Spark RDD的设计与运行原理
一、Spark RDD概念
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。RDD提供的转换接口都非常简单,都是类似map、filter、groupBy、join等粗粒度的数据转换操作,而不是针对某个数据项的细粒度修改。因此,RDD比较适合对于数据集中元素执行相同操作的批处理式应用,而不适合用于需要异步、细粒度状态的应用,比如Web应用系统、增量式的网页爬虫等。正因为这样,这种粗粒度转换接口设计,会使人直觉上认为RDD的功能很受限、不够强大。但是,实际上RDD已经被实践证明可以很好地应用于许多并行计算应用中,可以具备很多现有计算框架(比如MapReduce、SQL、Pregel等)的表达能力,并且可以应用于这些框架处理不了的交互式数据挖掘应用。
二、Spark RDD特征
Spark一切都是基于RDD的,RDD就是Spark输入的数据,作为输入数据的每个RDD有五个特征,其中分区、一系列的依赖关系和函数是三个基本特征,优先位置和分区策略是可选特征。
1,内存计算
Spark RDD运算数据是在内存中进行的,在内存足够的情况下,不会把中间结果存储在磁盘,所以计算速度非常高效。
2,惰性求值
所有的转换操作都是惰性的,也就是说不会立即执行任务,只是把对数据的转换操作记录下来而已。只有碰到action操作需要返回数据给驱动程序(driver program)的时候,他们才会被真正的执行。
3,容错性
Spark RDD具备容错特性,在RDD失效或者数据丢失的时候,可以根据DAG从父RDD重新把数据集计算出来,以达到数据容错的效果。
4,不变性
RDD是进程安全的,因为RDD是不可修改的。它可以在任何时间点被创建和查询,使得缓存,共享,备份都非常简单。在计算过程中,是RDD的不可修改特性保证了数据的一致性。
5,分区
分区是Spark RDD并行计算的基础。每个分区是对数据集的逻辑划分。可以对已存在的分区做某些转换操作创建新分区。
6,持久化
可以调用cache或者persist函数,把RDD缓存在内存、磁盘,下次使用的时候不需要重新计算而是直接使用。
7,粗粒度操作
通过使用map、filter、groupby等操作对RDD数据集进行集体操作。而不是只操作其中某些数据集元素。
8,数据本地化
Spark会把计算程序调度到尽可能离数据近的地方运行,即移动计算而不是移动数据。
三、Spark RDD 和 DSM
1,读写操作
RDD:RDD的读操作有粗粒度和细粒度两种,粗粒度操作针对的是RDD的整个数据集,相反,细粒度操作针对的是RDD数据集的个别元素。而写操作是粗粒度操作,即写的时候是整个数据集一起写,而不是只写其中的某个元素。
DSM:DSM的读写操作都是细粒度操作。
2,一致性
RDD: 一致性对于RDD来说没那么重要,因为它具有不可修改的特性,换句话说RDD是只读的。
DSM: DSM是强一致性的,如果开发者遵循开发协议,那么系统会保证数据的一致性,计算结果都是可预期的。
3,故障恢复机制
RDD : 如果RDD数据出现丢失情况,Spark RDD通过DAG很容易就可以从父RDD把丢失的数据重新计算出来。每一次进行转换操作生成的新RDD都是不可修改的,所以很容易对它进行重算并恢复数据。
DSM : DSM利用检查点技术达到数据恢复的效果,应用程序通过回滚到最近的检查点而不重新计算来达到数据恢复效果。
4,掉队问题缓解
有些节点的运算速度远远比其他节点慢,完成任务需要消耗更多的时间。发生这种情况的原因可能是负载不均衡,IO频繁,垃圾回收等等。
RDD - RDD通过备份task,即把task移到其他节点运行,来解决任务掉队问题。
DSM - 彻底解决掉队问题对于DSM来说比较困难。
5,内存不足的表现
如果没有足够的内存存储RDD,那么RDD会把数据转移到磁盘。
如果内存不够用,将会严重影响DSM的计算性能。它并不会把数据转移到磁盘。
四、Spark RDD的局限性
1,没有内置优化引擎
在处理结构化数据的时候,RDD并不能发挥Spark的高级优化器,比如catalyst优化器、钨丝执行引擎。开发者必须基于RDD的特征具体做优化。
2,处理结构化数据
RDD不能像DataFrame和数据集推断出数据的模型,必须开发者来指定。
3,性能局限性
作为内存里的JVM对象,随着数据量的增长,垃圾回收和Java序列化性能会越来越低,RDD的运算性能也会随之降低。
4,存储局限性
如果没有足够的内存存储RDD,Spark会把RDD溢写到磁盘,这样会导致计算性能低下。
五、Spark RDD依赖
Spark中RDD的数据结构里很重要的一个域是对父RDD的依赖,Spark中的依赖关系主要体现为两种形式,窄依赖(narrow dependency)和宽依赖(wide dependency)
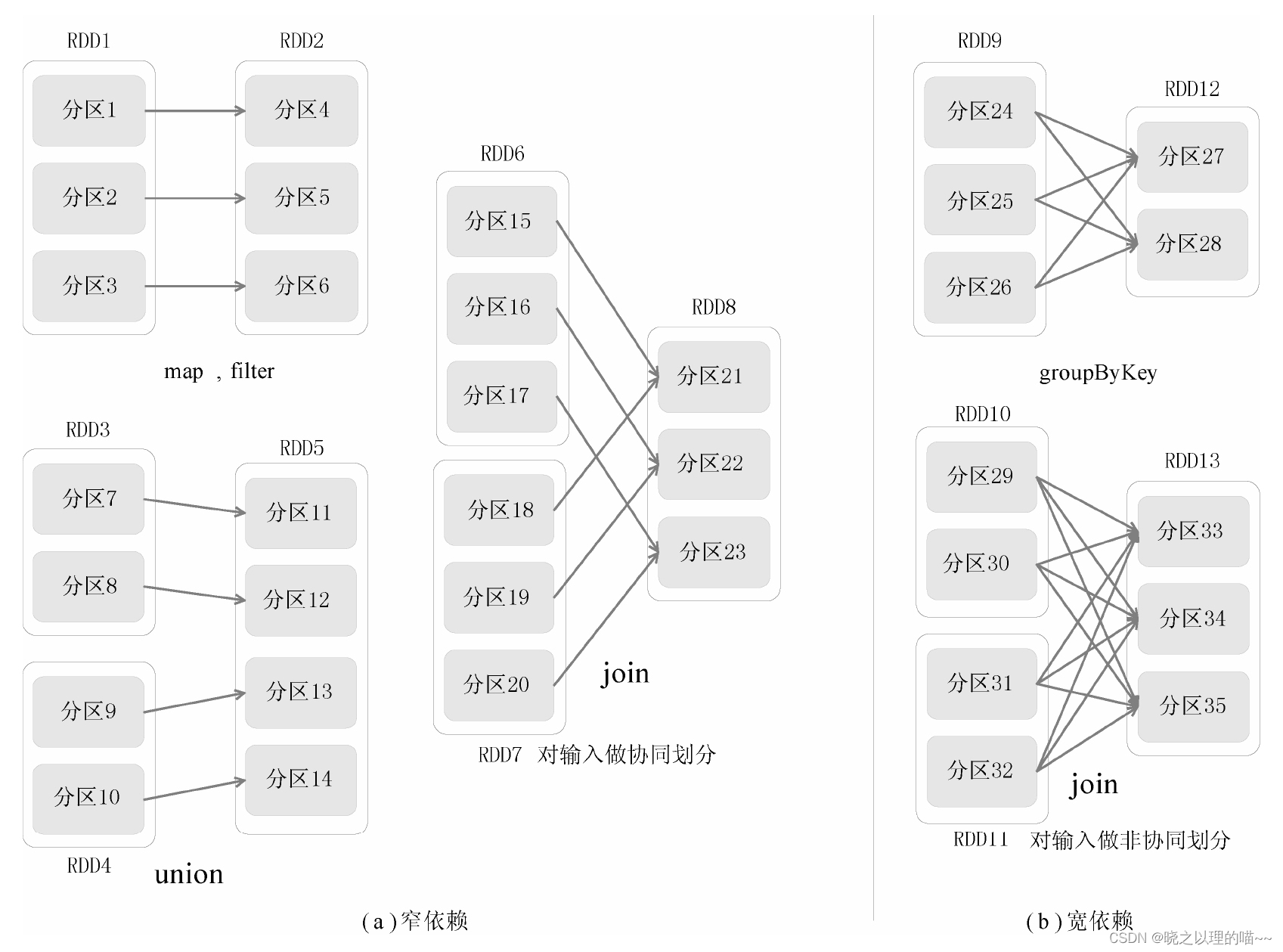
1,窄依赖
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;上图中,RDD1是RDD2的父RDD,RDD2是子RDD,RDD1的分区1,对应于RDD2的一个分区(即分区4);再比如,RDD6和RDD7都是RDD8的父RDD,RDD6中的分区(分区15)和RDD7中的分区(分区18),两者都对应于RDD8中的一个分区(分区21)。
窄依赖是指父RDD的每一个分区最多被一个子RDD的分区所用,表现为一个父RDD的分区对应于一个子RDD的分区(第一类),或多个父RDD的分区对应于一个子RDD的分区(第二类),也就是说一个父RDD的一个分区不可能对应一个子RDD的多个分区。
2,宽依赖
宽依赖表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。上图中,RDD9是RDD12的父RDD,RDD9中的分区24对应了RDD12中的两个分区(即分区27和分区28)。
宽依赖是指子RDD的每个分区都依赖于所有父RDD的所有分区或多个分区,也就是说存在一个父RDD的一个分区对应一个子RDD的多个分区。,
3,依赖之间的关系
RDD中不同的操作,会使得不同RDD分区之间产生不同的依赖关系。DAG调度器(DAGScheduler)根据RDD之间的依赖关系,把DAG图划分成若干个阶段。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),二者的主要区别在于是否包含Shuffle操作。
Spark中的一些操作会触发Shuffle过程,这个过程涉及数据的重新分发,因此,会产生大量的磁盘I/O和网络开销。这里以reduceByKey(func)操作为例介绍Shuffle过程。在reduceByKey(func)操作中,对于所有(key,value)形式的RDD元素,所有具有相同key的RDD元素的value会被归并,得到(key,value-list)的形式,然后,对这个value-list使用函数func计算得到聚合值,比如,(“hadoop”,1)、(“hadoop”,1)和(“hadoop”,1)这3个键值对,会被归并成(“hadoop”,(1,1,1))的形式,如果func是一个求和函数,可以计算得到汇总结果(“hadoop”,3)。

Shuffle过程不仅会产生大量网络传输开销,也会带来大量的磁盘I/O开销。Spark经常被认为是基于内存的计算框架,为什么也会产生磁盘I/O开销呢?对于这个问题,这里有必要做一个解释。
在Hadoop MapReduce框架中,Shuffle是连接Map和Reduce之间的桥梁,Map的输出结果需要经过Shuffle过程以后,也就是经过数据分类以后再交给Reduce处理,因此,Shuffle的性能高低直接影响了整个程序的性能和吞吐量。所谓Shuffle,是指对Map输出结果进行分区、排序、合并等处理并交给Reduce的过程。因此,MapReduce的Shuffle过程分为Map端的操作和Reduce端的操作。

(1)在Map端的Shuffle过程。Map的输出结果首先被写入缓存,当缓存满时,就启动溢写操作,把缓存中的数据写入磁盘文件,并清空缓存。当启动溢写操作时,首先需要把缓存中的数据进行分区,不同分区的数据发送给不同的Reduce任务进行处理,然后对每个分区的数据进行排序(Sort)和合并(Combine),之后再写入磁盘文件。每次溢写操作会生成一个新的磁盘文件,随着Map任务的执行,磁盘中就会生成多个溢写文件。在Map任务全部结束之前,这些溢写文件会被归并(Merge)成一个大的磁盘文件,然后,通知相应的Reduce任务来领取属于自己处理的那个分区数据。
(2)在Reduce端的Shuffle过程。Reduce任务从Map端的不同Map机器领回属于自己处理的那部分数据,然后,对数据进行归并(Merge)后交给Reduce处理。Spark作为MapReduce框架的一种改进,自然也实现了Shuffle的逻辑。
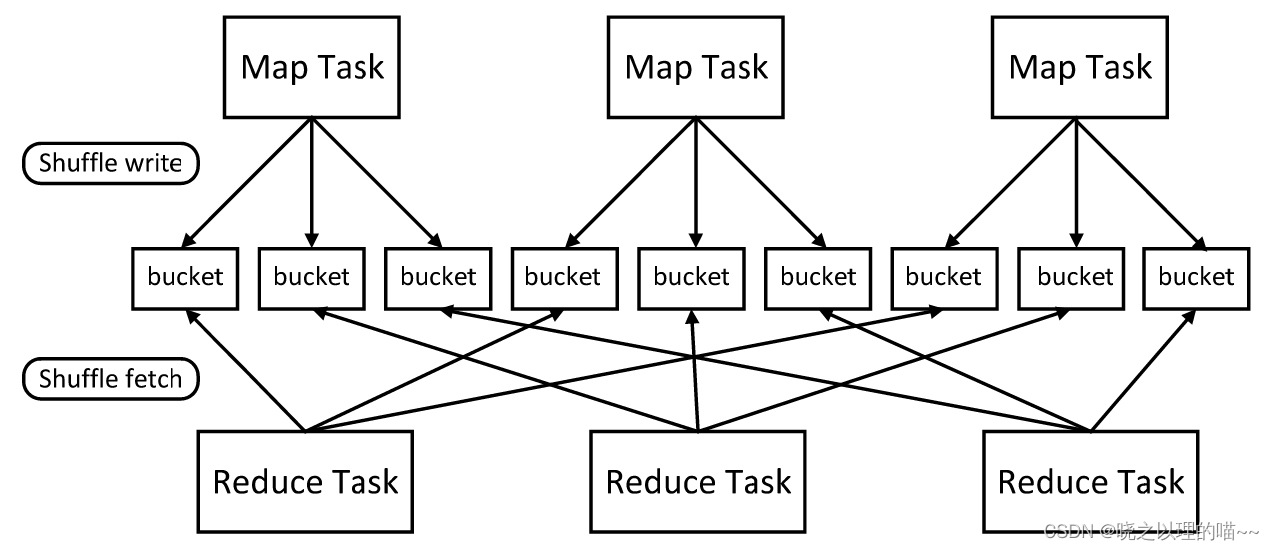
1)在Map端的Shuffle写入(Shuffle Write)方面。每一个Map任务会根据Reduce任务的数量创建出相应的桶(Bucket),因此,桶的数量是m×r,其中,m是Map任务的个数,r是Reduce任务的个数。Map任务产生的结果会根据设置的分区(partition)算法填充到每个桶中去。分区算法可以自定义,也可以采用系统默认的算法;默认的算法是根据每个键值对(key,value)的key,把键值对哈希到不同的桶中去。当Reduce任务启动时,它会根据自己任务的id和所依赖的Map任务的id,从远端或是本地取得相应的桶,作为Reduce任务的输入进行处理。
2)在Reduce端的Shuffle读取(Shuffle Fetch)方面。在Hadoop MapReduce的Shuffle过程中,在Reduce端,Reduce任务会到各个Map任务那里把数据自己要处理的数据都拉到本地,并对拉过来的数据进行归并(Merge)和排序(Sort),使得相同key的不同value按序归并到一起,供Reduce任务使用。这个归并和排序的过程,在Spark中是如何实现的呢?虽然Spark属于MapReduce体系,但是对传统的MapReduce算法进行了一定的改进。Spark假定在大多数应用场景中,Shuffle数据的排序操作不是必须的,比如在进行词频统计时,如果强制地进行排序,只会使性能变差,因此,Spark并不在Reduce端做归并和排序,而是采用了称为Aggregator的机制。Aggregator本质上是一个HashMap,里面的每个元素是<K,V>形式。以词频统计为例,它会将从Map端拉取到的每一个(key,value),更新或是插入HashMap中,若在HashMap中没有查找到这个key,则把这个(key,value)插入其中,若查找到这个key,则把value的值累加到V上去。这样就不需要预先把所有的(key,value)进行归并和排序,而是来一个处理一个,避免了外部排序这一步骤。但同时需要注意的是,Reduce任务所拥有的内存,必须足以存放属于自己处理的所有key和value值,否则就会产生内存溢出问题。因此,Spark文档中建议用户涉及这类操作的时候尽量增加分区的数量,也就是增加Map和Reduce任务的数量。增加Map和Reduce任务的数量虽然可以减小分区的大小,使得内存可以容纳这个分区。但是,在Shuffle写入环节,桶的数量是由Map和Reduce任务的数量决定的,任务越多,桶的数量就越多,就需要更多的缓冲区(Buffer),带来更多的内存消耗。因此,在内存使用方面,我们会陷入一个两难的境地,一方面,为了减少内存的使用,需要采取增加Map和Reduce任务数量的策略,另一方面,Map和Reduce任务数量的增多,又会带来内存开销更大的问题。最终,为了减少内存的使用,只能将Aggregator的操作从内存移到磁盘上进行。也就是说,尽管Spark经常被称为“基于内存的分布式计算框架”,但是,它的Shuffle过程依然需要把数据写入磁盘。
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其他RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
六、Spark RDD运行过程
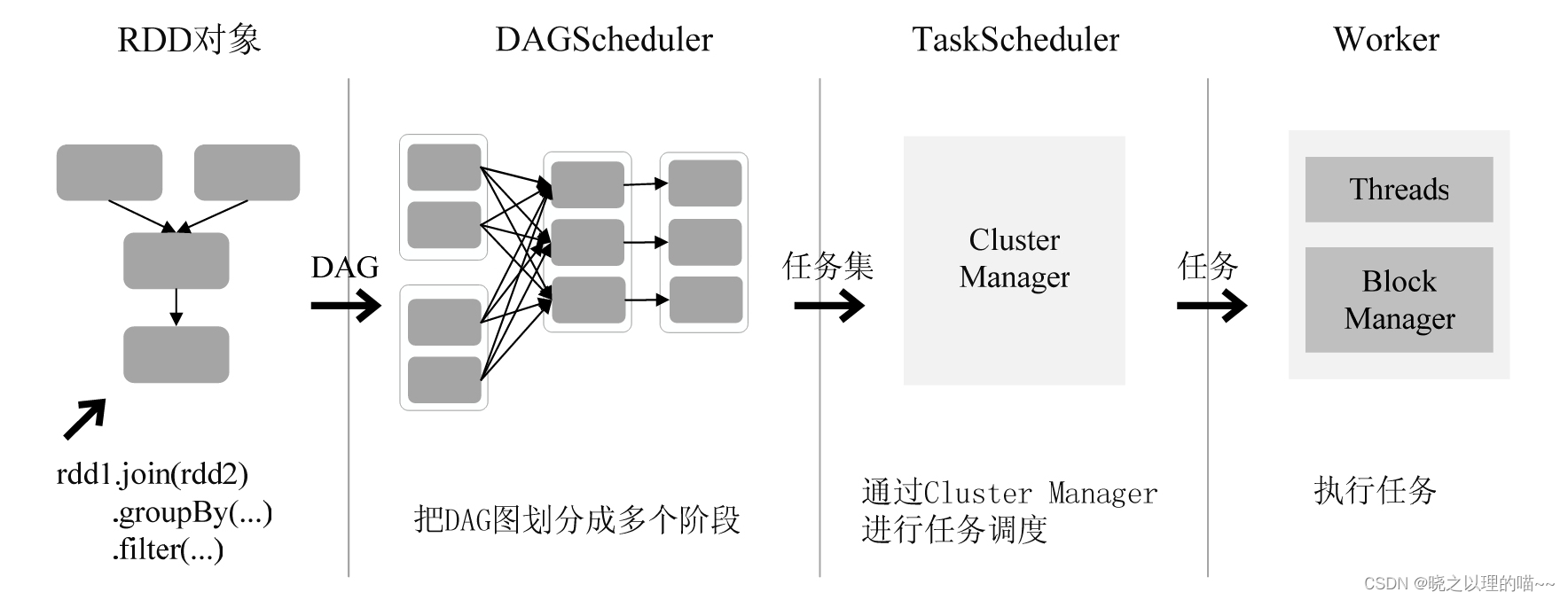
RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个任务,每个任务会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
文章来源:《Spark编程基础》 作者:林子雨
文章内容仅供学习交流,如有侵犯,联系删除哦!
相关文章:
Spark RDD的设计与运行原理
一、Spark RDD概念 一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段,并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的…...
Golang的下载与安装
Windows系统 进入golang官方下载网站:所有版本 - Go 编程语言如图所示 下载后打开您下载的 MSI 文件,然后按照提示安装 Go。 验证是否已安装 Go。...
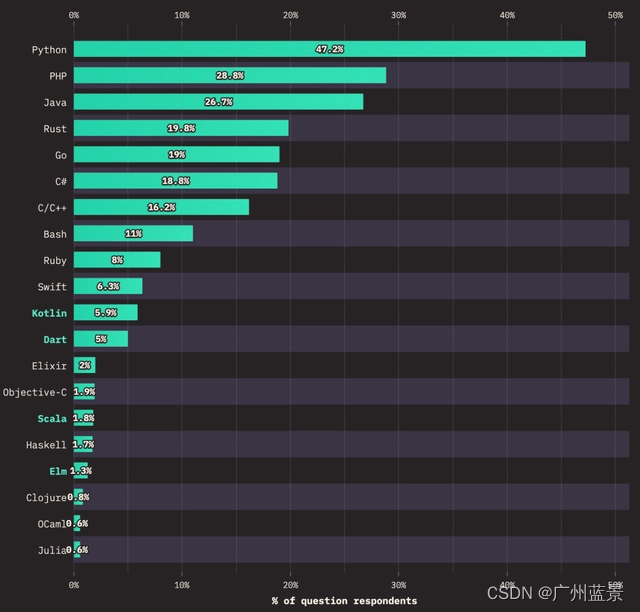
广州蓝景分享—8大Web前端开发的趋势
2023 年 1 月 11 日,2022 年度 StateOfJS 调查结果正式公布!StateOfJS 是前端生态圈中比较有影响力的且规模较大的数据调查。本文就来解读一下 2022 年 StateOfJS 的调查结果! JavaScript 发展很快,但似乎 JavaScript 开发人员的…...
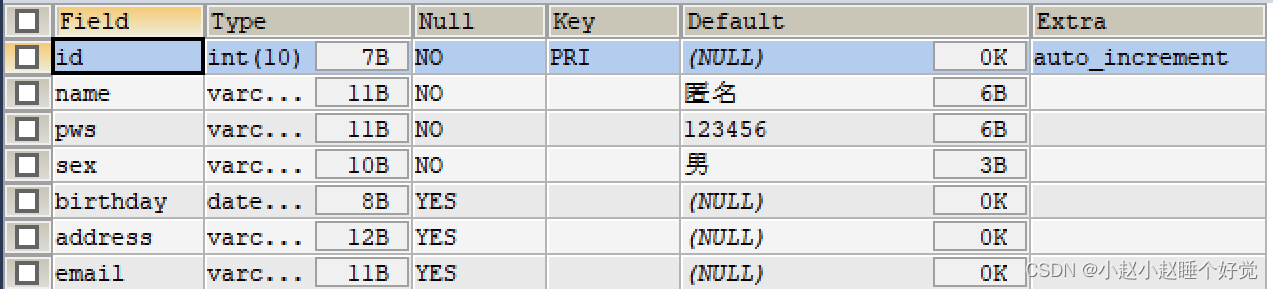
Java学习-MySQL-创建数据库表
Java学习-MySQL-创建数据库表 SHOW DATABASESUSE school CREATE TABLE IF NOT EXISTS student( id INT(10) NOT NULL AUTO_INCREMENT COMMENT 学号, name VARCHAR(30) NOT NULL DEFAULT 匿名 COMMENT 姓名, pws VARCHAR(20) NOT NULL DEFAULT 123456 COMMENT 密码, sex VARCHA…...

Ethercat学习-GD32以太网学习
文章目录1、GD32F4以太网简介2、以太网模框图简介3、以太网主要模块介绍SMI接口RMII接口与MII接口DMA控制器4、以太网配置流程5、其他1、GD32F4以太网简介 GD32F4系列以太网模块包含10/100Mbps以太网MAC,数据的收发都通过DMA进行操作,支持MII࿰…...
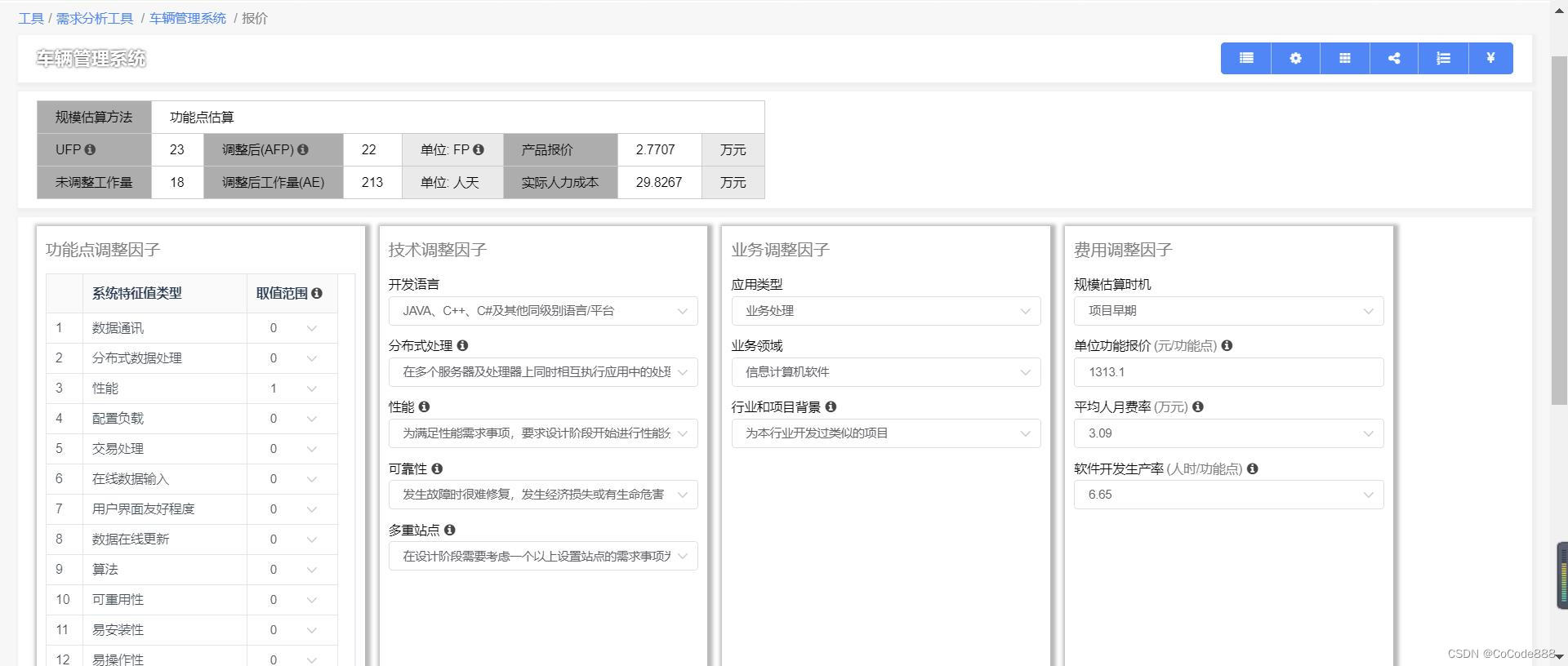
项目规模估算如何精准 4大注意事项
项目报价,需要首先进行项目规模估算,如何估算更精准,6大注意事项。 1、项目范围规划 在项目估算前,需要对项目范围进行规划,这包括所有活动以及开发可交付产品所需的流程。范围规划是前提,它明确定义了项目…...

低代码:助力乡村振兴事业开启“智慧模式”
伴随着脱贫攻坚目标任务的全面完成,我国“三农”工作重心历史性地转向全面推进乡村振兴,这也标志着我国农业农村工作迈上了一个新台阶。 什么是乡村振兴? 乡村振兴是新时代“三农”工作的总抓手,坚持农业农村优先发展,…...

Flutter——Isolate主线机制
简述 在DartFlutter应用程序启动时,会启动一个主线程其实也就是Root Isolate,在Root Isolate内部运行一个EventLoop事件循环。所以所有的Dart代码都是运行在Isolate之中的,它就像是机器上的一个小空间,具有自己的私有内存块和一个运行事件循…...
提取游戏《Limbus Company》(边狱公司)内素材
授人以鱼,不如授人以渔。 目录 注意事项 寻找音频文件 .bytes转为.fsb 必备工具 步骤 解决乱码 必备工具 步骤 提取.fsb文件 必备工具 可备工具 步骤 注意事项 文章关于出现乱码的处理方法和与编码相关的部分有误,已于2023/3/10更正。 相关…...
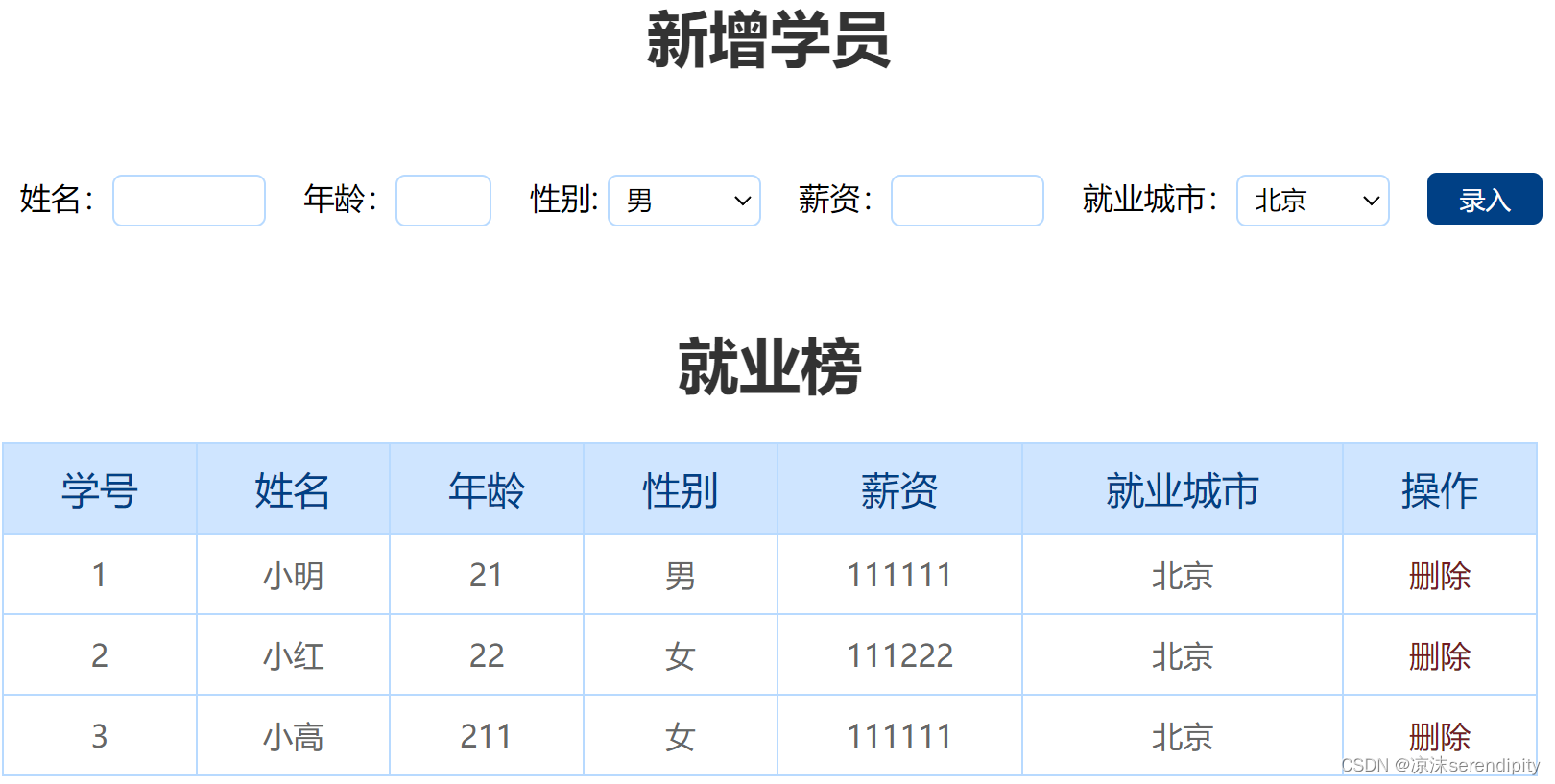
学生信息表
目录 一、功能说明 二、核心思想 三、所用知识回顾 四、基本框架 五、js功能实现部分 一、功能说明 (1)输入对应的信息,点击录入可以为下面的表格添加一条记录,注意当所填信息不完整时不允许进行提交。 (2&…...

FOTA在AUTOSAR中的应用
FOTA介绍 FOTA(Firmware Over-The-Air)移动终端的空中下载软件升级,指通过云端升级技术,为具有连网功能的设备:例如手机、平板电脑、便携式媒体播放器、移动互联网设备等提供固件升级服务,用户使用网络以按需、易扩展的方式获取智能终端系统升级包,并通过FOTA进行云端升…...
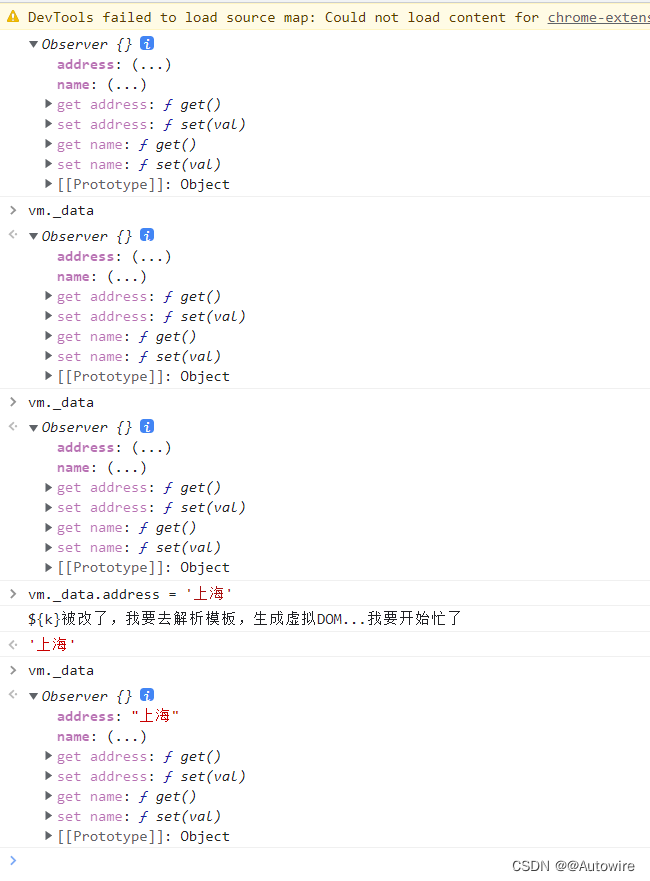
2023/3/10 Vue核心知识的学习- Vue - v-model双向绑定原理
https://www.jianshu.com/p/2682b5a26869 定义:vue中双向绑定就是指v-model指令,可以绑定一个响应式数据到视图,同时视图中变化能同步改变该值。 通过Object.defineProperty( )对属性设置一个set函数,当数据改变了就会来触发这个…...

面朝大海,春暖花开丨2023年Kaadas凯迪仕全国经销商大会成功召开
3月8日,We——2023年Kaadas凯迪仕全国经销商大会将在中国青岛星光岛会议中心隆重举行,盛会汇聚了超过1000名优秀合作伙伴,规模空前。Kaadas凯迪仕品牌创始人&集团总裁苏志勇先生、集团董事长苏祺云先生以及各高层领导均莅临现场。 大会伊…...

【ubuntu】安装cuda+anaconda的docker环境,并用Vscode远程访问
目录下载英伟达docker配置docker的基本安装环境为vscode安装ssh服务安装anaconda下载英伟达docker docker pull nvidia/cuda配置docker的基本安装环境 apt-get install sudo sudo apt-get update sudo apt-get install wget sudo ps -e|grep ssh为vscode安装ssh服务 sudo ap…...

Python(青铜时代)——容器类的公共方法
内置函数 内置函数:不需要使用 import 导入库,就可以直接使用的函数 函数描述备注len()计算容器中元素个数del( )删除变量max( )返回容器中元素最大值如果是字典,只针对key比较min( )返回容器中元素最小值如果是字典,…...

利用canvas给图片添加水印
前言前两天给个人网站添加了一个小功能,就是在文章编辑上传图片的时候自动给图片加上水印。给网页图片添加水印是个常见的功能,也是互联网内容作者保护自己版权的方法之一。本文简单记录一下借助canvas在前端实现图片添加水印的实现方法。canvas元素其实…...

保姆级使用PyTorch训练与评估自己的MobileViT网络教程
文章目录前言0. 环境搭建&快速开始1. 数据集制作1.1 标签文件制作1.2 数据集划分1.3 数据集信息文件制作2. 修改参数文件3. 训练4. 评估5. 其他教程前言 项目地址:https://github.com/Fafa-DL/Awesome-Backbones 操作教程:https://www.bilibili.co…...

Giscus,由 GitHub Discussions驱动的评论系统
在创建网站或博客时,许多人都希望能够为其内容提供评论功能,以与用户进行交流和互动。然而,实现这一点可能会非常复杂,需要处理许多不同的问题,如身份验证、反垃圾邮件、跨站脚本攻击等。为了帮助解决这些问题…...

【JSON文件解析】JSON文件
文章目录概要:本期主要介绍Qt解析JSON数据格式文件的方式。一、JSON数据格式1.JSON类似于XML,在JSON文件中,有且只有一个根节点2.JSON有两种主流包含型构造字符:{对象}、[数组]3.JSON的值主要包括:对象、数组、数字、字…...

OpenGL超级宝典学习笔记:纹理
前言 本篇在讲什么 本篇章记录对OpenGL中纹理使用的学习 本篇适合什么 适合初学OpenGL的小白 本篇需要什么 对C语法有简单认知 对OpenGL有简单认知 最好是有OpenGL超级宝典蓝宝书 依赖Visual Studio编辑器 本篇的特色 具有全流程的图文教学 重实践,轻理…...

如何将联系人从 iPhone 转移到 Android
从 iPhone 换到 Android 手机时,你可能需要保留重要的数据,例如通讯录。好在,将通讯录从 iPhone 转移到 Android 手机非常简单,你可以从本文中学习 6 种可靠的方法,确保随时保持连接,不错过任何信息。 第 1…...

SpringBoot+uniapp 的 Champion 俱乐部微信小程序设计与实现,论文初版实现
摘要 本论文旨在设计并实现基于 SpringBoot 和 uniapp 的 Champion 俱乐部微信小程序,以满足俱乐部线上活动推广、会员管理、社交互动等需求。通过 SpringBoot 搭建后端服务,提供稳定高效的数据处理与业务逻辑支持;利用 uniapp 实现跨平台前…...

【Java_EE】Spring MVC
目录 Spring Web MVC 编辑注解 RestController RequestMapping RequestParam RequestParam RequestBody PathVariable RequestPart 参数传递 注意事项 编辑参数重命名 RequestParam 编辑编辑传递集合 RequestParam 传递JSON数据 编辑RequestBody …...

深度学习习题2
1.如果增加神经网络的宽度,精确度会增加到一个特定阈值后,便开始降低。造成这一现象的可能原因是什么? A、即使增加卷积核的数量,只有少部分的核会被用作预测 B、当卷积核数量增加时,神经网络的预测能力会降低 C、当卷…...

AI病理诊断七剑下天山,医疗未来触手可及
一、病理诊断困局:刀尖上的医学艺术 1.1 金标准背后的隐痛 病理诊断被誉为"诊断的诊断",医生需通过显微镜观察组织切片,在细胞迷宫中捕捉癌变信号。某省病理质控报告显示,基层医院误诊率达12%-15%,专家会诊…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...

GO协程(Goroutine)问题总结
在使用Go语言来编写代码时,遇到的一些问题总结一下 [参考文档]:https://www.topgoer.com/%E5%B9%B6%E5%8F%91%E7%BC%96%E7%A8%8B/goroutine.html 1. main()函数默认的Goroutine 场景再现: 今天在看到这个教程的时候,在自己的电…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...