin和end,对这段区间进行PartSort选出keyi
选出了keyi后又划分出了区间,我们再次将这两个区间入栈
以此往复,就模拟实现了递归的快速排序
最后不要忘记了将栈销毁放置内存泄漏
队列版本
void QuickSortNonR2(int* a, int left, int right)
{Queue q;QueueInit(&q);QueuePush(&q, left);QueuePush(&q, right);while (!QueueEmpty(&q)){int begin = QueueFront(&q);QueuePop(&q);int end = QueueFront(&q);QueuePop(&q);int keyi = PartSort1(a, begin, end);if (begin < keyi){QueuePush(&q, begin);QueuePush(&q, keyi - 1);}if (end > keyi){QueuePush(&q, keyi + 1);QueuePush(&q, end);}}QueueDestroy(&q);
}和上面的栈版本类似
都是先入一段区间,拿到这段区间的begin和end,然后进行PartSort选出keyi,接着入两段区间继续PartSort
最后也是不要忘记了将队列释放掉即可
栈版本和队列版本最主要的区别就是一个是深度优先一个是广度优先
栈是深度,队列是广度
栈是先将最开始的[left, keyi - 1]排好,再排[keyi + 1, end]
而队列是[left, keyi - 1]和[keyi + 1, end]同时往下排
归并排序
void _MergeSort(int* a, int* tmp, int begin, int end)
{if (begin >= end)return;int mid = (begin + end) / 2;int begin1 = begin, end1 = mid;int begin2 = mid + 1, end2 = end;_MergeSort(a, tmp, begin1, end1);_MergeSort(a, tmp, begin2, end2);int i = begin;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] < a[begin2]){tmp[i++] = a[begin1++];}else{tmp[i++] = a[begin2++];}}while (begin1 <= end1){tmp[i++] = a[begin1++];}while (begin2 <= end2){tmp[i++] = a[begin2++];}memcpy(a + begin, tmp + begin, sizeof(int) * (end - begin + 1));
}void MergeSort(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("mallloc fail");return;}_MergeSort(a, tmp, 0, n - 1);free(tmp);
}归并排序的算法采用的是分治法,它需要开一段长度和排序数组已有大小的空间来配合完成排序
它的思想是:将已有的子序列合并,得到完全有序的序列
先让将数组中的值采用”分治“,分到有序的时候(一个数也算有序),再回到上一次分治的时候将其变成有序,以此类推一直往上到最开始完整的区间即可
这个不断解决子问题的问题当然是用递归解决好了
”分“过程
”治“过程

在MergeSort中,我们需要先开一段长度为n的空间,将其传给_MergeSort函数来配合这块空间递归完成排序
MergeSort中就三个步骤,一开空间,二排序,三释放
在这个子函数_MergeSort中,我们也要传左区间和右区间
下面来进入子函数中看看

我们先定义几个变量,即将该数组[left,right]再次分成两个区间,由中间值mid来划分,分别标记为begin1,end1,begin2,end2
这里的end1必须为mid,不能是mid+1
begin2只能是mid+1,不能是mid
也就是end1必须为偶数,否则该排序会出问题
若按照错误方法来:例如:begin = 0,end = 3,那么mid = 1,begin1 = 0,end1 = 2,递归左右区间为[0,2]也就是begin = 0,end = 2,那么mid = 1,begin1 = 0,end1 = 2,这样又递归就会出现栈溢出的情况,所以必须要按照 上面代码的方式走

我们需要取递归它的左右区间,从小问题开始解决

递归需要有个结束条件,那就是当这个区间不存在时结束递归

我们归并下来后按循环走,将两个小区间中最小的值放到我们前面传的tmp数组里然后i++,然后找第二小的,找到接着放进tmp数组第i个位置,i++循环往复
第一个循环走完其中某一个数组中的元素也就全部被拷贝进了tmp数组里,这时候我们只需要找到还没有全部走完的数组将其全部放到tmp数字第i个位置的后面即可
i必须从begin开始,不能是0
最后用memcpy函数将tmp数组中的值全部拷贝到a数组中即可
这样我们递归版本的归并排序就完成了
时间复杂度:O(N*logN)
空间复杂度:O(N)
稳定性:稳定
归并排序的缺点在于需要O(N)的空间复杂度
归并排序的使用更多的是使用在磁盘中的外排序问题,也就是当一个文件比较大我们的一个程序不足以支撑使用如此之多的数据来排序,那么这时候就可以使用归并排序分治
归并排序非递归
void MergeSortNonR(int* a, int n)
{int* tmp = (int*)malloc(sizeof(int) * n);if (tmp == NULL){perror("malloc fail");return;}int gap = 1;while (gap < n){for (int i = 0; i < n; i += 2 * gap){int begin1 = i, end1 = i + gap - 1;int begin2 = i + gap, end2 = i + 2 * gap - 1;if (begin2 >= n)break;if (end2 >= n)end2 = n - 1;int j = i;while (begin1 <= end1 && begin2 <= end2){if (a[begin1] <= a[begin2]){tmp[j++] = a[begin1++];}else{tmp[j++] = a[begin2++];}}while (begin1 <= end1){tmp[j++] = a[begin1++];}while (begin2 <= end2){tmp[j++] = a[begin2++];}memcpy(a + i, tmp + i, sizeof(int) * (end2 - i + 1));}gap *= 2;}free(tmp);
}非递归相比于递归的好处就是不怕栈溢出的风险
大体思路和前面递归版本的归并排序一样
我们需要先开一段空间

下面我们要开始模拟递归的过程
我们定义了一个gap,这个gap是每组的间隔,模拟了从最开始的两个数据排序,这个gap我们从1开始到布满整个数组为止停止循环,这就是第一个while
下面的for循环就是为了完成每一组的排序
for循环下面的内容当然就是单组的排序了

还是和前面一样,先定义好左右区间

这里也是和上面的递归版本一样
将小的数放到tmp数组中,当第一个循环走完再去找没走完的那个区间,将剩余数据一个个放到tmp数组中即可
最后再将tmp数组中的数据全部拷贝到a数组中即完成单趟排序
for循环走完后也就代表这一趟间隔gap为1的已经走完了,也就是两个数据已经有序了,那么要到四个数据开始排序

所以不要忘了gap *= 2
![]()
以此类推,当gap >= n时就代表已经走完了
所以循环结束条件为gap < n
但是如果只做到这里是还没有完成排序的,它只能完成2^n个数据的排序,这里分区间的时候会存在越界的情况,所以当数据不为2^n个数时,我们需要调整区间

这里的越界只有两种情况,一种是end2越界,一种是begin2和end2都越界
若begin2和end2都越界了,那么这躺排序已经不需要右区间,而左区间本身就有序,所以我们直接break即可
若只有end2越界,那么[begin2,end2]中是还存在数据需要我们排序的,我们不能直接break,只需让end2等于数组最大下标即可
最后不能忘记了释放掉tmp数组,防止内存泄漏
这样非递归版本的归并排序就完成了
计数排序
void CountSort(int* a, int n)
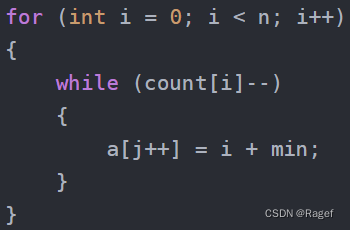
{int max = a[0], min = a[0];for (int i = 1; i < n; i++){if (a[i] > max)max = a[i];if (a[i] < min)min = a[i];}int range = max - min + 1;int* count = (int*)calloc(range, sizeof(int));for (int i = 0; i < n; i++){count[a[i] - min]++;}int j = 0;for (int i = 0; i < n; i++){while (count[i]--){a[j++] = i + min;}}free(count);
}计数排序又称鸽巢原理,它的思想本质是哈希
哈希的思想就是让某一个数据与其存储位置产生某种联系
计数排序里就采用了这种思想,它会对我们给的数组的每一个值用另一个数组的下标来计数
例如:5,5,3,6,那么另一个数组count取到的值count[3] = 1,count[5] = 2,count[6] = 1
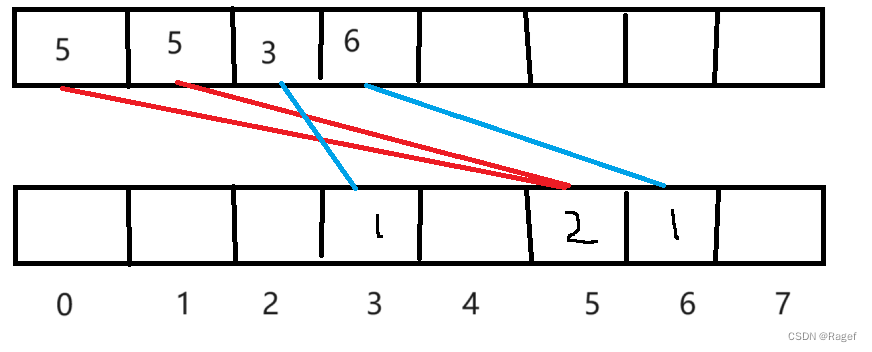

首先我们需要先找到该数组的最大值和最小值,这样才能确定区间
方法为用循环遍历整个数组

接下来根据这个范围来开空间(因为我们开的数组是要用下标来存储数据,所以要+1)
开的空间count使用了calloc函数,该函数和malloc的区别就是它可以初始化这块空间,这正是我们想要的,我们需要让这块空间的值都为0
然后这个for循环做的就是遍历原数组,将原数组的值减去最小值,这个值映射到count数组中,让这个下标的值++,这样就会统计这个值出现的次数,而与原数组建立的关系就是减去一个min的关系

这是最后一步
我们计数完毕后就可以从0开始遍历我们count数组,若这个count数组有值,说明原数组+min之后的值是存在的,我们直接将该值加上min放到原数组中即可,由于下标是从小到大的,所以排出来的数据必定是有序的
这样就能排好序了

最后记得释放掉count数组即可
这就是我们的计数排序了
时间复杂度:O(MAX(N,range))
由于我们最后一步是不仅仅要遍历原数组,还要将count数组的值全部过一遍,而count是根据range来开的,所以该排序的时间复杂度为N和range大的那一个
空间复杂度:O(range)
稳定性:稳定
计数排序在数据范围集中时效率很高
但是由于条件的限制只能排序整型,而且若数据不集中则会开极大的空间效率极低
所以它的使用场景有限
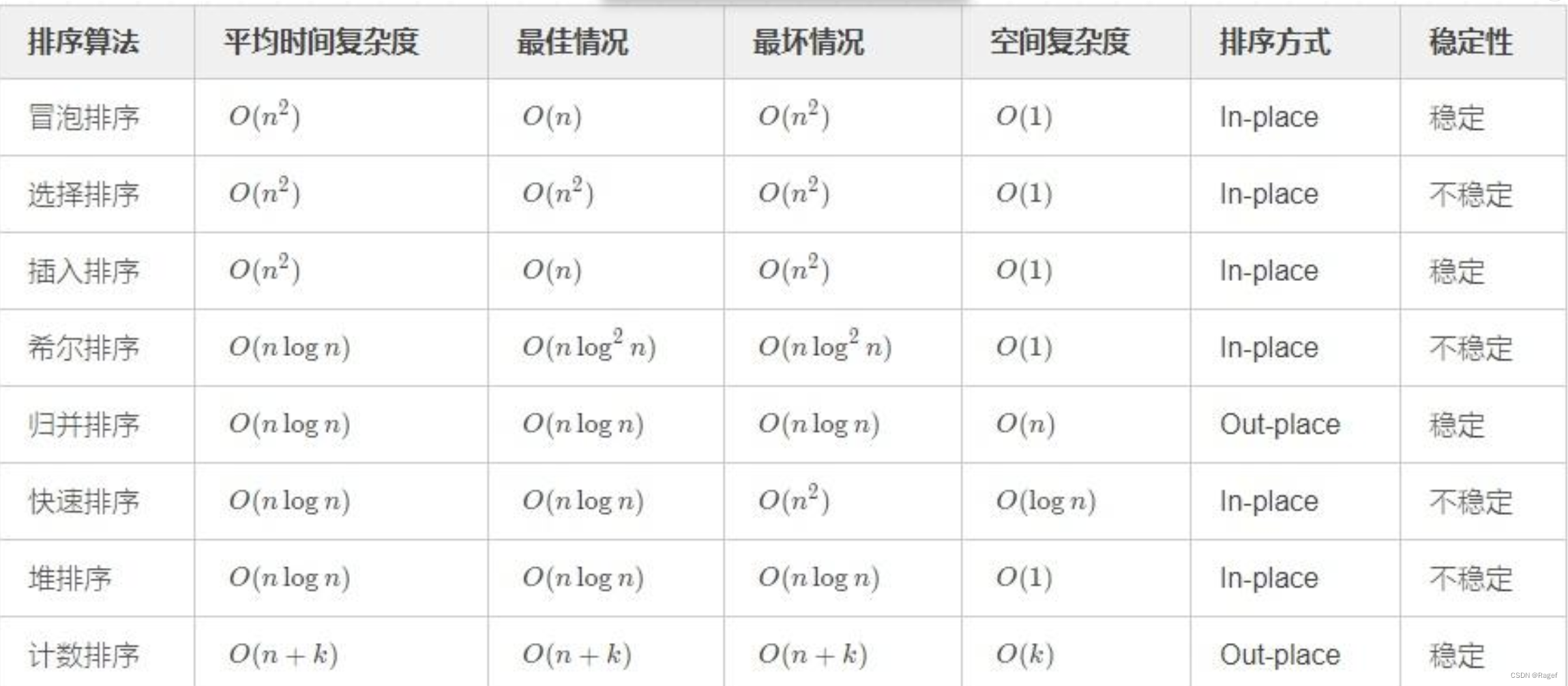
各排序时间、空间、稳定汇总
完
相关文章:
C数据结构:排序
目录 冒泡排序 选择排序 堆排序 插入排序 希尔排序 快速排序 hoare版本 挖坑法 前后指针法 快速排序优化 三数取中法 小区间优化 快速排序非递归 栈版本 队列版本 归并排序 归并排序非递归 编辑 计数排序 各排序时间、空间、稳定汇总 冒泡排序 void Bub…...

【Python】在 Pandas 中使用 AdaBoost 进行分类
我们都找到天使了 说好了 心事不能偷藏着 什么都 一起做 幸福得 没话说 把坏脾气变成了好沟通 我们都找到天使了 约好了 负责对方的快乐 阳光下 的山坡 你素描 的以后 怎么抄袭我脑袋 想的 🎵 薛凯琪《找到天使了》 在数据科学和机器学习的工作…...
)
持续总结中!2024年面试必问 20 道并发编程面试题(九)
上一篇地址:持续总结中!2024年面试必问 20 道并发编程面试题(八)-CSDN博客 十七、请解释什么是Callable和FutureTask。 Callable和FutureTask是Java并发API中的重要组成部分,它们用于处理可能产生结果的异步任务。 …...
Linux:线程池
Linux:线程池 线程池概念封装线程基本结构构造函数相关接口线程类总代码 封装线程池基本结构构造与析构初始化启动与回收主线程放任务其他线程读取任务终止线程池测试线程池总代码 线程池概念 线程池是一种线程使用模式。线程过多会带来调度开销,进而影…...

集成学习方法:Bagging与Boosting的应用与优势
个人名片 🎓作者简介:java领域优质创作者 🌐个人主页:码农阿豪 📞工作室:新空间代码工作室(提供各种软件服务) 💌个人邮箱:[2435024119qq.com] 📱…...

JEnv-for-Windows 2 java版本工具的安装使用踩坑
0.环境 windows11pro 1.工具下载 GitHub - Mu-L/JEnv-for-Windows: Change your current Java version with one line or JEnv-for-Windows:Change your current Java version with one line - GitCode 2.执行jenv 初始化 2.1 问题:PowerShell 未对文件\XXX.…...
linux中: IDEA 由于JVM 设置内存过小,导致打开项目闪退问题
1. 找到idea安装目录 由于无法打开idea,只能找到idea安装目录 在linux(debian/ubuntu)中idea的插件默认安装位置和配置文件在哪里? 默认路径: /home/当前用户名/.config/JetBrains/IntelliJIdea2020.具体版本号/options2. 找到jvm配置文件 IDEA安装…...

d3.js获取流程图不同的节点
在D3.js中,获取流程图中不同的节点通常是通过选择SVG元素并使用数据绑定来实现的。流程图的节点可以通过BPMN、JSON或其他数据格式定义,然后在D3.js中根据这些数据动态生成和选择节点。 以下是一个基本的示例,展示如何使用D3.js选择和操作流…...

MFC socket编程-服务端和客户端流程
MFC 提供了一套丰富的类库来简化 Windows 应用程序的网络编程。以下是使用 MFC 进行 socket 编程时服务端和客户端的基本流程: 服务端流程: 初始化 Winsock: 调用 AfxSocketInit 初始化 Winsock 库。 创建 CSocket 或 CAsyncSocket 对象&am…...

22.1 正则表达式-定义正则表达式、正则语法
1.定义正则表达式 正则表达式意在描述隐藏在数据中的某种模式或规则。 例如:下面的几个字符串看似各不相同: slimshady999roger1813Wagner但看似不同的数据却隐藏着相同的特征: 仅由英语字母和数字组成英语字母有小写也有大写总字符数介于 …...
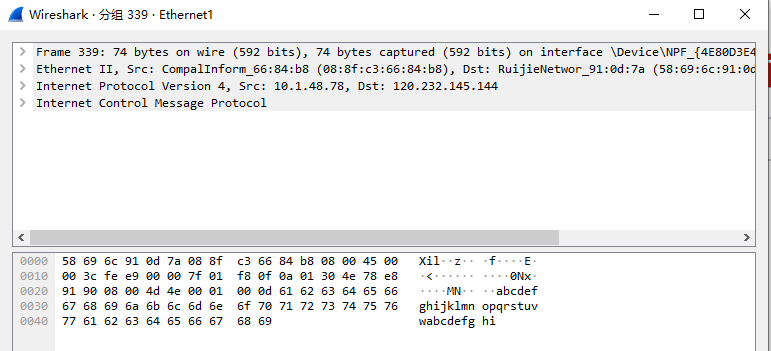
网络数据包抓取与分析工具wireshark的安及使用
WireShark安装和使用 WireShark是非常流行的网络封包分析工具,可以截取各种网络数据包,并显示数据包详细信息。常用于开发测试过程中各种问题定位。 1 任务目标 1.1 知识目标 了解WireShark的过滤器使用,通过过滤器可以筛选出想要分析的内容 掌握Wir…...
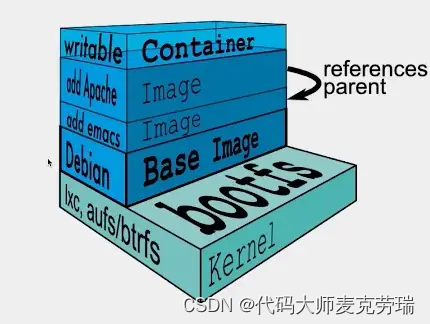
Docker镜像技术剖析
目录 1、概述1.1 什么是镜像?1.2 联合文件系统UnionFS1.3 bootfs和rootfs1.4 镜像结构1.5 镜像的主要技术特点1.5.1 镜像分层技术1.5.2 写时复制(copy-on-write)策略1.5.3 内容寻址存储(content-addressable storage)机制1.5.4 联合挂载(union mount)技术 2.机制原理…...
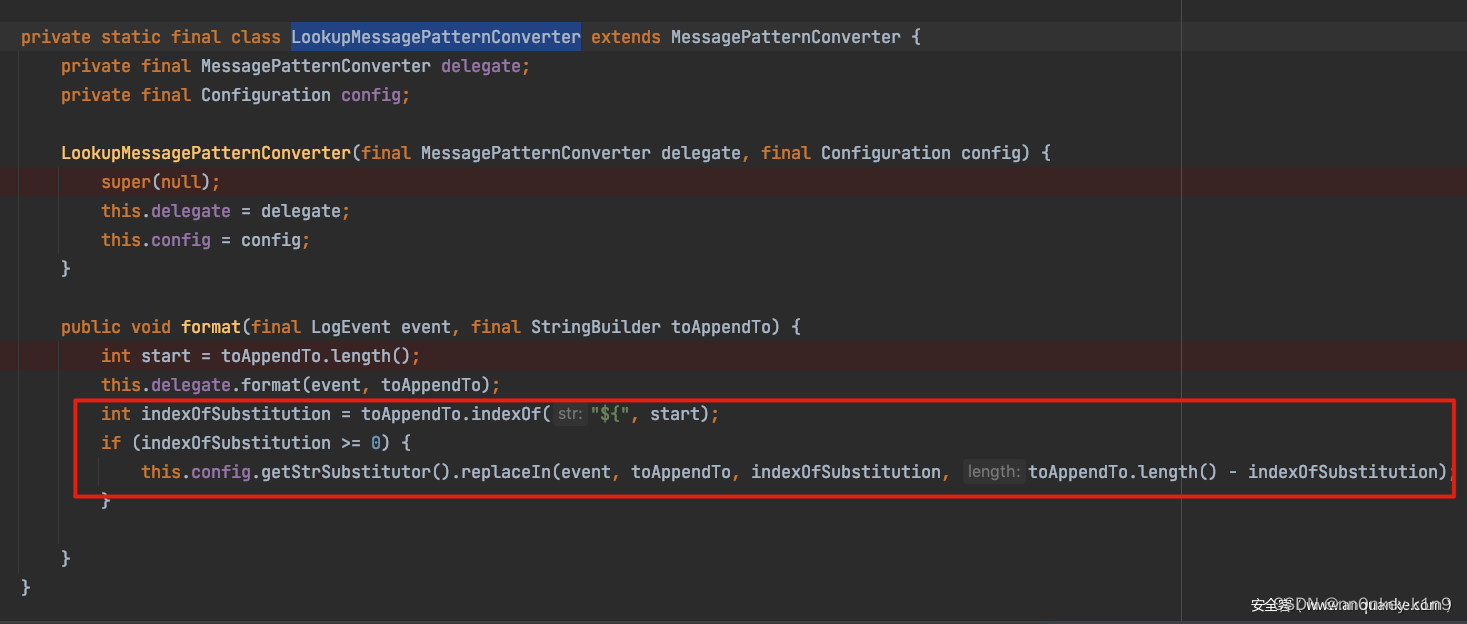
log4j漏洞学习
log4j漏洞学习 总结基础知识属性占位符之Interpolator(插值器)模式布局日志级别 Jndi RCE CVE-2021-44228环境搭建漏洞复现代码分析日志记录/触发点消息格式化 Lookup 处理JNDI 查询触发条件敏感数据带外漏洞修复MessagePatternConverter类JndiManager#l…...

架构设计 - WEB项目的基础序列化配置
摘要:web项目中做好基础架构(redis,json)的序列化配置有重要意义 支持复杂数据结构:Redis 支持多种不同的数据结构,如字符串、哈希表、列表、集合和有序集合。在将这些数据结构存储到 Redis 中时,需要将其序列化为字节…...
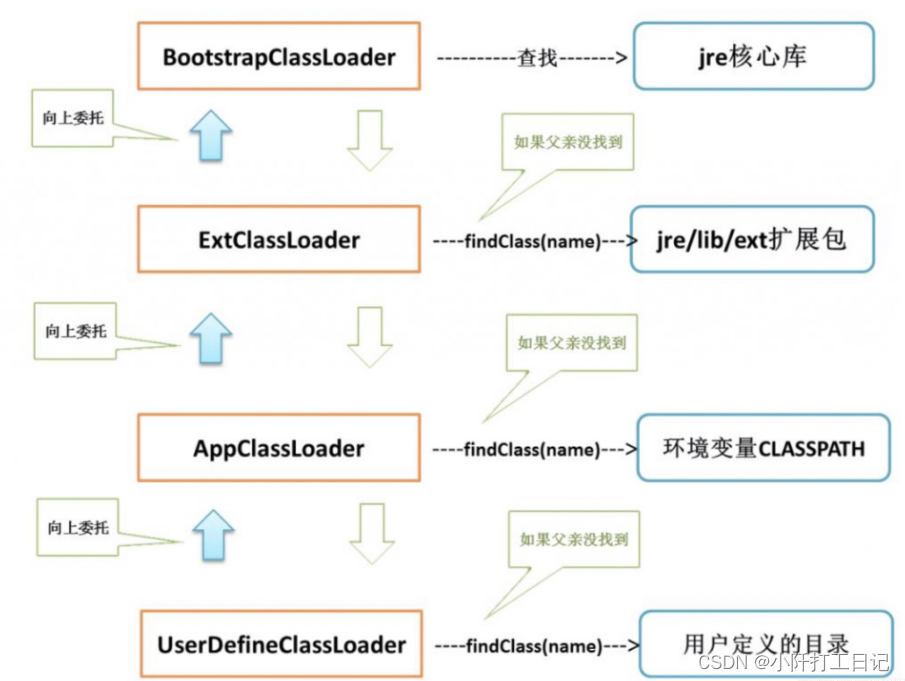
java(JVM)
JVM Java的JVM(Java虚拟机)是运行Java程序的关键部件。它不直接理解或执行Java源代码,而是与Java编译器生成的字节码(Bytecode)进行交互。下面是对Java JVM更详尽的解释: 1.字节码: 当你使用J…...

【网络安全】【深度学习】【入侵检测】SDN模拟网络入侵攻击并检测,实时检测,深度学习【二】
文章目录 1. 习惯终端2. 启动攻击3. 接受攻击4. 宿主机查看h2机器 1. 习惯终端 上次把ubuntu 22自带的终端玩没了,治好用xterm: 以通过 AltF2 然后输入 xterm 尝试打开xterm 。 然后输入这个切换默认的终端: sudo update-alternatives --co…...
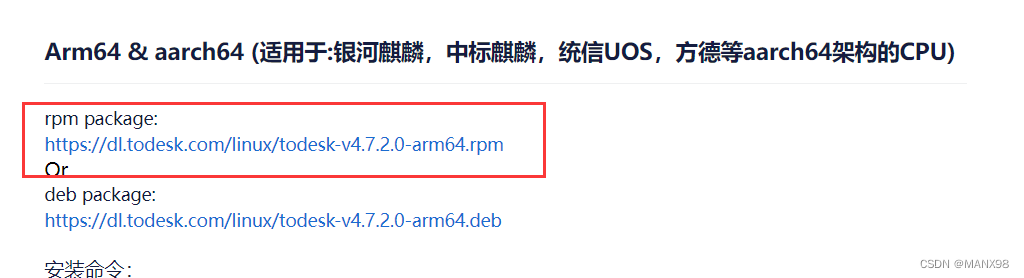
飞腾银河麒麟V10安装Todesk
下载安装包 下载地址 https://www.todesk.com/linux.html 安装 yum makecache yum install libappindicator-gtk3-devel.aarch64 rpm -ivh 下载的安装包文件后台启动 service todeskd start修改配置 编辑 /opt/todesk/config/config.ini 移除自动更新临时密码 passupda…...

JWT令牌、过滤器Filter、拦截器Interceptor
目录 JWT令牌 简介 JWT生成 解析JWT 登陆后下发令牌 过滤器(Filter) Filter快速入门 Filter拦截路径 过滤器链 登录校验Filter-流程 拦截器(Interceptor) Interceptor 快速入门 拦截路径 登录校验流程 JWT令牌 简介 全称:JSON Web Token(https://iwt.io/) …...

iText7画发票PDF——小tips
itext7教程: 1、https://blog.csdn.net/allway2/article/details/124295097 2、https://max.book118.com/html/2017/0720/123235195.shtm 3、https://www.cnblogs.com/fonks/p/15090635.html 4、https://www.cnblogs.com/sky-chen/p/13026203.html 5、官方ÿ…...

跟着刘二大人学pytorch(第---10---节课之卷积神经网络)
文章目录 0 前言0.1 课程链接:0.2 课件下载地址: 回忆卷积卷积过程(以输入为单通道、1个卷积核为例)卷积过程(以输入为3通道、1个卷积核为例)卷积过程(以输入为N通道、1个卷积核为例)…...

华为云AI开发平台ModelArts
华为云ModelArts:重塑AI开发流程的“智能引擎”与“创新加速器”! 在人工智能浪潮席卷全球的2025年,企业拥抱AI的意愿空前高涨,但技术门槛高、流程复杂、资源投入巨大的现实,却让许多创新构想止步于实验室。数据科学家…...

MPNet:旋转机械轻量化故障诊断模型详解python代码复现
目录 一、问题背景与挑战 二、MPNet核心架构 2.1 多分支特征融合模块(MBFM) 2.2 残差注意力金字塔模块(RAPM) 2.2.1 空间金字塔注意力(SPA) 2.2.2 金字塔残差块(PRBlock) 2.3 分类器设计 三、关键技术突破 3.1 多尺度特征融合 3.2 轻量化设计策略 3.3 抗噪声…...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(二)
HoST框架核心实现方法详解 - 论文深度解读(第二部分) 《Learning Humanoid Standing-up Control across Diverse Postures》 系列文章: 论文深度解读 + 算法与代码分析(二) 作者机构: 上海AI Lab, 上海交通大学, 香港大学, 浙江大学, 香港中文大学 论文主题: 人形机器人…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
FastAPI 教程:从入门到实践
FastAPI 是一个现代、快速(高性能)的 Web 框架,用于构建 API,支持 Python 3.6。它基于标准 Python 类型提示,易于学习且功能强大。以下是一个完整的 FastAPI 入门教程,涵盖从环境搭建到创建并运行一个简单的…...

使用分级同态加密防御梯度泄漏
抽象 联邦学习 (FL) 支持跨分布式客户端进行协作模型训练,而无需共享原始数据,这使其成为在互联和自动驾驶汽车 (CAV) 等领域保护隐私的机器学习的一种很有前途的方法。然而,最近的研究表明&…...

Robots.txt 文件
什么是robots.txt? robots.txt 是一个位于网站根目录下的文本文件(如:https://example.com/robots.txt),它用于指导网络爬虫(如搜索引擎的蜘蛛程序)如何抓取该网站的内容。这个文件遵循 Robots…...

select、poll、epoll 与 Reactor 模式
在高并发网络编程领域,高效处理大量连接和 I/O 事件是系统性能的关键。select、poll、epoll 作为 I/O 多路复用技术的代表,以及基于它们实现的 Reactor 模式,为开发者提供了强大的工具。本文将深入探讨这些技术的底层原理、优缺点。 一、I…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...