详解 HBase 的常用 API
一、环境准备
-
创建一个 Maven 工程并引入依赖
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>1.3.1</version> </dependency> <dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.3.1</version> </dependency> -
创建 API 测试类并获取 HBase 客户端连接
public class TestAPI {private static Connection conn = null;private static Admin admin = null; // DDL 操作客户端static {try { // 1.获取配置信息对象// 过时API// HBaseConfiguration conf1 = new HBaseConfiguration();// conf1.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");// 新APIConfiguration conf = HBaseConfiguration.create();conf.set("hbase.zookeeper.quorum","hadoop102,hadoop103,hadoop104");// 2.创建连接对象(新API)conn = ConnectionFactory.createConnection(conf);// 3.创建hbase管理员对象// 过时API// HBaseAdmin admin1 = new HBaseAdmin(conf1);// 新APIadmin = conn.getAdmin();} catch(Exception e) {e.printStackTrace(); }}// 关闭资源public static void close() {try {if(admin != null) {admin.close();}if(conn != null) {conn.close();}} catch(Exception e) {e.printStackTrace();}} }
二、HBase API 实操
1. 判断表是否存在
public static boolean isTableExist(String tableName) {// 过时API// boolean exist = admin1.tableExists(tableName);// 新APIboolean exist = admin.tableExists(TableName.valueOf(tableName));return exist;
}
2. 创建表
public static void createTable(String tableName, String... cfs) {// 1.判断传入列族信息if(cfs.length()<=0) {System.out.println("必须设置一个列族信息");return;}// 2.判断表是否存在if(isTableExist(tableName)) {System.out.println(tableName + "表已经存在");return;}// 3.创建表描述器HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName));// 4.循环添加列族for(String cfs : cfs) {// 5.创建列族描述器HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(cfs);// 6.添加单个列族hTableDescriptor.addFamily(hColumnDescriptor);}// 7.创建表admin.createTable(hTableDescriptor);System.out.println(tableName + "表创建成功!");
}
3. 删除表
public static void deleteTable(String tableName) {// 1.判断表是否存在if(!isTableExist(tableName)) {System.out.println(tableName + "表已经不存在!");return;}// 2.使表下线admin.disableTable(TableName.valueOf(tableName));// 3.删除表admin.deleteTable(TableName.valueOf(tableName));System.out.println(tableName + "表删除成功!");
}
4. 创建命名空间
public static void createNamespace(String ns) {// 1.创建命名空间描述器NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create(ns).build();try {// 2.创建命名空间admin.createNamespace(namespaceDescriptor); System.out.println(ns + "命名空间创建成功!");} catch(NamespaceExistException e) { // 生产上判断 ns 是否存在System.out.println(ns + "命名空间已经存在!");} catch(Exception e) {e.printStackTrace();}}
5. 插入数据
public static void putData(String tableName, String rowKey, String cf, String cn, String value) {// 1.创建hbase表操作对象Table table = conn.getTable(TableName.valueOf(tableName));// 2.创建 put 对象// HBase 底层存储的数据格式都是 byte[],可以通过 hbase.util 包下的 Bytes 类进行数据类型转换Put put = new Put(Bytes.toBytes(rowKey));// 3.给put对象赋值put.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn), Bytes.toBytes(value));// 4.插入数据table.put(put);// 5.关闭资源table.close();}
6. 获取数据
6.1 get
public static void getData(String tableName, String rowKey, String cf, String cn) {// 1.创建hbase表操作对象Table table = conn.getTable(TableName.valueOf(tableName));// 2.创建get对象Get get = new Get(Bytes.toBytes(rowKey));// 2.1.指定获取的列族// get.addFamily(Bytes.toBytes(cf));// 2.2.指定获取的列族和列// get.addColumn(Bytes.toBytes(cf), Bytes.toBytes(cn));// 2.3.指定获取数据的版本数// get.setMaxVersions(); // 相当于 scan 'tb',{RAW=>TRUE,VERSIONS=>10}// 3.获取一行的数据Result result = table.get(get);// 4.获取一行的所有 cellfor(Cell cell : result.rawCells()) {// 5.打印数据信息System.out.println("family:" + Bytes.toString(CellUtil.cloneFamily(cell)) +",qualifier:" + Bytes.toString(CellUtil.cloneQualifier(cell)) + ",value:" + Bytes.toString(CellUtil.cloneValue(cell)));}// 6.关闭资源table.close();
}
6.2 scan
public static void scanTable(String tableName) {// 1.创建hbase表操作对象Table table = conn.getTable(TableName.valueOf(tableName));// 2.构建scan对象Scan scan = new Scan(); // 全表// Scan scan = new Scan(Bytes.toBytes("1001"),Bytes.toBytes("1003")); // 限定 rowKey 范围,左闭右开// 3.扫描表ResultScanner resultScanner = table.getScanner(scan);// 4.解析resultScannerfor(Result result : resultScanner) { // 按 rowKey 从小到大遍历获取// 5.解析resultfor(Cell cell : result.rawCells()) {// 6.打印数据信息System.out.println("rk:" + Bytes.toString(CellUtil.cloneRow(cell)) +",family:" + Bytes.toString(CellUtil.cloneFamily(cell)) +",qualifier:" + Bytes.toString(CellUtil.cloneQualifier(cell)) + ",value:" + Bytes.toString(CellUtil.cloneValue(cell)));}}// 7.关闭资源table.close();
}
7. 删除数据
delete 操作最终还是 put 操作
public static void deleteData(String tableName, String rowKey, String cf, String cn) {// 1.创建hbase表操作对象Table table = conn.getTable(TableName.valueOf(tableName));// 2.构建delete对象Delete delete = new Delete(Bytes.toBytes(rowKey)); // 相当于 deleteall 命令// 2.1.设置删除列// delete.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn)); // 删除指定版本的列,不指定则为最大版本,小于该版本的列信息可以查询出来(慎用)// delete.addColumns(Bytes.toBytes(cf),Bytes.toBytes(cn)); // 删除列的所有版本// 2.2.设置删除的列族// delete.addFamily(Bytes.toBytes(cf));// 3.删除数据table.delete(delete);// 4.关闭资源table.close();
}
- 只指定 rowKey 删除:删除指定 rowKey 的所有列族所有版本数据,标记为 deleteFamily
- 指定 rowKey + 列族 [+ 版本]:删除指定 rowKey 的指定列族所有版本 (小于等于该版本) 数据,标记为 deleteFamily
- 指定 rowKey + 列族 + 列 [+ 版本]:
- addColumns():删除指定 rowKey 的指定列族的指定列的所有版本 (小于等于该版本) 数据,标记为 deleteColumn
- addColumn():删除指定 rowKey 的指定列族的指定列的最新版本 (该指定版本) 数据,标记为 delete,生产上慎用
三、与 MapReduce 交互
1. 环境搭建
-
查看 MR 操作 HBase 所需的 jar 包:
cd /opt/module/hbase bin/hbase mapredcp -
在 Hadoop 中导入环境变量
-
临时生效:
# 在命令行执行 export HBASE_HOME=/opt/module/hbase export HADOOP_HOME=/opt/module/hadoop-2.7.2 export HADOOP_CLASSPATH=`${HBASE_HOME}/bin/hbase mapredcp` -
永久生效:
# 在 /etc/profile.d/my_env.sh 配置 export HBASE_HOME=/opt/module/hbase export HADOOP_HOME=/opt/module/hadoop-2.7.2# 在 hadoop-env.sh 中配置,在有关 HADOOP_CLASSPATH 的 for 循环之后添加 export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:/opt/module/hbase/lib/*
-
-
分发配置到其他节点
-
启动 Hadoop 集群和 HBase 集群
2. 案例实操
2.1 官方案例
-
统计 stu 表中有多少行数据
/opt/module/hadoop-2.7.2/bin/yarn jar \ /opt/module/hbase/lib/hbase-server-1.3.1.jar \ rowcounter student -
使用 MapReduce 将本地数据导入到 HBase
# 在本地创建一个 tsv 格式的文件:fruit.tsv vim fruit.tsv 1001 Apple Red 1002 Pear Yellow 1003 Pineapple Yellow# 在 HDFS 中创建 input_fruit 文件夹并上传 fruit.tsv 文件 /opt/module/hadoop-2.7.2/bin/hdfs dfs -mkdir /input_fruit/ /opt/module/hadoop-2.7.2/bin/hdfs dfs -put fruit.tsv /input_fruit/# 创建 Hbase 表 Hbase(main):001:0> create 'fruit','info'# 执行 MapReduce 到 HBase 的 fruit 表中(若表不存在则报错) /opt/module/hadoop-2.7.2/bin/yarn jar \ /opt/module/hbase/lib/hbase-server-1.3.1.jar \ importtsv -Dimporttsv.columns=HBASE_ROW_KEY,info:name,info:color fruit \ hdfs://hadoop102:9000/input_fruit/fruit.tsv# 使用 scan 命令查看导入后的结果 Hbase(main):001:0> scan 'fruit'
2.2 自定义案例
-
案例 1:实现将 HDFS 中的数据写入到 Hbase 表中
-
编码:
// 构建 FruitMapper 用于读取 HDFS 中的文件数据 public class FruitMapper extends Mapper<LongWritable, Text, LongWritable, Text> {@overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {context.write(key, value);} }// 构建 FruitReducer 用于将 HDFS 中的文件数据写入 Hbase // TableReducer 默认的输出value类型是 Mutation,其子类有 put/delete 等 public class FruitReducer extends TableReducer<LongWritable, Text, NullWritable> {@overrideprotected void reduce(LongWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {// 1.遍历获取每行数据for(Text value : values) {// 2.切割一行数据String[] fields = value.toString().split("\t");// 3.构建put对象Put put = new Put(Bytes.toBytes(fields[0]));// 4.为put对象赋值put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("name"),Bytes.toBytes(fields[1]));put.addColumn(Bytes.toBytes("info"),Bytes.toBytes("color"),Bytes.toBytes(fields[2]));// 5.数据写入hbasecontext.write(NullWritable.get(),put);}} }// 构建 FruitDriver public class FruitDriver implements Tool {private Configuration conf = null;@overridepublic int run(String[] args) throws Exception {// 1.获取jobJob job = Job.getInstance(conf);// 2.设置驱动类路径job.setJarByClass(FruitDriver.class);// 3.设置Mapper及输出KV类型job.setMapperClass(FruitMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(Text.class);// 4.设置Reducer(不能使用普通的 Reducer 设置)TableMapReduceUtil.initTableReducerJob(args[1], FruitReducer.class, job);// 5.设置输入路径FileInputFormat.setInputPaths(job, new Path(args[0]));// 6.提交jobboolean result = job.waitForCompletion(true);return result ? 0 : 1;}@overridepublic void setConf(Configuration conf) {this.conf = conf;}@overridepublic Configuration getConf() {return conf;}public static void main(String[] args) {try {Configuration conf = new Configuration();int status = ToolRunner.run(conf, new FruitDriver(), args);System.exit(status); } catch(Exception e) {e.printStackTrace();}} } -
将代码打包后上传到 hbase 集群服务器并执行
# 首先创建 hbase fruit 表 # 执行: /opt/module/hadoop-2.7.2/bin/yarn jar \ /opt/module/hbase/Hbase-0.0.1-SNAPSHOT.jar com.xxx.FruitDriver \ /input_fruit/fruit.tsv fruit
-
-
案例 2:将 fruit 表中的一部分数据,通过 MR 迁入到 fruit2 表中
-
编码
// 构建 Fruit2Mapper 用于读取 Hbase 中的 Fruit 表数据 // TableMapper 默认的KV输入类型为 ImmutableBytesWritable, Result public class Fruit2Mapper extends TableMapper<ImmutableBytesWritable, Put> {@overrideprotected void map(ImmutableBytesWritable key, Result value, Context context) throws IOException, InterruptedException {// 1.构建PUT对象Put put = new Put(key.get()); // key 是 rowKey 值// 2.解析Resultfor(Cell cell : value.rawCells()) {// 3.获取列为 name 的 cellif("name".equals(Bytes.toString(CellUtil.cloneQualifier(cell)))) {// 4.为put对象赋值put.add(cell);}}// 5.写出context.write(key, put);} }// 构建 Fruit2Reducer 用于将数据写入 Hbase // TableReducer 默认的输出value类型是 Mutation,其子类有 put/delete 等 public class Fruit2Reducer extends TableReducer<ImmutableBytesWritable, Put, NullWritable> {@overrideprotected void reduce(ImmutableBytesWritable key, Iterable<Put> values, Context context) throws IOException, InterruptedException {// 遍历写出for(Put put : values) {context.write(NullWritable.get(), put);}} }// 构建 Fruit2Driver public class Fruit2Driver implements Tool {private Configuration conf = null;@overridepublic int run(String[] args) throws Exception {// 1.获取jobJob job = Job.getInstance(conf);// 2.设置驱动类路径job.setJarByClass(Fruit2Driver.class);// 3.设置Mapper及输出KV类型(不能使用普通的 Mapper 设置)TableMapReduceUtil.initTableMapperJob(args[0], new Scan(), Fruit2Mapper.class, ImmutableBytesWritable.class, Put.class, job);// 4.设置Reducer(不能使用普通的 Reducer 设置)TableMapReduceUtil.initTableReducerJob(args[1], Fruit2Reducer.class, job);// 5.提交jobboolean result = job.waitForCompletion(true);return result ? 0 : 1;}@overridepublic void setConf(Configuration conf) {this.conf = conf;}@overridepublic Configuration getConf() {return conf;}public static void main(String[] args) {try {// Configuration conf = new Configuration();Configuration conf = HbaseConfiguration.create();int status = ToolRunner.run(conf, new Fruit2Driver(), args);System.exit(status); } catch(Exception e) {e.printStackTrace();}} } -
集群测试:将代码打包后上传到 hbase 集群服务器并执行
# 首先创建 hbase fruit2 表 # 执行: /opt/module/hadoop-2.7.2/bin/yarn jar \ /opt/module/hbase/Hbase-0.0.1-SNAPSHOT.jar com.xxx.Fruit2Driver \ fruit fruit2 -
本地测试:
- 在 Maven 工程的 resources 目录下创建
hbase-site.xml文件 - 将
hbase/conf/hbase-site.xml的内容拷贝到上面创建的文件中 - 执行 Fruit2Driver 程序 main 方法
- 在 Maven 工程的 resources 目录下创建
-
四、集成 Hive
1. 与 Hive 对比
- Hive
- 数据仓库:Hive 的本质其实就相当于将 HDFS 中已经存储的文件在 Mysql 中做了一个双射关系,以方便使用 HQL 去管理查询
- 用于数据分析、清洗:Hive 适用于离线的数据分析和清洗,延迟较高
- 基于 HDFS、MapReduce:Hive 存储的数据依旧在 DataNode 上,编写的 HQL 语句终将是转换为 MapReduce 代码执行
- HBase
- 数据库:是一种面向列族存储的非关系型数据库
- 用于存储结构化和非结构化的数据:适用于单表非关系型数据的存储,不适合做关联查询,类似 JOIN 等操作
- 基于 HDFS:数据持久化存储的体现形式是 HFile,存放于 DataNode 中,被 ResionServer 以 region 的形式进行管理
- 延迟较低,接入在线业务使用:面对大量的企业数据, HBase 可以直线单表大量数据的存储,同时提供了高效的数据访问速度
2. 集成使用
2.1 环境搭建
-
在
/etc/profile.d/my_env.sh中配置 Hive 和 HBase 环境变量vim /etc/profile.d/my_env.shexport HBASE_HOME=/opt/module/hbase export HIVE_HOME=/opt/module/hive -
使用软链接将操作 HBase 的 Jar 包关联到 Hive
ln -s $HBASE_HOME/lib/hbase-common-1.3.1.jar $HIVE_HOME/lib/hbase-common-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-server-1.3.1.jar $HIVE_HOME/lib/hbaseserver-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-client-1.3.1.jar $HIVE_HOME/lib/hbase-client-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-protocol-1.3.1.jar $HIVE_HOME/lib/hbase-protocol-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-it-1.3.1.jar $HIVE_HOME/lib/hbase-it-1.3.1.jar ln -s $HBASE_HOME/lib/htrace-core-3.1.0-incubating.jar $HIVE_HOME/lib/htrace-core-3.1.0-incubating.jar ln -s $HBASE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop2-compat-1.3.1.jar ln -s $HBASE_HOME/lib/hbase-hadoop-compat-1.3.1.jar $HIVE_HOME/lib/hbase-hadoop-compat-1.3.1.jar -
在
hive-site.xml中添加 Zookeeper 连接信息<property><name>hive.zookeeper.quorum</name><value>hadoop102,hadoop103,hadoop104</value><description>The list of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property> <property><name>hive.zookeeper.client.port</name><value>2181</value><description>The port of ZooKeeper servers to talk to. This is only needed for read/write locks.</description> </property> -
下载 Hive 对应版本的源码包,使用 Eclipse 工具创建一个普通 Java 工程 import 这个 hbase-handler 文件夹到工程,在工程下创建一个 lib 文件并导入
hive/lib下所有的.jar文件(add build path),使用 export 重新编译hive-hbase-handler-1.2.2.jar(取消勾选 lib 目录),将新编译的 jar 包替换掉hive/lib下的 jar 包
2.2 案例实操
-
案例 1:建立 Hive 表,关联 HBase 表,插入数据到 Hive 表的同时能够影响 HBase 表
# 在 Hive 中创建表同时关联 HBase,然后分别进入 Hive 和 HBase 查看 CREATE TABLE hive_hbase_emp_table (empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int ) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");# 在 Hive 中创建临时中间表,用于 load 文件中的数据 # 提示:不能将数据直接 load 进 Hive 所关联 HBase 的那张表中 CREATE TABLE emp (empno int,ename string,job string,mgr int, hiredate string,sal double,comm double,deptno int ) row format delimited fields terminated by '\t';# 向 Hive 中间表中 load 数据 load data local inpath '/home/admin/softwares/data/emp.txt' into table emp;# 通过 insert 命令将中间表中的数据导入到 Hive 关联 Hbase 的那张表中 insert into table hive_hbase_emp_table select * from emp;# 查看 Hive 以及关联的 HBase 表中是否已经成功的同步插入了数据 select * from hive_hbase_emp_table;scan 'hbase_emp_table' -
案例 2:针对已经存在的 HBase 表
hbase_emp_table,在 Hive 中创建一个外部表来关联这张表,并使用 HQL 操作# 在 Hive 中创建外部表关联 HBase 表(必须创建外部表) CREATE EXTERNAL TABLE relevance_hbase_emp (empno int,ename string,job string,mgr int,hiredate string,sal double,comm double,deptno int ) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,info:ename,info:job,info:mgr,info:hiredate,info:sal,info:comm,info:deptno") TBLPROPERTIES ("hbase.table.name" = "hbase_emp_table");# 使用 HQL 操作 select * from relevance_hbase_emp;
相关文章:

详解 HBase 的常用 API
一、环境准备 创建一个 Maven 工程并引入依赖 <dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-server</artifactId><version>1.3.1</version> </dependency> <dependency><groupId>org.apach…...
JSR303校验
校验的需求 前端请求后端接口传输参数,需要校验参数。 在controller中需要校验参数的合法性,包括:必填项校验、数据格式校验等在service中需要校验业务规则,比如:课程已经审核过了,所以提交失败。 servi…...

04 远程访问及控制
1、SSH远程管理 SSH是一种安全通道协议,主要用来实现字符界面的远程登录、远程复制等功能。 SSH协议对通信双方的数据传输进行了加密处理(包括用户登陆时输入得用户口令)。 终端:接收用户的指令 TTY终端不能远程,它…...

[晕事]今天做了件晕事38 shell里的source 点号
今天碰到一个问题脚本里使用点号引入某个文件形式如下: . /tmp/abc但是脚本运行出现错误,一开始还以为是/tmp没有可执行权限(https://mzhan017.blog.csdn.net/article/details/112178736#t16),导致abc运行不了。 后来…...

java如何分割字符串
java要实现对字符串的分割,需要用到split语句 语法格式是 str.split(分隔符) 其中 str是字符串 示例代码如下 public class Stringsplit {public static void main(String[] args) {String a"蒸羊羔,蒸熊掌,蒸鹿尾,烧花…...
胡说八道(24.6.12)——数字电子技术以及Modelsim
上回书说到数电中的最常用的表达式——逻辑表达式(由布尔代数组成)以及常用的两种图表——真值表(真值表表示的是所有的输入可能的线性组合以及输出)和卡诺图(卡诺图则是一种化简工具,排除冗余项,合并可合并项)。 今天,先来看看昨天说的基本逻…...

【Android面试八股文】AsyncTask中的任务是串行的还是并行的
文章目录 串行执行并行执行示例代码串行执行(默认)并行执行总结AsyncTask 的任务执行方式可以是串行的,也可以是并行的,这取决于使用的执行器 ( Executor)。 串行执行 默认情况下,AsyncTask 使用的是 SERIAL_EXECUTOR,即任务按顺序一个接一个地执行。这意味着下一个任务…...
无人机RTMP推流EasyDSS直播平台推流成功,不显示直播按钮是什么原因?
互联网视频云平台/视频点播直播/视频推拉流EasyDSS支持HTTP、HLS、RTMP等播出协议,并且兼容多终端,如Windows、Android、iOS、Mac等。为了便于用户集成与二次开发,我们也提供了API接口供用户调用和集成。在无人机场景上,可以通过E…...

经验分享,xps格式转成pdf格式
XPS 是一种电子文档格式、后台打印文件格式和页面描述语言。有时候微软默认打印机保存的是xps格式,我们如何转换为pdf格式呢,这里分享一个免费好用的网站,可以实现。 网站:https://xpstopdf.com/zh/ 截图:...
基于51单片机的音乐彩灯设计
基于51单片机的音乐彩灯设计 (程序+原理图+设计报告) 功能介绍 具体功能: 由STC单片机ADC0809模块LM386功放模块喇叭音频接口发光二极管电源构成 1.通过音频线输入可以播放电脑、手机、MP3里面的音乐。 2.AD对音频…...

API接口设计的艺术:如何提升用户体验和系统性能
在数字时代,API接口的设计对于用户体验和系统性能有着至关重要的影响。良好的设计可以显著提升应用程序的响应速度、可靠性和易用性。以下是几个关键点,帮助改善API接口的设计: 1. 理解并定义清晰的要求 用户研究:与最终用户进行…...

韩兴国/姜勇团队在《Trends in Plant Science》发表植物根系氮素再分配的观点文章!
氮素是陆地生态系统中的关键限制性营养元素,通过生物固氮和土壤氮供应通常远低高等植物的氮需求。当土壤氮素供应无法充分满足植物茎叶生长需求时,植物会通过自身营养器官(如根或根茎)再分配来实现氮的内部循环和再利用。尽管植物…...
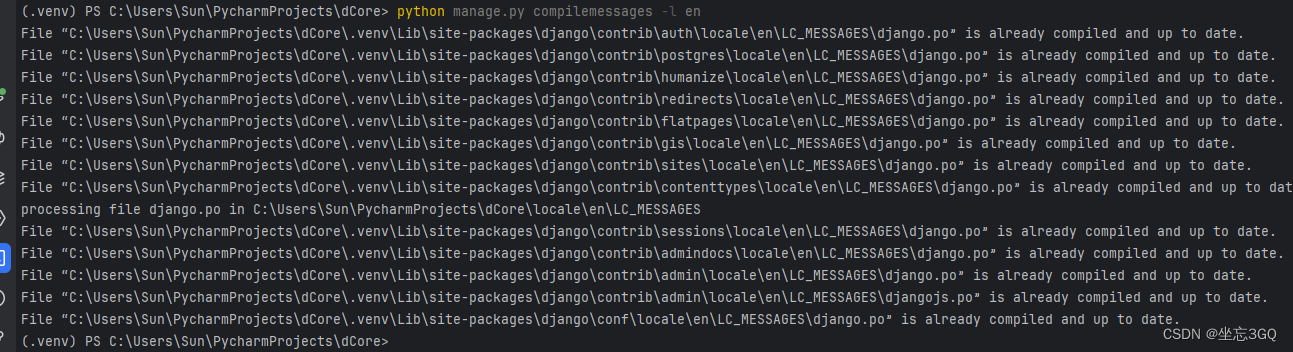
52.Python-web框架-Django - 多语言编译-fuzzy错误
目录 1.起因 2.原因 3.解决方法 3.1手动移除fuzzy标记 3.2重新生成po文件,并检查是否还存在fuzzy标记 3.3重新编译生成mo文件 1.起因 在Django的国际化和本地化过程中,当你发现某些字段仅显示msgid,而不显示msgstr时,可能是…...

Linux自旋锁
面对没有获取锁的现场,通常有两种处理方式。 互斥锁:堵塞自己,等待重新调度请求自旋锁:循环等待该锁是否已经释放 本文主要讲述自旋锁 自旋锁其实是一种很乐观的锁,他认为只要再等一下下锁便能释放,避免…...
服务器----阿里云服务器重启或关机,远程连接进不去,个人博客无法打开
问题描述 在使用阿里云免费的新加坡服务器时,发现重启或者是关机在开服务器后,就会出现远程连接不上、个人博客访问不了等问题 解决方法 进入救援模式连接主机,用户名是root,密码是自己设置的 点击访问博客查看更多内容...

go 定时任务
在 Go 语言中,可以使用内置的 time 包来实现定时任务。以下是一个简单的示例: go package main import ( "fmt" "time" ) func main() { timer : time.NewTimer(2 * time.Second) <-timer.C fmt.Println(…...
Java Character 类
Java Character 类 Character 类用于对单个字符进行操作。 Character 类在对象中包装一个基本类型 char 的值 char ch a;// Unicode 字符表示形式char uniChar \u039A; // 字符数组char[] charArray { a, b, c, d, e };然而,在实际开发过程中,我们经…...

MQTT协议应用场景
MQTT协议的应用场景非常丰富,特别是在物联网领域。以下是对MQTT协议应用场景的清晰归纳: 1.物联网设备控制和监控:MQTT被广泛应用于物联网设备之间的通信,如智能家居、智能城市和工业自动化等领域。设备可以发布自身状态到特定主题…...

3.4.马氏链-随机游走的常返性
随机游走的常返态 1. 随机游走常返性定义1.1. 随机游走常返值和可能集1.2. 随机游走常返性2. 简单随机游走: 维数与常返性的关系2.1. 简单随机游走2.2. 二维及以下简单随机游走常返, 三维及以上简单随机游走非常返3. 随机游走 ( d ≤ 2 ) (d\leq 2) (d≤2): 常返的充分条件4. 随…...

HOT100与剑指Offer
文章目录 前言一、41. 缺失的第一个正数(HOT100)二、6. 从尾到头打印链表(剑指Offer)总结 前言 一个本硕双非的小菜鸡,备战24年秋招,计划刷完hot100和剑指Offer的刷题计划,加油! 根…...

资本意志下的工程师生存指南:从高通裁员看技术与商业的博弈
1. 从一封信到四千七百张解雇单:当资本意志敲响工程师的门在科技行业,尤其是半导体这个以创新为生命线的领域,我们常常沉浸于晶体管密度、架构革新和制程竞赛的技术叙事中。然而,2015年夏天,一封来自华尔街的公开信&am…...

3分钟搞定Axure RP中文界面:全版本汉化终极指南
3分钟搞定Axure RP中文界面:全版本汉化终极指南 【免费下载链接】axure-cn Chinese language file for Axure RP. Axure RP 简体中文语言包。支持 Axure 11、10、9。不定期更新。 项目地址: https://gitcode.com/gh_mirrors/ax/axure-cn 还在为Axure RP的英文…...

对比按次与Token Plan套餐Taotoken如何帮助控制长期成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比按次与Token Plan套餐:Taotoken如何帮助控制长期成本 在接入和使用大模型API时,成本控制是开发者与团队…...

终极图像超分辨率神器:waifu2x-caffe完整使用指南
终极图像超分辨率神器:waifu2x-caffe完整使用指南 【免费下载链接】waifu2x-caffe waifu2xのCaffe版 项目地址: https://gitcode.com/gh_mirrors/wa/waifu2x-caffe 你是否曾为低分辨率图片的模糊细节而烦恼?想要将心爱的动漫壁纸放大到4K分辨率&a…...
)
从‘古董’到统一:聊聊Linux内核中buffer与cache合并背后的那些事儿(附free命令实战)
从‘古董’到统一:Linux内核中buffer与cache合并背后的设计哲学 在Linux系统的性能优化领域,free命令的输出一直是开发者关注的焦点。当你键入free -h时,那行看似简单的"buff/cache"统计背后,隐藏着一段跨越二十年的内…...

如何使用DevPod打造你的终极开源云开发环境:完整指南
如何使用DevPod打造你的终极开源云开发环境:完整指南 【免费下载链接】devpod Codespaces but open-source, client-only and unopinionated: Works with any IDE and lets you use any cloud, kubernetes or just localhost docker. 项目地址: https://gitcode.c…...

UML 关系详解
依赖(Dependency)含义:一个类的变化会影响到另一个类,但反之不一定。这是一种“使用”关系,通常是临时的、较弱的。典型场景:一个类作为另一个类方法的局部变量、方法参数,或调用静态方法。UML表…...

收藏 | 程序员小白也能掌握大模型开发,AI时代大有可为!
收藏 | 程序员小白也能掌握大模型开发,AI时代大有可为! 本文针对非AI专业背景的程序员,介绍了如何参与大模型应用开发。内容涵盖大模型基础、提示词编写与提示工程技巧,以及使用OpenAI API和LangChain框架进行应用开发的关键步骤。…...

Zotero插件市场TOP1新势力:Perplexity Connector v2.3正式发布,支持LLM上下文感知文献溯源,仅限前500名开发者早鸟激活
更多请点击: https://intelliparadigm.com 第一章:Perplexity Zotero整合方案全景概览 Perplexity 作为新一代 AI 驱动的研究型搜索引擎,其核心优势在于实时引用溯源与上下文感知问答;Zotero 则是学术工作者广泛采用的开源文献管…...

开源协作平台Polar:一体化设计如何重塑开发者工作流
1. 项目概述:一个面向开发者的开源协作平台最近在和一些独立开发者朋友聊天时,大家普遍提到一个痛点:当你想启动一个开源项目,或者和几个朋友一起搞点小东西时,整个协作流程其实挺割裂的。代码托管在GitHub或GitLab&am…...