【深度强化学习】(3) Policy Gradients 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下基于策略的深度强化学习方法,策略梯度法是对策略进行建模,然后通过梯度上升更新策略网络的参数。我们使用了 OpenAI 的 gym 库,基于策略梯度法完成了一个小游戏。完整代码可以从我的 GitHub 中获得:
https://github.com/LiSir-HIT/Reinforcement-Learning/tree/main/Model
1. 基于策略的深度强化学习
针对智能体在大规模离散动作下无法建模的难题,在基于值函数的深度强化学习中,利用神经网络对 Q 值函数近似估计,使深度学习与强化学习得到完美融合。
但是基于值函数的深度强化学习有一定的不足之处:
(1) 无法处理连续动作的任务。DQN 系列的算法可以较好地解决强化学习中大规模离散动作空间的任务,但在连续动作的任务中,难以实现利用深度神经网络对所有状态-动作的 Q 值函数近似表达。
(2) 无法处理环境中状态受到限制的问题。在基于值函数深度强化学习更新网络参数时,损失函数会依赖当前状态和下一个状态的值函数,当智能体在环境中观察的状态有限或建模受到限制时,就会导致实际环境中两个不同的状态有相同的价值函数,进而导致损失函数为零,出现梯度消失的问题。
(3) 智能体在环境中的探索性能较低。基于值函数的深度强化学习方法中,目标值都是从动作空间中选取一个最大价值的动作,导致智能体训练后的策略具有确定性,而面对一些需要随机策略进行探索的问题时,该方法就无法较好地解决。
由于基于值函数的深度强化学习存在上述的一些局限性,需要新的方法来解决这些问题,于是基于策略的深度强化学习被提出。该方法中将智能体当前的策略参数化,并且使用梯度的方法进行更新。
2. 策略梯度法
强化学习中策略梯度算法是对策略进行建模,然后通过梯度上升更新策略网络的参数。Policy Gradients 中无法使用策略的误差来构建损失函数,因为参数更新的目标是最大化累积奖励的期望值,所以策略更新的依据是某一动作对累积奖励的影响,即增加使累积回报变大的动作的概率,减弱使累积回报变小的动作的概率。
下图代表智能体在当前策略下,完成一个回合后构成的状态、动作序列 ,其中,Actor 是策略网络。每个回合结束后的累计回报为每个状态下采取的动作的奖励之和:

智能体在环境中执行策略 后状态转移概率:
回合累计回报的期望:
通过微分公式可以得到累计回报的梯度为:
利用累计回报的梯度更新策略网络的参数:
其中, 为梯度系数。通过上式的策略迭代可得,如果智能体在某个状态下采取的动作使累积回报增加,网络参数就会呈梯度上升趋势,该动作的概率就会增加,反之,梯度为下降趋势,减小该动作的概率。为了防止环境中所有的奖励都是正值,实现对于一些不好动作有一个负反馈,可以在总回报处减去一个基线。
3. 代码实现
策略函数 是一个概率密度函数,用于控制智能体的运动。
输入状态 s,输出每个动作 a 的概率分布。策略网络是指通过训练一个神经网络来近似策略函数。策略网络的参数
可通过策略梯度算法进行更新,从而实现对策略网络
的训练。
伪代码如下

模型构建部分代码如下:
# 基于策略的学习方法,用于数值连续的问题
import numpy as np
import torch
from torch import nn
from torch.nn import functional as F# ----------------------------------------------------- #
#(1)构建训练网络
# ----------------------------------------------------- #
class Net(nn.Module):def __init__(self, n_states, n_hiddens, n_actions):super(Net, self).__init__()# 只有一层隐含层的网络self.fc1 = nn.Linear(n_states, n_hiddens)self.fc2 = nn.Linear(n_hiddens, n_actions)# 前向传播def forward(self, x):x = self.fc1(x) # [b, states]==>[b, n_hiddens]x = F.relu(x)x = self.fc2(x) # [b, n_hiddens]==>[b, n_actions]# 对batch中的每一行样本计算softmax,q值越大,概率越大x = F.softmax(x, dim=1) # [b, n_actions]==>[b, n_actions]return x# ----------------------------------------------------- #
#(2)强化学习模型
# ----------------------------------------------------- #
class PolicyGradient:def __init__(self, n_states, n_hiddens, n_actions, learning_rate, gamma):# 属性分配self.n_states = n_states # 状态数self.n_hiddens = n_hiddensself.n_actions = n_actions # 动作数self.learning_rate = learning_rate # 衰减self.gamma = gamma # 折扣因子self._build_net() # 构建网络模型# 网络构建def _build_net(self):# 网络实例化self.policy_net = Net(self.n_states, self.n_hiddens, self.n_actions)# 优化器self.optimizer = torch.optim.Adam(self.policy_net.parameters(), lr=self.learning_rate)# 动作选择,根据概率分布随机采样def take_action(self, state): # 传入某个人的状态# numpy[n_states]-->[1,n_states]-->tensorstate = torch.Tensor(state[np.newaxis, :])# 获取每个人的各动作对应的概率[1,n_states]-->[1,n_actions]probs = self.policy_net(state)# 创建以probs为标准类型的数据分布action_dist = torch.distributions.Categorical(probs)# 以该概率分布随机抽样 [1,n_actions]-->[1] 每个状态取一组动作action = action_dist.sample()# 将tensor数据变成一个数 intaction = action.item()return action# 获取每个状态最大的state_valuedef max_q_value(self, state):# 维度变换[n_states]-->[1,n_states]state = torch.tensor(state, dtype=torch.float).view(1,-1)# 获取状态对应的每个动作的reward的最大值 [1,n_states]-->[1,n_actions]-->[1]-->floatmax_q = self.policy_net(state).max().item()return max_q# 训练模型def learn(self, transitions_dict): # 输入batch组状态[b,n_states]# 取出该回合中所有的链信息state_list = transitions_dict['states']action_list = transitions_dict['actions']reward_list = transitions_dict['rewards']G = 0 # 记录该条链的returnself.optimizer.zero_grad() # 优化器清0# 梯度上升最大化目标函数for i in reversed(range(len(reward_list))):# 获取每一步的reward, floatreward = reward_list[i]# 获取每一步的状态 [n_states]-->[1,n_states]state = torch.tensor(state_list[i], dtype=torch.float).view(1,-1)# 获取每一步的动作 [1]-->[1,1]action = torch.tensor(action_list[i]).view(1,-1)# 当前状态下的各个动作价值函数 [1,2]q_value = self.policy_net(state)# 获取已action对应的概率 [1,1]log_prob = torch.log(q_value.gather(1, action))# 计算当前状态的state_value = 及时奖励 + 下一时刻的state_valueG = reward + self.gamma * G# 计算每一步的损失函数loss = -log_prob * G# 反向传播loss.backward()# 梯度下降self.optimizer.step()4. 实例演示
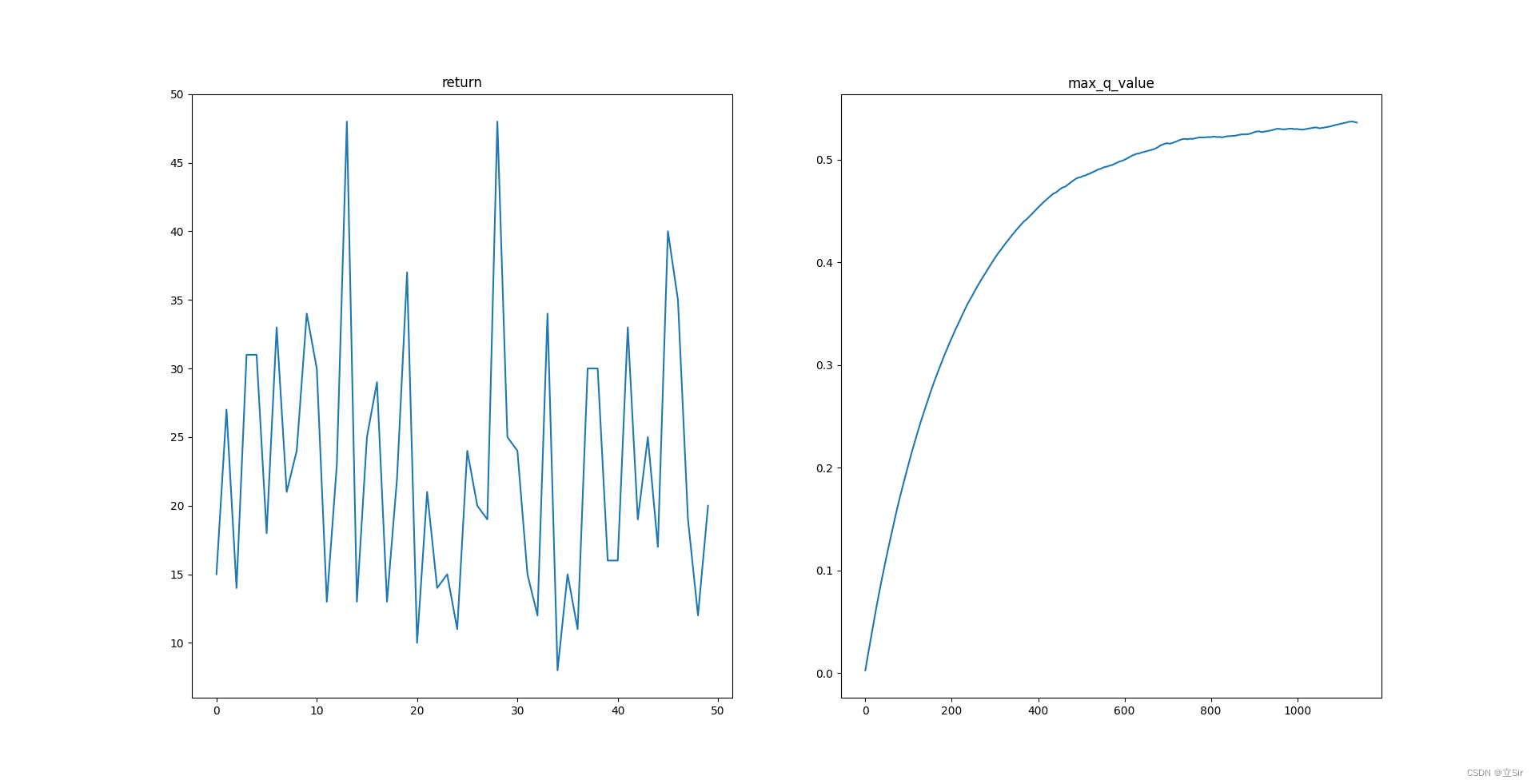
下面基于OpenAI 中的 gym 库,完成一个移动小车使得杆子竖直的游戏。状态states共包含 4 个,动作action有2个,向左和向右移动小车。迭代50回合,绘制每回合的 return 以及平均最大动作价值 q_max

代码如下:
import gym
import numpy as np
import matplotlib.pyplot as plt
from RL_brain import PolicyGradient# ------------------------------- #
# 模型参数设置
# ------------------------------- #n_hiddens = 16 # 隐含层个数
learning_rate = 2e-3 # 学习率
gamma = 0.9 # 折扣因子
return_list = [] # 保存每回合的reward
max_q_value = 0 # 初始的动作价值函数
max_q_value_list = [] # 保存每一step的动作价值函数# ------------------------------- #
#(1)加载环境
# ------------------------------- ## 连续性动作
env = gym.make("CartPole-v1", render_mode="human")
n_states = env.observation_space.shape[0] # 状态数 4
n_actions = env.action_space.n # 动作数 2# ------------------------------- #
#(2)模型实例化
# ------------------------------- #agent = PolicyGradient(n_states=n_states, # 4n_hiddens=n_hiddens, # 16n_actions=n_actions, # 2learning_rate=learning_rate, # 学习率gamma=gamma) # 折扣因子# ------------------------------- #
#(3)训练
# ------------------------------- #for i in range(100): # 训练10回合# 记录每个回合的returnepisode_return = 0# 存放状态transition_dict = {'states': [],'actions': [],'next_states': [],'rewards': [],'dones': [],}# 获取初始状态state = env.reset()[0]# 结束的标记done = False# 开始迭代while not done:# 动作选择action = agent.take_action(state) # 对某一状态采取动作# 动作价值函数,曲线平滑max_q_value = agent.max_q_value(state) * 0.005 + max_q_value * 0.995# 保存每一step的动作价值函数max_q_value_list.append(max_q_value)# 环境更新next_state, reward, done, _, _ = env.step(action)# 保存每个回合的所有信息transition_dict['states'].append(state)transition_dict['actions'].append(action)transition_dict['next_states'].append(next_state)transition_dict['rewards'].append(reward)transition_dict['dones'].append(done)# 状态更新state = next_state# 记录每个回合的returnepisode_return += reward# 保存每个回合的returnreturn_list.append(episode_return)# 一整个回合走完了再训练模型agent.learn(transition_dict)# 打印回合信息print(f'iter:{i}, return:{np.mean(return_list[-10:])}')# 关闭动画
env.close()# -------------------------------------- #
# 绘图
# -------------------------------------- #plt.subplot(121)
plt.plot(return_list)
plt.title('return')
plt.subplot(122)
plt.plot(max_q_value_list)
plt.title('max_q_value')
plt.show()左图代表每回合的return,右图为平均最大动作价值
相关文章:
【深度强化学习】(3) Policy Gradients 模型解析,附Pytorch完整代码
大家好,今天和各位分享一下基于策略的深度强化学习方法,策略梯度法是对策略进行建模,然后通过梯度上升更新策略网络的参数。我们使用了 OpenAI 的 gym 库,基于策略梯度法完成了一个小游戏。完整代码可以从我的 GitHub 中获得&…...
Windows基于Nginx搭建RTMP流媒体服务器(附带所有组件下载地址及验证方法)
RTMP服务时常用于直播时提供拉流推流传输数据的一种服务。前段时间由于朋友想搭建一套直播时提供稳定数据传输的服务器,所以就研究了一下如何搭建及使用。 1、下载nginx 首先我们要知道一般nginx不能直接配置rtmp服务,在Windows系统上需要特殊nginx版本…...
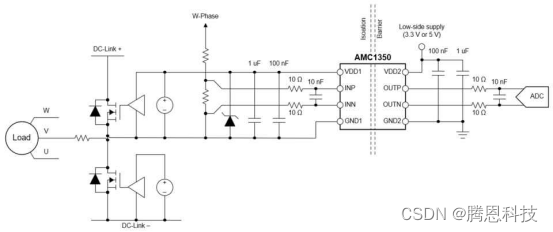
交流电机驱动器中的隔离电压感应
汽车和工业终端设备,如电机驱动器、串式逆变器和机载充电器,在高电压下运行,不能安全地与人直接互动。隔离电压测量通过保护人类免受高压电路执行一个功能的影响,有助于优化操作和确保使用的安全性。 设计用于高性能,隔…...

爬取知乎问题答案
参考博客:基于Python知乎回答爬虫 jieba关键字统计可视化_知乎爬虫搜索关键词_菠萝柚王子的博客-CSDN博客 1、安装依赖包 import numpy import requests import certifi from PIL import Image from lxml import etree import jieba from wordcloud import WordClo…...

通用智能理论
将智能定义为解决矛盾的能力,用解决矛盾的概率提升来评估智能程度,以此为基础推导智能原理,建立一种新的通用智能理论。 1 前言 通用人工智能(Artificial General Intelligence)是人类长久以来的梦想。经历了一次次挫败…...

保姆级使用PyTorch训练与评估自己的MixMIM网络教程
文章目录前言0. 环境搭建&快速开始1. 数据集制作1.1 标签文件制作1.2 数据集划分1.3 数据集信息文件制作2. 修改参数文件3. 训练4. 评估5. 其他教程前言 项目地址:https://github.com/Fafa-DL/Awesome-Backbones 操作教程:https://www.bilibili.co…...
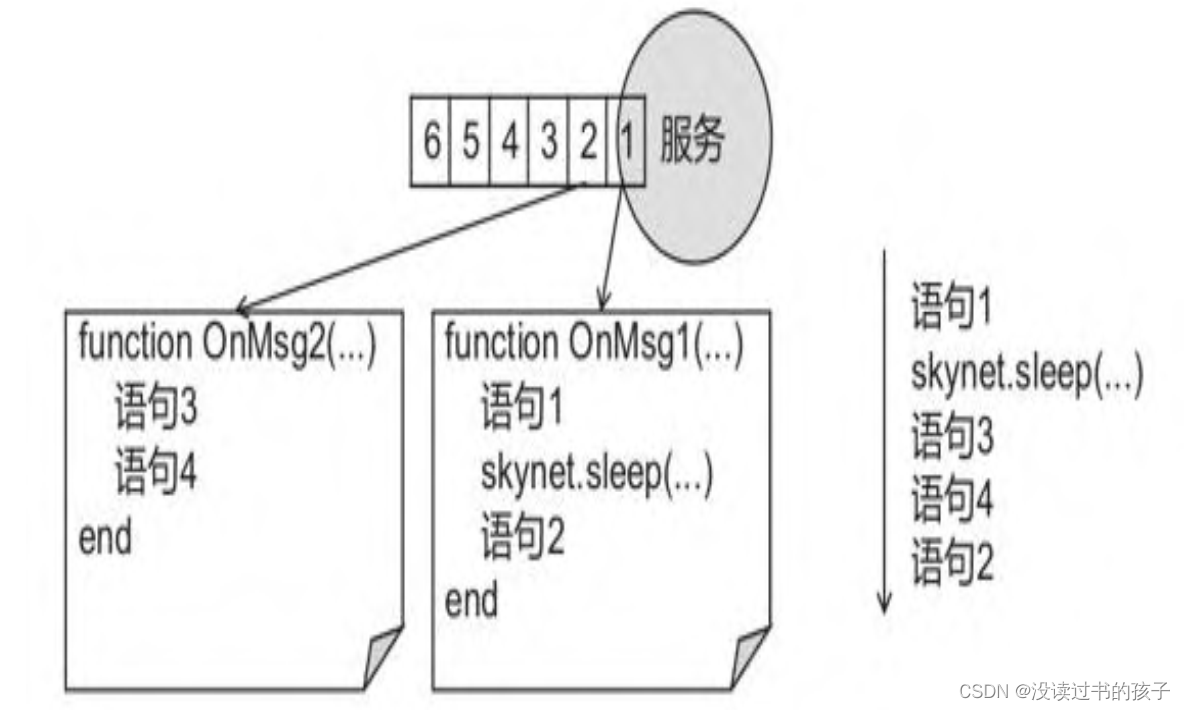
《百万在线 大型游戏服务端开发》前两章概念笔记
第1章 从角色走路说起 游戏网络通信的流程则是服务端先开启监听,等待客户端的连接,然后交互操作,最后断开。 套接字 每个Socket都包含网络连接中一端的信息。每个客户端需要一个Socket结构,服务端则需要N1个Socket结构ÿ…...

3BHE029110R0111 ABB
3BHE029110R0111 ABB变频器控制方式低压通用变频输出电压为380~650V,输出功率为0.75~400kW,工作频率为0~400Hz,它的主电路都采用交—直—交电路。其控制方式经历了以下四代。1U/fC的正弦脉宽调制࿰…...
)
实现防重复操作(JS与CSS)
实现防重复操作(JS与CSS) 一、前言 日常开发中我们经常会对按钮进行一个防重复点击的校验,这个通常使用节流函数来实现。在规定时间内只允许提交一次,可以有效的避免事件过于频繁的执行和重复提交操作,以及为服务器考…...
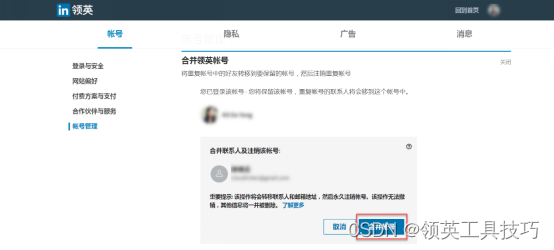
怎么合并或注销重复LinkedIn领英帐号?
您可能会发现您拥有多个领英帐户。如果您收到消息,提示您尝试使用的邮箱与另一个帐户已绑定,就表明您可能存在重复的领英帐户。如果您使用许多不同的邮箱地址,也可能会收到这样的提示。 领英精灵温馨提示: 目前,仅支持在 PC 端合并…...
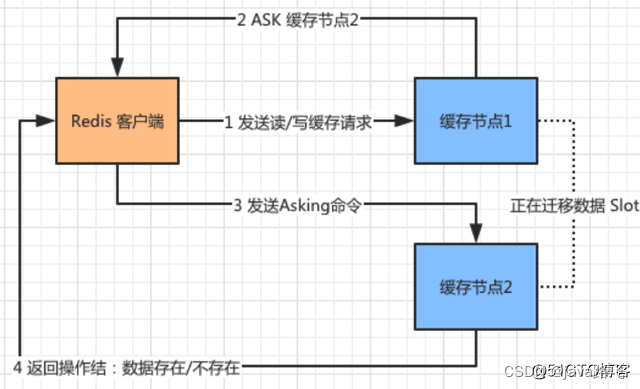
Redis高频面试题汇总(中)
目录 1.什么是redis事务? 2.如何使用 Redis 事务? 3.Redis 事务为什么不支持原子性 4.Redis 事务支持持久性吗 5.Redis事务基于lua脚本的实现 6.Redis集群的主从复制模型是怎样的? 7.Redis集群中,主从复制的数据同步的步骤 …...

【Flutter从入门到入坑之三】Flutter 是如何工作的
【Flutter从入门到入坑之一】Flutter 介绍及安装使用 【Flutter从入门到入坑之二】Dart语言基础概述 【Flutter从入门到入坑之三】Flutter 是如何工作的 本文章主要以界面渲染过程为例,介绍一下 Flutter 是如何工作的。 页面中的各界面元素(Widget&…...
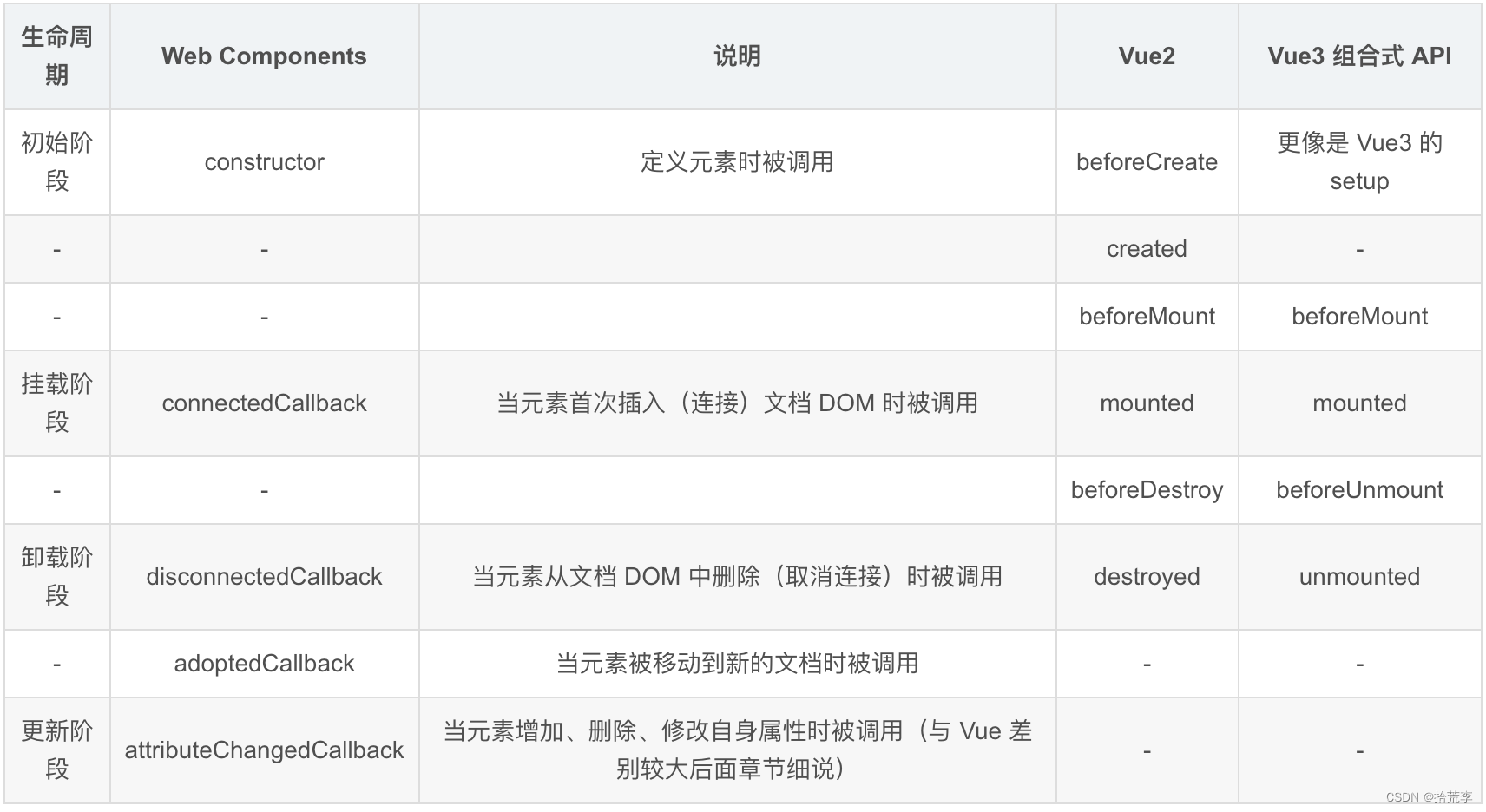
Web Components学习(2)-语法
一、Web Components 对 Vue 的影响 尤雨溪在创建 Vue 的时候大量参考了 Web Components 的语法,下面写个简单示例。 首先写个 Vue 组件 my-span.vue: <!-- my-span.vue --> <template><span>my-span</span> </template>…...
Lesson 9.2 随机森林回归器的参数
文章目录一、弱分类器的结构1. 分枝标准与特征重要性2. 调节树结构来控制过拟合二、弱分类器的数量三、弱分类器训练的数据1. 样本的随机抽样2. 特征的随机抽样3. 随机抽样的模式四、弱分类器的其他参数在开始学习之前,先导入我们需要的库。 import numpy as np im…...

Kubernetes Secret简介
Secret概述 前面文章中学习ConfigMap的时候,我们说ConfigMap这个资源对象是Kubernetes当中非常重要的一个对象,一般情况下ConfigMap是用来存储一些非安全的配置信息,如果涉及到一些安全相关的数据的话用ConfigMap就非常不妥了,因…...
)
Redis 哨兵(Sentinel)
文章目录1.概述2. 没有哨兵下主从效果3.搭建多哨兵3.1 新建目录3.2 复制redis3.3 复制配置文件3.4 修改配置文件3.5 启动主从3.6 启动三个哨兵3.7 查看日志3.8 测试宕机1.概述 在redis主从默认是只有主具备写的能力,而从只能读。如果主宕机,整个节点不具…...

精读笔记 - How to backdoor Federated Learning
文章目录 精读笔记 - How to backdoor Federated Learning1. 基本信息2. 系统概要3. 攻击模型3.1 问题形式化定义3.1.1 前提假设3.1.2 攻击目标3.2 创新点3.2.1 Semantic Backdoor3.2.2 攻击方法4. 实验验证4.1 图像分类4.2 实验操作4.2.1 超参数设置4.2.2 衡量标准4.3 结果分析…...
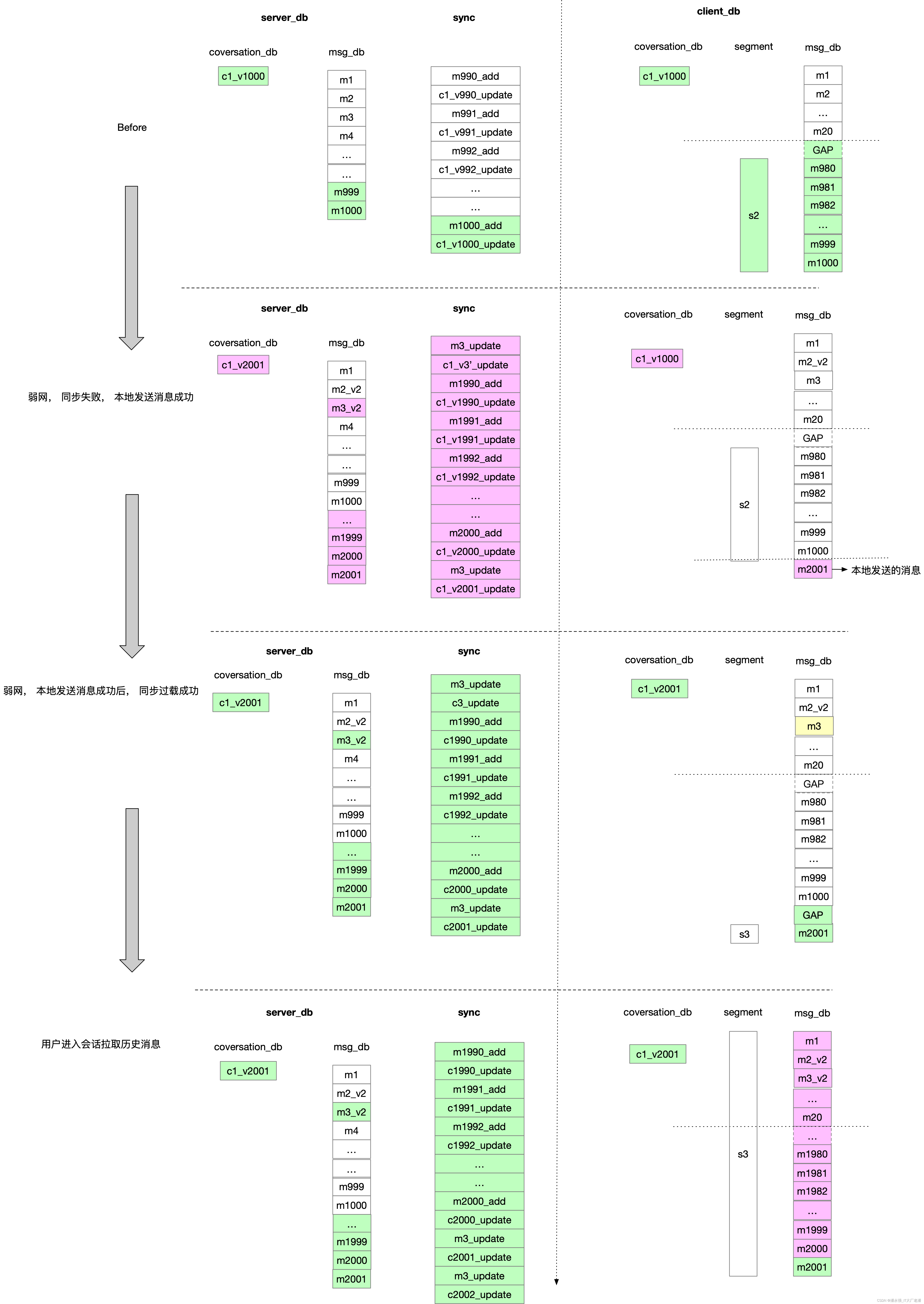
即时通讯系列-N-客户端如何在推拉结合的模式下保证消息的可靠性展示
结论先行 原则: server拉取的消息一定是连续的原则: 端侧记录的消息的连续段有两个作用: 1. 记录消息的连续性, 即起始中间没有断层, 2. 消息连续, 同时意味着消息是最新的,消息不是过期的。同…...
关于js数据类型的理解
目录标题一、js数据类型分为 基本数据类型和引用数据类型二、区别:传值和传址三、深浅拷贝传值四、数据类型的判断一、js数据类型分为 基本数据类型和引用数据类型 1、基本数据类型 Number、String、Boolean、Null、undefined、BigInt、Symbol 2、引用数据类型 像对…...

大一上计算机期末考试考点
RGB颜色模型也称为相加混色模型 采样频率大于或等于原始声音信号最高频率的两倍即可还原出原始信号. 声音数字化过程中,采样是把时间上连续的模拟信号在时间轴上离散化的过程。 量化的主要工作就是将幅度上连续取值的每一个样本转换为离散值表示。 图像数字化过…...

5个秘诀:用UE5-MCP模型控制协议实现AI游戏开发革命
5个秘诀:用UE5-MCP模型控制协议实现AI游戏开发革命 【免费下载链接】UE5-MCP MCP for Unreal Engine 5 项目地址: https://gitcode.com/gh_mirrors/ue/UE5-MCP UE5-MCP(Model Control Protocol)是一款专为Unreal Engine 5设计的AI驱动…...

收藏!大厂高薪陷阱:月薪7万想跑路,3年百万仍焦虑,程序员必看避坑指南
咱就是说,现在职场人的内耗越来越离谱,尤其是程序员圈子,这种矛盾更是被无限放大。有人拿着月薪7万的高薪却天天想跑路,有人工作三年就年入百万,却依旧焦虑到失眠——这到底是钱没给够,还是我们搞错了职场的…...

eDiary使用教程
eDiary使用教程CSDN文章 前言 在信息爆炸的今天,我们每天都有太多的思绪、工作笔记、生活点滴需要记录,却又担心隐私泄露,或是被臃肿的笔记软件拖慢效率。如果你也在寻找一款轻量、安全、无广告的本地记录工具,那么eDiary 电子日…...

智能红外协处理器模块:UART接口的NEC协议网关
1. 项目概述红外通信作为最成熟、成本最低的短距离无线控制技术之一,至今仍广泛应用于家电遥控、工业设备状态指示、简易数据透传等场景。本项目所描述的红外解码编码模块并非传统意义上由主控MCU直接完成载波调制/解调的“裸硬件”方案,而是一种高度集成…...
)
保姆级教程:用HomeAssistant+Node-RED让小爱音箱变身ChatGPT语音助手(含避坑指南)
智能家居革新:用HomeAssistant与Node-RED解锁小爱音箱的AI对话潜能 在智能家居领域,小米的小爱音箱一直以其出色的语音识别和丰富的生态著称。然而,你是否想过让它突破内置功能的限制,拥有更强大的对话能力?本文将带你…...

2026大专电子商务就业压力大吗?
2026年大专电子商务专业就业压力分析电子商务行业近年来发展迅速,但随着市场竞争加剧,大专学历的电子商务专业毕业生可能面临一定的就业压力。以下是详细分析,包含行业趋势、就业方向、提升竞争力的方法等,并重点介绍CDA数据分析师…...

垃圾网站穷疯了,什么都要钱
垃圾。。。。。...

Windows 安装 Node.js 后 node -v 正常但 npm -v报错,解决方法
一、问题现象 最近在 Windows 上安装 Node.js,安装完成后先检查版本: node -v终端返回: v24.14.0说明 Node.js 已经安装成功,node 命令也可以正常识别。但是继续执行: npm -v却直接报错,提示无法加载 C:\Pr…...

求职招聘小程序平台运营版源码系统-含全功能PHP后台+完整的搭建教程
求职者服务功能视频招聘专区:设有专门的视频招聘板块,求职者可在此浏览企业发布的招聘视频,直观了解企业的工作环境、企业文化等信息,同时也能上传自己的视频简历,增加求职亮点。精准职位搜索:支持求职者通…...

Android模糊效果终极指南:用BlurView轻松实现iOS风格毛玻璃界面
Android模糊效果终极指南:用BlurView轻松实现iOS风格毛玻璃界面 【免费下载链接】BlurView Android blur view 项目地址: https://gitcode.com/gh_mirrors/blu/BlurView 你是否曾经羡慕iOS系统那优雅的毛玻璃效果,想在Android应用中也实现同样惊艳…...