算法金 | 一个强大的算法模型:t-SNE !!

大侠幸会,在下全网同名「算法金」
0 基础转 AI 上岸,多个算法赛 Top
「日更万日,让更多人享受智能乐趣」
t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种用于降维和数据可视化的非线性算法。它被广泛应用于图像处理、文本挖掘和生物信息学等领域,特别擅长处理高维数据。
本文旨在详细介绍 t-SNE 算法的基本概念、数学基础、算法步骤、代码示范及其在不同领域的应用案例。我们还将探讨 t-SNE 的常见误区和注意事项,并与其他降维算法进行对比,以帮助铁子们更好地理解和应用 t-SNE 算法。

by datacamp

t-SNE 的基本概念
1.1 什么是 t-SNE
t-SNE 是一种非线性降维技术,用于将高维数据映射到低维空间,以便进行可视化。它通过保持高维空间中数据点之间的局部相似性来生成低维空间的表示。这种方法特别适用于揭示复杂数据集中的模式和结构
1.2 t-SNE 的核心思想
t-SNE 的核心思想是通过两步过程实现高维到低维的映射。首先,t-SNE 在高维空间中使用高斯分布来计算数据点之间的条件概率。然后,在低维空间中,t-SNE 使用 t 分布来计算相似度,并通过最小化两个分布之间的 Kullback-Leibler 散度(KL 散度)来优化数据点的位置。这个过程可以通过梯度下降法进行优化,从而得到低维空间中的表示。
2. t-SNE 的数学基础
对看公司很痛苦的同学,可直接跳过公式
2.1 高斯分布与条件概率
在 t-SNE 算法中,首先需要在高维空间中计算数据点之间的相似度。为此,我们使用高斯分布来表示这种相似度。

2.2 Kullback-Leibler 散度
在低维空间中,t-SNE 使用 t 分布来计算数据点之间的相似度。与高维空间中的条件概率类

2.3 梯度下降法
为了最小化 KL 散度,t-SNE 使用梯度下降法来优化低维空间中数据点的位置。梯度下降法是一种迭代优化算法,每次迭代更新数据点的位置,使 KL 散度逐渐减小。具体来说,t-SNE 计算 KL 散度对每个数据点位置的梯度,并按照负梯度的方向更新数据点的位置:


3. t-SNE 的算法步骤
3.1 高维空间中的相似度计算
在 t-SNE 算法中,首先需要计算高维空间中数据点之间的相似度。具体步骤如下:
- 对于每个数据点 (x_i),计算其与其他数据点 (x_j) 的欧氏距离 (|x_i - x_j|)
- 使用高斯分布计算条件概率 (p_{j|i}),即在给定 (x_i) 的情况下选择 (x_j) 作为邻居的概率:
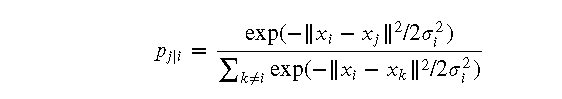
- 计算联合概率 (p_{ij}):
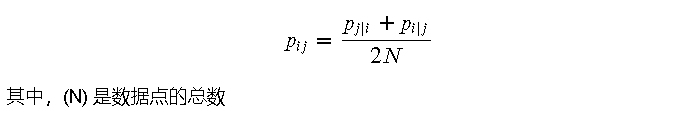
3.2 低维空间中的相似度计算
在低维空间中,t-SNE 使用 t 分布来计算数据点之间的相似度。具体步骤如下:
- 对于每个低维数据点 (y_i),计算其与其他数据点 (y_j) 的欧氏距离 (|y_i - y_j|)
- 使用 t 分布计算相似度 (q_{ij}):
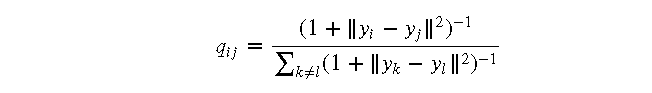
3.3 损失函数的优化
t-SNE 通过最小化高维空间和低维空间之间的相似度分布的 Kullback-Leibler 散度来优化低维空间中数据点的位置。具体步骤如下:
- 计算 KL 散度:
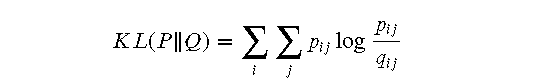
- 计算 KL 散度对每个低维数据点位置的梯度:

- 使用梯度下降法更新低维数据点的位置:
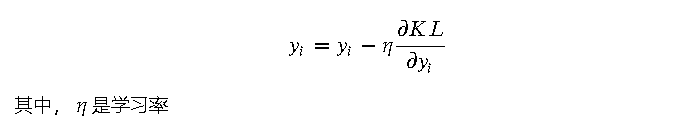
通过上述步骤迭代优化,t-SNE 最终可以得到一个低维空间中的表示,使得高维数据的局部相似性在低维空间中得以保留

4. t-SNE 的代码示范
在这部分,我们将生成一个带有武侠风格的数据集,包含三个门派的武侠人物。数据集的特征包括武力值、智力值和身法值。我们将使用 t-SNE 进行降维,并展示其可视化效果。接下来,我们会调整 t-SNE 的参数以观察其对降维结果的影响。
4.1 数据集生成与基本实现
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
from sklearn.datasets import load_iris# 生成武侠人物数据集
np.random.seed(42)
num_samples_per_class = 50
data = {'武力值': np.hstack([np.random.normal(loc=5, scale=1, size=num_samples_per_class),np.random.normal(loc=7, scale=1, size=num_samples_per_class),np.random.normal(loc=9, scale=1, size=num_samples_per_class)]),'智力值': np.hstack([np.random.normal(loc=3, scale=1, size=num_samples_per_class),np.random.normal(loc=5, scale=1, size=num_samples_per_class),np.random.normal(loc=7, scale=1, size=num_samples_per_class)]),'身法值': np.hstack([np.random.normal(loc=1, scale=1, size=num_samples_per_class),np.random.normal(loc=2, scale=1, size=num_samples_per_class),np.random.normal(loc=3, scale=1, size=num_samples_per_class)]),'门派': np.hstack([np.full(num_samples_per_class, '少林'),np.full(num_samples_per_class, '武当'),np.full(num_samples_per_class, '峨眉')])
}
df = pd.DataFrame(data)# 将类别标签转换为数字
df['门派'] = df['门派'].astype('category').cat.codes# 打印前几行数据
print(df.head())# t-SNE 降维
X = df[['武力值', '智力值', '身法值']]
y = df['门派']
tsne = TSNE(n_components=2, random_state=42)
X_tsne = tsne.fit_transform(X)# 可视化 t-SNE 结果
plt.figure(figsize=(10, 7))
scatter = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y, cmap='viridis')
plt.colorbar(scatter, ticks=[0, 1, 2], label='门派')
plt.clim(-0.5, 2.5)
plt.title('t-SNE 结果可视化')
plt.xlabel('t-SNE 维度 1')
plt.ylabel('t-SNE 维度 2')
plt.show()

解释与结果解读
在基本实现中,我们生成了一个包含武侠人物特征和门派标签的数据集。数据集中的武侠人物分别来自少林、武当和峨眉三个门派。我们使用 t-SNE 将数据降维到二维,并可视化其结果。不同颜色表示不同的门派,从图中可以看到,同一门派的武侠人物在降维后的二维空间中聚集在一起,而不同门派的武侠人物则分布在不同的区域。
4.2 参数调优
接下来,我们调整 t-SNE 的两个关键参数:perplexity 和 learning_rate,并观察它们对降维结果的影响。
# 调整 perplexity 参数
tsne_perplexity = TSNE(n_components=2, perplexity=30, random_state=42)
X_tsne_perplexity = tsne_perplexity.fit_transform(X)plt.figure(figsize=(10, 7))
scatter_perplexity = plt.scatter(X_tsne_perplexity[:, 0], X_tsne_perplexity[:, 1], c=y, cmap='viridis')
plt.colorbar(scatter_perplexity, ticks=[0, 1, 2], label='门派')
plt.clim(-0.5, 2.5)
plt.title('t-SNE 结果 (perplexity=30)')
plt.xlabel('t-SNE 维度 1')
plt.ylabel('t-SNE 维度 2')
plt.show()# 调整 learning_rate 参数
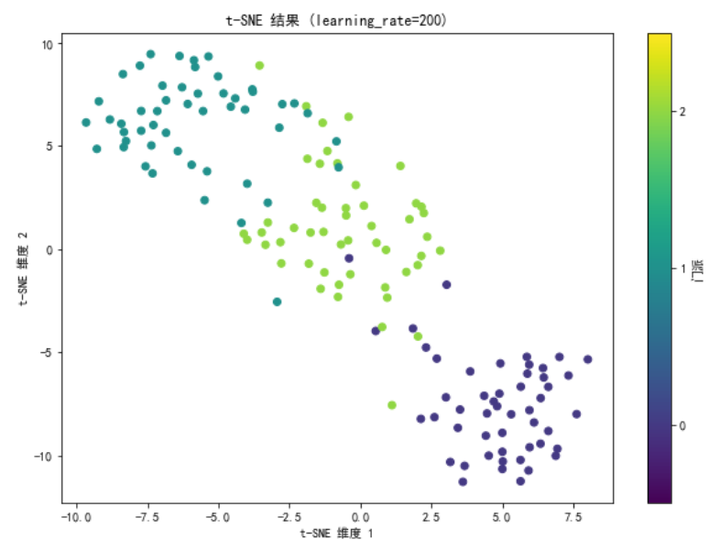
tsne_learning_rate = TSNE(n_components=2, learning_rate=200, random_state=42)
X_tsne_learning_rate = tsne_learning_rate.fit_transform(X)plt.figure(figsize=(10, 7))
scatter_learning_rate = plt.scatter(X_tsne_learning_rate[:, 0], X_tsne_learning_rate[:, 1], c=y, cmap='viridis')
plt.colorbar(scatter_learning_rate, ticks=[0, 1, 2], label='门派')
plt.clim(-0.5, 2.5)
plt.title('t-SNE 结果 (learning_rate=200)')
plt.xlabel('t-SNE 维度 1')
plt.ylabel('t-SNE 维度 2')
plt.show()
解释与结果解读
- 调整 perplexity 参数:
- 将 perplexity 设置为 30 后,我们再次对数据进行 t-SNE 降维。结果显示,调整 perplexity 会影响数据点在二维空间中的分布。perplexity 参数决定了 t-SNE 在计算高维空间中数据点的相似度时考虑的邻居数量。适当调整 perplexity 可以更好地平衡局部和全局数据结构。
- 调整 learning_rate 参数:
- 将 learning_rate 设置为 200 后,我们再次对数据进行 t-SNE 降维。结果显示,调整 learning_rate 会影响降维结果的收敛速度和最终效果。learning_rate 参数决定了梯度下降的步长,合适的 learning_rate 可以加速收敛并避免陷入局部最优解。
通过这些示例和详细解释,可以更好地理解 t-SNE 算法及其在实际数据集中的应用效果。希望这能帮助你更好地掌握 t-SNE 的使用方法和参数调优技巧。
每天一个简洁明了的小案例,如果你对这类文章感兴趣,
欢迎订阅、点赞和分享哦~
5. t-SNE 的应用案例
5.1 图像数据降维
t-SNE 在图像数据降维中非常有效。以下示例展示了如何将 t-SNE 应用于图像数据降维和可视化。我们将使用手写数字数据集(MNIST)进行演示。
import numpy as np
import pandas as pd
from sklearn.manifold import TSNE
from sklearn.datasets import fetch_openml
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt# 加载 MNIST 数据集
mnist = fetch_openml('mnist_784', version=1)
X = mnist.data / 255.0 # 将数据归一化到 [0, 1] 区间
y = mnist.target# 随机选择 10000 个数据点
np.random.seed(42)
indices = np.random.choice(X.shape[0], 10000, replace=False)
X_subset = X.iloc[indices]
y_subset = y.iloc[indices]# 标准化数据
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X_subset)# 应用 t-SNE 进行降维
tsne = TSNE(n_components=2, perplexity=30, n_iter=1000, random_state=42)
X_tsne = tsne.fit_transform(X_scaled)# t-SNE 可视化结果
plt.figure(figsize=(12, 8))
scatter_tsne = plt.scatter(X_tsne[:, 0], X_tsne[:, 1], c=y_subset.astype(int), cmap='tab10', s=1)
plt.legend(*scatter_tsne.legend_elements(), title="Digits")
plt.title('MNIST 数据集的 t-SNE 可视化')
plt.xlabel('t-SNE 维度 1')
plt.ylabel('t-SNE 维度 2')
plt.show()

5.2 文本数据降维
t-SNE 也广泛应用于文本数据降维。以下示例展示了如何将 t-SNE 应用于文本数据降维和可视化。我们将使用新闻组数据集进行演示。
5.3 生物信息学中的应用
在生物信息学中,t-SNE 常用于基因表达数据的降维和可视化。以下示例展示了如何将 t-SNE 应用于单细胞 RNA 序列数据的降维和可视化。

6. t-SNE 的误区和注意事项
6.1 t-SNE 不适合大数据集
t-SNE 的计算复杂度较高,对于大规模数据集,计算时间和内存消耗都非常大。因此,t-SNE 不适合直接应用于大数据集。在处理大数据集时,可以考虑以下几种方法:
- 先使用其他降维方法(如 PCA)进行预处理,将数据维度降低到较小的范围,然后再应用 t-SNE
- 选择一部分代表性数据点进行 t-SNE 降维,而不是对整个数据集进行降维
- 使用基于树的近似算法(如 Barnes-Hut t-SNE)来加速计算
6.2 参数选择的影响
t-SNE 的降维效果对参数的选择非常敏感。两个关键参数是 perplexity 和 learning_rate。perplexity 参数控制每个数据点的有效邻居数量,一般设置在 5 到 50 之间;learning_rate 参数控制梯度下降的步长,通常设置在 10 到 1000 之间。以下是一些经验性的参数选择建议:
- 对于较小的数据集,可以选择较小的 perplexity 和较大的 learning_rate
- 对于较大的数据集,可以选择较大的 perplexity 和较小的 learning_rate
- 通过实验和可视化结果调整参数,以获得最佳的降维效果
6.3 结果的解释与可视化误导
t-SNE 的可视化结果虽然直观,但有时会产生误导。需要注意以下几点:
- t-SNE 只保留局部相似性,低维空间中距离较远的数据点在高维空间中不一定距离较远,因此低维空间中的距离不能直接解释为高维空间中的距离
- t-SNE 的随机性较强,不同的运行可能产生不同的结果,可以通过设置随机种子来获得可重复的结果
- 可视化结果中的簇并不总是表示真实的分类,需要结合其他信息进行综合分析

7. t-SNE 与其他降维算法的对照
7.1 与 PCA 的对照
PCA(主成分分析)和 t-SNE 是两种常用的降维算法,但它们的原理和应用场景有所不同:
- 基本原理:PCA 是一种线性降维方法,通过找到数据最大方差的方向(主成分),将高维数据投影到低维空间。t-SNE 是一种非线性降维方法,通过最小化高维空间和低维空间之间的概率分布差异,将高维数据嵌入到低维空间
- 应用场景:PCA 适用于数据维度较低且线性关系较强的情况,如数据预处理和特征选择。t-SNE 适用于高维数据和非线性关系较强的情况,如数据可视化和模式识别
- 计算复杂度:PCA 计算复杂度较低,适合大规模数据集。t-SNE 计算复杂度较高,不适合大规模数据集
7.2 与 LLE 的对照
LLE(局部线性嵌入)和 t-SNE 都是非线性降维方法,但它们的实现方式不同:
- 基本原理:LLE 通过保持数据局部邻居关系,将高维数据嵌入到低维空间。t-SNE 通过最小化高维空间和低维空间之间的概率分布差异,将高维数据嵌入到低维空间
- 应用场景:LLE 适用于数据维度较低且局部线性关系较强的情况,如图像数据和时间序列数据。t-SNE 适用于高维数据和非线性关系较强的情况,如文本数据和生物信息学数据
- 计算复杂度:LLE 的计算复杂度中等,适用于中等规模的数据集。t-SNE 的计算复杂度较高,不适合大规模数据集
7.3 不同算法的优劣势
每种降维算法都有其优劣势,选择合适的算法取决于具体的数据集和任务需求:
- PCA:优点是计算速度快,结果容易解释,适用于线性关系较强的数据集。缺点是无法处理非线性关系
- t-SNE:优点是能够揭示数据的非线性结构,适用于高维数据和复杂模式识别。缺点是计算复杂度高,参数选择敏感,不适合大规模数据集
- LLE:优点是能够保持数据的局部邻居关系,适用于局部线性关系较强的数据集。缺点是对数据噪声敏感,计算复杂度中等
通过以上对比,可以更好地理解不同降维算法的适用场景和特点,从而选择最适合具体任务的算法
8. 相关与相对的概念引出与对比
8.1 降维与聚类
降维和聚类是数据分析中的两种不同但相关的方法:
- 降维:降维是将高维数据映射到低维空间,以便进行可视化或简化分析。降维方法包括 PCA、t-SNE、LLE 等。降维的目的是减少特征数量,同时尽量保留原始数据的结构信息
- 聚类:聚类是将数据分为若干组,使得同组数据点之间的相似度尽可能高,而不同组之间的相似度尽可能低。常用的聚类方法包括 K-means、层次聚类、DBSCAN 等。聚类的目的是发现数据中的自然分组或模式
虽然降维和聚类有不同的目标,但它们可以结合使用。例如,降维可以用于将高维数据投影到低维空间,从而便于进行聚类分析
8.2 t-SNE 与 UMAP
UMAP(Uniform Manifold Approximation and Projection)是另一种非线性降维方法,常用于与 t-SNE 进行比较:
- 基本原理:t-SNE 通过最小化高维空间和低维空间之间的概率分布差异,将高维数据嵌入到低维空间。UMAP 通过构建高维空间的邻接图,然后通过优化图嵌入,将数据投影到低维空间
- 应用场景:t-SNE 适用于高维数据和复杂模式识别,特别是在可视化方面效果显著。UMAP 在保持全局和局部结构方面表现更好,计算速度更快,适合处理大规模数据集
- 计算复杂度:t-SNE 计算复杂度较高,不适合大规模数据集。UMAP 计算复杂度较低,更适合大规模数据集
8.3 t-SNE 与 MDS
MDS(多维尺度分析)和 t-SNE 都是用于降维和数据可视化的算法:
- 基本原理:MDS 通过保留高维空间中数据点之间的距离,将数据嵌入到低维空间。t-SNE 通过最小化高维空间和低维空间之间的概率分布差异,将数据嵌入到低维空间
- 应用场景:MDS 适用于数据点之间距离信息较为可靠的情况,如心理学和市场研究中的数据分析。t-SNE 适用于高维数据和复杂模式识别,如图像和文本数据
- 计算复杂度:MDS 计算复杂度中等,适用于中等规模的数据集。t-SNE 计算复杂度较高,不适合大规模数据集
[ 抱个拳,总个结 ]
- t-SNE 的核心概念:t-SNE 是一种非线性降维方法,通过保持高维空间中数据点之间的局部相似性,将高维数据嵌入到低维空间,以便进行可视化和模式识别
- 应用场景:t-SNE 广泛应用于图像处理、文本挖掘和生物信息学等领域,特别适用于高维和非线性数据的可视化
- 数学基础:t-SNE 通过计算高维空间中的条件概率和低维空间中的相似度,并最小化两个分布之间的 Kullback-Leibler 散度来优化低维表示
- 算法步骤:t-SNE 包括高维空间中的相似度计算、低维空间中的相似度计算以及通过梯度下降法优化损失函数的步骤
- 代码实现:使用 Python 和 scikit-learn 库可以实现 t-SNE 算法,并结合不同的参数调优和可视化效果进行展示
- 应用案例:t-SNE 在图像数据、文本数据和生物信息学中的应用展示了其强大的降维和可视化能力
- 误区和注意事项:t-SNE 不适合大规模数据集,参数选择对结果影响较大,低维空间中的距离解释需要谨慎
- 与其他降维算法的对照:t-SNE 与 PCA、LLE、UMAP 和 MDS 等降维算法在原理、应用场景和计算复杂度上各有不同,可以根据具体任务选择合适的算法
- 相关与相对的概念:降维和聚类可以结合使用,t-SNE 与 UMAP 和 MDS 等方法在保留数据结构和计算效率上有不同的优劣势
通过以上的详细介绍,希望大侠对 t-SNE 算法有了更深入的理解和认识。在实际应用中,结合数据特点和任务需求,选择合适的降维方法,才能发挥数据分析和可视化的最大效用。
- 科研为国分忧,创新与民造福 -

日更时间紧任务急,难免有疏漏之处,还请大侠海涵
内容仅供学习交流之用,部分素材来自网络,侵联删
[ 算法金,碎碎念 ]
全网同名,日更万日,让更多人享受智能乐趣
如果觉得内容有价值,烦请大侠多多 分享、在看、点赞,助力算法金又猛又持久、很黄很 BL 的日更下去;
同时邀请大侠 关注、星标 算法金,围观日更万日,助你功力大增、笑傲江湖
相关文章:
算法金 | 一个强大的算法模型:t-SNE !!
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 t-SNE(t-Distributed Stochastic Neighbor Embedding)是一种用于降维和数据可视化的非线性算法。它被广泛应用于…...

用IAST工具强化“越权检测”能力,提升系统安全性
什么是越权漏洞 越权漏洞是一种常见的逻辑安全漏洞。越权漏洞指的是攻击者利用系统中的漏洞,获得超过其正常权限的访问权限,执行未授权操作。 越权漏洞主要分为两种类型:水平越权(横向越权)和垂直越权(纵…...
VirtualStudio配置QT开发环境
环境 VirtualStudio2022Qt5.12.10 安装msvc工具链(这一步不是必须的) 打开virtual studio,打开Virtual Studio Installer界面选择要安装的msvc版本,点击安装 安装VirtualStudio扩展 在线安装 打开virtual Studio,…...

Nature发文介绍使用ChatGPT帮助学术写作的三种方式
文章链接:https://www.nature.com/articles/d41586-024-01042-3 一、介绍 这篇文章是由Dritjon Gruda撰写的,讨论了生成性人工智能(AI)在学术写作、编辑和同行评审中的三种应用方式。Gruda认为,尽管学术界对聊天机器…...

【网络安全的神秘世界】Kali 自带 Burp Suite 使用指南:字体与CA证书设置详解等
🌝博客主页:泥菩萨 💖专栏:Linux探索之旅 | 网络安全的神秘世界 | 专接本 | 每天学会一个渗透测试工具 Kali 自带 Burp Suite 使用指南目录 Burp Suite的打开方式设置Burp Suite软件的字体大小查看Burp Suite 默认代理在火狐浏览器…...

【Go】爬虫数据解密_使用Go语言实现TripleDES加密和解密
是你多么温馨的目光 教我坚毅望着前路 叮嘱我跌倒不应放弃 没法解释怎可报尽亲恩 爱意宽大是无限 请准我说声真的爱你 🎵 Beyond《真的爱你》 引言 Triple Data Encryption Standard (TripleDES 或 3DES) 是一种对称加密算法,它通…...
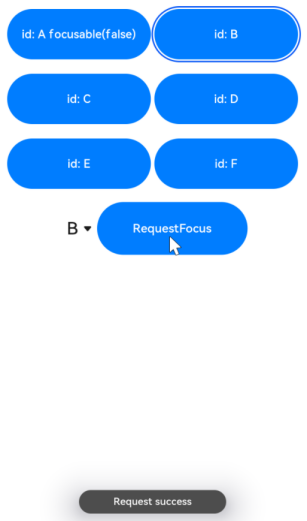
【HarmonyOS NEXT】鸿蒙 如何在包含web组件的页面 让默认焦点有效
页面包含web组件Button组件等,把页面的默认焦点放到Button组件上,不起效果。 因为web组件默认会在组件加载完成后获取焦点; 可以在web的网页加载完成时onPageEnd回调中,将设置默认获焦的组件通过focusControl.requestFocus方法主…...

mysql常用参数配置详解my.cnf my.ini
1.关注生产中高频常用参数 # 数据库时区 log_timestamps = system # 刷盘策略 0,1,2 innodb_flush_log_at_trx_commit # 定义了 InnoDB 用于写日志数据的缓冲区大小。当事务发生时,日志首先被写入这个缓冲区,然后再被刷新(flush)到磁盘上的重做日志文件(redo log file…...
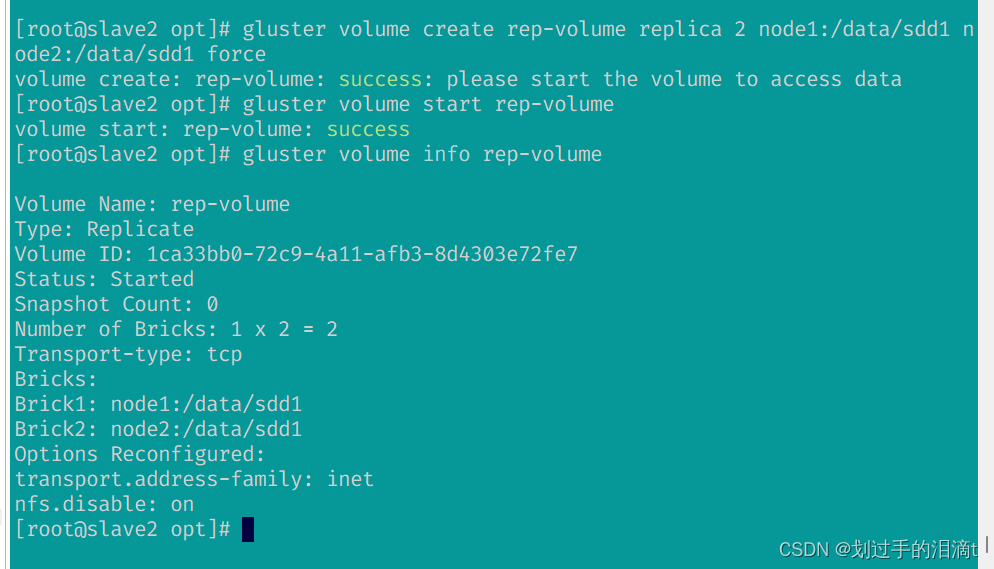
GlusterFS企业分布式存储
GlusterFS 分布式文件系统代表-nfs常见分布式存储Gluster存储基础梳理GlusterFS 适合大文件还是小文件存储? 应用场景术语Trusted Storage PoolBrickVolumes Glusterfs整体工作流程-数据访问流程GlusterFS客户端访问流程 GlusterFS常用命令部署 GlusterFS 群集准备环…...
)
SSH生成SSH密钥(公钥和私钥)
在设置SSH服务时,生成SSH密钥(公钥和私钥)是一个常见的任务。这些密钥用于安全地进行身份验证,无需输入密码。以下是如何生成SSH密钥的步骤: 1. 生成SSH密钥对 首先,您需要在客户端机器上生成一个SSH密钥…...

阶段性总结:如何快速上手一个新的平台或者技术
作为研发一枚,为了实现客户的各种需求,为了避免重复造轮子,通常需要快速调查到哪个轮子(比如各种平台,或者开发包等)好用,然后快速熟悉和上手。在接触到一个新的平台或者技术的时候,…...

kettle从入门到精通 第七十一课 ETL之kettle 再谈http post,轻松掌握body中传递json参数
场景: kettle中http post步骤如何发送http请求且传递body参数? 解决方案: http post步骤中直接设置Request entity field字段即可。 1、手边没有现成的post接口,索性用python搭建一个简单的接口,关键代码如下&#…...

第十二章:会话控制
会话控制 文章目录 会话控制一、介绍二、cookie2.1 cookie 是什么2.2 cookie 的特点2.3 cookie 的运行流程2.4 浏览器操作 cookie2.5 cookie 的代码操作(1)设置 cookie(2)读取 cookie(3)删除 cookie 三、se…...

【LeetCode滑动窗口算法】长度最小的子数组 难度:中等
我们先看一下题目描述: 解法一:暴力枚举 时间复杂度:o(n^3) class Solution { public:int minSubArrayLen(int target, vector<int>& nums){int i 0, j 0;vector<int> v;for (;i < nums.size();i){int sum nums[i];fo…...
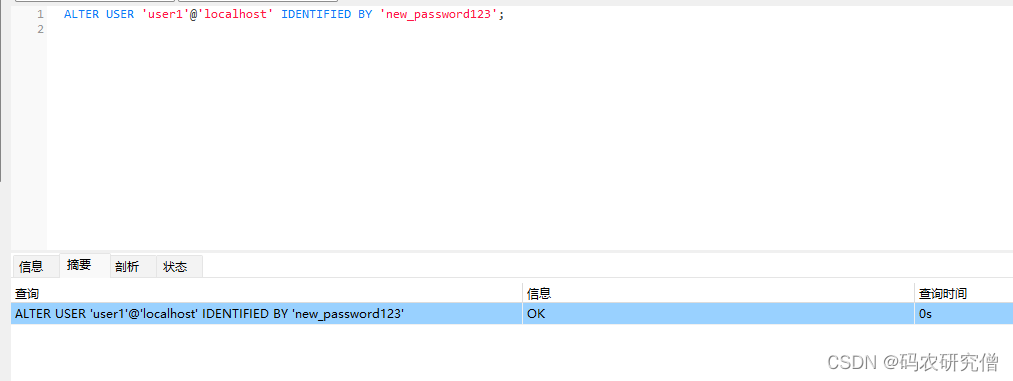
MySQL 用户权限管理:授权、撤销、密码更新和用户删除(图文解析)
目录 前言1. 授予权限2. 撤销权限3. 查询权限4. Demo 前言 公司内部的数据库权限一般针对不同人员有不同的权限分配,而不都统一给一个root权限 1. 授予权限 授予用户权限的基本命令是GRANT 可以授予的权限种类很多,涵盖从数据库和表级别到列和存储过…...

Day39
Day39 JSP JSP底层 全称为Java Server Pages,JSP实际上就是一个servelet JSP:HTML页面Java代码,本质:servlet。 public class login_jsp{//JSP的9大内置对象private JSPWriter out;//当前JSP输出流对象private HttpServletRequest request;…...

Nginx之HTTP模块详解
Nginx是模块化的代码架构,其代码由核心代码与功能模块代码构成。Nginx的主要功能模块是HTTP功能模块,HTTP功能模块在HTTP核心功能的基础上为Nginx对HTTP请求的处理流程提供了扩展功能,这些扩展功能可以让用户很方便地应对访问控制、数据处理、…...

JCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断
JJCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断 目录 JJCR一区 | Matlab实现GAF-PCNN、GASF-CNN、GADF-CNN的多特征输入数据分类预测/故障诊断分类效果格拉姆矩阵图GAF-PCNNGASF-CNNGADF-CNN 基本介绍程序设计参考资料 分类效果 格拉姆…...

最新Prompt预设词分享,DALL-E3文生图+文档分析
使用指南 直接复制使用 可以前往已经添加好Prompt预设的AI系统测试使用(可自定义添加使用) 支持GPTs SparkAi SparkAi创作系统是基于ChatGPT进行开发的Ai智能问答系统和Midjourney绘画系统,支持OpenAI-GPT全模型国内AI全模型。支持GPT-4o…...

基于SpringBoot+Vue会所产后护理系统设计和实现
基于SpringBootVue会所产后护理系统设计和实现 🍅 作者主页 网顺技术团队 🍅 欢迎点赞 👍 收藏 ⭐留言 📝 🍅 文末获取源码联系方式 📝 🍅 查看下方微信号获取联系方式 承接各种定制系统 &#…...

手游刚开服就被攻击怎么办?如何防御DDoS?
开服初期是手游最脆弱的阶段,极易成为DDoS攻击的目标。一旦遭遇攻击,可能导致服务器瘫痪、玩家流失,甚至造成巨大经济损失。本文为开发者提供一套简洁有效的应急与防御方案,帮助快速应对并构建长期防护体系。 一、遭遇攻击的紧急应…...

51c自动驾驶~合集58
我自己的原文哦~ https://blog.51cto.com/whaosoft/13967107 #CCA-Attention 全局池化局部保留,CCA-Attention为LLM长文本建模带来突破性进展 琶洲实验室、华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

STM32+rt-thread判断是否联网
一、根据NETDEV_FLAG_INTERNET_UP位判断 static bool is_conncected(void) {struct netdev *dev RT_NULL;dev netdev_get_first_by_flags(NETDEV_FLAG_INTERNET_UP);if (dev RT_NULL){printf("wait netdev internet up...");return false;}else{printf("loc…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

【决胜公务员考试】求职OMG——见面课测验1
2025最新版!!!6.8截至答题,大家注意呀! 博主码字不易点个关注吧,祝期末顺利~~ 1.单选题(2分) 下列说法错误的是:( B ) A.选调生属于公务员系统 B.公务员属于事业编 C.选调生有基层锻炼的要求 D…...

Linux-07 ubuntu 的 chrome 启动不了
文章目录 问题原因解决步骤一、卸载旧版chrome二、重新安装chorme三、启动不了,报错如下四、启动不了,解决如下 总结 问题原因 在应用中可以看到chrome,但是打不开(说明:原来的ubuntu系统出问题了,这个是备用的硬盘&a…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...