Linux:基础IO(二.缓冲区、模拟一下缓冲区、详细讲解文件系统)
上次介绍了:Linux:基础IO(一.C语言文件接口与系统调用、默认打开的文件流、详解文件描述符与dup2系统调用)
文章目录
- 1.缓冲区
- 1.1概念
- 1.2作用与意义
- 2.语言级别的缓冲区
- 2.1刷新策略
- 2.2具体在哪里
- 2.3支持格式化
- 3.自己来模拟一下缓冲区
- 3.1项目文件规划
- 3.2mystdio.h
- 3.3mystdio.c
- 3.4test.c
- 4.文件系统
- 4.1磁盘机械结构
- 4.2磁盘的物理存储
- 4.3磁盘的逻辑存储
- 4.4文件系统
- 5.文件名
- 5.1再看文件的增删改查
1.缓冲区
1.1概念
在计算机中,内存被划分为不同的区域,其中一部分被用作缓冲区,用于临时存储数据
-
内存区域:
- 物理结构:计算机的内存是由许多存储单元组成的,每个存储单元都有一个唯一的地址。这些存储单元按照地址顺序排列,形成了一块连续的内存区域。
- 访问方式:程序可以通过地址访问内存中的数据,读取或写入存储单元的内容。不同的内存区域有不同的用途,例如代码区、数据区、堆区和栈区等。
-
缓冲区:
- 定义:缓冲区是内存中的一块区域,用于临时存储数据。通常用于临时存储输入数据、输出数据或中间数据,以便程序能够有效地处理这些数据。
- 特点:缓冲区是一种有限大小的内存区域,数据在缓冲区中暂时存储,等待被处理或传输到目标设备。
- 用途:缓冲区在计算机程序设计中被广泛应用,例如用于输入输出操作、网络通信、文件读写等场景。
-
缓冲区的工作原理:
- 输入缓冲区:当数据被输入到程序中时,数据首先被存储在输入缓冲区中。程序可以逐个字符或一定量的数据从输入缓冲区中读取,进行处理。
- 输出缓冲区:当程序输出数据时,数据首先被存储在输出缓冲区中。系统会根据缓冲区的策略或限制,将数据逐个字符或一定量的数据发送到目标设备。
缓冲区作为一块内存区域,提供了一个临时存储数据的空间,帮助程序高效地处理输入和输出
打开一个文件进行读取或写入时,文件内容并不是直接加载到整个内存中,而是加载到内存中的一个特定区域,即缓冲区(Buffer)。缓冲区是内存中的一个临时存储区域,用于存储从文件读取的数据或待写入文件的数据。
在读取文件时,操作系统会一次性从磁盘读取一定数量的数据块到缓冲区中,然后程序可以从这个缓冲区中读取数据,而不是每次都直接从磁盘读取。这样可以减少磁盘I/O操作的次数,提高读取效率。
在写入文件时,程序会将数据写入到缓冲区中,而不是直接写入到磁盘。当缓冲区满或者程序显式调用
flush方法或关闭文件时,缓冲区中的数据才会被一次性写入到磁盘中。这种延迟写入的方式也可以提高写入效率,并减少磁盘操作的次数。需要注意的是,缓冲区的大小是有限的,它不能无限地存储数据。因此,在处理大文件时,数据会分批次地加载到缓冲区中,并进行处理。同时,缓冲区的管理是由操作系统和文件系统来负责的,程序员通常不需要直接操作缓冲区,而是通过文件I/O函数或方法来间接地使用缓冲区。
1.2作用与意义
缓冲区在计算机系统中具有的意义和作用,主要体现在以下几个方面:
-
数据传输的效率:缓冲区可以暂时存储数据,使得数据传输过程中的速度更加稳定和高效。当数据产生和消费的速度不匹配时,缓冲区可以平衡数据的传输,避免数据丢失或传输阻塞。
-
数据处理的灵活性:缓冲区可以暂时存储数据,使得程序能够按照自己的速度处理数据,而不受外部数据产生或消费速度的限制。这种灵活性有助于提高程序的性能和稳定性。
-
数据交互的安全性:缓冲区可以对输入数据进行有效的验证和处理,防止恶意输入或缓冲区溢出等安全问题。通过合理设置缓冲区大小和数据校验机制,可以保护系统免受攻击。
-
系统资源的管理:缓冲区可以帮助管理系统资源的分配和使用,避免资源的浪费和不必要的阻塞。通过合理设计缓冲区的大小和处理策略,可以优化系统的性能和资源利用率。
最主要的是提高效率:聚集数据,一次拷贝
2.语言级别的缓冲区
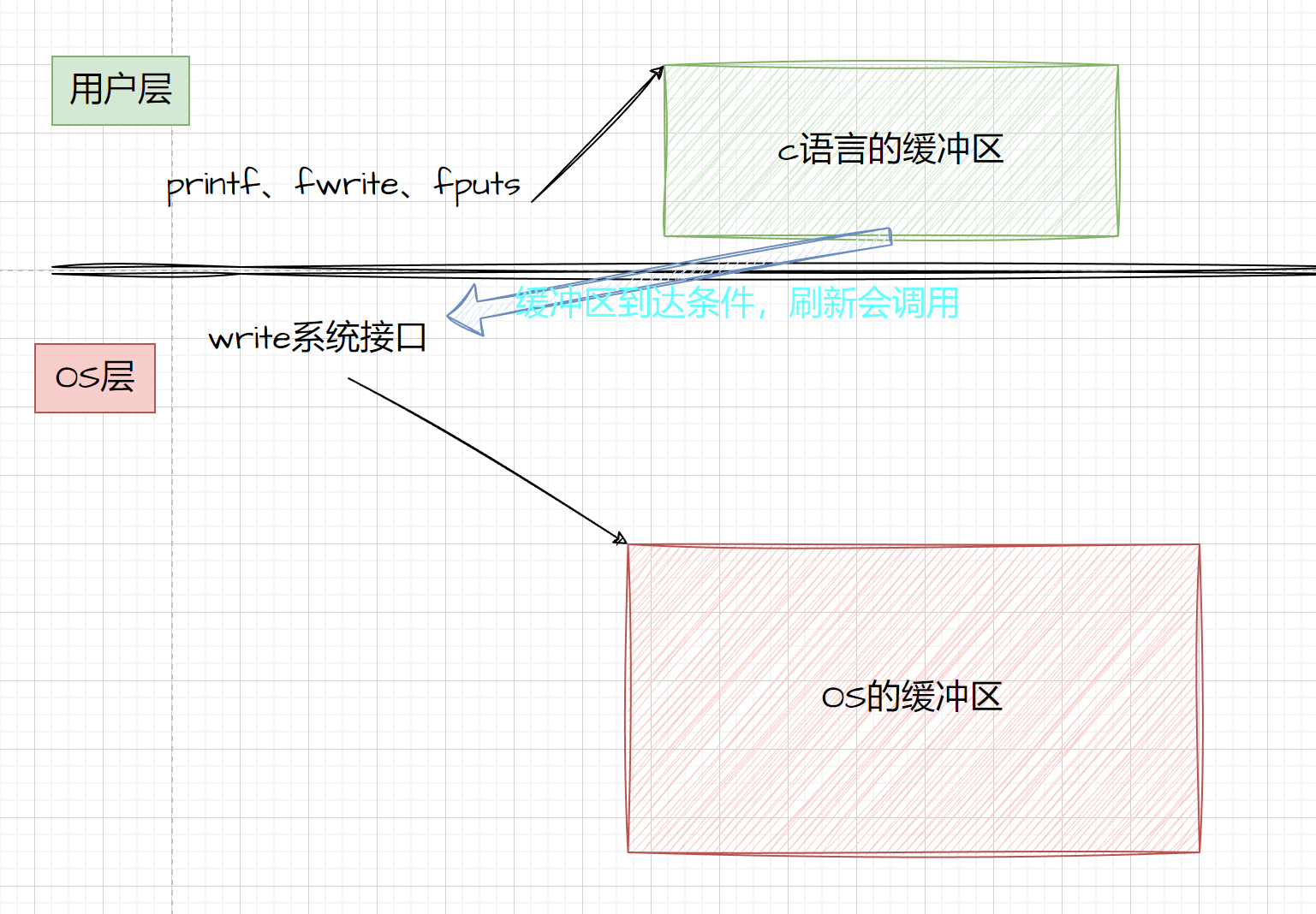
在文件I/O操作中,提到的缓冲区既可以是操作系统级别的,也可以是C语言标准库或特定编程语言库提供的。这两者在某些情况下是协同工作的,但它们的实现和用途有所不同。
操作系统级别的缓冲区:
- 当操作系统读取或写入文件时,它通常会使用内部缓冲区来优化磁盘操作。操作系统会根据需要,将一部分数据从磁盘读取到内存中的缓冲区,或者将缓冲区中的数据写入磁盘。这种缓冲区的管理对应用程序来说是透明的,应用程序不需要直接与之交互。
C语言标准库提供的缓冲区:
-
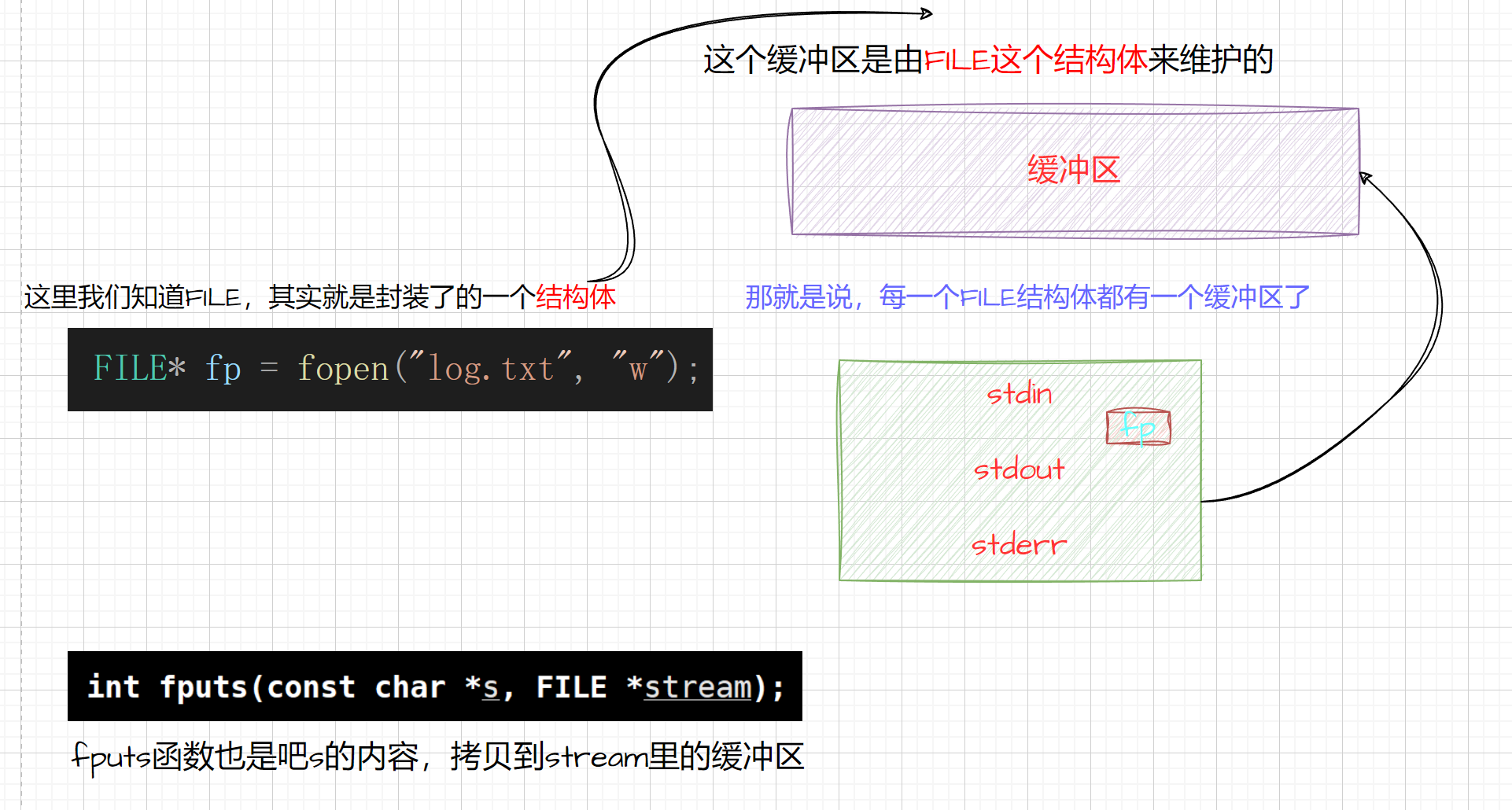
在C语言中,标准库函数(如
fread、fwrite、fgetc、fputc等)也使用了缓冲区。这些函数在内部维护了一个缓冲区,用于存储从文件读取的数据或待写入文件的数据(通常被称为“用户空间缓冲区”或“标准I/O缓冲区”。)。当使用这些函数进行文件操作时,数据首先被读取或写入到这个内部缓冲区,然后再由库函数决定何时将数据从缓冲区传输到磁盘或从磁盘加载到缓冲区。 -
当你调用例如
fwrite函数写入数据时,这些数据首先被写入到这个用户空间缓冲区中,而不是直接写入到操作系统或硬件的缓冲区。当缓冲区满或者显式调用fflush函数时,C语言标准库才会将缓冲区中的数据传递给操作系统,由操作系统进一步处理。操作系统也有自己的缓冲区,用于与硬件进行交互,例如磁盘I/O。操作系统的缓冲区通常被称为“内核缓冲区”或“系统缓冲区”。这些缓冲区用于在内核空间与用户空间之间传输数据,以及将数据从内存传输到磁盘或从磁盘加载到内存。
因此,可以说C语言的缓冲区(用户空间缓冲区)在将数据写入文件时,会先将数据存储在用户空间的缓冲区中,然后在适当的时候(如缓冲区满或显式调用
fflush)将数据传递给操作系统的缓冲区(系统缓冲区),最后由操作系统负责将数据写入磁盘。
- 这里c语言级别的缓冲区能大大减少我们调用系统调用的次数。 (也是提高效率)
没有缓冲区时,我们每有一个字符,就要调用一次系统接口(
write()函数)此时有了缓冲区,我们可以每次放进缓冲区里,最后再进行调用系统接口。只要调用一次
系统调用也是有成本的
- 有了缓冲区,能大大提高c语言中
io函数的返回效率,减少使用时间。
- 如printf函数只要写到缓冲区后,就能返回了
仔细一想:我们用户也只能通过调用OS提供的接口来让OS进行文件操作,那么c语言的缓冲区就是在调用系统接口上进行的优化
2.1刷新策略
缓冲区的刷新策略指的是何时将缓冲区中的数据写入到输出设备或从输入设备读取新数据的策略。在 C 语言中,通常有以下几种缓冲区刷新策略:
- 全缓冲:当缓冲区填满或者遇到换行符
\n时,缓冲区会被刷新,数据被写入到输出设备或者从输入设备读取新数据。这种策略通常用于文件 I/O 操作,例如stdio中的FILE结构。 - 行缓冲:当遇到换行符
\n时,缓冲区会被刷新,数据被写入到输出设备或者从输入设备读取新数据。这种策略通常用于标准输入/输出流,例如stdout和stdin。 - 无缓冲:数据不会被缓存,而是立即写入到输出设备或者从输入设备读取。这种策略通常用于特定的设备或者特殊的 I/O 操作。
当我们强制刷新时,或者进程结束。缓冲区也会刷新
在 C 语言中,可以使用 setbuf()、setvbuf() 和 fflush() 等函数来控制缓冲区的刷新策略。例如,fflush() 函数可以强制将缓冲区中的数据立即写入到输出设备,而不必等到缓冲区被填满或遇到换行符。
2.2具体在哪里
#include <stdio.h>
#include <fcntl.h>
#include <unistd.h>
#include<string.h>
int main()
{const char* s1 = "write\n";write(1, s1, strlen(s1));const char* s2 = "fprintf\n";fprintf(stdout, "%s", s2);const char* s3 = "fwrite\n";fwrite(s3, strlen(s3), 1, stdout);return 0;
}

这里我们把结果重定向到
test.txt。现在是正常的,但是下面我们做出一些改动。
int main()
{const char* s1 = "write\n";write(1, s1, strlen(s1));const char* s2 = "fprintf\n";fprintf(stdout, "%s", s2);const char* s3 = "fwrite\n";fwrite(s3, strlen(s3), 1, stdout);fork();return 0;
}
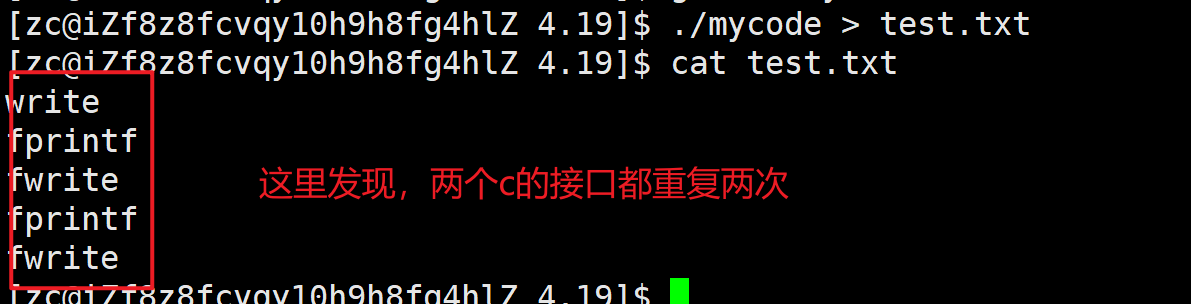
一开始我们都是向标准输出打印,采用行缓冲的刷新策略;但是我们使用重定向到test.txt 文件了,刷新策略变为全缓冲
fprintf与fwrite都是写入进stdout的缓冲区。缓冲区本身也是数据。
进程结束时,会刷新缓冲区,刷新到操作系统。刷新的本质就是清空,也是修改数据,那就会发生写时拷贝
父进程与子进程都刷新一次,一共两次
write接口是直接放到操作系统的缓冲区的,与进程没有关系
当调用
write系统调用时,数据会被写入到操作系统的内核缓冲区中。内核缓冲区是操作系统用来暂存数据的内存区域,数据在这里等待被写入到文件中
2.3支持格式化
缓冲区在 C 语言中支持输入输出的格式化操作,使得程序员可以方便地对输入和输出的数据进行格式化处理。键盘和显示器都是字符设备,通过缓冲区的格式化操作,可以实现对键盘输入和显示器输出的数据进行格式化控制。
-
输入格式化操作:当用户从键盘输入数据时,这些数据首先会被存储在输入缓冲区中。程序员可以使用输入格式化函数如
scanf()来从输入缓冲区中读取数据,并根据指定的格式进行解析和处理 -
输出格式化操作:当程序需要将数据输出到显示器时,这些数据会先被存储在输出缓冲区中。程序员可以使用输出格式化函数如
printf()来将数据按照指定的格式输出到显示器上。通过格式化字符串中的格式控制符,可以指定输出的数据类型、宽度、精度等信息。
3.自己来模拟一下缓冲区
3.1项目文件规划

- mystdio.h:用来编写FILE结构体,和各种接口的声明
- mystdio.c:用来具体实现各种接口
- test.c:用来进行功能的测试
makefile内容一览:
filetest:mystdio.c test.cgcc -o $@ $^
.PHONY:clean
clean:rm filetest -f
3.2mystdio.h
#pragma once#define SIZE 4096//缓冲区大小
#define NONE_FLUSH (1<<1)
#define LINE_FLUSH (1<<2)
#define FULL_FLUSH (1<<3) //三种刷新模式typedef struct _myFILE
{//...char outbuffer[SIZE];//这是缓冲区int pos;//这是缓冲区下标int cap;//缓冲区容量int fileno;//文件的no编号int flush_mode;//缓冲区刷新模式
}myFILE;myFILE* my_fopen(const char* pathname, const char* mode);int my_fwrite(myFILE* fp, const char* s, int size);void my_fflush(myFILE* fp);void my_fclose(myFILE* fp);3.3mystdio.c
#include<stdio.h>
#include <string.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <fcntl.h>
#include <stdlib.h>
#include <unistd.h>
#include"4.22.h"myFILE* my_fopen(const char* pathname, const char* mode)
{int flag = 0;if (strcmp(mode, "r") == 0){flag |= O_RDONLY;}else if (strcmp(mode, "w") == 0){flag |= (O_CREAT | O_WRONLY | O_TRUNC);}else if (strcmp(mode, "a") == 0){flag |= (O_CREAT | O_WRONLY | O_APPEND);}else{return NULL;}int fd = 0;if (flag & O_WRONLY){fd = open(pathname, flag, 0666);}else{fd = open(pathname, flag);}if (fd < 0){return NULL;}myFILE* myf = (myFILE*)malloc(sizeof(myFILE));myf->pos = 0;myf->cap = SIZE;myf->fileno = fd;myf->flush_mode = LINE_FLUSH;return myf;
}void my_fflush(myFILE* fp)
{write(fp->fileno, fp->outbuffer, fp->pos);fp->pos = 0;
}int my_fwrite(myFILE* fp, const char* s, int size)
{memcpy(fp->outbuffer+fp->pos, s, size);fp->pos += size;if (fp->flush_mode == LINE_FLUSH && fp->outbuffer[fp->pos - 1] == '\n'){my_fflush(fp);}else if (fp->flush_mode == LINE_FLUSH && fp->cap==fp->pos){my_fflush(fp);}
}void my_fclose(myFILE* fp)
{my_fflush(fp);close(fp->fileno);free(fp);fp = NULL;
}
3.4test.c
#include"mystdio.h"
#include<stdio.h>
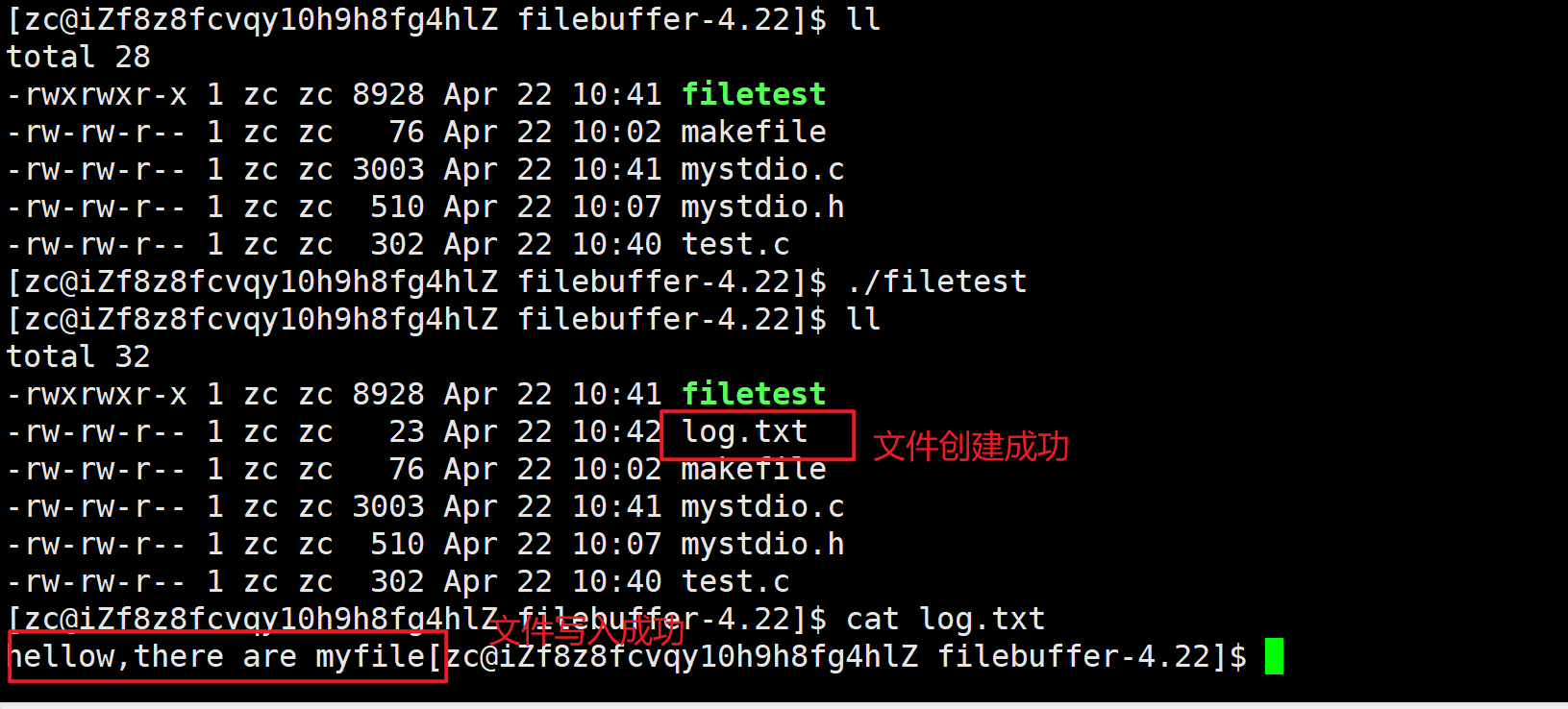
#include<string.h>const char* filename="./log.txt";int main()
{myFILE* fp=my_fopen(filename,"w");if(fp==NULL) return 1;const char* buffer="hellow,there are myfile";my_fwrite(fp, buffer, strlen(buffer));my_fclose(fp);return 0;
}
4.文件系统
4.1磁盘机械结构

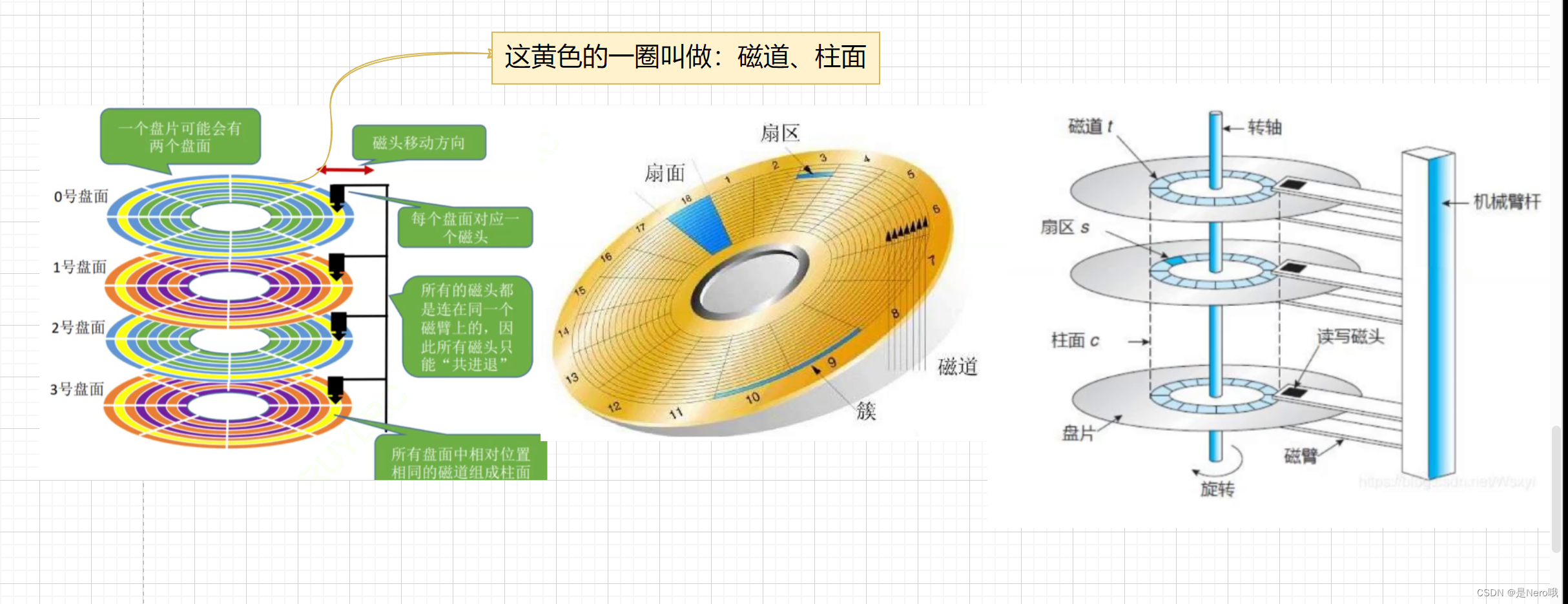
硬盘驱动器是计算机中常见的数据存储设备,它由多个组件组成,其中包括盘片、磁头、主轴、马达等:
-
盘片(Platter):硬盘驱动器通常包含多个盘片,每个盘片都是一个圆形的磁性介质,通常由金属或玻璃制成,表面被覆盖上磁性材料。数据存储在盘片的表面上,每个盘片都有内侧和外侧两面,数据存储在不同的磁道上。
-
磁头(Head):硬盘驱动器中的磁头负责读取和写入数据。磁头通过在盘片表面上移动来访问不同位置上的数据,它可以在盘片上创建磁场来表示数据的0和1。通常,硬盘驱动器会有多个磁头,每个磁头对应一个盘面,可以同时读写多个盘片上的数据。
磁头的来回是为了定位磁道的,盘片的旋转是为了定位(寻址)制定磁道上的扇区的
-
主轴(Spindle):主轴是硬盘驱动器中的一个旋转部件,它负责旋转盘片。盘片被安装在主轴上,主轴通过马达驱动盘片旋转,通常转速在几千转每分钟到一万转每分钟之间,不同硬盘驱动器的转速可能有所不同。
-
马达(Motor):硬盘驱动器中的马达负责驱动主轴旋转、移动磁头和控制盘片的位置。马达通常包括主轴电机、磁头马达和定位马达等部件,它们协同工作以确保盘片的旋转、磁头的移动和数据的读写。
-
控制器(Controller):硬盘驱动器中的控制器负责管理数据的读写、磁头的移动、盘片的旋转等操作。控制器通常包括逻辑控制器和驱动器电路板,它们与计算机系统进行通信,控制硬盘驱动器的各项功能。
我们之前说的0与1,实际上只是一种抽象的概念。在不同的设备和存储介质中,0和1的表示方式可能会有所不同,这取决于具体的存储技术和物理原理
盘片上的数据存储是通过磁性材料来实现的,磁性材料可以在不同的磁场方向上表示0和1
- 磁性材料:盘片表面被覆盖上一层磁性材料,通常是氧化铁或类似的磁性材料。这种磁性材料可以在外加磁场的作用下保持磁性,并且可以在不同方向上表示不同的磁极性,从而实现数据的存储。
- 磁场的方向:硬盘驱动器中的磁头可以在盘片表面上创建磁场,通过改变磁场的方向来表示数据的0和1。当磁场方向朝向盘片表面时,表示为1;当磁场方向远离盘片表面时,表示为0。通过这种方式,磁头可以在盘片上创建一系列的磁场来表示数据的二进制形式。
4.2磁盘的物理存储
硬盘的物理储存结构主要包括磁道、扇区和柱面,这些是硬盘上数据存储的基本单位。下面我将简要解释它们的含义和作用:
- 磁道:硬盘的盘片表面被划分成多个同心圆环,每个环称为一个磁道,每一个都有自己的编号。磁道是硬盘上的存储单位之一,数据在磁道上被存储和组织。硬盘的磁头可以沿着磁道移动,读取或写入数据。
- 扇区:每个磁道被划分成若干个扇区,扇区是硬盘上存储数据的最小单位(基本单位)。通常,一个扇区的大小是512字节或4KB。当数据被写入硬盘时,它会被分割成适当大小的扇区,并存储在硬盘的不同扇区中。
- 柱面:硬盘上的每个盘片都有多个磁道,而所有盘片上相同位置的磁道组成一个柱面。磁头可以同时读取或写入同一柱面上的多个磁道,这有助于提高数据的读写效率。
- 盘面:硬盘的盘片表面被划分成多个盘面,每个盘面都可以存储数据。通常,硬盘有多个盘片叠在一起,每个盘片都有两个盘面(正面和背面),每一个也有自己的编号
如果我们想要定位一个扇区:
- 定位到柱面
- 确定是柱面里的哪一个磁头
- 找到目标扇区
上述方法称之为:CHS(柱面、磁头、扇区)定位法。系统会通过柱面号、磁头号和扇区号来唯一地确定硬盘上的一个位置。通过这种方式,系统可以精确地定位到目标扇区,以读取或写入文件的数据。
任何文件就是由多个扇区的数据构成的,系统在读取或写入文件时会逐个扇区地进行操作
4.3磁盘的逻辑存储
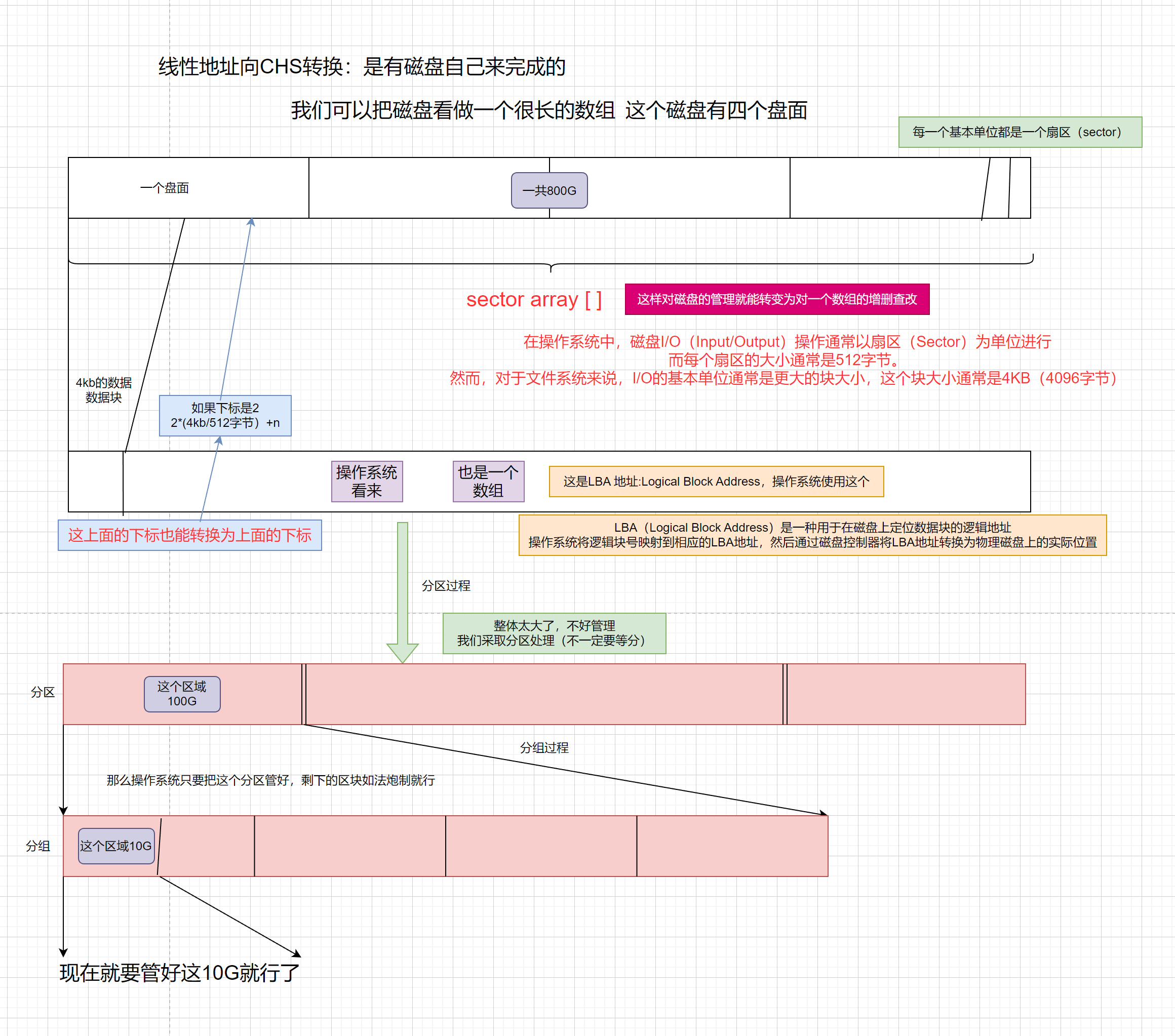
那么如何通过下标来确定实际位置呢?(下标如何转变CHS)
确定盘片:首先将数组下标除以单盘的大小(一个盘的扇区数量),得到该数组元素所在的盘片号。
计算在盘片内的偏移量:将数组下标取模单盘大小,得到在盘片内的偏移量。
确定磁道:将在盘片内的偏移量除以一个磁道的扇区个数,得到该数组元素所在的磁道号。
确定扇区:将在盘片内的偏移量取模一个磁道的扇区个数,得到该数组元素所在的扇区号。
最终的物理地址即为盘片号、磁道号和扇区号的组合。
最后我们把一个800G的磁盘管理,经过分区分组。转变为对10G的区域进行管理,那具体怎么管理呢?
我们先来看看Linux下的文件特性
文件=内容+属性
内容的大小不确定,可能很大,可能很小
属性的大小是固定的:属性的类别是一样的,但是每个类别里的内容不一样。文件名不属于属性
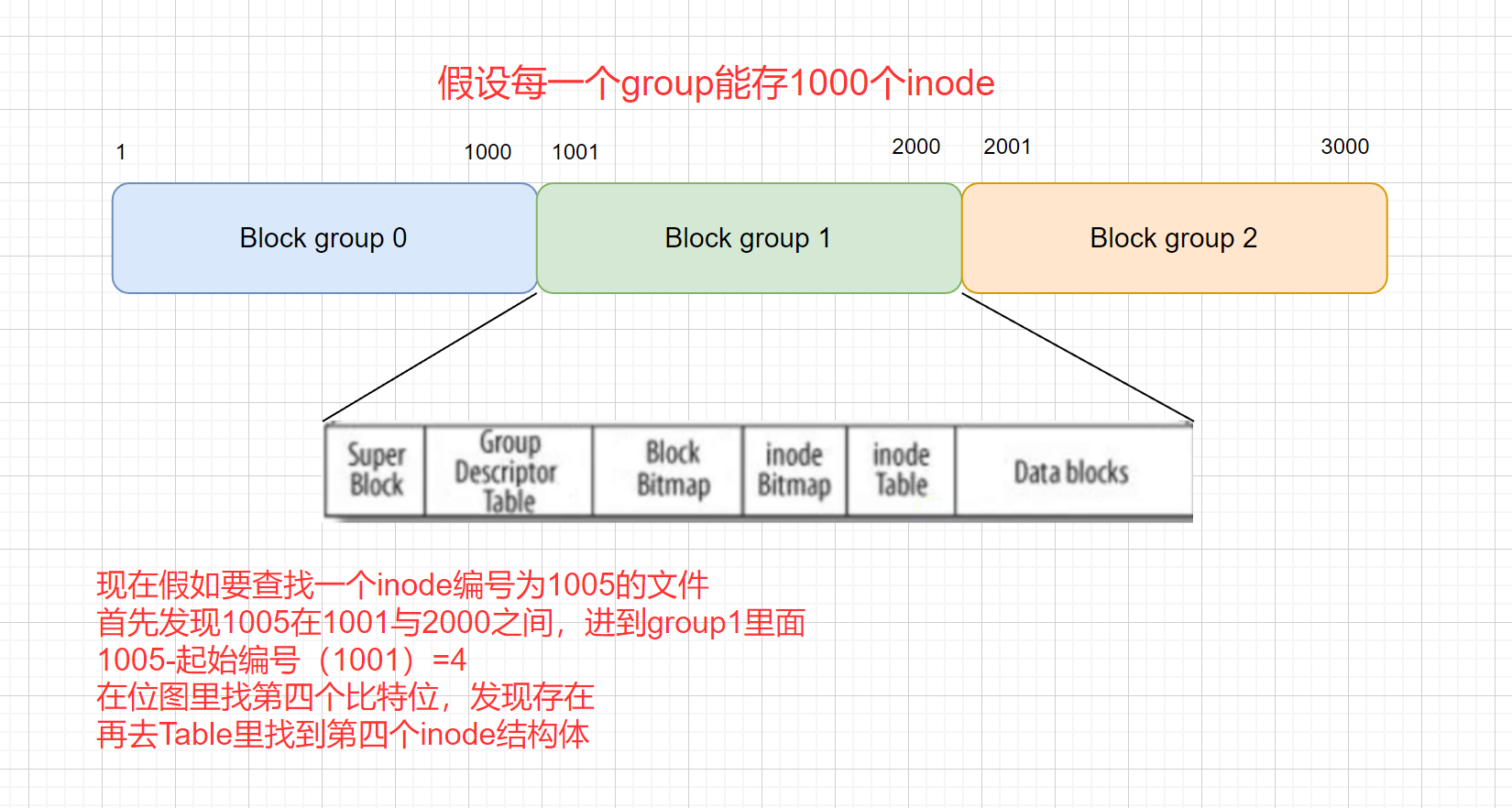
struct inode//文件的属性集 {//类型//大小//权限//时间//...int inode_num;//inode的编号 };大小是固定的128字节,4kb/128b=32(一个数据块block能存32个文件的属性)。 系统中标识一个文件使用的是
inodeinode编号,在一个分区里是唯一的
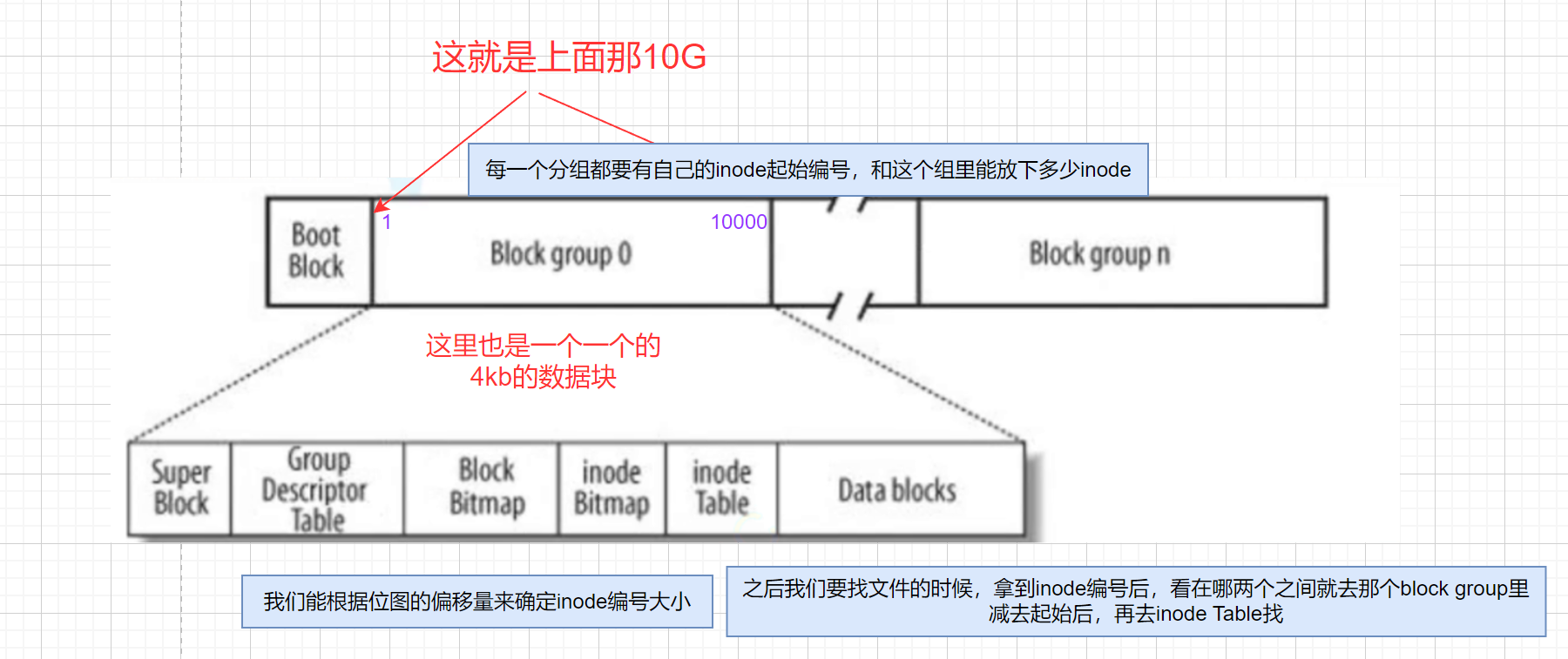
-
i节点表(inode Table):存放文件属性如文件大小,所有者,最近修改时间等。里面存的是一个个
inode表里面那么多inode,我们如何知道哪个被使用,哪个没有使用
-
inode位图(inode Bitmap):每个bit表示一个inode是否空闲可用
比特位的位置:代表第几个inode
比特位的位置内容:代表这个inode是否被使用
-
数据区(Data blocks):存放文件内容(这是一个非常非常大的区,里面有很多4kb的小数据块
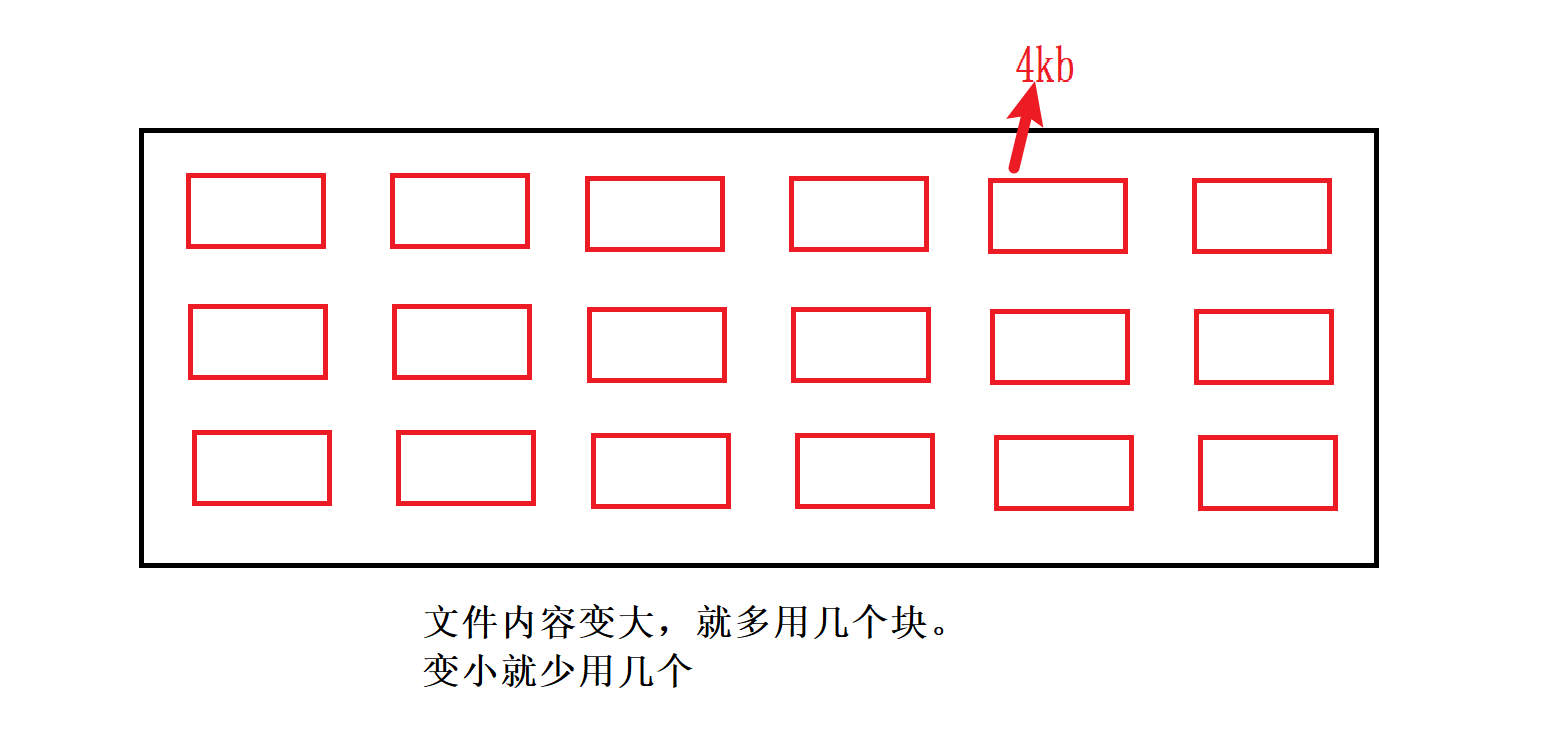
下面我们可以看到,最多对应15个block,那文件内容太大,不够用怎么办?
- 下标[0,11]就正常存使用的block,保存文件的内容
- 下标[12,13]指向的block里存的其他被使用的block的编号
- 下标[14]指向的block里存的也是其他block的编号,这些block里存的又是被使用的block的编号
-
块位图(Block Bitmap):Block Bitmap中记录着Data Block中哪个数据块已经被占用,哪个数据块没有被占用
比特位的位置:代表第几个4kb的数据块
比特位的位置内容:代表这个数据块是否被使用
struct inode {//...int block[15];//里面对应一个个使用的数据块的编号//... };那么现在:我们有了文件的inode编号后,就能在inode Table里找到inode,然后能进一步找到block(该文件对应的数据块)和其他属性
-
GDT(Group Descriptor Table):块组描述符,描述块组属性信息(一个块的宏观使用情况)
-
超级块(Super Block):存放文件系统本身的结构信息。记录的信息主要有:bolck 和 inode的总量,未使用的block和inode的数量,一个block和inode的大小,最近一次挂载的时间,最近一次写入数据的时间,最近一次检验磁盘的时间等其他文件系统的相关信息。Super Block的信息被破坏,可以说整个文件系统结构就被破坏了(不是所有的block group里都有super block,个别才有)
多个super block是为了进行数据备份
不是全都有是因为每次一变动,每个都要更新。降低了效率
Super Block 的备份通常是为了提高文件系统的容错性和可靠性。每个 Block Group 并不一定都有 Super Block,而是选择性地放置。这样做可以减少每次写操作时需要更新的 Super Block 数量,从而提高文件系统的性能
新建一个文件都干了什么呢?
在inode位图中找到一个未被使用的inode编号
填写inode结构体:根据新的inode编号在inode表里找到,填写inode结构体,包括文件的属性信息(如文件类型、权限、大小、创建时间等)和指向数据块的指针
更新inode表:将填写好的inode结构体写入inode表中,以便后续查找和访问。同时,更新inode位图中对应inode的状态为已占用。
分配数据块:根据文件大小和文件系统的块大小,确定需要分配的数据块数量,并在块位图中找到未被使用的数据块。将这些数据块分配给新文件,并更新块位图中对应数据块的状态为已占用。
将文件内容写入数据块:将文件的内容写入分配的数据块中,以完成文件的创建。文件的内容可以是文本、图像、音频等任意类型的数据。
删除一个文件呢?
- 找到文件的inode:首先,通过文件名在目录结构中查找到文件对应的inode号码。
- 释放数据块:根据文件的inode结构体中记录的数据块指针,找到文件所占用的数据块,并将这些数据块标记为未使用状态,以便后续被其他文件使用。
- 更新inode位图和块位图:将文件的inode和数据块对应的位图中的相应位标记为未使用状态,以释放这些资源。
这里我们看到不对数据块里的内容进行清理,只是标志为未使用(这样效率更快)。数据块内容会在后续被其他文件写入时覆盖,或者由文件系统的垃圾回收机制在需要时清理
找一个文件,就是通过inode编号找,前提:我们怎么知道文件在哪一个分组里面
4.4文件系统
我们上面讲的那个区域里的文件系统称为Ext* 。是一系列的 Linux 文件系统,最常见的是 Ext2、Ext3 和 Ext4
每一个分区有自己的文件系统。我们对分区初始化本质是向指定分区,写入全新的文件系统
Ext2(Second Extended File System)
- 特点: Ext2 是 Linux 中最早的可用文件系统之一,它是 Ext 文件系统的改进版本,引入了许多新的特性,如索引节点 (inode) 和快速文件系统 (Fast File System)。
- 优点: Ext2 文件系统简单、可靠,并且在 Linux 社区得到了广泛的支持和应用。它的设计目标是提供一个高性能的文件系统,同时保持数据的稳定性和一致性。
- 缺点: Ext2 文件系统不支持日志功能,因此在系统崩溃或意外断电时可能会导致数据丢失或损坏。同时,Ext2 文件系统没有提供数据的回收和压缩功能,会导致存储空间的浪费。
5.文件名
前面我们的起点都是inode编号,那我们一开始怎么得到inode呢?
- 目录也是文件。目录=inode+目录的内容
- 目录的内容都是——目录里的文件名与inode编号的映射关系
- 内容实际上就是一个映射表,将文件名映射到对应的inode编号。当你查看一个目录的内容时,你实际上是在查看这个映射表。这就是为什么目录本身也是一个文件,并且也有它自己的inode
我们之前讲过,对于目录没有w权限,就不能添加、删除文件。因为这些涉及对目录文件内容的修改
对于目录没有r权限,那么你将无法查看目录中的文件列表。因为我们无法读文件内容,不能查看文件名与inode编号的映射关系
5.1再看文件的增删改查
对一个文件进行的增删查改操作,都与该文件所处的目录有密切关系。这是因为文件系统中的文件和目录是以树形结构组织的,每个文件都通过其所在的目录进行定位和管理
那么,我们想要知道目录的inode,那就要知道目录所处目录的内容,才能知道目录对应的inode。以此类推
想要找到一个文件,我们要有路径,首先进行路径解析,从根目录往下进行。系统能够最终定位到指定路径的文件或目录,并获取其inode编号
-
增(创建文件):
- 在一个目录中创建一个新的文件,需要为该文件分配一个新的inode号。
- 在文件系统的inode表中查找一个未被使用的inode,分配给新文件。
- 在分组中分配数据块给新文件存储数据,并将数据写入这些数据块中。
- 在当前目录中,将新文件的名称与分配的inode号建立映射关系,这样就完成了新增文件的操作。
-
删(删除文件):
- 根据文件名称查找到对应的inode编号,进而确定文件所在的分组。
- 修改inode bitmap内容,将该inode对应的位标记为未使用,表示该inode已经被释放。文件内容使用的数据块,并将这些数据块标记为未使用状态
- 在当前目录文件中删除该文件的名称与inode编号的映射关系,完成文件的删除操作。
-
查(查找文件):
- 根据文件名称查找到对应的inode编号,确定文件所在的分组。
- 根据inode编号找到文件的数据块信息,获取文件的内容。
-
改(修改文件):
- 根据文件名称查找到对应的inode编号,确定文件所在的分组。
- 根据inode编号找到文件的数据块,对数据块中的内容进行修改。
inode编号只在一个分区里是唯一的,那我们怎么知道是在哪个分区
在Linux系统中,被写入文件系统的分区在被使用之前需要进行“挂载”操作。挂载的主要目的是将文件系统的分区与目录树中的某个目录关联起来,从而使得用户可以通过该目录访问和操作分区中的文件
在Linux系统中,每个分区都会挂载到文件系统的某个挂载点(mount point)下。通过查看文件或目录的路径,我们可以确定它所属的挂载点,进而确定它所在的分区(能直接根据路径看在哪个分区里,进行路径前缀匹配)
当在执行一些命令时,如果没有指定完整的文件路径,系统会根据当前进程的执行路径来查找文件。这是因为在Linux系统中,有一个环境变量叫做
PATH,它包含了一系列目录路径,系统会根据这些路径来搜索可执行文件。类似的,对于一些命令,如
find等,如果您没有指定完整的路径,系统会从当前目录开始搜索文件。这是因为这些命令会使用当前进程的工作目录作为搜索起点。因此,当您在执行命令时只提供文件名而没有路径时,系统会首先在当前目录下搜索这个文件名,然后再根据
PATH环境变量或当前目录来查找文件。系统会按照以下步骤来查找可执行文件:
首先,系统会检查当前进程的工作目录(也就是执行命令时所处的目录)下是否存在与提供的文件名相匹配的文件。如果找到了,系统会执行该文件。
如果在当前工作目录下没有找到匹配的文件,系统会继续在
PATH环境变量指定的目录列表中逐个查找。PATH环境变量包含了一系列目录路径,系统会按照这些路径的顺序来搜索可执行文件。如果在
PATH指定的所有目录中都没有找到匹配的文件,系统会提示找不到文件的错误。
好啦,这次内容到这里了。感谢大家支持!!!
相关文章:
Linux:基础IO(二.缓冲区、模拟一下缓冲区、详细讲解文件系统)
上次介绍了:Linux:基础IO(一.C语言文件接口与系统调用、默认打开的文件流、详解文件描述符与dup2系统调用) 文章目录 1.缓冲区1.1概念1.2作用与意义 2.语言级别的缓冲区2.1刷新策略2.2具体在哪里2.3支持格式化 3.自己来模拟一下缓…...

事件传播机制 与 责任链模式
1、基本概念 责任链模式(Chain of Responsibility Pattern)是一种行为型设计模式,将请求沿着处理链传递,直到有一个对象能够处理为止。 2、实现的模块有: Handler(处理者):定义一个…...
uniapp 展示地图,并获取当前位置信息(精确位置)
使用uniapp 提供的map标签 <map :keymapIndex class"container" :latitude"latitude" :longitude"longitude" ></map> 页面初始化的时候,获取当前的位置信息 created() {let that thisuni.getLocation({type: gcj02…...
)
Autosar实践——诊断配置(DaVinci Configuration)
文章目录 一、制作诊断数据库文件(cdd文件)二、导入诊断数据库文件并修复模块生成的问题三、创建SWC CS接口Service Ports四、创建Service Runnable五、关联SWC和DCM/DEM模块六、RTE代码编写22服务2E服务31服务DTC Set/Get关联文章列表: Autosar-软件架构 Autosar诊断-简介和…...
植物大战僵尸杂交版全新版v2.1解决全屏问题
文章目录 🚋一、植物大战僵尸杂交版❤️1. 游戏介绍💥2. 如何下载《植物大战僵尸杂交版》 🚀二、解决最新2.1版的全屏问题🌈三、画质增强以及减少闪退 🚋一、植物大战僵尸杂交版 《植物大战僵尸杂交版》是一款在原版《…...

【code-server】Code-Server 安装部署
Code-Server 安装部署 1.环境准备 可以参考 https://coder.com/docs/code-server/install code-server的安装流程进行安装,主机环境是 Centos7 建议使用 docker 方式进行安装,可能会出现如下报错,需要升级 GNC 的版本,由于影响较…...

博客摘录「 YOLOv5模型剪枝压缩」2024年5月11日
添加L1正则来约束BN层系数 语义边缘检测和语义分割的关系调研结果为,语义信息可以用来增强语义分割的效果,也有一定的优点和采用理由,但此类论文的数量并不是很多,语义分割的多数方法还是使用深度学习直接做像素分类。在对比两者…...

HttpSecurity
这是Spring Security提供的配置类, 用户保护基于HTTP的请求 ,通过HttpSecurity可以设置各种安全设置{认证,授权,CSRF保护,会话管理,异常处理} 主要功能和配置: 1.认证配置: 配置登录和登出功能,指定登录页面、登录处理 URL、成功和失败处理器等。配置认证方式,如表单登录、…...

Mysql union语句
开源项目SDK:https://github.com/mingyang66/spring-parent 个人文档:https://mingyang66.github.io/raccoon-docs/#/ mysql union操作符用于连接两个以上的select语句的结果组合到一个结果集,并去除重复的行,每个select语句的雷叔…...

MySQL之高级特性(四)
高级特性 查询缓存 什么情况下查询缓存能发挥作用 并不是什么情况下查询缓存都会提高系统性能的。缓存和失效都会带来额外的消耗,所以只有当缓存带来的资源节约大于本身的资源消耗时才会给系统带来性能提升。这跟具体的服务器压力模型有关。理论上,可…...

roles安装wordpress
debug模块 1.如何查看ansible-playbook执行过程中产生的具体信息 vim test3.yaml --- - hosts: allremote_user: roottasks:- name: lsshell: ls /rootregister: var_stdout # register:将var_stdout注册为变量- name: debugdebug:var: var_stdout # 查看所有的输出信息#var…...

【Python高级编程】饼状图中autopct和startangle用来做什么的
autopct 设置饼状图中每个扇区的百分比标签。接受一个格式字符串,用于指定如何格式化标签。默认值为 %.1f%%,表示保留一位小数的百分比格式。可以设置为 None 以禁用百分比标签。 startangle 设置饼状图中第一个扇区的起始角度。角度以顺时针方向从 3…...

【ARM Coresight Debug 系列 -- ARMv8/v9 Watchpoint 软件实现地址监控详细介绍】
请阅读【嵌入式开发学习必备专栏 】 文章目录 ARMv8/v9 Watchpoint exceptionsWatchpoint 配置信息读取Execution conditionsWatchpoint data address comparisonsSize of the data accessWatchpoint 软件配置流程Watchpoint Type 使用介绍WT, Bit [20]: Watchpoint TypeLBN, B…...

jvm工具-jps、jstat、jmap、jstack
一、jps jps -v 【输出进程启动参数】 [rootVM-8-2-centos ~]# jps -v 12401 Jps -Dapplication.home/usr/local/jdk1.8.0_241 -Xms8m 16964 jar 其他参考 Java八股文必看,入门到深入理解jvm虚拟机之基础故障指令【jps,jstate...】-CSDN博客 二、j…...
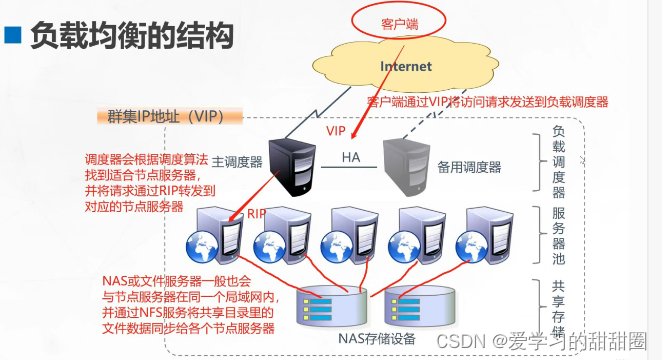
LVS负载均衡群集+NAT部署
目录 一、企业群集应用概述 1.1 群集的含义 1.2 企业群集分类 二、负载均衡群集架构和工作模式 2.1负载均衡的结构 2.2负载均衡群集工作模式分析 三、LVS虚拟服务器 3.1Linux Virtual Server 3.2LVS必要的工具 3.3LVS的负载调度算法 一、企业群集应用概述 1.1 群集的…...
使用 Oracle SQL Developer 导入数据
使用 Oracle SQL Developer 导入数据 1. 导入过程 1. 导入过程 选择要导入数据的表, 然后单击右键,选择"导入数据", 浏览本地文件,选择正确的工作表, 按默认, 按默认, 根据情况修改&…...

品质主管的面试题目
在品质主管的面试中,面试官可能会提出一系列问题来评估应聘者的经验、技能和专业知识。以下是一些常见的品质主管面试题,你可以提前准备,以更好地展示自己的能力和适应性。 一、自我介绍与背景了解 请简单介绍一下自己,包括教育背景、工作经验等。你在过去的工作经历中,主…...
算法专题总结链接地址
刷力扣的时候会遇到一些总结类型的题解,在此记录,方便自己以后找 前缀和 前缀和https://leetcode.cn/problems/unique-substrings-in-wraparound-string/solutions/432752/xi-fa-dai-ni-xue-suan-fa-yi-ci-gao-ding-qian-zhui-/ 单调栈 单调栈https:…...

Oracle--存储结构
总览 一、逻辑存储结构 二、物理存储结构 1.数据文件 2.控制文件 3.日志文件 4.服务器参数文件 5.密码文件 总览 一、逻辑存储结构 数据块是Oracle逻辑存储结构中的最小的逻辑单位,一个数据库块对应一个或者多个物理块,大小由参数DB_BLOCK_SIZE决…...
【计算机毕业设计】259基于微信小程序的医院综合服务平台
🙊作者简介:拥有多年开发工作经验,分享技术代码帮助学生学习,独立完成自己的项目或者毕业设计。 代码可以私聊博主获取。🌹赠送计算机毕业设计600个选题excel文件,帮助大学选题。赠送开题报告模板ÿ…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

【Zephyr 系列 10】实战项目:打造一个蓝牙传感器终端 + 网关系统(完整架构与全栈实现)
🧠关键词:Zephyr、BLE、终端、网关、广播、连接、传感器、数据采集、低功耗、系统集成 📌目标读者:希望基于 Zephyr 构建 BLE 系统架构、实现终端与网关协作、具备产品交付能力的开发者 📊篇幅字数:约 5200 字 ✨ 项目总览 在物联网实际项目中,**“终端 + 网关”**是…...
)
WEB3全栈开发——面试专业技能点P2智能合约开发(Solidity)
一、Solidity合约开发 下面是 Solidity 合约开发 的概念、代码示例及讲解,适合用作学习或写简历项目背景说明。 🧠 一、概念简介:Solidity 合约开发 Solidity 是一种专门为 以太坊(Ethereum)平台编写智能合约的高级编…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

uniapp手机号一键登录保姆级教程(包含前端和后端)
目录 前置条件创建uniapp项目并关联uniClound云空间开启一键登录模块并开通一键登录服务编写云函数并上传部署获取手机号流程(第一种) 前端直接调用云函数获取手机号(第三种)后台调用云函数获取手机号 错误码常见问题 前置条件 手机安装有sim卡手机开启…...