12_YouOnlyLookOnce(YOLOv3)新一代实时目标检测技术
1.1 回顾V1和V2
V1:05_YouOnlyLookOnce(YOLOV1)目标检测领域的革命性突破-CSDN博客
V2:07_YouOnlyLookOnce(YOLOv2)Better,Faster,Stronger-CSDN博客
1.2 简介
YOLOv3(You Only Look Once version 3)是YOLO系列目标检测算法的第三代版本,由Joseph Redmon等人在2018年推出。YOLO系列因其快速且准确的目标检测能力而广受欢迎,尤其适合需要实时处理的应用场景。YOLOv3在继承前代优势的基础上,通过一系列关键改进,进一步提升了检测精度和运行速度,实现了对各类尺度目标的有效检测。
-
Darknet-53作为骨干网络:YOLOv3采用了一个新的特征提取网络——Darknet-53,这个网络包含53个卷积层,每个卷积层后通常跟随批量归一化层(Batch Normalization)和Leaky ReLU激活函数,以加速训练并提高模型的非线性表达能力。Darknet-53没有池化层,而是利用步长为2的卷积层来下采样特征图,这有助于保持更多的空间信息。
-
特征金字塔网络(Feature Pyramid Networks, FPN):YOLOv3引入了FPN机制,能够在不同尺度上进行特征检测。它在Darknet-53的输出上添加了几个额外的卷积层,形成了三个不同尺度的特征图(13x13, 26x26, 52x52),每个尺度对应不同的对象尺寸,从而提高了对小目标的检测能力。这种设计允许模型在不同层级捕获多种尺度的信息,增强了模型的泛化能力和准确性。
-
多尺度预测:与YOLOv2相比,YOLOv3在每个特征图的每个网格上预测3个边界框,每个边界框包含位置信息、对象类别概率以及一个置信度分数,表明该框内存在对象的概率。这种多尺度和多框的策略有助于模型更灵活地适应不同大小和形状的对象。
-
优化的损失函数:YOLOv3采用了更加精细化的损失函数,既考虑了分类损失,也考虑了定位损失,同时对小对象的检测给予了更高的权重,以解决小对象检测难题。
-
实时性:尽管YOLOv3在精度上有了显著提升,但它仍然保持了较快的推理速度,使得它在诸如自动驾驶、视频监控和无人机导航等需要即时响应的场景中非常实用。
1.3 V3的性能
-
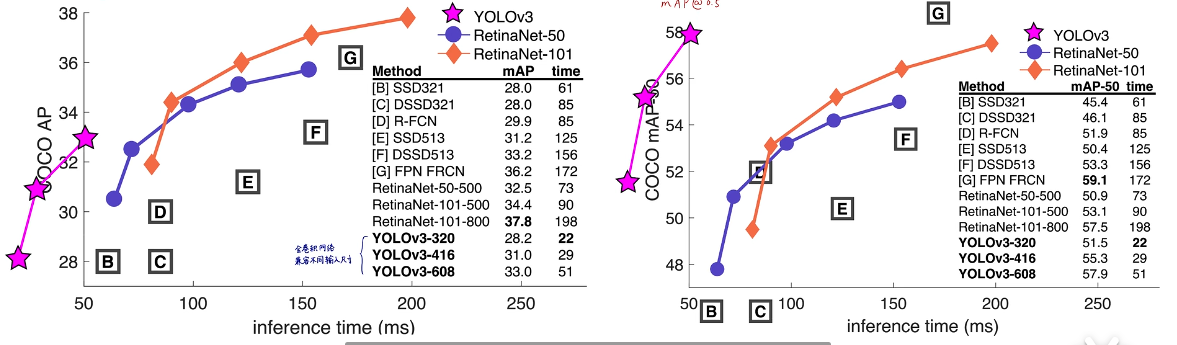
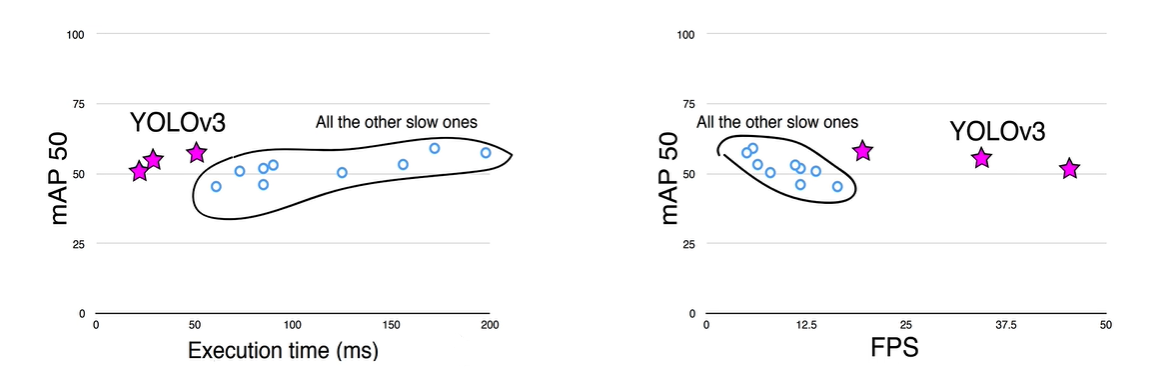
高精度与实时性平衡:YOLOv3在精确度和速度之间实现了良好的平衡。它在保持快速检测速度的同时,显著提高了检测精度。例如,在Titan X GPU上,YOLOv3能在大约51毫秒(ms)内完成一张图像的检测,达到57.9%的平均精度均值(AP50),这意味着它的检测速度非常快,同时具有较高的检测准确性。
-
多尺度检测能力:通过在不同尺度的特征图上进行预测,YOLOv3能有效检测从小到大的各种尺寸的目标。它的设计使得模型能够在多个分辨率级别上捕捉对象特征,这对于检测复杂场景中的多样化目标尤为重要。
-
改进的损失函数与正负样本匹配:YOLOv3采用了优化的损失函数,能够更好地处理分类和定位任务,同时,它采用基于聚类的方法来生成先验框,这有助于模型更好地适应不同目标的尺度和宽高比,提高了模型的稳定性和精度。
-
增强的特征提取网络:Darknet-53作为YOLOv3的骨干网络,提供了强大的特征提取能力。该网络结构的高效性使得模型可以在保持较高检测速度的同时,提升对目标特征的学习能力。
-
计算效率:相比其他先进的目标检测模型如SSD和RetinaNet,YOLOv3在某些配置下能够提供更快的检测速度。例如,它被报道在某些基准测试中,其运行速度可以达到SSD和RetinaNet的大约3.8倍,这对于资源受限或对延迟有严格要求的应用场景尤为重要。
-
适应多标签任务:YOLOv3通过改进的Softmax层设计,能够更好地处理一个网格内存在多个对象的情况,提高了模型在复杂场景下的表现。
1.4 DarkNet53
Darknet53特性概览
-
残差结构:Darknet53的一个关键特点是大量采用了残差学习(Residual Learning)的思想,即残差块(Residual Block)。每个残差块通常包含两个卷积层:一个3x3卷积层紧跟着一个1x1卷积层,中间穿插Batch Normalization(BN)和激活函数(通常是Leaky ReLU)。这些残差块通过快捷连接(skip connection)将输入直接加到经过若干卷积操作后的特征上,帮助解决深度网络中的梯度消失问题,使得模型能够更轻松地训练更深的网络。
-
下采样策略:与传统的池化层用于下采样不同,Darknet53主要使用步长为2的3x3卷积来进行特征图的下采样,这有助于减少信息损失,同时增加网络的深度。
-
网络深度:Darknet53相较于其前身Darknet19,深度大大增加至53层,这样的设计旨在进一步提升模型的特征表达能力。
-
卷积模块:网络中广泛使用了一种称为
DarknetConv2D的定制化卷积模块,该模块在每次卷积操作后都会进行L2正则化、批量归一化(BatchNorm)以及Leaky ReLU激活,这样的设计有利于训练稳定性和加速收敛。
网络结构
- 基础块:网络由一系列的卷积层堆叠而成,其中包含多个残差块。每个残差块通常由两组卷积层组成,先是一个较小的3x3卷积层(步长可能为2以进行下采样),接着是一个1x1卷积层用于调整通道数,所有这些之后都伴随有BN和激活函数。
- 层级特征:随着网络的深入,特征图的尺寸减小,但通道数增加,这种设计允许模型在不同尺度上捕获特征,这对于检测不同大小的目标至关重要。
- 输出层:最终,Darknet53产生多个不同尺度的特征图,这些特征图随后被用于构建特征金字塔,并在此基础上进行分类和边界框回归。
性能影响
Darknet53的设计使得YOLOv3不仅能够快速提取图像特征,还显著提高了检测精度,尤其是在处理小目标和多尺度目标时。它的深度和残差结构有助于学习更复杂的特征表示,而不会遭受严重的梯度消失或爆炸问题,从而提升了整个YOLOv3系统的性能。


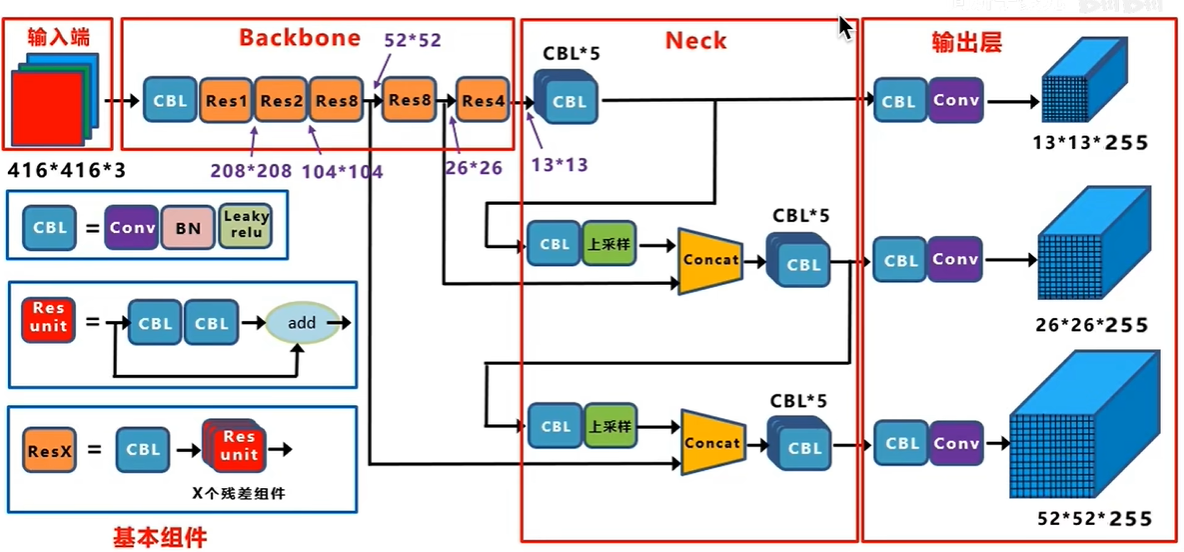
1.5 V3的网络架构
YOLOv3(You Only Look Once version 3)的网络架构设计精巧,旨在实现高速与高精度目标检测的平衡。以下是YOLOv3网络架构的关键组成部分和工作流程:
1. 输入层
- 输入图像:YOLOv3通常接受固定尺寸的输入图像,如416x416像素,这是为了方便网络结构中的下采样操作。
2. Darknet-53作为骨干网络
- 基础特征提取:首先,图像通过Darknet-53网络进行处理。Darknet-53包含53层,主要由卷积层构成,使用大量的残差块(Residual Blocks)来加深网络,每个残差块包括两个3x3卷积层(其中一个可进行下采样),并使用批量归一化(Batch Normalization)和Leaky ReLU激活函数。
3. 特征金字塔网络(Feature Pyramid Network, FPN)
- 多层次特征提取:Darknet-53的输出通过一系列上采样和特征融合操作形成特征金字塔。具体来说,网络在最后几个卷积层后,通过上采样操作(如最近邻插值或双线性插值)将低分辨率特征图与之前较高分辨率的特征图融合,形成了三个不同尺度的特征图(一般为52x52、26x26、13x13),分别对应于检测不同大小的目标。
4. 检测层(YOLO Layers)
-
多尺度预测:在每个尺度的特征图上,YOLOv3应用一个卷积层来预测该尺度上的目标信息。每个网格预测3个边界框(anchor boxes),每个边界框含有5个坐标参数(x, y, w, h, confidence score)以及C个条件类别概率(每个类别一个概率)。其中,(x, y)是边界框中心相对于网格单元的偏移,(w, h)是边界框的宽度和高度的预归一化值,confidence score表示边界框内存在物体的概率,以及框的精确度。
5. 输出层
- 输出格式:最终,YOLOv3输出是三个尺度的特征图,每个特征图上的每个网格预测出B个边界框,每个边界框关联C个类别概率,因此输出维度为(S1S1B*(5+C), S2S2B*(5+C), S3S3B*(5+C)),其中Si是每个特征图的大小。
6. 损失函数
- 优化目标:YOLOv3使用多部分损失函数,包括边界框的位置误差、对象存在的置信度误差、以及分类误差,通过优化这个复合损失来同时训练位置、置信度和类别预测。
255是怎么来的?85x3,就是每个grid cell生成3个anchor box,每一个anchor对应一个预测框,每一个预测框有5+80,5是XYWHC(中心点坐标,预测框长宽,置信度),80是coco数据集80个类别的条件类别概率。
13x13(416下采样32倍,每个 gridcell对应原图的感受野是32x32,负责预测大物体),26x26(下采样16倍,负责预测中等大小物体),52x52(下采样8倍,预测小物体)都是gridcell个数,每个girdcell对应3个anchor。

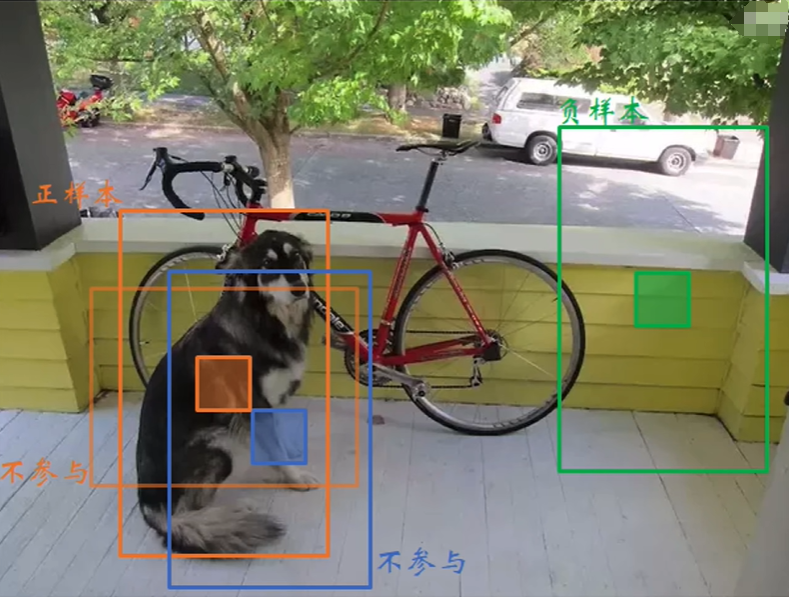
1.6 损失函数



2.pytorch复现
# Author:SiZhen
# Create: 2024/6/15
# Description:外接摄像头捕捉实时目标检测
# 参考视频https://www.bilibili.com/video/BV1Vg411V7bJ/?spm_id_from=333.999.0.0
import cv2
import numpy as np
import matplotlib.pyplot as plt#定义可视化图像函数
def look_img(img):#opencv读入图像格式为BGR,matplotlib可视化格式为RGB,需要转化img_RGB = cv2.cvtColor(img,cv2.COLOR_BGR2RGB)plt.imshow(img_RGB)plt.show()#导入与训练YOLOV3模型
net = cv2.dnn.readNet('yolov3.weights','yolov3.cfg')#获取三个尺度输出层的名称
layersNames = net.getLayerNames()
output_layers_names = [layersNames[i[0]-1]for i in net.getUnconnectedOutLayers()]with open('coco.names','r')as f:classes = f.read().splitlines()CONF_THRES = 0.2 #指定置信度阈值,阈值越大,置信度过滤越强
NMS_THRES = 0.4 #指定NMS阈值,阈值越小,NMS越强#处理帧函数
def process_frame(img):#获取图像宽高height,width,_ =img.shapeblob = cv2.dnn.blobFromImage(img,1/255,(416,416),(0,0,0),swapRB=True,crop=False)net.setInput(blob)#前向推断prediction = net.forward(output_layers_names)#从三个尺度输出结果中解析所有预测框信息boxes = []#存放预测框坐标objectness = []#存放置信度class_probs = [] #存放类别概率class_ids = [] #存放预测框类别索引号class_names = [] #存放预测框类别名称for scale in prediction : #遍历三种尺度for bbox in scale: #遍历每个预测框obj = bbox[4] #获取该预测框的confidence(objecness)class_scores = bbox[5:] #获取该预测框在coco数据集80哥类别的概率class_id = np.argmax(class_scores) # 获取概率最高类别的索引号class_name = classes[class_id] # 获取概率最高类别的名称class_prob = class_scores[class_id] # 获取概率最高类别的概率# 获取预测框中心点坐标,预测框宽高center_x = int(bbox[0] * width)center_y = int(bbox[1] * height)w = int(bbox[2] * width)h = int(bbox[3] * height)# 计算预测左上角坐标x = int(center_x - w / 2)y = int(center_y - h / 2)# 将每个预测框的结果存放至上面的列表中boxes.append([x, y, w, h])objectness.append(float(obj))class_ids.append(class_id)class_names.append(class_name)class_probs.append(class_prob)#将预测框置信度objectness与各类别置信度class_pred相乘,获得最终该预测框的置信度confidenceconfidences = np.array(class_probs) *np.array(objectness)#置信度过滤,非极大值抑制NMSindexes = cv2.dnn.NMSBoxes(boxes, confidences, CONF_THRES, NMS_THRES)indexes = np.array(indexes)colors = np.random.uniform(0, 255, size=(len(boxes), 3))for i in indexes.flatten():#获取坐标x, y, w, h = boxes[i]# 获取置信度confidence = str(round(confidences[i], 2))# 获取颜色,画框color = colors[i % len(colors)]cv2.rectangle(img, (x, y), (x + w, y + h), color, 8)# 写类别名称和置信度# 图片,添加的文字,左上角坐标,字体,字体大小,颜色,字体粗细string = '{} {}'.format(class_names[i], confidence)cv2.putText(img, string, (x, y + 20), cv2.FONT_HERSHEY_COMPLEX, 1, (255, 255, 255), 2)return imgimport time
#获取摄像头,0表示获取系统默认摄像头,1为外接摄像头
cap = cv2.VideoCapture(1)
cap.open(1) #打开摄像头
#无限循环直到break被触发
while cap.isOpened():#获取画面success,frame = cap.read()if not success:print("Error")breakstrat_time = time.time()#处理帧函数frame = process_frame(frame)#展示处理后的三通道图像cv2.imshow('my_window',frame)if cv2.waitKey(1) in [ord('q'),27]: #按键盘上的q或esc退出break
#关闭摄像头
cap.release()#关闭图像窗口
cv2.destroyAllWindows()
相关文章:
12_YouOnlyLookOnce(YOLOv3)新一代实时目标检测技术
1.1 回顾V1和V2 V1:05_YouOnlyLookOnce(YOLOV1)目标检测领域的革命性突破-CSDN博客 V2:07_YouOnlyLookOnce(YOLOv2)Better,Faster,Stronger-CSDN博客 1.2 简介 YOLOv3(You Only Look Once version 3)是…...

安装 Nuxt.js 的步骤和注意事项
title: 安装 Nuxt.js 的步骤和注意事项 date: 2024/6/17 updated: 2024/6/17 author: cmdragon excerpt: Nuxt.js在Vue.js基础上提供的服务器端渲染框架优势,包括提高开发效率、代码维护性和应用性能。指南详细说明了从环境准备、Nuxt.js安装配置到进阶部署技巧&…...

【perl】环境搭建
1、Vscode Strawberry Perl 此过程与tcl环境搭建很类似,请参考我的这篇文章: 【vscode】 与 【tclsh】 联合搭建tcl开发环境_tclsh软件-CSDN博客 perl语言的解释器可以选择,strawberry perl。Strawberry Perl for Windows - Releases。 …...
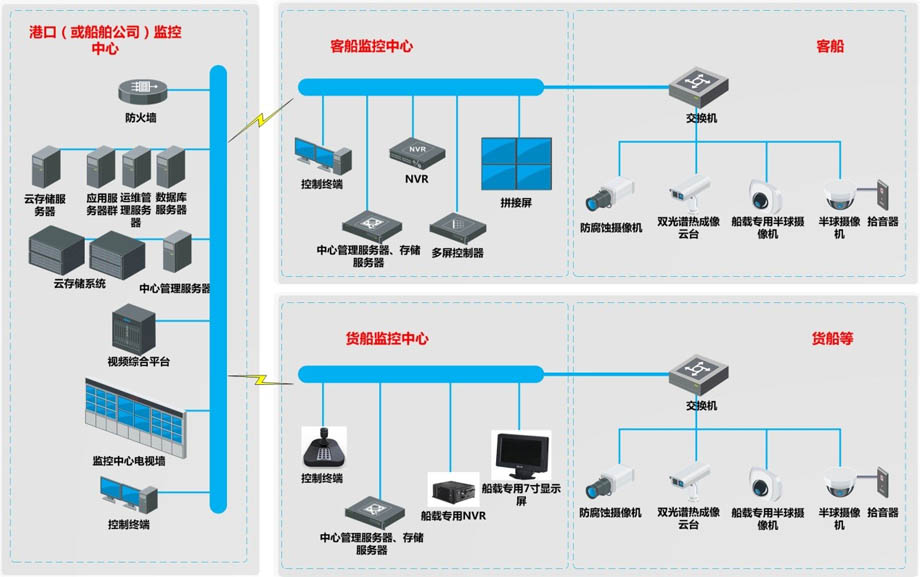
【车载音视频AI电脑】全国产海事船载视频监控系统解决方案
海事船载视频监控系统解决方案针对我国快速发展的内河航运、沿海航运和远洋航运中存在的航行安全和航运监管难题,为船舶运营方、政府监管部门提供一套集视频采集、存储、回放调阅为一体的视频监控系统,对中大型船舶运行中的内部重要部位情况和外部环境进…...
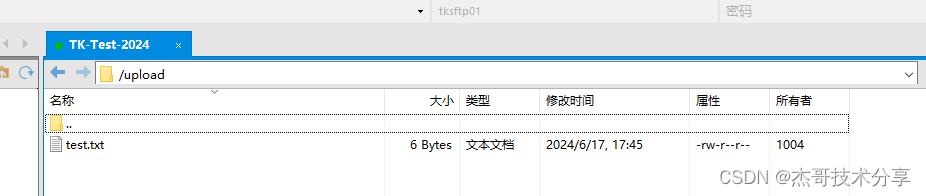
Centos SFTP搭建
SFTP配置、连接及挂载教程_sftp连接-CSDN博客1、确认是否安装yum list installed | grep openssh-server 2、创建用户和组 sudo groupadd tksftpgroup sudo useradd -g tksftpgroup -d /home/www/tk_data -s /sbin/nologin tksftp01 sudo passwd tksftp013. 配置SFTP注意&a…...

【中学教资科目二】01教育基础
01教育基础 前言第一节 教育的产生与发展1.1 教育的起源 第二节 教育学的产生和发展2.1 中国教育学的发展2.2 西方教育学的发展2.3 独立及多样化阶段2.4 马克思教育学2.5 现代教育发展 第三节 教育与社会的发展3.1 教育与文化的关系 第四节 教育与人的发展、4.1 个体身心发展的…...
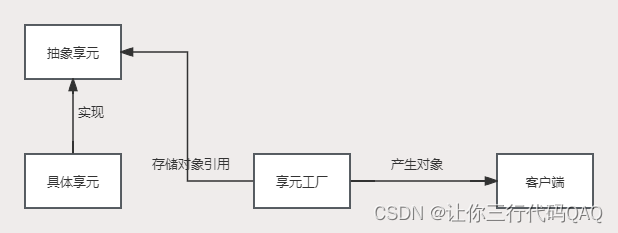
设计模式-享元模式Flyweight(结构型)
享元模式(Flyweight) 享元模式是一种结构型模式,它主要用于减少创建对象的数量,减少内存占用。通过重用现有对象的方式,如果未找到匹配对象则新建对象。线程池、数据库连接池、常量池等池化的思想就是享元模式的一种应用。 图解 角色 享元工…...

【刷题】LeetCode刷题汇总
目录 一、刷题题号1:两数之和 二、解法总结1. 嵌套循环2. 双指针 一、刷题 记录LeetCode力扣刷题 题号1:两数之和 双循环(暴力解法): class Solution {public int[] twoSum(int[] nums, int target) {int[] listne…...
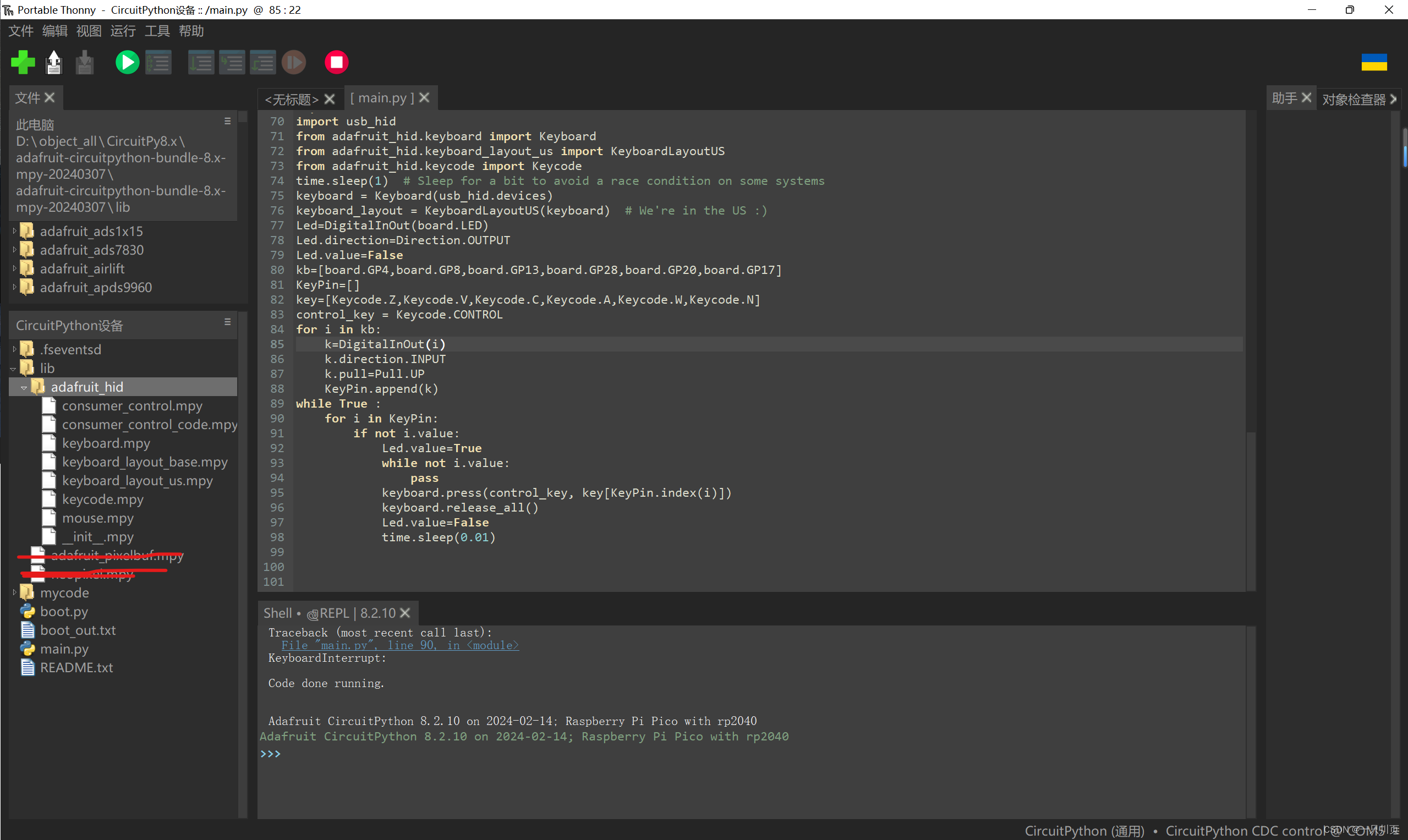
树莓派pico入坑笔记,快捷键键盘制作
使用usb_hid功能制作快捷键小键盘,定义了6个键,分别是 ctrlz ctrlv ctrlc ctrla ctrlw ctrln 对应引脚 board.GP4, board.GP8, board.GP13 board.GP28, board.GP20, board.GP17 需要用到的库,记得复制进单片机存储里面 然后是main主程…...

华为鲲鹏应用开发基础:鲲鹏处理器及关键硬件特性介绍(二)
1. 鲲鹏简介 1.1 鲲鹏处理器简介 鲲鹏处理器是华为自研的基于ARMv8指令集开发的数据中心级处理器 1.2 基于鲲鹏主板的多样化计算产品 1.3 基于鲲鹏920的华为TaiShan(泰山) 200服务器 1.3.1 TaiShan 2280服务器内部视图 1.3.2 TaiShan 2280服务器物理结构 1.3.3 TaiShan 2280服…...

Vue.js结合ASP.NET Core构建用户登录与权限验证系统
1. 环境准备2. 创建项目3. Vue配置步骤一: 安装包步骤二: 配置文件步骤三: 页面文件 4. 后台配置 在本教程中,我将利用Visual Studio 2022的强大集成开发环境,结合Vue.js前端框架和ASP.NET Core后端框架,从头开始创建一个具备用户登录与权限验…...
【html】如何利用id选择器实现主题切换
今天给大家介绍一种方法来实现主题切换的效果 效果图: 源码: <!DOCTYPE html> <html lang"zh"> <head><meta charset"UTF-8"><meta name"viewport" content"widthdevice-width, initia…...

服务器添加TLS域名证书核子之PKCS编解码
PKCS PKCS(Public Key Cryptography Standards)是一系列的标准,用于定义在公钥密码体系中涉及的一些基本结构和算法。PKCS#1 和 PKCS#8 是两个不同的标准,分别定义了不同的公钥私钥编码和封装格式。 PKCS#1 和PKCS#8区别 PKCS#1 PKCS#1 定义了一种用于RSA算法的公钥和私…...

使用 Selenium 自动化获取 CSDN 博客资源列表
使用 Selenium 自动化获取 CSDN 博客资源列表 在这篇博客中,我将向大家展示如何使用 Selenium 自动化工具来滚动并获取 CSDN 博客资源列表的全部数据。这篇文章的目标是通过模拟用户的滚动操作,加载所有的资源列表项,并提取它们的信息。 项目准备 首先,我们需要安装一些…...
智能制造全闪解决方案,八大痛点,一网打尽
当今,全球制造业面临多重大考验,如个性化需求剧增、成本上升、劳动力短缺及激烈竞争。应对这些挑战,智能制造成为转型关键,借助云技术、大数据、AI等前沿科技推动生产智能化,增强企业竞争力。 中国大力扶持智能制造&am…...
Python学习从0开始——Kaggle深度学习002
Python学习从0开始——Kaggle深度学习002 一、单个神经元1.深度学习2.线性单元示例 - 线性单元作为模型多个输入 3.Keras中的线性单元 二、深度神经网络1.层多种类型的层 2.激活函数3.堆叠密集层4.构建Sequential模型 三、随机梯度下降1.介绍2.损失函数3.梯度下降法1.梯度下降法…...

比利时海外媒体宣发,发稿促进媒体通稿发布新形势-大舍传媒
引言 随着全球化的推进,海外媒体的影响力也日益增强。在这一背景下,比利时海外媒体的宣发工作成为了媒体通稿发布的新形势。大舍传媒作为一家专注于宣传推广的公司,一直致力于与比利时博伊克邮报(boicpost)合作&#…...

摄影构图:人像摄影和风景摄影的一些建议
写在前面 博文内容涉及摄影中人像摄影和风景摄影的简单介绍《高品质摄影全流程解析》 读书笔记整理理解不足小伙伴帮忙指正 😃 生活加油 不必太纠结于当下,也不必太忧虑未来,当你经历过一些事情的时候,眼前的风景已经和从前不一样…...

安卓实现输入快递单号生成二维码,摄像头扫描快递单号生成的二维码,可以得到快递信息
背景: 1、实现二维码的生成和识别2、实现andriod(或虚拟机)部署,调用摄像头3、实现网络管理,包括数据库【取消】2、3可以组队实现,1必须单人实现 过程: 安卓APP主界面 输入快递单号信息&#…...

Mysql特殊用法分享
不存在则插入,存在则更新的2种写法 前置使用条件,必须有唯一索引 -- 1 REPLACE INTO REPLACE INTO typora.ip_view_times_record (ip, view_times, url) VALUES(10.25.130.64, 1, https://10.25.168.80/fhh/index.html?urlindex.md543);-- 2 ON DUPLI…...
)
从编译到闪灯:用Keil5 MDK-ARM完成你的第一个STM32点灯程序(超详细避坑指南)
从零点亮STM32:Keil5 MDK-ARM实战指南与避坑全解析 当你第一次拿到STM32开发板时,最令人兴奋的莫过于让板载的LED灯按照你的指令闪烁。这不仅是一个简单的"Hello World",更是打开嵌入式世界大门的钥匙。本文将带你用Keil5 MDK-ARM完…...

网络安全防护:AnythingtoRealCharacters2511 API接口安全设计
网络安全防护:AnythingtoRealCharacters2511 API接口安全设计 1. 企业级API安全的重要性 在现代AI服务架构中,API接口作为核心业务入口,面临着各种网络安全威胁。AnythingtoRealCharacters2511作为动漫转真人图像生成服务,其API…...

告别抓包烦恼:在Mumu模拟器Android 12上配置Frida的保姆级避坑指南
告别抓包困境:Mumu模拟器Android 12环境Frida全流程实战手册 移动应用安全测试领域正面临一个关键转折点——随着主流应用逐步放弃对Android 9及以下版本的支持,测试人员不得不将工作环境升级到Android 10平台。Mumu模拟器提供的Android 12镜像成为当前最…...

终极OpenCore安装指南:在PC上打造专业级Hackintosh系统
终极OpenCore安装指南:在PC上打造专业级Hackintosh系统 【免费下载链接】OpenCore-Install-Guide Repo for the OpenCore Install Guide 项目地址: https://gitcode.com/gh_mirrors/op/OpenCore-Install-Guide OpenCore是一个现代化的引导加载器,…...

基于深度学习的yolov8+v11+v5的仪器仪表读数识别 yolo+pose关键点的指针仪表读数工业检测 仪表读数
博主主页:[ ](https://blog.csdn.net/QQ_1309399183?typeblog) 博主简介:计算机视觉领域优质创作者、CSDN博客专家、阿里云专家博主、全网粉丝5万、专注计算机视觉技术领域和毕业相关项目实战,欢迎高校老师\讲师\同行交流合作 主要内容&am…...

GlosSI技术深度解析:实现系统级Steam控制器输入重定向的创新方案
GlosSI技术深度解析:实现系统级Steam控制器输入重定向的创新方案 【免费下载链接】GlosSI Tool for using Steam-Input controller rebinding at a system level alongside a global overlay 项目地址: https://gitcode.com/gh_mirrors/gl/GlosSI GlosSI&…...

PVE-CT容器部署Ubuntu轻量级桌面环境全攻略
1. PVE-CT容器与Ubuntu轻量桌面环境简介 如果你正在寻找一种在Proxmox VE(PVE)环境下快速部署轻量级Linux桌面的方法,那么使用LXC容器搭配Ubuntu系统绝对是值得考虑的选择。我最近在项目中尝试了这种方案,实测下来不仅资源占用低&…...

3步掌握Nexus Mods App:告别模组管理混乱的终极解决方案
3步掌握Nexus Mods App:告别模组管理混乱的终极解决方案 【免费下载链接】NexusMods.App Home of the development of the Nexus Mods App 项目地址: https://gitcode.com/gh_mirrors/ne/NexusMods.App 还在为游戏模组管理而烦恼吗?模组冲突、依赖…...

深度解密douyin-downloader:高性能抖音无水印下载器的技术实现与实战进阶
深度解密douyin-downloader:高性能抖音无水印下载器的技术实现与实战进阶 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and brow…...

FLUX.1-dev像素艺术生成器教程:提示词工程与16-bit风格关键词库
FLUX.1-dev像素艺术生成器教程:提示词工程与16-bit风格关键词库 1. 像素幻梦工坊简介 像素幻梦(Pixel Dream Workshop)是基于FLUX.1-dev扩散模型构建的新一代像素艺术生成工具。它采用明亮的16-bit像素风格界面设计,为创作者提供…...