【CVPR2021】LoFTR:基于Transformers的无探测器的局部特征匹配方法
LoFTR:基于Transformers的局部检测器
0. 摘要
我们提出了一种新的局部图像特征匹配方法。我们建议先在粗略级别建立像素级密集匹配,然后再在精细级别细化良好匹配,而不是按顺序进行图像特征检测、描述和匹配。与使用成本体积搜索对应关系的密集方法相比,我们在 Transformer 中使用自注意力层和交叉注意力层来获得以两个图像为条件的特征描述符。Transformer 提供的全局感受野使我们的方法能够在低纹理区域产生密集匹配,在这些区域,特征检测器通常难以产生可重复的兴趣点。在室内和室外数据集上的实验表明,LoFTR的性能远远优于最先进的方法。在已发布的方法中,LoFTR在视觉定位的两个公共基准中也排名第一。
源码地址:https://github.com/zju3dv/LoFTR
论文下载地址:https://arxiv.org/pdf/2104.00680.pdf
效果如下:
LoFTR
1. 简介
- 图像之间的局部特征匹配是许多 3D 计算机视觉任务的基石,包括运动结构 (SfM)、同步定位和映射 (SLAM)、视觉定位等。给定要匹配的两个图像,大多数现有的匹配方法由三个独立的阶段组成:特征检测、特征描述和特征匹配。在检测阶段,首先将角点等突出点检测为每个图像的兴趣点。然后,在这些兴趣点的邻域区域周围提取局部描述符。特征检测和描述阶段产生两组带有描述符的兴趣点,其点对点对应关系稍后通过最近邻搜索或更复杂的匹配算法找到
- 使用特征检测器减少了匹配的搜索空间,并且产生的稀疏对应关系足以满足大多数任务,例如相机姿态估计。但是,特征检测器可能无法提取由于纹理不佳、重复图案、视点变化、照明变化和运动模糊等各种因素、图像之间可重复的那些足够的兴趣点。这个问题在室内环境中尤为突出,低纹理区域或重复图案有时会占据视野中的大部分区域。图 1 显示了一个示例。如果没有可重复的兴趣点,即使有完美的描述符,也不可能找到正确的对应关系

- 最近的一些论文试图通过建立像素密集匹配来解决这个问题。可以从密集匹配项中选择置信度分数高的匹配项,从而避免特征检测。然而,这些作品中卷积神经网络(CNNs)提取的密集特征具有有限的感受野,可能无法区分不明显的区域。取而代之的是,人类在这些不起眼的地区找到对应关系,不仅基于当地社区,而且具有更大的全局背景。例如,图1中的低纹理区域可以根据它们与边缘的相对位置来区分。这一观察结果告诉我们,特征提取网络中的大感受野至关重要
- 基于上述观察结果,我们提出了基于局部特征的TRansformer(LoFTR),这是一种新型的无探测器的局部特征匹配方法。受开创性工作 SuperGlue [37] 的启发,我们使用 Transformer 与自我和交叉注意力层来处理(转换)从卷积主干中提取的密集局部特征。首先以较低的特征分辨率(图像尺寸的 1/8)在两组变换的要素之间提取密集匹配。从这些密集匹配中选择具有高置信度的匹配项,然后使用基于相关性的方法细化到亚像素级别。Transformer 的全局感受野和位置编码使转换后的特征表示与上下文和位置相关。通过多次交错自我和交叉注意力层,LoFTR 学习了在真值匹配中表现出的密集排列的全局同意匹配先验。还采用了线性变压器,将计算复杂度降低到可管理的水平。
- 我们评估了所提出的方法在室内和室外数据集的多个图像匹配和相机姿态估计任务上。实验表明,LoFTR 的性能远远优于基于探测器和无探测器的特征匹配基线。LoFTR 还实现了最先进的性能,并在两个视觉本地化公共基准上在已发布的方法中排名第一。与基于探测器的基线方法相比,LoFTR 即使在纹理低、运动模糊或重复图案的不明显区域也能产生高质量的匹配。
2. 相关工作
2.1 基于检测器的局部特征匹配
- 基于检测器的局部特征匹配。基于检测器的方法一直是局部特征匹配的主要方法。在深度学习时代之前,许多著名作品在传统手工制作的本土特色上都取得了不错的成绩。SIFT 和 ORB可以说是最成功的手工制作的局部特征,在许多 3D 计算机视觉任务中被广泛采用。通过基于学习的方法,可以显著提高局部特征的大视点和照明变化的性能。值得注意的是,LIFT 和 MagicPoint 是首批成功的基于学习的本地功能之一。他们采用基于探测器的手工设计方法,并取得了良好的性能。SuperPoint[9]以MagicPoint为基础,提出了一种通过同形异义适应的自监督训练方法。沿这条线的许多基于学习的局部特征也采用了基于检测器的设计。
-上述局部要素使用最近邻搜索来查找提取的兴趣点之间的匹配项。最近,SuperGlue提出了一种基于学习的局部特征匹配方法。SuperGlue接受两组兴趣点及其描述符作为输入,并使用图神经网络(GNN)学习它们的匹配,GNN是Transformers的一般形式。由于可以通过数据驱动的方法学习特征匹配中的先验,因此 SuperGlue 实现了令人印象深刻的性能,并在局部特征匹配方面开创了新的技术水平。然而,作为一种依赖于探测器的方法,它有一个根本的缺点,即无法检测无特征区域中的可重复兴趣点。SuperGlue 的注意力范围也仅限于检测到的兴趣点。我们的工作受到 SuperGlue 的启发,在 GNN 中使用自注意力和交叉注意力在两组描述符之间传递消息,但我们提出了一种无检测器设计,以避免特征检测器的缺点。我们还在 Transformer 中使用了注意力层的高效变体来降低计算成本
2.2 无检测器局部特征匹配
- 无检测器方法消除了特征检测器阶段,直接生成密集描述符或密集特征匹配。密集特征匹配的想法可以追溯到SIFT Flow。是第一个基于学习的方法,用于学习具有对比损失的像素特征描述符。与基于检测器的方法类似,最近邻搜索通常用作后处理步骤,以匹配密集描述符。NCNet提出了一种不同的方法,即以端到端的方式直接学习密集的对应关系。它构造 4D 成本体积以枚举图像之间所有可能的匹配项,并使用 4D 卷积来规范成本量并在所有匹配项之间强制邻域共识。稀疏NCNet 改进了NCNet,使其在处理稀疏卷积时更加高效。在我们的工作的同时,DRC-Net 遵循了这一工作思路,并提出了一种从粗到细的方法,以产生具有更高精度的密集匹配。尽管所有可能的匹配都包含在 4D 成本体积中,但 4D 卷积的感受场仍然局限于每个匹配的邻域区域。除了邻里共识之外,我们的工作重点是借助变形金刚中的全局感受野实现匹配之间的全局共识,这在 NCNet 及其后续作品中没有得到利用。还有学者提出了 SfM 与内窥镜视频的密集匹配管道。最近的研究方向侧重于桥接局部特征匹配和光流估计的任务,也与我们的工作有关
2.3 视觉任务中的transformer
- Transformer 已成为自然语言处理 (NLP) 中序列建模的事实标准,因为它们的简单性和计算效率。最近,Transformers在计算机视觉任务中也越来越受到关注,例如图像分类,目标检测和语义分割。在我们的工作的同时,建议使用Transformer进行视差估计。由于查询和关键向量之间的乘法,vanilla Transformer 的计算成本与输入序列的长度呈二次增长。最近在处理长语言序列的背景下提出了许多有效的变体。由于这些作品中没有假设输入数据,因此它们也非常适合处理图像
3. 方法
-
在图像对 A和 B中,现有的局部特征匹配方法使用特征检测器来提取兴趣点。我们建议通过无探测器设计来解决特征探测器的可重复性问题。图2给出了所提出的LoFTR方法的概述。
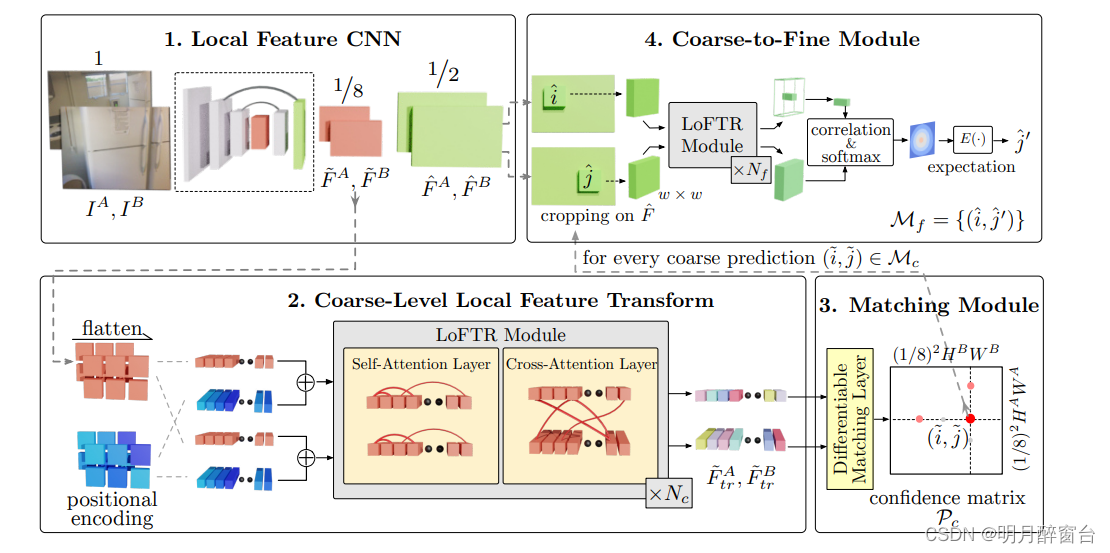
-
图2:所提方法概述,LoFTR 有四个组件:
- 1.局部特征 CNN 从图像对 I A 和 I B 中提取粗级特征图 F ̃A 和 F ̃B,以及精细特征图 FˆA 和 FˆB(第 3.1 节)。
-
- 将粗略的特征图展平化为一维向量,并添加位置编码。然后,添加的特征由局部特征 TRansformer (LoFTR) 模块处理,该模块具有 Nc 自注意力和交叉注意力层(第 3.2 节)。
-
- 使用可微匹配层来匹配变换后的特征,最终得到置信矩阵 Pc。根据置信度阈值和互近邻条件选择 Pc 中的匹配项,生成粗略匹配预测 Mc(第 3.3 节)。
-
- 对于每个选定的粗略预测 ( ̃i, ̃j) ∈ Mc,将从精细级特征图中裁剪出一个大小为 w × w 的局部窗口。粗略匹配将在此本地窗口中细化为亚像素级别,作为最终匹配预测 Mf(第 3.4 节)。
3.1 局部特征提取
- 我们使用带有 FPN(表示为局部特征 CNN)的标准卷积架构来提取来自两个图像的多级特征。我们使用 F ̃A 和 F ̃B 表示原始图像尺寸 1/8 处的粗级特征,FˆA 和 FˆB 表示原始图像尺寸 1/2 处的精细级特征
- 卷积神经网络(CNNs)具有平移等方差和局部性的归纳偏差,非常适合局部特征提取。CNN引入的下采样还减少了LoFTR模块的输入长度,这对于确保可控的计算成本至关重要。
3.2 3.2. Local Feature Transformer (LoFTR) 模块
- 局部特征提取后,F ̃A 和 F ̃B 通过 LoFTR 模块提取与位置和上下文相关的局部特征。直观地说,LoFTR 模块将特征转换为易于匹配的特征表示。我们将变换后的特征表示为 F ̃A tr 和 F ̃B tr 。
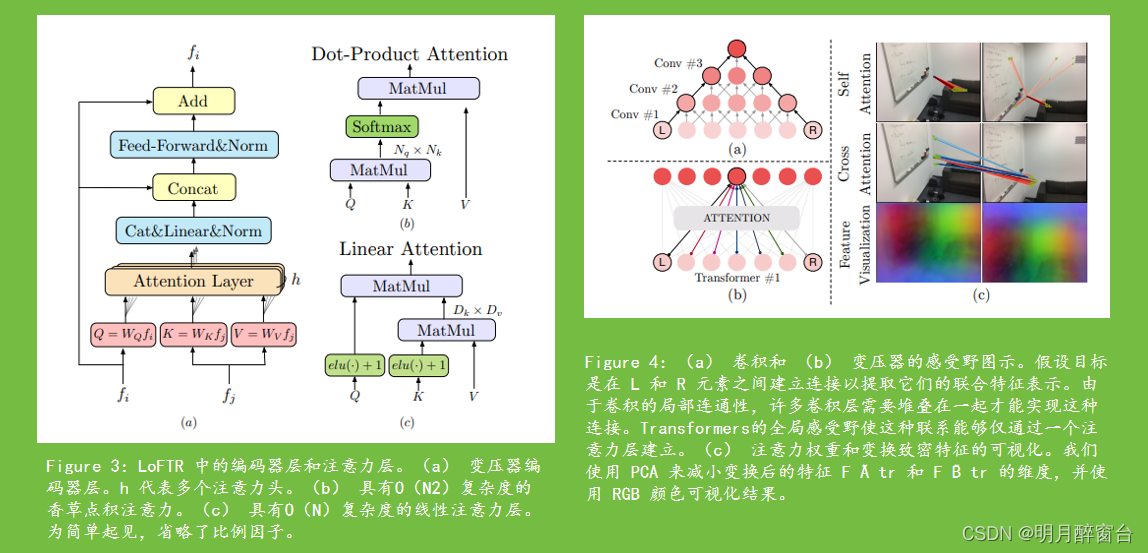
- 初步:Transformer: 我们首先在这里简单介绍一下 Transformer 作为背景。Transformer 编码器由顺序连接的编码器层组成。图3(a)显示了编码器层的结构。
- 编码器层中的关键要素是注意力层。注意图层的输入向量通常命名为 query、key 和 value。与信息检索类似,查询向量 Q 根据从 Q 的点积计算出的注意力权重和每个值 V 对应的键向量 K 从值向量 V 中检索信息。注意力层的计算图如图3(b)所示。从形式上讲,注意力层表示为:

- 直观地说,注意力操作通过测量查询元素与每个关键元素之间的相似性来选择相关信息。输出向量是按相似性分数加权的价值向量的总和。因此,如果相似度很高,则从值向量中提取相关信息。这个过程在图神经网络中也称为“消息传递”。
- 线性 Trandformer: 将 Q 和 K 的长度表示为 N,它们的特征维度表示为 D,Transformer 中 Q 和 K 之间的点积引入了计算成本,该成本随输入序列的长度呈二次增长 (O(N2 ))。在局部特征匹配的上下文中直接应用原版的 Transformer 是不切实际的,即使输入长度被局部特征 CNN 减少也是如此。为了解决这个问题,我们建议在 Transformer 中使用原版注意力层的有效变体。Linear Transformer 提出将原注意力层中使用的指数核替换为替代核函数 sim(Q, K) = φ(Q) ·φ(K) T ,其中 φ(·) = elu(·) + 1。图3(c)中的计算图说明了该操作。
- 利用矩阵产物的缔合性,可以先进行φ(K)T和V之间的乘法。由于 D ≪ N,计算成本降低到 O(N)。
- 位置编码: 我们在 DETR [3] 之后的 Transformer 中使用标准位置编码的 2D 扩展。与 DETR 不同的是,我们只将它们添加到主干输出中一次。我们将位置编码的正式定义留在补充材料中。直观地说,位置编码以正弦格式为每个元素提供唯一的位置信息。通过将位置编码添加到 F ̃A 和 F ̃B,转换后的特征将变得与位置相关,这对于 LoFTR 在非显着区域生成匹配的能力至关重要。如图4(c)的底行所示,尽管输入的RGB颜色在白墙上是均匀的,但转换后的特征F ̃A tr和F ̃B tr对于平滑的颜色渐变所展示的每个位置都是唯一的。图 6 中提供了更多可视化效果。
- Self-attention and Cross-attention Layers。对于自注意力层,输入特征 fi 和 fj(如图 3 所示)相同(F ̃A 或 F ̃B)。对于交叉注意力层,输入特征 fi 和 fj 是 (F ̃A 和 F ̃B) 或 (F ̃B 和 F ̃A),具体取决于交叉注意力的方向。在[37]之后,我们通过Nc时间交错LoFTR模块中的自我和交叉注意力层。LoFTR中自我和交叉注意力层的注意力权重在图4(c)的前两行中可视化。
3.3 建立粗级匹配
- 在LoFTR中可以应用两种类型的可微匹配层,一种是最优传输(OT)层,另一种是双softmax算子。变换特征之间的得分矩阵 S 首先由 S (i, j) = 1 τ ·hF ̃A tr (i), F ̃B tr (j)i.当与OT匹配时,−S可以用作部分分配问题的成本矩阵,如[37]所示。我们还可以在 S 的两个维度上应用 softmax(在下文中称为 dual-softmax)来获得软互最近邻匹配的概率。正式地,当使用dual-softmax时,匹配概率Pc由以下方式获得:

- 匹配选择: 基于置信矩阵 Pc,我们选择置信度高于 θc 阈值的匹配项,并进一步执行互最近邻 (MNN) 标准,该标准过滤可能的异常粗略匹配项。我们将粗略级别的匹配预测表示为:

3.4. 从粗到细模块
- 建立粗略匹配后,使用粗细模块将这些匹配细化为原始图像分辨率。受 [50] 的启发,我们为此使用了基于相关性的方法。对于每个粗略匹配 ( ̃i, ̃j),我们首先在精细级特征图 FˆA 和 FˆB 上定位其位置 (ˆi, ˆj),然后裁剪两组大小为 w × w 的局部窗口。然后,较小的 LoFTR 模块将每个窗口内的裁剪要素按 Nf 倍进行变换,从而生成两个分别以 ˆi 和 ˆj 为中心的变换后的局部特征图 FˆA tr (ˆi) 和 FˆB tr (ˆj)。然后,我们将 FˆA tr (ˆi) 的中心向量与 FˆB tr (ˆj) 中的所有向量相关联,从而生成一个热图,表示 ˆj 与 ˆi 邻域中每个像素的匹配概率。通过计算对概率分布的期望,我们得到了 I B 上具有亚像素精度的最终位置 ˆj ′。 收集所有匹配项 {(ˆi, ˆj ′ )} 生成最终精细级匹配项 Mf 。
3.5. 监督
- 最终损失由粗级和细级的损失组成:L = Lc + Lf 。
- 粗略级监督: 粗层的损失函数是最佳传输层或双 softmax 算子返回的置信矩阵 Pc 上的负对数似然损失。我们遵循 SuperGlue 使用相机姿势和深度图来计算训练期间置信矩阵的真值标签。我们将真值粗匹配Mgt_c定义为两组1/8分辨率的互近邻网 格。两个格网之间的距离通过其中心位置的重新投影距离来衡量。补充文件提供了更多详细信息。对于最佳输运层,我们使用与[37]相同的损耗公式。当使用 dual-softmax 进行匹配时,我们最小化了网格上的负对数似然损失,以 Mgt_c 为单位:
- 精细监督。我们使用 l2 损失进行精细化。在 [50] 之后,对于每个查询点 ˆi,我们还通过计算相应热图σ的总方差 2 (ˆi) 来衡量其不确定性。目标是优化具有低不确定性的精细仓位,从而得到最终的加权损失函数:
- 其中 ˆj ′ gt 是通过将每个 ˆi 从 FˆA tr (ˆi) warp 到 FˆB tr (ˆj) 来计算的,具有地面实况相机姿态和深度。在计算 Lf 时,如果 ˆi 的warp位置落在 FˆB tr (ˆj) 的局部窗口之外,则忽略 (ˆi, ˆj ′ )。在训练期间,梯度不会通过σ 2 (ˆi) 反向传播。
3.6 实施细节
我们在 ScanNet 数据集上训练 LoFTR 的室内模型,在 MegaDepth 上训练室外模型 。在 ScanNet 上,使用 Adam 训练模型,初始学习率为 1 × 10−3,批处理大小为 64。在 64 个 GTX 1080Ti GPU 上训练 24 小时后,它会收敛。本地功能CNN使用ResNet-18 [12]的修改版本作为主干。整个模型使用随机初始化的权重进行端到端训练。Nc 设置为 4,Nf 为 1。θc 被选为 0.2。窗口大小 w 等于 5。F ̃A tr 和 F ̃B tr 在实现中通过精细级 LoFTR 之前,先对 F ̃A 和 F ̃B 进行上采样并连接。在RTX 2080Ti上,具有dualsoftmax匹配的完整型号在640×480图像对上的运行速度为116 ms。在最佳传输设置下,我们使用了三个 sinkhorn 迭代,模型以 130 毫秒的速度运行。我们建议读者参考补充材料,了解有关训练和时间分析的更多详细信息。
4. 实验
4.1 单调估计
-
在第一个实验中,我们在广泛采用的 HPatches 数据集 上评估了 LoFTR 以进行单调估计。HPatches 包含 52 个在显著照明变化下的序列和 56 个在视点上表现出较大变化的序列。
-
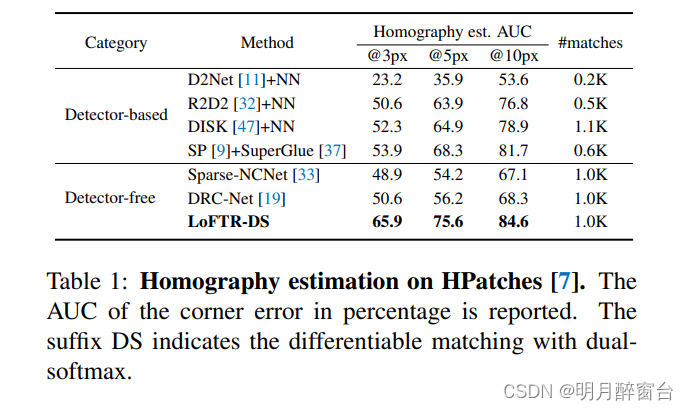
评估协议: 在每个测试序列中,一个参考图像与其余五个图像配对。所有图像的大小都调整为等于 480 的较短尺寸。对于每个图像对,我们提取一组在MegaDepth [21]上训练的LoFTR匹配项。我们使用 OpenCV 以 RANSAC 作为鲁棒估计器来计算单调估计。为了与产生不同匹配数量的方法进行公平的比较,我们计算了使用估计的 Hˆ 扭曲的图像与作为正确性标识符的真值 H 之间的角误差,如 [9] 所示。在 [37] 之后,我们报告了拐角误差的累积曲线下面积 (AUC),分别达到 3、5 和 10 像素的阈值。我们报告最多 1K 输出匹配的 LoFTR 结果。
-
基线方法:我们将LoFTR与三类方法进行了比较:1)基于检测器的局部特征,包括R2D2 、D2Net和DISK ,2)基于检测器的局部特征匹配器,即SuperPoint 特征之上的SuperGlue ,以及3)无检测器匹配器,包括Sparse-NCNet [33]和DRC-Net 。对于局部特征,我们提取最多 2K 的特征,我们提取相互最近邻作为最终匹配项。对于直接输出匹配的方法,我们限制最多 1K 匹配,与 LoFTR 相同。我们在原始实现中对所有基线使用默认超参数
-
表 1 显示,在所有误差阈值下,LoFTR 明显优于其他基线。具体而言,LoFTR 与其他方法之间的性能差距随着更严格的正确性阈值而增加。我们将最佳性能归因于无探测器设计提供的更多匹配候选和Transformer带来的全局感受野。此外,从粗到细模块还通过将匹配细化到亚像素级别来提高估计精度
4.2. 相对姿态估计
-
数据。我们使用 ScanNet 和 MegaDepth 分别在室内和室外场景中来证明 LoFTR 在姿态估计方面的有效性。
-
ScanNet 包含 1613 个单目序列,带有地面实况姿势和深度图。按照 SuperGlue 的程序,我们对 230M 图像对进行采样进行训练,重叠分数在 0.4 到 0.8 之间。我们在 [37] 的 1500 个测试对上评估了我们的方法。所有图像和深度图的大小都调整为 640 × 480。该数据集包含具有宽基线和广泛无纹理区域的图像对。
-
MegaDepth 由 196 个不同户外场景的 1M 互联网图像组成。作者还提供了COLMAP[40]的稀疏重建和从多视图立体计算的深度图。我们遵循DISK [47],仅使用“圣心大教堂”和“圣彼得广场”的场景进行验证,我们从中抽取了1500对进行公平比较。调整图像大小,使其较长的尺寸等于 840(用于训练)和 1200(用于验证)。MegaDepth 的主要挑战是在极端的视点变化和重复模式下进行匹配
-
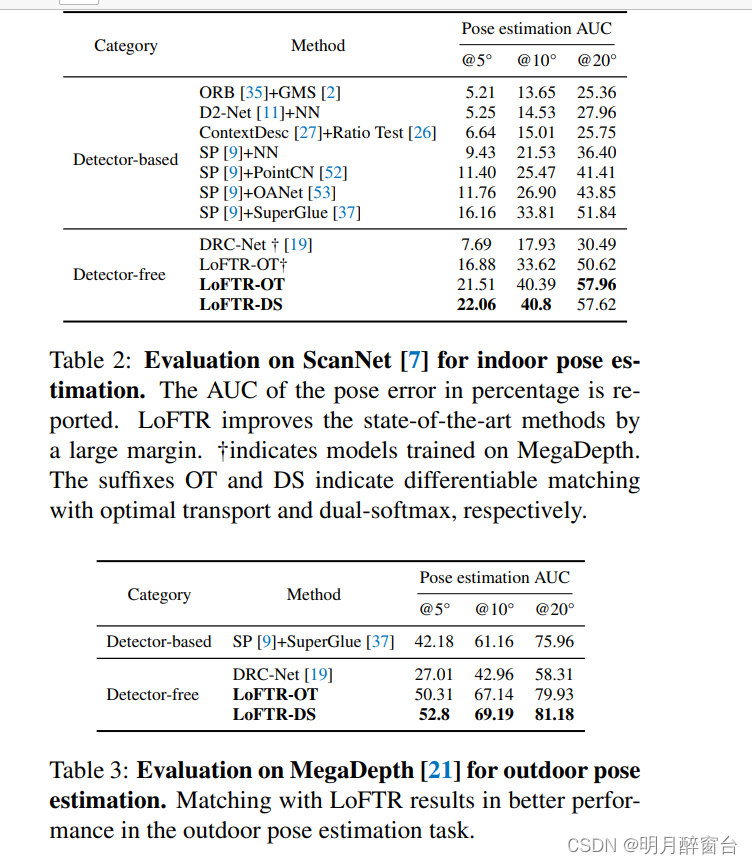
评估协议。在[37]之后,我们报告了阈值(5◦,10◦,20◦)处的姿态误差的AUC,其中姿态误差定义为旋转和平移中角度误差的最大值。为了恢复相机姿势,我们从与 RANSAC 的预测匹配中求解基本矩阵。由于缺少孔,我们没有比较 LoFTR 和其他基于探测器的方法之间的匹配精度为无检测器图像匹配方法定义的指标(例如,匹配分数或召回率 [13, 30])。我们认为DRCNet[19]是无探测器方法[34,33]中最先进的方法。

-
室内姿态估计结果。与所有竞争对手相比,LoFTR 在姿势精度方面取得了最佳性能(见表 2 和图 5)。将 LoFTR 与最佳传输或双 softmax 配对作为可微分匹配层可实现相当的性能。由于DRC-Net†的已发布模型是在MegaDepth上训练的,因此我们提供了在MegaDepth上训练的LoFTR的结果†以便进行公平的比较。在本次评估中†LoFTR†也大大优于DRC-Net(见图5),这表明我们的模型在数据集中的泛化性。
-
户外姿态估计结果。如表 3 所示,LoFTR 在 AUC@10° 时比无探测器方法 DRC-Net 性能高出 61%,证明了 Transformer 的有效性。对于 SuperGlue,我们使用开源本地化工具箱 HLoc [36] 中的设置。LoFTR的性能远远优于SuperGlue(AUC@10°时为13%),这证明了无探测器设计的有效性。与室内场景不同,LoFTR-DS在MegaDepth上的性能优于LoFTR-OT。更多的定性结果可以在图5中找到。
4.3. 视觉定位
-
视觉定位。除了在相对姿态估计方面实现具有竞争力的性能外,LoFTR 还可以实现视觉定位,这是估计给定图像相对于相应 3D 场景模型的 6 自由度姿态的任务。我们在长期视觉定位基准[43](下文中称为VisLoc基准)上评估LoFTR。它侧重于对不同条件下的视觉定位方法进行基准测试,例如昼夜变化、场景几何变化以及具有大量无纹理区域的室内场景。因此,视觉定位任务依赖于高度稳健的图像匹配方法
-
评估。我们在 VisLoc 的两条轨道上评估了 LoFTR,这些轨道包含几个挑战。首先,“手持设备的视觉定位”轨道需要完整的本地化管道。它基于两个数据集进行基准测试,即关于室外场景的AachenDay-Night数据集[38,54]和关于室内场景的InLoc [41]数据集。我们使用开源本地化管道 HLoc [36] 和 LoFTR 提取的匹配项。其次,“用于长期本地化的局部特征”轨道提供了一个固定的定位管道,用于评估局部特征提取器本身和匹配器(可选)。该跟踪使用亚琛 v1.1 数据集 [54]。我们在补充材料中提供了在 VisLoc 上测试 LoFTR 的实现细节。

-
结果。我们在表 4 和表 5 中提供了 LoFTR 的评估结果。我们已经评估了与最佳传输层或双软最大算子的 LoFTR 配对,并报告了结果更好的那个。LoFTR-DS 在局部特征挑战轨道中优于所有基线,显示出其在昼夜变化下的鲁棒性。然后,对于手持设备轨道的视觉定位,LoFTR-OT 在具有挑战性的 InLoc 数据集上优于所有已发布的方法,该数据集包含广泛的外观变化、更多无纹理区域、对称和重复元素。我们将这一突出性归因于Transformer和最佳传输层的使用,利用全球信息,共同将全球共识带入决赛。无探测器设计也起着关键作用,防止了基于探测器的方法在低纹理区域的可重复性问题。LoFTR-OT 在亚琛 v1.1 数据集的夜间查询中的表现与最先进的方法 SuperPoint + SuperGlue 相当,但在白天查询时表现稍差。
4.4. 了解 LoFTR
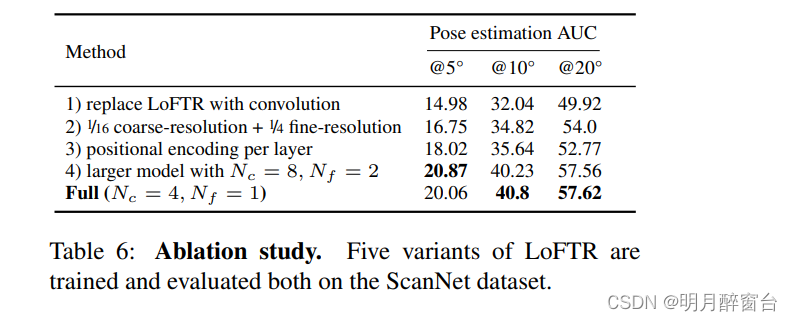
- 消融研究。为了充分了解 LoFTR 中的不同模块,我们评估了五种不同的变体,结果如表 6 所示:1) 用具有相当数量的参数卷积替换 LoFTR 模块会导致 AUC 显着下降,正如预期的那样。2) 使用较小版本的 LoFTR,分别具有 1/16 和 1/4 分辨率的粗细级特征图,导致运行时间为 104 ms,姿态估计精度下降。3) 使用 DETR 风格的 [3] Transformer 架构,该架构在每层都有位置编码,导致结果明显下降。4) 通过将 LoFTR 层数增加一倍至 Nc = 8 和 Nf = 2 来增加模型容量几乎不会改变结果。我们使用与ScanNet上的室内姿态估计相同的训练和评估协议进行这些实验,并具有最佳传输层进行匹配。
- 可视化注意力。我们在图 6 中可视化了注意力权重。

相关文章:
【CVPR2021】LoFTR:基于Transformers的无探测器的局部特征匹配方法
LoFTR:基于Transformers的局部检测器 0. 摘要 我们提出了一种新的局部图像特征匹配方法。我们建议先在粗略级别建立像素级密集匹配,然后再在精细级别细化良好匹配,而不是按顺序进行图像特征检测、描述和匹配。与使用成本体积搜索对应关系的密…...

总结一下 C# 如何自定义特性 Attribute 并进行应用
前言 Attribute(特性)是一种用于为程序元素(如类、方法、属性等)提供元数据信息的方法。 特性是一种声明式的信息,附加到程序元素上,提供额外的数据用于描述和控制这些元素的行为。 在编译和运行时&…...

三种暴露方法和引入方式
1.分别暴露 export ...export...用于按需导出一个或多个模块,在导入时需要使用花括号指定导入的模块名称,例如import { a, b } from module module.js中 export let a 1 export function b(){console.log(hello,vue) } 2.统一暴露 export { ...}用于统…...
“Git之道:掌握常用命令,轻松管理代码“
目录 1. 初始化和配置 2. 提交和更新 3. 分支和合并 4. 查看和比较 5. 远程仓库 6. 文件操作命令 1. 初始化和配置 git init:在当前目录初始化一个新的Git仓库git config:配置Git的全局或局部选项git clone:从远程仓库克隆一个本地副本…...

Linux vim 文本编辑 操作文本 三种模式
介绍 vi 是一个经典的行编辑器,支持模式编辑(包括普通模式、插入模式和命令模式)。 vim 保留vi核心功能的基础上,增加了多级撤销、语法高亮、插件支持等高级功能。 两者的最大区别,简单的来说vim就是vi的增强版 三…...
JavaFX DatePicker
JavaFX DatePicker允许从给定日历中选择一天。DatePicker控件包含一个带有日期字段和日期选择器的组合框。JavaFX DatePicker控件使用JDK8日期时间API。 import javafx.application.Application; import javafx.scene.Scene; import javafx.scene.control.DatePicker; import j…...

开展“安全生产月”活动向媒体投稿的好方法找到了
作为一名单位的信息宣传员,我的职责是确保每一次重要活动的声音都能准确无误地传达到社会的每一个角落。在这样的使命驱动下,我曾一度陷入了一种传统的投稿模式——依赖电子邮件,将精心准备的稿件一封封地发送给各大媒体。初入此行,我满心以为这便是信息传播的路径,却未料到,这…...

商讯杂志商讯杂志社商讯编辑部2024年第10期目录
案例分享 基于胜任素质的干部选拔和梯队建设体系探讨——以A区卫生健康系统为例 康文雁; 1-4 “家庭五险一金”对居民商业保险购买存在挤出效应——基于江苏省徐州、淮安、泰州三市的实证研究 李炳毅; 5-8 人口老龄化背景下促进徐州市经济高质量发展的探究 李艳秋;…...
在VS Code中快速生成Vue模板的技巧
配置vue.json: { "Print to console": {"prefix": "vue","body": ["<template>"," <div class\"\">\n"," </div>","</template>\n","<scri…...

新火种AI|Sora发布半年之后,AI视频生成领域风云再起
作者:一号 编辑:美美 AI视频最近有些疯狂,Sora可能要着急了。 自OpenAI的Sora发布以来,AI视频生成技术便成为了科技界的热门话题。尽管Sora以其卓越的性能赢得了广泛关注,但其迟迟未能面向公众开放,让人…...

《UNIX环境高级编程》第三版(电子工业出版社出品)——两年磨一剑的匠心译作
历时两年,《UNIX环境高级编程》的翻译工作终于落下帷幕。这一路走来,真可谓是如鱼饮水,冷暖自知。还记得最初看到招募译者消息的那一刻,内心的激动难以言表。我毫不犹豫地报名,而后经历了试译、海选等激烈的角逐&#…...

【RK3588/算能/Nvidia智能盒子】AI“值守”,规范新能源汽车充电站停车、烟火及充电乱象
近年来,中国新能源汽车高速发展,产量连续8年位居全球第一。根据中国充电联盟数据,截至2023年6月,新能源汽车保有量1620万辆,全国充电基础设施累计数量为665.2万台,车桩比约2.5:1。 虽然新能源汽车与充电桩供…...

使用ReentrantLock和ThreadPoolExecutor模拟抢课
这里主要是在场景下帮助理解ReentrantLock和线程池的使用。 import java.util.concurrent.locks.Lock; import java.util.concurrent.locks.ReentrantLock;public class GrabCourseTask implements Runnable {private final String studentName;private static int availableS…...

VirtFuzz:一款基于VirtIO的Linux内核模糊测试工具
关于VirtFuzz VirtFuzz是一款功能强大的Linux内核模糊测试工具,该工具使用LibAFL构建,可以利用VirtIO向目标设备的内核子系统提供输入测试用例,广大研究人员可以使用该工具测试Linux内核的安全性。 工具要求 1、Rust; 2、修补的Q…...
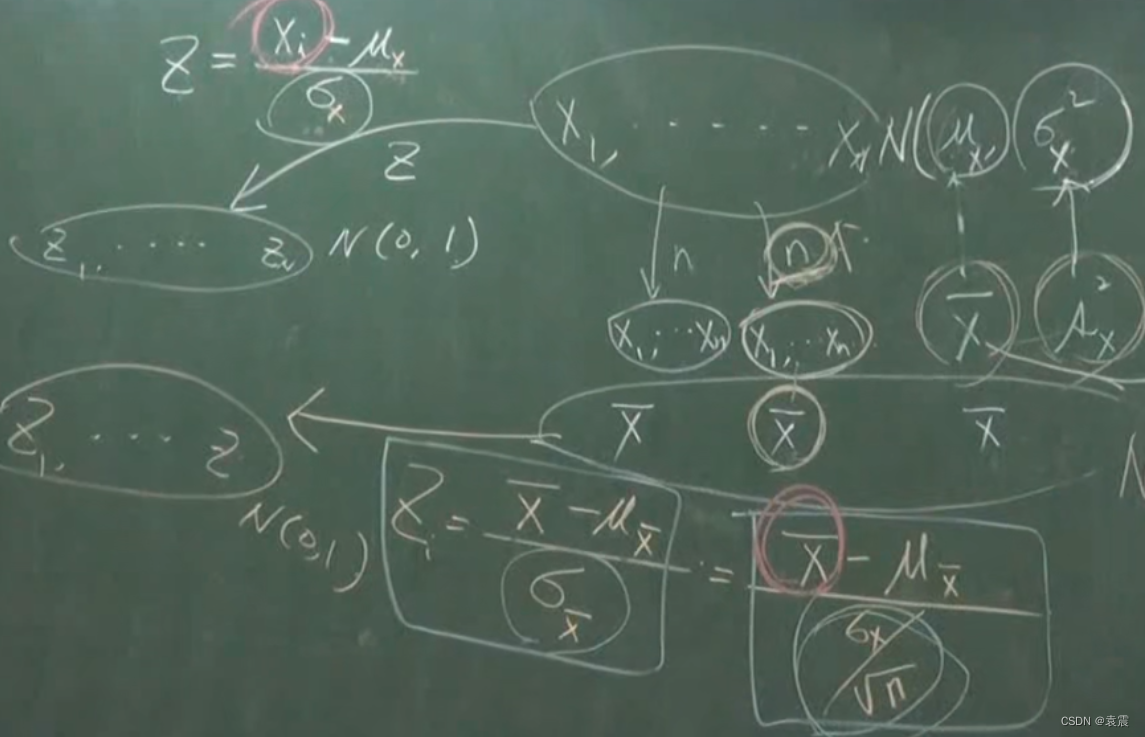
统计学一(术语,正态)
目录 一,常用术语 二,正态分布(Normal Distribution) 三,中心极限定理(Central Limit Theorem) 一,常用术语 population(族群):要统计的总的 populationSize(族群数量):要统计的总…...
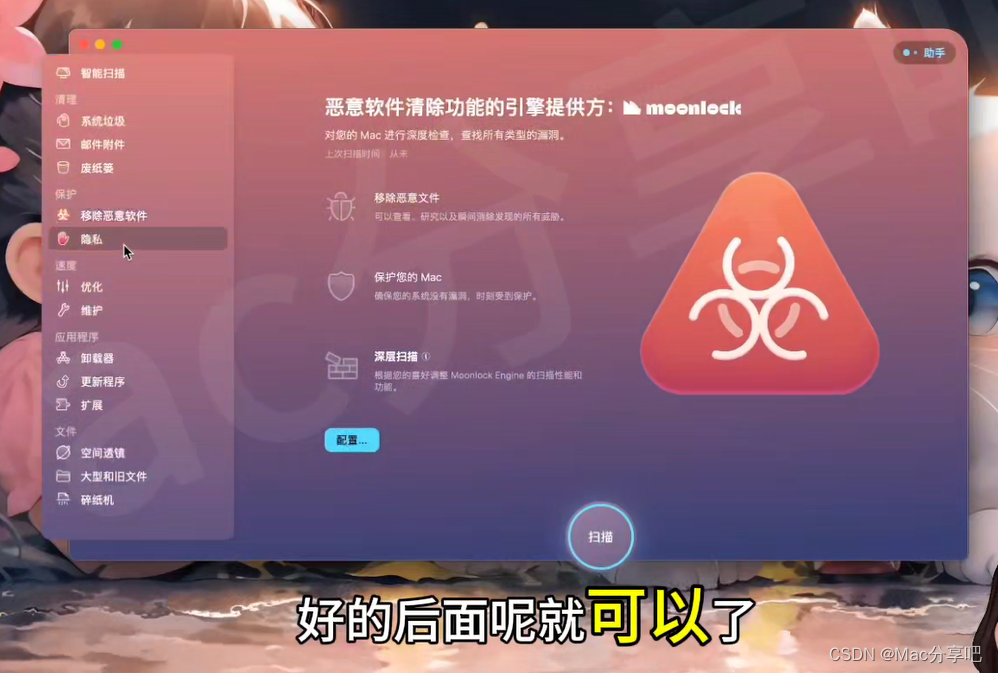
CleanMyMac X for Mac系统优化垃圾清理软件卸载 工具(小白轻松上手,简单易学)
Mac分享吧 文章目录 效果一、准备工作二、开始安装1、双击运行软件,将其从左侧拖入右侧文件夹中,等待安装完毕2、启动台显示软件图标,表示安装成功 三、运行测试1、打开软件,配置2、授权,允许完全磁盘访问 安装完成&a…...

从0开始开发一个简单web界面的学习笔记(HTML类)
文章目录 什么是HTML页面vscode 开放工具搭建第一个HTML页面编写vscode 如何快速生成代码框架html标签——注释、标题、段落、换行标签格式化标签img 标签(src 属性01)img 属性02(alt、title、width/height、border)a标签href属性a标签target属性表格标签01 基本属性表格标签02…...
【机器学习】对大规模的文本数据进行多标签的分类处理
1. 引言 1.1. NLP研究的背景 随着人工智能技术的飞速发展,智能助手、聊天机器人和虚拟客服的需求正呈现出爆炸性增长。这些技术不仅为人们提供了极大的生活便利,如日程管理、信息查询和情感陪伴,还在工作场景中显著提高了效率。聊天机器人凭…...

C++之std::type_identity
目录 1.简介 2.C20的std::type_identity 3.使用 type_identity 3.1.阻止参数推导 3.1.1.模板参数推导过程中的隐式类型转换 3.1.2.强制显式实例化 3.2.阻止推断指引 3.3.类型保持 3.4.满足一些稀奇古怪的语法 4.示例 5.总结 1.简介 std::type_identity 是 C17 引入的…...

头歌资源库(10)拼数字
一、 问题描述 二、算法思想 初始化一个长度为10的数组count,用于记录卡片中每个数字的数量。 从1开始依次尝试拼出正整数,直到无法拼出下一个数为止。 对于每个尝试拼出的正整数,遍历其每一位的数字,检查该数字在count中是否还…...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

【WiFi帧结构】
文章目录 帧结构MAC头部管理帧 帧结构 Wi-Fi的帧分为三部分组成:MAC头部frame bodyFCS,其中MAC是固定格式的,frame body是可变长度。 MAC头部有frame control,duration,address1,address2,addre…...

汽车生产虚拟实训中的技能提升与生产优化
在制造业蓬勃发展的大背景下,虚拟教学实训宛如一颗璀璨的新星,正发挥着不可或缺且日益凸显的关键作用,源源不断地为企业的稳健前行与创新发展注入磅礴强大的动力。就以汽车制造企业这一极具代表性的行业主体为例,汽车生产线上各类…...

涂鸦T5AI手搓语音、emoji、otto机器人从入门到实战
“🤖手搓TuyaAI语音指令 😍秒变表情包大师,让萌系Otto机器人🔥玩出智能新花样!开整!” 🤖 Otto机器人 → 直接点明主体 手搓TuyaAI语音 → 强调 自主编程/自定义 语音控制(TuyaAI…...

SiFli 52把Imagie图片,Font字体资源放在指定位置,编译成指定img.bin和font.bin的问题
分区配置 (ptab.json) img 属性介绍: img 属性指定分区存放的 image 名称,指定的 image 名称必须是当前工程生成的 binary 。 如果 binary 有多个文件,则以 proj_name:binary_name 格式指定文件名, proj_name 为工程 名&…...

Ubuntu Cursor升级成v1.0
0. 当前版本低 使用当前 Cursor v0.50时 GitHub Copilot Chat 打不开,快捷键也不好用,当看到 Cursor 升级后,还是蛮高兴的 1. 下载 Cursor 下载地址:https://www.cursor.com/cn/downloads 点击下载 Linux (x64) ,…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...

13.10 LangGraph多轮对话系统实战:Ollama私有部署+情感识别优化全解析
LangGraph多轮对话系统实战:Ollama私有部署+情感识别优化全解析 LanguageMentor 对话式训练系统架构与实现 关键词:多轮对话系统设计、场景化提示工程、情感识别优化、LangGraph 状态管理、Ollama 私有化部署 1. 对话训练系统技术架构 采用四层架构实现高扩展性的对话训练…...
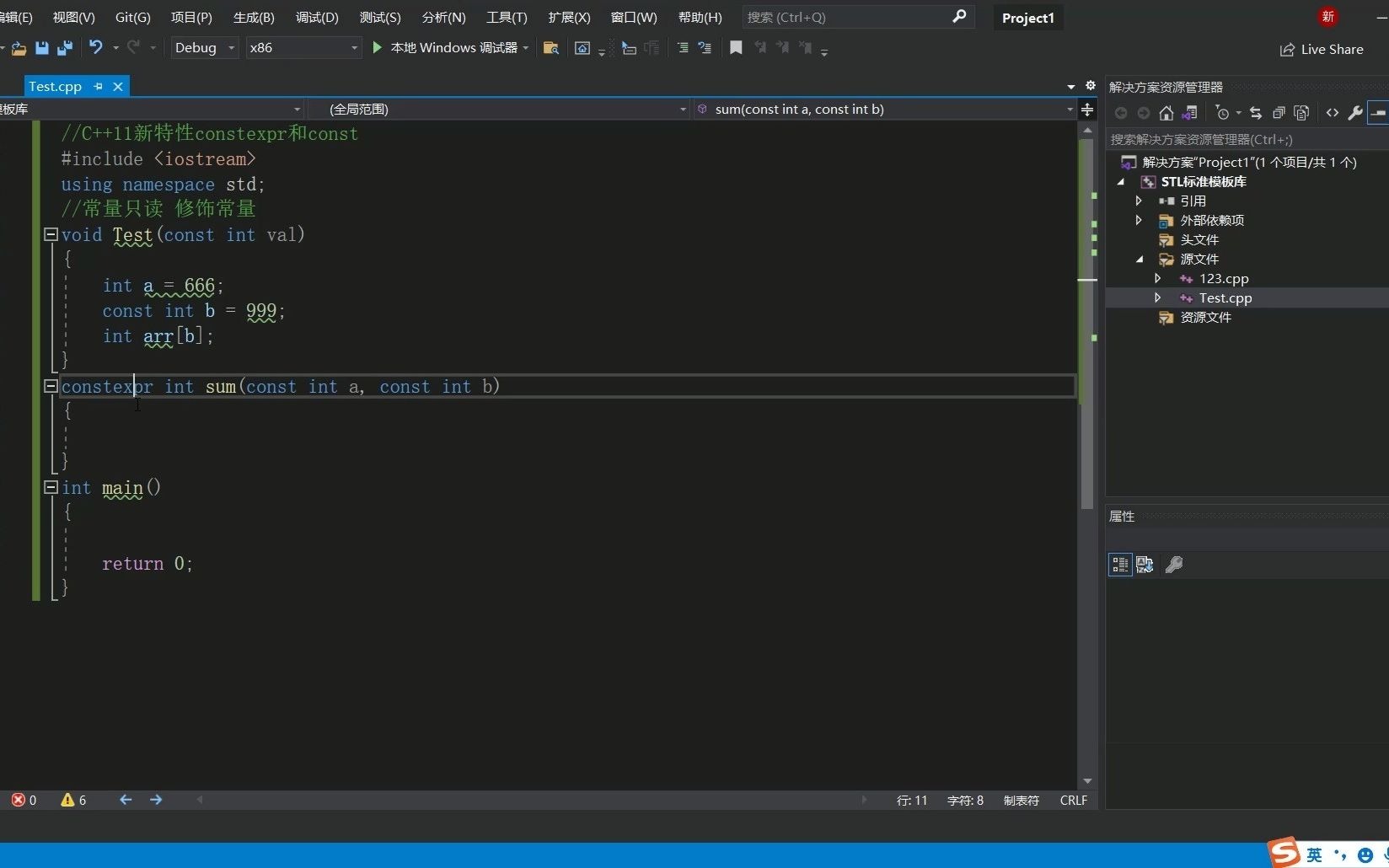
C++11 constexpr和字面类型:从入门到精通
文章目录 引言一、constexpr的基本概念与使用1.1 constexpr的定义与作用1.2 constexpr变量1.3 constexpr函数1.4 constexpr在类构造函数中的应用1.5 constexpr的优势 二、字面类型的基本概念与使用2.1 字面类型的定义与作用2.2 字面类型的应用场景2.2.1 常量定义2.2.2 模板参数…...