数据库选型实践:如何避开分库分表痛点 | OceanBase用户实践
随着企业业务的不断发展,数据量往往呈现出快速的增长趋势。使用MySQL的用户面对这种增长,普遍选择采用分库分表技术作为应对方案。然而,这一方案常在后期会遇到很多痛点。
分库分表的痛点
痛点 1:难以保证数据一致性。由于分库分表方案使得数据被分散存储于不同的数据库或数据表中,这在一定程度上使数据之间的关联变得更为复杂,确保数据的一致性的难度也随之增加。
痛点2:查询性能下降。分库分表会导致查询的性能下降,因为查询需要对多个数据库或数据表进行查询,增加了查询的时间和成本。非分区键查询需要借助其它的中间件或索引表进行查询。
痛点3:业务变更难度大。分库分表会增加系统的复杂度,当业务变更时,需要对所有分片进行修改和调整,增加了业务变更的难度和风险。
痛点4:数据迁移成本高。分库分表的场景下,数据的迁移成本很高,迁移过程中会涉及数据的拆分、合并和迁移等环节,增加了数据迁移的难度和成本。
痛点5:运维难度高。分库分表会增加系统的运维难度,需要对多个数据库或数据表进行管理和维护,增加了系统的故障排查和维护难度。尤其是自建 MySQL 集群。
痛点6:分库分表后的历史问题数据追溯困难。在分库分表的场景下,历史问题数据追溯问题是一个普遍存在的问题,由于数据被分散存储在多个数据库或数据表中,导致历史数据的追溯变得困难。
另外,使用 MySQL 分库分表的方案时,不仅需要依赖第三方工具,而且数据读写都比较复杂。
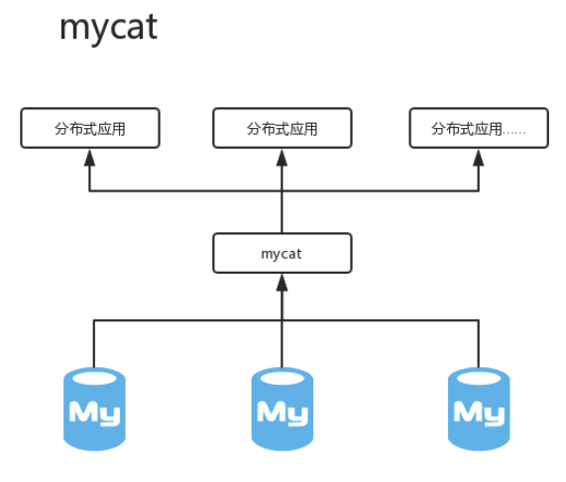
以上的常见挑战,也是OceanBase的客户,绿普惠所遭遇过的,因此,他们舍弃了 MySQL 分库分表方案,转而使用分布式数据库。经过绿普惠的初步筛选,在一众分布式数据库中,OceanBase 可以支持 HTAP 混合负载,且在 TPC-C 和 TPC-H 的评测中均取得了好成绩,故而展开了进一步的调研和测试。
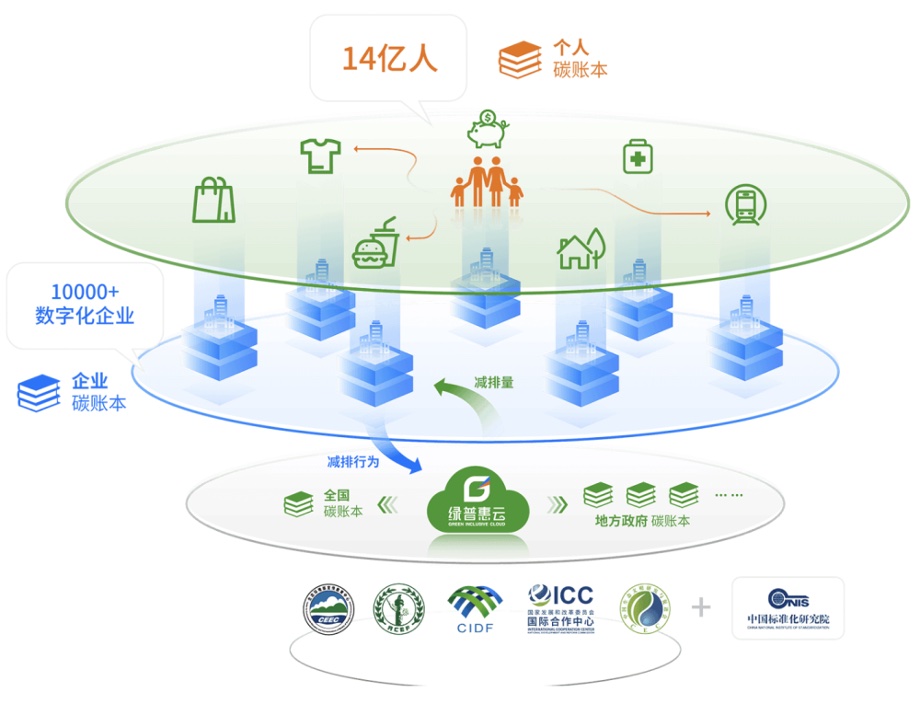
一、绿普惠的业务背景
系统上指数级增长的数据,要求技术人员在运营上采用有效的应对方案,而诸如分库分表的措施也带来了后期维护成本。在绿普惠的系统中,其中的关键平台之一是“绿普惠云-碳减排数字账本”。数字账本平台主要包括三个模块:租户查询系统、碳减排量交易系统和运营端报表系统。
- 租户查询系统:租户可以通过 API 进行减排量指定维度和场景查询操作,查询系统将返回相应的减排数据。
- 碳减排量交易系统:交易核心减排量处理,可以支持大数据量低延迟,满足事务 ACID 要求。
- 运营端报表系统:用于统计分析和生成报表,可以处理大量大事务和复杂查询。
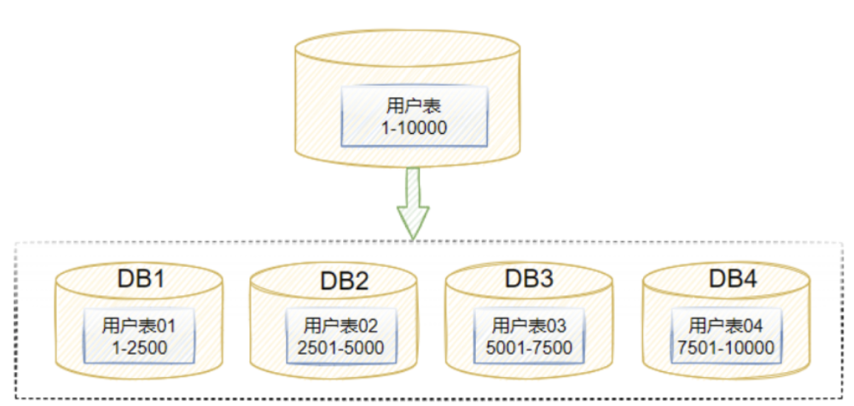
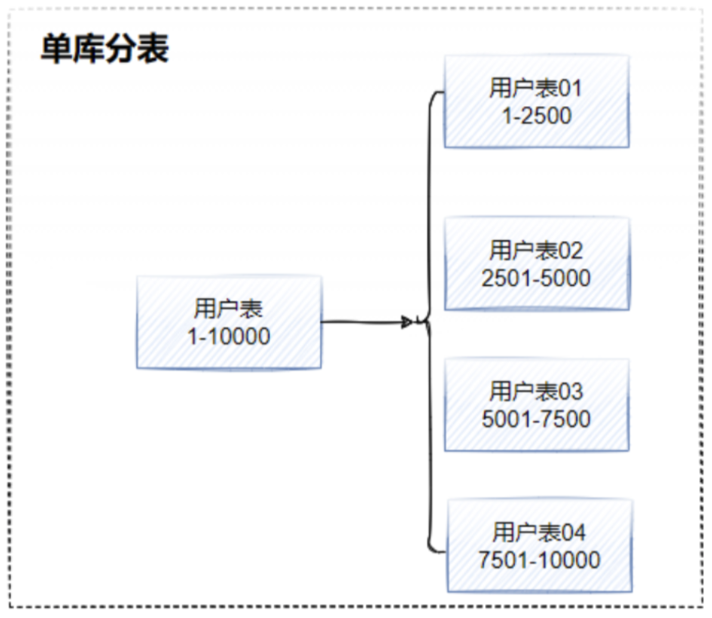
由于业务数据量庞大,目前绿普惠的存量数据表行数达到上亿行,还有每天上千万条的增量数据。面对庞大的数据量,他们采用了一种常见的数据处理方案 —— MySQL 分库分表。即通过将一个大的数据库拆分成多个小的数据库,或将一个大的数据表拆分成多个小的数据表来减轻单一数据库或数据表的负载压力,提高系统的性能和可用性。但是,其存在的痛点也让人束手无策。
二、调研过程及功能测试
在深入调研过程中,绿普惠了解到 OceanBase 已经应用在诸多行业,覆盖行业头部企业和一些中小型企业。对于绿普惠而言,他们看中了 OceanBase 的原生分布式无需分库分表、HTAP混合负载、并行执行优秀、存储成本低、数据迁移方便等特点。
(一)原生分布式
OceanBase 是原生的分布式数据库,可以保证多个数据副本之间的一致性,利用基于 Paxos 分布式一致性协议保证了在任一时刻,只有当多数派副本达成一致时,才能推选一个 Leader,通过保证主副本的唯一性来对外提供数据服务。相比分库分表方案,大大降低了绿普惠的运维难度和业务变更难度。利用 OceanBase 的多地多副本架构,以及高效的 Paxos 一致性协议工程实现,还支持数据副本分别存储在同城和异地,实现异地容灾。
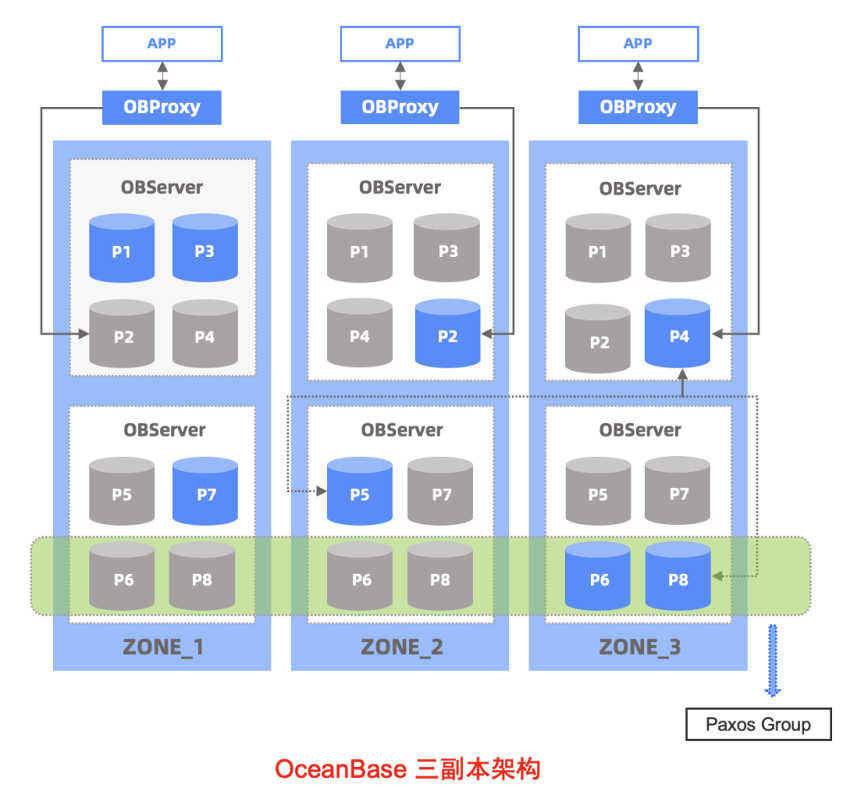
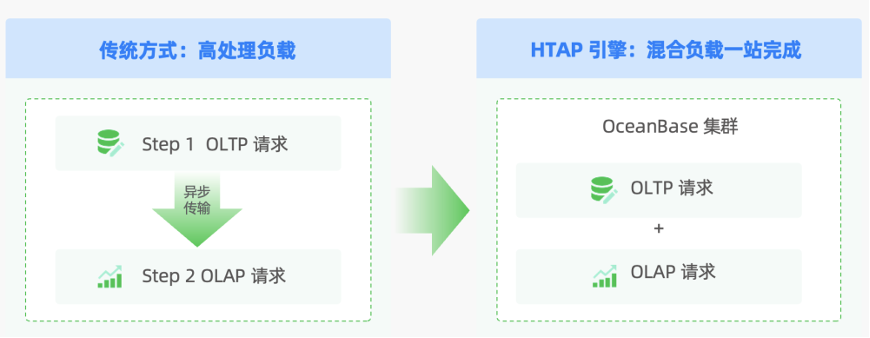
(二)HTAP 混合负载
除了原生分布式无需分库分表的特性,OceanBase 可以同时支持 OLTP 业务与 OLAP 业务,故而被称为 HTAP 数据库。但这不单是一句口号,背后涉及四个关键技术。
1. 读写分离
分库分表会导致查询的性能下降,而数据库的读写分离策略是一种将数据库的查询操作和写入操作分离的方案,目的是降低读写操作的相互影响并提升资源利用率。在 HTAP 数据库中,读写分离的应用场景非常普及。OceanBase 数据库天然支持读写分离的功能,即通过 OBProxy 代理服务和修改 OBServer 的配置即可实现业务的读写分离策略。
OceanBase 数据库在读取数据时,提供了两种一致性级别:强一致性和弱一致性,有效解决分库分表的查询性能问题。强一致性是指请求路由给主副本读取最新数据;弱一致性是指请求优先路由给备副本,不要求读取最新数据。通过应用侧为执行的 SQL 添加 SQL Hint 来显性开启弱一致性读就可以实现基于注释的读写分离功能,同时也衍生出种各种各样的读写分离策略,比如备优先读、只读 zone、只读副本,企业可以根据实际情况,对读写分离策略进行灵活的配置。
2. 大查询队列
对于数据库来说,相比于单条复杂大查询,让大量的 DML 和短查询尽快返回更有意义。为了避免一条大查询阻塞大量简单请求而导致系统吞吐量暴跌,避开分库分表的查询性能局限,当大查询和短请求同时争抢 CPU 时,OceanBase 会限制大查询的 CPU 使用。当一个线程执行的 SQL 查询耗时太长,这条查询就会被判定为大查询,一旦判定为大查询,就会进入大查询队列,然后执行大查询的线程会等在一个 Pthread Condition 上,为其它的租户工作线程让出 CPU 资源。
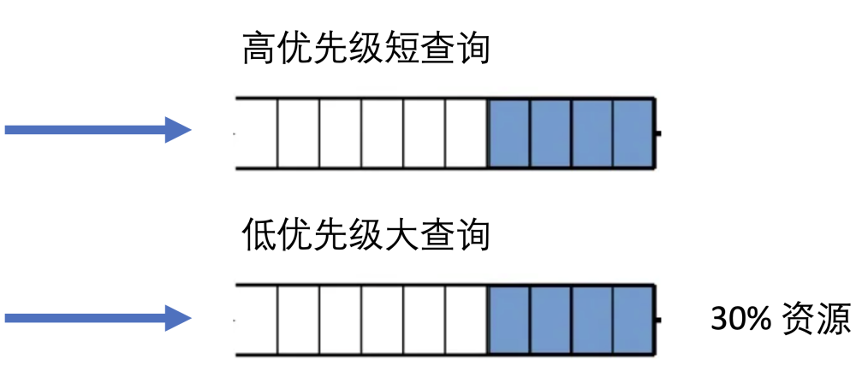
配置大查询的参数为 large_query_threshold,执行时间超过这个参数设置的阈值,则认为是大查询。
| 属性 | 描述 |
| 默认值 | 5s |
| 取值范围 | [1ms, +∞) |
如果系统中同时运行着大查询和小查询,OceanBase 会将一部分 CPU 资源分配给大查询,并通过配置参数 large_query_worker_percentage(默认值为 30%)来限制执行大查询最多可以使用的租户活跃工作线程数。
| 属性 | 描述 |
| 默认值 | 30 |
| 取值范围 | [0, 100] |
OceanBase 数据库通过限制大查询能使用的租户活跃工作线程数来约束大查询最多能够使用的 CPU 资源,以此来保证系统还会有足够的 CPU 资源来执行 OLTP(例如交易型的小事务)负载,通过这样的方式来保证对响应时间比较敏感的 OLTP 负载能够得到足够多的 CPU 资源尽快地被执行,无需面对分库分表导致查询的性能下降。
3. 资源隔离
资源隔离并不是一个新概念,传统方式下不共享物理资源,可以理解为物理资源隔离方案。这种方案下不同租户或同一租户内 OLAP 和 OLTP 使用不同的副本,只读副本服务 OLAP,全功能副本服务 OLTP,两种业务不共享物理资源。如果不考虑成本,物理资源隔离无疑是更好的选择。但现实中,大部分企业都会考虑硬件成本及其资源利用率。一方面,数据库硬件的购买和维护成本高昂,而所有硬件都需要定期换新;另一方面,数据库硬件在进行单项业务处理时,平均占用率水平较低。如果不能充分利用硬件资源,无疑会造成巨大的资源浪费。并且,基于此进行的分库分表方案需要对多个数据库或数据表进行管理和维护,增加运维难度。
而要充分利用硬件资源,不同租户或同一租户内 OLAP 和 OLTP 共享物理资源的逻辑资源隔离方案,自然脱颖而出。实际上,物理资源隔离和逻辑资源隔离不是二选一,而是互为补充的关系。理想的资源隔离方案是在完全物理隔离和逻辑隔离中找到平衡点,OceanBase 会给用户更多自由,帮助绿普惠在面对各类场景下都可以做出最合适的选择,有效降低分库分表带来的系统复杂度。
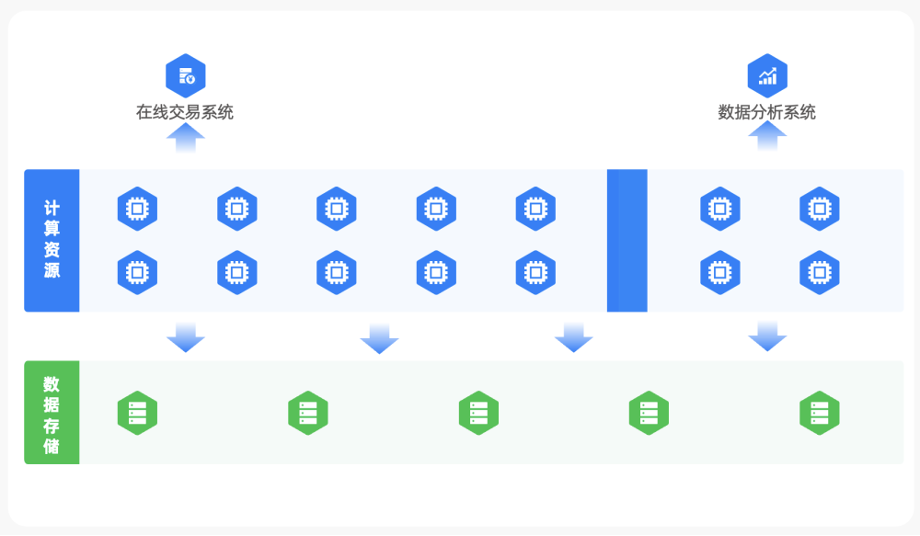
4. SQL 执行优化
SQL 的执行引擎需要处理很多情况,为什么要对这些情况进行细分呢?是因为 OceanBase 希望在每种情况下都能自适应地做到最优,不依赖现行的分库分表方法。从最大的层面上来说,每一条 SQL 的执行都有两种模式:串行执行或并行执行,可以通过在 SQL 中增加 hint /*+ parallel(N) */ 来决定是否走并行执行以及并行度是多少。
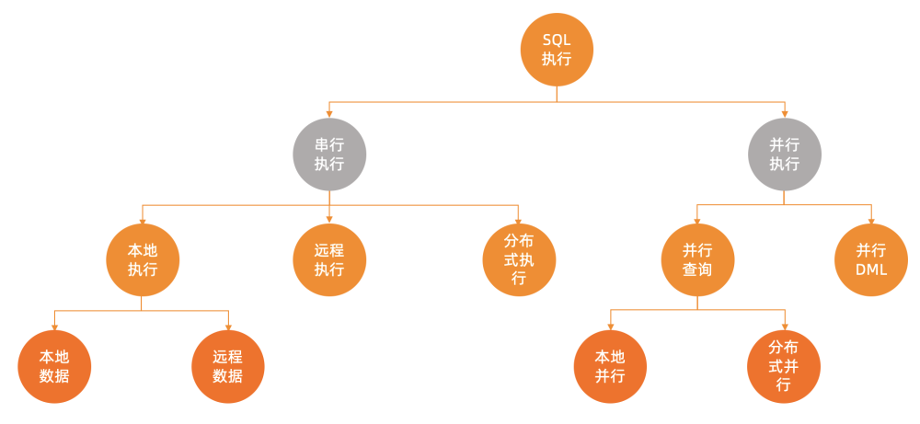
📍 模式一:串行执行
如果这张表或者这个分区是位于本机的,这条路线和单机 SQL 的处理是没有任何区别的。如果所访问的是另外一台节点上的数据,有两种做法:一种是当数据量比较小时,会把数据从远程拉取到本机(远程数据获取服务);当数据量比较大时,会自适应地选择远程执行,把这条 SQL 发送到数据所在节点上,将整条 SQL 代理给这个远程节点,执行结束之后再从远程节点返回结果。如果单条 SQL 要访问的数据位于很多个节点上,会把计算压到每个节点上,并且为了能够达到串行执行(在单机情况下开销最小)的效果,还会提供分布式执行能力,即把计算压给每个节点,让它在本机做处理,最后做汇总,并行度只有 1,不会因为分布式执行而增加资源额外的消耗,比分库分表在资源上利用率更高。对于串行的执行,一般开销最小。这种执行计划,在单机做串行的扫描,既没有上下文切换,也没有远程数据的访问,是非常高效的。
📍 模式二:并行执行
并行执行同时支持 DML 写入操作的并行执行和查询的并行执行,对并行查询分还会再去自适应地选择是本机并行执行还是分布式并行执行。对于当前很多小规模业务来说,串行执行的处理方式足够。但如果需要访问大量数据,可以在 OceanBase 单机内引入并行能力,目前,这个能力很多开源的单机数据库还不支持,但只要有足够多的 CPU,可以通过并行的方式使得单条 SQL 处理时间线性缩短,只要有一个高性能多核服务器增加并行就可以了。而分库分表较为麻烦,SQL 执行依赖中间件,难以进行性能调优。
针对同样形式的分布式执行计划,可以让它在多机上分布式去做并行,这样可以支撑更大的规模,突破单机 CPU 的数目,去做更大规模的并行,比如从几百核到几千核的能力。
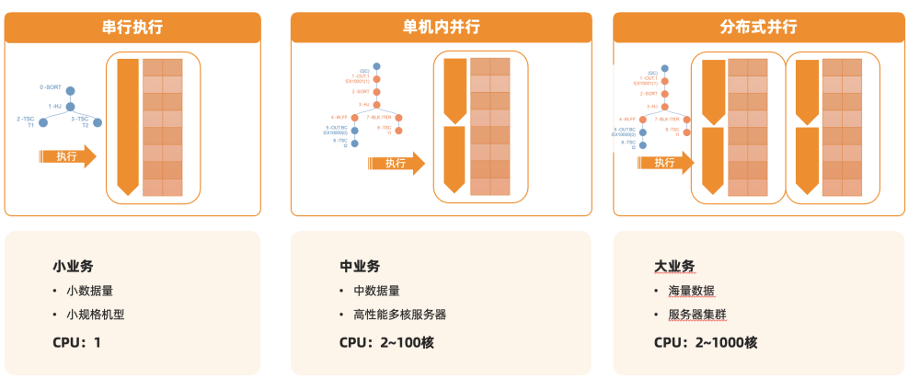
OceanBase 的并行执行框架可以自适应地处理单机内并行和分布式并行,优于传统的分库分表方案。这里所有并行处理的 Worker 既可以是本机上多个线程,也可以是位于很多个节点上的线程。分布式执行框架里有一层自适应数据的传输层,对于单机内的并行,传输层会自动把线程之间的数据交互转换成内存拷贝。这样把不同的两种场景完全由数据传输层抽象掉了,实际上并行执行引擎对于单机内的并行和分布式并行,在调度层的实现上是没有区别的。
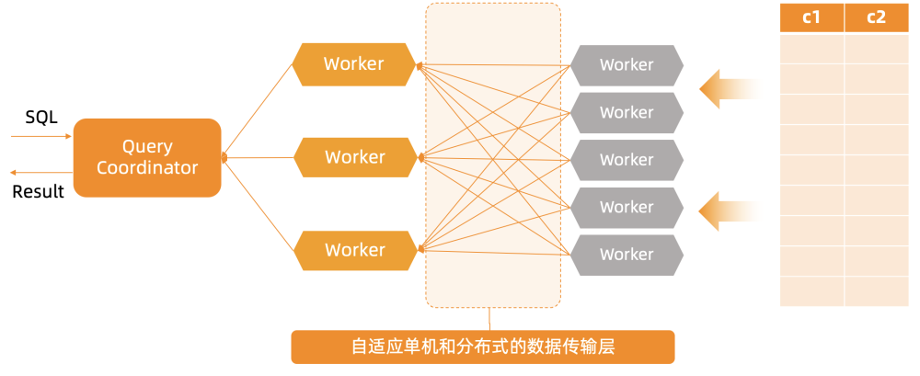
那么,如果不采用分库分表,什么时候适合并行执行,通过充分利用多个 CPU 和 I/O 资源,达到降低 SQL 执行时间的目的呢?当满足下列条件时,使用并行执行会优于串行执行:
- 访问的数据量大
- SQL 并发低
- 要求低延迟
- 有充足的硬件资源
(三)存储成本
相比分库分表简单地对数据库进行分片,作为一款 HTAP 数据库产品, OceanBase 使用基于 LSM-Tree 架构的存储引擎,同时支持 OLTP 与 OLAP 负载,这种存储架构提供了优秀的数据压缩能力。在 OceanBase 中,增量数据会写入 Clog 和 Memtable 中,OceanBase 的 Memtable 是内存中的 B+ Tree 索引,提供高效的事务处理能力。Memtable 会定期通过 Compaction 生成硬盘持久化数据 SSTable,多层 SSTable 会采用 Leveled Compaction 策略进行增量数据重整。SSTable 中数据块的存储分为两层,其中 2M 定长的数据块(宏块)作为 SSTable 写入 I/O 的最小单元,存储在宏块中的变长数据块(微块)作为数据块压缩和读 I/O 的最小单元。
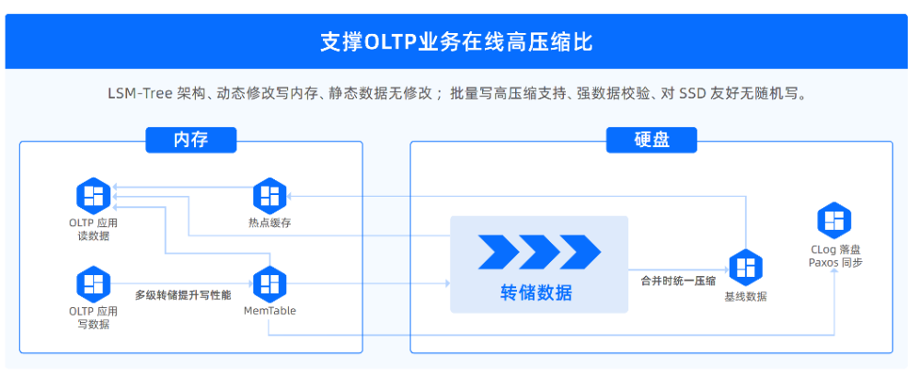
在这样的存储架构下, OceanBase 的数据压缩集中发生在 Compaction 过程中 SSTable 的写入时,数据的在线更新与压缩得到了解耦。批量落盘的特性使其采用更激进的压缩策略,相比分库分表而言,存储空间更少。OceanBase 从 2.0 版本开始引入了行列混存的微块存储格式( PAX ),充分利用了同一列数据的局部性和类型特征,在微块内部对一组行以列存的方式存储,并针对数据特征按列进行编码。变长的数据块和连续批量压缩的数据也可以让 OceanBase 通过同一个 SSTable 中已经完成压缩的数据块的先验知识,对下一个数据块的压缩进行指导,在数据块中压缩尽量多的数据行,并选择更优的编码算法。
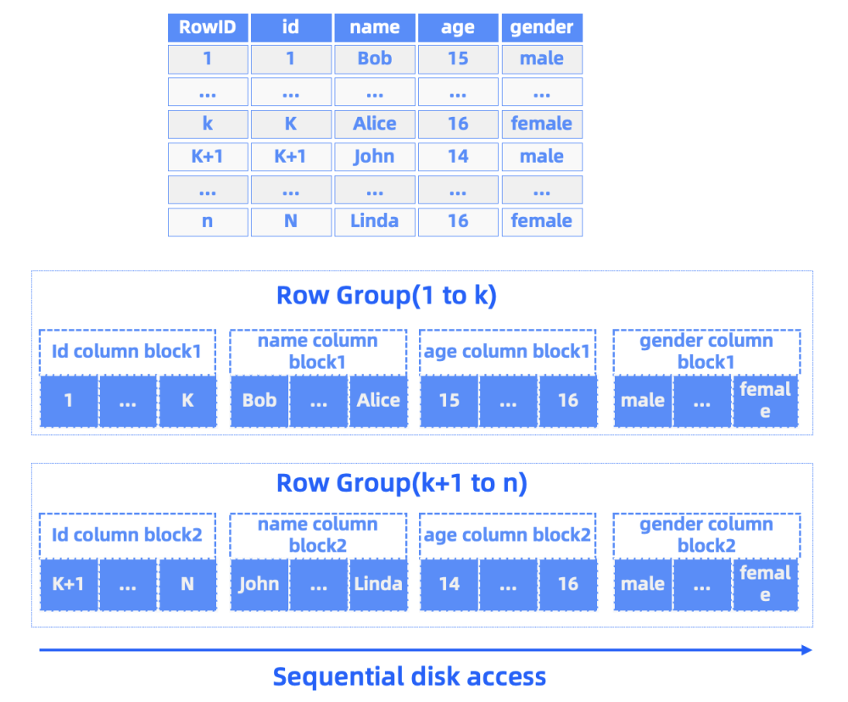
与部分在 schema 上指定数据编码的数据库实现不同, OceanBase 选择了用户不感知的数据自适应编码,在给用户带来更小负担的同时降低了存储成本,从历史库角度而言,用户也不需要针对历史库数据做出过多压缩与编码相关的配置调整。相比分库分表,OceanBase 之所以能够在事务性能和压缩率之间取得更好的平衡,都得益于 LSM-Tree 的存储架构。
当然, LSM-Tree 架构不是解决数据库压缩所有问题的万金油,如何通过数据压缩降低成本、提升性能是业界一直在讨论的话题。对 B+Tree 类的存储引擎进行更高效的压缩也有很多探索,比如基于可计算存储硬件的工作,利用存储硬件内部的透明压缩能力对 B+ Tree类存储引擎的数据压缩进行优化,使其写放大达到了接近 LSM-Tree 架构存储引擎的效果。但 LSM-Tree 中内存数据页更新与数据块落盘解耦,和 sstable 数据紧凑排布的特点,使得 LSM-Tree 相对 B+ Tree类存储引擎,仍然更适合在对查询、更新带来更少负面影响的前提下实现更高效的数据压缩,这是分库分表所不具备的特性。
(四)OMS 数据迁移
分库分表的场景下,数据的迁移成本很高。OceanBase 提供的数据迁移工具 OMS(OceanBase Migration Service)支持 MySQL 等关系型数据库与 OceanBase 双向自动迁移和数据校验,可以在大幅提升迁移效率的同时,进一步降低数据不一致的风险。OMS 还提供丰富的数据订阅 CDC 能力,支持数据流到 Kafka、MQ 等消息队列的同步。

在传统的数据库迁移方案中,基于分库分表场景,数据的迁移成本很高,为了保障迁移任务的稳定性和数据的一致性,通常通过停机迁移的方式进行数据迁移。停机期间需要暂时停止写入数据至源端数据库,待迁移完成并确认数据一致性后,再切换业务数据库。但停机迁移的耗时和业务数据量、网络状况相关,在业务量巨大的情况下,数据库的停机迁移可能耗时数天,对业务影响较大。
OMS 提供的不停服数据迁移功能,不影响迁移过程中源数据库持续对外提供服务,能够最小化数据迁移对业务的影响。在完成结构迁移、全量数据迁移和增量数据迁移后,源数据库的全量和增量数据均已实时同步至目标数据库中,数据校验通过后,业务可以从源端切换至目标端,有效避开分库分表场景下数据迁移的难度和成本。
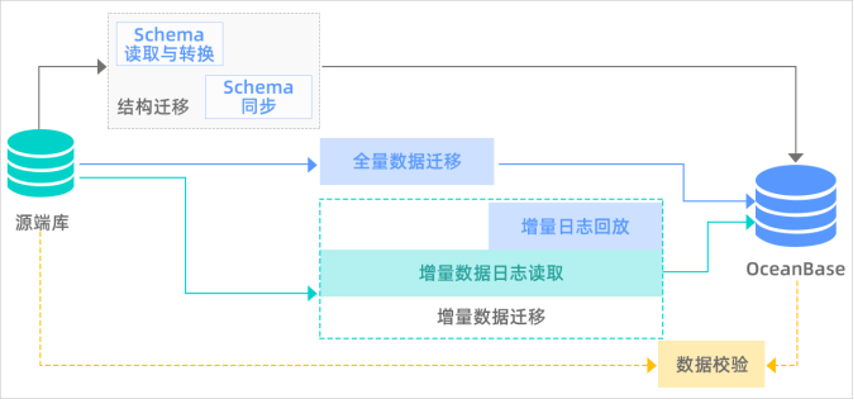
三、解决方案和性能测试
绿普惠通过 OceanBase 替换 MySQL 分库分表的方案如下:
- 通过 OMS 将异构数据库分库分表同步至 OceanBase 原生分区表(多表汇聚同步)。
- 迁移至 OceanBase 后多个实例融合为一个实例,摆脱分库分表下所依赖的中间件,大幅提升存储可扩展性。
- OceanBase 的 HTAP 模式,满足了业务上分析查询的业务得以前置,无需像分库分表那样等待 T+1 数据,直接于在线库实现实时决策等分析需求。
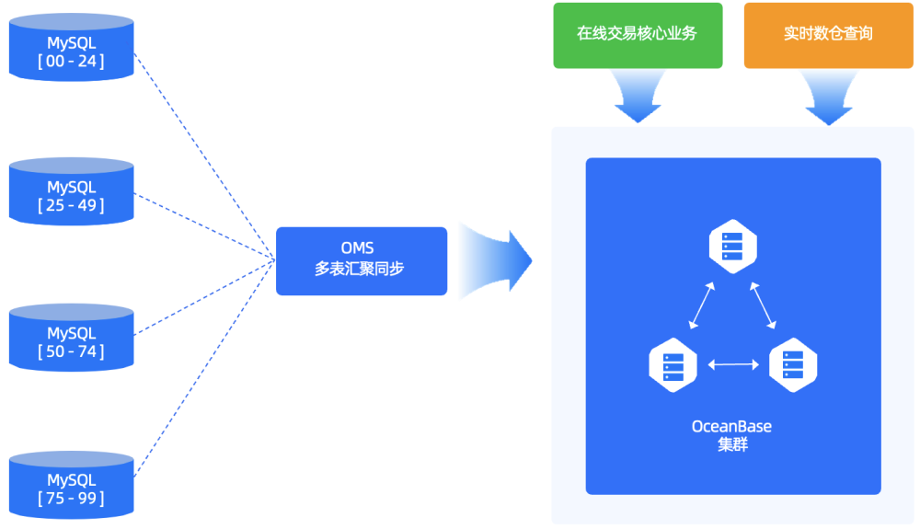
基于该方案,绿普惠在测试环境中部署了三个 OceanBase 3.1.4 版本的集群节点,相较于分库分表,对运维监控工具、分区功能、分区表读写性能等方面逐一展开了测试。
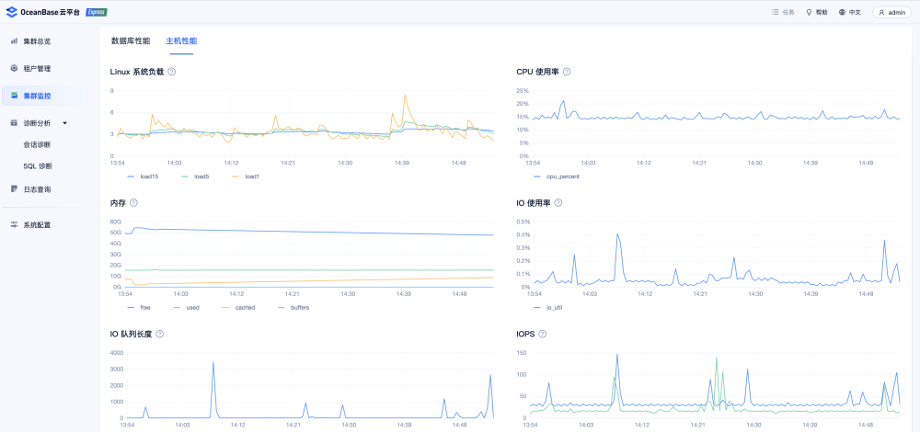
(一)OceanBase 集群运维监控
绿普惠使用了 OceanBase 的运维工具 OCP 来实现集群的运维管理和监控告警,利用 OCP 的告警功能,配置企业微信告警渠道,实现告警信息的实时推送到企业微信,保证了开发能够第一时间获取到 OceanBase 集群重要的告警信息,运维上远优于分库分表方案。
(二)分区功能测试
绿普惠的关键业务表是减排行为表,在 OceanBase 中,绿普惠给这张表做了二级分区,一级分区键为租户 id,二级分区键为手机号 sha256 加密字符串,表的定义类似于:

OceanBase 提供的分区功能非常强大,无需像分库分表一样进行缺乏弹性的物理分区,详细分区表可以点击文末“阅读原文”查看官方文档。
(三)分区表性能测试
提前测试可降低分库分表场景下的数据迁移的难度和成本。使用 OceanBase 3.1.4 社区版本可以创建分区表或者非分区表。对于非分区表,在数据量巨大的情况下性能肯定不好,所以我们没有对其进行压测。对于分区表,在数据量大的情况下,才能充分发挥其性能,所以绿普惠给分区表提前写入了三亿条数据,并且以递增线程数的方式去进行压测,每次压测执行三分钟。然后分析结果中的吞吐量,当吞吐量无法继续增加时,认为此时的线程数是系统能承受的最大并发数。
绿普惠的压测脚本分为两部分:第一部分是增删改查,测试插入、查询、修改,相当于 read write 性能;第二部分是事务,测试插入、修改,相当于是 write only 性能。测试环境是三台 32c 128g 的机器,测试的版本是较早的 OceanBase 3.1.4 社区版,整体优于分库分表的迁移复杂度。测试结果如下表所示:
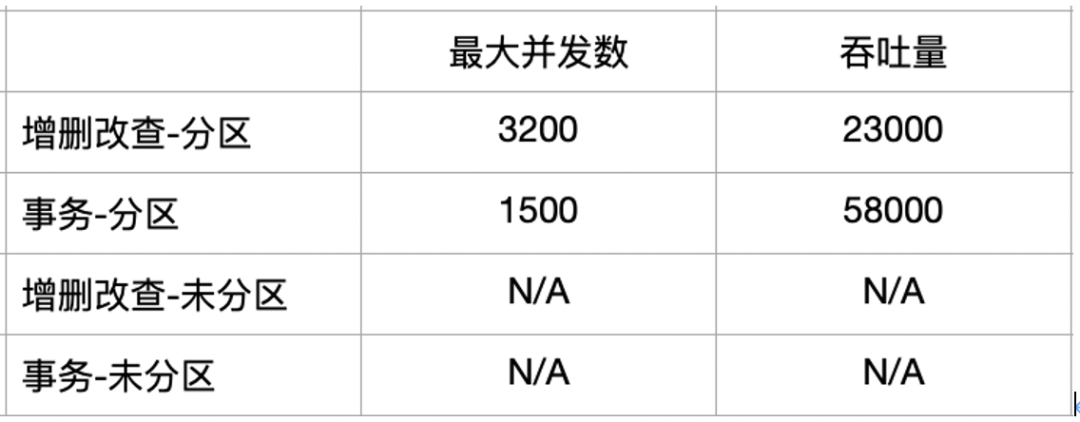
注:OceanBase 3.1.4 社区版的 sysbench 详细性能测试报告详见性能测试官方文档。
(四)测试过程中遇到的一些问题
在测试过程中,绿普惠发现当 OceanBase 3.14 社区版本在二级分区表数据量过大时,创建索引失败。不过该问题已经在 OceanBase 3.15 版本被解决。另外,OceanBase 的 MySQL 模式租户下,有 global 索引的分区表不支持 insert ignore,执行时直接报了 not supported。绿普惠猜测不支持的原因是全局索引插入成功之后,如果主表插入失败,这时不仅要回滚主表的改动,还需要回滚全局索引的改动。这个回滚数据的过程的实现复杂度非常高,OceanBase 暂时还没有支持该功能。相比分库分表,还是从性能和根源上避开不少痛点。

四、总结
在选择使用原生分布式 OceanBase 替代 MySQL 分库分表方案后,收益符合预期,主要包括几点:
- 降低运维难度:相比分库分表方案,大大降低了绿普惠的运维难度和业务变更难度。而且完全兼容 MySQL 的语法,强大的 CDC 能力支持,方便多种类型的下游进行数据消费。
- 比分库分表更灵活的动态扩容:单集群最大可超过上千节点,数据容量可以超过 PB 级。
- 强大于分库分表的数据更新能力:基于关系型数据库的更新能力,副本间毫秒级极低延迟。
- 优于分库分表的HTAP 一体化:一套引擎处理 OLTP 和基本的 OLAP 场景,同时基于资源组隔离技术,提供 OLTP/OLAP 业务资源隔离的可靠方案,免去复杂的实时数仓建设。
- 分布式并行计算引擎:强大的 SQL 优化器和执行器,支持向量化计算和海量数据的并行计算分析。
经过探索测试,绿普惠验证了 OceanBase 在性能、成本等方面的优势,避开了分库分表的诸多痛点,符合当前业务发展的需求,且 HTAP 混合负载能力与企业的实际业务场景非常契合,后续必定会有更加深入的合作。
相关文章:
数据库选型实践:如何避开分库分表痛点 | OceanBase用户实践
随着企业业务的不断发展,数据量往往呈现出快速的增长趋势。使用MySQL的用户面对这种增长,普遍选择采用分库分表技术作为应对方案。然而,这一方案常在后期会遇到很多痛点。 分库分表的痛点 痛点 1:难以保证数据一致性。由于分库分…...

3个火火火的AI项目,开源了!
友友们,今天我要给你们安利三个超酷的开源项目,它们都和AI有关,而且每一个都能让你的日常生活变得更加有趣和便捷!(最近AI绘图又又超神了,分享以下美图养眼) 01 字节出品,文字转语音Seed-TTS 字节推出了一…...

算法 | 子集数排列树满m叉树二分搜索归并排序快速排序
子集树:O(2^n) 一个序列的所有子集为2^n,即可看成具有2^n个叶节点的满二叉树 int backtrack(int k) //k表示扩展结点在解空间树中所处的层次 {if(k>n) //n标识问题的规模output(x); //x是存放当前解的一维数组if(constraint(k)…...

SpringBoot配置第三方专业缓存技术jetcache方法缓存方案
jetcache方法缓存 我们可以给每个方法配置缓存方案 JetCache 是一个基于 Java 的缓存库,支持多种缓存方案和缓存策略,主要用于提升应用程序的性能和响应速度。它提供了多种缓存模式和特性,可以根据需求选择合适的缓存方案。 JetCache 的主…...
游戏开发丨基于PyGame的消消乐小游戏
文章目录 写在前面PyGame消消乐注意事项系列文章写在后面 写在前面 本期内容:基于pygame实现喜羊羊与灰太狼版消消乐小游戏 下载地址:https://download.csdn.net/download/m0_68111267/88700193 实验环境 python3.11及以上pycharmpygame 安装pygame…...
软件项目管理概述
1.什么是项目? 2.项目管理的定义 3.项目管理的本质 4.项目成功的标志 5.项目管理的基本方法 6.项目的生命周期(启动 计划 执行 控制 结束) 7.结合生活中的某件事,谈谈项目管理的作用 项目管理在日常生活中扮演着重要的角色&…...

FastAdmin后台开发框架 lang 任意文件读取漏洞复现
0x01 产品简介 FastAdmin是一款基于PHPBootstrap的开源后台框架,专为开发者精心打造。它基于ThinkPHP和Bootstrap两大主流技术构建,拥有完善的权限管理系统和一键生成CRUD等强大功能。FastAdmin致力于提高开发效率,降低开发成本,…...

数字时代PLM系统的重要性
什么是 PLM(产品生命周期管理)? 从最基本的层面上讲,产品生命周期管理 (PLM)是管理产品从最初构思、开发、服务和处置的整个过程的战略流程。换句话说,PLM 意味着管理产品从诞生到消亡所涉及的一切。 什么是 PLM 软件…...

安卓实现圆形按钮轮廓以及解决无法更改按钮颜色的问题
1.实现按钮轮廓 在drawable文件新建xml文件 <shape xmlns:android"http://schemas.android.com/apk/res/android"<!--实现圆形-->android:shape"oval"><!--指定内部的填充色--><solid android:color"#FFFFFF"/><!-…...

常用原语介绍
1.在Xilinx的example(wavegen example)中看到他们的顶层模块的输入输出管脚都手动例化原语IBUF以及OBUF——工具也会自动给我们加上不必要自己加 2.非mrcc个srcc的管脚输入的时钟信号,无法进入mmcm和bufg————试验过会报错 3.实际上&…...
29. 透镜阵列
导论: 物理传播光学(POP)不仅可以用于简单系统,也可以设计优化复杂的光学系统,比如透镜阵列。 设计流程: 透镜阵列建模 在孔径类型中选择“入瞳直径”,并输入2 在视场设定中。设置一个视场&…...

深入理解并打败C语言难关之一————指针(3)
前言: 昨天把指针最为基础的内容讲完了,并且详细说明了传值调用和传址调用的区别(这次我也是做到了每日一更,感觉有好多想写的但是没有写完),下面不多废话,下面进入本文想要说的内容 目录&#…...
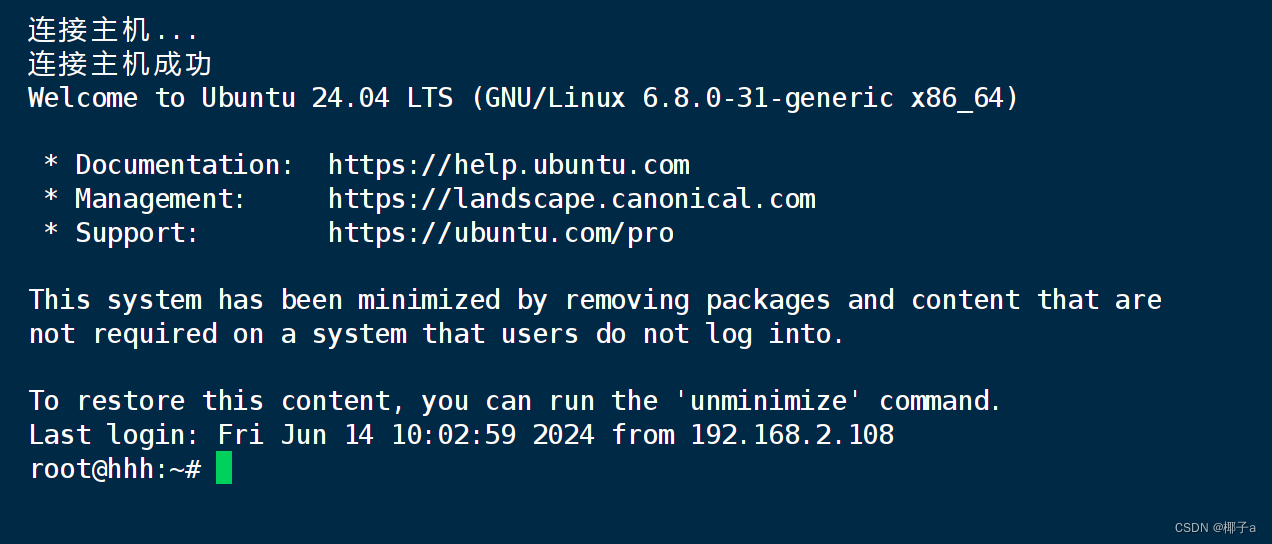
Ubuntu-24.04-live-server-amd64启用ssh
系列文章目录 Ubuntu-24.04-live-server-amd64安装界面中文版 Ubuntu安装qemu-guest-agent Ubuntu乌班图安装VIM文本编辑器工具 文章目录 系列文章目录前言一、输入安装命令二、使用私钥登录(可选)1.创建私钥2.生成三个文件说明3.将公钥复制到服务器 三…...
)
Leetcode 2786. 访问数组中的位置使分数最大(DP 优化)
Leetcode 2786. 访问数组中的位置使分数最大 DP 以每个位置为结尾的序列的分数取决于前方的分数,根据奇偶性计算,取最大值 超时 class Solution {public long maxScore(int[] nums, int x) {int n nums.length;long dp[] new long[n];Arrays.fill(dp…...

【docker实战】使用Dockerfile的COPY拷贝资源遇到的问题
事情是这样的。 在我负责的golang项目中,使用硬代码验证某块逻辑。比如: 于是,为了解决硬代码的问题,我制作了表格工具:【开源项目】Excel数据表自动生成工具v1.0版 – 经云的清净小站 (skycreator.top)。 使用表格工…...

如何用多线程执行 unittest 测试用例实现方案
前言 使用python做过自动化测试的小伙伴,想必都知道unittest和pytest这两个单元测试框架,其中unittest是python的官方库,功能相对于pytest来要逊色不少,但是uniitest使用上手简单,也受到的很多的小伙伴喜爱。一直以来都…...

Ascend310 EP模式下容器内进行推理测试
EP模式下容器内进行推理测试 本文的软硬件环境如下: 机器:x86台式机一台 OS: 5.4.0-26-generic Ubuntu20.04 LTS 推理卡:DLAP200-HP-2(凌华基于atlas200模块打造的两模块推理卡) 1. 推理卡固件和驱动安…...
(el-Transfer)操作(不使用 ts):Element-plus 中 Select 组件动态设置 options 值需求的解决过程
Ⅰ、Element-plus 提供的Select选择器组件与想要目标情况的对比: 1、Element-plus 提供Select组件情况: 其一、Element-ui 自提供的Select代码情况为(示例的代码): // Element-plus 提供的组件代码: <template><div class"f…...

Java基础之Math与Array类与System
文章目录 一、Math.random()二、Arrays.binarySearch()三、asList()四、System tip:以下是正文部分 一、Math.random() a < num < b int num (int)(Math.random() * (b - a 1)) a二、…...
警告:Hydration attribute mismatch on Note: this mismatch is check-only.(水合不匹配)
vue3Nuxt3运行代码是提示如下警告 [Vue warn]: Hydration attribute mismatch on <ul id"sub_menu_5_$$_sub1-popup" class"ant-menu ant-menu-sub ant-menu-inline" data-menu-list"true" style"display:none;">…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

第 86 场周赛:矩阵中的幻方、钥匙和房间、将数组拆分成斐波那契序列、猜猜这个单词
Q1、[中等] 矩阵中的幻方 1、题目描述 3 x 3 的幻方是一个填充有 从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。 给定一个由整数组成的row x col 的 grid,其中有多少个 3 3 的 “幻方” 子矩阵&am…...
:邮件营销与用户参与度的关键指标优化指南)
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南
精益数据分析(97/126):邮件营销与用户参与度的关键指标优化指南 在数字化营销时代,邮件列表效度、用户参与度和网站性能等指标往往决定着创业公司的增长成败。今天,我们将深入解析邮件打开率、网站可用性、页面参与时…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...
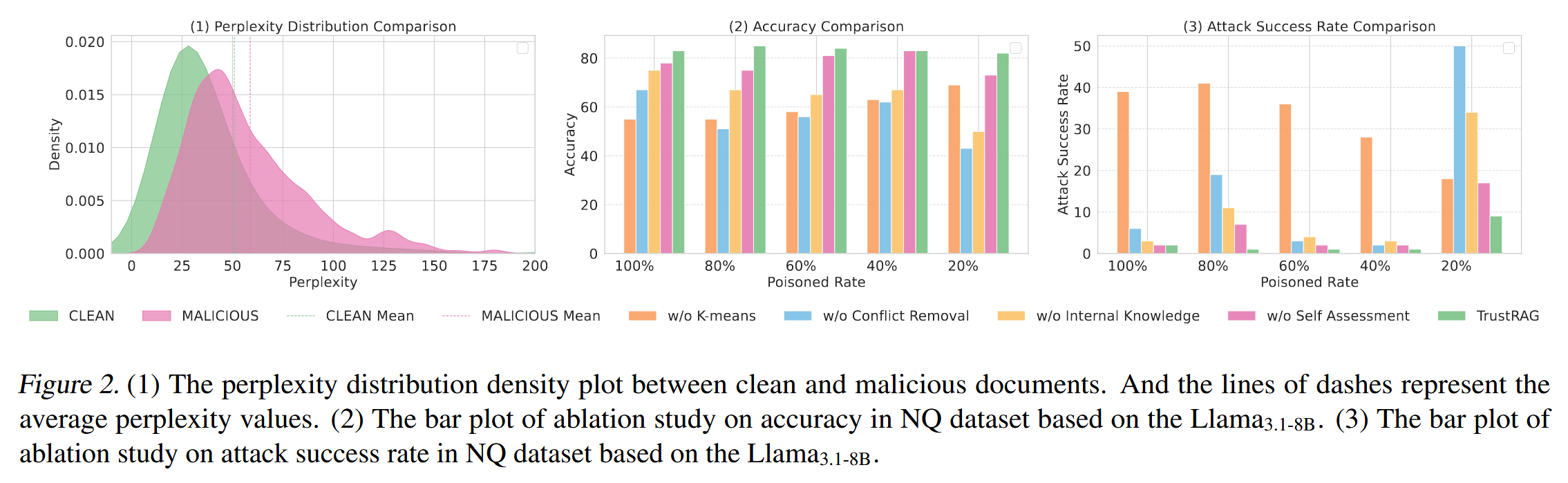
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...
6.9-QT模拟计算器
源码: 头文件: widget.h #ifndef WIDGET_H #define WIDGET_H#include <QWidget> #include <QMouseEvent>QT_BEGIN_NAMESPACE namespace Ui { class Widget; } QT_END_NAMESPACEclass Widget : public QWidget {Q_OBJECTpublic:Widget(QWidget *parent nullptr);…...

写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里
写一个shell脚本,把局域网内,把能ping通的IP和不能ping通的IP分类,并保存到两个文本文件里 脚本1 #!/bin/bash #定义变量 ip10.1.1 #循环去ping主机的IP for ((i1;i<10;i)) doping -c1 $ip.$i &>/dev/null[ $? -eq 0 ] &&am…...

python打卡第47天
昨天代码中注意力热图的部分顺移至今天 知识点回顾: 热力图 作业:对比不同卷积层热图可视化的结果 def visualize_attention_map(model, test_loader, device, class_names, num_samples3):"""可视化模型的注意力热力图,展示模…...
Copilot for Xcode (iOS的 AI辅助编程)
Copilot for Xcode 简介Copilot下载与安装 体验环境要求下载最新的安装包安装登录系统权限设置 AI辅助编程生成注释代码补全简单需求代码生成辅助编程行间代码生成注释联想 代码生成 总结 简介 尝试使用了Copilot,它能根据上下文补全代码,快速生成常用…...