Lesson 9.2 随机森林回归器的参数
文章目录
- 一、弱分类器的结构
- 1. 分枝标准与特征重要性
- 2. 调节树结构来控制过拟合
- 二、弱分类器的数量
- 三、弱分类器训练的数据
- 1. 样本的随机抽样
- 2. 特征的随机抽样
- 3. 随机抽样的模式
- 四、弱分类器的其他参数
- 在开始学习之前,先导入我们需要的库。
import numpy as np
import pandas as pd
import sklearn
import matplotlib as mlp
import seaborn as sns
import re, pip, conda
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor as RFR
from sklearn.tree import DecisionTreeRegressor as DTR
from sklearn.model_selection import cross_validate, KFold
- 当填写参数之后,随机森林可以变得更强大。比起经典机器学习算法逻辑回归、岭回归等,随机森林回归器的参数数量较多,因此我们可以将随机森林类的参数分为如下 4 大类别,其中标注为绿色的是我们从未学过的、只与集成算法相关的参数:
| 类型 | 参数 |
|---|---|
| 弱分类器数量 | n_estimators |
| 弱分类器的训练数据 | bootstrap, oob_score, max_samples, max_features, random_state |
| 弱分类器结构 | criterion, max_depth, min_samples_split, min_samples_leaf, min_weight_fraction_leaf, max_leaf_nodes, min_impurity_decrease |
| 其他 | n_jobs, verbose, ccp_alpha |
一、弱分类器的结构
- 在集成算法当中,控制单个弱评估器的结构是一个重要的课题,因为单个弱评估器的复杂度/结果都会影响全局,其中单棵决策树的结构越复杂,集成算法的整体复杂度会更高,计算会更加缓慢、模型也会更加容易过拟合,因此集成算法中的弱评估器也需要被剪枝。
- 随机森林回归器的弱评估器是回归树,因此集成评估器中有大量的参数都与弱评估器回归树中的参数重合:
| 类型 | 参数 |
|---|---|
| 弱分类器结构 | criterion:弱评估器分枝时的不纯度衡量指标 max_depth:弱评估器被允许的最大深度,默认None min_samples_split:弱评估器分枝时,父节点上最少要拥有的样本个数 min_samples_leaf:弱评估器的叶子节点上最少要拥有的样本个数 min_weight_fraction_leaf:当样本权重被调整时,叶子节点上最少要拥有的样本权重 max_leaf_nodes:弱评估器上最多可以有的叶子节点数量 min_impurity_decrease:弱评估器分枝时允许的最小不纯度下降量 |
- 这些参数在随机森林中的用法与默认值与决策树类 DecisionTreeRegressor 中完全一致,专门用于对决策树进行剪枝、控制单个弱评估器的结构,考虑到大家在决策树中已经充分掌握这些参数,我们不再对这些参数一一进行详细说明了。
- 在这里,我们重点复习一下以下两部分参数:
1. 分枝标准与特征重要性
criterion与feature_importances_与分类树中的信息熵/基尼系数不同,回归树中的 criterion 可以选择"squared_error"(平方误差),“absolute_error”(绝对误差)以及"poisson"(泊松偏差)。对任意样本 iii 而言,yiy_iyi 为真实标签,yi^\hat{y_i}yi^ 为预测标签,则各个 criterion 的表达式为:- 平方误差:∑(yi−yi^)2\sum{(y_i - \hat{y_i})^2}∑(yi−yi^)2。
- 绝对误差:∑∣yi−yi^∣\sum{|y_i - \hat{y_i}|}∑∣yi−yi^∣。
- 泊松偏差:2∑(yilog(yiyi^)−(yi−yi^))2\sum{(y_ilog(\frac{y_i}{\hat{y_i}})-(y_i - \hat{y_i}))}2∑(yilog(yi^yi)−(yi−yi^))。
- 其中平方误差与绝对误差是大家非常熟悉的概念,作为分枝标准,平方误差比绝对误差更敏感(类似于信息熵比基尼系数更敏感),并且在计算上平方误差比绝对误差快很多。
- 泊松偏差则是适用于一个特殊场景的:当需要预测的标签全部为正整数时,标签的分布可以被认为是类似于泊松分布的。正整数预测在实际应用中非常常见,比如预测点击量、预测客户/离职人数、预测销售量等。我们现在正在使用的数据(房价预测),也可能比较适合于泊松偏差。
- 另外,当我们选择不同的 criterion 之后,决策树的 feature_importances_ 也会随之变化,因为在 sklearn 当中,feature_importances_ 是特征对 criterion 下降量的总贡献量,因此不同的 criterion 可能得到不同的特征重要性。
- 对我们来说,选择 criterion 的唯一指标就是最终的交叉验证结果——无论理论是如何说明的,我们只取令随机森林的预测结果最好的 criterion。
2. 调节树结构来控制过拟合
max_depth是最粗犷的剪枝方式,从树结构层面来看,对随机森林抗过拟合能力影响最大的参数。max_depth 的默认值为 None,也就是不限深度。因此当随机森林表现为过拟合时,选择一个小的 max_depth 会很有效。max_leaf_nodes与min_sample_split是比max_depth更精细的减枝方式,但限制叶子数量和分枝,既可以实现微调,也可以实现大刀阔斧的剪枝。max_leaf_nodes 的默认值为 None,即不限叶子数量。min_sample_split 的默认值为 2,等同于不限制分枝。min_impurity_decrease最精细的减枝方式,可以根据不纯度下降的程度减掉相应的叶子。默认值为 0,因此是个相当有空间的参数。
二、弱分类器的数量
n_estimators是森林中树木的数量,即弱评估器的数量,在 sklearn 中默认 100,它是唯一一个对随机森林而言必填的参数。n_estimators 对随机森林模型的精确程度、复杂度、学习能力、过拟合情况、需要的计算量和计算时间都有很大的影响,因此 n_estimators 往往是我们在调整随机森林时第一个需要确认的参数。- 对单一决策树而言,模型复杂度由树结构(树深、树宽、树上的叶子数量等)与数据量(样本量、特征量)决定,而对随机森林而言,模型复杂度由森林中树的数量、树结构与数据量决定,其中树的数量越多,模型越复杂。
- 当模型复杂度上升时,模型的泛化能力会先增加再下降(相对的泛化误差会先下降再上升),我们需要找到模型泛化能力最佳的复杂度。在实际进行训练时,最佳复杂度往往是一个比较明显的转折点,当复杂度高于最佳复杂度时,模型的泛化误差要么开始上升,要么不再下降。
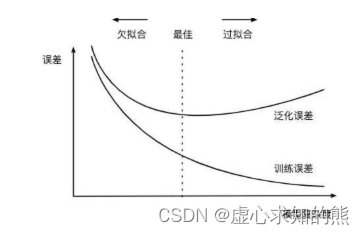
- 对随机森林而言,该图像的横坐标可以被无缝切换为参数 n_estimators 上的值。当 n_estimators 越大时:
- (1) 模型的复杂程度上升,泛化能先增强再减弱(或不变)。
- (2) 模型的学习能力越来越强,在训练集上的分数可能越来越高,过拟合风险越来越高。
- (3) 模型需要的算力和内存越来越多。
- (4) 模型训练的时间会越来越长。
- 因此在调整 n_estimators 时,我们总是渴望在模型效果与训练难度之间取得平衡,同时我们还需要使用交叉验证来随时关注模型过拟合的情况。在 sklearn 现在的版本中,n_estimators 的默认值为 10。
def RMSE(cvresult,key):return (abs(cvresult[key])**0.5).mean()reg_f = RFR(n_estimators=3)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_f = cross_validate(reg_f,X,y,cv=cv,scoring="neg_mean_squared_error",return_train_score=True,verbose=True,n_jobs=-1)
#[Parallel(n_jobs=-1)]: Using backend LokyBackend with 16 concurrent workers.
#[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 0.8s finishedRMSE(result_f,"test_score")
#36398.0444570051reg_f = RFR(n_estimators=100)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_f = cross_validate(reg_f,X,y,cv=cv,scoring="neg_mean_squared_error",return_train_score=True,verbose=True,n_jobs=-1)
#[Parallel(n_jobs=-1)]: Using backend LokyBackend with 16 concurrent workers.
#[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 1.9s finishedRMSE(result_f,"test_score")
#30156.835268943938reg_f = RFR(n_estimators=500)
cv = KFold(n_splits=5,shuffle=True,random_state=1412)
result_f = cross_validate(reg_f,X,y,cv=cv,scoring="neg_mean_squared_error",return_train_score=True,verbose=True,n_jobs=-1)
#[Parallel(n_jobs=-1)]: Using backend LokyBackend with 16 concurrent workers.
#[Parallel(n_jobs=-1)]: Done 5 out of 5 | elapsed: 7.1s finishedRMSE(result_f,"test_score")
#30305.720408696703
- 对上述总结:
| 类型 | 参数 |
|---|---|
| 弱分类器数量 | n_estimators:弱评估器的数量 |
三、弱分类器训练的数据
- 对每个特征决策树都会找到不纯度下降程度最大的节点进行分枝,因此原则上来说,只要给出数据一致、并且不对决策树进行减枝的话,决策树的结构一定是完全相同的。
- 对集成算法来说,平均多棵相同的决策树的结果并没有意义,因此集成算法中每棵树必然是不同的树,Bagging 算法是依赖于随机抽样数据来实现这一点的。
- 随机森林会从提供的数据中随机抽样出不同的子集,用于建立多棵不同的决策树,最终再按照 Bagging 的规则对众多决策树的结果进行集成。因此在随机森林回归器的参数当中,有数个关于数据随机抽样的参数。
1. 样本的随机抽样
bootstrap参数的输入为布尔值,默认 True,控制是否在每次建立决策树之前对数据进行随机抽样。如果设置为 False,则表示每次都使用全部样本进行建树,如果为 True,则随机抽样建树。- 从语言的意义上来看,bootstrap 可以指代任意类型的随机抽样,但在随机森林中它特指有放回随机抽样技术。
- 如下图所示,在一个含有 m 个样本的原始训练集中,我们进行随机采样。每次采样一个样本,并在抽取下一个样本之前将该样本放回原始训练集,也就是说下次采样时这个样本依然可能被采集到,这样采集 max_samples 次,最终得到 max_samples 个样本组成的自助集。
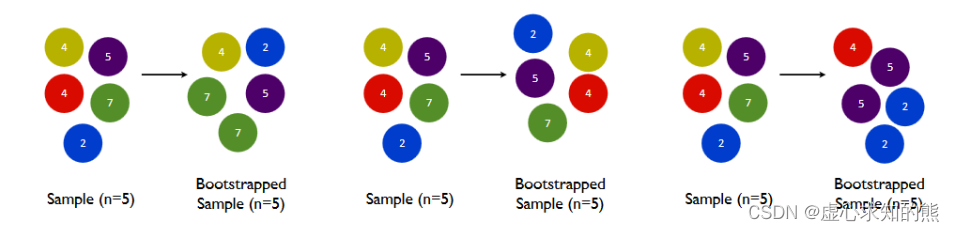
- 通常来说,max_samples 是等于 m 的(行业惯例),也就是抽样数据集的大小与原始数据集一致,但是如果原始数据集太大、或者太小,我们也可以自由调整 max_samples 的大小。
- 由于是随机采样,这样每次的自助集和原始数据集不同,和其他的采样集也是不同的。这样我们就可以自由创造取之不尽用之不竭,并且互不相同的自助集,用这些自助集来训练我们的弱分类器,我们的弱分类器自然也就各不相同了。
- 然而有放回抽样也会有自己的问题。由于是有放回,一些样本可能在同一个自助集中出现多次,而其他一些却可能被忽略。当抽样次数足够多、且原始数据集足够大时,自助集大约平均会包含全数据的 63%,这个数字是有数学依据的。因为在 max_samples 次抽样中,一个样本被抽到某个自助集中的概率为:1−(1−1m)max_samples1-(1-\frac{1}{m})^{max\_samples}1−(1−m1)max_samples
- 这个式子是怎么来的呢?对于任意一个样本而言:
- 一次抽样时抽到该样本的概率为 1m\frac{1}{m}m1。
- 一次抽样时抽不到该样本的概率为 1−1m1-\frac{1}{m}1−m1。
- 总共抽样
max_samples次,一次也没有抽到该样本的概率就是 (1−1m)max_samples(1-\frac{1}{m})^{max\_samples}(1−m1)max_samples。 - 因此 1 减去该概率,就是一个样本在抽样中一定会被抽到某个自助集的概率。
- 当 m 刚好等于
max_samples时,公式可以被修改为:1−(1−1m)m1-(1-\frac{1}{m})^{m}1−(1−m1)m - 这明显是一个经典的极限问题,由洛必达法则(L’Hôpital’s rule)我们可知:当 m 足够大时(接近极限时),这个概率收敛于 1-(1/e),其中 e 是自然常数,整体概率约等于 0.632。
- 因此,会有约 37% 的训练数据被浪费掉,没有参与建模,这些数据被称为袋外数据(out of bag data,简写为oob)。
- 在实际使用随机森林时,袋外数据常常被我们当做验证集使用,所以我们或许可以不做交叉验证、不分割数据集,而只依赖于袋外数据来测试我们的模型即可。
- 当然,这也不是绝对的,当树的数量 n_estimators 不足,或者 max_samples 太小时,很可能就没有数据掉落在袋外,自然也有无法使用 oob 数据来作为验证集了。
- 在随机森林回归器中,当 boostrap=True 时,我们可以使用参数
oob_score和max_samples,其中: oob_score控制是否使用袋外数据进行验证,输入为布尔值,默认为 False,如果希望使用袋外数据进行验证,修改为 True 即可。max_samples表示自助集的大小,可以输入整数、浮点数或 None,默认为 None。- 当我们输入整数 m,则代表每次从全数据集中有放回抽样 m 个样本。
- 当我们输入浮点数 f,则表示每次从全数据集中有放回抽样 f * 全数据量个样本。
- 当我们输入 None,则表示每次抽样都抽取与全数据集一致的样本量(X.shape[0])。
- 在使用袋外数据时,我们可以用随机森林的另一个重要属性:
oob_score_来查看我们的在袋外数据上测试的结果,遗憾的是我们无法调整oob_score_输出的评估指标,它默认是 R2。
reg = RFR(n_estimators=20, bootstrap=True #进行随机抽样, oob_score=True #按袋外数据进行验证, max_samples=500).fit(X,y)
#D:\ProgramData\Anaconda3\lib\site-packages\sklearn\base.py:445: UserWarning: X does not have #valid feature names,
#but RandomForestRegressor was fitted with feature names
# warnings.warn(#重要属性oob_score_
reg.oob_score_ #在袋外数据上的R2为83%
#0.8254774869029703reg = RFR(n_estimators=20, bootstrap=False, oob_score=True, max_samples=500).fit(X,y) #直接无法运行,因为boostrap=False时oob_score分数根本不存在
-
reg = RFR(n_estimators=20, bootstrap=True #允许抽样, oob_score=False #但不进行计算, max_samples=500).fit(X,y)
reg.oob_score_ #虽然可以训练,但oob_score无法被调用
2. 特征的随机抽样
max_features数据抽样还有另一个维度:对特征的抽样。在学习决策树时,我们已经学习过对特征进行抽样的参数 max_features,在随机森林中 max_features 的用法与决策树中完全一致,其输入也与决策树完全一致:- (1) 当我们输入整数,表示每次分枝时随机抽取 max_features 个特征。
- (2) 当我们输入浮点数,表示每次分枝时抽取 round(max_features * n_features) 个特征。
- (3) 当我们输入 auto 或者 None,表示每次分枝时使用全部特征 n_features。
- (4) 当我们输入 sqrt,表示每次分枝时使用 sqrt(n_features)。
- (5)当我们输入 log2,表示每次分枝时使用 log2(n_features)。
sqrt_ = []
log_ = []
for n_features in range(1,101,2):sqrt_.append(np.sqrt(n_features))log_.append(np.log2(n_features))
xaxis = range(1,101,2)
plt.figure(figsize=(8,6),dpi=80)
#RMSE
plt.plot(xaxis,sqrt_,color="green",label = "sqrt(n)")
plt.plot(xaxis,log_,color="orange",label = "log2(n)")
plt.xticks(range(1,101,10))
plt.legend()
plt.show()
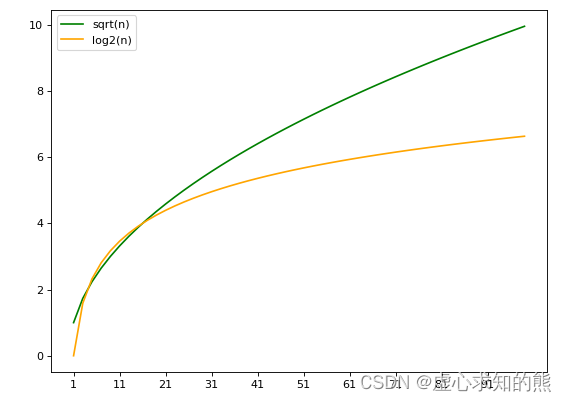
- 不难发现,sqrt(n_features) 和 log2(n_features) 都会返回一个比原始特征量小很多的数,但一般情况下 log2 返回的值比 sqrt 返回的值更小,因此如果我们想要树之间的差异更大,我们可以设置模式为 log2。在实际使用时,我们往往会先使用上述的文字输入,观察模型的结果,然后再在有效的范围附近进行网格搜索。
- 需要注意的是,无论对数据进行怎样的抽样,我们能够控制的都只是建立单棵树时的数据而已。在总数据量有限的情况下,单棵树使用的数据量越大,每一棵树使用的数据就会越相似,每棵树的结构也就会越相似,bagging 的效果难以发挥、模型也很容易变得过拟合。因此,当数据量足够时,我们往往会消减单棵树使用的数据量。
3. 随机抽样的模式
- 随机抽样的模式函数是:
random_state。 - 随机模式的相关说明:
- random_state 是一个较为抽象的参数,对于刚接触 sklearn 运作方式的人们来说,random_state 可能会比较难以理解。
- 在日常生活中,当我们讨论随机时,我们指的是真正的随机,包括如下三个方面:
- (1) 不可预测。
- (2) 不可有目的地重复。
- (3) 实验之间完全相互独立。
- 就比如游戏当中抽卡,比如抛硬币,我们无法预料会抛出正面还是反面、并且抛出一次正面自后、无法有目的地再次抛出正面,无论上一次是正面还是反面,都不影响下一次抛硬币的时候的结果。真正的随机一定伴随着物理实验,是只有自然界才有的现象。
- 在计算机的世界中,任意的随机一定是通过某种计算方式得到和实现的,这种随机是伪随机。无论是随机抽样,还是随机打乱数据顺序等等,其实背后都有着计算机的规则在进行控制,只要我们找到背后的规则,我们就可以有目的地重复随机的结果,而 random_state 就是在随机过程当中,控制随机规则的参数。
- 例如,现在我们需要在 [1,2,3,4,5] 中随机抽取 3 个数字,我们可以有多种规则:
- 0 号规则:4,5,1。
- 1 号规则:2,1,5。
- 2 号规则:1,5,4。
- 3 号规则:2,5,4。
- …
list_ = [1,2,3,4,5]
import random
random.sample(list_,k=3) #随机从列表中抽取样本,抽取3个
- 根据排列组合的规则,总共有 A53A_5^3A53=60 种选择。每当我们执行抽样的代码时,计算机会在所有规则中选择一个返回给我们。当我们多次执行抽样代码,计算机会返回不同的结果,营造一种随机的氛围,但并非真正的在列表中进行了不可预测、不可重复的抽样。- 只要我们设置随机数种子,我们就可以重复抽样的结果,令本来应该随机的过程变成固定过程。
#random.seed是random模块中的随机数种子,等同于sklearn中的random_state
random.seed(0) #0号规则
random.sample(list_,k=3)
random.seed(2)
random.sample(list_,k=3)
- 即便只有 60 种选择,我们的随机数种子也可以设置为任意的数字。当然,无论我们设置怎样的数字,最终计算机都会从这 60 中选择中挑选一个返回给我们,这也是计算机的规则决定的。无论我们输入了什么数字,只要我们认为当下随机操作返回的结果是可以接受的,就可以持续使用我们设置的数字。
random.seed(1412)
random.sample(list_,k=3)
random.seed(2333)
random.sample(list_,k=3)
- 在决策树当中,我们已经学习过控制随机模式的参数 random_state,这个参数是随机数种子,它控制决策树当中多个具有随机性的流程。在 sklearn 实现的随机森林当中,决策树上也存在众多有随机性的流程:
- (1)「强制」随机抽取每棵树建立时分枝用的特征,抽取的数量可由参数 max_features 决定。
- (2)「强制」随机排序每棵树分枝时所用的特征。
- (3)「可选」随机抽取每棵树建立时训练用的样本,抽取的比例可由参数 max_samples 决定。
- 因此每次使用随机森林类时,我们建立的集成算法都是不同的,在同一个数据集上多次建树自然也会产生不同的模型结果。因此在工程部署和教学当中,我们在建树的第一步总是会先设置随机数种子为一个固定值,让算法固定下来。在设置的时候,需要注意两个问题:
- 第一,不同库中的随机数种子遵循不同的规则,对不同库中的随机数种子给与相同的数字,也不会得到相同的结果。
import pandas as pd
import random
list_ = [1,2,3,4,5]
list_p = pd.Series(list_)
list_p
#0 1
#1 2
#2 3
#3 4
#4 5
#dtype: int64#random中的随机抽样
random.seed(1)
random.sample(list_,k=3)
#[2, 1, 5]#pandas中的随机抽样
list_p.sample(n=3,random_state=1).values
#array([3, 2, 5], dtype=int64)
- 同样的,sklearn 中的随机抽样、numpy 中的随机抽样、cuda 中的随机抽样在相同的随机数种子数值下,都会得到不同的结果。
- 第二,如何选择最佳随机数种子?
- 当数据样本量足够大的时候(数万),变换随机数种子几乎不会对模型的泛化能力有影响,因此在数据量巨大的情况下,我们可以随意设置任意的数值。
- 当数据量较小的时候,我们可以把随机数种子当做参数进行调整,但前提是必须依赖于交叉验证的结果。选择交叉验证结果中均值最高、方差最低的随机数种子,以找到泛化能力最强大的随机模式。
| 类型 | 参数 |
|---|---|
| 弱分类器的训练数据 | bootstrap:是否对样本进行随机抽样 oob_score:如果使用随机抽样,是否使用袋外数据作为验证集 max_samples:如果使用随机抽样,每次随机抽样的样本量 max_features:随机抽取特征的数目 random_state:控制一切随机模式 |
四、弱分类器的其他参数
| 类型 | 参数 |
|---|---|
| 其他 | n_jobs:允许调用的线程数 verbose:打印建树过程 ccp_alpha:结构风险$ |
- 我们已经了解过前三个参数,需要稍微说明一下 verbose 参数。
- 随机森林的 verbose 参数打印的是建树过程,但只有在树的数量众多、建模耗时很长时,verbose 才会打印建树的具体过程,否则它只会打印出一行两简单的报告。
- 这些参数中需要重点说明的是 warm_start。warm_start 是控制增量学习的参数,默认为 False,该参数可以帮助随机森林处理巨量数据,解决围绕随机森林的众多关键问题。
相关文章:
Lesson 9.2 随机森林回归器的参数
文章目录一、弱分类器的结构1. 分枝标准与特征重要性2. 调节树结构来控制过拟合二、弱分类器的数量三、弱分类器训练的数据1. 样本的随机抽样2. 特征的随机抽样3. 随机抽样的模式四、弱分类器的其他参数在开始学习之前,先导入我们需要的库。 import numpy as np im…...

Kubernetes Secret简介
Secret概述 前面文章中学习ConfigMap的时候,我们说ConfigMap这个资源对象是Kubernetes当中非常重要的一个对象,一般情况下ConfigMap是用来存储一些非安全的配置信息,如果涉及到一些安全相关的数据的话用ConfigMap就非常不妥了,因…...
)
Redis 哨兵(Sentinel)
文章目录1.概述2. 没有哨兵下主从效果3.搭建多哨兵3.1 新建目录3.2 复制redis3.3 复制配置文件3.4 修改配置文件3.5 启动主从3.6 启动三个哨兵3.7 查看日志3.8 测试宕机1.概述 在redis主从默认是只有主具备写的能力,而从只能读。如果主宕机,整个节点不具…...

精读笔记 - How to backdoor Federated Learning
文章目录 精读笔记 - How to backdoor Federated Learning1. 基本信息2. 系统概要3. 攻击模型3.1 问题形式化定义3.1.1 前提假设3.1.2 攻击目标3.2 创新点3.2.1 Semantic Backdoor3.2.2 攻击方法4. 实验验证4.1 图像分类4.2 实验操作4.2.1 超参数设置4.2.2 衡量标准4.3 结果分析…...
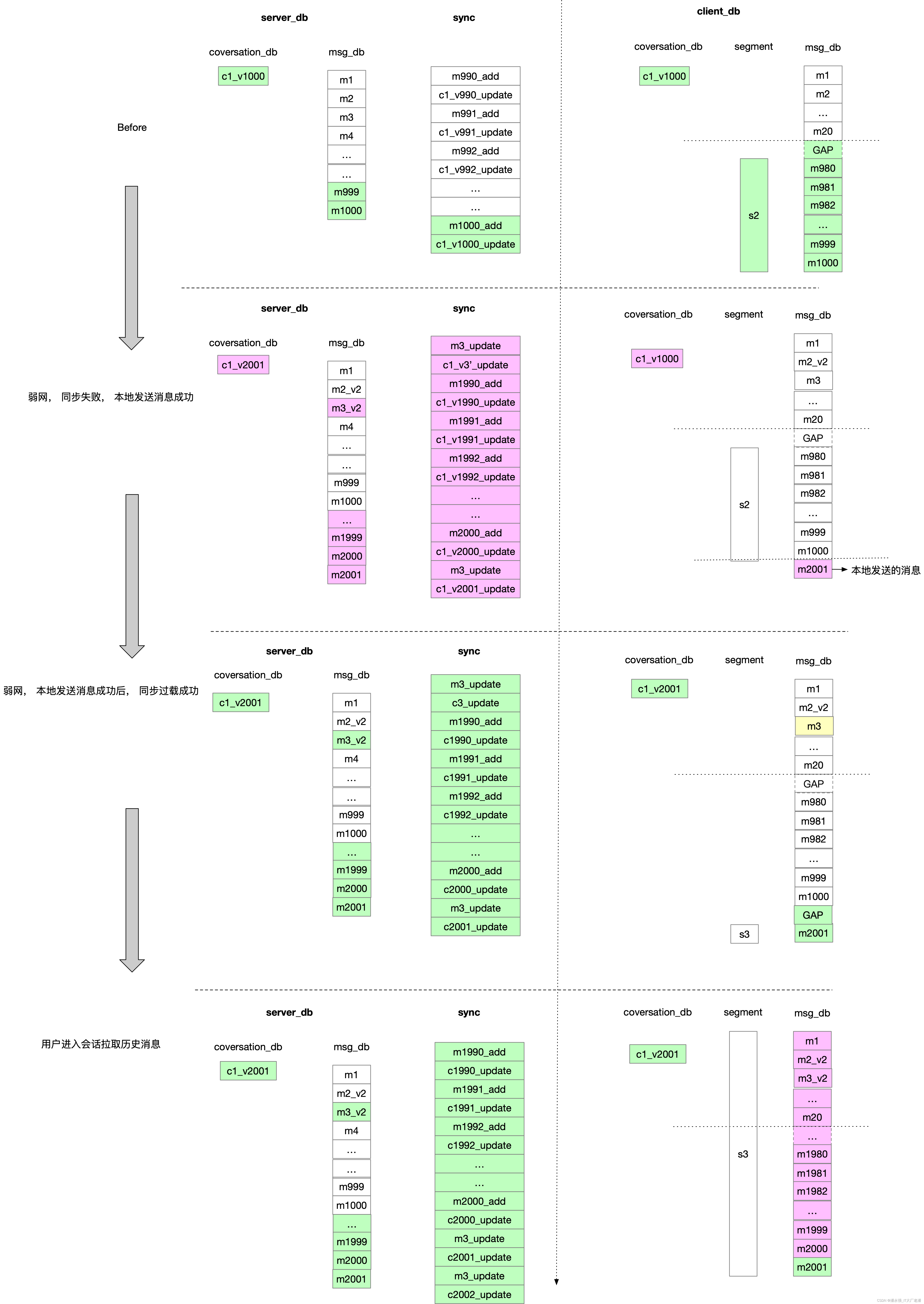
即时通讯系列-N-客户端如何在推拉结合的模式下保证消息的可靠性展示
结论先行 原则: server拉取的消息一定是连续的原则: 端侧记录的消息的连续段有两个作用: 1. 记录消息的连续性, 即起始中间没有断层, 2. 消息连续, 同时意味着消息是最新的,消息不是过期的。同…...
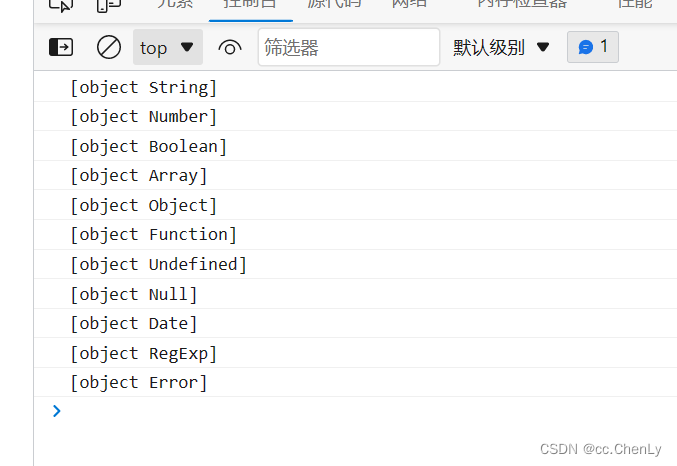
关于js数据类型的理解
目录标题一、js数据类型分为 基本数据类型和引用数据类型二、区别:传值和传址三、深浅拷贝传值四、数据类型的判断一、js数据类型分为 基本数据类型和引用数据类型 1、基本数据类型 Number、String、Boolean、Null、undefined、BigInt、Symbol 2、引用数据类型 像对…...

大一上计算机期末考试考点
RGB颜色模型也称为相加混色模型 采样频率大于或等于原始声音信号最高频率的两倍即可还原出原始信号. 声音数字化过程中,采样是把时间上连续的模拟信号在时间轴上离散化的过程。 量化的主要工作就是将幅度上连续取值的每一个样本转换为离散值表示。 图像数字化过…...
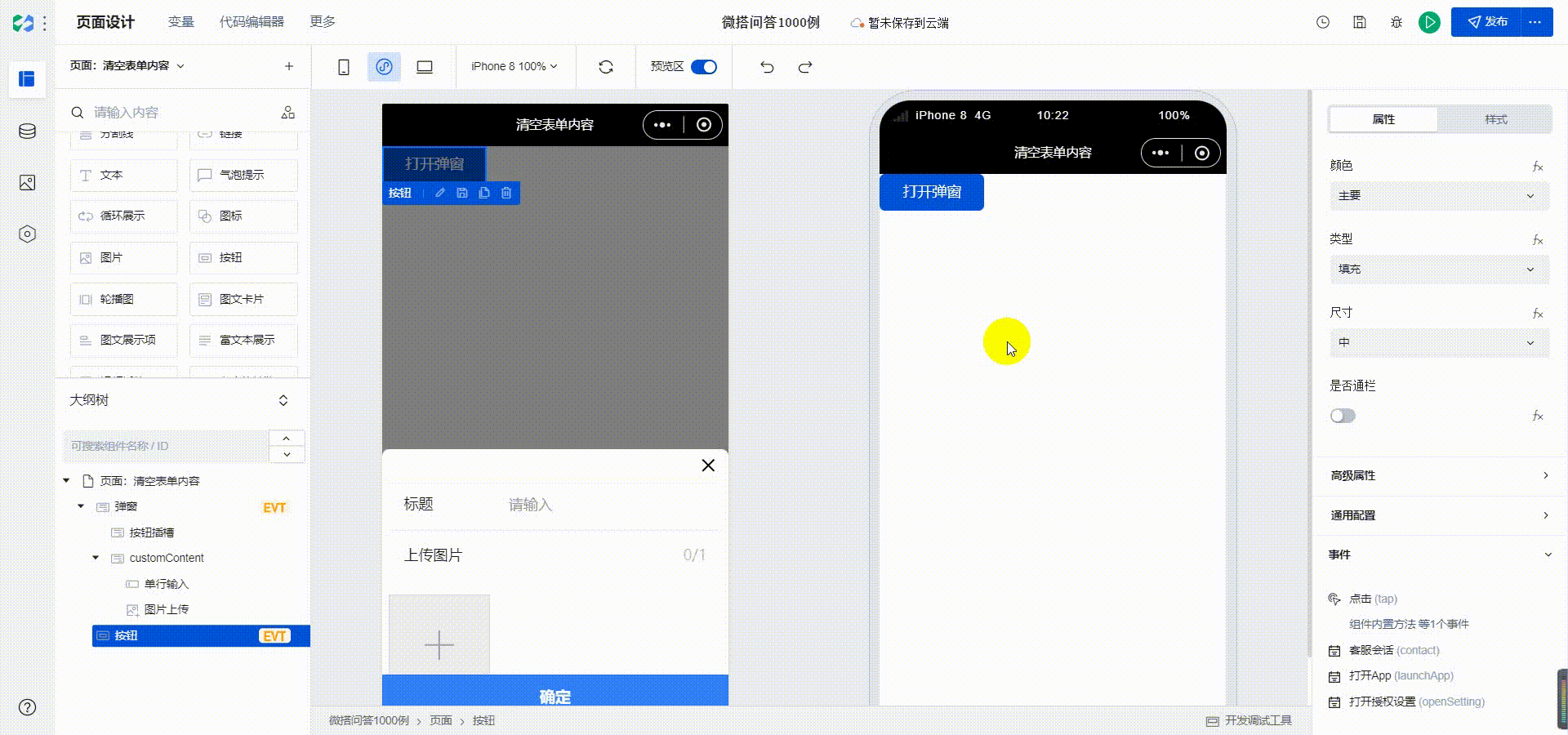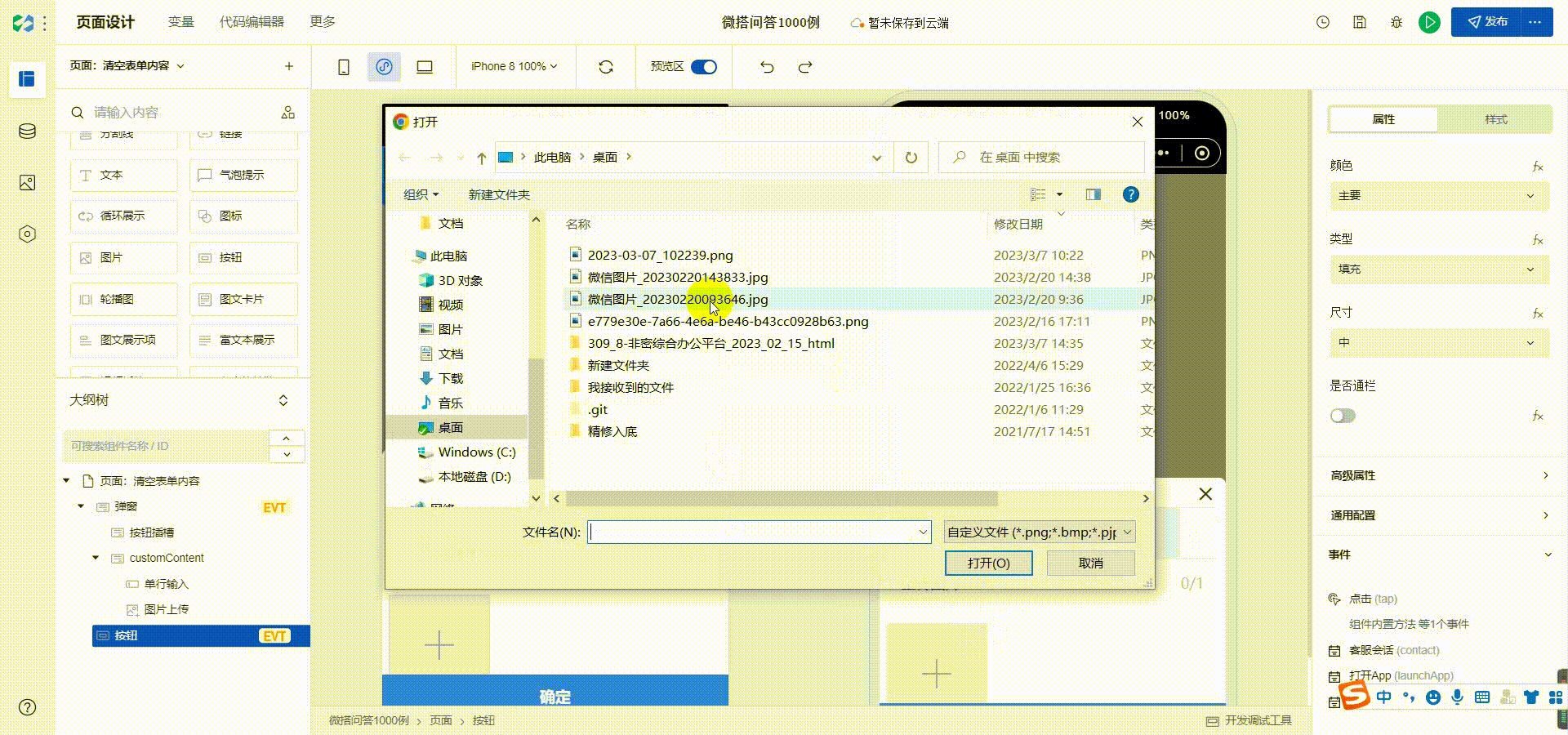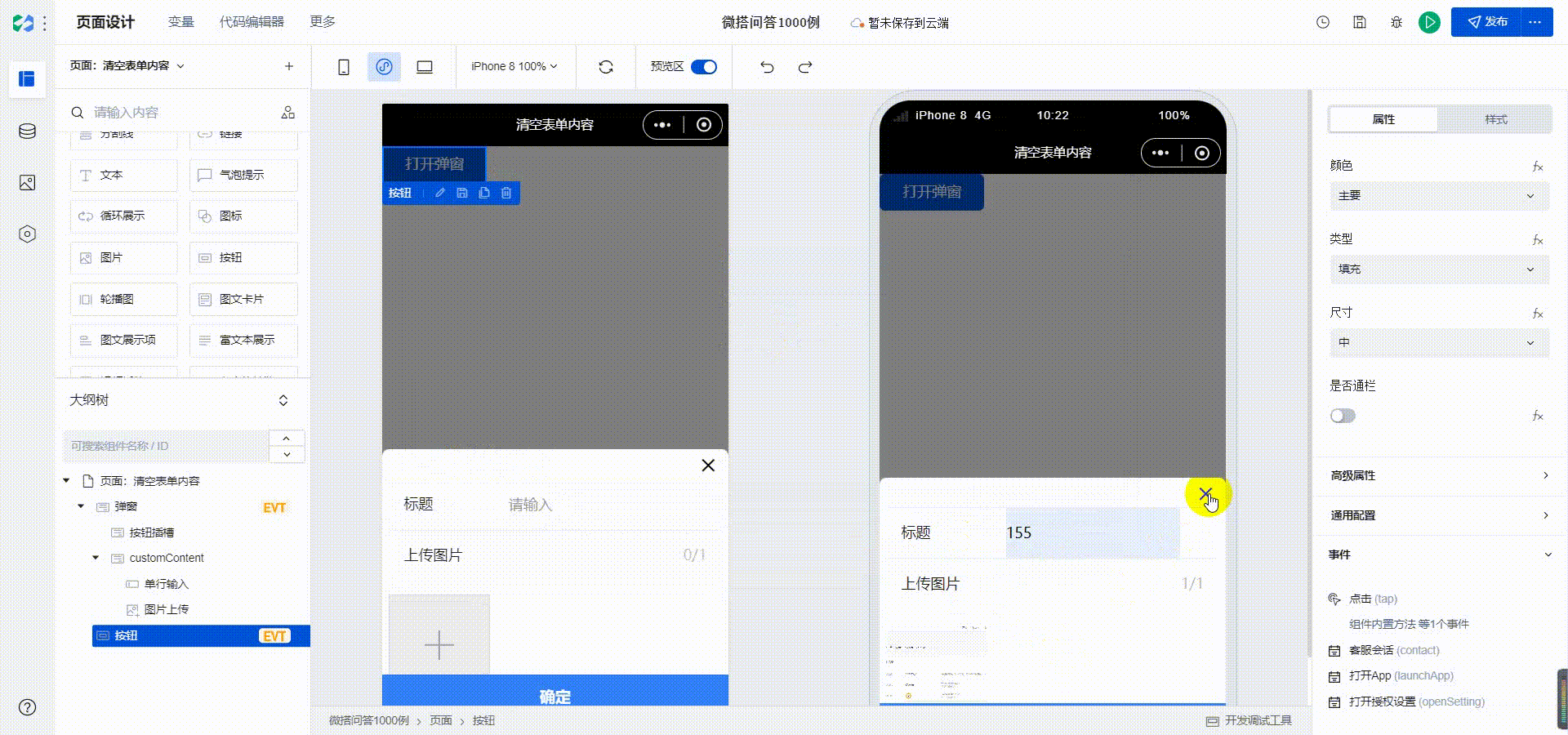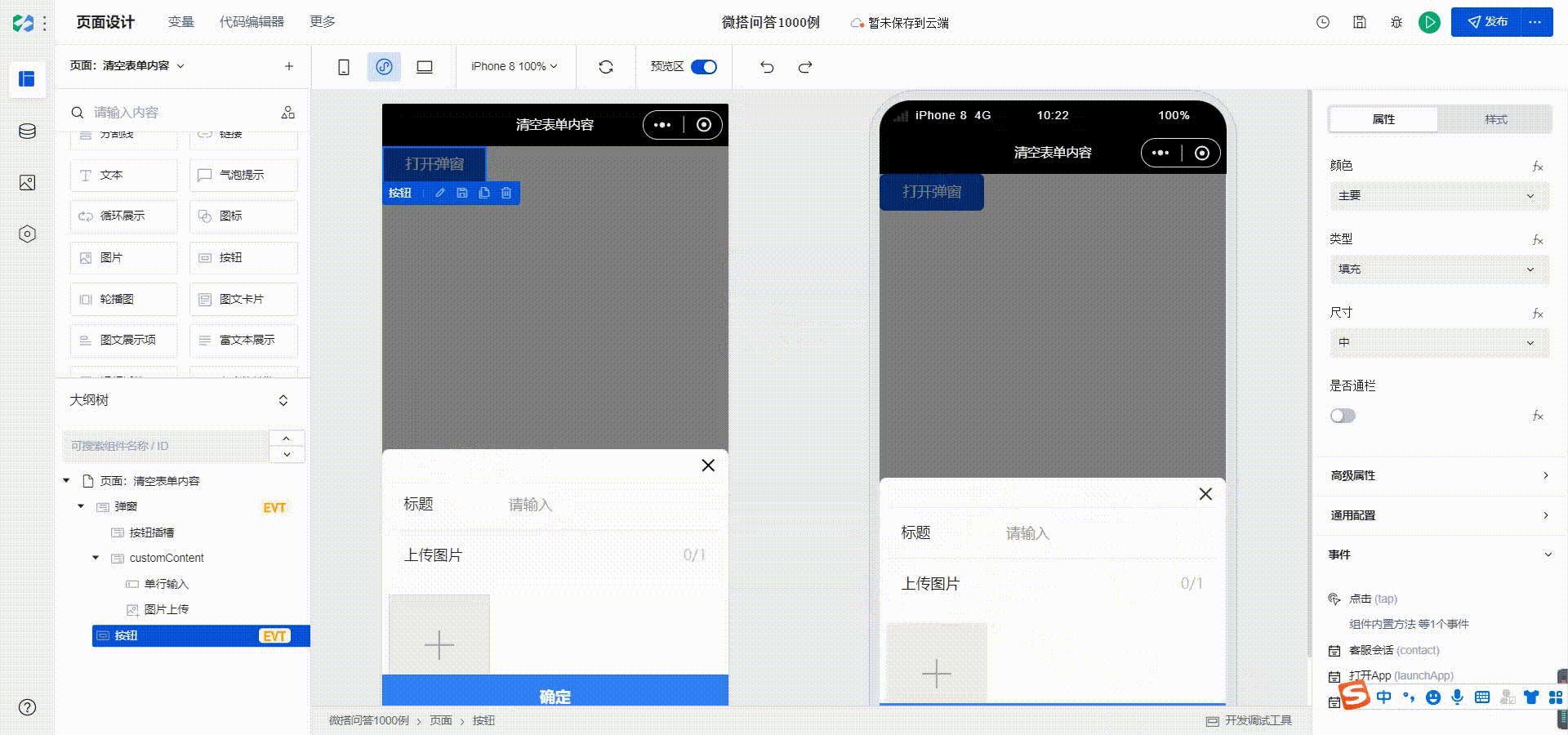
微搭问搭001-如何清空表单的数据
韩老师,我点关闭按钮后,弹窗从新打开,里面的数据还在,这个可以从新打开清除不? 点关闭的时候清掉 就是清楚不掉也?咋清掉 清掉表单内容有属性可以做到? $page.widgets.id**.value “” 就可以实…...
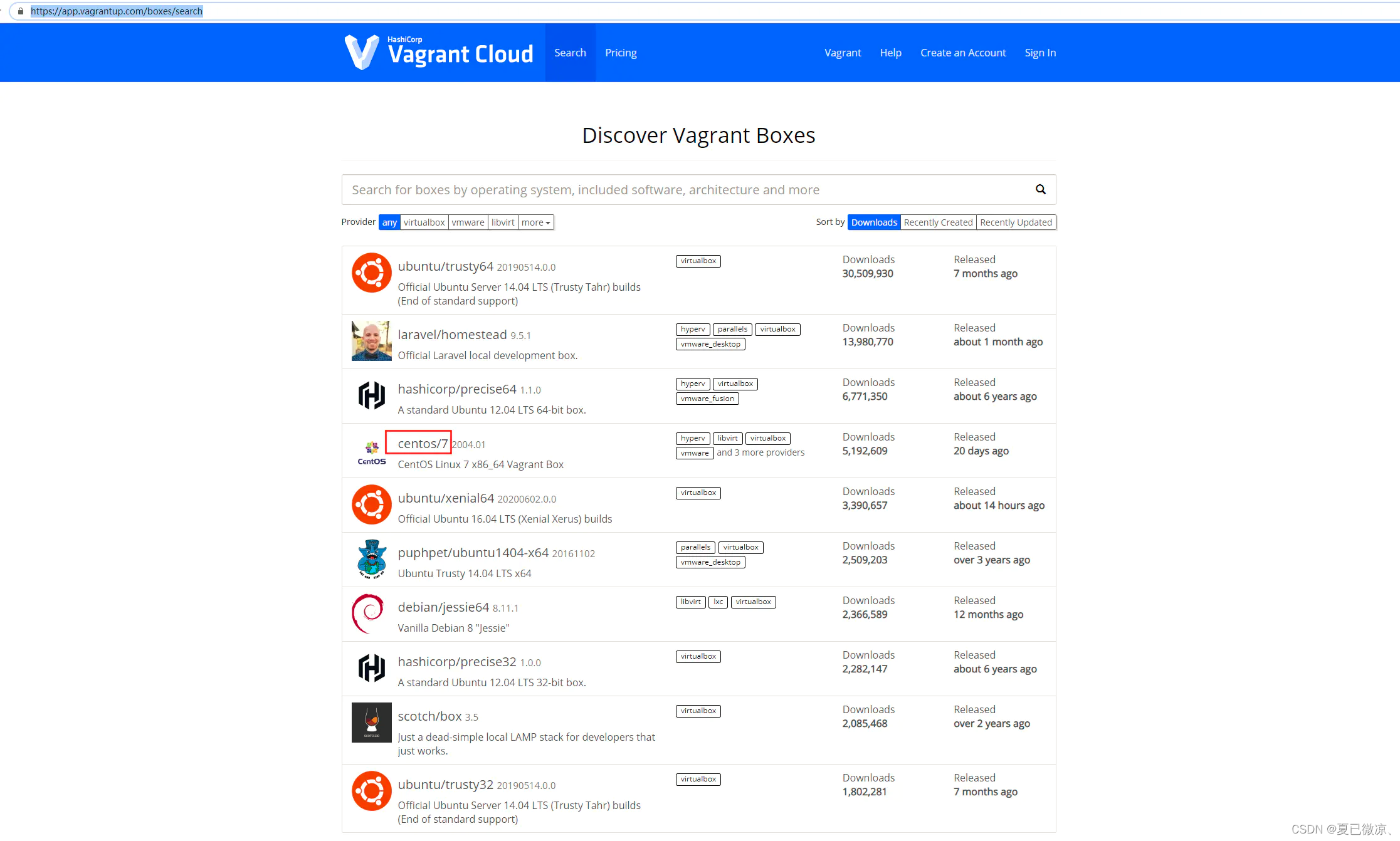
Windows7,10使用:Vagrant+VirtualBox 安装 centos7
一、Vagrant,VirtualBox 是什么二、版本说明1、win7下建议安装版本2、win10下建议安装版本三、Windows7下安装1、安装Vagrant2、安装VirtualBox3、打开VirtualBox,配置虚拟机默认安装地址四、windows7下载.box文件,安装centos 71、下载一个.b…...

基于JavaEE开发博客系统项目开发与设计(附源码)
文章目录1.项目介绍2.项目模块3.项目效果1.项目介绍 这是一个基于JavaEE开发的一个博客系统。实现了博客的基本功能,前台页面可以进行文章浏览,关键词搜索,登录注册;登陆后支持对文章进行感谢、评论;然后还可以对评论…...
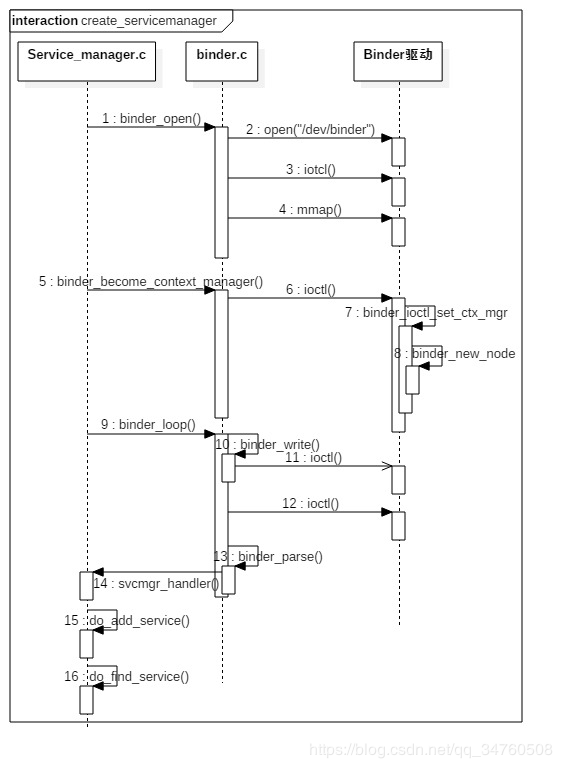
Android Framework——zygote 启动 SystemServer
概述 在Android系统中,所有的应用程序进程以及系统服务进程SystemServer都是由Zygote进程孕育(fork)出来的,这也许就是为什么要把它称为Zygote(受精卵)的原因吧。由于Zygote进程在Android系统中有着如此重…...
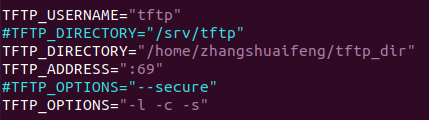
在ubuntu上搭建SSH和FTP和NFS和TFTP
一、SSH服务搭建使用如下命令安装 SSH 服务;ssh 的配置文件为/etc/ssh/sshd_config,使用默认配置即可。sudo apt-get install openssh-server开启 SSH 服务以后我们就可以在 Windwos 下使用终端软件登陆到 Ubuntu,比如使用 Mobaxterm。二、FT…...

ThinkPHP 6.1 模板篇之文件加载
本文主要讲述模板中如何使用包含文件、引入css/js文件及路径优化。 包含文件 使用{include}标签来加载公用重复的文件,比如头部、尾部和导航部分 包含用法 1.创建公用文件 在模版 view 目录创建一个 common公共目录,分别创建 header、footer 和 nav …...

操作系统内核与安全分析课程笔记【1】链表、汇编与makefile
文章目录链表循环双向链表哈希链表其他链表汇编内联汇编扩展内联汇编makefile链表 链表是linux内核中关键的数据结构。在第二次课中,重点介绍了循环双向链表和哈希链表。这两种链表都在传统的双向链表的基础之上进行了针对效率的优化。(ps:这部分可以通…...
| 机考必刷)
华为OD机试题 - 九宫格按键输入(JavaScript)| 机考必刷
更多题库,搜索引擎搜 梦想橡皮擦华为OD 👑👑👑 更多华为OD题库,搜 梦想橡皮擦 华为OD 👑👑👑 更多华为机考题库,搜 梦想橡皮擦华为OD 👑👑👑 华为OD机试题 最近更新的博客使用说明本篇题解:九宫格按键输入题目输入输出示例一输入输出说明示例二输入输出说…...

PMSM控制_foc 控制环路
整个系统的控制过程有以下部分,以无感FOC,双电阻电流采样,控制周期为 10KHz 为例: 1、在每隔一个 PWM 周期采样一次两相电流 2、进行 FOC 的计算 (1)clarke 变换,将电流变换至静止坐标系下的 Ia…...

Linux 练习七 (IPC 共享内存)
文章目录System V 共享内存机制:shmget shmat shmdt shmctl案例一:有亲缘关系的进程通信案例二:非亲缘关系的进程通信内存写端write1.c内存读端read1.c案例三:不同程序之间的进程通信程序一,写者shmwr.c程序二…...

【数据库原理复习】ch4 完整性约束 SQL定义
这里写目录标题基本概念实体完整性参照完整性违规处理用户自定义完整性约束条件定义完整性约束命名字句基本概念 完整性约束主要包括 实体完整性参照完整性用户自定义完整性 实体完整性 关系模型中实体完整性通常在建表时候添加primary key完成 # primary key定义 create …...

【2023年的就业形势依旧严峻】
2023年口罩放开的第一年,也是第一个招聘会,挤满了求职者和用人单位,大多数都是想着重新开始,抓住金三银四的好时机,找到心仪的工作和符合岗位要求的人才,一起整装出发。我们理想的状态是,经济已…...
Linux下LED灯驱动模板详解
一、地址映射我们先了解MMU,全称是Memory Manage Unit。在老版本的Linux中要求处理器必须有MMU,但是现在Linux内核已经支持五MMU。MMU主要完成的功能如下:1、完成虚拟空间到物理空间的映射2、内存保护,设置存储器的访问权限&#…...

R语言AI模型部署方案:精准离线运行详解
R语言AI模型部署方案:精准离线运行详解 一、项目概述 本文将构建一个完整的R语言AI部署解决方案,实现鸢尾花分类模型的训练、保存、离线部署和预测功能。核心特点: 100%离线运行能力自包含环境依赖生产级错误处理跨平台兼容性模型版本管理# 文件结构说明 Iris_AI_Deployme…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

中南大学无人机智能体的全面评估!BEDI:用于评估无人机上具身智能体的综合性基准测试
作者:Mingning Guo, Mengwei Wu, Jiarun He, Shaoxian Li, Haifeng Li, Chao Tao单位:中南大学地球科学与信息物理学院论文标题:BEDI: A Comprehensive Benchmark for Evaluating Embodied Agents on UAVs论文链接:https://arxiv.…...

蓝桥杯 2024 15届国赛 A组 儿童节快乐
P10576 [蓝桥杯 2024 国 A] 儿童节快乐 题目描述 五彩斑斓的气球在蓝天下悠然飘荡,轻快的音乐在耳边持续回荡,小朋友们手牵着手一同畅快欢笑。在这样一片安乐祥和的氛围下,六一来了。 今天是六一儿童节,小蓝老师为了让大家在节…...

Golang dig框架与GraphQL的完美结合
将 Go 的 Dig 依赖注入框架与 GraphQL 结合使用,可以显著提升应用程序的可维护性、可测试性以及灵活性。 Dig 是一个强大的依赖注入容器,能够帮助开发者更好地管理复杂的依赖关系,而 GraphQL 则是一种用于 API 的查询语言,能够提…...

linux 错误码总结
1,错误码的概念与作用 在Linux系统中,错误码是系统调用或库函数在执行失败时返回的特定数值,用于指示具体的错误类型。这些错误码通过全局变量errno来存储和传递,errno由操作系统维护,保存最近一次发生的错误信息。值得注意的是,errno的值在每次系统调用或函数调用失败时…...
:滤镜命令)
ffmpeg(四):滤镜命令
FFmpeg 的滤镜命令是用于音视频处理中的强大工具,可以完成剪裁、缩放、加水印、调色、合成、旋转、模糊、叠加字幕等复杂的操作。其核心语法格式一般如下: ffmpeg -i input.mp4 -vf "滤镜参数" output.mp4或者带音频滤镜: ffmpeg…...

《基于Apache Flink的流处理》笔记
思维导图 1-3 章 4-7章 8-11 章 参考资料 源码: https://github.com/streaming-with-flink 博客 https://flink.apache.org/bloghttps://www.ververica.com/blog 聚会及会议 https://flink-forward.orghttps://www.meetup.com/topics/apache-flink https://n…...

CRMEB 框架中 PHP 上传扩展开发:涵盖本地上传及阿里云 OSS、腾讯云 COS、七牛云
目前已有本地上传、阿里云OSS上传、腾讯云COS上传、七牛云上传扩展 扩展入口文件 文件目录 crmeb\services\upload\Upload.php namespace crmeb\services\upload;use crmeb\basic\BaseManager; use think\facade\Config;/*** Class Upload* package crmeb\services\upload* …...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...